springboot集成kafka消费数据
springboot集成kafka消费数据
文章目录
- springboot集成kafka消费数据
- 1.引入pom依赖
- 2.添加配置文件
- 2.1.添加KafkaConsumerConfig.java
- 2.2.添加KafkaIotCustomProperties.java
- 2.3.添加application.yml配置
- 3.消费者代码
1.引入pom依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.8.11</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.1.2</version></dependency>
2.添加配置文件
2.1.添加KafkaConsumerConfig.java
@Configuration
@EnableConfigurationProperties(KafkaIotCustomProperties.class)
@Slf4j
public class KafkaConsumerConfig {@AutowiredKafkaIotCustomProperties kafkaIotCustomProperties;@BeanKafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());// 并发数 多个微服务实例会均分factory.setConcurrency(3);factory.setBatchListener(true);ContainerProperties containerProperties = factory.getContainerProperties();// 是否设置手动提交containerProperties.setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);return factory;}private ConsumerFactory<String, String> consumerFactory() {Map<String, Object> consumerConfigs = consumerConfigs();log.info("消费者的配置信息:{}",JSONObject.toJSONString(consumerConfigs));return new DefaultKafkaConsumerFactory<>(consumerConfigs);}@Beanpublic Map<String, Object> consumerConfigs() {Map<String, Object> propsMap = new HashMap<>();// 服务器地址propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaIotCustomProperties.getBootstrapServers());// 是否自动提交propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, kafkaIotCustomProperties.isEnableAutoCommit());// 自动提交间隔propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, kafkaIotCustomProperties.getAutoCommitInterval());//会话时间propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, kafkaIotCustomProperties.getSessionTimeOut());//key序列化propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, kafkaIotCustomProperties.getKeyDeserializer());//value序列化propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, kafkaIotCustomProperties.getValueDeserializer());// 心跳时间propsMap.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, kafkaIotCustomProperties.getHeartbeatInterval());// 分组idpropsMap.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaIotCustomProperties.getGroupId());//消费策略propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, kafkaIotCustomProperties.getAutoOffsetReset());// poll记录数propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, kafkaIotCustomProperties.getMaxPollRecords());//poll时间propsMap.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, kafkaIotCustomProperties.getMaxPollInterval());return propsMap;}}
2.2.添加KafkaIotCustomProperties.java
@Component
@ConfigurationProperties(prefix = "fxyh.realdata.kafka")
@Data
public class KafkaIotCustomProperties {private List<String> topics;private String groupId;private String sessionTimeOut;private String bootstrapServers;private String autoOffsetReset;private boolean enableAutoCommit;private String autoCommitInterval;private String fetchMinSize;private String fetchMaxWait;private String maxPollRecords;private String maxPollInterval;private String heartbeatInterval;private String keyDeserializer;private String valueDeserializer;
}
2.3.添加application.yml配置
fxyh:realdata:kafka:bootstrapServers: 192.168.80.251:9092topics: ["test1","test2"]groupId: shengtingrealdatagroup#后台的心跳线程必须在30秒之内提交心跳,否则会reBalancesessionTimeOut: 30000# autoOffsetReset: earliest#取消自动提交,即便如此 spring会帮助我们自动提交enableAutoCommit: false#自动提交间隔autoCommitInterval: 1000#拉取的最小字节fetchMinSize: 1#拉去最小字节的最大等待时间fetchMaxWait: 500maxPollRecords: 50#300秒的提交间隔,如果程序大于300秒提交,会报错maxPollInterval: 300000#心跳间隔heartbeatInterval: 10000keyDeserializer: org.apache.kafka.common.serialization.StringDeserializervalueDeserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: latest
3.消费者代码
@Slf4j
@Component
public class DeviceDataConsumer {@Autowiredprivate KafkaIotCustomProperties kafkaIotCustomProperties;@KafkaListener(topics = {"#{@kafkaIotCustomProperties.topics}"}, groupId = "#{@kafkaIotCustomProperties.groupId}", containerFactory = "kafkaListenerContainerFactory",properties = {"#{@kafkaIotCustomProperties.autoOffsetReset}"})public void topicTest(List<ConsumerRecord<String, String>> records, Acknowledgment ack) {for (ConsumerRecord<String, String> record : records) {log.info("topic_test 消费了: Topic:" + record.topic() + ",groupId:" + kafkaIotCustomProperties.getGroupId() + ",Message:" + record.value());//手动提交偏移量ack.acknowledge();}}
}
相关文章:

springboot集成kafka消费数据
springboot集成kafka消费数据 文章目录 springboot集成kafka消费数据1.引入pom依赖2.添加配置文件2.1.添加KafkaConsumerConfig.java2.2.添加KafkaIotCustomProperties.java2.3.添加application.yml配置 3.消费者代码 1.引入pom依赖 <dependency><groupId>org.spri…...

