大模型推理引擎面试复习大纲
Transformer原理
基本组成、注意力机制含义
transformer有哪些模块,各个模块有什么作用?
transformer的模块可以分为以下几类:
Encoder模块:transformer的编码器,它由多个相同的encoder层堆叠而成,每个encoder层包含两个子层,分别是多头自注意力层和前馈全连接层。Encoder模块的作用是将输入的文本序列转换为一组连续的向量,表示文本的语义和语法信息。
多头自注意力层的作用?
多头自注意力层可以让模型同时关注不同的位置和不同的特征子空间,从而捕捉到更丰富的信息和语义。例如,对于一个句子,不同的头可能会关注到不同的词性、语法、语义等方面的信息,从而提高模型的理解能力。
多头自注意力层可以增加模型的表达能力和泛化能力,因为不同的头可以学习到不同的参数和权重,从而增加模型的容量和多样性。例如,对于一个翻译任务,不同的头可能会学习到不同的对齐方式,从而提高模型的翻译质量。
多头自注意力层可以提高模型的效率和稳定性,因为每个头的维度都比单个的自注意力层小,从而减少了计算量和内存消耗。例如,对于一个 512 维的输入,如果使用一个自注意力层,那么计算量为 512512=262144;如果使用 8 个头,每个头的维度为 64,那么计算量为 864*64=32768,相比之下,计算量减少了 8 倍。
transformer的encoder模块中前馈全连接层的作用?
transformer的encoder模块中前馈全连接层是一个由两个线性层和一个激活函数组成的简单网络,它接在多头自注意力层的后面,用来对自注意力层的输出进行进一步的变换。
前馈全连接层的作用主要有以下几点:
前馈全连接层可以增加模型的非线性能力,因为自注意力层本质上是一个线性变换,而前馈全连接层引入了激活函数(如ReLU),从而增加了模型的复杂度和表达能力。
前馈全连接层可以提高模型的抽象能力,因为前馈全连接层可以将自注意力层的输出映射到一个更高维的空间,从而提取出更高级的特征和语义。
前馈全连接层可以增强模型的稳定性,因为前馈全连接层配合残差连接和层归一化,可以防止梯度消失或爆炸,提高模型的深度和性能 。
Decoder模块:transformer的解码器,它由多个相同的decoder层堆叠而成,每个decoder层包含三个子层,分别是多头自注意力层、Encoder-Decoder注意力层和前馈全连接层。Decoder模块的作用是根据Encoder模块的输出和自身的历史输出,生成目标文本序列。
Positional Encoding模块:transformer的位置编码器,它是一种用正弦和余弦函数生成的波形,用来表示文本序列中每个token的位置信息。Positional Encoding模块的作用是让transformer能够捕捉到文本序列的顺序和结构信息,因为transformer本身没有循环或卷积结构,无法直接感知位置信息。
Add & Norm模块:transformer的残差连接和层归一化模块,它接在每个子层的后面,用来平衡和稳定模型的训练。Add & Norm模块的作用是将子层的输入和输出相加,然后进行层归一化,防止梯度消失或爆炸,提高模型的深度和性能。
Encoder-Decoder注意力层的作用?
Encoder-Decoder注意力层可以让解码器的输出与编码器的输出进行交叉注意力计算,从而实现源语言和目标语言之间的对齐。这样可以提高模型的翻译质量和生成流畅度。
Encoder-Decoder注意力层可以让解码器的输出融合编码器的输出中的全局信息和上下文信息,从而增强模型的理解能力和生成能力。这样可以提高模型的泛化能力和鲁棒性。
Encoder-Decoder注意力层可以让解码器的输出根据编码器的输出中的不同特征子空间进行多头注意力计算,从而捕捉到更丰富的信息和语义5。这样可以提高模型的表达能力和多样性。
transformer中decoder模块的mask有什么作用?
transformer中decoder模块的mask是一种用来防止模型看到未来信息的技术,它可以保证模型的预测是因果的,即只依赖于当前和之前的输入,而不依赖于之后的输入。这样可以提高模型的泛化能力和生成质量。
transformer中decoder模块有两种mask,分别是:
Masked self-attention mask:这种mask是用来遮住decoder的输入序列中当前位置之后的token,使得模型在计算自注意力时,只能看到当前位置及之前的token,而不能看到之后的token。这种mask可以防止模型在生成过程中,提前看到要生成的内容,从而影响模型的预测。例如,如果模型要生成一个句子,它不能在生成第一个单词时,就看到第二个单词,否则就会失去生成的意义。
