golang实现skiplist 跳表
跳表
package mainimport ("errors""math""math/rand"
)func main() {// 双向链表///**先理解查找过程Level 3: 1 6Level 2: 1 3 6Level 1: 1 2 3 4 6比如 查找2 ; 从高层往下找;如果查找的值比当前值小 说明没有可查找的值2比1大 往当前层的下个节点查找,3层的后面没有了或者比后面的6小 ,往下层找2层 查找值比下个节点3还小 往下层找最后一层找到比如查找 4没有找到 3层往下到2层; 2层里 4比3大继续往前,比6小,往下层找从第一层的继续往前找比如查找 5第一层的3开始往前找到6比查找值5大,说明没有待查找值*//**插入流程找到插入的位置确定他当前的层数在他的层数连接当前节点如何确定层数?来一个概率的算法就行这样在数量大的时候能基本能达到2分查找的效果(概率是1/2)更新索引数组?我们在查找的时候的路径就可以拿来做插入的数据比如查找4找的路径是 3层的 1,2层的3 ;如果4是第三层的更新3层 1->4>6更新2层 1->3->4->6*//**删除流程 基本同上*//***/}// MAX_LEVEL 最高层数
const MAX_LEVEL = 16type T comparabletype skipListHandle[T comparable] interface {insert(data T, score int32) (err error)delete(data T, score int32) intfindNode(data T, score int32) (error, *skipListNode[T])
}type skipListNode[T comparable] struct {data T// 排序分数score int32//层高level int// 下个节点 同时也是索引forwards []*skipListNode[T]
}type skipList[T comparable] struct {head, tail *skipListNode[T]// 跳表高度level int// 跳表长度length int32
}func createSkipList[T comparable](data T) *skipList[T] {return &skipList[T]{level: 1,length: 0,head: createNode[T](data, math.MinInt32, MAX_LEVEL),}
}func createNode[T comparable](data T, score int32, level int) *skipListNode[T] {return &skipListNode[T]{data: data,score: score,forwards: make([]*skipListNode[T], MAX_LEVEL, MAX_LEVEL),level: level,}
}
func (list *skipList[T]) Insert(data T, score int32) error {currenNode := list.head// 找到插入的位置// 记录插入的路径 记录第一个比待查找的值小的位置path := [MAX_LEVEL]*skipListNode[T]{}for i := MAX_LEVEL - 1; i >= 0; i-- {for currenNode.forwards[i] != nil {// 如果插入的位置比当前数据小 直接跳出循环并且高度下降if currenNode.forwards[i].score > score {path[i] = currenNodebreak}// 插入位置比当前的大,在当前层继续往前找currenNode = currenNode.forwards[i]}// 如果currenNode.forwards[i] == nil 说明是最后一个值了 所以直接插入if currenNode.forwards[i] == nil {path[i] = currenNode}}// 随机算法求得最大层数level := 1for i := 1; i < MAX_LEVEL; i++ {if rand.Int31()%7 == 1 {level++}}newNode := createNode(data, score, level)// 原有节点连接for i := 0; i <= level-1; i++ {next := path[i].forwards[i]// path[i]拿到第一个插入值小的位置 forwards[i] 是指在当前层它指向的下个节点newNode.forwards[i] = nextpath[i].forwards[i] = newNode}// 更新levelif level > list.level {list.level = level}list.length++return errors.New("插入失败")
}func (list *skipList[T]) Delete(data T, score int32) int {currenNode := list.head// 找到插入的位置// 记录插入的路径 记录第一个比待查找的值小的位置path := [MAX_LEVEL]*skipListNode[T]{}for i := list.level - 1; i >= 0; i-- {path[i] = list.headfor currenNode.forwards[i] != nil {// 記錄刪除的位置if currenNode.forwards[i].score == score && currenNode.forwards[i].data == data {path[i] = currenNodebreak}// 插入位置比当前的大,在当前层继续往前找currenNode = currenNode.forwards[i]}}currenNode = path[0].forwards[0]for i := currenNode.level - 1; i >= 0; i-- {if path[i] == list.head && currenNode.forwards[i] == nil {list.level = i}if nil == path[i].forwards[i] {path[i].forwards[i] = nil} else {path[i].forwards[i] = path[i].forwards[i].forwards[i]}}list.length--return 0
}func (list skipList[T]) FindNode(v T, score int32) (err error, node *skipListNode[T]) {cur := list.headfor i := list.level - 1; i >= 0; i-- {for nil != cur.forwards[i] {if cur.forwards[i].score == score && cur.forwards[i].data == v {return nil, cur.forwards[i]} else if cur.forwards[i].score > score {break}cur = cur.forwards[i]}}return errors.New("请传入查找的值"), nil
}测试
package mainimport ("testing"
)func Test_createNode(t *testing.T) {sl := createSkipList[int](0)sl.Insert(1, 95)t.Log(sl.head.forwards[0])t.Log(sl.head.forwards[0].forwards[0])t.Log(sl)t.Log("-----------------------------")sl.Insert(2, 88)t.Log(sl.head.forwards[0])t.Log(sl.head.forwards[0].forwards[0])t.Log(sl.head.forwards[0].forwards[0].forwards[0])t.Log(sl)t.Log("-----------------------------")sl.Insert(3, 100)t.Log(sl.head.forwards[0])t.Log(sl.head.forwards[0].forwards[0])t.Log(sl.head.forwards[0].forwards[0].forwards[0])t.Log(sl.head.forwards[0].forwards[0].forwards[0].forwards[0])t.Log(sl)t.Log("-----------------------------")t.Log(sl.FindNode(2, 88))t.Log("-----------------------------")sl.Delete(1, 95)t.Log(sl.head.forwards[0])t.Log(sl.head.forwards[0].forwards[0])t.Log(sl.head.forwards[0].forwards[0].forwards[0])t.Log(sl)t.Log("-----------------------------")
}相关文章:

