2024年美赛数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
data1.head(3)
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
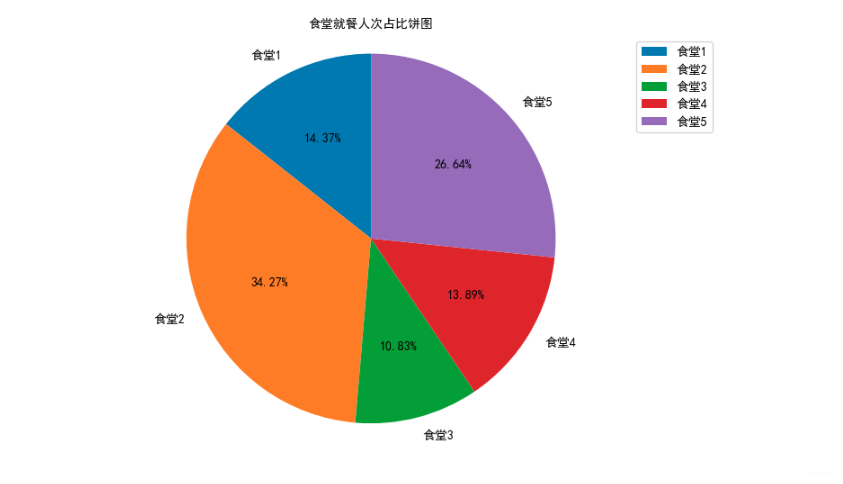
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
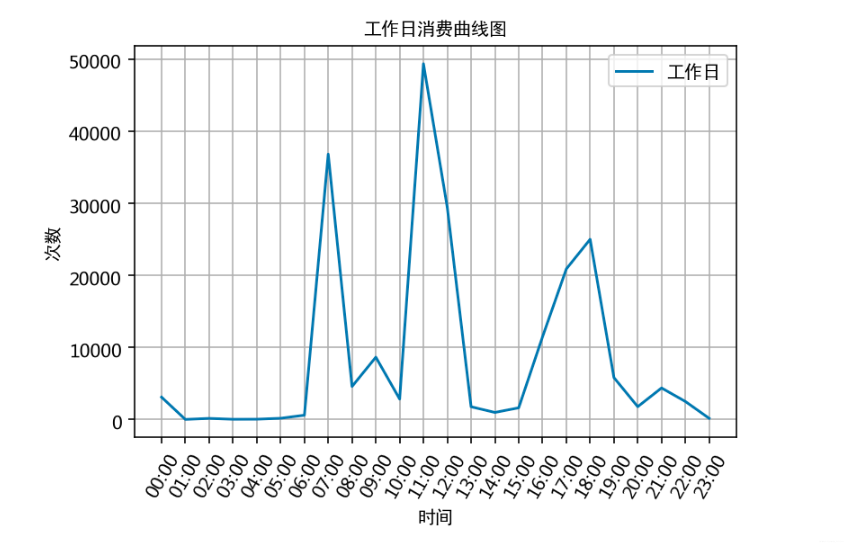
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
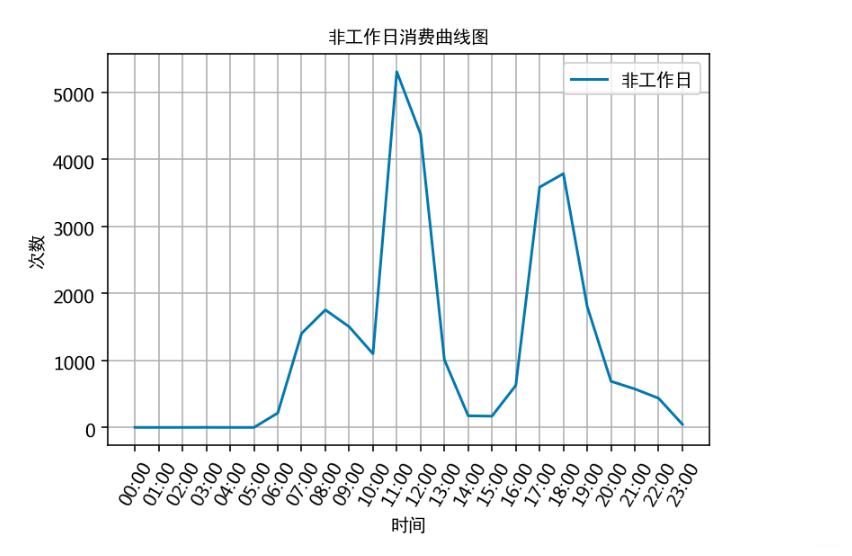
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
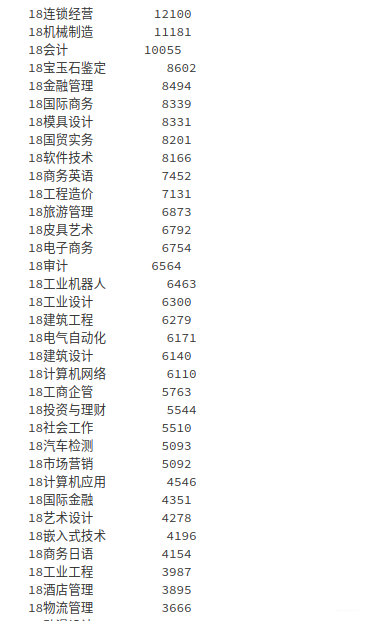
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
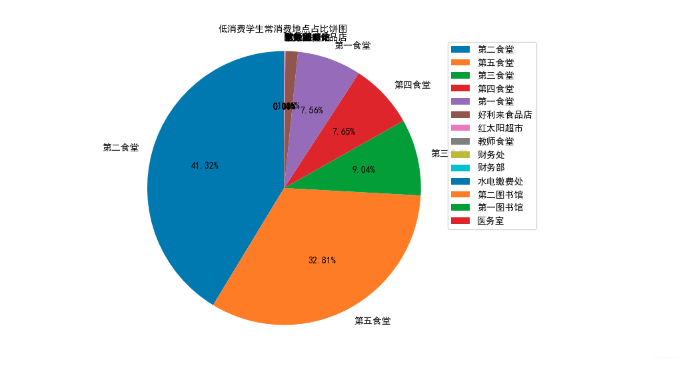
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2024年美赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...
测试覆盖率 之 Cobertura的使用
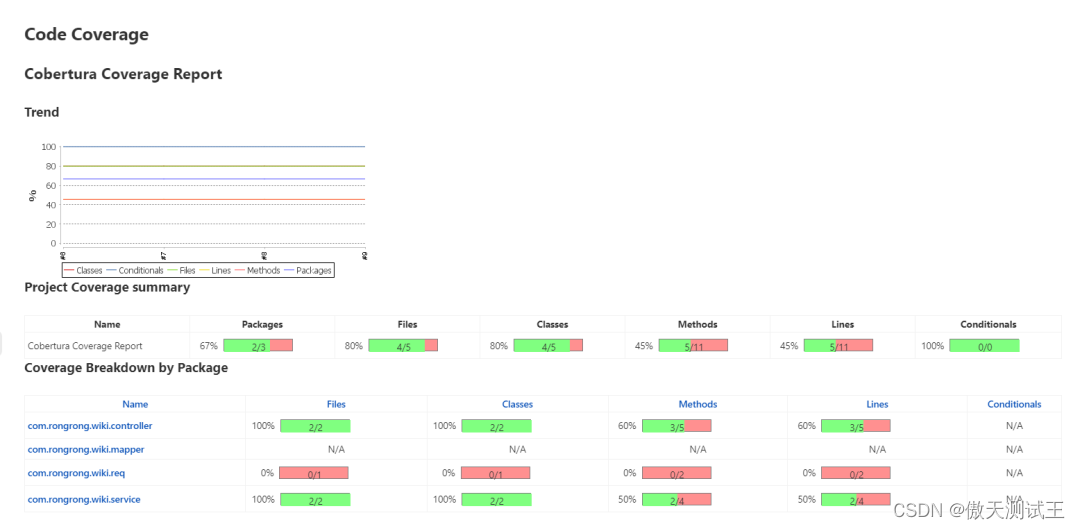
什么是代码覆盖率? 代码覆盖率是对整个测试过程中被执行的代码的衡量,它能测量源代码中的哪些语句在测试中被执行,哪些语句尚未被执行。 为什么要测量代码覆盖率? 众所周知,测试可以提高软件版本的质量和可预测性。…...

