MongoDB聚合:$bucketAuto
按照指定的表达式对输入文档进行分类后放入指定数字的桶中,跟$bucket不太一样,$bucketAuto可以指定分组的数量(颗粒度),$bucketAuto会根据groupBy的值和颗粒度自动生成桶的边界。
语法
{$bucketAuto: {groupBy: <表达式>,buckets: <数字>,output: {<输出1>: { <$accumulator 表达式> },...}granularity: <字符串>}
}
groupBy
表达式,对文档进行分组的表达式。若指定字段路径,需要在字段名前加上美元符号$并用引号引起来,如:$field_name。
buckets
整数,32位的正整数,指定桶的数量也就是输入文档分组的数量。
output
文档,可选,指定了输出文档中除_id字段外要包含的其他字段,必须要使用汇总(累加器)表达式:
<输出字段1>: { <accumulator>: <表达式1> },
...
如果指定了输出字段,则count字段不会自动添加,需要的话要手动添加。如果不指定输出字段则默认添加一个count字段。
output: {<输出字段1>: { <accumulator>: <expres表达式1sion1> },...count: { $sum: 1 }
}
每个桶文档包含:
- 一个桶边界下限的
_id:_id.min字段指定了桶边界的下限(含)。_id.max字段指定了桶边界的上限(不含)。除系列中的最后一个桶外,该界限对所有桶都是排他性的,因为在最后一个桶中,该界限是包含的。
count字段,包含文件桶中的文件数量。如果未指定输出文档,则默认包含count字段。
granularity
可选,字符串,指定了一个字符串,用于指定首选数列,以确保计算的边界边缘以首选的整数或其10的幂次结束。只有当所有groupBy值都是数值且都不是NaN时才有效。
支持的颗粒度:“R5”,“R10”,“R20”,“R40”,“R80”,“1-2-5”,“E6”,“E12”,“E24”,“E48”,“E96”,“E192”,“POWERSOF2”。
说明
如果出现以下情况,桶数量可能少于指定数量:
- 输入文件的数量少于指定的文件桶数量。
groupBy表达式的唯一值数量少于指定的存储桶数量。- 粒度的间隔数少于桶数。
- 粒度不够精细,无法将文档均匀分布到指定数量的桶中。
groupBy字段的粒度或唯一值的数量决定了文档是否能均匀分布到不同的桶。如果粒度不够,$bucketAuto阶段可能无法将结果均匀地分配到各个桶。
粒度
$bucketAuto接受一个可选的粒度参数,确保所有数据桶的边界都遵循指定的首选数列。使用首选数列可以更好地控制分组表达式中数值范围内的数据桶边界。当groupBy表达式的范围以指数形式扩展时,还可以使用首选数列帮助对数和均匀地设置数据桶边界。
雷纳数列
雷纳数列是通过取10的5次方根、10次方根、20次方根、40次方根或80次方根,然后将相当于1.0到 10.0(R80 为 10.3)之间数值的根的各种幂包含在内而得出的一组数字。
将粒度设置为 R5、R10、R20、R40 或 R80,可将数据桶边界限制为系列中的值。当 groupBy 值超出 1.0 至 10.0(R80 为 10.3)范围时,系列值将乘以 10 的幂。
R5 数列以 10 的五次方根 1.58 为基础,包括该根的各种幂次(四舍五入),直至 10。R5 数列的推导过程如下:
例如:
- 10 0/5 = 1
- 10 1/5 = 1.584 ~ 1.6
- 10 2/5 = 2.511 ~ 2.5
- 10 3/5 = 3.981 ~ 4.0
- 10 4/5 = 6.309 ~ 6.3
- 10 5/5 = 10
同样的方法也适用于其他雷纳系列,以提供更精细的粒度,即 1.0 和 10.0 之间的更多间隔(R80 为 10.3)。
E 序列
E 数字系列与雷纳数列类似,它们以特定的相对误差将 1.0 到 10.0 的区间细分为10的6、12、24、48、96或192的次方根。
将粒度设置为 E6、E12、E24、E48、E96 或 E192,可将桶边界限制为序列中的值。当 groupBy 值超出 1.0 到 10.0 的范围时,系列值将乘以 10 的幂。
1-2-5 序列
1-2-5 数列类似于三值数列雷纳数列。
将粒度设为 1-2-5,可将桶边界限制为 10 的三次根的各种幂,四舍五入到一位有效数字。
例如,以下数值属于 1-2-5 系列:0.1、0.2、0.5、1、2、5、10、20、50、100、200、500、1000 等…
2的次幂序列
将粒度设置为 POWERSOF2,限制桶边界为2的次幂
以下数字遵循2的幂序列:
- 2^0 = 1
- 2^1 = 2
- 2^2 = 4
- 2^3 = 8
- 2^4 = 16
- 2^5 = 32
- …
一种常见的实现方式是,各种计算机组件(如内存)通常都遵守POWERSOF2的首选数字集:1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, …
不同粒度的比较
下面的操作演示了指定不同的粒度值如何影响$bucketAuto确定桶边界的方式。集合的_id从 0 到 99:
{ _id: 0 }
{ _id: 1 }
...
{ _id: 99 }
不同的粒度值会被代入到下面的操作中:
db.things.aggregate( [{$bucketAuto: {groupBy: "$_id",buckets: 5,granularity: <granularity>}}
] )
下表中的结果显示了不同的粒度值如何产生不同的桶边界:
| 粒度 | 结果 | 说明 |
|---|---|---|
| 无粒度 | { “_id” : { “min” : 0, “max” : 20 }, “count” : 20 }{ “_id” : { “min” : 20, “max” : 40 }, “count” : 20 }{ “_id” : { “min” : 40, “max” : 60 }, “count” : 20 }{ “_id” : { “min” : 60, “max” : 80 }, “count” : 20 }{ “_id” : { “min” : 80, “max” : 99 }, “count” : 20 } | |
| R20 | { “_id” : { “min” : 0, “max” : 20 }, “count” : 20 }{ “_id” : { “min” : 20, “max” : 40 }, “count” : 20 }{ “_id” : { “min” : 40, “max” : 63 }, “count” : 23 }{ “_id” : { “min” : 63, “max” : 90 }, “count” : 27 }{ “_id” : { “min” : 90, “max” : 100 }, “count” : 10 } | |
| E24 | { “_id” : { “min” : 0, “max” : 20 }, “count” : 20 }{ “_id” : { “min” : 20, “max” : 43 }, “count” : 23 }{ “_id” : { “min” : 43, “max” : 68 }, “count” : 25 }{ “_id” : { “min” : 68, “max” : 91 }, “count” : 23 }{ “_id” : { “min” : 91, “max” : 100 }, “count” : 9 } | |
| 1-2-5 | { “_id” : { “min” : 0, “max” : 20 }, “count” : 20 }{ “_id” : { “min” : 20, “max” : 50 }, “count” : 30 }{ “_id” : { “min” : 50, “max” : 100 }, “count” : 50 } | 指定的桶数超过系列中的间隔数。 |
| POWERSOF2 | { “_id” : { “min” : 0, “max” : 32 }, “count” : 32 }{ “_id” : { “min” : 32, “max” : 64 }, “count” : 32 }{ “_id” : { “min” : 64, “max” : 128 }, “count” : 36 } | 指定的桶数超过系列中的间隔数。 |
举例
下面的文档是收藏艺术品的集合:
{ "_id" : 1, "title" : "The Pillars of Society", "artist" : "Grosz", "year" : 1926,"price" : NumberDecimal("199.99"),"dimensions" : { "height" : 39, "width" : 21, "units" : "in" } }
{ "_id" : 2, "title" : "Melancholy III", "artist" : "Munch", "year" : 1902,"price" : NumberDecimal("280.00"),"dimensions" : { "height" : 49, "width" : 32, "units" : "in" } }
{ "_id" : 3, "title" : "Dancer", "artist" : "Miro", "year" : 1925,"price" : NumberDecimal("76.04"),"dimensions" : { "height" : 25, "width" : 20, "units" : "in" } }
{ "_id" : 4, "title" : "The Great Wave off Kanagawa", "artist" : "Hokusai","price" : NumberDecimal("167.30"),"dimensions" : { "height" : 24, "width" : 36, "units" : "in" } }
{ "_id" : 5, "title" : "The Persistence of Memory", "artist" : "Dali", "year" : 1931,"price" : NumberDecimal("483.00"),"dimensions" : { "height" : 20, "width" : 24, "units" : "in" } }
{ "_id" : 6, "title" : "Composition VII", "artist" : "Kandinsky", "year" : 1913,"price" : NumberDecimal("385.00"),"dimensions" : { "height" : 30, "width" : 46, "units" : "in" } }
