【sklearn练习】模型评估
一、交叉验证 cross_val_score 的使用
1、不用交叉验证的情况:
from __future__ import print_function
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifieriris = load_iris()
X = iris.data
y = iris.target# test train split #
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))输出结果:
0.97368421052631582、使用交叉验证
from sklearn.model_selection import cross_val_score
knn2 = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn2, X, y, cv=5, scoring='accuracy')
print(scores)输出结果:
[0.96666667 1. 0.93333333 0.96666667 1. ]
二、确定合适模型参数
1、迭代模型中n_neighbors参数
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:knn = KNeighborsClassifier(n_neighbors=k)
## loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error') # for regressionscores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classificationk_scores.append(scores.mean())plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
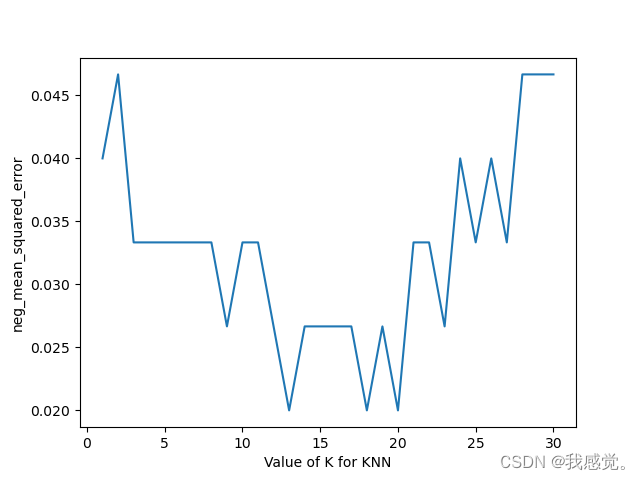
plt.show()画出scores为:

下面是画loss的代码:
k_range = range(1, 31)
k_loss = []
for k in k_range:knn = KNeighborsClassifier(n_neighbors=k)loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error') # for regression## scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classificationk_loss.append(loss.mean())plt.plot(k_range, k_loss)
plt.xlabel('Value of K for KNN')
plt.ylabel('neg_mean_squared_error')
plt.show()画出loss为:
三、cross_val_score 中的 scoring参数(本标题内容可删,可以是一个链接插入解释这个参数即可)
cross_val_score 函数中的 scoring 参数用于指定评估模型性能的评分指标。评分指标是用来衡量模型预测结果与真实结果之间的匹配程度的方法。在机器学习任务中,选择合适的评分指标对于模型的评估和选择非常重要,因为不同的任务和数据可能需要不同的评估标准。以下是一些常见的评分指标以及它们在 cross_val_score 中的使用方式:
-
分类问题的评分指标:
scoring="accuracy":用于多类分类问题,计算正确分类的样本比例。scoring="precision":计算正类别预测的精确度,即正类别的真正例与所有正类别预测的样本之比。scoring="recall":计算正类别预测的召回率,即正类别的真正例与所有真实正类别的样本之比。scoring="f1":计算 F1 分数,它是精确度和召回率的调和均值,用于综合考虑模型的性能。
示例使用方法:
from sklearn.model_selection import cross_val_scorescores_accuracy = cross_val_score(estimator, X, y, cv=5, scoring="accuracy") scores_precision = cross_val_score(estimator, X, y, cv=5, scoring="precision") scores_recall = cross_val_score(estimator, X, y, cv=5, scoring="recall") scores_f1 = cross_val_score(estimator, X, y, cv=5, scoring="f1") -
回归问题的评分指标:
scoring="neg_mean_squared_error":用于回归问题,计算负均方误差(Negative Mean Squared Error),即平均预测值与真实值的平方差。scoring="r2":计算决定系数(R-squared),用于度量模型对目标变量的解释方差程度,取值范围在0到1之间。
示例使用方法:
from sklearn.model_selection import cross_val_scorescores_mse = cross_val_score(estimator, X, y, cv=5, scoring="neg_mean_squared_error") scores_r2 = cross_val_score(estimator, X, y, cv=5, scoring="r2") -
其他评分指标:
- 除了上述常见的评分指标外,还可以使用其他自定义评分函数或指标,例如 AUC、log损失等,只需将评分函数传递给
scoring参数即可。
示例使用方法:
from sklearn.metrics import roc_auc_score from sklearn.model_selection import cross_val_scorescoring_function = make_scorer(roc_auc_score) scores_auc = cross_val_score(estimator, X, y, cv=5, scoring=scoring_function) - 除了上述常见的评分指标外,还可以使用其他自定义评分函数或指标,例如 AUC、log损失等,只需将评分函数传递给
根据任务和数据类型,选择适当的评分指标非常重要,它有助于衡量模型的性能,确定模型是否满足预期的要求,并在不同模型之间进行比较和选择。不同的评分指标可以反映模型性能的不同方面,因此需要根据具体情况进行选择。
四、learning_curve函数的使用
1、learning_curve函数功能
learning_curve 是一个用于评估机器学习模型性能的可视化工具。它通常用于了解模型在不同训练数据集大小下的性能变化,以帮助决定是否需要更多的训练数据或模型是否已经过拟合。learning_curve 可以帮助你可视化训练集和验证集上的性能指标,通常是准确性(accuracy)或损失函数(loss)随着训练数据集大小的变化而变化的情况。
在 Python 中,可以使用 sklearn.model_selection.learning_curve 函数来创建学习曲线。
2、例子
代码:
from __future__ import print_function
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as npdigits = load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss = learning_curve(SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',train_sizes=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)plt.plot(train_sizes, train_loss_mean, 'o-', color="r",label = "Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",label = "Cross-validation")plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()结果为:
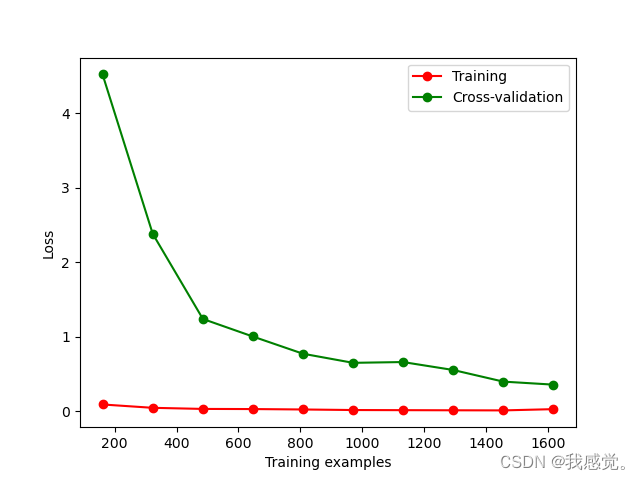
当把SVC的参数gamma改为0.01后执行程序得到结果为:
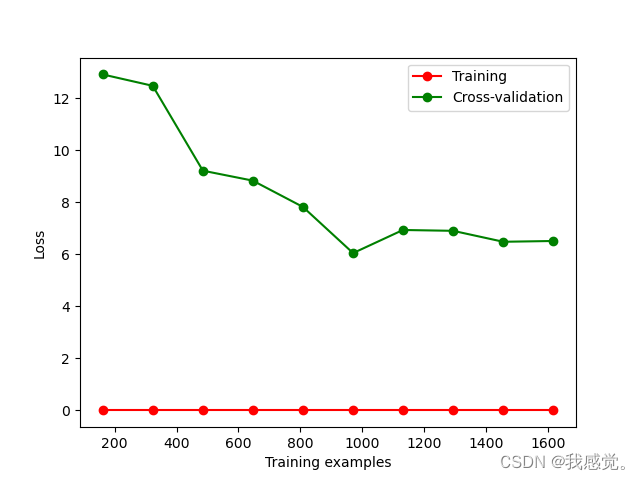
可见,对于训练集,模型更加精确了,损失很少,但对于测试集,损失很大,且随着训练的进行损失不会下降,发生了过拟合,gamma参数的作用为【问GPT】。
五、解决过拟合(validation_curve函数的使用)
1、validation_curve函数功能
validation_curve 函数是 scikit-learn(sklearn)库中的一个工具函数,用于评估模型在不同超参数设置下的性能,并帮助你找到最优的超参数配置。它的主要功能是绘制不同超参数值的模型性能曲线,以便你可以直观地看到模型性能如何随着超参数的变化而变化。
validation_curve 函数通常用于调整模型的超参数,例如正则化参数、决策树深度、学习率等。它帮助你了解不同超参数值对模型性能的影响,以便选择最佳的超参数配置。
以下是 validation_curve 函数的一些关键参数:
-
estimator:要评估的机器学习模型,通常是一个分类器或回归器的实例。 -
X:特征矩阵,包含输入样本的特征值。 -
y:目标向量,包含对应于输入样本的目标值或标签。 -
param_name:要调整的超参数的名称,例如正则化参数、树的深度等。 -
