协方差矩阵自适应调整的进化策略(CMA-ES)
关于CMA-ES,其中 CMA 为协方差矩阵自适应(Covariance Matrix Adaptation),而进化策略(Evolution strategies, ES)是一种无梯度随机优化算法。CMA-ES 是一种随机或随机化方法,用于非线性、非凸函数的实参数(连续域)优化。
作者Nikolaus Hansen于2016年在Machine Learning上发布了关于CMA-ES详细教学。

原文链接:The CMA Evolution Strategy: A Tutorial
CMA-ES讲座Slide:cma-es.key (polytechnique.fr)
更多教学内容查看:Talks (seminars, tutorials,… most including slides)
CMA-ES源码:https://cma-es.github.io
更多内容请查看作者主页:Homepage of Nikolaus Hansen (polytechnique.fr)

CMA-ES
- 1. 前言
- 1.1 黑盒优化
- 1.2 Why Evolution Strategies?
- 1.3 ES进化策略的基本思想
- 1.4 进化策略的分类
- 1.4.1 不可重组的进化策略
- 1.4.2 可重组的进化策略
- 2. 准备知识
- 2.1 正定矩阵的特征分解
- 2.2 多元正态分布
- 2.3 黑箱随机优化
- 2.4 Hessian矩阵和协方差矩阵
- 3. CMA-ES理论
- 3.1 采样
- 3.2 选择与重组:更新均值
- 3.3 协方差矩阵自适应
- 3.3.1 估计协方差矩阵
- 3.3.2 协方差矩阵的Rank- μ \mathbf{\mu} μ更新
- 3.3.3 协方差矩阵的Rank-one更新
- 3.3.4 协方差矩阵结合
- 3.4 步长控制
1. 前言
1.1 黑盒优化
优化就是计算一个函数的最大值或者最小值的问题。假设函数f(x)的具体表达式是未知的,把它看作一个黑盒函数,我们只能通过向盒子输入得到输出。它可能存在局部最小点和全局最小点,很显然进行坐标点穷举然后对比出最小值的方法是不可行的,这时就需要我们根据策略一步步地向最小值逼近,不同策略就对应着不同的优化算法。
在机器学习的过程中,搭建的模型并不是一开始就能根据输入获得我们想要的结果,所以就需要对我们的模型进行优化,以使误差函数值(loss)达到最小或者适应度函数值(fitness)达到最大。
所谓的黑盒优化就是指寻找黑盒函数的全局最优解。非形式化的来说,一个黑盒函数F可理解为从输入 X ( x 1 , x 2 , x 3... ) X(x1,x2,x3...) X(x1,x2,x3...)到输出的一个映射。但是映射关系F的具体表达式及梯度信息均未知,我们只能通过不断地将数据输入到黑盒函数中然后通过得到的输出值来猜测黑盒函数的结构信息。下图表示一个黑盒问题的映射关系。

1.2 Why Evolution Strategies?
ES是一种无梯度随机优化算法,具有较好的并行扩展性(scalability), 不变性(invariance under some transformations), 和较为充分的理论分析,在中等规模(变量个数在3~300范围内)的复杂优化问题上具有较好的效果。
这里不得不提一下 OpenAI上的这篇文章Evolution Strategies as a Scalable Alternative to Reinforcement Learning 由于具有良好的并行性,ES用很短的时间完成了模型的训练。这篇文章所引起对ES的关注可能比其他论文加起来都多。
1.3 ES进化策略的基本思想
进化策略(Evolution Strategies, ES)做黑箱优化(Black box optimization)的主要思路,即通过反复迭代调整一个正态分布进行搜索。进化策略中迭代的正态分布一般写成 N ( m t , σ t 2 C t ) N({{m}_{t}},\sigma _{t}^{2}{{C}_{t}}) N(mt,σt2Ct),包含三个参数 m t , σ t , C t {{m}_{t}},{{\sigma }_{t}},{{C}_{t}} mt,σt,Ct,而正态分布参数所起的作用为:
• m t {{m}_{t}} mt均值,决定分布的中心位置。在算法中,决定搜索区域;
• σ t {{\sigma }_{t}} σt 步长参数,决定分布的整体方差(global variance)。在算法中,决定搜索范围的大小和强度。
• C t {{C}_{t}} Ct协方差矩阵,决定分布的形状。在算法中决定变量之间的依赖关系,以及搜索方向之间的相对尺度(scale).
ES算法设计的核心就是如何对这些参数进行调整,尤其是步长参数和协方差矩阵的调整,以达到尽可能好的搜索效果。对这些参数的调整在ES算法的收敛速率方面有非常重要的影响。一般的,ES调整参数的基本思路是,调整参数使得产生好解的概率逐渐增大(沿好的搜索方向进行搜索的概率增大)。
一般的,进化策略在搜索中反复迭代以下步骤:
- Sampling:采样产生一个或者一组候选解(candidate solutions);
- Evaluation:对新产生的解计算对应的目标函数值;
- Selection:依据目标函数值选择部分或者全部解;
- Update:使用选择的解更新分布参数.
在进化算法中,一次完整的迭代称为一代(generation),一个候选解称为一个个体,计算目标函数值的过程称为评估。每次迭代产生的新的候选解称为子代(offspring),通过选择得到的用于产生子代的解称为父代(parent)。
CMA-ES 调整参数的基本思路是,调整参数使得产生好解的概率逐渐增大(沿好的搜索方向进行搜索的概率增大)。

