阿里云云原生弹性方案:用弹性解决集群资源利用率难题
作者:赫曦
随着上云的认知更加普遍,我们发现除了以往占大部分的互联网类型的客户,一些传统的企业,一些制造类的和工业型企业客户也都开始使用云原生的方式去做 IT 架构的转型,提高集群资源使用率也成为企业上云的一致共识。大家上云的同时,开始思考有没有云原生的方法能**更好地实现提高集群资源使用率这个核心目标。 **
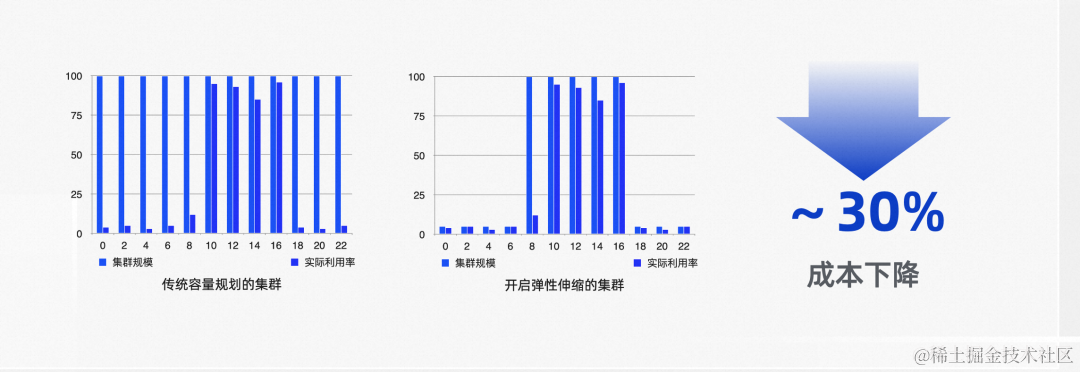
如何提升集群资源使用率呢,其实这个问题是要去解决规划容量和真实需求容量直接存在差异,这里边最重要的一个途径就是通过弹性来解决一些问题,实现成本优化。 传统的容量规划为了保证业务高峰稳定性,资源需要按照业务最高使用量进行常备,如左图所示,这种方案虽然保证了稳定性,但是资源利用率很低,成本浪费比较大。使用弹性伸缩后,资源容量曲线和实际业务资源需求的曲线贴合度增高,也就是我们追求的资源利用率有了明显的提升,从而整体成本也得到下降。
阿里云云原生弹性解决方案
明确了弹性的目标后,那我们下面具体看看阿里云容器服务各维度提供了哪些弹性解决方案。
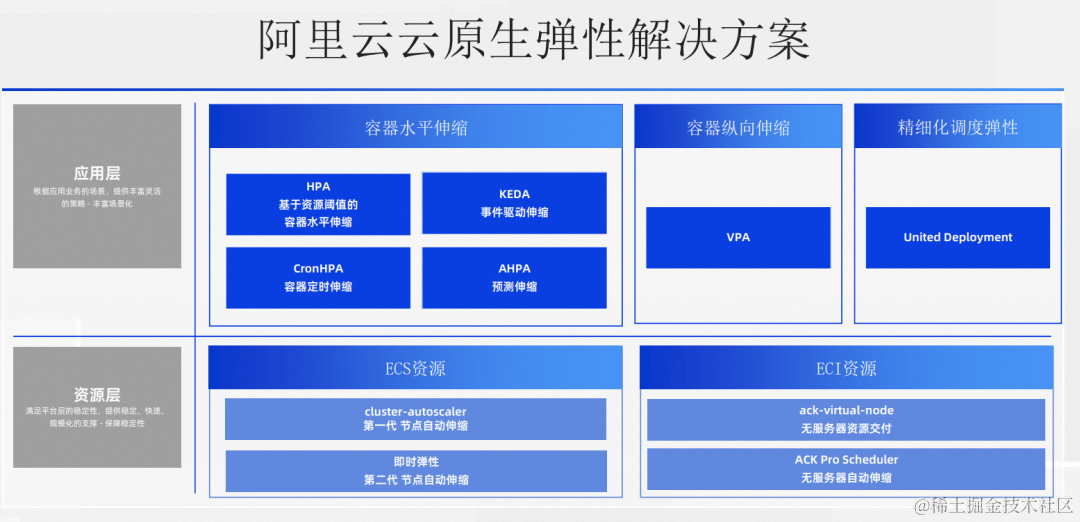
弹性是分成不同维度的。如果我们把 IT 架构分成两个层次的话,最上面一层是应用层。 应用层上面如果做弹性,按照伸缩的方向可以分为水平和纵向,另外还有精细化调度,解决应用层和调度器的一些策略问题的。使用最普遍的是容器水平伸缩,阿里云在这里也为大家提供了很丰富的弹性能力,以便大家能用最合适的组件来扩缩自己的业务 Pods。后面会为大家具体分析如何根据自己的业务特性来选择。
第二个层次是资源层, 也就是云厂商主要负责维护和提供给客户(包括 K8s 平台和底层虚机、网络、存储等资源的供给)。从资源形态可以分为节点交付和无服务器资源交付两类。在资源层,我们主要做的就是怎么去满足这个应用平台的稳定性,以及怎么去解决容量规划和实际的业务使用上的这个差异。这个是在资源层弹性需要核心建设的能力。
接下来,我们会针对于上面的这一些能力,给大家做一些深度的解析,来看一下阿里云 ACK 在弹性各个层次是怎么投入的,有哪些能力建设。
应用层弹性
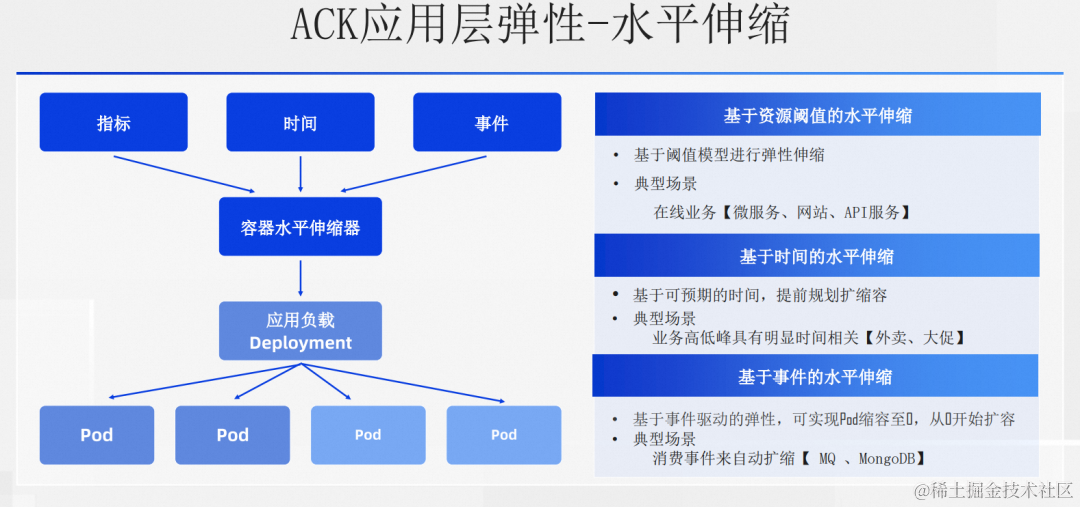
首先我们先来看应用层的水平伸缩。先看触发源,从触发源的类型可以分成 3 大类,指标、资源和事件。基于指标或者说资源阈值模型的就是咱们最常见的 HPA,HPA 适合业务高低峰能用指标来描述的业务,比如有的微服务业务高低峰会反映在 CPU、内存这类资源指标上,再比如说网站或者 API 可以通过访问量来决定是否需要扩缩,这些都是比较适合 HPA 的场景。
有的服务和时间是强相关的,比如外卖业务,饭点附近高峰,其他时候低峰,还比如促销场景,在规划好的促销时间段内会盈来高峰,这类就很适合使用 CronHPA,基于时间来扩缩 Pods。还有一类是以上两种都不能很好覆盖的,就是事件类型的,比如消费消息的业务,需要根据 MQ 中消息的多少来判断是否需要扩缩,这种就可以考虑使用 KEDA 来满足。
再看看这其中使用最普遍的也是大家最熟悉的 HPA 上阿里云扩展了哪些能力。首先弹性指标方面是否丰富,应该是大家比较关心的,这个也是第一个阿里云容器服务重点建设的方向。像传统的 HPA,大家可能理解指标就是 CPU、内存。这个是社区版本的 resource metrics 里唯一定义的两种的这个伸缩指标。
对于不同的业务场景,对于不同的这个业务形态,简简单单的 CPU 跟内存是没有办法满足业务的诉求的。那阿里云在 HPA 弹性指标这个维度做的事情,就是找到合适不同业务场景的伸缩指标,来进行丰富,让这个链路使用起来更简单。
为此,阿里云 ACK 提供了 Metrics Adapter 这个组件来完成指标转化,支持用户自定义指标,比如 GPU 的利用率、Prometheus 的指标都是可以通过它让 HPA 感知到。除了自定义指标,阿里云产品常用指标也在其中默认支持,比如 Ingress/Istio/AHAS QPS,用户需要的话可以直接在 HPA 配置使用。

