Hadoop之mapreduce参数大全-2
25.指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间
mapreduce.reduce.shuffle.fetch.retry.timeout-ms是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间(以毫秒为单位)。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程称为fetch。由于网络问题或其他原因,fetch操作可能会失败。为了提高任务的容错能力,MapReduce框架会允许Reduce任务在fetch操作失败时进行重试。通过设置mapreduce.reduce.shuffle.fetch.retry.timeout-ms属性,可以指定在重试过程中的超时时间。
默认情况下,Reduce任务在fetch操作失败时会进行无限次的重试,直到成功获取数据或达到任务超时时间。通过将mapreduce.reduce.shuffle.fetch.retry.timeout-ms属性设置为一个正整数,可以指定在重试过程中的超时时间。例如,将该属性设置为10000毫秒的配置如下所示:
mapreduce.reduce.shuffle.fetch.retry.timeout-ms=10000
需要注意的是,设置合理的超时时间可以避免Reduce任务在shuffle阶段的fetch操作中无限重试,从而影响任务的执行效率。如果超时时间过短,可能会导致Reduce任务在shuffle阶段的fetch操作中获取不完整数据,从而影响任务的执行结果。如果超时时间过长,可能会导致Reduce任务在shuffle阶段的fetch操作中无限重试,从而影响任务的执行效率。因此,在设置mapreduce.reduce.shuffle.fetch.retry.timeout-ms属性时,需要根据具体情况进行调整和优化。
26.指定在Reduce任务在shuffle阶段的网络重试之间的最大延迟时间
mapreduce.reduce.shuffle.retry-delay.max.ms是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段的网络重试之间的最大延迟时间(以毫秒为单位)。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程可能会因为网络问题而失败。为了提高任务的容错能力,MapReduce框架会允许Reduce任务在网络重试之间有一定的延迟时间。通过设置mapreduce.reduce.shuffle.retry-delay.max.ms属性,可以指定在网络重试之间的最大延迟时间。
默认情况下,Reduce任务在网络重试之间的最大延迟时间为30秒。通过将mapreduce.reduce.shuffle.retry-delay.max.ms属性设置为一个正整数,可以指定在网络重试之间的最大延迟时间。例如,将该属性设置为120000毫秒(即2分钟)的配置如下所示:
mapreduce.reduce.shuffle.retry-delay.max.ms=120000
需要注意的是,设置合理的最大延迟时间可以平衡任务的容错能力和性能。如果最大延迟时间过短,可能会导致Reduce任务在shuffle阶段的网络重试中频繁地进行重试,从而影响任务的执行效率。如果最大延迟时间过长,可能会导致Reduce任务在shuffle阶段的网络重试中重试失败,从而影响任务的执行结果。因此,在设置mapreduce.reduce.shuffle.retry-delay.max.ms属性时,需要根据具体情况进行调整和优化。
27.指定在Reduce任务在shuffle阶段可以从一个Map任务同时获取数据的并发连接数
mapreduce.reduce.shuffle.parallelcopies是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段可以从一个Map任务同时获取数据的并发连接数。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。通过设置mapreduce.reduce.shuffle.parallelcopies属性,可以指定从一个Map任务同时获取数据的并发连接数。
默认情况下,Reduce任务可以从一个Map任务同时获取数据的并发连接数为2。通过将mapreduce.reduce.shuffle.parallelcopies属性设置为一个正整数,可以指定从一个Map任务同时获取数据的并发连接数。例如,将该属性设置为10的配置如下所示:
mapreduce.reduce.shuffle.parallelcopies=10
需要注意的是,设置合理的并发连接数可以平衡任务的网络带宽利用率和任务的执行效率。如果并发连接数过小,可能会导致Reduce任务在shuffle阶段的网络传输效率低下,从而影响任务的执行效率。如果并发连接数过大,可能会导致Reduce任务在shuffle阶段的网络带宽占用过高,从而影响其他任务的执行。因此,在设置mapreduce.reduce.shuffle.parallelcopies属性时,需要根据具体情况进行调整和优化。
28.指定在Reduce任务在shuffle阶段连接Map任务的超时时间
mapreduce.reduce.shuffle.connect.timeout是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段连接Map任务的超时时间(以毫秒为单位)。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。通过设置mapreduce.reduce.shuffle.connect.timeout属性,可以指定连接Map任务的超时时间。
默认情况下,Reduce任务连接Map任务的超时时间为5分钟(即300000毫秒)。通过将mapreduce.reduce.shuffle.connect.timeout属性设置为一个正整数,可以指定连接Map任务的超时时间。例如,将该属性设置为10分钟(即600000毫秒)的配置如下所示:
mapreduce.reduce.shuffle.connect.timeout=600000
需要注意的是,设置合理的超时时间可以避免Reduce任务在shuffle阶段的网络连接中无限等待,从而影响任务的执行效率。如果超时时间过短,可能会导致Reduce任务在shuffle阶段的网络连接中频繁地超时,从而影响任务的执行结果。如果超时时间过长,可能会导致Reduce任务在shuffle阶段的网络连接中无限等待,从而影响任务的执行效率。因此,在设置mapreduce.reduce.shuffle.connect.timeout属性时,需要根据具体情况进行调整和优化。
29.指定在Reduce任务在shuffle阶段从Map任务读取数据的超时时间
mapreduce.reduce.shuffle.read.timeout是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段从Map任务读取数据的超时时间(以毫秒为单位)。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。通过设置mapreduce.reduce.shuffle.read.timeout属性,可以指定从Map任务读取数据的超时时间。
默认情况下,Reduce任务从Map任务读取数据的超时时间为5分钟(即300000毫秒)。通过将mapreduce.reduce.shuffle.read.timeout属性设置为一个正整数,可以指定从Map任务读取数据的超时时间。例如,将该属性设置为10分钟(即600000毫秒)的配置如下所示:
mapreduce.reduce.shuffle.read.timeout=600000
需要注意的是,设置合理的超时时间可以避免Reduce任务在shuffle阶段的网络读取中无限等待,从而影响任务的执行效率。如果超时时间过短,可能会导致Reduce任务在shuffle阶段的网络读取中频繁地超时,从而影响任务的执行结果。如果超时时间过长,可能会导致Reduce任务在shuffle阶段的网络读取中无限等待,从而影响任务的执行效率。因此,在设置mapreduce.reduce.shuffle.read.timeout属性时,需要根据具体情况进行调整和优化。
30.指定在Reduce任务在shuffle阶段可以同时监听的Map任务数量
mapreduce.shuffle.listen.queue.size是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段可以同时监听的Map任务数量。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。Reduce任务会向Map任务发送网络连接请求,然后等待Map任务的响应。通过设置mapreduce.shuffle.listen.queue.size属性,可以指定Reduce任务可以同时监听的Map任务数量。
默认情况下,Reduce任务可以同时监听的Map任务数量为10。通过将mapreduce.shuffle.listen.queue.size属性设置为一个正整数,可以指定Reduce任务可以同时监听的Map任务数量。例如,将该属性设置为20的配置如下所示:
mapreduce.shuffle.listen.queue.size=20
需要注意的是,设置合理的监听队列大小可以平衡任务的网络连接效率和任务的执行效率。如果监听队列大小过小,可能会导致Reduce任务在shuffle阶段的网络连接效率低下,从而影响任务的执行效率。如果监听队列大小过大,可能会导致Reduce任务在shuffle阶段的网络连接过多,从而影响其他任务的执行。因此,在设置mapreduce.shuffle.listen.queue.size属性时,需要根据具体情况进行调整和优化。
31.指定在Reduce任务在shuffle阶段是否启用网络连接的Keep-Alive特性
mapreduce.shuffle.connection-keep-alive.enable是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段是否启用网络连接的Keep-Alive特性。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。通过设置mapreduce.shuffle.connection-keep-alive.enable属性,可以指定在Reduce任务在shuffle阶段是否启用网络连接的Keep-Alive特性。
默认情况下,Reduce任务在shuffle阶段启用网络连接的Keep-Alive特性。通过将mapreduce.shuffle.connection-keep-alive.enable属性设置为false,可以禁用网络连接的Keep-Alive特性。例如,将该属性设置为false的配置如下所示:
mapreduce.shuffle.connection-keep-alive.enable=false
需要注意的是,启用网络连接的Keep-Alive特性可以减少网络连接的建立和断开次数,从而提高任务的网络传输效率。但是,在某些网络环境下,禁用网络连接的Keep-Alive特性可以提高任务的网络传输稳定性。因此,在设置mapreduce.shuffle.connection-keep-alive.enable属性时,需要根据具体情况进行调整和优化。
32.指定在Reduce任务在shuffle阶段网络连接的Keep-Alive超时时间
mapreduce.shuffle.connection-keep-alive.timeout是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段网络连接的Keep-Alive超时时间(以毫秒为单位)。
在MapReduce任务中,Reduce任务在shuffle阶段需要从多个Map任务获取中间数据,这个过程是通过网络传输完成的。通过设置mapreduce.shuffle.connection-keep-alive.timeout属性,可以指定网络连接的Keep-Alive超时时间。
默认情况下,Reduce任务在网络连接的Keep-Alive超时时间为10秒(即10000毫秒)。通过将mapreduce.shuffle.connection-keep-alive.timeout属性设置为一个正整数,可以指定网络连接的Keep-Alive超时时间。例如,将该属性设置为20秒(即20000毫秒)的配置如下所示:
