Hive 的 安装与部署
目录
- 1 安装 MySql
- 2 安装 Hive
- 3 Hive 元数据配置到 MySql
- 4 启动 Hive
Hive 官网
1 安装 MySql
为什么需要安装 MySql?
- 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。以我们需要将Hive 的元数据地址改为 MySql,可支持多窗口操作。
(1)检查当前系统是否安装过 Mysql,如果有,则删除
[huwei@hadoop101 ~]$ rpm -qa|grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64
[huwei@hadoop101 ~]$ sudo rpm -e --nodeps mariadb-libs
rpm -qa用于列出系统中已安装的所有软件包的名称,CentOS 6系统自带的数据库 MySql,CentOS 7系统自带的数据库是 mariadb(本质上就是 MySQL),根据自己的系统来确定。
(2)将 MySql 安装包拷贝到 /opt/software 目录下
(3)解压 MySql 安装包
新建 mysql_rpm 文件夹,并将MySQL 安装包中的文件解压在此处
[huwei@hadoop101 software]$ mkdir mysql_rpm
[huwei@hadoop101 software]$ tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C ./mysql_rpm/
注意,
mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar没有以gz结尾,不是压缩文件
(4)在安装目录下执行 rpm 安装
注意:按照 顺序 依次执行
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
(5)初始化数据库
[huwei@hadoop101 mysql_rpm]$ sudo mysqld --initialize --user=mysql
(6)查看临时生成的 root 用户的密码
[huwei@hadoop101 mysql_rpm]$ sudo cat /var/log/mysqld.log
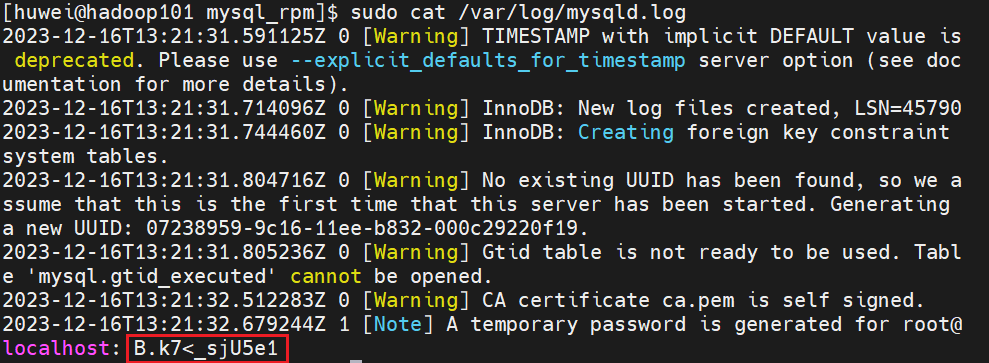
复制保存临时密码
(7)启动 MySql 服务
[huwei@hadoop101 mysql_rpm]$ sudo systemctl start mysqld
(8)登录 MySql 数据库
[huwei@hadoop101 mysql_rpm]$ mysql -uroot -p
不建议直接在
-p后直接输入密码,因为临时密码中可能含有一些特殊字符,shell 可能会把这些特殊字符解析导致出问题
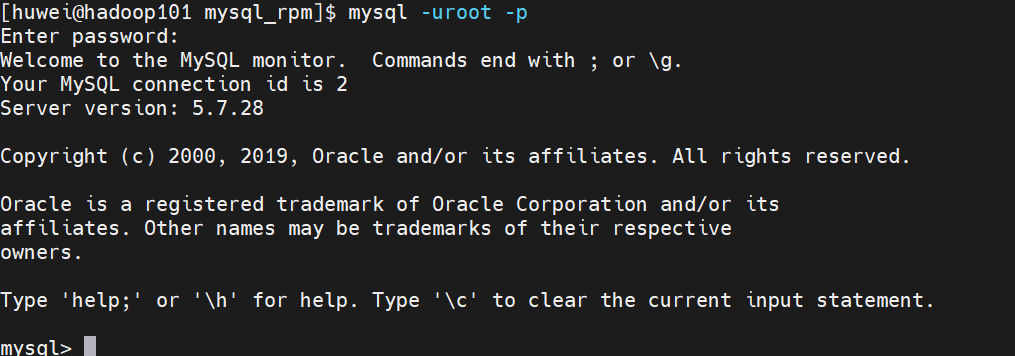
(9)必须先修改 root 用户的密码,否则执行其他的操作会报错
这里我将 root 用户的密码改为 root
mysql> set password = password("root");
(10)修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
此时我是在主机 hadoop101 上安装的 MySQL,如果我想在主机 hadoop102 上登录MySQL,是登录不上的
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
退出 MySQL 数据库
mysql> exit;
2 安装 Hive
(1)把 apache-hive-3.1.2-bin.tar.gz上传到 linux 的 /opt/software 目录下
(2)解压 apache-hive-3.1.2-bin.tar.gz 到 /opt/module/ 目录下面
[huwei@hadoop101 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
(3)修改 apache-hive-3.1.2-bin 的名称为 hive-3.1.2
[huwei@hadoop101 software]$ cd ../module/
[huwei@hadoop101 module]$ mv apache-hive-3.1.2-bin/ hive-3.1.2
(4)修改 /etc/profile.d/my_env.sh,添加环境变量
[huwei@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
使环境变量生效
[huwei@hadoop101 module]$ source /etc/profile
(5)解决日志Jar包冲突
[huwei@hadoop101 module]$ cd hive-3.1.2/lib/