伸缩指标再往下是伸缩对象,我们知道 HPA 的伸缩对象是哪些呢?可以伸缩 Deployment,可以伸缩 Statefulset,实际上 HPA 不关心具体的伸缩对象是 Department 还是 Statefulset。它实际上感知的是一个泛化的 scale subresource。也就是说只要实现了 subresource 这种资源对象,它就能够被 HPA 管理,被 HPA 伸缩。所以在伸缩对象这个维度上,我们找到有哪些领域场景是需要去定义成一个伸缩对象的,然后进行支持。比如说阿里云 ACK 在 Spark 和 Presto Cluster 上面去做了对应的 CRD,并且这些 CRD 同样也是可以被 HPA 去接管的,满足这些领域场景的自动水平伸缩的这个需求。

资源层弹性
应用层的自动伸缩负责对 Pods 的自动伸缩控制。设想一个场景,某个服务在突增的业务高峰需要 100 个 Pods 扛住流量,集群常备的资源够跑 50 个Pods,那会剩余 50 个 Pods 没有资源可以调度。这个就是资源层弹性要解决的问题了,资源层弹性负责集群有足够的资源调度 Pods,且在不需要那么多资源的时候,自动释放,不造成太大的浪费。
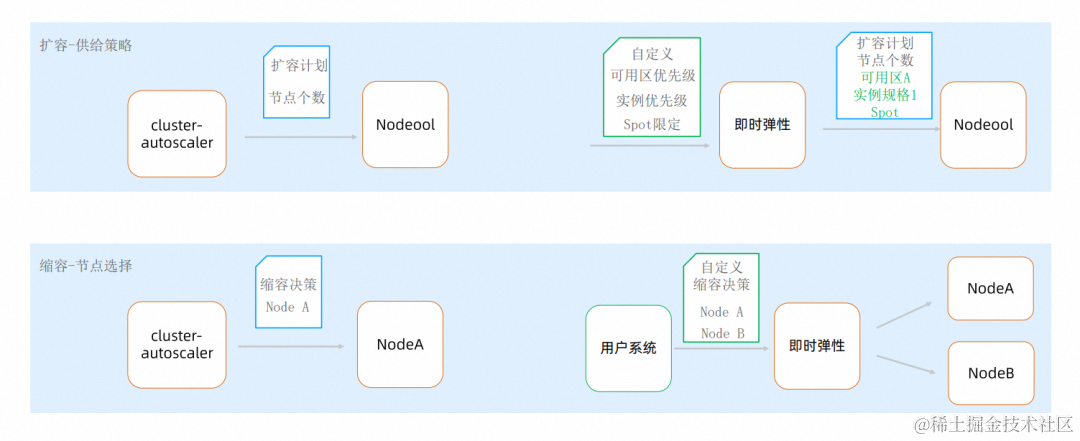
更细地拆分的话,有 5 个维度的核心问题是资源层弹性最关心的,也是直接影响我们资源层弹性方案选型。我们刚才介绍过,从资源类型维度来分,资源层弹性可以分为 ECS 和 ECI,那我们就以他们各自的的典型组件 cluster-autoscaler 和 VK 来举例说说资源层弹性的 5 个维度。
首先看成本,VK/cluster-autoscaler 的成本对比主要的区别在于超卖比,ECI 不支持超卖,通常离线作业的超卖比平均在 1:2-1:4 之间。然后看效率,cluster-autoscaler 是近分钟级别的(1 分钟多并且会随着节点池的个数、连续弹性的负载个数出现不稳定的交付)。ECI 是 1 分钟内的快速交付。再看可以支持的多大的集群规模,VK 的规模化问题在于 One Pod One Node 模型对底层 API 与 APIServer 的冲击是直接的冲击,cluster-autoscaler 是集群/节点两级的模型,相比而言,规模化场景下 cluster-autoscaler 的容量上限会更高。兼容性方面,cluster-autoscaler 是全兼容,ECI 对于需要内核参数、Daemonset 等场景支持存在差异。最后是运维难易,VK 为免运维,cluster-autoscaler 为强运维。

