pytorch详细探索各种cnn卷积神经网络
目录
torch.nn.functional子模块详解
conv1d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
conv2d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
conv3d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
conv_transpose1d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
conv_transpose2d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
conv_transpose3d
用法和用途
使用技巧
适用领域
参数
注意事项
示例代码
unfold
用法和用途
注意事项
参数
返回值
示例代码
fold
用法和用途
注意事项
参数
返回值
示例代码
总结
torch.nn.functional子模块详解
conv1d
torch.nn.functional.conv1d 是 PyTorch 深度学习框架中的一个函数,用于应用一维卷积。这个函数通常用于处理时间序列数据或一维信号数据(如音频信号),在神经网络中用于特征提取和学习信号的局部模式。
用法和用途
- 用法:
conv1d用于在一维输入信号上应用卷积运算。 - 用途: 常用于处理序列数据,如时间序列分析、语音识别或任何一维信号处理任务。
使用技巧
- 选择合适的核大小(kW): 核大小决定了卷积窗口的宽度,它应根据输入数据的特性来选择。
- 调整步长(stride): 步长决定了卷积窗口移动的距离。较大的步长可以减少输出的维度。
- 使用填充(padding): 填充可以帮助你控制输出的维度。特别是 'same' 填充可以保持输入和输出的维度相同。
- 设置组(groups): 通过设置组,可以使得网络分别学习不同组的特征,这在处理多通道数据时特别有用。
适用领域
- 音频信号处理: 如语音识别、音乐生成等。
- 时间序列预测: 如股票价格预测、天气预测等。
- 任何需要分析或处理一维数据的场景。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iW)。 - weight: 卷积核,形状为
(out_channels, in_channels/groups, kW)。 - bias: 可选的偏置项,形状为
(out_channels)。 - stride: 卷积核的步长,默认为 1。
- padding: 输入的隐式填充,默认为 0。
- dilation: 卷积核元素之间的间距,默认为 1。
- groups: 输入分组数,默认为 1。
注意事项
- 当使用 CUDA 设备和 CuDNN 时,该操作可能选择非确定性算法以提高性能。如果需要确定性操作,请设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
- 使用
padding='same'时,如果卷积核长度是偶数且扩张是奇数,可能需要内部进行完整的pad()操作,可能降低性能。
示例代码
import torch
import torch.nn.functional as F# 输入数据
inputs = torch.randn(33, 16, 30) # 随机生成输入数据# 卷积核
filters = torch.randn(20, 16, 5) # 随机生成卷积核# 应用一维卷积
output = F.conv1d(inputs, filters)
在这个例子中,inputs 是一个随机生成的一维信号,而 filters 是卷积核。F.conv1d 函数应用这些卷积核于输入信号,生成卷积后的输出。
conv2d
torch.nn.functional.conv2d 是 PyTorch 中的一个函数,用于在图像数据上应用二维卷积。这个函数是卷积神经网络(CNN)中的核心,用于处理二维数据,如图像,以提取特征和进行图像识别等任务。
用法和用途
- 用法:
conv2d在二维输入(通常是图像)上应用卷积核,以提取特征。 - 用途: 广泛用于图像处理和计算机视觉任务,如图像分类、对象检测、图像分割等。
使用技巧
- 选择合适的卷积核大小(kH, kW): 卷积核的大小决定了特征提取的粒度。
- 调整步长(stride): 步长控制卷积核移动的距离,可以用来控制输出特征图的大小。
- 使用填充(padding): 填充用于控制输出特征图的空间维度。'same' 填充保持输入和输出的空间维度相同。
- 考虑扩张(dilation): 扩张可以增加卷积核感受野的大小,有助于捕捉更大范围的特征。
- 设置组(groups): 组卷积允许网络在不同的输入通道组上分别学习特征,有助于模型的多样性。
适用领域
- 图像识别: 识别图像中的对象、人脸、场景等。
- 视频分析: 处理视频数据,如动作识别、事件检测。
- 医学图像处理: 比如 MRI 或 CT 扫描的分析。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iH, iW)。 - weight: 卷积核,形状为