vue表格插件vxe-table导出 excel
vxe-table 默认支持导出 CSV、HTML、XML、TXT格式的文件,不支持 xlsx 文件 要想导出 xlsx 文件,需要使用 vxe-table-plugin-export-xlsx 依赖 参考:https://cnpmjs.org/package/vxe-table-plugin-export-xlsx/v/2.1.0-beta 1.安装 npm inst…...
stable diffusion使用相关
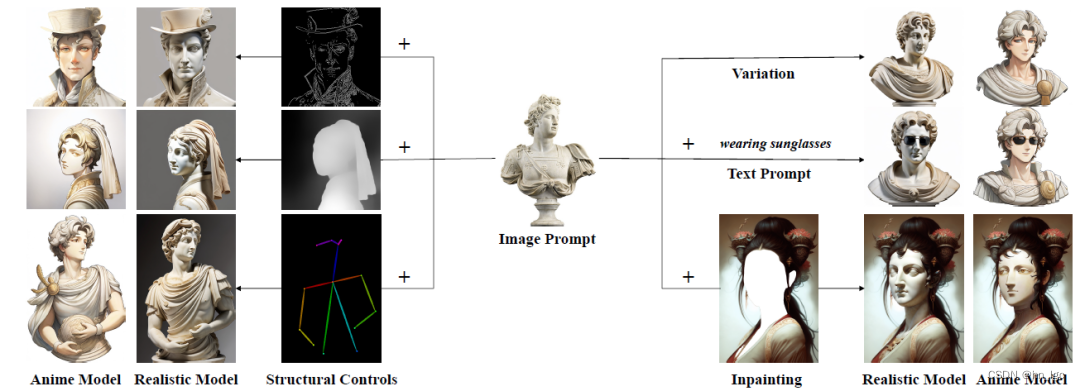
IP Adapter,我愿称之它为SD垫图 IP Adapter是腾讯lab发布的一个新的Stable Diffusion适配器,它的作用是将你输入的图像作为图像提示词,本质上就像MJ的垫图。 IP Adapter比reference的效果要好,而且会快很多,适配于各种…...
)
Center项目创建——数据初始化(Linux/Windows版本)
本博客主要讲述Center的模块安装配置和数据初始化 1、定义安装Install函数,IP地址由makefile自动传入,也就是用户自动传入 bool Install(std::string ip); 2、编写Install函数 #define CENTER_CONF "ip bool XCenter::Install(std::string ip)…...