1.4 进化策略的分类
1.4.1 不可重组的进化策略
ES中,一个新解是通过在 N ( m t , σ t 2 C t ) N({{m}_{t}},\sigma _{t}^{2}{{C}_{t}}) N(mt,σt2Ct)采样产生的。一般的,一个新解可以写成 x = m t + σ t y , y ∼ N ( 0 , C t ) x={{m}_{t}}+{{\sigma }_{t}}y,y\sim N(0,{{C}_{t}}) x=mt+σty,y∼N(0,Ct)
根据产生解和选择解的方式的不同,算法可以分为不同的类型。主要包含以下三种类型:
(1+1)-ES:每次迭代只产生一个新解,通过和父代进行比较,较好的一个成为下一次迭代的父代,否则直接舍去或淘汰,并相应地调整分布参数。
Step1: 选择一个初始解x和变异强度 σ \sigma σ
Step2: 通过变异创建新的解:y=x+N(0, σ \sigma σ)
Step3:如果f(y)<f(x),则将x替换成y
Step4: 如果满足终止条件,算法停止,否则执行Step2
- 形式简单,更易于理论分析;
- 性能良好,某些变异个体代表精英;
- 集中在局部搜索;
( μ + λ ) \mathbf{(\mu + \lambda)} (μ+λ)-ES:引入种群的方法,使用多个父代和子代,初始化 μ \mu μ个初始解,通过初始解和变异强度 σ \sigma σ创建 λ \lambda λ个变异解,在子代中选择最优个体与父代合并
Step1: 初始化具有 μ \mu μ个解的初始种群和变异强度 σ \sigma σ
Step2:创建 λ \lambda λ个变异解,生成子代时从 μ \mu μ个父代中随机选择:y(j)=x(i)+N(0, σ \sigma σ)
Step3: 将父代与子代合并形成一个新的种群集合P,在P中选择最优的 μ \mu μ个解,以确保种群大小不变。
P = ( ∪ j = 1 λ { y ( j ) } ) ∪ ( ∪ i = 1 μ { x ( i ) } ) P=\left( \cup _{j=1}^{\lambda }\left\{ {{y}^{(j)}} \right\} \right)\cup \left( \cup _{i=1}^{\mu }\left\{ {{x}^{(i)}} \right\} \right) P=(∪j=1λ{y(j)})∪(∪i=1μ{x(i)})
Step4: 如果满足终止条件,算法停止,否则执行Step2
- 引入种群的思想,易于并行化;
- 围绕最优点进行搜索,可能会长时间陷入某个局部范围;
- 当前主要用于多目标优化;
注: ( μ + λ ) (\mu + \lambda) (μ+λ)-ES和(1+1)-ES 被称为精英算法,指算法集中在当前所找到的最优解附近进行搜索。
( μ , λ ) \mathbf{(\mu,\lambda)} (μ,λ)-ES: 每次迭代产生 λ \lambda λ个新解,其中较好的 μ \mu μ个成为下一次迭代的父代,其他的直接舍去,并相应的调整分布参数。
- 所有解都只存活一代,避免长时间陷入某个范围;
- ( μ , λ ) (\mu,\lambda) (μ,λ)-ES每次只保留产生的最好的解,这种常用于理论分析。
该算法包含两种变体:
(1) 选择后代中最好的一个作为分布均值
m ← arg min x i f ( x i ) m\leftarrow \arg {{\min }_{{{x}_{i}}}}f({{x}_{i}}) m←argminxif(xi)
(2) 以最佳µ个子代的加权平均值作为分布均值(CMA采用的策略)
m ← ∑ i = 1 μ w i x i : λ m\leftarrow \sum\limits_{i=1}^{\mu }{{{w}_{i}}}{{x}_{i:\lambda }} m←i=1∑μwixi:λ
1.4.2 可重组的进化策略
在可重组进化策略中,首先选择一组父代个体进行重组以寻找一个新解,之后对该解采用之前介绍的变异操作。重组时并不是选择两个父代或所有父代,而是随机选择 ρ ∈ [ 1 , μ ] \rho \in [1,\mu ] ρ∈[1,μ]个父代,当 ρ = 1 \rho =1 ρ=1时说明没有重组。重组方式主要有两种:中间和离散。在中间重组算子中$\rho $个选择的平均解向量计算如下:
y = 1 ρ ∑ i = 1 ρ x ( i ) y=\frac{1}{\rho }\sum\limits_{i=1}^{\rho }{{{x}^{(i)}}} y=ρ1i=1∑ρx(i)
可重组ES: ( μ / ρ + λ ) − ES (\mu /\rho +\lambda )-\text{ES} (μ/ρ+λ)−ES
Step1:初始化具有μ个解${{x}^{(i)}},i=1,2,\ldots ,\mu $的初始种群,和变异强度σ
Step2:创建λ个变异解,每个解使用从μ个父代中随机选择 ρ \rho ρ个按如下方式:
- 通过 ρ \rho ρ个父代个体的中间重组或离散重组,计算重组解y
- 对重组解进行变异: y ( j ) = y ( i ) + N ( 0 , σ ) {{y}^{(j)}}={{y}^{(i)}}+N(0,\sigma ) y(j)=y(i)+N(0,σ)
Step3:将父代和子代合并成一个新的父代种群P,从P中选择最好的μ个解,以保证种群大小不变:
P = ( ∪ j = 1 λ { y ( j ) } ) ∪ ( ∪ i = 1 μ { x ( i ) } ) P=\left( \cup _{j=1}^{\lambda }\left\{ {{y}^{(j)}} \right\} \right)\cup \left( \cup _{i=1}^{\mu }\left\{ {{x}^{(i)}} \right\} \right) P=(∪j=1λ{y(j)})∪(∪i=1μ{x(i)})
Step4:如果满足终止条件,算法停止,否则执行Step2。
而对于 ( μ / ρ , λ ) − ES (\mu /\rho ,\lambda )-\text{ES} (μ/ρ,λ)−ES中,在上述算法的Step3中,只使用子代种群来创建新种群。
2. 准备知识
2.1 正定矩阵的特征分解
对于任意一个正定矩阵 C ∈ R n × n C\in {{R}^{n\times n}} C∈Rn×n,都有特征向量的标准正交基 B = [ b 1 , … , b n ] T B={{[{{b}_{1}},\ldots ,{{b}_{n}}]}^{T}} B=[b1,…,bn]T其对应的特征值为 d 1 2 , … , d n 2 > 0 d_{1}^{2},\ldots ,d_{n}^{2}>0 d12,…,dn2>0,也就是说对于每个 b i b_{i} bi都有 C b i = d i 2 b i C{{b}_{i}}=d_{i}^{2}{{b}_{i}} Cbi=di2bi,C的正交分解为: C=B D 2 B T \text{C=B}{{\text{D}}^{\text{2}}}{{\text{B}}^{\text{T}}} C=BD2BT,其中B是正交矩阵,满足 B T B = B B T = I {{B}^{T}}B=B{{B}^{T}}=I BTB=BBT=I, B B B的列向量构成一个标准正交基的特征向量, D 2 D^{2} D2是对角矩阵,其主对角元素为矩阵C的特征值。
C − 1 = ( B D 2 B T ) − 1 = B T − 1 D − 2 B − 1 = B D − 2 B T = B [ 1 d 1 2 ⋯ ⋯ ⋯ ⋮ 1 d 2 2 ⋯ ⋯ ⋮ ⋮ ⋱ ⋮ ⋮ ⋮ ⋯ 1 d n 2 ] B T \left. {{\text{C}}^{-1}}={{\left( \text{B}{{\text{D}}^{2}}{{\text{B}}^{\text{T}}} \right)}^{-1}}={{\text{B}}^{\text{T}}}^{-1}{{\text{D}}^{-2}}{{\text{B}}^{-1}}=\text{B}{{\text{D}}^{-2}}{{\text{B}}^{\text{T}}}=\text{B}\left[ \begin{matrix} \frac{1}{d_{1}^{2}} & \cdots & \cdots & \cdots \\\vdots & \frac{1}{d_{2}^{2}} & \cdots & \cdots \\ \vdots & \vdots & \ddots & \vdots \\\vdots & \vdots & \cdots & \frac{1}{d_{n}^{2}} \\\end{matrix} \right. \right]{{\text{B}}^{\text{T}}} C−1=(BD2BT)−1=BT−1D−2B−1=BD−2BT=B d121⋮⋮⋮⋯d221⋮⋮⋯⋯⋱⋯⋯⋯⋮dn21 BT
C 1 2 = B D B T {{C}^{\frac{1}{2}}}=BD{{B}^{T}} C21=BDBT
C − 1 2 = B D − 1 B T = B diag ( 1 d 1 , ⋯ , 1 d n ) B T {{C}^{-\frac{1}{2}}}=B{{D}^{-1}}{{B}^{T}}=B\text{diag}(\frac{1}{{{d}_{1}}},\cdots ,\frac{1}{{{d}_{n}}}){{B}^{T}} C−21=BD−1BT=Bdiag(d11,⋯,dn1)BT
其中 D 2 =DD=diag ( d 1 , … … , d n ) 2 =diag ( d 1 2 , … … , d n 2 ) {{\text{D}}^{\text{2}}}\text{=DD=diag}{{({{\text{d}}_{\text{1}}},\ldots \ldots ,{{\text{d}}_{\text{n}}})}^{\text{2}}}\text{=diag}(\text{d}_{\text{1}}^{\text{2}},\ldots \ldots ,\text{d}_{\text{n}}^{\text{2}}) D2=DD=diag(d1,……,dn)2=diag(d12,……,dn2), d i d_{i} di是特征值的平方根,协方差矩阵是半正定的矩阵。
2.2 多元正态分布
多元正态分布N(m, C),其中m是均值,C是协方差。
对于一个二维向量x和一个正定实对称矩阵C,方程 x T C x = D x^{T}Cx = D xTCx=D,其中D是常量,描述了一个中心在原点的椭圆。中心在原点的椭圆协方差矩阵的几何解释如下图:椭圆的主轴对应协方差的特征向量,主轴长度对应协方差的特征值的大小。
特征分解: C=B D 2 B T \text{C=B}{{\text{D}}^{\text{2}}}{{\text{B}}^{\text{T}}} C=BD2BT
如果 D= δ I \text{D=}\delta \text{I} D=δI,此时如下图左所示为一个圆;如果B=I, C = D 2 C = D^{2} C=D2,此时如图中间所示,进行了一定程度的拉伸,椭圆的主轴与坐标轴垂直;右图进行了一定方向的旋转,更加接近于最优解的方向。

正态分布N(m,C)可以写成以下形式:
N ( m , C ) ∼ m + N ( 0 , C ) ∼ m + C 1 2 N ( 0 , I ) ∼ m + B D B T N ( 0 , l ) ⏟ ∼ N ( 0 , l ) ∼ m + B D N ( 0 , I ) ⏟ ∼ N ( 0 , D 2 ) , \begin{aligned} \mathcal{N}(\boldsymbol{m},\boldsymbol{C})& \thicksim m+\mathcal{N}(0,C) \\ &\sim m+C^{\frac12}\mathcal{N}(0,\mathbf{I}) \\ &\sim m+BD\underbrace{B^{\mathsf{T}}\mathcal{N}(\mathbf{0},\mathbf{l})}_{\sim\mathcal{N}(\mathbf{0},\mathbf{l})} \\ &\sim m+B\underbrace{DN(0,\mathbf{I})}_{\sim\mathcal{N}(\mathbf{0},\mathbf{D}^2)}, \end{aligned} N(m,C)∼m+N(0,C)∼m+C21N(0,I)∼m+BD∼N(0,l) BTN(0,l)∼m+B∼N(0,D2) DN(0,I),
2.3 黑箱随机优化
考虑一个黑箱搜索情景,想要最小化代价函数,目标是寻找一个或者多个候选解x,使函数f(x)尽可能的小。而黑箱搜索所能提供的信息只有函数f(x)。搜索点可以自由的选择,但是同时意味着大的搜索信息量。
f : R n → R x ↦ f ( x ) \begin{matrix}f\colon\mathbb{R}^n\to\mathbb{R}\\x\mapsto f(x)\end{matrix} f:Rn→Rx↦f(x)
一个随机优化的流程如下:
-
初始化分布参数 θ \theta θ
-
迭代次数g: 0,1,2,…
-
从分布中采样 λ \lambda λ个独立的点 P ( x ∣ θ ( g ) ) → x 1 , … , x λ P\left( x|\theta^{(g)} \right) \rightarrow x_{1},{\ldots,x}_{\lambda} P(x∣θ(g))→x1,…,xλ
-
利用f(x)评估样本 x 1 , … , x λ x_{1},{\ldots,x}_{\lambda} x1,…,xλ
-
更新参数 θ ( g + 1 ) = F θ ( θ ( g ) , ( x 1 , f ( x 1 ) ) , … , ( x λ , f ( x λ ) ) ) {{\theta }^{(g+1)}}={{F}_{\theta }}({{\theta }^{(g)}},({{x}_{1}},f({{x}_{1}})),\ldots ,({{x}_{\lambda }},f({{x}_{\lambda }}))) θ(g+1)=Fθ(θ(g),(x1,f(x1)),…,(xλ,f(xλ)))
-
中断条件满足,结束
在CMA进化算法中,分布函数P是一个多元正态分布。在给定均值和协方差后,正态分布具有最大的熵。
2.4 Hessian矩阵和协方差矩阵
一个凸二次目标函数 f H : x → 1 2 x T H x {{f}_{H}}:x\to \frac{1}{2}{{x}^{\text{T}}}Hx fH:x→21xTHx, 其中,H是Hessian矩阵为正定矩阵,简单理解为二阶偏导数组成的方阵,形式如下:
H ( f ) = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] \mathrm{H(f)=}\begin{bmatrix}\frac{\partial^2f}{\partial x_1^2}&\frac{\partial^2f}{\partial x_1\partial x_2}&\cdots&\frac{\partial^2f}{\partial x_1\partial x_n}\\\frac{\partial^2f}{\partial x_2\partial x_1}&\frac{\partial^2f}{\partial x_2^2}&\cdots&\frac{\partial^2f}{\partial x_2\partial x_n}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial^2f}{\partial x_n\partial x_1}&\frac{\partial^2f}{\partial x_n\partial x_2}&\cdots&\frac{\partial^2f}{\partial x_n^2}\end{bmatrix} H(f)= ∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f
在我们搜索的分布函数正态分布N(m, C)中,C与H有相近的关系。前面推导中: B T C − 1 B = D 2 , D 2 {{\text{B}}^{\text{T}}}{{\text{C}}^{-1}}\text{B}={{\text{D}}^{2}},{{\text{D}}^{2}} BTC−1B=D2,D2是个对角阵,假如H=C=I, f H {{f}_{H}} fH等同于优化函数 f H : x → 1 2 x T H x {{f}_{H}}:x\to \frac{1}{2}{{x}^{\text{T}}}Hx fH:x→21xTHx,设置 C − 1 = H C^{- 1} = H C−1=H,在凸二次规划,设置搜索分布的协方差矩阵等于Hession矩阵的逆矩阵等同于把一个椭球函数缩放到一个球面上。因此认为协方差矩阵优化等同于Hessian矩阵逆矩阵的优化。进一步选择协方差矩阵对于搜索空间是等价的,因为对于所有满秩的n阶矩阵A,我们都能找到一个正定Hession矩阵。
1 2 ( Ax ) T Ax = 1 2 x T A T Ax = 1 2 x T Hx \frac{1}{2}{{\left( \text{Ax} \right)}^{\text{T}}}\text{Ax}=\frac{1}{2}{{\text{x}}^{\text{T}}}{{\text{A}}^{\text{T}}}\text{Ax}=\frac{1}{2}{{\text{x}}^{\text{T}}}\text{Hx} 21(Ax)TAx=21xTATAx=21xTHx
3. CMA-ES理论
相关符号说明:

3.1 采样
CMA-ES 算法的基本特点有:
- 无梯度优化,不使用梯度信息。
- 局部搜索中无梯度算法通常比梯度算法慢,通常需要 O(n) 倍的评估。
- 在复杂优化问题如 n o n − s e p a r a b l e , i l l − c o n d i t i o n e d , o r r u g g e d / m u l t i − m o d a l non-separable, ill-conditioned, or rugged/multi-modal non−separable,ill−conditioned,orrugged/multi−modal上表现良好。
CMA-ES作为一种随机搜索算法是通过运用高斯正态分布随机产生 λ \lambda λ个样本点作为优化过程中的初始种群。首先生成一组多元正态分布 N ( m ( g ) , C ( g ) ) N\left( {{m}^{(g)}},{{C}^{(g)}} \right) N(m(g),C(g)),对其进行线性变化转成标准正态分布的一个变形:
N ( m ( g ) , C ( g ) ) ∼ m ( g ) + N ( 0 , C ( g ) ) ∼ m ( g ) + C 1 2 N ( 0 , I ) ∼ m ( g ) + B D B T N ( 0 , I ) ∼ m ( g ) + B D N ( 0 , I ) \begin{aligned} N\big(m^{(g)},C^{(g)}\big)& \sim m^{(g)}+N\Big(0,C^{(g)}\Big) \\ &\sim m^{(g)}+C^{\frac{1}{2}}N(0,I) \\ &\sim m^{(g)}+BDB^{T}N(0,I) \\ &\sim m^{(g)}+BDN(0,I) \end{aligned} N(m(g),C(g))∼m(g)+N(0,C(g))∼m(g)+C21N(0,I)∼m(g)+BDBTN(0,I)∼m(g)+BDN(0,I)
得到粒子采样的基本公式为: x k ( g + 1 ) ∼ m ( g ) + σ ( g ) N ( 0 , C ( g ) ) , k = 1 , … , λ x_{k}^{(g+1)}\sim{{m}^{(g)}}+{{\sigma }^{(g)}}N\left( 0,{{C}^{(g)}} \right),k=1,\ldots ,\lambda xk(g+1)∼m(g)+σ(g)N(0,C(g)),k=1,…,λ
进一步可以得到粒子采样的展开式为: x ( g + 1 ) + σ ( g ) B D N ( 0 , I ) , k = 1 , … , λ {{x}^{(g+1)}}+{{\sigma }^{(g)}}BDN(0,I),k=1,\ldots ,\lambda x(g+1)+σ(g)BDN(0,I),k=1,…,λ
其中 x k ( g + 1 ) ∈ R n x_{k}^{(g+1)}\in {{R}^{n}} xk(g+1)∈Rn是第g+1代的第k个子代(搜索点), m ( g ) ∈ R n {{m}^{(g)}}\in {{R}^{n}} m(g)∈Rn表示均值,是第g代搜索分布的中心位置 (也称为期望), σ ( g ) ∈ R {{\sigma }^{(g)}}\in R σ(g)∈R是第g代的全局步长, C ( g ) ∈ R n × n {{C}^{(g)}}\in {{R}^{n\times n}} C(g)∈Rn×n表示第g代的协方差矩阵, λ \lambda λ≥2是样本大小(种群大小)
从粒子采样的基本公式可以看出,CMA-ES 算法的种群突变主要是通过控制均值m,步长 σ \sigma σ以及协方差矩阵C实现的,因此,这三个参数是决定算法性能好坏的重要因素。
3.2 选择与重组:更新均值
均值m(g+1)通过采用数据 x 1 ( g+1 ) , … … , x λ ( g+1 ) \text{x}_{\text{1}}^{(\text{g+1})},\ldots \ldots ,\text{x}_{\lambda }^{(\text{g+1})} x1(g+1),……,xλ(g+1)的加权均值来更新。上面的公式中,从λ个后代中选取μ个权重最大的作为更新均值的样本数据。
m ( g + 1 ) = ∑ i = 1 μ w i x i : λ ( g + 1 ) \begin{matrix} {{m}^{(g+1)}} & = & \sum\limits_{i=1}^{\mu }{{{w}_{i}}}\mathbf{x}_{i:\lambda }^{(g+1)} \\\end{matrix} m(g+1)=i=1∑μwixi:λ(g+1)
∑ i = 1 μ w i = 1 , w 1 ≥ w 2 ≥ ⋯ ≥ w μ > 0 \sum_{i=1}^{\mu}w_i=1,\quad w_1\geq w_2\geq\cdots\geq w_{\mu}>0 ∑i=1μwi=1,w1≥w2≥⋯≥wμ>0
后代方差有效性选择的数量 μ eff \mu_{\text{eff}} μeff计算 ( 1 ≤ μ eff ≤ μ ) (1 \leq \mu_{\text{eff}} \leq \mu) (1≤μeff≤μ),通常 μ eff ≈ μ / 4 {{\mu }_{\text{eff}}}\approx \mu /4 μeff≈μ/4是一个合理的值。
均值 m ( g + 1 ) {{m}^{(g+1)}} m(g+1)的更新公式为: m ( g+1 ) = m ( g ) + c m ∑ i=1 μ ω i ( x i : λ ( g+1 ) - m ( g ) ) {{\text{m}}^{(\text{g+1})}}\text{=}{{\text{m}}^{(\text{g})}}\text{+}{{\text{c}}_{\text{m}}}\sum\limits_{\text{i=1}}^{\mu }{{{\omega }_{\text{i}}}}\left( \text{x}_{\text{i}:\lambda }^{(\text{g+1})}\text{-}{{\text{m}}^{(\text{g})}} \right) m(g+1)=m(g)+cmi=1∑μωi(xi:λ(g+1)-m(g))
3.3 协方差矩阵自适应
3.3.1 估计协方差矩阵
在整个算法的更新机制中协方差矩阵C的更新是至关重要的,接下来看一下协方差矩阵的更新。在最初估计协方差的时候,假设总体包含足够多的可以用于准确估计协方差矩阵的信息,为了方便,我们假定步长 σ ( g ) \sigma^{(g)} σ(g)=1,可以根据粒子采样的基本公式估计原始协方差矩阵,得到经验协方差矩阵为:
C e m p ( g + 1 ) = 1 λ − 1 ∑ i = 1 λ ( x i ( g + 1 ) − 1 λ ∑ j = 1 λ x j ( g + 1 ) ) ( x i ( g + 1 ) − 1 λ ∑ j = 1 λ x j ( g + 1 ) ) T C_{emp}^{(g+1)}=\frac{1}{\lambda -1}\sum\limits_{i=1}^{\lambda }{\left( x_{i}^{(g+1)}-\frac{1}{\lambda }\sum\limits_{j=1}^{\lambda }{x_{j}^{(g+1)}} \right)}{{\left( x_{i}^{(g+1)}-\frac{1}{\lambda }\sum\limits_{j=1}^{\lambda }{x_{j}^{(g+1)}} \right)}^{T}} Cemp(g+1)=λ−11i=1∑λ(xi(g+1)−λ1j=1∑λxj(g+1))(xi(g+1)−λ1j=1∑λxj(g+1))T
经验协方差矩阵 C emp ( g + 1 ) C_{\text{emp}}^{(g + 1)} Cemp(g+1)是协方差矩阵 C ( g ) C^{(g)} C(g)的无偏估计,其中经验协方差的无偏估计量为1/ λ \lambda λ-1,现考虑一种不同的方式获得 C ( g ) C^{(g)} C(g)的估计量。
C λ ( g + 1 ) = 1 λ ∑ i = 1 λ ( x i ( g + 1 ) − m ( g ) ) ( x i ( g + 1 ) − m ( g ) ) T C_{\lambda }^{(g+1)}=\frac{1}{\lambda }\sum\limits_{i=1}^{\lambda }{\left( x_{i}^{(g+1)}-{{m}^{(g)}} \right)}{{\left( x_{i}^{(g+1)}-{{m}^{(g)}} \right)}^{T}} Cλ(g+1)=λ1i=1∑λ(xi(g+1)−m(g))(xi(g+1)−m(g))T
协方差矩阵 C λ ( g + 1 ) C_{\lambda}^{(g + 1)} Cλ(g+1)也是协方差矩阵 C ( g ) C^{(g)} C(g)的无偏估计。上述两式的显著差异主要在于参考均值的不同,对于 C emp ( g + 1 ) C_{\text{emp}}^{(g + 1)} Cemp(g+1)来说,它是使用采样点 x i ( g + 1 ) {x_{i}}^{(g + 1)} xi(g+1)来进行估计,而对于 C λ ( g + 1 ) C_{\lambda}^{(g + 1)} Cλ(g+1)来说,它使用的是采样分布的均值 m ( g ) m^{(g)} m(g)进行估计的。
可以根据以上式子重新估计协方差矩阵,为了得到更好的协方差矩阵,可使用加权选择机制进行更新,得到如下:
C μ ( g + 1 ) = ∑ i = 1 μ w i ( x i , λ ( g + 1 ) − m ( g ) ) ( x i , λ ( g + 1 ) − m ( g ) ) T \mathbf{C}_{\mu}^{(g+1)}=\sum_{i=1}^{\mu}w_{i}\left(x_{i,\lambda}^{(g+1)}-m^{(g)}\right)\biggl(x_{i,\lambda}^{(g+1)}-m^{(g)}\biggr)^{\mathsf{T}} Cμ(g+1)=∑i=1μwi(xi,λ(g+1)−m(g))(xi,λ(g+1)−m(g))T
我们将更新后的协方差矩阵与多元正态算法EMNA估计进行比较,而EMNA中的协方差矩阵类似于如下:
C EMN A g l o b a l ( g + 1 ) = 1 μ ∑ i = 1 μ ( x i : λ ( g + 1 ) − m ( g + 1 ) ) ( x i : λ ( g + 1 ) − m ( g + 1 ) ) T \mathbf{C}_{\text{EMN}{{\text{A}}_{global}}}^{(g+1)}=\frac{1}{\mu }\sum\limits_{i=1}^{\mu }{\left( x_{i:\lambda }^{(g+1)}-{{m}^{(g+1)}} \right)}{{\left( x_{i:\lambda }^{(g+1)}-{{m}^{(g+1)}} \right)}^{T}} CEMNAglobal(g+1)=μ1i=1∑μ(xi:λ(g+1)−m(g+1))(xi:λ(g+1)−m(g+1))T
以上是两种协方差矩阵更新的可视化图,等值线表示策略应向右上方移动。左侧:λ=150 N(0,I)分布点的样本。中间:µ=50个选候样本点,用于确定估算方程的条目。右侧:搜索下一代(实心椭球)的分布。
3.3.2 协方差矩阵的Rank- μ \mathbf{\mu} μ更新
上面提出了一个最初的协方差矩阵估计, 但仍然不能得到一个特别好的协方差矩阵,为了得到更好的协方差矩阵,可以利用之前多代的信息进行补偿。例如,在足够多的代数之后, 估计协方差矩阵的均值为:
C ( g + 1 ) = 1 g + 1 ∑ i = 0 g 1 σ ( i ) 2 C μ ( i + 1 ) {{C}^{(g+1)}}=\frac{1}{g+1}\sum\limits_{i=0}^{g}{\frac{1}{{{\sigma }^{{{(i)}^{2}}}}}}C_{\mu }^{(i+1)} C(g+1)=g+11i=0∑gσ(i)21Cμ(i+1)
此时是一个可靠的估计, 为了比较不同代的,合并不同的 σ ( i ) \sigma^{(i)} σ(i)。在上式中所有生成步骤的权重相同,为了给近几代分配更高的权重,引入了指数平滑。令初始矩阵 C ( 0 ) = I C^{(0)} = I C(0)=I则矩阵写为:
C ( g + 1 ) = ( 1 − c μ ) C ( g ) + c μ 1 σ ( g ) 2 C μ ( g + 1 ) {{C}^{(g+1)}}=\quad (1-{{c}_{\mu }}){{\mathbf{C}}^{(g)}}+{{c}_{\mu }}\frac{1}{{{\sigma }^{(g)}}^{2}}\mathbf{C}_{\mu }^{(g+1)} C(g+1)=(1−cμ)C(g)+cμσ(g)21Cμ(g+1)
其中: 0≤ c μ c_{\mu} cμ≤1,是协方差矩阵C的学习率
(1)如果 c μ c_{\mu} cμ=1,则没有保留之前的信息,此时 C ( g + 1 ) = 1 σ ( g ) 2 C μ ( g + 1 ) {{C}^{(g+1)}}=\frac{1}{{{\sigma }^{{{(g)}^{2}}}}}C_{\mu }^{(g+1)} C(g+1)=σ(g)21Cμ(g+1)
(2)如果 c μ c_{\mu} cμ=0,则没有发生学习,此时 C ( g + 1 ) = C ( 0 ) {{C}^{(g+1)}}={{C}^{(0)}} C(g+1)=C(0)
一般地,另 c μ ≈ min ( 1 , μ eff / n 2 ) {{c}_{\mu }}\approx \min (1,{{\mu }_{\text{eff}}}/{{n}^{2}}) cμ≈min(1,μeff/n2)是比较合理的,其中 y i : λ ( g + 1 ) = ( x i : λ ( g + 1 ) − m ( g ) ) / σ ( g ) y_{i:\lambda }^{(g+1)}=(x_{i:\lambda }^{(g+1)}-{{m}^{(g)}})/{{\sigma }^{(g)}} yi:λ(g+1)=(xi:λ(g+1)−m(g))/σ(g), z i : λ ( g + 1 ) = C ( g ) − 1 / 2 y i : λ ( g + 1 ) z_{i:\lambda }^{(g+1)}={{C}^{{{(g)}^{-1/2}}}}y_{i:\lambda }^{(g+1)} zi:λ(g+1)=C(g)−1/2yi:λ(g+1),由于上式中的外部乘积之和的秩为min( μ \mu μ,n), 所以此时的更新方式称为协方差矩阵秩 μ \mu μ更新。
最后,我们将上式推广到 λ \lambda λ权重值,这些值既不需要和为1,也不再是非负。
