响应式编程Reactor API大全(下)
Reactor 是一个基于响应式编程的库,主要用于构建异步和事件驱动的应用程序。Reactor 提供了丰富的 API,包括创建、转换、过滤、组合等操作符,用于处理异步数据流。以下是一些 Reactor 的主要 API 示例:
pom依赖
<dependencyManagement><dependencies><dependency><groupId>io.projectreactor</groupId><artifactId>reactor-bom</artifactId><version>2023.0.0</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>io.projectreactor</groupId><artifactId>reactor-core</artifactId></dependency><dependency><groupId>io.projectreactor</groupId><artifactId>reactor-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.2</version><scope>test</scope></dependency></dependencies>
61. 使用 Reactor 的 then 方法进行后续操作
then 方法用于在当前数据流完成后执行后续操作。
import reactor.core.publisher.Flux;public class ReactorThenExample {public static void main(String[] args) {Flux<Integer> source = Flux.just(1, 2, 3);// 在当前数据流完成后执行后续操作source.then(Mono.fromRunnable(() -> System.out.println("Done"))).subscribe();}
}
62. 使用 Reactor 的 publishOn 方法进行线程切换
publishOn 方法用于切换数据流的发布线程,从而改变元素处理的线程。
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;public class ReactorPublishOnExample {public static void main(String[] args) {Flux<Integer> source = Flux.range(1, 3);// 将数据流的发布线程切换到另一个线程池source.publishOn(Schedulers.elastic()).map(value -> value * 2).subscribe(System.out::println);}
}
63. 使用 Reactor 的 subscribeOn 方法进行订阅线程切换
subscribeOn 方法用于切换数据流的订阅线程,影响整个数据流的执行线程。
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;public class ReactorSubscribeOnExample {public static void main(String[] args) throws InterruptedException {Flux<Integer> source = Flux.range(1, 3).log();// 将数据流的订阅线程切换到另一个线程池 另一个线程:parallel-1source.subscribeOn(Schedulers.parallel()).map(value -> value * 2).subscribe(System.out::println);Thread.sleep(23333);}
}
64. 使用 Reactor 的 delayElements 方法进行元素延迟
delayElements 方法用于延迟数据流中元素的发送。
import reactor.core.publisher.Flux;
import java.time.Duration;public class ReactorDelayElementsExample {public static void main(String[] args) throws InterruptedException {Flux<Integer> source = Flux.range(1, 3);// 延迟每个元素的发送source.delayElements(Duration.ofSeconds(1)).subscribe(System.out::println);Thread.sleep(23333);}
}
65. 使用 Reactor 的 concatWith 方法进行数据流连接
concatWith 方法用于将两个数据流连接在一起,保持顺序。
import reactor.core.publisher.Flux;public class ReactorConcatWithExample {public static void main(String[] args) {Flux<Integer> source1 = Flux.just(1, 2, 3);Flux<Integer> source2 = Flux.just(4, 5, 6);// 将两个数据流连接在一起,保持顺序source1.concatWith(source2).subscribe(System.out::println);}
}
66. 使用 Reactor 的 merge 方法进行多数据流合并
merge 方法用于将多个数据流合并成一个数据流,并发执行。
import reactor.core.publisher.Flux;public class ReactorMergeExample {public static void main(String[] args) {Flux<Integer> source1 = Flux.just(1, 2, 3);Flux<Integer> source2 = Flux.just(4, 5, 6);// 将两个数据流合并成一个数据流Flux<Integer> mergedFlux = Flux.merge(source1, source2);mergedFlux.subscribe(System.out::println);}
}
67. concatWith和merge的比较
- 执行顺序:
concatWith: 这个方法会按照合并的顺序执行Flux。它会等待第一个Flux完成(包括完成信号或错误信号),然后再开始下一个Flux。merge: 这个方法会并发执行所有的Flux,它不会等待前一个Flux完成。因此,元素的顺序可能是交错的。
- 参数类型:
concatWith: 它接受一个单独的Flux作为参数,将这个Flux追加到当前Flux的末尾。merge: 它接受可变参数,可以传入多个Flux,并同时合并它们。
public class FluxConcatWithMergeExample {public static void main(String[] args) throws InterruptedException {Flux<Integer> flux1 = Flux.just(1, 2, 3).delayElements(Duration.ofMillis(100));Flux<Integer> flux2 = Flux.just(4, 5, 6).delayElements(Duration.ofMillis(50));Flux<Integer> flux3 = Flux.just(7, 8, 9).delayElements(Duration.ofMillis(75));// 使用 concatWith 方法,按顺序执行flux1.concatWith(flux2).concatWith(flux3).subscribe(v ->{System.out.println("concatWith = " + v);});// 使用 merge 方法,并发执行Flux.merge(flux1, flux2, flux3).subscribe(v ->{System.out.println("merge = " + v);});Thread.sleep(22333);}
}
68. 使用 Reactor 的 mergeSequential 方法进行多数据流合并
mergeSequential 方法用于按顺序合并多个数据流,保持各个数据流的元素顺序。
import reactor.core.publisher.Flux;public class ReactorMergeSequentialExample {public static void main(String[] args) {Flux<Integer> source1 = Flux.just(1, 2, 3);Flux<Integer> source2 = Flux.just(4, 5, 6);// 按顺序合并两个数据流Flux<Integer> mergedFlux = Flux.mergeSequential(source1, source2);mergedFlux.subscribe(System.out::println);}
}
69. 使用 Reactor 的 combineLatest 方法进行多数据流合并
combineLatest 方法用于合并多个数据流的最新元素。
import reactor.core.publisher.Flux;public class ReactorCombineLatestExample {public static void main(String[] args) {Flux<Integer> source1 = Flux.just(1, 2, 3);Flux<Integer> source2 = Flux.just(4, 5, 6);// 合并两个数据流的最新元素Flux<Integer> combinedFlux = Flux.combineLatest(source1, source2, (a, b) -> a + b);combinedFlux.subscribe(System.out::println);}
}
71. 使用 Reactor 的 doOnNext 方法进行每个元素的附加操作
doOnNext 方法用于在每个元素发出时执行附加操作,例如日志记录、统计等。
