K8S 日志方案
一、统一日志管理的整体方案
通过应用和系统日志可以了解Kubernetes集群内所发生的事情,对于调试问题和监视集群活动来说日志非常有用。对于大部分的应用来说,都会具有某种日志机制。因此,大多数容器引擎同样被设计成支持某种日志机制。
对于容器化应用程序来说,最简单和最易接受的日志记录方法是将日志内容写入到标准输出和标准错误流。 但是,容器引擎或运行时提供的本地功能通常不足以支撑完整的日志记录解决方案。例如,如果一个容器崩溃、一个Pod被驱逐、或者一个Node死亡,应用相关者可能仍然需要访问应用程序的日志。
因此,日志应该具有独立于Node、Pod或者容器的单独存储和生命周期,这个概念被称为集群级日志记录。集群级日志记录需要一个独立的后端来存储、分析和查询日志。Kubernetes本身并没有为日志数据提供原生的存储解决方案,但可以将许多现有的日志记录解决方案集成到Kubernetes集群中。在Kubernetes中,有三个层次的日志:
-
基础日志
-
Node级别的日志
-
群集级别的日志架构
1、基础日志
kubernetes基础日志即将日志数据输出到标准输出流,可以使用kubectl logs命令获取容器日志信息。如果Pod中有多个容器,可以通过将容器名称附加到命令来指定要访问哪个容器的日志。例如,在Kubernetes集群中的kube-system命名空间下有一个名称为etcd-master的Pod,就可以通过如下的命令获取日志:
[root@master log]# kubectl logs etcd-master -n kube-system
2、Node级别的日志
容器化应用写入到stdout和stderr的所有内容都是由容器引擎处理和重定向的。例如,docker容器引擎会将这两个流重定向到日志记录驱动,在Kubernetes中该日志驱动被配置为以json格式写入文件。docker json日志记录驱动将每一行视为单独的消息。当使用docker日志记录驱动时,并不支持多行消息,因此需要在日志代理级别或更高级别上处理多行消息。 默认情况下,如果容器重新启动,kubectl将会保留一个已终止的容器及其日志。如果从Node中驱逐Pod,那么Pod中所有相应的容器也会连同它们的日志一起被驱逐。Node级别的日志中的一个重要考虑是实现日志旋转,这样日志不会消耗Node上的所有可用存储。Kubernetes目前不负责轮转日志,部署工具应该建立一个解决方案来解决这个问题。
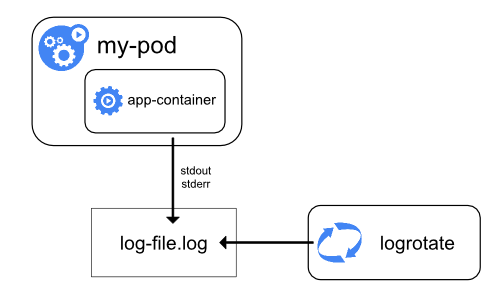
在Kubernetes中有两种类型的系统组件:运行在容器中的组件和不在容器中运行的组件。例如:
-
Kubernetes调度器和kube-proxy在容器中运行。
-
kubelet和容器运行时,例如docker,不在容器中运行。
在带有systemd的机器上,kubelet和容器运行时写入journaId。如果systemd不存在,它们会在/var/log目录中写入.log文件。在容器中的系统组件总是绕过默认的日志记录机制,写入到/var/log目录,它们使用golg日志库。可以找到日志记录中开发文档中那些组件记录严重性的约定。 类似于容器日志,在/var/log目录中的系统组件日志应该被轮转。这些日志被配置为每天由logrotate进行旋转,或者当大小超过100mb时进行旋转。
3、集群级别的日志架构
Kubernetes本身没有为群集级别日志记录提供原生解决方案,但有几种常见的方法可以采用:
-
使用运行在每个Node上的Node级别的日志记录代理;
-
在应用Pod中包含一个用于日志记录的sidecar。
-
将日志直接从应用内推到后端。
经过综合考虑,本文档采用通过在每个Node上包括Node级别的日志记录代理来实现群集级别日志记录。日志记录代理暴露日志或将日志推送到后端的专用工具。通常,logging-agent是一个容器,此容器能够访问该Node上的所有应用程序容器的日志文件。 因为日志记录必须在每个Node上运行,所以通常将它作为DaemonSet副本、或一个清单Pod或Node上的专用本机进程。然而,后两种方法后续将会被放弃。使用Node级别日志记录代理是Kubernetes集群最常见和最受欢迎的方法,因为它只为每个节点创建一个代理,并且不需要对节点上运行的应用程序进行任何更改。但是,Node级别日志记录仅适用于应用程序的标准输出和标准错误。 Kubernetes本身并没有指定日志记录代理,但是有两个可选的日志记录代理与Kubernetes版本打包发布:和谷歌云平台一起使用的Stackdriver和Elasticsearch,两者都使用自定义配置的fluentd作为Node上的代理。在本文的方案中,Logging-agent 采用 Fluentd,而 Logging Backend 采用 Elasticsearch,前端展示采用kibana。即通过 Fluentd 作为 Logging-agent 收集日志,并推送给后端的Elasticsearch;kibana从Elasticsearch中获取日志,并进行统一的展示。