(out_channels, in_channels/groups, kH, kW)。 - bias: 可选的偏置张量,形状为
(out_channels)。默认为 None。 - stride: 卷积核的步长,可以是单个数字或元组
(sH, sW)。默认为 1。 - padding: 输入的隐式填充,可以是字符串 {'valid', 'same'},单个数字或元组
(padH, padW)。默认为 0。 - dilation: 卷积核元素之间的间距,可以是单个数字或元组
(dH, dW)。默认为 1。 - groups: 将输入分成组进行卷积,
in_channels和out_channels都应该能被组数整除。默认为 1。
注意事项
- 当使用 CUDA 设备和 CuDNN 时,此操作可能选择非确定性算法以提高性能。如果需要确定性操作,请设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
- 使用
padding='same'时,如果卷积核长度是偶数且扩张是奇数,可能需要内部进行完整的pad()操作,可能降低性能。
示例代码
import torch
import torch.nn.functional as F# 定义卷积核和输入
filters = torch.randn(8, 4, 3, 3) # 卷积核
inputs = torch.randn(1, 4, 5, 5) # 输入图像# 应用二维卷积
output = F.conv2d(inputs, filters, padding=1)
在这个例子中,inputs 表示输入图像的张量,而 filters 是卷积核。使用 F.conv2d 函数,我们可以将这些卷积核应用于输入图像,从而生成卷积后的输出特征图。
conv3d
torch.nn.functional.conv3d 是 PyTorch 框架中的一个函数,用于在三维数据上应用三维卷积。这个函数主要用于处理具有三维结构的数据,如体积数据或视频序列,常见于医学影像分析、视频处理和三维数据建模等领域。
用法和用途
- 用法:
conv3d在三维输入数据上应用卷积核,提取特征。 - 用途: 主要用于三维数据的特征提取,如体积成像、视频序列分析等。
使用技巧
- 卷积核尺寸(kT, kH, kW): 根据输入数据的特点选择合适的卷积核尺寸,以有效捕捉数据的空间和时间特征。
- 步长(stride): 控制卷积核的移动步长,可以调整输出数据的大小。
- 填充(padding): 填充可以用于控制输出数据的空间尺寸。特别是 'same' 填充可以使输出和输入具有相同的尺寸。
- 扩张(dilation): 扩张用于增加卷积核元素之间的间距,有助于提取更大范围的特征。
- 组(groups): 组卷积可以使得不同的组独立学习特征,对于多通道数据来说尤其有用。
适用领域
- 医学成像: 如 CT 和 MRI 数据的分析。
- 视频处理: 对视频序列进行分析,如动作识别。
- 三维数据建模: 在计算机视觉和图形学中处理三维数据。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iT, iH, iW)。 - weight: 卷积核,形状为
(out_channels, in_channels/groups, kT, kH, kW)。 - bias: 可选的偏置张量,形状为
(out_channels)。默认为 None。 - stride: 卷积核的步长,可以是单个数字或元组
(sT, sH, sW)。默认为 1。 - padding: 输入的隐式填充,可以是字符串 {'valid', 'same'},单个数字或元组
(padT, padH, padW)。默认为 0。 - dilation: 卷积核元素之间的间距,可以是单个数字或元组
(dT, dH, dW)。默认为 1。 - groups: 将输入分成组,
in_channels应该能被组数整除。默认为 1。
注意事项
- 使用 CUDA 和 CuDNN 时,可能选择非确定性算法以提高性能。如果需要确定性操作,可设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
- 使用
padding='same'时,如果卷积核长度是偶数且扩张是奇数,可能需要内部进行完整的pad()操作,这可能会降低性能。
示例代码
import torch
import torch.nn.functional as F# 定义卷积核和输入
filters = torch.randn(33, 16, 3, 3, 3) # 卷积核
inputs = torch.randn(20, 16, 50, 10, 20) # 三维输入数据# 应用三维卷积
output = F.conv3d(inputs, filters)
在这个例子中,inputs 是一个三维数据张量,而 filters 是卷积核。使用 F.conv3d 函数,可以在三维数据上应用这些卷积核,生成卷积后的输出特征图。这在处理具有时间或深度维度的数据时非常有用。
conv_transpose1d
