【数模百科】一篇文章讲清楚灰色预测模型GM(1,1)附python代码
本篇文章摘录自GM(1,1) - 数模百科 ,如果想了解更多有关灰色预测模型的信息,请移步 灰色预测模型 - 数模百科
首先,“灰色”这个词在这里不是指颜色,而是形容一种信息状态,介于黑(信息全无)和白(信息全有)之间。咱们有时候对一些事情知道一点儿,但又说不上很清楚,这就有点“灰色”的感觉。
灰色预测模型是一种特别设计来解决数据信息不全的情况下的预测问题的算法。这个模型的出现,主要是为了帮助我们在只有少量数据或者数据不够可靠的时候也能做出比较合理的预测。比方说,当我们手头的历史信息不够完整,或者数据太少,用常规的统计方法就不太行的时候,灰色预测模型就能发挥作用。
这个模型的做法是,它会先对我们拿到手的原始数据进行一番处理,比如做一些插值或者推算,以此来猜测未来可能会出现的走势。模型会根据数据的走势是上升还是下降,分成两种不同的类型,然后用不同的计算方式去预测。
举个例子,GM(1,1)模型就是专门用来预测那些呈现上升趋势的数据序列的。它通过一些数学上的处理,比如累加和简化计算,来估算这种趋势会如何延续。而GM(2,1)模型则是用来看那些下降趋势的数据,它的处理方法跟GM(1,1)有点像,但是会多一个步骤,它不仅仅进行一次加总处理,还会对加总过的数据进行再一次的处理。这样就可以应对那些变化更加复杂的数据序列。
灰色预测模型用起来简单方便,而且很灵活,所以在经济分析、环境预测、物流规划这些领域都很受欢迎。它对于短期内的预测和那些不太规则的数据处理特别有用。不过,如果我们要预测的是很长远的未来,或者要分析长期的趋势,这个模型就可能不太适用了。
虽然灰色预测模型很有用,但因为它属于一种灰箱模型,也就是说它的内部工作原理不是完全透明的,所一般比赛期间不优先使用。
模型假设
-
系统内的变量可分为确定性因素和随机性因素。
随机性因素服从白噪声分布,即期望值为0,方差恒定。 -
系统内各因素之间存在一定的关联性和规律性。
-
系统因素在预测时间范围内具有局部平稳性,即系统特性和规律不发生根本变化。
数据集要求
-
数据应为连续的时间序列数据,由一系列按时间顺序排列的观测值组成。
-
数据集至少包含四个数据点,前三个数据点需均匀间隔。
-
数据收集过程中应尽量减少人为误差和异常值,确保数据的准确性。
-
数据集中的因素需满足灰色系统的关联性和规律性假设。
数据处理要求
进行数据归一化处理,消除不同量纲和数值范围的差异。
通过标准化或正规化方法将数据转换到统一尺度,以提高模型的预测精度。
数据检验
极比值检验
灰色预测模型是一种常用于处理小样本和不完全信息情况下的预测方法。为了确保灰色预测模型能够对数据序列进行有效的预测,我们必须先对数据进行级比值检验。级比值检验是一种预先检查,用以评价数据序列的规律性和灰色预测模型的适用性。
级比值是通过计算连续两期数据的比值来定义的,具体地,如果我们有一个数据序列 ,则第 i 期的级比值表示为
对于灰色预测模型的适应性检验,我们通常要求级比值落在特定的范围内,这个范围由下述公式确定:
其中, e 是自然对数的底数,n 是数据序列的样本量。如果数据序列中的级比值均满足上述条件,那么我们可以初步判断该数据序列适合应用灰色预测模型,因为这表明数据的发展趋势具有一定的规律性和稳定性。
然而,即使数据序列的级比值不完全符合上述范围,也并非意味着灰色预测模型完全不适用。实际情况中,我们可以通过适当的数据预处理来改善级比值,例如对数据进行平滑处理、取对数或者差分等,以期达到更好的预测效果。
需要注意的是,级比值检验只是模型适用性判断的初步步骤。在确定使用灰色预测模型后,还需要结合其他统计指标和检验方法,对模型进行进一步的检验和评估,以确保预测结果的准确性和可靠性。
例如,如果我们有一个产品的销售量数据序列 {120, 150, 180, 210} ,则计算得到的级比值序列为 \{0.8, 0.833, 0.857} 。假设样本量 n = 4 ,代入到级比值的标准范围计算公式中,我们可以得到合理的级比值范围大约为 [0.675, 1.48] 。可以看出,所有的级比值都在这个范围内,因此我们可以初步判断该数据序列适合使用灰色预测模型进行分析。
后差比检验
后差比检验是评价灰色预测模型拟合精度的重要方法,它主要用于确保模型的预测结果具有较高的准确性。具体来说,当我们构建了一个灰色预测模型后,会根据模型得到一系列的预测值。为了评估这些预测值的精确度,我们需要将它们与实际观测值进行对比,计算出两者之间的差异,即残差。
残差反映了模型预测值与实际观测值之间的偏差程度。为了定量地评估这种偏差,我们会计算残差的方差,并将其与原始数据的方差进行比较。具体的计算公式为:
C = 残差方差/原始数据方差
其中,后差比C值是一个无量纲的指标,用于衡量灰色预测模型的拟合效果。C值越小,意味着模型的拟合效果越好,预测结果与实际数据的吻合程度越高,从而预测的准确性越高。通常情况下,如果C值小于0.35,通常被认为模型具有较好的拟合精度;如果C值介于0.35到0.65之间,模型也可以接受,但精度相对较低;如果C值大于0.65,则表明模型拟合效果不理想。
例如,假设我们有一组数据和通过灰色预测模型得到的预测结果,计算出残差方差为0.02,原始数据方差为0.05,则后验差比C值为0.4。这个值介于0.35到0.65之间,可以认为模型的拟合效果是可接受的,但还有改进的空间。
值得注意的是,后差比检验虽然是一个重要的评估指标,但它不能单独决定模型的好坏。在实际应用中,我们还需要结合其他因素,如模型的稳定性、预测目标、数据特点等,综合评估模型的性能。只有全面考虑这些因素,我们才能更准确地判断模型的可靠性和实用性。
GM(1,1)
GM(1,1)模型是灰色系统理论中的一个基本模型,"GM"代表"灰色模型",括号里的第一个"1"表示这个变量是一阶的,第二个"1"表示模型中只包含一个变量,即考虑变量随时间的一阶变化率。
发明这个算法的动机主要是为了解决现实世界中的不确定性和不完整信息问题。在很多情况下,我们拿到的数据是不完整的,或者有噪声,也就是说数据的质量不是很高,这在经济、环境、工程技术等领域是很常见的。传统的统计模型需要大量精确的数据来预测未来趋势,而在信息不足的情况下,这些模型就不太管用了。于是,灰色模型就应运而生,它可以用相对较少和不完整的数据来做出还算可靠的预测。
GM(1,1)模型的适用场景很广泛,特别是在数据量不大、信息不完全、难以用传统方法建模的情况下。比如,新产品的销量预测(因为新产品缺少历史数据)、新技术发展趋势分析(由于技术变化快,旧数据可能不适用)等场景。它通过对原始数据进行一定的处理,建立起一个数学模型,然后用这个模型来预测未来的变化趋势。