mapreduce.shuffle.connection-keep-alive.timeout=20000
需要注意的是,设置合理的Keep-Alive超时时间可以避免网络连接的Keep-Alive特性导致的网络资源浪费。如果超时时间过短,可能会导致网络连接频繁地断开和建立,从而影响任务的网络传输效率。如果超时时间过长,可能会导致网络连接的Keep-Alive特性占用过多的网络资源,从而影响其他任务的网络传输。因此,在设置mapreduce.shuffle.connection-keep-alive.timeout属性时,需要根据具体情况进行调整和优化。
33.指定任务执行的超时时间
mapreduce.task.timeout是Apache Hadoop MapReduce任务配置中的一个属性,用于指定任务执行的超时时间(以毫秒为单位)。
在MapReduce任务中,如果任务在指定的超时时间内没有完成,任务会被认为是超时并被终止执行。通过设置mapreduce.task.timeout属性,可以指定任务的超时时间。
默认情况下,任务的超时时间为无限长,即没有超时限制。通过将mapreduce.task.timeout属性设置为一个正整数,可以指定任务的超时时间。例如,将该属性设置为60000毫秒(即60秒)的配置如下所示:
mapreduce.task.timeout=60000
需要注意的是,设置合理的超时时间可以避免任务因为各种原因导致的无限执行状态,从而节省资源和提高系统的稳定性。如果超时时间过短,可能会导致正常执行的任务被错误地终止,从而影响任务的执行结果。如果超时时间过长,可能会导致系统资源的浪费。因此,在设置mapreduce.task.timeout属性时,需要根据具体情况进行调整和优化。
34.指定Map任务的内存上限
mapreduce.map.memory.mb是Hadoop YARN中的一个配置参数,用于指定Map任务的内存上限。
默认值为3840(即3.84 GB),表示每个Map任务可以使用的最大内存量为3.84 GB。您可以根据您的实际需求来调整这个值,以确保Map任务在运行时有足够的内存可用。
mapreduce.map.memory.mb=3840
请注意,增大此值可能会增加内存压力,导致YARN集群的性能下降。因此,在调整此参数时,请根据您的实际情况进行评估和测试。
35.指定Map任务的虚拟CPU核心数
mapreduce.map.cpu.vcores是Hadoop YARN中的一个配置参数,用于指定Map任务的虚拟CPU核心数。
默认值为1,表示每个Map任务将获得一个虚拟CPU核心。您可以根据实际需求来调整这个值,以确保Map任务在运行时具有足够的CPU资源。
mapreduce.map.cpu.vcores = 1
请注意,增大此值可能会增加CPU资源压力,导致YARN集群的性能下降。因此,在调整此参数时,请根据您的实际情况进行评估和测试。
36.设置Reduce任务可以使用的内存量
mapreduce.reduce.memory.mb是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务的内存大小(以MB为单位)。该参数用于设置Reduce任务可以使用的内存量,以满足Reduce任务在执行过程中的内存需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.memory.mb</name><value>2048</value> <!-- 设置Reduce任务的内存大小,单位为MB -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,过小的值可能会导致内存不足而影响任务的执行效率,过大的值可能会导致内存溢出而影响任务的稳定性。因此,需要根据实际情况进行适当的调整。
37.指定Reduce任务的CPU虚拟核心数
mapreduce.reduce.cpu.vcores是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务的CPU虚拟核心数。该参数用于设置Reduce任务可以使用的CPU核心数,以满足Reduce任务在执行过程中的CPU需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.cpu.vcores</name><value>4</value> <!-- 设置Reduce任务的CPU虚拟核心数 -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,过小的值可能会导致CPU资源不足而影响任务的执行效率,过大的值可能会导致浪费CPU资源而影响任务的效率。因此,需要根据实际情况进行适当的调整。
38.指定MapReduce任务使用的Java虚拟机参数
mapred.child.java.opts是Hadoop MapReduce中的一个配置参数,用于指定MapReduce任务使用的Java虚拟机参数。该参数用于设置任务子进程的Java虚拟机参数,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapred.child.java.opts</name><value>-Xmx2048m -Xms1024m -server</value> <!-- 设置任务子进程的Java虚拟机参数 -->
</property>
其中,-Xmx2048m表示最大堆内存大小为2048MB,-Xms1024m表示初始堆内存大小为1024MB,-server表示使用服务器模式运行JVM。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,过大的堆内存大小可能会导致内存溢出,过小的堆内存大小可能会导致任务无法正常运行。因此,需要根据实际情况进行适当的调整。同时,还可以根据任务的具体需求添加其他合适的Java虚拟机参数。
39.指定MapReduce任务使用的环境变量
mapred.child.env是Hadoop MapReduce中的一个配置参数,用于指定MapReduce任务使用的环境变量。该参数用于设置任务子进程的环境变量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapred.child.env</name><value>VAR1=value1 VAR2=value2</value> <!-- 设置任务子进程的环境变量 -->
</property>
其中,VAR1=value1表示设置环境变量VAR1的值为value1,VAR2=value2表示设置环境变量VAR2的值为value2。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,添加合适的环境变量可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的环境变量。
40.指定MapReduce任务的管理员用户环境变量
mapreduce.admin.user.env是Hadoop MapReduce中的一个配置参数,用于指定MapReduce任务的管理员用户环境变量。该参数用于设置管理员用户在执行MapReduce任务时的环境变量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.admin.user.env</name><value>VAR1=value1 VAR2=value2</value> <!-- 设置管理员用户的环境变量 -->
</property>
其中,VAR1=value1表示设置管理员用户的环境变量VAR1的值为value1,VAR2=value2表示设置管理员用户的环境变量VAR2的值为value2。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,添加合适的环境变量可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的环境变量。
41.指定MapReduce应用的Application Master的日志级别
yarn.app.mapreduce.am.log.level是YARN中的一个配置参数,用于指定MapReduce应用的Application Master的日志级别。该参数用于设置Application Master的日志输出级别,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>yarn.app.mapreduce.am.log.level</name><value>INFO</value> <!-- 设置Application Master的日志输出级别 -->
</property>
其中,INFO表示日志输出级别为INFO,还可以设置其他级别,例如DEBUG、WARN等。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的日志输出级别可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的日志级别。
42.指定Map任务的日志级别
mapreduce.map.log.level是Hadoop MapReduce中的一个配置参数,用于指定Map任务的日志级别。该参数用于设置Map任务的日志输出级别,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.map.log.level</name><value>INFO</value> <!-- 设置Map任务的日志输出级别 -->
</property>
其中,INFO表示日志输出级别为INFO,还可以设置其他级别,例如DEBUG、WARN等。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的日志输出级别可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的日志级别。
43.指定Reduce任务的日志级别
mapreduce.reduce.log.level是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务的日志级别。该参数用于设置Reduce任务的日志输出级别,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.log.level</name><value>INFO</value> <!-- 设置Reduce任务的日志输出级别 -->
</property>
其中,INFO表示日志输出级别为INFO,还可以设置其他级别,例如DEBUG、WARN等。
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的日志输出级别可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的日志级别。
44.指定Reduce任务中合并中间结果的内存阈值
mapreduce.reduce.merge.inmem阈值是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务中合并中间结果的内存阈值。该参数用于设置Reduce任务在合并中间结果时的最大内存使用量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.merge.inmem.threshold</name><value>1000</value> <!-- 设置Reduce任务合并中间结果的内存阈值,单位为MB -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的内存阈值可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的参数。
45.指定Reduce任务中合并Shuffle数据的百分比阈值
mapreduce.reduce.shuffle.merge.percent是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务中合并Shuffle数据的百分比阈值。该参数用于设置Reduce任务在合并Shuffle数据时的最大百分比使用量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.shuffle.merge.percent</name><value>0.5</value> <!-- 设置Reduce任务合并Shuffle数据的百分比阈值 -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的百分比阈值可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的参数。
