集成xxljob项目如何迁移到K8S

前言
大家好,今天我们将基于XXL-Job,探讨任务调度迁移到云端的相关话题。
XXL-Job是一款功能强大、易用可靠的国产分布式任务调度平台,是目前国内使用比较广泛的分布式任务调度平台之一。它的主要特点包括:
- 支持分布式、多线程任务调度;
- 具有完整的管理后台,可以实现任务调度的创建、修改、启动和监控;
- 提供了丰富的调度方式,包括cron表达式、API调用、消息队列等;
- 支持任务执行过程的日志记录和错误处理,可以帮助用户快速定位问题。
随着云计算的全面普及和发展,越来越多企业开始认识到公共云平台的无限潜力。许多企业开始将自己的应用程序和业务迁移到云环境中,以获取更高的灵活性、弹性和可扩展性。然而,任务调度作为企业中的一个重要业务组件,对于软件开发和运营的质量都有着极大的影响。在云环境下部署和运行任务调度组件,需要考虑诸多因素,如安全性、可靠性、性能等。因此,企业需要认真思考如何在云平台上部署和运行任务调度组件,以保证运营效率、降低成本、提高应用程序的质量和性能。
云端迁移过程
由于历史原因,我们的 xxl-job-admin 端是部署在 k8s 集群外部的。在我们的项目中,我们是使用XML文件来集成xxl-job的,相关的集成配置如下所示:
<bean id="xxlJobExecutor" class="com.xxl.job.core.executor.impl.XxlJobSpringExecutor"><property name="adminAddresses" value="${xxl.job.admin.addresses}"/><property name="appname" value="${xxl.job.executor.appname}"/><property name="ip" value="${xxl.job.executor.ip}"/><property name="port" value="${xxl.job.executor.port}"/><property name="accessToken" value="${xxl.job.accessToken}" /><property name="logPath" value="${xxl.job.executor.logpath}"/><property name="logRetentionDays" value="${xxl.job.executor.logretentiondays}"/>
</bean>
其中,相关配置值如下:
xxl.job.admin.addresses = http://127.0.0.1/xxl-job-admin
xxl.job.executor.appname = xxl-job-executor-sample
xxl.job.executor.ip =
xxl.job.executor.port = 30065
xxl.job.accessToken = mytoken
xxl.job.executor.logpath = /etc/logs
xxl.job.executor.logretentiondays = -1
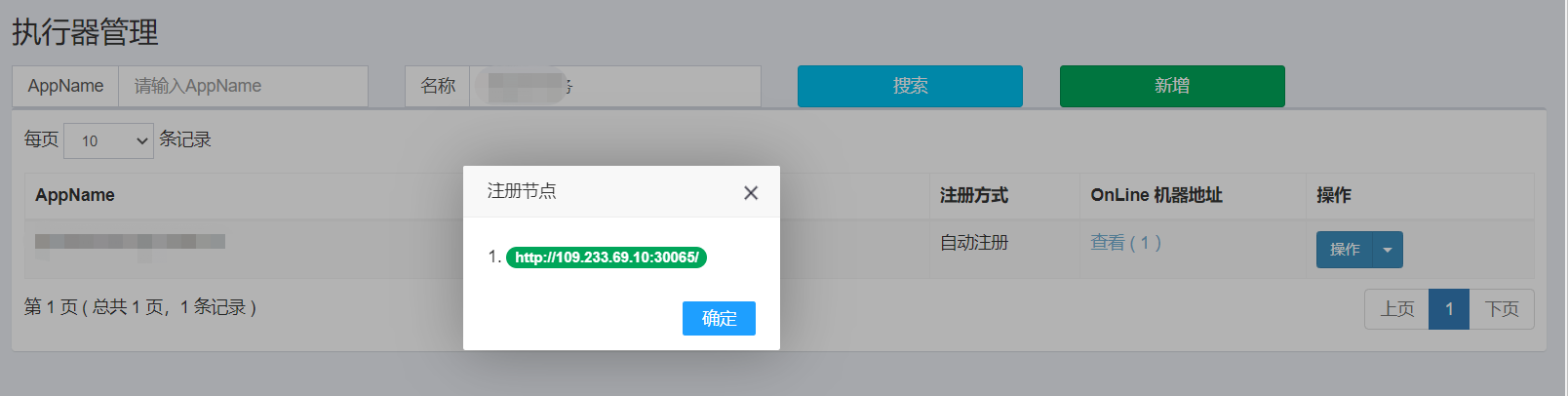
解决注册IP错误问题
当我们使用了与其他普通 Spring 项目的 JAR 包相同的部署方式将任务调度组件部署到了 k8s 上后,虽然我们通过管理页面看到已经成功将服务注册到了 xxl-job-admin,但我们发现该服务的 IP 地址为 k8s 中 Pod 的私有 IP 地址。因为k8s 集群内部通信的私有 IP 地址在集群外不可访问,这导致了任务无法正常执行,系统提示 IP 地址无效。
那么该如果解决这个问题呢?
阅读XXL-Job源码可以深入了解XXL-Job框架的实现细节和内部机制。在XXL-Job源码中,可以找到一些关键方法,帮助我们了解IP和port的获取规则。
具体来说,这些方法位于com.xxl.job.core.executor.XxlJobExecuto类中的initEmbedServer方法。当执行器启动时,会优先使用配置文件中的IP和端口,如果配置文件未指定,则通过NetUtils获取本地主机地址和默认端口。在注册成功后,执行器就可以通过该IP和端口与注册中心进行正常通信。部分源码如下:
port = port > 0 ? port : NetUtil.findAvailablePort(9999);
ip = ip != null && ip.trim().length() > 0 ? ip : IpUtil.getIp();
由此可见,为了解决这个问题,我们有两种方法可以尝试。
- 我们可以直接将配置文件中的 xxl.job.executor.ip 指定为正确的IP地址,这样XXL-Job就可以正确地找到执行器并与之通信了。
- 在XXL-Job的管理页面上将执行器的注册方式改为手动录入,并直接填写正确的IP地址。
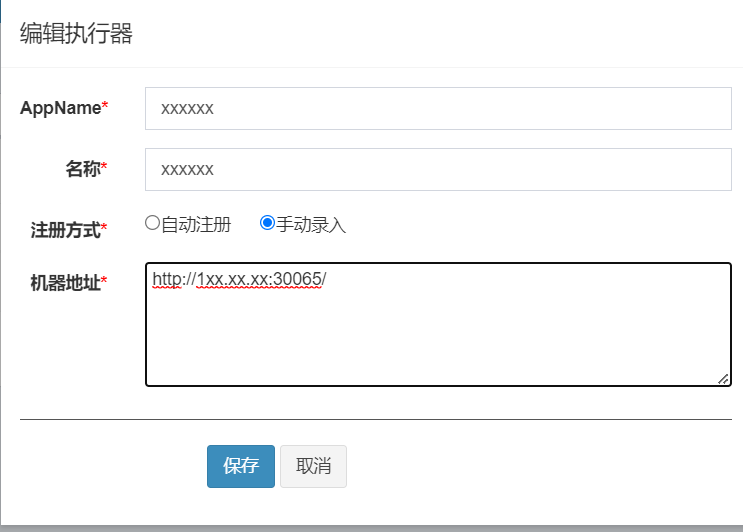
无论使用哪种方法,唯一的要求就是确保与执行器实际运行的IP地址匹配。这样就可以使XXL-Job正常工作了。
实现动态注册IP
无论采用前面提到的两种方式中的哪一种,均存在一个xxl-job配置写死IP地址的问题,而无法实现IP的动态获取,这对于后期的维护和动态扩缩容都是不利的。那么如何在保证获取到的IP正确的前提下实现自动获取呢?
