大模型背景下计算机视觉年终思考小结(一)
1. 引言
在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下:
- 使用射线图像和其他医学图像领域的医学诊断应用
- 使用卫星图像分析建筑物和土地利用率相关应用
- 各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计等

上述应用所采用的计算机视觉的方法遵循统一的标准流程:
- 首先定义需要解决的问题所属类别(分类、检测、跟踪、分割) 以及相应输入数据的分辨率等
- 接着需要人工标注数据
- 选择一个网络进行训练,验证和进行一些统计值分析
- 建立推理脚本并进行部署
到2023年底,人工智能领域迎来了来自生成式AI的新爆发:大语言模型(LLM)和图像生成式模型。每个人都在谈论它,那么它对计算机视觉领域的应用有什么改变呢?本文我们将探索是否可以利用它们来构建数据集,以及如何利用新的架构和新的预训练权重,或者从大模型中进行蒸馏学习。
2. 理想的计算机视觉应用开发
在工业界,我们通常感兴趣的是可以以相对较小的成本来构建和部署计算机视觉相关应用,小规模计算机视觉特性如下:
- 小规模计算机视觉开发成本不应过高
- 它不应该需要庞大的基础设施来训练(想想算力和数据规模)
- 它不需要具备强大的研究技能,而是现有技术的扩展应用
- 推理应该是轻量化和快速的,这样它就可以在嵌入式或部署在CPU/GPU服务器上
小规模计算机视觉显然不是当今人工智能的趋势,因为我们看到具有数十亿参数的模型开始成为一些应用程序的标准设计。我们听到了很多关于这方面的消息,但重要的是要记住,关注较小的规模在某些场景的应用也是至关重要的,并不是所有项目都应该遵循谷歌、Meta、OpenAI或微软的大模型规模趋势。事实上,大多数有趣的计算机视觉项目实际上比那些成为头条新闻的项目规模要小得多。
考虑到这一点,我们还能利用人工智能的最新发展来进行相关应用开发吗?首先让我们深入了解下计算机视觉下的基础模型。
3. 计算机视觉基础模型
最近的大语言模型(LLM)非常流行,因为大家可以轻松地在应用程序中使用基础模型(许多是开源的,或者可以通过API使用), 事实上大家也可以把GPT、Bert、Llama想象成这样的提取文本特征的基础模型。基础模型是一个非常大的通用神经网络,可作为大多数下游任务的基础。它包含了关于非常广泛的主题、语义、语法等的知识。
类比到计算机视觉领域中,我们已经使用这样的模型有一段时间了:在过去的10年里,使用在ImageNet上预先训练的神经网络(100万张标记的图像)作为下游任务的“基础”模型是标准的训练流程。大家可以在上面建立自己的神经网络,如果需要的话,可以根据自己的数据对其进行微调。

ImageNet上预训练的视觉网络和大语言预训练模型LLM之间有两个主要的概念上的差异:
- 训练二者的数据类型不同:ImageNet上视觉网络的训练依赖于纯有监督学习,一个1000个类别的分类任务;然而
LLM属于生成式模型,它们是使用原始文本以自监督的方式进行训练的(任务通常为预测下一个单词) - 这些基础模型对新任务的适应:ImageNet上预训练网络需要新的学习过程来适应新任务。对于LLM,虽然也可以对模型进行微调,但该模型足够强大,通常可以直接用于下游任务,而无需做进一步的训练,只需提供给模型正确的提示信息,使其对新任务有用
目前大多数计算机视觉应用,如分类、目标检测、语义分割等任务,仍然使用ImageNet预训练网络的权重。让我们回顾一下最近推出的新模型,这些模型可能对我们的计算机视觉任务有用。
4. 大规模视觉模型
在计算机视觉的世界里,除了ImageNet外,今年来有很多自监督网络的例子,其中一些是生成式模型(想想最新的GAN和最近大火的扩散模型)。它们仅在原始图像或图像-文本对(例如图像及其描述)上进行训练。它们通常被称为LVM(大规模视觉模型)。
- DINOV2: 一组大型ViT集合(视觉transformer,1B参数量),明确旨在成为计算机视觉的良好基础模型,即这样的模型可以提取一些通用的视觉特征,也就是说,这些特征适用于不同的图像任务,无需进行进一步的微调即可使用, 而且它以完全自监督的方式进行训练。

- SAM: 一个致力于高分辨率图像的ViT,专门设计用于分割,并实现零样本分割(无需注释即可生成新的分割mask)。使用LoRA可以廉价地“微调”SAM,从而大幅减少必要的训练图像数量。另一个用例是使用SAM作为医学图像分割中的补充输入。