C ( g + 1 ) = ( 1 − c μ ∑ w i ) C ( g ) + c μ ∑ i = 1 λ w i y i . λ ( g + 1 ) y i . λ ( g + 1 ) ⊺ = C ( g ) 1 / 2 ( I + c μ ∑ i = 1 λ w i ( z i . λ ( g + 1 ) z i . λ ( g + 1 ) ⊺ − I ) ) C ( g ) 1 / 2 \begin{aligned}C^{(g+1)}&=(1-c_\mu\sum w_i)\mathbf{C}^{(g)}+c_\mu\sum_{i=1}^\lambda w_i\mathbf{y}_{i.\lambda}^{(g+1)}\mathbf{y}_{i.\lambda}^{(g+1)^\intercal}\\\\&=\mathbf{C}^{(g)1/2}\bigg(\mathbf{I}+c_\mu\sum_{i=1}^\lambda w_i\left(\mathbf{z}_{i.\lambda}^{(g+1)}\mathbf{z}_{i.\lambda}^{(g+1)\intercal}-\mathbf{I}\right)\bigg)\mathbf{C}^{(g)1/2}\end{aligned} C(g+1)=(1−cμ∑wi)C(g)+cμi=1∑λwiyi.λ(g+1)yi.λ(g+1)⊺=C(g)1/2(I+cμi=1∑λwi(zi.λ(g+1)zi.λ(g+1)⊺−I))C(g)1/2
其中 w 1 ≥ ⋯ ≥ w μ > 0 ≥ w μ + 1 ≥ w λ {{w}_{1}}\ge \cdots \ge {{w}_{\mu }}>0\ge {{w}_{\mu +1}}\ge {{w}_{\lambda }} w1≥⋯≥wμ>0≥wμ+1≥wλ,并且通常 ∑ i = 1 μ w i = 1 \sum\limits_{i=1}^{\mu }{{{w}_{i}}}=1 i=1∑μwi=1, ∑ i = 1 λ w i ≈ 0 \sum\limits_{i=1}^{\lambda }{{{w}_{i}}}\approx 0 i=1∑λwi≈0
3.3.3 协方差矩阵的Rank-one更新
之前使用所有选定的搜索步生成协方差矩阵, 现在使用一个选定的搜索步在生成序 列中重复更新协方差矩阵。首先, 给出一组向量 y 1 , ⋯ , y g ∈ R n , y g ≥ n {{y}_{1}},\cdots ,{{y}_{g}}\in {{R}^{n}},{{y}_{g}}\ge n y1,⋯,yg∈Rn,yg≥n令N(0,I)表示独立的正态分布随机数,则
N ( 0 , 1 ) y 1 + ⋯ + N ( 0 , 1 ) y g ∼ N ( 0 , ∑ i = 1 g y i y i T ) \mathcal{N}(0,1){{y}_{1}}+\cdots +\mathcal{N}(0,1){{y}_{g}}\sim\mathcal{N}\left( 0,\sum\limits_{i=1}^{{{g}_{{}}}}{{{y}_{i}}}y_{i}^{T} \right) N(0,1)y1+⋯+N(0,1)yg∼N(0,i=1∑gyiyiT)
令上式协方差矩阵公式的和仅由一个被加数组成,将 y i : λ ( g + 1 ) = ( x i : λ ( g + 1 ) − m ( g ) ) / σ ( g ) y_{i:\lambda }^{(g+1)}=(x_{i:\lambda }^{(g+1)}-{{m}^{(g)}})/{{\sigma }^{(g)}} yi:λ(g+1)=(xi:λ(g+1)−m(g))/σ(g)代入得到:
C ( g + 1 ) = ( 1 − c 1 ) C ( g ) + c 1 y ( g + 1 ) y ( g + 1 ) T {{\mathbf{C}}^{(g+1)}}=(1-{{c}_{1}}){{\mathbf{C}}^{(g)}}+{{c}_{1}}y_{{}}^{(g+1)}y_{{}}^{(g+1)T} C(g+1)=(1−c1)C(g)+c1y(g+1)y(g+1)T
式子右边的加数和的秩为1 ,并把最大似然添加到协方差矩阵 C ( g ) C^{(g)} C(g)中, 因此在下一代产生 y ( g + 1 ) y^{(g + 1)} y(g+1)的概率变大了。使用选定的步骤 y i : λ ( g + 1 ) = ( x i : λ ( g + 1 ) − m ( g ) ) / σ ( g ) y_{i:\lambda }^{(g+1)}=(x_{i:\lambda }^{(g+1)}-{{m}^{(g)}})/{{\sigma }^{(g)}} yi:λ(g+1)=(xi:λ(g+1)−m(g))/σ(g)去更新协方差矩阵,因为 y y T = − y ( − y ) T y{{y}^{T}}=-y{{(-y)}^{T}} yyT=−y(−y)T,所以相关步的符号与协方差矩阵的更新无关, 也就是说,在计算协方差矩阵时会丢失符号信息。为了引入符号信息,构建了演化路径。演化路径是一系列连续代的变异步长之和,这个和叫做累积,利用演化路径可有效的去除随机化。要构建演化路径,可以忽略步长。例如,可以通过求和来构建三个搜索步的演化路径
m ( g + 1 ) − m ( g ) σ ( g ) + m ( g ) − m ( g − 1 ) σ ( g − 1 ) + m ( g − 1 ) − m ( g − 2 ) σ ( g − 2 ) \frac{{{m}^{(g+1)}}-{{m}^{(g)}}}{{{\sigma }^{(g)}}}+\frac{{{m}^{(g)}}-{{m}^{(g-1)}}}{{{\sigma }^{(g-1)}}}+\frac{{{m}^{(g-1)}}-{{m}^{(g-2)}}}{{{\sigma }^{(g-2)}}} σ(g)m(g+1)−m(g)+σ(g−1)m(g)−m(g−1)+σ(g−2)m(g−1)−m(g−2)
在实践中,为了构造演化路径 p c ∈ R n {{p}_{\text{c}}}\in {{\mathbb{R}}^{n}} pc∈Rn,我们使用指数平滑,并且从 p c ( 0 ) = 0 p_{\text{c}}^{(0)}=0 pc(0)=0开始,则有如下:
p c ( g + 1 ) = ( 1 − c c ) p c ( g ) + c c ( 2 − c c ) μ eff m ( g + 1 ) − m ( g ) c m σ ( g ) p_{\text{c}}^{(g+1)}=(1-{{c}_{\text{c}}})p_{\text{c}}^{(g)}+\sqrt{{{c}_{\text{c}}}(2-{{c}_{\text{c}}}){{\mu }_{\text{eff}}}}\frac{{{m}^{(g+1)}}-{{m}^{(g)}}}{{{c}_{\text{m}}}{{\sigma }^{(g)}}} pc(g+1)=(1−cc)pc(g)+cc(2−cc)μeffcmσ(g)m(g+1)−m(g)
它描述了分布均值的移动,并且将每次迭代中移动方向 m ( g + 1 ) − m ( g ) σ ( g ) \frac{{{m}^{(g+1)}}-{{m}^{(g)}}}{{{\sigma }^{(g)}}} σ(g)m(g+1)−m(g)做加权平均,使得这些方向中相反的方向分量相互抵消,相同的分量则进行叠加。
这类似于神经网络优化中常用的 Momentum。在神经网络中 momentum 起什么作用呢?因此,进化路径代表了最好的搜索方向之一。
当 c c = 1 c_{c} = 1 cc=1和 μ eff = 1 \mu_{\text{eff}} = 1 μeff=1时,上式变为: p c ( g + 1 ) = x i : λ ( g + 1 ) − m ( g ) σ ( g ) p_{c}^{(g+1)}=\frac{x_{i:\lambda }^{(g+1)}-{{m}^{(g)}}}{{{\sigma }^{(g)}}} pc(g+1)=σ(g)xi:λ(g+1)−m(g),此时利用演化路径更新协方差矩阵C的秩1公式为:
C ( g + 1 ) = ( 1 − c 1 ) C ( g ) + c 1 p c ( g + 1 ) p c ( g + 1 ) T {{C}^{(g+1)}}=(1-{{c}_{1}}){{C}^{(g)}}+{{c}_{1}}p_{\text{c}}^{(g+1)}p_{\text{c}}^{(g+1)T} C(g+1)=(1−c1)C(g)+c1pc(g+1)pc(g+1)T
注:这里面的系数因子是按照如下方式设计
• 因子 μ ω = 1 ∑ i = 1 μ ω i 2 \mu_{\omega} = \frac{1}{\sum_{i = 1}^{\mu}{\omega_{i}}^{2}} μω=∑i=1μωi21的设计是根据 μ ω m t − 1 − m t σ t ∼ N ( 0 , C t ) \sqrt{\mu_{\omega}}\frac{m_{t - 1} - m_{t}}{\sigma_{t}}\sim N(0,C_{t}) μωσtmt−1−mt∼N(0,Ct),这是因为 μ ω m t − 1 − m t σ t = μ ω ∑ i = 1 μ ω i y i : λ \sqrt{\mu_{\omega}}\frac{m_{t - 1} - m_{t}}{\sigma_{t}} = \sqrt{\mu_{\omega}}\sum_{i = 1}^{\mu}{\omega_{i}y_{i:\lambda}} μωσtmt−1−mt=μω∑i=1μωiyi:λ,因此可以看成是一个从上述分布采样得到的随机向量(确切的说,如果 x i : λ {{x}_{i:\lambda }} xi:λ是随机选择的)
• 因子 c ( 2 − c ) \sqrt{c(2-c)} c(2−c)的设计原理是 ( 1 − c ) 2 + ( c ( 2 − c ) ) 2 = 1 {{(1-c)}^{2}}+{{(\sqrt{c(2-c)})}^{2}}=1 (1−c)2+(c(2−c))2=1,这两条被称为平稳性条件,使得 p c ( g + 1 ) p_{\text{c}}^{(g+1)} pc(g+1)本身看起来像一个从当前分布 N ( 0 , C t ) N(0,C_{t}) N(0,Ct)产生的搜索方向 p c ( g + 1 ) p_{\text{c}}^{(g+1)} pc(g+1)∼ N ( 0 , C t ) N(0,C_{t}) N(0,Ct)。所以 p c ( g + 1 ) p_{\text{c}}^{(g+1)} pc(g+1)像一个mutation一样用来更新协方差矩阵。
• 变化率/学习率c的设计原理是 c − 1 ∝ n {{c}^{-1}}\propto n c−1∝n,即学习率与所调整的变量自由度(参数个数)成反比。
3.3.4 协方差矩阵结合
将以上协方差矩阵秩 μ \mu μ与秩1结合得到更新后的组合如下:
C ( g + 1 ) = ( 1 − c 1 − c μ ∑ μ w j ) ⏟ can be close or eqnal to 0 C ( g ) + c 1 p c ( g + 1 ) p c ( g + 1 ) ⏟ rank-cone update + c μ ∑ i = 1 λ w i y i λ ( g + 1 ) ( y i λ ( g + 1 ) ) T ⏟ rank- μ update \begin{array}{rcl}\mathbf{C}^{(g+1)}&=&\underbrace{(1-c_1-c_\mu\sum_{\mu}w_j)}_{\text{can be close or eqnal to }0}\mathbf{C}^{(g)}+c_1\underbrace{p_{\mathbf{c}}^{(g+1)}p_{\mathbf{c}}^{(g+1)}}_{\text{rank-cone update}}+c_\mu\underbrace{\sum_{i=1}^{\lambda}w_iy_{\mathbf{i}\lambda}^{(g+1)}\left(y_{\mathbf{i}\lambda}^{(g+1)}\right)^{\mathsf{T}}}_{\text{rank-}\mu\text{update}}\end{array} C(g+1)=can be close or eqnal to 0 (1−c1−cμμ∑wj)C(g)+c1rank-cone update pc(g+1)pc(g+1)+cμrank-μupdate i=1∑λwiyiλ(g+1)(yiλ(g+1))T
如果 c 1 = 0 c_{1} = 0 c1=0则为协方差矩阵秩 μ \mu μ更新,如果 c μ = 0 c_{\mu} = 0 cμ=0则为协方差矩阵秩1更新其中: c 1 ≈ 2 / n 2 {{c}_{1}}\approx 2/{{n}^{2}} c1≈2/n2, c μ ≈ m i n ( μ eff / n 2 , 1 − c 1 ) {{c}_{\mu }}\approx min({{\mu }_{\text{eff}}}/{{n}^{2}},1-{{c}_{1}}) cμ≈min(μeff/n2,1−c1) , y i : λ ( g + 1 ) = ( x i : λ ( g + 1 ) − m ( g ) ) / σ ( g ) y_{i:\lambda }^{(g+1)}=(x_{i:\lambda }^{(g+1)}-{{m}^{(g)}})/{{\sigma }^{(g)}} yi:λ(g+1)=(xi:λ(g+1)−m(g))/σ(g), ∑ w j = ∑ i = 1 λ w i ≈ − c 1 / c μ \sum{{{w}_{j}}}=\sum\limits_{i=1}^{\lambda }{{{w}_{i}}}\approx -{{c}_{1}}/{{c}_{\mu }} ∑wj=i=1∑λwi≈−c1/cμ
学习率 c1,cµ的设计原理和上面一样,也就是 c 1 ≈ 2 n 2 , c μ ≈ μ w n 2 {{c}_{1}}\approx \frac{2}{{{n}^{2}}}\text{,}{{c}_{\mu }}\approx \frac{{{\mu }_{w}}}{{{n}^{2}}} c1≈n22,cμ≈n2μw,即学习率与所调整的变量自由度(参数个数)成反比。
• 秩1更新有效的利用了连续两代均值的偏差关系
• 秩 μ \mu μ更新利用了 μ \mu μ个样本相对于均值m的偏差,使用的是当前代选出的 μ \mu μ个样本的统计信息来更新矩阵,更充分的利用了种群中的信息
• 前者适用于小种群,后者信息全面适用于大种群,结合秩1 更新与秩 μ \mu μ更新可以更好地利用有用信息
3.4 步长控制
步长的调节在演化策略中也是非常重要的,步长不宜过大也不宜过小:
• 步长过大容易跳过最优点
• 步长过小会过多的浪费时间
• 因此步长的调整需要动态地随问题的变化而调整
CMA-ES 默认使用累积式步长调整 (Cumulative step size adaptation,CSA) 。CSA 是当前最成功、用的最多的步长调整方式。CSA 的原理可以理解为:相继搜索的方向应该是共轭的。
- 当演化路径太短时,搜索步之间会相互抵消,此时步长需要减小
- 当演化路径较长时,每个搜索步之间的方向相似,搜索路径可由指向相同的少量长路径来代替, 此时应增加步长
- 当演化路径较长,理想情况下单个步骤的方向大致垂直时,各搜索步是不相关的,此时是理想步长

