SQL性能分析-整理
昨日对MySQL的索引整理了一份小文档,对结构/分类/语法等做了一个小总结,具体文章可点击:MySQL-索引回顾,索引知识固然很重要,但引入运用到实际工作中更重要。
参考之前的文章:SQL优化总结以及参考百度/CSDN/尚硅谷/黑马程序员/阿里云开发者社区,我个人把SQL性能分析的知识再整理了一下,学就要学彻底,事不宜迟,直接进入正题吧。
SQL执行频率
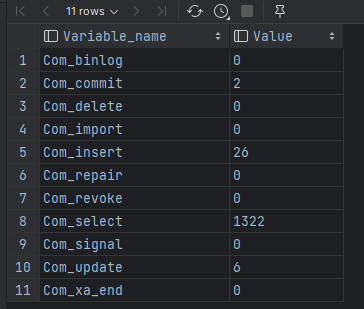
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
-
Com_delete: 删除次数
-
Com_insert: 插入次数
-
Com_select: 查询次数
-
Com_update: 更新次数
我们可以在当前数据库再执行几次查询操作及更新操作,然后再次查看执行频次,看看 Com_select 参数会不会变化。
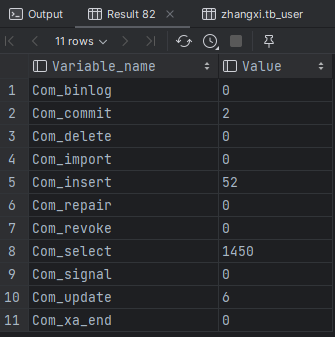
通过上述指令,我们可以查看到当前数据库到底是以查询为主,还是以增删改为主,从而为数据库优化提供参考依据。 如果是以增删改为主,我们可以考虑不对其进行索引的优化。 如果是以查询为主,那么就要考虑对数据库的索引进行优化了。
那么通过查询SQL的执行频次,我们就能够知道当前数据库到底是增删改为主,还是查询为主。 那假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢? 次数我们可以借助于慢查询日志。
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。
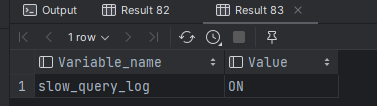
我这边是已经开启了,如果想要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息/var/lib/mysql/localhost-slow.log
systemctl restart mysqld
然后,再次查看开关情况,慢查询日志就已经打开了。
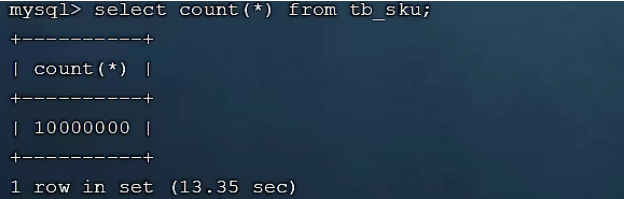
测试:
select * from tb_user; -- 这条SQL执行效率比较高, 执行耗时 0.00sec
select count(*) from tb_sku; -- 由于tb_sku表中, 预先存入了1000w的记录, count一次,耗时13.35sec
B. 检查慢查询日志 :
最终我们发现,在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL是不会记录的。
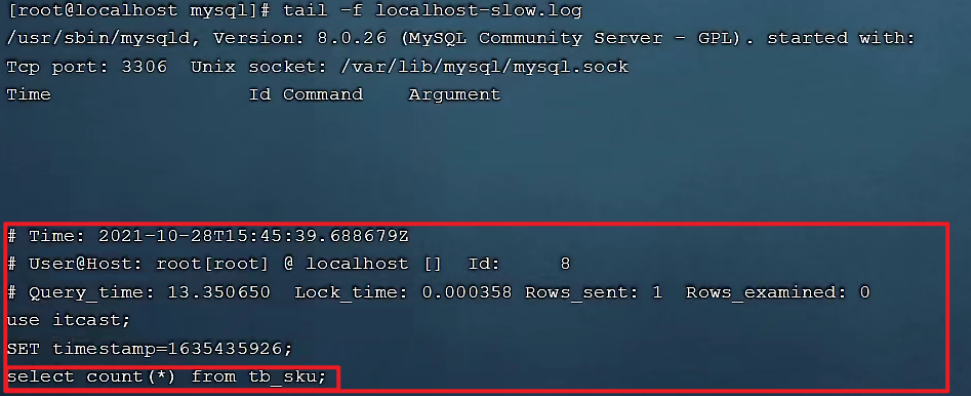
那这样,通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化。
profile详情
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作:
SELECT @@have_profiling ;
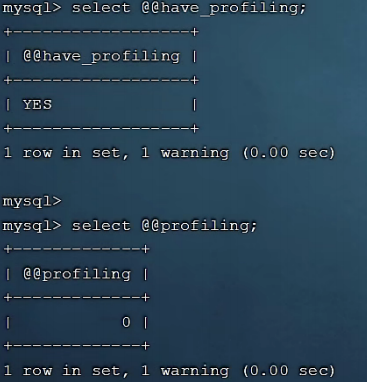
可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/global级别开启profiling:
SET profiling = 1;
开关已经打开了,接下来,我们所执行的SQL语句,都会被MySQL记录,并记录执行时间消耗到哪儿去了。 我们直接执行如下的SQL语句:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
查看每一条SQL的耗时情况:
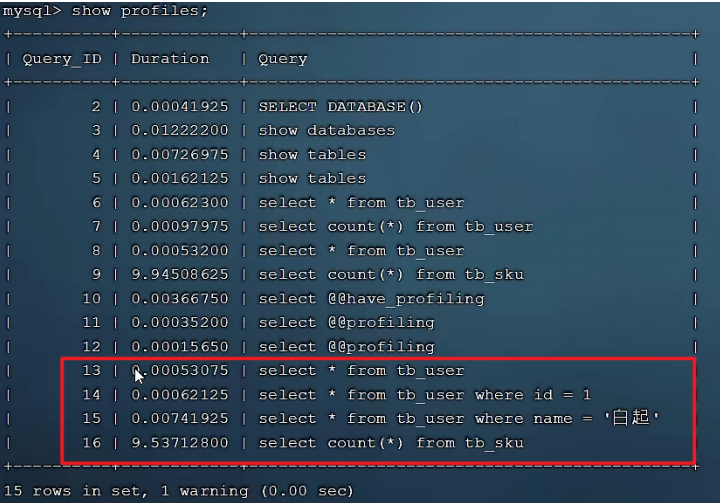
查看指定SQL各个阶段的耗时情况 :

explain
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
语法:
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

Explain 执行计划中各个字段的含义:

索引使用
验证索引效率
在讲解索引的使用原则之前,先通过一个简单的案例,来验证一下索引,看看是否能够通过索引来提升数据查询性能。在演示的时候,我们还是使用之前准备的一张表 tb_sku , 在这张表中准备了1000w的记录。
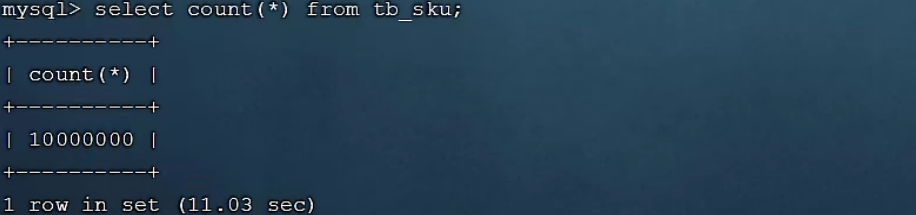
这张表中id为主键,有主键索引,而其他字段是没有建立索引的。 我们先来查询其中的一条记录,看看里面的字段情况,执行如下SQL:
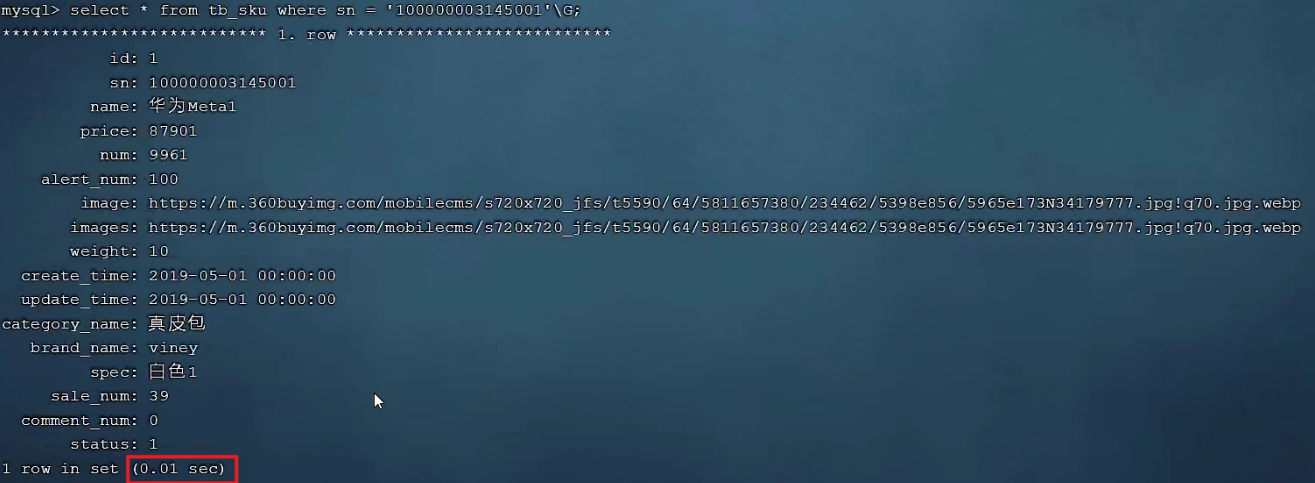
select * from tb_sku where id = 1\G;
SQL末尾使用’\G’可以纵向方向展示数据,在数据少的情况下很方便的(使用Navicat第三方工具是不支持’\G’的)。

可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。 那么接下来,我们再来根据 sn 字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';
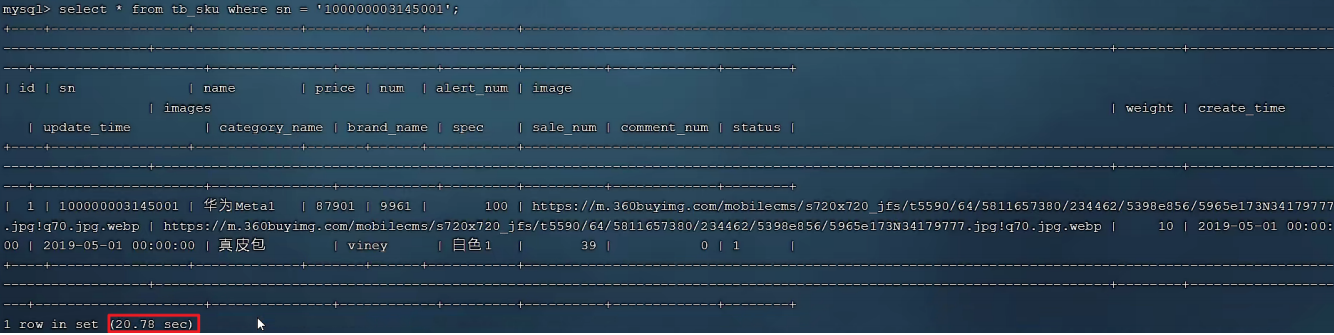
我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
创建索引:
create index idx_sku_sn on tb_sku(sn) ;

然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT * FROM tb_sku WHERE sn = '100000003145001';
我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
以 tb_user 表为例,我们先来查看一下之前 tb_user 表所创建的索引。

在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age,status。
对于最左前缀法则指的是,查询时,最左变的列,也就是profession必须存在,否则索引全部失效。而且中间不能跳过某一列,否则该列后面的字段索引将失效。 接下来,我们来演示几组案例,看一下
具体的执行计划:
explain select * from tb_user where profession = '软件工程' and age = 31 and status= '0';

explain select * from tb_user where profession = '软件工程' and age = 31;

explain select * from tb_user where profession = '软件工程';

以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age字段索引长度为2、status字段索引长度为5。
explain select * from tb_user where age = 31 and status = '0';

explain select * from tb_user where status = '0';

而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引最左边的列profession不存在。
explain select * from tb_user where profession = '软件工程' and status = '0';

上述的SQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索引的长度就是47.
当执行SQL语句: explain select * from tb_user where age = 31 and status = '0' and profession = '软件工程'; 时,是否满足最左前缀法则,走不走上述的联合索引,索引长度?

可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
注意 : 最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关。
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
explain select * from tb_user where profession = '软件工程' and age > 30 and status = '0';

当范围查询使用> 或 < 时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字段是没有走索引的。
explain select * from tb_user where profession = '软件工程' and age >= 30 and status = '0';

当范围查询使用>= 或 <= 时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引的。
所以,在业务允许的情况下,尽可能的使用类似于 >= 或 <= 这类的范围查询,而避免使用 > 或 <。
索引失效情况
索引列运算
不要在索引列上进行运算操作, 索引将失效。
在tb_user表中,除了前面介绍的联合索引之外,还有一个索引,是phone字段的单列索引。

A. 当根据phone字段进行等值匹配查询时, 索引生效。
explain select * from tb_user where phone = '17799990015';

B. 当根据phone字段进行函数运算操作之后,索引失效。
explain select * from tb_user where substring(phone,10,2) = '15';

字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
接下来,我们通过两组示例,来看看对于字符串类型的字段,加单引号与不加单引号的区别:
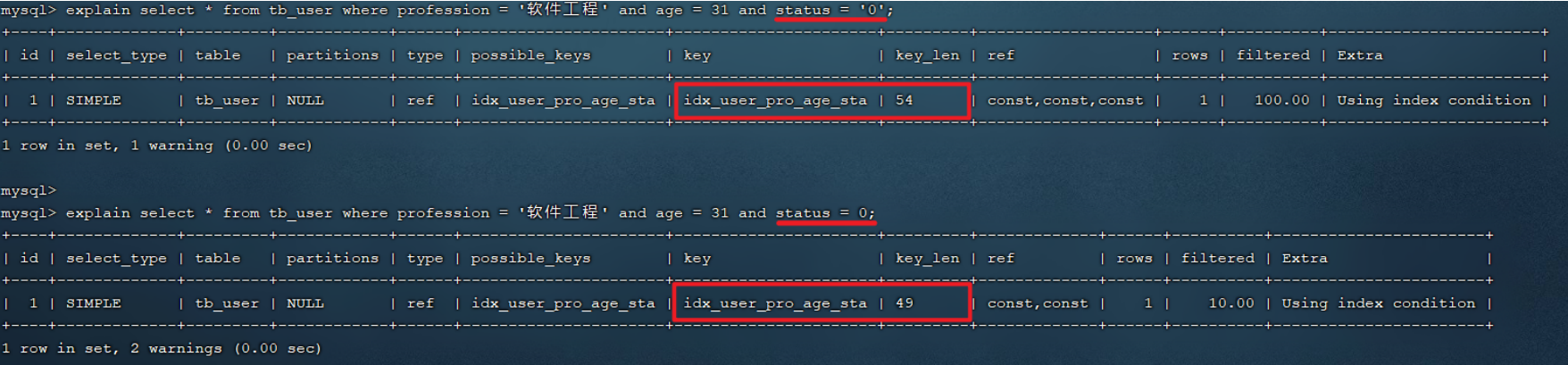
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status = 0;
explain select * from tb_user where phone = '17799990015';
explain select * from tb_user where phone = 17799990015;