为了实现xxl-job自动获取注册IP的目的,在获取IP的过程中,我们可以结合Dubbo框架的获取IP逻辑,改造获取IP的顺序。按照以下顺序获取IP:
-
首先根据环境变量获取IP,如果环境变量中存在,则获取环境变量中的IP地址。
-
如果环境变量中不存在,则根据配置文件获取IP,如果配置文件中存在,则获取配置文件中的IP地址。
-
如果配置文件中不存在,则获取本地IP地址。
这样的优先级顺序可以确保我们始终能够获得一个可用的注册IP。通过这种方式会让获取IP更加智能化和可靠。以下是具体改造步骤:
- 在 deploy.yaml 文件中添加环境变量。
spec:template:spec:containers:- env:- name: XXLJOB_IP_TO_REGISTRYvalueFrom:fieldRef:apiVersion: v1fieldPath: status.hostIP
- 使用Java代码中的注释@Configuration和@Bean注释来替代使用XML文件进行Bean的注册和配置。
@Slf4j
@Configuration
public class XxlJobConfiguration {@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {log.info(">>>>>>>>>>> xxl-job config init start...");// 获取ip规则优先级, 环境变量(此值为deploy.yaml中配置)>配置文件>默认(本地)String ip = System.getenv("XXLJOB_IP_TO_REGISTRY");ip = StringUtils.isBlank(ip) ? PropertiesCacheUtil.getConfigValue("xxl.job.executor.ip") : ip;String port = PropertiesCacheUtil.getConfigValue("xxl.job.executor.port");String logRetentionDays = PropertiesCacheUtil.getConfigValue("xxl.job.executor.logretentiondays");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.admin.addresses")));xxlJobSpringExecutor.setAppname(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.appname")));xxlJobSpringExecutor.setIp(ip);if (StringUtils.isNotBlank(port)) {xxlJobSpringExecutor.setPort(Integer.parseInt(port));}xxlJobSpringExecutor.setAccessToken(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.accessToken")));xxlJobSpringExecutor.setLogPath(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.logpath")));if (StringUtils.isNotBlank(logRetentionDays)) {xxlJobSpringExecutor.setLogRetentionDays(Integer.parseInt(logRetentionDays));}log.info(">>>>>>>>>>> xxl-job config init end...");return xxlJobSpringExecutor;}
}
通过这样的改造,我们可以更加智能可靠地获取注册IP,实现了xxl-job自动获取IP地址的目的。
解决分片问题
无论使用上面提到的写死配置方式还是实现动态注册IP,都是仅适用于单机的情况,如果需要部署多台任务调度组件,那么又该如何配置才能保证每个服务都可以被调度,以达到实现分片处理的目的呢?
方法1:
我们可以通过在deploy.yaml文件中配置Pod的反亲和性,使得单台宿主机上仅能部署一个服务,并且配置在service.yaml中配置代理策略为Local的方式来达到上述目的。具体配置如下:
deploy.yaml改造如下:
spec:template:spec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- topologyKey: kubernetes.io/hostnamelabelSelector:matchExpressions:- key: appoperator: Invalues:- 你的APP名称
service.yaml 改造如下:
spec:## 代理策略:默认Cluster。Cluster表示:流量可以转发到其他节点上的Pod。Local表示:流量只发给本机的PodexternalTrafficPolicy: Local
经过上面的改造,我们成功的解决了分片问题,但是又带来了新的问题,如下图所示:
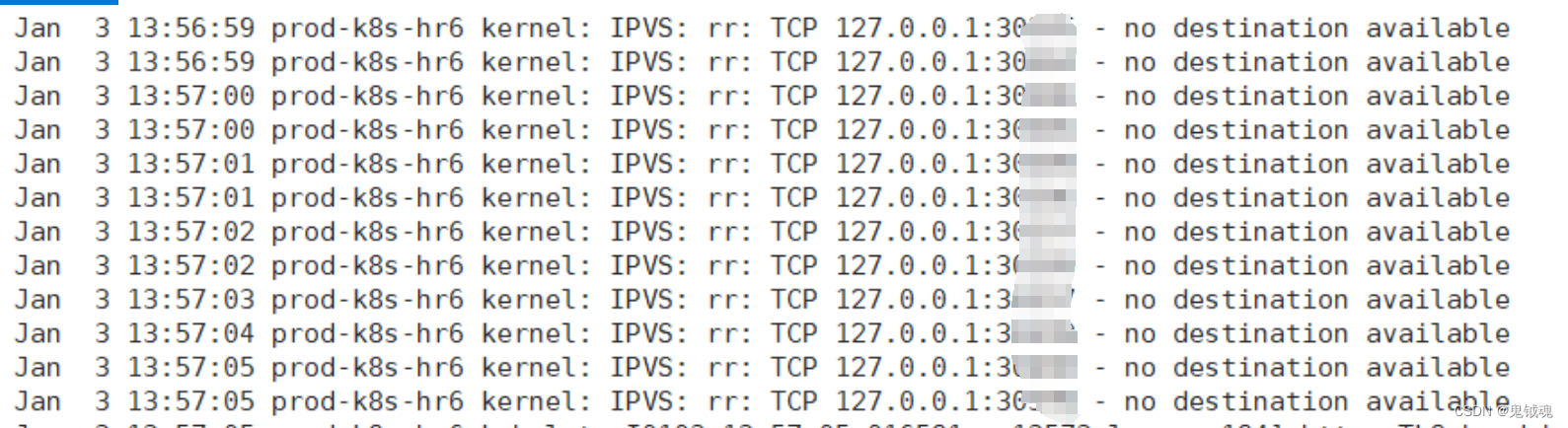
上面的方法都是使用Deployment方式部署的,那么,我们是否可以换下思路使用StatefulSet方式部署呢?这就衍生出了下面的方法。
方法2:
- 改造配置:
## 注册到xxljob的端口,多个使用英文逗号分隔
xxl.job.executor.port = 30065,30066,30067
- 改造代码
@Slf4j
@Configuration
public class XxlJobConfiguration {@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {log.info(">>>>>>>>>>> xxl-job config init.");// 获取ip规则优先级, 配置中心>环境变量(此值为deploy.yml中配置)String ip = PropertiesCacheUtil.getConfigValue("xxl.job.executor.ip");ip = StringUtils.isBlank(ip) ? System.getenv("XXLJOB_IP_TO_REGISTRY") : ip;log.info("==>ip:{}", ip);String podName = StringUtils.trimToEmpty(System.getenv("POD_NAME"));log.info("==>POD_NAME:{}", podName);String[] split = StringUtils.split(podName, "-");String index = split[split.length - 1];log.info("==>index:{}", index);String allPort = PropertiesCacheUtil.getConfigValue("xxl.job.executor.port");String[] portSplit = StringUtils.split(allPort, ",");String port = portSplit[Integer.parseInt(index)];log.info("==>port:{}", port);String logRetentionDays = PropertiesCacheUtil.getConfigValue("xxl.job.executor.logretentiondays");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.admin.addresses")));xxlJobSpringExecutor.setAppname(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.appname")));xxlJobSpringExecutor.setIp(ip);if (StringUtils.isNotBlank(port)) {xxlJobSpringExecutor.setPort(Integer.parseInt(port));}xxlJobSpringExecutor.setAccessToken(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.accessToken")));xxlJobSpringExecutor.setLogPath(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.logpath")));if (StringUtils.isNotBlank(logRetentionDays)) {xxlJobSpringExecutor.setLogRetentionDays(Integer.parseInt(logRetentionDays));}return xxlJobSpringExecutor;}
}
@Slf4j
@Component
public class InitNotifyDataFromDBHandler {@XxlJob("initNotifyDataFromDBHandler")public void initNotifyDataFromDBHandler(String params) {// XxlJobHelper.getShardIndex():当前分片序号(从0开始),执行器集群列表中当前执行器的序号;// XxlJobHelper.getShardTotal():总分片数,执行器集群的总机器数量;String podName = StringUtils.trimToEmpty(System.getenv("POD_NAME"));log.info("==>POD_NAME:{}", podName);XxlJobHelper.log("==>POD_NAME:{}", podName);String[] split = StringUtils.split(podName, "-");String index = split[split.length - 1];log.info("==>index:{}", index);XxlJobHelper.log("==>index:{}", index);// 下标0:机器总数目,下标1:当前机器在总机器中的位置下标String[] args = {XxlJobHelper.getShardTotal() + "", index};// 其他业务逻辑}}