golang实现skiplist 跳表
跳表 package mainimport ("errors""math""math/rand" )func main() {// 双向链表///**先理解查找过程Level 3: 1 6Level 2: 1 3 6Level 1: 1 2 3 4 6比如 查找2 ; 从高层往下找;如果查找的值比当前值小 说明没有可查找的值2比1大 往当前…...
尝试OmniverseFarm的最基础操作
目标 尝试OmniverseFarm的最基础操作。本地机器作为Queue和Agent,同时在本地提交任务。 主要参考了官方文档: Farm Queue — Omniverse Farm latest documentation Farm Agent — Omniverse Farm latest documentation Farm Examples — Omniverse Far…...
)
第28关 k8s监控实战之Prometheus(二)
------> 课程视频同步分享在今日头条和B站 大家好,我是博哥爱运维。 这节课我们用prometheus-operator来安装整套prometheus服务 https://github.com/prometheus-operator/kube-prometheus/releases 开始安装 1. 解压下载的代码包 wget https://github.com/…...

基于 SpringBoot + magic-api + Vue3 + Element Plus + amis3.0 快速开发管理系统
Tansci-Boot 基于 SpringBoot2 magic-api Vue3 Element Plus amis3.0 快速开发管理系统 Tansci-Boot 是一个前后端分离后台管理系统, 前端集成 amis 低代码前端框架,后端集成 magic-api 的接口快速开发框架。包含基础权限、安全认证、以及常用的一…...

Kafka(四)Broker
目录 1 配置Broker1.1 Broker的配置broker.id0listererszookeeper.connectlog.dirslog.dir/tmp/kafka-logsnum.recovery.threads.per.data.dir1auto.create.topics.enabletrueauto.leader.rebalance.enabletrue, leader.imbalance.check.interval.seconds300, leader.imbalance…...

