Mysql:重点且常用的操作和理论知识整理 ^_^
目录
1 基础的命令操作
2 DDL 数据库定义语言
2.1 数据库操作
2.2 数据表操作
2.2.1 创建数据表
2.2.2 修改和删除数据表
2.2.3 添加外键
3 DML 数据库操作语言
3.1 插入语句(INSERT)
3.2 修改语句(UPDATE)
3.3 删除语句
3.3.1 DELETE命令
3.3.2 TRUNCATE命令
4 DQL 数据库查询语言
4.1 SELECT语句的简单使用
4.2 WHERE条件子句
4.3 连接查询
4.3.1 内连接查询
4.3.2 左连接查询
4.3.3 右连接查询
4.3.4 自连接查询
4.3.5 子连接查询
4.4 分页和排序
4.4.1 分页
4.4.2 排序
4.5 聚合函数
4.6 分组查询
4.7 HAVING筛选
5 MD5加密
6 事务的ACID原则
6.1 原子性(Atomicity)
6.2 一致性(Consistency)
6.3 持久性(Durability)
6.4 隔离性(Isolation)
6.5 事务的隔离级别
6.5.1 脏读:
6.5.2 不可重复读:
6.5.3 虚读(幻读)
7 数据库的备份
8 规范数据库设计
1 基础的命令操作
mysql -uroot -p123 -- 连接数据库SHOW DATABASES; -- 展示所有的数据库CREATE DATABASE school; -- 创建一个数据库USE school; -- 使用数据库SHOW TABLES; -- 展示所有的数据表EXIT; -- 退出连接DESC shopping.address; -- 显示表的结构SHOW CREATE TABLE shopping.address; -- 查看创建数库表的语句SHOW CREATE DATABASE shopping; -- 查看创建数据库的语句SELECT VERSION(); -- 查询数据库版本2 DDL 数据库定义语言
2.1 数据库操作
-- 1.创建数据库
CREATE DATABASE school;
CREATE DATABASE IF NOT EXISTS school; -- 也可以使用这个,如果不存在则创建-- 2.查看数据库;
SHOW DATABASES;-- 3.使用指定数据库
USE school;-- 4.删除数据库
DROP DATABASE [IF EXISTS] school;2.2 数据表操作
2.2.1 创建数据表
CREATE TABLE [IF NOT EXISTS] student ( -- student为表名no INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', -- 设置该字段不为空且设为自增name varchar(10) COMMENT '姓名',age INT(4) COMMENT '年龄',password VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码', -- DEFAULT 设置默认值gender char(2) COMMENT '性别',PRIMARY KEY (no) -- 设置字段 no 为主键
) ENGINE=INNODB DEFAULT CHARSET=utf8; --设置引擎和默认编码关于数据库引擎和编码的一些解释:
关于数据库引擎:
数据库引擎在MySQL 5.5版本之前是MyISAM,之后的版本是InnoDB
区别:
1、MyISAM不支持事务,InnoDB支持事务
2、MyISAM不支持外键,InnoDB支持外键
3、MyISAM不支持行级锁,InnoDB支持行级锁
4、MyISAM不支持全文索引,InnoDB支持全文索引
5、MyISAM表空间较小,InnoDB表空间较大常规使用操作:
MYISAM
# 节约空间,速度较快InnoDB
# 安全性高; 支持事务的处理; 支持多表多用户操作字符编码:
设置数据库表的字符集编码,
不设置的话,Mysql默认的字符集编码(不支持中文的~),
Mysql的默认编码是Latin1,不支持中文2.2.2 修改和删除数据表
-- 1.修改表名: ALTER TABLE 旧表名 RENAME AS 新表名;
ALTER TABLE teacher RENAME AS teacher1; -- 2.添加表的字段:ALTER TABLE 表名 ADD 字段名 列属性
ALTER TABLE teacher1 ADD age INT(4) -- 3.修改表的字段(重命名和修改约束)
-- ALTER TABLE 表名 MODIFY 字段名 列属性[]
ALTER TABLE teacher1 MODIFY age VARCHAR(11) -- 修改约束,将INT(4)改为了VARCHAR(11)-- ALTER TABLE 表名 CHANGE 旧名字 新名字 列属性[]
ALTER TABLE teacher1 CHANGE age age1 INT(4) --修改重命名age改为age1 同时将VARCHAR(11) 改为INT(4)-- 总结(一般情况下的):change 用来字段的重命名,不能修改字段类型和约束;但是上述中change修改字段类型仍是可以成功的
-- modify 不能用来字段重命名,只能修改字段类型和约束-- 4.删除表的字段:ALTER TABLE 表名 DROP 字段名
ALTER TABLE teacher1 DROP age1-- 5.删除表: DROP TABLE [IF EXISTS] 表名
DROP TABLE [IF EXISTS] teacher12.2.3 添加外键
1. 创建表时添加外键:
(1)对一个列添加外键约束:
比如学生表的 gradeid 要引用年级表的 gradeid