torch.nn.functional.conv_transpose1d 是 PyTorch 框架中的一个函数,用于在一维数据上应用反卷积(也称为转置卷积)。这个操作通常用于增加数据的空间维度,常见于信号处理和生成模型中,如音频生成或时间序列数据的上采样。
用法和用途
- 用法:
conv_transpose1d通过转置卷积核在一维输入数据上执行操作,从而增加数据的空间维度。 - 用途: 常用于时间序列数据的生成任务,如音频合成,或在卷积自编码器和生成对抗网络(GAN)中进行上采样。
使用技巧
- 卷积核大小(kW): 选择合适的卷积核大小,以控制特征提取的粒度和上采样的效果。
- 步长(stride): 步长决定了输出信号的扩展程度。较大的步长可以显著增加输出的维度。
- 填充(padding): 用于控制输出信号的大小。适当的填充可以帮助获得所需的输出维度。
- 输出填充(output_padding): 进一步调整输出尺寸,确保输出的维度是期望的大小。
- 分组(groups): 分组操作允许网络在不同的输入通道组上独立进行学习。
- 扩张(dilation): 扩张参数可以调整卷积核中元素的间隔,用于捕捉更广泛的上下文。
适用领域
- 音频信号处理: 如音频合成和音乐生成。
- 时间序列数据上采样: 在各种时间序列分析任务中,如股市预测或天气模式分析。
- 神经网络的解卷积层: 用于生成模型,如自编码器和生成对抗网络。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iW)。 - weight: 卷积核,形状为
(in_channels, out_channels/groups, kW)。 - bias: 可选的偏置项,形状为
(out_channels)。默认为 None。 - stride: 卷积核的步长,可以是单个数字或元组
(sW,)。默认为 1。 - padding: 输入的隐式填充,可以是单个数字或元组
(padW,)。默认为 0。 - output_padding: 输出的附加填充,可以是单个数字或元组
(out_padW)。默认为 0。 - groups: 将输入分成组进行卷积,
in_channels应该能被组数整除。默认为 1。 - dilation: 卷积核元素之间的间距,可以是单个数字或元组
(dW,)。默认为 1。
注意事项
- 使用 CUDA 和 CuDNN 时,可能选择非确定性算法以提高性能。如果需要确定性操作,可设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
示例代码
import torch
import torch.nn.functional as F# 定义权重和输入
weights = torch.randn(16, 33, 5) # 卷积核
inputs = torch.randn(20, 16, 50) # 一维输入数据# 应用一维反卷积
output = F.conv_transpose1d(inputs, weights)
在这个示例中,inputs 是一维输入数据,weights 是卷积核。通过使用 F.conv_transpose1d 函数,可以在输入数据上应用反卷积,从而增加其空间维度。这在需要增大数据尺寸或生成新的数据时非常有用。
conv_transpose2d
torch.nn.functional.conv_transpose2d 是 PyTorch 框架中的一个函数,用于在二维数据(通常是图像)上应用二维转置卷积操作,有时也称为“反卷积”或“deconvolution”。这个操作主要用于图像或特征图的上采样,即增加其空间尺寸,常见于图像生成、分割和超分辨率等计算机视觉任务。
用法和用途
- 用法:
conv_transpose2d通过转置卷积核在二维输入数据上执行操作,以增加数据的空间维度。 - 用途: 常用于图像的上采样,如在自编码器或生成对抗网络(GAN)中从低分辨率特征图生成高分辨率图像。
使用技巧
- 卷积核大小(kH, kW): 选择合适的卷积核大小,以控制特征提取的粒度和上采样的效果。
- 步长(stride): 步长决定了输出图像的扩展程度。较大的步长可以显著增加输出的尺寸。
- 填充(padding): 用于控制输出图像的大小。适当的填充可以帮助获得所需的输出尺寸。
- 输出填充(output_padding): 进一步调整输出尺寸,确保输出的维度是期望的大小。
- 分组(groups): 分组操作允许网络在不同的输入通道组上独立进行学习。
- 扩张(dilation): 扩张参数可以调整卷积核中元素的间隔,用于捕捉更广泛的上下文。
适用领域
- 图像生成: 如在 GAN 或 VAE 中生成高分辨率图像。
- 图像分割: 在分割任务中从低分辨率特征图生成高分辨率的分割图。
- 图像超分辨率: 提升图像的分辨率。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iH, iW)。 - weight: 卷积核,形状为
(in_channels, out_channels/groups, kH, kW)。 - bias: 可选的偏置项,形状为
(out_channels)。默认为 None。 - stride: 卷积核的步长,可以是单个数字或元组
(sH, sW)。默认为 1。 - padding: 输入的隐式填充,可以是单个数字或元组
