【同济子豪兄斯坦福CS224W中文精讲】NetworkX代码学习笔记
文章目录
- 安装配置
- 创建图
- 可视化图
- 图数据挖掘
- 参考资料
安装配置
matplotlib中文字体设置
import networkx as nx
import matplotlib.pyplot as plt
# 魔法指令,设置后在jupyter notebook中绘制的图形会显示在输出单元格中,而不是弹出一个新窗口
%matplotlib inline # windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
测试代码
plt.plot([1,2,3], [100,500,300])
plt.title('matplotlib中文字体测试', fontsize=25)
plt.xlabel('X轴', fontsize=15)
plt.ylabel('Y轴', fontsize=15)
plt.show()
创建图
内置图创建
全连接无向图:G = nx.complete_graph(7)
全连接有向图:G = nx.complete_graph(7, nx.DiGraph())
随机图:G = nx.erdos_renyi_graph(10, 0.5)
空手道俱乐部数据集:G = nx.karate_club_graph()
雨果《悲惨世界》人物关系图:G = nx.les_miserables_graph()
Florentine families graph:G = nx.florentine_families_graph()
G = nx.random_k_out_graph(10, 3, 0.5, seed=seed)
创建一个10个节点,每个节点出度为3的有向图,0.5指每条边的生成概率
G = nx.from_pandas_edgelist(df, 'White', 'Black', edge_attr=True, create_using=nx.MultiDiGraph())
从pandas的DataFrame数据中创建一个有向多重图,利用表中White列和Black列的数据创建有向图,一行数据代表一条边,表中其他列都作为这条边的属性被存储起来。另外如果一条边会对应多行数据,这些数据存储在以0、1、2…为key值的字典中,使用G.get_edge_data(node1, node2)得到
Ego图创建
# 原图创建
n = 1000
m = 2
seed = 20532
G = nx.barabasi_albert_graph(n, m, seed=seed)
# 将原图中degree最大的节点作为ego图的中心
largest_hub, degree = sorted(G.degree(), key=itemgetter(1))[-1]
hub_ego = nx.ego_graph(G, largest_hub, radius=1) # 确定好中心节点
pos = nx.spring_layout(hub_ego, seed=seed)
nx.draw(hub_ego, pos, node_color="b", node_size=50, with_labels=False)
# 单独设置中心节点的图属性
options = {"node_size": 300, "node_color": "r"}
nx.draw_networkx_nodes(hub_ego, pos, nodelist=[largest_hub], **options)
plt.show()
连接表创建图
代码模板
# 导入 csv 文件定义的三元组连接表,构建有向图
df = pd.read_csv('triples.csv')
G = nx.DiGraph()
edges = [edge for edge in zip(df['head'], df['tail'])]
G.add_edges_from(edges) # 根据二元组顶点对列表创建图
# 可视化
pos = nx.spring_layout(G, seed=123) # 为图G的可视化生成布局,spring_layout是一种弹簧模型布局,seed=123设置了随机数种子值,保证了多次运行时得到的布局相同,增加可复现性
plt.figure(figsize=(15,15))
nx.draw(G, pos=pos, with_labels=True) # pos参数设置了节点布局信息
邻接表保存/创建图
# 将图以邻接表形式保存,邻接表形式的数据每行代表一条边,每条边的节点之间使用特定分隔符进行分隔
nx.write_edgelist(G, path="grid.edgelist", delimiter=":") # delimiter设置的是节点之间的分隔符
# 从本地文件 grid.edgelist 读取邻接表
H = nx.read_edgelist(path="grid.edgelist", delimiter=":")
常用图属性
图绘制:nx.draw()
连接数:G.size()
节点展示:G.nodes
节点数:G.number_of_nodes()
展示带属性的节点:G.node(data=True)
无向图连通域分析:nx.connected_components(H)
