Oracle行转列函数,列转行函数
Oracle行转列函数,列转行函数
Oracle 可以通过
PIVOT,UNPIVOT,分解一行里面的值为多个列,及来合并多个列为一行。
PIVOT
PIVOT是用于将行数据转换为列数据的查询操作(类似数据透视表)。通过使用PIVOT,您可以按照特定的列值将数据进行汇总,并将其转换为新的列。
语法
pivot(
聚合函数for需要转为列的字段名in(需要转为列的字段值))
SELECT *
FROM (-- 源数据查询SELECT column1, column2, ..., pivot_column, value_columnFROM your_source_table
)
PIVOT (-- 聚合函数和列定义aggregate_function(value_column)FOR pivot_column IN (value1 AS alias1, value2 AS alias2, ..., valuen AS aliasn)
);
-
aggregate_function:指定用于对value_column进行聚合操作的函数,如SUM、AVG等。(FOR关键字前面的部分只能使用聚合函数) -
value_column: 指定要聚合的源数据列。 -
pivot_column: 指定要透视的列,其唯一值将被用作新列的列头。且源数据查询的select中必须包含这个字段,以便PIVOT函数可以使用到它。(可以理解为用这个字段来进行group by) -
value1 AS alias1, value2 AS alias2, ..., valuen AS aliasn: 为透视列的每个唯一值指定一个别名,这些别名将成为新列的列头。遗憾的是这里不是使用子查询。
准备
CREATE TABLE sales_data (product_name VARCHAR2(100),region VARCHAR2(50),sale_month VARCHAR2(10),sale_amount NUMBER
);
-- 商品 A 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-01', 5000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-01', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-01', 4500);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-02', 8000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-02', 7500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-02', 6000);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-03', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-03', 8500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-03', 6200);-- 商品 B 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-01', 6000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-01', 8000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-01', 5500);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-02', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-02', 9000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-02', 6500);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-03', 7800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-03', 9200);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-03', 6900);-- 商品 C 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-01', 5500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-01', 6000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-01', 4800);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-02', 6500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-02', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-02', 5800);INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-03', 7200);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-03', 7800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-03', 6000);样例一
-- 每个商品在不同的地区的总销售额SELECTproduct_name,region,sum( SALE_AMOUNT )
FROMsales_data
GROUP BYproduct_name,region
ORDER BYproduct_name,region
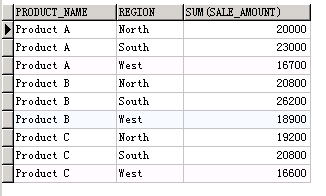
这样是一行一行显示的,我们来转换为一列一列的显示。
-- 以商品为行 地区为列
SELECT*
FROM( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) FOR region IN ( 'North', 'South', 'West' ) ) ORDER BY product_name 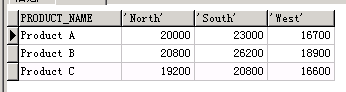
-- 已地区为行 商品为列
SELECT*
FROM( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region 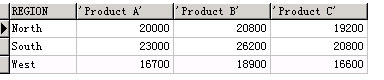
多个聚合函数
每个商品在不同地区的销售总额,每个商品在不同地区的销售平均值
SELECT*
FROM( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ),avg( SALE_AMOUNT ) FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region ;
-- > ORA-00918: 未明确定义列
-- 这样直接写两个聚合函数在pivot里面是会报错。是因为两个聚合函数都没有使用,默认是使用in里面的值作为列名。
-- 所以当我们在使用多个聚合函数的时候需要至少一个为聚合函数指定 as
SELECT*
FROM( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) as sum,avg( SALE_AMOUNT )as avg FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region ;

