【机器学习 西瓜书】期末复习笔记整理
一些杂点:
测试集如何归一化? —— 不是用测试集的均值和标准差,而是用训练集的!
机器学习: 对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
参考计算例题:
机器学习【期末复习总结】——知识点和算法例题(详细整理)_机器学习期末-CSDN博客
机器学习期末考试-CSDN博客
机器学习期末练习题_机器学习计算题-CSDN博客
一、绪论
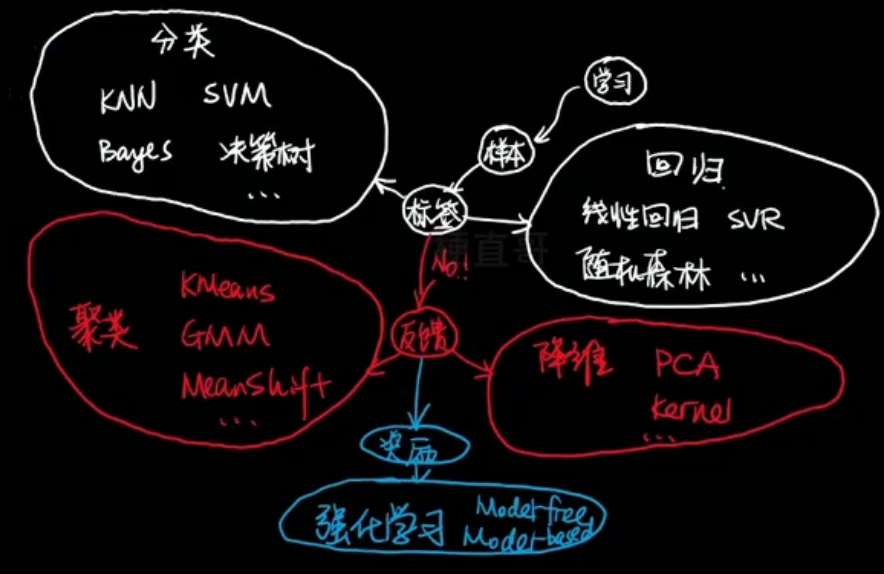
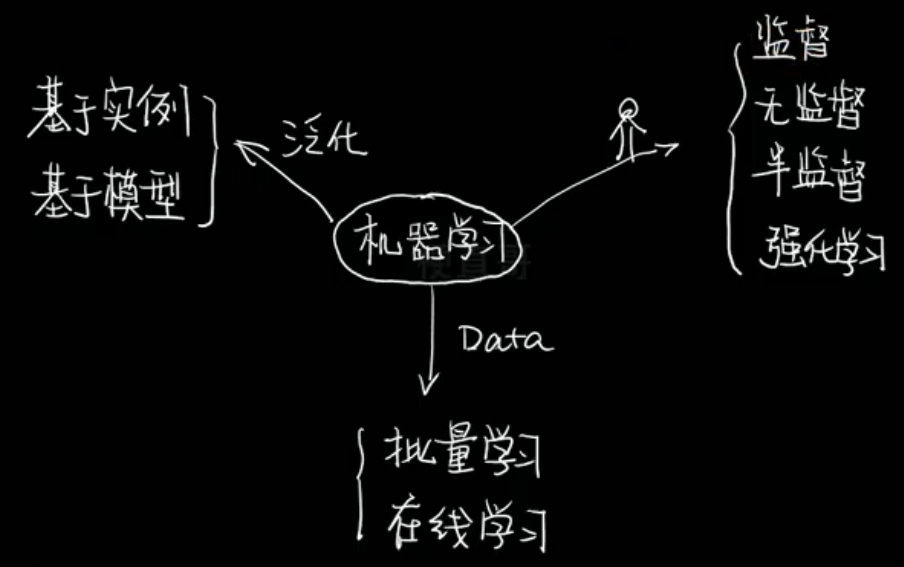
无监督学习 Unsupervised Learning
训练数据未经标记
聚类 —— K均值算法 K-means、密度聚类 DBSCAN、最大期望算法
降维 —— 主成分分析 PCA、核方法
关联规则学习 —— 挖掘特征间关联关系,Apriori方法、Eclat方法
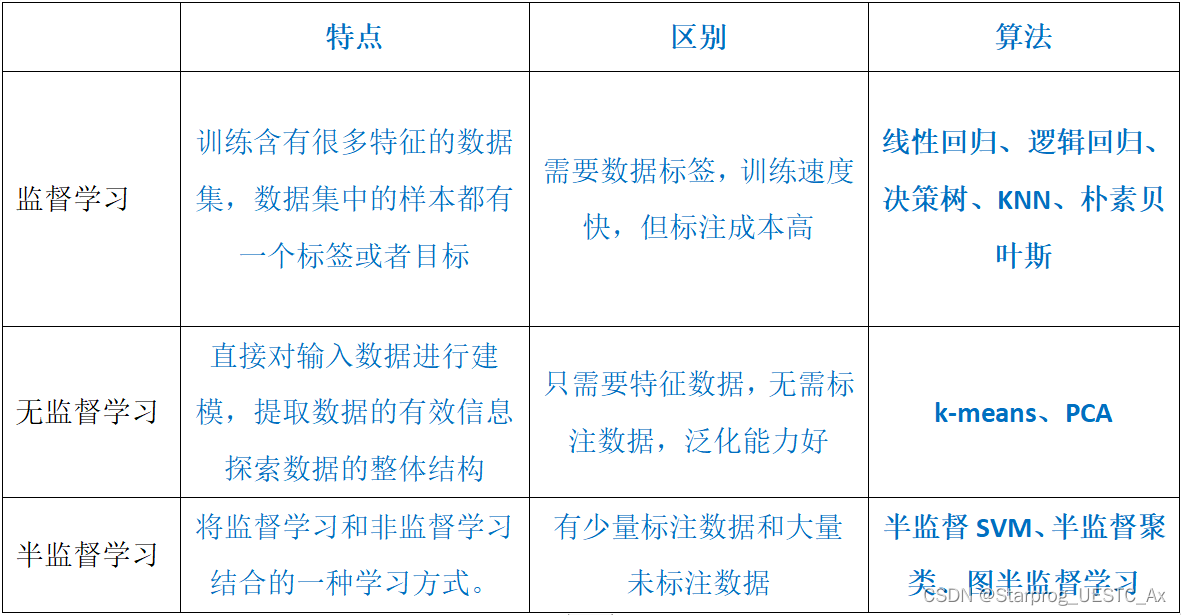



机器学习术语
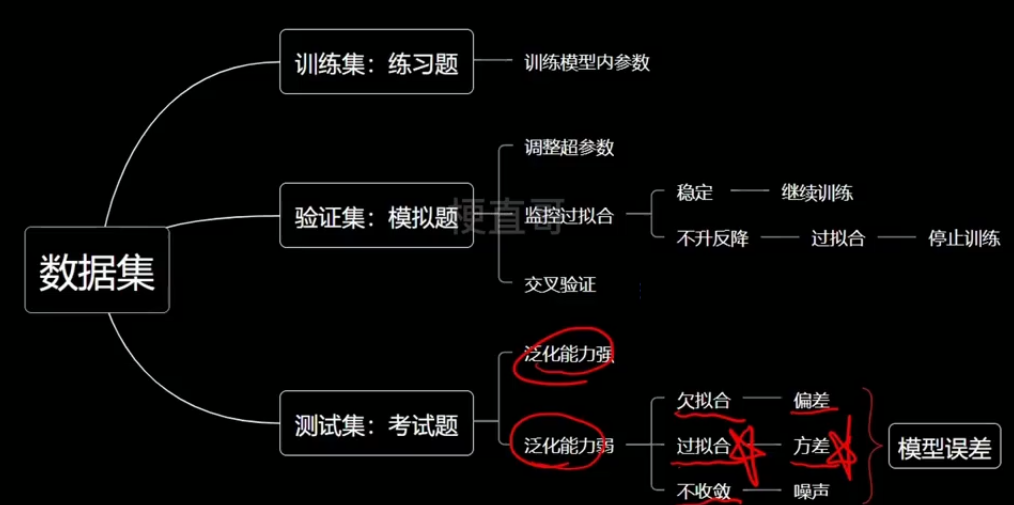
① 训练集:
作用:估计模型
学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的。
② 验证集:
作用:确定网络结构或者控制模型复杂程度的参数
对学习出来的模型,调整分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。
③ 测试集:
作用:检验最终选择最优的模型的性能如何
主要是测试训练好的模型的分辨能力(识别率等)
假设空间 p5
监督学习(supervised learning)的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space)。

【机器学习】假设空间与版本空间-CSDN博客
二、模型评估与选择
1、经验误差与过拟合


2、评估方法
2.1、留出法


2.2、交叉验证法



2.3、自助法

![]()
2.4、验证集
训练集(Training Set):用于训练模型。
验证集(Validation Set):用于调整和选择模型。
测试集(Test Set):用于评估最终的模型。

3、性能度量
3.1、错误率与精度
3.2、查准率与查全率(准确率与召回率)

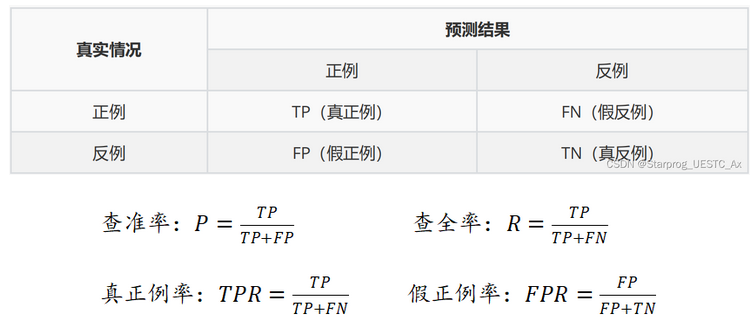
以检测核酸为例:

评价指标:

F1 Score
基于召回率(Recall)与精确率(Precision)的调和平均,即将召回率和精确率综合起来评价,计算公式为【更接近于两个数较小的那个,所以精确率和召回率接近时, 值最大,很多推荐系统的评测指标就是用F值的】


