Postgresql常见(花式)操作完全示例
案例说明
将Excel数据导入Postgresql,并实现常见统计(数据示例如下)
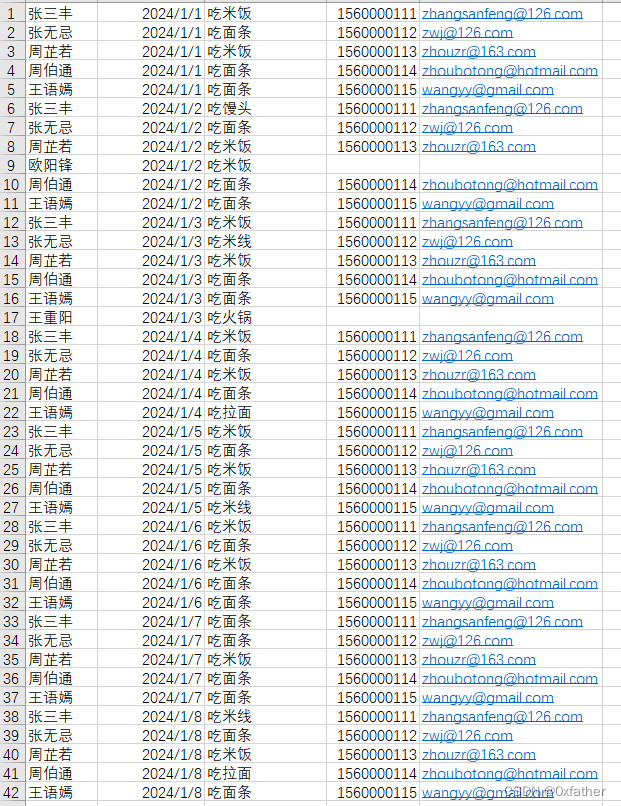
导入Excel数据到数据库
使用Navicat工具连接数据库,使用导入功能可直接导入,此处不做过多介绍,详细操作请看下图:
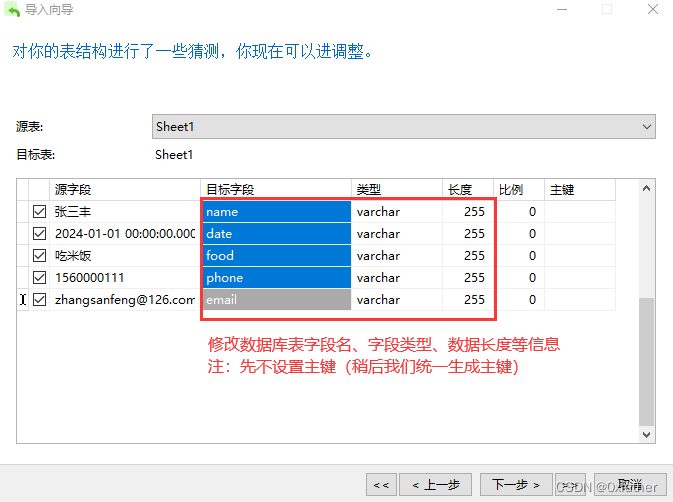
点击“下一步”完成导入操作(导入完成后,我们将表名命名为“eatLog”)。
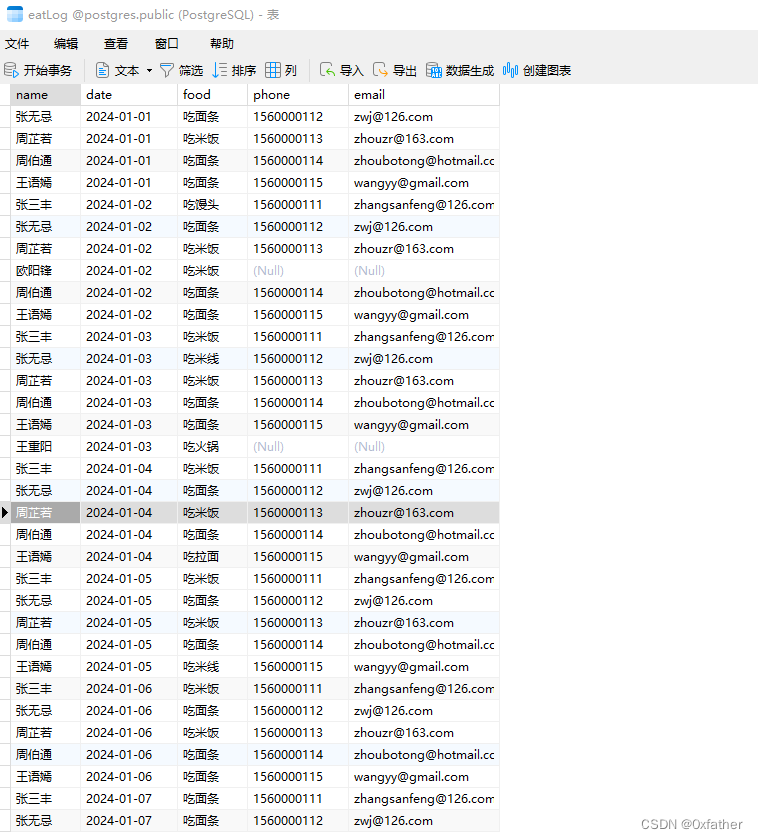
给数据表添加自增主键
导入的数据是没有主键的,这样不利于我们对数据的管理(如:在查询时,没有数据主键不能对数据进行修改等),因此我们需要扩展主键字段
添加主键字段
修改表设计,增加主键id字段(此时请勿添加主键约束)
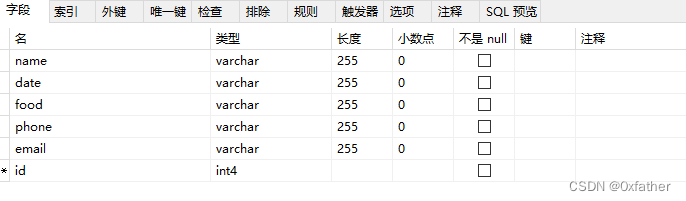
创建自增序列
Postgresql没有像Oracle、MySQL那样的默认自增序列,因此要实现自增,可以通过自定义序列来实现
create SEQUENCE seq_eatlog_id
start with 1
increment by 1
no MINVALUE
no MAXVALUE
cache 1;语句说明:
seq_eatlog_id:自定义的自增序列名称,根据自己需要命名
start with 1:序列从1开始