经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
接下来,我们来看一下这三条SQL语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据profession字段查询,符合最左前缀法则,联合索引是可以生效的,我们主要看一下,模糊查询时,%加在关键字之前,和加在关键字之后的影响。
explain select * from tb_user where profession like '软件%';
explain select * from tb_user where profession like '%工程';
explain select * from tb_user where profession like '%工%';
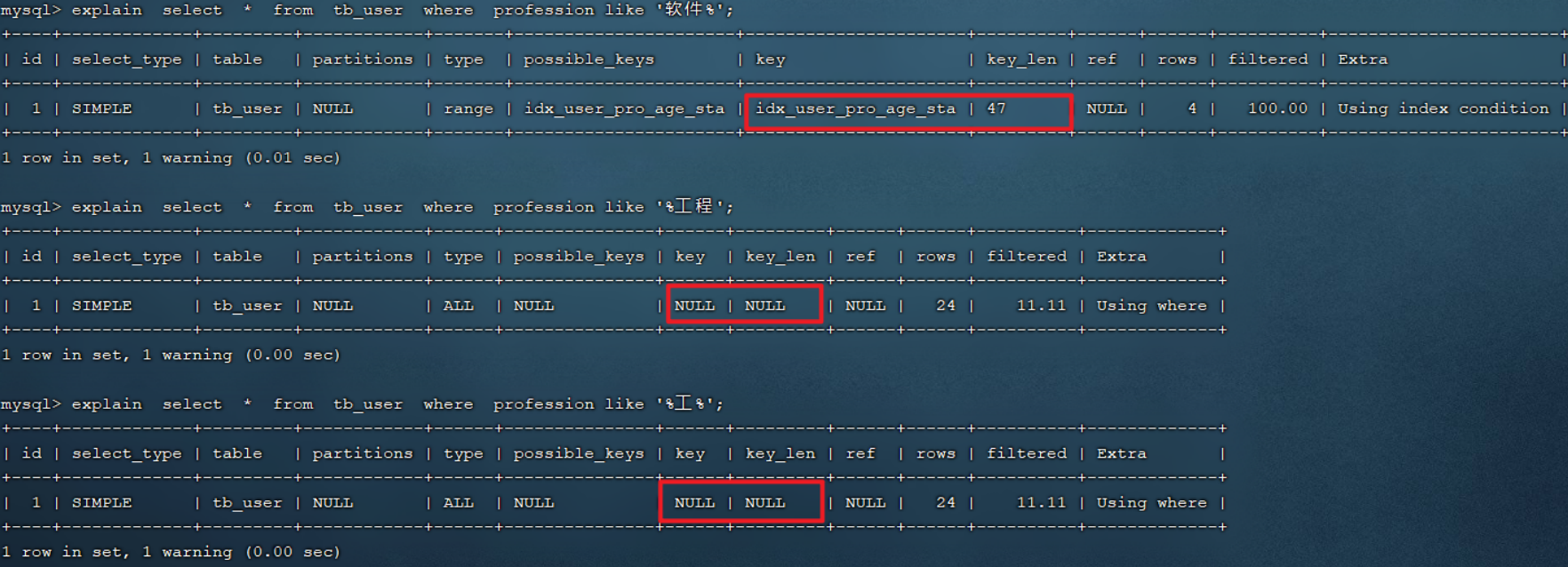
经过上述的测试,我们发现,在like模糊查询中,在关键字后面加%,索引可以生效。而如果在关键字前面加了%,索引将会失效。
or连接条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select * from tb_user where id = 10 or age = 23;
explain select * from tb_user where phone = '17799990017' or age = 23;
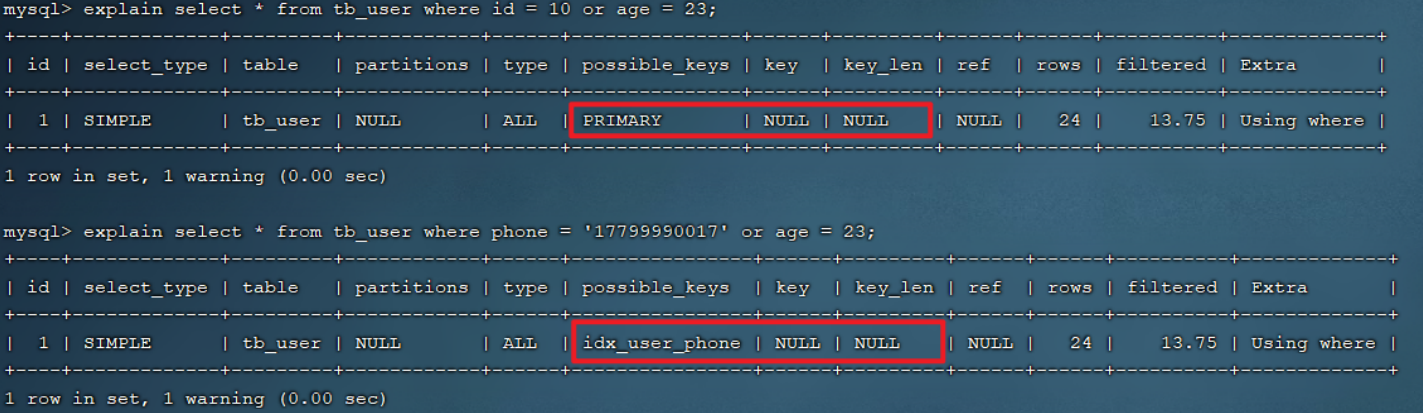
由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
然后,我们可以对age字段建立索引。
create index idx_user_age on tb_user(age);

建立了索引之后,我们再次执行上述的SQL语句,看看前后执行计划的变化。

最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
select * from tb_user where phone >= '17799990005';
select * from tb_user where phone >= '17799990015';