注意
我这里用了
select再给嵌套了一层,并且去掉了Name字段。为什么?
我们使用
select*试试。
SELECT*
FROMsales_data PIVOT ( sum( SALE_AMOUNT ) AS sum, avg( SALE_AMOUNT ) AS avg FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) )
ORDER BYregion
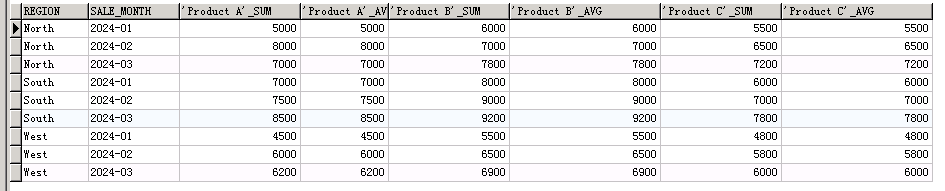
会发现想象的不太一样。😂
其实,这是因为
pivot会以移出pivot_column和value_column后的字段组合当成唯一键(就类似以那几个字段group by)。所以
直接使用 pivot这个查询翻译成自然语言就是:查询每个地区,每个月的,商品的销售额。
多个FOR
也就是自己查询 对于product_name,region,销售额的总和。直接用列显示
SELECT*
FROM( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT (sum( SALE_AMOUNT ) AS sum FOR ( product_name, region ) IN (( 'Product A', 'North' ) AS result1,( 'Product A', 'South' ) AS result2,( 'Product A', 'West' ) AS result3,( 'Product B', 'North' ) AS result4,( 'Product B', 'South' ) AS result5,( 'Product B', 'West' ) AS result16,( 'Product C', 'North' ) AS result7,( 'Product C', 'South' ) AS result8,( 'Product C', 'West' ) AS result9 ) )