increment 1:序列自增步长为1(每次加1)
no MINVALUE:没有最小值约束
no MAXVALUE:没有最大值约束
cache 1:在数据库中始终缓存下一个序列
更新序列到数据表
update "eatLog"
set id = nextval('seq_eatlog_id')nextval函数可获取下一个序列,可使用 select nextval('seq_eatlog_id') 来查询下一个序列。
注:调用一次nextval(),序列将被消费掉,因此不要轻易使用nextval()来查询序列,避免序列顺序混乱。
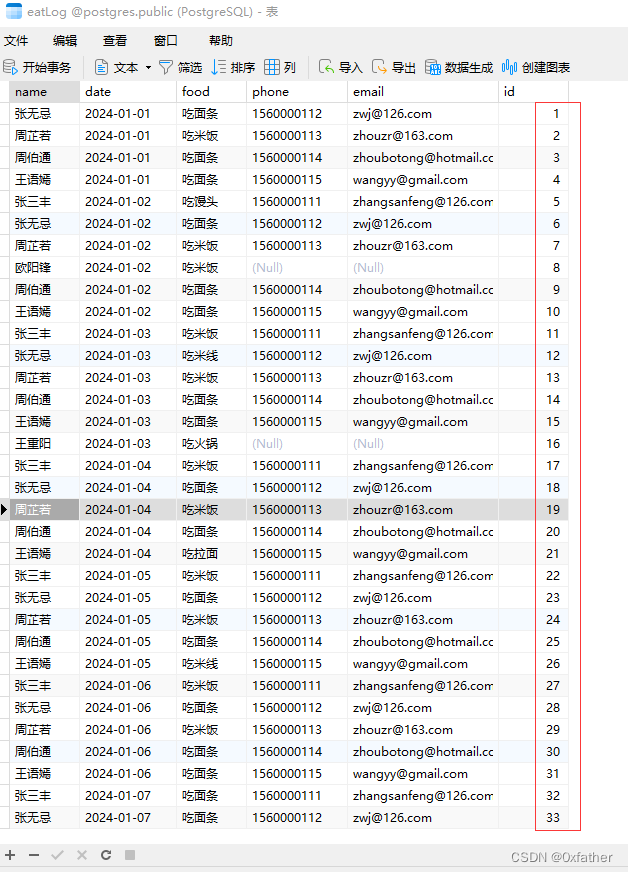
此时id已填充为自增的序列值(此时可以再修改表设计,给该表增加主键非空约束,顺手把date字段的数据类型修改为日期类型,数据会自动转换)
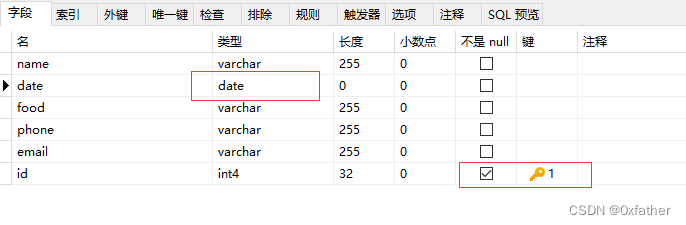
给表主键增加自增序列
上面将主键已填充,但是在新增数据时,仍需手动添加主键,否则会提示主键为空问题。
insert into "eatLog" values('乔峰',to_date('2024-01-04','YYYY-MM-DD'),'吃拉面',null,'xiaofeng@tianlong.com');题外话:
Postgresql的表名和字段都是区分大小写的,因此针对驼峰名称必须添加双引号进行操作,否则会提示表或字段不存在
全大写或全小写的表名可以省略双引号

