【Storm】【五】Storm集成Kafka
Storm集成Kafka
一、整合说明
Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下:
- Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持;
- Storm Kafka Integration (0.10.x+) : 包含 Kafka 新版本的 consumer API,主要对 Kafka 0.10.x + 提供整合支持。
这里我服务端安装的 Kafka 版本为 2.2.0(Released Mar 22, 2019) ,按照官方 0.10.x+ 的整合文档进行整合,不适用于 0.8.x 版本的 Kafka。
二、写入数据到Kafka
2.1 项目结构
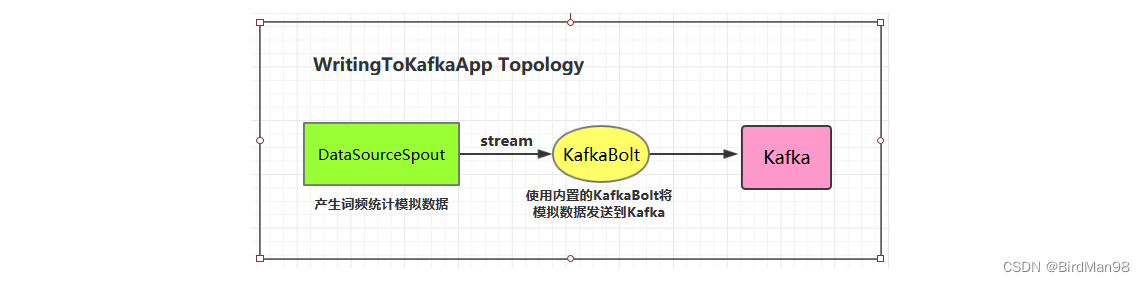
2.2 项目主要依赖
<properties><storm.version>1.2.2</storm.version><kafka.version>2.2.0</kafka.version>
</properties><dependencies><dependency><groupId>org.apache.storm</groupId><artifactId>storm-core</artifactId><version>${storm.version}</version></dependency><dependency><groupId>org.apache.storm</groupId><artifactId>storm-kafka-client</artifactId><version>${storm.version}</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version></dependency>
</dependencies>
2.3 DataSourceSpout
/*** 产生词频样本的数据源*/
public class DataSourceSpout extends BaseRichSpout {private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");private SpoutOutputCollector spoutOutputCollector;@Overridepublic void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {this.spoutOutputCollector = spoutOutputCollector;}@Overridepublic void nextTuple() {// 模拟产生数据String lineData = productData();spoutOutputCollector.emit(new Values(lineData));Utils.sleep(1000);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {outputFieldsDeclarer.declare(new Fields("line"));}/*** 模拟数据*/private String productData() {Collections.shuffle(list);Random random = new Random();int endIndex = random.nextInt(list.size()) % (list.size()) + 1;return StringUtils.join(list.toArray(), "\t", 0, endIndex);}}
产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
2.4 WritingToKafkaApp
/*** 写入数据到 Kafka 中*/
public class WritingToKafkaApp {private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";private static final String TOPIC_NAME = "storm-topic";public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();// 定义 Kafka 生产者属性Properties props = new Properties();/** 指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找其他 broker 的信息。* 不过建议至少要提供两个 broker 的信息作为容错。*/props.put("bootstrap.servers", BOOTSTRAP_SERVERS);/** acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。* acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。* acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。* acks=all : 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。*/props.put("acks", "1");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaBolt bolt = new KafkaBolt<String, String>().withProducerProperties(props).withTopicSelector(new DefaultTopicSelector(TOPIC_NAME)).withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper<>());builder.setSpout("sourceSpout", new DataSourceSpout(), 1);builder.setBolt("kafkaBolt", bolt, 1).shuffleGrouping("sourceSpout");if (args.length > 0 && args[0].equals("cluster")) {try {StormSubmitter.submitTopology("ClusterWritingToKafkaApp", new Config(), builder.createTopology());} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {e.printStackTrace();}} else {LocalCluster cluster = new LocalCluster();cluster.submitTopology("LocalWritingToKafkaApp",new Config(), builder.createTopology());}}
}
2.5 测试准备工作
进行测试前需要启动 Kakfa:
1. 启动Kakfa
Kafka 的运行依赖于 zookeeper,需要预先启动,可以启动 Kafka 内置的 zookeeper,也可以启动自己安装的:
# zookeeper启动命令
bin/zkServer.sh start# 内置zookeeper启动命令
bin/zookeeper-server-start.sh config/zookeeper.properties
启动单节点 kafka 用于测试:
# bin/kafka-server-start.sh config/server.properties
2. 创建topic
# 创建用于测试主题
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 --replication-factor 1 --partitions 1 --topic storm-topic# 查看所有主题bin/kafka-topics.sh --list --bootstrap-server hadoop001:9092
3. 启动消费者
启动一个消费者用于观察写入情况,启动命令如下:
# bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic storm-topic --from-beginning
2.6 测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true
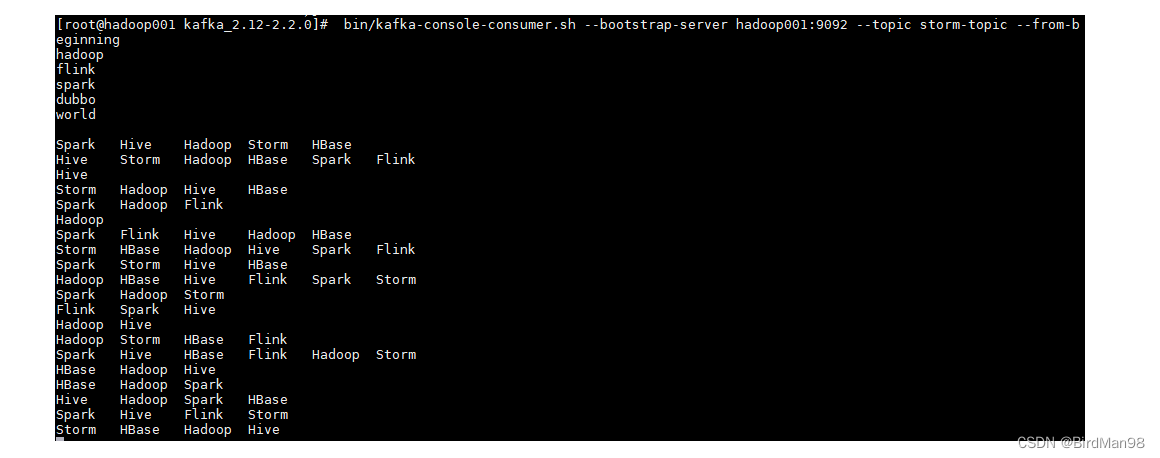
启动后,消费者监听情况如下:
三、从Kafka中读取数据
3.1 项目结构
3.2 ReadingFromKafkaApp
/*** 从 Kafka 中读取数据*/
public class ReadingFromKafkaApp {private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";private static final String TOPIC_NAME = "storm-topic";public static void main(String[] args) {final TopologyBuilder builder = new TopologyBuilder();builder.setSpout("kafka_spout", new KafkaSpout<>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1);builder.setBolt("bolt", new LogConsoleBolt()).shuffleGrouping("kafka_spout");// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动if (args.length > 0 && args[0].equals("cluster")) {try {StormSubmitter.submitTopology("ClusterReadingFromKafkaApp", new Config(), builder.createTopology());} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {e.printStackTrace();}} else {LocalCluster cluster = new LocalCluster();cluster.submitTopology("LocalReadingFromKafkaApp",new Config(), builder.createTopology());}}private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig(String bootstrapServers, String topic) {return KafkaSpoutConfig.builder(bootstrapServers, topic)// 除了分组 ID,以下配置都是可选的。分组 ID 必须指定,否则会抛出 InvalidGroupIdException 异常.setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup")// 定义重试策略.setRetry(getRetryService())// 定时提交偏移量的时间间隔,默认是 15s.setOffsetCommitPeriodMs(10_000).build();}// 定义重试策略private static KafkaSpoutRetryService getRetryService() {return new KafkaSpoutRetryExponentialBackoff(TimeInterval.microSeconds(500),TimeInterval.milliSeconds(2), Integer.MAX_VALUE, TimeInterval.seconds(10));}
}3.3 LogConsoleBolt
/*** 打印从 Kafka 中获取的数据*/
public class LogConsoleBolt extends BaseRichBolt {private OutputCollector collector;public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {this.collector=collector;}public void execute(Tuple input) {try {String value = input.getStringByField("value");System.out.println("received from kafka : "+ value);// 必须 ack,否则会重复消费 kafka 中的消息collector.ack(input);}catch (Exception e){e.printStackTrace();collector.fail(input);}}public void declareOutputFields(OutputFieldsDeclarer declarer) {}
}
这里从 value 字段中获取 kafka 输出的值数据。
在开发中,我们可以通过继承 RecordTranslator 接口定义了 Kafka 中 Record 与输出流之间的映射关系,可以在构建 KafkaSpoutConfig 的时候通过构造器或者 setRecordTranslator() 方法传入,并最后传递给具体的 KafkaSpout。
默认情况下使用内置的 DefaultRecordTranslator,其源码如下,FIELDS 中 定义了 tuple 中所有可用的字段:主题,分区,偏移量,消息键,值。
public class DefaultRecordTranslator<K, V> implements RecordTranslator<K, V> {private static final long serialVersionUID = -5782462870112305750L;public static final Fields FIELDS = new Fields("topic", "partition", "offset", "key", "value");@Overridepublic List<Object> apply(ConsumerRecord<K, V> record) {return new Values(record.topic(),record.partition(),record.offset(),record.key(),record.value());}@Overridepublic Fields getFieldsFor(String stream) {return FIELDS;}@Overridepublic List<String> streams() {return DEFAULT_STREAM;}
}
3.4 启动测试
这里启动一个生产者用于发送测试数据,启动命令如下:
# bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic storm-topic