- 重写K8S中yaml部署文件
## 创建StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:name: your-appnamespace: your-namespace
spec:serviceName: your-appreplicas: 3selector:matchLabels:app: your-apptemplate:metadata:annotations:statefulset.kubernetes.io/pod-name: $(POD_NAME)labels:app: your-appspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: project.nodeoperator: Invalues:- your-project-nodevolumes:- name: timezonehostPath:path: /usr/share/zoneinfo/Asia/Shanghaicontainers:- env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: DUBBO_IP_TO_REGISTRYvalueFrom:fieldRef:apiVersion: v1fieldPath: status.hostIP- name: XXLJOB_IP_TO_REGISTRYvalueFrom:fieldRef:apiVersion: v1fieldPath: status.hostIPimage: your-imageimagePullPolicy: Alwaysname: your-appterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilednsPolicy: ClusterFirstrestartPolicy: AlwaysterminationGracePeriodSeconds: 30
## 创建service
---
apiVersion: v1
kind: Service
metadata:name: service-your-app-0namespace: your-namespace
spec:selector:statefulset.kubernetes.io/pod-name: your-app-0type: NodePortsessionAffinity: Noneports:- name: xxljob-your-appport: 30065targetPort: 30065nodePort: 30065
---
apiVersion: v1
kind: Service
metadata:name: service-your-app-1namespace: your-namespace
spec:selector:statefulset.kubernetes.io/pod-name: your-app-1type: NodePortsessionAffinity: Noneports:- name: xxljob-your-appport: 30066targetPort: 30066nodePort: 30066
---
apiVersion: v1
kind: Service
metadata:name: service-your-app-2namespace: your-namespace
spec:selector:statefulset.kubernetes.io/pod-name: your-app-2type: NodePortsessionAffinity: Noneports:- name: xxljob-your-appport: 30067targetPort: 30067nodePort: 30067
经过上面的改造,我们成功的解决了使用第一种方法带来的问题。但是这个方法同样以下缺点,但是这种缺点相对来说是可以忽略的,因为生产环境不会随便增减副本数量。
- 在K8S的dashboard页面直接新增副本数量无效,需要先新增配置文件中的端口,再新增部署yaml中对应的Service,才能真正实现副本数量的增加。
小结
以上就是今天分享的任务调度上云的相关内容,我们的目标不仅仅是将任务调度程序迁移到云端,更是要通过实现自动注册功能,使任务调度程序能自动加入云端调度集群,从而更方便地进行任务调度,提升运行效率和可扩展性。
相关文章:
集成xxljob项目如何迁移到K8S
前言 大家好,今天我们将基于XXL-Job,探讨任务调度迁移到云端的相关话题。 XXL-Job是一款功能强大、易用可靠的国产分布式任务调度平台,是目前国内使用比较广泛的分布式任务调度平台之一。它的主要特点包括: 支持分布式、多线程…...
-解决方案集锦)
类型“{}”上不存在属性“xxx”。ts(2339)-解决方案集锦
类型“{}”上不存在属性“xxx”。ts(2339)-解决方案集锦 文章目录 类型“{}”上不存在属性“xxx”。ts(2339)-解决方案集锦一、方案一(优先尝试)二、方案二(优先尝试)三、方案三这该是多么痛苦的一篇笔记啊!࿰…...