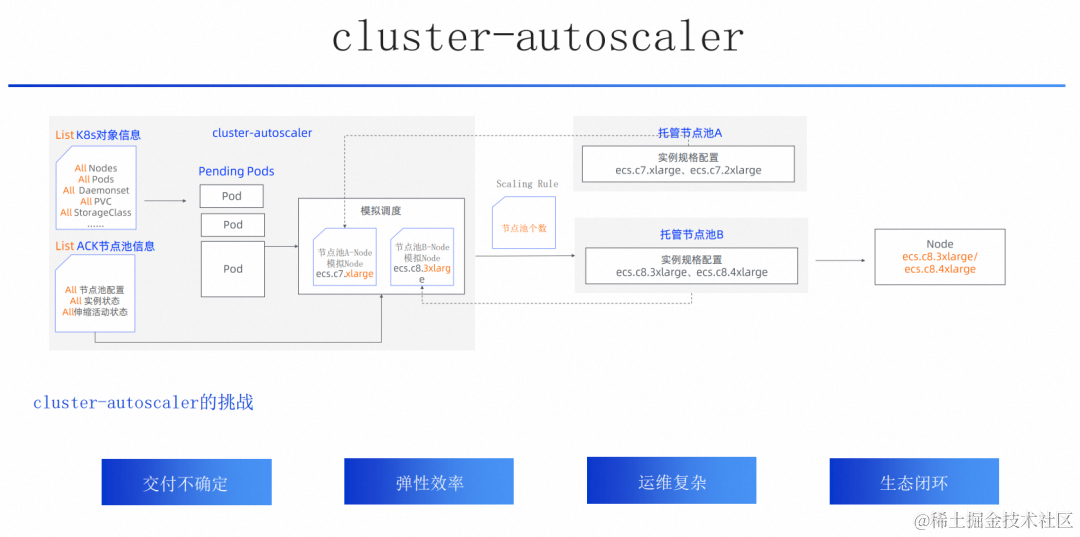
我们具体看下业界使用普遍的 cluster-autoscaler 和它面临的挑战。首先 cluster-autoscaler 是轮询模式,图上是一个 loop 的基本逻辑示意图。每个 loop 中,cluster-autoscaler 对全集群的状态机的维护,找到集群中不可调度的 Pods,然后把每个开启弹性的节点池抽象为一个 Virtual Node(以下简称为 One Nodepool One Virtual Node),判断是否可以部署(到节点池供给的资源上)后,增加对应节点池的节点个数,实现扩容。这就是大多数弹性客户在使用 cluster-autoscaler 的基本逻辑。
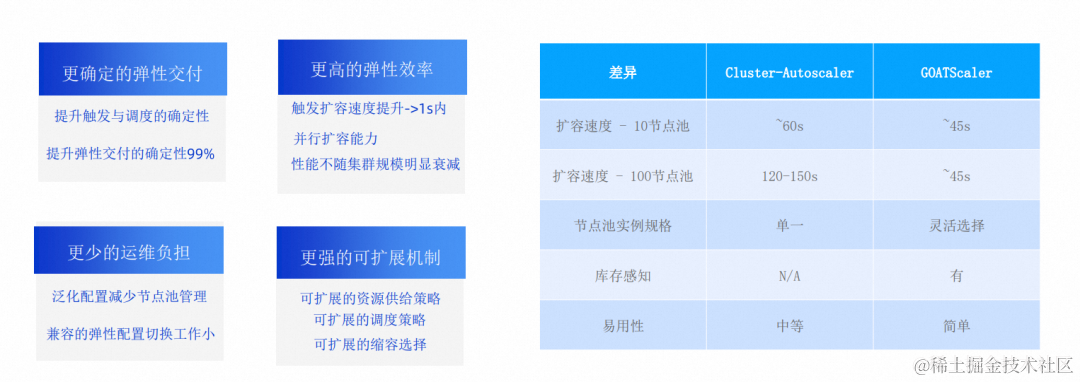
同时对很多应用和工作负载来说这套机制都运行的不错。但是随着更多的用户上云,ACK 也被更广泛地使用,用户正在将各种不同类型的工作负载转移到 ACK上,也就对基于依赖全集群状态维护和 One Nodepool One Virtual Node 的 cluster-autoscaler 的这套机制引入了更多的挑战。主要集中在:交付资源不完全确定、弹性效率受集群规模和业务类型发散度大、运维复杂和生态闭环这几点。
即时弹性
cluster-autoscaler 交付的不确定性、运维复杂性以及不够快的弹性速度、相对闭环的生态是很多开发者对于生产环境开启弹性的 4 个最大的顾虑。为了解决这些顾虑我们研发了第二代节点伸缩产品——即时弹性。
即时弹性是一个基于事件驱动的节点伸缩控制器,兼容现有的弹性节点池语义与行为,支持所有类型的应用无感开启与使用。有以下特性:
- 更准: 即时弹性摒弃了第一代弹性组件的 One Nodepool One Virtual Node 的抽象方式和预调度装箱模式,在扩容时候决策从简单的只包含节点个数的 Scaling Rule,扩充到支持具体实例规格的 Scaling Plan,使得扩容更准。
- 更快: 基于事件驱动和并行扩容让即时弹性更灵敏更快速。
- 更轻: 即时弹性能自动选择实例规格,需要节点池数目更少,管理运维更轻,
- 更 YOU: 在扩容和缩容阶段都支持了可扩展机制,让用户逻辑参与到弹性节点生命周期来。
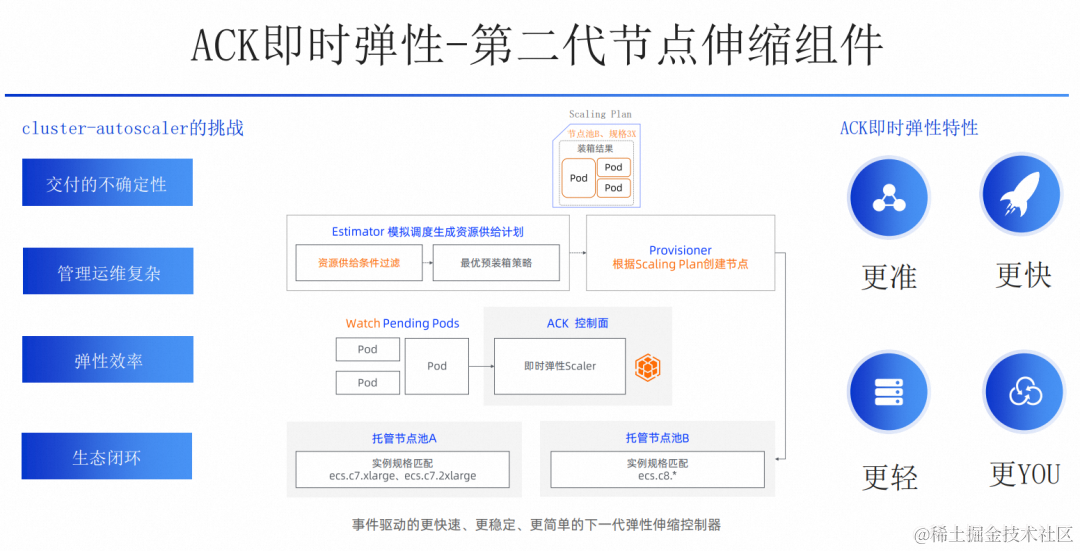
下面我们针对这四个方面,用具体的业务 case 为大家对比两代节点伸缩组件的细节差异。
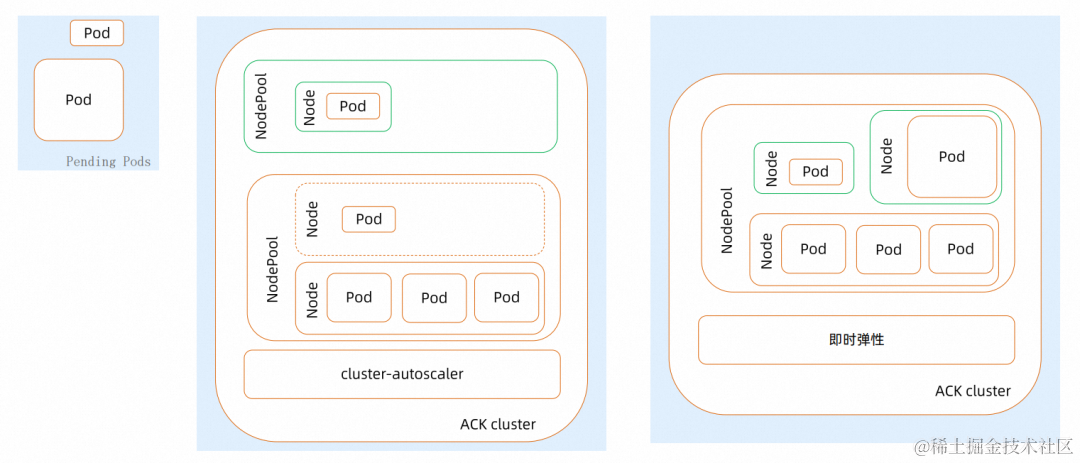
看个典型的扩容场景,集群内的节点资源已经被 3 个 Pods 占满,这个时候出现了一个 Request 资源更小的 Pods,假设这个 Pods 可以调度到现有节点池的新节点上。如果是 cluster-autoscaler,会触发已有节点池弹一个相同大小节点,需求资源更小的 Pods 可以调度,但是节点资源利用率很低。
如果我们想要更好地节点资源利用率,那只能再创建一个新的节点池,配置上更合适的小资源的实例规格,但是这样又加重了后续运维负担。那如果使用即时弹性的话,只需要在同一个节点池内配置好多种规格的实例,即时弹性会根据 Request 资源挑选合适的实例规格进行扩容。可以看出,即时弹性的交付确定性对资源利用率和运维这两方面都带了好处。
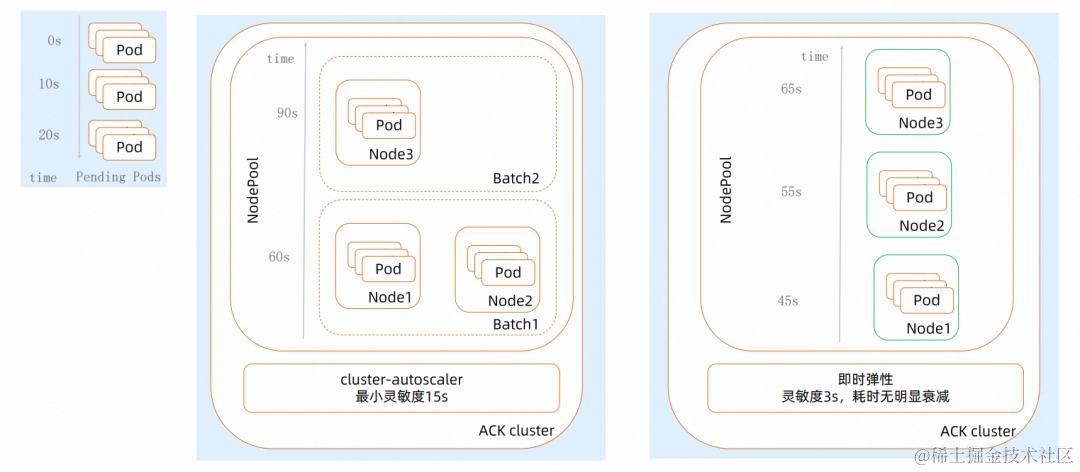
然后我们再看看弹性效率方面。cluster-autoscaler 我们说过是轮询模式的,最小间隔 15s,它的扩缩处理是分批次的,比较适合单次交付这种模型,但是如果遇到像流失计算、Workflow 这类分批或者一个时段连续出现不可调度 Pods 的场景,cluster-autoscaler 就会出现跨批次处理,批次之间还可能出现互相影响,导致弹性效率不稳定。
