【HuggingFace Transformer库学习笔记】基础组件学习:Datasets
基础组件——Datasets
datasets基本使用

导入包
from datasets import *
加载数据
datasets = load_dataset("madao33/new-title-chinese")
datasetsDatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5850})validation: Dataset({features: ['title', 'content'],num_rows: 1679})
})
加载数据集合集中的某一项子集
boolq_dataset = load_dataset("super_glue", "boolq")
boolq_datasetDatasetDict({train: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 9427})validation: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 3270})test: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 3245})
})
按照数据集划分进行加载
dataset = load_dataset("madao33/new-title-chinese", split="train")
datasetDataset({features: ['title', 'content'],num_rows: 5850
})
dataset = load_dataset("madao33/new-title-chinese", split="train[10:100]")
datasetDataset({features: ['title', 'content'],num_rows: 90
})
dataset = load_dataset("madao33/new-title-chinese", split="train[:50%]")
datasetDataset({features: ['title', 'content'],num_rows: 2925
})
dataset = load_dataset("madao33/new-title-chinese", split=["train[:50%]", "train[50%:]"])
dataset[Dataset({features: ['title', 'content'],num_rows: 2925}),Dataset({features: ['title', 'content'],num_rows: 2925})]
查看数据集
datasets = load_dataset("madao33/new-title-chinese")
datasetsDatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5850})validation: Dataset({features: ['title', 'content'],num_rows: 1679})
})
查看某一个数据
datasets["train"][0]{'title': '望海楼是危险的赌博','content': '近期妥善处理)'}
查看某一些数据
datasets["train"][:2]{'title': ['望海楼是危险的赌博'],'content': ['撒打发是','在推进“双一流”高校建设进程中']}
查看列名
datasets["train"].column_names['title', 'content']
查看列属性
{'title': Value(dtype='string', id=None),'content': Value(dtype='string', id=None)}
数据集划分
可使用train_test_split这个函数
dataset = datasets["train"]
dataset.train_test_split(test_size=0.1) # 按测试集比例为10%划分DatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5265})test: Dataset({features: ['title', 'content'],num_rows: 585})
})
对于分类任务,指定标签字段,然后让这个数据集均衡划分标签字段
dataset = boolq_dataset["train"]
dataset.train_test_split(test_size=0.1, stratify_by_column="label") # 分类数据集可以按照比例划分DatasetDict({train: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 8484})test: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 943})
})
数据选取与过滤
# 选取
datasets["train"].select([0, 1])Dataset({features: ['title', 'content'],num_rows: 2
})
# 过滤
## 传入一个lambda函数,让其只取含有中国的数据
filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"])
filter_dataset["title"][:5]['世界探寻中国成功秘诀','信心来自哪里','世界减贫跑出加速度','和音瞩目历史交汇点','风采感染世界']
数据映射
def add_prefix(example):example["title"] = 'Prefix: ' + example["title"]return example
prefix_dataset = datasets.map(add_prefix) # 每个title数据前面添加了前缀
prefix_dataset["train"][:10]["title"]['Prefix: 危险的','Prefix: 大力推进高校治理能力建设','Prefix: 坚持事业为上选贤任能','Prefix: “大朋友”的话儿记心头','Prefix: 用好可持续发展这把“金钥匙”','Prefix: 跨越雄关,我们走在大路上','Prefix: 脱贫奇迹彰显政治优势','Prefix: 拱卫亿万人共同的绿色梦想','Prefix: 育人育才','Prefix: 净化网络语言']
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
def preprocess_function(example, tokenizer=tokenizer):model_inputs = tokenizer(example["content"], max_length=512, truncation=True)labels = tokenizer(example["title"], max_length=32, truncation=True)# label就是title编码的结果model_inputs["labels"] = labels["input_ids"]return model_inputs
processed_datasets = datasets.map(preprocess_function) # 添加了分类标签
processed_datasetsDatasetDict({train: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
processed_datasets = datasets.map(preprocess_function, batched=True) # 使用批处理
processed_datasetsDatasetDict({train: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
去除某一字段
processed_datasets = datasets.map(preprocess_function, batched=True, remove_columns=datasets["train"].column_names)
processed_datasetsDatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
保存与加载
# 保存
processed_datasets.save_to_disk("./processed_data")
# 加载
processed_datasets = load_from_disk("./processed_data")
加载本地数据集
# 加载本地csv文件
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
datasetDataset({features: ['label', 'review'],num_rows: 7766
})
dataset = Dataset.from_csv("./ChnSentiCorp_htl_all.csv")
datasetDataset({features: ['label', 'review'],num_rows: 7766
})
加载文件夹内全部文件作为数据集
# 使用data_dir加载全部文件夹内文件
dataset = load_dataset("csv", data_dir="./all_data/", split='train')
datasetDataset({features: ['label', 'review'],num_rows: 23298
})
# 使用data_files加载文件夹内指定文件
dataset = load_dataset("csv", data_files=["./all_data/ChnSentiCorp_htl_all.csv", "./all_data/ChnSentiCorp_htl_all copy.csv"], split='train')
datasetDataset({features: ['label', 'review'],num_rows: 15532
})
通过其他方式读取数据,再将其转换成datasets
import pandas as pddata = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data.head()