(padH, padW)。默认为 0。 - output_padding: 输出的附加填充,可以是单个数字或元组
(out_padH, out_padW)。默认为 0。 - groups: 将输入分成组进行卷积,
in_channels应该能被组数整除。默认为 1。 - dilation: 卷积核元素之间的间距,可以是单个数字或元组
(dH, dW)。默认为 1。
注意事项
- 使用 CUDA 和 CuDNN 时,可能选择非确定性算法以提高性能。如果需要确定性操作,可设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
示例代码
import torch
import torch.nn.functional as F# 定义权重和输入
weights = torch.randn(4, 8, 3, 3) # 卷积核
inputs = torch.randn(1, 4, 5, 5) # 二维输入数据# 应用二维反卷积
output = F.conv_transpose2d(inputs, weights, padding=1)
这个示例中,inputs 是一个二维输入数据张量(如图像),weights 是卷积核。使用 F.conv_transpose2d 函数可以在输入数据上应用反卷积,从而增加其空间尺寸。这在生成模型和图像处理任务中非常有用,特别是当需要从压缩或降采样的特征图中重构高分辨率图像时。
conv_transpose3d
torch.nn.functional.conv_transpose3d 是 PyTorch 中的一个函数,用于在三维数据上应用三维转置卷积操作,有时也被称为“反卷积”或“deconvolution”。这种操作通常用于三维数据的上采样,即增加其空间尺寸,常见于体积数据处理、三维图像重建和三维生成模型等应用。
用法和用途
- 用法:
conv_transpose3d通过转置卷积核在三维输入数据上执行操作,增加数据的空间维度。 - 用途: 主要用于三维数据的上采样,例如在医学图像重建、三维图像生成和视频处理中。
使用技巧
- 卷积核大小(kT, kH, kW): 选择合适的卷积核大小,以控制特征提取的粒度和上采样的效果。
- 步长(stride): 步长决定了输出体积的扩展程度。较大的步长可以显著增加输出的尺寸。
- 填充(padding): 用于控制输出体积的大小。适当的填充可以帮助获得所需的输出尺寸。
- 输出填充(output_padding): 进一步调整输出尺寸,确保输出的维度是期望的大小。
- 分组(groups): 分组操作允许网络在不同的输入通道组上独立进行学习。
- 扩张(dilation): 扩张参数可以调整卷积核中元素的间隔,用于捕捉更广泛的上下文。
适用领域
- 医学图像重建: 如 CT 和 MRI 数据的三维重建。
- 三维图像生成: 在计算机视觉和图形学中生成三维图像。
- 视频数据处理: 在视频序列中进行上采样或生成任务。
参数
- input: 输入张量,形状为
(minibatch, in_channels, iT, iH, iW)。 - weight: 卷积核,形状为
(in_channels, out_channels/groups, kT, kH, kW)。 - bias: 可选的偏置项,形状为
(out_channels)。默认为 None。 - stride: 卷积核的步长,可以是单个数字或元组
(sT, sH, sW)。默认为 1。 - padding: 输入的隐式填充,可以是单个数字或元组
(padT, padH, padW)。默认为 0。 - output_padding: 输出的附加填充,可以是单个数字或元组
(out_padT, out_padH, out_padW)。默认为 0。 - groups: 将输入分成组进行卷积,
in_channels应该能被组数整除。默认为 1。 - dilation: 卷积核元素之间的间距,可以是单个数字或元组
(dT, dH, dW)。默认为 1。
注意事项
- 使用 CUDA 和 CuDNN 时,可能选择非确定性算法以提高性能。如果需要确定性操作,可设置
torch.backends.cudnn.deterministic = True。 - 支持复数数据类型(complex32, complex64, complex128)。
示例代码
import torch
import torch.nn.functional as F# 定义权重和输入
weights = torch.randn(16, 33, 3, 3, 3) # 卷积核
inputs = torch.randn(20, 16, 50, 10, 20) # 三维输入数据# 应用三维反卷积
output = F.conv_transpose3d(inputs, weights)
在这个示例中,inputs 是一个三维输入数据张量(如体积数据或视频序列),weights 是卷积核。通过使用 F.conv_transpose3d 函数,可以在输入数据上应用反卷积,从而增加其空间尺寸。这在需要从压缩或降采样的数据中重构高分辨率三维图像时非常有用。
unfold