最大连通子图:Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0])
创建节点
G.add_node() 添加单个节点
G.add_nodes_from() 从列表中添加多个节点
添加带属性的节点
方法一:add_nodes_from()参数为节点属性字典二元组列表
方法二:add_node()参数中写明节点属性
# 方法一
G.add_nodes_from([('关羽',{'武器': '青龙偃月刀','武力值':90,'智力值':80}),('张飞',{'武器': '丈八蛇矛','武力值':85,'智力值':75}),('吕布',{'武器':'方天画戟','武力值':100,'智力值':70})
])
# 方法二
G.add_node(0, feature=5, label=0)
创建连接
方法名与创建节点的方法名类似
# 单个连接
G.add_edge(0, 1, weight=0.5, like=3)
# 多个连接
G.add_edges_from([(1, 2, {'weight': 0.3, 'like':5}),(2, 0, {'weight': 0.1, 'like':8})
])
节点连接数
# 指定节点
node_id = 1
# 指定节点的所有相邻节点
for neighbor in G.neighbors(node_id):print("Node {} has neighbor {}".format(node_id, neighbor))
可视化图
使用NetworkX自带的可视化函数
nx.draw,绘制不同风格的图。设置节点尺寸、节点颜色、节点边缘颜色、节点坐标、连接颜色等。
代码模板
nx.draw(G,pos, # 节点坐标(使用某种布局入spring_layout布局得到节点坐标node_color='#A0CBE2', # 节点颜色edgecolors='red', # 节点外边缘的颜色edge_color="blue", # edge的颜色node_size=100, # 节点尺寸with_labels=False,# arrowsize=10, # 如果是有向图,设置箭头尺寸width=3,
)
看一个设置每个节点坐标以可视化的例子
G = nx.Graph()
G.add_edge(1, 2)
G.add_edge(1, 3)
G.add_edge(1, 5)
G.add_edge(2, 3)
G.add_edge(3, 4)
G.add_edge(4, 5)
# 设置每个节点可视化时的坐标
pos = {1: (0, 0), 2: (-1, 0.3), 3: (2, 0.17), 4: (4, 0.255), 5: (5, 0.03)}# 设置其它可视化样式
options = {"font_size": 36,"node_size": 3000,"node_color": "white","edgecolors": "black", "linewidths": 5, # 节点线宽"width": 5, # edge线宽
}nx.draw_networkx(G, pos, **options)ax = plt.gca()
ax.margins(0.20) # 在图的边缘留白,防止节点被截断
plt.axis("off")
plt.show()
在看一个单独设置各个节点样式的例子
G = nx.house_graph()
# 设置节点坐标
pos = {0: (0, 0), 1: (1, 0), 2: (0, 1), 3: (1, 1), 4: (0.5, 2.0)}
plt.figure(figsize=(10,8))
# 绘制“墙角”的四个节点
nx.draw_networkx_nodes(G, pos, node_size=3000, nodelist=[0, 1, 2, 3], node_color="tab:blue")
# 绘制“屋顶”节点
nx.draw_networkx_nodes(G, pos, node_size=2000, nodelist=[4], node_color="tab:orange")
# 绘制连接
nx.draw_networkx_edges(G, pos, alpha=0.5, width=6)
plt.axis("off") # 去掉坐标轴
plt.show()
自定义节点图标的处理
# 给每个节点添加各自的图片
for n in G.nodes:xf, yf = ax.transData.transform(pos[n]) # data坐标 转 display坐标xa, ya = fig.transFigure.inverted().transform((xf, yf)) # display坐标 转 figure坐标a = plt.axes([xa - icon_center, ya - icon_center, icon_size, icon_size])a.imshow(G.nodes[n]["image"])a.axis("off")
处理.gz文件
# 通过gzip库和shutil库解压缩.gz文件展示结构
import gzip
import shutil
input_file = 'knuth_miles.txt.gz'