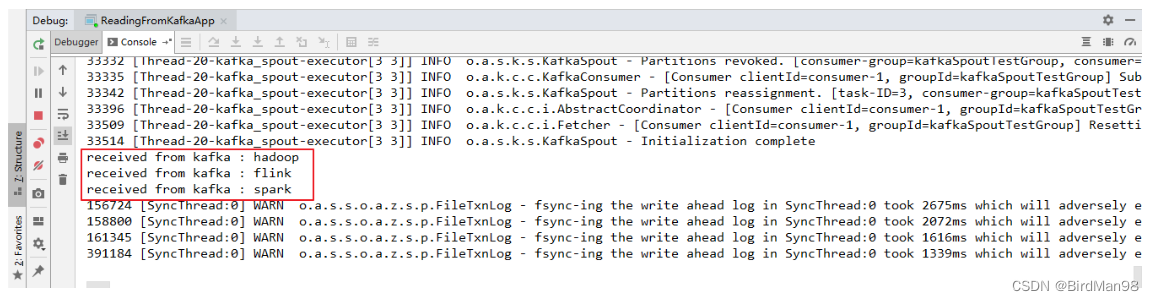
本地运行的项目接收到从 Kafka 发送过来的数据:
用例源码下载地址:storm-kafka-integration
参考资料
- Storm Kafka Integration (0.10.x+)
相关文章:
【Storm】【五】Storm集成Kafka
Storm集成Kafka 一、整合说明二、写入数据到Kafka三、从Kafka中读取数据一、整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持;Storm Kafka …...