5. 图文大模型
图文大模型的主要以图像文本对作为模型的输入,这类模型随着对比学习的快速发展也得到了迅速的崛起,举例如下:
-
CLIP: 图像和文本描述的特征对齐,非常适合少样本分类任务,并在实践应用中作为各种下游CV任务的基础模型

-
Scaling Open-Vocabulary Object Detection: 现有的开放世界目标检测算法中,得益于大规模的图像-文本对,预训练的encoder有较多的数据支撑,但在应用于目标检测时,由于检测数据集比起图像-文本数据集数量规模少很多,限制了开放世界目标检测算法的性能。这里作者用self-training的范式来扩展检测数据集。

6. 文生图大模型
文生图模型现在属于大规模生成式模型,通常为多模式的任务(包括在其架构中能够理解复杂文本的大型语言基础模型),比较出名的例子为StableDiffusion以及DALL-E

这两项工作的细节,可以直接去对应官网进行更全面的研究。
7. 视觉多任务大模型
- Florence-2: unified Computer Vision (Microsoft)

该模型采用了一种基于prompt的统一表示方法,广泛适用于各种 CV 和 Visual-Language 任务。与现有的 CV 大模型在迁移学习方面表现出色不同,它在执行各种任务时可以通过简单的指令来处理不同的空间层次和语义粒度的复杂性。Florence-2 核心为通过采用文本提示作为任务说明来支持语义描述生成(image captioning),目标检测(object detection)、定位(grounding)和分割(segmentation)等相关视觉任务。
8. 多用途大模型
业内还涌现一批封闭源代码,仅通过API调用的大型多用途大模型,虽然不以视觉为中心,但展示了卓越的视觉功能,而且还具有生成式功能:比如Open AI的GPT-4V 以及Google的Gemini(下图所示),都带来了行业内新的大模型发展高度。与之对比,还有许多开源的、较小规模的多用途视觉+文本大模型也在开发中,例如LlaVA。