而即时弹性是基于事件的,Pods 出现不可调度的事件后即时弹性就会开始处理,并且支持同一节点池的并行扩容,这样就大大降低了触发扩容的耗时。我们这个例子中可以看到有 3 批 Pods,间隔是 10s,在 cluster-autoscaler 因为最后这个 20s 的这批 Pods 出现了跨批次,导致所有 Pods 耗时 90s 才能全部调度;而即时弹性,Pods 没有因为批次而延迟的问题,每一批基本耗时都可以稳定在 45s 上下。
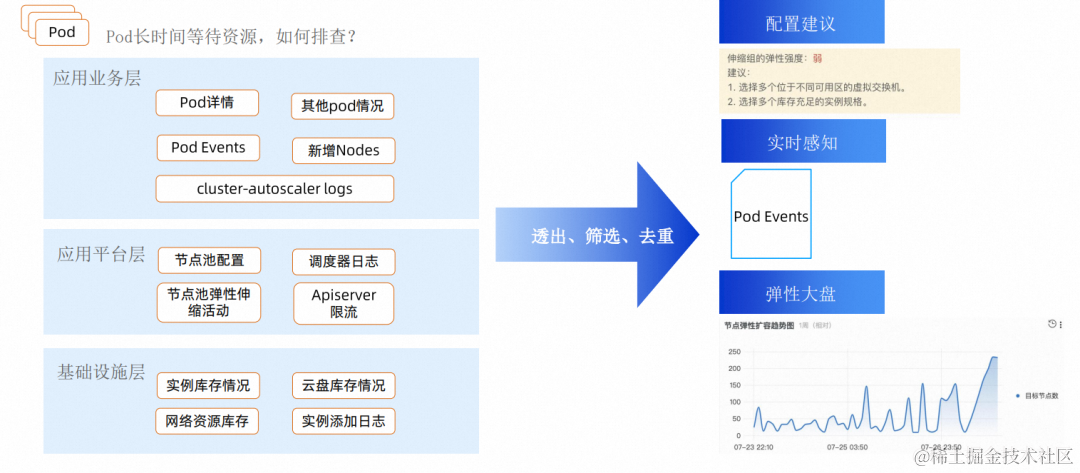
再来看看运维方面,运维的成本其实是前期很容易忽视后期很容易头疼的点,将近一半的弹性用户都有对运维工作复杂的抱怨。复杂性一方面来自 cluster-autoscaler 交付不确定性带来的节点池数目膨胀,还有很重要的一方面来着 cluster-autoscaler 问题排查的复杂度,我们看一个经常用户会问到的问题,Pods 预期是可以通过弹性扩容部署的,但是很长时间就是没有调度下去。这种问题在 cluster-autoscaler 中要排查的话,可能从业务层到基础设施层各层的日志都需要排查,随着集群规模变大,复杂度是指数级上升的。
那用户理想的方式是怎样的呢,咱们从产品全流程看,首先配置时候有提示,尽量前置的规避掉一些配置上容易出错的点。然后 Pods Pending 时候,弹性相关的需要用户关注的都能通过 Pod Events 透出,用户只需要 describe 一下 Pods 就可以看到。最后,如果 Pods 已经被删了,或者需要看一些统计方面的情况,能有大盘进行追溯,这些简化运维的能力也都会在即时弹性产品上推出。
最后看下扩展能力方面,cluster-autoscaler 因为要维持全局状态,生态是比较封闭的,用户没法参与到节点生命周期中来。即时弹性在扩容方面,会允许用户指定更细节的扩容要求,比如可用区、实例规格的优先级,以及对竞价实例的限定,最后的扩容计划会遵循用户这些策略。在缩容方面,也很开放,用户可以遵循即时弹性协议的 Policy,来按照自己的逻辑指定缩容的节点,即时弹性来为这些节点缩容。
总结下,相比传统的 cluster-autoscaler,即时弹性拥有更快速的弹性速度,更稳定的弹性效率, 特别是在集群的规模变大或者弹性伸缩的频率变高的场景下,即时弹性相交传统的弹性模型,拥有 50% 以上的效率提升。 此外,即时弹性还简化了节点池的使用复杂度,根据不同的应用选择合适的规格是运维人员非常困扰的问题,即时弹性通过自动模拟装箱策略,可以在开发者配置少量筛选规则的范围内,在阿里云超过 1500 款的机型中选择合适业务的机型,进行弹性供给。不仅降低了开发者的使用成本,还提升了节点池弹性的成功率。
企业云原生弹性案例与解析
我们用一个生产环境的实际案例来举例说明,上面提到的各层次弹性方案在具体情况下是如何被选择、运作和实际效果是怎样的。首先介绍这个用户的一些基本情况和特点:
- 规模: 用户主要想把弹性运用在一个月活达到上亿级别的游戏的 AI 场景。月活很高但是流量却无法预测,可能因为客户涌入而有突增的流量。
- 模型抽象方面: 用户将一个游戏对战房对应一个业务负载的 Pods,每个作战房的玩家数目有固定上限。
- 扩容需求: 除了基本的扩容要求外,用户为了保证稳定性希望 Pods 可以基于节点打散。其次,用户一方面希望能随业务高低峰自动扩缩 Pods 数目,但是为了更好地应对突增流量,用户需要总是有固定数目的 Pods 冗余。
- 缩容需求: 为了保证玩家体验,用户希望有玩家的 Pods 及其所在 Node 能等待玩家离场后再缩容,并且需要在节点缩容前去收集一些数据和日志,节点同时也需要在数据和日志收集完成后缩容,否则会导致数据或日志缺失。
应用层弹性方案
从用户业务场景分析,业务负载的变化和玩家数量是正相关的,其他维度上没有找到更好地规律,因此我们推荐用户通过 Aliyun Prometheus 采集玩家数目,然后安装 Metrics Adapter 组件将玩家数目转化为 HPA 的 custom metrics。为了满足最后算出的副本数总是带冗余量的,而侵入式地修改 HPA 的内部算法是一个维护成本较高的方案,因此我们建议用户在指标侧加入相应的冗余量,来保证 HPA 的输出副本数是带冗余数目的。

