使用函数计算,数禾如何实现高效的数据处理?
作者:邱鑫鑫,王彬,牟柏旭
公司背景和业务
数禾科技以大数据和技术为驱动,为金融机构提供高效的智能零售金融解决方案,服务银行、信托、消费金融公司、保险、小贷公司等持牌金融机构,业务涵盖消费信贷、小微企业信贷、场景分期等多个领域,提供营销获客、风险防控、运营管理等服务。数禾科技通过自主开发的消费信贷产品,连接金融机构与普罗大众,赋能金融机构数字化转型,迎接中国消费升级的大潮。
数禾当前有三款主要产品,还呗,还享花,小店邦。每款产品都有大量的受众,每天会产生大量的应用日志,数据通过压缩后归档到阿里云 OSS 存储,以达到最优的存储成本。
低效的数据处理
应用日志通过 SLS 收集,压缩并归档到 OSS,整个链路都非常顺滑。但日常有些业务需要查看详细的应用日志,由于日志收集会将 APP 上不同应用的日志都打到一起。因此,获取某个应用的日志,需要从 OSS 解压大量的文件,并从中过滤出特定的应用,才可以进一步分析排查。这个过程在实效性和数据处理效率上都存在很大的问题,为此,数禾运维团队计划从源头重构整个任务处理链路,以求以最低的开发成本,最高的处理效率,最优的资源费用,最好的扩展性打造高可用,易升级,低维护的解决方案。
首先想到的采用容器自建的方案。自建的处理程序从 Kafka 获取数据,并负责数据的处理,K8s 集群保证任务的弹缩,配合自建的发布平台,初步能够满足设计的需求。
该方案的优势在于,对于 K8s 的使用和任务发布平台,数禾运维团队都有了不少的积累,整体实施起来难度会比较小。但对比设想的链路目标,却还有些欠缺,主要表现在:
1. 任务开发成本较高: 从 Kafka 获取数据,数据的业务处理、异步压缩上传,任务的发布更新系统对接,K8s 的弹缩策略,都需要研发人员全新开发。
2. 链路弹性有限: 一是 K8s 通过指标弹出资源速度需要 10+s,对于突发的日志流量,可能会出现资源弹出不及时的情况;二是 Kafka Topic 数据处理的并发度受限于 Topic Partition,当消费程序达到 Partition 数目时,消费程序没法继续水平扩大并发度。
3. 资源利用率不够极致: 在业务低峰期,特别是夜间,存在流量很小甚至是无流量的时段,但处理程序还是得最小保持 1 个实例的运行,造成了一定的资源浪费。
4. 升级维护工作依然很多: 业务处理逻辑的修改,发布平台的更新对接,K8s 平台的弹缩规则等,都需要持续的维护。
就在数禾运维团队陷入选型沉思的时候,阿里云函数计算(后面简称 FC)团队的交流让数禾运维团队眼前一亮,阿里云函数计算在 Kafka->FC 的链路已经打磨多时,对于数禾的业务需求,正可以使用到函数计算很多的已有功能,数禾的研发团队只需要专注在自身的业务处理逻辑,就能快速的搭建一套高可用,易升级,低维护的任务处理链路。
函数计算的出现恰逢其时
函数计算是事件驱动的全托管计算服务。使用函数计算,客户无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算会准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。
通过函数计算自带的 Kafka 触发器和定时触发器,数禾运维团队架构出了一套理想的解决方案。架构图如下:
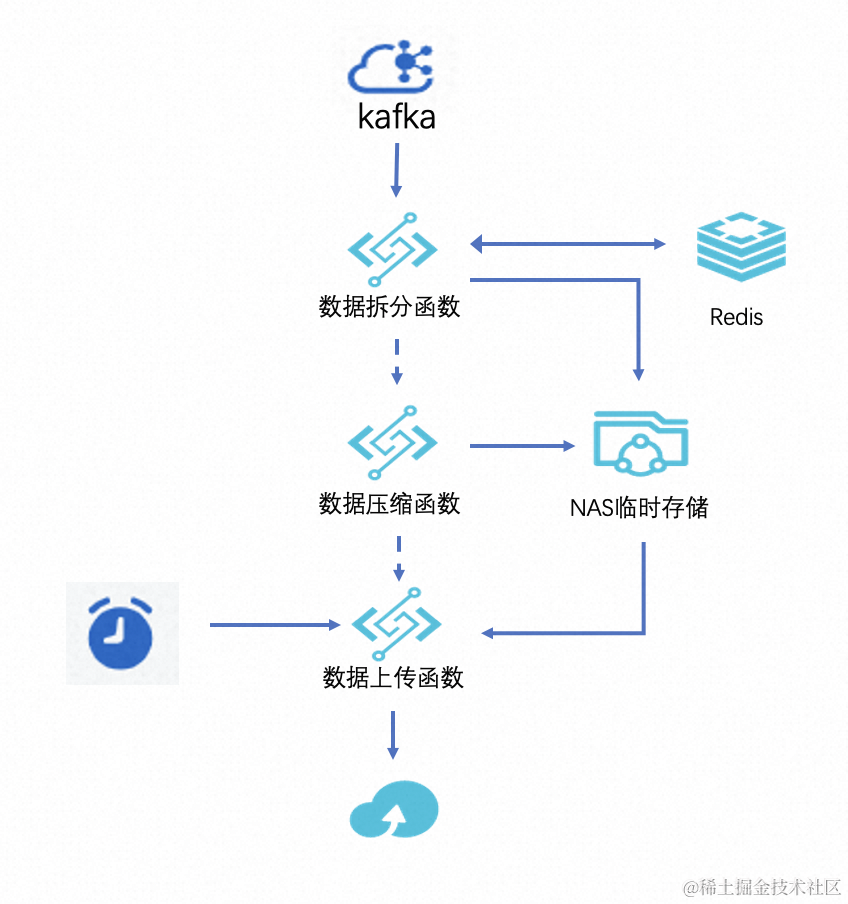
函数的处理逻辑如下:
-
数据拆分函数
通过 Kafka 触发器触发,触发器会将 Kafka 数据攒批,以 batch 的形式发送到函数计算,函数计算处理逻辑负责将数据块通过标识字段拆分,同一个应用的数据汇聚到一起,在 NAS 目录形成独立的文件。属于 io 密集型操作。