经过测试我们发现,相同的SQL语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为什么呢?
就是因为MySQL在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。 因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
接下来,我们再来看看 is null 与 is not null 操作是否走索引。
执行如下两条语句 :
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;
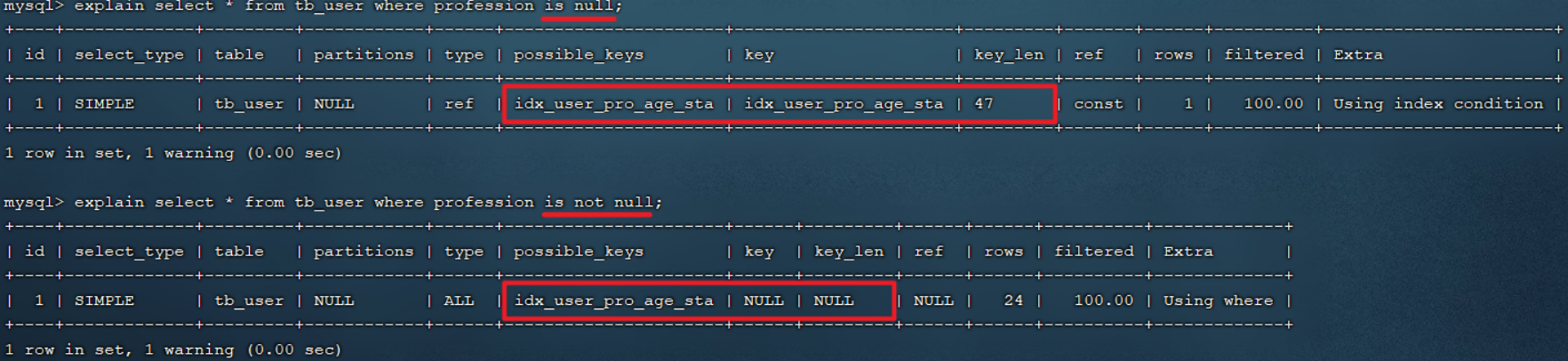
接下来,我们做一个操作将profession字段值全部更新为null。

然后,再次执行上述的两条SQL,查看SQL语句的执行计划。
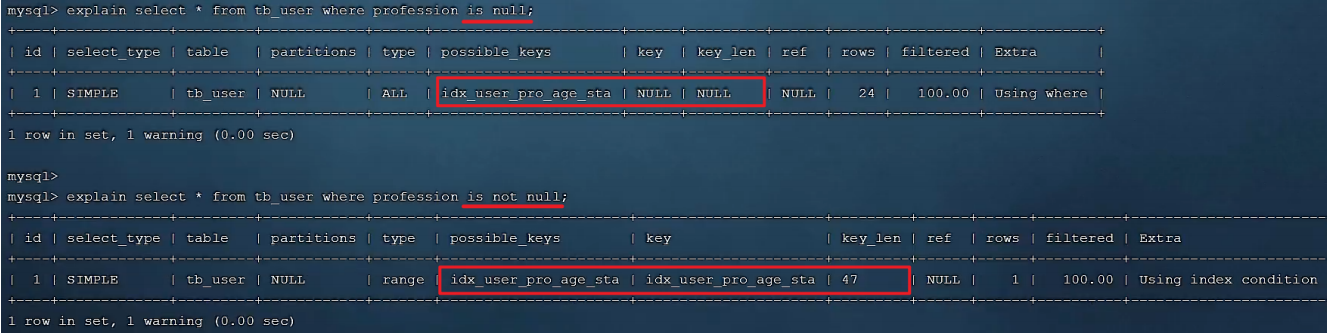
最终我们看到,一模一样的SQL语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象,这是和数据库的数据分布有关系。查询时MySQL会评估,走索引快,还是全表扫描快,如果全表扫描更快,则放弃索引走全表扫描。 因此,is null 、is not null是否走索引,得具体情况具体分析,并不是固定的。
SQL提示
目前tb_user表的数据情况如下:
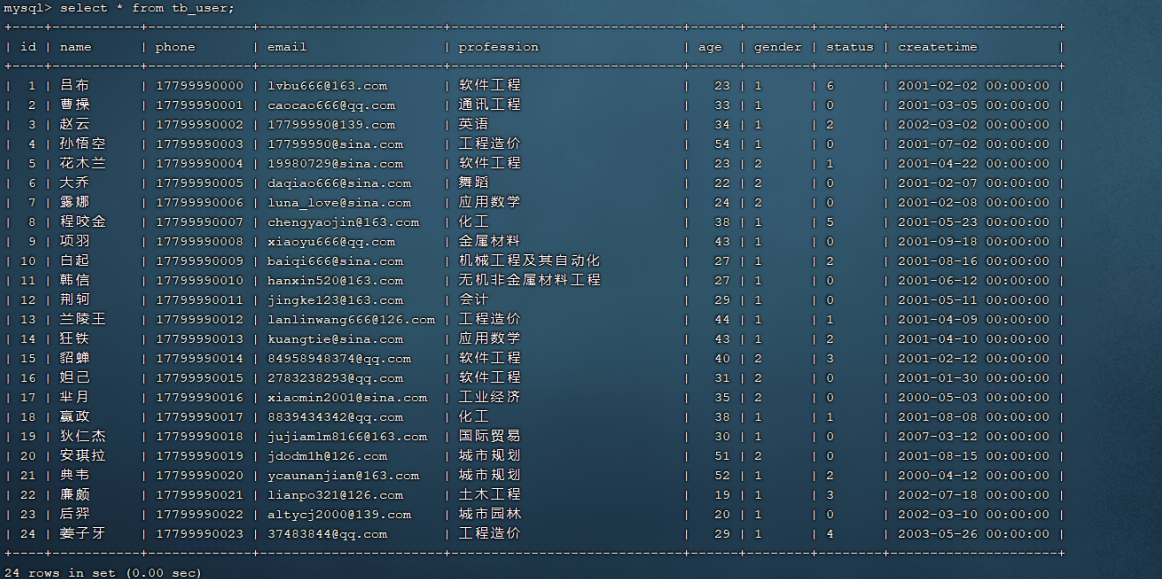
索引情况如下:

把上述的 idx_user_age, idx_email 这两个之前测试使用过的索引直接删除。
drop index idx_user_age on tb_user;
drop index idx_email on tb_user;
A. 执行SQL : explain select * from tb_user where profession = '软件工程';

查询走了联合索引。
B. 执行SQL,创建profession的单列索引:create index idx_user_pro on tb_user(profession);

C. 创建单列索引后,再次执行A中的SQL语句,查看执行计划,看看到底走哪个索引。

测试结果,我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个索引都可能用到,最终MySQL选择了idx_user_pro_age_sta索引。这是MySQL自动选择的结果。
那么,我们能不能在查询的时候,自己来指定使用哪个索引呢? 答案是肯定的,此时就可以借助于MySQL的SQL提示来完成。 接下来,介绍一下SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
1). use index : 建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysql内部还会再次进行评估)。
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';
2). ignore index : 忽略指定的索引。
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';
3). force index : 强制使用索引。
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
示例演示:
A. use index
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';

B. ignore index
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';

C. force index
explain select * from tb_user force index(idx_user_pro_age_sta) where profession = '软件工程';

覆盖索引
尽量使用覆盖索引,减少select *。 那么什么是覆盖索引呢? 覆盖索引是指 查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
接下来,我们来看一组SQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
explain select id, profession from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select id,profession,age, status, name from tb_user where profession = '软件工程' and age = 31 and status = '0' ;
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
上述这几条SQL的执行结果为:

从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两条SQL的结果为 Using where; Using Index ; 而后面两条SQL的结果为: Using index condition 。
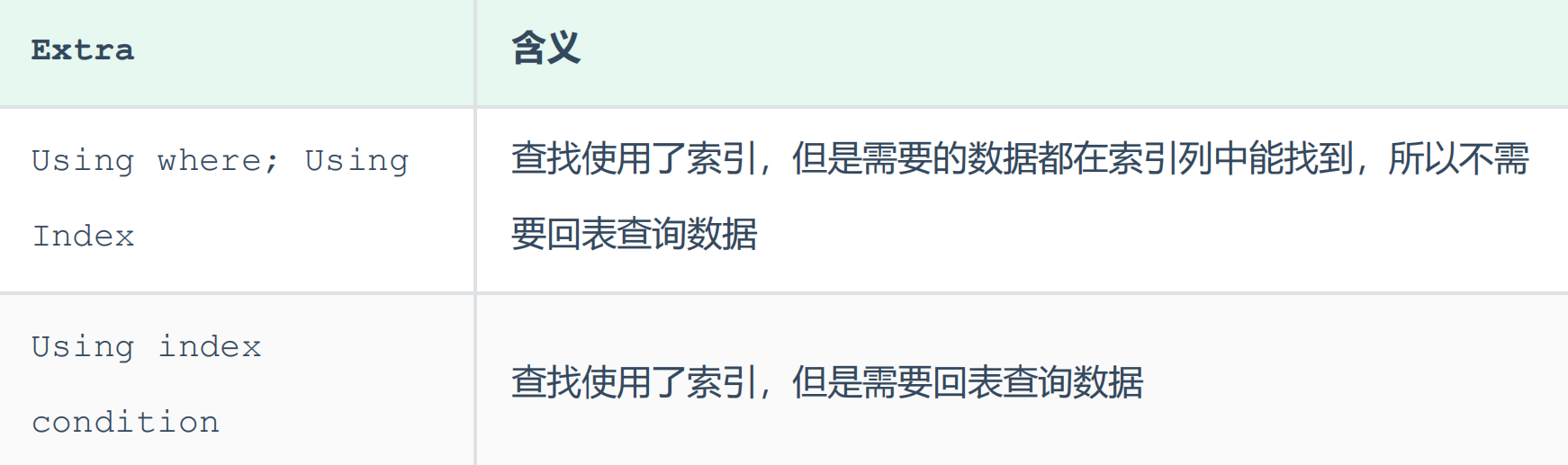
因为,在tb_user表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。 所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据了,这个过程就是回表。 而我们如果一直使用select * 查询返回所有字段值,很容易就会造成回表查询(除非是根据主键查询,此时只会扫描聚集索引)。
为了大家更清楚的理解,什么是覆盖索引,什么是回表查询,我们一起再来看下面的这组SQL的执行过程。
A. 表结构及索引示意图:
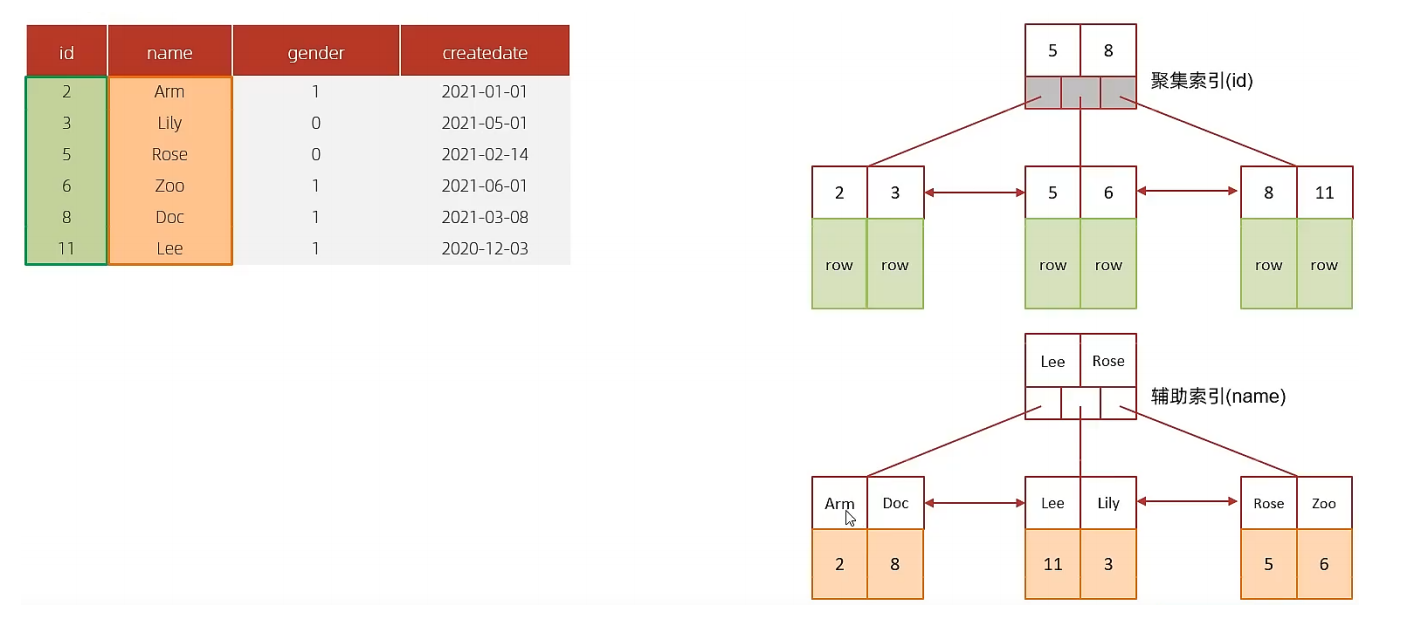
id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
B. 执行SQL : select * from tb_user where id = 2;
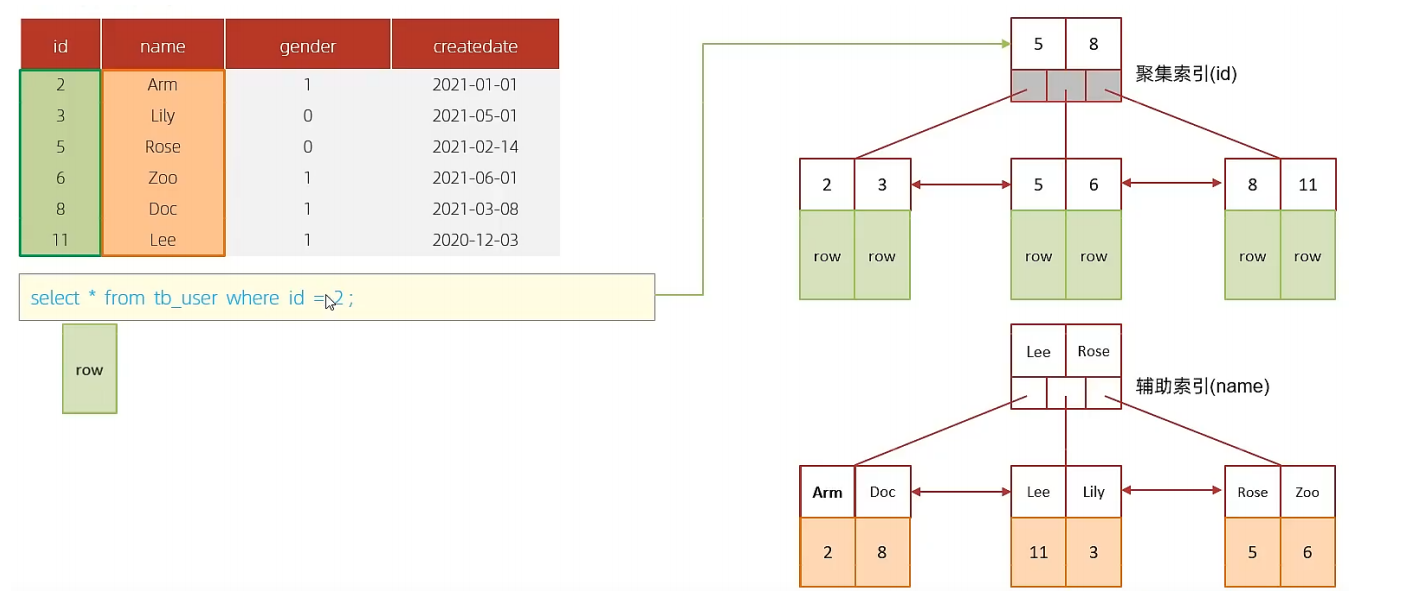
根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
C. 执行SQL:selet id,name from tb_user where name = 'Arm';
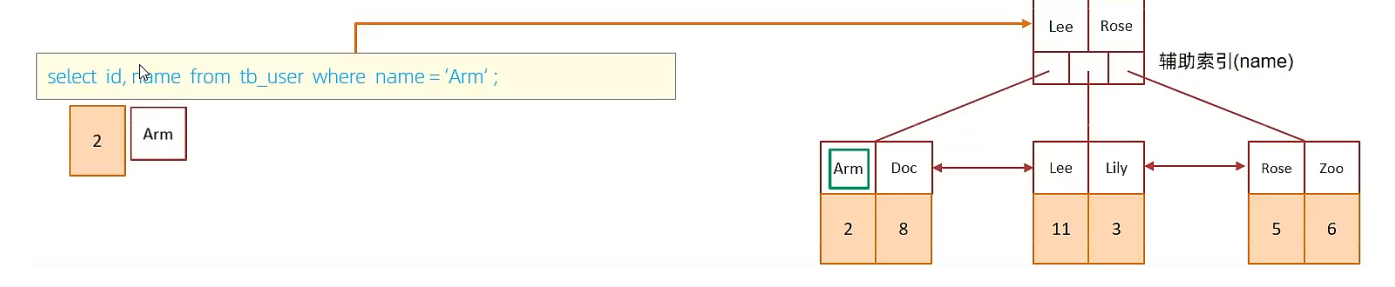
虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
D. 执行SQL:selet id,name,gender from tb_user where name = 'Arm';
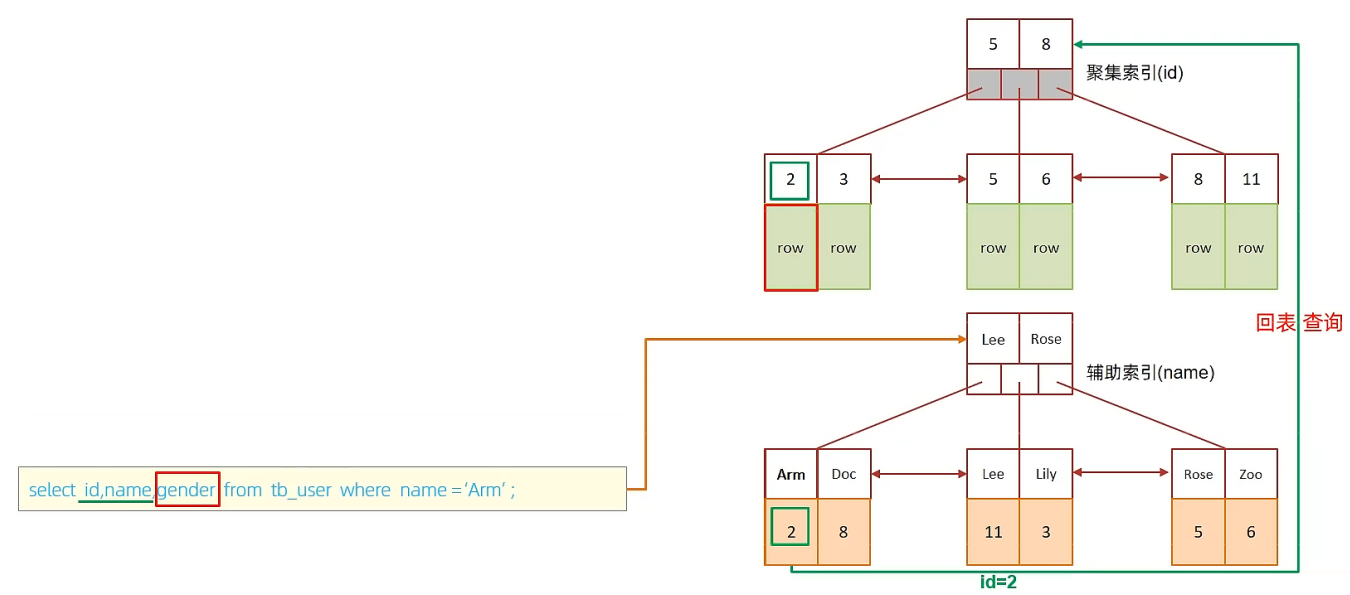
由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
面试题:
一张表, 有四个字段(id, username, password, status), 由于数据量大, 需要对以下SQL语句进行优化, 该如何进行才是最优方案
select id,username,password from tb_user where username = 'zhangxi';
答案: 针对于 username, password建立联合索引
SQL为: create index idx_user_name_pass on tb_user(username,password);
这样可以避免上述的SQL语句,在查询的过程中,出现回表查询。
前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
1). 语法
create index idx_xxxx on table_name(column(n)) ;
示例:
为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5));