Encoder-decoder attention mask:这种mask是用来遮住encoder的输出序列中无效的部分,即pad的部分,使得模型在计算交叉注意力时,只能看到有效的token,而不能看到无效的token。这种mask可以防止模型在对齐过程中,受到无关的信息的干扰,从而提高模型的对齐精度。例如,如果模型要进行机器翻译,它不能在对齐源语言和目标语言时,把pad的部分也考虑进去,否则就会导致错误的对齐。
使用encoder-decoder attention mask计算交叉注意力时使用的mask作用是什么?这个mask计算位于transformer的那个网络层中?
使用encoder-decoder attention mask计算交叉注意力时,mask的作用是遮住encoder的输出序列中无效的部分,即pad的部分,使得模型在计算交叉注意力时,只能看到有效的token,而不能看到无效的token。这种mask可以防止模型在对齐过程中,受到无关的信息的干扰,从而提高模型的对齐精度。
这个mask计算位于transformer的decoder模块中的每个decoder层的第二个子层,即encoder-decoder attention层。这个层的作用是让decoder的输出与encoder的输出进行交互,从而实现源语言和目标语言之间的对齐。
transformer中多头有什么好处?
多头注意力机制可以增加模型的表达能力和泛化能力,因为不同的头可以学习到不同的参数和权重,从而增加模型的容量和多样性。例如,对于一个翻译任务,不同的头可能会学习到不同的对齐方式,从而提高模型的翻译质量。
多头注意力机制可以提高模型的效率和稳定性,因为每个头的维度都比单个的自注意力层小,从而减少了计算量和内存消耗5 。例如,对于一个 512 维的输入,如果使用一个自注意力层,那么计算量为 512512=262144;如果使用 8 个头,每个头的维度为 64,那么计算量为 864*64=32768,相比之下,计算量减少了 8 倍。
大模型fine-tunning技术
什么是微调?
微调是一种迁移学习的方法,它指的是在一个已经预训练好的模型的基础上,用少量的数据来对模型进行再训练,使得模型能够适应新的任务或领域。微调的目的是利用已有的模型,减少训练新模型的时间和资源消耗。
parameter-efficient fine-tunning技术
参数高效的fine-tunning技术。通过训练一小组参数来解决传统微调技术需要大量资源的问题。这些参数可能是现有模型参数的子集或新添加一组参数。这些方法在参数效率、内存效率、训练速度、模型的最终质量和附加推理成本方面存在差异。
蒸馏(distillation)
由hinton等人2015年引进。
适配器训练(adapter training)
由Houlsby等人2019年引入。
适配器是添加到预训练模型中的小型神经网络,用于特定任务的微调。这些适配器只占原始模型大小的一部分,这使得训练更快,内存需求更低。
渐进收缩(progressive shrinking)
由kaplan等人于2020年引入。这种技术涉及在fine-tuning期间逐渐减小预训练模型的大小。
prompt-tuning技术
prompt-tuning是一种更近期的精调预训练语言模型的方法。重点是调整输入提示(input prompt)而非修改模型参数。这意味着预训练模型保持不变,只有输入提升被修改以适应下游的任务。通过设计和优化一组提示,可以使预训练模型执行特定任务。
prefix tuning(前缀调整)
前缀调整涉及学习特定任务的连续提示。在推理过程中将其添加到输入之前。通过优化这个连续提示,模型可以适应特定任务而不修改底层模型参数。这节省了计算资源并实现了高效的精调。
P-tuning
P-tuning是针对自然语言理解(NLU)任务的,它使用了一个LSTM作为prompt-encoder,将可学习的token编码成virtual token embedding,然后插入到输入序列中,最后预测一个[MASK]位置的输出。
P-Tuning:由Liu等人在论文“P-Tuning: GPT Understands, Learns, and Generates Any Language”(2021)中提出。P-Tuning涉及训练可学习的称为“提示记号”的参数,这些参数与输入序列连接。这些提示记号是特定于任务的,在精调过程中进行优化,使得模型可以在保持原始模型参数不变的情况下在新任务上表现良好。
大模型推理加速的技术
相关文章:

大模型推理引擎面试复习大纲
Transformer原理 基本组成、注意力机制含义 transformer有哪些模块,各个模块有什么作用? transformer的模块可以分为以下几类: Encoder模块:transformer的编码器,它由多个相同的encoder层堆叠而成,每个enc…...

网络安全 | 苹果承认 GPU 安全漏洞存在,iPhone 12、M2 MacBook Air 等受影响
1 月 17 日消息,苹果公司确认了近期出现的有关 Apple GPU 存在安全漏洞的报告,并承认 iPhone 12 和 M2 MacBook Air 受影响。 该漏洞可能使攻击者窃取由芯片处理的数据,包括与 ChatGPT 的对话内容等隐私信息。 安全研究人员发现,…...

C++ 数论相关题目(约数)
1、试除法求约数 主要还是可以成对的求约数进行优化,不然会超时。 时间复杂度根号n #include <iostream> #include <vector> #include <algorithm>using namespace std;int n;vector<int> solve(int a) {vector<int> res;for(int i…...

freeswitch on centos dockerfile模式
概述 freeswitch是一款简单好用的VOIP开源软交换平台。 centos7 docker上编译安装fs的流程记录,本文使用dockerfile模式。 环境 docker engine:Version 24.0.6 centos docker:7 freeswitch:v1.6.20 dockerfile 创建空目录…...

Hologres + Flink 流式湖仓建设
Hologres + Flink 流式湖仓建设 1 Flink + Hologres 特性1.2 实时维表 Lookup1.3 高性能实时写入与更新1.4 多流合并1.5 Hologres 作为 Flink 的数据源1.6 元数据自动发现与更新2 传统实时数仓分层方案2.1传统实时数仓分层方案 1:流式 ETL2.2 传统实时数仓分层方案 2:定时调度…...
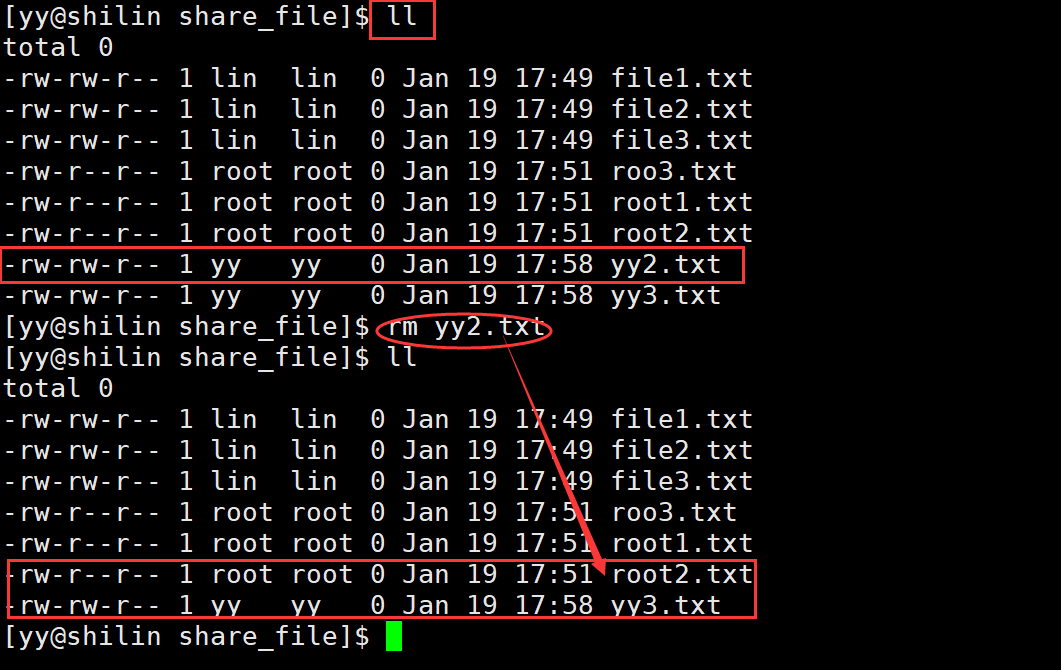
Linux粘滞位的理解,什么是粘滞位?
文章目录 前言如何理解?粘滞位的操作最后总结一下 前言 粘滞位(Stickybit),或粘着位,是Unix文件系统权限的一个旗标。最常见的用法在目录上设置粘滞位,如此以来,只有目录内文件的所有者或者root…...