GVRP-LNP-VCMP讲解
目录 GVRP讲解 动态创建Vlan并将端口加入Vlan GVRP消息类型 GVRP工作原理 LNP讲解 动态修改接口链路类型 VCMP讲解 动态创建Vlan 相关概念 Vlan同步 VCMP与GVRP的区别 GVRP讲解 动态创建Vlan并将端口加入Vlan GVRP(GARR Vlan Registration Protocol…...

28个精品Python爬虫实战项目
先来说说Python的优势!然后给大家看下这28个实战项目的实用性!Python跟其他语言相比,有以下优点:1. 简单Python是所有编程语言里面,代码量最低,非常易于读写,遇到问题时,程序员可以把…...

相信人还是相信ChatGPT,龙测首席AI专家给出了意料之外的答案
最近,关于ChatGPT的话题太火了!各大社交软件都是他的消息!从去年12月份ChatGPT横空出世,再到近期百度文心一言、复旦Moss的陆续宣布,点燃了全球对AIGC(内容人工智能自动生成)领域的热情…...

安卓逆向_5 --- jeb 和 AndroidStudio 动态调试 smali
Jeb 工具的使用 :https://www.52pojie.cn/forum.php?modviewthread&tid742250:https://zhuanlan.zhihu.com/p/302856081动态调试 smali 有两种方法: Jeb 调试AndroidStudio smalidea 插件动态调试。1、Jeb 动态调试 smali JEB是一个…...

docker-容器命令
1.新建启动 docker run options image command [arg..] options: --name"容器新名字" -d:后台运行程序 -it:交互式运行 -P: 随机端口 -p: 指定端口 docker run -it ubuntu /bin/bash docker run -it ubuntu:v1 /bin/bash docker run -it 1c352…...
Spring——是什么?作用?内容?用到的设计模式?
目录 什么是spring? spring是为了解决什么问题而衍生的?(历史)Spring解决了实际生产中的什么问题? spring包含了哪些部分?(组成) Spring的特点是什么? spring框架中…...
Qt交叉编译环境搭建
环境及版本: 编译机:Deepin 20.3 Qt 5.12.9 arm编译工具: gcc-linaro-6.5.0-2018.12-x86_64_arm-linux-gnueabihf.tar.xz 运行机:创龙335X开发板 1.下载arm编译工具: gcc-linaro-6.5.0-2018.12-x86_64_arm-linux-…...

Java switch case 语句
Java 的 switch case 语句是一种常用的控制流语句,用于基于不同的输入值执行不同的操作。本文将详细介绍 Java switch case 语句的作用、用法以及在实际工作中的应用。 一、switch case 语句的作用 switch case 语句是一种多分支条件语句,它基于不同的输…...

Linux下MQTT客户端消息订阅与发布实现
MQTT(消息队列遥测传输)是一个基于客户端-服务器的消息发布/订阅传输协议。它基于TCP协议,默认端口号为1883,为此,它也需要一个消息中间件 。MQTT协议是轻量、简单、开放和易于实现的,这些特点使它适用范围非常广泛。在很多情况下…...

代码规范----编程规约(下)
目录 四、OOP规约 五、日期时间 六、集合处理 四、OOP规约 (1)、避免通过一个类的对象引用访问此类的静态变量或静态方法,无谓增加编译器解析成本,直接用类名来访问即可 (2)、所有的覆写方法࿰…...
c++连接mysql
开始想用mysql connector/c8.0 来操作数据库cmake加上配置后一直编译错误 我这里也没有截屏编译错误大概意思是driver.h里面声明的一个check_lib函数里面用了一个未定义的check找遍了资料都没有找到解决办法最后还是用了原始API如果有人有解决办法请留个位置先上在用的cmake配置…...
CentOS7操作系统安装nginx实战(多种方法,超详细)
文章目录前言一. 实验环境二. 使用yum安装nginx2.1 添加yum源2.1.1 使用官网提供的源地址(方法一)2.1.2 使用epel的方式进行安装(方法二)2.2 开始安装nginx2.3 启动并进行测试2.4 其他的一些用法:三. 编译方式安装ngin…...