三种收集方案的优缺点

二、安装统一日志管理组件
在本文中采用方案一,使用Node日志记录代理的方面进行Kubernetes的统一日志管理,相关的工具采用:
-
日志记录代理(logging-agent):日志记录代理用于从容器中获取日志信息,使用Fluentd;
-
日志记录后台(Logging-Backend):日志记录后台用于处理日志记录代理推送过来的日志,使用Elasticsearch;
-
日志记录展示:日志记录展示用于向用户显示统一的日志信息,使用Kibana。
在Kubernetes中通过了Elasticsearch 附加组件,此组件包括Elasticsearch、Fluentd和Kibana。Elasticsearch是一种负责存储日志并允许查询的搜索引擎。Fluentd从Kubernetes中获取日志消息,并发送到Elasticsearch;而Kibana是一个图形界面,用于查看和查询存储在Elasticsearch中的日志。
1、 部署Elasticsearch
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索和数据分析引擎引擎,Elasticsearch使用Java进行开发,并使用Lucene作为其核心实现所有索引和搜索的功能。它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Elasticsearch不仅仅是Lucene和全文搜索,它还提供如下的能力:
-
分布式的实时文件存储,每个字段都被索引并可被搜索;
-
分布式的实时分析搜索引擎;
-
可以扩展到上百台服务器,处理PB级结构化或非结构化数据。
在Elasticsearch中,包含多个索引(Index),相应的每个索引可以包含多个类型(Type),这些不同的类型每个都可以存储多个文档(Document),每个文档又有多个属性。索引 (index) 类似于传统关系数据库中的一个数据库,是一个存储关系型文档的地方。Elasticsearch 使用的是标准的 RESTful API 和 JSON。此外,还构建和维护了很多其他语言的客户端,例如 Java, Python, .NET, 和 PHP。
下面是Elasticsearch的YAML配置文件,在此配置文件中,定义了一个名称为elasticsearch-logging的ServiceAccount,并授予其能够对命名空间、服务和端点读取的访问权限;并以StatefulSet类型部署Elasticsearch。
[root@master log]# vim es-statefulset.yaml
kind: Namespace
apiVersion: v1
metadata:name: logginglabels:k8s-app: loggingkubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile
---
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:name: elasticsearch-loggingnamespace: logginglabels:k8s-app: elasticsearch-loggingaddonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: elasticsearch-logginglabels:k8s-app: elasticsearch-loggingaddonmanager.kubernetes.io/mode: Reconcile
rules:- apiGroups:- ""resources:- "services"- "namespaces"- "endpoints"verbs:- "get"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: elasticsearch-logginglabels:k8s-app: elasticsearch-loggingaddonmanager.kubernetes.io/mode: Reconcile
subjects:- kind: ServiceAccountname: elasticsearch-loggingnamespace: loggingapiGroup: ""
roleRef:kind: ClusterRolename: elasticsearch-loggingapiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1
kind: StatefulSet
metadata:name: elasticsearch-loggingnamespace: logginglabels:k8s-app: elasticsearch-loggingversion: v7.10.2addonmanager.kubernetes.io/mode: Reconcile
spec:serviceName: elasticsearch-loggingreplicas: 2selector:matchLabels:k8s-app: elasticsearch-loggingversion: v7.10.2template:metadata:labels:k8s-app: elasticsearch-loggingversion: v7.10.2spec:serviceAccountName: elasticsearch-loggingcontainers:- image: quay.io/fluentd_elasticsearch/elasticsearch:v7.10.2name: elasticsearch-loggingimagePullPolicy: IfNotPresentresources:# need more cpu upon initialization, therefore burstable classlimits:cpu: 1000mmemory: 3Girequests:cpu: 100mmemory: 3Giports:- containerPort: 9200name: dbprotocol: TCP- containerPort: 9300name: transportprotocol: TCPlivenessProbe:tcpSocket:port: transportinitialDelaySeconds: 5timeoutSeconds: 10readinessProbe:tcpSocket:port: transportinitialDelaySeconds: 5timeoutSeconds: 10volumeMounts:- name: elasticsearch-loggingmountPath: /dataenv:- name: "NAMESPACE"valueFrom:fieldRef:fieldPath: metadata.namespace- name: "MINIMUM_MASTER_NODES"value: "1"volumes:- name: elasticsearch-loggingemptyDir: {}# Elasticsearch requires vm.max_map_count to be at least 262144.# If your OS already sets up this number to a higher value, feel free# to remove this init container.initContainers:- image: alpine:3.6command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"]name: elasticsearch-logging-initsecurityContext:privileged: true通过执行如下的命令部署Elasticsearch:
[root@master log]# kubectl create -f es-statefulset.yaml下面Elasticsearch的代理服务YAML配置文件,代理服务暴露的端口为9200。
[root@master log]# vim es-service.yaml
apiVersion: v1
kind: Service
metadata:name: elasticsearch-loggingnamespace: logginglabels:k8s-app: elasticsearch-loggingkubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/name: "Elasticsearch"
spec:clusterIP: Noneports:- name: dbport: 9200protocol: TCPtargetPort: 9200- name: transportport: 9300protocol: TCPtargetPort: 9300publishNotReadyAddresses: trueselector:k8s-app: elasticsearch-loggingsessionAffinity: Nonetype: ClusterIP
通过执行如下的命令部署Elasticsearch的代理服务:[root@master log]# kubectl create -f es-service.yaml2、部署Fluentd
Fluentd是一个开源数据收集器,通过它能对数据进行统一收集和消费,能够更好地使用和理解数据。Fluentd将数据结构化为JSON,从而能够统一处理日志数据,包括:收集、过滤、缓存和输出。Fluentd是一个基于插件体系的架构,包括输入插件、输出插件、过滤插件、解析插件、格式化插件、缓存插件和存储插件,通过插件可以扩展和更好的使用Fluentd。
Fluentd的整体处理过程如下,通过Input插件获取数据,并通过Engine进行数据的过滤、解析、格式化和缓存,最后通过Output插件将数据输出给特定的终端。