资源层弹性方案
资源层弹性方案我们分扩容和缩容两方面来介绍。
扩容方面,虽然业务负载层实现了冗余 Pods,但是在较大量的突增流量的情况下,仍然需要快速地供给资源。阿里云提供了预先加载节点组件镜像和用户镜像的自定义镜像方案和工具,帮助节省新节点扩容和业务启动过程中镜像拉取的时间。同时,还提供了多节点池并行扩容,让分属于不同节点池的业务的资源供给不互相影响,可以同时进行。除了快用户还需要基于节点 HostName 的打散,我们优化了弹性组件中基于 HostName 的预调度调度策略,让弹性决策更加准确。
在稳定性得到保证的前提下,资源成本永远是用户最关心的问题之一。阿里云抢占式实例(Spot 实例)的市场价格会随供需变化而浮动,相对于按量付费实例能最高节约 90% 的实例成本。 集群使用抢占式实例是能够大幅节省成本的,但是抢占式实例随着动态库存和出价会不定时回收。
为尽可能降低抢占式实例的中断回收的影响,阿里云弹性提供了抢占式实例回收前提前主动排水、提前扩出新节点以备补偿等多种能力。这样对抢占式中断回收有一定容忍性地业务,比如离线数据类型业务,用户选择了使用抢占式实例作为弹性资源供给类型。对稳定性要求较高,我们也提供了成本最优策略,可以保证在按量实例的多种实例规格中,每次都可以扩容出成本最低的实例规格。
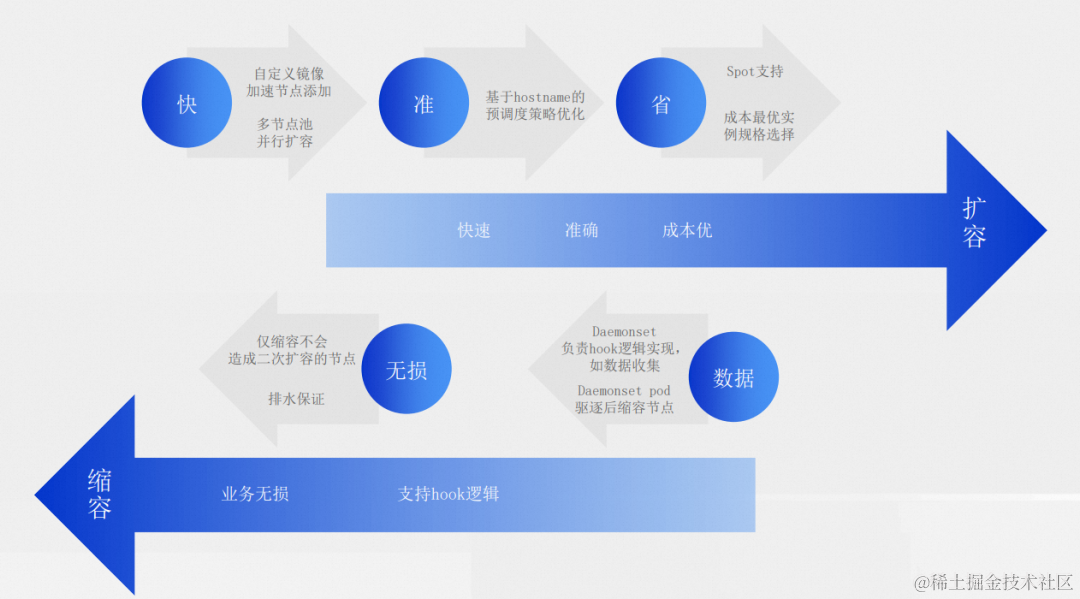
缩容方面,为了满足玩家退场再缩容的需求,阿里云弹性提供了自定义的排水等待时间,保证在用户指定时间内等待排水完成,不删节点资源。用户通过 K8s 的优雅退出来保证 Pods 被删前玩家都已经退场。这样两层保障即可让最终的缩容效果满足玩家退场节点再缩容的需求。
另外,用户缩容前数据日志收集的需求也是类似的,不同地方时这类针对每个节点都需要的服务一般是以 Daemonset 部署的,而一般缩容都是默认跳过 Daemonset Pods,并且用户场景中也只是需要对某一类或者某几类的 Daemonset Pods 进行排水并等待,因此我们在弹性缩容时添加了对指定 Daemonset Pods 进行缩容的支持,同时用户也可以标记需要等待完成排水的 Daemonset Pods,以达到数据日志收集完全后,节点才被缩容的需求。
点击此处查看容器服务 Kubernetes 版 ACK 弹性伸缩相关帮助文档。
相关文章:
阿里云云原生弹性方案:用弹性解决集群资源利用率难题
作者:赫曦 随着上云的认知更加普遍,我们发现除了以往占大部分的互联网类型的客户,一些传统的企业,一些制造类的和工业型企业客户也都开始使用云原生的方式去做 IT 架构的转型,提高集群资源使用率也成为企业上云的一致…...
Spring-BeanPostProcessor PostConstruct init InitializingBean 执行顺序
执行顺序探究 新建一个对象用于测试 Component public class Student implements InitializingBean {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name name;}public int getAge() {return age;}pu…...
【算法】递归
递归 递归初始递归:数列求和递归的应用:任意进制转换递归深度限制递归可视化:分形树递归可视化:谢尔宾斯基Sierpinski三角形递归的应用:汉诺塔递归的应用:探索迷宫 分治策略和递归优化问题兑换最少个数硬币…...
DC-1靶机刷题记录
靶机下载地址: 链接:https://pan.baidu.com/s/1GX7qOamdNx01622EYUBSow?pwd9nyo 提取码:9nyo 参考答案: https://c3ting.com/archives/kai-qi-vulnhnbshua-tiDC-1.pdf【【基础向】超详解vulnhub靶场DC-1】 https://www.bilibi…...
rust跟我学七:获取外网IP地址
图为RUST吉祥物 大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info是怎么获取到本机的外网IP地址。 首先,先要了解get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址:[…...