{ "_id" : 7, "title" : "The Scream", "artist" : "Munch","price" : NumberDecimal("159.00"),"dimensions" : { "height" : 24, "width" : 18, "units" : "in" } }
{ "_id" : 8, "title" : "Blue Flower", "artist" : "O'Keefe", "year" : 1918,"price" : NumberDecimal("118.42"),"dimensions" : { "height" : 24, "width" : 20, "units" : "in" } }
单面聚合
在下面的操作中,输入文档将根据price字段中的值分成四组:
db.artwork.aggregate( [{$bucketAuto: {groupBy: "$price",buckets: 4}}
] )
该操作会返回以下文件:
{"_id" : {"min" : NumberDecimal("76.04"),"max" : NumberDecimal("159.00")},"count" : 2
}
{"_id" : {"min" : NumberDecimal("159.00"),"max" : NumberDecimal("199.99")},"count" : 2
}
{"_id" : {"min" : NumberDecimal("199.99"),"max" : NumberDecimal("385.00")},"count" : 2
}
{"_id" : {"min" : NumberDecimal("385.00"),"max" : NumberDecimal("483.00")},"count" : 2
}
多面聚合
…。
可在$facet阶段内使用$bucketAuto,对输入文档artwork进行多个聚合管道处理。
下面的聚合管道根据price、year和area将artwork 中的文档分组:
db.artwork.aggregate( [{$facet: {"price": [{$bucketAuto: {groupBy: "$price",buckets: 4}}],"year": [{$bucketAuto: {groupBy: "$year",buckets: 3,output: {"count": { $sum: 1 },"years": { $push: "$year" }}}}],"area": [{$bucketAuto: {groupBy: {$multiply: [ "$dimensions.height", "$dimensions.width" ]},buckets: 4,output: {"count": { $sum: 1 },"titles": { $push: "$title" }}}}]}}
] )
操作返回以下内容:
{"area" : [{"_id" : { "min" : 432, "max" : 500 },"count" : 3,"titles" : ["The Scream","The Persistence of Memory","Blue Flower"]},{"_id" : { "min" : 500, "max" : 864 },"count" : 2,"titles" : ["Dancer","The Pillars of Society"]},{"_id" : { "min" : 864, "max" : 1568 },"count" : 2,"titles" : ["The Great Wave off Kanagawa","Composition VII"]},{"_id" : { "min" : 1568, "max" : 1568 },"count" : 1,"titles" : ["Melancholy III"]}],"price" : [{"_id" : { "min" : NumberDecimal("76.04"), "max" : NumberDecimal("159.00") },"count" : 2},{"_id" : { "min" : NumberDecimal("159.00"), "max" : NumberDecimal("199.99") },"count" : 2},{"_id" : { "min" : NumberDecimal("199.99"), "max" : NumberDecimal("385.00") },"count" : 2 },{"_id" : { "min" : NumberDecimal("385.00"), "max" : NumberDecimal("483.00") },"count" : 2}],"year" : [{ "_id" : { "min" : null, "max" : 1913 }, "count" : 3, "years" : [ 1902 ] },{ "_id" : { "min" : 1913, "max" : 1926 }, "count" : 3, "years" : [ 1913, 1918, 1925 ] },{ "_id" : { "min" : 1926, "max" : 1931 }, "count" : 2, "years" : [ 1926, 1931 ] }]
}
相关文章:

MongoDB聚合:$bucketAuto
按照指定的表达式对输入文档进行分类后放入指定数字的桶中,跟$bucket不太一样,$bucketAuto可以指定分组的数量(颗粒度),$bucketAuto会根据groupBy的值和颗粒度自动生成桶的边界。 语法 {$bucketAuto: {groupBy: <…...
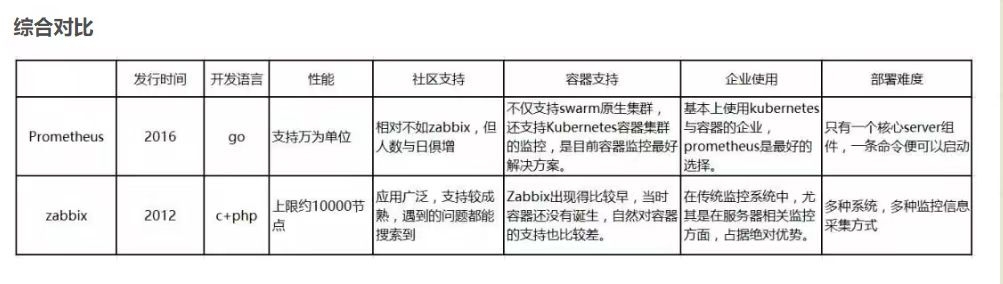
认识监控系统zabbix
利用一个优秀的监控软件,我们可以: ●通过一个友好的界面进行浏览整个网站所有的服务器状态 ●可以在 Web 前端方便的查看监控数据 ●可以回溯寻找事故发生时系统的问题和报警情况 了解zabbix zabbix是什么? ●zabbix 是一个基于 Web 界面的提供分布…...
东北编程语言???
在GitHub闲逛,偶然发现了东北编程语言: 东北编程语言是由Zhanyong Wan创造的,它使用东北方言词汇作为基本关键字。这种编程语言的特点是简单易懂,适合小学文化程度的人学习,并且易于阅读、编写和记忆。它的语法与其他编…...
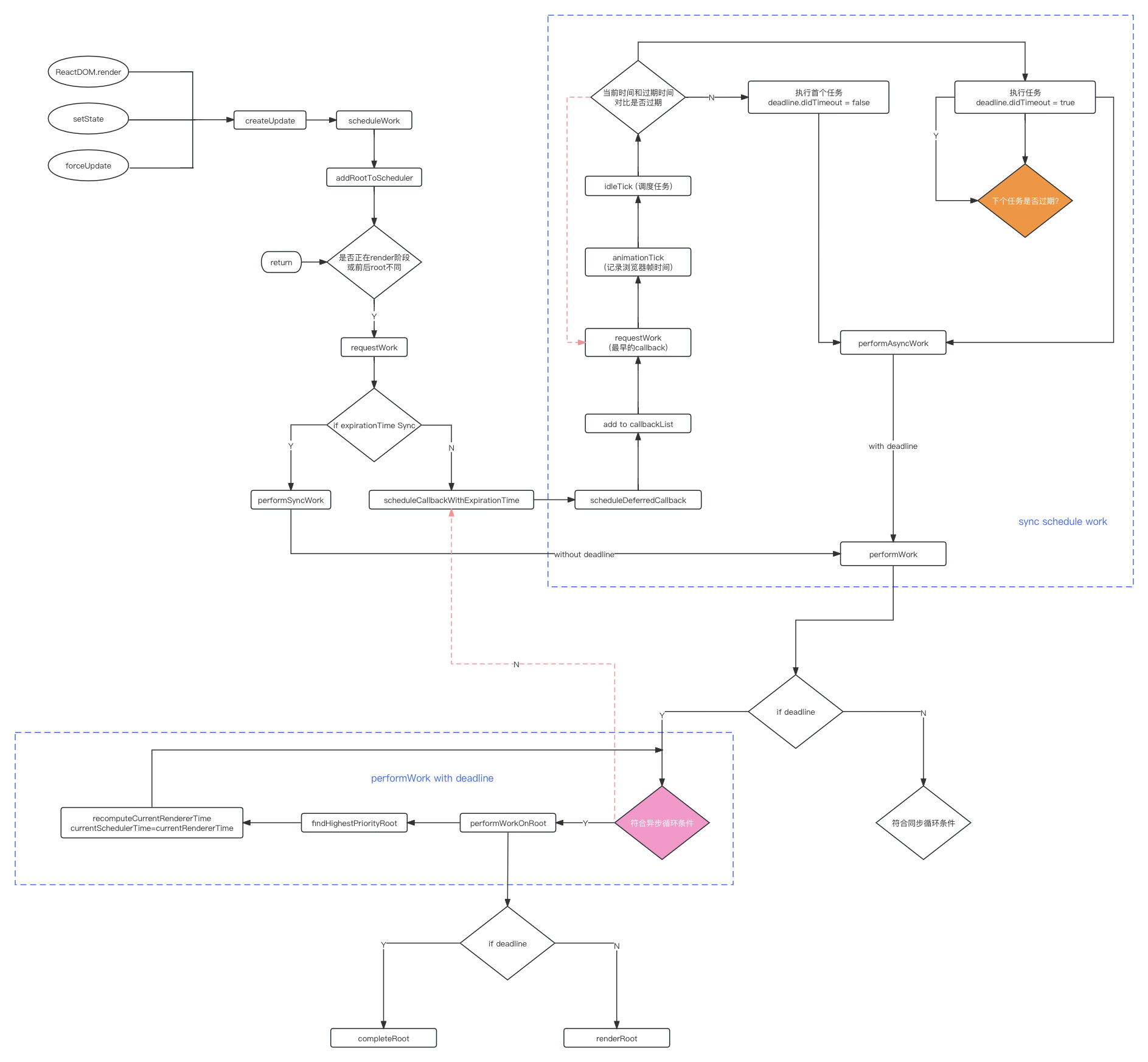
React16源码: React中的schedule调度整体流程
schedule调度的整体流程 React Fiber Scheduler 是 react16 最核心的一部分,这块在 react-reconciler 这个包中这个包的核心是 fiber reconciler,也即是 fiber 结构fiber 的结构帮助我们把react整个树的应用,更新的流程,能够拆成…...

