世界人口数据分析与探索
文章目录
- 世界人口数据集介绍
- 数据集 1:世界国家统计数据:
- 数据集 2:世界人口详细信息(2023 年):
- 数据集 3:按年份划分的世界人口(1950-2023):
- 数据分析
- 导入必要的库
- 导入准备分析的文件
- 获取基本信息
- 数据可视化
- 土地面积分析
- 人口分析
- 生育率分析
- 中位年龄分析
- 结论
世界人口数据集介绍
探索全面的数据集,提供对全球人口统计和特定国家特征的深刻见解。这些数据集来源于worldometers.info和维基百科等知名平台,涵盖了广泛的关键指标,为深入分析和探索提供了丰富的资源。
数据集 1:世界国家统计数据:
深入研究世界各国的详细统计数据,包括地区、土地面积、生育率和中位年龄等基本因素。该数据集提供了人口和地理属性的整体视图。
数据集 2:世界人口详细信息(2023 年):
深入了解 2023 年各国的人口格局。该数据集涵盖了大量与人口相关的详细信息,包括年度变化、密度、净移民、城市人口等。
数据集 3:按年份划分的世界人口(1950-2023):
揭示 1950 年至 2023 年世界人口的演变(每个国家的年度粒度)。该数据集可让您分析和了解七十年来的人口趋势。
这些数据集共同为寻求探索和了解全球人口和特定国家特征的复杂动态的研究人员、分析师和爱好者奠定了坚实的基础。无论是研究历史趋势还是关注最新的人口统计资料,这些数据集都为不同的分析视角提供了丰富的信息。
注意
此数据集是从worldometers和wikipedia.org创建的。如果您想了解更多信息,可以访问网站。
数据分析
导入必要的库
import numpy as np
import pandas as pd import os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))
导入准备分析的文件
countries_df=pd.read_csv('/input/world-population-dataset/world_country_stats.csv')
population_df=pd.read_csv('/input/world-population-dataset/world_population_by_country_2023.csv')
population_by_year=pd.read_csv('/input/world-population-dataset/world_population_by_year_1950_2023.csv')
从名为"countries_df"中随机抽取2行数据进行随机抽样,以便更好地了解数据的特征和分布。
countries_df.sample(2)

获取基本信息
countries_df.info()

通过info()可以看出
从输出结果来看,数据框包含五列:
- country: 字符串类型,包含 234 个非空值。
- region: 字符串类型,包含 234 个非空值。
- land_area: 整数类型,包含 234 个非空值。
- fertility_rate: 浮点数类型,包含 233 个非空值。
- median_age:浮点数类型,包含 233 个非空值。
其中, fertility_rate,median_age各有一个缺失值。
countries_df.describe()

分析结果可知:
land_area:
平均面积约为 555,956.8 平方单位
标准差为 1,691,024,表示面积的变化范围较大
最小面积为 0,最大面积为 16,376,870
fertility_rate:
平均生育率为 2.41
标准差为 1.16,表示生育率的相对变异性
最低生育率为 0.8,最高生育率为 6.7
median_age:
平均年龄为 31.31
标准差为 9.63,表示年龄的相对变异性
最小年龄为 15,最大年龄为 54
计算每列中的缺失值数量
countries_df.isnull().sum()
获得每列中缺失值的总数。

查看完整的 countries_df 数据
countries_df

数据可视化
我将使用plotly来绘制大部分图。 Plotly 是一个数据可视化库,允许用户使用 Python、R 和 Julia 创建交互式动态图表。 它提供了一个高级界面,用于创建各种图表和图形,包括折线图、条形图、散点图、热图等。 您可以使用每个图右上角显示的工具与图进行交互
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
土地面积分析
创建了一个条形图,该图显示了国家的土地面积分布
fig=px.bar(countries_df.sort_values(by='land_area',ascending=False),y='land_area',x='country',color='land_area',title='Land Area Distribution')
fig.show()

创建了一个条形图,显示了土地面积最大的前十个国家。通过使用 head(10) 来仅选择前十个最大的国家,并调整了x轴和y轴。
fig=px.bar(countries_df.sort_values(by='land_area',ascending=False).head(10),x='land_area',y='country',color='land_area',title='Top 10 Largest Countries')
fig.show()