所有这些模型都是强大的基础模型,涵盖了许多视觉文本领域,并擅长在许多情况下进行判别式或生成式任务。
9. 总结
本文主要用来回顾了23年相关大模型在计算机视觉多个领域的发展现状,以及一些突出的技术论文概要分享,主要涉及图像大模型到图文大模型以及生成式大模型。对于这些大模型,在实际工作和项目中,我们更多的应该是思考如何在我们特定的、小规模的背景下利用好它们。
本章节主要为相关论文的梳理和概述总结,下一节我们会针对实际项目中如何结合大模型进行数据集的构造等方向进行归纳总结。
10. 参考链接
主要参考论文和文献资料梳理如下:
DINO V2
SAM
SAMed
SAM medical image segmentation
CLIP
Scaling Open-Vocabulary Object Detection
StableDiffusion
DALL-E
Florence-2
GPT-4V
Gemini
LlaVA
Small Scale Computer Vision
相关文章:
大模型背景下计算机视觉年终思考小结(一)
1. 引言 在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下: 使用射线图像和其他医学图像领域的医学诊断应用使用卫星图像分析建筑物和土地利用率相关应用各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计…...
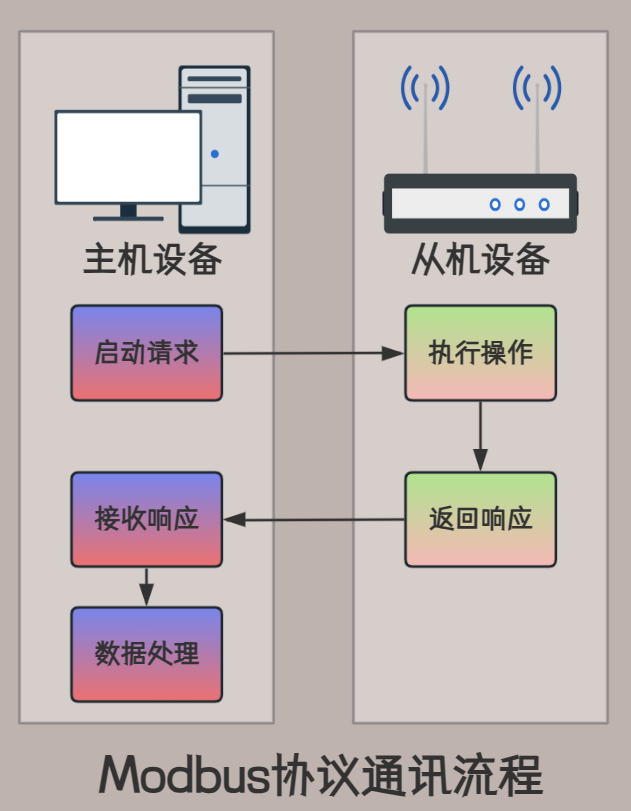
Modbus协议学习第一篇之基础概念
什么是“协议” 大白话解释:协议是用来正确传递消息数据而设立的一种规则。传递消息的双方(两台计算机)在通信时遵循同一种协议,即可理解彼此传递的消息数据。 Modbus协议模型 Modbus协议模型较为简单,使用一种称为应用…...
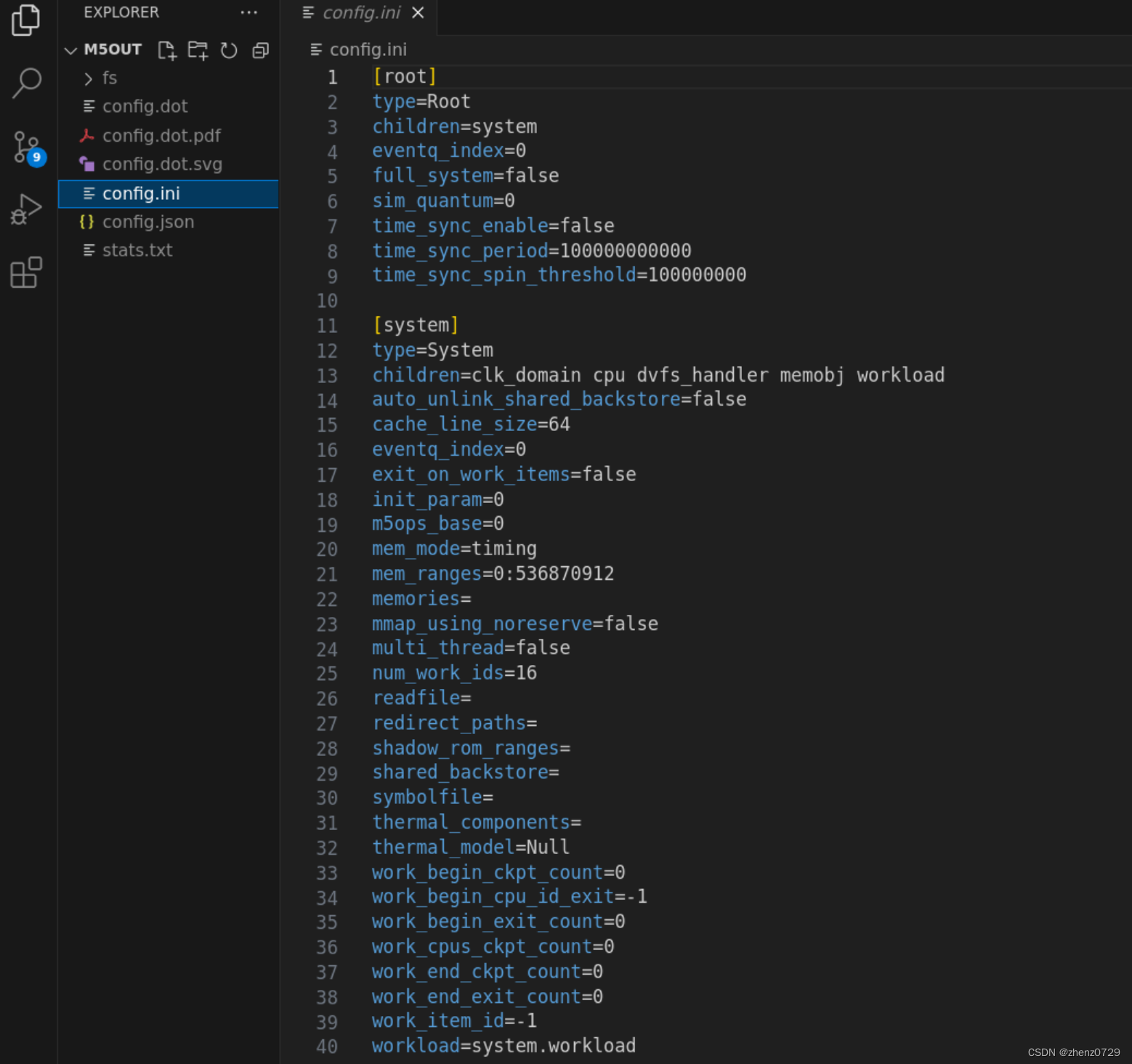
gem5学习(12):理解gem5 统计信息和输出——Understanding gem5 statistics and output
目录 一、config.ini 二、config.json 三、stats.txt 官方教程:gem5: Understanding gem5 statistics and output 在运行 gem5 之后,除了仿真脚本打印的仿真信息外,还会在根目录中名为 m5out 的目录中生成三个文件: config.i…...