dataset = Dataset.from_pandas(data)
datasetDataset({features: ['label', 'review'],num_rows: 7766
})
# List格式的数据需要内嵌{},明确数据字段
data = [{"text": "abc"}, {"text": "def"}]
# data = ["abc", "def"]
Dataset.from_list(data)Dataset({features: ['text'],num_rows: 2
})
通过自定义加载脚本加载数据集
load_dataset("json", data_files="./cmrc2018_trial.json", field="data")DatasetDict({train: Dataset({features: ['title', 'paragraphs', 'id'],num_rows: 256})
})
dataset = load_dataset("./load_script.py", split="train")
datasetdataset[0]{'id': 'TRIAL_800_QUERY_0','context': '基于《跑跑卡丁车》与《泡泡堂》上所开发的游戏,由韩国Nexon开发与发行。中国大陆由盛大游戏运营,这是Nexon时隔6年再次授予盛大网络其游戏运营权。台湾由游戏橘子运营。玩家以水枪、小枪、锤子或是水炸弹泡封敌人(玩家或NPC),即为一泡封,将水泡击破为一踢爆。若水泡未在时间内踢爆,则会从水泡中释放或被队友救援(即为一救援)。每次泡封会减少生命数,生命数耗完即算为踢爆。重生者在一定时间内为无敌状态,以踢爆数计分较多者获胜,规则因模式而有差异。以2V2、4V4随机配对的方式,玩家可依胜场数爬牌位(依序为原石、铜牌、银牌、金牌、白金、钻石、大师) ,可选择经典、热血、狙击等模式进行游戏。若游戏中离,则4分钟内不得进行配对(每次中离+4分钟)。开放时间为暑假或寒假期间内不定期开放,8人经典模式随机配对,采计分方式,活动时间内分数越多,终了时可依该名次获得奖励。','question': '生命数耗完即算为什么?','answers': {'text': ['踢爆'], 'answer_start': [127]}}
相关文章:
【HuggingFace Transformer库学习笔记】基础组件学习:Datasets
基础组件——Datasets datasets基本使用 导入包 from datasets import *加载数据 datasets load_dataset("madao33/new-title-chinese") datasetsDatasetDict({train: Dataset({features: [title, content],num_rows: 5850})validation: Dataset({features: [titl…...

[机缘参悟-126] :实修 - 从系统论角度理解自洽的人生:和谐、稳定,不拧巴,不焦虑,不纠结
目录 一、从系统论理解自洽 1.1 什么是系统 1.2 什么是自洽 1.3 什么是不自洽 1.4 为什么要自洽 1.5 不自洽的系统面临的挑战 二、人生需要自洽 2.1 人生自洽的意义 2.2 一个不自洽的人生会怎么样? 2.3 不自洽的特征 2.4 不自洽的人没有稳定的人格 三、…...