FOREIGN KEY (gradedid) REFERENCES grade(gradedid)CREATE TABLE [IF NOT EXISTS] student ( -- student为表名no INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', -- 设置该字段不为空且设为自增name varchar(10) COMMENT '姓名',age INT(4) COMMENT '年龄',password VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码', -- DEFAULT 设置默认值gender char(2) COMMENT '性别',PRIMARY KEY (no) -- 设置字段 no 为主键FOREIGN KEY (gradedid) REFERENCES grade(gradedid)
) ENGINE=INNODB DEFAULT CHARSET=utf8; --设置引擎和默认编码(2)对多个列添加外键约束:
CONSTRAINT fk_gradedid FOREIGN KEY (gradedid) REFERENCES grade(gradedid)CREATE TABLE [IF NOT EXISTS] student ( -- student为表名no INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', -- 设置该字段不为空且设为自增name varchar(10) COMMENT '姓名',age INT(4) COMMENT '年龄',password VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码', -- DEFAULT 设置默认值gender char(2) COMMENT '性别',PRIMARY KEY (no) -- 设置字段 no 为主键CONSTRAINT fk_gradedid FOREIGN KEY (gradedid) REFERENCES grade(gradedid), -- fk_gradedid为约束的名字,便于后续的删除外键操作CONSTRAINT fk_scoredid FOREIGN KEY (scoredid) REFERENCES score(scoredid)
) ENGINE=INNODB DEFAULT CHARSET=utf8; --设置引擎和默认编码2. 给已创建的表添加外键:
(1)对一个列添加外键约束:
ALTER TABLE Orders
ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);(2)对多个列添加外键约束:
ALTER TABLE Orders
ADD CONSTRAINT FK_PersonOrder
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);(3)删除 FOREIGN KEY 外键约束
ALTER TABLE Orders
DROP FOREIGN KEY FK_PersonOrder;3 DML 数据库操作语言
3.1 插入语句(INSERT)
语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);实例:
INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country)
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway');3.2 修改语句(UPDATE)
语法:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;实例:
UPDATE Customers
SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
WHERE CustomerID = 1;3.3 删除语句
3.3.1 DELETE命令
1.删除指定的数:
语法:
DELETE FROM table_name WHERE condition;实例:
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';2. 删除表中的全部数据:
语法:
DELETE FROM table_name;实例:
DELETE FROM Customers;3.3.2 TRUNCATE命令
作用:完全清空一个数据表,表的结构和索引约束不会变
TRUNCATE TABLE 表名;总结:DELETE 和 TRUNCATE 的区别:
区别:
# 相同点:都能删除数据,都不会删除表的结构
# 不同点:TRUNCATE 会重新设置自增列,计数器归零; 不会影响事务
DELETE 的问题(重启数据库的现象)
# InnoDB 自增列会重1开始(存在内存中,断电即失)
# MyISAM 自增列会继续累加(存在文件中,不会丢失)
4 DQL 数据库查询语言
4.1 SELECT语句的简单使用
1. 指定查询字段:
语法:
SELECT column1, column2, ...
FROM table_name;实例:
SELECT CustomerName, City, Country FROM Customers;2. 查询所有列:
语法:
SELECT * FROM table_name;实例:
SELECT * FROM Customers;3. 起别名:AS
可以给字段起别名,也可以给表起别名
语法:
SELECT column_name AS 字段别名
FROM table_name AS 表别名;实例:
SELECT student AS '学号'
FROM table_name AS t;补充:函数 Concat (a, b) 拼接字符串
SELECT CONCAT ('姓名:', Name) AS 新名字 FROM 表名;4. 去重操作:DISTINCT
SELECT DISTINCT studentNo FROM 表名;4.2 WHERE条件子句
作用:检索数据中符合条件的值 --> 搜索的条件由一个或者多个表达式组成!
