【迅搜17】SCWS分词(二)自定义字典及分词器
SCWS分词(二)自定义字典及分词器
经过上篇文章的学习,相信大家对分词的概念已经有了更深入的了解了吧。我们也知道了,SCWS 是 XS 中的一个重要组成部分,但它也是可以单独拿出来使用的。而对于分词器来说,不管是 SCWS 还是现在流行的 IK、Jieba ,其实概念方面都是差不多的。比如说它们都需要字典来做为分词的依据,也会有停用词库这一类的附加字典。今天,我们主要来学习的就是 SCWS 字典相关的一些配置。此外,还有自定义分词器的实现。
自定义字典
上回已经说过,SCWS 有提供一个非常小的,但词汇量非常大的字典。不过现在的网络社会,各种新鲜词汇层出不穷,总会有超出默认字典的新词出现。同时,还有一种情况就是一些专业领域的专业词汇,比如医学或者工程上面的,也不会在通用的字典库中。像这类的词项,我们就可以通过自定义字典库来添加。
XS 的字典库分为两种,一种是全局的,一种是针对某个项目的。对于全局字典库,我们可以在 XS 的安装目录中的 etc 目录下找到。
# /usr/local/xunsearch/etc
[root@localhost etc]# ll
total 14832
-rw-r--r--. 1 501 games 14315504 May 23 2022 dict.utf8.xdb
-rw-r--r--. 1 root root 447 May 23 2022 dict_user.txt
-rw-r--r--. 1 root root 843730 Nov 11 20:55 py.xdb
-rw-r--r--. 1 root root 3729 May 23 2022 rules.ini
-rw-r--r--. 1 root root 4424 May 23 2022 rules.utf8.ini
-rw-r--r--. 1 root root 4383 May 23 2022 rules_cht.utf8.ini
-rw-r--r--. 1 root root 272 May 23 2022 stopwords.txt默认情况下,dict.uft8.xdb 就是 XS 自带的那个字典库。而 dict_user.txt 则是我们可以自己定义的字典库。py.xdb 是拼音库、rules开头的文件名全都是规则文件,也就是我们各种词要如何组合,词性变化与评分配置等。最后还有一个 stopwords.txt 停用词库。好了,咱们先用之前的数据来测试吧,就是最早那篇文章里的数据。
> php vendor/hightman/xunsearch/util/Indexer.php --source=csv --clean ./config/demo3_56.101.ini
1,关于 xunsearch 的 DEMO 项目测试,项目测试是一个很有意思的行为!,1314336158
2,测试第二篇,这里是第二篇文章的内容,1314336160
3,项目测试第三篇,俗话说,无三不成礼,所以就有了第三篇,1314336168> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini ''
在 3 条数据中,大约有 3 条包含 ,第 1-3 条,用时:0.0014 秒。1. 关于 xunsearch 的 DEMO 项目测试 #1# [100%,0.00]
项目测试是一个很有意思的行为!
Chrono:1314336158 Author: 2. 测试第二篇 #2# [100%,0.00]
这里是第二篇文章的内容
Chrono:1314336160 Author: 3. 项目测试第三篇 #3# [100%,0.00]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:我们先来测试一个不正常的词,比如说“无三”。很明显,它不是一个传统意义上的正常的单词,但就像很多专业词汇一样,我们假设“无三”就是一个专业词汇。目前直接搜索“无三”肯定是没有数据的。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '无三'
--------------------
解析后的 QUERY 语句:Query(无三@1)
--------------------
在 3 条数据中,大约有 0 条包含 无三 ,第 0-0 条,用时:0.0009 秒。好了,那么咱们就打开 dict_user.txt 进行配置。
// vim /usr/local/xunsearch/etc/dict_user.txt
# Custom dictionary for scws (UTF-8 encoding)
# 每行一条记录,以 # 开头的号表示注释忽略
# 每行最多包含 4 个字段,依次代表 "词条" "TF" "IDF" "词性"
# 字段之间用空格或制表符分开,特殊词性 "!" 用于表示删除该词
# 参见 scws 自定义词典帮助:
# http://bbs.xunsearch.com/showthread.php?tid=1303
# $Id$
#
# WORD TF IDF ATTR
# ------------------------------------------------------
无三可以看到文件上方的注释已经很清晰了,四个字段,分别是词条、TF词频、IDF逆文档频率和词性,用逗号分隔,并按行划分。后面三个字段属性其实是可以不用写的,它会有默认值。
我们直接添加一个“无三”,后面的不用填,然后重新索引添加数据。再次查询,就可以看到“无三”可以被搜索到了。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '无三'
--------------------
解析后的 QUERY 语句:Query(无三@1)
--------------------
在 3 条数据中,大约有 1 条包含 无三 ,第 1-1 条,用时:0.0020 秒。1. 项目测试第三篇 #3# [100%,0.62]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:后面的三个参数,我也不知道怎么填,查了一些资料也没讲得特别明白的。所以咱们保持默认就好,或者说你明确的知道这个新词的词性,那就把 TF 和 IDF 都设置成 1 ,然后指定词性就好了。大部分专业词汇其实都是名词居多的,直接设置一个 n 就行了。
项目字典
接下来我们来自定义一个项目字典。这种字典就是针对某一个具体项目的,比如说针对我们的 demo 项目,那么就直接找到安装目录的 data 目录,然后找到 demo 文件夹,在这个文件夹中创建一个 dict_user.txt 文件。关于项目数据目录的问题,我们之前在学习索引管理时就说过,后面学习 Xapian 的时候也会再说一下。
好了,直接在项目目录下面的 dict_user.txt 文件中添加新词吧,词条规则和全局文件是一样的。
// vim /usr/local/xunsearch/data/demo/dict_user.txt
无三不对于项目字典,我们在在代码中也可以直接操作,比如使用 XSIndex 对象的 getCustomDict() 方法就可以获取到自定义字典的内容,使用 setCustomDict() 就可以设置当前项目的自定义字典信息。
print_r($xs->index->getCustomDict()); // 无三不$dict = <<<EOF无三不无三不成 0 0 nEOF;
print_r($xs->index->setCustomDict($dict));print_r($xs->index->getCustomDict());
// 无三不
// 无三不成 0 0 n在上面的代码中,我们通过 PHP 来设置了自定义字典,大家可以再回到项目目录下,看看 dict_user.txt 文件是不是也已经被重写成了新的内容,多了“无三不成”这样一个单词。这种功能有个什么好处呢?那就是我们的字典也可以通过在 MySQL 或其它数据库中进行存储,然后直接在 PHP 代码中操作字典,是不是非常方便。
当然,txt 格式的明文字典效率其实不高的,而且如果单词数量比较多,占用的空间也会比较大。SCWS 在命令行还提供了一个 scws-gen-dict 工具。和上篇文章中我们命令行操作 scws 的工具是放在一起的。这个工具可以将 txt 文件转换为 xdb 文件,也就是 SCWS 的默认词典文件一样的压缩格式。如果确实有非常大量的专业词汇,建议还是转换一下哦。这里我就不演示了,SCWS 还是比较智能的,普通的 txt 文件其实大部分情况下还是能满足需求的。
接下来咱们测试一下。
php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '无三不成'
--------------------
解析后的 QUERY 语句:Query((无三不成@1 SYNONYM (无三不@78 AND 不成@79)))
--------------------
在 1 条数据中,大约有 1 条包含 无三不成 ,第 1-1 条,用时:0.0018 秒。1. 项目测试第三篇 #3# [100%,0.15]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:“无三不成”这个新词没问题。那么“无三不”呢?
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query ' 无三不'
--------------------
解析后的 QUERY 语句:Query((无三不@1 SYNONYM (无三@78 AND 三不@79)))
--------------------
在 1 条数据中,大约有 0 条包含 无三不 ,第 0-0 条,用时:0.0008 秒。嗯?咋查不到数据了?明明添加到字典里了啊!使用 SDK 的分词工具来看也是正常分词的,分词结果中有“无三不成”、“无三不”这两个单词。
$tokenizer = new XSTokenizerScws; // 直接创建实例
$words = $tokenizer->getResult("俗话说,无三不成礼,所以就有了第三篇");
foreach($words as $w){echo $w['word']."/".$w['attr']."/".$w['off']," ";
}
// 话说/n/0 俗话/n/0 话说/n/3 ,/un/9 无三不成/n/12 无三不/@/12 不成/d/18 礼/n/24 ,/un/27 所以/c/30 就/d/36 就有/v/36 有了/v/39 了第/m/42 第三/m/45 三篇/q/48好吧,自己玩出来的火,就得自己灭。原理我也没搞明白,但是从上面 getQuery() 的分析中,我们可以通过两种方式来搜索到。
使用 fuzzy 模糊查询
在 getQuery() 返回的数据中,我们看到了“无三不”以及它的同义二元词“无三”和“三不”。在同义词中,是 AND 连接,也就是必须要同时出现“无三”和“三不”(其实应该也不需要这样,比如搜索“俗话说”,是AND同义词,但是可以搜索到)。但咱们换成 setFuzzy() 效果,全部变成 OR ,就可以通过全局字典中的“无三”查到了。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '无三不' --fuzzy
--------------------
解析后的 QUERY 语句:Query((无三不@1 SYNONYM (无三@78 OR 三不@79)))
--------------------
在 1 条数据中,大约有 1 条包含 无三不 ,第 1-1 条,用时:0.0018 秒。1. 项目测试第三篇 #3# [100%,0.15]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:好吧,承认我是猜的,上面的分析不是权威分析哦。希望有懂得大佬能在评论区指点一下。
删除全局字典中的那个“无三”,再重新索引数据。
很奇怪,我们直接删全局字典中的那个“无三”,重新索引添加数据之后,使用“无三不”就可以搜索到数据了。这个真的不知道原因,也不瞎猜了,反正就告诉大家,这样可以搜到。ES 类似的能力我没有测,将来或者说小伙伴有兴趣的可以使用 ES 的 IK 分词器测一下,并在评论区说下啥效果哦,就当是一个小作业啦!
停用词库
XS 的停用词库这一块,即使在官方文档上也没有详细的说明,全网也找不到什么有用的资料,真的独一份哦。
停用词的意思就是这个词不用了,不参与分词。或者说分词器如果看到这个词了,直接略过不管它。如果你学过 ES 中的 IK ,一定会知道这个东西。而且 XS 中也是使用 stopwords 这个文件名来定义停用词库的。
前面在 XS 安装目录的 etc 中目录中,大家就已经看到有一个 stopwords.txt 文件了吧,直接打开它,里面已经有一堆默认内容了,我们再添加一个。
# vim etc/stopwords.txt
………………
俗话说添加完之后,来测试一下吧。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '俗话说'
--------------------
解析后的 QUERY 语句:Query((俗话说@1 SYNONYM (俗话@78 AND 话说@79)))
--------------------
在 1 条数据中,大约有 1 条包含 俗话说 ,第 1-1 条,用时:0.0020 秒。1. where is which who #3# [100%,0.23]
俗话说,无三不成礼,所以就有了第三篇
Chrono: Author:还是能查到?跟你说,不管你是重建索引,还是重启服务,都没用,这个停用词库感觉就跟没配一样,完全不起作用。这是为啥呢?因为默认情况下,XS 就根本没启用停用词库的功能。所以在官方文档上,你会看到有同学报怨说这个功能没用。但其实,咱们只要开启加载这个功能及停用词库就好啦。
查看我们启动服务器的 xs-ctl.sh 脚本。就是安装目录下面的 bin 目录中的那个脚本文件,我的虚拟机上是位于 /usr/local/xunsearch/bin/xs-ctl.sh 。给最后启动服务的两行代码中,加上 -s etc/stopwords.txt 就可以了。
# vim bin/xs-ctl.sh
………………
# run
case "$cmd" instart|stop|faststop|fastrestart|restart|reload)# indexif test "$server" != "search"; then# bin/xs-indexd $opt_index $opt_pub -k $cmd # 这里是之前的bin/xs-indexd $opt_index $opt_pub -s etc/stopwords.txt -k $cmdfi# searchif test "$server" != "index"; then# bin/xs-searchd $opt_search $opt_pub -k $cmd # 这里是之前的bin/xs-searchd $opt_search $opt_pub -s etc/stopwords.txt -k $cmdfi;;
*)echo "Unknown command: $cmd"show_usage;;