总的来说,GM(1,1)模型就像是一个特别设计的工具,能在数据不充分的情况下帮我们抓住主要趋势,给出一个大致的未来走向预测。当然,这个模型也有它的局限性,如果数据太过随机或者变化太剧烈,它的预测准确度就会下降。所以,在使用GM(1,1)模型时,我们还需要结合实际情况和其他分析方法来共同判断。
举个例子。
假设你想知道一个城市未来的人口增长情况。我们可以使用GM(1,1)模型来预测。
首先,我们找到过去几年的人口数据,比如5年前、4年前、3年前、2年前和1年前的数据。然后,我们对这些数据进行加总,得到一个新的序列。
接下来,我们计算这个新序列相邻两项的均值,也就是找出每两个数据之间的平均值。
然后,我们可以建立一个简单的模型,描述这个新序列的变化。这个模型基于一个数学公式,通过解方程我们可以估计出公式里的参数。
最后,我们使用这个模型和参数,来预测未来几年的人口增长情况。
GM(1,1)模型可以帮助我们估计未来的人口增长趋势,但需要注意的是,模型的准确性可能受到数据质量和模型参数选择的影响。所以在使用模型时,我们要谨慎对待结果,综合考虑多个因素。
定义与详解
定义
灰色预测模型GM(1,1)是一种专门用来对数据量不多的情况下进行预测的方法。它是基于灰色系统理论提出的,能够通过构建一个简单的数学模型来预测数据的未来走势。这个模型特别适用于单调的变化过程,也就是那些增长或下降趋势比较明显、数据变化呈现出某种指数规律的序列,但它不能描述波动变化或非单调的情况。
首先,我们有一个原始的数据序列:
这里的 x^{(0)}(t) 就是我们在第 t 个时间点观测到的数值。为了让模型能够更容易处理这些数据,我们要对原始数据进行一次累加操作(I-AGO),得到另一个新的序列:
在这个新序列中, 表示的是从第一个数据点到第 t 个数据点的累计值。
GM(1,1)模型认为,这个累加后的数据序列可以通过一个一阶线性微分方程来描述,这个方程是:
在这个方程中, a 是一个我们要估计的参数,叫做发展系数。它可以告诉我们数据累加序列的增长或下降的速度:如果 a 的值比较大,意味着数据变化得快;相反,如果 a 的值小,数据变化得慢。而 u 是另一个参数,称为灰色作用量,它代表了除了增长趋势之外,可能还会影响数据变化的其他因素。
当我们对上面的微分方程进行积分,就可以得到这样一个表达式:
这个表达式可以帮助我们计算出在任何一个时间点 t 的累加数据值,其中 是初始的累加数据值,
表示各个时间点。通过这个公式,我们就可以预测未来数据的走势了。
求解
首先,我们有一组原始数据,记作序列 X^{(0)}。这个序列是我们想要进行预测的数据,可以表示为:
其中,n 是已知数据点的数量。我们的目标是预测这个序列未来的值。
步骤1:构造紧邻均值生成序列
为了建立预测模型,我们首先需要从原始数据构造紧邻均值生成序列,记作 。这个新序列是通过累加原始数据来获取的,公式如下:
这样做可以使数据序列更平滑,更适合进行灰色预测。
步骤2:求解模型参数
接下来,我们需要求解微分方程来得到模型的两个参数:发展系数 a 和灰色作用量 u。这些参数帮助我们了解数据的增长趋势和水平。方程可以表示为:
通过回归分析或最小二乘法,我们可以求解出 a 和 u。
步骤3:反演计算原始数据的预测值
一旦我们有了 a 和 u 这两个参数,就可以计算原始数据的预测值。如果我们想要预测未来 m 个时期的值,预测公式如下:
在这里,m 是我们想要预测的未来时间步数。
总结起来,灰色预测模型GM(1,1)通过累加原始数据构造新序列,然后用这个新序列求解模型参数,最后通过这些参数来预测原始序列未来的值。这个方法简单而且在数据不足时特别有效。
代码
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt# 定义GM(1,1)类
class GM11:def __init__(self):self.a = 0 # 灰色作准指数self.b = 0 # 灰色作准常数self.X0 = None # 初始数据序列self.X_cum = None # 累加数据序列def fit(self, X):self.X0 = Xn = len(X)self.X_cum = np.cumsum(X) # 累加生成数列Z = 0.5 * (self.X_cum[:-1] + self.X_cum[1:]) # 紧邻均值生成数列B = np.vstack((-Z, np.ones(n - 1))).TY = X[1:]U = np.dot(B.T, B)self.a, self.b = np.dot(np.linalg.inv(U), np.dot(B.T, Y)) # 最小二乘估计参数def predict(self, n):# 预测n个数据点X_pred = np.zeros(n)X_pred[0] = self.X0[0]# 将累加预测数据进行还原# 见数模百科# 生成示例数据
X = np.array([20, 25, 30, 35, 40, 45])# 创建GM(1,1)模型实例
model = GM11()
model.fit(X)# 预测未来的数据
m = 3 # 预测未来3个数据点
X_pred_future = model.predict(len(X) + m)[len(X):]# 绘制原始数据和预测数据
plt.plot(range(len(X)), X, 'o-', label='Original')
plt.plot(range(len(X), len(X) + m), X_pred_future, 'x--', label='Future Prediction')
plt.legend()
plt.show()这段代码展示了使用GM(1,1)模型对一组数据进行灰色预测的过程。
-
导入所需的库。
-
定义GM(1,1)类。
-
初始化GM(1,1)类:初始化了灰色作准指数(a)和灰色作准常数(b)两个参数。
-
fit函数:此函数用于拟合GM(1,1)模型。它接受一个数据集作为输入(X),并计算得出a和b参数。通过最小二乘法,使用数据的累加、均值和标准差等,求解了灰色作准指数a和灰色作准常数b。
-
predict函数:此函数用于根据已拟合的GM(1,1)模型预测新数据。它接受一个数据集作为输入(X),并通过迭代预测新的数据点。预测的方法根据GM(1,1)模型的公式进行计算。 -
创建GM(1,1)模型实例:创建了一个GM(1,1)模型的实例对象model。
-
模型拟合:使用fit函数拟合了GM(1,1)模型,得到了a和b参数。
-
预测新数据:使用
predict函数根据已拟合的模型预测了新的数据点,得到了X_pred。 -
绘制数据:使用Matplotlib库绘制了原始数据和预测数据的折线图。
最终,通过运行这段代码,可以展示原始数据和预测数据的对比结果,以观察GM(1,1)模型的拟合效果。
输出结果:

优缺点
优点:
-
模型简单,易于理解和应用。
-
计算效率高,适用于数据量较少的情况。
-
对于一阶线性累加序列的预测准确度较高。
-
在短期预测中具有一定的预测能力。
缺点:
-
对数据质量要求高,在异常值和噪声的情况下容易产生较大的误差。
-
对于非线性和多阶累加序列的建模能力较弱。
-
在预测长期趋势和变化方向时的准确度较低。
-
对参数选择和估计方法敏感,可能存在一定的主观性。
需要根据具体问题的特点和数据的特征来选择是否使用灰色预测模型,并结合其他模型和方法进行综合分析和预测。
本篇文章摘录自 数模百科 —— GM(1,1)
GM(1,1) - 数模百科# 白话文GM(1,1)模型是灰色系统理论中的一个基本模型,"GM"代表"灰色模型",括号里的第一个"1"表示这个变量是一阶的,第二个"1"表示模型中只包含一个变量,即考虑变量随时间的一阶变化率。![]() https://modelwiki.cn/wiki/d67addc8-ff9f-43f1-92f1-60ed94d1a521
https://modelwiki.cn/wiki/d67addc8-ff9f-43f1-92f1-60ed94d1a521
数模百科是一个由一群数模爱好者搭建的数学建模知识平台。我们想让大家只通过一个网站,就能解决自己在数学建模上的难题,把搜索和筛选的时间节省下来,投入到真正的学习当中。
我们团队目前正在努力为大家创建最好的信息集合,从用最简单易懂的话语和生动形象的例子帮助大家理解模型,到用科学严谨的语言讲解模型原理,再到提供参考代码。我们努力为数学建模的学习者和参赛者提供一站式学习平台,目前网站已上线,期待大家的反馈。
如果你想和我们的团队成员进行更深入的学习和交流,你可以通过公众号数模百科找到我们,我们会在这里发布更多资讯,也欢迎你来找我们唠嗑。
相关文章:
【数模百科】一篇文章讲清楚灰色预测模型GM(1,1)附python代码
本篇文章摘录自GM(1,1) - 数模百科 ,如果想了解更多有关灰色预测模型的信息,请移步 灰色预测模型 - 数模百科 首先,“灰色”这个词在这里不是指颜色,而是形容一种信息状态,介于黑(信息全无)和白…...