[huwei@hadoop101 module]$ ll
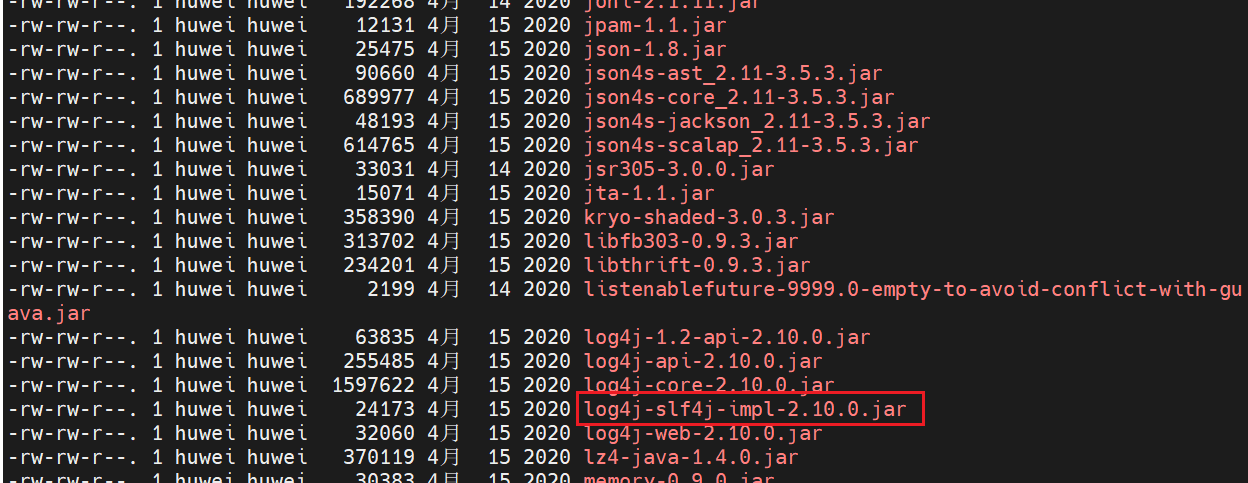
hive 工作时底层是基于 hadoop 的,hadoop 里也有日志的 jar 包,二者可能会有冲突,将 hive 中的
log4j-slf4j-impl-2.10.0.jar删除,在hive运行时直接使用 hadoop 提供的日志 jar 包。
[huwei@hadoop101 lib]$ rm -rf log4j-slf4j-impl-2.10.0.jar
3 Hive 元数据配置到 MySql
(1)在 $HIVE_HOME/conf目录下新建 hive-site.xml 文件
[huwei@hadoop101 ~]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
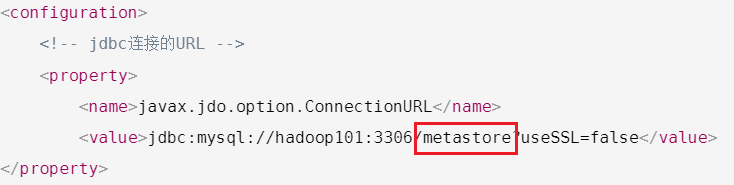
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false</value>
</property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value>
</property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- Hive元数据存储的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
(2)拷贝驱动
上传 JDBC 驱动至/opt/software/ ,然后将 MySql 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
[huwei@hadoop101 software]$ cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
(3)初始化元数据库
登录 mysql
[huwei@hadoop101 ~]$ mysql -uroot -proot
由于在 hive-site.xml 文件中指定了存放元数据的数据库 metastore
所以新建 Hive 元数据库 metastore
mysql> create database metastore;
Query OK, 1 row affected (0.01 sec)mysql> quit;
Bye
初始化 Hive 元数据库
[huwei@hadoop101 ~]$ schematool -initSchema -dbType mysql -verbose
4 启动 Hive
(1)启动 hadoop 集群
[huwei@hadoop101 ~]$ hdp_cluster.sh start
从下面三种启动方式中选择一种即可
(3)普通方式启动 hive
[huwei@hadoop101 ~]$ hive
(4)元数据服务方式启动 hive
hive的元数据是存在 MySql 里的,如果不使用元数据服务的话,hive直接会操作MySql里的元数据,使用元数据服务的话,hive会操作元数据服务,元数据服务再去操作 MySql 里的元数据
① 在 hive-site.xml 文件中添加如下配置信息
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/conf
[huwei@hadoop101 conf]$ vim hive-site.xml
<!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop101:9083</value></property>
② 启动 metastore
[huwei@hadoop101 ~]$ hive --service metastore
③ 新开启一个窗口,启动 hive
[huwei@hadoop101 ~]$ hive
(5)JDBC 方式启动 hive
这里是引用
① 在 hive-site.xml 文件中添加如下配置信息
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/conf
[huwei@hadoop101 conf]$ vim hive-site.xml
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop101</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
② 启动 hiveserver2
[huwei@hadoop101 ~]$ hive --service hiveserver2
③ 新开启一个窗口,启动 beeline 客户端
[huwei@hadoop101 conf]$ beeline -u jdbc:hive2://hadoop101:10000 -n huwei
注意:
-n后跟的是当前的用户名