在本文中, Fluentd 作为 Logging-agent 进行日志收集,并将收集到的日志推送给后端的Elasticsearch。对于Kubernetes来说,DaemonSet确保所有(或一些)Node会运行一个Pod副本。因此,Fluentd被部署为DaemonSet,它将在每个节点上生成一个pod,以读取由kubelet,容器运行时和容器生成的日志,并将它们发送到Elasticsearch。为了使Fluentd能够工作,每个Node都必须标记beta.kubernetes.io/fluentd-ds-ready=true。
[root@master log]# kubectl label nodes node1 beta.kubernetes.io/fluentd-ds-ready=true [root@master log]# kubectl label nodes node2 beta.kubernetes.io/fluentd-ds-ready=true
下面是Fluentd的ConfigMap配置文件,此文件定义了Fluentd所获取的日志数据源,以及将这些日志数据输出到Elasticsearch中。
在Fluented配置文件中,有下面的一些关键指令:
-
source指令确定输入源。
-
match指令确定输出目标。
-
filter指令确定事件处理管道。
-
system指令设置系统范围的配置。
-
label指令将输出和过滤器分组以进行内部路由
-
@include ** **指令包含其他文件。
[
root@master log]# fluentd-es-configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:name: fluent-bit-confignamespace: logginglabels:k8s-app: fluent-bit
data:# Configuration files: server, input, filters and output# ======================================================fluent-bit.conf: |[SERVICE]Flush 1Log_Level infoDaemon offParsers_File parsers.confHTTP_Server OnHTTP_Listen 0.0.0.0HTTP_Port 2020
@INCLUDE input-kubernetes.conf@INCLUDE filter-kubernetes.conf@INCLUDE output-elasticsearch.conf
input-kubernetes.conf: |[INPUT]Name tailTag kube.*Path /var/log/containers/*.logParser dockerDB /var/log/flb_kube.dbMem_Buf_Limit 20MBSkip_Long_Lines OnRefresh_Interval 10
filter-kubernetes.conf: |[FILTER]Name kubernetesMatch kube.*Kube_URL https://kubernetes.default.svc:443Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crtKube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/tokenKube_Tag_Prefix kube.var.log.containers.Merge_Log OnMerge_Log_Key log_processedK8S-Logging.Parser OnK8S-Logging.Exclude Off
output-elasticsearch.conf: |[OUTPUT]Name esMatch *Host ${FLUENT_ELASTICSEARCH_HOST}Port ${FLUENT_ELASTICSEARCH_PORT}Logstash_Format OnReplace_Dots OnRetry_Limit False
parsers.conf: |[PARSER]Name apacheFormat regexRegex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$Time_Key timeTime_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]Name apache2Format regexRegex ^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^ ]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$Time_Key timeTime_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]Name apache_errorFormat regexRegex ^\[[^ ]* (?<time>[^\]]*)\] \[(?<level>[^\]]*)\](?: \[pid (?<pid>[^\]]*)\])?( \[client (?<client>[^\]]*)\])? (?<message>.*)$
[PARSER]Name nginxFormat regexRegex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$Time_Key timeTime_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]Name jsonFormat jsonTime_Key timeTime_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]Name dockerFormat jsonTime_Key timeTime_Format %Y-%m-%dT%H:%M:%S.%LTime_Keep On
[PARSER]# http://rubular.com/r/tjUt3Awgg4Name criFormat regexRegex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<message>.*)$Time_Key timeTime_Format %Y-%m-%dT%H:%M:%S.%L%z