因此需要给主键id字段添加自增序列,以便后续新增数据。
alter table "eatLog" alter COLUMN id set DEFAULT nextval('seq_eatlog_id');
再次执行插入语句,即可添加成功(以后添加数据无需再管主键id字段了)。

常见日期操作
获取周
查询数据中的日期在当年第几周,并将周信息保存到数据库中,以便后续按周统计
表设计中增加“周(week)”字段
select date_part('week',date::timestamp) week from "eatLog";将周信息更新到表中
update "eatLog"
set week = date_part('week',date::timestamp)获取月
查询月份方式一(格式化字符方式):
select to_char(date,'MM') from "eatLog";查询月份方式二(日期函数获取):
select date_part('month',date::timestamp) from "eatLog";查询月份方式三(提取函数获取):
select extract(month from date) as month from "eatLog";查询部分时段数据
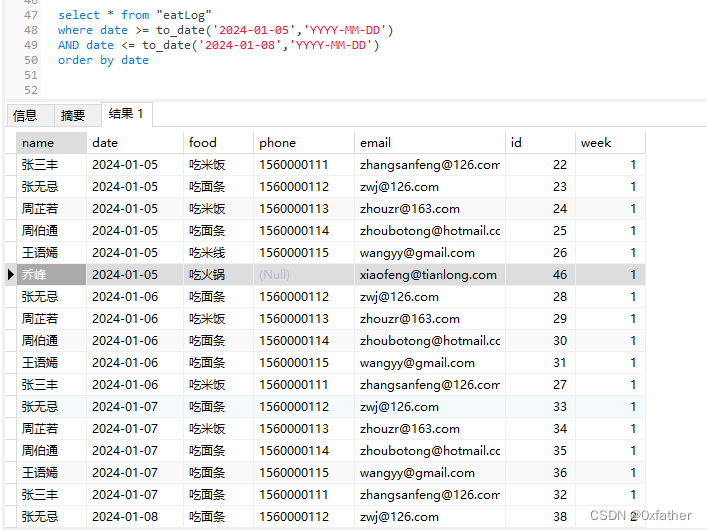
select * from "eatLog"
where date >= to_date('2024-01-05','YYYY-MM-DD')
AND date <= to_date('2024-01-08','YYYY-MM-DD')
and phone is not null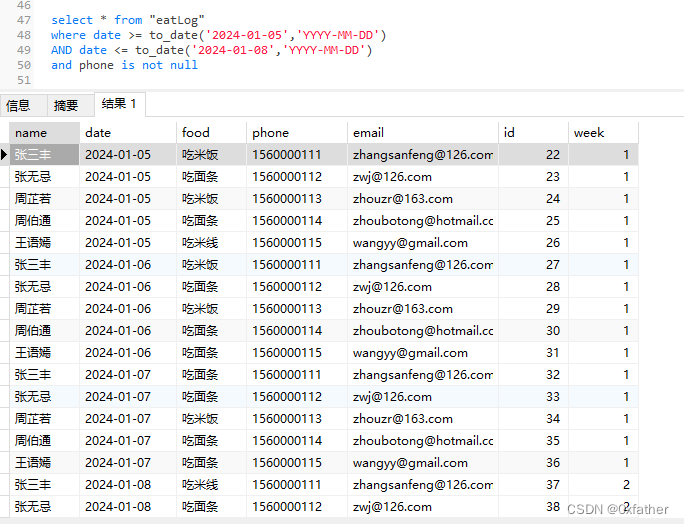
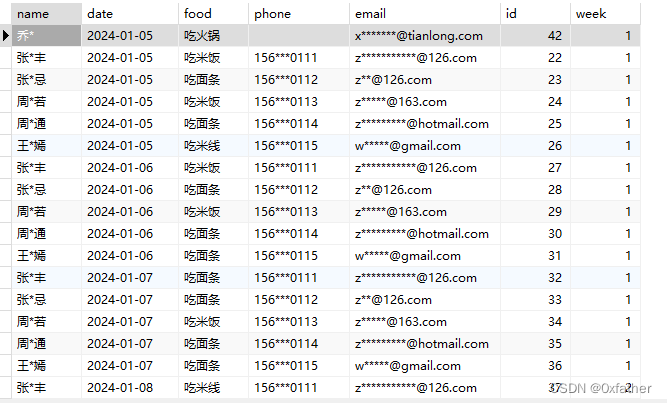
数据脱敏
姓名脱敏
使用“*”号代替姓名中除第一个字和最后一个字的所有字符,两个字的名字仅替换最后一个字。
----三字及以上姓名脱敏
update "eatLog"
set name = concat(left(name,1),repeat('*', length(name) - 2),right(name,1)
)
where length(name) > 2;----两字姓名脱敏
update "eatLog"
set name = concat(left(name,1),repeat('*', length(name) - 1)
)
where length(name) = 2;concat()函数:用于拼接字符串
left()函数:用于截取字符串,指定从左截取多少位
right()函数:用于截取字符串,指定从右截取多少位
repeat()函数:用于替换字符串,指定替换多少位
手机号脱敏
保留手机号前三位和后四位,其他信息用“*”号代替
update "eatLog"
set phone = concat(left(phone,3),repeat('*',length(phone) - 7),right(phone,4)
)
注:身份证、银行卡脱敏思路相同
邮箱脱敏
update "eatLog"
set email = concat(left(email,1),repeat('*',position('@' in email) - 2),substring(email from position('@' in email))
)
substring()函数:截取字符串
position()函数:定位字符或字符串所在下标位置
数据统计
分组统计
根据周、饮食类型分组查询