总结
pivot函数是写在表名后面的,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。
pivot会以移出pivot_column与value_column剩下的字段组合成唯一键,每个唯一值占一行,查询每一组满足唯一键的聚合函数的值。
pivot当使用多个聚合函数的时候至少需要指定一个as
pivot的in中是不支持使用子查询的,这是个缺点,但是也可以使用动态拼接的方式把想要转换为列的值拼接到这。
UNPIVOT
UNPIVOT是PIVOT的相反操作。它用于将列数据转换为行数据。将多列合并多为一列,合并为一列后自然需要多行才能展示全数据
语法
UNPIVOT(
被合并列的列名for合并后的列名in (被合并的列(),…))
SELECT*
FROMtableName UNPIVOT ( fieldValueName FOR fieldName IN ( filedValue,... ))
- fieldValueName:被合并列的列名,可以随便起名称。
- fieldName:合并后的列名,可以随便起名称。
- filedValue:被合并的列。可以有多个。
准备
CREATE TABLE sales_by_region (product_name VARCHAR2(100), -- 商品region_name VARCHAR2(50), -- 地区sales_q1 NUMBER, -- 第一季度sales_q2 NUMBER, -- 第二季度sales_q3 NUMBER, -- 第三季度sales_q4 NUMBER -- 第四季度
);-- 商品 A 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'North', 5000, 8000, 7000, 9000);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'South', 7000, 7500, 8500, 9200);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'West', 4500, 6000, 6200, 6900);-- 商品 B 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'North', 6000, 7000, 7800, 8000);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'South', 8000, 9000, 9200, 9500);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'West', 5500, 6500, 6900, 7200);-- 商品 C 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'North', 5500, 6500, 7200, 7800);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'South', 6000, 7000, 7800, 8200);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'West', 4800, 5800, 6000, 6500);
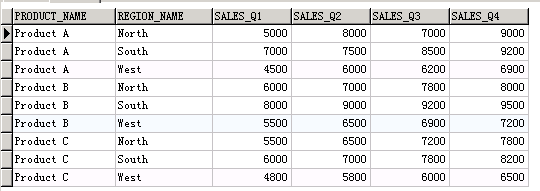
样例一
-- 普通查询
select * from sales_by_region
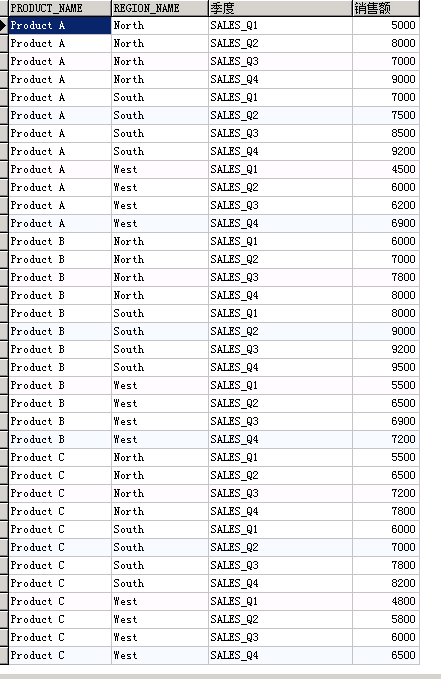
把四个季度的销售额合并到一个列中。
SELECT*
FROMsales_by_region UNPIVOT (销售额 FOR 季度 IN ( sales_q1, sales_q2 , sales_q3, sales_q4 )
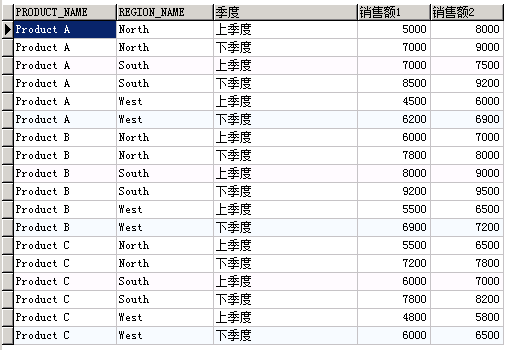
多个合并列
SELECT*
FROMsales_by_region UNPIVOT ( (销售额1 ,销售额2 ) FOR 季度 IN ( ( sales_q1, sales_q2 ) as '上季度' ,( sales_q3, sales_q4 ) as '下季度') );
上季度的销售额1 就相当于sales_q1,
上季度的销售额2 就相当于sales_q2,
下季度的销售额1 就相当于sales_q3,
下季度的销售额1 就相当于sales_q4,
有点绕,对应好即可。
总结
unpivot函数也是写在表名后面,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。(与pivot一样)unpivot会以移出被合并的列,然后将剩余的列组合成一个唯一值,每一个唯一值占一行。unpivot被合并的列的列名会在,fieldName中当做值来显示。- 被合并的列可以通过
as改变在fieldName显示的值。- 大部分用法跟
pivot一致,可以相互参考。
ales_q3,下季度的销售额1 就相当于sales_q4,
有点绕,对应好即可。
总结
unpivot函数也是写在表名后面,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。(与pivot一样)unpivot会以移出被合并的列,然后将剩余的列组合成一个唯一值,每一个唯一值占一行。unpivot被合并的列的列名会在,fieldName中当做值来显示。- 被合并的列可以通过
as改变在fieldName显示的值。- 大部分用法跟
pivot一致,可以相互参考。
相关文章:
Oracle行转列函数,列转行函数
Oracle行转列函数,列转行函数 Oracle 可以通过PIVOT,UNPIVOT,分解一行里面的值为多个列,及来合并多个列为一行。 PIVOT PIVOT是用于将行数据转换为列数据的查询操作(类似数据透视表)。通过使用PIVOT,您可以按照特定的列值将数据进行汇总,并将…...

线程同步--生产者消费者模型
文章目录 一.条件变量pthread线程库提供的条件变量操作 二.生产者消费者模型生产者消费者模型的高效性基于环形队列实现生产者消费者模型中的数据容器 一.条件变量 条件变量是线程间共享的全局变量,线程间可以通过条件变量进行同步控制条件变量的使用必须依赖于互斥锁以确保线…...