import reactor.core.publisher.Flux;public class ReactorDoOnNextExample {public static void main(String[] args) {Flux<Integer> source = Flux.range(1, 3);// 在每个元素发出时执行附加操作source.doOnNext(value -> System.out.println("Processing: " + value)).subscribe(System.out::println);}
}
79. 使用 Reactor 的 fromCallable 方法创建带有返回值的 Mono
fromCallable 方法用于创建一个 Mono,其值由提供的 Callable 对象返回。
import reactor.core.publisher.Mono;import java.util.concurrent.Callable;public class ReactorFromCallableExample {public static void main(String[] args) {// 创建带有返回值的 MonoMono<String> resultMono = Mono.fromCallable(() -> {// 执行一些计算return "Result";});resultMono.subscribe(System.out::println);}
}
80. 使用 Reactor 的 using 方法进行资源管理
using 方法用于在数据流的生命周期内管理资源,例如打开和关闭文件、网络连接等。
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;public class ReactorUsingExample {public static void main(String[] args) {// 使用 using 方法管理资源Flux<String> resultFlux = Flux.using(() -> getResource(), // 打开资源resource -> getData(resource), // 使用资源获取数据流resource -> releaseResource(resource) // 关闭资源);resultFlux.subscribe(System.out::println);}private static Mono<String> getResource() {System.out.println("Opening resource");return Mono.just("Resource");}private static Flux<String> getData(Mono resource) {System.out.println("Getting data from resource: " + resource);return Flux.just("Data1", "Data2", "Data3");}private static Mono<Void> releaseResource(Mono resource) {System.out.println("Releasing resource: " + resource);return Mono.empty();}
}
82. 使用 Reactor 的 scan 方法进行累积操作
scan 方法用于对数据流中的元素进行累积操作,并生成一个新的数据流。
import reactor.core.publisher.Flux;public class ReactorScanExample {public static void main(String[] args) {Flux<Integer> source = Flux.just(1, 2, 3, 4, 5);// 对数据流中的元素进行累积操作source.scan(0, (acc, value) -> acc + value).subscribe(System.out::println);}
}
83. 使用 Reactor 的 takeWhile 方法进行条件性的元素获取
takeWhile 方法用于根据指定的条件获取数据流中的元素,直到条件不满足。
import reactor.core.publisher.Flux;public class ReactorTakeWhileExample {public static void main(String[] args) {Flux<Integer> source = Flux.just(1, 2, 3, 4, 5);// 根据条件获取元素,直到条件不满足source.takeWhile(value -> value < 4).subscribe(System.out::println);}
}
84. 使用 Reactor 的 thenMany 方法进行串联操作
thenMany 方法用于在当前数据流完成后执行另一个数据流,将它们串联起来。
import reactor.core.publisher.Flux;public class ReactorThenManyExample {public static void main(String[] args) {Flux<Integer> source1 = Flux.just(1, 2, 3);Flux<Integer> source2 = Flux.just(4, 5, 6);// 在当前数据流完成后执行另一个数据流source1.thenMany(source2).subscribe(System.out::println);}
}
85. 使用 Reactor 的 ignoreElements 方法忽略所有元素
ignoreElements 方法用于忽略数据流中的所有元素,只关注完成信号或错误信号。
import reactor.core.publisher.Flux;public class ReactorIgnoreElementsExample {public static void main(String[] args) {Flux<Integer> source = Flux.just(1, 2, 3);// 忽略所有元素,只关注完成信号source.ignoreElements().doOnTerminate(() -> System.out.println("Completed")).subscribe();}
}
在 Reactor 中,Sink 是一个用于手动推送元素(signals)到 Subscriber 的接口。它允许你在创建 Flux 或 Mono 的过程中手动控制元素的生成。Reactor 提供了两种 Sink:FluxSink 用于创建 Flux,MonoSink 用于创建 Mono。
98. 使用 FluxSink 发送元素和完成信号
import reactor.core.publisher.Flux;public class FluxSinkExample {public static void main(String[] args) {Flux.create(fluxSink -> {for (int i = 0; i < 5; i++) {fluxSink.next(i); // 发送元素}fluxSink.complete(); // 发送完成信号}).subscribe(System.out::println);}
}
99. 使用 FluxSink 发送元素和错误信号
import reactor.core.publisher.Flux;public class FluxSinkErrorExample {public static void main(String[] args) {Flux.create(fluxSink -> {for (int i = 0; i < 5; i++) {fluxSink.next(i); // 发送元素}fluxSink.error(new RuntimeException("Simulated error")); // 发送错误信号}).subscribe(System.out::println,error -> System.err.println("Error: " + error.getMessage()));}
}
100. 使用 MonoSink 发送元素和完成信号
import reactor.core.publisher.Mono;public class MonoSinkExample {public static void main(String[] args) {Mono.create(monoSink -> {monoSink.success("Hello, Mono!"); // 发送元素}).subscribe(System.out::println);}
}
101. 使用 MonoSink 发送错误信号
import reactor.core.publisher.Mono;public class MonoSinkErrorExample {public static void main(String[] args) {Mono.create(monoSink -> {monoSink.error(new RuntimeException("Simulated error")); // 发送错误信号}).subscribe(System.out::println,error -> System.err.println("Error: " + error.getMessage()));}
}
102. 使用 FluxSink 进行背压控制
在 Reactor 中,FluxSink 也提供了一些方法用于实现背压控制,以避免在高速生产者和低速消费者之间的元素溢出。
import reactor.core.publisher.Flux;
import reactor.core.publisher.FluxSink;public class FluxSinkBackpressureExample {public static void main(String[] args) {Flux.create(fluxSink -> {for (int i = 0; i < 1000; i++) {fluxSink.next(i);}}, FluxSink.OverflowStrategy.BUFFER) // 指定背压策略.onBackpressureBuffer(10, buffer -> System.err.println("Buffer overflow! Discarding: " + buffer)).subscribe(value -> {// 模拟慢速消费者try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(value);});}