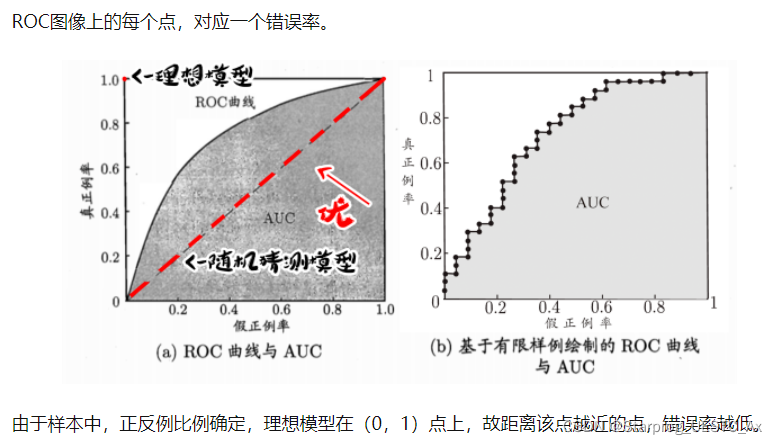
3.3、ROC曲线
ROC 曲线的纵坐标和横坐标分别为真正例率和假正例率。

根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算引出两个重要量的值,分别以它们为横纵坐标作图,就得到了 “ ROC曲线 ”
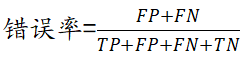
3.4、方差与偏差



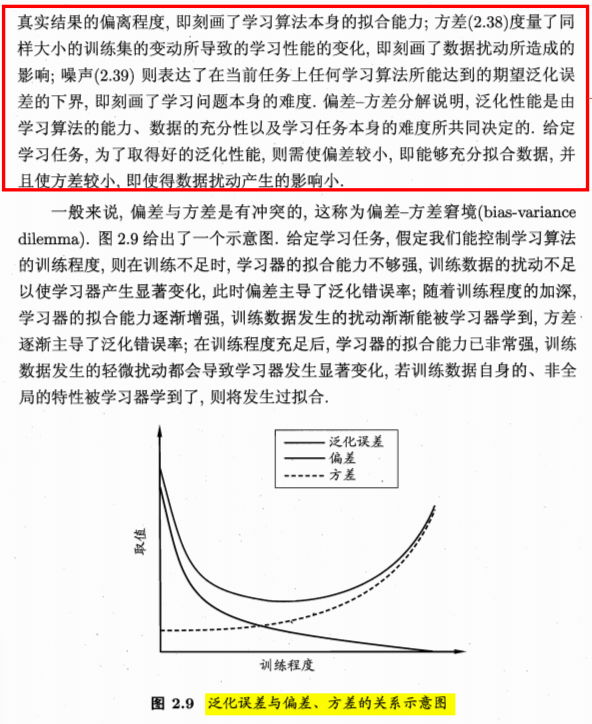
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据。度量了学习算法期望预测与真实结果的偏离程度;即刻画了学习算法本身的拟合能力;
高偏差(欠拟合): 训练误差和验证误差十分接近,但很大
应对方法: 引入更多相关特征;采用多项式特征;减弱正则化
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。度量了同样大小训练集的变动所导致的学习性能的变化;即刻画了数据扰动所造成的影响;
高方差(过拟合): 训练误差较小,验证误差较大
应对方法: 增加训练样本;去除非主要特征;加强正则化
一般训练趋势:高偏差->高方差
模型复杂度并非越高越好,可能复杂度变高,效果反而更差
噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界;即刻画了学习问题本身的难度。
泛化误差=方差➕偏差➕噪声
三、线性模型
1、线性回归模型
线性回归、多项式回归多用于预测,逻辑回归多用于分类。
https://katya.blog.csdn.net/article/details/135046372?ydreferer=aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NzE4NzE0Ny9jYXRlZ29yeV8xMjQ4NDI5Ni5odG1sP3NwbT0xMDAxLjIwMTQuMzAwMS41NDgy

KNN算法:大老粗
非参数模型,计算量大,好在数据无假设
线性算法:头脑敏锐
可解释性好,建模迅速,线性分布的假设
2、线性判别分析 LDA

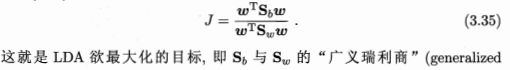
类内散度矩阵Sw 类间散度矩阵Sb。
3、多分类学习
![]()
OVO(One vs One )Cn2个分类器
OVR (One vs Rest ) n个分类器

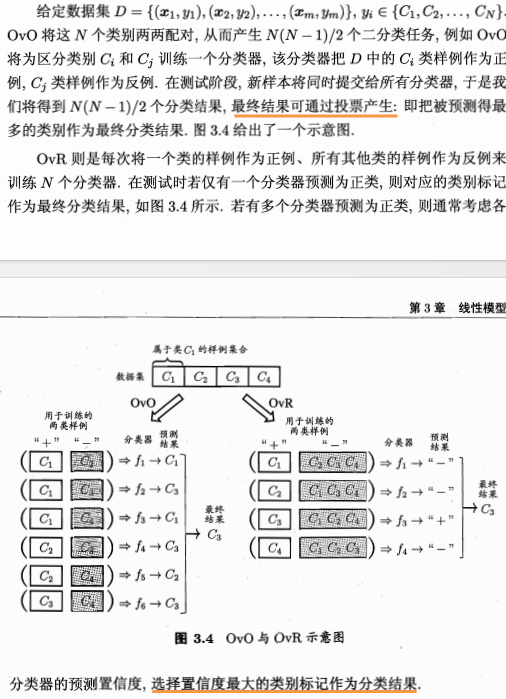

纠错输出码 距离最小。
4、类别不均衡问题
类别不平衡就是指分类任务中不同类别的训练样例数目差别很大的情况。

策略 —— 再缩放(再平衡)。
再缩放的思想虽简单,但实际操作却并不平凡,主要因为“训练集是真实样本总体的无偏采样”这个假设往往并不成立,也就是说,我们未必能有效地基于训练集观测几率来推断出真实几率。
现有技术大体上有三类做法:
第一类是直接对训练集里的反类样例进行“欠采样”(undersampling),即去除一些反例使得正、反例数目接近,然后再进行学习;
第二类是对训练集里的正类样例进行“过采样”(oversampling),即增加一些正例使得正、反例数目接近,然后再进行学习;
第三类则是直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将式(3.48)嵌入到其决策过程中,称为“阈值移动”(threshold-moving)。
欠采样法的时间开销通常远小于过采样法;因为前者丢弃了很多反例,使得分类器训练集远小于初始训练集,而过采样法增加了很多正例,其训练集大于初始训练集。
需注意的是,过采样法不能简单地对初始正例样本进行重复采样,否则会招致严重的过拟合;另一方面,欠采样法若随机丢弃反例,可能丢失一些重要信息;
四、决策树
1、决策树学习模型
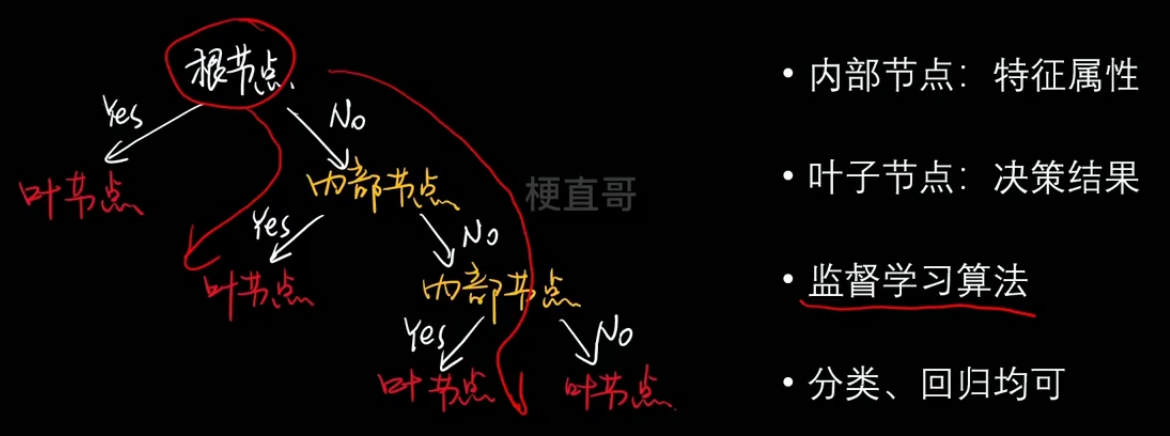
- 特征选择、节点分类、阈值确定
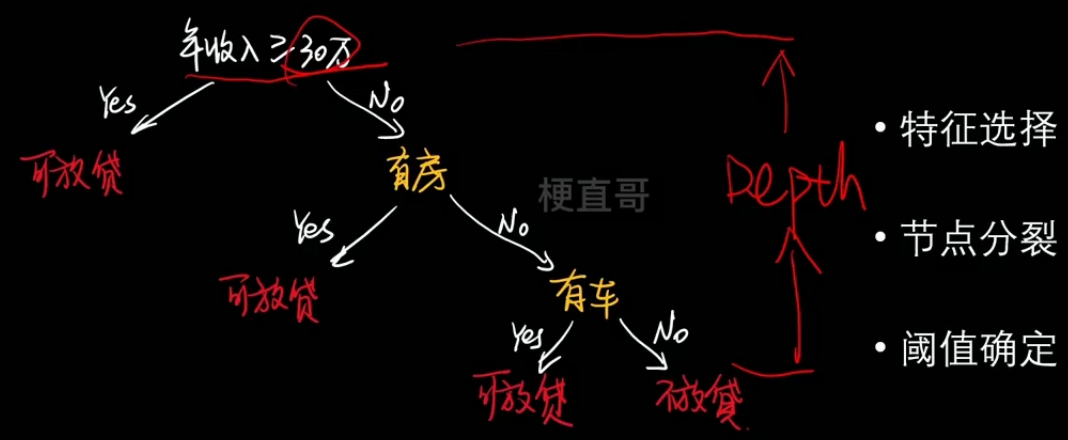
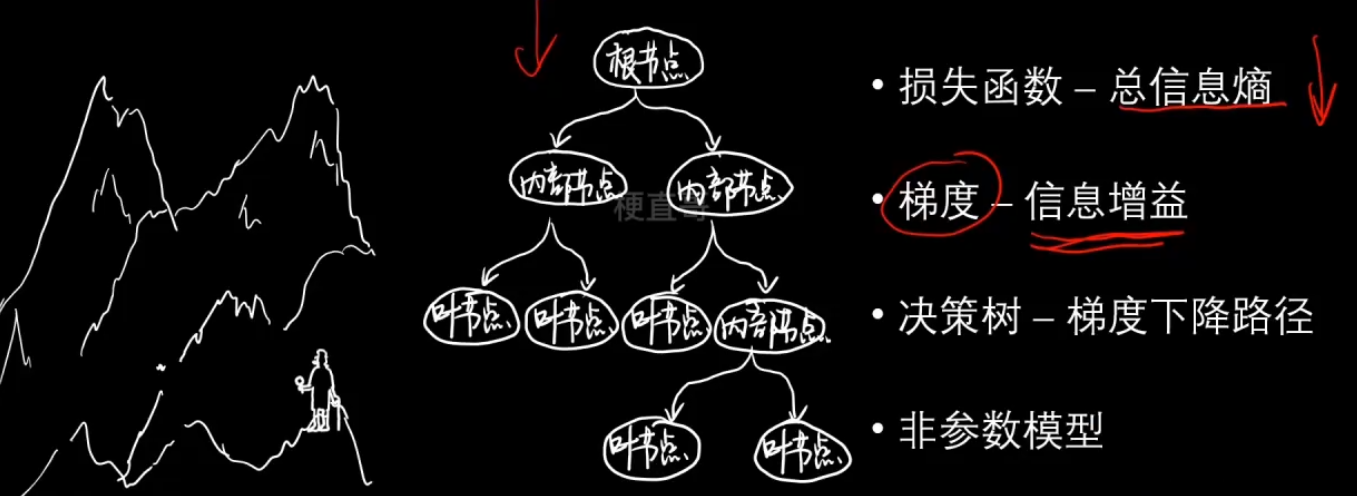
*** ?决策树算法流程