React hook+AntD pro实现Form表单的二次封装
React hookAntD pro实现Form表单的二次封装 封装Form表单1、在src/types下新建 antd/form/index.ts,进行Form表的配置、数据等类型的限制2、在 根目录/components 下新建 BaseForm/index.tsx文件3、在BaseForm/createFormIpt.tsx中,抽取对不同类型的表单…...
)
python异步切片下载文件(内置redis获取任务 mongo更新任务状态等)
异步切片下载二进制文件并上传桶删除本地文件 import json import os import asyncio from urllib import parseimport aiohttp import aioredis from motor.motor_asyncio import AsyncIOMotorClient from retrying import retry from minio import Minio from minio.error im…...
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(10)-Fiddler如何设置捕获Firefox浏览器的Https会话
1.简介 经过上一篇对Fiddler的配置后,绝大多数的Https的会话,我们可以成功捕获抓取到,但是有些版本的Firefox浏览器仍然是捕获不到其的Https会话,需要我们更进一步的配置才能捕获到会话进行抓包。 2.宏哥环境 1.宏哥的环境是Wi…...
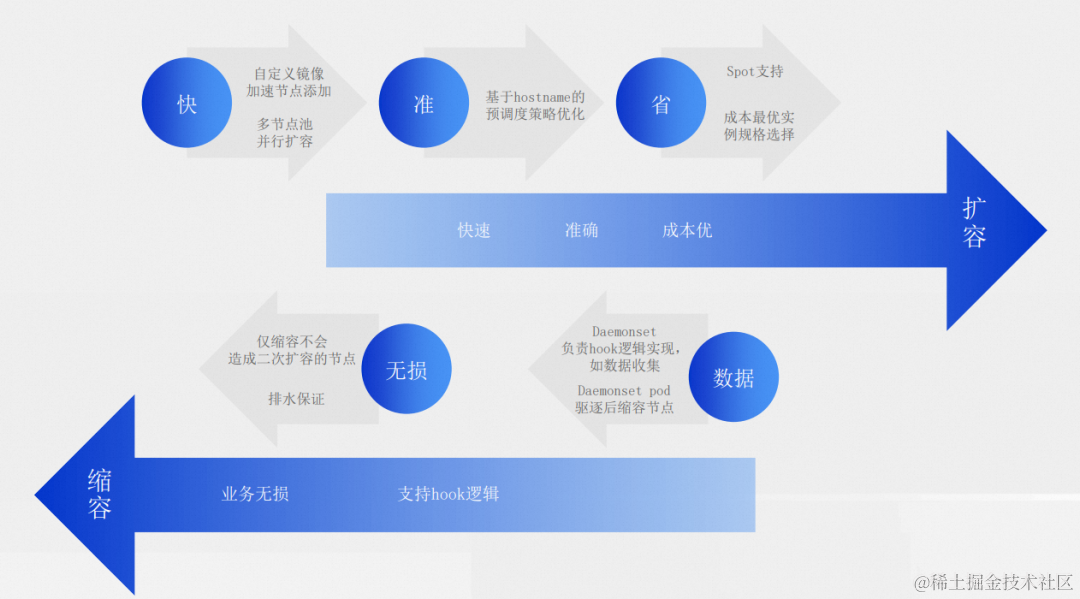
阿里云云原生弹性方案:用弹性解决集群资源利用率难题
作者:赫曦 随着上云的认知更加普遍,我们发现除了以往占大部分的互联网类型的客户,一些传统的企业,一些制造类的和工业型企业客户也都开始使用云原生的方式去做 IT 架构的转型,提高集群资源使用率也成为企业上云的一致…...
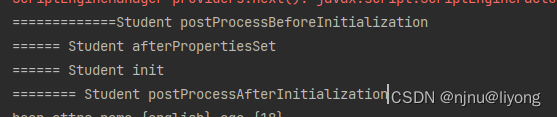
Spring-BeanPostProcessor PostConstruct init InitializingBean 执行顺序
执行顺序探究 新建一个对象用于测试 Component public class Student implements InitializingBean {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name name;}public int getAge() {return age;}pu…...
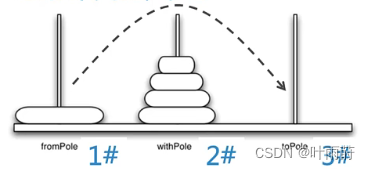
【算法】递归
递归 递归初始递归:数列求和递归的应用:任意进制转换递归深度限制递归可视化:分形树递归可视化:谢尔宾斯基Sierpinski三角形递归的应用:汉诺塔递归的应用:探索迷宫 分治策略和递归优化问题兑换最少个数硬币…...
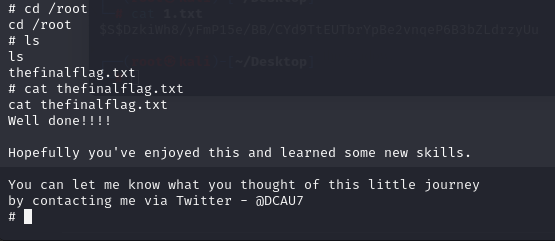
DC-1靶机刷题记录
靶机下载地址: 链接:https://pan.baidu.com/s/1GX7qOamdNx01622EYUBSow?pwd9nyo 提取码:9nyo 参考答案: https://c3ting.com/archives/kai-qi-vulnhnbshua-tiDC-1.pdf【【基础向】超详解vulnhub靶场DC-1】 https://www.bilibi…...
rust跟我学七:获取外网IP地址
图为RUST吉祥物 大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info是怎么获取到本机的外网IP地址。 首先,先要了解get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址:[…...