与前面的进化路径相似,构造另一个进化路径(有些文献里面称为共轭路径 conjugate evolution path)
p σ ( g + 1 ) = ( 1 − c σ ) p σ ( g ) + c σ ( 2 − c σ ) μ e f f B ∑ i = 1 μ w i z i : λ \begin{array}{rcl}p_\sigma^{(g+1)}&=&(1-c_\sigma)p_\sigma^{(g)}+\sqrt{c_\sigma(2-c_\sigma)\mu_{\mathrm{eff}}}B\sum_{i=1}^{\mu}w_iz_{i:\lambda}\end{array} pσ(g+1)=(1−cσ)pσ(g)+cσ(2−cσ)μeffB∑i=1μwizi:λ
或者写成:
p σ ( g + 1 ) = ( 1 − c σ ) p σ ( g ) + c σ ( 2 − c σ ) μ e f f C ( g ) − 1 2 m ( g + 1 ) − m ( g ) c m σ ( g ) \begin{array}{rcl}p_{\sigma}^{(g+1)}&=&(1-c_{\sigma})p_{\sigma}^{(g)}+\sqrt{c_{\sigma}(2-c_{\sigma})\mu_{\mathrm{eff}}}C^{(g)^{-\frac{1}{2}}}\frac{m^{(g+1)}-m^{(g)}}{c_{\mathrm{m}}\sigma^{(\mathrm{g})}}\\\end{array} pσ(g+1)=(1−cσ)pσ(g)+cσ(2−cσ)μeffC(g)−21cmσ(g)m(g+1)−m(g)
其中: c σ < 1 , c σ ( 2 − c σ ) μ e f f {{c}_{\sigma }}<1,\sqrt{{{c}_{\sigma }}\left( 2-{{c}_{\sigma }} \right){{\mu }_{eff}}} cσ<1,cσ(2−cσ)μeff是归一化常数
• 更新项 B ∑ i = 1 μ w i z i : λ B\sum\limits_{i=1}^{\mu }{{{w}_{i}}}{{z}_{i:\lambda }} Bi=1∑μwizi:λ= C ( g ) − 1 2 m ( g + 1 ) − m ( g ) c m σ ( g ) {{C}^{(g)}}^{-\frac{1}{2}}\frac{{{m}^{(g+1)}}-{{m}^{(g)}}}{{{c}_{\text{m}}}{{\sigma }^{(g)}}} C(g)−21cmσ(g)m(g+1)−m(g),而 C ( g ) − 1 2 {{C}^{(g)}}^{-\frac{1}{2}} C(g)−21 = B D − 1 B T = BD^{- 1}B^{T} =BD−1BT。因此,这个方向实际上是去掉尺度因子 D 之后的搜索方向。
• 考虑另一种解释. 在上述路径中取 c σ {{c}_{\sigma }} cσ= 1 ,即不进行累积。这时候实际上是"平均搜索方向",并且"大致"服从标准正态分布。在 c σ {{c}_{\sigma }} cσ< 1 情况下的累积则代表通过历史平均来消除或减小随机性。
为了更新步长, 我们把 ∥ p σ ( g + 1 ) ∥ \left\| p_{\sigma }^{(g+1)} \right\| pσ(g+1) 与它的期望步长 E ∥ N ( 0 , I ) ∥ {\mathbf{E}\|\mathcal{N}(\mathbf{0},\mathbf{I})\|} E∥N(0,I)∥进行比较,有:
ln σ ( g + 1 ) = ln σ ( g ) + c σ d σ ( ∥ p σ ( g + 1 ) ∥ E ∥ N ( 0 , I ) ∥ − 1 ) \ln {{\sigma }^{(g+1)}}=\ln {{\sigma }^{(g)}}+\frac{{{c}_{\sigma }}}{{{d}_{\sigma }}}\left( \frac{\|\mathbf{p}_{\sigma }^{(g+1)}\|}{\mathbf{E}\|\mathcal{N}(\mathbf{0},\mathbf{I})\|}-1 \right) lnσ(g+1)=lnσ(g)+dσcσ(E∥N(0,I)∥∥pσ(g+1)∥−1)
其中, d σ d_{\sigma} dσ≈1 , 是阻尼参数, c σ c_{\sigma} cσ表示步长的学习率, 为服从标准正态分布 N ( 0 , I ) N(0,I) N(0,I)的欧几里得范数的期望。
因为 σ ( g ) > 0 {{\sigma }^{(g)}}>0 σ(g)>0,则上式可以写成:
σ ( g + 1 ) = σ ( g ) exp ( c σ d σ ( ∥ p σ ( g + 1 ) ∥ E ∥ N ( 0 , I ) ∥ − 1 ) ) {{\sigma }^{(g+1)}}={{\sigma }^{(g)}}\exp \left( \frac{{{c}_{\sigma }}}{{{d}_{\sigma }}}\left( \frac{\|\mathbf{p}_{\sigma }^{(g+1)}\|}{\mathbf{E}\|\mathcal{N}(\mathbf{0},\mathbf{I})\|}-1 \right) \right) σ(g+1)=σ(g)exp(dσcσ(E∥N(0,I)∥∥pσ(g+1)∥−1))
在平稳性条件下有 p σ ( g + 1 ) p_{\sigma }^{(g+1)} pσ(g+1)∼ N(0, I) ,即搜索路径可以看成是一个 n 维标准正态分布的随机向量,因此其模长服从卡方分布 ∥ p σ ( g + 1 ) ∥ ∼ χ ( n ) \left\| p_{\sigma }^{(g+1)} \right\|\sim\chi (\text{n}) pσ(g+1) ∼χ(n),并且 E ∥ N ( 0 , I ) ∥ {\mathbf{E}\|\mathcal{N}(\mathbf{0},\mathbf{I})\|} E∥N(0,I)∥,而且 E ∥ N ( 0 , I ) ∥ = n {\mathbf{E}\|\mathcal{N}(\mathbf{0},\mathbf{I})\|}=\sqrt{n} E∥N(0,I)∥=n,因此,如果模长大于平均值,则指数上是正的,步长变大,否则指数上是负的,步长减小。
确定步长的长度,只需将路径的长度与其在随机选择下的预期长度进行比较即可,因为连续步之间相互独立,所以它们是不相关的,也就是说:
• 如果演化路径比预期的长,则步长增加
• 如果演化路径比预期的短, 则步长减小
• 在理想的条件下,选择不会偏向演化路径的长度,并且该长度等于随机选择下的预期长度 c σ {{c}_{\sigma }} cσ, d σ {{d}_{\sigma }} dσ是调整步长变化幅度的控制参数,通常设置为 c σ ∝ 1 n , d σ > 1 {{c}_{\sigma }}\propto \frac{1}{n},{{d}_{\sigma }}>1 cσ∝n1,dσ>1,此外从实验上来说,算法对 c σ {{c}_{\sigma }} cσ的设置不敏感,可以取到 c σ ∝ 1 n {{c}_{\sigma }}\propto \frac{1}{\sqrt{n}} cσ∝n1以进行快速调整,大部分情况下效果相差不大。
注:在如果每次迭代步长几乎不变,大致有 ∥ s t + 1 ∥ ∼ n \|{{s}_{t+1}}\|\sim\sqrt{n} ∥st+1∥∼n,那么会有如下近似: ( m t − m t − 1 ) T C t − 1 ( m t + 1 − m t ) ≈ 0 {{\left( {{m}_{t}}-{{m}_{t-1}} \right)}^{T}}C_{t}^{-1}\left( {{m}_{t+1}}-{{m}_{t}} \right)\approx 0 (mt−mt−1)TCt−1(mt+1−mt)≈0
即相继的搜索方向关于协方差矩阵的逆 C t − 1 C_{t}^{- 1} Ct−1是共轭的,而在二次函数上,这个 C t − 1 C_{t}^{- 1} Ct−1收敛于 Hessian
矩阵(相差一个标量因子)。从这个角度来说, p σ ( g + 1 ) p_{\sigma }^{(g+1)} pσ(g+1)被称为共轭进化路径。这个是很好的性质。