(6)使用 hive
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test;
(7)编写启动 metastore 和 hiveserver2 脚本
前面第2、3种启动的方式导致需要打开多个 shell 窗口,编写启动 metastore 和 hiveserver2 脚本
[huwei@hadoop101 ~]$ cd bin
[huwei@hadoop101 bin]$ vim hiveservice.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
thenmkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)echo $pid[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}function hive_start()
{metapid=$(check_process HiveMetastore 9083)cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"server2pid=$(check_process HiveServer2 10000)cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}function hive_stop()
{metapid=$(check_process HiveMetastore 9083)[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"server2pid=$(check_process HiveServer2 10000)[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}case $1 in
"start")hive_start;;
"stop")hive_stop;;
"restart")hive_stopsleep 2hive_start;;
"status")check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常";;
*)echo Invalid Args!echo 'Usage: '$(basename $0)' start|stop|restart|status';;
esac
添加执行权限
[huwei@hadoop101 bin]$ chmod u+x hiveservice.sh
启动服务
[huwei@hadoop101 bin]$ hiveservice.sh start
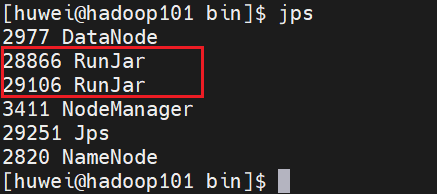
此时,我们发现有两个 RunJar 进程,就是hive服务进程了
相关文章:
Hive 的 安装与部署
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作…...
【HBase】——优化
1 RowKey设计 重要:一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于 哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度…...

