Spark---RDD(Key-Value类型转换算子)
文章目录
- 1.RDD Key-Value类型
- 1.1 partitionBy
- 1.2 reduceByKey
- 1.3 groupByKey
- reduceByKey和groupByKey的区别
- 分区间和分区内
- 1.4 aggregateByKey
- 获取相同key的value的平均值
- 1.5 foldByKey
- 1.6 combineByKey
- 1.7 sortByKey
- 1.8 join
- 1.9 leftOuterJoin
- 1.10 cogroup
1.RDD Key-Value类型
Key-Value类型的算子即对键值对进行操作。
1.1 partitionBy
将数据按照指定的 Partitioner(分区器) 重新进行分区。Spark 默认的分区器为HashPartitioner,Spark除了默认的分区器外,常见的分区器还有:RangePartitioner、Custom Partitioner、SinglePartitioner等。
函数定义:
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
//使用HashPartitioner分区器并设置分区个数为2val data1: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)data1.partitionBy(new HashPartitioner(2));data1.collect().foreach(println)

1.2 reduceByKey
可以将数据按照相同的 Key 对 Value 进行聚合
函数定义:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
//将数据按照相同的key对value进行聚合val data1: RDD[(String, Int)] = sparkRdd.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("a",4),("b",5)))val data2: RDD[(String, Int)] = data1.reduceByKey((x: Int, y: Int) => {x + y})data2.collect().foreach(println)

1.3 groupByKey
将数据源的数据根据 key 对 value 进行分组
函数定义:
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
val dataRDD1 = sparkRdd.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("a",4),("b",5)))val data1 = dataRDD1.groupByKey()//指定分区个数为2val data2 = dataRDD1.groupByKey(2)//指定分区器和分区个数val data3 = dataRDD1.groupByKey(new HashPartitioner(2))data1.collect().foreach(println)println("-------------------->")data2.collect().foreach(println)println("-------------------->")data3.collect().foreach(println)