华为:交换机忘记console密码重置
一、背景 许多旧项目经过长时间使用后,因为没有特定的管理运维人员,初始对接人也将初始账号密码等重要信息丢失,现需要进后台查看配置或更改网络配置,需重置密码 二、重置密码,不重置设备方法 1、使用console插入交…...

2024年甘肃省职业院校技能大赛信息安全管理与评估 样题三 模块一
竞赛需要完成三个阶段的任务,分别完成三个模块,总分共计 1000分。三个模块内容和分值分别是: 1.第一阶段:模块一 网络平台搭建与设备安全防护(180 分钟,300 分)。 2.第二阶段:模块二…...

Go 中 slice 的 In 功能实现探索
文章目录 遍历二分查找map key性能总结 之前在知乎看到一个问题:为什么 Golang 没有像 Python 中 in 一样的功能?于是,搜了下这个问题,发现还是有不少人有这样的疑问。 补充:本文写于 2019 年。GO 现在已经支持泛型&am…...
 pyDAL的一些性能优化)
pyDAL一个python的ORM(终) pyDAL的一些性能优化
一、大批量插入数据 对于 大量数据插入时,虽然pyDAL也手册中有个方法:bulk_insert(),但是手册也说了,虽然方法上是一次可以多条数据,如果后端数据库是关系型数据库,他转换为SQL时它是一条一条的插入的&…...