1. 逻辑运算符
--1. AND && 逻辑与
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 条件1 AND 条件2 AND ...;
SELECT studentNo, studentResult FROM result
WHERE studentResult >= 95 AND studentResult <= 100
-- WHERE studentResult >= 95 && studentResult <= 100--2. 模糊查询区间 BETWEEN ... AND ...
SELECT studentNo, studentResult FROM result
WHERE studentResult BETWEEN 95 AND 100--3. OR 逻辑或
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 条件1 OR 条件2 OR ...;--4. NOT != 逻辑非
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE NOT 条件;
-- 除了1001号学生之外的同学的成绩
SELECT StudentNo, StudentResult FROM student WHERE NOT StudentNo= 1001;
-- SELECT StudentNo, StudentResult FROM student WHERE StudentNo != 1001;2.模糊查询(比较运算符)
-- 模糊查询比较运算符:
-- 1. 空判断 IS NULL
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 字段 IS NULL;-- 2. 非空判断 IS NOT NULL
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 字段 IS NOT NULL;-- 3. IN
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 字段 IN (值1, 值2 , ...);
SELECT StudentName FROM student WHERE StudentNo IN (1001, 1002, 1003);-- 4. % 和 _
% 表示0-任意一个子字符; _ 表示一个字符
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 字段 LIKE '%关键字%';
SELECT StudentName FROM student WHERE StudentName LIKE '张%';SELECT StudentName FROM student WHERE StudentName LIKE '张_';-- 5. 范围查询
语法:SELECT 字段1, 字段2, ... FROM 表名 WHERE 字段 BETWEEN 值1 AND 值2;4.3 连接查询
# 步骤1:分析查询的字段来自哪些表
# 步骤2:确定如何连接这些表
# 步骤3:确定交叉点(这两个表中,哪个数据是相同的)
# 步骤4:判断条件4.3.1 内连接查询
如果表中至少有一个匹配,返回就行
# 1. 内连接查询(如果表中至少有一个匹配,返回就行)
# 语法:SELECT 字段1, 字段2, ... FROM 表1 INNER JOIN 表2 ON 表1.字段=表2.字段;
SELECT * FROM student INNER JOIN score ON student.StudentNo=score.StudentNo;-- 实例:
-- 比如以下SQL语句,需要查询这些字段:studentNo, studentName, subjectNo, studentResult
-- 但是student表中没有subjectNo字段,所以需要连接result表
-- 但是student和result表中都有studentNo字段,会重复,所以需要设置别名,指定查询哪张表的studentNoSELECT s.studentNo, studentName, subjectNo, studentResult
FROM student AS s
INNER JOIN result AS r
ON s.StudentNo=r.StudentNo;4.3.2 左连接查询
会从左表中返回所有的值,即使右表中没有匹配
# 2. 左连接查询 (会从左表中返回所有的值,即使右表中没有匹配)
# 语法:SELECT 字段1, 字段2, ... FROM 表1 LEFT JOIN 表2 ON 表1.字段=表2.字段;SELECT * FROM student LEFT JOIN score ON student.StudentNo=score.StudentNo;
SELECT s.studentNo, studentName, subjectNo, studentResult
FROM student AS s
LeFT JOIN result AS r
ON s.StudentNo=r.StudentNo;4.3.3 右连接查询
会从右表中返回所有的值,即使左表中没有匹配
# 3. 右连接查询(会从右表中返回所有的值,即使左表中没有匹配)
# 语法:SELECT 字段1, 字段2, ... FROM 表1 RIGHT JOIN 表2 ON 表1.字段=表2.字段;SELECT * FROM student RIGHT JOIN score ON student.StudentNo=score.StudentNo;
SELECT s.studentNo, studentName, subjectNo, studentResult
