数学建模day16-预测模型
本讲首先将介绍灰色预测模型,然后将简要介绍神经网络在数据预测中的应用,在本讲的最
后,我将谈谈清风大佬对于数据预测的一些看法。
注:本文源于数学建模学习交流相关公众号观看学习视频后所作
目录
灰色系统
GM(1,1)模型: Grey(Gray) Model
GM(1,1)原理
OLS原理介绍
完全多重共线性问题再探究
再回到GM(1,1)原理
一阶微分方程
一阶齐次线性微分方程
一阶非齐次线性微分方程
再回到GM(1,1)原理
准指数规律的检验
发展系数与预测情形的探究
GM(1,1)模型的评价
GM(1,1)模型的检验
GM(1,1)模型的拓展
什么时候用灰色预测?
灰色预测的例题
预测的题目的一些小套路
Matlab代码
main.m
gm11.m
metabolism_gm11.m
new_gm11.m
整体理解
灰色预测运行结果
更换新的数据集1
更换新的数据集2
更换新的数据集3
BP神经网络预测——万金油
神经网络的介绍
机器学习中的训练集,验证集和测试集
例题
例题1:辛烷值的预测
数据的导入
使用神经网络进行预测
关键的步骤
结果分析
保存结果
保存结果并对进行预测
例题2:神经网络在多输出中的运用
清风大佬对于预测模型的看法
加入符合背景的变量
一篇不错的论文
本节作业1:画流程图
结语
灰色系统

灰色预测是对既含有已知信息又含有不确定信息的系统进行预测,就是对在一定范围内变化的、与时间有关的灰色过程进行预测。
灰色预测对原始数据进行生成处理来寻找系统变动的规律,并生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
GM(1,1)模型: Grey(Gray) Model
GM(1,1)是使用原始的离散非负数据列,通过一次累加生成削弱随机性的较有规律的新的离散数据列,然后通过建立微分方程模型,得到在离散点处的解经过累减生成的原始数据的近似估计值,从而预测原始数据的后续发展。
(我们在此只探究GM(1,1)模型,第一个‘1’表示微分方程是一阶的,后面的‘1’表示只有一个变量)
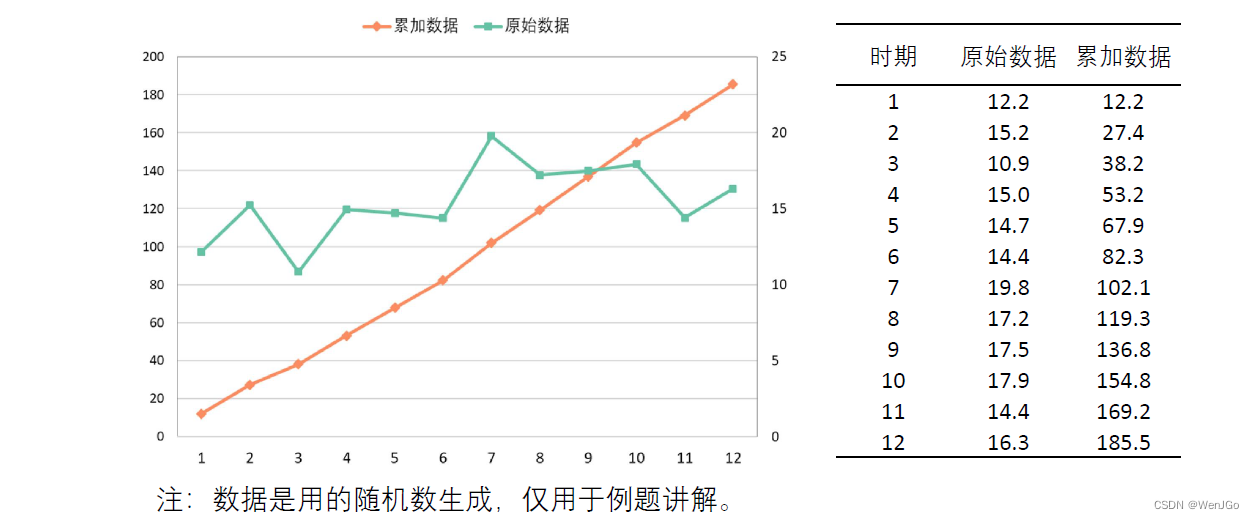
GM(1,1)原理
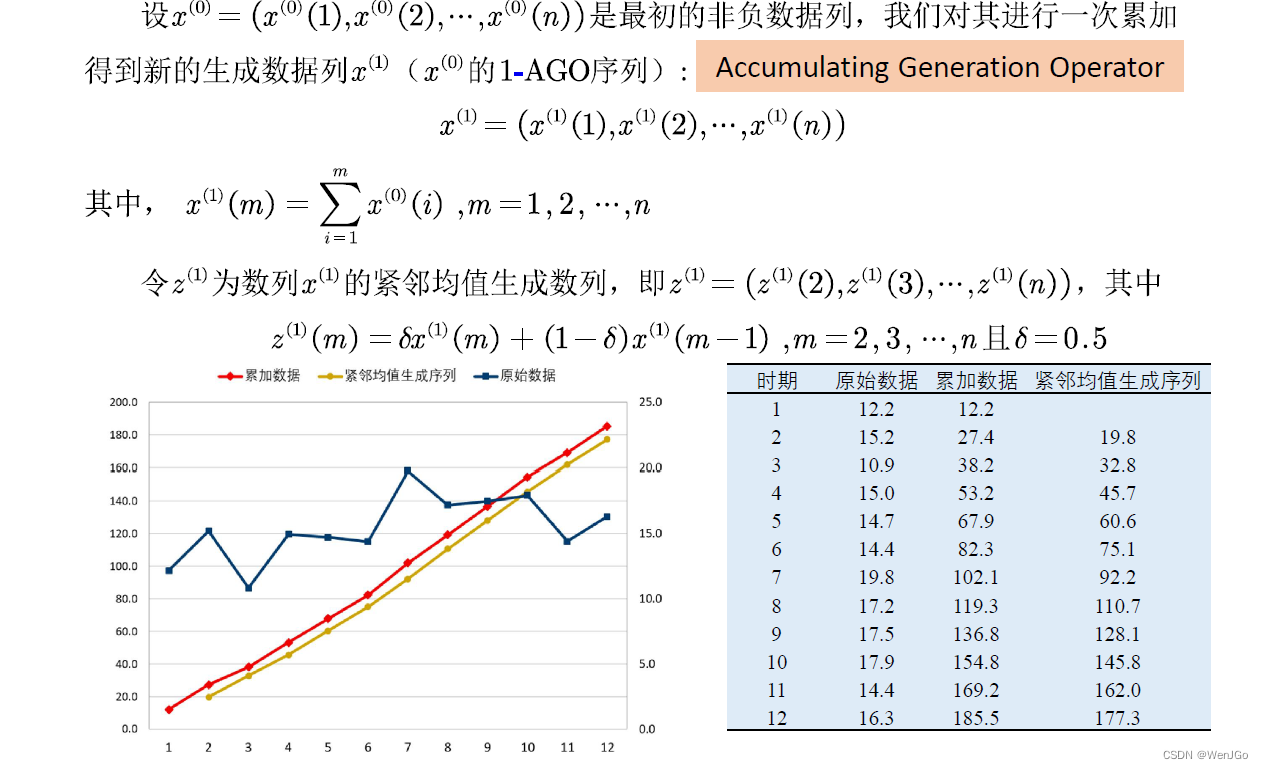

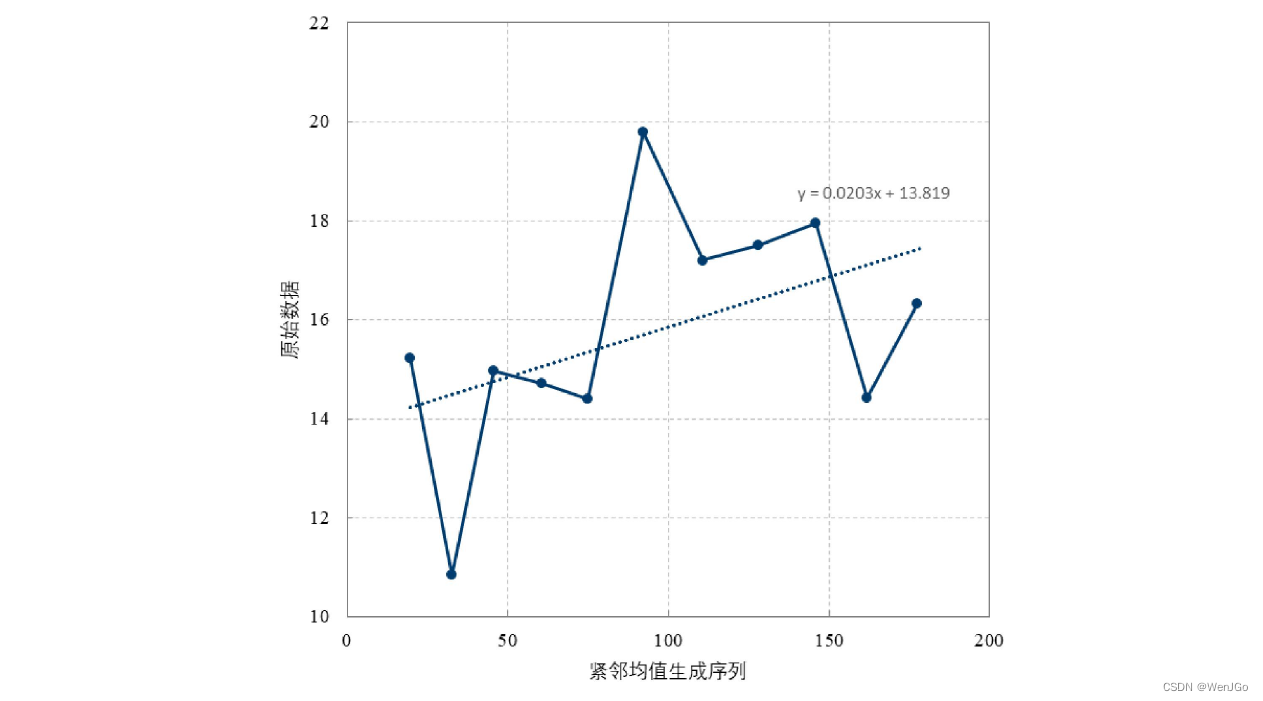
OLS原理介绍
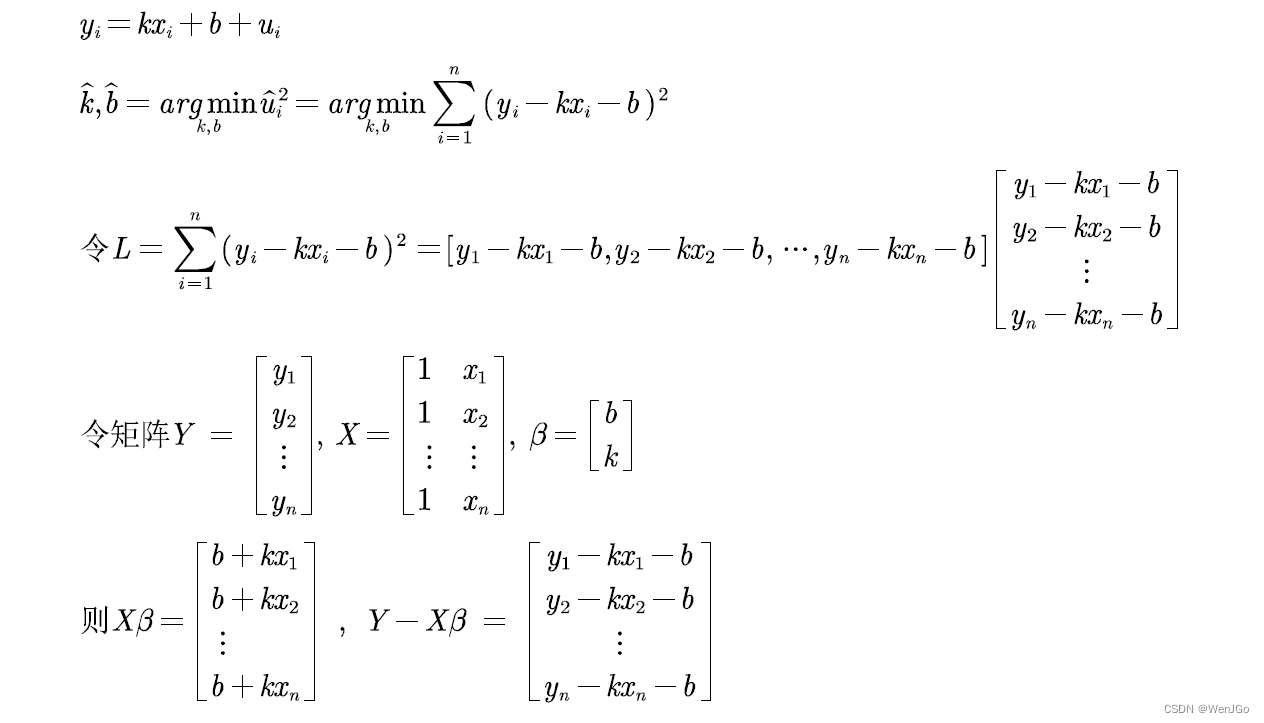
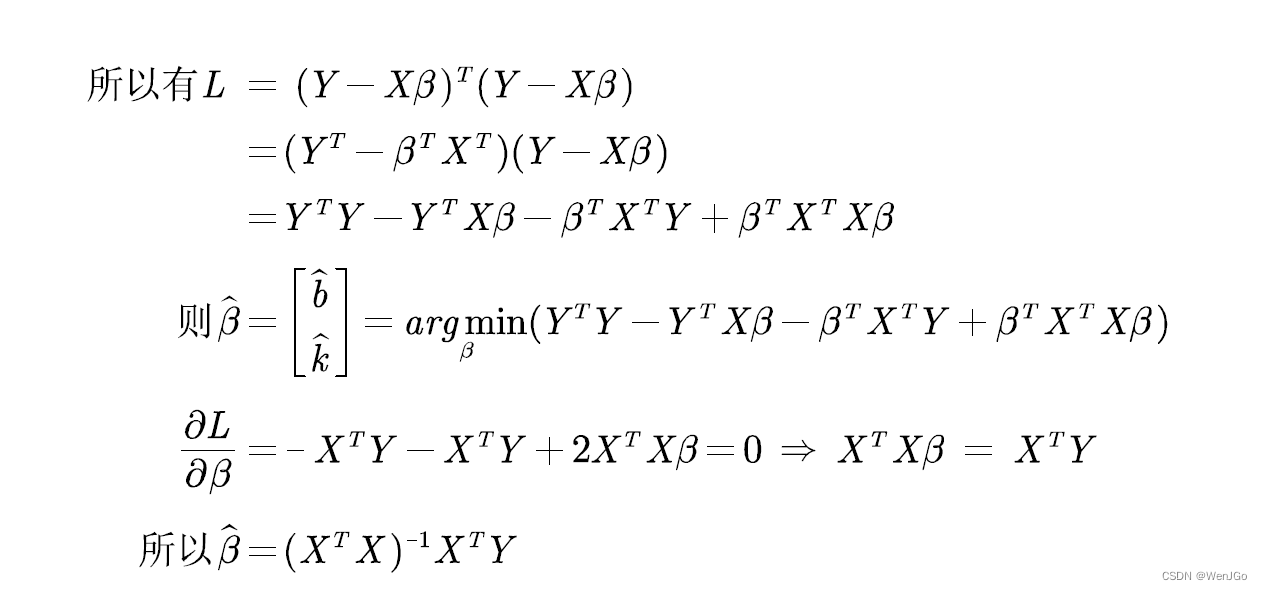
矩阵求导:常用的向量矩阵求导公式_向量求导法则-CSDN博客
完全多重共线性问题再探究