esac这个参数就表明加载指定的停用词库,并启用停用词功能。然后再来测试。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '俗话说'
--------------------
解析后的 QUERY 语句:Query(<alldocuments>)
--------------------
在 3 条数据中,大约有 3 条包含 俗话说 ,第 1-3 条,用时:0.0015 秒。1. 关于 xunsearch 的 DEMO 项目测试 #1# [100%,0.00]
项目测试是一个很有意思的行为!
Chrono:1314336158 Author: 2. 测试第二篇 #2# [100%,0.00]
这里是第二篇文章的内容
Chrono:1314336160 Author: 3. 项目测试第三篇 #3# [100%,0.00]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:注意看,我们搜索“俗话说”,getQuery() 返回的结果是“alldocument”,就和空查询条件一样。下面的搜索结果也是全部结果都出来了。也就是说,“俗话说”这个停用词已经生效了,SCWS 看到它根本就不管,直接略过。由于没有别的词了,我们的查询结果就和完全没有搜索条件一样,直接返回全部数据了。
我是怎么找到这个功能的?额,在 Github 的 XS 源码中搜 stopword ,结果就找到在 import.cc 、indexed.c 和 searchd.c 中有相关的内容。再仔细看下源码,它们在 -s 这个参数的注释中都写明了要通过这个参数加载停用词库。接着就来看 xs-ctl.sh 脚本,发现在启动索引和搜索服务时,压根就没传这两个参数。剩下的,就不用我多说了吧。
自定义分词器
接下来,我们来试试自定义分词器的功能。这一块是针对 SDK 来说的。在索引配置文件中,我们之前说过有默认的 scws、full、split、none、xlen、xstep 这几种分词类型。其实它们的源码都在 vendor/hightman/xunsearch/lib/XSTokenizer.class.php 这个文件里面。除了 scws 是请求服务端进行分词的,其它几种其实都是 PHP 代码的算法实现,比如说 split ,最终就是一个 explode() 。具体源码大家可以自己去看一下。
这些分词器,其实都是实现了一个 XSTokenizer 接口。而这个接口中,只有一个方法,那就是 getTokens() 方法。那么,如果要实现我们自己自定义的分词器,其实只要和那些自带的分词器一样,实现这个接口方法就可以了嘛。
我们在 vendor/hightman/xunsearch/lib 目录下新建一个 XSTokenizerJieba.class.php 文件,我想使用 Jieba 分词来实现一个分词器。Jiaba-PHP(结巴分词PHP版) https://github.com/fukuball/jieba-php 的文档和说明大家可以在这个 Github 链接上看一下。
# vendor/hightman/xunsearch/lib/XSTokenizerJieba.class.phprequire_once XS_LIB_ROOT . '/../../../autoload.php';class XSTokenizerJieba implements XSTokenizer
{public function __construct($arg = null){}public function getTokens($value, XSDocument $doc = null){// composer require fukuball/jieba-php:dev-masterini_set("memory_limit", "-1");\Fukuball\Jieba\Jieba::init();\Fukuball\Jieba\Finalseg::init();return \Fukuball\Jieba\Jieba::cut($value);;}
}为什么是在 vendor/hightman/xunsearch/lib 目录呢?能不能像 ini 文件一样放到一个我们指定的目录中呢?抱歉,我看了源码,不行。
// vendor/hightman/xunsearch/lib/XSFieldScheme.class.php
public function getCustomTokenizer()
{if (isset(self::$_tokenizers[$this->tokenizer])) {return self::$_tokenizers[$this->tokenizer];} else {if (($pos1 = strpos($this->tokenizer, '(')) !== false&& ($pos2 = strrpos($this->tokenizer, ')', $pos1 + 1))) {$name = 'XSTokenizer' . ucfirst(trim(substr($this->tokenizer, 0, $pos1)));$arg = substr($this->tokenizer, $pos1 + 1, $pos2 - $pos1 - 1);} else {$name = 'XSTokenizer' . ucfirst($this->tokenizer);$arg = null;}if (!class_exists($name)) {$file = $name . '.class.php';if (file_exists($file)) {require_once $file;} else if (file_exists(XS_LIB_ROOT . DIRECTORY_SEPARATOR . $file)) {require_once XS_LIB_ROOT . DIRECTORY_SEPARATOR . $file;}if (!class_exists($name)) {throw new XSException('Undefined custom tokenizer `' . $this->tokenizer . '\' for field `' . $this->name . '\'');}}$obj = $arg === null ? new $name : new $name($arg);if (!$obj instanceof XSTokenizer) {throw new XSException($name . ' for field `' . $this->name . '\' dose not implement the interface: XSTokenizer');}self::$_tokenizers[$this->tokenizer] = $obj;return $obj;}
}为指定字段加载分词器的源码就是上面这段,你可以看到,它固定了分词器的名称。然后在下面 require 时,判断了名称如果在当前目录存在,就加载,如果不存在,则接上 XS_LIB_ROOT 目录去加载。可问题是,$name 在前面是通过前缀的方式来固定的,这就相当于给了我们两个选择。
一是自定义分词器要放在运行当前代码的目录路径下,也就是直接 require_once "XSTokenizerJiaba.php" 这一行的效果。比如我们在 source 目录下运行 php 代码,则这个自定义文件就要放在 source 目录下。
二是放在 vendor/hightman/xunsearch/lib 目录下,也就是第二个拼接上 XL_LIB_ROOT 的效果,require_once XS_LIB_ROOT."XSTokenizerJiaba.php" 。
反正怎么都不是太爽。如果确实需要用到,还是使用第一种吧,毕竟 composer 里面的东西,能不动不就要动了。
好了,不多吐槽了,这一块说不定将来也会有变动呢。我们还是先来测功能。将配置文件中的相关字段的分词器换成我们自定义的。
# config/demo3_56.101.ini
……………………
[subject]
type = title
#tokenizer=scws(15)
tokenizer=jieba[message]
type = body
#tokenizer=scws(15)
tokenizer=jieba
……………………重新索引数据后,进行测试。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '俗话说'
--------------------
解析后的 QUERY 语句:Query((俗话说@1 SYNONYM (俗话@78 AND 话说@79)))
--------------------
在 2 条数据中,大约有 1 条包含 俗话说 ,第 1-1 条,用时:0.0027 秒。1. 项目测试第三篇 #3# [100%,0.39]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:“俗话说”要是查不到,可以取消前面的停用词功能哦。我们可以直接使用分词器的 getTokens() 来进行直接的分词测试,并且看看当前默认的分词器用得是哪个。
var_dump($xs->getFieldTitle()->getCustomTokenizer());
// object(XSTokenizerJieba)#9 (0) {}var_dump((new XSTokenizerJieba())->getTokens('俗话说,无三不成礼,所以就有了第三篇'));
// array(11) {
// [0]=>
// string(9) "俗话说"
// [1]=>
// string(3) ","
// [2]=>
// string(6) "无三"
// [3]=>
// string(6) "不成"
// [4]=>
// string(3) "礼"
// [5]=>
// string(3) ","
// [6]=>
// string(6) "所以"
// [7]=>
// string(3) "就"
// [8]=>
// string(3) "有"
// [9]=>
// string(3) "了"
// [10]=>
// string(9) "第三篇"
// }var_dump((new XSTokenizerScws)->getResult('俗话说,无三不成礼,所以就有了第三篇'));
// array(16) {
// [0]=>
// array(3) {
// ["off"]=>
// int(0)
// ["attr"]=>
// string(4) "n"
// ["word"]=>
// string(9) "俗话说"
// }
// [1]=>
// array(3) {
// ["off"]=>
// int(0)
// ["attr"]=>
// string(4) "n"
// ["word"]=>
// string(6) "俗话"
// }
// [2]=>
// array(3) {
// ["off"]=>
// int(3)
// ["attr"]=>
// string(4) "n"
// ["word"]=>
// string(6) "话说"
// }
// ………………………………
// ………………………………看到两个分词器的效果不同了吧。当然,Jiaba 我们没有做任何配置,而 SCWS 默认是 3 也就是最短词和二元一起进行分词的,所以“话说”也会被分出来。
解决单字 Like 问题
大家还记得吧?早前的文章中,我们就说过一个问题,那就是搜索“项”这种默认不会分词的单字,也就是不会建立倒排索引的单字,是无法查询出数据的。那么在学习了分词的原理之后,特别是字典以及上期讲的复合分词等级的内容之后,大家是不是有想法,也能猜到如何来解决这个问题了吧。使用字典,可能比较麻烦,你需要将很多单字加到字典,而且我测试有的情况下还没效果。那么使用复合分词等级呢?咱们就直接设置分词复合等级为 15 。也就是配置文件中的 title 和 body 字段,都将它们的 tokenizer 设置成 scws(15) 。
接下来重新索引添加数据,然后查询试试。
> php ./vendor/hightman/xunsearch/util/Quest.php ./config/demo3_56.101.ini --show-query '项'
--------------------
解析后的 QUERY 语句:Query(项@1)
--------------------
在 2 条数据中,大约有 2 条包含 项 ,第 1-2 条,用时:0.0012 秒。1. 关于 xunsearch 的 DEMO 项目测试 #1# [100%,0.16]
项目测试是一个很有意思的行为!
Chrono:1314336158 Author: 2. 项目测试第三篇 #3# [99%,0.16]
俗话说,无三不成礼,所以就有了第三篇
Chrono:1314336168 Author:可以通过单个“项”字查询到数据了吧。复合分词等级的知识上次已经说过,设置成 15 其实就是各种词项、二元、重要单字、全部单字都进行拆分,拆分出来的内容非常多。其实这么做的结果大家也能想到,就是它会带来一个非常重大的问题:倒排索引库会变得非常大,而且如果 body 字段是那种文献类型的超长文章或超大文章,索引缓冲也会出问题导致索引失败。即使是在 ES 中,也没法这么玩的。
又回到当初的那个问题了。搜索引擎+分词器(倒排索引),不是 Like !!
总结
自定义字典有点意思吧?更重要的是,咱们还有全网唯一一份的 XS 中停用词的使用方法哦。这不来个赞真的对不起这篇文章啊。另外,通过自定义分词器,咱们也能看出来,XS 完全也是可以使用别的分词工具的嘛。不管是你是想用第三方的 Jieba 分词还是别的什么非常特殊的行业切分格式,都可以通过代码自己来实现。最后,关于分词的内容,在 ES 中现在最流行的是 IK 分词器,小伙伴们在学习 ES 的时候,如果学到了 IK 的部分,其实有这两篇 SCWS 的基础垫底,掌握起来还是会比较轻松的。毕竟什么词性、分词级别、字典,甚至字典名称有很多都是相同的。
分词部分的学习结束了,我们的搜索引擎整体课程也就接近尾声了。后面的两篇文章是扩展部分,也是很有意思的哦,我们会看一下 Xapian 官方文档中我发现的一些有用的内容。最后还会介绍一套非常有意思的完全 PHP 实现的搜索引擎方案哦。
测试代码:
https://github.com/zhangyue0503/dev-blog/blob/master/xunsearch/source/17.php
参考文档:
http://www.xunsearch.com/doc/php/guide/index.dict
http://www.xunsearch.com/doc/php/guide/ini.tokenizer
相关文章:
自定义字典及分词器)
【迅搜17】SCWS分词(二)自定义字典及分词器
SCWS分词(二)自定义字典及分词器 经过上篇文章的学习,相信大家对分词的概念已经有了更深入的了解了吧。我们也知道了,SCWS 是 XS 中的一个重要组成部分,但它也是可以单独拿出来使用的。而对于分词器来说,不…...