[PARSER]Name syslogFormat regexRegex ^\<(?<pri>[0-9]+)\>(?<time>[^ ]* {1,2}[^ ]* [^ ]*) (?<host>[^ ]*) (?<ident>[a-zA-Z0-9_\/\.\-]*)(?:\[(?<pid>[0-9]+)\])?(?:[^\:]*\:)? *(?<message>.*)$Time_Key timeTime_Format %b %d %H:%M:%S通过执行如下的命令创建Fluentd的ConfigMap:
[root@master log]# kubectl create -f fluentd-es-configmap.yamlFluentd本身的YAML配置文件如下所示:
[root@master log]# vim fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata:name: fluent-bitnamespace: logging --- apiVersion: rbac.authorization.k8s.io/v1 kin
d: ClusterRole
metadata:name: fluent-bit-read
rules:
- apiGroups: [""]resources:- namespaces- podsverbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: fluent-bit-read
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: fluent-bit-read
subjects:
- kind: ServiceAccountname: fluent-bitnamespace: logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluent-bitnamespace: logginglabels:k8s-app: fluent-bit-loggingversion: v1kubernetes.io/cluster-service: "true"
spec:selector:matchLabels:k8s-app: fluent-bit-loggingtemplate:metadata:labels:k8s-app: fluent-bit-loggingversion: v1kubernetes.io/cluster-service: "true"annotations:prometheus.io/scrape: "true"prometheus.io/port: "2020"prometheus.io/path: /api/v1/metrics/prometheusspec:containers:- name: fluent-bitimage: fluent/fluent-bit:1.5imagePullPolicy: Alwaysports:- containerPort: 2020env:- name: FLUENT_ELASTICSEARCH_HOSTvalue: "elasticsearch-logging.logging.svc.cluster.local"- name: FLUENT_ELASTICSEARCH_PORTvalue: "9200"volumeMounts:- name: varlogmountPath: /var/log- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: true- name: fluent-bit-configmountPath: /fluent-bit/etc/terminationGracePeriodSeconds: 10volumes:- name: varloghostPath:path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containers- name: fluent-bit-configconfigMap:name: fluent-bit-configserviceAccountName: fluent-bittolerations:- key: node-role.kubernetes.io/masteroperator: Existseffect: NoSchedule- operator: "Exists"effect: "NoExecute"- operator: "Exists"effect: "NoSchedule"通过执行如下的命令部署Fluentd:
[root@master log]# kubectl create -f fluentd-es-ds.yaml3、部署Kibana
Kibana是一个开源的分析与可视化平台,被设计用于和Elasticsearch一起使用的。通过kibana可以搜索、查看和交互存放在Elasticsearch中的数据,利用各种不同的图表、表格和地图等,Kibana能够对数据进行分析与可视化。Kibana部署的YAML如下所示,通过环境变量ELASTICSEARCH_URL,指定所获取日志数据的Elasticsearch服务,此处为:http://elasticsearch-logging:9200,elasticsearch.cattle-logging是elasticsearch在Kubernetes中代理服务的名称。
[
通过执行如下的命令部署Kibana的代理服务:
[root@master log]# kubectl create -f kibana-deployment.yaml
下面Kibana的代理服务YAML配置文件,代理服务的类型为NodePort。
[root@master log]# vim kibana-service.yaml --- apiVersion: v1 kind: Service metadata:name: kibana-loggingnamespace: logginglabels:k8s-app: kibana-loggingkubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilekubernetes.io/name: "Kibana" spec:type: NodePortports:- port: 5601protocol: TCPtargetPort: uiselector:k8s-app: kibana-logging
通过执行如下的命令部署Kibana的代理服务:
[root@master log]# kubectl create -f kibana-service.yaml
三、日志数据展示
获取Kibana的对外暴露的端口
[root@master log]# kubectl get svc --namespace=kube-system
从输出的信息可以知道,kibana对外暴露的端口为32639,因此在Kubernetes集群外可以通过:http://{NodeIP}:32639 访问kibana