华为:交换机忘记console密码重置
一、背景 许多旧项目经过长时间使用后,因为没有特定的管理运维人员,初始对接人也将初始账号密码等重要信息丢失,现需要进后台查看配置或更改网络配置,需重置密码 二、重置密码,不重置设备方法 1、使用console插入交…...

2024年甘肃省职业院校技能大赛信息安全管理与评估 样题三 模块一
竞赛需要完成三个阶段的任务,分别完成三个模块,总分共计 1000分。三个模块内容和分值分别是: 1.第一阶段:模块一 网络平台搭建与设备安全防护(180 分钟,300 分)。 2.第二阶段:模块二…...

Go 中 slice 的 In 功能实现探索
文章目录 遍历二分查找map key性能总结 之前在知乎看到一个问题:为什么 Golang 没有像 Python 中 in 一样的功能?于是,搜了下这个问题,发现还是有不少人有这样的疑问。 补充:本文写于 2019 年。GO 现在已经支持泛型&am…...
 pyDAL的一些性能优化)
pyDAL一个python的ORM(终) pyDAL的一些性能优化
一、大批量插入数据 对于 大量数据插入时,虽然pyDAL也手册中有个方法:bulk_insert(),但是手册也说了,虽然方法上是一次可以多条数据,如果后端数据库是关系型数据库,他转换为SQL时它是一条一条的插入的&…...