保送阿里云的云原生学习路线
近期好多人都有咨询学习云原生有什么资料。与其说提供资料不如先说一说应该如何学习云原生。 Linux基础知识:云原生技术通常在Linux环境中运行,因此建议首先掌握Linux的基础知识,包括命令行操作、文件系统、权限管理等。 容器化技术&#x…...

【昕宝爸爸小模块】深入浅出之JDK21 中的虚拟线程到底是怎么回事(二)
➡️博客首页 https://blog.csdn.net/Java_Yangxiaoyuan 欢迎优秀的你👍点赞、🗂️收藏、加❤️关注哦。 本文章CSDN首发,欢迎转载,要注明出处哦! 先感谢优秀的你能认真的看完本文&…...
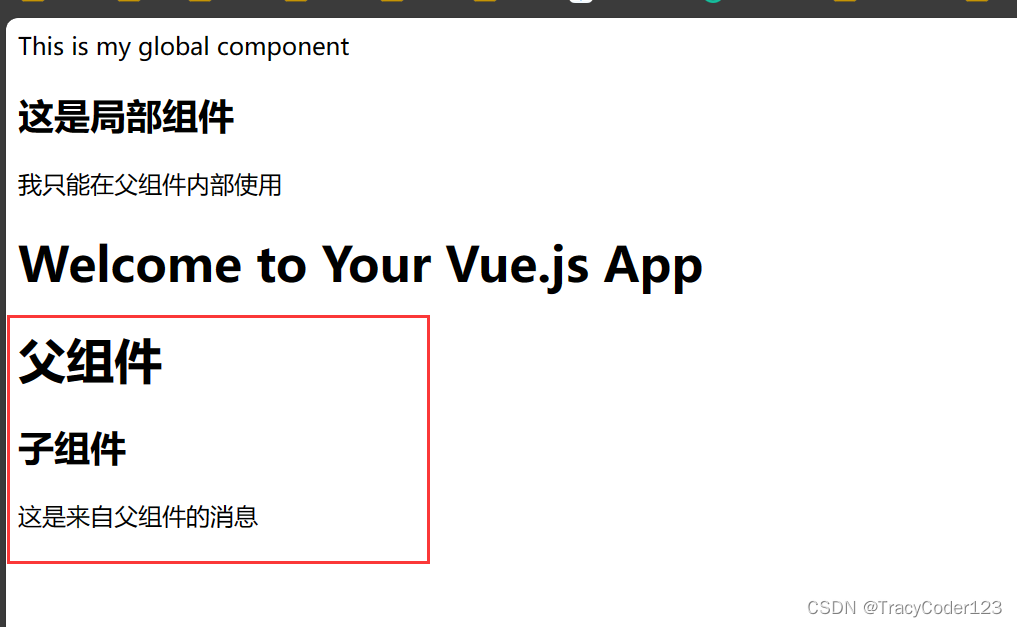
两周掌握Vue3(三):全局组件、局部组件、Props
文章目录 一、全局组件1.创建全局组件2.在main.js中注册全局组件3.使用全局组件 二、局部组件1.创建局部组件2.在另一个组件中注册、使用局部组件 三、Props1.定义一个子组件2.定义一个父组件3.效果 代码仓库:跳转 本博客对应分支:03 一、全局组件 Vue…...