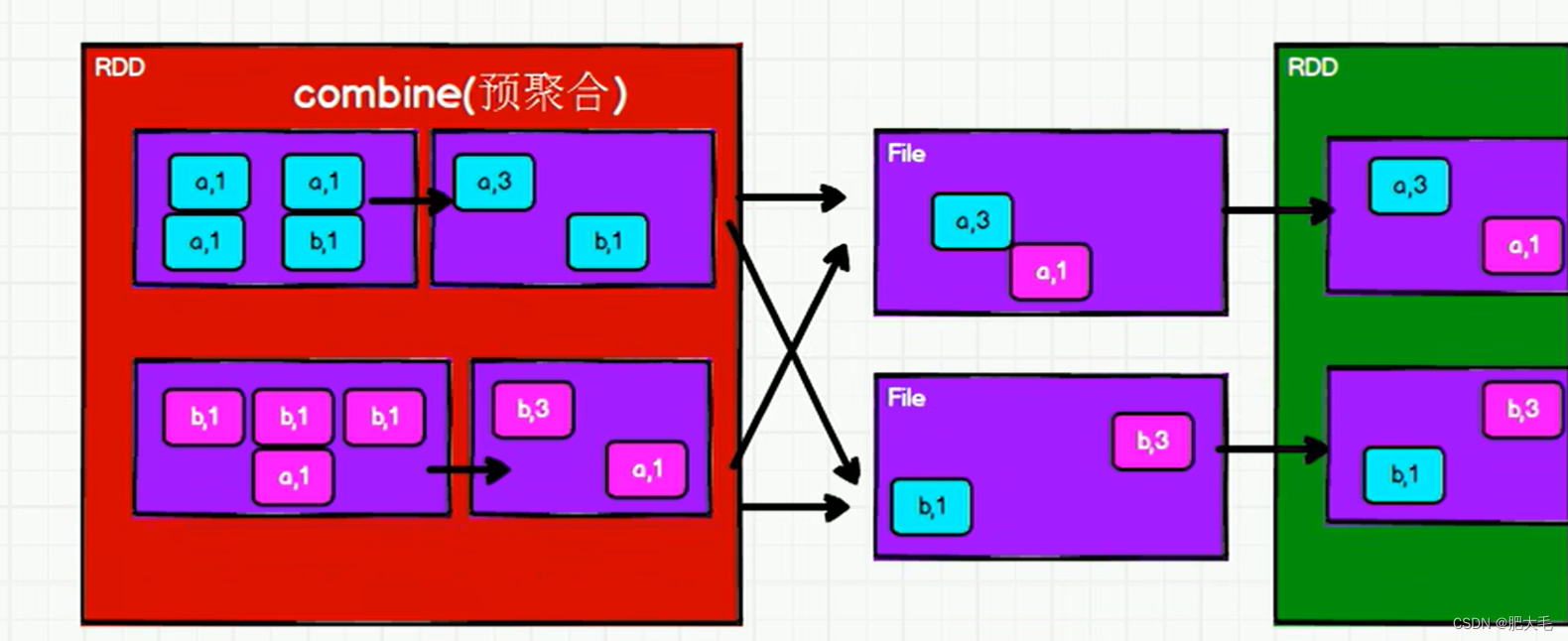
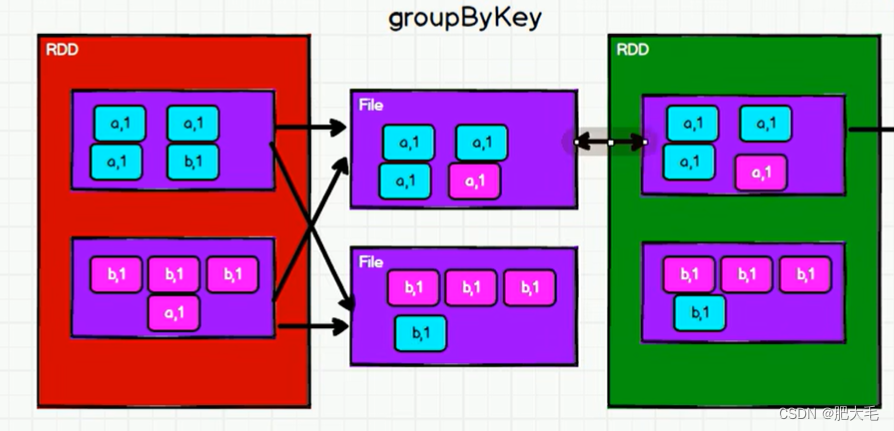
reduceByKey和groupByKey的区别
从功能的角度来看:reduceByKey包含了分组和聚合功能,而groupByKey只包含了分组功能。
从shuffle的角度来看:为了避免占用过多的内存空间,reduceByKey和groupByKey在执行的过程中,都会执行shuffle操作,将数据打散写入到磁盘的临时文件中,而reduceByKey在进行shuffle前会对数据进行预聚合的操作,致使shuffle的效率得到的提升,因为减少了落盘的数据量。但是groupByKey在shuffle前不会进行预聚合操作。所以,reduceByKey在进行分组的时候,效率相对groupByKey来说较高。
reduceByKey:
groupByKey:
分区间和分区内
分区间: 顾名思义,分区间就是指的多个分区之间的操作。如reduceByKey在shuffle操作后将不同分区的数据传输在同一个分区中进行聚合。
分区内: 分区内字面意思指的是单个分区内之间的操作。如reduceByKey的预聚合功能就是在分区内完成
1.4 aggregateByKey
将数据根据不同的规则进行分区内计算和分区间计算,如reduceByKey中分区间和分区内都是聚合操作,而使用aggregateByKey可以设置分区间和分区内执行不同的操作。
函数定义:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
//取出每个分区内相同 key 的最大值然后分区间相加// aggregateByKey 算子是函数柯里化,存在两个参数列表// 1. 第一个参数列表中的参数表示初始值// 2. 第二个参数列表中含有两个参数// 2.1 第一个参数表示分区内的计算规则// 2.2 第二个参数表示分区间的计算规则val data1 = sparkRdd.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)),2)val data2 = data1.aggregateByKey(0)((x,y)=>{Math.max(x,y)},(x,y)=>{x+y})data2.collect().foreach(println)**
注意:最终的结果会受到设置的初始值的影响,返回结果的值的类型和初始值保持一致。
获取相同key的value的平均值
val data1:RDD[(String,Int)] = sparkRdd.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("b", 4),("b",5),("a",6)),2)//设置初始值,初始值为一个元组,元组第一个元素表示value,第二个表示出现次数,初始默认都为0val data2:RDD[(String,(Int,Int))] = data1.aggregateByKey((0,0))((t, v)=> {(t._1 + v, t._2 + 1)} ,//分区内计算(t1, t2) => {(t1._1 + t2._1, t1._2 + t2._2)}//分区间计算)//和除以次数求出平均值val data3 = data2.mapValues({case (sum, count) => sum / count})data3.collect().foreach(println)

1.5 foldByKey
当分区内和分区间的计算规则相同的时候,aggregateByKey 就可以简化为 foldByKey
函数定义:
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
val dataRDD1 = sparkRdd.makeRDD(List(("a",1),("b",2),("a",3)))val dataRDD2 = dataRDD1.foldByKey(0)(_+_)dataRDD2.collect().foreach(println)