46.指定Reduce任务中读取Shuffle数据时的缓冲区使用百分比
mapreduce.reduce.shuffle.input.buffer.percent是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务中读取Shuffle数据时的缓冲区使用百分比。该参数用于设置Reduce任务在读取Shuffle数据时的最大百分比使用量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.shuffle.input.buffer.percent</name><value>0.5</value> <!-- 设置Reduce任务读取Shuffle数据时的缓冲区使用百分比 -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的百分比值可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的参数。
47.指定Reduce任务中读取数据时的缓冲区使用百分比
mapreduce.reduce.input.buffer.percent是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务中读取数据时的缓冲区使用百分比。该参数用于设置Reduce任务在读取数据时的最大百分比使用量,以满足任务在执行过程中的需求。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.input.buffer.percent</name><value>0.5</value> <!-- 设置Reduce任务读取数据时的缓冲区使用百分比 -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的百分比值可以满足任务在执行过程中的需求。同时,还可以根据任务的具体需求添加其他合适的参数。
48.指定Reduce任务在进行Shuffle操作时的最大内存使用百分比
mapreduce.reduce.shuffle.memory.limit.percent是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务在进行Shuffle操作时的最大内存使用百分比。该参数用于限制Reduce任务在进行Shuffle操作时使用的内存大小,以防止内存溢出和提高任务的稳定性。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.shuffle.memory.limit.percent</name><value>0.5</value> <!-- 设置Reduce任务在进行Shuffle操作时的最大内存使用百分比 -->
</property>
需要注意的是,设置该参数的值需要根据实际的业务场景和集群配置进行调整,选择合适的最大内存使用百分比可以提高任务的稳定性和性能。同时,还可以根据任务的具体需求添加其他合适的参数。
49.指定是否启用Shuffle传输过程中的SSL加密
mapreduce.shuffle.ssl.enabled是Hadoop MapReduce中的一个配置参数,用于指定是否启用Shuffle传输过程中的SSL加密。该参数用于保障MapReduce任务中数据传输的安全性。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.ssl.enabled</name><value>true</value> <!-- 启用SSL加密 -->
</property>
需要注意的是,启用SSL加密需要在集群中安装合适的SSL证书,并根据实际情况进行配置。同时,还需要确保集群中的相关组件支持SSL加密。如果需要禁用SSL加密,可以将该参数的值设置为false。
50.指定Shuffle传输过程中使用的文件缓冲区大小
mapreduce.shuffle.ssl.file.buffer.size是Hadoop MapReduce中的一个配置参数,用于指定Shuffle传输过程中使用的文件缓冲区大小。该参数用于控制文件读写操作的缓存大小,以提高数据传输的效率。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.ssl.file.buffer.size</name><value>65536</value> <!-- 设置文件缓冲区大小为65536字节 -->
</property>
需要注意的是,文件缓冲区大小的设置需要根据集群的硬件配置和实际的传输需求进行调整。如果集群的硬件配置较高,可以适当增加文件缓冲区大小以提高数据传输的效率。如果集群的硬件配置较低,可以适当减小文件缓冲区大小以节省内存消耗。同时,还需要根据实际的传输需求进行调整,以达到最佳的传输性能。
51.指定Shuffle传输过程中可以同时连接的节点数
mapreduce.shuffle.max.connections是Hadoop MapReduce中的一个配置参数,用于指定Shuffle传输过程中可以同时连接的节点数。该参数用于控制Shuffle传输的并发度,以保障任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.max.connections</name><value>4096</value> <!-- 设置可以同时连接的节点数为4096 -->
</property>
需要注意的是,可以同时连接的节点数取决于集群的硬件配置和实际的传输需求。如果集群的硬件配置较高,可以适当增加可以同时连接的节点数以提高数据传输的并发度。如果集群的硬件配置较低,可以适当减小可以同时连接的节点数以避免过多的网络连接导致的性能问题。同时,还需要根据实际的传输需求进行调整,以达到最佳的传输性能。
52.指定Shuffle传输过程中可以同时处理的线程数
mapreduce.shuffle.max.threads是Hadoop MapReduce中的一个配置参数,用于指定Shuffle传输过程中可以同时处理的线程数。该参数用于控制Shuffle传输的并发度,以保障任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.max.threads</name><value>1024</value> <!-- 设置可以同时处理的线程数为1024 -->
</property>
需要注意的是,可以同时处理的线程数取决于集群的硬件配置和实际的传输需求。如果集群的硬件配置较高,可以适当增加可以同时处理的线程数以提高数据传输的并发度。如果集群的硬件配置较低,可以适当减小可以同时处理的线程数以避免过多的线程导致的性能问题。同时,还需要根据实际的传输需求进行调整,以达到最佳的传输性能。
53.指定是否允许使用File#transferTo()方法进行Shuffle数据传输
mapreduce.shuffle.transferTo.allowed是Hadoop MapReduce中的一个配置参数,用于指定是否允许使用File#transferTo()方法进行Shuffle数据传输。该参数用于控制Shuffle传输的方式,以保障任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.transferTo.allowed</name><value>true</value> <!-- 允许使用File#transferTo()方法进行Shuffle数据传输 -->
</property>
需要注意的是,使用File#transferTo()方法进行Shuffle数据传输可以提高数据传输的效率,但是如果集群的文件系统不支持直接File#transferTo(),可能会导致性能问题。如果集群的文件系统不支持直接File#transferTo(),可以将该参数的值设置为false,以使用其他的数据传输方式。同时,还需要根据实际的传输需求进行调整,以达到最佳的传输性能。
54.指定Shuffle传输过程中使用的缓冲区大小
mapreduce.shuffle.transfer.buffer.size是Hadoop MapReduce中的一个配置参数,用于指定Shuffle传输过程中使用的缓冲区大小。该参数用于控制Shuffle传输的缓冲区大小,以提高数据传输的效率。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.shuffle.transfer.buffer.size</name><value>524288</value> <!-- 设置缓冲区大小为524288字节 -->
</property>
需要注意的是,缓冲区大小的设置需要根据集群的硬件配置和实际的传输需求进行调整。如果集群的硬件配置较高,可以适当增加缓冲区大小以提高数据传输的效率。如果集群的硬件配置较低,可以适当减小缓冲区大小以节省内存消耗。同时,还需要根据实际的传输需求进行调整,以达到最佳的传输性能。
55.指定Reduce任务中读取数据时的标记和重置缓冲区大小的百分比
mapreduce.reduce.markreset.buffer.percent是Hadoop MapReduce中的一个配置参数,用于指定Reduce任务中读取数据时的标记和重置缓冲区大小的百分比。该参数用于控制Reduce任务在读取数据时的标记和重置操作的缓冲区大小,以提高数据读取的效率。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.markreset.buffer.percent</name><value>0.5</value> <!-- 设置标记和重置缓冲区大小的百分比为0.5 -->
</property>
需要注意的是,标记和重置缓冲区大小的百分比的设置需要根据集群的硬件配置和实际的读取需求进行调整。如果集群的硬件配置较高,可以适当增加标记和重置缓冲区大小的百分比以提高数据读取的效率。如果集群的硬件配置较低,可以适当减小标记和重置缓冲区大小的百分比以节省内存消耗。同时,还需要根据实际的读取需求进行调整,以达到最佳的读取性能。
56.指定是否启用 map speculative execution(推测执行)功能
mapreduce.map.speculative是Hadoop MapReduce中的一个配置参数,用于指定是否启用 speculative execution(推测执行)功能。该参数用于控制Map任务是否启用推测执行,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.map.speculative</name><value>true</value> <!-- 启用 speculative execution功能 -->
</property>
需要注意的是,启用推测执行功能可以提高任务的稳定性和性能,但是如果集群的负载较高,可能会导致额外的资源消耗。如果集群的负载较高,可以将该参数的值设置为false,以禁用推测执行功能。同时,还需要根据实际的负载情况和性能需求进行调整,以达到最佳的任务性能。
57.指定是否启用 reduce speculative execution(推测执行)功能
mapreduce.reduce.speculative是Hadoop MapReduce中的一个配置参数,用于指定是否启用 speculative execution(推测执行)功能。该参数用于控制Reduce任务是否启用推测执行,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.reduce.speculative</name><value>true</value> <!-- 启用 speculative execution功能 -->
</property>
需要注意的是,启用推测执行功能可以提高任务的稳定性和性能,但是如果集群的负载较高,可能会导致额外的资源消耗。如果集群的负载较高,可以将该参数的值设置为false,以禁用推测执行功能。同时,还需要根据实际的负载情况和性能需求进行调整,以达到最佳的任务性能。
58.指定启用 speculative execution(推测执行)功能时,允许的最大运行中任务数