代码随想录第五十二天——最长递增子序列,最长连续递增序列,最长重复子数组
leetcode 300. 最长递增子序列 题目链接:最长递增子序列 dp数组及下标的含义 dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度递推公式 位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 1 的最大值 所以if (nums[i] > nums[j]) dp[i]…...
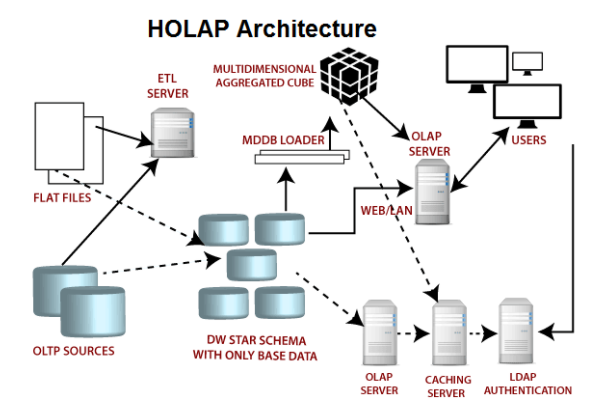
【大数据架构】OLAP实时分析引擎选型
OLAP引擎面临的挑战 常见OLAP引擎对比 OLAP分析场景中,一般认为QPS达到1000就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1…...
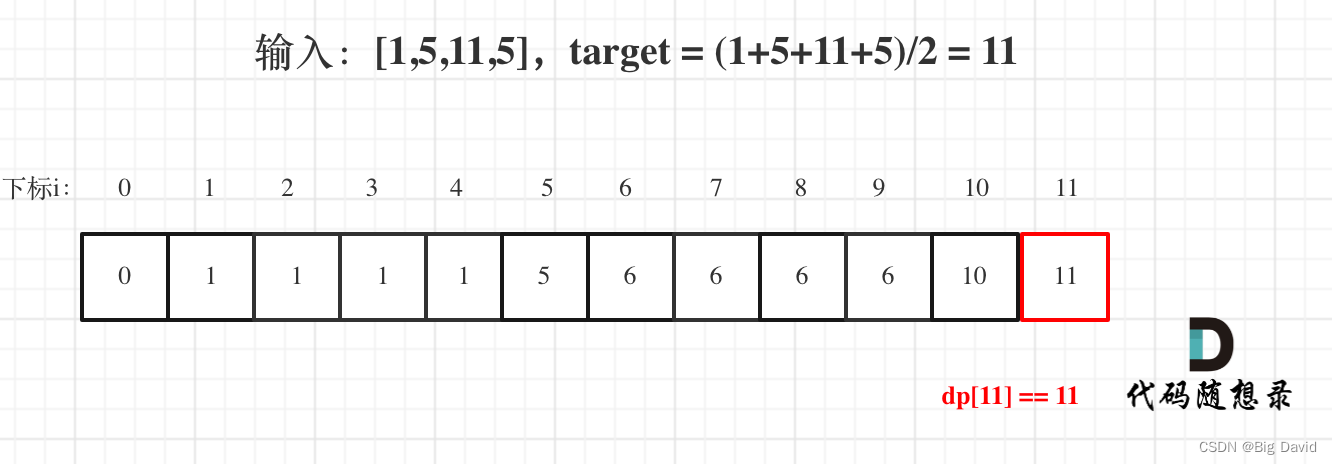
代码随想录刷题题Day29
刷题的第二十九天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀 刷题语言:C Day29 任务 ● 01背包问题,你该了解这些! ● 01背包问题,你该了解这些! 滚动数组 …...
CVE-2023-51385 OpenSSH ProxyCommand命令注入漏洞
一、背景介绍 ProxyCommand 是 OpenSSH ssh_config 文件中的一个配置选项,它允许通过代理服务器建立 SSH 连接,从而在没有直接网络访问权限的情况下访问目标服务器。这对于需要经过跳板机、堡垒机或代理服务器才能访问的目标主机非常有用。 二、漏洞简…...