2、信息增益、增益率计算
信息熵:
熵本身代表不确定性,是不确定性的一种度量。熵越大,不确定性越高,信息量越高。

为什么用log?—— 两种解释,可能性的增长呈指数型;log可以将乘法变为加减法。
信息增益(互信息):代表了一个特征能够为一个系统带来多少信息。

ID3决策树学习算法 —— 以信息增益为准则划分属性。
增益率

基尼指数


基尼系数运算稍快;
物理意义略有不同,信息熵表示的是随机变量的不确定度;
基尼系数表示在样本集合中一个随机选中的样本被分错的概率,也就是纯度。
基尼系数越小,纯度越高。
模型效果上差异不大。
4、剪枝 —— 对付过拟合
为什么要剪枝?
复杂度过高。
预测复杂度:O(logm)
训练复杂度:O(n x m x logm)
logm为数的深度,n为数据的维度。
容易过拟合。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升则停止划分,并将当前结点标记为叶结点;
后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
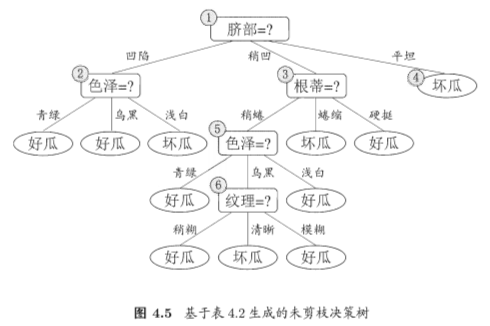
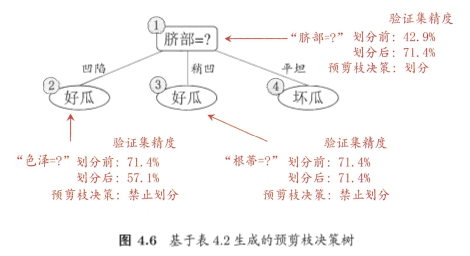

5、连续与缺失值
二分法,对连续属性进行处理。
6、多变量决策树
非叶节点不再是仅对某个属性,而是对属性的线性组合进行测试。
五、神经网络
1、感知机
MP神经元

激活函数

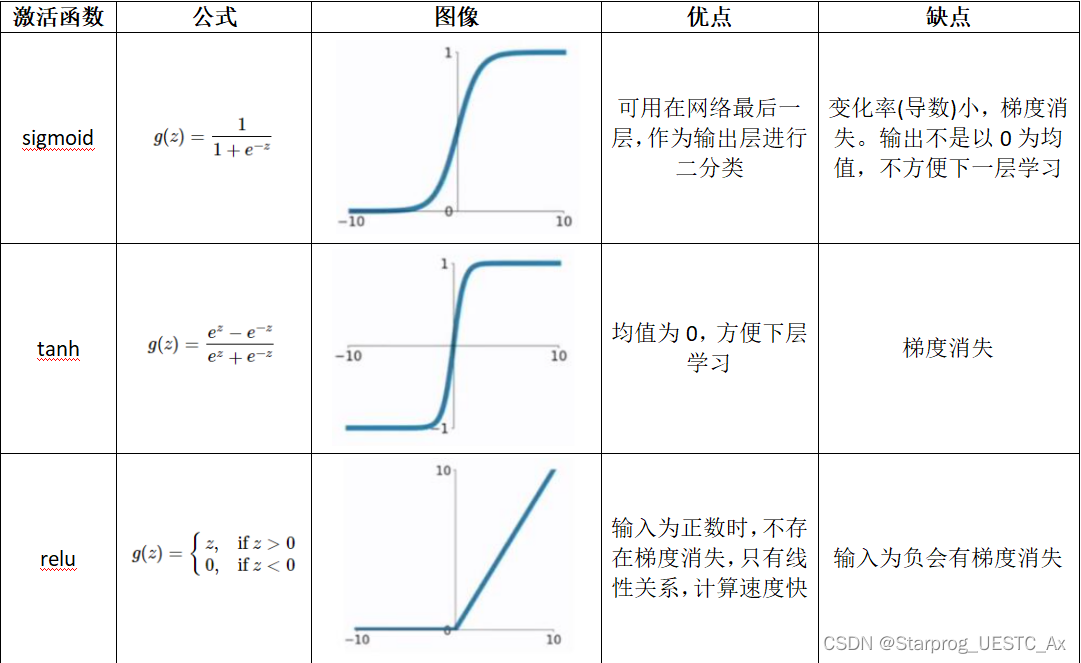

单层感知机
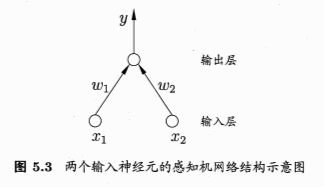




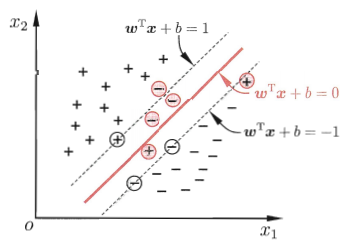
wTx+b=0对应于特征空间一个超平面s,将空间分成两个部分,也称分离超平面。
单层感知机的学习能力非常有限, 只能解决线性可分问题。
多层感知机
多层前馈神经网络:只与下一层连接;同层或跨层不连接;
前馈:正向
2、BP算法 / 误差逆传播算法
西瓜书《机器学习》第五章部分课后题_试述将线性函数f(x)=wtx用作神经元激活函数的缺陷-CSDN博客
试设计一个算法,能通过动态调整学习率显著提升收敛速度,编程实现该算法,并选择两个 UCI 数据集与标准的 BP 算法进行实验比较,
https://www.cnblogs.com/bryce1010/p/9386970.html
3、输出层节点 计算网络参数
4、训练法则
5、网络收敛性
六、SVM支持向量机
1、支持向量机概念 / 目标
支持向量 support vector —— 距离决策边界最近的点,每个类别的极端数据点
超平面 hyperplane —— “隔离带”中间的平分线
间隔 margin —— 最大化margin
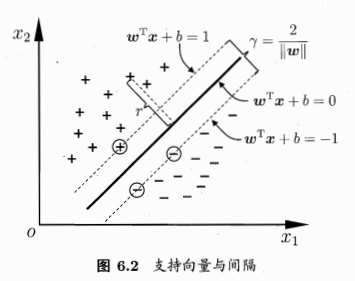
优化目标:—— 最大化间隔margin 也就是 最大化距离 d,也就是点到超平面的垂直距离。
注意此处的距离和线性模型中的距离不同,线性模型中的距离是 yhat-y (斜边)
软间隔

那么怎么保证 这个减去的值不能太大呢?

也就是说尽量让所有数据容错值的和最小。让二者取一个平衡。
C 就是一个新的超参数,用来调节两者的权重值。
再看一下这个求和的形式,是不是特别像正则化?其实就可以看成正则化。
正则化项是一次的,所以叫L1正则。这里省略了绝对值符号,因为其就是正数。
2、核函数原理及作用 —— 降低计算复杂度
将样本从原始空间映射到一个更高维的特征空间。
空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。


核函数:是映射关系的内积。
映射函数本身仅仅是一种映射关系,并没有增加维度的特性,不过可以利用核函数的特性,构造可以增加维度的核函数,这通常是我们希望的。
要注意,核函数和映射没有关系。核函数只是用来计算映射到高维空间之后的内积的一种简便方法!