Stable Diffusion的结构要被淘汰了吗?详细解读谷歌最新大杀器VideoPoet
Diffusion Models视频生成-博客汇总 前言:视频生成领域长期被Stable Diffusion统治,大部分的方式都是在预训练的图片Stable Diffusion的基础上加入时间层,学习动态信息。虽然有CoDi《【NeurIPS 2023】多模态联合视频生成大模型CoDi》等模型尝试过突破这一结构的局限,但是都…...

深度学习与大数据推动下的自然语言处理革命
引言: 在当今数字化时代,深度学习和大数据技术的迅猛发展为自然语言处理(Natural Language Processing, NLP)领域注入了新的活力。这些技术的进步不仅推动了计算机对人类语言理解与生成的能力,也在搜索引擎、语音助手、…...

产品经理必备之最强管理项目过程工具----禅道
目录 一.禅道的下载安装 二.禅道的使用 2.1 创建用户 2.2 产品经理的角色 2.3 项目经理的角色 研发的角色 2.4 测试主管的角色 研发角色 三.禅道使用的泳道图 一.禅道的下载安装 官网:项目管理软件 开源项目管理软件 免费项目管理软件 IPD管理软件 - 禅…...

美易官方:贝莱德预计美联储将在6月份开始降息,欧洲央行紧随其后
正文: 根据贝莱德的最新预测,美联储将在6月份开始降息,这一消息早于欧洲央行的预期。贝莱德高级投资策略师Laura Cooper表示:“我们更倾向于6月份降息、然后重新校准政策。”预计美联储在年底前将会降息75至100个基点。 与此同时…...

视觉检测系统:工厂生产零部件的智能检测
在工厂的生产加工过程中,工业视觉检测系统被广泛应用,并且起着重要的作用。它能够对不同的零部件进行多功能的视觉检测,包括尺寸和外观的缺陷。随着制造业市场竞争越来越激烈,对产品质检效率的要求不断提高,传统的人工…...