再回到GM(1,1)原理
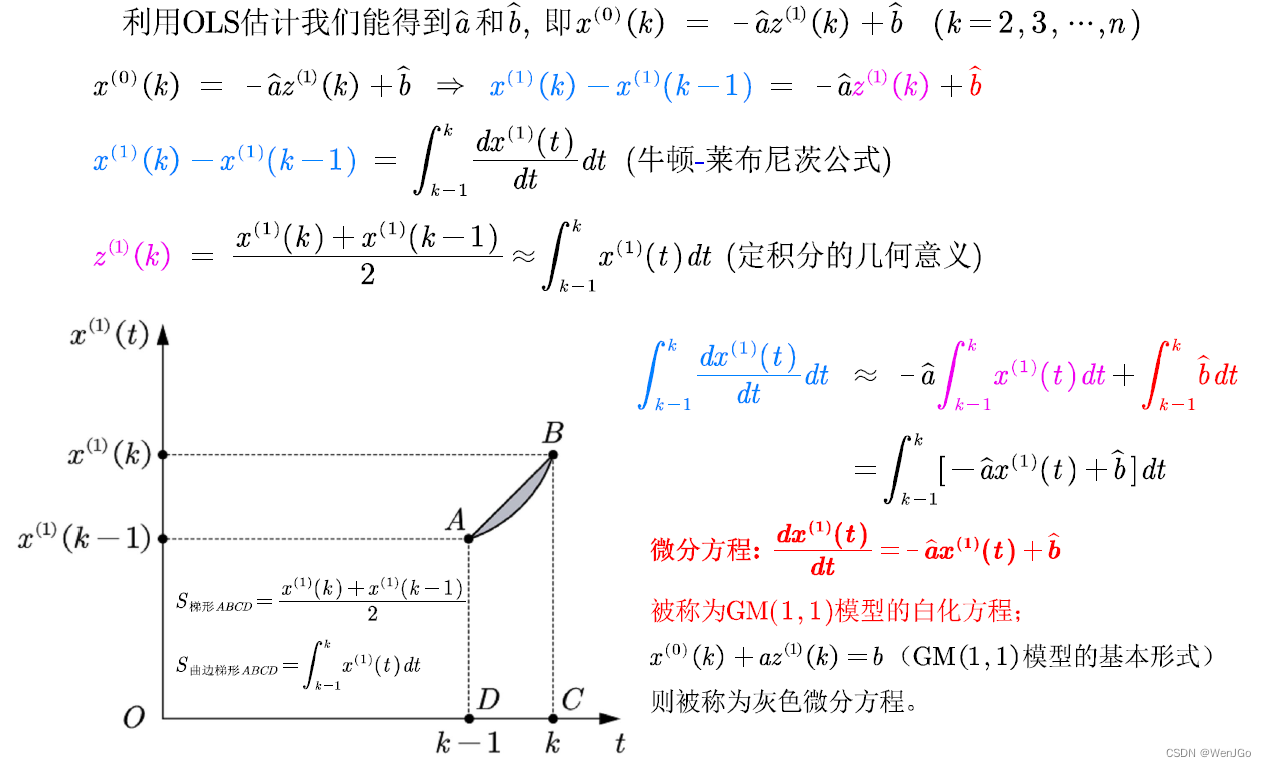

一阶微分方程
一阶齐次线性微分方程

一阶非齐次线性微分方程
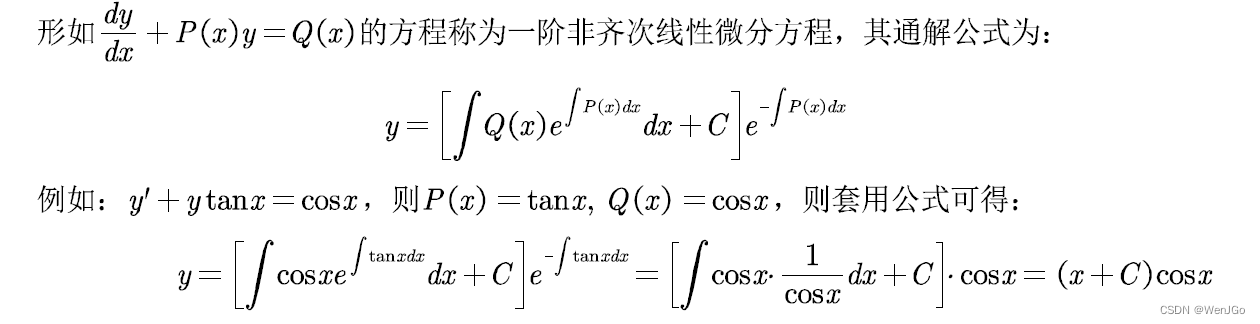
参考:同济大学《高等数学上册》第七版315页和334页
再回到GM(1,1)原理

准指数规律的检验

刘思峰,谢乃明,等. 2010. 灰色系统理论及其应用[M]. 5版. 北京:科学出版社
发展系数与预测情形的探究
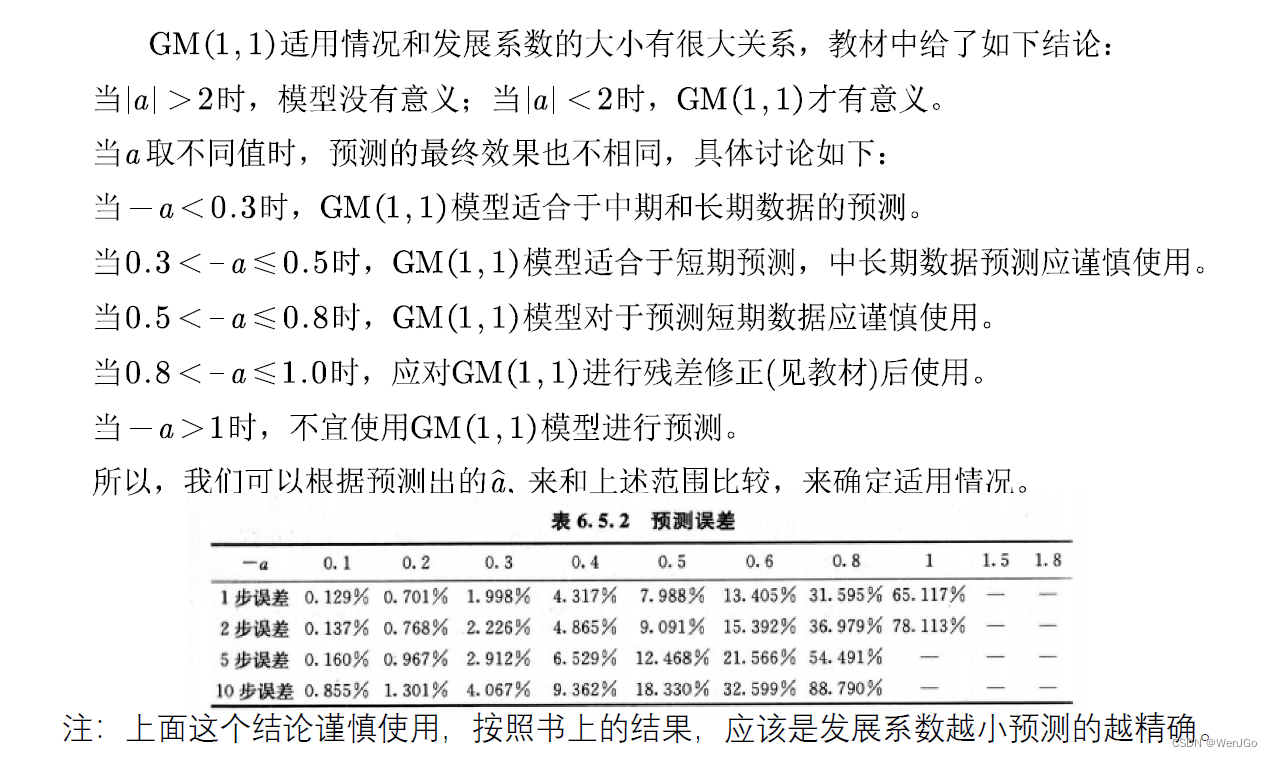
GM(1,1)模型的评价