线性组合、直积仍是核函数。

3、支持向量机的应用
七、贝叶斯分类器
监督式模型分为判别式模型和生成式模型。
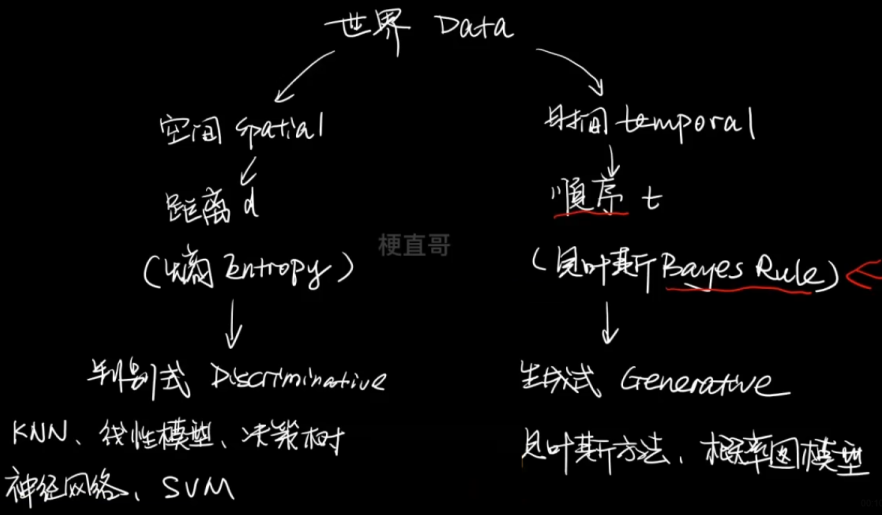
判别模型和生成模型的区别:
判别式模型:输入一个特征X可以直接得到一个y。
生成式模型:上来先学习一个联合概率分布 p(x,y),
再用他根据贝叶斯法则求条件概率密度分布。
—— 没有决策边界的存在
判别式数据对于数据分布特别复杂的情况,比如文本图像视频;
而生成式模型对于数据有部分特征缺失的情况下效果更好,
而且更容易添加数据的先验知识 p(x)
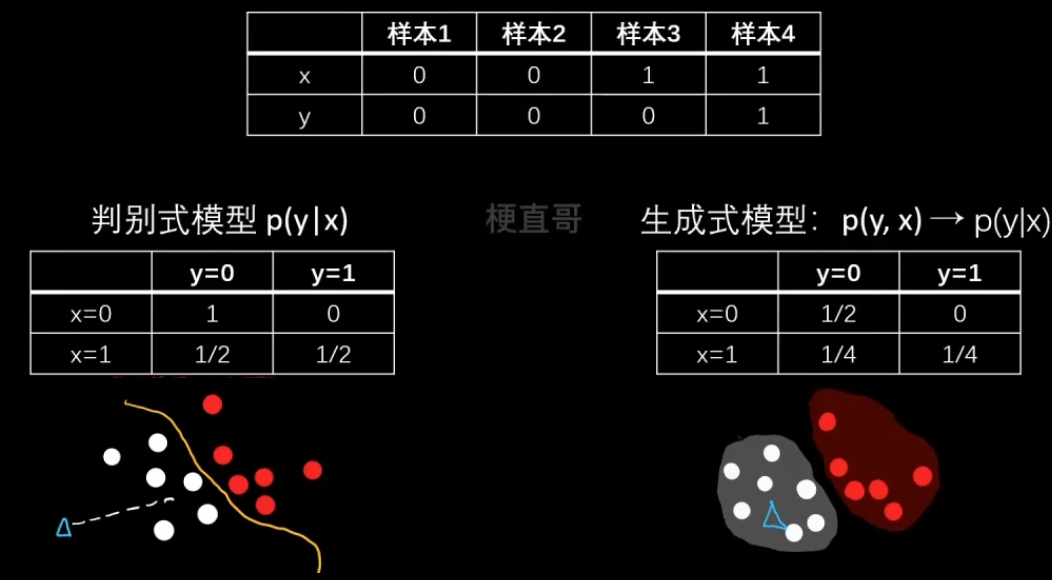
1、贝叶斯决策论


则
建立了四个概率分布之间的关系,已知变量 X 和 未知变量(模型参数)w 之间的计算关系。
假定 X 表示数据,W 表示模型的参数。
Likelihood翻译成可能性或者是似然函数,最大似然估计指的就是这个。

2、极大似然估计
根据事件 x 的观察结果 c ,推断 θ 为多少时,x 最有可能发生。


3、朴素贝叶斯条件 / 概念


*** p152 例子
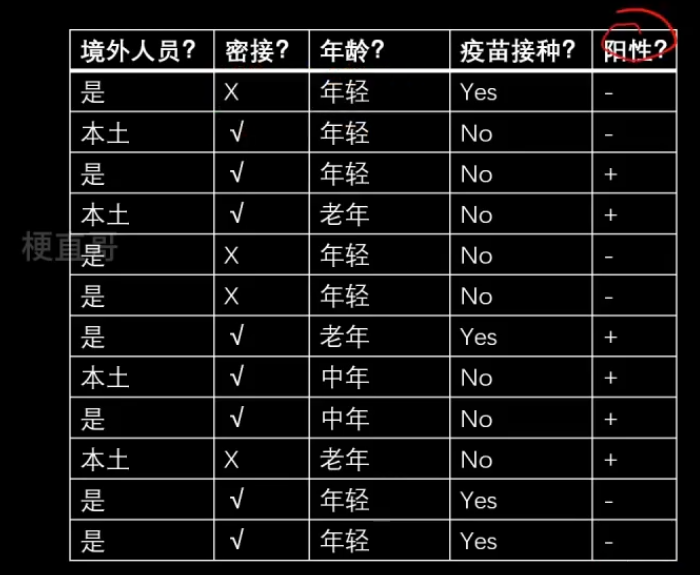
能不能直接根据这些经验(上面的数据),来判断一个境外人员有没有得新冠呢?
即求解:

比较难求的显然就是 Likelihood,所以朴素贝叶斯假设特征之间相互独立。

根据中心极限定理,频率就等于概率,虽然这里数据没有那么多,也一样可以这么算。


4、EM算法
期望最大化算法,Expectation Maximization
目的:使得似然函数最大化
引入 隐变量(未观测变量)
先猜一个 z 的分布,就是蓝色的分布,然后用它来逼近。

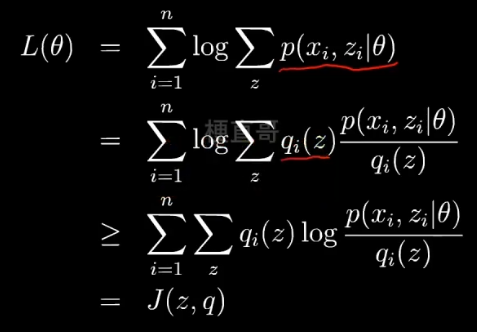
利用Jensen不等式:期望的函数 ≥ 函数的期望,
函数就是log函数,后面的一坨是期望,把q看成一个分布,分式看成z的函数。
现在就可以通过不断改变 z,q来搜索L(θ),从而找到他的最大值。

![]()

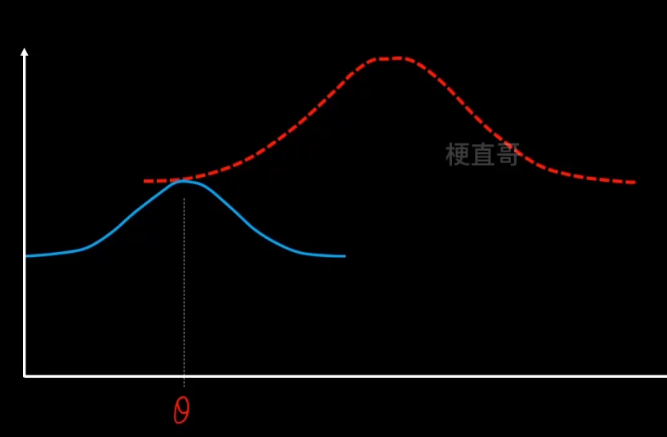
EM算法步骤
1、E步骤,先固定q分布不变(θ值不变),使用MLE来最大化z。
沿着固定的θ值,向上搜索,碰到红线之后就停止。
2、M步骤,固定z不变,让q最大化寻优。
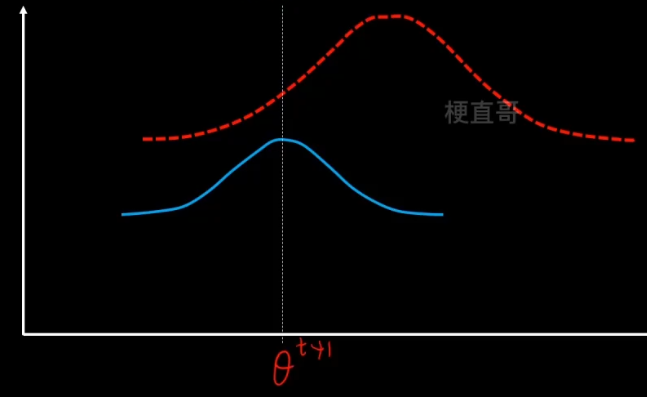
重复这个步骤,反复迭代,直到找到最优的θ*。

注意虽然EM的迭代一定会收敛,但是不一定收敛到最优的参数值,可能陷入局部最优,所以结果很受初始值的影响。
5、分类器怎么计算
6、估计后验概率策略
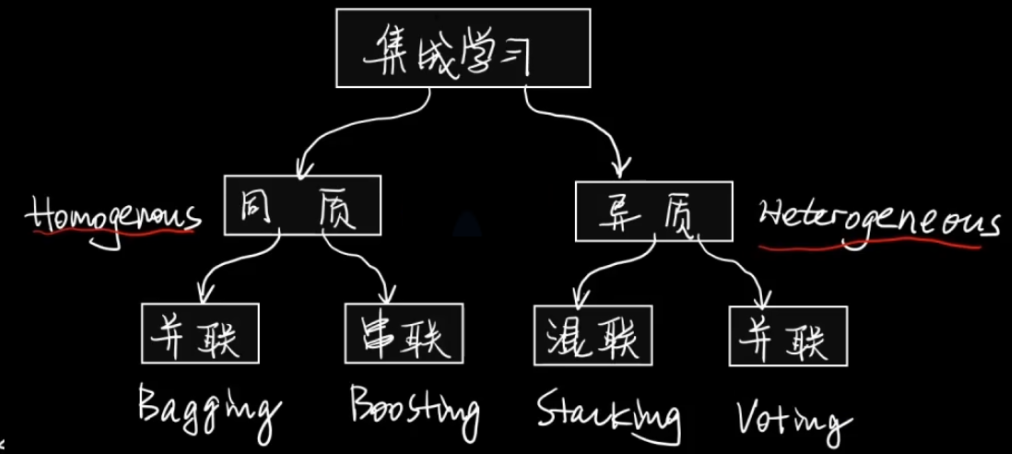
八、集成学习
1、集成原理
集成学习通过构建并结合多个学习器来完成学习任务。
也被称为 多分类器系统、基于委员会的学习等。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即
个体学习器间存在强依赖关系、必须串行生成的序列化方法 —— Boosting
个体学习器间不存在强依赖关系、可同时生成的并行化方法 —— Bagging和“随机森林”(Random Forest)
集成学习按照 所使用的 单个子模型是不是同一种 分为同质的方法和异质的方法。
按照 子模型的连接方式 可以分为串行策略、并行策略和串并结合的策略。
2、Boosting算法 —— 串行
基本思想