1.6 combineByKey
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
函数定义:
def combineByKey[C](
createCombiner: V => C,//对数据进行转换
mergeValue: (C, V) => C, //分区内合并
mergeCombiners: (C, C) => C): RDD[(K, C)] //分区间合并
//将数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))求每个 key 的平均值
val rddSource: RDD[(String, Int)] = sparkRdd.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),2)
val combinRdd: RDD[(String, (Int, Int))] = rddSource.combineByKey(((x:Int)=>{(x,1)}),//对每个value进行转换,转换后为(value,1),第一个元素为值,第二个元素为出现的次数((t1:(Int,Int),v)=>{(t1._1+v,t1._2+1)}),//分区内合并((t1,t2)=>{(t1._1+t2._1,t1._2+t2._2)})//分区间合并
)//mapValues算子是在key保持不变的时候对value进行操作val mapRdd: RDD[(String, Int)] = combinRdd.mapValues({case ((sum: Int, count: Int)) => sum / count})mapRdd.collect().foreach(println)

由此看出,combineByKey和aggreateByKey的不同之处在于,combineByKey可以不设置初始值,只需要对第一个元素进行转换,转换到合适的计算格式即可。
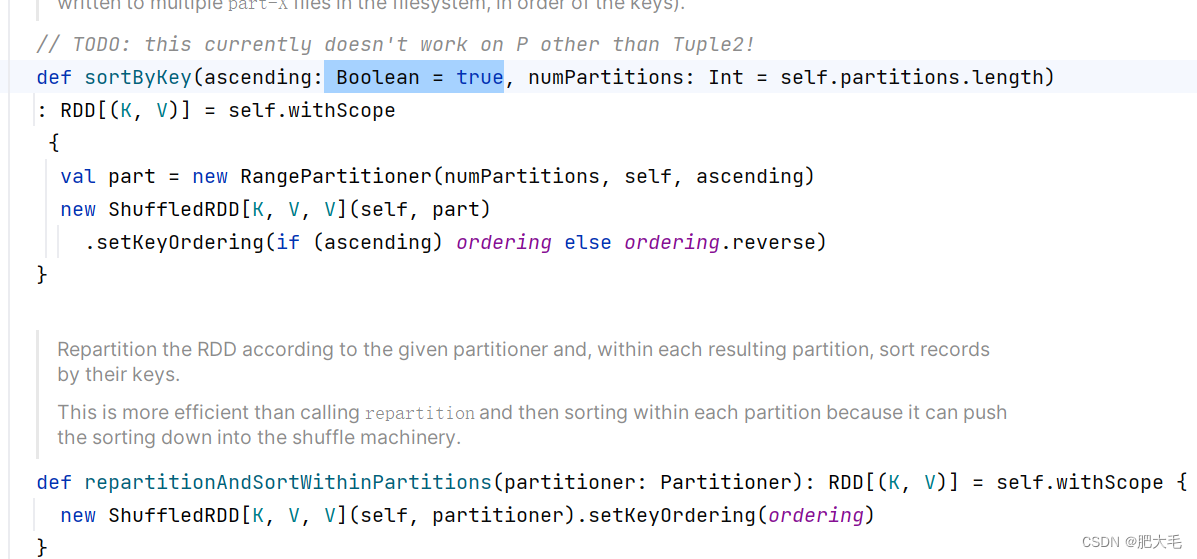
1.7 sortByKey
在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序的
函数定义:
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
//升序排序val dataRDD1 = sparkRdd.makeRDD(List(("a",1),("b",2),("c",3)))val sortRdd: RDD[(String, Int)] = dataRDD1.sortByKey()sortRdd.collect().foreach(print)

sortByKey默认为升序排序,如果想要降序排序,只需要将sortByKey第一个参数修改为false即可。
1.8 join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD
函数定义:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
//join操作相当于数据库中的内连接,在连接的时候自动去除两边的悬浮元组val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(Array((1, 4), (2, 5), (3, 6)))rdd0.join(rdd1).collect().foreach(print)//修改rdd1,使其少了key=3的这个元素val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(Array((1, 4), (2, 5)))rdd0.join(rdd1).collect().foreach(print)
1.9 leftOuterJoin
类似于 SQL 语句的左外连接
函数定义:
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(List((1, "a"), (2, "b")))val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(List((1, 4), (2, 5),(3, 6)))val rddRes = rdd0.leftOuterJoin(rdd1)rddRes.collect().foreach(print)
1.10 cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD,即先对
函数定义:
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
val rdd0: RDD[(Int, String)] = sparkRdd.makeRDD(List((1, "a"), (2, "b"),(3,"c")))val rdd1: RDD[(Int, Int)] = sparkRdd.makeRDD(List((1, 4), (2, 5)))val rddRes = rdd0.cogroup(rdd1)rddRes.collect().foreach(print)

相关文章:
Spark---RDD(Key-Value类型转换算子)
文章目录 1.RDD Key-Value类型1.1 partitionBy1.2 reduceByKey1.3 groupByKeyreduceByKey和groupByKey的区别分区间和分区内 1.4 aggregateByKey获取相同key的value的平均值 1.5 foldByKey1.6 combineByKey1.7 sortByKey1.8 join1.9 leftOuterJoin1.10 cogroup 1.RDD Key-Value…...