通过点击"Discover",添加索引就能够实时看到从容器中获取到的日志信息:
例如添加索引logstash-*,添加完成效果如下:

相关文章:
K8S 日志方案
一、统一日志管理的整体方案 通过应用和系统日志可以了解Kubernetes集群内所发生的事情,对于调试问题和监视集群活动来说日志非常有用。对于大部分的应用来说,都会具有某种日志机制。因此,大多数容器引擎同样被设计成支持某种日志机制。 对…...

GPT2 GPT3
what is prompt 综述1.Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing(五星好评) 综述2. Paradigm Shift in Natural Language Processing(四星推荐) 综述3. Pre-Trained Models: Past, Present and Future Pro…...

2024年人工智能顶会/顶刊截稿时间汇总
人工智能顶会/顶刊汇总 ,方便查阅,持续更新,若有错误烦请大家及时提出! 一、CCF A类 简称 全称录用率频次内容官网截稿日期IJCAIInternational Joint Conference on Artificial Intelligence2020年12.55%,2021年13.9%…...
AI芯片:神经网络研发加速器、神经网络压缩简化、通用芯片 CPU 加速、专用芯片 GPU 加速
AI芯片: 神经网络研发加速器、神经网络压缩简化、通用芯片 CPU 加速、专用芯片 GPU 加速 神经网络研发加速器神经网络编译器各自实现的神经网络编译器 神经网络加速与压缩(算法层面)知识蒸馏低秩分解轻量化网络剪枝量化 通用芯片 CPU 加速x86…...
系列七、Spring Security中基于Jdbc的用户认证 授权
一、Spring Security中基于Jdbc的用户认证 & 授权 1.1、概述 前面的系列文章介绍了基于内存定义用户的方式,其实Spring Security中还提供了基于Jdbc的用户认证 & 授权,再说基于Jdbc的用户认证 & 授权之前,不得不说一下Spring Se…...

网络安全(网络安全)—2024自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
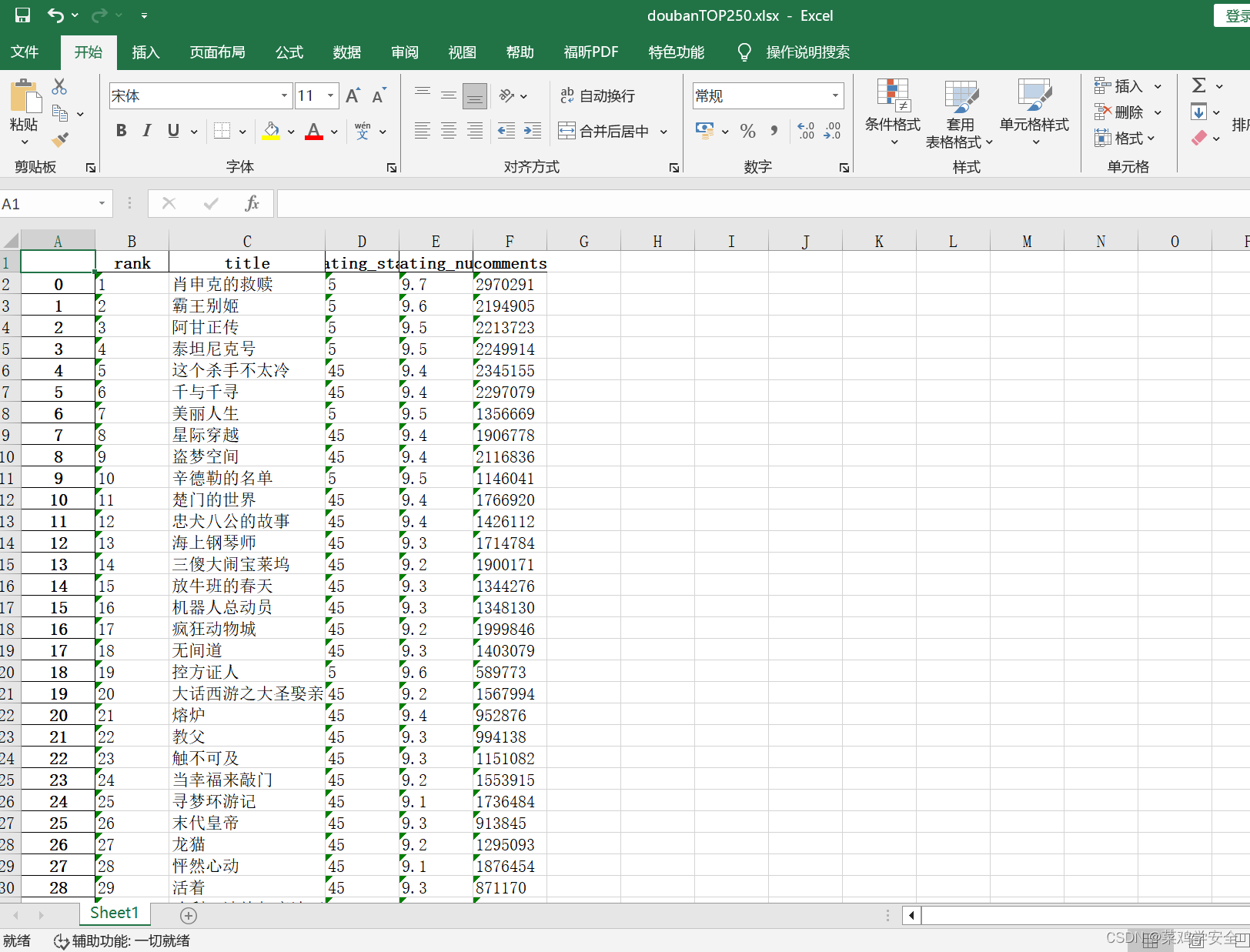
python爬虫小练习——爬取豆瓣电影top250
爬取豆瓣电影top250 需求分析 将爬取的数据导入到表格中,方便人为查看。 实现方法 三大功能 1,下载所有网页内容。 2,处理网页中的内容提取自己想要的数据 3,导入到表格中 分析网站结构需要提取的内容 代码 import requests…...