2). 前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email) / count(*) from tb_user ;
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
3). 前缀索引的查询流程

单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
我们先来看看 tb_user 表中目前的索引情况:

在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条SQL语句,看看其执行计划:

通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
create unique index idx_user_phone_name on tb_user(phone,name);

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
如果查询使用的是联合索引,具体的结构示意图如下:
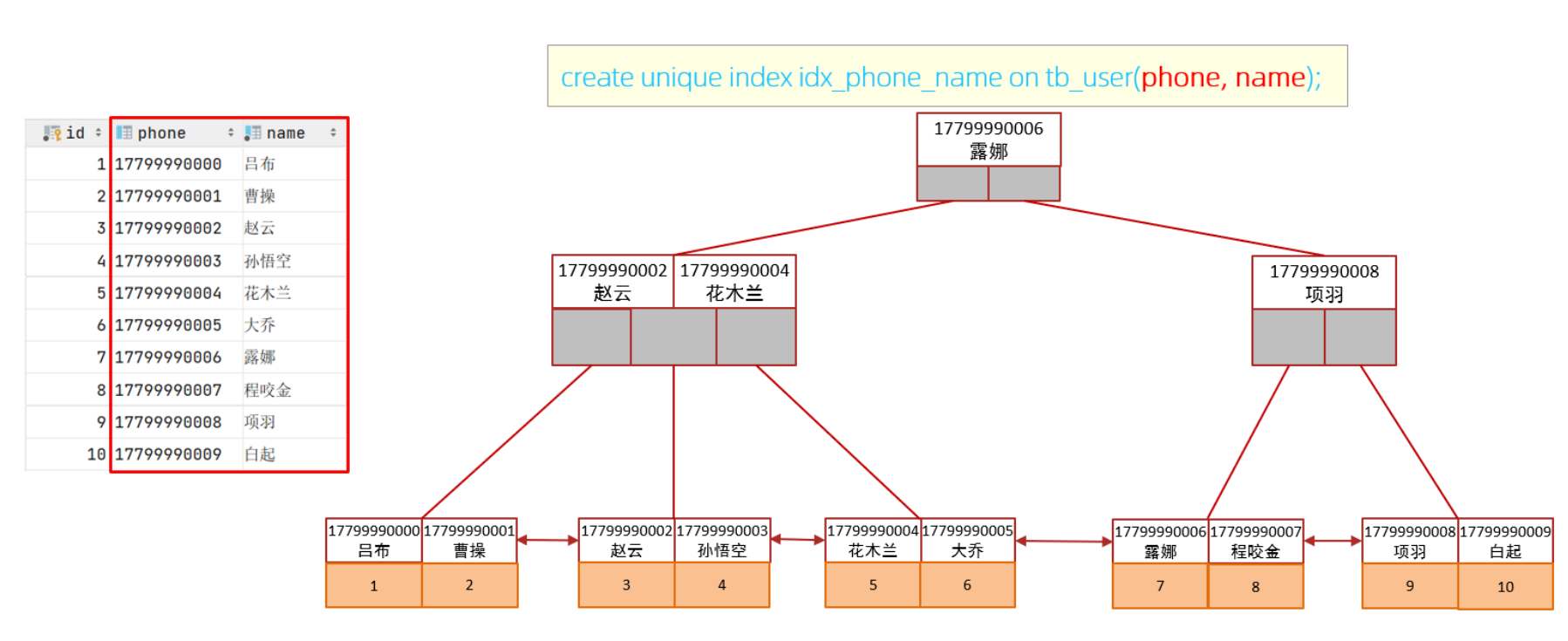
索引设计原则
1). 针对于数据量较大,且查询比较频繁的表建立索引。
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
相关文章:
SQL性能分析-整理
昨日对MySQL的索引整理了一份小文档,对结构/分类/语法等做了一个小总结,具体文章可点击:MySQL-索引回顾,索引知识固然很重要,但引入运用到实际工作中更重要。 参考之前的文章:SQL优化总结以及参考百度/CSDN…...