output_file = 'knuth_miles.txt'with gzip.open(input_file, 'rb') as f_in, open(output_file, 'wb') as f_out:shutil.copyfileobj(f_in, f_out)# 文件展示
with open('knuth_miles.txt', 'r') as file:content = file.read()print(content)
按照节点度以可视化模板
# 可视化函数
def draw(G, pos, measures, measure_name):nodes = nx.draw_networkx_nodes(G, pos, node_size=250, cmap=plt.cm.plasma, node_color=list(measures.values()),nodelist=measures.keys())nodes.set_norm(mcolors.SymLogNorm(linthresh=0.01, linscale=1, base=10))# labels = nx.draw_networkx_labels(G, pos)edges = nx.draw_networkx_edges(G, pos)# plt.figure(figsize=(10,8))plt.title(measure_name)plt.colorbar(nodes)plt.axis('off')plt.show()draw(G, pos, dict(G.degree()), 'Node Degree')
图数据挖掘
pagerank算法
计算节点重要度
代码示例
G = nx.star_graph(7)
pagerank = nx.pagerank(G, alpha=0.8)
节点连接数
G.degree() # 得到每个节点的连接数
degree_sequence = sorted((d for n, d in G.degree()), reverse=True)# 绘制degree rank plot
plt.figure(figsize=(12,8))
plt.plot(degree_sequence, "b-", marker="o")
plt.title('Degree Rank Plot', fontsize=20)
plt.ylabel('Degree', fontsize=25)
plt.xlabel('Rank', fontsize=25)
plt.tick_params(labelsize=20) # 设置坐标文字大小
plt.show()# degree直方图
X = np.unique(degree_sequence, return_counts=True)[0]
Y = np.unique(degree_sequence, return_counts=True)[1]
plt.figure(figsize=(12,8))
plt.bar(X, Y)
plt.title('Degree Histogram', fontsize=20)
plt.ylabel('Number', fontsize=25)
plt.xlabel('Degree', fontsize=25)
plt.tick_params(labelsize=20) # 设置坐标文字大小
plt.show()
图特征分析
# 半径
nx.radius(G)
# 直径
nx.diameter(G)
# 偏心度:每个节点到图中其它节点的最远距离
nx.eccentricity(G)
# 中心节点,偏心度与半径相等的节点
nx.center(G)
# 外围节点,偏心度与直径相等的节点
nx.periphery(G)
# 图中连接的稠密程度
nx.density(G)
# 最短距离
pathlengths = []
for v in G.nodes():spl = nx.single_source_shortest_path_length(G, v)for p in spl:print('{} --> {} 最短距离 {}'.format(v, p, spl[p]))pathlengths.append(spl[p])
# 平均最短距离
sum(pathlengths) / len(pathlengths)
# 不同距离的节点对个数
dist = {}
for p in pathlengths:if p in dist:dist[p] += 1else:dist[p] = 1
节点重要度特征
无向图
nx.degree_centrality(G)
nx.eigenvector_centrality(G)
必经之地:nx.betweenness_centrality(G)
去哪都近:nx.closeness_centrality(G)
nx.pagerank(DiG, alpha=0.85)
nx.katz_centrality(G, alpha=0.1, beta=1.0)
有向图
nx.in_degree_centrality(DiG)
nx.out_degree_centrality(DiG)
nx.eigenvector_centrality_numpy(DiG)
社群属性
三角形个数:nx.triangles(G)
聚集系数:nx.clustering(G)
重要的全图特征
桥:nx.bridges(G)
共同的邻居:nx.common_neighbors(G, 0, 4)
katz index计算