创建了一个名为 Region_df 的新数据框,通过使用 groupby 按照地区进行分组,并使用 agg 计算了每个地区的平均生育率、平均年龄和总土地面积。reset_index() 用于将地区作为列重新设置为索引。
Region_df=countries_df.groupby(by='region').agg({'fertility_rate':'mean','median_age':'mean','land_area':'sum'}).reset_index()
Region_df

创建了一个饼图,展示了各个地区的土地面积分布。通过设置 names 参数为 ‘region’,values 参数为 ‘land_area’,并添加 hole 参数以创建一个带有中空部分的饼图。
fig=px.pie(Region_df,names='region',values='land_area',hole=0.2,title='Land Area Distribution by Region')
fig.update_traces(textinfo='label+percent')
fig.show()

使用 countries_df[‘region’].unique() 获取了数据框中 ‘region’ 列的唯一值,并将其转换为列表。这样可以得到包含所有地区名称的列表。
region=list(countries_df['region'].unique())
region

创建了一个新的数据框 x,通过迭代每个地区,选择每个地区土地面积最大的国家,并将这些信息存储在 x 中。您使用了 concat 函数将每个地区的数据框连接在一起,并通过 ignore_index=True 重新设置索引。
x=pd.DataFrame()
for reg in region:temp_df=countries_df[countries_df['region']==reg].sort_values(by='land_area',ascending=False).head(1)[['region','country','land_area']]x=pd.concat([x,temp_df],ignore_index=True)
x

创建了一个散点图,显示了每个地区土地面积最大的国家。使用 px.scatter 函数,设置 x 轴为 ‘region’,y 轴为 ‘land_area’,颜色按照 ‘country’ 区分,而大小则由 ‘land_area’ 决定。
fig = px.scatter(x,x='region',y='land_area', color="country",size='land_area',title='Maximum Land Area of country in each region in the World')
fig.show()

人口分析
查看数据集中的三行样本数据
population_df.sample(3)

创建了一个折线图,展示了各个国家的人口分布。通过设置 x 轴为 ‘country’,y 轴为 ‘population’,可以很容易地观察到不同国家的人口变化趋势。
fig=px.line(population_df,x='country',y='population',title='Population Distribution over Countries')
fig.show()

创建了一个条形图,显示了人口最多的前十个国家。通过使用 head(10) 来选择人口最多的前十个国家,并设置 x 轴为 ‘population’,y 轴为 ‘country’,颜色由 ‘population’ 决定。
fig=px.bar(population_df.sort_values(by='population',ascending=False).head(10),x='population',y='country',color='population',title='Top 10 Most Populated Countries')
fig.show()

查看 population_df 数据框中的两行样本数据
population_df.sample(2)

创建了两个条形图,分别显示了最城市化的前15个国家和最不城市化的前15个国家的城市人口分布。通过使用 sort_values 和 head(15) 来选择相应的国家,并设置 x 轴为 ‘population_urban’,y 轴为 ‘country’,颜色由 ‘population_urban’ 决定
fig=px.bar(population_df.sort_values(by='population_urban',ascending=False).head(15),x='population_urban',y='country',color='population_urban',title='Top 15 Most Urbanized Countries: Urban Population Distribution')
fig.show()
fig=px.bar(population_df.sort_values(by='population_urban',ascending=True).head(15),x='population_urban',y='country',color='population_urban',title='Least Urbanized Countries: Urban Population Distribution (Top 15)')
fig.show()


查看 population_by_year 数据框中的两行样本数据
population_by_year.sample(2)

创建了两个条形图,分别显示了1950年和2023年人口最多的前15个国家。通过使用 sort_values 和 head(15) 来选择相应的国家,并设置 x 轴为 ‘country’,y 轴为 ‘1950’ 或 ‘2023’。
fig , axes= plt.subplots(nrows=1,ncols=2 ,figsize=(25,10))
sns.barplot(population_by_year.sort_values(by='1950',ascending=False).head(15),x='country',y='1950',ax=axes[0])
axes[0].set_title('Most Populated countries in 1950')
axes[0].set_xticklabels(axes[0].get_xticklabels(),rotation=90)
sns.barplot(population_by_year.sort_values(by='2023',ascending=False).head(15),x='country',y='2023',ax=axes[1])
axes[1].set_title('Most Populated countries in 2023')
axes[1].set_xticklabels(axes[1].get_xticklabels(),rotation=90)
plt.show()