FROM student AS s
RIGHT JOIN result AS r
ON s.StudentNo=r.StudentNo;4.3.4 自连接查询
# 4. 自连接查询
# 自己的表和自己的表的连接,核心:一张表拆为两张一样的表即可
# 查询父子信息
SELECT a.name AS '父类', b.name AS '子类'
FROM category AS a, category AS b
WHERE a.id=b.pid;比如以下数据表:

| id | name |
| 2 | 人工智能 |
| 4 | 历史外语 |
| 5 | 大数据 |
| 9 | 古代史 |
| id | name | pid |
| 5 | 大数据 | 2 |
| 9 | 古代史 | 4 |
| 10 | 现代史 | 4 |
4.3.5 子连接查询
# 1. 子查询
# 查询出成绩高于学号为1001的学生所有成绩
# 1.1 查询出学号为1001的学生成绩
SELECT studentResult FROM result WHERE studentNo='1001';
# 1.2 查询出成绩高于1001的学生成绩
SELECT studentResult FROM result WHERE studentResult > 80;
# 1.3 合并
SELECT studentResult FROM result WHERE studentResult > (SELECT studentResult FROM result WHERE studentNo='1001');4.4 分页和排序
4.4.1 分页
-- 分页limit 和 排序 order by
-- 1. 分页limit
# 语法:SELECT 字段1, 字段2, ... FROM 表名 LIMIT 起始索引, 查询条数;--起始位置:
-- 第一页 limit 0, 5 (1-1)*5
-- 第二页 limit 5, 5 (2-1)*5
-- 第三页 limit 10, 5 (3-1)*5
-- 第N页 limit (N-1)*5, 5 (N-1)*pageSize, pageSize [pageSize页面大小, N表示当前页];-- 总几页数: 总条数/页面大小
4.4.2 排序
-- 2. 排序 order by
-- 语法:SELECT 字段1, 字段2, ... FROM 表名 ORDER BY 字段1, 字段2, ... ASC|DESC; ASC升序(默认值); DESC降序 SELECT * FROM Websites
ORDER BY country,alexa DESC;查询结果首先会根据
country字段进行排序,然后在相同country值的记录中,会按照alexa字段进行排序。
一张表中可以同时按升序和降序查询:
-- 从"Customers"表中选择所有客户,按"Country"升序排序,按"CustomerName"列降序排序:SELECT * FROM Customers
ORDER BY Country ASC, CustomerName DESC;4.5 聚合函数
-- 聚合函数
1. count() 计数
2. sum() 求和
3. avg() 平均值
4. max() 最大值
5. min() 最小值1. count() 计数
--查询学生总数
SELECT COUNT(*) FROM student;
--查询选修了课程的学生数
SELECT COUNT(DISTINCT studentNo) FROM result;COUNT(字段) -> 会忽略 所有的null 值
COUNT(*) -> 不会忽略null值,本质是计算行数
COUNT(1) -> 不会忽略null值,本质是计算行数2. sum() 求和
--查询学生总成绩
SELECT SUM(studentResult) FROM result;3. avg() 平均值
--查询学生平均成绩
SELECT AVG(studentResult) FROM result;4. max() 最大值
--查询学生最高成绩
SELECT MAX(studentResult) FROM result;5. min() 最小值
--查询学生最低成绩
SELECT MIN(studentResult) FROM result;4.6 分组查询
GROUP BY语句通常与聚合函数(COUNT()、MAX(),MIN(),SUM(),AVG()) 按一列或多列对结果集进行分组。
语法:
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);--实例1:
--统计 access_log表中 各个 site_id 的访问量:
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;--实例2:
--列出了每个发货人发送的订单数量:
SELECT Shippers.ShipperName, COUNT(Orders.OrderID) AS NumberOfOrders FROM Orders
LEFT JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID
GROUP BY ShipperName;4.7 HAVING筛选
having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。
--SQL实例:-- 1.显示每个地区的总人口数和总面积.