openssl3.2 - 官方demo学习 - mac - hmac-sha512.c
文章目录 openssl3.2 - 官方demo学习 - mac - hmac-sha512.c概述笔记END openssl3.2 - 官方demo学习 - mac - hmac-sha512.c 概述 MAC算法为HMAC, 设置参数(摘要算法为SHA3-512), 用key初始化, 对明文做MAC数据. 笔记 /*! \file hmac-sha512.c \note openssl3.2 - 官方demo…...
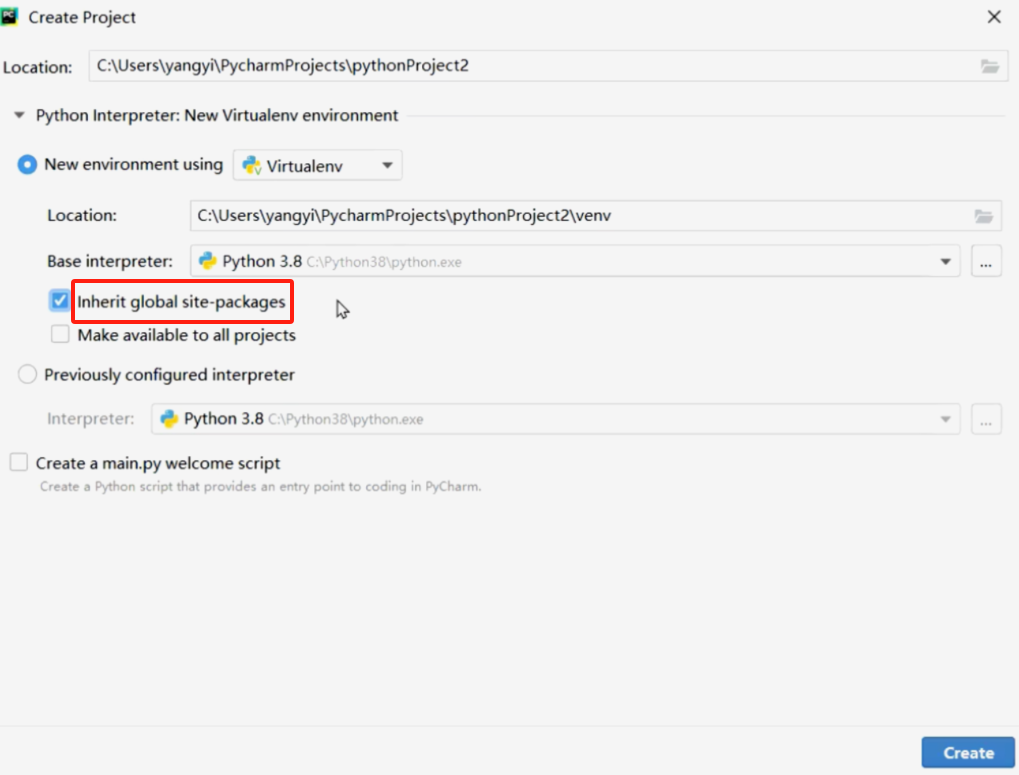
pycharm的使用技巧
1.新建文件时,自动生成代码 settings->editor->file and code templates,选择python script ${NAME} 文件名 ${DATE} 日期 2.自动补齐自定义段落 settings->editor->live templates,在右侧点击+号,添加自定义的内容 完成之后,在下方勾选python 3.修改注释的…...