import networkx as nx
import numpy as np
from numpy.linalg import inv
G = nx.karate_club_graph()# 计算主特征向量
L = nx.normalized_laplacian_matrix(G)
e = np.linalg.eigvals(L.A)
print('最大特征值', max(e))# 折减系数
beta = 1/max(e)# 创建单位矩阵
I = np.identity(len(G.nodes))# 计算 Katz Index
S = inv(I - nx.to_numpy_array(G)*beta) - I
两个节点是否连通:nx.has_path(G, source='昌吉东路', target='同济大学')
任意两个节点之间的最短路径:nx.shortest_path(G, source='昌吉东路', target='同济大学', weight='time')
最短路径长度:nx.shortest_path_length(G, source='昌吉东路', target='同济大学', weight='time')
全图平均最短路径长度:nx.average_shortest_path_length(G, weight='time')
graphlet个数计算
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
import itertoolsG = nx.karate_club_graph()
target = nx.complete_graph(3)
num = 0
for sub_nodes in itertools.combinations(G.nodes(), len(target.nodes())): # 遍历全图中,符合graphlet节点个数的所有节点组合subg = G.subgraph(sub_nodes) # 从全图中抽取出子图if nx.is_connected(subg) and nx.is_isomorphic(subg, target): # 如果子图是完整连通域,并且符合graphlet特征,输出原图节点编号num += 1print(subg.edges())
参考资料
- 同济子豪兄课程repo地址:https://github.com/TommyZihao/zihao_course/tree/main/CS224W
相关文章:
【同济子豪兄斯坦福CS224W中文精讲】NetworkX代码学习笔记
文章目录 安装配置创建图可视化图图数据挖掘参考资料 安装配置 matplotlib中文字体设置 import networkx as nx import matplotlib.pyplot as plt # 魔法指令,设置后在jupyter notebook中绘制的图形会显示在输出单元格中,而不是弹出一个新窗口 %matplo…...
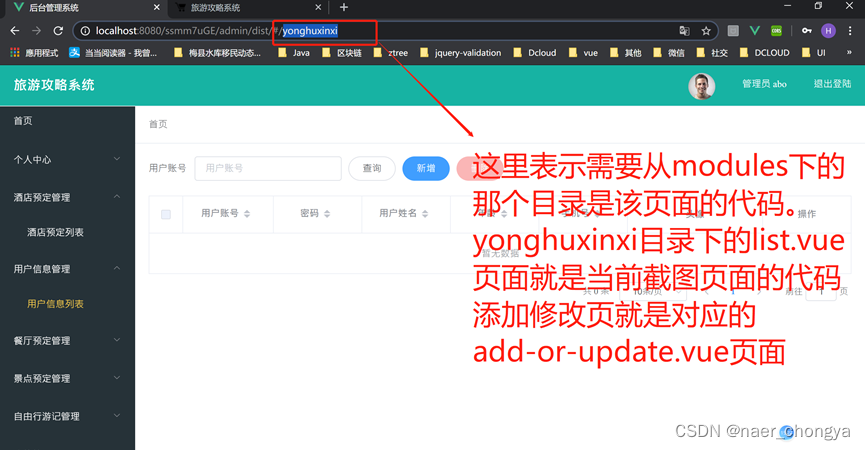
java+ssm+vue代码视频学习讲解
一、ssm 1.项目文件结构 2.数据库连接信息 3.其他配置信息 4.java代码文件目录介绍 5.entity层代码 6.controller,service,dao,entity层之间的关系 7.controller层代码 8.登陆拦截功能实现 AuthorizationInterceptor.java 9.文件上传功能 …...
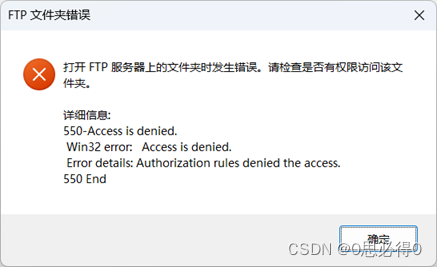
[计算机提升] 创建FTP共享
4.7 创建FTP共享 4.7.1 FTP介绍 在Windows系统中,FTP共享是一种用于在网络上进行文件传输的标准协议。它可以让用户通过FTP客户端程序访问并下载或上传文件,实现文件共享。 FTP共享的用途非常广泛,例如可以让多个用户共享文件、进行文件备份…...
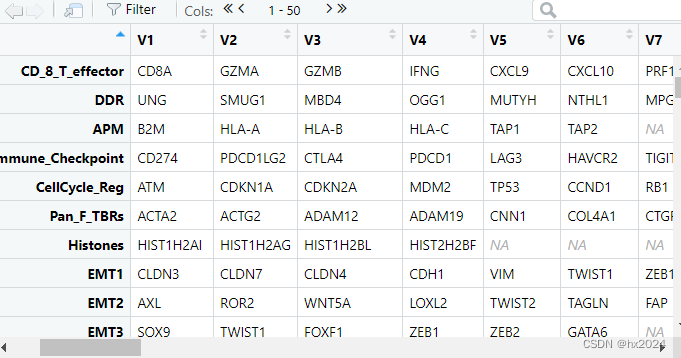
R语言将list转变为dataframe(常用)
在R语言使用中常常遇到list文件需要转变为dataframe格式文件处理。这是需要写循环来进行转换。IOBR查看其收录的相关基因集(自备)_iobr_deg-CSDN博客 示例文件 list文件: 循环转换为dataframe data <- signature_tme dat <- as.data.frame(t(sapply(data, …...
【JAVA】OPENGL+TIFF格式图片,不同阈值旋转效果
有些科学研究领域会用到一些TIFF格式图片,由于是多张图片相互渐变,看起来比较有意思: import java.io.IOException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.logging.*;/*** 可以自已定义日志打印格式…...
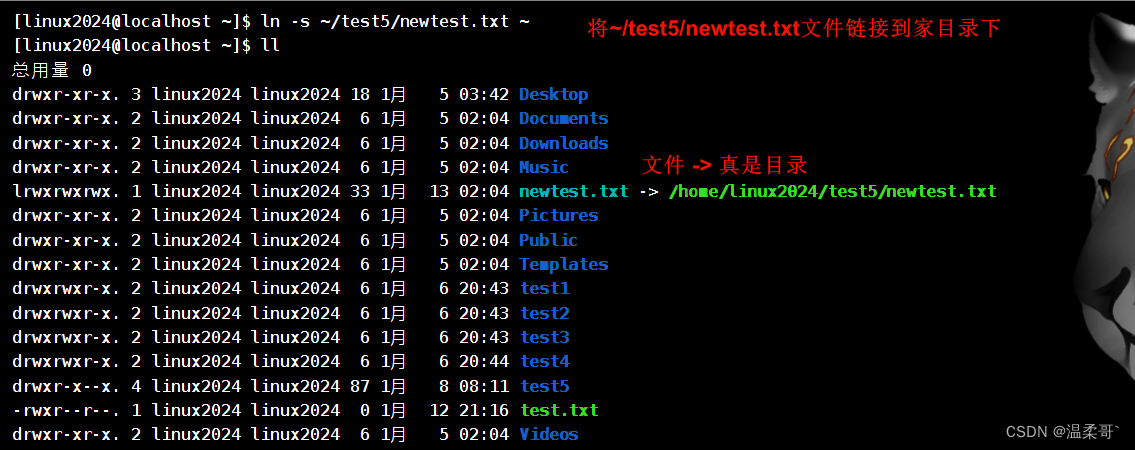
Linux系统中使用ln命令创建软连接
大家应该和我一样,第一次听到软连接这个词时感觉好高级啊,但其实也就那么回事,你完全可以将他类比为Windows系统中的快捷方式。 链接只是一个指向,并不是物理移动,类似Windows系统的快捷方式 1.功能和语法 功能&…...