SELECT region, SUM(population), SUM(area) FROM bbc GROUP BY region先以region把返回记录分成多个组,这就是GROUP BY的字面含义。分完组后,然后用聚合函数对每组中
的不同字段(一或多条记录)作运算。-- 2.显示每个地区的总人口数和总面积.仅显示那些面积超过1000000的地区。
SELECT region, SUM(population), SUM(area)
FROM bbc
GROUP BY region
HAVING SUM(area)>1000000在这里,我们不能用where来筛选超过1000000的地区,因为表中不存在这样一条记录。
相反,having子句可以让我们筛选成组后的各组数据
5 MD5加密
# MD5 加密
UPDATE student SET studentPwd=MD5(studentPwd) where id = 1;# 插入的时候加密:
INSERT INTO student (studentName, studentPwd) VALUES ('张三', MD5('123456'));# 如何校验:将用户传递过来的密码进行MD5加密,然后和数据库中的加密的密码进行比较6 事务的ACID原则
6.1 原子性(Atomicity)
要么都成功,要么都失败:比如下面的银行转账:这两个步骤一起成功,或者一起失败,不能只发生其中一个动作

6.2 一致性(Consistency)
事务前后的数据完整性要一致 比如上面的银行转账:一开始A和B总共有1000元,转来转去还是1000
6.3 持久性(Durability)
事务一旦提交,对数据库中的数据改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响;如果没有提交,还保持原样。
比如上述的银行转账例子:
操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:4006.4 隔离性(Isolation)
多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务之间要相互隔离
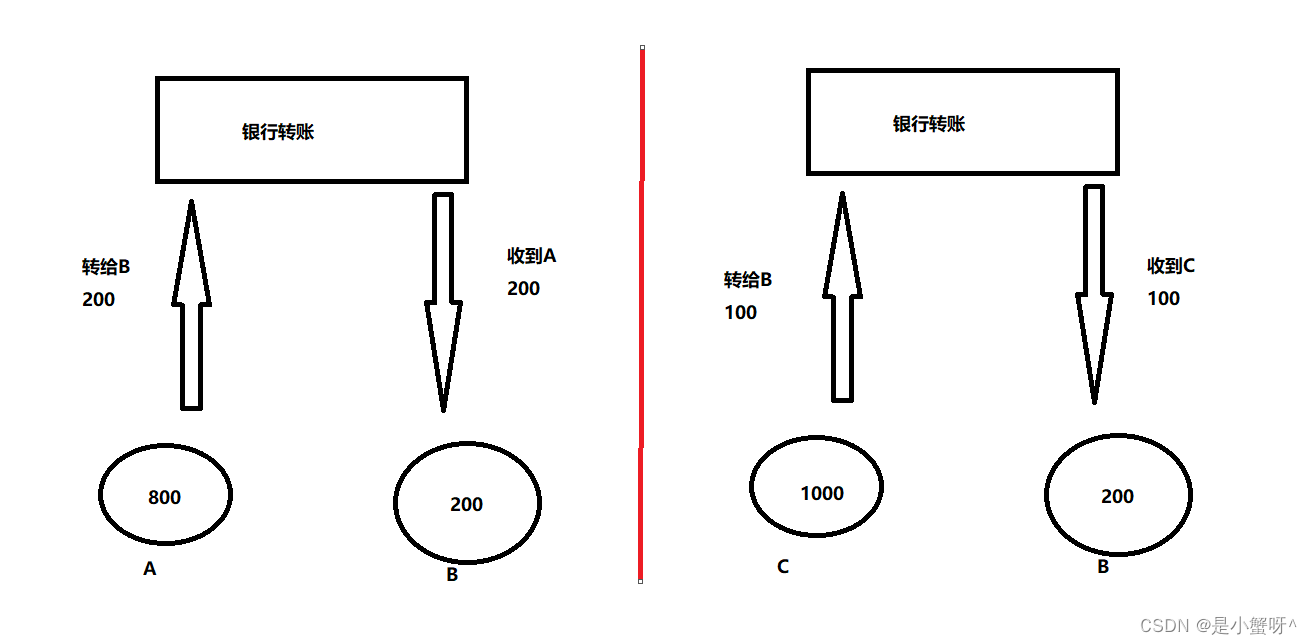
比如上述的A和C两个事务:
事务一)A向B转账200
事务二)C向B转账100
两个事务同时进行,如果没有隔离性其中一个事务可能读取到另外一个事务还没有提交的数据
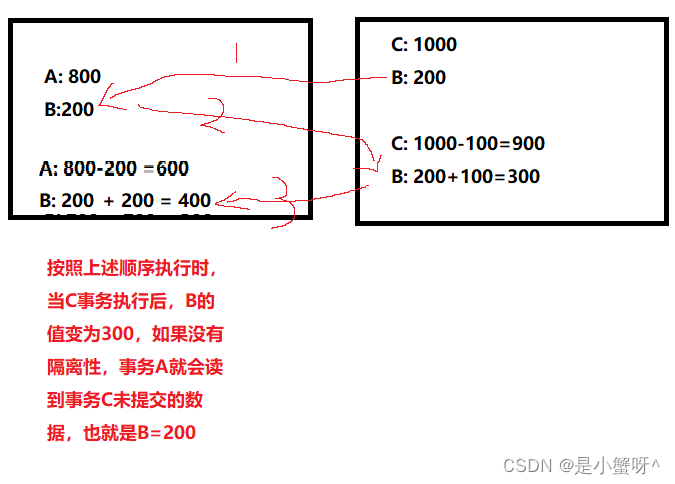
6.5 事务的隔离级别
6.5.1 脏读:
指一个事务读取了另外一个事务未提交的数据
6.5.2 不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
页面统计查询值:
| A | 100 |
| B | 300 |
| C | 200 |
生成报表时,B事务已经提交了,有人转账100元进来:
| A | 100 |
| B | 400 |
| C | 200 |
6.5.3 虚读(幻读)
是指在一个事务内读取到了别的事务插入的数据,导致前后读取数目总量不一致。
(一般是行影响,如下图所示:多了一行)
| A | 100 |
| B | 400 |
| C | 200 |
| A | 100 |