【MQTT】使用MQTT在Spring Boot项目中实现异步消息通信
目录 使用MQTT在Spring Boot项目中实现异步消息通信步骤1:引入MQTT库依赖步骤2:配置MQTT连接信息步骤3:创建MQTT配置类步骤4:发送MQTT消息发布MQTT消息消费MQTT消息 总结 前置文章: (一)MQTT协议…...

Java 中泛型的基本使用
目录 一、泛型类的使用 二、泛型接口的使用 三、泛型方法的使用 相关测试 一、泛型类的使用 /* 泛型类,T 表示 Java 中的任意类型,也就是说构造方法中 data 属性可以传递任意类型的值*/ class ResultData<T>{Integer code;String msg;T data;p…...

Java初学者软件安装与idea快捷键
一.Java初学者软件安装 视频教程: 最通俗易懂的JDK、IDEA的安装使用权威指南_哔哩哔哩_bilibili 文档教程: Java 开发环境配置 | 菜鸟教程 (runoob.com) 二.java的快捷方式与插件 快捷键: 史上最全的IDEA快捷键总结_idea的快捷语法_扬帆…...
微信商家转账到零钱怎么开通?场景模板
商家转账到零钱是什么? 使用商家转账到零钱这个功能,可以让商户同时向多个用户的零钱转账。商户可以使用这个功能用于费用报销、员工福利发放、合作伙伴货款或分销返佣等场景,提高效率。 商家转账到零钱的使用场景有哪些? 商家…...
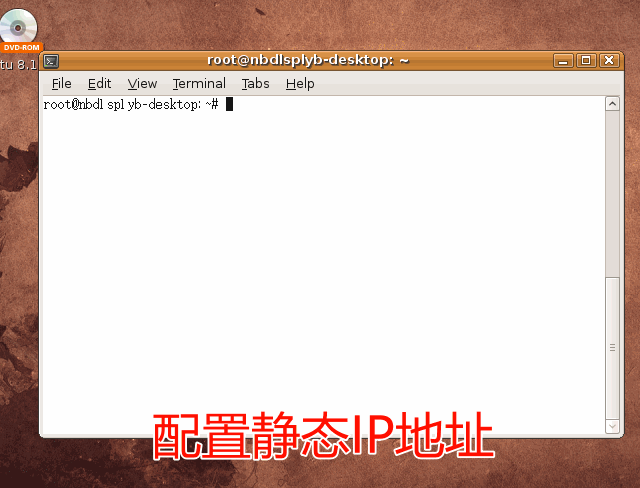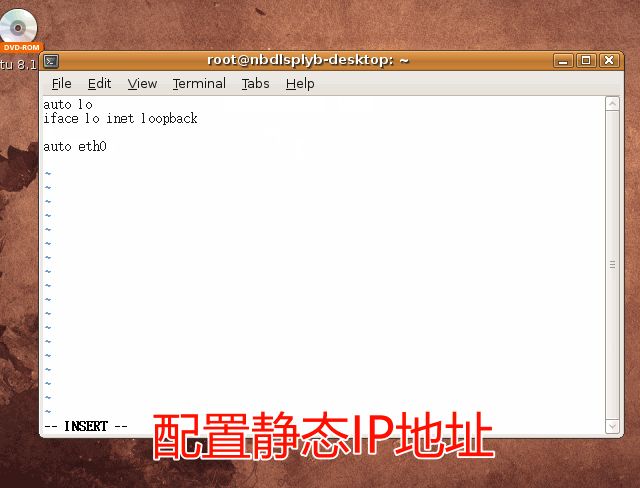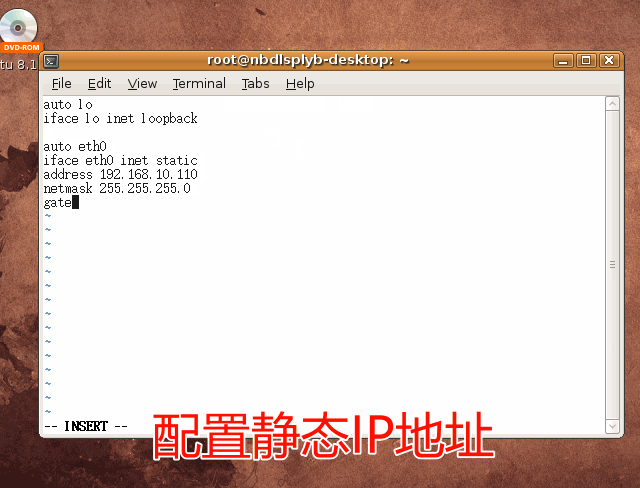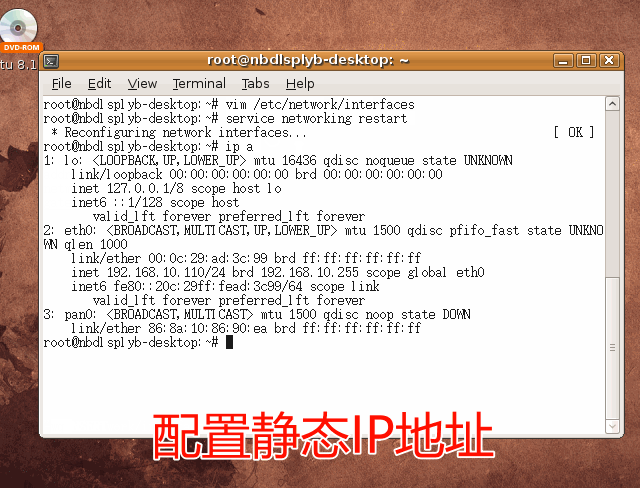
(菜鸟自学)搭建虚拟渗透实验室——安装Ubantu 8.10 靶机
安装Ubantu 8.10 靶机 新建虚拟机 选择Ubuntu系统 网络适配器模式选用桥接模式 镜像选用ubuntu8.10版本 点击“开启此虚拟机”以开始安装Ubuntu Linux系统 安装ubuntu 首先需要选择安装时的语言,这里选择“中文(简体)” 选择“安装…...