参考文献:
A survey of the state-of-the-art, Swarm and Evolutionary Computation, 2020
相关文章:
协方差矩阵自适应调整的进化策略(CMA-ES)
关于CMA-ES,其中 CMA 为协方差矩阵自适应(Covariance Matrix Adaptation),而进化策略(Evolution strategies, ES)是一种无梯度随机优化算法。CMA-ES 是一种随机或随机化方法,用于非线性、非凸函数的实参数(…...
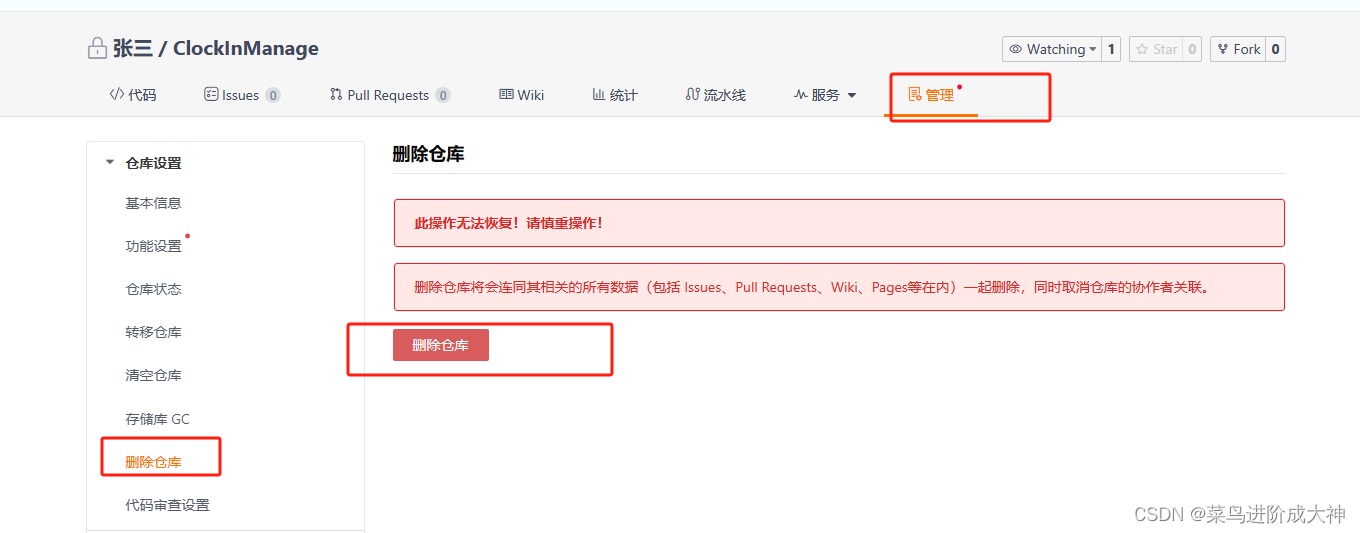
gitee完整使用教程,创建项目并上传
目录 一 什么是gitee 二 安装Git 三 登录gitee,生成密钥 四 配置SSH密钥 五 创建项目 六 克隆仓库到本地 七 关联本地工程到远程仓库 八 添加文件 九 异常处理 十 删除仓储 十一 git常用命令 一 什么是gitee gitee是开源中国推出的基于git的代码托管服务…...