常用计算电磁学算法特性与电磁软件分析
常用计算电磁学算法特性与电磁软件分析 参考网站: 计算电磁学三大数值算法FDTD、FEM、MOM ADS、HFSS、CST 优缺点和应用范围详细教程 ## 基于时域有限差分法的FDTD的计算电磁学算法(含Matlab代码)-框架介绍 参考书籍:The finite…...
PLC数组队列搜索FC(SCL代码+梯形图程序)
根据输入数据搜索输入数据队列中和输入数据相同的数,函数返回其所在队列的位置。这里我们需要用到博途PLC的数组指针功能,有关数组指针的详细使用方法,可以参考下面文章: 博途PLC数组指针: https://rxxw-control.blog.csdn.net/article/details/134761364 区间搜索FC …...

NUS CS1101S:SICP JavaScript 描述:前言、序言和致谢
前言 原文:Foreword 译者:飞龙 协议:CC BY-NC-SA 4.0 我有幸在我还是学生的时候见到了了不起的 Alan Perlis,并和他交谈了几次。他和我共同深爱和尊重两种非常不同的编程语言:Lisp 和 APL。跟随他的脚步是一项艰巨的任…...

软件测试常见问题2
1.用jmeter怎么进行测试? 使用JMeter进行测试的步骤如下: 启动JMeter,右键点击测试计划,选择添加->Threads(Users)->线程组,在线程组下创建请求。在请求中添加HTTP请求信息头,右键点击HTTP请求&…...
WPF XAML(一)
一、XAML的含义 问:XAML的含义是什么?为什么WPF中会使用XAML?而不是别的? 答:在XAML是基于XML的格式,XML的优点在于设计目标是具有逻辑性易读而且简单内容也没有被压缩。 其中需要提一下XAML文件在 Visu…...

每日一题:LeetCode-LCR 007. 三数之和
每日一题系列(day 18) 前言: 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🔎…...
四元数傅里叶变换(Quaternion Fourier Transforms) 在信号和图像处理中的应用
引言: 信号和图像处理是现代科学和工程领域中非常重要的一个方向,它涉及到对信号和图像进行分析、压缩、增强和恢复等操作。传统的信号和图像处理方法主要依赖于傅里叶变换和滤波器等工具,但这些方法在处理复杂系统时存在一定的局限性。近年来,四元数傅里叶变换作为一种新兴…...
vue项目之.env文件.env.dev、test、pro
.env文件是vue运行项目时的环境配置文件。 .env: 全局默认配置文件,所有环境(开发、测试、生产等)均会加载并合并该文件 .env.development(开发环境默认命名) 开发环境的配置,文件名默认为.env.development,如果需要改名也是可以的…...

Fabric2.2:在有系统通道的情况下搭建应用通道
写在最前 在使用Fabric-SDK-Go1.0.0操作Fabric网络时遇到了bug。Fabric-SDK-GO的当前版本没有办法在没有系统通道的情况下创建应用通道,而Fabric的最新几个版本允许在没有系统通道的情况下搭建应用通道。为了解决这个矛盾并使用Fabric-SDK-GO完成后续的项目开发&…...
)
测试人员必备基本功(2)
容易被忽视的bug 第二章 修改表单容易被忽视的bug 文章目录 容易被忽视的bug第二章 修改表单容易被忽视的bug 前言一、修改表单二、具体功能1.修改角色2.接口设计 三、测试设计1.测试点2.容易发现bug的测试点如下: 总结 前言 一个WEB系统的所有功能模块࿰…...
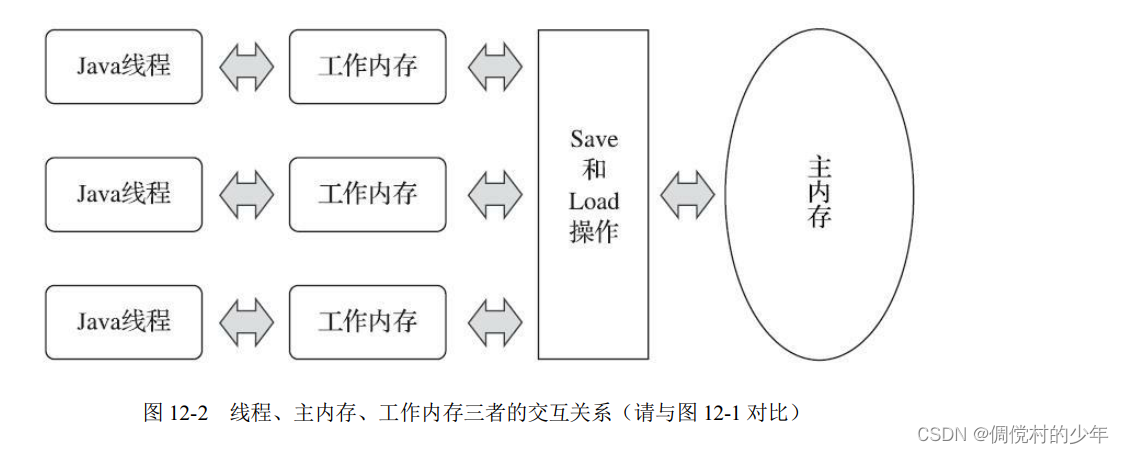
第十二章 Java内存模型与线程(一)
文章目录 12.3 Java内存模型12.3.1 主内存与工作内存12.3.2 内存间交互操作小结12.3.3 对于volatile型变量的特殊规则12.3.5 原子性、可见性与有序性12.3.6 先行发生原则 12.3 Java内存模型 12.3.1 主内存与工作内存 1.Java 内存模型规定了所有的变量都存储在主内存ÿ…...
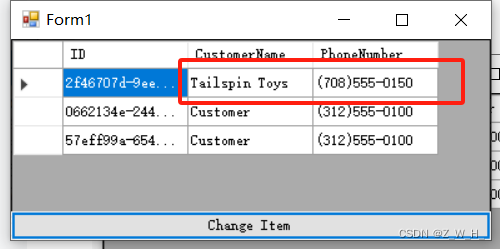
C# WPF 数据绑定
需求 后台变量发生改变,前端对应的相关属性值也发生改变 实现 接口 INotifyPropertyChanged 用于通知客户端(通常绑定客户端)属性值已更改。 示例 示例一 官方示例代码如下 using System; using System.Collections.Generic; using System.ComponentModel; using Sys…...