GM(1,1)模型的检验

GM(1,1)模型的拓展

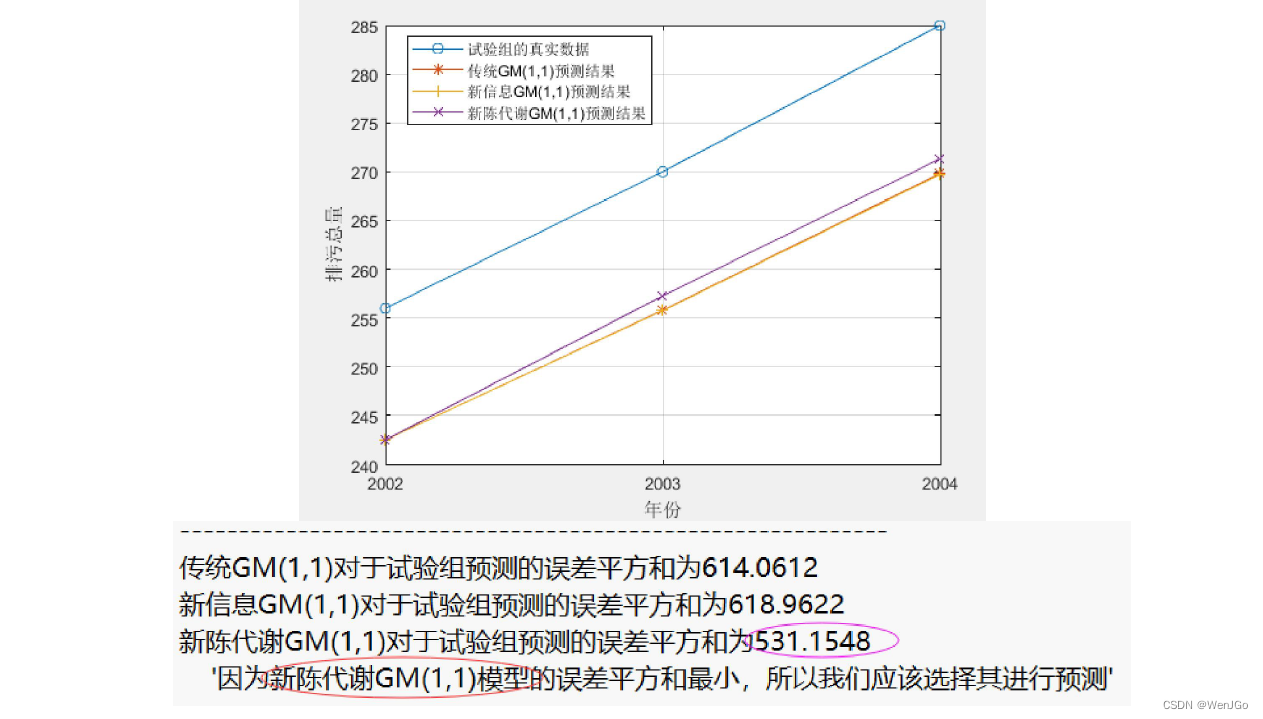
作者找了一个灰色预测的例子,在这个例子中新陈代谢模型的预测效果最好。
什么时候用灰色预测?
下面是清风大佬的看法,使用哪种模型进行预测是仁者见仁智者见智的事情:
(1)数据是以年份度量的非负数据(如果是月份或者季度数据一定要用我们上一讲学过的时间序列模型);
(2)数据能经过准指数规律的检验(除了前两期外,后面至少90%的期数的光滑比要低于0.5);
(3)数据的期数较短且和其他数据之间的关联性不强(小于等于10,也不能太短了,比如只有3期数据),要是数据期数较长,一般用传统的时间序列模型比较合适。
灰色预测的例题
预测的题目的一些小套路
(1)看到数据后先画时间序列图并简单的分析下趋势(例如:我们上一讲学过的时间序列分解)
(2)将数据分为训练组和试验组,尝试使用不同的模型对训练组进行建模,并利用试验组的数据判断哪种模型的预测效果最好(比如我们可以使用SSE这个指标来挑选模型,常见的模型有指数平滑、ARIMA、灰色预测、神经网络等)。
(3)选择上一步骤中得到的预测误差最小的那个模型,并利用全部数据来重新建模,并对未来的数据进行预测。
(4)画出预测后的数据和原来数据的时序图,看看预测的未来趋势是否合理。
Matlab代码
main.m
%% 输入原始数据并做出时间序列图
clear;clc
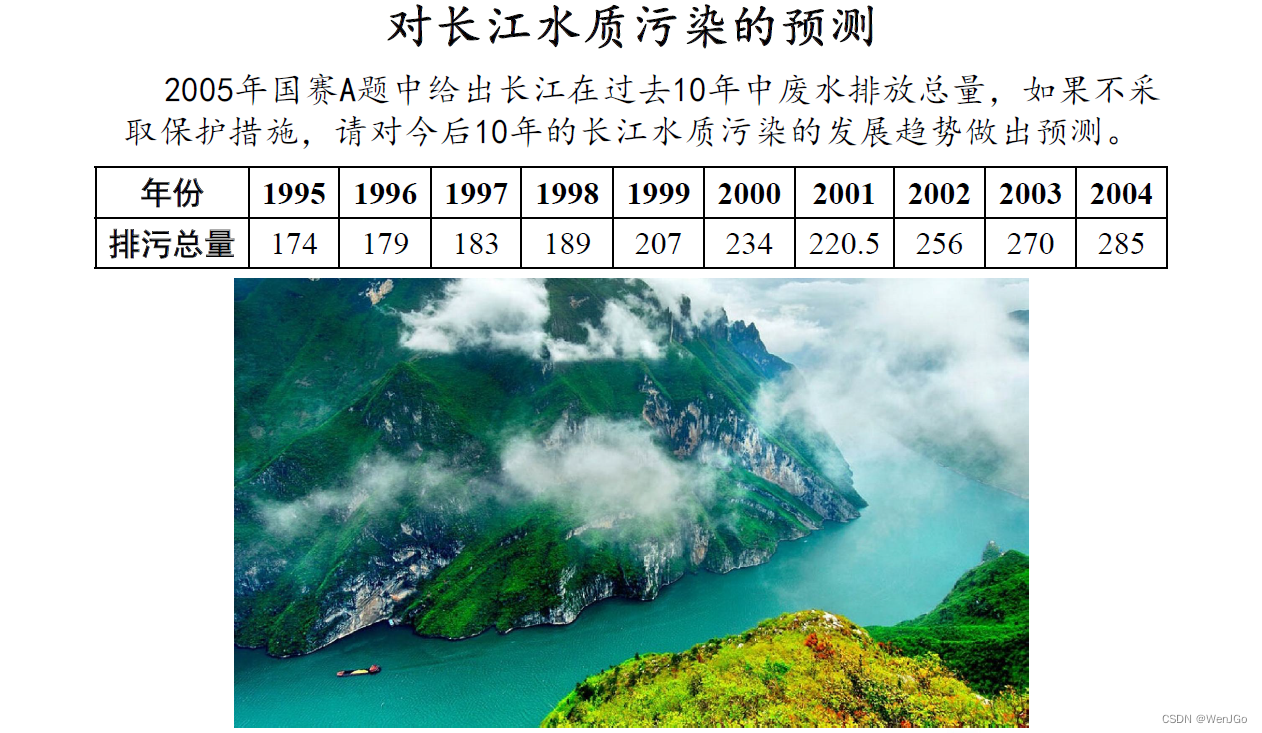
year =[1995:1:2004]'; % 横坐标表示年份,写成列向量的形式(加'就表示转置)
x0 = [174,179,183,189,207,234,220.5,256,270,285]'; %原始数据序列,写成列向量的形式(加'就表示转置)
% year = [2009:2015]; % 其实本程序写成了行向量也可以,因为我怕你们真的这么写了,所以在后面会有判断。
% x0 = [730, 679, 632, 599, 589, 532, 511];
% year = [2010:2017]'; % 该数据很特殊,可以通过准指数规律检验,但是预测效果却很差
% x0 = [1.321,0.387,0.651,0.985,1.235,0.987,0.854,1.021]';
% year = [2014:2017]';
% x0 = [2.874,3.278,3.337,3.390]';% 画出原始数据的时间序列图
figure(1); % 因为我们的图形不止一个,因此要设置编号
plot(year,x0,'o-'); grid on; % 原式数据的时间序列图
set(gca,'xtick',year(1:1:end)) % 设置x轴横坐标的间隔为1
xlabel('年份'); ylabel('排污总量'); % 给坐标轴加上标签%% 因为我们要使用GM(1,1)模型,其适用于数据期数较短的非负时间序列
ERROR = 0; % 建立一个错误指标,一旦出错就指定为1
% 判断是否有负数元素
if sum(x0<0) > 0 % x0<0返回一个逻辑数组(0-1组成),如果有数据小于0,则所在位置为1,如果原始数据均为非负数,那么这个逻辑数组中全为0,求和后也是0~disp('亲,灰色预测的时间序列中不能有负数哦')ERROR = 1;
end% 判断数据量是否太少
n = length(x0); % 计算原始数据的长度
disp(strcat('原始数据的长度为',num2str(n))) % strcat()是连接字符串的函数,第一讲学了,可别忘了哦
if n<=3disp('亲,数据量太小,我无能为力哦')ERROR = 1;
end% 数据太多时提示可考虑使用其他方法(不报错)
if n>10disp('亲,这么多数据量,一定要考虑使用其他的方法哦,例如ARIMA,指数平滑等')
end% 判断数据是否为列向量,如果输入的是行向量则转置为列向量
if size(x0,1) == 1x0 = x0';
end
if size(year,1) == 1year = year';
end%% 对一次累加后的数据进行准指数规律的检验(注意,这个检验有时候即使能通过,也不一定能保证预测结果非常好,例如上面的第三组数据)
if ERROR == 0 % 如果上述错误均没有发生时,才能执行下面的操作步骤disp('------------------------------------------------------------')disp('准指数规律检验')x1 = cumsum(x0); % 生成1-AGO序列,cumsum是累加函数哦~ 注意:1.0e+03 *0.1740的意思是科学计数法,即10^3*0.1740 = 174rho = x0(2:end) ./ x1(1:end-1) ; % 计算光滑度rho(k) = x0(k)/x1(k-1)% 画出光滑度的图形,并画上0.5的直线,表示临界值figure(2)plot(year(2:end),rho,'o-',[year(2),year(end)],[0.5,0.5],'-'); grid on;text(year(end-1)+0.2,0.55,'临界线') % 在坐标(year(end-1)+0.2,0.55)上添加文本set(gca,'xtick',year(2:1:end)) % 设置x轴横坐标的间隔为1xlabel('年份'); ylabel('原始数据的光滑度'); % 给坐标轴加上标签disp(strcat('指标1:光滑比小于0.5的数据占比为',num2str(100*sum(rho<0.5)/(n-1)),'%'))disp(strcat('指标2:除去前两个时期外,光滑比小于0.5的数据占比为',num2str(100*sum(rho(3:end)<0.5)/(n-3)),'%'))disp('参考标准:指标1一般要大于60%, 指标2要大于90%,你认为本例数据可以通过检验吗?')Judge = input('你认为可以通过准指数规律的检验吗?可以通过请输入1,不能请输入0:');if Judge == 0disp('亲,灰色预测模型不适合你的数据哦~ 请考虑其他方法吧 例如ARIMA,指数平滑等')ERROR = 1;enddisp('------------------------------------------------------------')
end%% 当数据量大于4时,我们利用试验组来选择使用传统的GM(1,1)模型、新信息GM(1,1)模型还是新陈代谢GM(1,1)模型; 如果数据量等于4,那么我们直接对三种方法求一个平均来进行预测
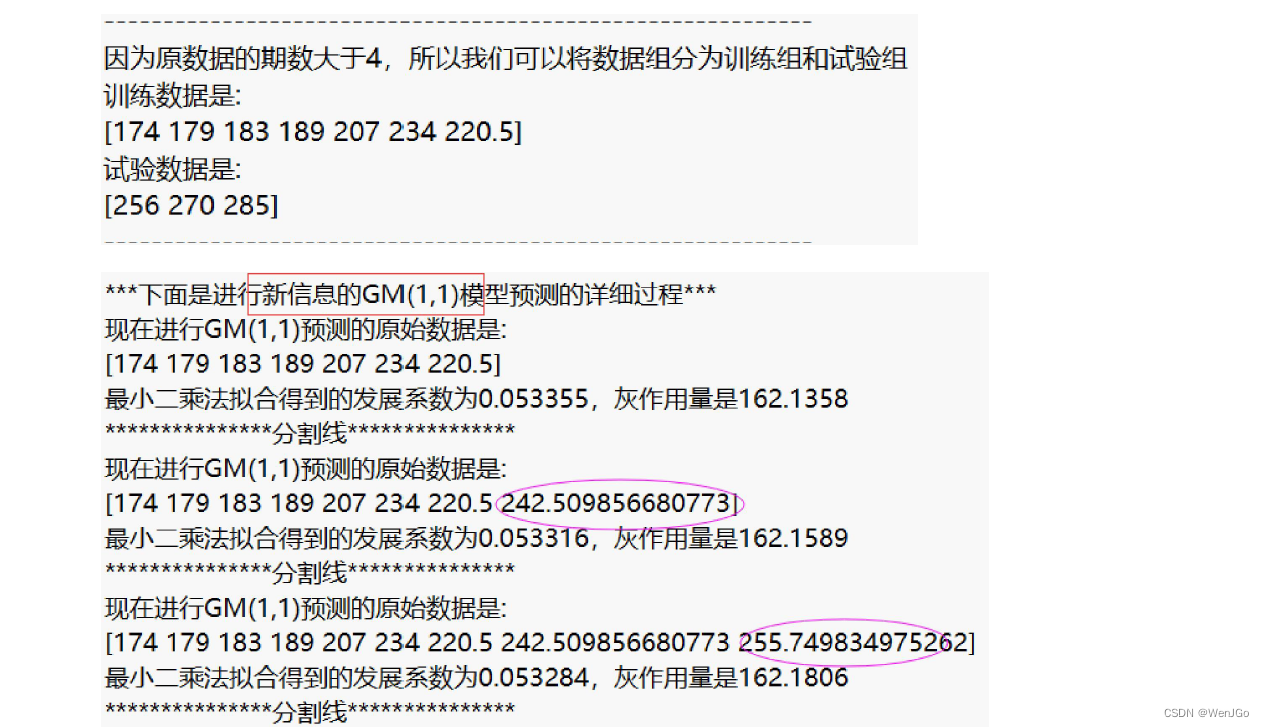
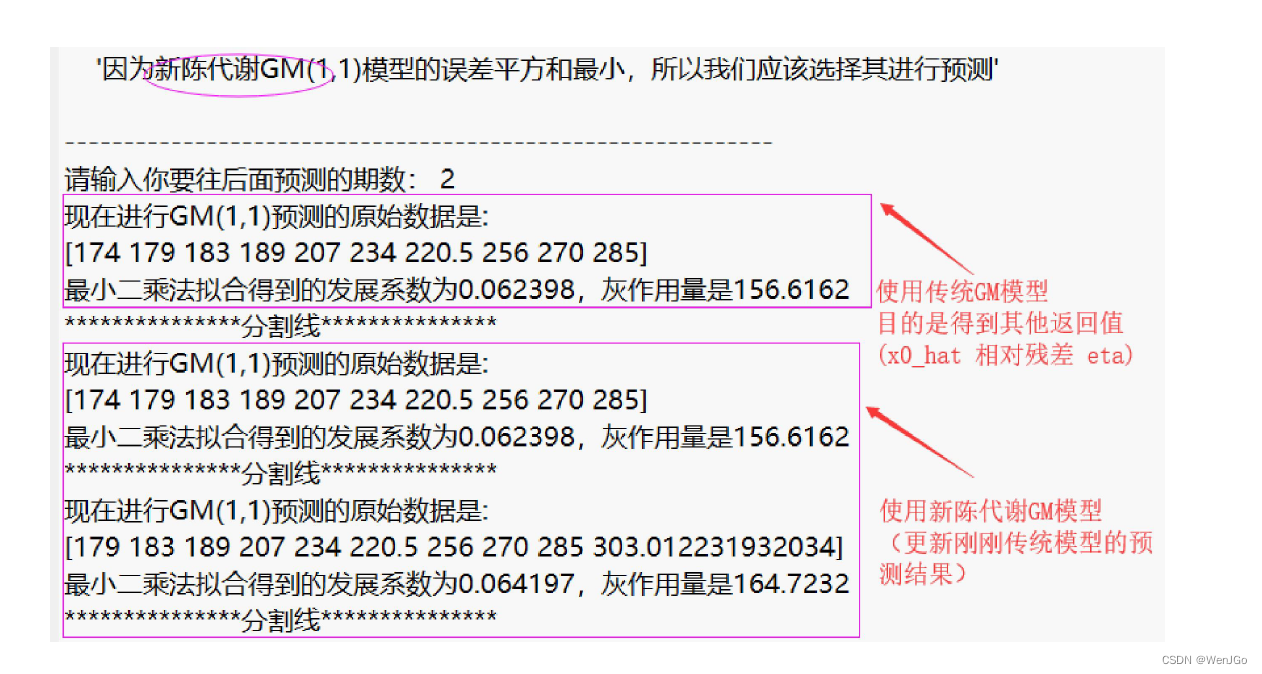
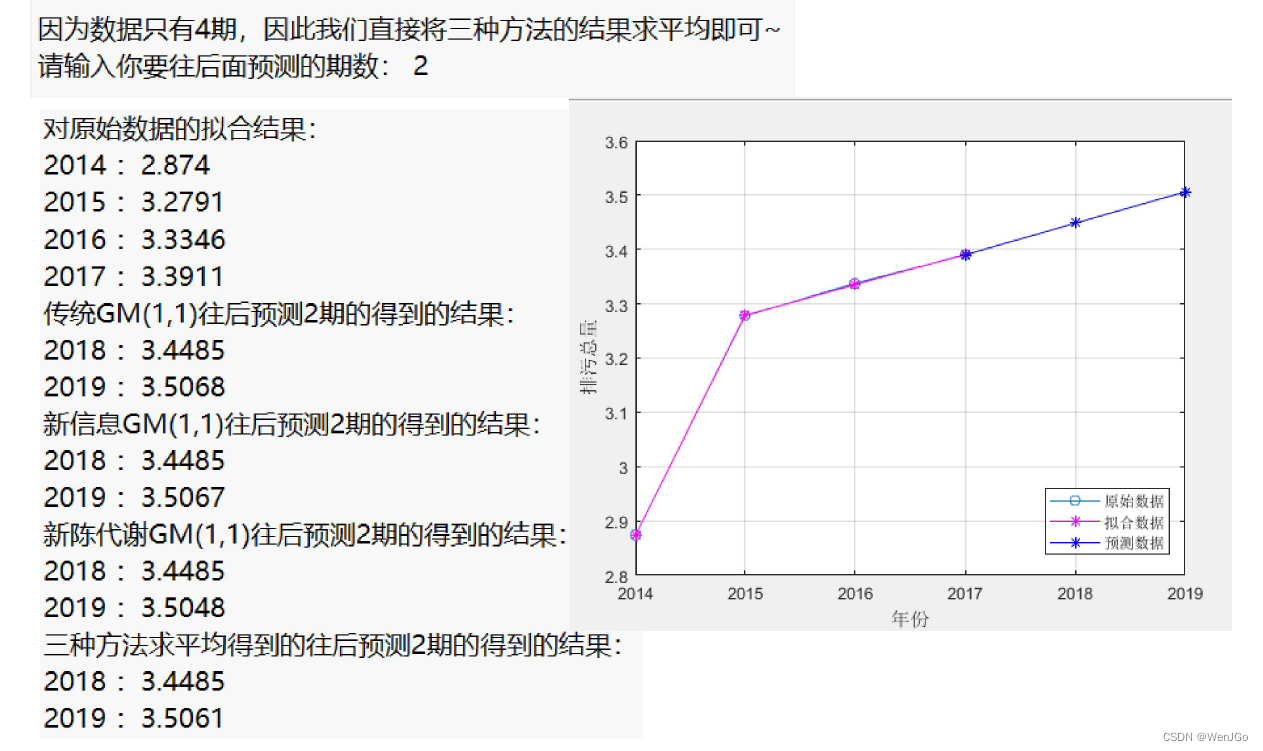
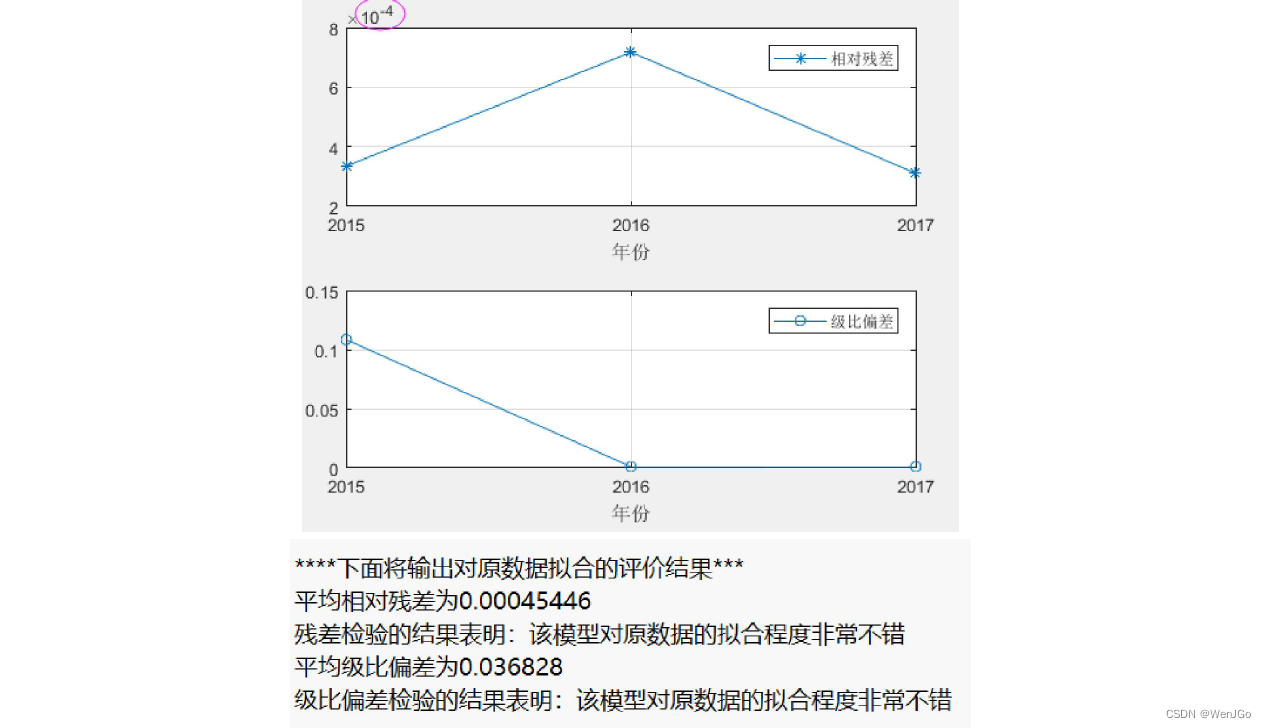
if ERROR == 0 % 如果上述错误均没有发生时,才能执行下面的操作步骤if n > 4 % 数据量大于4时,将数据分为训练组和试验组(根据原数据量大小n来取,n为5-7个则取最后两年为试验组,n大于7则取最后三年为试验组)disp('因为原数据的期数大于4,所以我们可以将数据组分为训练组和试验组') % 注意,如果试验组的个数只有1个,那么三种模型的结果完全相同,因此至少要取2个试验组if n > 7test_num = 3;elsetest_num = 2;endtrain_x0 = x0(1:end-test_num); % 训练数据disp('训练数据是: ')disp(mat2str(train_x0')) % mat2str可以将矩阵或者向量转换为字符串显示, 这里加一撇表示转置,把列向量变成行向量方便观看test_x0 = x0(end-test_num+1:end); % 试验数据disp('试验数据是: ')disp(mat2str(test_x0')) % mat2str可以将矩阵或者向量转换为字符串显示disp('------------------------------------------------------------')% 使用三种模型对训练数据进行训练,返回的result就是往后预测test_num期的数据disp(' ')disp('***下面是传统的GM(1,1)模型预测的详细过程***')result1 = gm11(train_x0, test_num); %使用传统的GM(1,1)模型对训练数据,并预测后test_num期的结果disp(' ')disp('***下面是进行新信息的GM(1,1)模型预测的详细过程***')result2 = new_gm11(train_x0, test_num); %使用新信息GM(1,1)模型对训练数据,并预测后test_num期的结果disp(' ')disp('***下面是进行新陈代谢的GM(1,1)模型预测的详细过程***')result3 = metabolism_gm11(train_x0, test_num); %使用新陈代谢GM(1,1)模型对训练数据,并预测后test_num期的结果% 现在比较三种模型对于试验数据的预测结果disp(' ')disp('------------------------------------------------------------')% 绘制对试验数据进行预测的图形(对于部分数据,可能三条直线预测的结果非常接近)test_year = year(end-test_num+1:end); % 试验组对应的年份figure(3)plot(test_year,test_x0,'o-',test_year,result1,'*-',test_year,result2,'+-',test_year,result3,'x-'); grid on;set(gca,'xtick',year(end-test_num+1): 1 :year(end)) % 设置x轴横坐标的间隔为1legend('试验组的真实数据','传统GM(1,1)预测结果','新信息GM(1,1)预测结果','新陈代谢GM(1,1)预测结果') % 注意:如果lengend挡着了图形中的直线,那么lengend的位置可以自己手动拖动xlabel('年份'); ylabel('排污总量'); % 给坐标轴加上标签% 计算误差平方和SSESSE1 = sum((test_x0-result1).^2);SSE2 = sum((test_x0-result2).^2);SSE3 = sum((test_x0-result3).^2);disp(strcat('传统GM(1,1)对于试验组预测的误差平方和为',num2str(SSE1)))disp(strcat('新信息GM(1,1)对于试验组预测的误差平方和为',num2str(SSE2)))disp(strcat('新陈代谢GM(1,1)对于试验组预测的误差平方和为',num2str(SSE3)))if SSE1<SSE2if SSE1<SSE3choose = 1; % SSE1最小,选择传统GM(1,1)模型elsechoose = 3; % SSE3最小,选择新陈代谢GM(1,1)模型endelseif SSE2<SSE3choose = 2; % SSE2最小,选择新信息GM(1,1)模型elsechoose = 3; % SSE3最小,选择新陈代谢GM(1,1)模型endModel = {'传统GM(1,1)模型','新信息GM(1,1)模型','新陈代谢GM(1,1)模型'};disp(strcat('因为',Model(choose),'的误差平方和最小,所以我们应该选择其进行预测'))disp('------------------------------------------------------------')%% 选用误差最小的那个模型进行预测predict_num = input('请输入你要往后面预测的期数: ');% 计算使用传统GM模型的结果,用来得到另外的返回变量:x0_hat, 相对残差relative_residuals和级比偏差eta[result, x0_hat, relative_residuals, eta] = gm11(x0, predict_num); % 先利用gm11函数得到对原数据拟合的详细结果% % 判断我们选择的是哪个模型,如果是2或3,则更新刚刚由模型1计算出来的预测结果if choose == 2result = new_gm11(x0, predict_num);endif choose == 3result = metabolism_gm11(x0, predict_num);end%% 