如何使用ActiveMQ详细讲解
ActiveMQ 是一款流行的消息中间件,支持多种通信协议和消息模式,包括点对点、发布/订阅、事务处理等。下面是使用 ActiveMQ 的基本步骤: 1. 下载和安装 ActiveMQ: • 前往 ActiveMQ 的官方网站(http://activemq.apach…...

【python入门】day28:记录用户登录日志
演示 代码 #-*- coding:utf-8 -*- print(记录用户登录日志----------------------------) import time def show_info():print(输入提示数字,执行相应操作:0退出,1查看登录日志) def write_logininfo(username):#----------记录日志with open(log.txt,a,encodingutf-8)as file…...

sqlserver2012 跨服务器查询
在 SQL Server 2012 中,跨服务器查询可以通过链接服务器来实现。以下是执行跨服务器查询的步骤: 创建链接服务器: 首先,你需要在 SQL Server 2012 上创建一个链接服务器对象。可以使用系统存储过程 sp_addlinkedserver 来完成这一…...
无人机视角、多模态、模型剪枝、国产AI芯片部署
无人机视角、多模态、模型剪枝、国产AI芯片部署是当前无人机技术领域的重要研究方向,其原理和应用价值在以下几个方面进行详细讲述。 一、无人机视角:无人机视角是指在无人机上搭载摄像头等设备,通过航拍图像获取环境信息,并进行…...

DaisyDisk for mac 中文激活版 可视化磁盘清理工具
DaisyDisk 是一款专为 Mac 设计的磁盘空间分析工具。它以直观、图形化的方式展示硬盘使用情况,帮助用户迅速找到占用空间大的文件和文件夹。通过扫描磁盘,DaisyDisk 生成彩色的扇形图表,每个扇区代表一个文件或文件夹,大小直观反映…...

Linux debain12 安装phpredis和mysql扩展
在php和mysql安装好之后,直接执行以下命令,就可以安装php的mysql相关扩展 apt-get install php-mysql //安装php与mysql的组件 安装phpredis扩展 首页安装redis sudo apt install redis-server 检查Redis服务是否在您的Debian 12上成功安装&#x…...
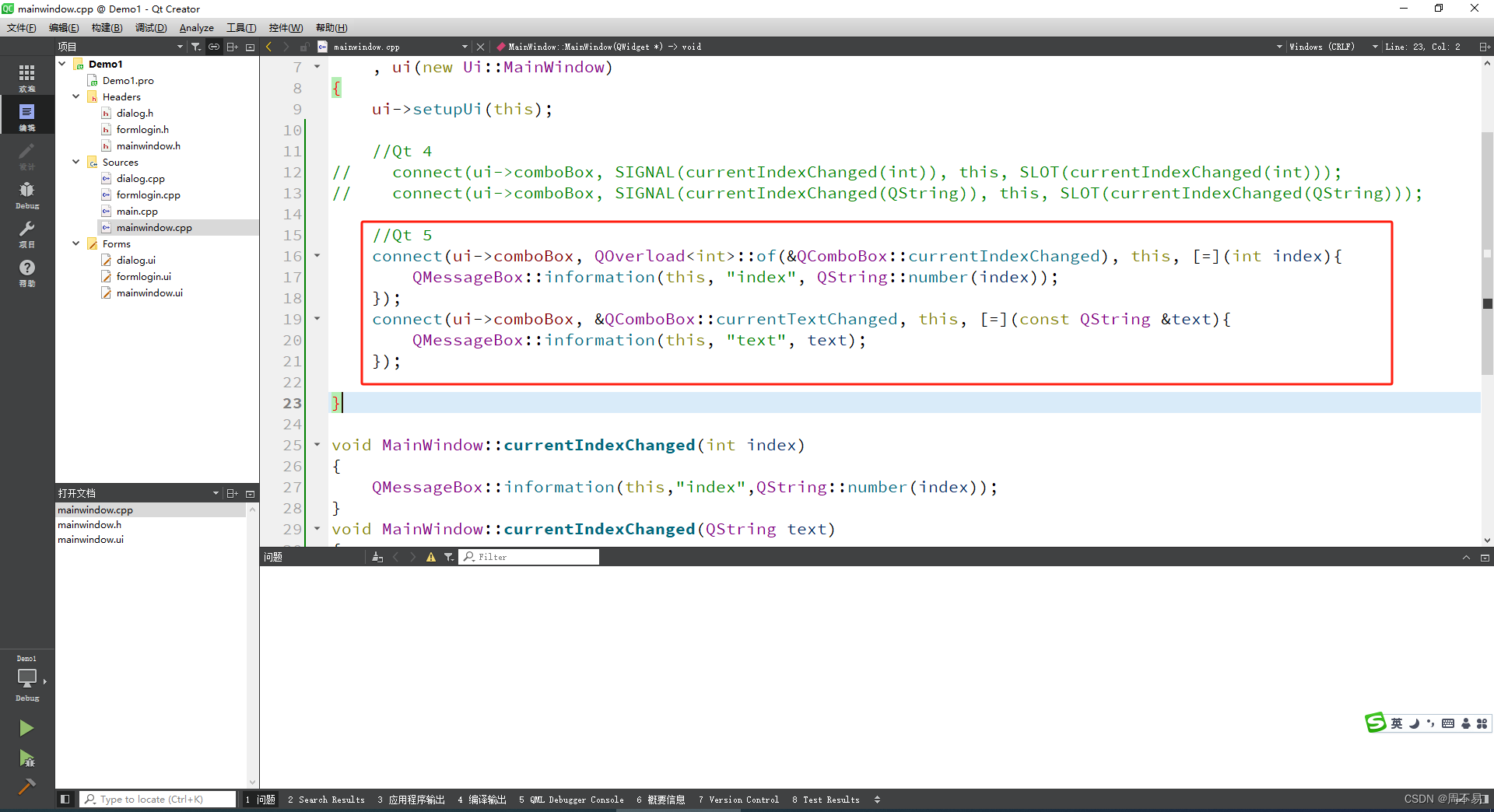
七、Qt 信号和槽
在QT4以上的版本,在窗体上用可以通过选中控件,然后点击鼠标右键单击按钮,选择“转到槽”。可以自动创建信号和槽。 选择clicked(),并点击 ok Qt Creator会给头文件和代码文件自动添加 这个按钮的单击事件(信号和槽)。 …...