Spring事务的四大特性+事务的传播机制+隔离机制
Spring事务的四大特性 ① 原子性 atomicity 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 事务是一个原子操作, 由一系列动作组成。 组成一个事务的多个数据库操作是一个不可分割的原子单元,只有所有的…...
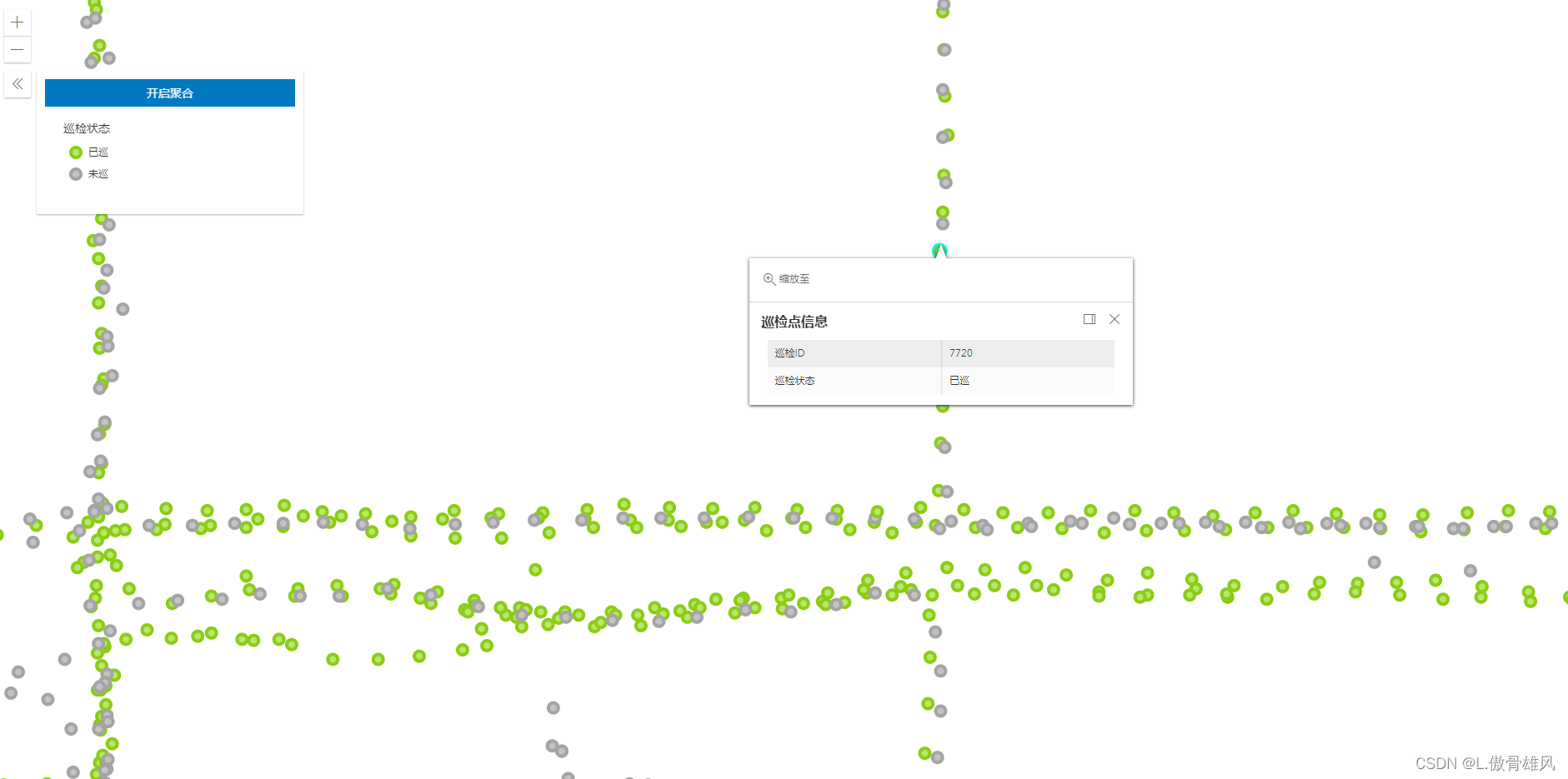
基于arcgis js api 4.x开发点聚合效果
一、代码 <html> <head><meta charset"utf-8" /><meta name"viewport"content"initial-scale1,maximum-scale1,user-scalableno" /><title>Build a custom layer view using deck.gl | Sample | ArcGIS API fo…...
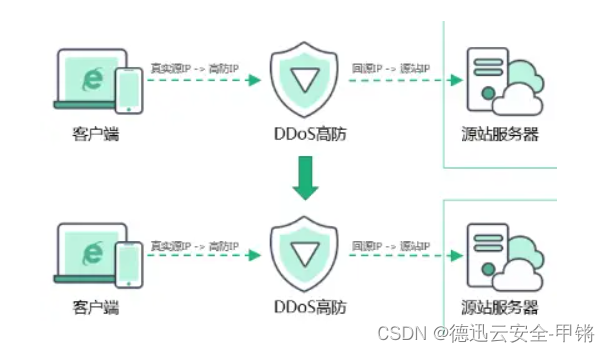
什么是DDOS高防ip?DDOS高防ip是怎么防护攻击的