输出使用最佳的模型预测出来的结果disp('------------------------------------------------------------')disp('对原始数据的拟合结果:')for i = 1:ndisp(strcat(num2str(year(i)), ' : ',num2str(x0_hat(i))))enddisp(strcat('往后预测',num2str(predict_num),'期的得到的结果:'))for i = 1:predict_numdisp(strcat(num2str(year(end)+i), ' : ',num2str(result(i))))end%% 如果只有四期数据,那么我们就没必要选择何种模型进行预测,直接对三种模型预测的结果求一个平均值~elsedisp('因为数据只有4期,因此我们直接将三种方法的结果求平均即可~')predict_num = input('请输入你要往后面预测的期数: ');disp(' ')disp('***下面是传统的GM(1,1)模型预测的详细过程***')[result1, x0_hat, relative_residuals, eta] = gm11(x0, predict_num);disp(' ')disp('***下面是进行新信息的GM(1,1)模型预测的详细过程***')result2 = new_gm11(x0, predict_num);disp(' ')disp('***下面是进行新陈代谢的GM(1,1)模型预测的详细过程***')result3 = metabolism_gm11(x0, predict_num);result = (result1+result2+result3)/3;disp('对原始数据的拟合结果:')for i = 1:ndisp(strcat(num2str(year(i)), ' : ',num2str(x0_hat(i))))enddisp(strcat('传统GM(1,1)往后预测',num2str(predict_num),'期的得到的结果:'))for i = 1:predict_numdisp(strcat(num2str(year(end)+i), ' : ',num2str(result1(i))))enddisp(strcat('新信息GM(1,1)往后预测',num2str(predict_num),'期的得到的结果:'))for i = 1:predict_numdisp(strcat(num2str(year(end)+i), ' : ',num2str(result2(i))))enddisp(strcat('新陈代谢GM(1,1)往后预测',num2str(predict_num),'期的得到的结果:'))for i = 1:predict_numdisp(strcat(num2str(year(end)+i), ' : ',num2str(result3(i))))enddisp(strcat('三种方法求平均得到的往后预测',num2str(predict_num),'期的得到的结果:'))for i = 1:predict_numdisp(strcat(num2str(year(end)+i), ' : ',num2str(result(i))))endend%% 绘制相对残差和级比偏差的图形(注意:因为是对原始数据的拟合效果评估,所以三个模型都是一样的哦~~~)figure(4)subplot(2,1,1) % 绘制子图(将图分块)plot(year(2:end), relative_residuals,'*-'); grid on; % 原数据中的各时期和相对残差legend('相对残差'); xlabel('年份');set(gca,'xtick',year(2:1:end)) % 设置x轴横坐标的间隔为1subplot(2,1,2)plot(year(2:end), eta,'o-'); grid on; % 原数据中的各时期和级比偏差legend('级比偏差'); xlabel('年份');set(gca,'xtick',year(2:1:end)) % 设置x轴横坐标的间隔为1disp(' ')disp('****下面将输出对原数据拟合的评价结果***')%% 残差检验average_relative_residuals = mean(relative_residuals); % 计算平均相对残差 mean函数用来均值disp(strcat('平均相对残差为',num2str(average_relative_residuals)))if average_relative_residuals<0.1disp('残差检验的结果表明:该模型对原数据的拟合程度非常不错')elseif average_relative_residuals<0.2disp('残差检验的结果表明:该模型对原数据的拟合程度达到一般要求')elsedisp('残差检验的结果表明:该模型对原数据的拟合程度不太好,建议使用其他模型预测')end%% 级比偏差检验average_eta = mean(eta); % 计算平均级比偏差disp(strcat('平均级比偏差为',num2str(average_eta)))if average_eta<0.1disp('级比偏差检验的结果表明:该模型对原数据的拟合程度非常不错')elseif average_eta<0.2disp('级比偏差检验的结果表明:该模型对原数据的拟合程度达到一般要求')elsedisp('级比偏差检验的结果表明:该模型对原数据的拟合程度不太好,建议使用其他模型预测')enddisp(' ')disp('------------------------------------------------------------')%% 绘制最终的预测效果图figure(5) % 下面绘图中的符号m:洋红色 b:蓝色plot(year,x0,'-o', year,x0_hat,'-*m', year(end)+1:year(end)+predict_num,result,'-*b' ); grid on;hold on;plot([year(end),year(end)+1],[x0(end),result(1)],'-*b')legend('原始数据','拟合数据','预测数据') % 注意:如果lengend挡着了图形中的直线,那么lengend的位置可以自己手动拖动set(gca,'xtick',[year(1):1:year(end)+predict_num]) % 设置x轴横坐标的间隔为1xlabel('年份'); ylabel('排污总量'); % 给坐标轴加上标签
end
gm11.m
function [result, x0_hat, relative_residuals, eta] = gm11(x0, predict_num)% 函数作用:使用传统的GM(1,1)模型对数据进行预测% x0:要预测的原始数据% predict_num: 向后预测的期数% 输出变量 (注意,实际调用时该函数时不一定输出全部结果,就像corrcoef函数一样~,可以只输出相关系数矩阵,也可以附带输出p值矩阵)% result:预测值% x0_hat:对原始数据的拟合值% relative_residuals: 对模型进行评价时计算得到的相对残差% eta: 对模型进行评价时计算得到的级比偏差n = length(x0); % 数据的长度x1=cumsum(x0); % 计算一次累加值z1 = (x1(1:end-1) + x1(2:end)) / 2; % 计算紧邻均值生成数列(长度为n-1)% 将从第二项开始的x0当成y,z1当成x,来进行一元回归 y = kx +by = x0(2:end); x = z1;% 下面的表达式就是第四讲拟合里面的哦~ 但是要注意,此时的样本数应该是n-1,少了一项哦k = ((n-1)*sum(x.*y)-sum(x)*sum(y))/((n-1)*sum(x.*x)-sum(x)*sum(x));b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/((n-1)*sum(x.*x)-sum(x)*sum(x));a = -k; %注意:k = -a哦% 注意: -a就是发展系数, b就是灰作用量disp('现在进行GM(1,1)预测的原始数据是: ')disp(mat2str(x0')) % mat2str可以将矩阵或者向量转换为字符串显示disp(strcat('最小二乘法拟合得到的发展系数为',num2str(-a),',灰作用量是',num2str(b)))disp('***************分割线***************')x0_hat=zeros(n,1); x0_hat(1)=x0(1); % x0_hat向量用来存储对x0序列的拟合值,这里先进行初始化for m = 1: n-1x0_hat(m+1) = (1-exp(a))*(x0(1)-b/a)*exp(-a*m);endresult = zeros(predict_num,1); % 初始化用来保存预测值的向量for i = 1: predict_numresult(i) = (1-exp(a))*(x0(1)-b/a)*exp(-a*(n+i-1)); % 带入公式直接计算end% 计算绝对残差和相对残差absolute_residuals = x0(2:end) - x0_hat(2:end); % 从第二项开始计算绝对残差,因为第一项是相同的relative_residuals = abs(absolute_residuals) ./ x0(2:end); % 计算相对残差,注意分子要加绝对值,而且要使用点除% 计算级比和级比偏差class_ratio = x0(2:end) ./ x0(1:end-1) ; % 计算级比 sigma(k) = x0(k)/x0(k-1)eta = abs(1-(1-0.5*a)/(1+0.5*a)*(1./class_ratio)); % 计算级比偏差
endmetabolism_gm11.m
function [result] = metabolism_gm11(x0, predict_num)
% 函数作用:使用新陈代谢的GM(1,1)模型对数据进行预测
% 输入变量
% x0:要预测的原始数据
% predict_num: 向后预测的期数
% 输出变量
% result:预测值result = zeros(predict_num,1); % 初始化用来保存预测值的向量for i = 1 : predict_num result(i) = gm11(x0, 1); % 将预测一期的结果保存到result中x0 = [x0(2:end); result(i)]; % 更新x0向量,此时x0多了新的预测信息,并且删除了最开始的那个向量end
end
new_gm11.m
function [result] = new_gm11(x0, predict_num)
% 函数作用:使用新信息的GM(1,1)模型对数据进行预测
% 输入变量
% x0:要预测的原始数据
% predict_num: 向后预测的期数
% 输出变量
% result:预测值result = zeros(predict_num,1); % 初始化用来保存预测值的向量for i = 1 : predict_num result(i) = gm11(x0, 1); % 将预测一期的结果保存到result中x0 = [x0; result(i)]; % 更新x0向量,此时x0多了新的预测信息end
end整体理解
1. 画出原始数据的时间序列图,并判断原始数据中是否有负数或期数是否低于4期,如果是的话则报错,否则执行下一步;
2. 对一次累加后的数据进行准指数规律检验,返回两个指标:
指标1:光滑比小于0.5的数据占比(一般要大于60%)
指标2:除去前两个时期外,光滑比小于0.5的数据占比(一般大于90%)并让用户决定数据是否满足准指数规律,满足则输入1,不满足则输入0
3. 如果上一步用户输入0,则程序停止;如果输入1,则继续下面的步骤。
4. 让用户输入需要预测的后续期数,并判断原始数据的期数:
4.1 数据期数为4:
分别计算出传统的GM(1,1)模型、新信息GM(1,1)模型和新陈代谢GM(1,1)模型对于未来期数的预测结果,为了保证结果的稳健性,对三个结果求平均值作为预测值。
4.2 数据期数为5,6或7:
取最后两期为试验组,前面的n-2期为训练组;用训练组的数据分别训练三种GM模型,并将训练出来的模型分别用于预测试验组的两期数据;利用试验组两期的真实数据和预测出来的两期数据,可分别计算出三个模型的SSE;选择SSE最小的模型作为我们建模的模型。
4.3 数据期数大于7:
取最后三期为试验组,其他的过程和4.2类似。
5. 输出并绘制图形显示预测结果,并进行残差检验和级比偏差检验。
灰色预测运行结果