springboot log4j配置xml实例说明
提供样本配置代码 xml <?xml version"1.0" encoding"UTF-8"?> <!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL --> <!-- status log4j2内部日志级别 --> <configurat…...
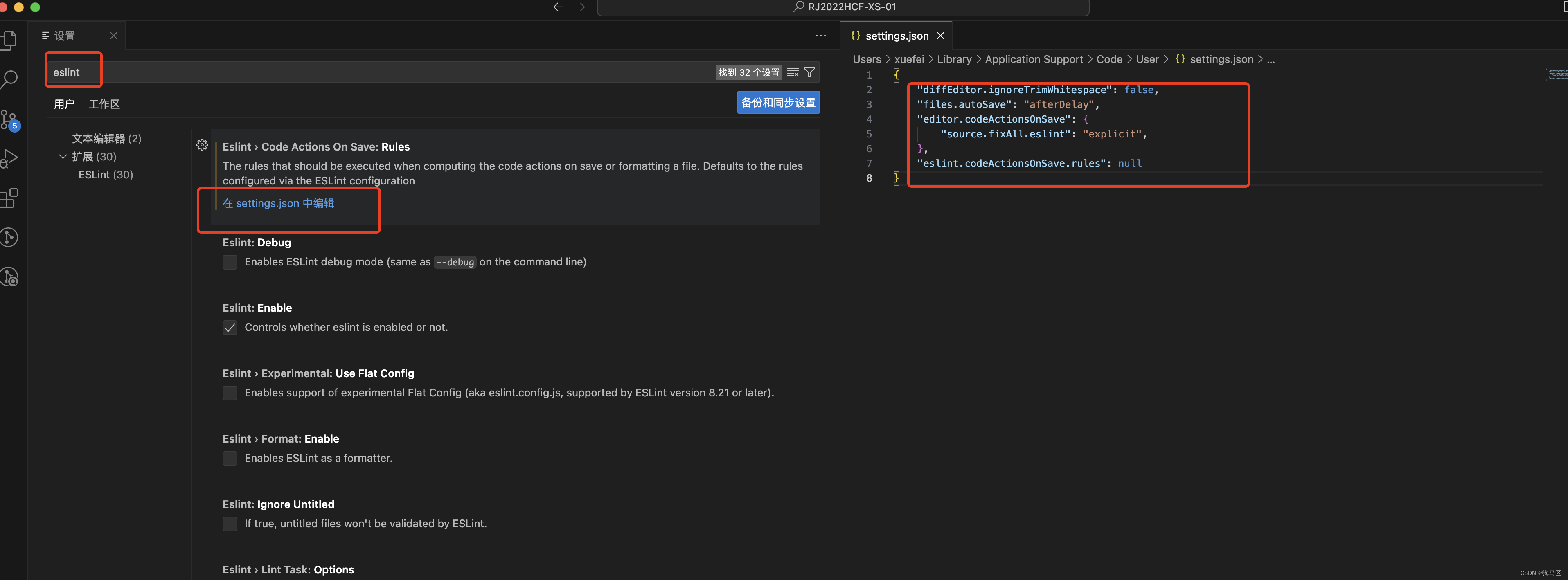
VsCode重新安装需要配机的ESLint和 Prettier - Code formatter 配置
新电脑安装完Vscode后,需要装几个插件,这里记录下: {"diffEditor.ignoreTrimWhitespace": false,"files.autoSave": "afterDelay","editor.codeActionsOnSave": {"source.fixAll.eslint"…...
录屏功能怎么打开?简单操作,一学就会!
录屏功能在当今互联网时代变得越来越重要,无论是游戏录制、在线课程录制还是屏幕操作演示,录屏功能都为我们提供了便捷的解决方案。可是您知道录屏功能怎么打开吗?接下来,让我们一起探索如何在电脑上开启录屏功能,记录…...