Vulnhub靶机:driftingblues 2
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.15) 靶机:driftingblues2(10.0.2.18) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entr…...

CentOS 7 权限管理实战指南:用户组管理相关命令详解
前言 深入了解 CentOS 7 用户组管理的命令,掌握关键的用户组操作技巧。从创建和删除用户组、修改组属性,到设置组密码和管理组成员,这篇文章详细介绍了 CentOS 7 系统下常用的用户组管理命令,为读者小伙伴提供了实用而全面的指南…...

Python操作MySQL入门教程,使用pymysql操作MySQL,有录播直播私教课
创建数据库 create database gx character set utf8mb4;连接数据库 #!/usr/bin/python3import mysql as pymysql# 打开数据库连接 db pymysql.connect(hostlocalhost,port3306,userroot,passwordzhangdapeng520,databasegx)# 使用 cursor() 方法创建一个游标对象 cursor cur…...

面试 React 框架八股文十问十答第七期
面试 React 框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)React 废弃了哪些生命…...
Docker教程
docker 安装 官方文档 wget -qO- https://get.docker.com/ | sh sudo usermod -aG docker your-user sudo usermod -aG docker ${USER} newgrp docker # 更新docker用户组 cat /etc/group | grep docker docker --version 使用非root用户管理 帮助启动类 命令 system…...