-
数据压缩函数
在一批数据到达函数计算拆分汇聚之后,先对数据进行压缩,然后将压缩后的数据追加到 NAS 目录对应的文件,在写 NAS 前,借助 Redis 处理并发锁的问题,大大减少了小文件的数量,属于算力密集型操作。
-
数据上传函数通过定时触发器触发,将第二步压缩完成的数据上传到 OSS 对应目录,然后清理本地目录。属于 io 密集型操作。
通过将处理逻辑拆分,将对资源要求不同的操作拆分到不同函数,实现了每个函数资源利用率的最大化,降低了总体实现的费用成本。
相比通过 ECS/K8s 自建的方案,优势还是十分明显的:
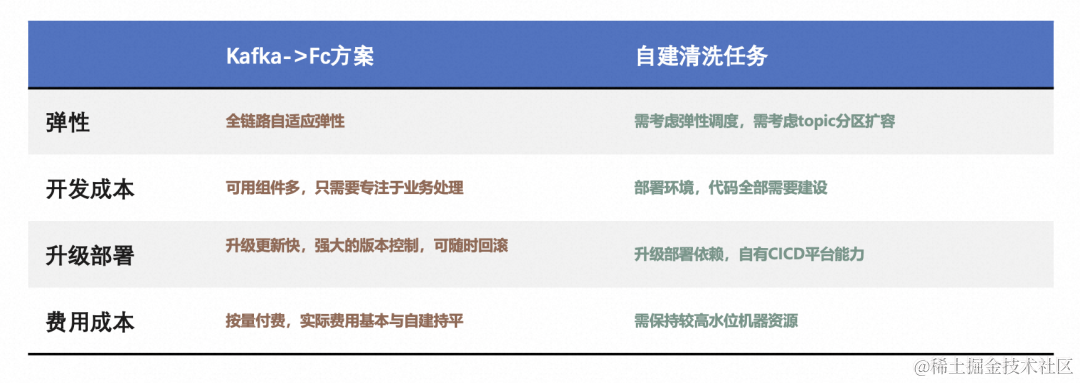
从对比可以看出,采用函数计算的方式,在开发效率,弹性,升级部署,费用成本方面,相对 ECS/K8s 自建方案,都有明显的优势。
落地中的问题
Serverless 理念跟整个任务的架构十分的契合,但在落地中还是可以看到有些处理不够优雅的地方,总结起来主要有两处:
-
函数计算同步调用的攒批大小是 16M,异步调用的攒批大小是 128K,为了降低调用函数的计算频率,达到更好的攒批效果,从而在成本和性能上都达到好的效果,使得触发器配置时只能配置同步调用,同步调用时,函数计算侧的并行度取决于调用方,这就要求触发器任务配置多任务分片,造成了一定的资源浪费。
-
在第一个函数中,主要处理逻辑是根据 Kafka 消息的应用 id 信息,拆分数据,将同一个 id 应用的数据聚合在一起,由于本身 NAS 和 OSS 都没有提供文件锁,所以当多个函数并发写同一个 id 应用文件时,如果程序层面不处理文件锁的问题,会导致写数据相互覆盖。对于每个函数实例拆分小文件的方案,由于 Kafka 消息中应用的种类很多,拆分数据总是会形成很多小文件,数据合并需要很长的时间。经过多种方案的检验比较,最终选择了通过 Redis 处理文件锁,每个应用全局最多产生 10 个并发写文件,函数计算运行实例写 NAS 文件时,先去 Redis 获取文件锁,获取成功才能真正开始写入。这种方案在写数据性能上有很好的表现,代码复杂度得到了一定的增加,但总体可控。
最终,这些问题没有成为数禾方案的卡点,通过交流和方案验证,最终都得到了一定程度的解决。
出色的效果和进一步的期待
在全链路角度看,整条链路非常的 Serverless,资源使用效率也非常高,再配合函数计算 2023 云栖大会推出的梯度计价,整个方案在资源成本上也达到了非常好的控制。
在期望方面,针对本次场景落地中遇到的问题,还是希望可以得到更好的优化。异步调用放宽消息体大小,可以以最少的触发器资源,达到函数计算的大并发处理。通过 NAS/OSS 原生支持文件锁的能力,可以减少文件的数量,同时也减少业务层代码在这方面的处理复杂度。
任务从 10 月份上线以来,数禾运维团队在该任务的运维投入上得到了人力释放,几乎达到了 0 运维; 在功能迭代上,通过函数计算控制台提供的多版本和灰度能力,快速的完成了升级的灰度。
后续数禾运维团队会将更多适合 Serverless 的业务采用函数计算方案,最大限度将精力专注在公司业务,逐渐剥离运维和底层资源的简单维护。数禾运维团队也十分开放的与函数计算团队探讨更多的场景,希望将公司的业务架构在新一代的 Serverless 架构上。
相关文章:
使用函数计算,数禾如何实现高效的数据处理?
作者:邱鑫鑫,王彬,牟柏旭 公司背景和业务 数禾科技以大数据和技术为驱动,为金融机构提供高效的智能零售金融解决方案,服务银行、信托、消费金融公司、保险、小贷公司等持牌金融机构,业务涵盖消费信贷、小…...