springboot mybatis-plus swing实现报警监听
通过声音控制报警器,实现声光报警,使用beautyeye_lnf.jar美化界面如下 EnableTransactionManagement(proxyTargetClass true) SpringBootApplication EnableScheduling public class AlarmWarnApplication {public static void main(String[] args) …...

【计算机网络】网络层——详解IP协议
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【网络编程】 本专栏旨在分享学习计算机网络的一点学习心得,欢迎大家在评论区交流讨论💌 目录 🐱一、I…...
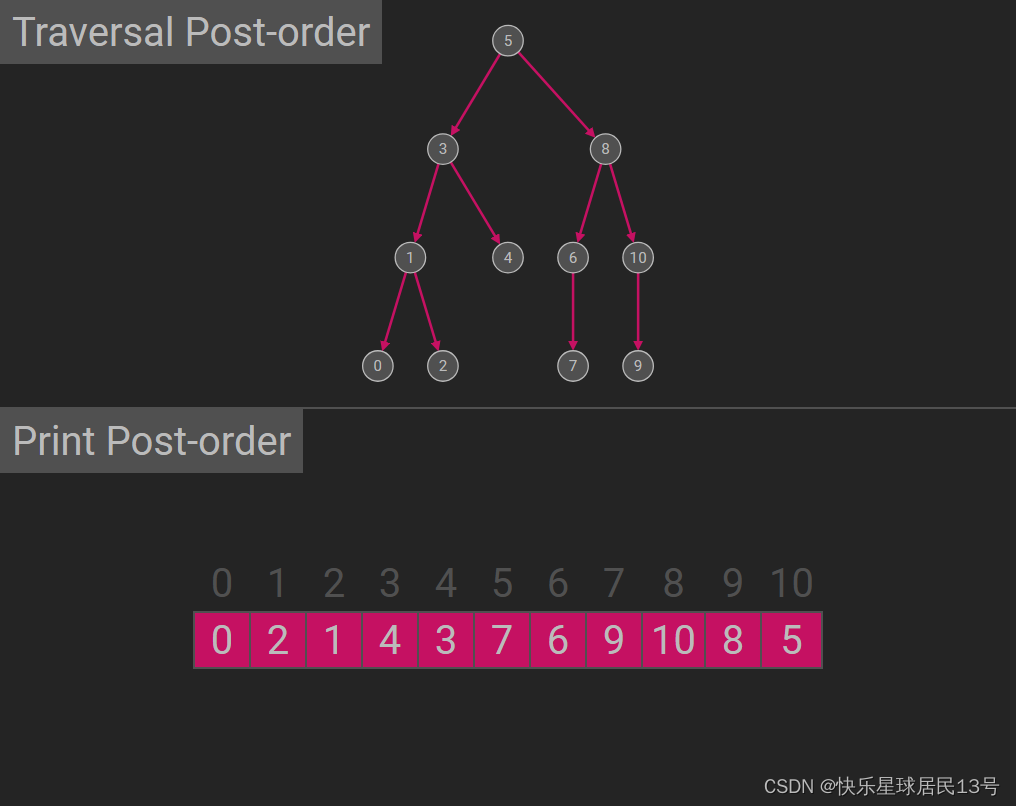
【Java数据结构】03-二叉树,树和森林
4 二叉树、树和森林 重点章节,在选择,填空,综合中都有考察到。 4.1 掌握二叉树、树和森林的定义以及它们之间的异同点 1. 二叉树(Binary Tree) 定义: 二叉树是一种特殊的树结构,其中每个节点…...