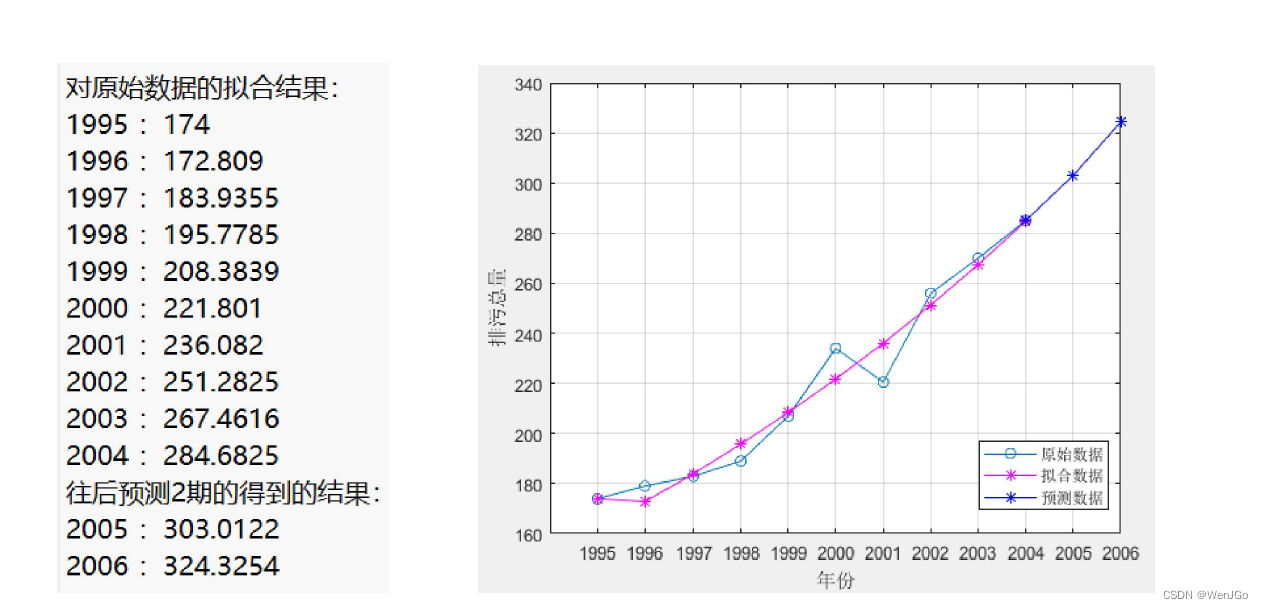
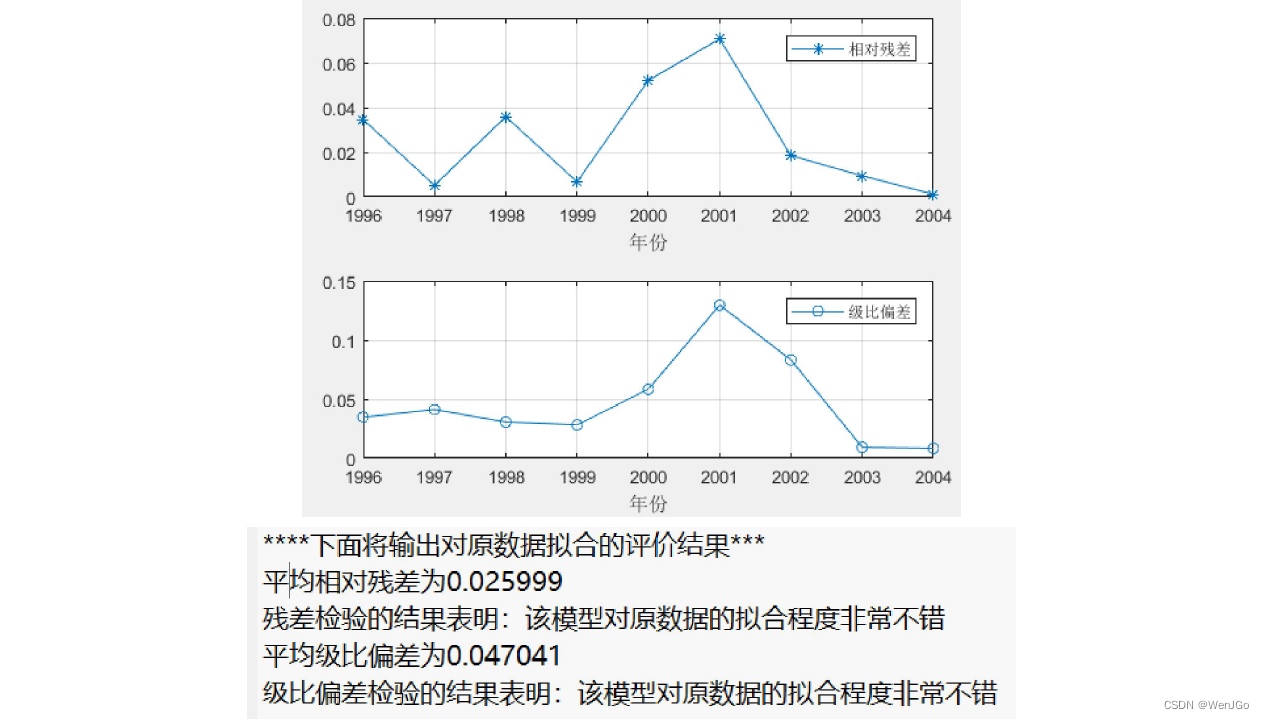
更换新的数据集1
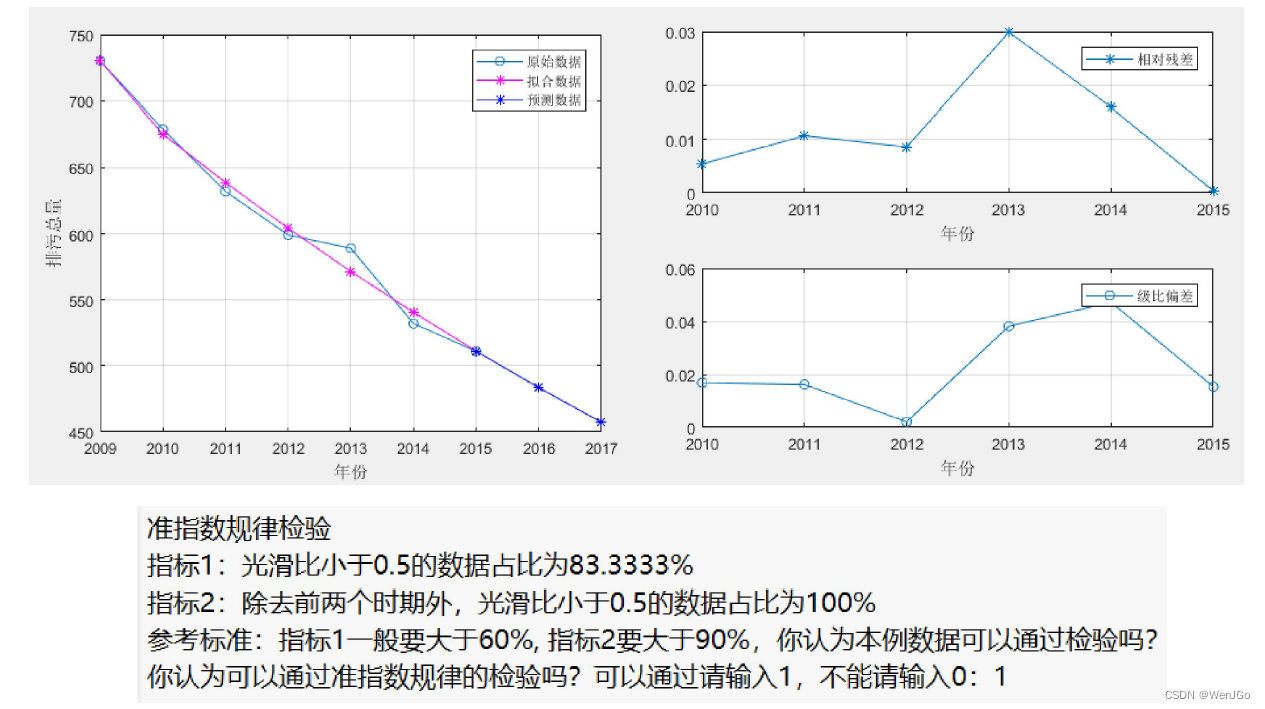
更换新的数据集2
准指数规律检验失效了,拟合的效果很差
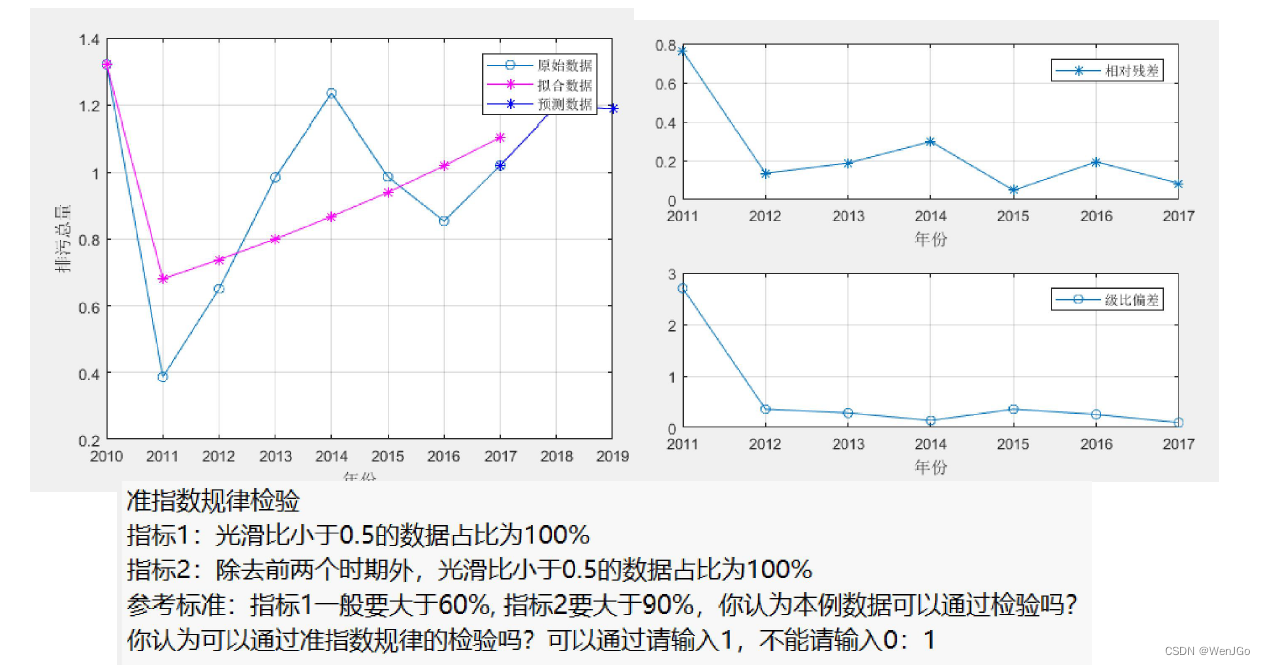
平均相对残差为0.24327,平均级比偏差为0.59674
更换新的数据集3
BP神经网络预测——万金油
原理的视频介绍(只看前20分钟,后面的讲的不怎么好,可跳过)
专题 通过四个matlab建模案例彻底精通BP神经网络_哔哩哔哩_bilibili
神经网络原理的简单介绍:一、最简单的神经网络--Bp神经网络_最简单神经网络-CSDN博客
神经网络的应用:利用MATLAB 2016a进行BP神经网络的预测-CSDN博客
神经网络的介绍