}
在上述例子中,通过指定 FluxSink.OverflowStrategy.BUFFER 背压策略,当消费者无法跟上生产者的速度时,缓冲区将被用来存储元素。使用 onBackpressureBuffer 方法可以在溢出时执行自定义的操作。
103. 使用 FluxSink 进行手动请求
FluxSink 也提供了 request 方法,允许消费者手动请求元素。
import reactor.core.publisher.Flux;
import reactor.core.publisher.FluxSink;public class FluxSinkManualRequestExample {public static void main(String[] args) {Flux.create(fluxSink -> {for (int i = 0; i < 100; i++) {fluxSink.next(i);if (i % 10 == 0 && fluxSink.requestedFromDownstream() == 0) {// 当请求的元素达到 0 时,等待下游再次请求while (fluxSink.requestedFromDownstream() == 0) {// 等待下游请求try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}}}fluxSink.complete();}).subscribe(System.out::println);}
}
在这个例子中,当消费者请求的元素达到 0 时,生产者会等待下游再次请求。这种手动控制请求的方式可以更灵活地处理背压。
107. 使用 Reactor 的 Hooks 进行全局错误处理
Hooks 是 Reactor 提供的一组钩子,可以用于全局错误处理,捕获整个流的错误。
import reactor.core.publisher.Flux;
import reactor.core.publisher.Hooks;public class ReactorHooksErrorHandlingExample {public static void main(String[] args) {// 使用 Hooks 进行全局错误处理Hooks.onOperatorError((error, reference) -> {System.err.println("Global Error Handling: " + error.getMessage());return error;});Flux<Integer> source = Flux.just(1, 2, 0, 4, 5);// 流中的错误将被全局处理source.map(x -> 10 / x).subscribe(data -> System.out.println("Received: " + data),error -> System.err.println("Subscriber Error: " + error.getMessage()));}
}
在这个例子中,我们使用 Hooks.onOperatorError 来设置全局错误处理,当流中发生错误时,会调用全局错误处理的回调方法。这可以用于捕获整个流的错误,而不是每个 subscribe 中单独处理。
109. 使用 Reactor 的 ConnectableFlux 进行热序列
ConnectableFlux 是 Reactor 提供的一种特殊类型的 Flux,它允许在订阅之前预热(开始生成元素),并在多个订阅者之间共享相同的序列。
import reactor.core.publisher.ConnectableFlux;
import reactor.core.publisher.Flux;import java.time.Duration;public class ReactorConnectableFluxExample {public static void main(String[] args) {ConnectableFlux<Integer> connectableFlux = Flux.range(1, 3).delayElements(Duration.ofSeconds(1)).publish(); // 将普通的 Flux 转换为 ConnectableFluxconnectableFlux.connect(); // 开始生成元素// 第一个订阅者connectableFlux.subscribe(data -> System.out.println("Subscriber 1: " + data));try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}// 第二个订阅者,共享相同的序列connectableFlux.subscribe(data -> System.out.println("Subscriber 2: " + data));// 结果:// Subscriber 1: 1// Subscriber 1: 2// Subscriber 2: 2// Subscriber 1: 3// Subscriber 2: 3}
}
在这个例子中,我们使用 publish 方法将普通的 Flux 转换为 ConnectableFlux,通过 connect 方法开始生成元素。第一个订阅者在元素生成过程中订阅,然后等待了 2 秒后,第二个订阅者也开始订阅,两者共享相同的序列。这种方式可以用于创建热序列,使得订阅者能够共享相同的元素序列。
110. 使用 Reactor 的 Flux.defer 实现延迟订阅
Flux.defer 允许你在每次订阅时创建一个新的 Flux,从而实现延迟订阅。这对于需要在每次订阅时执行一些逻辑的场景非常有用。
import reactor.core.publisher.Flux;public class ReactorFluxDeferExample {public static void main(String[] args) {Flux<Integer> deferredFlux = Flux.defer(() -> {// 在每次订阅时创建新的 FluxSystem.out.println("Creating new Flux");return Flux.just(1, 2, 3);});// 第一个订阅deferredFlux.subscribe(data -> System.out.println("Subscriber 1: " + data));// 第二个订阅deferredFlux.subscribe(data -> System.out.println("Subscriber 2: " + data));// 结果:// Creating new Flux// Subscriber 1: 1// Subscriber 1: 2// Subscriber 1: 3// Creating new Flux// Subscriber 2: 1// Subscriber 2: 2// Subscriber 2: 3}
}
在这个例子中,Flux.defer 中的 lambda 表达式将在每次订阅时执行,因此每个订阅都会创建一个新的 Flux。这对于那些需要在每次订阅时重新生成数据的情况非常有用。
119. 使用 Reactor 的 Flux.handle 处理元素和错误
Flux.handle 方法用于处理元素和错误,通过提供一个 BiConsumer 处理每个元素,并通过提供一个 BiConsumer 处理错误。
import reactor.core.publisher.Flux;public class ReactorFluxHandleExample {public static void main(String[] args) {Flux<Integer> source = Flux.just(1, 2, 0, 4, 5);// 处理元素和错误Flux<Integer> handledFlux = source.handle((value, sink) -> {if (value != 0) {sink.next(value); // 处理元素} else {sink.error(new RuntimeException("Cannot divide by zero")); // 处理错误}});handledFlux.subscribe(System.out::println,error -> System.err.println("Error: " + error.getMessage()));}
}
在这个例子中,我们使用 Flux.handle 处理每个元素,如果元素不为零,则将其发送到下游;如果元素为零,则通过 sink.error 处理错误。这可以用于处理元素和错误的场景。
120. 使用 Reactor 的 Mono.handle 处理元素和错误
Mono.handle 方法与 Flux.handle 类似,用于处理单个元素和错误。
import reactor.core.publisher.Mono;public class ReactorMonoHandleExample {public static void main(String[] args) {Mono<Integer> source = Mono.just(10);// 处理元素和错误Mono<Integer> handledMono = source.handle((value, sink) -> {if (value > 0) {sink.next(value); // 处理元素} else {sink.error(new RuntimeException("Invalid value")); // 处理错误}});handledMono.subscribe(System.out::println,error -> System.err.println("Error: " + error.getMessage()));}
}
在这个例子中,我们使用 Mono.handle 处理单个元素,如果元素为正数,则发送到下游;如果元素不为正数,则通过 sink.error 处理错误。这可以用于处理单个元素和错误的场景。
太太太多了,到此为止吧~~~~
学习打卡day08:响应式编程Reactor API大全(下)
相关文章:
)
响应式编程Reactor API大全(下)
Reactor 是一个基于响应式编程的库,主要用于构建异步和事件驱动的应用程序。Reactor 提供了丰富的 API,包括创建、转换、过滤、组合等操作符,用于处理异步数据流。以下是一些 Reactor 的主要 API 示例: pom依赖 <dependencyMan…...