什么是跨域以及怎么处理跨域问题
文章目录 什么是跨域?跨域问题常见场景怎么处理跨域1、配置代理2、CORS(跨域资源共享)3、JSONP(仅限 GET 请求)4、使用 WebSocket 注意事项: 什么是跨域? 跨域(Cross-Origin&#x…...

【Linux Shell】11. 输入/输出 重定向
文章目录 【 1. 重定向简介 】【 2. 输出重定向 】【 3. 输入重定向 】【 4. Here Document 】【 5. /dev/null 文件 】 【 1. 重定向简介 】 大多数 UNIX 系统命令从终端接受输入并将所产生的输出发送回到原来输入的终端。一个命令通常从标准输入的地方读取输入ÿ…...

数据库-简单表的操作And查看表的结构
查看表的结构 desc 表名;mysql> use study; Database changed mysql> create table Class(class_id int ,class_name varchar(128),class_teachar varchar(64)) ; Query OK, 0 rows affected (0.06 sec) mysql> show tables; ----------------- | Tables_in_study…...

<设计模式修炼>模板方法模式的使用场景和注意事项学习
介绍 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。 2) 简单说ÿ…...
android 分享文件
1.在AndroidManifest.xml 中配置 FileProvider <providerandroid:name"android.support.v4.content.FileProvider"android:authorities"com.example.caliv.ffyy.fileProvider"android:exported"false"android:grantUriPermissions"true…...
UE5 C++(十一)— 碰撞检测
文章目录 代理绑定BeginOverlap和EndOverlapHit事件的代理绑定碰撞设置 代理绑定BeginOverlap和EndOverlap 首先,创建自定义ActorC类 MyCustomActor 添加碰撞组件 #include "Components/BoxComponent.h"public:UPROPERTY(VisibleAnywhere, BlueprintRea…...

时序数据库InfluxDB、TimeScaleDB简介
一、时序数据库作用、优点 1、作用: 时序数据库通常被用在监控场景,比如运维和 IOT(物联网)领域。这类数据库旨在存储时序数据并实时处理它们。 比如。我们可以写一个程序将服务器上 CPU 的使用情况每隔 10 秒钟向 InfluxDB 中…...

复试 || 就业day05(2024.01.08)项目一
文章目录 前言代码模拟梯度下降构建函数与导函数函数的可视化求这个方程的最小值(直接求导)求方程最小值(不令方程导为0)【梯度下降】eta0.1eta 0.2eta 50eta 0.01画出eta0.1时的梯度下降x的变化过程 总结 前言 💫你…...