进程和线程的比较
目录 一、前言 二、Linux查看进程、线程 2.1 Linux最大进程数 2.2 Linux最大线程数 2.3 Linux下CPU利用率高的排查 三、线程的实现 四、上下文切换 五、总结 一、前言 进程是程序执行相关资源(CPU、内存、磁盘等)分配的最小单元,是一…...
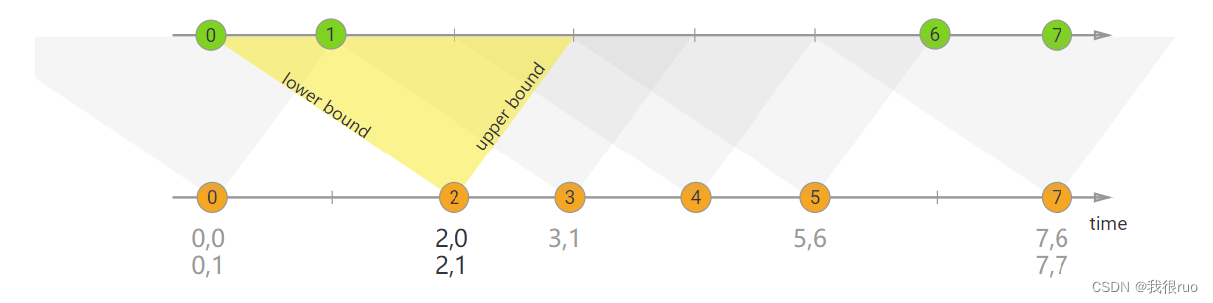
深入理解 Flink(四)Flink Time+WaterMark+Window 深入分析
Flink Window 常见需求背景 需求描述 每隔 5 秒,计算最近 10 秒单词出现的次数 —— 滑动窗口 每隔 5 秒,计算最近 5 秒单词出现的次数 —— 滚动窗口 关于 Flink time 种类 TimeCharacteristic ProcessingTimeIngestionTimeEventTime WindowAssign…...

科技创新领航 ,安川运动控制器为工业自动化赋能助力
迈入工业4.0时代,工业自动化的不断发展,让高精度运动控制成为制造业高质量发展的重要技术手段。北京北成新控伺服技术有限公司作为一家集工业自动化产品销售、系统设计、开发、服务于一体的高新技术企业,其引进推出的运动控制产品一直以卓越的…...

图像异或加密及唯密文攻击
异或加密 第一种加密方式为异或加密,异或加密的原理是利用异或的可逆性质,原始图像的像素八位bit分别与伪随机二进制序列异或,得到的图像就为加密图像。如下图对lena图像进行加密。 伪随机序列为一系列二进制代码,它受加密秘钥控…...

React Grid Layout基础使用
摘要 React Grid Layout是一个用于在React应用程序中创建可拖拽和可调整大小的网格布局的库。它提供了一个灵活的网格系统,可以帮助开发人员构建响应式的布局,并支持拖拽、调整大小和动画效果。本文将介绍如何使用React Grid Layout来创建自适应的布局。…...

第11章 1 文件及IO操作
文章目录 文件的概述及基本操作步骤 p151文件的写入操作 p152文件的读取操作及文件复制 p153文件的读取操作文件复制 with语句的使用 p154一维数据和二维数据的存储与读取 p155高维数据的存储和读取 p156os模块中的常用的函数 p157os.path模块中常用的函数 p158 文件的概述及基…...

Tomcat服务实例部署
目录 **Tomcat 由一系列的组件构成,其中核心的组件有三个:** 什么是 servlet? 什么是 JSP? Tomcat 功能组件结构: Container 结构分析: Tomcat 请求过程: ## Tomcat 服务部署 1.关闭防火墙…...
)
Flutter开发踩坑记:CocoaPods安装失败全流程解决方案(含Ruby版本升级)
Flutter开发实战:CocoaPods安装失败的系统级解决方案 当你满怀期待地运行flutter doctor准备大展身手时,屏幕上突然跳出"CocoaPods not installed"的红色警告,这种挫败感每个Flutter开发者都深有体会。不同于简单的"安装-运行…...

5分钟搞定AI超清画质增强:镜像部署与使用全攻略
5分钟搞定AI超清画质增强:镜像部署与使用全攻略 1. 引言:为什么需要AI画质增强 1.1 低清图像的普遍困扰 我们每天都会遇到各种低质量图片:模糊的老照片、压缩过度的网络图片、分辨率不足的截图。传统放大方法就像简单拉伸橡皮筋࿰…...

KMS_VL_ALL_AIO:智能激活脚本的高效办公解决方案
KMS_VL_ALL_AIO:智能激活脚本的高效办公解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 在数字化办公环境中,Windows系统和Office办公套件的激活管理常常成为用户…...

终极指南:如何免费将CAJ文件转换为高质量PDF?caj2pdf完整使用教程
终极指南:如何免费将CAJ文件转换为高质量PDF?caj2pdf完整使用教程 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: …...

FireRedASR-AED-L语音搜索应用:电商场景实战
FireRedASR-AED-L语音搜索应用:电商场景实战 1. 引言 想象一下这个场景:一位正在做饭的用户手上沾满面粉,突然想起需要购买烘焙材料,只需对着手机说"帮我找高筋面粉",下一秒就能看到精准的商品搜索结果。这…...
)
保姆级避坑指南:用Gromacs 2023版跑通蛋白质结合自由能伞形采样(附完整配置文件)
Gromacs 2023版蛋白质结合自由能伞形采样全流程避坑指南 第一次用Gromacs做伞形采样时,我对着报错信息熬了三个通宵。现在回想起来,90%的问题都源于教程没交代清楚的细节——比如gmx pdb2gmx处理多链蛋白时的选项差异,或是云计算平台提交任务…...

UNIT-00:Berserk Interface辅助数据库课程设计:从ER图到SQL
UNIT-00:Berserk Interface辅助数据库课程设计:从ER图到SQL 你是不是正在为数据库课程设计发愁?面对一个模糊的业务需求,要从零开始画出清晰的ER图,再设计出规范化的数据库模式,最后还要写出一堆建表和查询…...

手把手教你部署GLM-4v-9B:9B参数多模态模型,单卡就能跑
手把手教你部署GLM-4v-9B:9B参数多模态模型,单卡就能跑 1. GLM-4v-9B模型简介 GLM-4v-9B是智谱AI于2024年开源的多模态大模型,具有以下核心特点: 参数规模:90亿参数,单张24GB显存的显卡即可运行多模态能…...

3种文档转换难题的解决方案:Cloud Document Converter工具深度解析
3种文档转换难题的解决方案:Cloud Document Converter工具深度解析 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 核心价值:文档格式转换的效…...

res-downloader高效配置指南:全平台资源捕获从入门到精通
res-downloader高效配置指南:全平台资源捕获从入门到精通 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcode.…...