select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
行转列统计
统计所有数据
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
group by extract(week from t1.date),t1.food
order by extract(week from t1.date),t1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week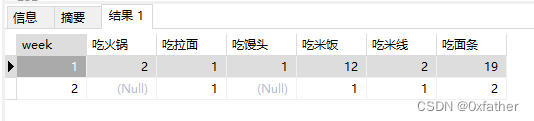
行转列使用crosstab(sql1,sql2)函数
参数说明:
sql1:统计数据的语句
sql2:行转列的列查询SQL
crosstab的sql1返回值中必须有且只有三个字段:
第一个字段表示行ID(可由分组生成),
第二个字段表示分组目录(即待转换列),
第三个字段表示统计数据
as中的内容是转换的列名及列值类型,此处的列明必须完全列出,与实际数据相符,否则会报错误。
注一:
postgresql默认未安装扩展函数,因此要使用crosstab()函数,必须先启用扩展
使用命令:
CREATE EXTENSION IF NOT EXISTS tablefunc;
注二:
行转列时,sql2参数必须进行排序,若不排序,虽然能转成功,但是会发现数据可能已经混乱,postgresql在行转列时,通过as中指定顺序匹配,而非是通过字段名称匹配,所以orader by固定数据位置,很容易造成匹配错误(as中的顺序可以使用sql2执行之后确认是否一致)
统计部分数据
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date),t1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week
在crosstab的sql参数中,若已经使用了单引号('),则需要使用两个单引号('')表示一个单引号,用于转义,否则SQL执行报错
另外,SQL查询时,若表名或字段使用驼峰时,必须使用双引号修饰,否则会找不到对象(Postgresql严格区分大小写,全大写或全小写时可以省略双引号修饰)
自定义统计列
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)',$$values('吃火锅'),('吃米饭'),('吃米线'),('吃面条')$$
)
as (week int,吃火锅 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week可通过$$values()$$来指定转哪些列,注意values()的顺序必须与as中的顺序一致
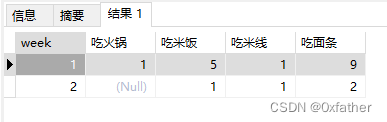
其他操作
计算精度问题
试想,我们的数据是统计每周的饮食统计,那每种饮食在每周占比是多少呢?
select m1.week,m1.food,m1.food_count, (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date('2024-01-05','YYYY-MM-DD')AND t2.date <= to_date('2024-01-08','YYYY-MM-DD')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date)) week_count