【STM32】HAL库的STOP低功耗模式UART串口唤醒,解决首字节出错的问题(全网第一解决方案)
【STM32】HAL库的STOP低功耗模式UART串口唤醒,解决首字节出错的问题(全网第一解决方案) 前文: 【STM32】HAL库的STOP低功耗模式UART串口唤醒,第一个接收字节出错的问题(疑难杂症) 目前已解决 …...

Python 语法糖
一、基本概念 语法糖,可以理解为:“甜蜜” 的便捷语法。 它是编程语言为程序提供的更简洁、更易读的语法实现的语法结构,它并不影响语言的功能,仅仅是一种更便捷的书写方式。 这就像你制作蛋糕时,使用现代烤箱而不是…...
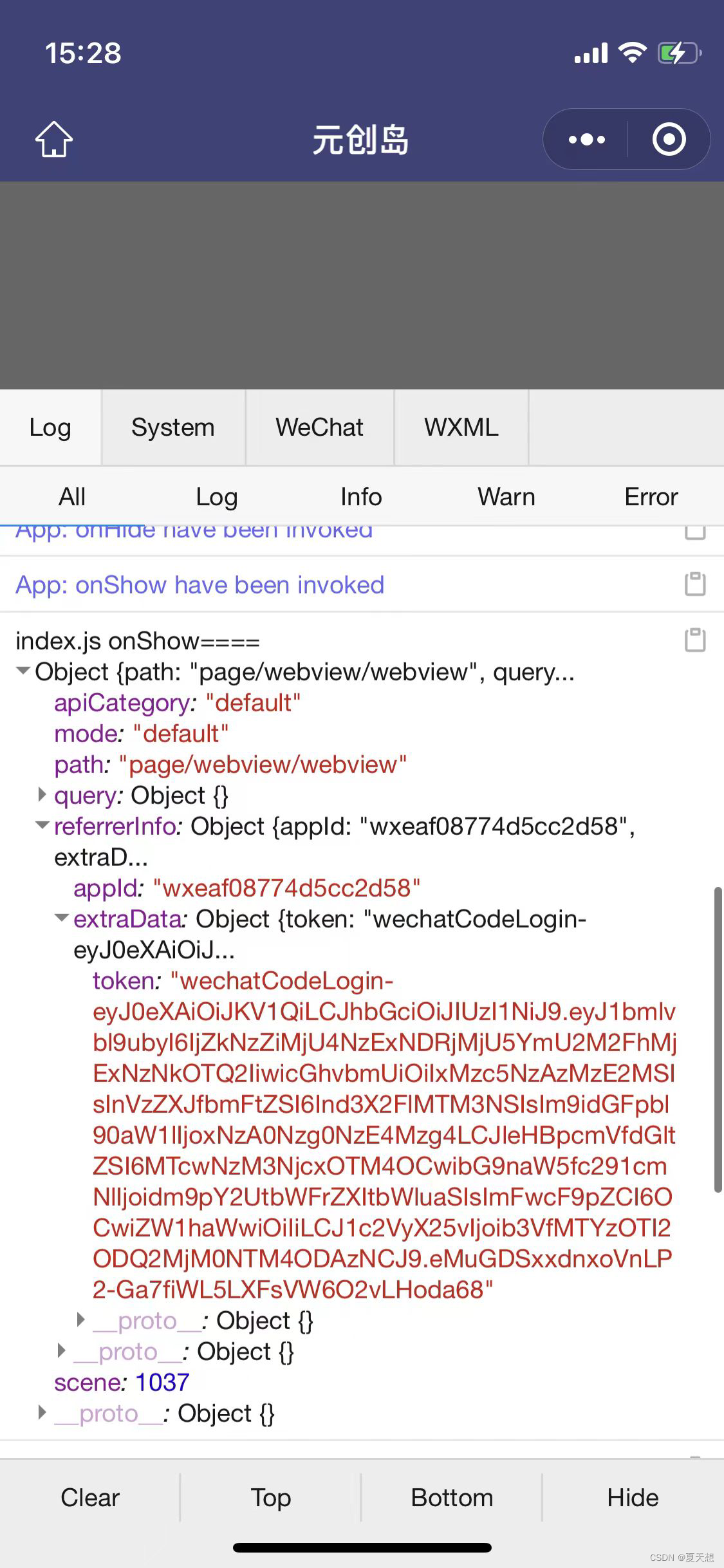
一个小程序跳转到另一个小程序中如何实现
小程序 保证两个小程序是一样的主体才可以跳转。怎么知道是不是同样的主体呢? 小程序的后台管理-设置-基本设置-基本信息。查看主体信息。 跳转 <button clicktoOtherMini()>跳转到另一个小程序</button> function toOtherMini(){wx.navigateToMini…...
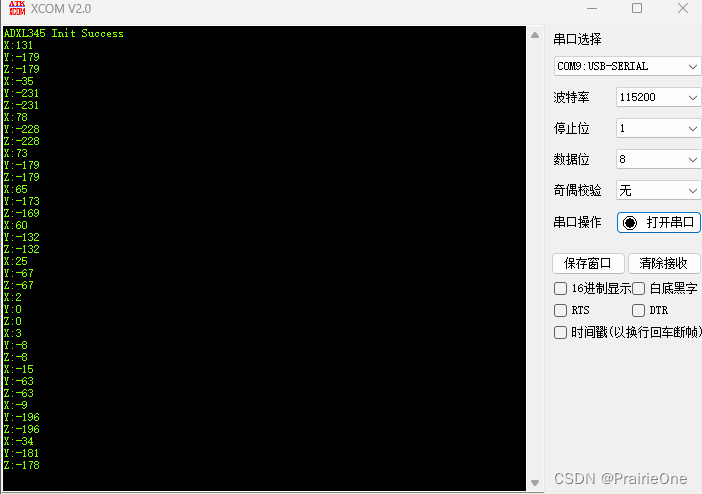
STM32+HAL库驱动ADXL345传感器(SPI协议)