Web前端篇——element-plus组件设置全局中文
背景:在使用el-date-picker组件时,发现组件中的文字默认都是英文。 设置全局中文的方法如下:(本文只介绍CDN方式) <script src"//unpkg.com/element-plus/dist/locale/zh-cn"></script> <s…...

【iOS】数据存储方式总结(持久化)沙盒结构
在iOS开发中,我们经常性地需要存储一些状态和数据,比如用户对于App的相关设置、需要在本地缓存的数据等等,本篇文章将介绍六个主要的数据存储方式 iOS中数据存储方式(数据持久化) 根据要存储的数据大小、存储数据以及…...

硬盘重新分区怎么恢复分区之前的文件?
分区是常见的故障,通常由多种原因引起。一方面,硬盘老化或者受到损坏可能会导致分区表出现问题;另一方面,用户误操作,如格式化或分区不当,也可能导致分区丢失。针对此问题,解决方法包括使用专业…...

C++每日一练(15):简单幂计算
题目描述 输入两个数a和b,求a的b次方。 输入 输入两个整数a,b(1<a<10,1<b<15)。 输出 输出一个正整数,该值<1000000000000。 输入样例 3 3 输出样例 27 参考答案 #include<bits/stdc.h&…...

扫雷游戏【可展开一片,超详细,保姆级别,此一篇足够】
一、C语言代码实现的扫雷游戏的运行 C语言实现扫雷 二、扫雷游戏的分析与设计 1.扫雷游戏的界面设计 在玩家玩扫雷的时候,它会给你一个二维的棋盘(下面的讲解都以9x9规格为例子),然后点击你想排查的坐标,若不是雷的&…...

鸿蒙开发-DevEco Studio Profiler工具进行帧率分析
Frame Profiler概述 DevEco Studio内置Profiler分析调优工具,其中Frame分析调优功能,用于录制GPU数据信息,录制完成展开之后的子泳道对应录制过程中各个进程的帧数据,主要用于深度分析应用或服务卡顿丢帧的原因。此外,…...

Google推出Telecom Jetpack库,让Android通话应用创建更简单
Google推出Telecom Jetpack库,让Android通话应用创建更简单 Telecom Jetpack库的最新Alpha版本已经推出。该库提供了多个API,以简化Android开发者创建语音和/或视频通话应用程序的过程,支持常见功能,例如接听/拒绝、音频路由等等…...

倒计时1天|解锁「PolarDB开发者大会」正确打开方式
1月17日 9:30-16:30 北京嘉瑞文化中心 PolarDB开发者大会 明天就要和大家就见面啦~ 大会参会指南现已出炉 各位开发者们,请查收~ 👇👇👇 点击 大会主页 or 扫描上方二维码 一键抵达大会官网👇 查看…...