基于商品列表的拖拽排序后端实现
目录 一:实现思路 二:实现步骤 二:实现代码 三:注意点 一:实现思路 后台实现拖拽排序通常需要与前端进行配合,对商品的列表拖拽排序,前端需要告诉后端拖拽的元素和拖动的位置。 这里我们假…...
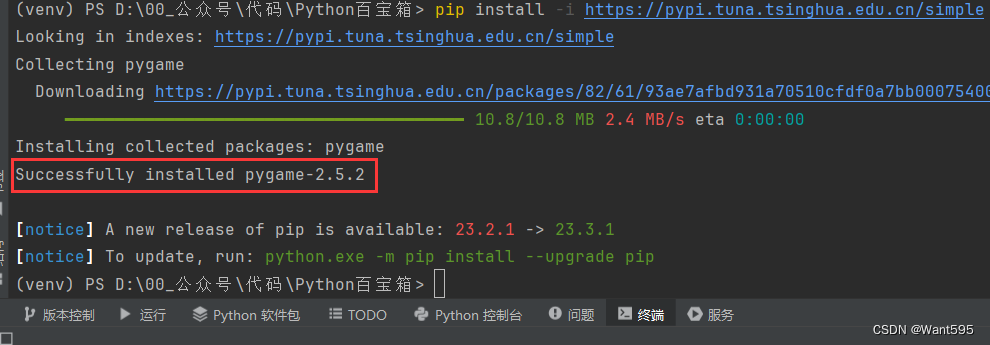
小游戏实战丨基于PyGame的贪吃蛇小游戏
文章目录 写在前面PyGame贪吃蛇注意事项系列文章写在后面 写在前面 本期内容:基于pygame的贪吃蛇小游戏 下载地址:https://download.csdn.net/download/m0_68111267/88700188 实验环境 python3.11及以上pycharmpygame 安装pygame的命令:…...
AOP(面向切面编程)基于XML方式配置
概念解释:(理解基本概念方可快速入手) 连接点(joinpoint) 被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法。 切入点(pointcut&#x…...
多线程的概念
多线程 同时执行多个任务,例如一个人一边听歌,一边跳舞 继承Thread类实现多线程的方式 定义一个MyThread类继承Thread类,重写里面的run方法 package com.itxs.demo01;/*** Classname : MyThread* Description : TODO 自定义线程继承Thread类*…...
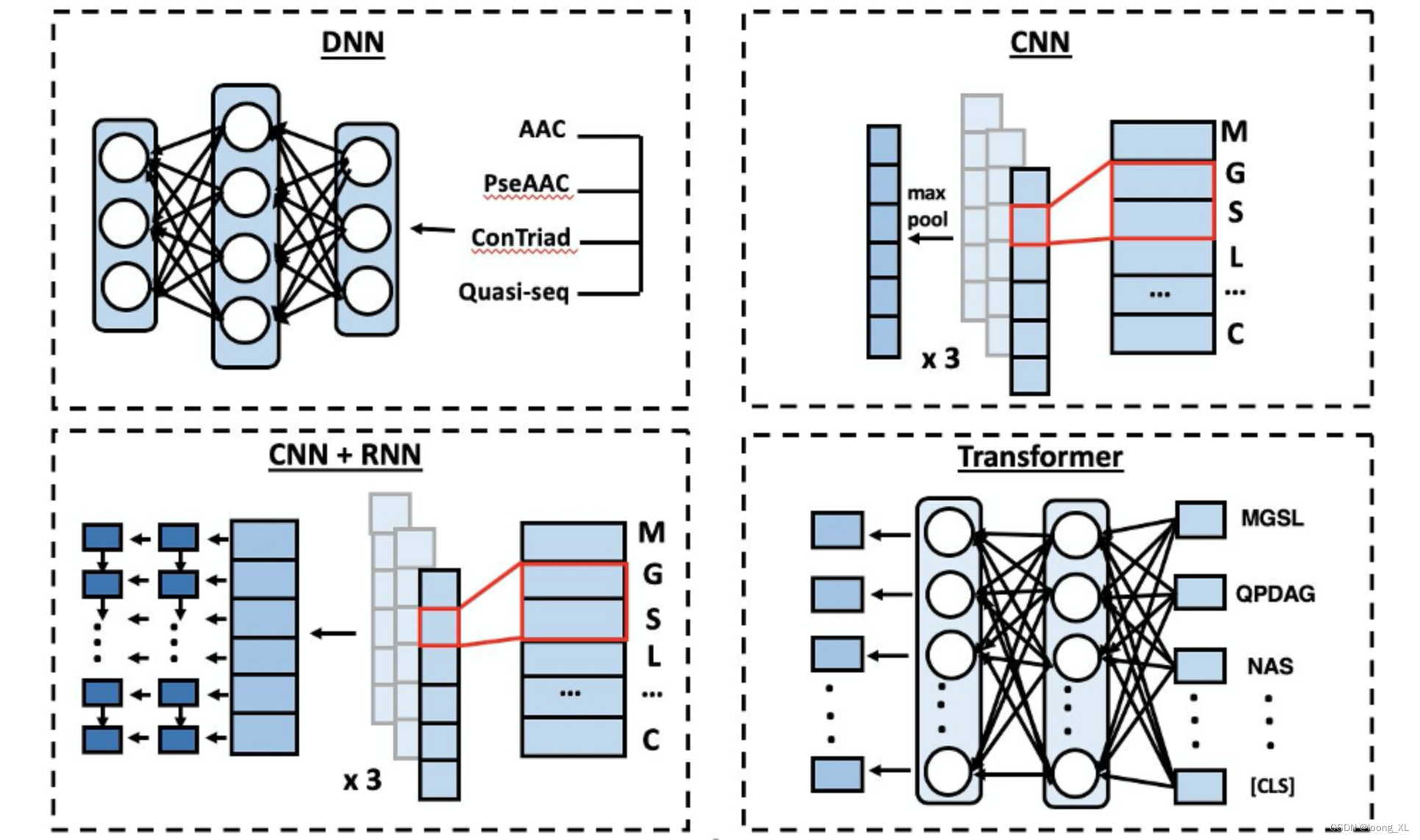
DeepPurpose 生物化学深度学习库;蛋白靶点小分子药物对接亲和力预测虚拟筛选
参考: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/107649770 https://github.com/kexinhuang12345/DeepPurpose ##安装 pip install DeepPurpose rdkitDeepPurpose包括: 数据: 关联TDC库下载,是同一作者开发的 https://blog.csdn.net/weixin_42357472/artic…...