深度学习记录--偏差/方差(bias/variance)
误差问题 拟合神经网络函数过程中会出现两种误差:偏差(bias)和方差(variance) 偏差和误差的区别 欠拟合(underfitting) 当偏差(bias)过大时,如左图,拟合图像存在部分不符合值,称为欠拟合(underfitting) 过拟合(overfitting) …...
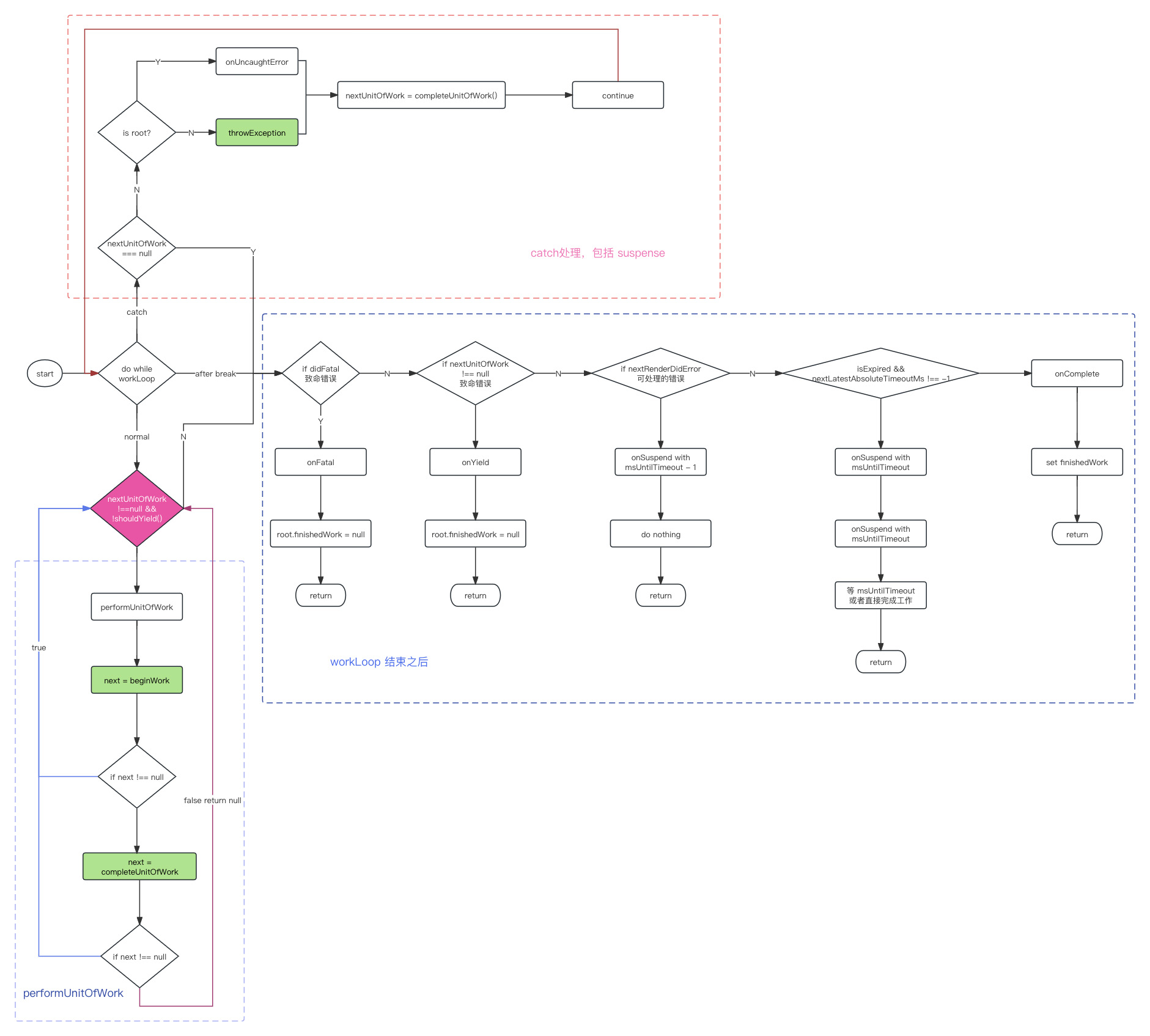
React16源码: React中的renderRoot的源码实现
renderRoot 1 )概述 renderRoot 是一个非常复杂的方法这个方法里处理很多各种各样的逻辑, 它主要的工作内容是什么?A. 它调用 workLoop 进行循环单元更新 遍历整个 Fiber Tree,把每一个组件或者 dom 节点对应的Fiber 节点拿出来单一的进行更…...
GitHub项目推荐-incubator
项目地址 Github地址:GitHub - apache/incubator-anser 官网:Apache Answer | Free Open-source Q&A Platform 项目简述 这是Apache的一个开源在线论坛,也可以部署成为一个自有的QA知识库。项目主要使用了Go和Typescript来开发&#…...