后台代码New出来DataGridTextColumn 动态添加到DataGrain 设置 Margin属性
在 WPF 中给 DataGridTextColumn 设置 MarginProperty 可以通过自定义 DataGridTemplateColumn 来实现。以下是一个示例代码: <DataGrid><DataGrid.Columns><DataGridTemplateColumn><DataGridTemplateColumn.CellTemplate><DataTempla…...
)
MySQL面试题(下)
09)查询学过「张三」老师授课的同学的信息 SELECTs.*,c.cname,t.tnameFROMt_mysql_teacher t,t_mysql_student s,t_mysql_course c,t_mysql_score scWHEREt.tidc.tid and c.cidsc.cid and sc.sids.sid and tname 张三 10)查询没有学全所有课程的同学的…...

【Linux】如何检查Linux用户是否具有sudo权限
问题背景或前提知识 在Linux系统中,sudo(superuser do)是一个重要的命令,它允许普通用户以系统管理员的身份执行命令。了解用户是否拥有sudo权限对于系统管理和安全性来说是非常重要的。 技术名词解释 sudo:一种程序…...

2024.1.13 Kafka六大机制和Structured Streaming
目录 一 . Kafka中生产者数据分发策略 二. Kafka消费者的负载均衡机制 三 . 数据不丢失机制 生产者端是如何保证数据不丢失的呢? Broker端如何保证数据不丢失 消费端如何保证数据不丢失 Kafka中消费者如何对数据仅且只消费一次 四 . 启动Kafka eagle命令 数…...

遥感影像-语义分割数据集:Landsat8云数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该云数据集包括RGB三通道的高分辨率图像,在全球不同区域的分辨率15米。这些图像采集自Lansat8的五种主要土地覆盖类型,即水、植被、湿地、城市、冰雪和贫瘠土地。 KeyValue卫星类型landsat8覆盖区域未知场景水、植被、…...

YOLOV8在coco128上的训练
coco128是coco数据集的子集只有128张图片 训练代码main.py from ultralytics import YOLO# Load a model model YOLO("yolov8n.yaml") # build a new model from scratch model YOLO("yolov8n.pt") # load a pretrained model (recommended for trai…...