| B | 400 |
| C | 200 |
| D | 500 |
7 数据库的备份
-- Mysql备份-- 1. 物理备份,直接拷贝-- 2. 导出整个数据库或数据表--3. 使用 mysqldump命令导出
-- mysqldump -h主机名 -u用户名 -p密码 数据库名 表名 > 导出的路径/导出的文件名
mysqldump -hLocalhost -uroot -p111 school student > D:/a.sql-- mysqldump -h主机名 -u用户名 -p密码 数据库名 > 导出的路径/导出的文件名
mysqldump -hLocalhost -uroot -p111 school > D:/b.sql
8 规范数据库设计
# 为什么使用数据规范化
# 1.信息重复
# 2.更新异常
# 3.插入异常
# 3.1 无法正常显示信息
#
# 4.删除异常
# 4.1 丢失有效的信息三大范式:
1. 第一范式:(1NF):
要求数据库表中的每一列都是不可分割的原子数据项
2. 第二范式(2NF): 在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关.
如果一个关系满足第一范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式.
例如:订单表(订单编号、产品编号、定购日期、价格、……),"订单编号"为主键,"产品编号"和主键列没有直接的关系,即"产品编号"列不依赖于主键列,应删除该列。
也可以这样理解:在第一范式的基础上消除非主键对主键的部分依赖
3. 第三范式(3NF):
在第一、第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
相关文章:
Mysql:重点且常用的操作和理论知识整理 ^_^
目录 1 基础的命令操作 2 DDL 数据库定义语言 2.1 数据库操作 2.2 数据表操作 2.2.1 创建数据表 2.2.2 修改和删除数据表 2.2.3 添加外键 3 DML 数据库操作语言 3.1 插入语句(INSERT) 3.2 修改语句(UPDATE) 3.3 删除语句 3.3.1 DELETE命令 3.3.2 TRUNCATE命令 4 …...

小车辅助脚本编写
小车辅助脚本编写 在远程控制中需要启动非常多的 Launch 文件,在终端启动很麻烦,编写一些脚本可以简化操作 robot_client.sh #!/bin/bashecho "开始执行Bash脚本"# 启动zedm roslaunch zed_wrapper zedm.launch & sleep 5# 启动realsen…...
Modern C++ 一个例子学习条件变量
目录 问题程序 施魔法让BUG浮出水面 条件变量注意事项 修改程序 问题程序 今天无意中看到一篇帖子,关于条件变量的,不过仔细看看发现它并达不到原本的目的。 程序如下,读者可以先想想他的本意,以及有没有问题: #…...
ora-12154无法解析指定的连接标识符
用户反映查询的时候报错ora-12154 这个系统只做历史数据查询使用,使用并不平凡,该数据库曾做过一次服务器间的迁移。 用户描述,所有oracle客户端查询该视图都报tns错误,一般ora-12154会发生在连接数据库时,因为tns配…...