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date('2024-01-05','YYYY-MM-DD')
AND t1.date <= to_date('2024-01-08','YYYY-MM-DD')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food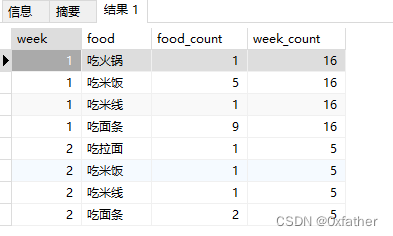
计算占比时请注意精度问题
select m1.week,m1.food,round(m1.food_count::numeric / (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date('2024-01-05','YYYY-MM-DD')AND t2.date <= to_date('2024-01-08','YYYY-MM-DD')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date))::numeric * 100,2) "rate(%)"
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date('2024-01-05','YYYY-MM-DD')
AND t1.date <= to_date('2024-01-08','YYYY-MM-DD')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food
Postgresql在计算时默认使用int来计算,因此不会取小数,若需要保留小数,需指明参加运算的字段类型,可通过“::numeric”来指明运算字段为数字型,这样运算结果可以保留小数
要具体精确到多少位,需要使用round()函数
行转列后效果
select * from crosstab('select m1.week,m1.food,round(m1.food_count::numeric / (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')AND t2.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date))::numeric * 100,2) "rate(%)"
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week
以上,就是Postgresql在使用中常见操作及示例说明,希望对您有所帮助。
相关文章:
Postgresql常见(花式)操作完全示例
案例说明 将Excel数据导入Postgresql,并实现常见统计(数据示例如下) 导入Excel数据到数据库 使用Navicat工具连接数据库,使用导入功能可直接导入,此处不做过多介绍,详细操作请看下图: 点击“下…...
【Docker】数据管理
🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Docker的相关操作吧 目录 🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 前言 一.数据卷 示例演示 示例剖析…...
认识异常及异常处理机制之try-catch
异常类 什么是异常?就像人会犯错一样,程序在运行的过程中也会犯错。程序中的错误有两类,一类称为Error(错误),另一类称为Exception(异常)。Error类和Exception类都为Throwable的子类…...