Element UI Input组件内容格式化:换行时行首添加圆点
<el-input v-model"input"placeholder"请输入"type"textarea":rows"8"focus"handleFocus"input.native"handleInput" /> 解释一下: Element UI对 input 事件做了一层包装,无法返回…...
十、Qt 操作PDF文件
《一、QT的前世今生》 《二、QT下载、安装及问题解决(windows系统)》《三、Qt Creator使用》 《四、Qt 的第一个demo-CSDN博客》 《五、带登录窗体的demo》 《六、新建窗体时,几种窗体的区别》 《七、Qt 信号和槽》 《八、Qt C 毕业设计》 《九、Qt …...

开源软件合规风险与开源协议的法律效力
更多内容:OWASP TOP 10 之敏感数据泄露 OWASP TOP 10 之失效的访问控制 OWASP TOP 10 之失效的身份认证 一、开源软件主要合规风险 1、版权侵权风险 没有履行开源许可证规定的协议导致的版权侵权,例如没有按照许可要求的保留…...
2024全新开发API接口调用管理系统网站源码 附教程
2024全新开发API接口调用管理系统网站源码 附教程 用layui框架写的 个人感觉很简洁 方便使用和二次开发...
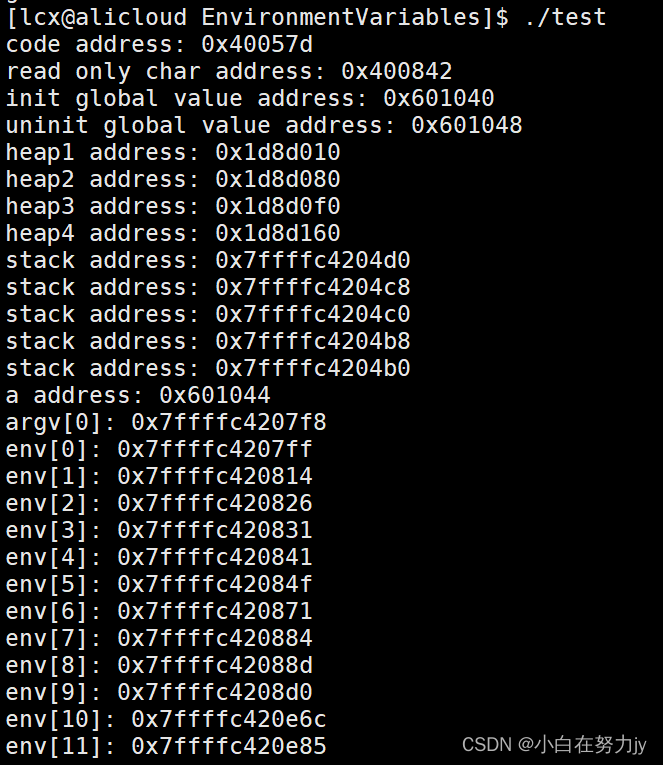
[Linux 进程(四)] 再谈环境变量,程序地址空间初识
文章目录 1、前言2、环境变量2.1 main函数第三个参数 -- 环境参数表2.2 本地环境变量和env中的环境变量2.3 配置文件与环境变量的全局性2.4 内建命令与常规命令2.5 环境变量相关的命令 3、程序地址空间 1、前言 上一篇我们讲了环境变量,如果有不明白的先读一下上一…...
)
【C++】STL(标准模板库)
文章目录 1. 基本概念2. 容器2.1. 容器的分类2.2. vector2.2.1. 构造vector对象2.2.2. vector的赋值 1. 基本概念 STL(Standard Template Library,标准模板库)是惠普实验室开发的一系列软件的统称,现在已经成为C标准库的重要组成部分。STL的…...