索引的概述和使用
1、概述 索引占用存储空间,并不是越多越好,太多的索引会影响系统性能 索引分类 聚集索引: 逻辑顺序和物理顺序是一致的(表中行数的位置决定了该行在内存中存储的位置),因此效率优先于非聚集索引ÿ…...

力扣210. 课程表 II
深度优先遍历 思路: 搜索逻辑参见力扣207.课程表需要课程安排的顺序,课程搜索完成时,将其存储起来即可;存储课程的顺序需要注意: 输入依赖中 [A, B]图中表示 B -> A ,表示先 B 后 A&#x…...
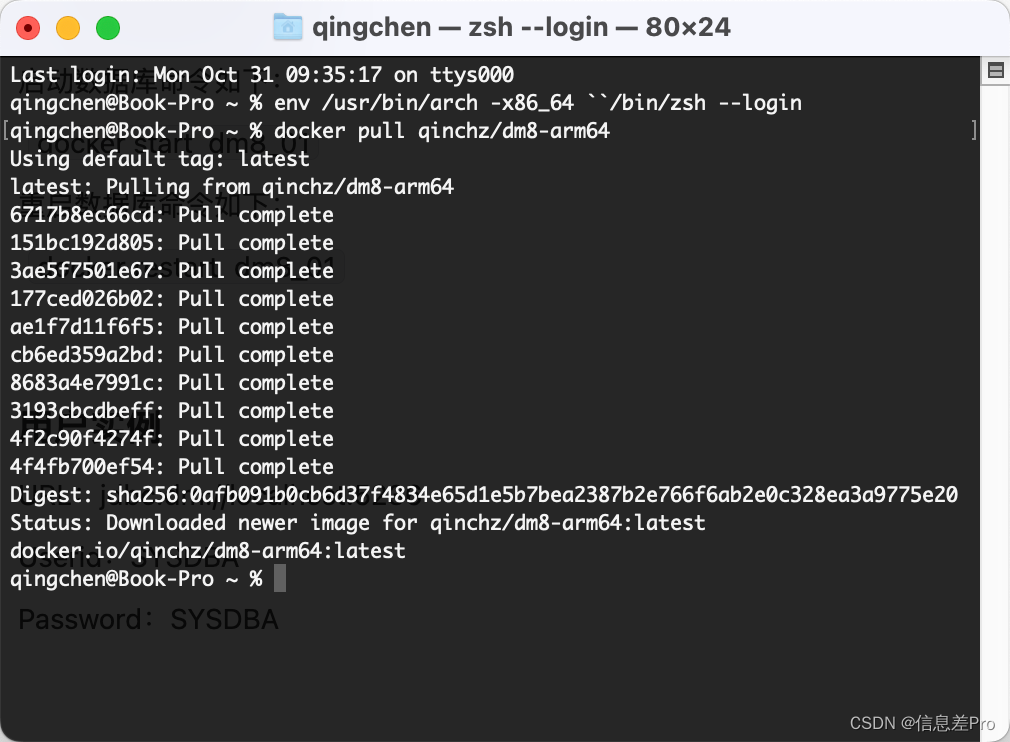
[Docker] Mac M1系列芯片上完美运行Docker
docker pull qinchz/dm8-arm64 container_name: dm8ports:- "5236:5236"mem_limit: 1gmemswap_limit: 1gvolumes:- /data/dm8:/home/dmdba/data 数据库实例参数已修改,接近oracle使用习惯 #字符集 utf-8 CHARSET1 #VARCHAR 类型对象的长度以字符为单位 …...

CompletableFuture、ListenableFuture高级用列
CompletableFuture 链式 public static void main(String[] args) throws Exception {CompletableFuture<Integer> thenCompose T1().thenCompose(Compress::T2).thenCompose(Compress::T3);Integer result thenCompose.get();System.out.println(result);}// 假设这些…...
什么是云服务器,阿里云优势如何?
阿里云服务器ECS英文全程Elastic Compute Service,云服务器ECS是一种安全可靠、弹性可伸缩的云计算服务,阿里云提供多种云服务器ECS实例规格,如经济型e实例、通用算力型u1、ECS计算型c7、通用型g7、GPU实例等,阿里云百科aliyunbai…...