单例模式---JAVA
目录 “饿汉”模式 完整代码 “懒汉”模式 完整代码 单例模式:保证某个类在程序中只存在唯一一份实例, 而不会创建出多个实例。 单例模式可以通过实例创建的时间来分为两种:“饿汉”和“懒汉”模式。 “饿汉”模式 所谓的“饿汉”模式实则就是在类…...
maven管理使用
maven基本使用 一、简介二、配置文件三、项目结构maven基本标签实践(例子) 四、pom插件配置五、热部署六、maven 外部手动加载jar打包方式Maven上传私服或者本地 一、简介 基于Ant 的构建工具,Ant 有的功能Maven 都有,额外添加了其他功能.本地仓库:计算机中一个文件夹,自己定义…...

如何在一个系统中同时访问异构的多种数据库
如何在一个系统中同时访问异构的多种数据库 比如在一个系统中,要同时访问MySQL,H2, MsAccess, Mongodb. 要是使用Hibernate, MyBatis这些ORM,难度简直不敢想像。 要是MySQL还使用了分库分表,那更加不得了,一大堆的组件都要配合着…...
)
半监督学习 - 半监督聚类(Semi-Supervised Clustering)
什么是机器学习 半监督聚类是一种集成了有标签数据和无标签数据的聚类方法,其目标是在聚类的过程中利用有标签数据的信息来提高聚类性能。在半监督聚类中,一部分数据集有已知的标签,而另一部分没有标签。 以下是半监督聚类的基本思想和一些…...
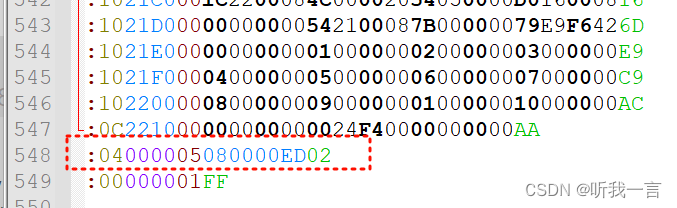
实现STM32烧写程序-(3) Hex文件结构
简介 要对STM32进行更新动作, 就需要对程序文件进行解析, 大部分编译的生成程序文件是Hex或者Bin, 先来看看Hex的结构吧。 资料 Hex文件 简介 Hex文件格式最早由Intel公司于1973年创建。它最初是为了在Intel 8080微处理器上存储和传输二进制数据而设计的。随后,Hex…...
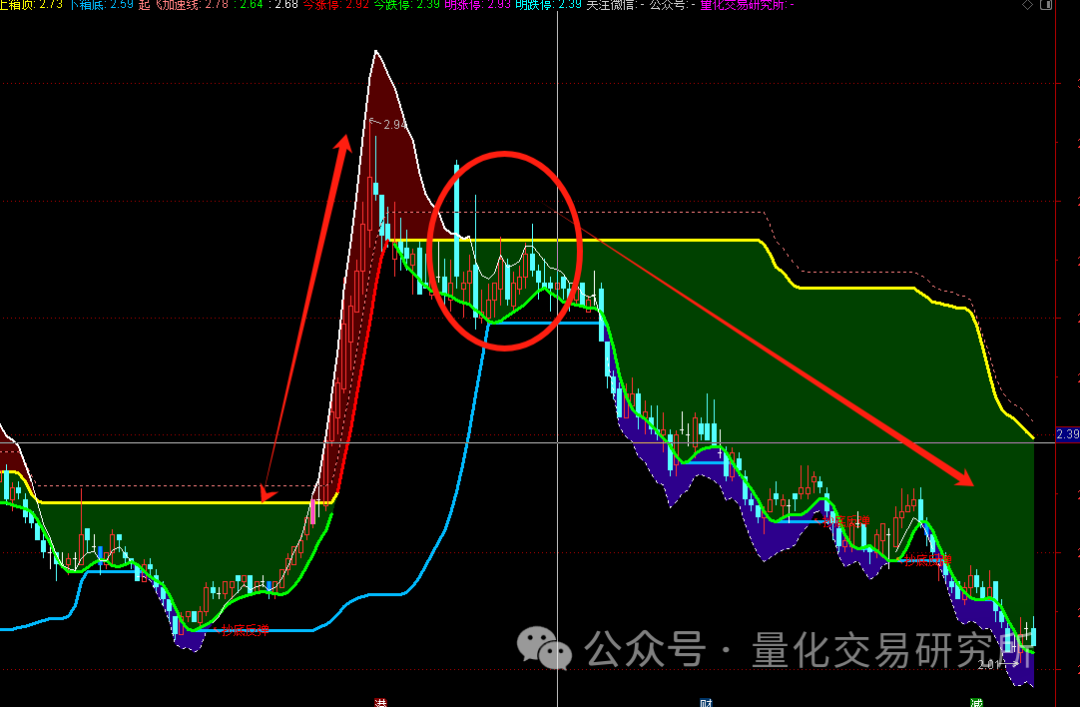
精品量化公式——“区域突破”,应对当下行情较好的主图看盘策略
不多说,直接上效果如图: ► 日线表现 代码评估 技术指标代码评估: VAR1, VAR2, VAR3:这些变量是通过指数移动平均(EMA)计算得出的。EMA是一种常用的技术分析工具,用于平滑价格数据并减少市场“…...