机器学习中的训练集,验证集和测试集
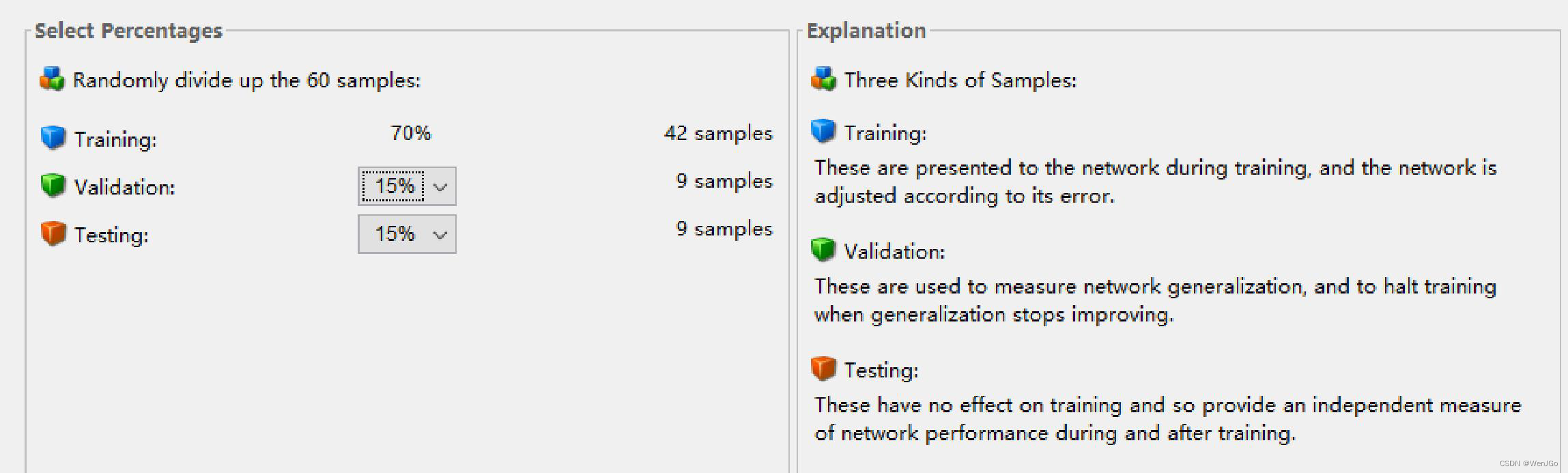

机器学习中的训练集,验证集和测试集-CSDN博客
例题
例题1:辛烷值的预测
【改编】辛烷值是汽油最重要的品质指标,传统的实验室检测方法存在样品用量大,测试周期长和费用高等问题,不适用于生产控制,特别是在线测试。近年发展起来的近红外光谱分析方法(NIR),作为一种快速分析方法,已广泛应用于农业、制药、生物化工、石油产品等领域。其优越性是无损检测、低成本、无污染,能在线分析,更适合于生产和控制的需要。
实验采集得到50组汽油样品(辛烷值已通过其他方法测量),并利用傅里叶近红外变换光谱仪对其进行扫描,扫描范围900~1700nm,扫描间隔为2nm,即每个样品的光谱曲线共含401个波长点,每个波长点对应一个吸光度。
(1)请利用这50组样品的数据,建立这401个吸光度和辛烷值之间的模型。
(2)现给你10组新的样本,这10组样本均已经过近红外变换光谱仪扫描,请预测这10组新样本的辛烷值。
数据的导入
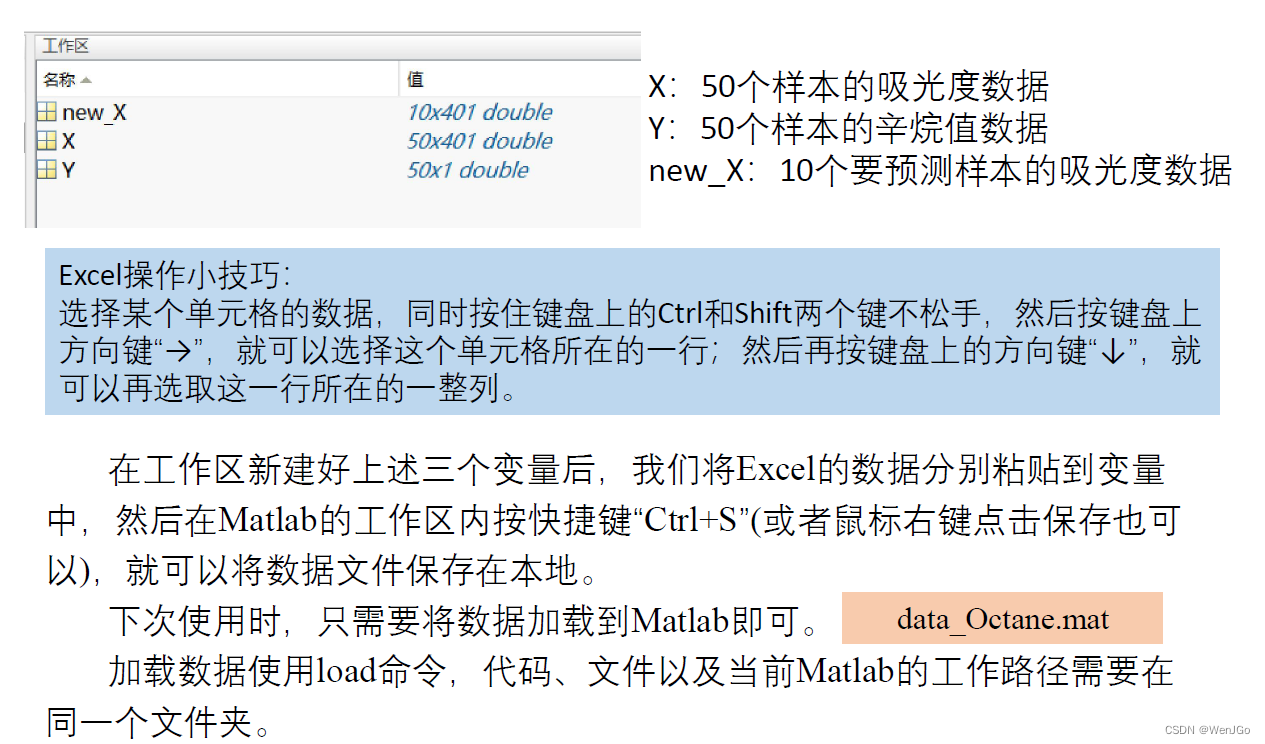
使用神经网络进行预测
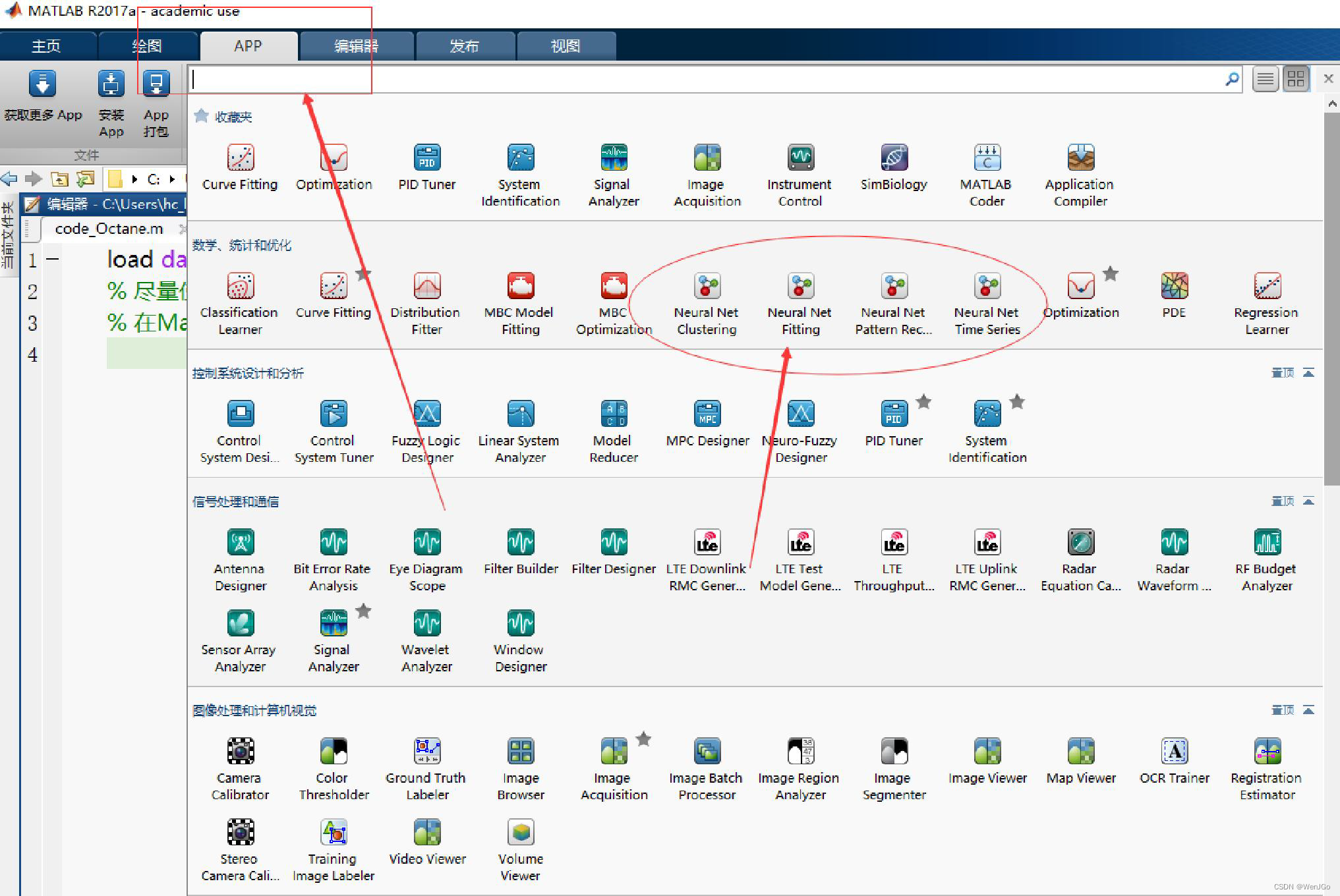
注意:老版本的Matlab的神经网络拟合工具箱可能不在这个位置
关键的步骤
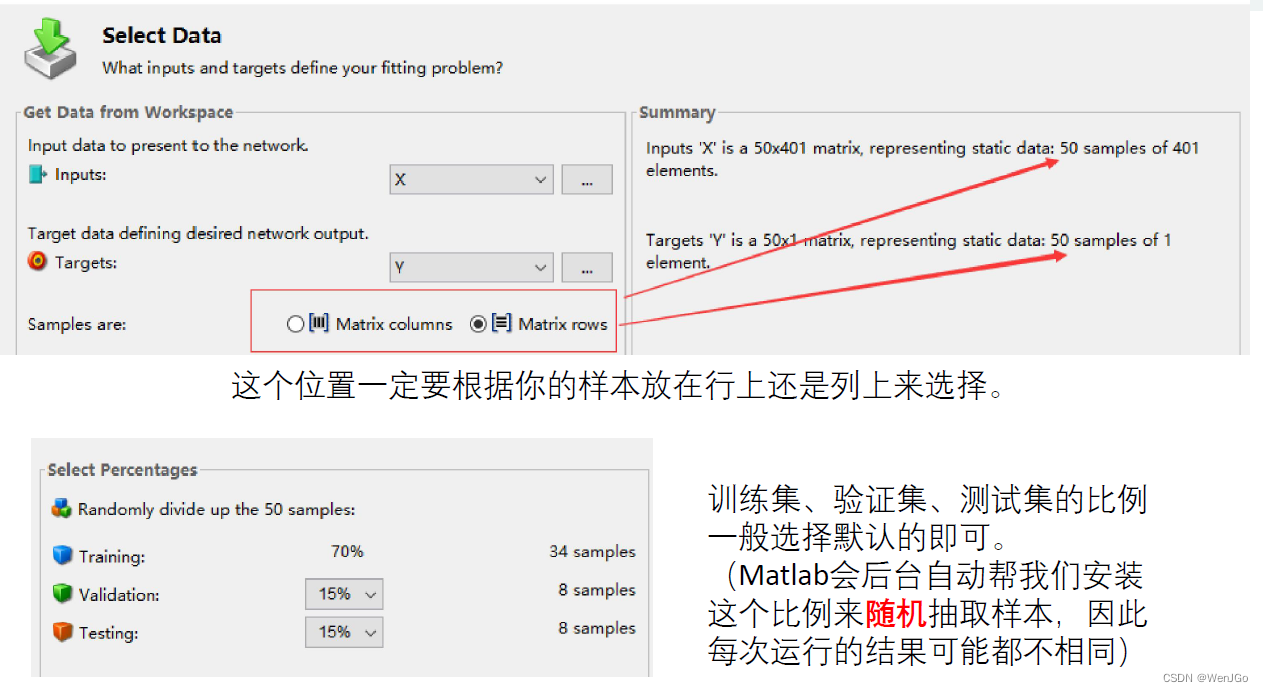
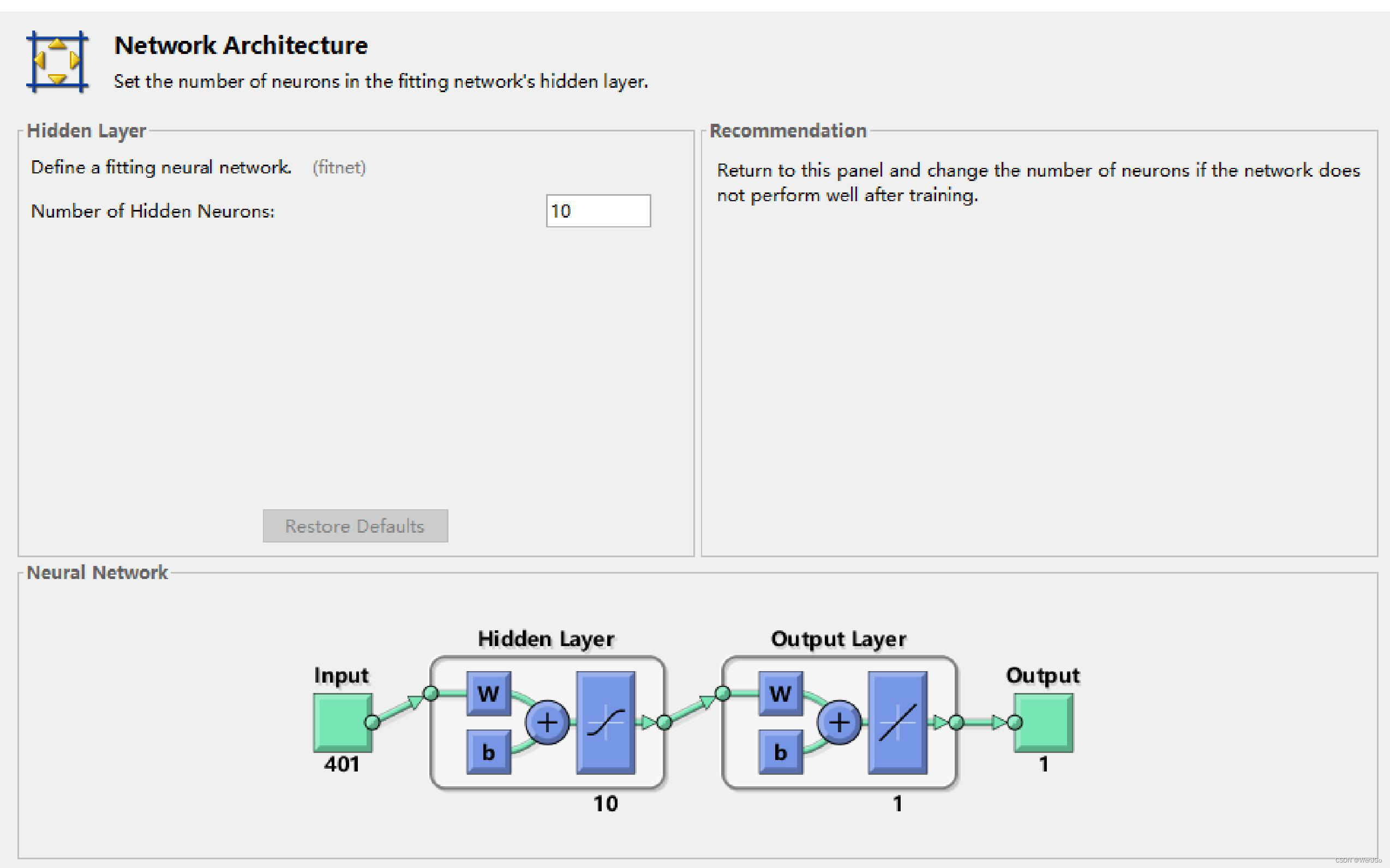
隐层神经元的个数,这个参数可以根据拟合的结果再次进行调整。
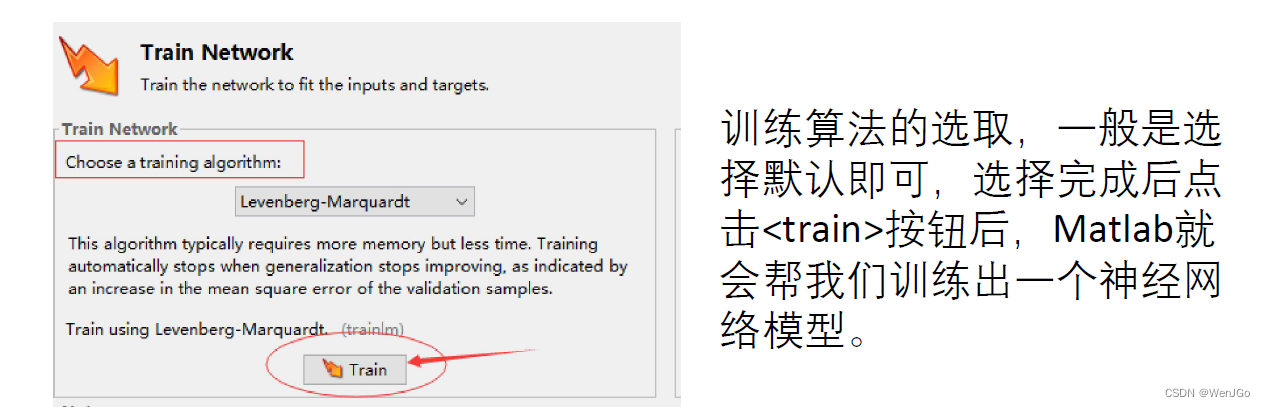
莱文贝格-马夸特方法(Levenberg–Marquardt algorithm):
能提供数非线性最小化(局部最小)的数值解。此算法能借由执行时修改参数达到结合高斯-牛顿算法以及梯度下降法的优点,并对两者之不足作改善(比如高斯-牛顿算法之反矩阵不存在或是初始值离局部极小值太远)
贝叶斯正则化方法(Bayesian-regularization):
贝叶斯正则化在神经网络拟合中的通俗理解_贝叶斯正则化神经网络-CSDN博客
量化共轭梯度法(Scaled Conjugate Gradient ):
《模式识别与智能计算——MATLAB技术实现》
结果分析
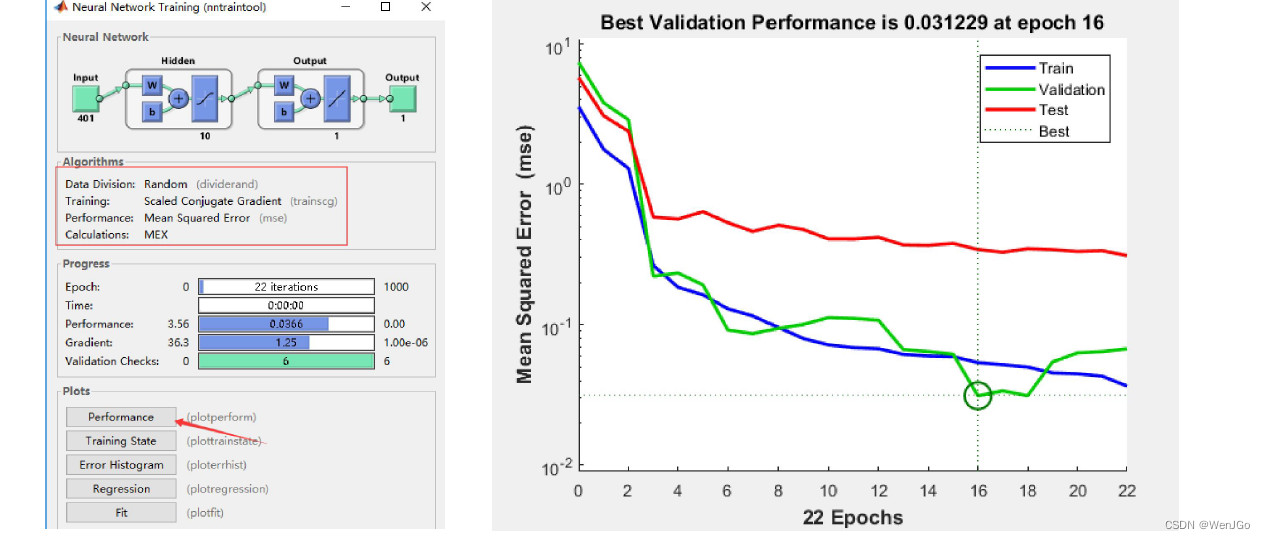
epoch:1个epoch等于使用训练集中的全部样本训练一次,每训练一次,神经网络中的参数经过调整。MSE: Mean Squared Error 均方误差 MSE = SSE/n
一般来说,经过更多的训练阶段后,误差会减小,但随着网络开始过度拟合训练数据,验证数据集的误差可能会开始增加。在默认设置中,在验证数据集的MSE连续增加六次后,训练停止,最佳模型对应于的最小的MSE。
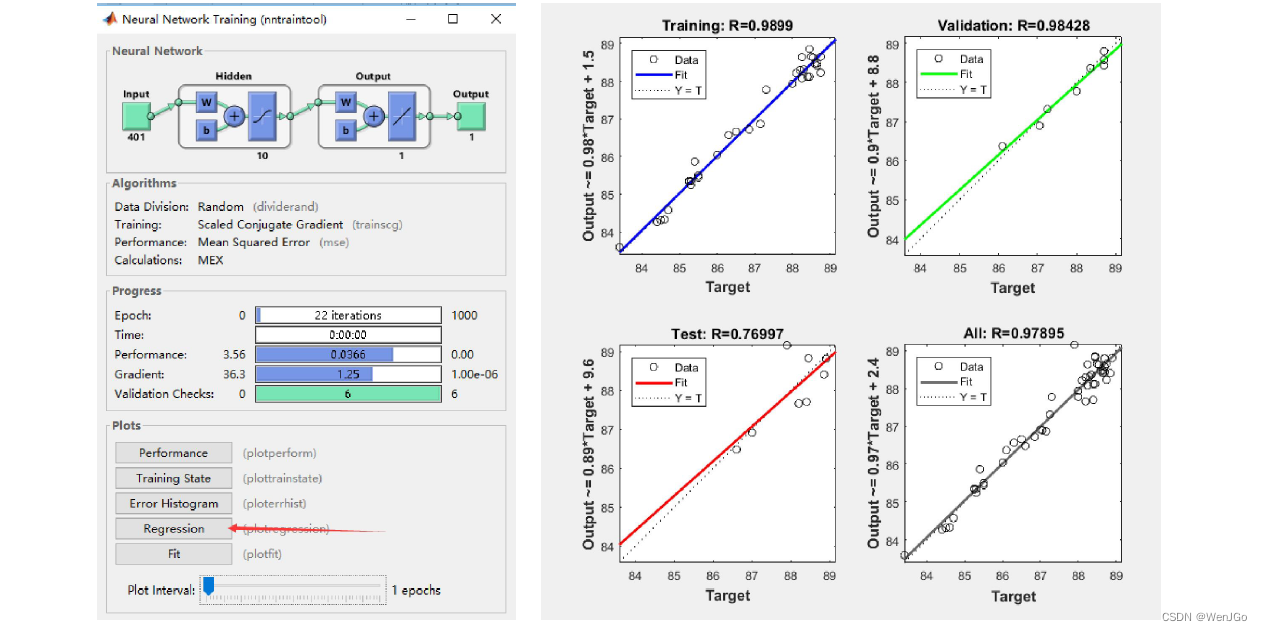
将拟合值对真实值回归,拟合优度越高,说明拟合的的效果越好。
保存结果
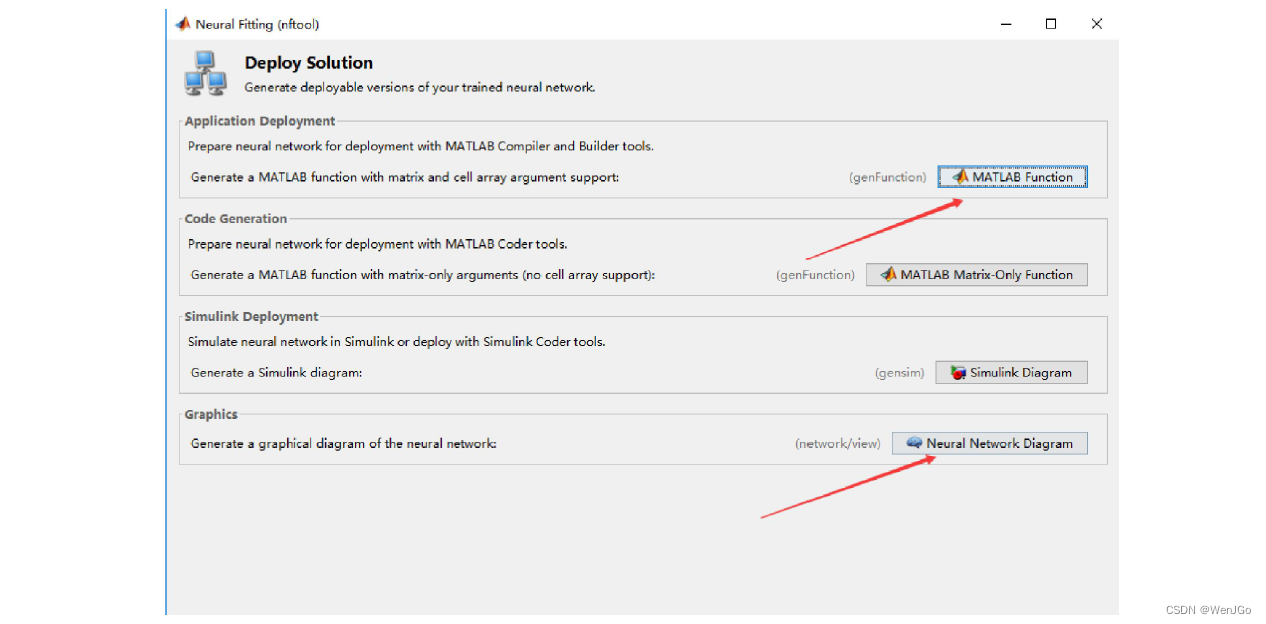
可以保存神经网络函数的代码,以及神经网络图。
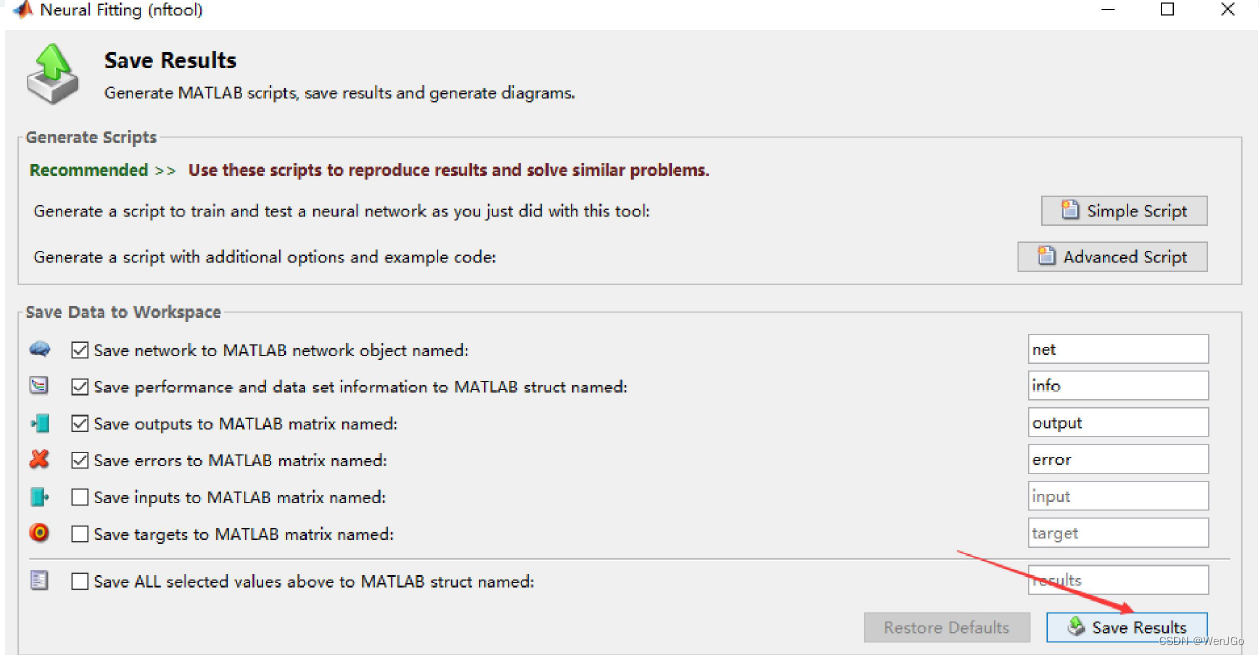
保存好训练出来的神经网络模型和结果
保存结果并对进行预测