mapreduce.job.speculative.speculative-cap-running-tasks是Hadoop MapReduce中的一个配置参数,用于指定启用 speculative execution(推测执行)功能时,允许的最大运行中任务数。该参数用于控制在启用推测执行功能时,允许的最大运行中任务数,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.speculative-cap-running-tasks</name><value>2</value> <!-- 允许的最大运行中任务数为2 -->
</property>
需要注意的是,允许的最大运行中任务数的设置需要根据集群的硬件配置和实际的性能需求进行调整。如果集群的硬件配置较高,可以适当增加允许的最大运行中任务数以提高任务的性能。如果集群的硬件配置较低,可以适当减小允许的最大运行中任务数以避免过多的资源消耗。同时,还需要根据实际的性能需求进行调整,以达到最佳的任务性能。
59.指定启用 speculative execution(推测执行)功能时,允许的最大任务数
mapreduce.job.speculative.speculative-cap-total-tasks是Hadoop MapReduce中的一个配置参数,用于指定启用 speculative execution(推测执行)功能时,允许的最大任务数。该参数用于控制在启用推测执行功能时,允许的最大任务数,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.speculative-cap-total-tasks</name><value>4</value> <!-- 允许的最大任务数为4 -->
</property>
需要注意的是,允许的最大任务数的设置需要根据集群的硬件配置和实际的性能需求进行调整。如果集群的硬件配置较高,可以适当增加允许的最大任务数以提高任务的性能。如果集群的硬件配置较低,可以适当减小允许的最大任务数以避免过多的资源消耗。同时,还需要根据实际的性能需求进行调整,以达到最佳的任务性能。
60.指定启用 speculative execution(推测执行)功能时,允许的最小任务数
mapreduce.job.speculative.minimum-allowed-tasks是Hadoop MapReduce中的一个配置参数,用于指定启用 speculative execution(推测执行)功能时,允许的最小任务数。该参数用于控制在启用推测执行功能时,允许的最小任务数,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.minimum-allowed-tasks</name><value>1</value> <!-- 允许的最小任务数为1 -->
</property>
需要注意的是,允许的最小任务数的设置需要根据集群的硬件配置和实际的性能需求进行调整。如果集群的硬件配置较高,可以适当增加允许的最小任务数以提高任务的性能。如果集群的硬件配置较低,可以适当减小允许的最小任务数以避免过多的资源消耗。同时,还需要根据实际的性能需求进行调整,以达到最佳的任务性能。
61.指定在启用 speculative execution(推测执行)功能时,如果没有进行推测执行的重试次数
mapreduce.job.speculative.retry-after-no-speculate是Hadoop MapReduce中的一个配置参数,用于指定在启用 speculative execution(推测执行)功能时,如果没有进行推测执行的重试次数。该参数用于控制在启用推测执行功能时,如果没有进行推测执行的重试次数,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.retry-after-no-speculate</name><value>2</value> <!-- 重试次数为2次 -->
</property>
需要注意的是,重试次数的设置需要根据集群的硬件配置和实际的性能需求进行调整。如果集群的硬件配置较高,可以适当增加重试次数以提高任务的性能。如果集群的硬件配置较低,可以适当减小重试次数以避免过多的资源消耗。同时,还需要根据实际的性能需求进行调整,以达到最佳的任务性能。
62.指定在启用 speculative execution(推测执行)功能时,如果进行推测执行失败的重试次数
mapreduce.job.speculative.retry-after-speculate是Hadoop MapReduce中的一个配置参数,用于指定在启用 speculative execution(推测执行)功能时,如果进行推测执行失败的重试次数。该参数用于控制在启用推测执行功能时,如果进行推测执行失败的重试次数,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.retry-after-speculate</name><value>3</value> <!-- 重试次数为3次 -->
</property>
需要注意的是,重试次数的设置需要根据集群的硬件配置和实际的性能需求进行调整。如果集群的硬件配置较高,可以适当增加重试次数以提高任务的性能。如果集群的硬件配置较低,可以适当减小重试次数以避免过多的资源消耗。同时,还需要根据实际的性能需求进行调整,以达到最佳的任务性能。
63.指定Map任务的输出收集器类
mapreduce.job.map.output.collector.class是Hadoop MapReduce中的一个配置参数,用于指定Map任务的输出收集器类。该参数用于控制Map任务的输出收集器的实现类,以实现Map任务的中间结果的收集和输出。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.map.output.collector.class</name><value>org.apache.hadoop.mapred.lib.IdentityMapOutputCollector</value> <!-- 设置为IdentityMapOutputCollector类 -->
</property>
需要注意的是,输出收集器类的设置需要根据实际的需求和中间结果的类型进行调整。不同的输出收集器类有不同的实现方式和功能,可以根据实际需求选择合适的输出收集器类。同时,还需要根据实际的Map任务逻辑和输出格式进行调整,以实现Map任务的正确输出。
64.指定启用 speculative execution(推测执行)功能时,判断任务节点是否为慢节点的阈值
mapreduce.job.speculative.slowtaskthreshold是Hadoop MapReduce中的一个配置参数,用于指定启用 speculative execution(推测执行)功能时,判断任务节点是否为慢节点的阈值。该参数用于控制在启用推测执行功能时,判断任务节点是否为慢节点的阈值,以提高任务的稳定性和性能。
可以通过以下方式设置该参数的值:
<property><name>mapreduce.job.speculative.slowtaskthreshold</name><value>60000</value> <!-- 阈值为60000毫秒 -->
</property>
需要注意的是,判断任务节点是否为慢节点的阈值的设置需要根据实际的性能需求和任务特点进行调整。如果阈值设置过小,可能会导致过多的慢节点被判断为快节点,从而影响推测执行的准确性和性能。如果阈值设置过大,可能会导致过多的快节点被判断为慢节点,从而影响推测执行的准确性和性能。因此,需要根据实际的性能需求和任务特点进行调整,以达到最佳的任务性能。
65.控制是否启用"ubertask"
mapreduce.job.ubertask.enable是Hadoop MapReduce框架中的一个配置属性。该属性用于控制是否启用"ubertask",ubertask是指将小规模的作业合并为一个单独的任务,以减少任务启动和执行的开销。
当mapreduce.job.ubertask.enable设置为true时,MapReduce框架将尝试将小型作业的Map和Reduce任务合并为一个单一的任务。这个任务会在本地运行,而不是在集群上启动独立的任务。这样,可以显著减少作业启动的开销,因为它无需为每个小任务启动独立的JVM(Java虚拟机)。
在一些特定的情况下,ubertask可以提高性能,特别是对于那些包含大量小型任务的作业。但对于大规模任务,ubertask可能会导致单个任务的执行时间过长,降低整体作业的性能。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.ubertask.enable:
<property><name>mapreduce.job.ubertask.enable</name><value>true</value> <!-- 或者 false,根据需要设置 -->
</property>
这样的配置可以在mapred-site.xml或mapred-default.xml等Hadoop配置文件中进行。当这个属性设置为true时,ubertask将被启用,否则将被禁用。
66.设置ubertask中最大的Map任务数
mapreduce.job.ubertask.maxmaps是Hadoop MapReduce框架中的一个配置属性,用于设置ubertask中最大的Map任务数。Ubertask是一种优化机制,它将小规模的Map和Reduce任务合并为一个单一的任务,以减少任务启动和执行的开销。
当mapreduce.job.ubertask.enable被设置为true时,可以使用mapreduce.job.ubertask.maxmaps来指定ubertask中最多允许的Map任务数。这个属性的值可以根据作业的性质和集群的配置进行调整。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.ubertask.maxmaps:
<property><name>mapreduce.job.ubertask.maxmaps</name><value>4</value> <!-- 设置为期望的最大Map任务数 -->
</property>
这个配置表示ubertask中最多允许4个Map任务。通过调整这个值,可以在满足作业需求的同时,控制ubertask中Map任务的规模。需要注意的是,这个值应该根据具体的作业和集群性能进行优化,以避免单个ubertask变得过于庞大,导致性能问题。
在使用ubertask时,还需要关注ubertask的大小对整个作业性能的影响,并根据实际情况进行调整。
67.设置ubertask中最大的Reduce任务数
mapreduce.job.ubertask.maxreduces是Hadoop MapReduce框架中的一个配置属性,用于设置ubertask中最大的Reduce任务数。Ubertask是一种优化机制,它将小规模的Map和Reduce任务合并为一个单一的任务,以减少任务启动和执行的开销。
当mapreduce.job.ubertask.enable被设置为true时,可以使用mapreduce.job.ubertask.maxreduces来指定ubertask中最多允许的Reduce任务数。这个属性的值可以根据作业的性质和集群的配置进行调整。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.ubertask.maxreduces:
<property><name>mapreduce.job.ubertask.maxreduces</name><value>2</value> <!-- 设置为期望的最大Reduce任务数 -->
</property>
这个配置表示ubertask中最多允许2个Reduce任务。通过调整这个值,可以在满足作业需求的同时,控制ubertask中Reduce任务的规模。需要注意的是,这个值应该根据具体的作业和集群性能进行优化,以避免单个ubertask变得过于庞大,导致性能问题。
在使用ubertask时,还需要关注ubertask的大小对整个作业性能的影响,并根据实际情况进行调整。
68.设置ubertask允许的最大字节数
mapreduce.job.ubertask.maxbytes是Hadoop MapReduce框架中的一个配置属性,用于设置ubertask允许的最大字节数。Ubertask是一种优化机制,它将小规模的Map和Reduce任务合并为一个单一的任务,以减少任务启动和执行的开销。
当mapreduce.job.ubertask.enable被设置为true时,可以使用mapreduce.job.ubertask.maxbytes来指定ubertask允许的最大字节数。这个属性的值可以根据作业的性质和集群的配置进行调整。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.ubertask.maxbytes:
<property><name>mapreduce.job.ubertask.maxbytes</name><value>5368709120</value> <!-- 设置为期望的最大字节数 -->
</property>
这个配置表示ubertask允许的最大字节数为5 GB。通过调整这个值,可以在满足作业需求的同时,控制ubertask的规模。需要注意的是,这个值应该根据具体的作业和集群性能进行优化,以避免单个ubertask变得过于庞大,导致性能问题。
在使用ubertask时,还需要关注ubertask的大小对整个作业性能的影响,并根据实际情况进行调整。
69.控制是否将作业的事件数据(timeline data)发送到Hadoop Timeline Service(ATS)
mapreduce.job.emit-timeline-data是Hadoop MapReduce框架中的一个配置属性,用于控制是否将作业的事件数据(timeline data)发送到Hadoop Timeline Service(ATS)。
Hadoop Timeline Service(ATS)是Hadoop生态系统中的一个组件,用于收集、存储和查询作业执行过程中产生的事件和元数据。通过ATS,用户可以了解作业的执行情况、任务的状态变化、任务的计数器等信息。
当mapreduce.job.emit-timeline-data配置属性被设置为true时,MapReduce框架会将作业产生的事件数据发送到ATS。这些事件数据包括作业启动、作业完成、任务启动、任务完成等事件,用于记录作业的执行过程和性能信息。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.emit-timeline-data:
<property><name>mapreduce.job.emit-timeline-data</name><value>true</value> <!-- 或者 false,根据需要设置 -->
</property>
如果设置为true,作业的事件数据将被发送到ATS,用户可以通过ATS的界面或API查询和分析这些数据。这对于作业的监控、性能调优以及故障排查都非常有帮助。
需要注意的是,如果集群中未启用ATS服务,或者配置不正确,即使将mapreduce.job.emit-timeline-data设置为true,也无法成功发送事件数据。因此,在启用这个配置属性之前,确保ATS服务已正确配置和运行。
70.设置共享缓存(Shared Cache)的模式
mapreduce.job.sharedcache.mode是Hadoop MapReduce框架中的一个配置属性,用于设置共享缓存(Shared Cache)的模式。共享缓存是Hadoop生态系统的一项功能,旨在提高任务的启动速度,减少资源冗余,以及更有效地利用集群资源。
以下是mapreduce.job.sharedcache.mode的可能值和解释:
- distributed: 这是默认值。在这个模式下,共享缓存中的资源会被分发到每个任务所在的节点,从而减少对共享缓存的集中依赖。这种模式适用于需要在每个节点上使用相同资源的场景,可以减少网络传输开销。
- centralized: 在这个模式下,共享缓存中的资源只会被放置在一个中心节点上,任务需要使用这些资源时会从中心节点拉取。这种模式适用于资源较大、集中管理的场景,可以减少每个节点上的存储开销。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.job.sharedcache.mode:
<property><name>mapreduce.job.sharedcache.mode</name><value>distributed</value> <!-- 或者 centralized,根据需要设置 -->
</property>
需要根据实际应用场景和集群配置来选择合适的共享缓存模式。使用共享缓存可以有效地减少任务启动时资源的加载时间,提高整个作业的执行效率。
71.设置FileInputFormat在生成输入切片(input split)时的最小切片大小
mapreduce.input.fileinputformat.split.minsize是Hadoop MapReduce框架中的一个配置属性,用于设置FileInputFormat在生成输入切片(input split)时的最小切片大小。
在MapReduce作业中,输入文件被切分成多个切片,每个切片对应一个Map任务。mapreduce.input.fileinputformat.split.minsize属性用于控制这些切片的最小大小,以确保切片不会太小而导致任务数量过多,从而影响整个作业的性能。
在Hadoop配置文件中,可以通过以下方式设置mapreduce.input.fileinputformat.split.minsize:
<property><name>mapreduce.input.fileinputformat.split.minsize</name><value>134217728</value> <!-- 设置为期望的最小切片大小 -->
</property>
上述配置中,mapreduce.input.fileinputformat.split.minsize的值为134217728字节(128 MB),表示生成的输入切片的最小大小为128 MB。可以根据实际需求和输入文件的特性调整这个值。
调整mapreduce.input.fileinputformat.split.minsize的值可能对作业性能有影响。设置过小的值可能导致切片数量过多,增加任务启动和管理的开销;而设置过大的值可能导致切片太大,无法充分利用集群中的并行性。因此,建议根据实际场景进行调优。
72.设置 FileInputFormat 在获取文件列表状态(list status)时使用的线程数量
mapreduce.input.fileinputformat.list-status.num-threads 是 Hadoop MapReduce 框架中的一个配置属性,用于设置 FileInputFormat 在获取文件列表状态(list status)时使用的线程数量。
在 MapReduce 作业中,FileInputFormat 用于生成输入切片(input split)。获取文件列表状态是指获取输入目录中的文件列表,以便将文件划分为适当大小的输入切片。为了提高获取文件列表状态的效率,Hadoop 提供了多线程的机制。
在 Hadoop 配置文件中,可以通过以下方式设置 mapreduce.input.fileinputformat.list-status.num-threads:
<property><name>mapreduce.input.fileinputformat.list-status.num-threads</name><value>8</value> <!-- 设置为期望的线程数量 -->
</property>
上述配置中,mapreduce.input.fileinputformat.list-status.num-threads 的值为 8,表示在获取文件列表状态时将使用 8 个线程。可以根据集群的性能和实际需求来调整线程数量。
注意:在调整该属性时,应该小心,确保不会超过系统的资源限制。设置合理的线程数量有助于提高获取文件列表状态的效率,但设置过多的线程可能会导致资源争夺和性能下降。因此,在调整任何与线程数相关的配置时,需要根据实际情况进行测试和优化。
73.设置 LineInputFormat 在生成输入切片(input split)时的行数
mapreduce.input.lineinputformat.linespermap 是 Hadoop MapReduce 框架中的一个配置属性,用于设置 LineInputFormat 在生成输入切片(input split)时的行数。
在 MapReduce 作业中,LineInputFormat 用于处理文本文件,将文件按行拆分为输入切片。mapreduce.input.lineinputformat.linespermap 允许用户指定每个输入切片包含的行数,从而控制生成的 Map 任务的数量。
在 Hadoop 配置文件中,可以通过以下方式设置 mapreduce.input.lineinputformat.linespermap:
<property><name>mapreduce.input.lineinputformat.linespermap</name><value>1000</value> <!-- 设置为期望的每个输入切片的行数 -->
</property>
上述配置中,mapreduce.input.lineinputformat.linespermap 的值为 1000,表示每个输入切片将包含大约 1000 行。这样可以通过控制每个切片的大小来影响 Map 任务的数量,进而影响整个作业的性能。
调整 mapreduce.input.lineinputformat.linespermap 的值可以在某种程度上优化 MapReduce 作业的性能。设置合理的行数有助于平衡任务的并行性和输入数据的划分,从而提高作业的整体效率。但需要注意,设置过小的值可能导致生成的切片数量过多,增加任务启动和管理的开销,而设置过大的值可能导致某些 Map 任务处理过大的数据块而效率降低。因此,选择合适的行数需要根据实际场景进行调优。
74.设置客户端提交的 MapReduce 作业相关文件的副本数
mapreduce.client.submit.file.replication 是 Hadoop MapReduce 框架中的一个配置属性,用于设置客户端提交的 MapReduce 作业相关文件的副本数。
在 MapReduce 作业中,客户端提交的文件包括作业的 JAR 文件、配置文件等。mapreduce.client.submit.file.replication 属性允许用户指定这些文件的副本数。副本数影响文件的冗余度和数据的可靠性,以及文件在 Hadoop 分布式文件系统(如 HDFS)中的存储情况。
在 Hadoop 配置文件中,可以通过以下方式设置 mapreduce.client.submit.file.replication:
<property><name>mapreduce.client.submit.file.replication</name><value>3</value> <!-- 设置为期望的文件副本数 -->
</property>
上述配置中,mapreduce.client.submit.file.replication 的值为 3,表示客户端提交的文件将被存储为 HDFS 副本数为 3 的文件。这样可以提高文件的可靠性,因为在某个节点不可用时,仍然可以从其他节点获取文件。
注意:在调整这个属性时,应该权衡副本数和存储成本。较大的副本数会增加存储成本和网络传输开销,但提高了数据的冗余度和可靠性。适当的副本数取决于集群的特性和需求,需要根据实际情况进行调整。
75.控制在 MapReduce 作业中,当任务失败时是否保留该任务的输出文件
mapreduce.task.files.preserve.failedtasks 是 Hadoop MapReduce 框架中的一个配置属性,用于控制在 MapReduce 作业中,当任务失败时是否保留该任务的输出文件。
在 MapReduce 作业中,当一个任务失败时,通常会重试该任务或者将失败的任务输出的临时文件删除。mapreduce.task.files.preserve.failedtasks 属性允许用户指定是否在任务失败时保留其输出文件。
在 Hadoop 配置文件中,可以通过以下方式设置 mapreduce.task.files.preserve.failedtasks:
<property><name>mapreduce.task.files.preserve.failedtasks</name><value>true</value> <!-- 或者 false,根据需要设置 -->
</property>
上述配置中,mapreduce.task.files.preserve.failedtasks 的值为 true,表示当任务失败时保留该任务的输出文件。如果设置为 false,则在任务失败时将删除该任务的输出文件。
保留失败任务的输出文件可能有助于调试任务失败的原因,但也会占用额外的存储空间。在实际应用中,可以根据需要进行设置。如果任务失败的原因容易通过日志等方式查找,可能可以将该属性设置为 false 以减少不必要的存储开销。
相关文章:

Hadoop之mapreduce参数大全-2
25.指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间 mapreduce.reduce.shuffle.fetch.retry.timeout-ms是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间(以毫秒为单位&#x…...
)
目标检测YOLO实战应用案例100讲-基于图像增强的鸟类目标检测(续)
目录 SRGAN网络模型改进研究 3.1 SRGAN超分辨率模型 3.1.1 SRGAN网络结构 3.1.2 SRGAN的损失函数...

MYSQL分表容量预估:简明指南
随着数据量的日益增长,分表技术成为优化mysql数据库性能的重要策略。本文介绍一种简明有效的预估分表容量大小的方法,帮助开发者和数据库管理员进行有效的资源规划。 背景 在处理大规模数据时,为了优化性能和管理便利,常常采用分…...
面试宝典进阶之Java线程面试题
T1、【初级】线程和进程有什么区别? (1)线程是CPU调度的最小单位,进程是计算分配资源的最小单位。 (2)一个进程至少要有一个线程。 (3)进程之间的内存是隔离的,而同一个…...
BOM简介
1.1 常用的键盘事件 1.1.1 键盘事件 键盘事件触发条件onkeydown按键被按下时触发onkeypress按键被按下时触发onkeyup按键被松开时触发 注意:addEventListener事件不需要加on <script>//1. keydown 按键按下的时候触发,按任意键都触发,也可以识…...