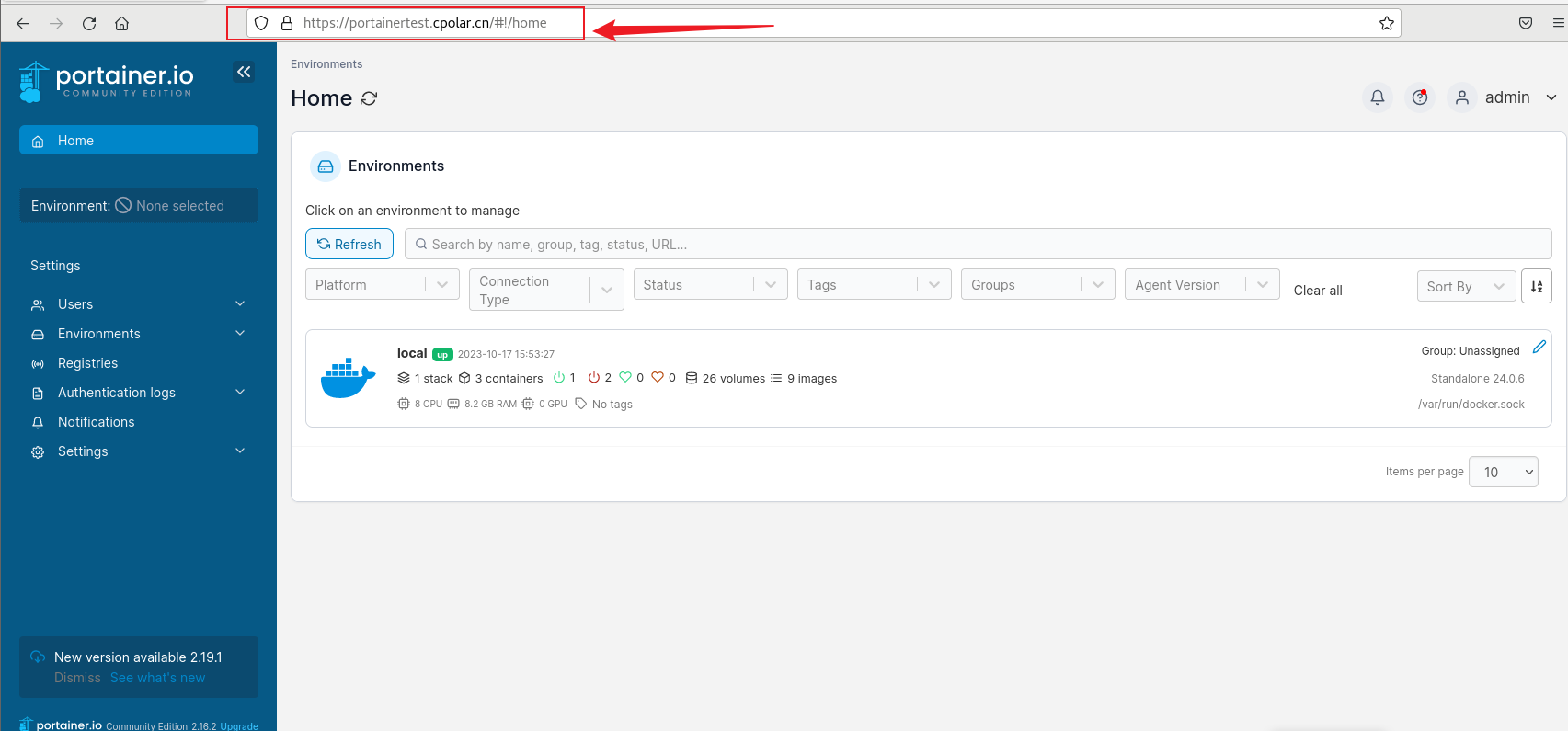
如何通过内网穿透实现公网访问Portainer管理监控Docker容器
文章目录 前言1. 部署Portainer2. 本地访问Portainer3. Linux 安装cpolar4. 配置Portainer 公网访问地址5. 公网远程访问Portainer6. 固定Portainer公网地址 正文开始前给大家推荐个网站,前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风…...
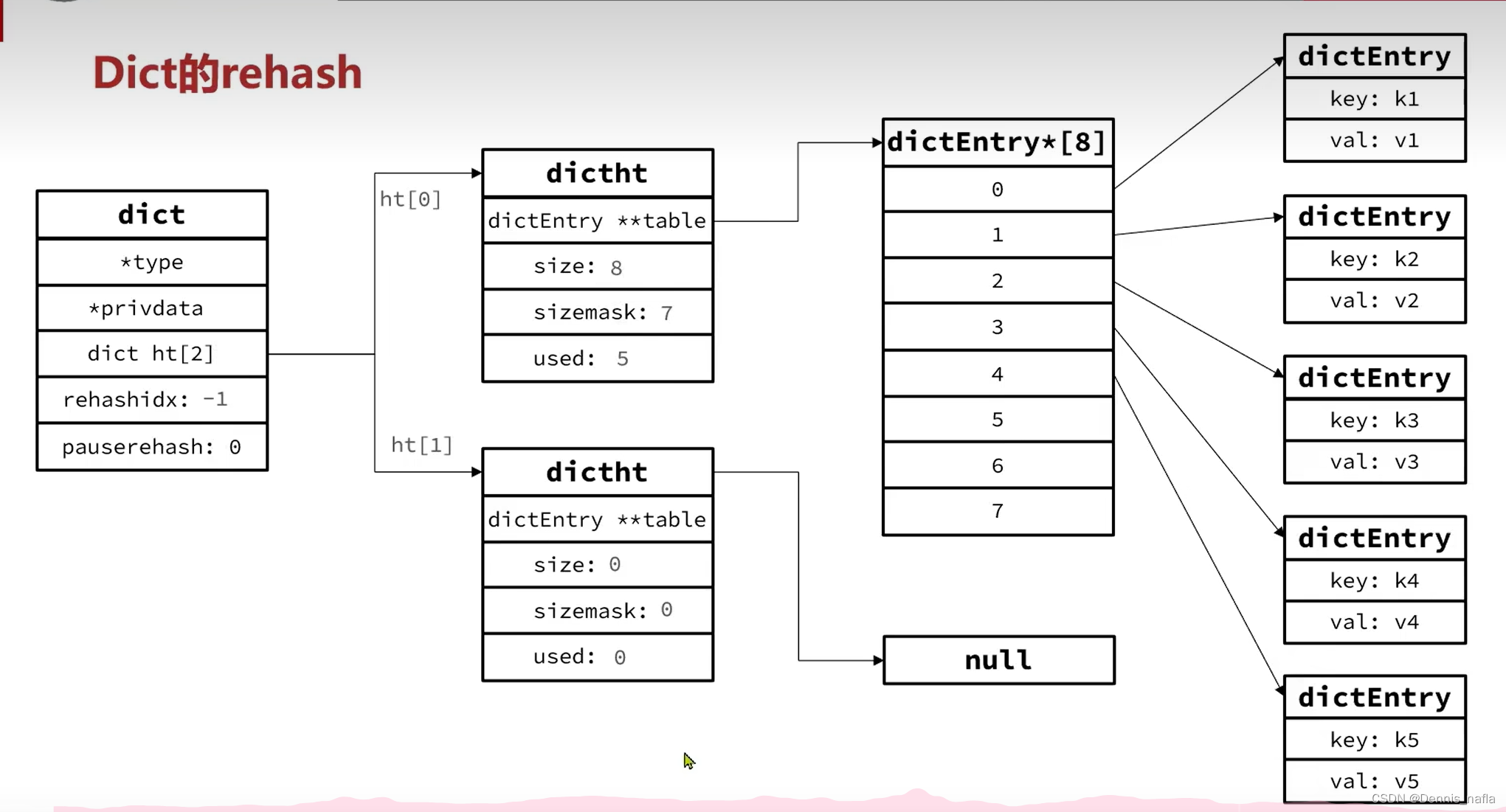
Redis原理篇(Dict的收缩扩容机制和渐进式rehash)
Dict(即字典) Redis是一种键值型数据库,其中键与值的映射关系就是Dict实现的。 Dict通过三部分组成:哈希表(DictHashTable),哈希节点(DictEntry),字典(Dict)…...