如何使用ActiveMQ
ActiveMQ是Apache的一款开源消息总线,主要用来做消息的分发。使用ActiveMQ,通常需要以下步骤: 一、启动ActiveMQ 首先需要下载ActiveMQ,然后进行启动。启动后,可以在控制台创建队列,初始用户名和密码通常…...

《Python 3 基础》- numpy的array,python的list、tuple的区别与联系再辨析
这里写自定义目录标题 一、基本认识二、list与传统数组(以C为例)的联系与区别三、1维list切片规则四、2维list类似于2维数组,但表达方式需适应五、list与元组的联系与区别1. tuple的创建方法类似于list,tuple用(&#…...

写点东西《最佳 Web 框架不存在 》
写点东西《🥇最佳 Web 框架不存在 🚫》 TLDR;您选择的 Web 应用程序框架并不重要。嗯,它很重要,但并不像其他人希望您相信的那样重要。 2024 年存在如此多的库和框架,而且最好的库和框架仍然备受争议&…...
游戏开发丨基于PyGlet的简易版Minecraft我的世界游戏
文章目录 写在前面我的世界PyGlet简介实验内容游戏按键程序设计引入文件 运行结果写在后面 写在前面 本期内容:基于PyGlet的简易版Minecraft我的世界游戏 实验环境: pycharmpyglet 项目下载地址:https://download.csdn.net/download/m0_6…...