自然语言处理5——发掘隐藏规律 - Python中的关联规则挖掘
目录 写在开头1. 了解关联规则挖掘的概念和实际应用1.1 关联规则挖掘在市场分析和购物篮分析中的应用1.2 关联规则的定义和基本原理1.3 应用场景2. 使用Apriori算法和FP-growth算法进行关联规则挖掘2.1 Apriori算法的工作原理和实现步骤2.2 FP-growth算法的优势和使用方法2.3 A…...

【记录】重装系统后的软件安装
考完研重装了系统,安装软件乱七八糟,用到什么装什么。在这里记录一套标准操作,备用。一个个装还是很麻烦,我为什么不直接写个脚本直接下载安装包呢?奥,原来是我太菜了还不会写脚本啊!先记着吧&a…...
- ACodec(七))
Android 13 - Media框架(31)- ACodec(七)
之前的章节中我们解了 input buffer 是如何传递给 OMX 的,以及Output buffer 是如何分配并且注册给 OMX 的。这一节我们就来看ACodec是如何处理OMX的Callback的。 1、OMXNodeInstance Callback 这一节我们只大致记录Callback是如何传递给ACodec的。在之前的学习中我…...

快速了解VR全景拍摄技术运用在旅游景区的优势
豆腐脑加了糖、烤红薯加了勺,就连索菲亚大教堂前都有了“人造月亮”,在这个冬季,“尔滨”把各地游客宠上了天。面对更多的游客无法实地游玩,哈尔滨冰雪世界再添新玩法,借助VR全景拍摄技术对冬季经典冰雪体验项目进行全…...

分布形态的度量_峰度系数的探讨
集中趋势和离散程度是数据分布的两个重要特征,但要全面了解数据分布的特点,还应掌握数据分布的形态。 描述数据分布形态的度量有偏度系数和峰度系数, 其中偏度系数描述数据的对称性,峰度系数描述与正态分布的偏离程度。 峰度系数反映分布峰的尖峭程度的重要指标. 当…...
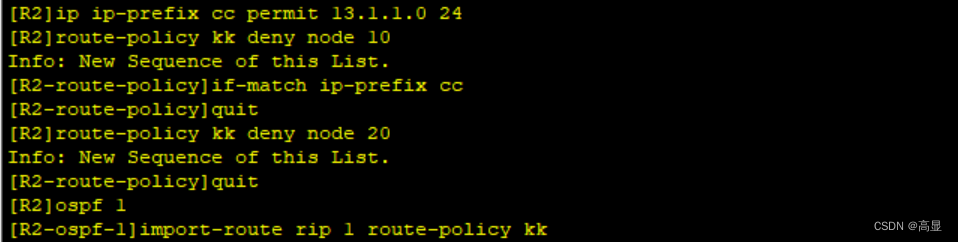
HCIP 重发布
拓扑图&IP划分如下: 第一步,配置接口IP&环回地址 以R1为例,R2~R4同理 interface GigabitEthernet 0/0/0 ip address 12.1.1.1 24 interface GigabitEthernet 0/0/1 ip address 13.1.1.1 24 interface LoopBack 0 ip address 1.1.1.…...

FX图中的节点代表什么操作
在 FX 图中,每个节点代表一个操作。这些操作可以是函数调用、方法调用、模块实例调用,也可以是 torch.nn.Module 实例的调用。每个节点都对应一个调用站点,如运算符、方法和模块。 一.节点操作 下面是一些节点可能代表的操作: 1…...