Microsoft Remote Desktop for Mac 中文正式版下载 微软远程连接软件
Microsoft Remote Desktop 是一款专为 Mac 用户设计的远程桌面工具,它可以帮助用户通过网络连接到其他计算机,实现远程控制和操作。 软件下载:Microsoft Remote Desktop for Mac 中文正式版下载 该工具支持多种远程连接协议,包括 …...

解读Vue的原型及原型链
在 JavaScript 中,每个对象都有一个关联的原型(prototype)。原型是一个对象,其他对象可以通过原型实现属性和方法的继承。原型链是一种由对象组成的链式结构,它通过原型的引用连接了一系列对象,形成了一种继…...
queue、C++)
拓扑排序(优先队列)queue、C++
N个小朋友,编号 1∼N,要排成一队。在安排每个人的顺序时,有 M 个要求,每个要求包含两个整数 a,b,表示小朋友 a 要排在小朋友 b 的前面。 请你找出符合所有要求的排队顺序。 输入格式 第一行包含整数 N,M。接下来 M 行…...

【Spring】SpringBoot 统一功能处理
文章目录 前言1. 拦截器1.1 什么是拦截器1.2 拦截器的使用1.2.1 自定义拦截器1.2.2 注册配置拦截器 1.3 拦截器详解1.3.1 拦截路径1.3.2 拦截器执行流程1.3.3 适配器模式 2. 统一数据返回格式3. 统一异常处理 前言 在日常使用 Spring 框架进行开发的时候,对于一些板…...
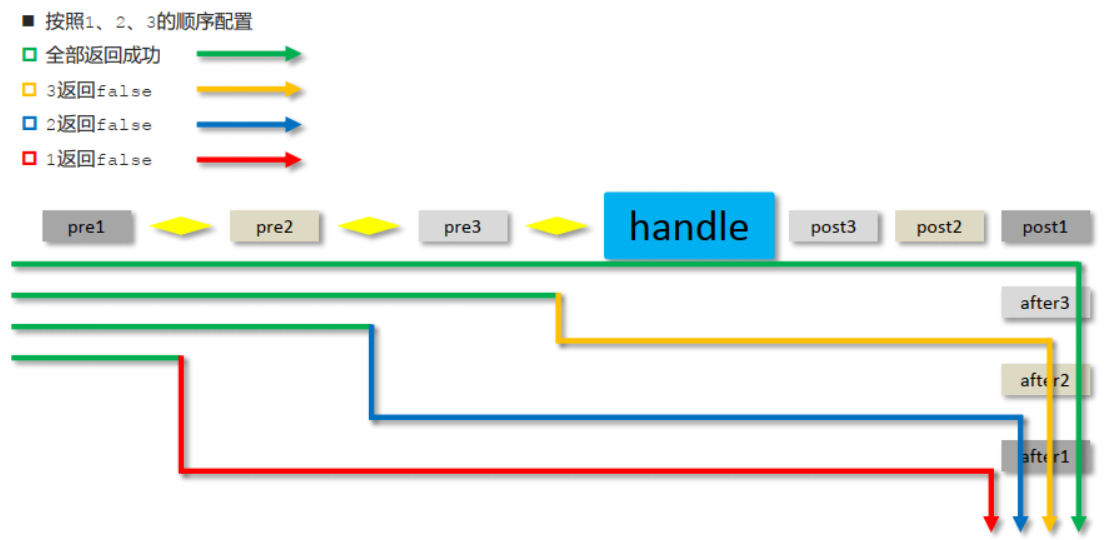
拦截器HandlerInterceptor | springmvc系列
拦截器,通俗来来将,就是我们将访问某个路径的请求给拦截下来,然后可以对这个请求做一些操作 基本使用 创建拦截器类 让类实现HandlerInterceptor接口,重写接口中的三个方法。 Component //定义拦截器类,实现Handle…...

【SQL server】DML触发器监控数据库字段值改变
文章目录 前言DML触发器基本思路创建触发器固定字段触发示例完整示例代码变量声明查询新旧值插入数据到日志表效果视频动态字段触发示例完整代码示例触发器基本信息变量声明定义游标打开游标临时表创建循环处理字段...
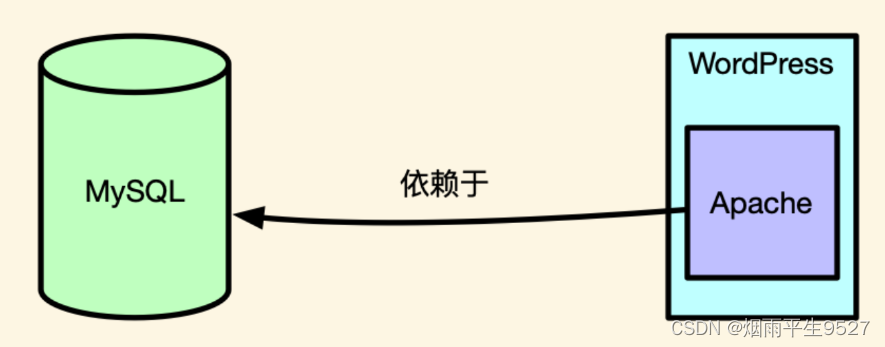
Docker容器(二)安装与初体验wordpress
一、安装 1.1关闭SeLinux SeLinux(Security-Enhanced Linux)是一种基于Linux内核的安全模块,旨在提供更严格的访问控制和安全策略。它通过强制实施安全策略来限制系统资源的访问,从而保护系统免受恶意软件和未经授权的访问。 在…...