设计模式——享元模式
享元模式(Flyweight Pattern)是一种结构型设计模式,它的主要目的是通过共享已存在的对象来大幅度减少需要创建的对象数量,从而降低系统内存消耗和提高性能。它通过将对象的状态划分为内部状态(Intrinsic State…...
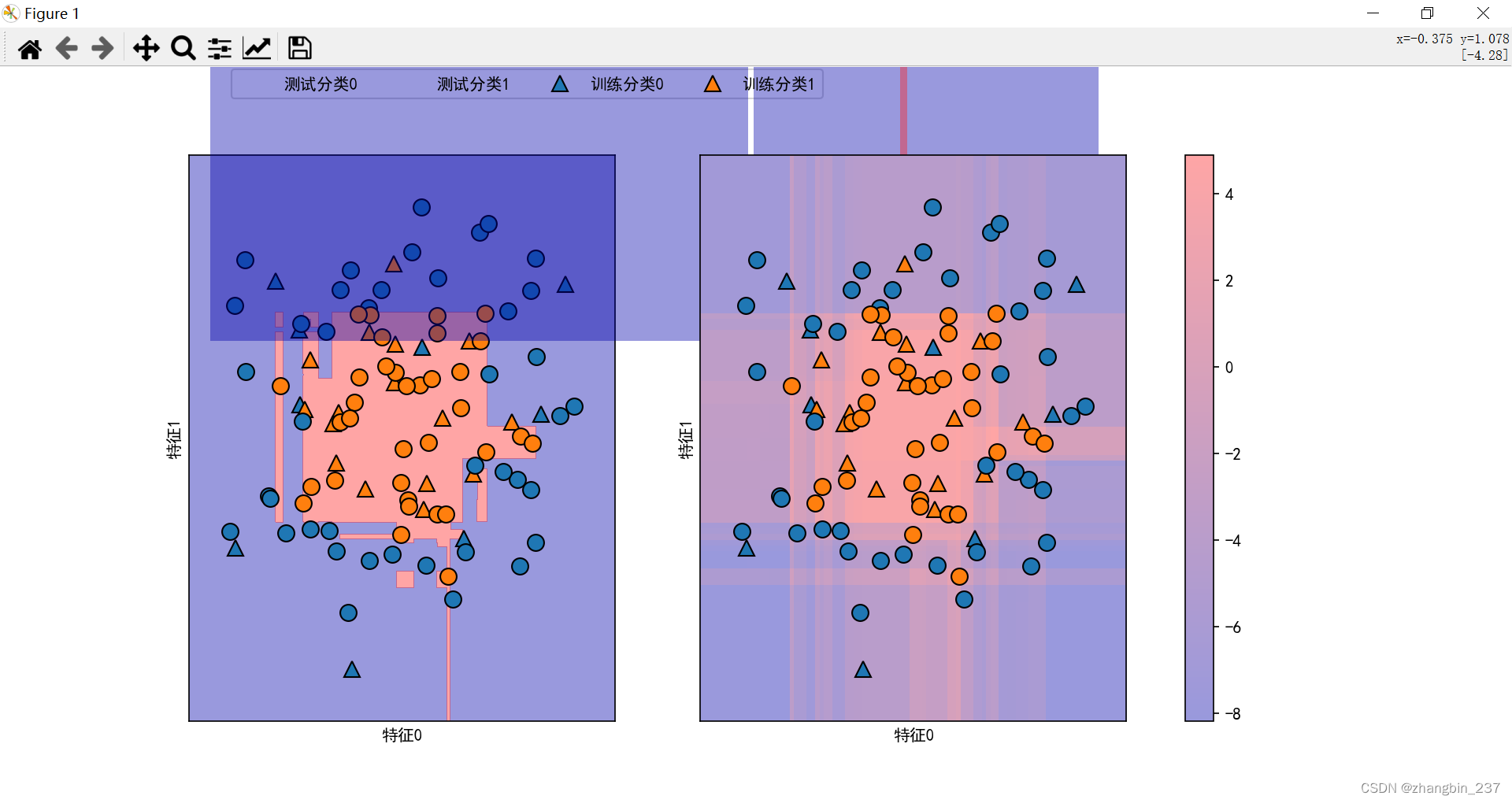
【Python机器学习】分类器的不确定估计——决策函数
scikit-learn接口的分类器能够给出预测的不确定度估计,一般来说,分类器会预测一个测试点属于哪个类别,还包括它对这个预测的置信程度。 scikit-learn中有两个函数可以用于获取分类器的不确定度估计:decidion_function和predict_pr…...