如何寻找到相对完整的真正的游戏的源码 用来学习?
在游戏开发的学习之路上,理论与实践是并重的两个方面。对于许多热衷于游戏开发的学习者来说,能够接触到真实的、完整的游戏源码无疑是一个极好的学习机会。但问题来了:我们该如何寻找到这些珍贵的资源呢? 开源游戏项目 GitHub:地…...
数模学习day11-系统聚类法
本文参考辽宁石油化工大学于晶贤教授的演示文档聚类分析之系统聚类法及其SPSS实现。 目录 1.样品与样品间的距离 2.指标和指标间的“距离” 相关系数 夹角余弦 3.类与类间的距离 (1)类间距离 (2)类间距离定义方式 1.最短…...

SpringBoot+Redis实现接口防刷功能
场景描述: 在实际开发中,当前端请求后台时,如果后端处理比较慢,但是用户是不知情的,此时后端仍在处理,但是前端用户以为没点到,那么再次点击又发起请求,就会导致在短时间内有很多请求…...

TensorRT加速推理入门-1:Pytorch转ONNX
这篇文章,用于记录将TransReID的pytorch模型转换为onnx的学习过程,期间参考和学习了许多大佬编写的博客,在参考文章这一章节中都已列出,非常感谢。 1. 在pytorch下使用ONNX主要步骤 1.1. 环境准备 安装onnxruntime包 安装教程可…...

springboot常用扩展点
当涉及到Spring Boot的扩展和自定义时,Spring Boot提供了一些扩展点,使开发人员可以根据自己的需求轻松地扩展和定制Spring Boot的行为。本篇博客将介绍几个常用的Spring Boot扩展点,并提供相应的代码示例。 1. 自定义Starter(面试常问) Sp…...
19道ElasticSearch面试题(很全)
点击下载《19道ElasticSearch面试题(很全)》 1. elasticsearch的一些调优手段 1、设计阶段调优 (1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引; (…...

向爬虫而生---Redis 拓宽篇3 <GEO模块>
前言: 继上一章: 向爬虫而生---Redis 拓宽篇2 <Pub/Sub发布订阅>-CSDN博客 这一章的用处其实不是特别大,主要是针对一些地图和距离业务的;就是Redis的GEO模块。 GEO模块是Redis提供的一种高效的地理位置数据管理方案,它允许我们存储和查询…...

Vue项目里实现json对象转formData数据
平常调用后端接口传参都是json对象,当提交表单遇到有附件需要传递时,通常是把附件上传单独做个接口,也有遇到后端让提交接口一并把附件传递到后端,这种情况需要把参数转成formData的数据,需要用到new FormData()。json…...