param_range:超参数的一组不同取值。validation_curve将在这些不同的取值上评估模型性能。 -
scoring:用于评估模型性能的评分指标,例如准确度(accuracy)、均方误差(MSE)、F1 分数等。 -
cv:交叉验证的折数,用于计算性能的平均值和标准差。 -
n_jobs:并行计算的数量,用于加速计算。
validation_curve 函数返回一个包含训练得分和验证得分的数组,以及对应于每个超参数值的均值和标准差。这些信息可以用于绘制性能曲线,以便可视化超参数的选择。
2、迭代gamma的值,选择合适的gamma:
代码:
from __future__ import print_function
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as npdigits = load_digits()
X = digits.data
y = digits.target
param_range = np.logspace(-6, -2.3, 5)
train_loss, test_loss = validation_curve(SVC(), X, y, param_name='gamma', param_range=param_range, cv=10,scoring='neg_mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)plt.plot(param_range, train_loss_mean, 'o-', color="r",label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",label="Cross-validation")plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()结果为:
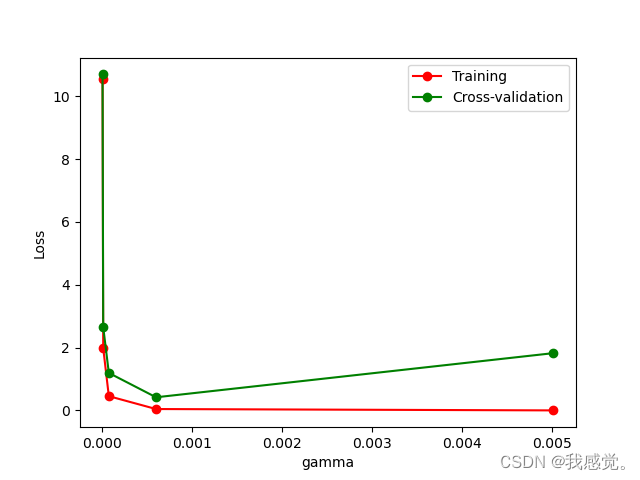
相关文章:
【sklearn练习】模型评估
一、交叉验证 cross_val_score 的使用 1、不用交叉验证的情况: from __future__ import print_function from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifieriris…...
Gazebo的模型下载。
git clone zouxu634866/gazebo_modelshttps://gitee.com/zouxu6348660/gazebo_models.git,并完成路径配置。 (本文提供了gitee下载,国外的Github下载较慢。)...
支持方法重载吗?)
MyBatis - DAO 接口(Mapper.xml)支持方法重载吗?
方法重载(Method Overloading)是指在同一个类中定义多个方法,它们具有相同的方法名但参数列表不同。 Dao 在 MyBatis 的 DAO 层接口中,是允许方法重载的。 在 DAO 层接口中,可以根据不同的需求和条件定义多个方法&am…...
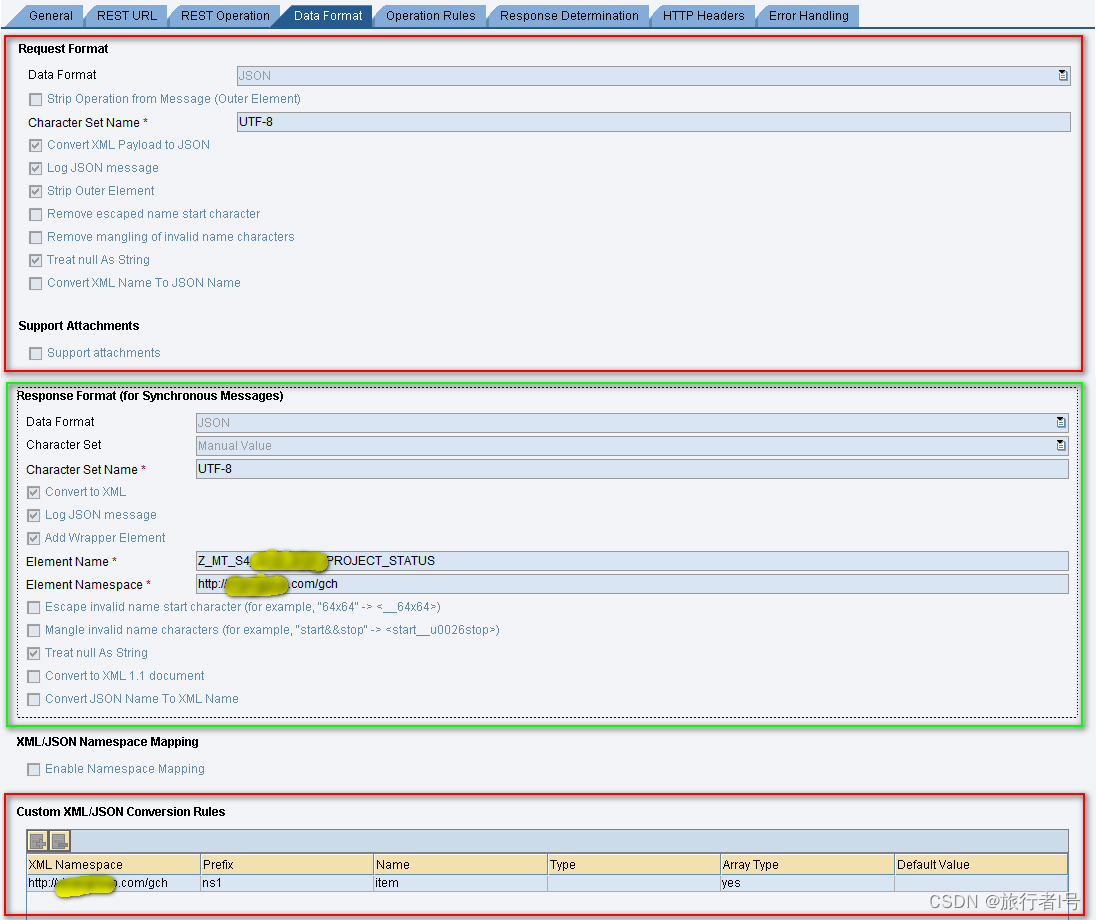
SAP PI之Rest adapter
一,简介 REST风格接口是以http为传输协议,以xml或json或text为有效负载。下图展示了REST到XI再返回的一个过程,一个REST接口包含的信息有:服务URL、URL中带的参数、http方法(post/get/put等)、http头部、body部分的有效载荷。而X…...
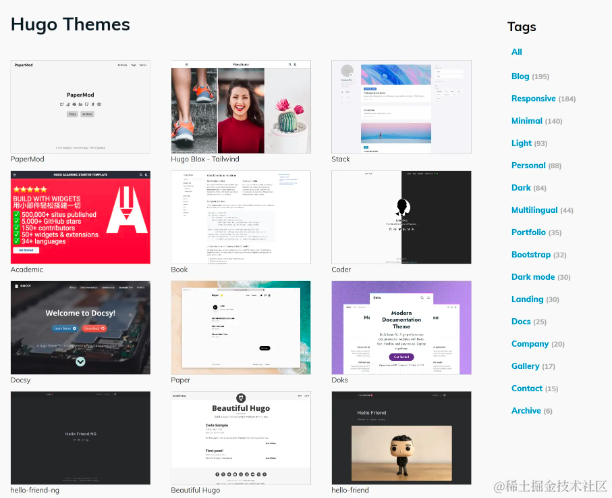
推荐几个Github高星GoLang管理系统
在Web开发领域,Go语言(Golang)以其高效、简洁、高并发等特性逐渐成为许多开发者的首选语言。有许多优秀的Go语言Web后台管理系统,这些项目星星众多,提供了丰富的功能和良好的代码质量。本文将介绍一些GitHub高星的GoLa…...