在线的货币兑换平台源码下载
在线的货币兑换平台,可帮助全球各地的个人和企业将货币从一种货币兑换为另一种货币。该货币兑换平台是 Codecanyon 中最先进的脚本。 源码下载:https://download.csdn.net/download/m0_66047725/88728084...
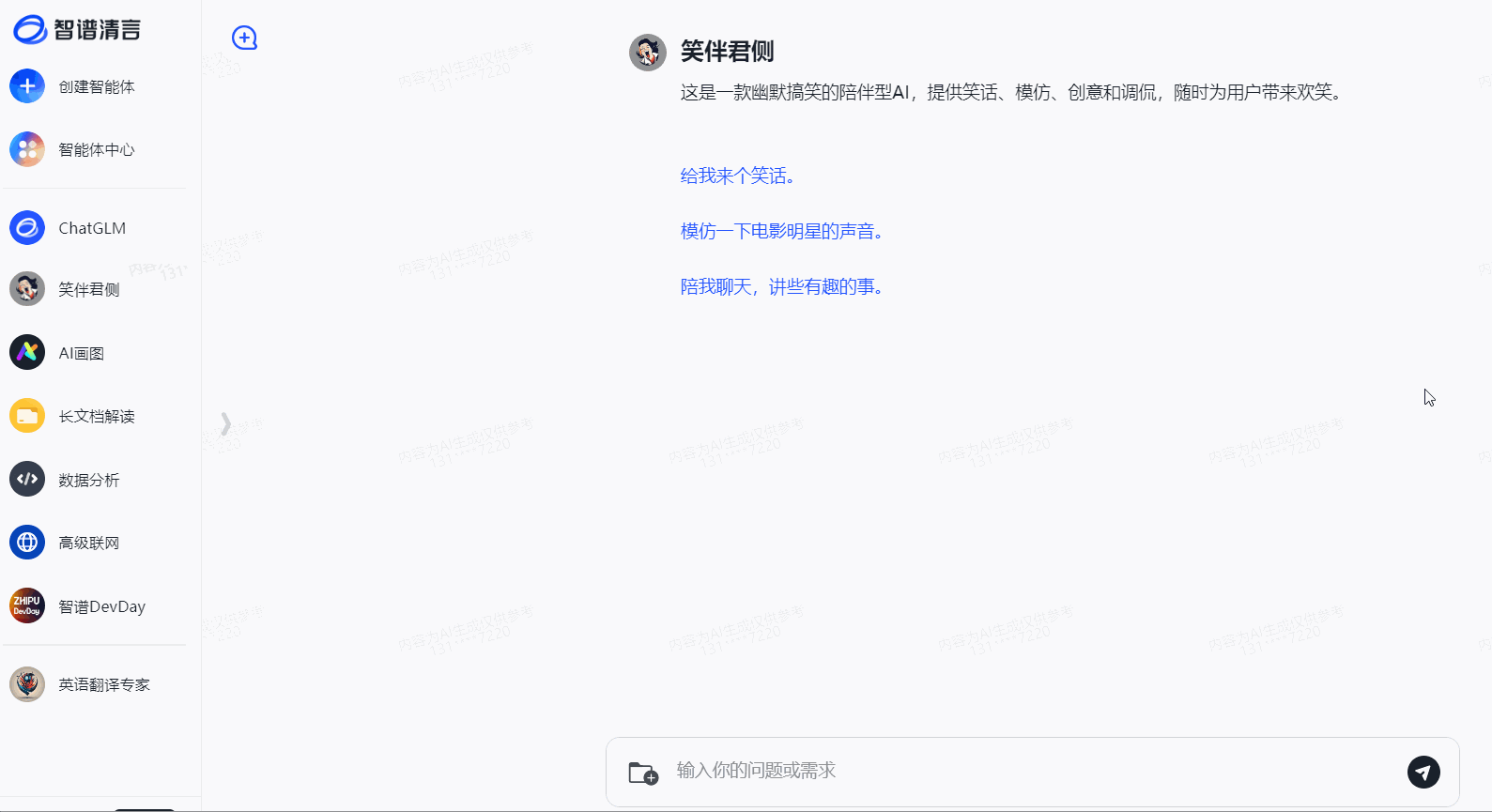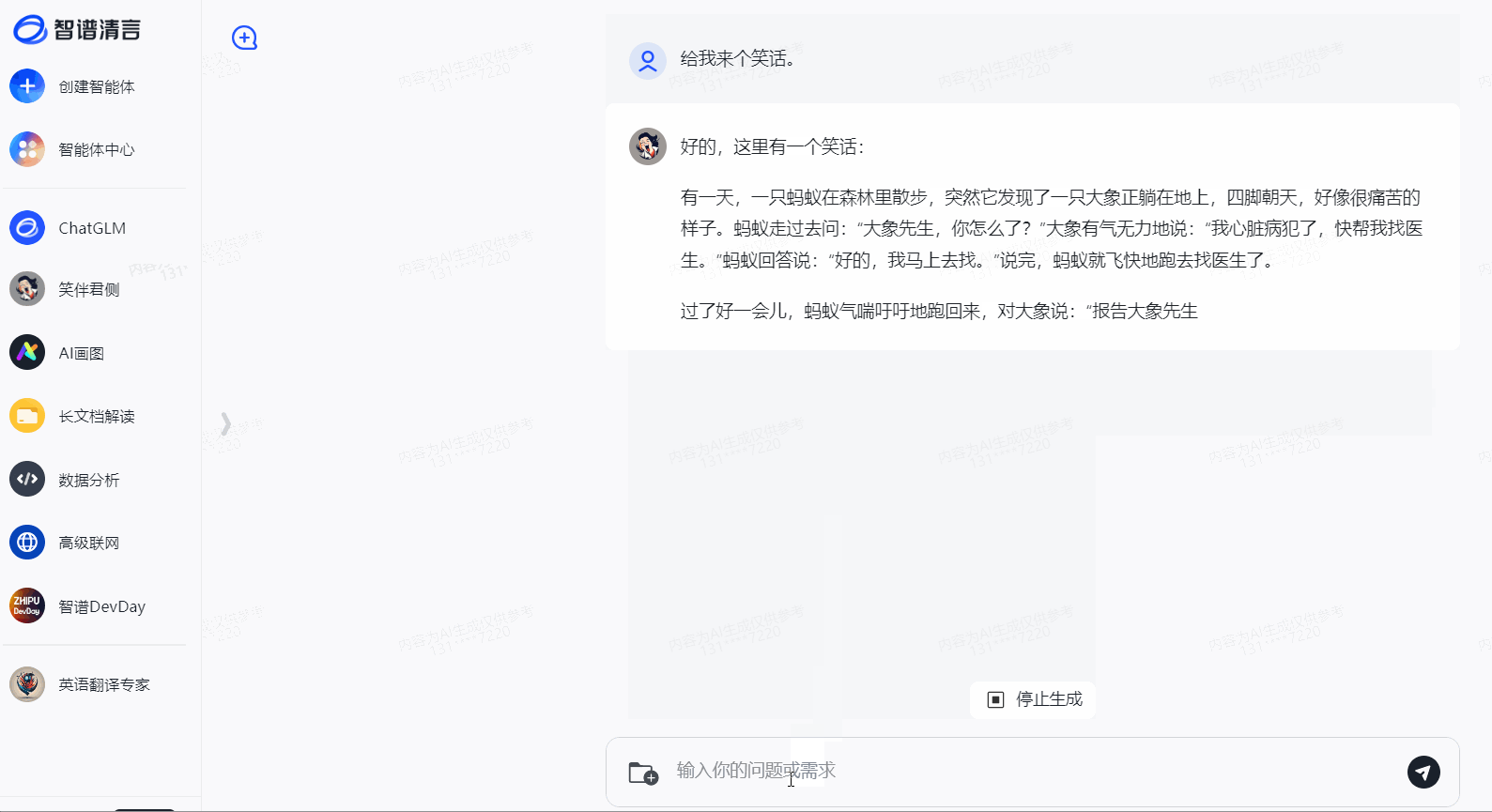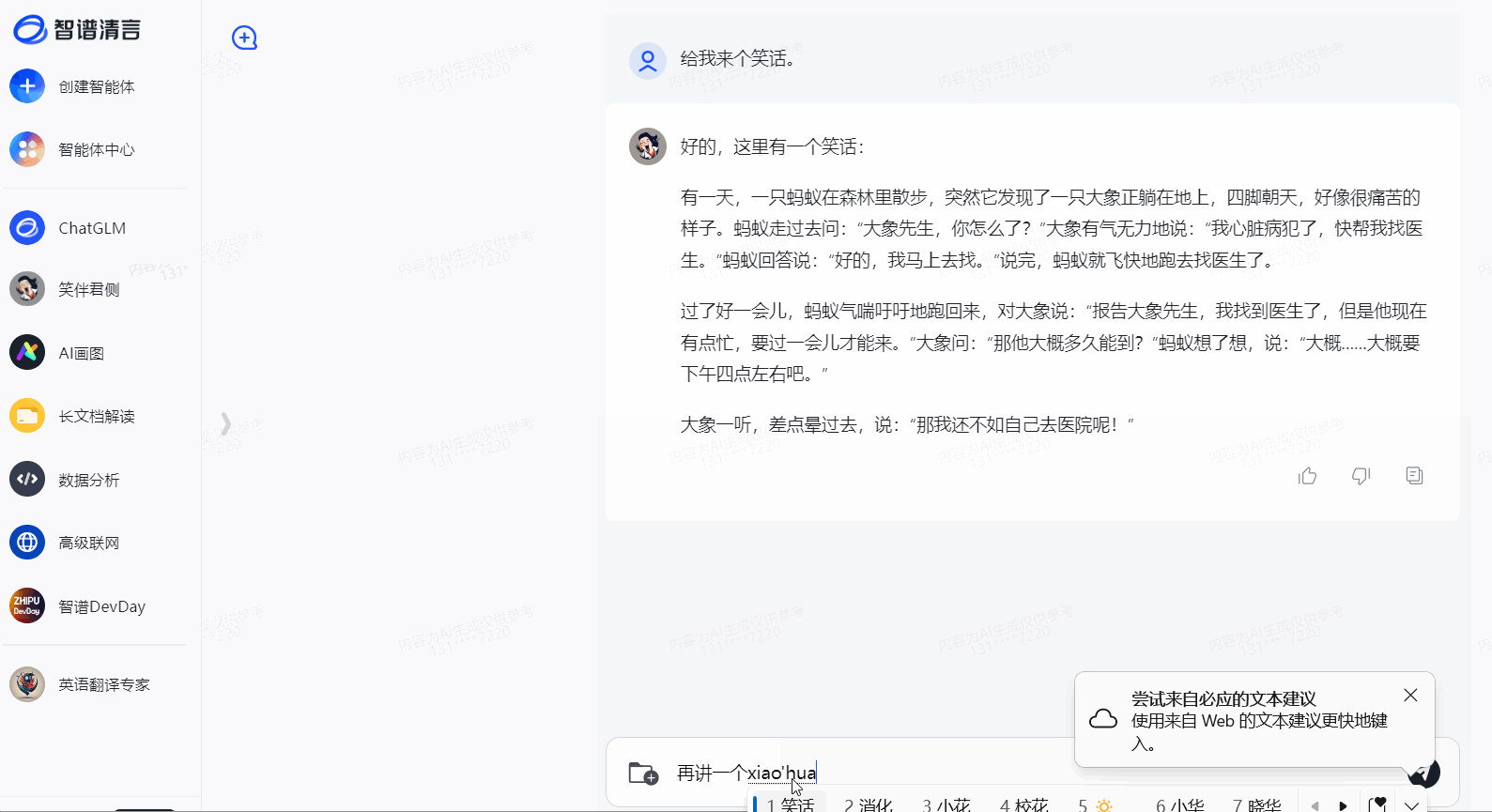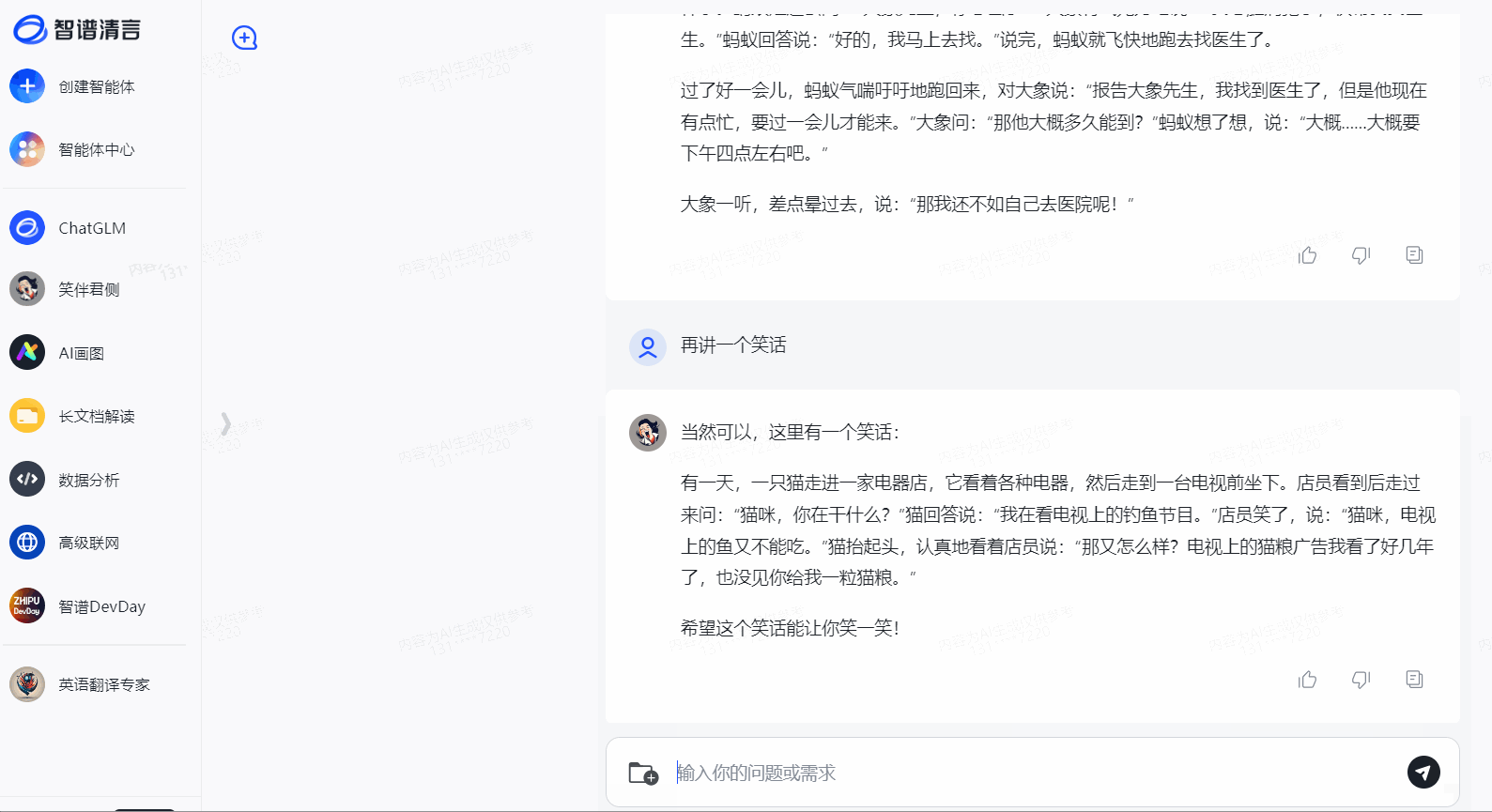
LLMs之GLM-4:GLM-4的简介、安装和使用方法、案例应用之详细攻略