HCIA-Datacom题库(自己整理分类的)_15_VRP平台多选【9道题】
1.VRP操作平台存在哪些命令行视图? 用户视图 接口视图 协议视图 系统视图 2.以下哪些存储介质是华为路由器常用的存储介质 SDRAM NVRAM Flash Hard Disk SD Card 解析:Hard Disk是硬盘,一般网络设备没有。 3.VRP支持通过哪几种方式对路由器…...

html5基础入门
html5基础语法与标签 前言前端开发零基础入门介绍前端开发行业介绍:大前端时代:前端开发主要技术介绍学习方法IDE简介vscode快捷键: 总结 HTML语法与基础标签互联网基本原理HTTP协议(请求、响应)什么是前端、后端&…...
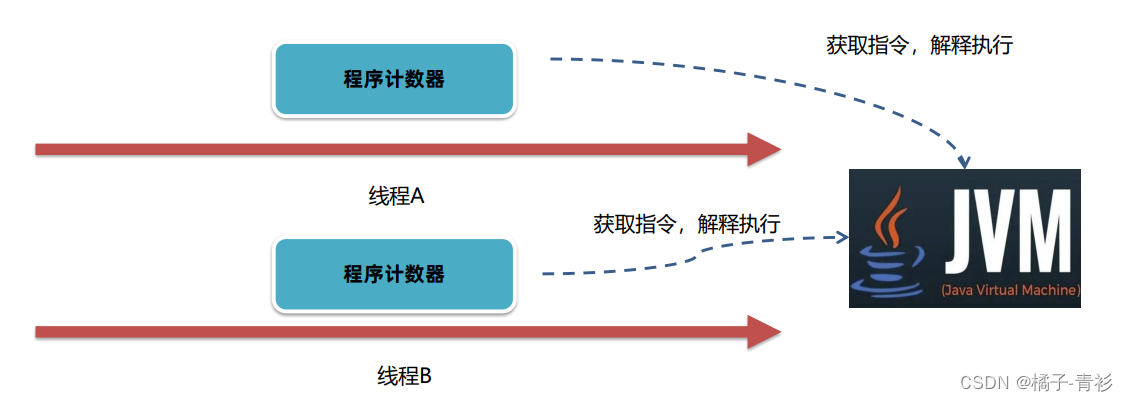
JVM工作原理与实战(十五):运行时数据区-程序计数器
专栏导航 JVM工作原理与实战 RabbitMQ入门指南 从零开始了解大数据 目录 专栏导航 前言 一、运行时数据区 二、程序计数器 总结 前言 JVM作为Java程序的运行环境,其负责解释和执行字节码,管理内存,确保安全,支持多线程和提供…...

计算机体系结构----存储系统
本文严禁转载,仅供学习使用。参考资料来自中国科学院大学计算机体系结构课程PPT以及《Digital Design and Computer Architecture》、《超标量处理器设计》、同济大学张晨曦教授资料。如有侵权,联系本人修改。 1.1 引言 1.1.1虚拟和物理内存 程序员看到…...
)
华为OD机试2024年最新题库(Python)
我是一名软件开发培训机构老师,我的学生已经有上百人通过了华为OD机试,学生们每次考完试,会把题目拿出来一起交流分享。 重要:2024年1月-5月,考的都是OD统一考试(C卷),题库已经整理…...