【JAVA】哪些集合类是线程安全的
🍎个人博客:个人主页 🏆个人专栏:JAVA ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 Vector: HashTable: Collections.synchronizedList()、Collections.synchronizedSet()、Collections.syn…...

K8S 日志方案
一、统一日志管理的整体方案 通过应用和系统日志可以了解Kubernetes集群内所发生的事情,对于调试问题和监视集群活动来说日志非常有用。对于大部分的应用来说,都会具有某种日志机制。因此,大多数容器引擎同样被设计成支持某种日志机制。 对…...

GPT2 GPT3
what is prompt 综述1.Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing(五星好评) 综述2. Paradigm Shift in Natural Language Processing(四星推荐) 综述3. Pre-Trained Models: Past, Present and Future Pro…...

2024年人工智能顶会/顶刊截稿时间汇总
人工智能顶会/顶刊汇总 ,方便查阅,持续更新,若有错误烦请大家及时提出! 一、CCF A类 简称 全称录用率频次内容官网截稿日期IJCAIInternational Joint Conference on Artificial Intelligence2020年12.55%,2021年13.9%…...
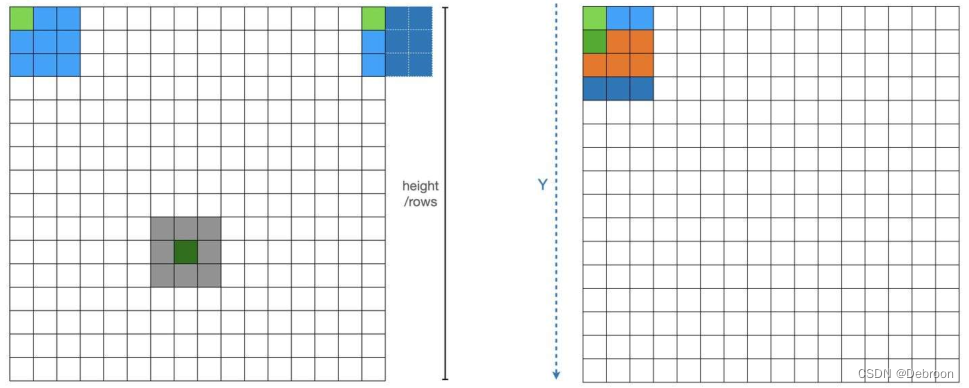
AI芯片:神经网络研发加速器、神经网络压缩简化、通用芯片 CPU 加速、专用芯片 GPU 加速
AI芯片: 神经网络研发加速器、神经网络压缩简化、通用芯片 CPU 加速、专用芯片 GPU 加速 神经网络研发加速器神经网络编译器各自实现的神经网络编译器 神经网络加速与压缩(算法层面)知识蒸馏低秩分解轻量化网络剪枝量化 通用芯片 CPU 加速x86…...
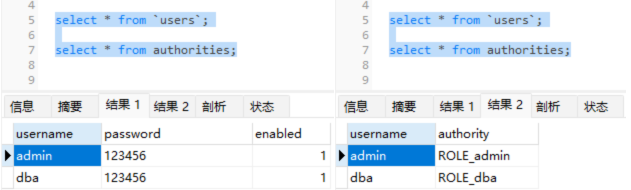
系列七、Spring Security中基于Jdbc的用户认证 授权
一、Spring Security中基于Jdbc的用户认证 & 授权 1.1、概述 前面的系列文章介绍了基于内存定义用户的方式,其实Spring Security中还提供了基于Jdbc的用户认证 & 授权,再说基于Jdbc的用户认证 & 授权之前,不得不说一下Spring Se…...