Java中的集合框架
概念与作用 集合概念 现实生活中:很多事物凑在一起 数学中的集合:具有共同属性的事物的总体 java中的集合类:是一种工具类,就像是容器,储存任意数量的具有共同属性的对象 在编程时,常常需要集中存放多个…...

Rustdesk打开Win10 下客户端下面服务不会自启,显示服务未运行
环境: Rustdesk1.19 问题描述: Rustdesk打开Win10 下客户端下面服务不会自启,显示服务未运行 解决方案: 1.查看源代码 pub async fn start_all() {crate::hbbs_http::sync::start();let mut nat_tested = false;check_zombie()...

【SPDK】【NoF】使用SPDK部署NVMe over TCP
SPDK NVMe over Fabrics Target是一个用户空间应用程序,通过以太网,Infiniband或光纤通道等结构呈现块设备,SPDK目前支持RDMA和TCP传输。 本文将在已经编译好SPDK的基础上演示如何使用SPDK搭建NVMe over TCP,前提是您已经将一块NVMe硬盘挂载…...

Spring boot 3 集成rocketmq-spring-boot-starter解决版本不一致问题
安装RocketMQ根据上篇文章使用Docker安装RocketMQ并启动之后,有个隐患详情见下文 Spring Boot集成 <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.2…...
--获取某度热榜)
python爬虫实战(6)--获取某度热榜
1. 项目描述 需要用到的类库 pip install requests pip install beautifulsoup4 pip install pandas pip install openpyxl然后,我们来编写python脚本,并引入需要的库: import requests from bs4 import BeautifulSoup import pandas as p…...

十三、K8S之亲和性
亲和性 一、概念 在K8S中,亲和性(Affinity)用来定义Pod与节点关系的概念,亲和性通过指定标签选择器和拓扑域约束来决定 Pod 应该调度到哪些节点上。与污点相反,它主要是尽量往某节点靠。 亲和性是 Kubernetes 中非常…...