卷积和滤波对图像操作的区别
目录 问题引入 解释 卷积 滤波 问题引入 卷积和滤波是很相似的,都是利用了卷积核进行操作 那么他们之间有什么区别呢? 卷积:会影响原图大小 滤波:不会影响原图大小 解释 卷积 我们用这样一段代码来看 import torch.nn as …...

李沐深度学习-线性回归从零开始
# 核心Tensor,autograd import torch from IPython import display import numpy as np import random from matplotlib import pyplot as pltimport syssys.path.append(路径) from d2lzh_pytorch import * backward()函数:一次小批量执行完在进行反向传播 线性回归…...
CentOS 8.5 安装图解
特特特别的说明 CentOS发行版已经不再适合应用于生产环境,客观条件不得不用的话,优选7.9版本,8.5版本次之,最次6.10版本(比如说Oracle 11GR2就建议在6版本上部署)! 引导和开始安装 选择倒计时结…...
好用的流程图工具
分享工作中常用的装逼工具 目前市面上的流程图或者思维导图工具挺多的,但是有的会限制使用数量或者收费,典型的有processon、Xmind,推荐今天Mermaid(官网)。 快速上手 中文教程:Mermaid 初学者用户指南 | Mermaid 中文网。我们选择…...
数据结构:链式栈
stack.h /* * 文件名称:stack.h * 创 建 者:cxy * 创建日期:2024年01月18日 * 描 述: */ #ifndef _STACK_H #define _STACK_H#include <stdio.h> #include <stdlib.h>typedef struct stack{int data…...