Spark---RDD(Key-Value类型转换算子)
文章目录 1.RDD Key-Value类型1.1 partitionBy1.2 reduceByKey1.3 groupByKeyreduceByKey和groupByKey的区别分区间和分区内 1.4 aggregateByKey获取相同key的value的平均值 1.5 foldByKey1.6 combineByKey1.7 sortByKey1.8 join1.9 leftOuterJoin1.10 cogroup 1.RDD Key-Value…...

后台代码New出来DataGridTextColumn 动态添加到DataGrain 设置 Margin属性
在 WPF 中给 DataGridTextColumn 设置 MarginProperty 可以通过自定义 DataGridTemplateColumn 来实现。以下是一个示例代码: <DataGrid><DataGrid.Columns><DataGridTemplateColumn><DataGridTemplateColumn.CellTemplate><DataTempla…...
)
MySQL面试题(下)
09)查询学过「张三」老师授课的同学的信息 SELECTs.*,c.cname,t.tnameFROMt_mysql_teacher t,t_mysql_student s,t_mysql_course c,t_mysql_score scWHEREt.tidc.tid and c.cidsc.cid and sc.sids.sid and tname 张三 10)查询没有学全所有课程的同学的…...

【Linux】如何检查Linux用户是否具有sudo权限
问题背景或前提知识 在Linux系统中,sudo(superuser do)是一个重要的命令,它允许普通用户以系统管理员的身份执行命令。了解用户是否拥有sudo权限对于系统管理和安全性来说是非常重要的。 技术名词解释 sudo:一种程序…...