【测绘程序设计】——空间直角坐标转换
测绘工程中经常遇到空间直角坐标转换——比如,北京54(或西安80)空间直角坐标转换成CGCS2000(或WGS-84)空间直角坐标,常用转换模型包括:①布尔沙模型(国家级及省级范围);②莫洛坚斯基模型(省级以下范围);③三维四参数(小于22局部区域) 等。 本文分享了基于布…...
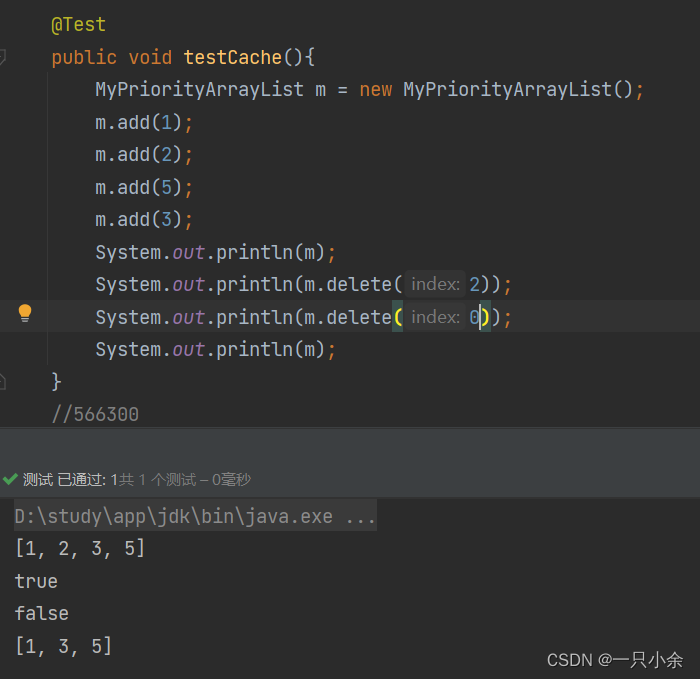
数组--java--动态数组--有序数组--底层
java数组基础--java中的数组创建数组空间占用初始化数组访问元素插入查找删除元素动态数组扩容插入和添加重写toString删除二维数组二维数组注意点有序数组实现测试写在开头: 这篇文章包括数组的基础、一点底层的内容和一些稍微深入的东西。 作为第一个深入学习的数…...

Linux下使用C语言实现简单的聊天室程序
本文章介绍一种基于Linux使用C语言实现简单的局域网聊天室程序的方法,支持消息群发,历史数据查询,好友列表查看,好友上线下线提醒等功能。聊天界面如下图所示:下面将按步骤介绍该系统的设计实现,首先在linu…...

【数学】任意一个正整数n最多只有一个质因数大于根号n,怎么证明?
定理 任意一个正整数n最多只有一个大于n\sqrt{n}n的质因子,并且该大于n\sqrt{n}n质因子的幂次是1。 证明(反证法) 证明:最多只有一个大于n\sqrt{n}n的质因子 假设n存在两个大于n\sqrt{n}n的质因子,分别为p…...

【ES6】var let const 之面试题系列
关于 var、let、const 是前端开发人员经常用到的关键字,也是经典的面试题,接下来就站在面试题的角度来看待它们之间的区别。 一、区别 1. var 声明的范围是函数作用域,let 和 const 声明的范围是块作用域,块作用域是函数作用域的…...
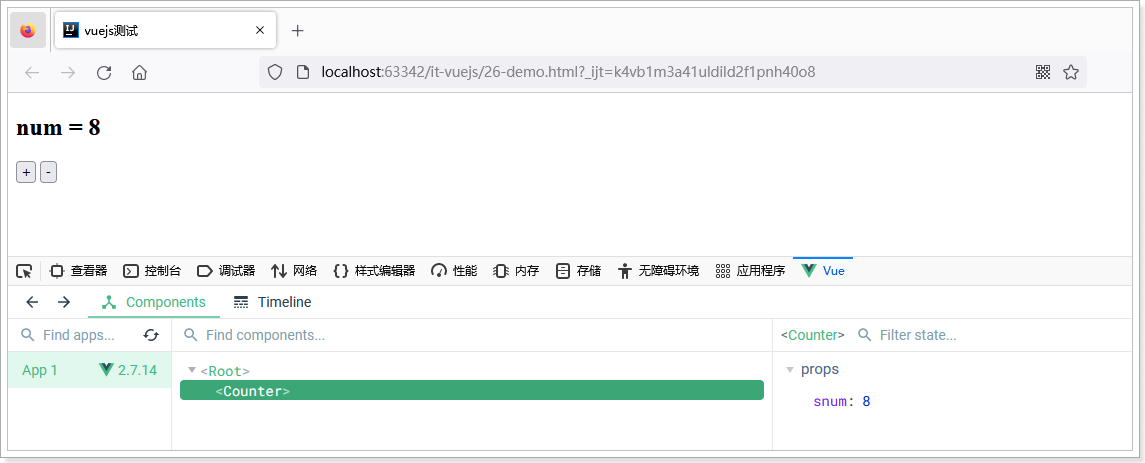
Vue基础入门讲义(四)-组件化
文章目录1.引言2.定义全局组件3.组件的复用4.局部注册5.组件通信5.1.父向子传递props5.2.传递复杂数据5.3.子向父的通信1.引言 在大型应用开发的时候,页面可以划分成很多部分。往往不同的页面,也会有相同的部分。例如可能会有相同的头部导航。 但是如果…...