云原生周刊:K8sGPT 加入 CNCF | 2024.1.8
开源项目推荐 VolSync VolSync 使用 rsync 或 rclone 在集群之间异步复制 Kubernetes 持久卷。它还支持通过 Restic 创建持久卷的备份。 KubeClarity KubeClarity 是一种用于检测和管理软件物料清单 (SBOM) 以及容器映像和文件系统漏洞的工具。它扫描运行时 K8s 集群和 CI/…...
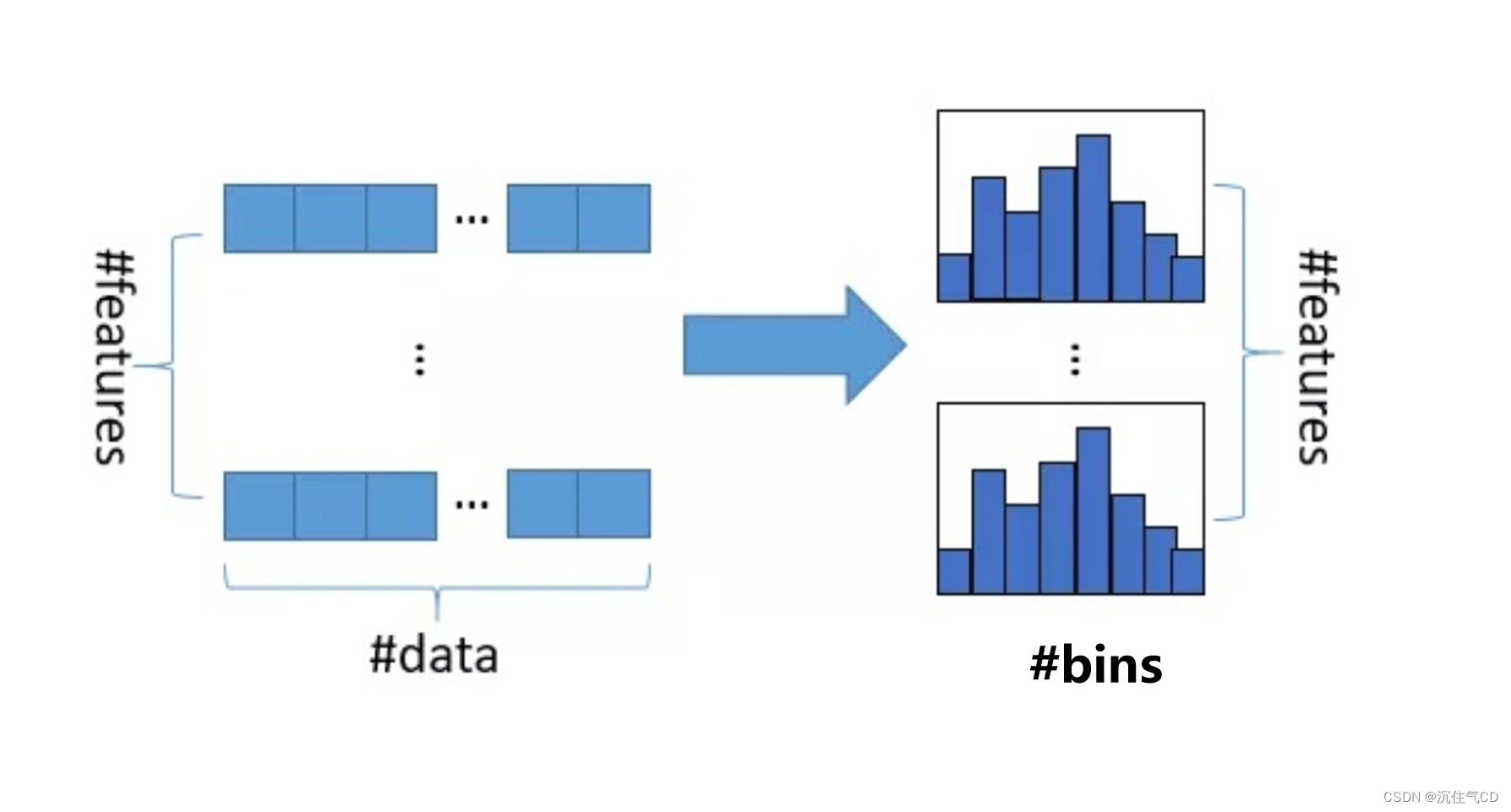
LightGBM原理和调参
背景知识 LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,具有支持高效率的并行训练、更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以处理海量数据等优点。 普通的GBDT算法不支持用mini-batch的方式训练,在每一次…...

ROS无人机开发常见错误
飞控部分 一、解锁时飞控不闪红灯,无任何反应,地面站也无报错 解决办法: 打开地面站的遥控器一栏 首先检查右下角Channel Monitor是否有识别出遥控各通道的值,如果没有,检查遥控器是否打开,遥控器和接收…...
)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为AVI视频格式(C#)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为视频格式(C#) Baumer工业相机Baumer工业相机的图像转换为OpenCV的图像的技术背景在NEOAPI SDK里实现相机图像转换为视频格式 工业相机通过OpenCV实现相机图像转换为视频格式的优…...

第一次面试总结 - 迈瑞医疗 - 软件测试
🧸欢迎来到dream_ready的博客,📜相信您对专栏 “本人真实面经” 很感兴趣o (ˉ▽ˉ;) 专栏 —— 本人真实面经,更多真实面试经验,中大厂面试总结等您挖掘 注:此次面经全靠小嘴八八,没…...