Odrive 学习系列二:将烧录工具从ST-Link V2修改为JLink
一、背景: 通过观察odrive解压后的内容,可以看到在下面配置文件及makefile文件中的配置设置的均为openOCD + stlink v2,例如makefile中: # This is only a stub for various commands. # Tup is used for the actual compilation.BUILD_DIR = build FIRMWARE = $(BUILD_DI…...

ffmpeg api-codec-param-test.c源码讲解
try_decode_video_frame /*** 尝试解码视频帧** param codec_ctx 解码器上下文* param pkt 待解码的视频数据包* param decode 是否解码标志,如果为1,则进行解码,如果为0,则不解码* return 返回0表示成功,否则表示出错…...
json解析get_json_object()函数)
Hive学习(14)json解析get_json_object()函数
一、语法 目的:在一个标准JSON字符串中,按照指定方式抽取指定的字符串。 string get_json_object(string <json>, string <path>) 参数说明 json:必填。STRING类型。标准的JSON格式对象,格式为{Key:Value, Key:Val…...
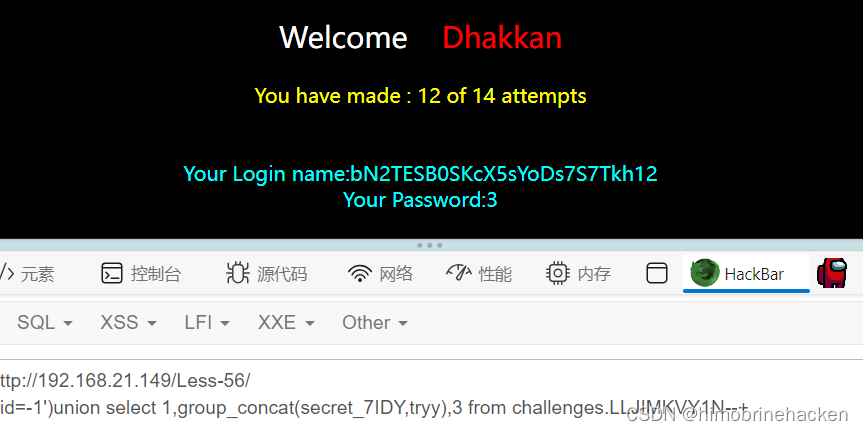
sqlilabs第五十五五十六关
Less-55(GET - challenge - Union- 14 queries allowed -Variation 2) 手工注入 结束 自动注入 想到一个办法能绕过需要用到IP池就可以(但是我没有) Less-56(GET - challenge - Union- 14 queries allowed -Variation 3) 手工注入...

Vue2 实现带输入的动态表格,限制el-input输入位数以及输入规则(负数、小数、整数)
Vue2 实现el-input带输入限制的动态表格,限制输入位数以及输入规则(负数、小数、整数) 在这个 Vue2 项目中,我们实现一个限制输入位数(整数16位,小数10位)以及输入规则(负数、小数、…...

反爬虫策略:使用FastAPI限制接口访问速率
目录 引言 一、网络爬虫的威胁 二、FastAPI 简介 三、反爬虫策略 四、具体实现 五、其他反爬虫策略 六、总结 引言 在当今的数字时代,数据已经成为了一种宝贵的资源。无论是商业决策、科学研究还是日常生活,我们都需要从大量的数据中获取有价值的…...
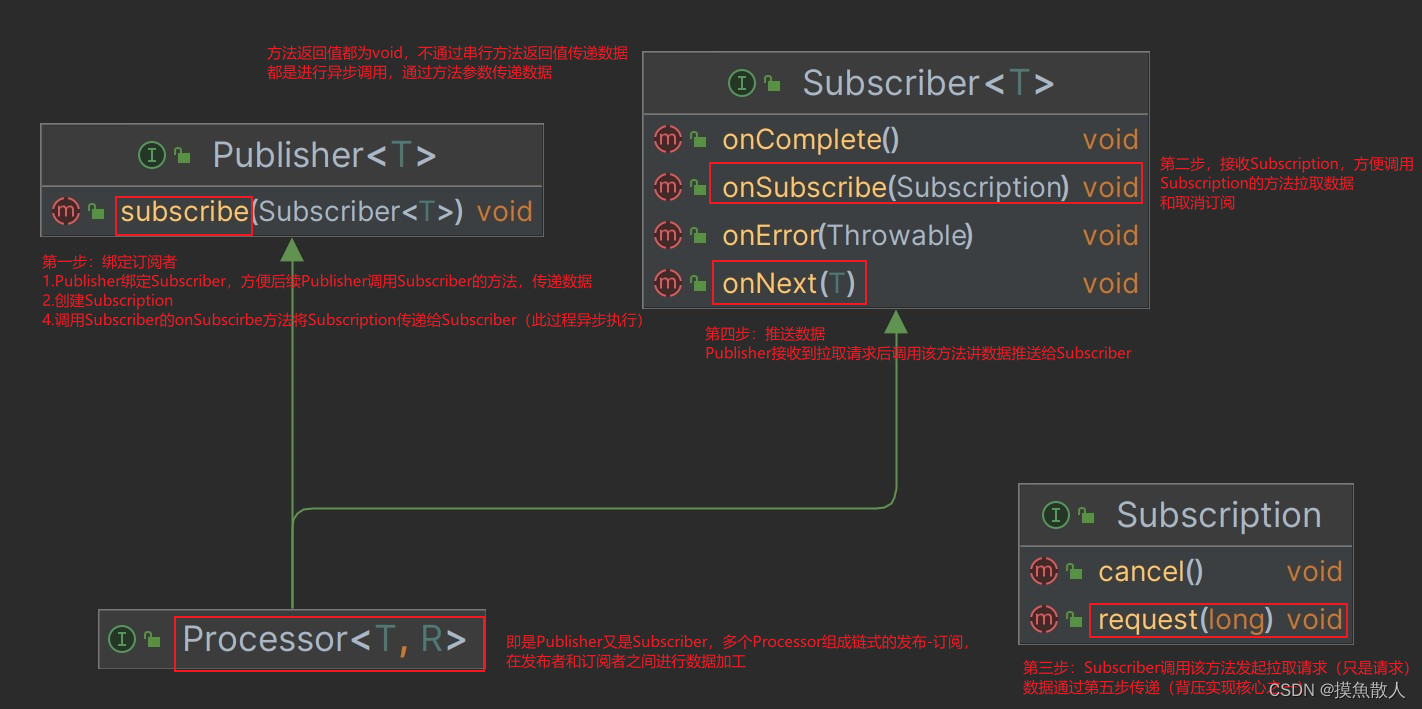
响应式编程初探-自定义实现Reactive Streams规范
最近在学响应式编程,这里先记录下,响应式编程的一些基础内容 1.名词解释 Reactive Streams、Reactor、WebFlux以及响应式编程之间存在密切的关系,它们共同构成了在Java生态系统中处理异步和响应式编程的一系列工具和框架。 Reactive Streams…...