对于网关的理解-Gateway
因为在使用微服务的时候,会有多端请求。会产生以下问题: 1.客户端需要记住每一个微服务的url 2.主机端口也会直接暴露 3.每一个微服务都需要认证 4.存在跨域问题 所以网关可以解决统一访问、隐藏真实的服务器地址、网关进行统一认证、解决跨域问题、…...

win10 - Snipaste截图工具的使用
win10 - Snipaste截图工具的使用 Step 1:下载 下载链接 提取码:wuv2 Step 2:直接解压可用 找到解压好的目录,并双击exe文件即可 Step 3:设置开机启动 在电脑右下角找到snipaste图标,右键,找…...
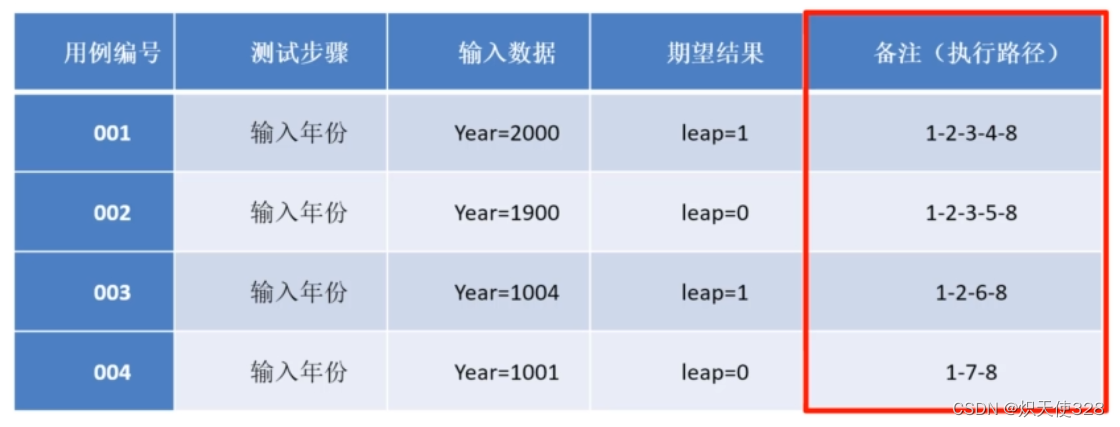
Selenium 学习(0.19)——软件测试之基本路径测试法——拓展案例
1、案例 请使用基本路径法为变量year设计测试用例,year的取值范围是1000<year<2001。代码如下: 2、步骤 先画控制流程图 再转化为控制流图(标出节点) V(G) 总区域数 4 V(G) E - N 2 (边数 - 节点数 2…...

工作记录-------正则表达式---小白也能看懂
什么是正则表达式 正则表达式是一种强大的工具,用于匹配和识别文本模式。 下面是一个基本的介绍: ^ 和 $: 这些是锚定字符,分别匹配字符串的开头和结尾。例如,^Hello匹配以 “Hello” 开头的字符串,end$匹配以 “en…...

C3-1.3.1 无监督学习——异常检测
C3-1.3.1 无监督学习——异常检测 1、举例:异常值检测示例——密度评估法 1.1 举一个例子 这里做的是 查看飞机发动机 异常检测: 左侧:X1 ,X2 … 是 可能会影响发动机状态的特征右侧: Dataset:训练数据集New engine…...

1.4.1机器学习——梯度下降+α学习率大小判定
1.4.1梯度下降 4.1、梯度下降的概念 ※【总结一句话】:系统通过自动的调节参数w和b的值,得到最小的损失函数值J。 如下:是梯度下降的概念图。 我们有一个损失函数 J(w,b),包含两个参数w和b(你可以想象成J(w,b) w*x…...

在IntelliJ IDEA中,.idea文件是什么,可以删除吗
相信有很多小伙伴,在用idea写java代码的时候,创建工程总是会出现.idea文件,该文件也从来没去打开使用过,那么它在我们项目里面,扮演什么角色,到底能不能删除它呢? 1、它是什么?有什么…...

【Spring Cloud】Gateway组件的三种使用方式
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《Spring Cloud》。🎯🎯 &am…...

对象的复制
方式一:sv 的new函数 trans tr1,tr2; malbox.get(tr2); tr1 new tr2;//仅用于浅拷贝,拷贝后tr1,tr2为两个独立的对象方式二:uvm 域的自动化常用函数:copy / clone / 使用前提: 1. 函数都可用于uvm_object类型&…...

【统计推断实战】从置信区间到假设检验:如何用数据做出可靠决策
1. 从产品迭代案例看统计推断的价值 最近团队上线了一个新功能,产品经理信心满满地宣称能提升15%的用户留存率。但上线一周后数据波动很大,有人觉得效果明显,有人却说毫无变化。这时候该信谁的?其实这就是统计推断大显身手的时刻—…...

Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧
Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧 Kubescape是一款开源的Kubernetes安全平台,专为IDE、CI/CD管道和集群设计,提供风险分析、安全合规检查和错误配置扫描功能,帮助Kubernetes用户和管理员节省宝…...

PortAudio性能测试与调优:如何实现最低延迟音频处理的完整指南
PortAudio性能测试与调优:如何实现最低延迟音频处理的完整指南 【免费下载链接】portaudio PortAudio is a cross-platform, open-source C language library for real-time audio input and output. 项目地址: https://gitcode.com/gh_mirrors/po/portaudio …...

ARM HCR_EL2寄存器解析与虚拟化控制
1. ARM HCR_EL2寄存器架构解析HCR_EL2(Hypervisor Configuration Register)是ARMv8/v9架构中用于控制虚拟化行为的关键系统寄存器。作为Hypervisor的主要控制接口,它定义了EL2对低特权级(EL1/EL0)执行环境的监控策略。…...

为什么你的Ziatype输出总是发灰?3分钟定位CMYK→RGB色域坍缩根源并一键修复
更多请点击: https://intelliparadigm.com 第一章:Ziatype印相发灰现象的直观诊断与认知重构 Ziatype是一种基于铁-银工艺的古典摄影印相法,其典型特征是高对比度、深沉黑位与细腻中间调。然而在实际操作中,“发灰”(…...

解密智能工具:3步实现Windows高效安装Android应用
解密智能工具:3步实现Windows高效安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字生活日益融合的今天,你是否曾为Windows…...

Alph:一键统一配置AI编程助手MCP服务器的命令行工具
1. 项目概述:告别手动配置的混乱时代 如果你和我一样,日常开发中同时用着 Cursor、Claude Code、Gemini CLI 这些 AI 编程助手,那你一定对下面这个场景深恶痛绝:每次想给它们接入一个新的 MCP 服务器,都得像个考古学家…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...

Spratt Skills:基于LLM规划与代码执行的OpenClaw家庭自动化架构实践
1. 项目概述:Spratt Skills,一个为OpenClaw打造的家庭自动化基础设施套件 如果你正在使用OpenClaw,并且已经厌倦了让LLM(大语言模型)去处理那些它天生就不擅长的事情——比如定时发送消息、轮询航班状态、或者可靠地写…...

长期使用Taotoken Token Plan套餐带来的成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐带来的成本控制感受 1. 从按需付费到预算规划 对于个人开发者或小型团队而言,大模型…...