链表-两两交换链表中的节点
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 // 递归版本 class Solution {public ListNode swapPairs(ListNode head) {// base case 退出提交if(head nu…...

vue下载文件流效果demo(整理)
在 Vue 项目中,你可以使用 FileSaver.js 库来方便地下载文件流。FileSaver.js 封装了不同浏览器的下载方式,使得下载文件更加简单和兼容。以下是一个完整的示例方法: 首先,安装 FileSaver.js 库: <template>&l…...
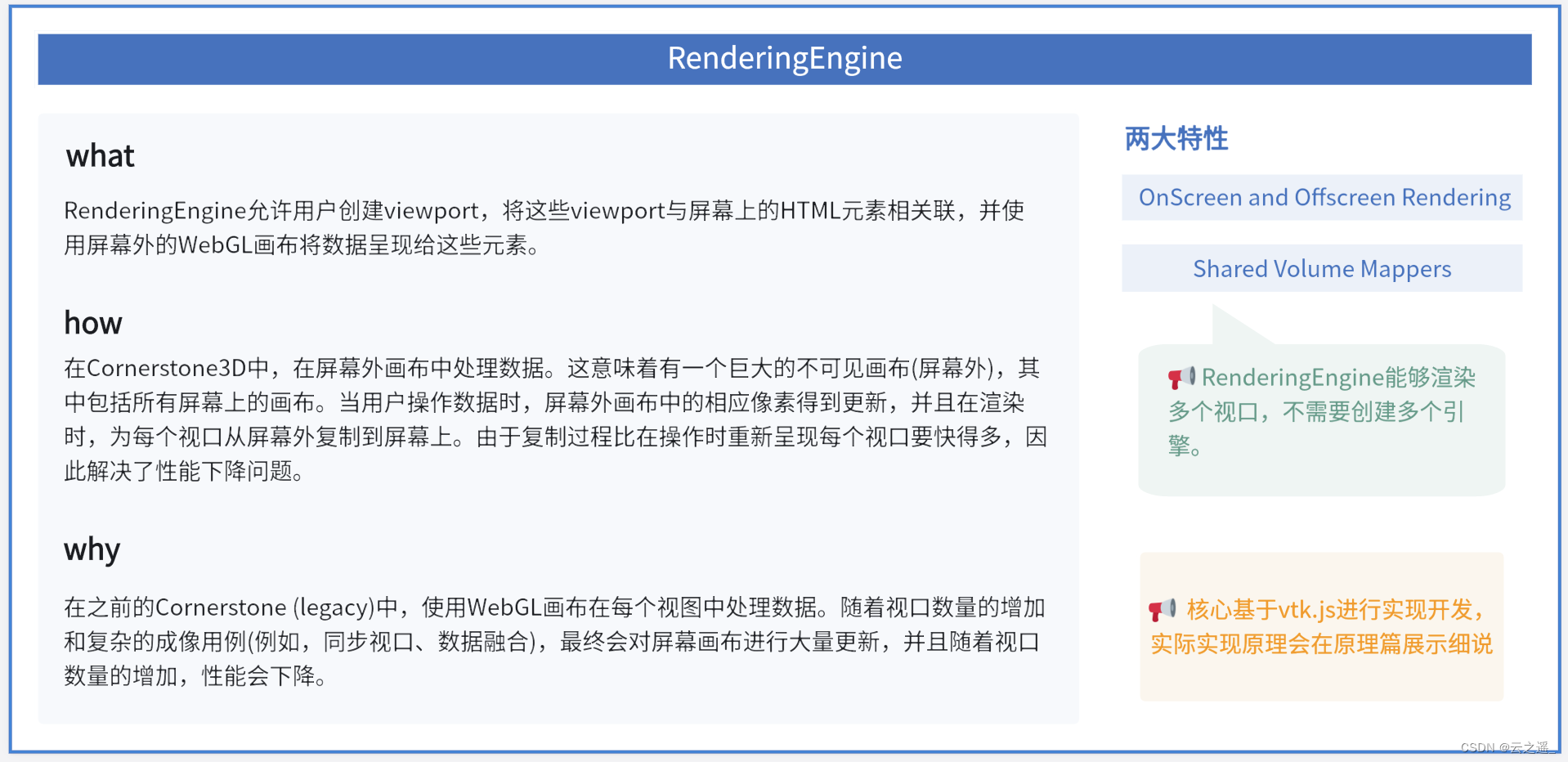
【从0上手cornerstone3D】如何渲染一个基础的Dicom文件(含演示)
一、Cornerstone3D 是什么? Cornerstone3D官网:https://www.cornerstonejs.org/ 在线查看显示效果(加载需时间,可先点击运行),欢迎fork 二、代码示例 了解了Cornerstone是什么,有什么作用后&…...