openssl3.2 - 官方demo学习 - mac - gmac.c
文章目录 openssl3.2 - 官方demo学习 - mac - gmac.c概述笔记END openssl3.2 - 官方demo学习 - mac - gmac.c 概述 使用GMAC算法, 设置参数(指定加密算法 e.g. AES-128-GCM, 设置iv) 用key执行初始化, 然后对明文生成MAC数据 官方注释给出建议, key, iv最好不要硬编码出现在程…...
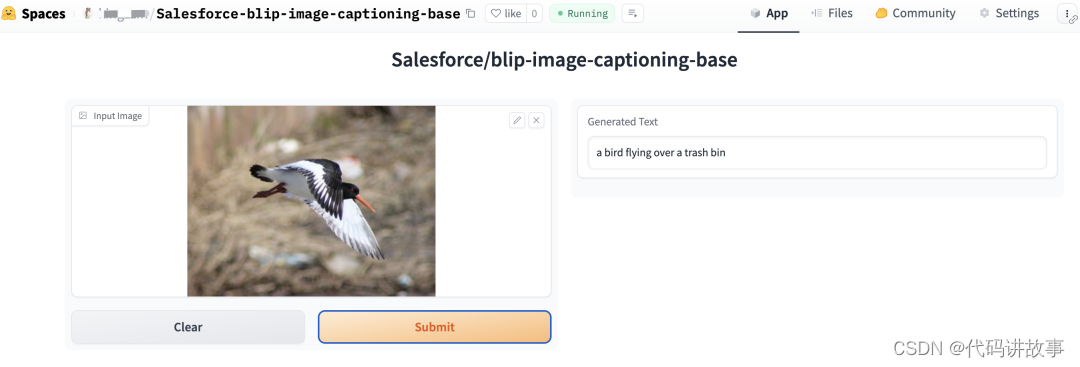
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍
HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍。 Hugging Face是一家开源模型库公司。 2023年5月10日,Hugging Face宣布C轮1亿美元融资,由Lux Capital领投,红杉资本、Coatue、Betaworks、NBA球星Kevin Durant等跟投…...