小程序显示兼容处理,home键处理
定义: env(safe-area-inset-bottom)和env(safe-area-inset-top)是CSS中的变量,用于获取设备底部和顶部安全区域的大小 示例: padding-bottom: calc(env(safe-area-inset-bottom) 12px); /* 兼容iOS> 11.2 */安全间距类型: …...
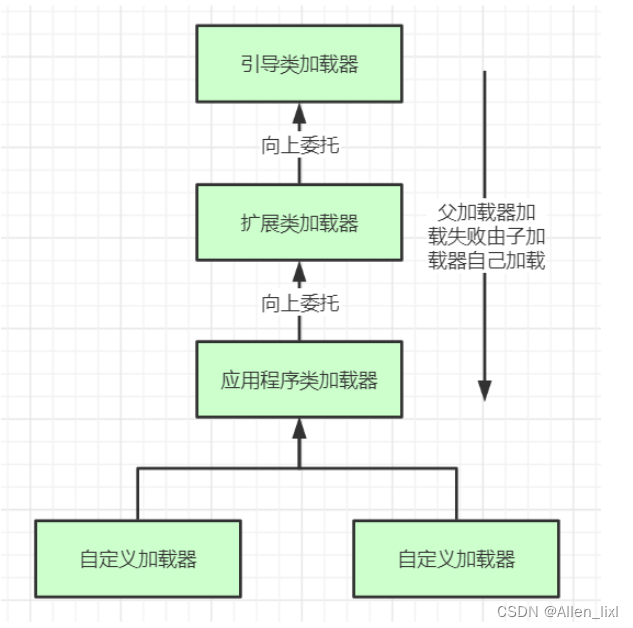
【java八股文】之JVM基础篇
【java八股文】之JVM基础篇-CSDN博客 【java八股文】之MYSQL基础篇-CSDN博客 【java八股文】之Redis基础篇-CSDN博客 【java八股文】之Spring系列篇-CSDN博客 【java八股文】之分布式系列篇-CSDN博客 【java八股文】之多线程篇-CSDN博客 【java八股文】之JVM基础篇-CSDN博…...

2024美赛数学建模思路 - 案例:异常检测
文章目录 赛题思路一、简介 -- 关于异常检测异常检测监督学习 二、异常检测算法2. 箱线图分析3. 基于距离/密度4. 基于划分思想 建模资料 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 一、简介 – 关于异常…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan部署详细教程
2026年京东云OpenClaw/Hermes Agent配置Token Plan部署详细教程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

iOS种子下载终极指南:iTorrent让你的iPhone变身专业下载中心
iOS种子下载终极指南:iTorrent让你的iPhone变身专业下载中心 【免费下载链接】iTorrent Torrent client for iOS 16 项目地址: https://gitcode.com/gh_mirrors/it/iTorrent 还在为iPhone无法下载种子文件而烦恼吗?iTorrent这款专业的iOS种子客户…...

深度解析XGBoost环境配置:从零构建高性能梯度提升库
深度解析XGBoost环境配置:从零构建高性能梯度提升库 【免费下载链接】xgboost Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C and more. Runs on single machine, Hadoop, Spark, Dask, Flink…...

从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析
从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 你是否曾经好奇,人工智能技术如何精准识别游戏中的…...

3分钟学会在Windows上安装安卓应用:APK-Installer完整指南
3分钟学会在Windows上安装安卓应用:APK-Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,…...

突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换
突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换 【免费下载链接】IfcOpenShell Open source IFC library and geometry engine 项目地址: https://gitcode.com/gh_mirrors/if/IfcOpenShell 在建筑信息模型(BIM)技术日益普…...

BGP状态机详解:从邻居建立到故障排查的完整指南
1. 项目概述:从“拒绝一切”到“稳定对话”的BGP邻居建立之旅如果你在网络运维或者数据中心工作的岗位上待过一阵子,肯定对BGP(边界网关协议)又爱又恨。爱的是它作为互联网“大管家”的稳定和强大,恨的是它一旦出问题&…...

i.MX6ULL电容触摸驱动开发:从硬件原理到Linux输入子系统实战
1. 项目概述:从零到一,搞定i.MX6ULL电容触摸最近在搞一个基于i.MX6ULL的工控HMI项目,客户要求界面操作必须流畅跟手,这就对触摸屏的响应速度和精度提出了硬性要求。市面上很多现成的模块要么驱动兼容性差,要么调试信息…...

终极指南:如何用YOLOv8 AI自瞄系统快速提升游戏瞄准精度
终极指南:如何用YOLOv8 AI自瞄系统快速提升游戏瞄准精度 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 RookieAI_yolov8是一款基于YO…...

新手开发者首次在Taotoken模型广场选型与试用的全过程记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手开发者首次在Taotoken模型广场选型与试用的全过程记录 作为一名刚开始接触大模型应用的开发者,我最近尝试了Taotok…...