STM32HAL库驱动ADXL345传感器(SPI协议) ADXL345传感器简介实物STM32CubeMX配置SPI配置片选引脚配置串口配置 特别注意(重点部分)核心代码效果展示 ADXL345传感器简介 ADXL345 是 ADI 公司推出的基于 iMEMS 技术的 3 轴、数字输出加…...
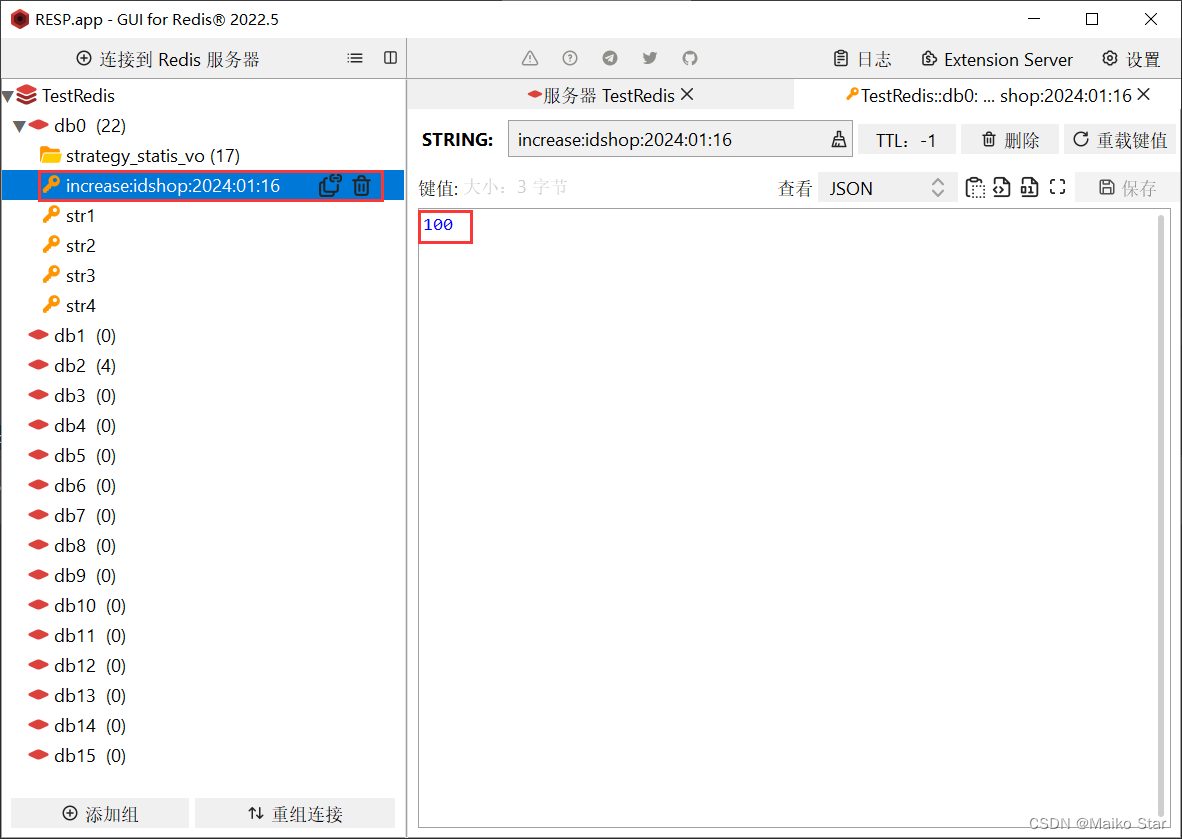
Redis实现全局唯一Id
一、全局唯一ID 每个店铺都可以发布优惠券: 当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题: id的规律性太明显 受单表数据量的限制 场景分析:如果我们的…...
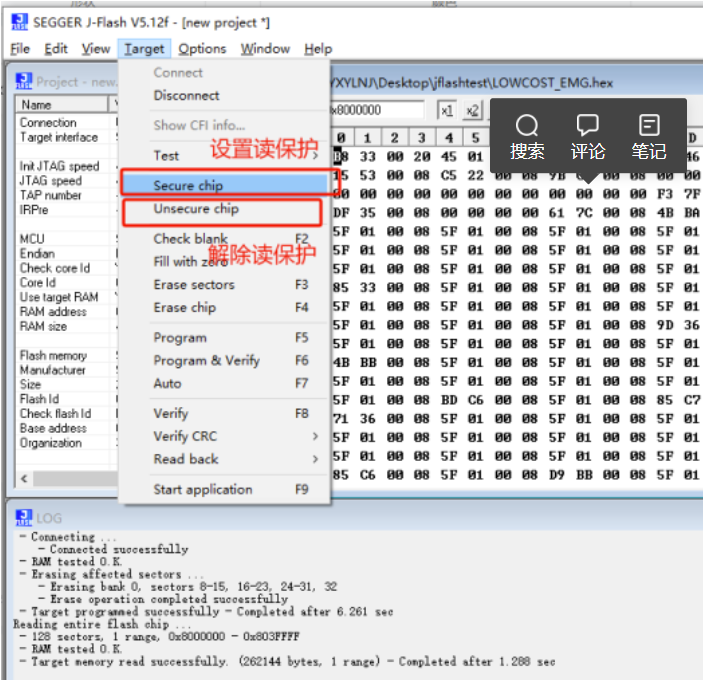
【J-Flash基本使用总结】
【J-Flash基本使用总结】 VX:hao541022348 ■ 烧录文件■ 创建新的工程■ 烧录模式-SWD模式■ J-Flash下载程序到单片机 ■ J-Flash拼接多个hex或bin文件■ J-Flash读单片机的option byte■ J-Flash读单片机Flash数据■ 将读出来的文件用jflash烧录到其他的芯片■ 设…...