【已解决】fatal: Authentication failed for ‘https://github.com/.../‘
文章目录 异常原因解决方法 异常原因 在 Linux 服务器上使用git push命令,输入用户名和密码之后,总会显示一个报错: fatal: Authentication failed for https://github.com/TianJiaQi-Code/Linux.git/ # 致命:无法通过验证访问起…...

SqlAlchemy使用教程(二) 入门示例及编程步骤
SqlAlchemy使用教程(一) 原理与环境搭建SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解 二、入门示例与基本编程步骤 在第一章中提到,Sqlalchemy提供了两套方法来访问数据库,由于Sqlalchemy 官方文档结构有些乱,对于ORM的使用步骤的描…...

HTML+JS+CSS移动端购物车选购界面
代码打包资源下载:【免费】HTMLJSCSS移动端购物车选购界面资源-CSDN文库 关键部分说明: UIGoods 类: 构造函数: 创建 UIGoods 实例时,传入商品数据 g,初始化商品的数据和选择数量。getTotalPrice() 方法…...

微服务治理:为什么要分析微服务的依赖关系?
在微服务架构中,单个服务相互协作以交付功能。这些协作会在服务之间形成依赖关系,其中一个服务依靠另一个服务来完成自己的任务。虽然依赖关系使功能得以实现,但不受控制的依赖关系可能会导致一系列挑战: 复杂性: 错综复杂的依赖…...

【程序员的自我修养—系统调用与API】
系统调用 背景: 为了避免有限的系统资源被多个不同的应用程序同时访问,需要加以保护,避免冲突;提供一套统一的接口,是应用程序能做一些由操作系统支持的行为;接口通过中断的方式实现,Linux使用…...
使用宝塔面板部署后端项目到服务器
文章目录 前言第一步:安装数据库第二步:打包后端项目第三步:配置数据库第四步:部署后端项目第五步:前后端联调测试总结 前言 在之前我已经写了一篇如何去部署前端项目,虽然能访问网站,但是没有…...