torch.nn.functional.unfold 是 PyTorch 中的一个函数,用于从批量输入张量中提取滑动的局部块。这个函数通常用于图像处理中,以提取图像中的局部区域并进行进一步处理。
用法和用途
- 用法:
unfold函数将一个四维输入张量(通常是一批图像)转换为一个二维张量,其中每一列都是从输入张量中提取的局部块。 - 用途: 这个函数在图像处理任务中很有用,如在实现自定义的卷积操作、局部区域处理或特征提取等。
注意事项
- 目前仅支持四维输入张量(批处理图像样式的张量)。
- 展开的张量中的多个元素可能会引用单一的内存位置。因此,原地操作(尤其是向量化的操作)可能会导致不正确的行为。如果需要对张量进行写操作,请先克隆它。
参数
- input: 输入张量,形状通常为
(batch_size, channels, height, width)。 - kernel_size: 提取的局部块的大小,可以是单个整数或一个
(kH, kW)的元组。 - dilation: 卷积核元素之间的间距,可以是单个整数或一个
(dH, dW)的元组。默认为 1。 - padding: 在输入的各个维度上的隐式零填充,可以是单个整数或一个
(padH, padW)的元组。默认为 0。 - stride: 卷积核的步长,可以是单个整数或一个
(sH, sW)的元组。默认为 1。
返回值
- 返回一个二维张量,其中每一列代表从输入张量中提取的一个局部块。
示例代码
import torch
import torch.nn.functional as F# 示例输入张量
input = torch.randn(1, 3, 5, 5) # 一个有3个通道的5x5图像# 使用 unfold 提取 3x3 块
unfolded = F.unfold(input, kernel_size=3)# 查看结果
print(unfolded.shape) # 输出张量的维度
在这个示例中,input 是一个四维张量,代表一批图像。使用 unfold 函数,我们可以从每个图像中提取 3x3 的局部块。结果是一个二维张量,其列数取决于输入图像的尺寸、卷积核大小、填充和步长。
fold
torch.nn.functional.fold 是 PyTorch 中的一个函数,用于将一组滑动的局部块组合回一个大的包含张量。这个函数通常用于实现称为 "折叠" 的操作,它是 unfold 函数的逆操作,主要用于重建图像或特征图。
用法和用途
- 用法:
fold函数将一个二维张量(通常是经过某种处理的展开的图像块)转换回一个四维张量(即重建后的图像或特征图)。 - 用途: 这个函数通常用于卷积神经网络中,特别是在自定义的卷积或逆卷积操作、图像重建或特征图合成中。
注意事项
- 目前仅支持未批处理的(3D)或批处理的(4D)图像样式输出张量。
参数
- input: 输入张量,通常是一个二维张量,每一列代表从某个张量中提取的一个局部块。
- output_size: 输出张量的空间尺寸,可以是一个
(oH, oW)的元组。 - kernel_size: 局部块的大小,可以是单个整数或一个
(kH, kW)的元组。 - dilation: 卷积核元素之间的间距,可以是单个整数或一个
(dH, dW)的元组。默认为 1。 - padding: 在输出的各个维度上的隐式零填充,可以是单个整数或一个
(padH, padW)的元组。默认为 0。 - stride: 卷积核的步长,可以是单个整数或一个
(sH, sW)的元组。默认为 1。
返回值
- 返回一个四维张量,代表重建后的图像或特征图。
示例代码
import torch
import torch.nn.functional as F# 示例输入张量
input = torch.randn(1, 9, 16) # 假设这是一个展开的图像块# 使用 fold 重建图像
output_size = (5, 5) # 假设原始图像大小为 5x5
folded = F.fold(input, output_size=output_size, kernel_size=3)# 查看结果
print(folded.shape) # 输出张量的维度
在这个示例中,input 是一个二维张量,代表一系列展开的图像块。使用 fold 函数,我们可以将这些块重建回原始尺寸的图像。结果是一个四维张量,其尺寸取决于输出尺寸、卷积核大小、填充和步长。
总结
PyTorch 的 torch.nn.functional 子模块提供了一系列功能强大的函数,用于实现卷积神经网络中的关键操作。这些函数涵盖从基本的卷积操作到高级数据变换技术,使其成为处理和分析图像、音频和视频数据的重要工具。这些函数的灵活性和多样性使其在深度学习领域中具有广泛的应用,如图像处理、音频分析、时间序列预测等。conv1d, conv2d, conv3d: 分别用于一维、二维和三维数据的卷积操作,广泛应用于特征提取和数据分析。conv_transpose1d, conv_transpose2d, conv_transpose3d: 对应的反卷积操作,用于数据的上采样和维度扩展。unfold: 从批量输入张量中提取局部块,适用于自定义卷积操作和局部特征分析。fold: 将展开的局部块组合回原始张量,用于图像重建和特征图合成。它们的高效实现和易用性进一步加强了 PyTorch 在科学研究和工业应用中的地位。
相关文章:

pytorch详细探索各种cnn卷积神经网络
目录 torch.nn.functional子模块详解 conv1d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv2d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv3d 用法和用途 使用技巧 适用领域 参数 注意事项 示例代码 conv_transpose1d 用法…...

OpenCV——八邻域断点检测
目录 一、理论基础1、八邻域2、断点检测 二、代码实现三、结果展示四、参考链接 OpenCV——八邻域断点检测由CSDN点云侠原创,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、理论基础 1、八邻域 图1 八邻域示意图 图…...

leetcode238:除自身以外数组的乘积
文章目录 1.使用除法(违背题意)2.左右乘积列表3.空间复杂度为O(1)的方法 在leetcode上刷到了这一题,一开始并没有想到好的解题思路,写篇博客再来梳理一下吧。 题目要求: 不使用除法在O(n)时间复杂度内 1.使用除法&am…...
VTK开发调试环境下载(VTK开发环境一步到位直接开发,无需自己配置编译 VS2017+Qt5.12.10+VTK)
一、无与伦比的优势 直接下载代码就可以调试的VTK代码仓库。 二、资源制作原理 这个资源根据VTK源码 编译出动态库文件 pdb lib dll 文件( x64 debug ) 并将这两者同时放在一个代码仓库里,下载就能用。 三、使用方法(vtk-so…...