生成式对抗网络GAN
Generative Adversarial Nets由伊恩古德费洛(Ian J.Goodfellow)等人于2014年发表在Conference on Neural Information Processing Systems (NeurIPS)上。NeurIPS是机器学习和计算神经科学领域的顶级国际学术会议之一。 1. GAN在哪些领域大放异彩 图像生…...
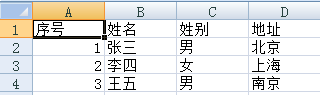
Python如何使用Excel文件
使用Python操作Office——EXCEL 首先介绍下office win32 com接口,这个是MS为自动化提供的操作接口,比如我们打开一个EXCEL文档,就可以在里面编辑VB脚本,实现我们自己的效果。对于这种一本万利的买卖,Python怎么能放过…...

前端基础:回顾es6相关知识
Author note(题记): ECMAscript is international standard of javascript。 ECMA 是 js的国际标准版语言。 let and const 为什么之前用var现在需要用let,const呢? 其实就是因为规范作用域的问题。var的作用域无块级 for (var i 0; i <…...

Hive条件函数详细讲解
Hive 中的条件函数允许你在查询中基于某些条件执行逻辑操作。以下是你提到的条件函数的详细讲解,包括案例和使用注意事项: IF() 功能:根据条件返回两个表达式中的一个。语法:IF(boolean_test, value_if_true, value_if_false)案例:SELECT IF(1=1, true, false); 结果为 tr…...

java应用CPU过高查找原因
用top查到占用cpu最高的进程pid 根据进程ID找到占用CPU高的线程 ps -mp 60355 -o THREAD,tid | sort -r 用 printf "%x \n" 将tid换为十六进制:xid printf "%x \n" 6036 根据16进制格式的线程ID查找线程堆栈信息 jstack 60355 |grep ebcb -A…...
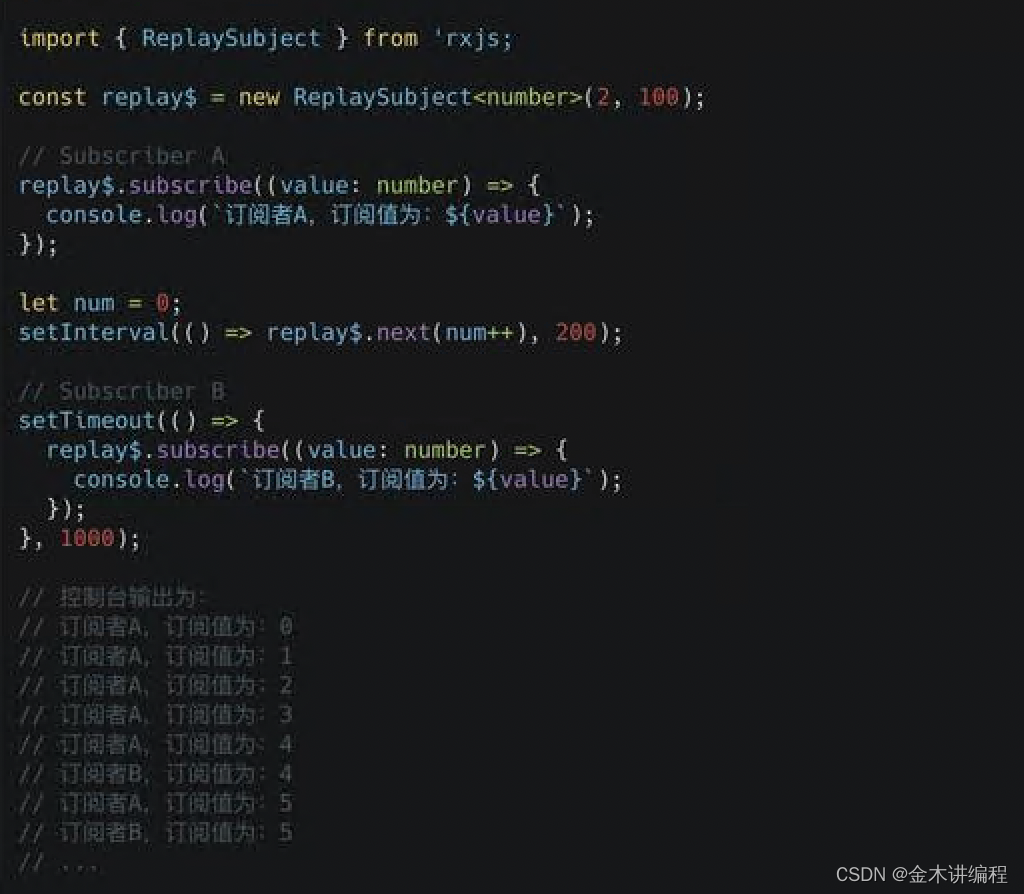
RXJS中Subject, BehaviorSubject, ReplaySubject, AsyncSubject的区别?
在RxJS(Reactive Extensions for JavaScript)中,Subject、BehaviorSubject、ReplaySubject和AsyncSubject都是Observable的变体,它们用于处理观察者模式中的不同场景。以下是它们之间的主要区别: 1、Subject: 是一种特…...