LLMs之GLM-4:GLM-4的简介、安装和使用方法、案例应用之详细攻略 导读:2024年01月16日,智谱AI在「智谱AI技术开放日(Zhipu DevDay)」推出新一代基座大模型GLM-4。GLM-4 的主要亮点和能力如下:>> 性能与GPT-4相近:多模态、长文…...
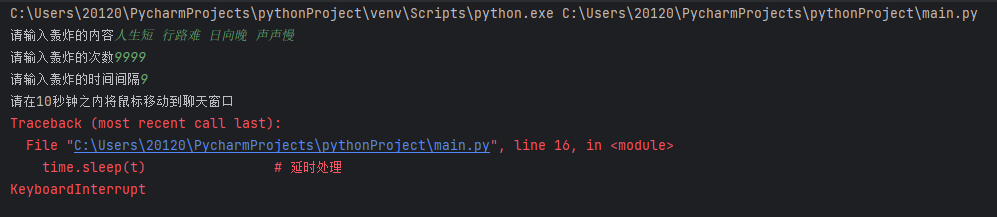
用Python“自动连发消息”
自动连发消息,基本上C和Python的思路都是不停的模拟“击键”操作,还有一种VB的脚本写法,反成每种语言都能写,更厉害的可以用java做出个GUI界面,先上代码。 一 代码 import pyautogui # 鼠标 import p…...