网络安全(网络安全)—2024自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
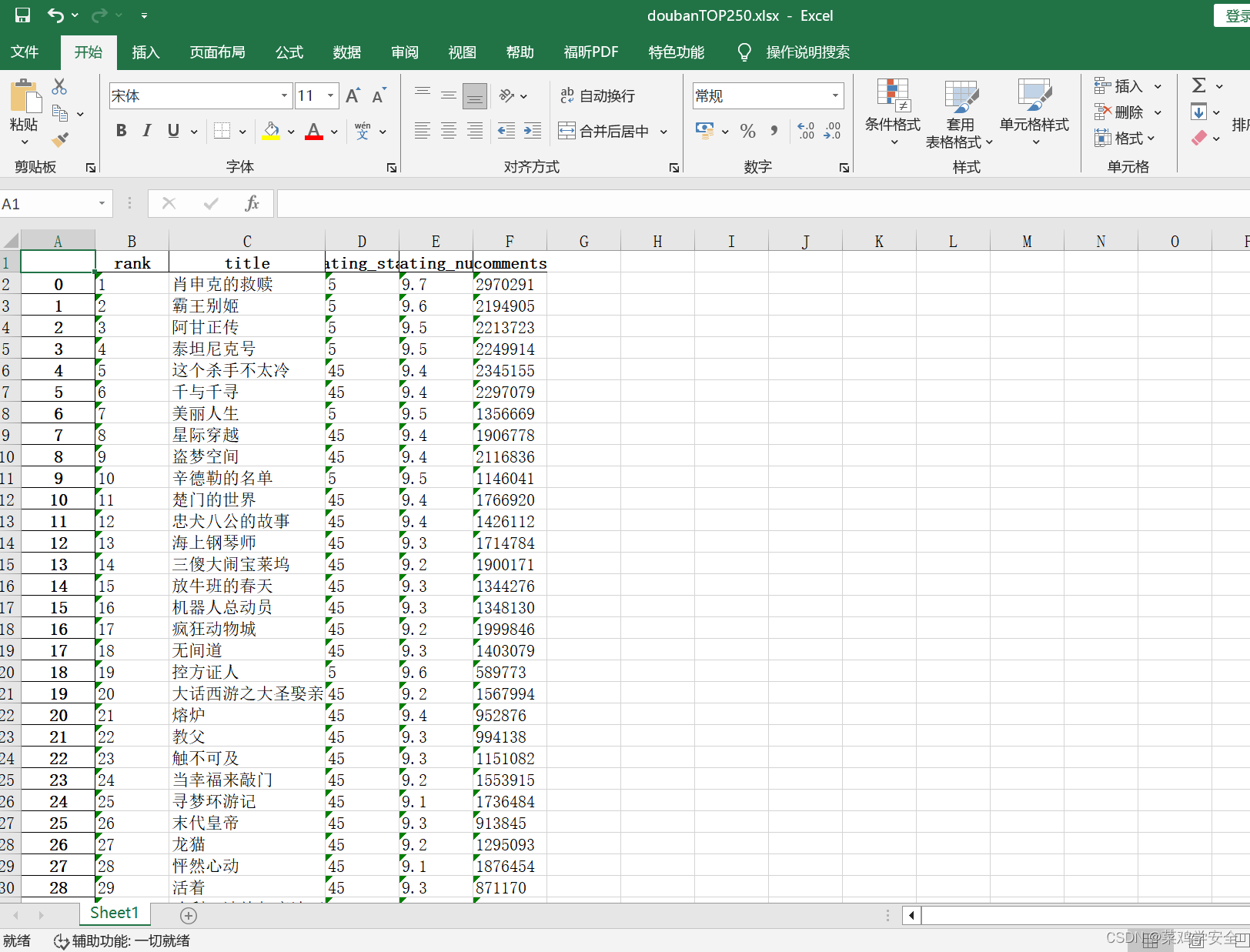
python爬虫小练习——爬取豆瓣电影top250
爬取豆瓣电影top250 需求分析 将爬取的数据导入到表格中,方便人为查看。 实现方法 三大功能 1,下载所有网页内容。 2,处理网页中的内容提取自己想要的数据 3,导入到表格中 分析网站结构需要提取的内容 代码 import requests…...

Vulnhub靶机:driftingblues 2
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.15) 靶机:driftingblues2(10.0.2.18) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entr…...

CentOS 7 权限管理实战指南:用户组管理相关命令详解
前言 深入了解 CentOS 7 用户组管理的命令,掌握关键的用户组操作技巧。从创建和删除用户组、修改组属性,到设置组密码和管理组成员,这篇文章详细介绍了 CentOS 7 系统下常用的用户组管理命令,为读者小伙伴提供了实用而全面的指南…...

Python操作MySQL入门教程,使用pymysql操作MySQL,有录播直播私教课
创建数据库 create database gx character set utf8mb4;连接数据库 #!/usr/bin/python3import mysql as pymysql# 打开数据库连接 db pymysql.connect(hostlocalhost,port3306,userroot,passwordzhangdapeng520,databasegx)# 使用 cursor() 方法创建一个游标对象 cursor cur…...