【Java 设计模式】创建型之单例模式
文章目录 1. 定义2. 应用场景3. 代码实现1)懒汉式2)饿汉式 4. 应用示例结语 在软件开发中,单例模式是一种常见的设计模式,它确保一个类只有一个实例,并提供一个全局访问点。单例模式在需要控制某些资源,如数…...
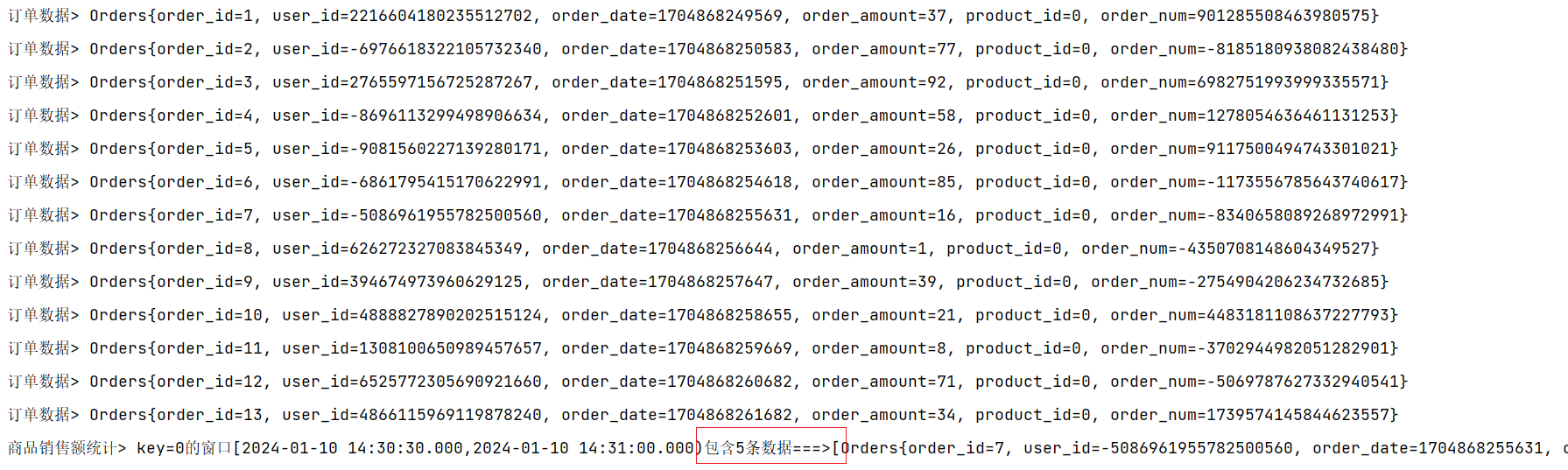
FlinkAPI开发之窗口(Window)
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 窗口的概念 Flink是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。…...
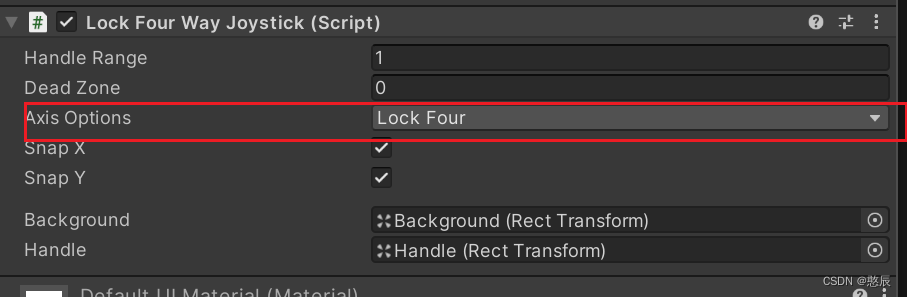
【Unity】Joystick Pack摇杆插件实现锁四向操作
Joystick Pack 简介:一款Unity摇杆插件,非常轻量化 摇杆移动类型:圆形、横向、竖向 摇杆类型: Joystick描述Fixed固定位置Floating浮动操纵杆从用户触碰的地方开始,一直固定到触碰被释放。Dynamic动态操纵…...