如何使用LightPicture+cpolar搭建个人云图床随时随地公网访问
文章目录 1.前言2. Lightpicture网站搭建2.1. Lightpicture下载和安装2.2. Lightpicture网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 1.前言 现在的手机越来越先进,功能也越来越多,而手机…...

手把手复现文献案例:用Design-Expert做阿维菌素发酵培养基的响应面优化
手把手复现文献案例:用Design-Expert做阿维菌素发酵培养基的响应面优化 在生物工程和发酵工艺优化领域,响应面法(Response Surface Methodology, RSM)已成为提升产物产量的黄金标准。本文将以胡栋等学者2018年发表在《中国抗生素杂…...

FPGA硬件在环验证:GateRocket方案加速系统级调试
1. 项目概述:为什么FPGA验证需要“硬件在环”?在FPGA设计领域,尤其是当项目规模膨胀到数百万甚至上千万门级时,纯软件仿真(Simulation)会变成一个令人头疼的瓶颈。想象一下,你写了一段新的RTL代…...

如何将Android电视变身全能上网终端:TV Bro电视浏览器终极指南
如何将Android电视变身全能上网终端:TV Bro电视浏览器终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作困难而烦恼吗…...

管道工程必看避坑指南粮油储罐通气帽选型要点
在粮油仓储的体系当中,通气帽看起来是一个不显得很起眼的小零件,却常常在关键的时候出现变化。我们看到很多项目,前期设计的时候非常华丽色彩很鲜艳,到后期运行的时候经常出现故障,去探究原因,原来是通气帽…...

轻量级索引引擎flyto-indexer:从倒排索引原理到私有数据检索实战
1. 项目概述:一个为数据检索而生的索引引擎最近在折腾一个数据聚合类的项目,需要从海量的、结构不一的文档里快速找到特定信息。试过直接用数据库的模糊查询,也试过一些开源的全文检索引擎,但总觉得差点意思:要么是配置…...

Linux服务器远程桌面实战:xrdp配置与Windows无缝连接指南
1. 为什么需要xrdp远程桌面? 刚接触Linux服务器的朋友经常会问我一个问题:"能不能像Windows那样直接用远程桌面连接?"说实话,我第一次管理Linux服务器时也有同样的困惑。毕竟对于习惯了Windows图形界面的用户来说&#…...

基于大语言模型的自动化信息处理系统:从RSS聚合到AI摘要的实践
1. 项目概述:一个能帮你“读”新闻的AI助手 在信息爆炸的时代,每天光是处理订阅的RSS、关注的社交媒体动态、收藏的YouTube视频和没读完的长文,就足以让人精疲力尽。我们总想保持对行业趋势的敏感,却又被海量信息淹没,…...

Hermes Agent:引爆企业AI革命!自进化智能体协作实战与落地指南
Hermes Agent 是一款自进化AI代理系统,具备完整学习循环、跨会话记忆、用户建模等核心特性。本文深入解析其架构、多智能体协作机制及自进化能力,并通过智能客服、DevOps自动化、数据分析等企业级案例,展示如何构建高效AI代理系统。同时提供性…...

告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间
告别重复点击!淘金币自动化脚本让你每天多出20分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

中国半导体产业崛起:资本驱动下的存储器攻坚与全产业链布局
1. 行业格局的十字路口:当西方整合遇上东方崛起最近几年,半导体行业的头条新闻几乎被一系列重磅并购案所占据:恩智浦收购飞思卡尔、安华高并购博通、英特尔鲸吞阿尔特拉。这些动辄数百亿美元的巨无霸交易,背后传递出一个清晰的信号…...