leetcode刷题记录
栈 2696. 删除子串后的字符串最小长度 哈希表 1. 两数之和 用map来保存每个数和他的索引 383. 赎金信 用map来存储字符的个数 链表 2. 两数相加 指针的移动 动态规划 53. 最大子数组和 2707. 字符串中的额外字符 递归 101. 对称二叉树 数学 1276. 不浪费原料的汉堡…...
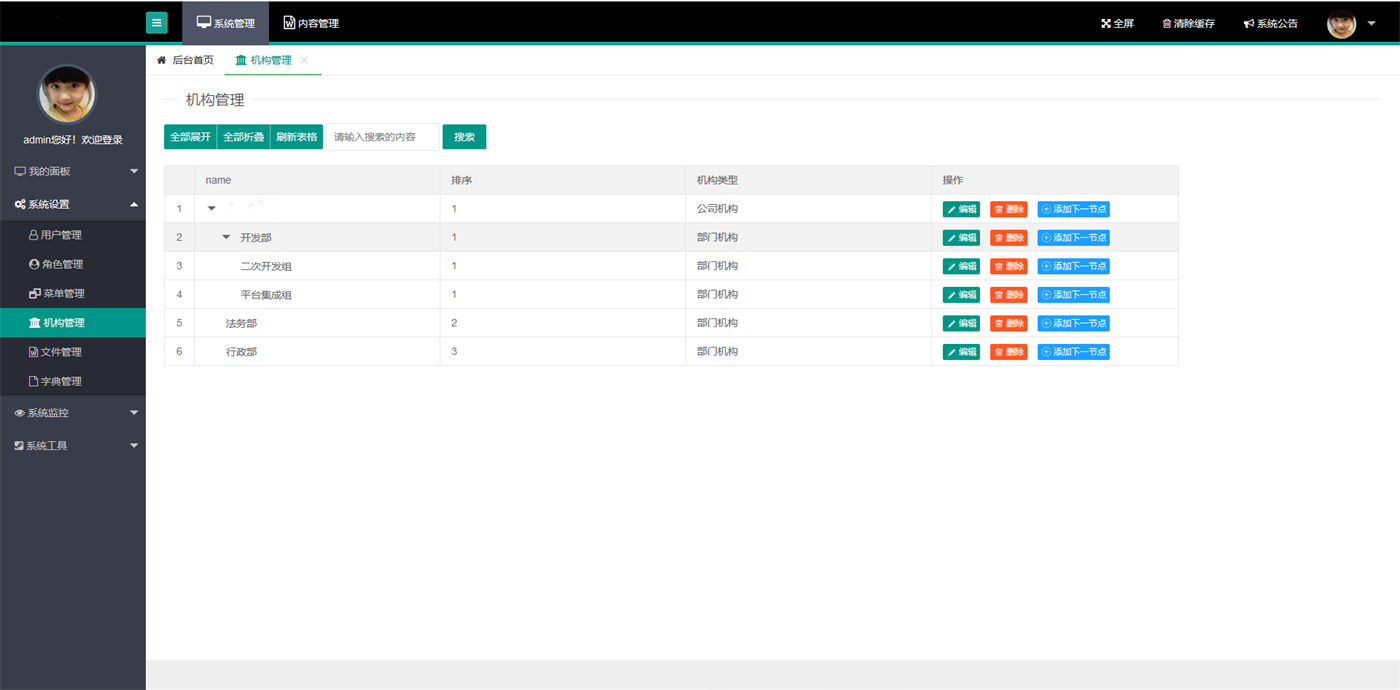
SpringMVC通用后台管理系统源码
整体的SSM后台管理框架功能已经初具雏形,前端界面风格采用了结构简单、 性能优良、页面美观大的Layui页面展示框架 数据库支持了SQLserver,只需修改配置文件即可实现数据库之间的转换。 系统工具中加入了定时任务管理和cron生成器,轻松实现系统调度问…...

深度解析Dubbo的基本应用与高级应用:负载均衡、服务超时、集群容错、服务降级、本地存根、本地伪装、参数回调等关键技术详解
负载均衡 官网地址: http://dubbo.apache.org/zh/docs/v2.7/user/examples/loadbalance/ 如果在消费端和服务端都配置了负载均衡策略, 以消费端为准。 这其中比较难理解的就是最少活跃调用数是如何进行统计的? 讲道理, 最少活跃数…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查
告别时间混乱:一份超全的Hive日期函数使用手册与常见错误排查 在数据开发领域,时间数据处理一直是高频且易错的环节。无论是日志分析、用户行为追踪还是财务报表生成,准确的时间计算都是确保数据质量的基础。Hive作为大数据生态中广泛使用的数…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

Pandrator:基于Python的自动化内容生成与数据转换工具实践
1. 项目概述与核心价值最近在折腾一些自动化数据处理和内容生成的工作流,发现了一个挺有意思的开源项目,叫Pandrator。乍一看这个名字,可能会联想到“潘多拉”和“生成器”的结合,实际上它也确实是一个功能强大的内容转换与生成工…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...