上面两张图是1950年和2023年的人口比较,我们可以看到中国和印度是1950年以来人口最多的国家
计算从1950年到2023年人口变化的百分比,并创建了一个显示前20个国家变化百分比的条形图。使用 px.bar 函数,设置 x 轴为 ‘country’,y 轴为 ‘change in %’,并设置标题为 ‘% Change in Population from 1950 to 2023’。
population_by_year['change in % ']=((population_by_year['2023']-population_by_year['1950'])/population_by_year['1950'])*100
z=population_by_year.sort_values(by='change in % ',ascending=False).head(20)
px.bar(z,x='country',y='change in % ',text_auto='0.2s',title='% Change in Population from 1950 to 2023 ')

生育率分析
countries_df.sample(2)

创建了一个条形图,显示了生育率最高的前20个国家。通过使用 sort_values 和 head(20) 来选择生育率最高的国家,并设置 x 轴为 ‘country’,y 轴为 ‘fertility_rate’,颜色由 ‘fertility_rate’ 决定。
fig=px.bar(countries_df.sort_values(by='fertility_rate',ascending=False).head(20),x='country',y='fertility_rate',color='fertility_rate',title='Countries with highest Fertility rate')
fig.show()

Region_df

创建了一个条形图,显示了各个地区的生育率分布。通过设置 y 轴为 ‘fertility_rate’,x 轴为 ‘region’,颜色由 ‘fertility_rate’ 决定,并更新了一些文本显示的样式。
fig=px.bar(Region_df,y='fertility_rate',x='region',color='fertility_rate',text_auto='0.2s',title='Fertility Rate Distribution by Region')
fig.update_traces(textfont_size=12, textangle=0, textposition="outside", cliponaxis=False)
fig.show()

创建了一个名为 y 的新数据框,通过迭代每个地区,选择每个地区生育率最高的国家,并将这些信息存储在 y 中。使用了 concat 函数将每个地区的数据框连接在一起,并通过 ignore_index=True 重新设置索引。
y=pd.DataFrame()
for reg in region:temp_df=countries_df[countries_df['region']==reg].sort_values(by='fertility_rate',ascending=False).head(1)[['region','country','fertility_rate']]y=pd.concat([y,temp_df],ignore_index=True)
y

创建了一个散点图,显示了每个地区生育率最高的国家。使用 px.scatter 函数,设置 x 轴为 ‘region’,y 轴为 ‘fertility_rate’,颜色按照 ‘country’ 区分,而大小则由 ‘fertility_rate’ 决定
fig = px.scatter(y,x='region',y='fertility_rate', color="country",size='fertility_rate',title='Maximum Fertility rate of country in each region in the World')
fig.show()

中位年龄分析
countries_df.sample(2)

创建一个条形图,显示了各个国家的中位年龄分布。通过使用 sort_values 函数来按中位年龄排序,并设置 x 轴为 ‘country’,y 轴为 ‘median_age’,颜色由 ‘median_age’ 决定。
fig=px.bar(countries_df.sort_values(by='median_age',ascending=False),x='country',y='median_age',color='median_age',title='Median Age Distribustion over countries')
fig.show()

创建一个条形图,显示了中位年龄最高的前20个国家。通过使用 head(20) 来选择中位年龄最高的国家,并设置 x 轴为 ‘country’,y 轴为 ‘median_age’,颜色由 ‘median_age’ 决定。
fig=px.bar(countries_df.sort_values(by='median_age',ascending=False).head(20),x='country',y='median_age',color='median_age',title='Countries with highest median age')
fig.show()

Region_df

创建一个条形图,显示了各个地区的中位年龄分布。通过设置 y 轴为 ‘median_age’,x 轴为 ‘region’,颜色由 ‘median_age’ 决定,并更新了一些文本显示的样式。
fig=px.bar(Region_df,y='median_age',x='region',color='median_age',text_auto='0.2s',title=' Median Age Distribution by Region ')
fig.show()

结论
- 土地面积:
世界各国土地面积差异很大,Rssia拥有巨大的土地面积,接下来是China和US,而其他国家相对较小。
- 人口:
人口分布差异明显,印度,中国,美国拥有大量人口,而其他国家人口较少。
1950年和2023年的人口最多的国家也有所变化,反映了人口分布的演变。
- 城市化:
一些国家在城市化方面表现出色,其城市人口较多,