利用Qt输出XML文件
使用Qt输出xml文件 void PixelConversionLibrary::generateXML() {QFile file("D:/TEST.xml");//创建xml文件if (!file.open(QIODevice::WriteOnly | QIODevice::Text))//以只写方式,文本模式打开文件{qDebug() << "generateXML:Failed to op…...
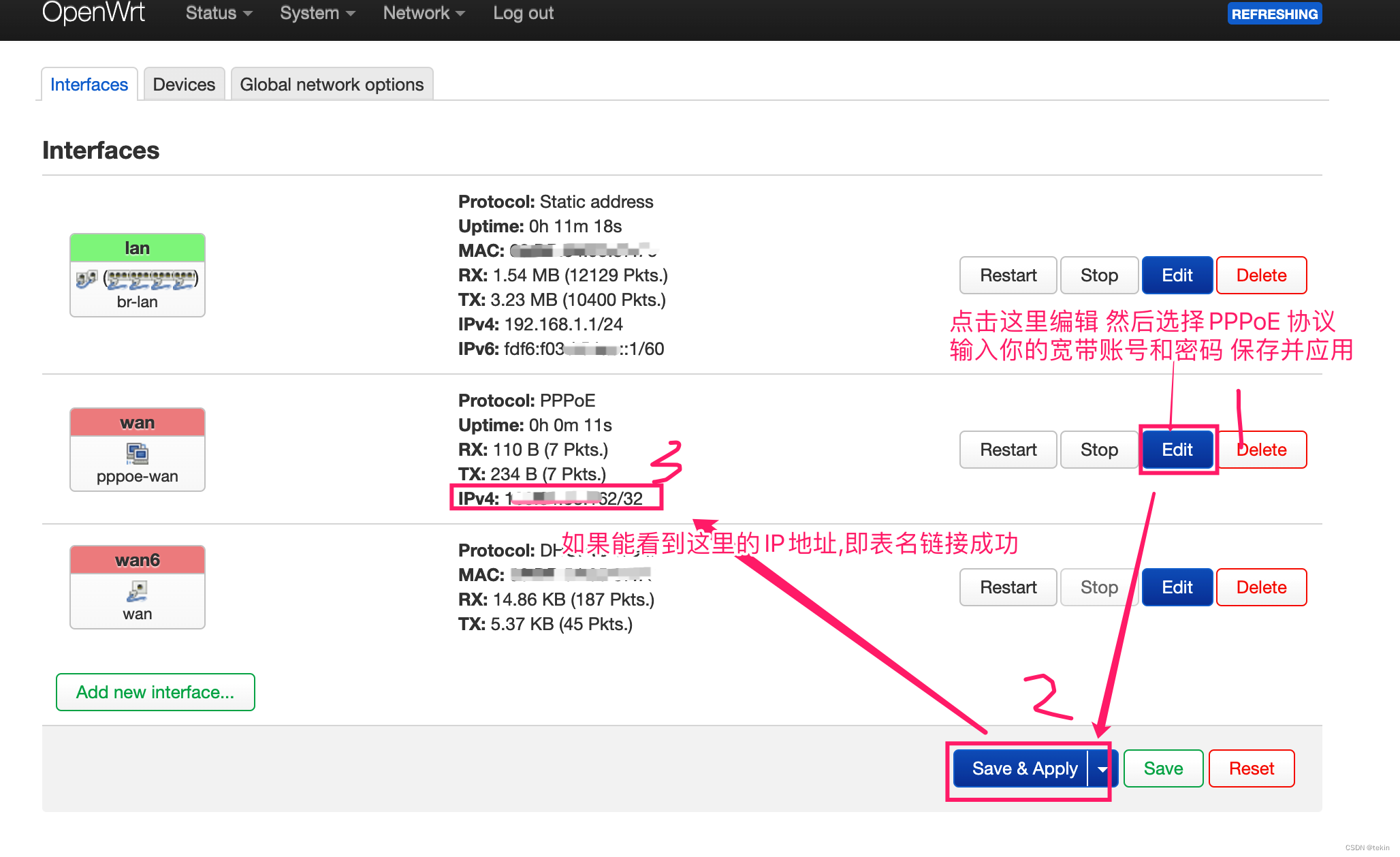
OpenWrt智能路由器Wan PPPoE拨号配置方法
OpenWrt智能路由器的wan PPPoE拨号配置方法和我们常见的不太一样, 需要先找到wan网卡,然后将协议切换为 PPPoE然后才能看到输入上网账号和密码的地方. 首先登录路由器 http://openwrt.lan/ 然后找到 Network --> Interfaces 这里会显示你当前的路由器的所有接口, 选择 …...

(十一)IIC总线-AT24C02-EEPROM
文章目录 IIC总线篇AT24C02-EEPROM篇主要特性引脚说明AT24Cxx用几位数据地址随机寻址的(存储器组织)AT24C02设备操作AT24CXX设备寻址EEPROM写操作的种类EEPROM读操作的种类实现单字节写实现任意读读写应用 IIC总线篇 前面介绍过了,请参考 (十)IIC总线-PCF8591-ADC/…...

现在做电商还有发展空间吗?哪个平台的盈利比较大?
我是电商珠珠 对于部分人来说,实体店的投入太大,一上来就是十几w,有时候还看不到结果。 所以有的人就瞄准了电商这个圈子,做线上平台。 大家都知道,近年来直播电商很火,所以很多商家都会去找达人带货&am…...