Java实现责任链模式
责任链模式是一种设计模式,用于处理请求的解耦。在责任链模式中,多个对象都有机会处理请求,从而避免了请求发送者和接收者之间的直接依赖关系。每个处理者都可以决定是否处理请求以及将请求传递给下一个处理者。 简介 责任链模式由一条链组…...
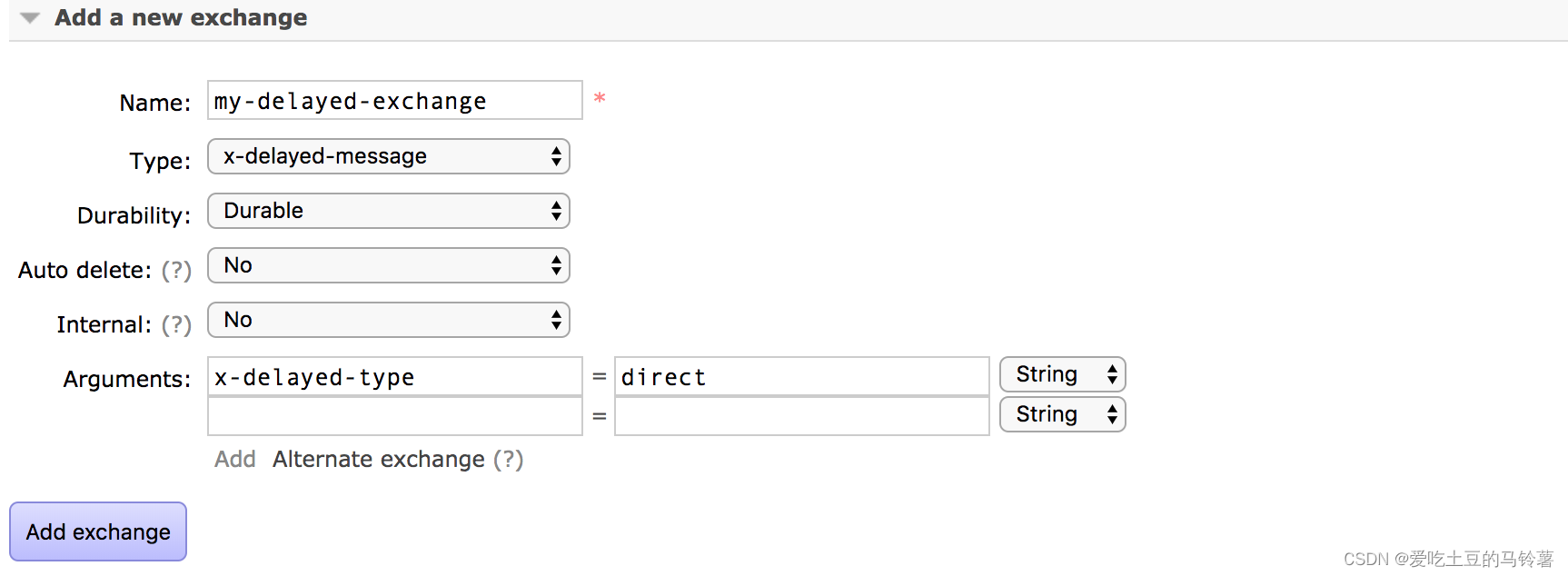
rabbitmq延时队列相关配置
确保 RabbitMQ 的延时消息插件已经安装和启用。你可以通过执行以下命令来安装该插件: rabbitmq-plugins enable rabbitmq_delayed_message_exchange 如果提示未安装,以下是安装流程: 查看mq版本: 查看自己使用的 MQ(…...