随着互联网的快速发展,网络安全问题日益突出,DDoS攻击和CC攻击等网络威胁对企业和网站的正常运营造成了巨大的威胁。为了解决这些问题,高防IP作为一种网络安全服务应运而生。高防IP通过实时监测和分析流量,识别和拦截恶意流量&…...
)
提示词工程: 大语言模型的Embedding(嵌入和Fine-tuning(微调)
本文是针对这篇文章(https://www.promptengineering.org/master-prompt-engineering-llm-embedding-and-fine-tuning/)的中文翻译,用以详细介绍Embedding(语义嵌入)和Fine Tuning(微调)的概念和…...
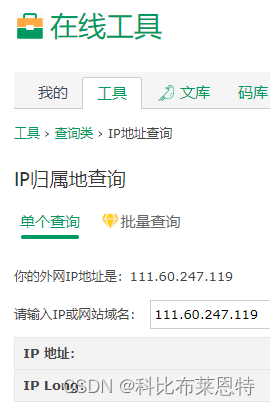
rust获取本地外网ip地址的方法
大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info的使用。 get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址&a…...
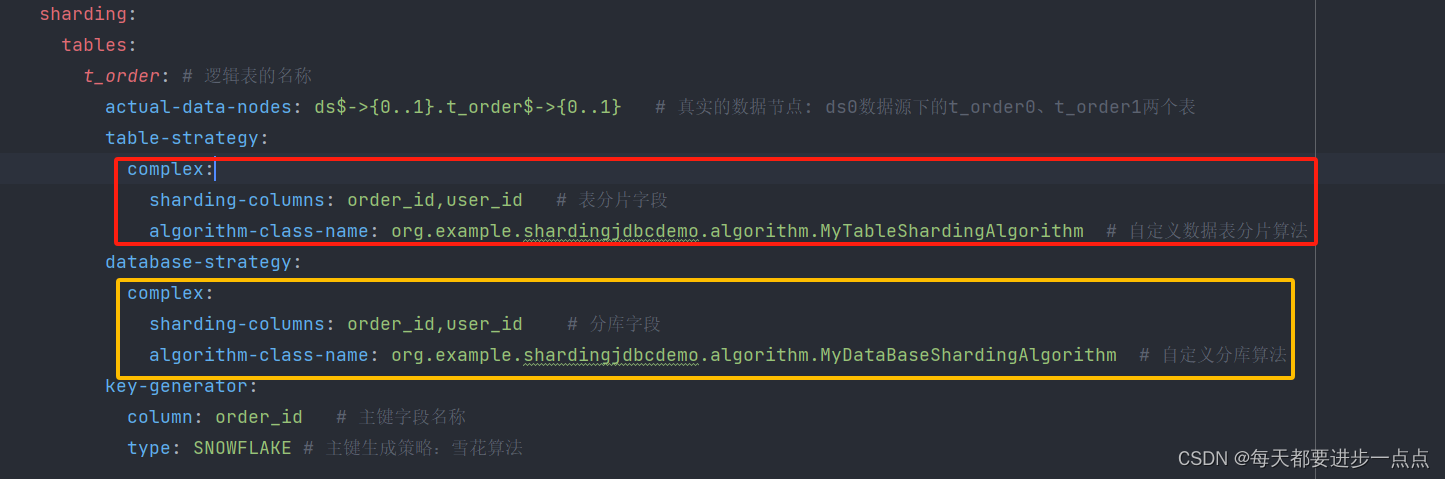