走迷宫(c语言)
前言: 制作一个迷宫游戏是一个有趣的编程挑战。首先,我们需要设计一个二维数组来表示迷宫的布局,其中每个元素代表迷宫中的一个格子。我们可以使用不同的值来表示空格、墙壁和起点/终点。接下来,我们需生成迷宫。在生成迷宫的过程…...

星露谷物语SMAPI模组加载器:从新手到专家的终极指南
星露谷物语SMAPI模组加载器:从新手到专家的终极指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾梦想为星露谷物语添加全新的游戏体验?SMAPI模组加载器正是实现这…...

如何快速实现微信小游戏开发:weapp-adapter的完整实践指南
如何快速实现微信小游戏开发:weapp-adapter的完整实践指南 【免费下载链接】weapp-adapter weapp-adapter of Wechat Tiny Game in ES6 项目地址: https://gitcode.com/gh_mirrors/we/weapp-adapter 对于熟悉Web前端开发的程序员来说,微信小游戏开…...

React Starter Kit 与Create React App对比:哪个更适合你的项目?
React Starter Kit 与Create React App对比:哪个更适合你的项目? 【免费下载链接】react-starter-kit Start your first React App. By using React, Redux, and React-Router. 项目地址: https://gitcode.com/gh_mirrors/reac/react-starter-kit …...

CANN/Ascend C 基于语言扩展层C API编程
基于语言扩展层C API编程 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https:…...

OBS-VST插件完整指南:5分钟让直播音频秒变专业的终极方案
OBS-VST插件完整指南:5分钟让直播音频秒变专业的终极方案 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想在OBS Studio中免费获得专业级音频处理效果吗?OBS-VST插件正是你需要的解决方…...

AI气象模型统一基准:可复现、多源真值、时空一致的评测标尺
1. 这不是又一个“天气数据集”,而是一把标尺:为什么AI气象建模急需统一基准“AI Weather Models”这个词组最近两年在气象学会议、AI顶会和工业界技术白皮书里出现的频率,已经快赶上“大模型”本身了。但我和团队在去年参与三个不同机构的AI…...

Unity城市建造工作流:模块化建筑与性能优化实践
1. 这不是“贴图堆砌”,而是一套可落地的城市建造工作流你有没有试过在Unity里搭一座像样的城镇?不是那种靠几个Cube拼起来的“示意场景”,而是真正有生活气息、有建筑逻辑、有视觉节奏的城镇——街道有宽窄变化,建筑有主次关系&a…...

RTA-OS任务实战:从AUTOSAR规范到嵌入式汽车软件调度
1. 项目概述与核心价值在嵌入式汽车软件开发领域,AUTOSAR标准已经成为了事实上的行业规范,它定义了从应用软件到基础软件的完整架构。在这个庞大的体系中,操作系统(OS)作为最底层、最核心的软件组件之一,负…...
)
别再硬啃旧SDK了!用Unity 2021.3 + OpenXR搞定Vive Pro Eye眼动数据采集(附避坑指南)
现代VR眼动追踪开发指南:Unity 2021.3与OpenXR实战 在VR技术快速迭代的今天,眼动追踪已成为提升沉浸感的关键技术。Vive Pro Eye作为行业标杆设备,其开发方式正经历从私有SDK到开放标准的重大转变。本文将带你跨越技术代沟,掌握基…...

别再手动Cherry-pick了!用IDEA的Squash功能,3步合并Git提交历史
告别零碎Commit:IDEA交互式变基实战指南 在团队协作开发中,每个开发者都经历过这样的场景:为了修复一个看似简单的Bug,你在本地分支上提交了五六个"WIP"(Work in Progress)或"fix typo"…...