python的tabulate包在命令行下输出表格不对齐
用tabulate可以在命令行下输出表格。 from tabulate import tabulate# 定义表头 headers [列1, 列2, 列3]# 每行的内容 rows [] rows.append((张三,数学,英语)) rows.append((李四,信息科技,数学))# 使用 tabulate 函数生成表格 output tabulate(rows, headersheaders, tab…...
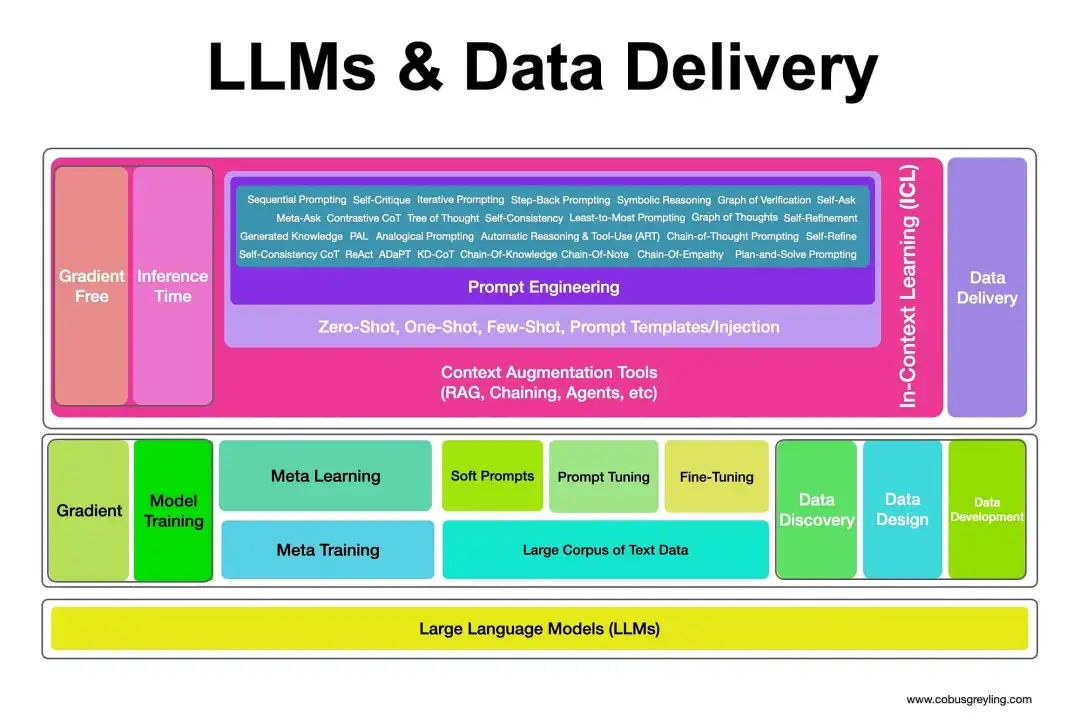
LLM之幻觉(二):大语言模型LLM幻觉缓减技术综述
LLM幻觉缓减技术分为两大主流,梯度方法和非梯度方法。梯度方法是指对基本LLM进行微调;而非梯度方法主要是在推理时使用Prompt工程技术。LLM幻觉缓减技术,如下图所示: LLM幻觉缓减技术值得注意的是: 检索增强生成&…...

C# 使用多线程,关闭窗体时,退出所有线程
this.Close(); 只是关闭当前窗口,若不是主窗体的话,是无法退出程序的,另外若有托管线程(非主线程),也无法干净地退出;Application.Exit(); 强制所有消息中止,退出所有的窗体&…...

数据结构实验6:图的应用
目录 一、实验目的 1. 邻接矩阵 2. 邻接矩阵表示图的结构定义 3. 图的初始化 4. 边的添加 5. 边的删除 6. Dijkstra算法 三、实验内容 实验内容 代码 截图 分析 一、实验目的 1.掌握图的邻接矩阵的存储定义; 2.掌握图的最短路径…...

Spring Boot整合JUnit
引言 测试是软件开发过程中不可或缺的一环,而JUnit作为Java生态中最流行的测试框架之一,与Spring Boot的整合为开发者提供了一套强大的测试工具。本文将讨论Spring Boot整合JUnit的技术细节、最佳实践以及测试驱动开发(TDD)的优雅…...
)
uniapp写小程序实现清除缓存(存储/获取/移除/清空)
在uni-app中,可以使用uni.setStorageSync和uni.getStorageSync来进行数据的存储和获取。而移除缓存数据可以使用uni.removeStorageSync,清空缓存数据可以使用uni.clearStorageSync。 以下是使用示例: 存储数据: uni.setStorage…...