【JAVA】在 Queue 中 poll()和 remove()有什么区别
🍎个人博客:个人主页 🏆个人专栏:JAVA ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 poll() 方法: remove() 方法: 区别总结: 结语 我的其他博客 前言 在Java的Queue接口中&…...

常用Java代码-Java中的Optional类和null安全编程
在Java中,Optional 是一个可以为null的容器对象。如果值存在则isPresent()方法返回true。调用get()方法会返回值,如果值为null则抛出NullPointerException。以下是一个详细的代码详解。 在之前的Java版本中,程序员需要手动检查是否为null&am…...

android.os.NetworkOnMainThreadException
问题 android.os.NetworkOnMainThreadException详细问题 核心代码如下: import android.os.Bundle;import androidx.appcompat.app.AppCompatActivity;import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ja…...

Java生成四位数随机验证码
引言: 我们生活中登录的时候都要输入验证码,这些验证码是为了增加注册或者登录难度,减少被人用脚本疯狂登录注册导致的一系列危害,减少数据库的一些压力。 毕竟那些用脚本生成的账号都是垃圾账号 本次实践:生成这样的…...
)
编程探秘:Python深渊之旅-----数据可视化(八)
客户提出了对数据报告和图表的具体要求,这使得团队需要快速掌握数据可视化的技巧。派超决定深入了解 Python 中的数据可视化工具。 派超(兴奋地):我们有机会做些真正酷炫的数据报告了!我听说 Python 有很棒的图表库。…...
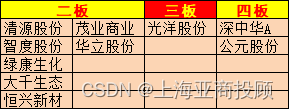
上海亚商投顾:创业板指冲高回落 光伏、航运股逆势走强
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指1月12日冲高回落,创业板指午后跌近1%。北证50指数跌超6%,倍益康、华信永道、众诚科…...

Python3 中常用字符串函数介绍
介绍 Python 中有几个与 字符串数据类型相关的内置函数。这些函数让我们能够轻松修改和操作字符串。我们可以将函数视为在代码元素上执行的操作。内置函数是在 Python 编程语言中定义的,并且可以随时供我们使用的函数。 在本教程中,我们将介绍在 Pytho…...

Python - 深夜数据结构与算法之 AVL 树 红黑树
目录 一.引言 二.高级树的简介 1.树 2.二叉树 3.二叉搜索树 4.平衡二叉树 三.AVL 树 ◆ 插入节点 ◆ 左旋 ◆ 右旋 ◆ 左右旋 ◆ 右左旋 ◆ 一般形式 ◆ 实际操作 ◆ 总结 四.红黑树 ◆ 概念 ◆ 示例 ◆ 对比 五.总结 一.引言 前面我们介绍了二叉树、二叉…...

Zookeeper使用详解
介绍 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布…...
)
C#属性(Property)
文章目录 一、C#属性(Property)?二、属性的用法总结 一、C#属性(Property)? C#属性(Property)是一种访问器(accessor),用于封装一个类的字段&…...

在docker中搭建部署clickhouse
因需要给网关日志拉取并存储供数据分析师分析,由于几十个项目的网关请求数量很大,放在mysql不合适,MongoDB不适合分析,于是准备存放在clickhouse,clickhouse对于读写支持也比较友好,说干就干 1、在服务器中…...
)
第九部分 使用函数 (三)
目录 一、文件名操作函数 1、dir 2、notdir 3、suffix 4、basename 5、addsuffix 6、addprefix 7、join 一、文件名操作函数 下面我们要介绍的函数主要是处理文件名的。每个函数的参数字符串都会被当做一个或是 一系列的文件名来对待。 1、dir $(dir <names..>…...

基础命令继续
1:创建目录命令 mkdir命令 注意:创建文件夹需要修改权限,请确保操作均在HOME目录内,不要在Home外操作,涉及到权限问题,HOME外无法识别 小结: 练习: 2:touch创建文件 2:c…...

uni-app做A-Z排序通讯录、索引列表
上图是效果图,三个问题 访问电话通讯录,拿数据拿到用户的联系人数组对象,之后根据A-Z排序根据字母索引快速搜索 首先说数据怎么拿 - 社区有指导https://ask.dcloud.net.cn/question/64117 uniapp 调取通讯录 // #ifdef APP-PLUSplus.contac…...