Unity3D PVP游戏位置同步算法优化详解
在Unity3D中,PVP(Player versus Player)游戏的位置同步是一项重要的技术,它决定了游戏中玩家之间的互动体验。本文将详细介绍Unity3D PVP游戏位置同步算法的优化方法,并给出相应的技术详解和代码实现。 对啦ÿ…...

如何轻松配置开源工具:3步实现WeMod高级功能解锁
如何轻松配置开源工具:3步实现WeMod高级功能解锁 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod Pro订阅费烦恼吗?W…...
)
CVPR 2023新作DoNet实战:用Python+Detectron2搞定重叠细胞分割(附代码)
DoNet实战指南:基于Detectron2的细胞重叠分割全流程解析医学图像分析领域近年来迎来爆发式增长,其中细胞实例分割作为基础性技术,在癌症筛查、药物研发等场景中扮演关键角色。然而传统方法面对细胞重叠、半透明边界等复杂情况时往往表现不佳。…...

C166架构下XDATA解决全局变量内存溢出问题
1. 问题现象与背景分析在C166架构的嵌入式开发中,当程序包含大量初始化全局变量时,开发者经常会遇到两个经典错误:*** ERROR 172 IN LINE 9 OF test.c: HDATA0: length exceeded: act172032, max65536 Error 106: Section Overflow Section: …...

LiDAR增强信道估计:融合几何感知提升毫米波MIMO-OFDM系统性能
1. 项目概述与核心思路在毫米波大规模MIMO-OFDM系统中,尤其是在车联网这类高动态、低时延的应用场景里,获取精确的信道状态信息(CSI)是保障通信可靠性与高效性的基石。传统的信道估计方法,无论是基于最小二乘ÿ…...

别再报错‘不在sudoers文件中’了!手把手教你用visudo安全配置CentOS/RHEL用户sudo权限
安全配置Linux系统sudo权限的终极指南当你第一次在终端输入sudo命令时,看到"用户不在sudoers文件中"的提示,那种挫败感每个Linux用户都深有体会。但别急着用chmod修改文件权限——这种"野路子"虽然能快速解决问题,却可能…...

LLM多智能体驱动微服务自治:从架构设计到Sock Shop实战评估
1. 项目概述:当微服务遇见大模型,自管理不再是空谈在云原生和微服务架构成为主流的今天,我们运维工程师面对的早已不是几台物理服务器,而是一个由成百上千个容器化服务实例构成的、动态且复杂的生态系统。服务间的调用链路像一张错…...

国防采购如何吸引商业AI创新:OTA协议与敏捷合作模式解析
1. 项目概述:当国防采购遇上商业AI创新在过去的十几年里,我接触过不少政府与科技企业间的合作项目,从早期的云计算服务到后来的大数据分析平台。但最近几年,一个趋势愈发明显:以人工智能为代表的颠覆性技术,…...

Windows 11系统下,Fiddler代理端口不是8888?这份Mumu模拟器网络调试避坑指南请收好
Windows 11系统下Fiddler与Mumu模拟器网络调试实战指南在移动应用开发和测试过程中,网络调试工具与模拟器的配合使用是必不可少的环节。许多开发者习惯性地认为Fiddler的默认代理端口就是8888,但在实际配置中,这个假设往往会导致一系列难以排…...

解锁 Codex 逆向能力!一键部署 JS 逆向全能 Skill
让 Codex 默认支持 JS 逆向 Codex GPT-5.4 默认对逆向和爬虫类请求比较保守,常见表现是只讲原则,不继续落地。市面上的常规做法是先发提示词,我这边因为每次重复发送比较麻烦,所以进一步封装成了 Skill,实际验证可行。…...

CSS Grid布局深入解析:掌握现代布局技术
CSS Grid布局深入解析:掌握现代布局技术 引言 CSS Grid布局是CSS3引入的强大布局系统,它提供了一种二维网格布局方式,可以轻松实现复杂的页面布局。本文将深入探讨Grid布局的核心概念、高级技巧和最佳实践。 一、Grid布局基础 1.1 Grid容器与…...