C盘满了,我用什么思路清理?
20240115 上周六同事传了一个很大的虚拟机给我,C盘就红了 虽然是飞秋选错了存储文件的路径,但后来忘了,就开始毫无目的删除文件,过程中会有没有权限删除的,这样还是没有改善。 咨询了公司IT技术人员, 告…...

Simulink简介
Simulink 是一个模块图环境,用于多域仿真以及基于模型的设计。它支持系统级设计、仿真、自动代码生成以及嵌入式系统的连续测试和验证。Simulink 提供图形编辑器、可自定义的模块库以及求解器,能够进行动态系统建模和仿真。Simulink 与 MATLAB 相集成&am…...

学习Vue封装的过渡与动画总结
今天学习了Vue封装的过渡与动画,接下来说一下Vue是如何实现的,首先原生的方法是在style元素中给指定元素添加过渡的过渡或动画,但Vue就不需要直接获取到需要过渡或动画的元素,而是使用一个<transition>的标签来包裹住想要过…...
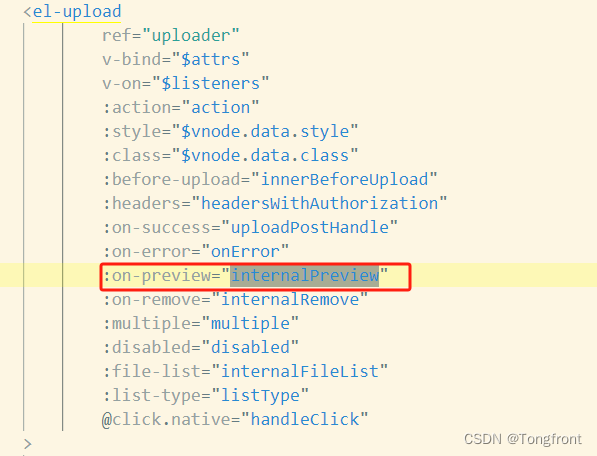
vue2 pdfjs-2.8.335-dist pdf文件在线预览功能
1、首先先将 pdfjs-2.8.335-dist 文件夹从网上搜索下载,复制到public文件夹下. 2、在components下新建组件PdfViewer.vue文件 3、在el-upload 中调用 pdf-viewer 组件 4、在el-upload 中的 on-preview方法中加上对应的src路径 internalPreview(file) { //判断需要…...

messages,CentOS 7不收集日志或不存在 /var/log/messages
/var/log/message, /var/log/secure等都不记录了,并且都是空文件。 重启机器:reboot 无效 重启日志: systemctl start rsyslog 无效 怀疑空间不足,删除/var/log/messages,重新运行rsyslog 无效 重装下rsyslog,于是…...

Express安装与基础使用
一、express 介绍 express 是一个基于 Node.js 平台的极简、灵活的 WEB 应用开发框架, 官方网站: Express - 基于 Node.js 平台的 web 应用开发框架 - Express中文文档 | Express中文网 中文文档: 路由 - Express 中文文档 简单来说&am…...

vue2使用electron以及打包配置
1.创建项目 vue create vue-project 2.安装electron vue add electron-builder会自动安装相关依赖 安装成功后会在src下自动生成一个background.js文件就是相应的electron的配置信息 use strictimport { app, protocol, BrowserWindow } from electron import { createProto…...
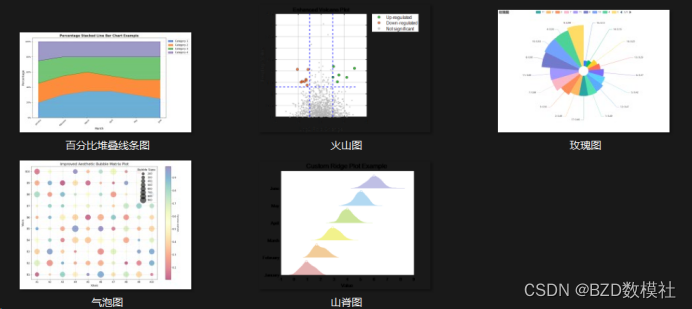
科研绘图(五)玫瑰图
柱状图的高级平替可视化 “玫瑰图”,通常也被称为“科克斯图”。它类似于饼图,但不同之处在于每个部分(或“花瓣”)的角度相同,半径根据它表示的值而变化。这种可视化工具对于周期性地显示信息非常有用,比…...
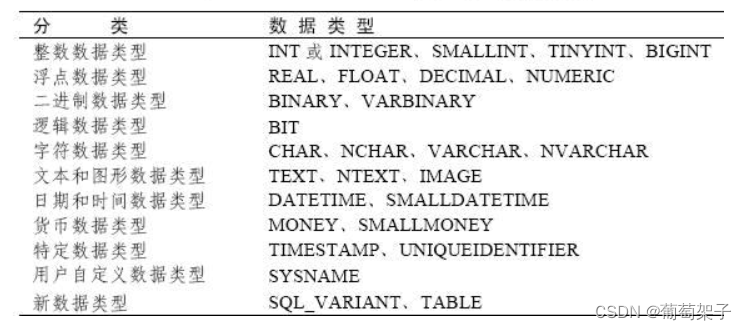
SQL Server 数据类型
文章目录 一、文本类型(字母、符号或数字字符的组合)二、整数类型三、精确数字类型四、近似数字(浮点)类型五、日期类型六、货币类型七、位类型八、二进制类型 一、文本类型(字母、符号或数字字符的组合) 在…...

【.NET Core】C#预处理器指令
【.NET Core】C#预处理器指令 文章目录 【.NET Core】C#预处理器指令一、概述二、可为空上下文(#nullable)三、条件编译2.1 定义DEBUG是编译代码2.2 未定义MYTEST时,将编译以下代码 四、定义符号五、定义区域六、错误和警告信息 一、概述 预…...
)
自定义类型详解(2)
文章目录 5. 通讯录的实现 5. 通讯录的实现 实现一个通讯录: 通讯录中保存人的信息: 名字年龄性别电话住址 通讯录中可以存放100个人的信息增加联系人删除指定联系人修改指定联系人查找指定联系人显示所有联系人的信息排序功能 首先,我们需要…...
- 5月22日-第三题- 数据传输网络调优】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习-非AI方向(通软嵌软测试算法数据科学)- 5月22日-第三题- 数据传输网络调优】(题目+思路+JavaC++Python解析+在线测试)
题目内容 有一个由 NNN 个数据交换节点(编号为 000 到 N−1N-1...

第P5周:Pytorch实现运动鞋识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人体悟:今天学习了动态学习率有种豁然开朗的感觉,在引入该部分之后模型的学习速度和学习质量都得到了较大提升!...

第38天:SQL详解之DML
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、基本查询与投影 1.1 查询所有列 1.2 投影与别名 二、数据筛选(WHERE 子句) 2.1 等值与比较筛选 2.2 多条件组合(AND / OR) 2.3 范围查询(BETWEEN) 2.4 CASE 表达式与…...

如何在5分钟内为Unity游戏安装BepInEx模组框架:终极完整指南
如何在5分钟内为Unity游戏安装BepInEx模组框架:终极完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx(全称Bepis Injector Extensible&#…...

3分钟掌握md2pdf:离线Markdown转PDF的终极指南
3分钟掌握md2pdf:离线Markdown转PDF的终极指南 【免费下载链接】md2pdf Offline markdown to pdf, choose -> edit -> transform 🥂 项目地址: https://gitcode.com/gh_mirrors/md/md2pdf 你是否经常需要将Markdown文档转换为PDF格式&#…...

如何快速完成AI智能图像分层:layerdivider完整使用指南
如何快速完成AI智能图像分层:layerdivider完整使用指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对复杂的插画设计&#x…...

一部95分钟AI电影杀进戛纳后,影视行业开始不淡定了
作者:王聪彬今年戛纳电影节的C位,不是红毯,不是明星,也不是哪位导演的新片,AI把C位抢了。8支由火山引擎视频生成大模型Seedance 2.0创作的AI影片,第一次正式登上戛纳舞台。过去代表全球电影工业最高门槛的戛…...

工控行业IO信号Web监控平台原理及技术实现方案
本文从实际使用角度出发,意在解决行业系统中的IO信号监控痛点。一台设备的 IO 信号点动辄成百上千——从简单的门锁状态、急停按钮,到复杂的真空压力模拟量、主轴转速等。这些信号的实时监控直接关系到设备稼动率(OEE)和良品率&am…...

AI术语速查卡:50个高频词的实战解读与避坑指南
1. 这不是词典,是AI时代的生存速查卡你有没有过这种体验:刚打开一篇AI技术文章,三句话里冒出“transformer”“fine-tuning”“latent space”——每个词都像蒙着雾的玻璃窗,看得见轮廓,摸不着边界?开会时同…...

还在熬夜调地图?让AI替你干
你还在为地图开发熬夜吗? "这个标注位置怎么不对?" "图层叠加出问题了,谁来看看?" "地图加载太慢,客户在催……" 每次做地图相关项目,开发者群里总是一片哀嚎。查文档、…...