而其他国家则相对较少。
- 生育率:
生育率在不同国家和地区之间存在差异,一些国家生育率较高,而其他国家则较低。
- 中位年龄:
中位年龄在不同国家和地区之间存在差异,一些国家中位年龄较高,而其他国家则较低。
- 地区差异:
同一地区内的国家在人口、城市化、生育率和中位年龄等方面可能存在差异。
这里只提供一些简单的分析和思路,具体的分析还需要大家多角度深入的展开研究。
相关文章:
世界人口数据分析与探索
文章目录 世界人口数据集介绍数据集 1:世界国家统计数据:数据集 2:世界人口详细信息(2023 年):数据集 3:按年份划分的世界人口(1950-2023): 数据分析导入必要…...

自动驾驶的未来:BEV与Occupancy网络全景解析与实战揭秘!
自动驾驶领域中,什么是BEV?什么是Occupancy? 作者:小柠檬 | 来源:公众号「3DCV」 BEV是Bird’s Eye View 的缩写,意为鸟瞰视图。在自动驾驶领域,BEV 是指从车辆上方俯瞰的场景视图。BEV 图像可以…...

大众点评评论采集软件使用教程
导出字段: 店铺ID 评论ID 发布时间 人均消费 评分 详情链接 点赞数 浏览数 评论数 最后更新时间 发布平台 推荐 评论详情 原始评论 图片数 图片链接 用户等级 用户名称 用户头像 VIP 私...

2024年前端面试中JavaScript的30个高频面试题之中级知识
基础知识 高级知识 13. 什么是闭包?闭包的用例有哪些? 闭包是一个功能,它允许函数捕获定义该函数的环境(或保留对作用域中变量的访问)即使在该作用域已经关闭后。 我们可以说闭包是函数和词法环境的组合,其中定义了该函数。 换句话说,闭包为函数提供了访问自己的作用域、…...
postman 简单测试(一)
1.postman官网 Postman API Platform 2.研究了一下postman 一些简单的功能,自己做个记录,同时希望能节约点测试时间。 2.1新建一个 collections 长期测的话,最好注册一个账号,开放更多功能。 2.2新建一个请求 后端要先搭建起来…...

12.1、2、3-同步状态机的结构以及Mealy和Moore状态机的区别
同步状态机的结构以及Mealy和Moore状态机的区别 1,介绍Mealy型状态机和Moore型状态机的两种结构2,设计高速电路的方法 由于寄存器传输级(RTL)描述的是以时序逻辑抽象所得到的有限状态机为依据,因此,把一个时…...
前端框架前置课Node.js学习(1) fs,path,模块化,CommonJS标准,ECMAScript标准,包
目录 什么是Node.js 定义 作用: 什么是前端工程化 Node.js为何能执行Js fs模块-读写文件 模块 语法: 1.加载fs模块对象 2.写入文件内容 3.读取文件内容 Path模块-路径处理 为什么要使用path模块 语法 URL中的端口号 http模块-创建Web服务 需求 步骤: 案例:浏…...
)
SpringBoot源码启动流程(待完善)
SpringBoot源码启动流程 1. 构造SpringApplication对象 1.1 推测web应用类型 判断关键类是否存在来区分类型 REACTIVENONESERVLET static WebApplicationType deduceFromClasspath() {if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null) && !ClassUtils.isP…...
存内计算技术打破常规算力局限性
目录 前言 关于存内计算 1、常规算力局限性 2、存内计算诞生记 3、存内计算核心 存内计算芯片研发历程及商业化 1、存内计算芯片研发历程 2、存内计算先驱出道 3、存内计算商业化落地 基于知存科技存内计算开发板ZT1的降噪验证 (一)任务目标以…...
uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -投票帖子明细实现
锋哥原创的uniapp微信小程序投票系统实战: uniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )_哔哩哔哩_bilibiliuniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )共计21条视频…...

RabbitMQ入门到实战——高级篇
消息的可靠性 生产者的可靠性(确保消息一定到达MQ) 生产者重连 这⾥除了enabled是false外,其他 initial-interval 等默认都是⼀样的值。 生产者确认 生产者确认代码实现 application中增加配置:(publisher-returns…...