【打卡】牛客网:BM84 最长公共前缀
自己写的: 题目要求时间复杂度是o(n*len),说明可以遍历所有的字符。 空间复杂度o(1),说明不能用字符串存储公共前缀,所以用下标来记录。 调试过程: 大概花了20min。 我调试前的做法是,在while循环中&…...
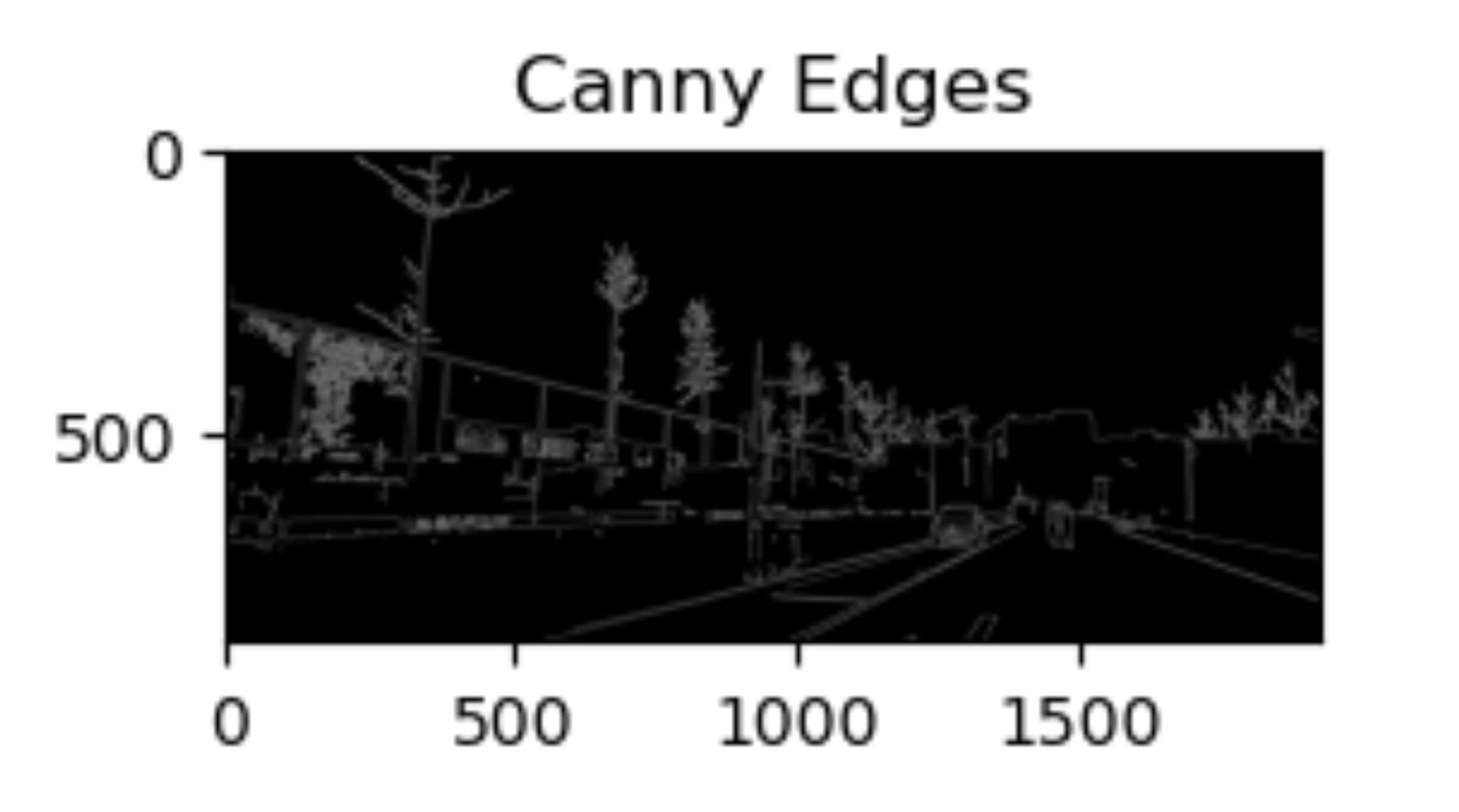
我在Vscode学OpenCV 图像处理三(图像梯度--边缘检测【图像梯度、Sobel 算子、 Scharr 算子、 Laplacian 算子、Canny 边缘检测】)
文章目录 一、图像梯度1.1 介绍1.2 涉及函数 二、高频强调滤波器2.1 Sobel 算子2.1.1 Sobel 理论基础2.1.2 Sobel 算子及函数使用(1)对参数取绝对值(2)控制dx,dy方向的求导阶数1. **计算 x 方向边缘(梯度&a…...
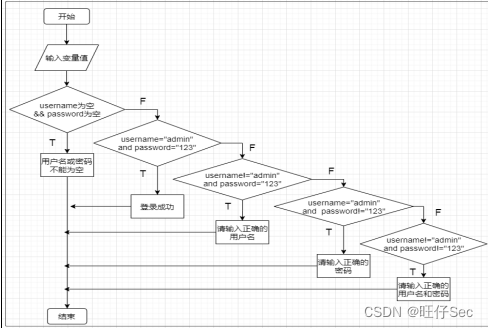
2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑤
单元测试 一、任务要求 题目1:根据下列流程图编写程序实现相应处理,执行j10*x-y返回文字“j1:”和计算值,执行j(x-y)*(10⁵%7)返回文字“j2:”和计算值,执行jy*log(x10)返回文字“j3:”和计算值…...
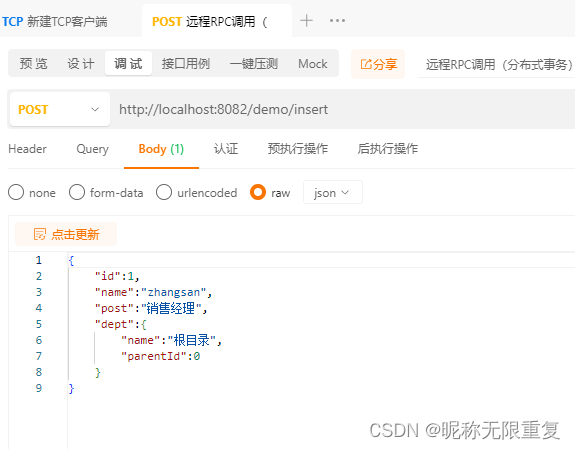
seata分布式事务(与dubbo集成)
1.seata是什么? Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。 2.seata的注解 GlobalTransactional:全局事务注解,添加了以后可实现分布式事务的回滚和提交,用法与spring…...