例题2:神经网络在多输出中的运用
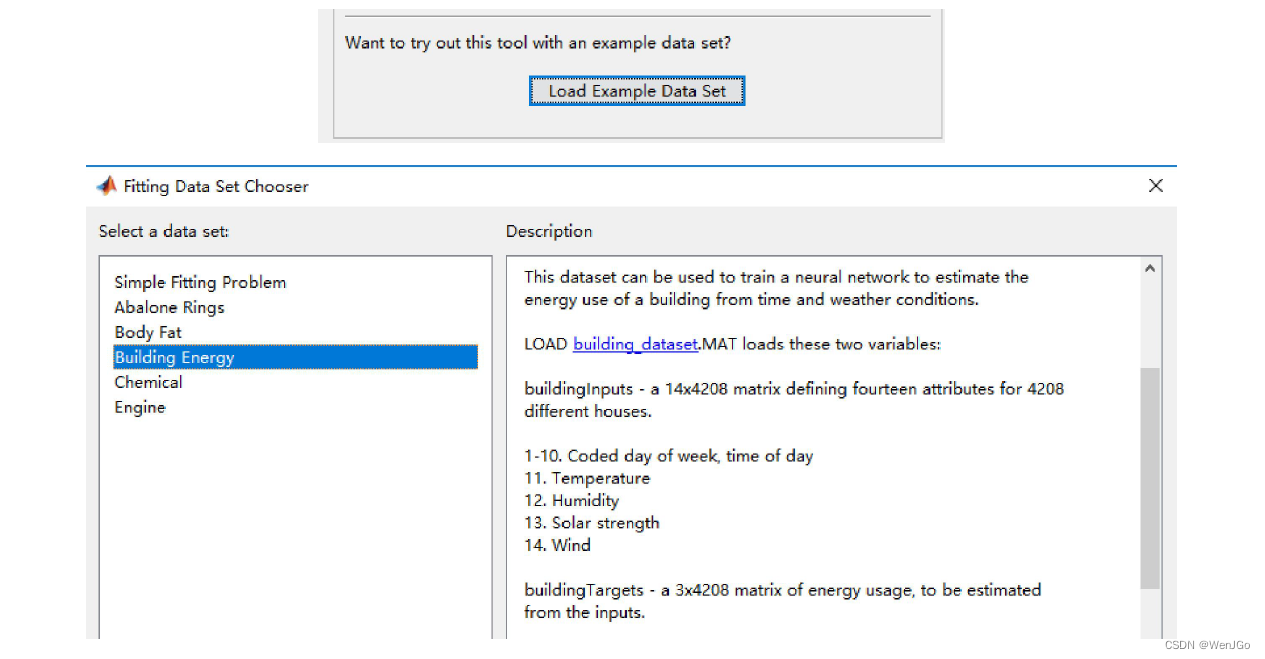
这里我们使用的是Matlab自带的测试数据集哦,如果你没有找到这
个数据集,可能的原因是你的Matlab版本太低。
清风大佬对于预测模型的看法

加入符合背景的变量


一篇不错的论文

来源:百度文库(莱斯利人口模型)
基于Leslie模型的二孩政策对中国未来10年人口的预测.pdf
本节作业1:画流程图
将本节学到的模型(灰色预测和神经网络)整理成流程图,使得国赛建模时经过简单的修改即可使用。
(流程图的作用:模型的思路生动清晰和减少查重)
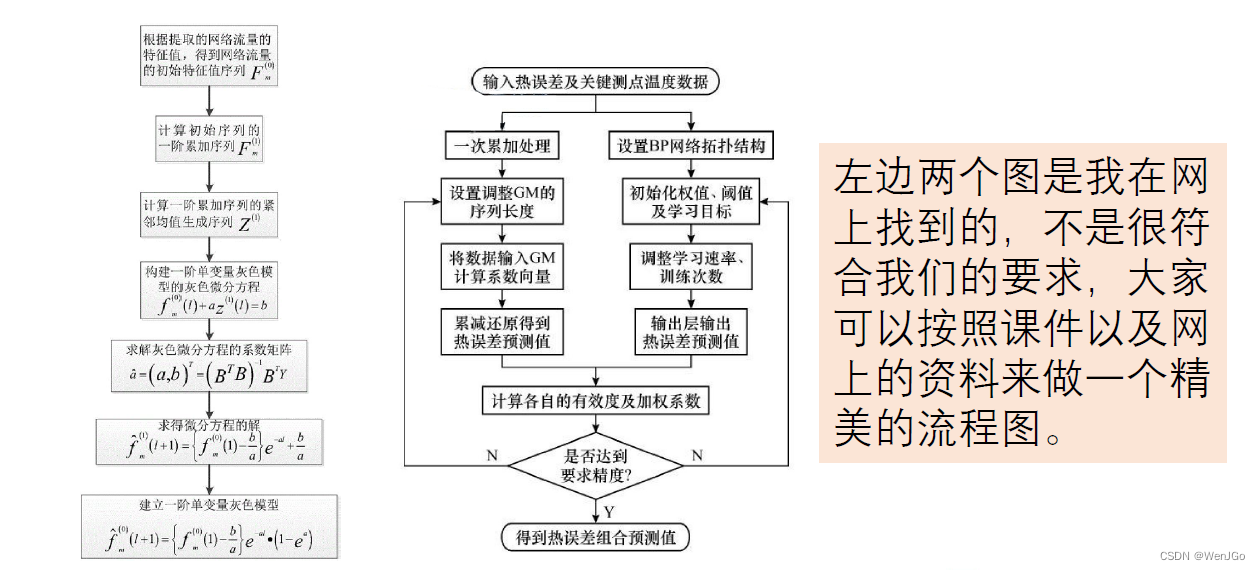
结语
ヾ( ̄▽ ̄)Bye~Bye~
写到深夜现在已经是凌晨两点,再见了兄弟们~~~
相关文章:
数学建模day16-预测模型
本讲首先将介绍灰色预测模型,然后将简要介绍神经网络在数据预测中的应用,在本讲的最 后,我将谈谈清风大佬对于数据预测的一些看法。 注:本文源于数学建模学习交流相关公众号观看学习视频后所作 目录 灰色系统 GM(1,1)…...
Vue3响应式系统(一)
一、副作用函数。 副作用函数指的是会产生副作用的函数。例如:effect函数会直接或间接影响其他函数的执行,这时我们便说effect函数产生了副作用。 function effect(){document.body.innerText hello vue3 } 再例如: //全局变量let val 2f…...