数据结构:二叉树
数据结构:二叉树 文章目录 数据结构:二叉树1.一些特殊的二叉树1.满二叉树2.完全二叉树 2.手动创建一颗二叉树3.二叉树深度优先遍历4.二叉树层序遍历5.二叉树基础操作1.创建二叉树2.二叉树节点个数3.二叉树叶子节点个数4.二叉树的高度5.二叉树第k层节点个…...
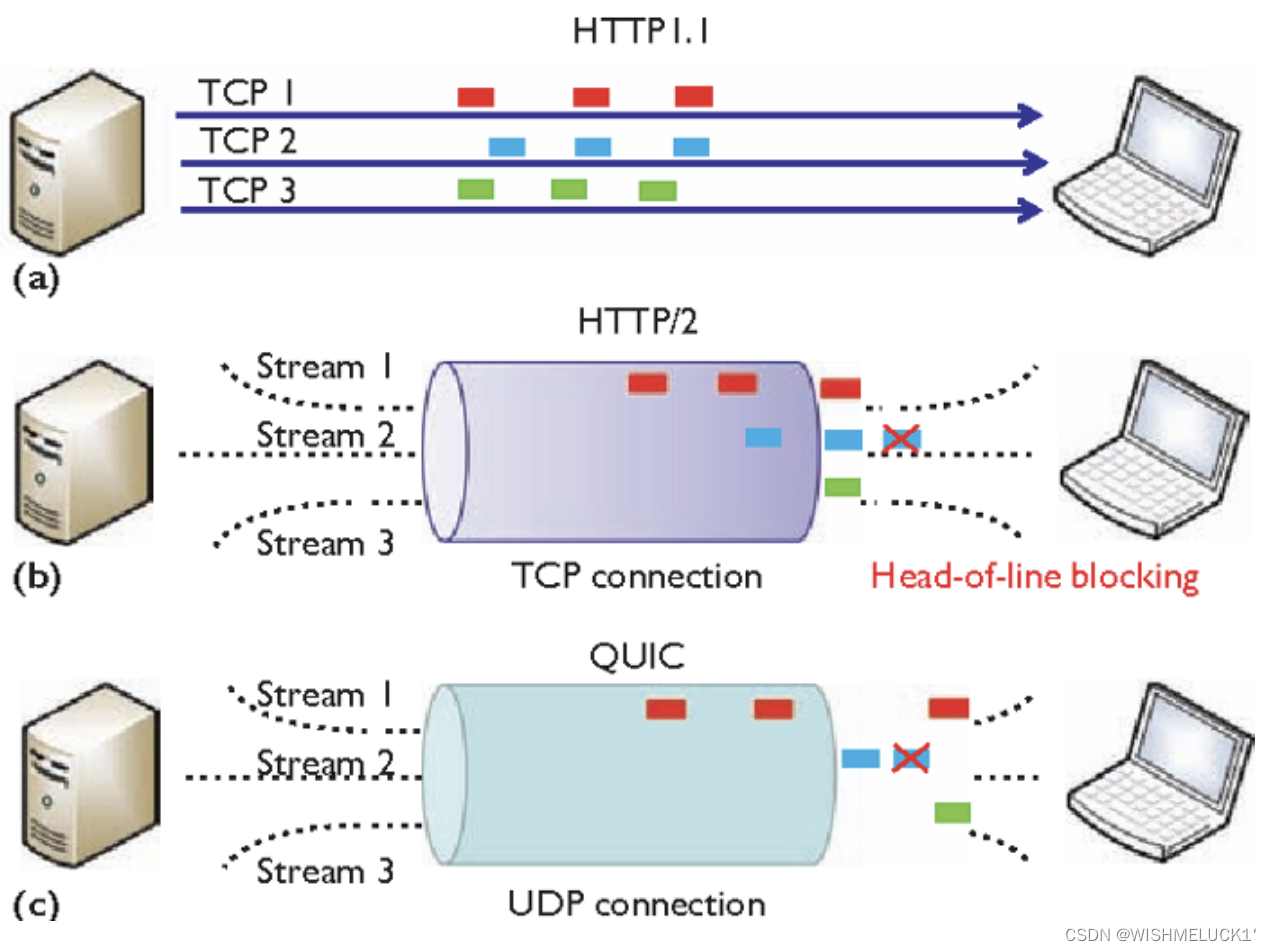
HTTP超文本传输协议
原文链接: 1.5 万字 40 张图解 HTTP 常见面试题(值得收藏)_图解http 小林-CSDN博客https://blog.csdn.net/qq_34827674/article/details/124089736?ops_request_misc%257B%2522request%255Fid%2522%253A%2522170521531616777224478386%252…...
视频SDK的技术架构优势和价值
为了满足企业对于高质量视频的需求,美摄科技推出了一款强大的视频SDK(软件开发工具包),旨在帮助企业轻松实现高效、稳定的视频功能,提升用户体验,增强企业竞争力。 一、美摄视频SDK的技术实现方式 美摄视…...

Invalid bound statement (not found)(xml文件创建问题)
目录 解决方法: 这边大致讲一下我的经历,不想看的直接点目录去解决方法 今天照着老师视频学习,中间老师在使用动态SQL时,直接复制了一份,我想这么简单的一个,我直接从网上找内容创建一个好了,…...

正则表达式2 常见模式
继上次的正则表达式速攻1/2-CSDN博客 还有一些常见的匹配模式可以直接使用 电子邮箱 xxxxxx.域名 的情况 \b[A-Za-z0-9._%-][A-Za-z0-9.-]\.[A-Z|a-z]{2,}\bhttp或者https网址 的情况 http[s]?://(?:[a-zA-Z]|[0-9]|[$-_.&]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F…...