宝塔发布网站问题汇总和记录
1、添加网站站点后打不开 解决办法,关闭防跨站攻击2 2、laravel项目部署到linux的时候出现The stream or file "/home/www/storage/logs/laravel.log" could not be opened in append mode 给目录加权限 chmod -R 777 storage 3、Class "Redis"…...

决战排序之巅(二)
决战排序之巅(二) 排序测试函数 void verify(int* arr, int n) 归并排序递归方案代码可行性测试 非递归方案代码可行性测试 特点分析 计数排序代码实现代码可行性测试 特点分析 归并排序 VS 计数排序(Release版本)说明1w rand( ) …...

自动化网络监控:每分钟自动检测网站可用性
🧙♂️ 诸位好,吾乃诸葛妙计,编程界之翘楚,代码之大师。算法如流水,逻辑如棋局。 📜 吾之笔记,内含诸般技术之秘诀。吾欲以此笔记,传授编程之道,助汝解技术难题。 &…...
Asp .Net Core 系列:集成 Ocelot+Consul实现网关、服务注册、服务发现
什么是Ocelot? Ocelot是一个开源的ASP.NET Core微服务网关,它提供了API网关所需的所有功能,如路由、认证、限流、监控等。 Ocelot是一个简单、灵活且功能强大的API网关,它可以与现有的服务集成,并帮助您保护、监控和扩展您的微…...