【算法题】55. 跳跃游戏
题目 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例 1ÿ…...
工业企业能源管理平台,可以帮助企业解决哪些方面的能源问题?
随着全球工业化进程的加快,工业企业在生产经营过程中消耗的能源也越来越庞大。能源成本的上升和环境保护的压力使得工业企业对能源管理的重要性有了深刻的认识。为了提高能源利用效率、降低能源消耗、减少环境污染,工业企业在能源管理方面迫切需要一套规…...
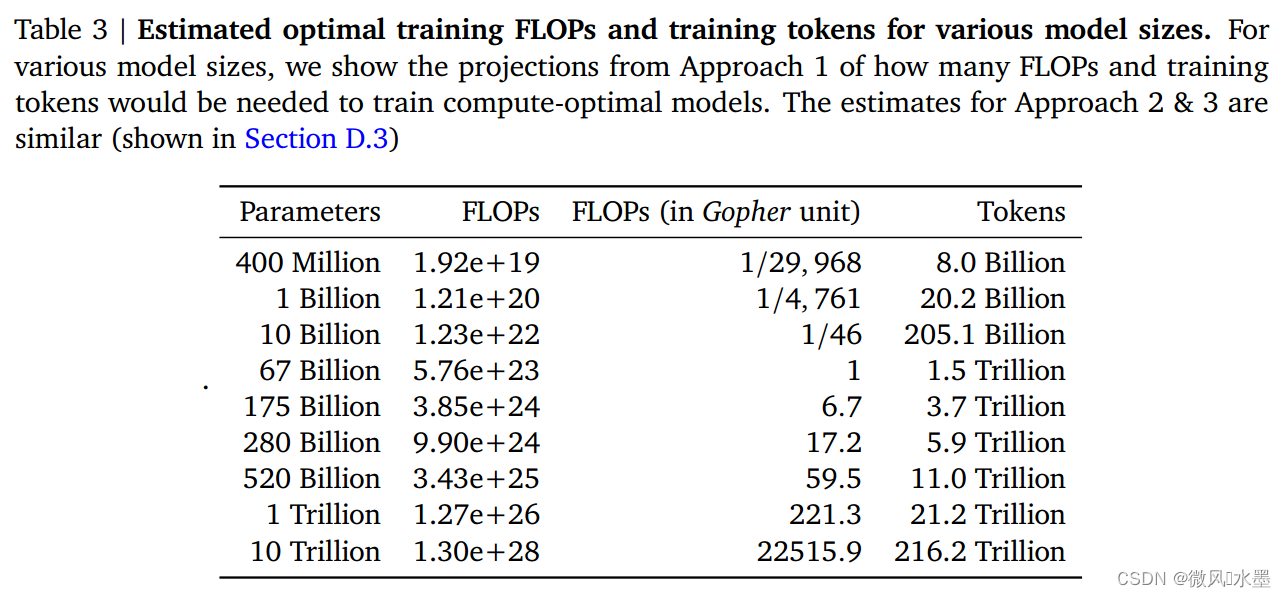
LLM:Training Compute-Optimal Large Language Models
论文:https://arxiv.org/pdf/2203.15556.pdf 发表:2022 前文回顾: OpenAI在2020年提出《Scaling Laws for Neural Language Models》:Scaling Laws(缩放法则)也一直影响了后续大模型的训练。其给出的结论是最佳计算效…...
http跟https有什么区别?
HTTP(Hypertext Transfer Protocol)和HTTPS(HTTP Secure)是两种不同的通信协议,它们在数据传输的安全性方面有明显的区别: 1. 安全性: - HTTP:是一种明文传输协议,数…...