05.阿里Java开发手册——前后端规约
【强制】前后端交互的 API,需要明确协议、域名、路径、请求方法、请求内容、状态码、响 应体。 说明: 协议:生产环境必须使用 HTTPS。路径:每一个 API 需对应一个路径,表示 API 具体的请求地址: aÿ…...

Linux网络服务部署yum仓库
目录 一、网络文件 1.1.存储类型 1.2.FTP 文件传输协议 1.3.传输模式 二、内网搭建yum仓库 一、网络文件 1.1.存储类型 直连式存储:Direct-Attached Storage,简称DAS 存储区域网络:Storage Area Network,简称SAN࿰…...

智慧工地AI识别安全预警解决方案---豌豆云
实现在工地内所有视频覆盖区域对工人未穿工作服的24小时AI识别监测,发现人员未穿工作服及时报警至平台; 实现在工地内重点关注区域的AI人员统计; 实现在工地内监控覆盖区域的烟雾、火源24小时AI识别检测,发现烟雾、火源时及时报警,并通知相关负责人采取…...
红队打靶练习:TOMMY BOY: 1
目录 信息收集 1、arp 2、nmap 3、nikto 4、whatweb WEB robots.txt get flag1 get flag2 FTP登录 文件下载 更改代理 ffuf爆破 get flag3 crunch密码生成 wpscan 1、密码爆破 2、登录wordpress ssh登录 get flag4 信息收集 get flag5 信息收集 1、arp …...

Springboot中的@DependsOn注解
在我的最近的Spring Boot项目中,我遇到了涉及两个Bean的情况,Bean1和Bean2。在初始化过程中,我需要Bean2依赖于Bean1。 其中Spring中的 DependsOn 注解,允许我指定在创建Bean2之前,Spring应确保Bean1已初始化。 Depen…...
Django教程第5章 | Web开发实战-数据统计图表(echarts、highchart)
专栏系列:Django学习教程 前言 highchart,国外。 echarts,国内。 本项目集成 hightchart和echarts图表库实现数据统计功能。 包括:折线图,柱状图,饼图和数据集图。 效果图 echats Highcharts 源代码…...
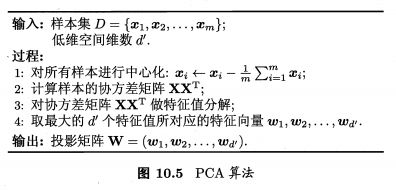
【机器学习 西瓜书】期末复习笔记整理
一些杂点: 测试集如何归一化? —— 不是用测试集的均值和标准差,而是用训练集的! 机器学习: 对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。 参考计算例题: 机器学习【期末复习…...

回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测
回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测 目录 回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于SO-GRU蛇群算法优化门控循环单元的数…...
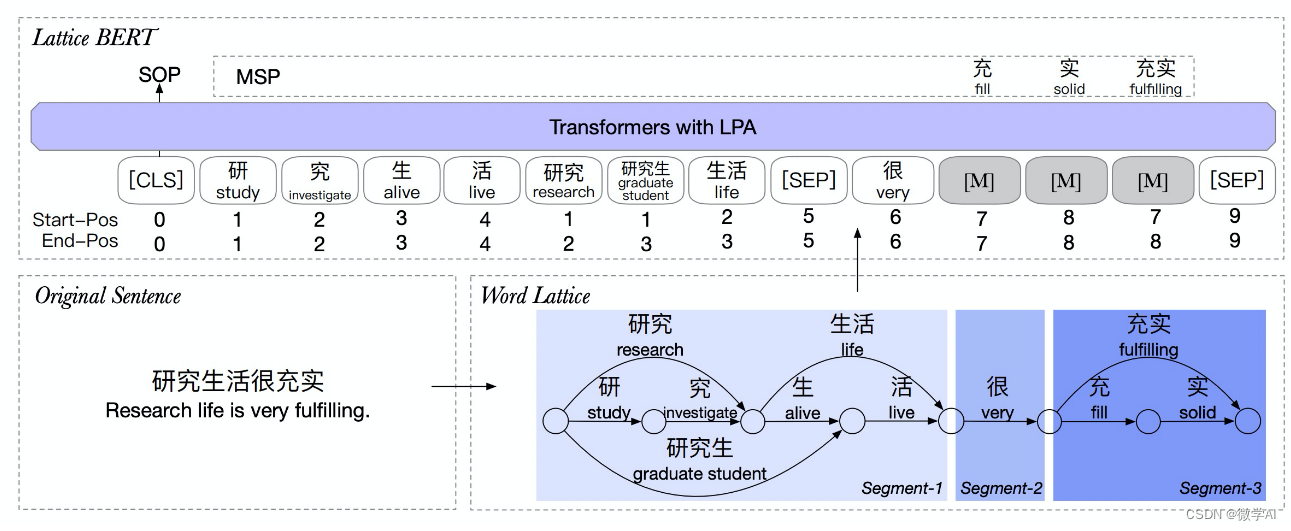
自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答。T5模型和BERT模型是两种常用的自然语言处理模型。T5是一种序列到序列模型,可以处理各种NLP任务,而BERT主要用于预训练语言表示。T5使用了类似于BERT的预训…...