每个子模型在训练过程中更加关注上一个模型中表现不好的样本点,以此来提高模型效果。
训练一系列的弱学习器,弱学习器是指仅比随机猜测好一点点的模型,例如较小的决策树。
训练的方式使用加权的数据,在训练的早期,对于错分的数据给予较大的权重。
对于训练好的弱分类器,如果是分类任务则按照权重进行投票,如果是回归任务则进行加权,然后再进行预测。
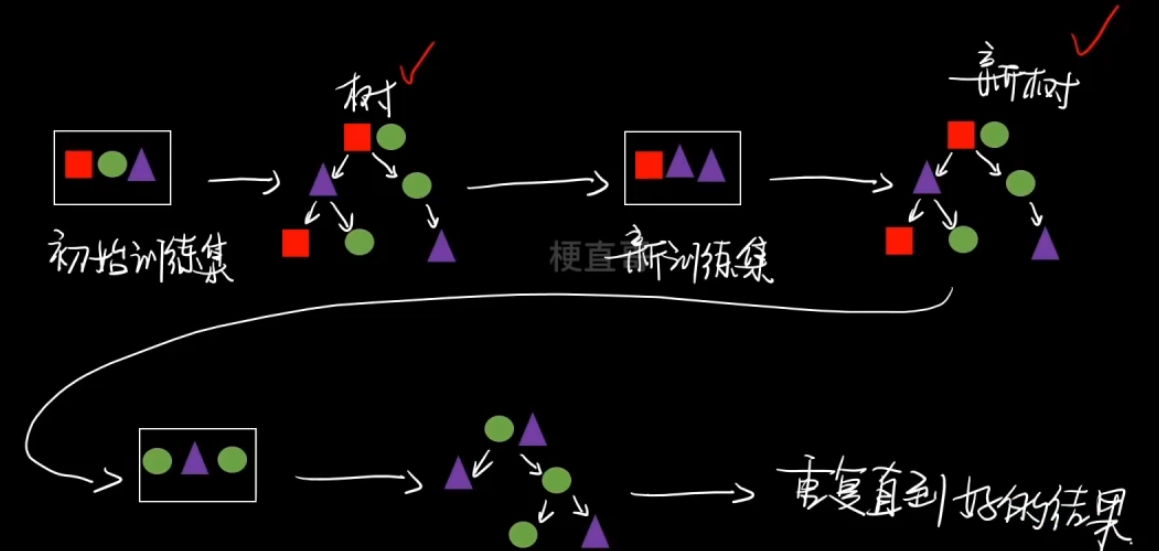
*** AdaBoost算法 p174

标准AdaBoost只适用于二分类任务。

从偏差-方差分解的角度看,Boosting 主要关注降低偏差,因此 Boosting能基于泛化性能相当弱的学习器构建出很强的集成。
3、Bagging与随机森林RF —— 并行
Bagging

数据组织方式不同,从总的数据集中抽样组成新的子集。
所有支路使用同样的算法。
分类还是使用投票的方式集成,回归任务则是使用平均的方式集成。
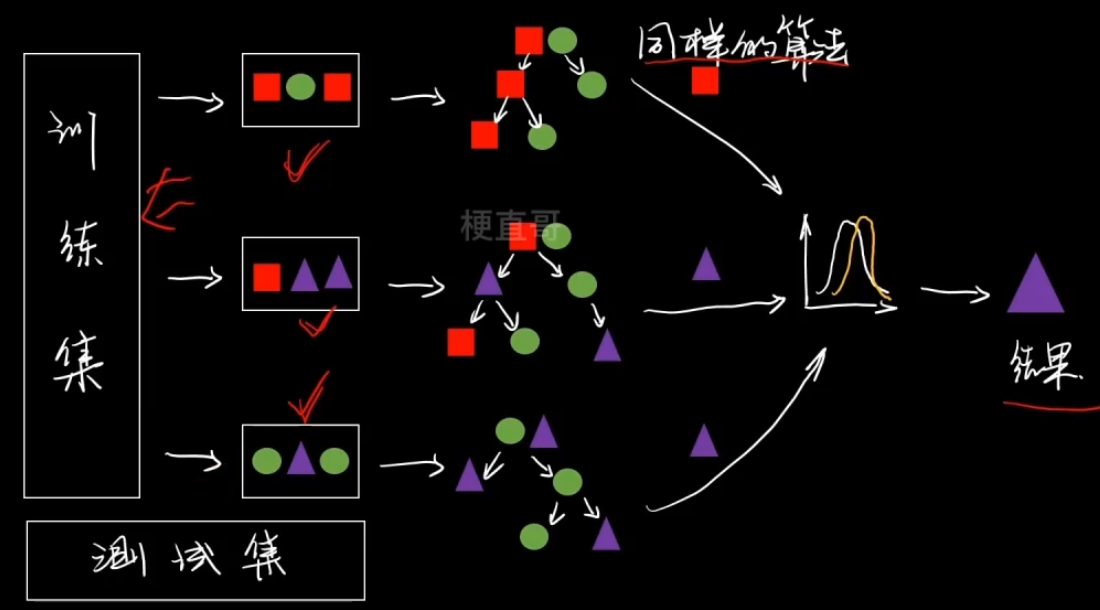
从偏差-方差分解的角度看,Bagging 主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更为明显。

有36.8%的样本没被抽到,那么:
不区分训练、测试集,用没被取到的作为测试集。
随机森林 RF


值得一提的是,随机森林的训练效率常优于 Bagging,因为在个体决策树的构建过程中,Bagging使用的是“确定型”决策树,在选择划分属性时要对结点的所有属性进行考察而随机森林使用的“随机型”决策树则只需考察一个属性子集。
4、结合策略
1)平均法(简单平均法、加权平均法)
2)投票法(绝对多数投票法、相对多数投票法、加权投票法)
3)学习法(Stacking等)


其实是一个二次学习的过程。
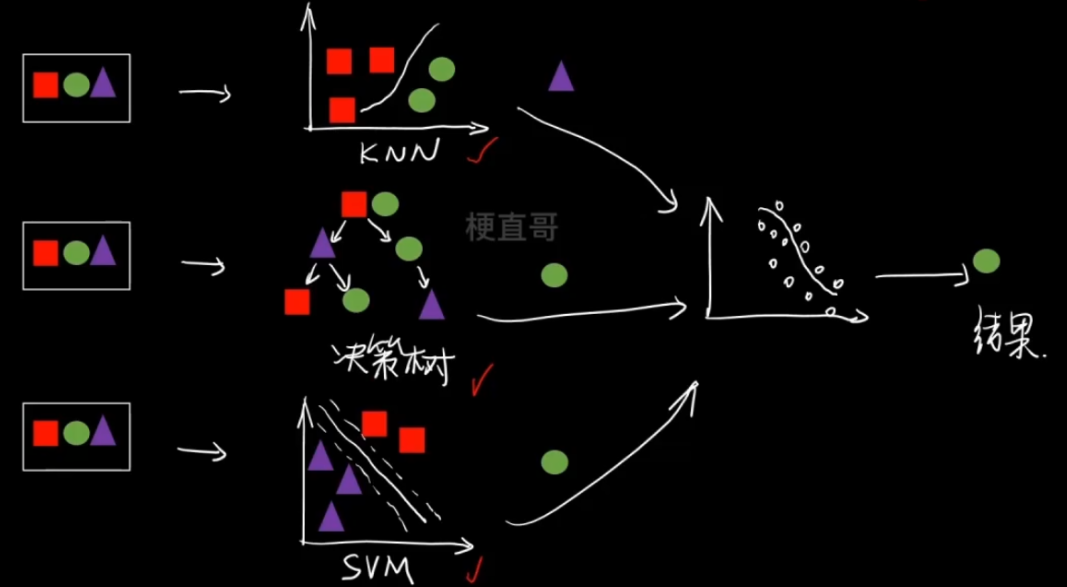
先用第一份数据 训练这三个模型,
再用第二份数据 经过这三个模型输出之后训练第二级的模型4。
*** 5、多样性 p185
九、聚类学习
1、聚类原理
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个 簇。
2、性能度量 / 有效性指标




3、距离计算
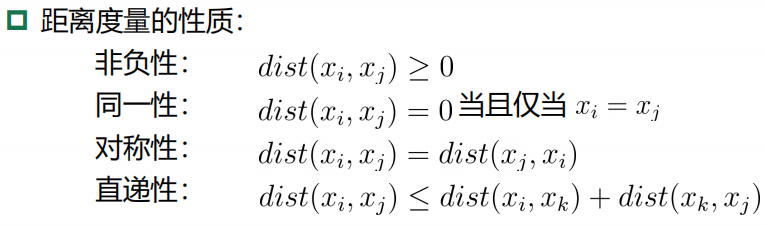




4、原型聚类 kmeans
通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解。
k-均值
根据样本点与簇质心距离判定
以样本间距离衡量簇内相似度

K均值聚类算法步骤:
- 选择k个初始质心,初始质心的选择是随机的,每一个质心是一个类
- 计算样本到各个质心 欧式距离,归入最近的簇
- 计算新簇的质心,重复2 3,直到质心不再发生变化或者达到最大迭代次数
K 均值算法的运行结果依赖于初始选择的聚类中心,找到的结果是局部最优解,未必是全局最优解。