rust跟我学三:文件时间属性获得方法
图为RUST吉祥物 大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info是怎样获得杀毒软件的病毒库时间的。 首先,先要了解get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址…...

解决一个mysql的更新属性长度问题
需求背景: 线上有一个 platform属性,原有长度为 varchar(10),但是突然需要填入一个11位长度的值;而偏偏这个属性在线上100张表中有50张都存在,并且名字各式各样,庆幸都包含 platform;例如 platf…...

[网络安全]DHCP 部署与安全
一 、DHCP作用 (Dynamic HOst Configure Protocol ) 动态IP配置协议 作用:动态自动分配IP地址 二、DHCP相关概念 地址池/作用域: (IP、子网掩码、网关、DNS、周期) 三、DHCP优点 减少工程量 避免IP避免 提高地址利用率 四、DHCP原理 成为DHCP租约过程 步骤: 1.发送 DHC…...

自建ES集群
常用命令 # 重命名文件夹 mv elasticsearch-7.10.2 elasticsearch# 移动文件到文件夹 mv elasticsearch-7.10.2-linux-x86_64.tar.gz middleware-tar/ mv kibana-7.10.2-linux-x86_64.tar.gz middleware-tar/# 创建data文件夹 mkdir /home/admin/elasticsearch/data 自建Ela…...

git rev-parse v406 ‘v4.0.4‘^{} master什么意思?
git rev-parse 是一个 Git 命令,用于解析出 git 对象(如分支、标签、提交等)的完整 SHA-1 哈希值。这个命令对于理解 git 中各种引用的内部表示非常有用。 让我们一步步分析 git rev-parse v406 v4.0.4^{} master 这条命令: v406…...
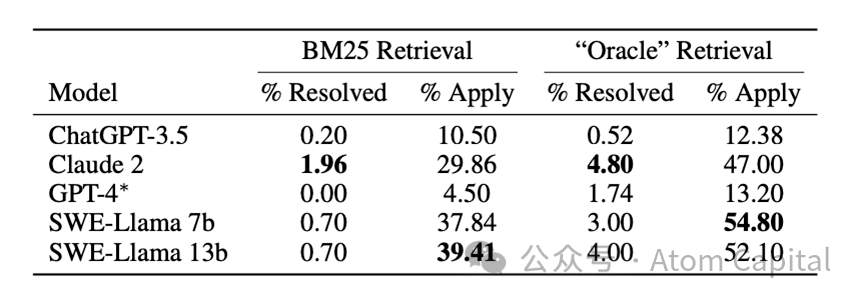
AI 编程的机会和未来:从 Copilot 到 Code Agent
大模型的快速发展带来了 AI 应用的井喷。统计 GPT 使用情况,编程远超其他成为落地最快、使用率最高的场景。如今,大量程序员已经习惯了在 AI 辅助下进行编程。数据显示,GitHub Copilot 将程序员工作效率提升了 55%,一些实验中 AI …...

git push --set-upstream origin master时超时失败的解决方案
问题描述 提示:这里描述项目中遇到的问题: git push --set-upstream origin master时,超时失败,显示如下错误: connect to host git.acwing.com port 22: Connection timed out fatal: Could not read from remote …...

beego的模块篇 - config自定义文件配置
加载自定义配置到beego.AppConfig中可以配置:Beego框架 app.conf配置参数及环境配置-CSDN博客 1. 文件配置 目前支持解析的文件格式有 ini、json、xml、yaml 安装依赖库: go get github.com/beego/beego/v2/core/config 1.1 ini文件配置使用 配置文…...