三、Sharding-JDBC系列03:自定义分片算法
目录 一、概述 1.1、分片算法 精确分片算法 范围分片算法 复合分片算法 Hint分片算法 1.2、分片策略 标准分片策略 复合分片策略 行表达式分片策略 Hint分片策略 不分片策略 二、自定义分片算法 - 复合分片算法 (1)、创建数据库和表 (2)、自定义分库算法 (3)、…...
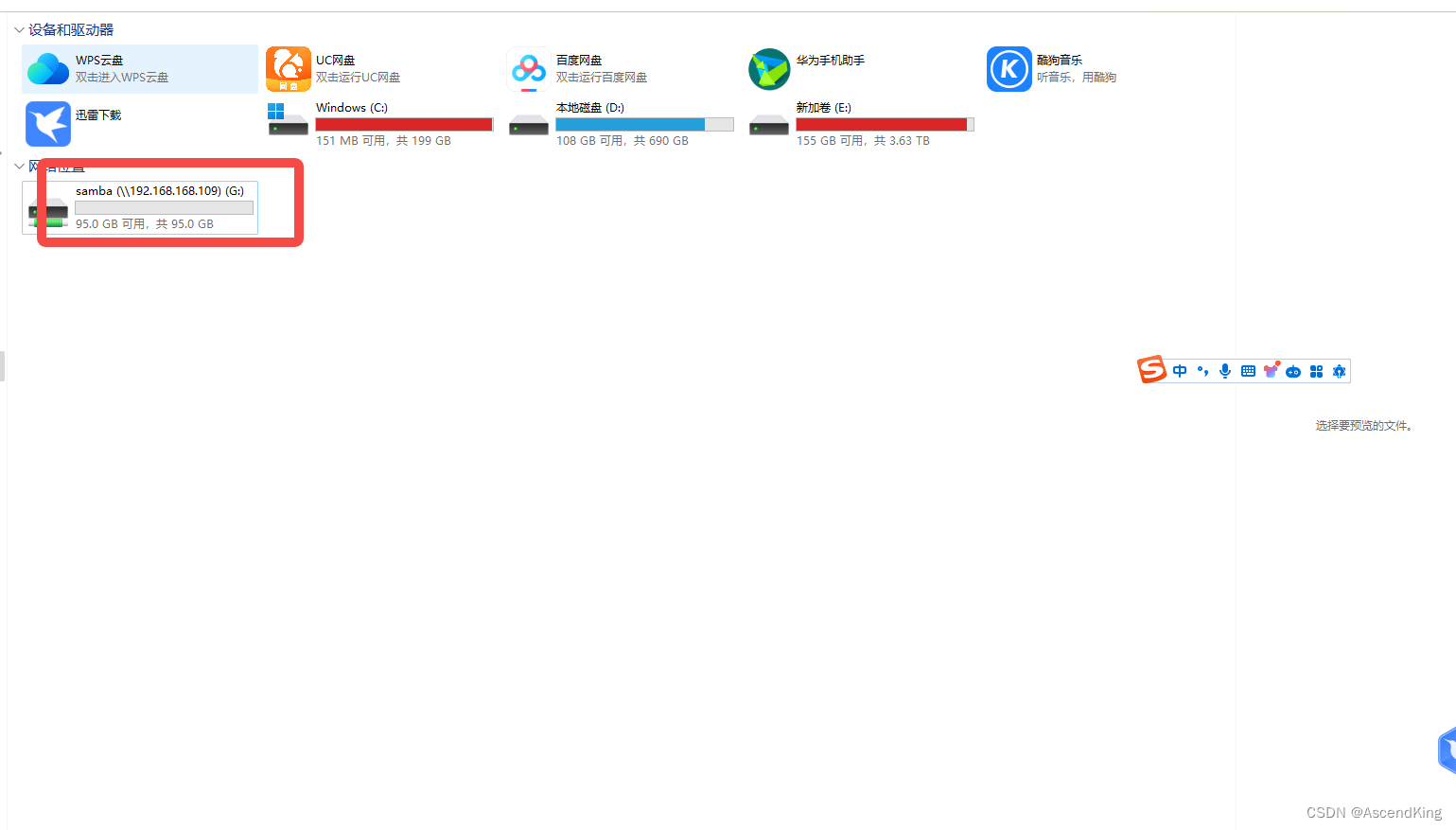
像操作本地文件一样操作linux文件 centos7环境下samba共享服务搭建详细教程
1.安装dnf yum -y install dnf 2.安装samba dnf install samba -y 3.配置 3.1创建并设置用户信息 #创建用户 useradd -M -s /sbin/nologin samba echo 123|passwd --stdin samba mkdir /home/samba chown -R samba:samba /home/samba smbpasswd -a samba smaba设置密码示…...