29 旋转工具箱
效果演示 实现了一个菜单按钮的动画效果,当鼠标悬停在菜单按钮上时,菜单按钮会旋转315度,菜单按钮旋转的同时,菜单按钮旋转的8个小圆圈也会依次旋转360度,并且每个小圆圈的旋转方向和菜单按钮的旋转方向相反࿰…...
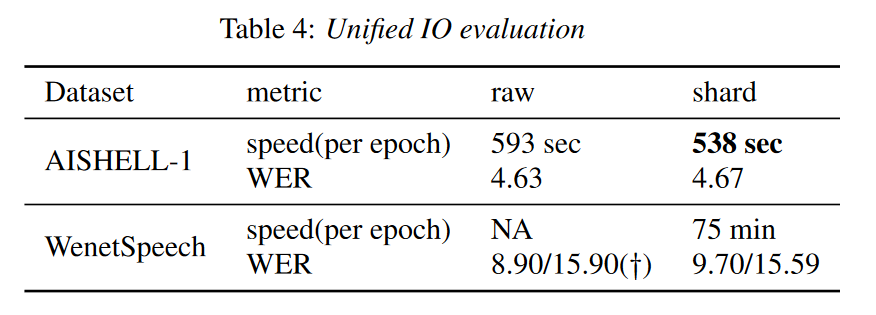
WeNet2.0:提高端到端ASR的生产力
摘要 最近,我们提供了 WeNet [1],这是一个面向生产(工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)…...
)
第九部分 使用函数 (四)
目录 一、foreach 函数 二、if 函数 三、call 函数 一、foreach 函数 foreach 函数和别的函数非常的不一样。因为这个函数是用来做循环用的,Makefile 中的 foreach 函数几乎是仿照于 Unix 标准 Shell(/bin/sh)中的 for 语句,或…...

Display Driver Uninstaller:Windows显卡驱动终极清理方案
Display Driver Uninstaller:Windows显卡驱动终极清理方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstal…...

RAG和向量索引
为特定用例设计代理时,需要确保语言模型已建立基础并使用与用户所需内容相关的事实信息。 虽然语言模型针对大量数据进行了训练,但它们可能无权访问你想要向用户提供的知识。 若要确保代理基于特定数据提供准确且特定于域的响应,可使用检索增…...

给 Agent 配一个浏览器:Cloudflare Browser Run 全面解析
互联网是为人类建的,Agent 要用它 Agent 需要和网页交互。填表单、提取数据、截图、导航——这些是 Agent 执行任务的基本动作。问题是,整个互联网的设计预设是"有一个人坐在屏幕前操作"。Agent 不是人,它没有鼠标,没有…...

VidToText
链接:https://pan.quark.cn/s/370e0f7f3f42vidToText 离线语音转文字 工具,绝对能帮你解放双手,自带模型不用联网,95% 高准确率,音视频秒转文字,办公和创作效率直接翻倍!且这款软件免费使用&…...

基于大语言模型的AI狼人杀游戏:双层角色扮演与模型竞技场设计
1. 项目概述:当狼人杀遇上AI,一场全新的推理盛宴毕业之后,想凑齐8到12个人,在周末的晚上围坐一圈,点上外卖,来一场酣畅淋漓的狼人杀,几乎成了一种奢望。这个游戏的精髓在于社交,但剥…...

9D传感器融合技术:原理、优化与应用
1. 9D传感器融合技术概述在当今的智能设备领域,精确的姿态感知已成为标配功能。从智能手机的自动旋转屏幕到VR头显的动作追踪,背后都离不开多传感器数据的融合处理。9D传感器融合技术通过整合加速度计、陀螺仪和磁力计的数据(各提供3轴测量&a…...

FPGA神经形态计算架构与Class 7实现详解
1. FPGA神经形态计算架构概述 神经形态计算是一种模拟生物神经系统信息处理机制的新型计算范式,其核心在于脉冲神经网络(SNiking Neural Network, SNN)的硬件实现。与传统人工神经网络不同,SNN通过精确模拟神经元间的脉冲时序依赖可塑性(STDP)来实现更接…...

ToDesk、向日葵、UU远程横评:谁才是2026国产远控首
ToDesk、向日葵、UU远程横评:谁才是2026国产远控首选一、前言:国产远控崛起,2026 怎么选?远程控制早已从 “小众工具” 变成个人、办公、游戏、运维的刚需。2026 年国产远控阵营已全面崛起,ToDesk、向日葵、UU 远程成为…...

3个技巧快速掌握加密压缩包密码找回:ArchivePasswordTestTool新手指南
3个技巧快速掌握加密压缩包密码找回:ArchivePasswordTestTool新手指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾…...

PyQt5实战:从Designer拖拽到打包exe,手把手打造你的第一个多页面桌面应用
PyQt5实战:从Designer拖拽到打包exe,手把手打造你的第一个多页面桌面应用 在数字化浪潮席卷各行各业的今天,图形用户界面(GUI)开发已成为程序员必备技能之一。而PyQt5作为Python最强大的GUI框架,凭借其丰富…...