python flask学生管理系统
预览 前端 jquery css html bootstrap: 4.x 后端 python: 3.6.x flask: 2.0.x 数据库 mysql: 5.7 学生管理模块 登录、退出查看个人信息、修改个人信息成绩查询查看已选课程选课、取消选课搜索课程课程列表分页功能 教师模块 登录、退出查看个人信息、修改个人信息录入…...
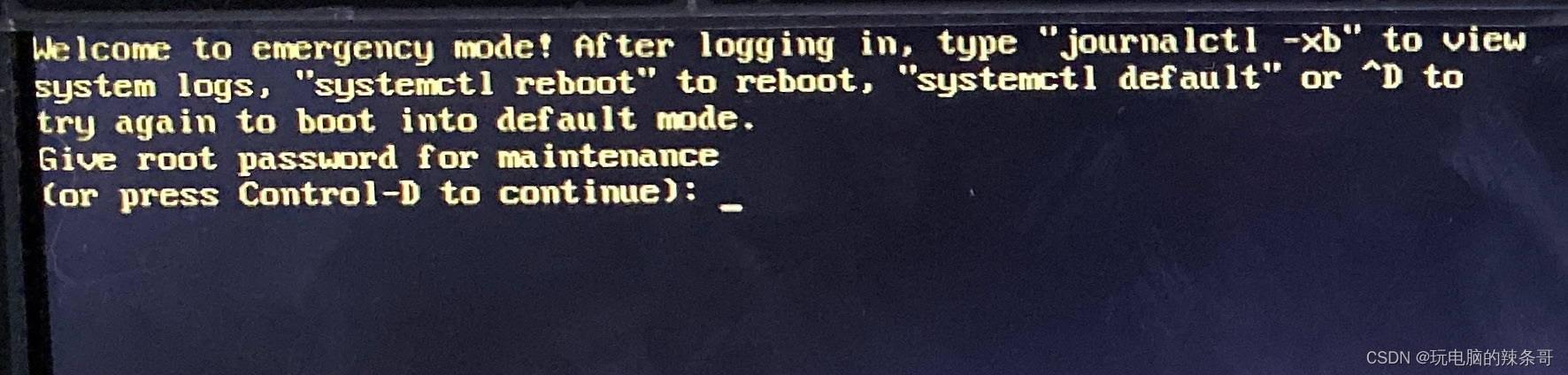
IDC机房服务器搬迁之运行了几年的服务器没关过机,今天关机下架,再上架突然起不来了,怎么快速处理?
环境 戴尔R420 服务器 1U 2台直连存储 4U CentOS 7 问题描述 IDC机房服务器搬迁之运行了几年的服务器没关过机,今天关机下架,再上架突然起不来了,怎么快速处理? 服务器上电开机就出现进入紧急模式 Welcome to emergency mode! After logging in, type “journalctl …...

基于位的权限系统
基于位的权限系统是一种利用二进制位运算进行权限管理的技术。在这种系统中,不同的权限被编码为2的幂次方 (例如1、2、4、8等),每个权限对应一个独立的二进制位(可想而知运算速度是非常快的)。通过将这些权限值组合在一起形成一个…...

[AIGC] Spring Boot Docker 部署指南
Spring Boot Docker 部署指南 引言 近年来,容器化部署成为了越来越流行的部署方式。Docker 是目前最受欢迎的容器化平台之一,它提供了一种将应用程序与其依赖项打包在一起,并以容器的形式运行的方法。Spring Boot 是一种用于快速开发和微服…...