【工具】推荐一个好用的代码画图工具
PlantUML 官网地址:https://plantuml.com/zh/ 跳转 支持各种结构化数据画图支持代码调用jar包生成图片 提供在线画图能力 https://www.plantuml.com/plantuml/uml/SyfFKj2rKt3CoKnELR1Io4ZDoSa70000 有兴趣可以尝试下 over~~...
)
Leetcode14-判断句子是否为全字母句(1832)
1、题目 全字母句 指包含英语字母表中每个字母至少一次的句子。 给你一个仅由小写英文字母组成的字符串 sentence ,请你判断 sentence 是否为 全字母句 。 如果是,返回 true ;否则,返回 false 。 示例 1: 输入&am…...

HTTP和TCP代理原理及实现,主要是理解
Web 代理是一种存在于网络中间的实体,提供各式各样的功能。现代网络系统中,Web 代理无处不在。我之前有关 HTTP 的博文中,多次提到了代理对 HTTP 请求及响应的影响。今天这篇文章,我打算谈谈 HTTP 代理本身的一些原理,…...

GroundTruth-MCP:为AI生成代码构建实时事实核查防火墙
1. 项目概述:当AI助手自信地写出过时代码时你的AI助手刚刚又“自信满满”地给你生成了一堆过时的代码。它告诉你React 19里forwardRef用得没问题,Next.js 15的cookies()还是同步函数,或者用字符串模板拼接SQL查询“既简洁又高效”。更糟的是&…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...
)
Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图)
更多请点击: https://intelliparadigm.com 第一章:Sora 2生成素材在AE中频繁掉帧?20年合成老炮儿用CUDA Graph重构图层管线,性能提升3.8倍(含Profile对比图) 当Sora 2输出的4K/60fps高动态范围视频序列导入…...

无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略
无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略 【免费下载链接】Drone-Hacking-Tool Drone Hacking Tool is a GUI tool that works with a USB Wifi adapter and HackRF One for hacking drones. 项目地址: https://gitcode.com/gh_mirrors/dr/Dron…...
)
从‘Hello World’到打开PRT文件:一个完整的NX C++外部exe开发入门实战(VS2015 + NX12)
从‘Hello World’到打开PRT文件:一个完整的NX C外部exe开发入门实战(VS2015 NX12) 在工业设计领域,NX(原Unigraphics)作为一款功能强大的CAD/CAM/CAE软件,其二次开发能力为工程师提供了极大的…...

Neovim涂抹光标插件:提升编码体验的动态轨迹设计
1. 项目概述:一个为Neovim设计的“涂抹光标”插件 如果你和我一样,是个重度Neovim用户,每天有超过8小时的时间泡在终端和代码编辑器里,那你肯定对光标的“存在感”有要求。默认的方块或下划线光标,在长时间编码后&…...

ARM Firmware Suite与Integrator开发板嵌入式开发指南
1. ARM Firmware Suite与Integrator开发板概述ARM Firmware Suite(AFS)是ARM架构下专为嵌入式系统开发设计的固件套件,在Integrator系列开发板上发挥着核心作用。这套工具链最初由ARM Limited在1999-2002年间开发,至今仍在许多传统…...

[已解决]Vscode插件Keil Assistant连接Keil后出现的头文件路径无法寻找问题
问题详情 按照网络上的教程按照并且配置好vscode的Keil Assistant插件后,成功打开了Keil工程并且编译成功。但是头文件无法跳转,以及出现红色波浪线报错。 解决方法 在.vscode\c_cpp_properties.json中添加以下两行路径: "includePath&q…...

Cloudflare + PlanetScale:在边缘运行全栈应用,数据库也不例外
全栈开发者面对的一道老难题 Cloudflare Workers 解决了计算层的全球分发问题——你的代码跑在 Cloudflare 遍布全球的 300 多个数据中心里,离用户近,启动快,不需要管理任何服务器。 但数据不一样。 数据库天然是"有状态的"&#x…...

从服务器到手机:手把手教你修改游戏客户端IP,让私服在手机上跑起来
移动游戏私服客户端IP修改实战指南 当你在服务器上成功部署了游戏私服后,最令人沮丧的莫过于发现手机上的官方客户端无法连接到你的私人服务器。这个看似简单的"最后一公里"问题,往往成为许多私服搭建者的拦路虎。本文将彻底解决这个痛点&…...