面试 React 框架八股文十问十答第七期
面试 React 框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)React 废弃了哪些生命…...
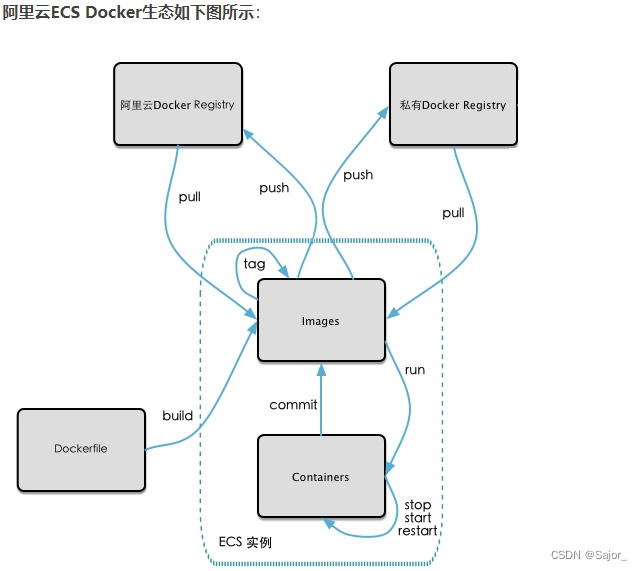
Docker教程
docker 安装 官方文档 wget -qO- https://get.docker.com/ | sh sudo usermod -aG docker your-user sudo usermod -aG docker ${USER} newgrp docker # 更新docker用户组 cat /etc/group | grep docker docker --version 使用非root用户管理 帮助启动类 命令 system…...
)
AI大神吴恩达力荐,轻松入门大语言模型实战(附中文PDF+代码)
这本书由AI科普大神Jay Alammar与BERTopic算法作者Maarten Grootendorst联合撰写,是O’Reilly出版的LLM入门标杆指南,获吴恩达推荐。全书以图解方式讲解LLM原理、提示工程、文本分类生成、多模态应用及优化技术,分为理解原理、应用及优化三部…...

井下无信号密闭空间:UWB基站断联失效,无感定位纯视觉独立解算
井下无信号密闭空间:UWB基站断联失效,无感定位纯视觉独立解算矿山井下巷道、采掘工作面、密闭峒室等区域,属于典型无外源通信、信号隔绝的密闭作业空间。数字孪生与视频孪生技术逐步下沉矿山安全生产领域,镜像视界浙江科技有限公司…...

体验 Taotoken 官方价折扣与活动价带来的实际成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验 Taotoken 官方价折扣与活动价带来的实际成本优势 对于需要频繁调用大模型 API 的开发者和团队而言,成本控制是一个…...
)
centos7启动yum 安装失败原因(个人观点如有错误请指正)
第一步:修复 DNS(最关键) bash 运行 echo "nameserver 8.8.8.8" >> /etc/resolv.conf echo "nameserver 114.114.114.114" >> /etc/resolv.conf第二步:下载阿里云 CentOS7 国内源 bash 运行 curl…...

使用Node.js和Taotoken快速构建一个智能客服聊天接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken快速构建一个智能客服聊天接口 本教程面向具备Node.js基础的后端开发者,旨在指导你如何使用Open…...

python flash加一个字段
USE product_db; ALTER TABLE products ADD COLUMN remark TEXT COMMENT 商品备注信息,支持长文本 AFTER cost_price;2. 修改数据访问层(product_dao.py)需要在以下函数中添加 remark 字段的处理:修改 get_all_products 函数&…...

WorldArena榜单第一名Pelican-Unify 1.0:迈向具身智能统一范式的新里程碑
北京人形机器人创新中心团队发布首个统一理解、推理、想象与行动的具身基础模型 2026年5月 | 技术解读 图1 Pelican-Unify 1.0 统一具身智能模型概览:理解、推理、想象与行动的闭环融合 一、具身智能的范式演进:从模块化到统一化 具身智能(…...

Cortex-M55内存属性与缓存机制深度解析
1. Cortex-M55内存属性与缓存机制解析 在嵌入式系统开发中,正确配置内存属性对于系统性能和功能正确性至关重要。Cortex-M55作为Armv8-M架构的处理器,通过内存保护单元(MPU)和内存属性间接寄存器(MAIR_ATTR)提供了灵活的内存属性配置能力。本文将深入剖析…...

UE5 Paper2D像素对齐核心:BitmapUtils.h原理与实战
1. 这个头文件不是“工具库”,而是UE5 Paper2D底层渲染的呼吸中枢 你打开UE5源码目录,搜索 BitmapUtils.h ,大概率会在 Engine/Source/Runtime/Paper2D/Public/ 路径下找到它——它不像 Math/Vector2D.h 那样被高频引用,也不…...

PDFPatcher完全指南:用免费开源工具解决PDF格式难题的5个实战技巧
PDFPatcher完全指南:用免费开源工具解决PDF格式难题的5个实战技巧 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址:…...