图像处理------亮度
from PIL import Imagedef change_brightness(img: Image, level: float) -> Image:"""按照给定的亮度等级,改变图片的亮度"""def brightness(c: int) -> float:return 128 level (c - 128)if not -255.0 < level < 25…...

AI工程师必备:三款主流工具的实操落地指南
1. 项目概述:一份真正“够用”的AI资讯简报,到底长什么样?你有没有过这种体验:每天早上打开邮箱,收进十几封AI领域的Newsletter——有的标题写着“深度解析LLM推理优化”,点开发现通篇是论文摘要堆砌&#…...
到底怎么选?)
别再只会用PWM调速度了!STM32驱动直流有刷电机,H桥的三种模式(单极/双极/受限)到底怎么选?
STM32驱动直流有刷电机的三种H桥模式深度解析与实战选型指南 在嵌入式电机控制领域,PWM调速早已成为基础技能,但真正决定系统性能的往往是H桥工作模式的选择。当你的电机出现异常发热、刹车响应迟缓或低速抖动时,问题很可能就出在模式选择不当…...

从“能读文档”到“能开会吵架”,技术人英语进阶路线图
在软件测试领域,英语能力早已不是简历上“通过CET-4”的一行小字,而是决定职业天花板的关键变量。对于测试从业者而言,英语学习存在一条隐秘却深刻的分水岭:左边是能借助翻译插件磕磕绊绊读完需求文档的“生存模式”,右…...

大中小型企业数据配置年度成本估算分析
引言 在数字化转型浪潮下,数据已成为企业的核心资产。无论是初创公司、中型企业还是大型集团,合理规划数据存储、处理与分析的成本,对于优化IT预算、提升投资回报率至关重要。本文旨在为不同规模的企业提供一个清晰、可操作的年度数据配置成本…...

鸿蒙同城兴趣圈页面构建:活动热区地图、话题动态与安全提示模块详解
鸿蒙同城兴趣圈页面构建:活动热区地图、话题动态与安全提示模块详解 前言 在 HarmonyOS 6.0 应用开发中,社交类页面的地理可视化、话题互动和安全提示是提升用户体验的关键补充模块。本文将以“同城兴趣圈”应用中的“活动热区”模拟地图、“话题动态”帖…...

兜兜转转又回到大浪浪的S05,遥看当年黑丝在,今朝尽染满头霜。
偶然翻看CSDN头像,恍然惊觉已是十五载光阴。2011年拍照于此设头像。初来S05,一路辗转S01,兜兜转转,历经浮沉,如今终究重回最初的S05。这十几年来,方寸代码天地,见证了我的所有成长与蜕变。一路行…...
)
用 5 款全栈电商微系统打通你的前后端核心逻辑链路(附级联 Prompt)
各位大前端、全栈开发以及正在寻求技术进阶的同仁们,大家好。在日常的技术社区里,我们经常能看到各种流于表面的前端 UI 静态页或者几行代码拼凑的后端 CRUD 示例。但真正能在一个全栈工程师的履历中起到定海神针作用的,往往是那些功能内敛、…...

专业的郑州苹果手机维修联系电话口碑佳的
在当今数字化时代,苹果手机已成为人们生活中不可或缺的一部分。然而,手机使用过程中难免会出现各种故障,这时候选择一家专业靠谱的维修店就显得尤为重要。在郑州,果速修凭借其卓越的服务和良好的口碑,成为众多苹果用户…...

AArch64 SCTLR_EL3寄存器解析与安全配置实践
1. AArch64 SCTLR_EL3系统控制寄存器深度解析在Armv8-A/v9-A架构的安全世界中,SCTLR_EL3寄存器扮演着系统控制中枢的角色。作为EL3(最高特权级别)的系统控制寄存器,它直接决定了安全监控模式(Secure Monitor࿰…...

Mythos模型:通用AI在漏洞挖掘与 exploit 生成中的范式跃迁
1. 这不是一次普通升级:Mythos 的能力跃迁到底意味着什么“Claude Mythos Preview”——这个名字在2026年4月的AI圈里炸开时,我正调试一个用Opus 4.6做代码审计的自动化流水线。看到基准测试数据的第一反应不是兴奋,而是下意识关掉了终端窗口…...