html学习之路:简述html文档头部 <meta> 的 http-equiv 属性
🧋当输入网址打开网页时,设置html头部meta的http-equiv属性,可以帮助浏览器更加精确和正常却的显示网页内容,比如设置网页多久自动刷新,设置网页在浏览器缓存中的时限,设置多少事件跳转到指定的网页地址&am…...
逆矩阵计算
目录 一、逆矩阵的定义 核心:AB BA E 1)定义 2)注意 3)逆矩阵存在的条件|A| ! 0 二、核心公式: 三、求逆矩阵(核心考点) 1、伴随矩阵法 2、初等变换法(重点掌握ÿ…...

《豫鄂烽火燎原大小焕岭》:一部穿越时空的历史史诗
《豫鄂烽火燎原大小焕岭》:一部穿越时空的历史史诗 一部赓续红色血脉的生动教材 一部讴歌时代英雄和人民精神宝典 当历史的烽烟渐渐远去,留下的是一页页泛黄的记忆和无数英雄的壮丽诗篇。李传铭的力作《豫鄂烽火燎原大小焕岭》正是这样一部深情的回望&am…...

浅研究下 DHCP 和 chrony
服务程序: 1.如果有默认配置,请先备份,再进行修改 2.修改完配置文件,请重启服务或重新加载配置文件,否则不生效 有些软件,安装包的名字和系统里服务程序的名字不一样(安装包名字:…...
【算法】动态中位数(对顶堆)
题目 依次读入一个整数序列,每当已经读入的整数个数为奇数时,输出已读入的整数构成的序列的中位数。 输入格式 第一行输入一个整数 P,代表后面数据集的个数,接下来若干行输入各个数据集。 每个数据集的第一行首先输入一个代表…...

mysql服务多实例运行
1、官网下载mysql安装包 https://downloads.mysql.com/archives/community/ 2、解压安装包 tar -zxvf mysql-8.1.0-linux-glibc2.28-aarch64.tar.xz -C /usr/localmv /usr/local/mysql-8.1.0-linux-glibc2.28-aarch64 /usr/local/mysql 3、创建mysql用户组 groupadd…...

「HDLBits题解」Module fadd
本专栏的目的是分享可以通过HDLBits仿真的Verilog代码 以提供参考 各位可同时参考我的代码和官方题解代码 或许会有所收益 题目链接:Module fadd - HDLBits module top_module (input [31:0] a,input [31:0] b,output [31:0] sum );//wire [15:0] t1, t2 ; wire co…...
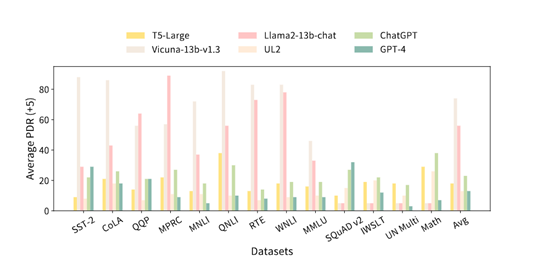
微软等开源评估ChatGPT、Phi、Llma等,统一测试平台
微软亚洲研究院、中国科学院自动化研究所、中国科学技术大学和卡内基梅隆大学联合开源了,用于评估、分析大语言模型的统一测试平台——PromptBench。 Prompt Bench支持目前主流的开源、闭源大语言模型,例如,ChatGPT、GPT-4、Phi、Llma1/2、G…...
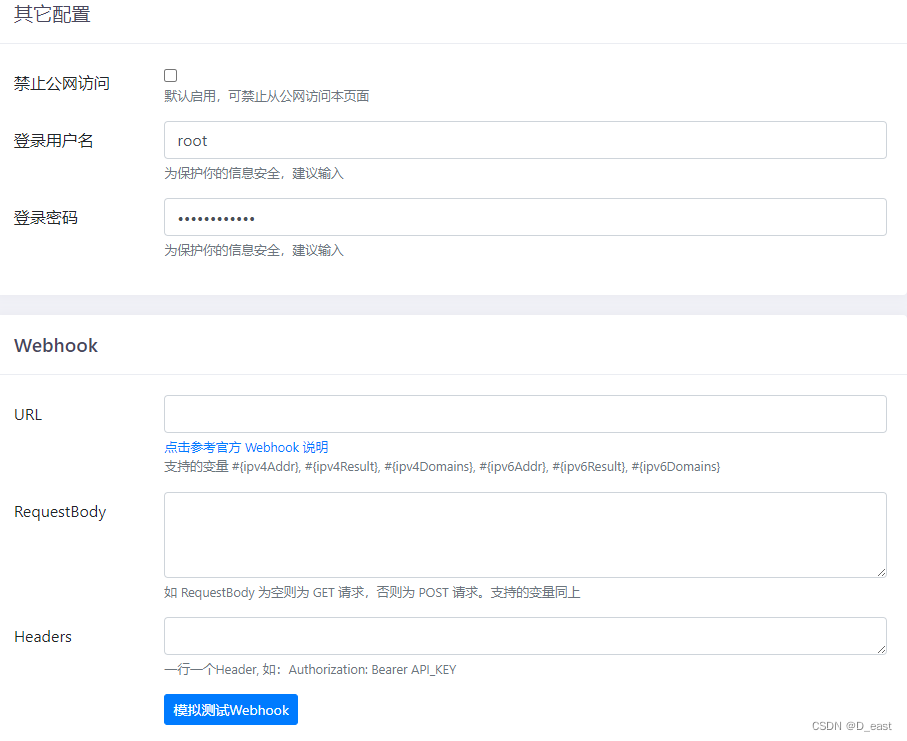
DDNS-GO配置使用教程
环境:openwrt 下载地址:Releases jeessy2/ddns-go GitHub 下载 ssh至openwrt根目录,根据你的处理器选择要下载的版本,我是路由器,选择的是 ddns-go_5.7.1_linux_arm64.tar.gz wget github链接 安装 tar -zxvf…...