MStart | MStart开发与学习
MStart | MStart开发与学习 1.学习 1.MStart |开机LOG显示异常排查及调整...
Etcd:context deadline exceeded原因探究及解决)
GoZero微服务个人探索之路(一)Etcd:context deadline exceeded原因探究及解决
产生错误原因就是与etcd交互时候需要指定: 证书文件的路径 客户端证书文件的路径 客户端密钥文件的路径 (同时这貌似是强制默认就需要指定了) 但我们怎么知道这三个文件路径呢,如下方法 1. 找到etcd的配置文件,里…...
C语言从入门到实战——结构体与位段
结构体与位段 前言一、结构体类型的声明1.1 结构体1.1.1 结构的声明1.1.2 结构体变量的创建和初始化 1.2 结构的特殊声明1.3 结构的自引用 二、 结构体内存对齐2.1 对齐规则2.2 为什么存在内存对齐2.3 修改默认对齐数 三、结构体传参四、 结构体实现位段4.1 什么是位段4.2 位段…...
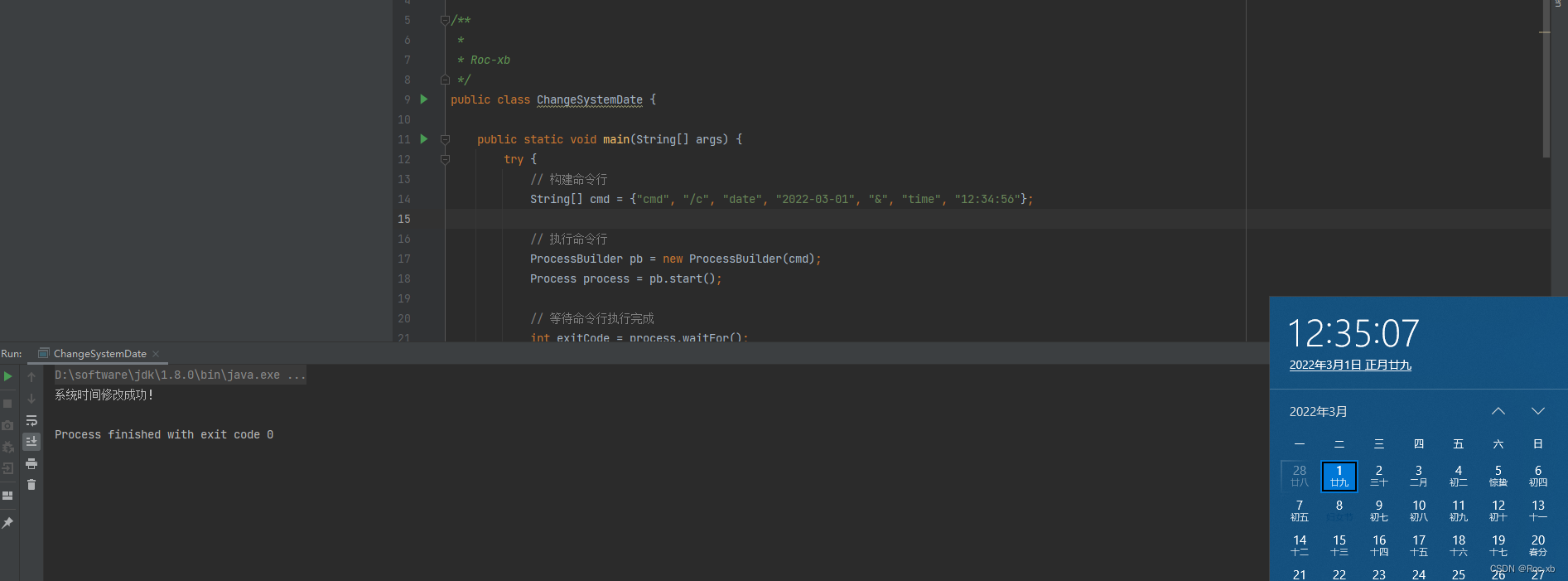
java如何修改windows计算机本地日期和时间?
本文教程,主要介绍,在java中如何修改windows计算机本地日期和时间。 目录 一、程序代码 二、运行结果 一、程序代码 package com;import java.io.IOException;/**** Roc-xb*/ public class ChangeSystemDate {public static void main(String[] args)…...

flink中的row类型详解
在Apache Flink中,Row 是一个通用的数据结构,用于表示一行数据。它是 Flink Table API 和 Flink DataSet API 中的基本数据类型之一。Row 可以看作是一个类似于元组的结构,其中包含按顺序排列的字段。 Row 的字段可以是各种基本数据类型&…...
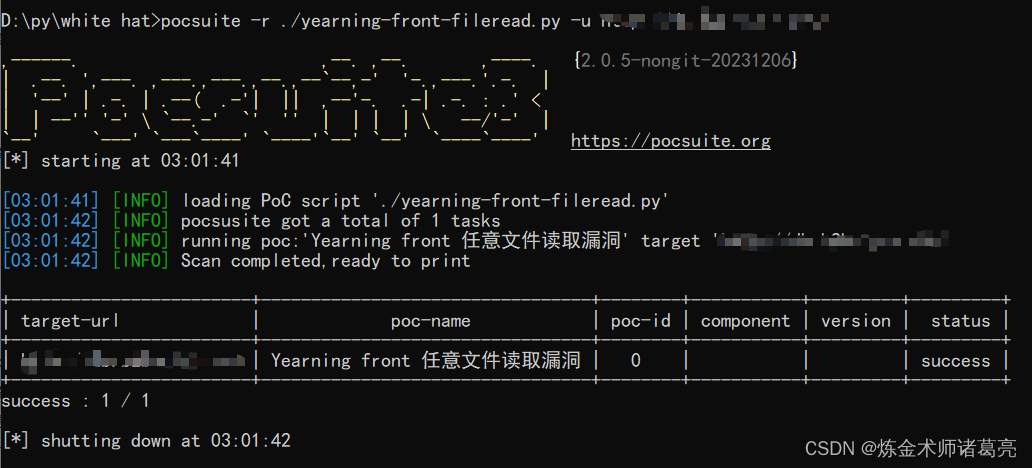
漏洞复现-Yearning front 任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...
K8S中SC、PV、PVC的理解
存储类(StorageClass)定义了持久卷声明(PersistentVolumeClaim)所需的属性和行为,而持久卷(PersistentVolume)是实际的存储资源,持久卷声明(PersistentVolumeClaim&#…...
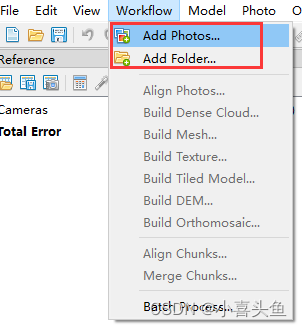
Agisoft Metashape 基于影像的外部点云着色
Agisoft Metashape 基于影像的外部点云着色 文章目录 Agisoft Metashape 基于影像的外部点云着色前言一、添加照片二、对齐照片三、导入外部点云四、为点云着色五、导出彩色点云前言 本教程介绍了在Agisoft Metashape Professional中,将照片中的真实颜色应用于从不同源获取的…...
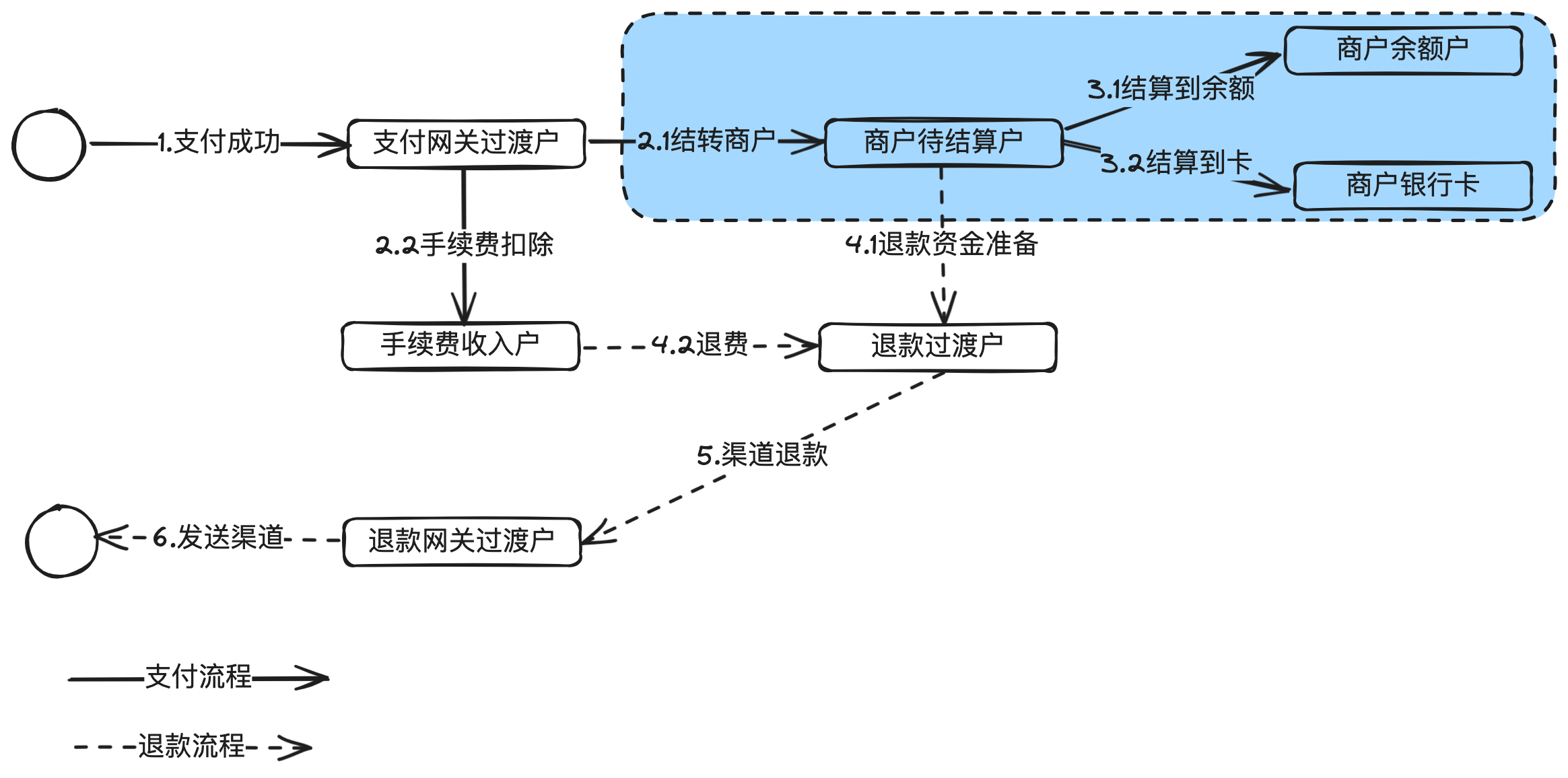
图解结算平台:准确高效给商户结款
这是《百图解码支付系统设计与实现》专栏系列文章中的第(4)篇。 本章主要讲清楚支付系统中商户结算涉及的基本概念,产品架构、系统架构,以及一些核心的流程和相关领域模型、状态机设计等。 1. 前言 收单结算是支付系统最重要的子…...

修改和调试 onnx 模型
1. onnx 底层实现原理 1.1 onnx 的存储格式 ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文…...

不同整数的最少数目和单词直接最短距离
写是为了更好的思考,坚持写作,力争更好的思考。 今天分享两个关于“最小、最短”的算法题,废话少说,show me your code! 一、不同整数的最少数目 给你一个整数数组arr和一个整数k。现需要从数组中恰好移除k个元素&…...
 (64 位) 更新失败解决方案)
【Microsoft Edge】版本 109.0.1518.55 (正式版本) (64 位) 更新失败解决方案
Microsoft Edge 版本号 109.0.1518.55(正式版本)(64位) 更新直接报错 检查更新时出错: 无法创建该组件(错误代码 3: 0x80040154 – system level) 问题出现之前 之前电脑日常硬盘百分百(删文件和移动文件都慢得像…...

深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 TF2基础常用函数 1、张量处理类 强制数据类型转换: a1 tf.constant([1,2,3], dtypetf.floa…...
:初识大模型)
大模型学习篇(一):初识大模型
目录 一、大模型的定义 二、大模型的基本原理与特点 三、大模型的分类 四、大模型的相关落地产品 五、总结 一、大模型的定义 大模型是指具有数千万甚至数亿参数的深度学习模型。大模型具有以下特点: 参数规模庞大:大模型的一个关键特征是其包含了…...
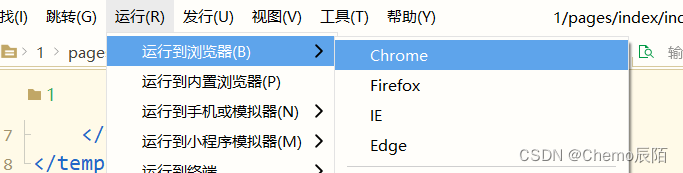
uni-app的学习【第二节】
四 路由配置及页面跳转 (1)路由配置 uni-app页面路由全部交给框架统一管理,需要在pages.json里配置每个路由页面的路径以及页面样式(类似小程序在app.json中配置页面路由) 接着第一节的文件,在pages里面新建三个页面 将之前的首页替换为下面的内容,其他页面如下图 然…...
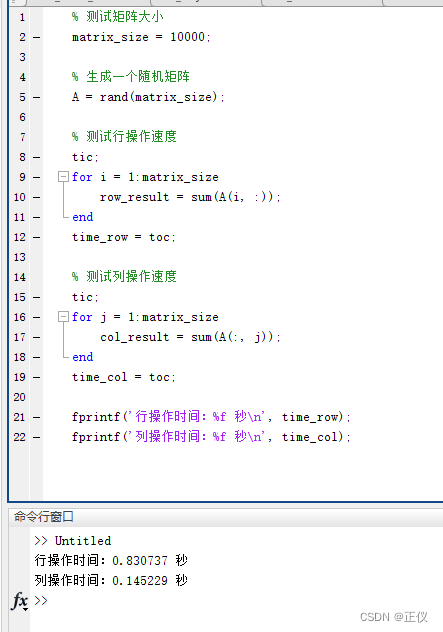
matlab行操作快?还是列操作快?
在MATLAB中,通常情况下,对矩阵的列进行操作比对行进行操作更有效率。这是因为MATLAB中内存是按列存储的,因此按列访问数据会更加连续,从而提高访问速度。 一、实例代码 以下是一个简单的测试代码, % 测试矩阵大小 ma…...
基于SSM的流浪动物救助站
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
任务13:使用MapReduce对天气数据进行ETL(获取各基站ID)
任务描述 知识点: 天气数据进行ETL 重 点: 掌握MapReduce程序的运行流程熟练编写MapReduce程序使用MapReduce进行ETL 内 容: 编写MapReduce程序编写Shell脚本,获取MapReduce程序的inputPath将生成的inputPath文件传入到Wi…...

基于动态生物标志物变化率的生物年龄预测:LightGBM模型与纵向数据分析实践
1. 项目概述与核心价值在预防医学和健康管理领域,我们常常面临一个根本性的难题:如何准确评估一个人的“真实”衰老程度?我们都知道,身份证上的“时序年龄”只是一个粗略的刻度,两个同龄人,一个可能精力充沛…...

别再只把PCA当降维工具了!用Python+Sklearn实战服装标准与消费支出分析
解锁PCA的隐藏技能:用Python实战服装标准与消费支出分析当我们谈论主成分分析(PCA)时,大多数人首先想到的是"降维"——这个标签如此深入人心,以至于我们常常忽略了PCA作为"数据解释器"和"可视…...

Nature|619372人循环代谢性状的遗传分析
尽管复杂疾病的全基因组关联研究(GWAS)通常会分析多达100多万人,但分子特征的研究却滞后了。在这里,研究对爱沙尼亚生物库和英国生物库中多达619,372名个体的249个循环代谢特征进行了GWAS荟萃分析。从8,398个趋同于共享基因和通路…...

DeepSeek总结的DuckDB动态函数应用插件
来源:https://github.com/teaguesterling/duckdb_func_apply DuckDB FuncApply 扩展 DuckDB 的动态函数应用 - 在运行时通过名称调用函数。 概述 FuncApply 扩展为 DuckDB 提供了动态函数调用能力,允许您: 使用 apply() 通过名称调用任何…...

为Hermes Agent配置Taotoken自定义供应商接入大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置Taotoken自定义供应商接入大模型 Hermes Agent 是一个功能强大的AI智能体开发框架,它支持通过自定义…...

基于决策树与Boosting的暗网流量多阶段分类系统设计与实践
1. 项目概述:为什么暗网流量分类是个“硬骨头”?在网络安全这个没有硝烟的战场上,流量分类技术就像是前沿阵地的“雷达”和“声呐”。它的任务很简单:从海量、混杂的网络数据流中,快速、准确地识别出哪些是正常的网页浏…...

校准机器学习与SHAP分析:构建可信专利价值评估模型
1. 项目概述:从“黑盒”预测到“透明”评估的跨越在技术管理和投资决策领域,判断一项专利或技术的长期价值,一直是个既关键又棘手的难题。传统的专家评估方法虽然能结合行业洞见,但往往耗时费力、主观性强,且难以应对海…...

CleanMyWechat:一键解放你的PC微信存储空间
CleanMyWechat:一键解放你的PC微信存储空间 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/CleanMy…...

当数字笔记遇上开源力量:Xournal++如何重新定义你的创作边界
当数字笔记遇上开源力量:Xournal如何重新定义你的创作边界 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Wind…...

【数据分析】基于matlab智慧城市温度与湿度分析系统【含Matlab源码 15555期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...