Android onLayout布局流程解析
组件布局流程结论 1.)layout流程始于ViewRootImpl的performLayout()方法,该方法会调用根View(DecorView)的layout()方法进行布局,因为DecorView是ViewGroup(FrameLayout),所以layout流程来到了ViewGroup(其…...

Flask-base实战案例:从零构建功能完备的博客系统
Flask-base实战案例:从零构建功能完备的博客系统 【免费下载链接】flask-base A simple Flask boilerplate app with SQLAlchemy, Redis, User Authentication, and more. 项目地址: https://gitcode.com/gh_mirrors/fl/flask-base Flask-base是一个功能强大…...

终极指南:Laravel DataTables 性能优化实战——不同场景下的表现对比
终极指南:Laravel DataTables 性能优化实战——不同场景下的表现对比 【免费下载链接】laravel-datatables jQuery DataTables API for Laravel 4|5|6|7|8|9|10 项目地址: https://gitcode.com/gh_mirrors/la/laravel-datatables Laravel DataTables 是一款强…...
)
Asp.Net MVC杂谈之:—步步打造表单验证框架[重排版](1)
在实际使用中,我们可以考虑多种形式来进行这一验证(注:本文目前只研究服务器端验证的情况),最直接的方式莫过于对每个表单值手动用C#代码进行验证了,比如: if(!Int32.TryParse(Request.Form[“age”], out age)){ xxxx… } If(age < xxx || age > xxx){ xxxx… }…...
:从原理到落地)
模型剪枝实战指南(一):从原理到落地
1. 模型剪枝的本质:为什么能剪? 我第一次接触模型剪枝时,最困惑的问题是:神经网络训练出来的参数不都是有用的吗?凭什么能随便删?后来在移动端部署ResNet模型时才发现,原来大多数神经网络都存在…...

AI推动SEO关键词优化的全新策略与实践明晰
在当前数字营销环境中,AI技术为SEO关键词优化带来了前所未有的变革。它通过自动化的数据分析与挖掘工具,能够帮助企业更准确地识别用户需求与搜索趋势。通过AI的支持,关键词挖掘变得更加高效和精准,企业可以快速获取相关关键词并优…...

终极音乐解锁方案:在浏览器中实现加密音乐文件高效转换完整指南
终极音乐解锁方案:在浏览器中实现加密音乐文件高效转换完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

DeepSeek-R1-Distill-Qwen-7B优化升级:提升推理速度的技巧
DeepSeek-R1-Distill-Qwen-7B优化升级:提升推理速度的技巧 1. 模型概述 DeepSeek-R1-Distill-Qwen-7B是基于Qwen架构的7B参数蒸馏模型,由DeepSeek团队开发。该模型通过知识蒸馏技术从更大的DeepSeek-R1模型中提取关键知识,在保持较高推理能…...

Maven Versions Plugin 使用指南
以下是对你提供内容的补充和整理,形成一篇关于 Maven Versions Plugin 使用指南的文章:Maven Versions Plugin 使用指南 Maven Versions Plugin 是一套用于管理项目版本、依赖版本和父版本的工具集合。它可以帮助你高效地更新项目版本号、检查依赖更新、…...

Intel XE核显PyTorch环境搭建避坑指南
1. 为什么选择Intel XE核显跑PyTorch? 最近很多小伙伴都在问,用Intel XE核显跑PyTorch到底靠不靠谱?作为一个在AI领域摸爬滚打多年的老司机,我可以很负责任地告诉你:完全可行!特别是对于预算有限的学生党&a…...
)
手把手教你用VSCode快速定位并修改RuoYi框架的页面标题和图标(避坑指南)
高效定制RuoYi前端界面:VSCode全局搜索实战指南 刚接触RuoYi框架的开发者常会遇到这样的困扰:想修改浏览器标签页标题或系统Logo,却不知从何下手。前后端分离的项目结构让配置文件散落在各处,而手动翻找无异于大海捞针。本文将带你…...