学习向量量化LVQ


高斯混合聚类
5、密度聚类 DBScan
DBSCAN算法:基于一组“邻域”参数来刻画样本 分布的紧密程度。
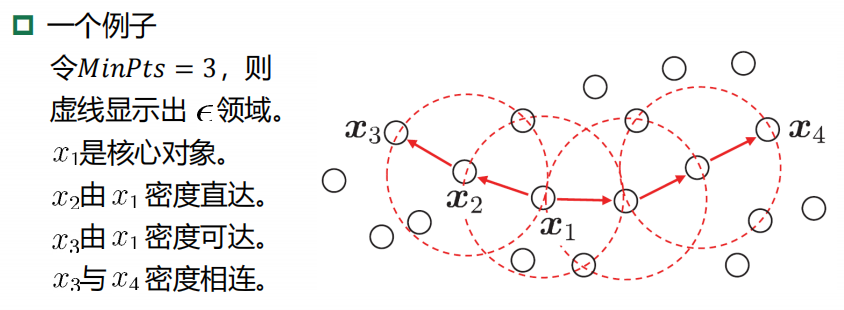

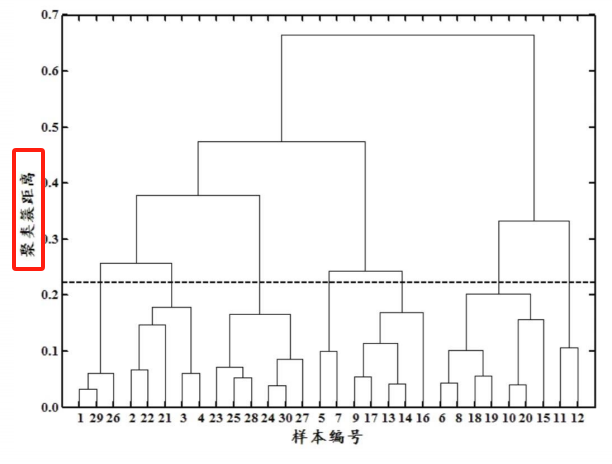
6、层次聚类
按照层次把数据划分到不同层的簇,形成树状结构,可以揭示数据间的分层结构。
在树形结构上不同层次划分可以得到不同粒度的聚类。
过程分为自底向上的聚合聚类和自顶向下的分裂聚类。
AGNES算法(自底向上的层次聚类算法)。
将每个样本看做一个簇,初始状态下簇的数目 = 样本的数目
簇间距离最小的相似簇合并
下图纵轴不是合并的次序,而是合并的距离
自顶向下的分裂聚类
所有样本看成一个簇
逐渐分裂成更小的簇
目前大多数聚类算法使用的都是自底向上的聚合聚类方法。
十、降维与度量学习
1、降维 / 维度约简 思想
通过某种数学变换将原始高维属性空间转变为一个低位“子空间”,在这个子空间中样本密度大幅提高,距离计算也变得容易。

多维缩放 MDS


2、k近邻学习 KNN
懒惰学习的代表,没有显式的训练过程,在训练阶段仅仅保存样本,训练时间开销为零,待收到测试样本后再进行处理。
维数灾难:在高维情形下出现的数据样本稀疏、距离计算困难等问题。

k个最近的邻居
民主集中制投票
分类表决与加权分类表决

K太小导致“过拟合”(过分相信某个数据),容易把噪声学进来
K太大导致“欠拟合”,决策效率低
Fit = 最优拟合(找三五个熟悉的人问问),通过超参数调参实现 ~
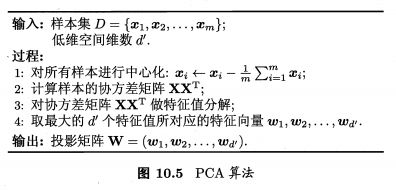
3、PCA主成分分析
回顾这部分之前,先来回忆下之前的基础知识:
高维向量的乘法叫做内积 / 点乘 , 集合含义就是投影。高维向量是定义在内积空间(准希尔伯特空间)的。
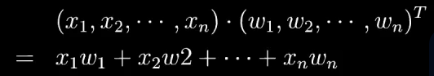
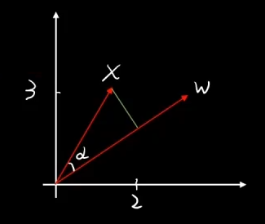
空间基底,就像空间中的坐标轴一样,可以表达成内积的形式。
基 乘以原向量,其结果刚好为新基的坐标。

拓展一下,把一个坐标投影到由一组新的基底构成的空间中怎么表示呢?
如下图,其中矩阵 W 其中的每一行 都是一个基向量,一共有 k 行,即由 k 个基向量。
数学上我们通常喜欢用一个列向量来表示基向量,而机器学习中通常使用行向量来表示样本。

降维的目标就是找到一个最优的特征空间,也就是一个新的基底矩阵,使得维数 k 小于原来的维数 n 。
那怎么才能确保在新的特征空间中数据的分布更好呢,也就是让数据的散度最大?
此时就需要使用 方差与协方差 —— 衡量数据的散度。
假定现在有n个随机变量,它的向量就是
![]()
在统计学中,方差就是用来衡量单个随机变量的离散程度。
其中m表示样本的数量,xk i 表示随机变量 xk 的第 i 个观测样本,一共m个。
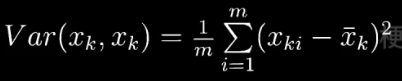
协方差是用来刻画两个随机变量相似的程度。
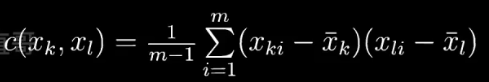
为了方便计算,令均值 = 0 。协方差矩阵就是下面的模样

对角线是方差,其余的均为协方差。
协方差矩阵 —— 能够捕捉数据在对角线方向上的离散程度
降维到 数据空间中 数据坐标的 方差最大 协方差最小的时候最好。
———— 协方差矩阵对角化,找出前面方差大的 k 行做基底。
线性代数中 如果一个向量 X 满足:
数 称为
的特征值,
称为
对应于特征值
的特征向量。
是一个线性变化矩阵,物理上 特征值
就表示对基向量
的缩放程度。

紫色的特征值比较大,它就沿着这个方向伸缩的比较大。
所以我们降维的目的就是为了找到 ——
数据协方差矩阵 特征值最大的那些特征向量。
算法步骤
假设我们有 m 条 n 维数据,把它排成一个 mxn 的矩阵
- 原始数据矩阵化 X 后,零均值化(去掉均值的影响)
- 求协方差矩阵
- 求协方差矩阵的特征值和特征向量
- 按特征值从大到小取特征向量前 k 行组成矩阵 W
即为降维后的数据
注意事项
- 验证集、测试集执行同样的降维
- 验证集、测试集执行零均值化操作时,均值须计算于训练集,因为训练集是观测到的数据
- 保证训练集、测试集独立同分布一致性,否则会出现方差漂移
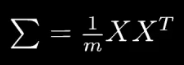
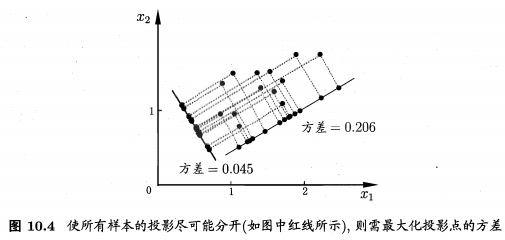
降维操作要做的就是 找到一条轴,将所有点投影到这条轴上,使得投影后的间距最大。
考试加油呐 ~ ovo
部分可参考
PCA 原理:为什么用协方差矩阵_pca协方差矩阵-CSDN博客
点乘?内积? - 知乎
https://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
机器学习算法: AdaBoost 详解 - 知乎
01.3 神经网络的基本工作原理 - AI-EDU
相关文章:
【机器学习 西瓜书】期末复习笔记整理
一些杂点: 测试集如何归一化? —— 不是用测试集的均值和标准差,而是用训练集的! 机器学习: 对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。 参考计算例题: 机器学习【期末复习…...

回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测
回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测 目录 回归预测 | Matlab基于SO-GRU蛇群算法优化门控循环单元的数据多输入单输出回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于SO-GRU蛇群算法优化门控循环单元的数…...
自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目25-T5模型和BERT模型的应用场景以及对比研究、问题解答。T5模型和BERT模型是两种常用的自然语言处理模型。T5是一种序列到序列模型,可以处理各种NLP任务,而BERT主要用于预训练语言表示。T5使用了类似于BERT的预训…...
分布式搜索——Elasticsearch
Elasticsearch 文章目录 Elasticsearch简介ELK技术栈Elasticsearch和Lucene 倒排索引正向索引倒排索引正向和倒排 ES概念文档和字段索引和映射Mysql与Elasticsearch 安装ES、Kibana安装单点ES创建网络拉取镜像运行 部署kibana拉取镜像部署 安装Ik插件扩展词词典停用词词典 索引…...

用python实现调用nosql
要使用Python调用NoSQL数据库,您需要使用适当的Python库。以下是使用Python调用MongoDB和Redis两个流行的NoSQL数据库的示例: 调用MongoDB 要使用Python调用MongoDB,您需要安装pymongo库。您可以使用以下命令在终端或命令提示符中安装它&…...

setTimeout和setInterval定时器的返回值
nodejs中定时器返回Timer对象,window中定时器返回number,所以可以使用ReturnType预定义类型推断—或者使用window.setInterval代替setInterval https://mybj123.com/13153.html...

C/C++指针
指针(pointer)是C/C语言中的一种数据类型。指针与int、char等数据类型相似,都是在内存中开辟相应类型的数据区域使用,不同的是int存储的是整数值,而指针存储的是内存地址。指针是在内存中开辟指针类型的区域存储内存地…...