Leetcod面试经典150题刷题记录 —— 数学篇
Leetcode面试经典150题刷题记录-系列Leetcod面试经典150题刷题记录——数组 / 字符串篇Leetcod面试经典150题刷题记录 —— 双指针篇Leetcod面试经典150题刷题记录 —— 矩阵篇Leetcod面试经典150题刷题记录 —— 滑动窗口篇Leetcod面试经典150题刷题记录 —— 哈希表篇Leetcod…...

x-cmd pkg | csview - 美观且高性能的 csv 数据查看工具
目录 介绍首次用户功能特点类似工具与竞品进一步阅读 介绍 csview 是一个用于在命令行中查看 CSV 文件的工具,采用 Rust 语言编写的,支持中日韩/表情符号。它允许用户在终端中以表格形式查看 CSV 数据,可以对数据进行排序、过滤、搜索等操作…...
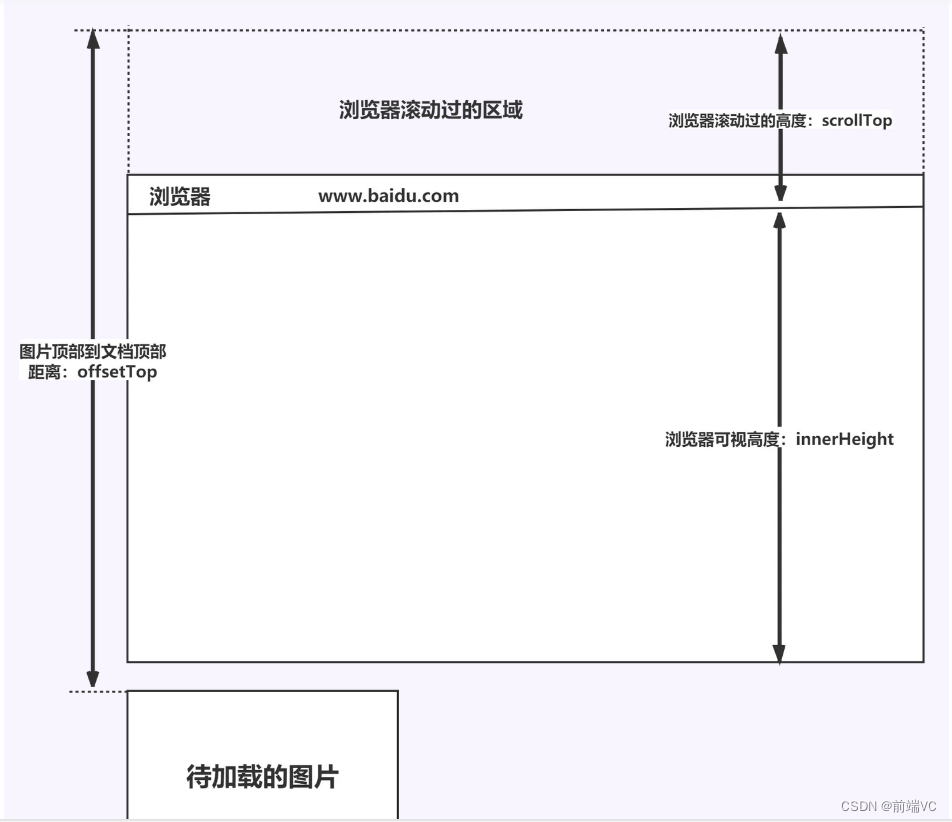
前端八股文(性能优化篇)
目录 1.CDN的概念 2.CDN的作用 3.CDN的原理 4.CDN的使用场景 5.懒加载的概念 6.懒加载的特点 7.懒加载的实现原理 8.懒加载与预加载的区别 9.回流与重绘的概念及触发条件 (1)回流 (2)重绘 10. 如何避免回流与重绘&#…...