js菜单隐藏显示
1、树状结构对应的表: 2、生成menulist的SQL语句 select {"id":"MenuID","parent":"ParentID","FirstLvMenu":"FirstLvMenu", "text":"MenuName","url":"MenuUrl",&quo…...
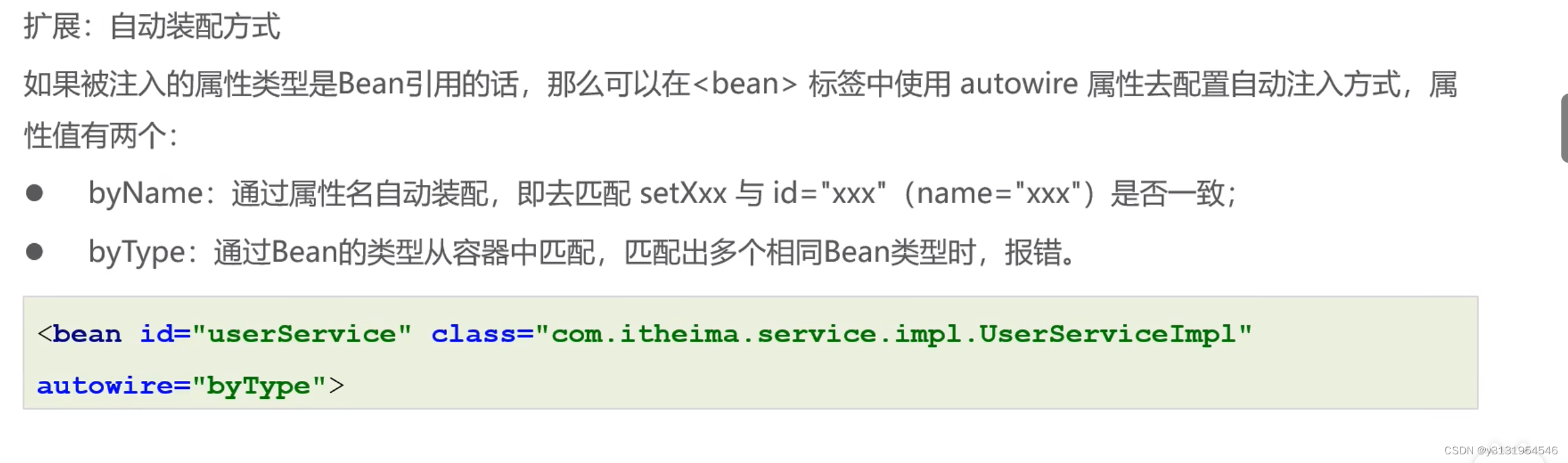
学习Spring的第五天(Bean的依赖注入)
Bean的依赖注入有两种方式: 一 . 常规Bean的依赖注入 很简单,不过多赘述了,注意ref: 是构造函数或set方法的参数,一般为对象, value: 是构造函数或set方法的参数,一般为值. 看下图 1.1 下面来演示一下集合数据类型的关于Bean的依赖注入 1.1.1这是List的注入(演示泛型为Strin…...

GAN在图像数据增强中的应用
在图像数据增强领域,生成对抗网络(GAN)的应用主要集中在通过生成新的图像数据来扩展现有数据集的规模和多样性。这种方法特别适用于训练数据有限的情况,可以通过增加数据的多样性来提高机器学习模型的性能和泛化能力。 以下是GAN在…...

Git推送本地文件到仓库
1. 在 Gitee 上创建一个新的仓库: 登录到 Gitee(https://gitee.com)账号。在 Gitee 主页上选择 "新建仓库" 或类似选项。输入仓库名称和描述,并选择其他相关选项(如公开/私有)。确认创建仓库 …...