flex弹性盒子常用的布局属性详解
想必大家在开发中经常会用到flex布局。而且还会经常用到 justify-content 属性实现分栏等等 接下来给大家分别讲一下 justify-content 的属性值。 以下是我敲的效果图大家可以清晰看出区别 space-between 属性值可以就是说两端对齐 space-evenly 属性值是每个盒子之间的…...
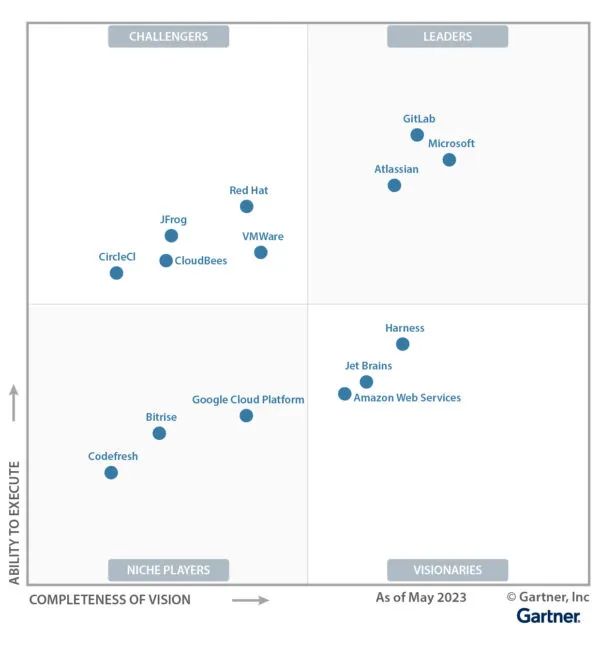
2023年Gartner® DevOps平台魔力象限发布,Atlassian被评为“领导者”
Atlassian在2023年Gartner魔力象限的DevOps平台评选中,被评为领导者。 Gartner根据执行能力和愿景的完整性,对全球14家DevOps平台提供商进行了评估,并发布2023年Gartner魔力象限。其中,Atlassian被评为领导者。 Atlassian提供了一…...
kylin集群使用nginx反向代理
前文已经提到,我安装了kylin集群。 kylin3集群问题和思考(单机转集群)-CSDN博客文章浏览阅读151次,点赞3次,收藏6次。由于是同一个集群的,元数据没有变化,所以,直接将原本的kylin使用…...
小红书搜索团队提出全新框架:验证负样本对大模型蒸馏的价值
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错…...

汽车销售领域相关专业术语
引言 本文是笔者在从事汽车销售领域信息化建设过程,积累的一些专业术语注解,供诸位参考交流。 专业术语清单 4S店 汽车销售服务4S店;是由经销商投资建设,按照汽车生产厂家规定的标准建造,是一种集整车销售(Sale)、零配件(Sparepart)、售后服务(Service)、信息…...

代币合约 ERC20 Token接口
代币合约 在以太坊上发布代币就要遵守以太坊的规则,那么以太坊有什么规则呢?以太坊的精髓就是利用代码规定如何运作,由于在以太坊上发布智能合约是不能修改和删除的,所以智能合约一旦发布,就意味着永久有效,不可篡改…...