耦合详解-模块
耦合详解 耦合(Coupling)是衡量软件模块之间相互依赖程度的指标。低耦合是优秀软件设计的核心目标之一,它使系统更易于维护、测试和扩展。 1. 耦合的本质 耦合描述的是两个模块(类、组件、服务)之间的依赖关系强度。当修改一个模块时,需要修改其他模块的程度越高,耦合…...

Python偏函数partial的用法小结
functools.partial(func, /, *args, **keywords) 会返回一个新可调用对象,它把原函数 func 的部分位置参数和/或关键字参数“预先绑定”。 这样你就能得到一个“定制版”的函数,后续只需要补齐剩余参数即可调用。返回对象类型是 functools.partial 实例&…...

AI赋能软件测试:基于PyTorch视觉模型实现自动化GUI测试脚本生成效果演示
AI赋能软件测试:基于PyTorch视觉模型实现自动化GUI测试脚本生成效果演示 1. 效果亮点预览 想象一下这样的场景:一个AI系统正在自动测试你的软件界面,它能像人类测试工程师一样"看"懂屏幕上的每个元素,发现那些传统脚本…...
)
别再只改默认密码了!Nacos 1.x/2.x 生产环境安全加固保姆级清单(附漏洞自查脚本)
Nacos生产环境安全加固全指南:从基础配置到漏洞防御 在微服务架构盛行的今天,Nacos作为服务发现和配置管理的核心组件,其安全性直接影响整个系统的稳定性。许多团队在部署Nacos时往往只满足于修改默认密码,却忽视了完整的安全防护…...

Qwen2.5-14B-Instruct在AI编剧赛道的突破:像素剧本圣殿Glitch标题交互体验分享
Qwen2.5-14B-Instruct在AI编剧赛道的突破:像素剧本圣殿Glitch标题交互体验分享 1. 像素剧本圣殿:AI编剧的新范式 在数字内容创作领域,剧本创作一直是最具挑战性的任务之一。传统编剧需要花费大量时间构思情节、塑造角色、打磨对白ÿ…...

Lingbot-Depth-Pretrain-ViTL-14在互联网内容审核中的深度场景理解应用
Lingbot-Depth-Pretrain-ViTL-14在互联网内容审核中的深度场景理解应用 每天,互联网上都会产生数以亿计的图片和视频。对于平台的内容审核团队来说,这既是流量的盛宴,也是巨大的挑战。传统的审核方式,无论是依赖人工还是基于二维…...
)
河海大学材料科学与工程及材料与化工专业考研复试资料(含《材料分析方法》笔试专项)
温馨提示:文末有联系方式河海大学材料类考研复试资料全面升级 本套资料专为报考河海大学材料科学与工程、材料与化工两个硕士专业的考生设计,聚焦复试核心笔试科目——《材料分析方法》,助力精准高效备考。由2025届一志愿录取考生权威整理 所…...

Vivado项目文件太多分不清?这份FPGA开发必备的‘文件后缀速查手册’请收好
Vivado项目文件管理终极指南:从后缀识别到高效工作流 当你第一次打开一个成熟的Vivado项目文件夹时,那种面对几十种陌生文件后缀的茫然感,相信每个FPGA开发者都记忆犹新。就像走进了一个满是神秘符号的仓库,每个文件似乎都在向你发…...

Qt桌面应用集成PaddleOCR:从环境搭建到精准识别的实践指南
1. 环境准备:搭建PaddleOCR的Qt开发环境 第一次在Qt里折腾PaddleOCR时,我对着官方文档折腾了半天还是报错,后来发现是第三方库的路径没配好。这里分享下我踩坑后总结的可靠方案。 核心依赖三件套:PaddlePaddle推理库、PaddleOCR C…...

Pixie微型LED链式显示模块技术解析与嵌入式驱动开发
1. Pixie显示模块技术解析与嵌入式驱动开发指南Pixie 是一款面向嵌入式系统的链式可扩展微型LED点阵显示模块,由Lixie Labs LLC(Connor Nishijima)设计并开源。其核心价值在于以极小物理尺寸(20.6mm 34.7mm)集成双57共…...