MSSQL行转列、列转行
行转列 SELECT * FROM student PIVOT ( SUM(score) FOR subject IN (语文, 数学, 英语) ) AS PivotedData; 列转行 SELECT * FROM student1 UNPIVOT ( score FOR subject IN ("语文","数学","英语") )AS PivotedData;...

【MySQL】创建和管理表
文章目录 前置 标识符命名规则一、MySQL数据类型二、创建和管理数据库2.1 创建数据库2.2 使用数据库2.3 修改数据库2.4 删除数据库 三、创建表3.1 创建方式一3.2 创建方式二3.3 查看数据表结构 四、修改表4.1 增加一个列4.2 修改一个列4.3 重命名一个列4.4 删除一个列 五、重命…...
缓存和数据库一致性
前言: 项目的难点是如何保证缓存和数据库的一致性。无论我们是先更新数据库,后更新缓存还是先更新数据库,然后删除缓存,在并发场景之下,仍然会存在数据不一致的情况(也存在删除失败的情况,删除…...
iOS UI掉帧和卡顿优化解决方案记录
UI卡顿原理 在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行…...
transbigdata 笔记: 轨迹密集化/稀疏化 轨迹平滑
1 密集化 transbigdata.traj_densify(data, col[Vehicleid, Time, Lng, Lat], timegap15) 轨迹致密化,保证至多每隔timegap秒都有一个轨迹点 这边插补使用的是pandas的interpolate,method设置的是index 1.1 举例 transbigdata 笔记: 官方…...

反向代理的本质是什么?
反向代理是一种网络架构模式,通常用于提供静态内容、处理安全、负载均衡和缓存等任务。在这种架构中,客户端发送的请求首先到达反向代理服务器,然后由反向代理服务器将请求转发给后端的实际服务器。反向代理服务器可以处理和修改请求和响应&a…...

Kali Linux保姆级教程|零基础从入门到精通,看完这一篇就够了!(附工具包)
作为一名从事网络安全的技术人员,不懂Kali Linux的话,连脚本小子都算不上。 Kali Linux预装了数百种享誉盛名的渗透工具,使你可以更轻松地测试、破解以及进行与数字取证相关的任何其他工作。 今天给大家分享一套Kali Linux资料合集…...
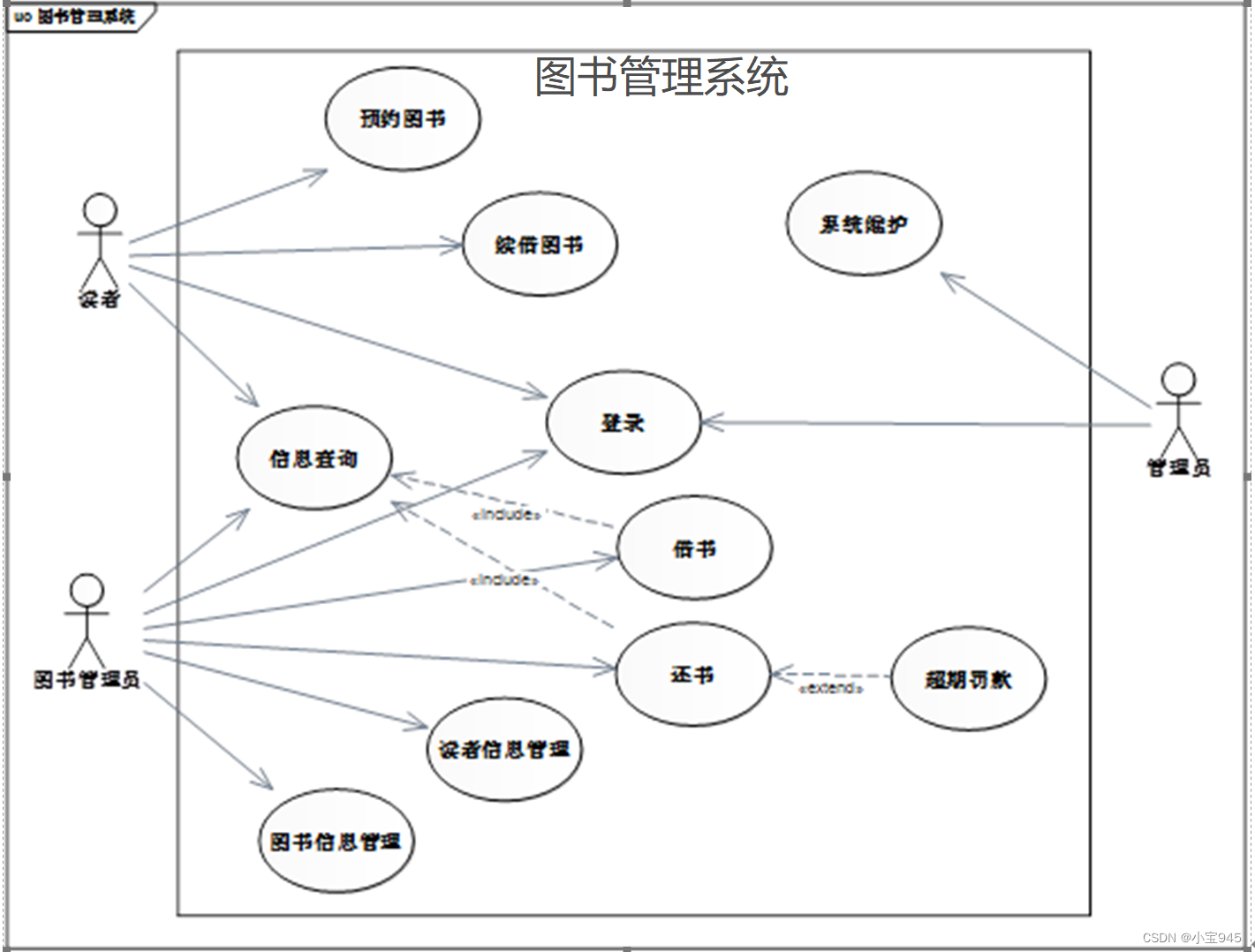
UML-用例图
提示:用例图是软件建模的开始,软件建模中的其他图形都将以用例图为依据。用例图列举了系统所需要实现的所有功能,除了用于软件开发的需求分析阶段,也可用于软件的系统测试阶段。 UML-用例图 一、用例图的基础知识1.用例图的构成元…...
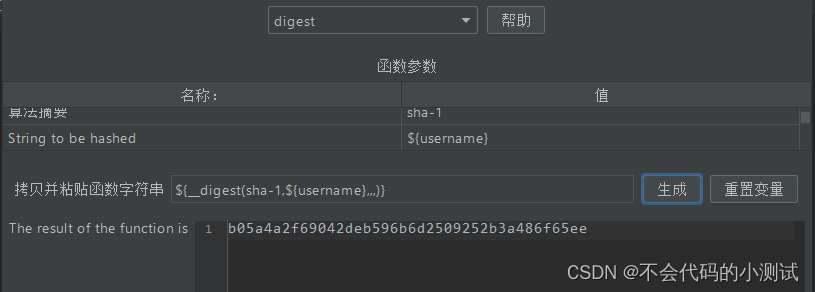
jmeter--8.加密传输
目录 1. Base64加密 2. MD5加密 3. SHA加密(sha1\sha\sha224\sha256\sha384\sha512) 4. RSA加密-公钥加密,私钥解密 1. Base64加密 1.1 在需要加密传输的接口下新增BeanShell 预处理程序,${username}可替换成value值ÿ…...