慢 SQL 的优化思路
分析慢 SQL 如何定位慢 SQL 呢? 可以通过 slow log 来查看慢SQL,默认的情况下,MySQL 数据库是不开启慢查询日志(slow query log)。所以我们需要手动把它打开。 查看下慢查询日志配置,我们可以使用 show …...

强化学习(一)简介
强化学习这一概念在历史上来源于行为心理学,来描述生物为了趋利避害而改变自己行为的学习过程。人类学习的过程其实就是为达到某种目的不断地与环境进行互动试错,比如婴儿学习走路。强化学习算法探索了一种从交互中学习的计算方法。 1、强化学习 强化学…...

外贸常用网站
外贸常用网站 网站阿里巴巴国际站阿里巴巴国内站Aliexpress 速卖通shopifyAmazon 亚马逊k3 开山女鞋网bao66 牛包包网爱搜鞋k3 开山网(女鞋)新款网(男女鞋)搜款网(男女衣服)17zwd(女装)17zwd(女装) 物流yunexpress 云途物流 其他amz123 跨境卖家导航amz520 跨境卖家导航 网站 …...

Android中集成FFmpeg及NDK基础知识
前言 在日常App开发中,难免有些功能是需要借助NDK来完成的,比如现在常见的音视频处理等,今天就以ffmpeg入手,来学习下Android NDK开发的套路. JNI和NDK 很多人并不清除JNI和NDK的概念,经常搞混这两样东西,先来看看它们各自的定义吧. JNI和NDK 很多人并不清除JNI和NDK的概念…...
1.13寒假集训
晚上兼职下班回来才有时间写题,早上根本起不来 A: 解题思路:我第一开始以为只要满足两个red以上的字母数量就行,但是过不了,后面才发现是red字符串,直接三个三个判断就行。 下面是c代码: #include<io…...

删除排序链表中的重复元素
说在前面 🎈不知道大家对于算法的学习是一个怎样的心态呢?为了面试还是因为兴趣?不管是出于什么原因,算法学习需要持续保持。 题目描述 给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只…...

echarts的dispatchAction
触发图表行为,通过dispatchAction触发。例如图例开关legendToggleSelect, 数据区域缩放dataZoom,显示提示框showTip等等。 官网:echarts (在 ECharts 中主要通过 on 方法添加事件处理函数。) events: ECharts 中的事件分为两种…...
Java IO学习和总结(超详细)
一、理解 I/O 是输入和输出的简写,指的是数据在计算机内部和外部设备之间的流动。简单来说,当你从键盘输入数据、从鼠标选择操作,或者在屏幕上看到图像,这些都是 I/O 操作。它就像是计算机与外部世界沟通的桥梁,没有 I…...
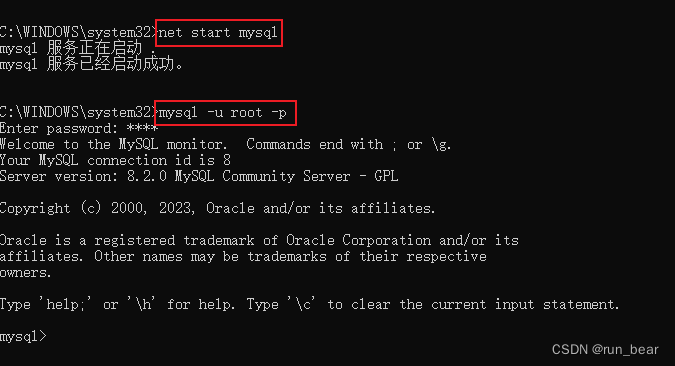
mysql忘记root密码后怎么重置
mysql忘记root密码后重置方法【windows版本】 重置密码步骤停掉mysql服务跳过密码进入数据库在user表中重置密码使用新密码登录mysql到此,密码就成功修改了,完结,撒花~ 重置密码步骤 当我们忘记mysql的密码时,连接mysql会报这样的…...
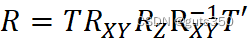
计算机图形学作业:三维线段的图形变换
1. 将三维空间某线段 P1P2进行如下的操作,请按要求回答问题: (1) 沿 X 轴、Y 轴和 Z 轴分别平移 dx、dy 和 dz 的长度,给出相应的变换矩阵。 变换矩阵为: T100001000010dxdydz1 (2)…...
)
Linux mren命令教程:批量重命名文件(附实际操作案例和注意事项)
Linux mren命令介绍 mren(全称multiple rename),它是用来对多个文件进行重命名的工具。这个命令在一次操作中可以批量改变多个文件的名称,特别是在需要对大量文件进行重命名时,mren将节省大量的时间和努力。 Linux m…...