springboot log4j配置xml实例说明
提供样本配置代码 xml <?xml version"1.0" encoding"UTF-8"?> <!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL --> <!-- status log4j2内部日志级别 --> <configurat…...
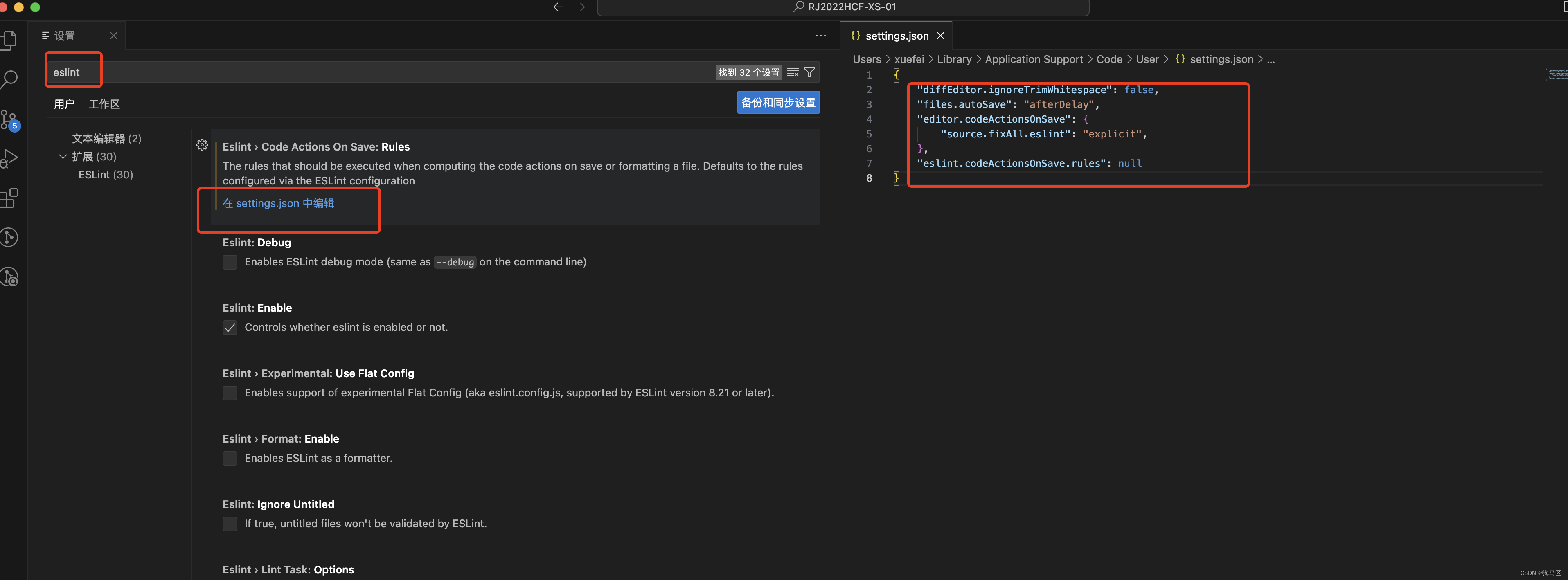
VsCode重新安装需要配机的ESLint和 Prettier - Code formatter 配置
新电脑安装完Vscode后,需要装几个插件,这里记录下: {"diffEditor.ignoreTrimWhitespace": false,"files.autoSave": "afterDelay","editor.codeActionsOnSave": {"source.fixAll.eslint"…...
录屏功能怎么打开?简单操作,一学就会!
录屏功能在当今互联网时代变得越来越重要,无论是游戏录制、在线课程录制还是屏幕操作演示,录屏功能都为我们提供了便捷的解决方案。可是您知道录屏功能怎么打开吗?接下来,让我们一起探索如何在电脑上开启录屏功能,记录…...

小程序显示兼容处理,home键处理
定义: env(safe-area-inset-bottom)和env(safe-area-inset-top)是CSS中的变量,用于获取设备底部和顶部安全区域的大小 示例: padding-bottom: calc(env(safe-area-inset-bottom) 12px); /* 兼容iOS> 11.2 */安全间距类型: …...
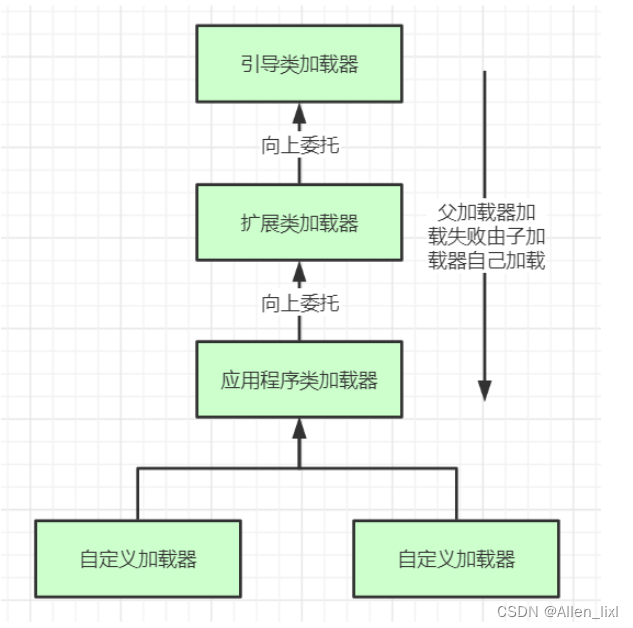
【java八股文】之JVM基础篇
【java八股文】之JVM基础篇-CSDN博客 【java八股文】之MYSQL基础篇-CSDN博客 【java八股文】之Redis基础篇-CSDN博客 【java八股文】之Spring系列篇-CSDN博客 【java八股文】之分布式系列篇-CSDN博客 【java八股文】之多线程篇-CSDN博客 【java八股文】之JVM基础篇-CSDN博…...

2024美赛数学建模思路 - 案例:异常检测
文章目录 赛题思路一、简介 -- 关于异常检测异常检测监督学习 二、异常检测算法2. 箱线图分析3. 基于距离/密度4. 基于划分思想 建模资料 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 一、简介 – 关于异常…...

【EI会议征稿通知】2024年通信技术与软件工程国际学术会议 (CTSE 2024)
2024年通信技术与软件工程国际学术会议 (CTSE 2024) 2024 International Conference on Communication Technology and Software Engineering (CTSE 2024) 2024年通信技术与软件工程国际学术会议 (CTSE 2024)将于2024年03月15-17日在中国长沙举行。会议专注于通信技术与软件工…...

Js面试之作用域与闭包
Js面试之作用域与闭包 作用域词法作用域动态作用域 闭包闭包使用场景封装私有变量模块化开发保持变量状态异步操作 注意事项 最近在整理一些前端面试中经常被问到的问题,分为vue相关、react相关、js相关、react相关等等专题,可持续关注后续内容ÿ…...