多节点 docker 部署 elastic 集群
参考 Install Elasticsearch with Docker Images 环境 docker # docker version Client: Docker Engine - CommunityVersion: 24.0.7API version: 1.43Go version: go1.20.10Git commit: afdd53bBuilt: Thu Oct 26 09:08:01 202…...
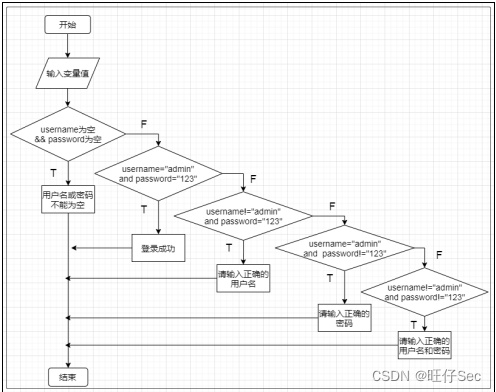
2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑨
单元测试 一、任务要求 题目1:根据下列流程图编写程序实现相应分析处理并显示结果。返回文字“xa*a*b的值:”和x的值;返回文字“xa-b的值:”和x的值;返回文字“xab的值:”和x的值。其中变量a、b均须为整型…...

STM32+FreeRTOS双分区开发避坑指南:Bootloader跳转前别忘了这行关键代码
STM32FreeRTOS双分区开发避坑指南:Bootloader跳转前别忘了这行关键代码 当你在STM32上实现BootloaderApp双分区架构时,是否遇到过这样的场景:Bootloader明明成功跳转到了应用程序,却在启动FreeRTOS调度器时突然崩溃?寄…...
)
手机当主力开发机?用Termux配置SSH连接远程服务器的完整流程(附防断连技巧)
手机变身开发终端:Termux全流程SSH配置与移动办公实战 在咖啡厅等朋友时突然需要紧急修复服务器故障,出差途中发现生产环境告警却找不到电脑——这些场景下,你的Android手机完全可以成为救命稻草。Termux这款终端模拟器配合SSH,能…...

Loop窗口管理工具:如何用径向菜单和智能暂存系统提升Mac多任务效率300%
Loop窗口管理工具:如何用径向菜单和智能暂存系统提升Mac多任务效率300% 【免费下载链接】Loop MacOS窗口管理 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 在当今多任务工作环境中,Mac用户经常面临窗口管理的挑战。每天在多个应用之间…...

EasyDarwin流媒体服务器初体验:除了RTMP推流,它的管理后台还能怎么玩?
EasyDarwin流媒体服务器深度探索:从RTMP推流到全功能实战 第一次接触EasyDarwin时,大多数人可能只是把它当作一个简单的RTMP推流工具——上传视频、获取流地址、完成播放,流程看似简单直接。但当我真正深入使用这个开源流媒体服务器后&#x…...

COMSOL相场模拟:枝晶生长与雪花形成的模型与教程
comsol相场模拟枝晶生长(雪花的形成) 有模型和教程 凌晨三点盯着显微镜下的冰晶生长,突然意识到这玩意儿和编程调试一样——参数调不好分分钟给你长歪。相场法模拟枝晶生长这事儿,本质上就是在用数学方程式和物理定律"种&qu…...
)
PX4飞控实战:为纳雷NRA12激光雷达手搓一个串口驱动(附完整源码)
PX4飞控实战:为纳雷NRA12激光雷达手搓一个串口驱动(附完整源码) 去年夏天,我在调试一台农业植保无人机时遇到了一个棘手的问题——现有的激光雷达在强光环境下表现不稳定。经过多次测试对比,最终选定了纳雷NRA12这款抗…...

OneNET物联网平台接入避坑指南:Android端用MQTTS协议请求数据,为什么你的Token总失效?
OneNET物联网平台MQTTS接入实战:Android端Token失效的深度排查与解决方案 第一次在Android应用中集成OneNET的MQTTS协议时,我盯着调试日志里反复出现的"401 Unauthorized"错误整整两天。官方文档看似清晰,但实际对接时才发现&…...

5步实现黑苹果零门槛配置:智能工具的降维打击方案
5步实现黑苹果零门槛配置:智能工具的降维打击方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 当你第三次因为ACPI补丁错误导致系统崩溃…...

SenseVoice Small多语言语音识别指南:中英粤日韩自动混合识别实操
SenseVoice Small多语言语音识别指南:中英粤日韩自动混合识别实操 1. 项目概述:极速语音转文字解决方案 SenseVoice Small是阿里通义千问推出的轻量级语音识别模型,专门针对多语言语音转文字场景优化。本项目基于该模型构建了一套高性能的语…...

快速掌握Fast-F1:Python赛车数据分析终极指南
快速掌握Fast-F1:Python赛车数据分析终极指南 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fast-F1 想要…...