2024.1.13 Kafka六大机制和Structured Streaming
目录 一 . Kafka中生产者数据分发策略 二. Kafka消费者的负载均衡机制 三 . 数据不丢失机制 生产者端是如何保证数据不丢失的呢? Broker端如何保证数据不丢失 消费端如何保证数据不丢失 Kafka中消费者如何对数据仅且只消费一次 四 . 启动Kafka eagle命令 数…...

遥感影像-语义分割数据集:Landsat8云数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该云数据集包括RGB三通道的高分辨率图像,在全球不同区域的分辨率15米。这些图像采集自Lansat8的五种主要土地覆盖类型,即水、植被、湿地、城市、冰雪和贫瘠土地。 KeyValue卫星类型landsat8覆盖区域未知场景水、植被、…...

YOLOV8在coco128上的训练
coco128是coco数据集的子集只有128张图片 训练代码main.py from ultralytics import YOLO# Load a model model YOLO("yolov8n.yaml") # build a new model from scratch model YOLO("yolov8n.pt") # load a pretrained model (recommended for trai…...

设计模式——享元模式
享元模式(Flyweight Pattern)是一种结构型设计模式,它的主要目的是通过共享已存在的对象来大幅度减少需要创建的对象数量,从而降低系统内存消耗和提高性能。它通过将对象的状态划分为内部状态(Intrinsic State…...
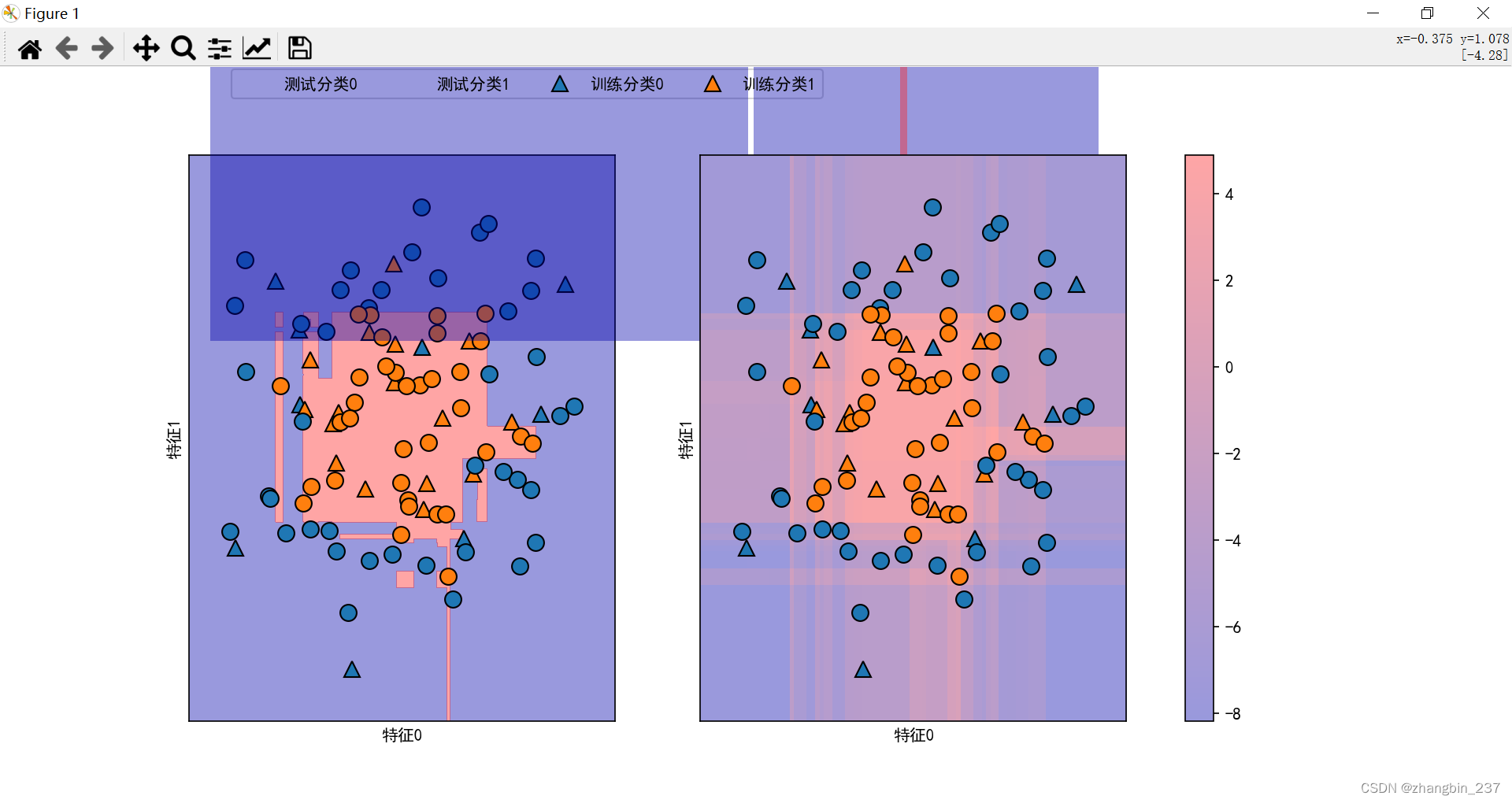
【Python机器学习】分类器的不确定估计——决策函数
scikit-learn接口的分类器能够给出预测的不确定度估计,一般来说,分类器会预测一个测试点属于哪个类别,还包括它对这个预测的置信程度。 scikit-learn中有两个函数可以用于获取分类器的不确定度估计:decidion_function和predict_pr…...