判断回文字符串—C语言
题目要求 输入一个字符串,判断该字符串是否为回文。回文就是字符串中心对称,从左向右读和从右向左读的内容是一样的。 输入格式: 输入在一行中给出一个不超过80个字符长度的、以回车结束的非空字符串。 输出格式: 输出在第1行中…...
如何在Docker本地搭建流程图绘制神器draw.io并实现公网远程访问
推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 前言 提到流程图,大家第一时间可能会想到Visio,不可否认,VIsio确实是功能强大,但是软…...

Agentic SOC:AI原生时代,安全运营的终极范式革命
2026年RSAC全球网络安全大会上,一个现象级的行业转折正在发生:全场超过90%的主流安全厂商将核心展位与重磅发布聚焦于Agentic SOC,全球500强企业中超过62%已启动相关试点,21%完成了核心生产环境的规模化落地。与之形成强烈对比的是…...
原理与应用)
高光谱图像处理实战:5分钟搞懂Pansharpening动态卷积网络(DyPNN)原理与应用
高光谱图像处理实战:5分钟搞懂Pansharpening动态卷积网络(DyPNN)原理与应用 遥感图像处理领域近年来迎来了一项突破性技术——动态卷积网络(DyPNN)在高光谱图像融合中的应用。这项技术彻底改变了传统Pansharpening方法…...

IUV5G数字室分酒店项目实战:从勘察到验收的避坑指南
1. 站点勘察:这些细节不注意会让你返工 第一次做酒店5G室分项目时,我在勘察环节踩过不少坑。记得有次因为没注意电梯井的测量方式,导致后期设计方案全部推翻重做。下面这些实战经验,能帮你省去至少50%的返工时间。 经纬度记录有个…...

2024年Image Caption数据集全攻略:从COCO到TextCaps的实战选择指南
2024年Image Caption数据集实战指南:从基础到行业落地的深度解析 当算法工程师第一次接触图像描述任务时,面对琳琅满目的数据集选择往往会陷入困惑——COCO的通用性、TextCaps的文本理解要求、VizWiz的特殊场景适用性,每个数据集都有其独特的…...

程序员的“无用论”:为什么你觉得数据结构与算法没用?
在计算机科学的学习过程中,数据结构与算法(DSA)常常被视为“面试敲门砖”。许多本科生甚至从业多年的开发者都会产生疑问:“我每天的工作就是 CRUD(增删改查)和调 API,为什么还要花那么多时间去…...

系统级音频均衡器如何提升macOS音质:开源eqMac完全指南
系统级音频均衡器如何提升macOS音质:开源eqMac完全指南 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac eqMac是一款开源的macOS系统级音频均衡器与音量混合…...

Jimeng AI Studio应用场景:独立艺术家数字创作工作流整合方案
Jimeng AI Studio应用场景:独立艺术家数字创作工作流整合方案 1. 引言:当艺术家遇见AI 想象一下,你是一位独立艺术家或设计师。灵感来了,你想立刻把它变成一幅画、一张海报,或者一个全新的视觉概念。但传统的数字创作…...

快速生成git安装配置脚本,快马平台助你一键搭建版本控制环境
最近在帮团队新成员配置开发环境时,发现git安装这个看似简单的步骤,其实藏着不少坑。不同操作系统下的安装方式差异很大,新手经常要反复查阅各种教程。于是我用InsCode(快马)平台快速搭建了一个git安装配置助手,整个过程比想象中顺…...

用STM32F103做个智能门禁卡管理终端:RC522读卡、OLED菜单、4x4键盘改密码,附工程源码
基于STM32F103的智能门禁终端开发实战:从模块整合到系统优化 在物联网设备开发领域,将多个功能模块整合为一个稳定可靠的终端系统是开发者常面临的挑战。本文将深入探讨如何基于STM32F103RCT6微控制器构建一个功能完善的智能门禁管理终端,涵盖…...

当Excel图表无法表达你的数据故事时:Charticulator开启零代码可视化创作新纪元
当Excel图表无法表达你的数据故事时:Charticulator开启零代码可视化创作新纪元 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 问题:数据…...