CSS3中多列布局详解
多列布局 概念:在CSS3之前,想要设计类似报纸那样的多列布局,有两种方式可以实现:一种是"浮动布局",另一种是“定位布局”。 这两种方式都有缺点:浮动布局比较灵活,但不容易控制&…...

Xmind 网页端登录及多端同步
好久没用 Xmind 了,前几天登录网页端突然发现没办法登录了,总是跳转到 Xmind AI 页面。本以为他们不再支持网页端了,后来看提示才知道只是迁移到了新的网址,由原来的 xmind.works 现在改成了的 xmind.ai。又花费好长时间才重新登录…...
Transformer从菜鸟到新手(七)
引言 上篇文章加速推理的KV缓存技术,本文介绍让我们可以得到更好的BLEU分数的解码技术——束搜索。 束搜索 我们之前生成翻译结果的时候,使用的是最简单的贪心搜索,即每次选择概率最大的,但是每次生成都选择概率最大的并不一定…...
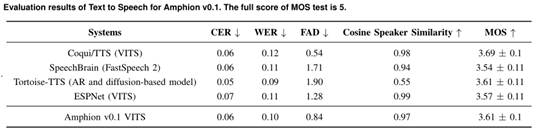
上海AI实验室等开源,音频、音乐统一开发工具包Amphion
上海AI实验室、香港中文大学数据科学院、深圳大数据研究院联合开源了一个名为Amphion的音频、音乐和语音生成工具包。 Amphion可帮助开发人员研究文本生成音频、音乐等与音频相关的领域,可以在一个框架内完成,以解决生成模型黑箱、代码库分散、缺少评估…...