LLVM系列(1): 在微软Visual Studio下编译LLVM
参考链接: Getting Started with the LLVM System using Microsoft Visual Studio — LLVM 18.0.0git documentation 1.安装visualstudio,版本需要大于vs2019 本机环境已安装visual studio2022,省略 2安装Makefile,版本需要大…...

分布式系统的三字真经CAP
文章目录 前言C(Consistency 数据一致性)A(Availability 服务可用性)P(Partition Tolerance 分区容错性)CAP理论最后 前言 你好,我是醉墨居士,我一起探索一下分布式系统的三字真经C…...

大模型背景下计算机视觉年终思考小结(一)
1. 引言 在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下: 使用射线图像和其他医学图像领域的医学诊断应用使用卫星图像分析建筑物和土地利用率相关应用各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计…...
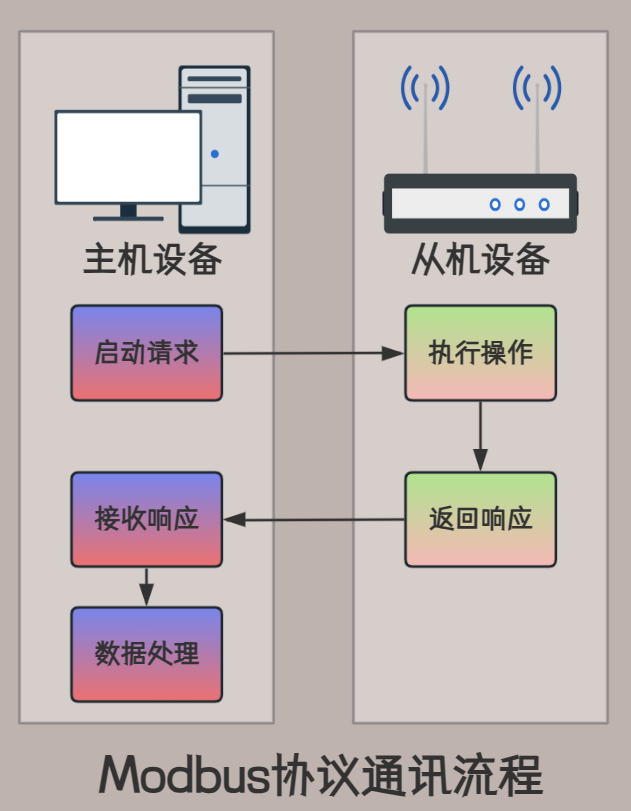
Modbus协议学习第一篇之基础概念
什么是“协议” 大白话解释:协议是用来正确传递消息数据而设立的一种规则。传递消息的双方(两台计算机)在通信时遵循同一种协议,即可理解彼此传递的消息数据。 Modbus协议模型 Modbus协议模型较为简单,使用一种称为应用…...
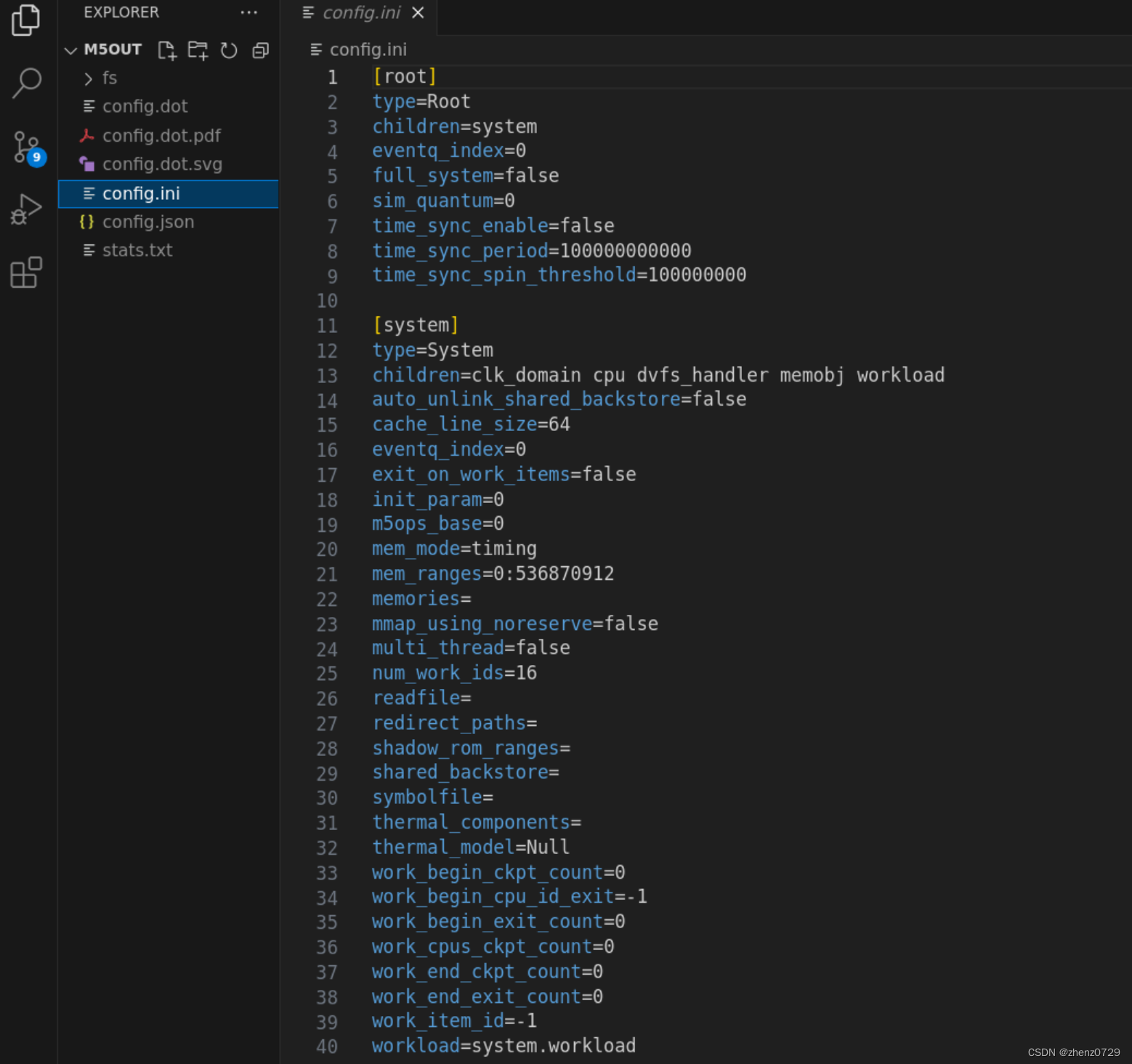
gem5学习(12):理解gem5 统计信息和输出——Understanding gem5 statistics and output
目录 一、config.ini 二、config.json 三、stats.txt 官方教程:gem5: Understanding gem5 statistics and output 在运行 gem5 之后,除了仿真脚本打印的仿真信息外,还会在根目录中名为 m5out 的目录中生成三个文件: config.i…...

索引的概述和使用
1、概述 索引占用存储空间,并不是越多越好,太多的索引会影响系统性能 索引分类 聚集索引: 逻辑顺序和物理顺序是一致的(表中行数的位置决定了该行在内存中存储的位置),因此效率优先于非聚集索引ÿ…...