前端对接电子秤、扫码枪设备serialPort 串口使用教程
因为最近工作项目中用到了电子秤,需要对接电子秤设备。以前也没有对接过这种设备,当时也是一脸懵逼,脑袋空空。后来就去网上搜了一下前端怎么对接,然后就发现了SerialPort串口。 Serialport 官网地址:https://serialpo…...
整数转罗马数字)
LeeCode前端算法基础100题(18)整数转罗马数字
一、问题详情: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并列的 1…...
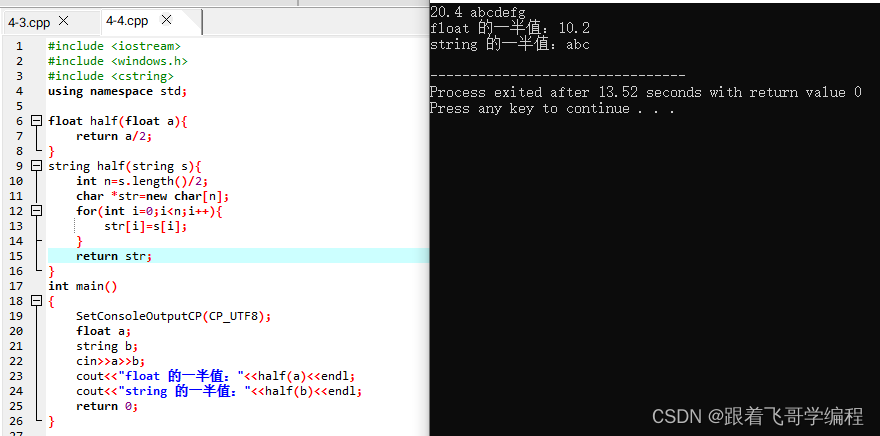
【C++ 程序设计入门基础】- 第4节-函数
1、函数 函数是对实现某一功能的代码的模块化封装。 函数的定义: 标准函数: 输入 n 对整数的 a、b ,输出它们的和。 #include <iostream> #include <windows.h> using namespace std;int add(int a,int b);//函数原型声明int…...

微信小程序逆向工程深度解析:wxappUnpacker实用指南
微信小程序逆向工程深度解析:wxappUnpacker实用指南 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向工程是移动应用安全研究的重…...

游戏模组革命:BepInEx框架让每个玩家都能打造个性化游戏体验
游戏模组革命:BepInEx框架让每个玩家都能打造个性化游戏体验 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 想要为心爱的游戏添加新功能、修改游戏机制,或…...

学习笔记·敏捷开发
“嗨,阿米戈!” “嗨,比拉博!” “今天我要给大家讲讲程序通常是怎么开发的。” “在 20 世纪,当现代 IT 还处于起步阶段时,每个人似乎都认为编程就像建筑或制造。” “事情通常是这样的:” “客户会解释他需要的程序类型——它应该做什么以及应该如何做。” “业…...

AI知识擦除:Gemini3.1Pro能否真正遗忘危险?
概念擦除:能否从 Gemini 3.1 Pro 中删除特定危险知识?——理性看待“遗忘”与“可控”在 2026 年的 AI 热点语境下,“可控”和“可验证”成为讨论主线。除了提升模型能力,人们也更关心另一件事:**当模型掌握了不希望被…...

基于 Git Flow 的团队协作与发布流程实践
在软件开发过程中,随着团队规模扩大、需求频繁迭代以及线上版本持续演进,如何管理代码分支成为影响研发效率的重要问题。上图展示的是一种经典的 Git 分支管理模型 —— Git Flow。 它通过明确的分支职责与合并策略,实现:功能开发…...

抖音内容下载终极指南:5分钟搞定批量下载与去水印
抖音内容下载终极指南:5分钟搞定批量下载与去水印 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...
处理时序数据,这5个参数配置技巧让你事半功倍)
别再死记硬背了!用PyTorch的nn.GRU()处理时序数据,这5个参数配置技巧让你事半功倍
PyTorch中GRU参数配置的实战艺术:从天气预测案例掌握5个关键技巧 时序数据就像一条永不停息的河流,而GRU(门控循环单元)则是我们从中提取智慧的渔网。许多开发者在使用PyTorch的nn.GRU()时,常常陷入参数配置的迷雾中—…...

7天深度拆解:openpilot自动驾驶系统技术实现与二次开发指南
7天深度拆解:openpilot自动驾驶系统技术实现与二次开发指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tr…...
)
嵌入式工程师避坑指南:手把手调试OV9281等MIPI摄像头Sensor(从DTS配置到示波器抓波形)
嵌入式工程师实战:OV9281 MIPI摄像头Sensor深度调试手册 当你在全志T507开发板上第一次点亮OV9281摄像头时,示波器上那个200mV的HS模式波形,可能比任何文档都更能让你理解MIPI的工作本质。这不是一篇按部就班的配置教程,而是一位经…...

终极指南:如何用amdgpu_top实时监控AMD显卡性能
终极指南:如何用amdgpu_top实时监控AMD显卡性能 【免费下载链接】amdgpu_top Tool to display AMDGPU usage 项目地址: https://gitcode.com/gh_mirrors/am/amdgpu_top 还在为AMD显卡性能监控而烦恼吗?想要像NVIDIA用户使用nvidia-smi那样轻松掌握…...