Codeforces Round 768 (Div. 1) D. Flipping Range(思维题 等价类性质 dp)
题目 思路来源 官方题解 洛谷题解 题解 可操作的最短区间长度肯定是gcd,记为g,然后考虑如何dp 考虑g个等价类,每个等价类i,ig,i2*g,... 每次翻转长度为g的区间,会同时影响到g个等价类总的翻转的奇偶性, 性质一&…...

springboot集成kafka消费数据
springboot集成kafka消费数据 文章目录 springboot集成kafka消费数据1.引入pom依赖2.添加配置文件2.1.添加KafkaConsumerConfig.java2.2.添加KafkaIotCustomProperties.java2.3.添加application.yml配置 3.消费者代码 1.引入pom依赖 <dependency><groupId>org.spri…...

ARM生态产品创新评估:从芯片到系统的技术选型方法论
1. 从一次投票看ARM生态的演进与产品创新逻辑2015年秋天,EE Times上的一则投票通知,可能被很多人当作一次普通的行业活动而滑过。标题很简单——“Vote for Best ARM-Based Product”。但如果你恰好是一位嵌入式开发者、半导体行业的从业者,或…...

基于Terraform与Ansible的OpenClaw私有化AI代理自动化部署实践
1. 项目概述如果你和我一样,对AI助手的能力有更高的期待,希望它能深度融入你的工作流,甚至能帮你处理一些自动化任务,那么OpenClaw这个项目绝对值得你花时间研究。它不是一个简单的聊天机器人,而是一个可以部署在你私有…...

模拟电路延时触发音频振荡器:DIY电子蟋蟀的原理与实现
1. 项目概述:一场源于图书馆的“电子恶作剧”这个故事始于1977年,几个高中二年级的学生,在图书馆的参考书区发现了一本出版于40年代的“宝藏”书籍。书里充满了各种能让青春期男孩兴奋不已的内容:爆炸性混合物、自燃的纸飞机、三碘…...

别再为论文格式掉头发了!Paperxie 一键搞定 4000 + 高校排版规范
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能格式排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 你有没有过这种经历:论文内容改到导师点头,却栽在格式这最后一关?…...

IGBT驱动技术革新:SCALE-iDriver磁隔离方案解析
1. IGBT驱动技术演进与SCALE-iDriver的突破在电力电子系统中,IGBT(绝缘栅双极型晶体管)作为核心功率开关器件,其驱动电路的性能直接决定了整个系统的效率和可靠性。传统IGBT驱动方案主要面临三大技术瓶颈:首先是隔离技…...

企业级ai应用如何通过taotoken实现稳定低成本的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级AI应用如何通过Taotoken实现稳定低成本的多模型调用 在构建面向生产环境的企业级AI应用时,开发团队常常面临两个…...

JAVA:类和对象完全解析
一、编程世界的乐高积木在面向对象编程(OOP)的宇宙中,类(Class)和对象(Object)如同乐高积木的基础模块。如果把程序看作一个虚拟城市,类就是建筑设计图,而对象则是根据图…...

CodeGPT:基于AI的Git提交信息自动生成工具实战指南
1. 项目概述:CodeGPT,一个用Go写的AI驱动Git工具 如果你和我一样,每天都要在终端里敲无数次 git commit -m "..." ,并且为写一个清晰、规范的提交信息而绞尽脑汁,那今天分享的这个工具绝对能让你眼前一亮…...
)
告别导入报错!手把手教你用Navicat把Excel数据完美搬进MySQL(含字段超限处理)
从Excel到MySQL:Navicat数据迁移全流程实战指南 数据迁移是开发者和数据分析师日常工作中的高频需求。想象一下这样的场景:市场部门发来一份包含3000条客户信息的Excel表格,需要快速导入到测试环境的MySQL数据库中进行功能验证;或…...

叫不动下属、又不能裁?中层必看!不撕破脸、不内耗,3招拿捏摆烂员工
很多中层都有这样的困境:上面领导催进度,下面员工躺平摆烂,叫不动、推不动;想辞退,却因编制、合同等原因动不了,要么硬刚撕破脸,要么忍气吞声自己扛,内耗严重还没成效。 其实&#…...