力扣210. 课程表 II
深度优先遍历 思路: 搜索逻辑参见力扣207.课程表需要课程安排的顺序,课程搜索完成时,将其存储起来即可;存储课程的顺序需要注意: 输入依赖中 [A, B]图中表示 B -> A ,表示先 B 后 A&#x…...

工业安全监控识别 智慧工业工地安全防护检测数据集的训练及应用 通过训练出的个人安全防护装备检测数据集的权重 推理检测识别人 头 脸部 眼镜 口罩 面罩 马甲 安全帽安全服的检测与识别 穿戴检测数据集
工业安全监控识别 智慧工业工地安全防护检测数据集的训练及应用 通过训练出的个人安全防护装备检测数据集的权重 推理检测识别人 头 脸部 眼镜 口罩 面罩 马甲 安全帽安全服的检测与识别 穿戴检测数据集 文章目录一、数据集情况二、类别编号与名称对照表三、典型应用场景四、适…...

Stack-on-a-budget揭秘:免费调度服务的终极性能对比指南
Stack-on-a-budget揭秘:免费调度服务的终极性能对比指南 【免费下载链接】stack-on-a-budget A collection of services with great free tiers for developers on a budget. Sponsored by Mockoon, the best mock API tool. https://mockoon.com 项目地址: https…...

jquery-confirm在真实项目中的应用:电商、后台管理、表单验证等场景实战
jquery-confirm在真实项目中的应用:电商、后台管理、表单验证等场景实战 【免费下载链接】jquery-confirm A multipurpose plugin for alert, confirm & dialog, with extended features. 项目地址: https://gitcode.com/gh_mirrors/jq/jquery-confirm j…...

WinRAR分卷压缩 vs 7-Zip分卷压缩:哪个更适合你?一次讲清区别、选型和实操
WinRAR分卷压缩 vs 7-Zip分卷压缩:深度对比与场景化选型指南 在数字文件传输与存储的日常场景中,大文件处理始终是个绕不开的痛点。无论是设计师需要发送PSD源文件给客户,还是开发人员要共享虚拟机镜像,当文件体积突破邮箱附件限…...

华硕笔记本性能优化终极指南:3步告别臃肿控制软件,用G-Helper重获流畅体验
华硕笔记本性能优化终极指南:3步告别臃肿控制软件,用G-Helper重获流畅体验 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar,…...

FakeLocation:你的手机位置自由指南,3个场景让位置掌控更简单
FakeLocation:你的手机位置自由指南,3个场景让位置掌控更简单 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 还在为社交软件的位置限制烦恼吗?…...

为什么迅雷下载比浏览器稳?从原理到实战的完整使用手册
目录 为什么迅雷下载比浏览器稳?从原理到实战的完整使用手册 前言 一、核心原理:为什么迅雷下载断网也不怕? 1. 断点续传:下载到一半断网也能续 2. 多线程下载:同时开多个 “下载通道” 3. P2P 分布式加速&#…...

多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台
多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台在数字孪生与视频孪生全域空间智能感知的建设进程中,各类管控场景普遍部署多品牌、多焦距、多布设姿态的异构摄像设备,衍生出大量编码格式各异、传输时延参差、时钟相位错位的多源异步…...

降AI率软件9平台覆盖测评:嘎嘎降自研稳定vs套壳工具单平台!
降AI率软件9平台覆盖测评:嘎嘎降自研稳定vs套壳工具单平台! 「支持知网维普」实际只能稳定降一个平台,这是怎么回事? 我是双学位本科生,毕业论文 3.5 万字。学校规定送知网做 AIGC 检测,但导师建议我自己…...

如何快速集成DatePicker到你的Android项目
如何快速集成DatePicker到你的Android项目 【免费下载链接】DatePicker Useful and powerful date picker for android 项目地址: https://gitcode.com/gh_mirrors/da/DatePicker DatePicker是一款功能强大且易于使用的Android日期选择器,支持单选和多选模式…...