Go 爬虫之 colly 从入门到不放弃指南
文章目录 概要介绍如何学习官方文档如何安装快速开始如何配置调试分布式代理层面执行层面存储层面存储多收集器配置优化持久化存储启用异步加快任务执行禁止或限制 KeepAlive 连接扩展总结如果想用 GO 实现爬虫能力,该如何做呢?抽时间研究了 Go 的一款爬虫框架 colly。 概要…...
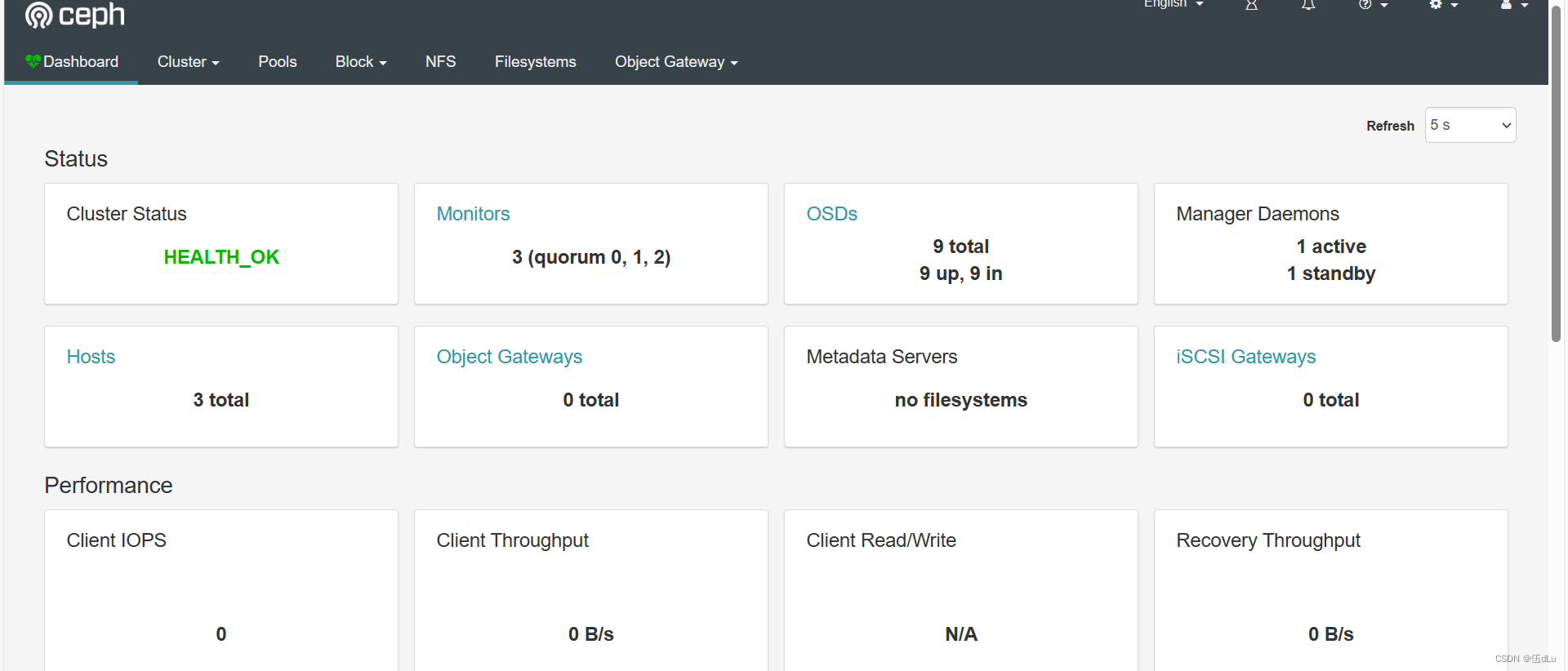
Ceph分布式存储(1)
目录 一.ceph分布式存储 Ceph架构(自上往下) OSD的存储引擎: Ceph的存储过程: 二. 基于 ceph-deploy 部署 Ceph 集群 20-40节点上添加3块硬盘,一个网卡: 10节点为admin,20-40为node&…...

制造业工厂为什么要实施MES系统呢?
MES是生产管理系统,生产管理是通过对生产系统的战略计划、组织、指挥、实施、协调、控制等活动,实现系统的物质变换、产品生产、价值提升的过程。在企业的价值链中,生产经营是企业核心能力的重要组成部分。 实施MES系统的原因 MES系统是中国比…...
)
保姆级教程:在VMware上安装BCLinux for Euler 21.10最小化系统(附镜像校验与网络配置)
虚拟化环境实战:BCLinux for Euler 21.10最小化系统部署全指南 在云计算和容器化技术盛行的今天,本地虚拟化环境仍然是开发者进行系统测试、软件验证的重要工具。BCLinux for Euler作为一款针对企业级场景优化的Linux发行版,其21.10版本在性能…...

如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南
如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为编写技术文档时需要在代码编辑器与图表预览工…...

5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南
5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行手机应用吗&#x…...

polars导入csv文件时指定列数据类型
polars导入csv文件时指定列数据类型schema {column1: pl.Int64,column2: pl.Float64,column3: pl.Utf8}df pl.read_csv(data.csv, schemaschema)def pddaoru_csv(filedir):order_5G[承建方,厂家,市名称,统计局区县,数据时间,小区名称,基站ID,小区ID,小区覆盖类别,频段,带宽,小…...

3步掌握HTTrack:免费网站离线下载工具终极指南
3步掌握HTTrack:免费网站离线下载工具终极指南 【免费下载链接】httrack HTTrack Website Copier, copy websites to your computer (Official repository) 项目地址: https://gitcode.com/gh_mirrors/ht/httrack 你是否经常遇到网络不稳定,却急需…...

从SPEF到STA:一份寄生参数文件如何影响你的芯片时序签核?
SPEF文件在芯片时序签核中的关键作用与实战解析 芯片设计工程师们常说:"SPEF文件是物理世界与逻辑世界的翻译官。"这句话精准概括了SPEF在芯片设计流程中的核心价值。当设计从逻辑综合进入物理实现阶段,金属连线的电阻电容效应开始显著影响信号…...

Linux命令行玩转CAN总线:像查日志一样用grep分析candump实时数据流
Linux命令行玩转CAN总线:像查日志一样用grep分析candump实时数据流 在Linux系统管理领域,日志分析是每个开发者都熟悉的日常操作。当面对CAN总线这样的专业数据流时,其实可以运用同样的思维——将candump视为持续输出的数据源,用g…...

LabVIEW开发者峰会:破解信息孤岛,构建实战技术生态
1. 为什么我们需要一场专属的LabVIEW开发者峰会?如果你是一名长期使用LabVIEW进行测控系统开发的工程师,可能经历过这样的场景:面对一个复杂的同步采集需求,你翻遍了官方帮助文档和范例,却总觉得方案不够优雅ÿ…...

氨基酸表活洁面慕斯科普
一、什么是洁面慕斯洁面慕斯是一种预发泡型的洁面产品,和传统膏状、洗面奶不同,它从泵头挤出来就是细腻绵密的泡沫,不需要消费者手动打泡,使用起来更加方便快捷。从成分体系来看,洁面慕斯本质还是表面活性剂清洁产品&a…...
)
别只傻等候补了!用Bypass分流抢票监控12306“捡漏”全攻略(含微信通知设置)
别只傻等候补了!用Bypass分流抢票监控12306"捡漏"全攻略(含微信通知设置) 春节临近,当你在12306官网上看到心仪车次显示"候补"或"无票"时,是否已经放弃希望?其实,…...