云原生周刊:K8sGPT 加入 CNCF | 2024.1.8
开源项目推荐 VolSync VolSync 使用 rsync 或 rclone 在集群之间异步复制 Kubernetes 持久卷。它还支持通过 Restic 创建持久卷的备份。 KubeClarity KubeClarity 是一种用于检测和管理软件物料清单 (SBOM) 以及容器映像和文件系统漏洞的工具。它扫描运行时 K8s 集群和 CI/…...
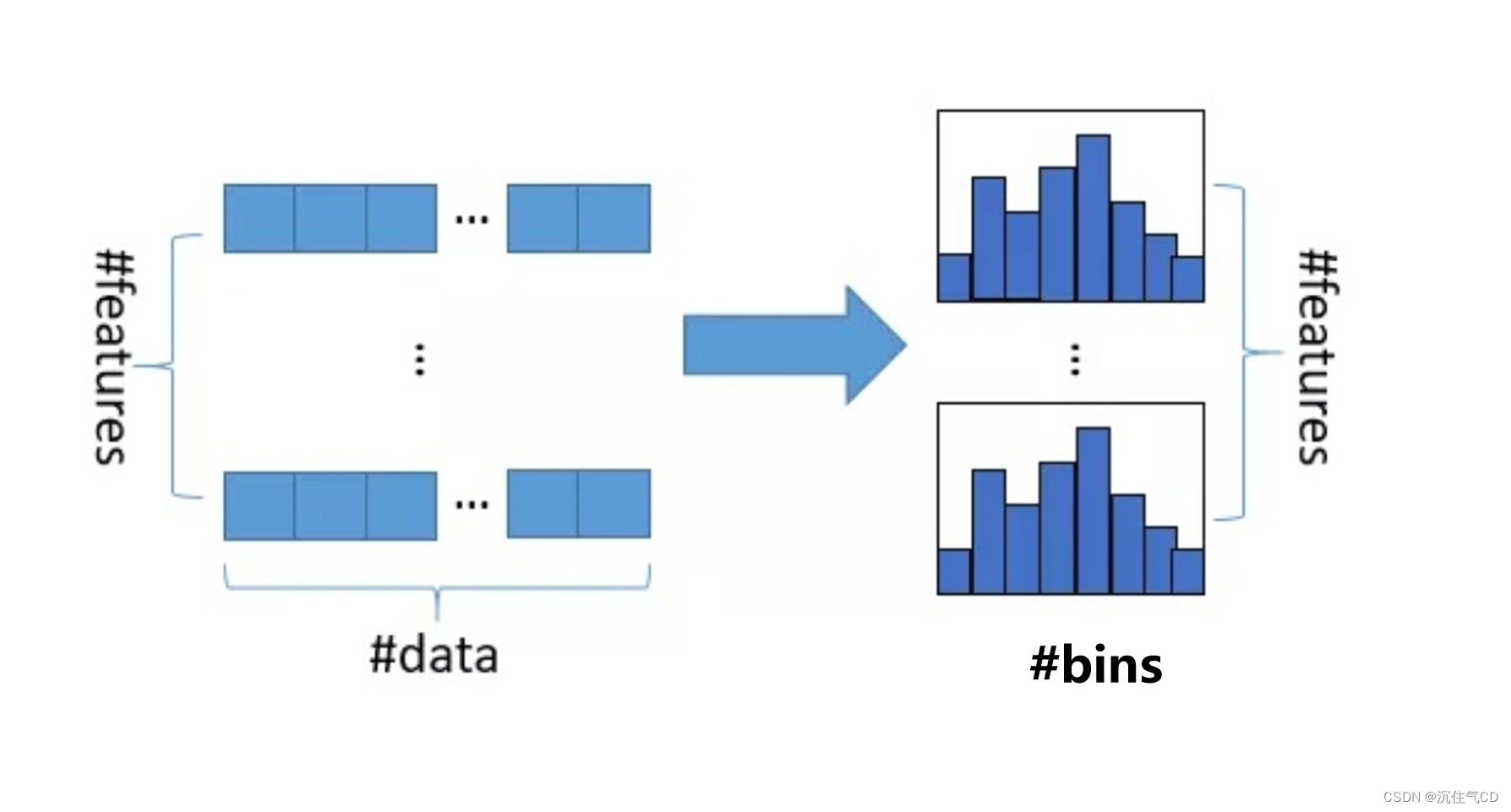
LightGBM原理和调参
背景知识 LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,具有支持高效率的并行训练、更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以处理海量数据等优点。 普通的GBDT算法不支持用mini-batch的方式训练,在每一次…...

ROS无人机开发常见错误
飞控部分 一、解锁时飞控不闪红灯,无任何反应,地面站也无报错 解决办法: 打开地面站的遥控器一栏 首先检查右下角Channel Monitor是否有识别出遥控各通道的值,如果没有,检查遥控器是否打开,遥控器和接收…...
)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为AVI视频格式(C#)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为视频格式(C#) Baumer工业相机Baumer工业相机的图像转换为OpenCV的图像的技术背景在NEOAPI SDK里实现相机图像转换为视频格式 工业相机通过OpenCV实现相机图像转换为视频格式的优…...