2024 基于 Rust 的 linter 工具速度很快
2024 年 Web 工具的一大趋势是使用 Rust 重写现有工具。Rust 是一种出色的编程语言,能生成运行速度惊人的二进制文件,且与其它 Web 工具的互操作性极佳,这得益于 WebAssembly 的帮助。swc 和 Turbopack 等工具的速度提升为快速开发体验带来了…...
)
JWT相关问题及答案(2024)
1、什么是 JWT,它通常用于什么目的? JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在不同实体之间安全地传输信息。它由三个部分组成:头部(Header)、载…...

Linux例行性工作 at和crontab命令
1,例行性工作 例行性工作 —— 在某一时刻,必须要做的事情 —— 定时任务 (比如:闹钟) 例行性工作分为两种:“单一的例行性工作 at”和“循环的例行性工作 crontab” 2,单一执行的例行性工作 …...

cookie共享和session共享实例演示
1、cookie共享实例 1.test1.share.com/index.php setcookie(dangqian, value, [domain > test1.share.com]); setcookie(gen, value, [domain > share.com]);2、test2.share.com/index.php $cookies $_COOKIE; // 打印所有Cookie的名称和值 foreach ($cookies as $n…...

设计模式之开闭原则:如何优雅地扩展软件系统
在现代软件开发中,设计模式是解决常见问题的最佳实践。其中,开闭原则作为面向对象设计的六大基本原则之一,为软件系统的可维护性和扩展性提供了强大的支持。本文将深入探讨开闭原则的核心理念,以及如何在实际项目中运用这一原则&a…...

Python Pandera 用于数据验证和清洗:是一个强大的工具用起来
今天为大家分享一个非常好用的 Python 库 - pandera。 Github地址:https://github.com/unionai-oss/pandera 在数据科学和数据分析中,数据的质量至关重要。不良的数据质量可能导致不准确的分析和决策。为了确保数据的质量,Python Pandera 库…...

英诺赛科推出BMS方案,搭载100V双向导通VGaN
BMS 俗称电池保姆或电池管家,主要是为了智能化管理及维护各个电池单元,防止电池出现过充电和过放电,保障电池安全使用的同时延长使用寿命。 当前市面上出现的电池管理系统大多数采用 Si MOS,由于 Si MOSFET 具有寄生二极管&#x…...
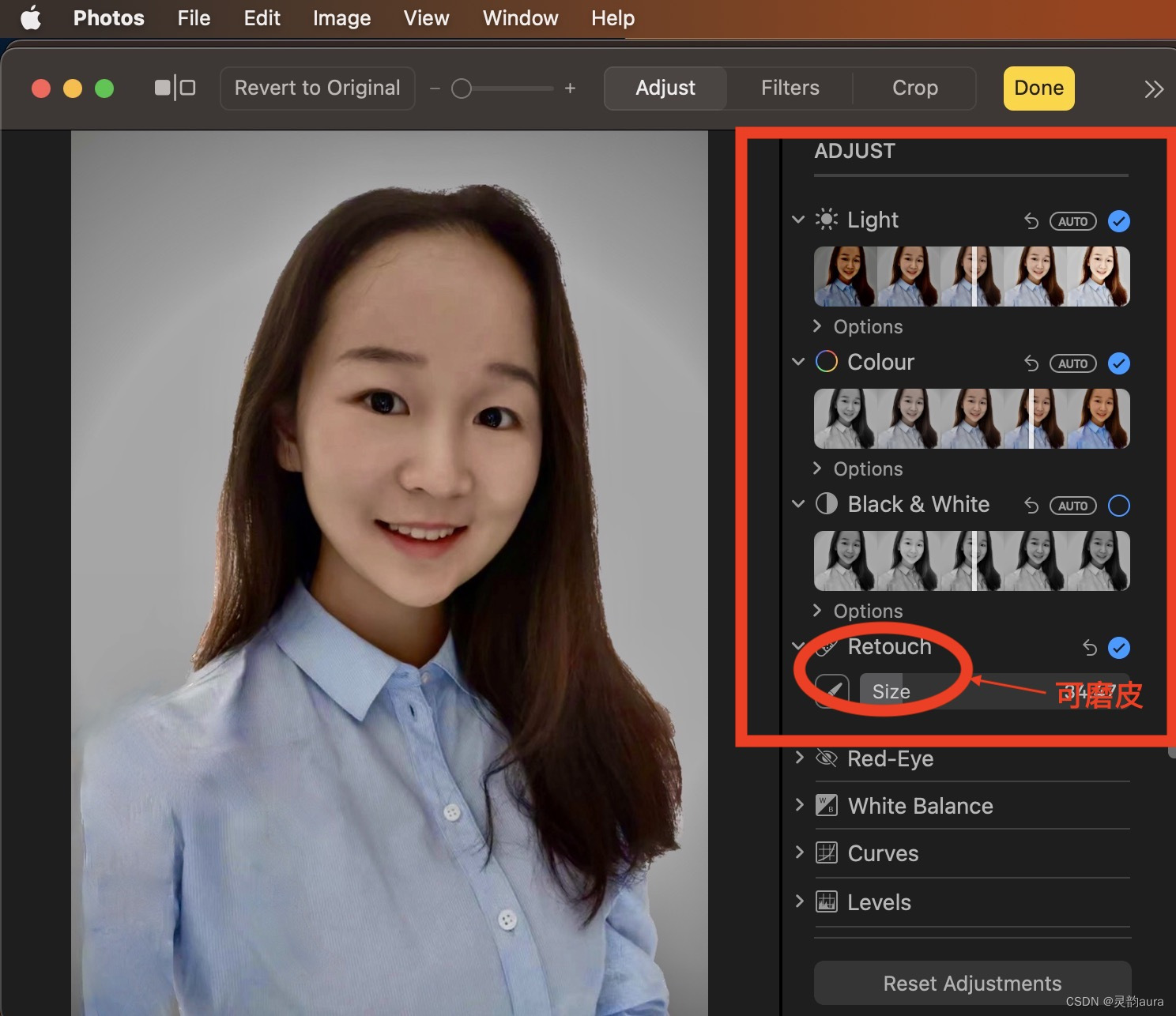
如何用Mac工具制作“苹果高管形象照”
大伙儿最近有没有刷到“苹果高管形象照”风格,详细说来就是: 以苹果官网管理层简介页面中,各位高管形象照为模型,佐以磨皮、美白、高光等修图术,打造的看上去既有事业又有时间有氧的证件照,又称“苹…...
回环检测算法:Stable Trangle Descriptor
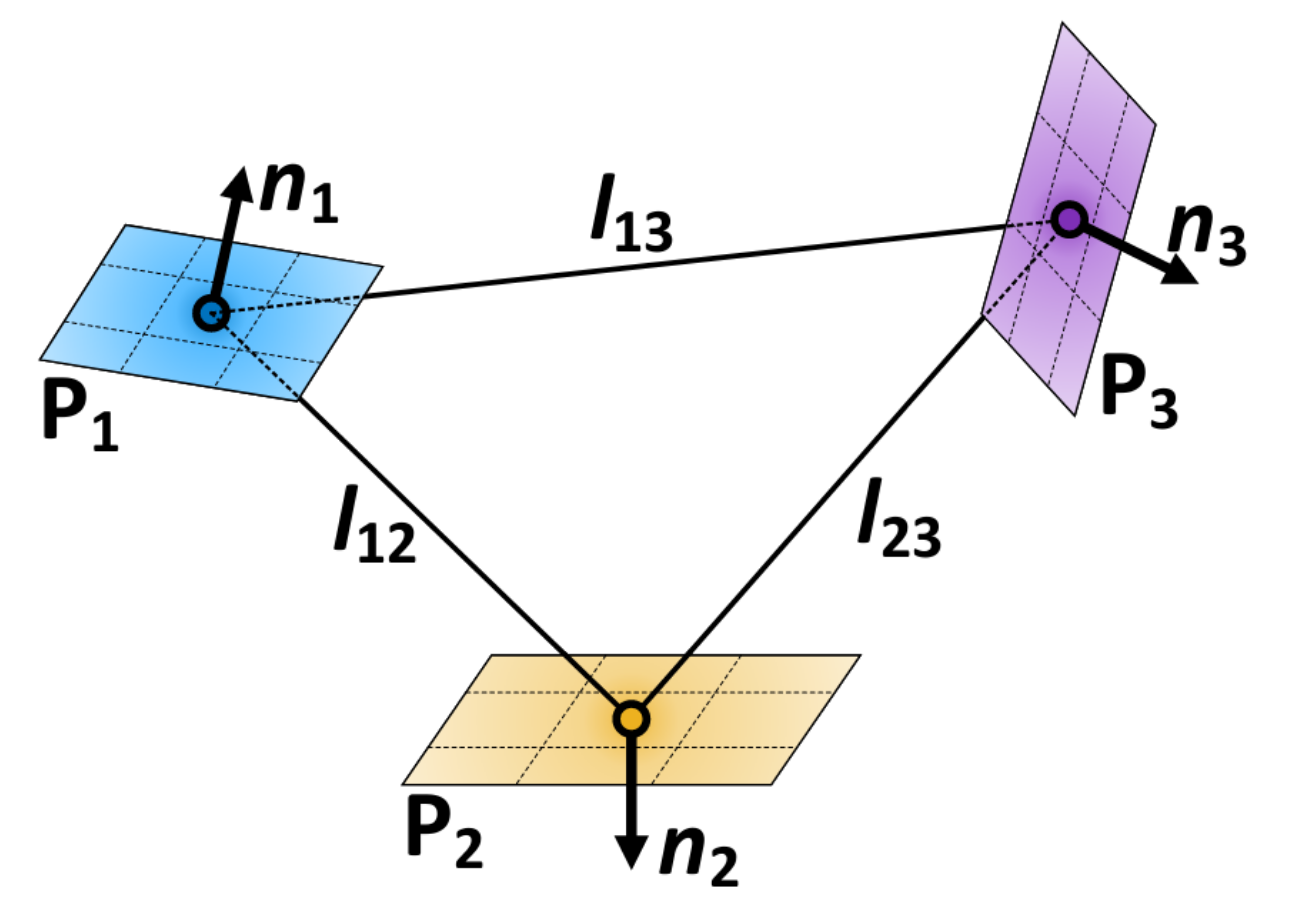
回环检测是指检测传感器的两次测量(如图像、激光雷达扫描)是否发生在同一场景,它是对于SLAM问题至关重要。基于激光雷达的回环检测应该满足如下要求: 无论视点如何变化,回环检测方法应该实现旋转和平移不变性…...
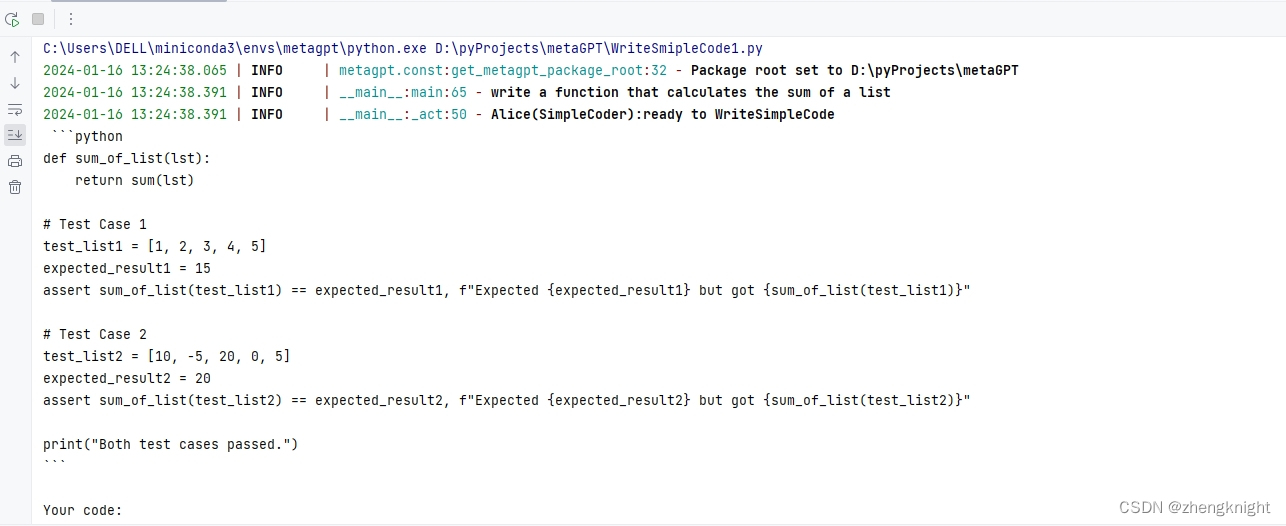
MetaGPT入门(二)
接着MetaGPT入门(一),在文件里再添加一个role类 class SimpleCoder(Role):def __init__(self,name:str"Alice",profile:str"SimpleCoder",**kwargs):super().__init__(name,profile,**kwargs)self._init_actions([Write…...
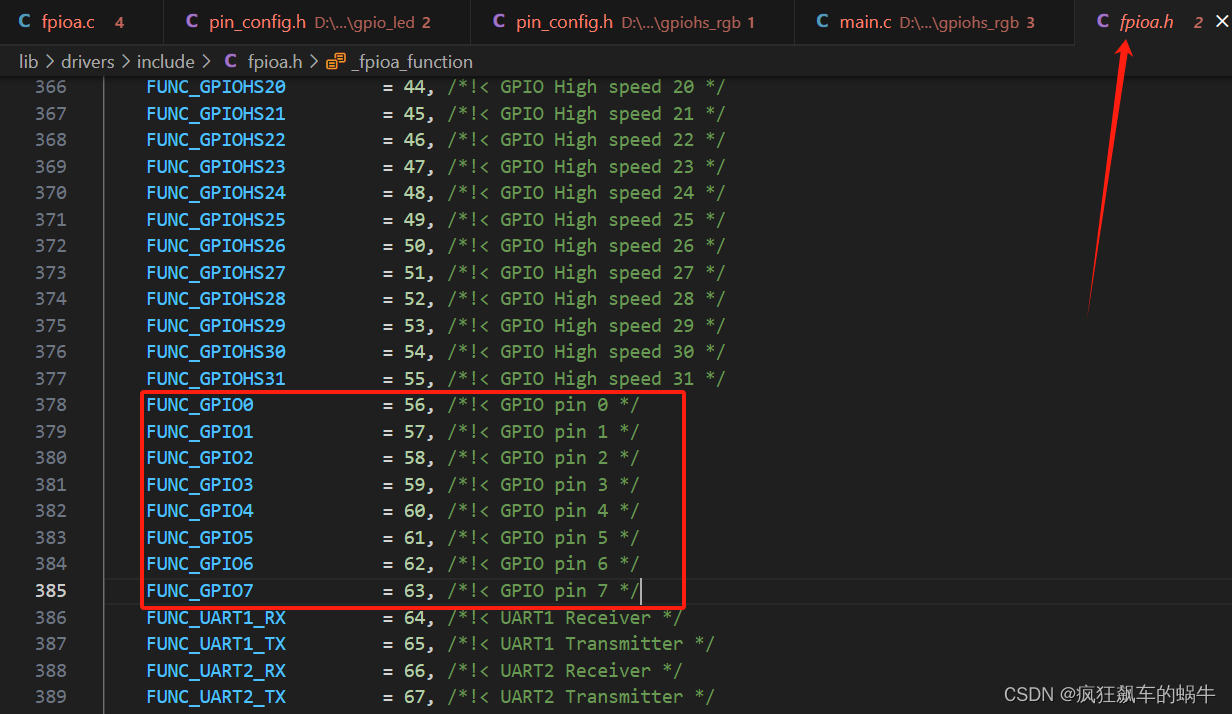
AI嵌入式K210项目(4)-FPIOA
文章目录 前言一、FPIOA是什么?二、FPIOA代码分析总结 前言 磨刀不误砍柴工,在正式开始学习之前,我们先来了解下K210自带的FPIOA,这个概念可能与我们之前学习STM32有很多不同,STM32每个引脚都有特定的功能,…...
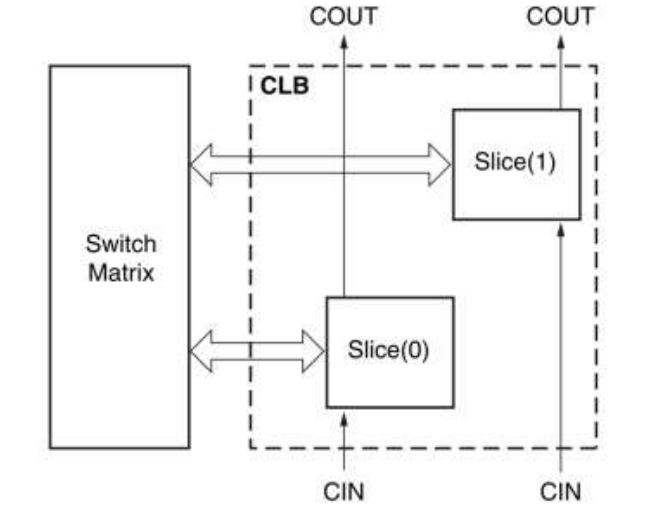
FPGA开发设计
一、概述 FPGA是可编程逻辑器件的一种,本质上是一种高密度可编程逻辑器件。 FPGA的灵活性高、开发周期短、并行性高、具备可重构特性,是一种广泛应用的半定制电路。 FPGA的原理 采用基于SRAM工艺的查位表结构(LUT),…...
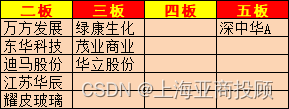
上海亚商投顾:沪指冲高回落 旅游板块全天强势
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日冲高回落,创业板指跌近1%,北证50指数跌超3%。旅游、零售板块全天强势…...

OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如
OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间控制而烦恼吗?OBS Advanced Timer计时器插件是你的直播时间管理…...

【Gemini重大Bug修复公告】:20年Google AI架构师亲述3个致命漏洞及72小时紧急修复全过程
更多请点击: https://intelliparadigm.com 第一章:Gemini重大Bug修复公告 近日,Google 工程团队紧急发布 Gemini API v0.5.3 补丁版本,修复了一个影响多模态推理一致性的高危竞态条件(Race Condition)Bug。…...

Postman便携版:基于Portapps架构的无痕API测试环境构建方案
Postman便携版:基于Portapps架构的无痕API测试环境构建方案 【免费下载链接】postman-portable 🚀 Postman portable for Windows 项目地址: https://gitcode.com/gh_mirrors/po/postman-portable 在API开发与测试领域,Postman已成为开…...

低查重AI教材生成秘籍,借助AI工具轻松完成教材编写!
2026 年 AI 教材写作工具助力教材编写 在编写教材的过程中,如何满足多样化的需求呢?针对不同年龄段的学生,他们的认知水平差别很大,教材内容如果过于深奥或者过于简单,都会影响学习效果。而在课堂教学、自主学习等多种…...

Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命
Thorium浏览器深度解析:如何通过编译优化实现300%性能提升的技术革命 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards …...

如何永久保存微信聊天记录:WeChatMsg完整解决方案让你真正拥有数据主权
如何永久保存微信聊天记录:WeChatMsg完整解决方案让你真正拥有数据主权 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_T…...

如何在Windows上快速安装苹果设备驱动:告别连接烦恼的完整指南
如何在Windows上快速安装苹果设备驱动:告别连接烦恼的完整指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.co…...

ThinkPHP 5.x远程代码执行漏洞原理与实战防御
1. 这个漏洞不是“理论存在”,而是真实打穿过生产环境的链路ThinkPHP 5.x远程代码执行漏洞(CVE-2018-1002015)——这个名字在2018年中后期的Web安全圈里,几乎等同于“默认可打穿”。它不像某些需要苛刻前置条件的逻辑漏洞…...

小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法
小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...

JMeter生产级接口测试实战:从环境配置到链路稳定性保障
1. 这不是又一篇“点点点”的JMeter入门指南,而是你真正能跑通、调得稳、查得清的接口测试实战手册很多人点开“JMeter教程”四个字,心里想的是:“不就是录个脚本、加个线程组、看个聚合报告吗?”——结果一上手,HTTP请…...