web块级如何居中,关于css/html居中问题
1. text-align:center; 可以实现其内部元素水平居中,通常用于字体水平居中,初学者也可以用于简单块级居中。这种方法对行内元素 (inline),行内块 (inline-block),行内表 (inline-table),inline…...

docker 部署 springboot 2.6.13 jar包流程笔记
1 . 将dockerfile复制到与jar包同一目录 Dockerfile # 基础镜像 FROM openjdk:8 # 环境变量 ENV APP_HOME/apps # 创建容器默认进入的目录 WORKDIR $APP_HOME # 复制jar包到容器中 COPY ./elastic-log-service.jar ./elastic-log-service.jar # 暴露端口 EXPOSE 8003 # 启动命…...

get_kline_serial 用法:K 线序列长度、末尾行与新 bar 判定
前言 分钟线、小时线策略里,指标几乎都挂在 get_kline_serial 返回的序列上。我常见三类报错:长度不够就访问 iloc[-20]、把未收盘的 close 当成定稿信号、以及同一根 K 线里重复下单。下面按天勤量化里的订阅方式、长度防护和与 is_changing 的配合写一…...

告别DLL缺失!用VS2019的Setup Project打包C++程序,保姆级配置指南
告别DLL缺失!用VS2019的Setup Project打包C程序,保姆级配置指南 在C开发中,最令人头疼的问题之一莫过于程序在其他电脑上运行时出现"DLL缺失"的错误。这种问题不仅影响用户体验,也让开发者陷入反复调试的困境。本文将带…...

我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射
我的第一个CANOpen主站:手把手教你用CanFestival-3源码配置心跳、SYNC和PDO映射 当你第一次面对工业现场总线协议时,那种既兴奋又忐忑的心情我至今记忆犹新。CANOpen作为工业自动化领域的"普通话",其主站开发往往是工程师进阶路上的…...

TS9580,TS3440,TS3400,G3000,G1810,G2810,G3810,G4810,TS9020,TS9120报错5B00,P07,E08,1700,5b04废墨垫清零,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案
3分钟掌握BilibiliDown:您的专业B站视频离线下载解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirror…...

UVM验证中的迭代模式:从寄存器遍历到配置组合的实战应用
1. 项目概述:为什么要在UVM中谈迭代模式?如果你做过芯片验证,尤其是用SystemVerilog和UVM搭过测试平台,那你肯定对“遍历”这个概念不陌生。比如,你需要检查一个存储阵列里每一个地址的读写是否正确,或者需…...

国产ARM主板实战:从设计选型到性能优化的嵌入式开发指南
1. 项目概述:从“能用”到“好用”的国产ARM主板之路最近几年,如果你关注过硬件开发、嵌入式系统或者国产化替代的圈子,一定会频繁听到“国产ARM主板”这个词。它不再是实验室里的样品,而是越来越多地出现在工业控制、边缘计算、智…...

【Autosar】MCAL - 从零到一的工程配置实战
1. 工程创建:从零搭建MCAL开发环境 第一次打开Autosar配置工具时,面对满屏的选项确实容易发懵。记得我刚接触MCAL配置时,光是工程创建就反复折腾了好几次。下面我就把踩过的坑和验证过的正确姿势分享给大家。 创建新工程时,工程名…...

告别BiSeNet的臃肿:手把手教你用STDC网络在MMSegmentation中实现更快的实时语义分割
从BiSeNet到STDC:在MMSegmentation中构建高效实时语义分割模型的实战指南 当你在深夜调试一个需要实时反馈的无人机视觉系统时,BiSeNet的多路径结构是否正在消耗你宝贵的计算资源?STDC网络的出现,为这类场景带来了新的可能性。本文…...

2026年热门抠图软件怎么选?好用的抠图工具实测对比与推荐指南
抠图的需求无处不在——做小红书封面、制作电商商品图、处理证件照、视频背景分离——但市面上的抠图工具繁杂多样,究竟哪个才是真正好用的?我们在2026年对市场上主流的抠图软件进行了全面实测,从操作体验、AI识别精度、输出质量、使用成本等…...