Django笔记(一):环境部署
目录 Python虚拟环境 安装virtualenv 创建环境 激活环境 关闭: 安装Django VSCode配置 Python插件 Django插件 解释器选择 Django部署 创建项目 创建app 创建模板 编写视图 编写路由 启动服务器 访问 Python虚拟环境 安装virtualenv pip i…...
用Pytorch实现线性回归模型
目录 回顾Pytorch实现步骤1. 准备数据2. 设计模型class LinearModel代码 3. 构造损失函数和优化器4. 训练过程5. 输出和测试完整代码 练习 回顾 前面已经学习过线性模型相关的内容,实现线性模型的过程并没有使用到Pytorch。 这节课主要是利用Pytorch实现线性模型。…...

三步搞定Windows和Office永久激活:KMS_VL_ALL_AIO智能激活全攻略
三步搞定Windows和Office永久激活:KMS_VL_ALL_AIO智能激活全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office突然…...

2026 年我作为资深工程师如何使用 LLM Agent:从副驾到主驾的真实工作流转变
从副驾到主驾,2026 年资深工程师的 LLM Agent 实战工作流:哪些交给 Agent,哪些必须自己做。 原文链接:AI 小老六 一年之差:Agent 从「勉强能用」变成了「几乎离不开」 2025 年初,行业里最强的推理模型还是…...

告别寄存器操作:在RA4M2上体验瑞萨FSP库点灯,对比STM32 HAL/LL库有何不同?
从STM32到RA4M2:FSP库与HAL/LL库的深度对比与实践指南 如果你已经习惯了STM32的HAL库或LL库开发,初次接触瑞萨RA4M2的FSP库可能会感到既熟悉又陌生。本文将带你深入比较这两种开发方式的异同,并通过一个实际的LED控制案例,展示如何…...

干货 | 细胞功能学实验合集
细胞增殖实验细胞增殖、凋亡及细胞周期调控,是肿瘤学研究中的核心表型指标,同时也是分子生物学与药理学领域的重点研究方向。在实验研究中,研究者通常通过在细胞内实现特定基因的过表达或干扰,来探究该基因对细胞增殖的调控作用&a…...

AArch64调试异常机制与自托管调试实践
1. AArch64调试异常机制概述在AArch64架构中,调试异常是处理器响应调试事件的核心机制。当程序执行过程中遇到预设的调试条件时,处理器会暂停正常执行流,转而进入异常处理流程。这种机制使得开发者能够在不引入额外硬件调试器的情况下&#x…...
)
从零到一:用Air724UG 4G模块和Python,手把手教你搭建一个物联网数据上报系统(含完整代码)
从零构建物联网数据上报系统:Air724UG与Python实战指南 在万物互联的时代,物联网技术正悄然改变着我们的生活和工作方式。想象一下,您只需轻点手机,就能实时查看千里之外温湿度数据;或是远程监控设备运行状态ÿ…...
)
保姆级教程:用Python脚本一键搞定OPIXray/HIXray数据集转YOLO格式(附避坑指南)
Python实战:OPIXray/HIXray数据集高效转YOLO格式全流程解析 在目标检测领域,数据格式转换往往是项目落地的第一道门槛。当我第一次拿到OPIXray和HIXray这两个专业X光安检数据集时,面对原始标注格式与YOLO训练需求的不匹配,也经历过…...

衍射光学元件微结构
衍射光学元件(DOEs)是利用刻蚀微结构的衍射特性将入射光束转换为所需光分布的光学元件,利用结构的周期性或无周期性分别创建离散的(分束器)或连续的模式(光束整形器、扩散器)。由于这些元件的工作原理是基于光通过这些图案表面的衍射,因此DOE光束整形器和…...

今天开始学爬虫1
1.1:import urllib错误 module urllib has no attribute request应该import urllib.requestimport urllib.requesturlhttp://www.baidu.com/ responseurllib.request.urlopen(url) contentresponse.read().decode(utf-8) print(content)2.1#返回字节 contentrespons…...

从源码到蓝图:使用Visual Paradigm高效逆向工程UML图
1. 逆向工程的价值与Visual Paradigm定位 接手一个遗留项目时,最头疼的往往不是写新代码,而是理解前人留下的"天书"。上周我就遇到个典型场景:客户紧急要求给三年前的老系统加功能,但项目文档只有一张模糊的截图和半页残…...