第一次面试总结 - 迈瑞医疗 - 软件测试
🧸欢迎来到dream_ready的博客,📜相信您对专栏 “本人真实面经” 很感兴趣o (ˉ▽ˉ;) 专栏 —— 本人真实面经,更多真实面试经验,中大厂面试总结等您挖掘 注:此次面经全靠小嘴八八,没…...

NPU加速!DeepSeek-V3大模型极速体验攻略
NPU加速!DeepSeek-V3大模型极速体验攻略 【免费下载链接】DeepSeek-V3-0324-w4a8-mtp-QuaRot 项目地址: https://ai.gitcode.com/Eco-Tech/DeepSeek-V3-0324-w4a8-mtp-QuaRot 导语:DeepSeek-V3系列大模型推出NPU硬件加速版本,标志着大…...

DAMO-YOLO手机检测一文详解:tinynas主干网络轻量化设计优势
DAMO-YOLO手机检测一文详解:tinynas主干网络轻量化设计优势 1. 引言:为什么我们需要一个又快又准的手机检测器? 想象一下,你正在开发一个智能会议室管理系统,需要实时统计参会人数和他们的行为。其中一个关键功能是检…...

效率提升神器:快马AI自动生成安装脚本,告别重复配置工作
效率提升神器:快马AI自动生成安装脚本,告别重复配置工作 每次给团队批量安装正版软件时,最头疼的就是重复配置。记得上个月部署开发环境,光是手动点下一步、选路径、勾选组件就花了整整一上午,还因为手滑选错选项导致…...

别再只盯着top命令了!用sysdig揪出Linux服务器上伪装成log、ntools的xmrig挖矿木马
深度追踪:用sysdig揪出Linux服务器上伪装成log、ntools的xmrig挖矿木马 当服务器CPU突然飙高,而top命令却显示一切正常时,作为运维工程师的你一定知道事情没那么简单。最近,一种新型的xmrig挖矿木马正在Linux服务器上肆虐…...

OpenClaw配置备份指南:Qwen3.5-9B环境快速迁移与恢复方法
OpenClaw配置备份指南:Qwen3.5-9B环境快速迁移与恢复方法 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致辛苦配置了两个月的OpenClaw环境全部丢失。最痛苦的不是重装软件,而是那些精心调试的模型参数、技…...

从XJTUSE编译原理小测出发:手把手教你用Python实现一个简易的词法分析器
从理论到实践:用Python构建词法分析器的完整指南 编译原理常被视为计算机科学中的"玄学"——课堂上听得云里雾里,考试时全靠死记硬背。但当我第一次用Python实现了一个能识别简单算术表达式的词法分析器后,那些抽象的状态转换图、有…...

macOS专属方案:OpenClaw+nanobot镜像的5个效率技巧
macOS专属方案:OpenClawnanobot镜像的5个效率技巧 1. 为什么选择OpenClawnanobot组合 作为一个长期使用macOS的开发者,我一直在寻找能够提升日常工作效率的自动化工具。直到遇到OpenClaw和nanobot这个组合,才真正找到了适合个人使用的智能助…...

AI 模型量化精度与推理速度平衡
AI模型量化精度与推理速度平衡:智能时代的效率与质量博弈 在人工智能技术快速发展的今天,AI模型的部署效率成为关键挑战。模型量化技术通过降低计算精度来提升推理速度,但如何在精度损失与速度提升之间找到平衡,成为开发者关注的…...

Tiled2Unity:解决Tiled地图与Unity引擎无缝集成的自动化转换方案
Tiled2Unity:解决Tiled地图与Unity引擎无缝集成的自动化转换方案 【免费下载链接】Tiled2Unity Export Tiled Map Editor (TMX) files into Unity 项目地址: https://gitcode.com/gh_mirrors/ti/Tiled2Unity Tiled2Unity是一款开源工具,核心功能是…...

别再只会用QProgressBar了!用QPainterPath绘制Qt自定义进度条的完整指南
用QPainterPath实现Qt动态进度条的终极艺术 当标准进度条无法满足现代UI设计需求时,Qt的绘图系统为我们打开了无限可能。想象一下:你的应用加载界面不是单调的横条,而是会呼吸的光环、跳动的粒子流或是随音乐律动的波形——这些令人眼前一亮的…...