python文化旅游服务系统 小程序系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈项目亮点应用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python文化旅游服…...

DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全
DataStore vs SharedPreferences 迁移指南:告别 ANR,拥抱类型安全 一句话收益:掌握从 SharedPreferences 迁移到 Jetpack DataStore 的完整路径,彻底消除主线程 I/O 阻塞与类型安全隐患。 适用版本:Android API 21&…...

GitHub Copilot X:AI编程助手如何重塑开发工作流与效率
1. 项目概述:当代码编辑器遇见“副驾驶”如果你和我一样,每天有超过一半的时间是在代码编辑器里度过的,那你一定对“效率”这个词有着近乎偏执的追求。从语法高亮、代码补全,到后来的LSP(Language Server Protocol&…...

深入解析TI C6474多核DSP架构:从硬件设计到并行编程实战
1. 项目概述:从单核到多核的必然演进在嵌入式信号处理领域,德州仪器(TI)的TMS320系列DSP一直是高性能、高可靠性的代名词。我接触TI DSP超过十年,从早期的C5000系列到后来的C6000系列,亲眼见证了其从单核、…...

SHE 密钥注入的“通配符魔法”:从 UID 通配到 AUTOSAR 分层落地
想象一下,你是一家汽车电子工厂的技术员,需要为成千上万个 ECU 刷写密钥。每个 ECU 都有一个独一无二的 ID(UID)。如果每次刷写都要读取这个 UID,再根据 UID 计算出专属的密钥数据,那产线的效率会大打折扣。…...

程序员如何平衡工作与生活?我的“时间块”管理法
作为一名深耕软件测试领域十年的老兵,我见过太多同行陷入"996是福报"的自我消耗:刚毕业的年轻人为了赶项目连续三个月住在公司,三十岁的测试主管在孩子升学夜还在改缺陷报告,干了十五年的资深测试工程师熬出了颈椎病却不…...

入门吉他弹唱怎么选?面单琴技术对比:繁星AC-10 vs 雅马哈FG800
一、测评背景与技术参数1.1 测评样品信息桶型:GA桶 vs D桶面板:西提卡云杉纯单板 vs 西提卡云杉背侧板:桃花芯木纯单板 vs 那都木/奥古曼合板琴颈:奥古曼 vs 那都木指板:玫瑰木 vs 玫瑰木有效弦长:650mm vs…...
)
模拟几种数据融合协作频谱感知技术在认知无线电应用中性能研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

自动化测试的最佳实践:这6个原则让你的测试脚本更稳定
在当前互联网行业快速迭代的开发模式下,自动化测试已经成为保障软件交付质量、提升测试效率的核心手段。据行业调研数据显示,成熟的互联网测试团队中,核心回归测试场景的自动化覆盖率已经超过80%,自动化测试承担了绝大部分重复性测…...

2026年,揭秘浙江废铝回收界的明星企业!
引言:废铝回收,绿色循环的先锋随着我国经济的快速发展和工业生产的不断扩大,废铝回收行业逐渐成为资源循环利用的重要环节。在浙江省,众多废铝回收企业脱颖而出,其中腾兰再生资源回收有限公司以其卓越的表现࿰…...