在ubuntu开发机上体验taotoken分钟级接入多种大模型的过程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 开发机上体验 Taotoken 分钟级接入多种大模型的过程 1. 准备工作与环境确认 在开始之前,我使用的是一台运行…...

如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南
如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字隐私日益重要的时代,硬件指纹追踪已成…...

多目标贝叶斯优化在复杂量子动力学模型参数校准中的应用
1. 项目概述与核心挑战在光化学和生物物理领域,模拟视网膜在视紫红质中的光异构化反应,是理解视觉初始步骤的基石。这个反应看似简单——一个分子键的旋转,但其背后的量子动力学过程却异常复杂。传统上,我们依赖量子化学计算来构建…...

从‘黑客工具’到‘运维神器’:我是如何在Linux日常运维中用Netcat替代Telnet和Nmap的
从‘黑客工具’到‘运维神器’:Netcat在Linux日常运维中的五大实战场景如果你在运维领域摸爬滚打多年,一定遇到过这样的窘境:需要快速检查某个服务端口是否开放,却发现telnet没安装;想扫描几个常用端口,nma…...

【紧急预警】ChatGPT默认图表存在3类隐性误导风险!金融/医疗行业已发生2起决策偏差事故
更多请点击: https://intelliparadigm.com 第一章:ChatGPT数据可视化建议 在利用ChatGPT辅助数据分析与可视化时,需特别注意输入提示(prompt)的结构化设计,以引导模型生成可执行、可复现的可视化代码。Cha…...

Backtrader止损策略终极指南:3种方法保护你的交易资金
Backtrader止损策略终极指南:3种方法保护你的交易资金 【免费下载链接】backtrader Python Backtesting library for trading strategies 项目地址: https://gitcode.com/gh_mirrors/ba/backtrader 在量化交易中,止损是保护资金安全的关键防线。B…...

2026论文降AI率必备清单:AI率92%暴降至5%!实测10款AI智能降重工具!学生党狂喜!
2026 年各大高校和期刊平台的 AI 检测系统又升级了,知网 AIGC、维普 AI、万方智能检测三大平台的算法迭代速度越来越快,上个月能蒙混过关的改写方式,这个月直接就会被标红预警。单纯的同义词替换、语序调整早就不管用了,想要有效降…...

从AUC稳健下界到量子场论:机器学习与物理的数学统一
1. 项目概述:当机器学习遇见量子场论如果你在机器学习领域待过一段时间,对AUC(Area Under the ROC Curve)这个指标一定不陌生。它是衡量二分类模型性能的黄金标准,一个完美的分类器AUC为1,随机猜测则为0.5。…...

树张量网络FPGA部署:亚微秒级AI推理的硬件架构与量化实践
1. 项目概述:当量子启发算法遇上硬件加速在机器学习模型日益庞大、推理延迟要求愈发严苛的今天,我们常常面临一个核心矛盾:模型的强大性能与部署时的资源消耗、计算延迟难以兼得。尤其是在高能物理实验的触发系统、工业实时检测或自动驾驶感知…...

鸣潮工具箱:3大核心功能解锁120FPS与专业抽卡分析
鸣潮工具箱:3大核心功能解锁120FPS与专业抽卡分析 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools是一款专为《鸣潮》玩家打造的开源工具箱,通过智能帧率解锁、专业画质优…...