加快网络安全事件响应速度的6个步骤
现代安全工具不断提高保护组织网络和端点免受网络犯罪分子侵害的能力。但坏人偶尔还是会找到办法进来。 安全团队必须能够阻止威胁并尽快恢复正常运行。这就是为什么这些团队不仅必须拥有正确的工具,而且还要了解如何有效地应对事件。可以自定义事件响应模板等资源…...
)
Docker 镜像的详解及创建(Dockerfile详解)
目录 镜像加载的原理 联合文件系统(UnionFS) 镜像结构的分层 Dockerfile Dockerfile结构 dockerfile常用命令 Dockerfile 编写规范 docker创建镜像的方法 基于现有镜像创建 示例: 基于本地模版创建 示例 基于Dockerfile 创建 示…...

JDBC事务
1.事务 数据库事务是一组数据库操作,它们被视为一个单一的逻辑工作单元,要么全部成功执行,要么全部回滚(撤销)到事务开始前的状态。事务是确保数据库数据一致性、完整性和可靠性的关键机制之一。 简单来说࿰…...

协方差矩阵自适应调整的进化策略(CMA-ES)
关于CMA-ES,其中 CMA 为协方差矩阵自适应(Covariance Matrix Adaptation),而进化策略(Evolution strategies, ES)是一种无梯度随机优化算法。CMA-ES 是一种随机或随机化方法,用于非线性、非凸函数的实参数(…...
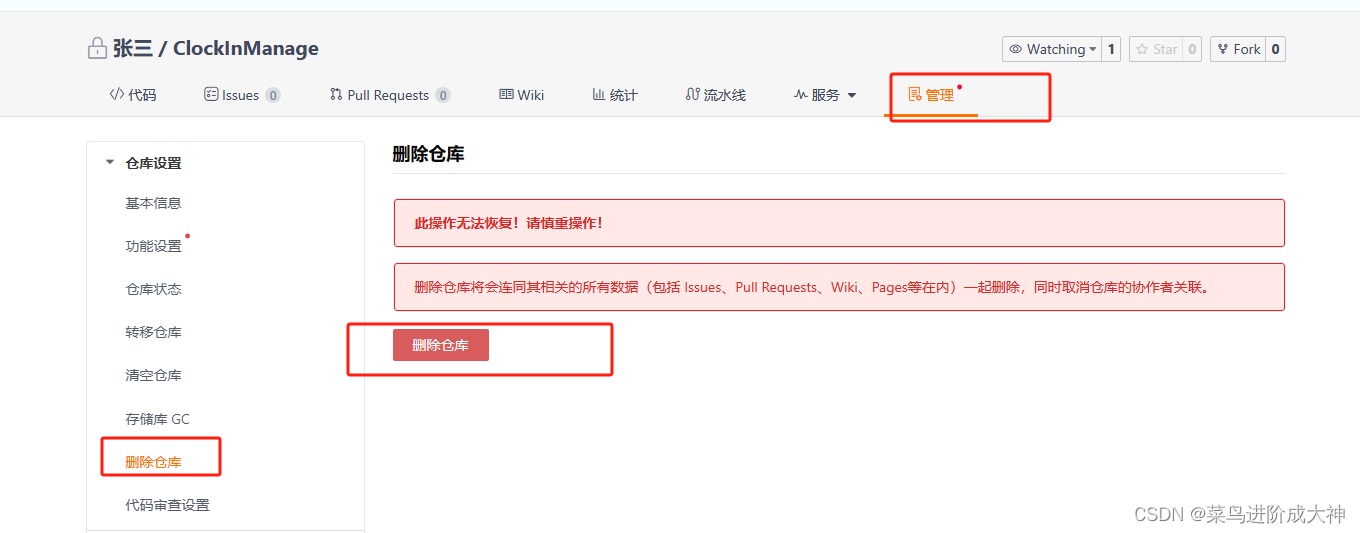
gitee完整使用教程,创建项目并上传
目录 一 什么是gitee 二 安装Git 三 登录gitee,生成密钥 四 配置SSH密钥 五 创建项目 六 克隆仓库到本地 七 关联本地工程到远程仓库 八 添加文件 九 异常处理 十 删除仓储 十一 git常用命令 一 什么是gitee gitee是开源中国推出的基于git的代码托管服务…...

PPT怎么转PDF?一键快捷操作与全方位转换方法测评
在日常工作中,我们经常需要将PowerPoint演示文稿转换成PDF格式。无论是为了保证演示文件的兼容性、方便分享给他人,还是用于打印和存档,PPT转PDF都是一项必不可少的技能。本文将为你深入讲解PPT转PDF的多种方法,包括快捷键操作、软…...

差点把用户数据泄漏给Claude Code后,我写了个 Rust 工具
两周前,我把公司的数据库接进了Claude Code,效率确实起飞了,直到我翻了一下会话记录。 两周前 公司的 PostgreSQL 数据库接进了Claude Code以后,AI 确实能干——帮我写迁移、联表、生成报表,效率直接起飞。 直到我随…...

对比按量计费与套餐计划在长期项目中的成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与套餐计划在长期项目中的成本差异 在长期技术项目的规划中,成本管理是一个需要持续关注的环节。对于依赖…...

如何用OneMore插件彻底改变你的OneNote笔记体验:终极效率提升指南
如何用OneMore插件彻底改变你的OneNote笔记体验:终极效率提升指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 你是否曾经在OneNote中花费大量时间调整…...

终极指南:如何用TQVaultAE管理你的泰坦之旅装备库
终极指南:如何用TQVaultAE管理你的泰坦之旅装备库 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在《泰坦之旅周年版》中因为背包空间不足而烦恼&#…...

Cursor Pro破解工具终极指南:5步解锁AI编程助手完整功能
Cursor Pro破解工具终极指南:5步解锁AI编程助手完整功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

Quantum ESPRESSO 终极快速入门指南:5天轻松掌握电子结构计算
Quantum ESPRESSO 终极快速入门指南:5天轻松掌握电子结构计算 【免费下载链接】q-e Mirror of the Quantum ESPRESSO repository. Please do not post Issues or pull requests here. Use gitlab.com/QEF/q-e instead. 项目地址: https://gitcode.com/gh_mirrors/…...

ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南
ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https://git…...

100行代码实现扩散模型:PyTorch版终极入门指南
100行代码实现扩散模型:PyTorch版终极入门指南 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytorch 你…...

手把手教你用Wireshark抓包分析:一个Easymesh设备到底是怎么‘发现’并‘加入’你家网络的?
用Wireshark解密Easymesh组网:从设备发现到网络接入的全流程解析 当你在客厅新添置了一台支持Easymesh的路由器,通电后它就像有自主意识般自动加入了现有的家庭网络——这种看似"魔法"般的体验背后,其实是一系列精密的协议交互在发…...