YOLOv5-第Y2周:训练自己的数据集
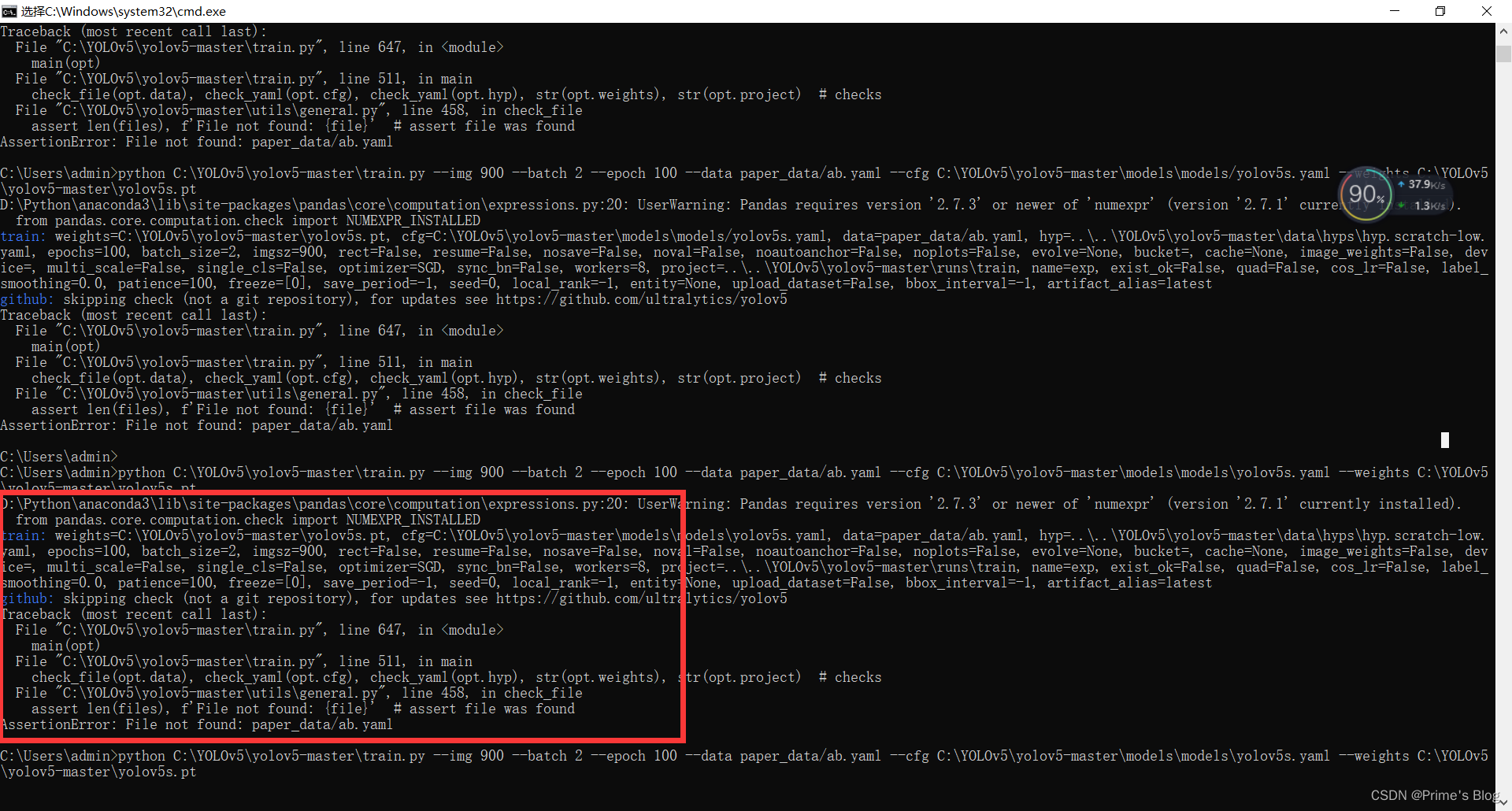
YOLOv5-第Y2周:训练自己的数据集 YOLOv5-第Y2周:训练自己的数据集一、前言二、我的环境三、准备数据集四、运行 split_train_val.py 文件五、生成 train.txt、test.txt、val.txt 文件六、创建ab.yaml文件七、开始使用自己的数据集训练八、总结 YOLOv5-第…...

解决fxml图标无法显示
原文地址:https://www.myjinji.top/articles/2023/10/11/1697033367492.html 代码正确无法显示 <Button fx:id"blockButton" onAction"#handleBlockButtonClick"><graphic><FontIcon iconLiteral"win10-add-shopping-cart…...
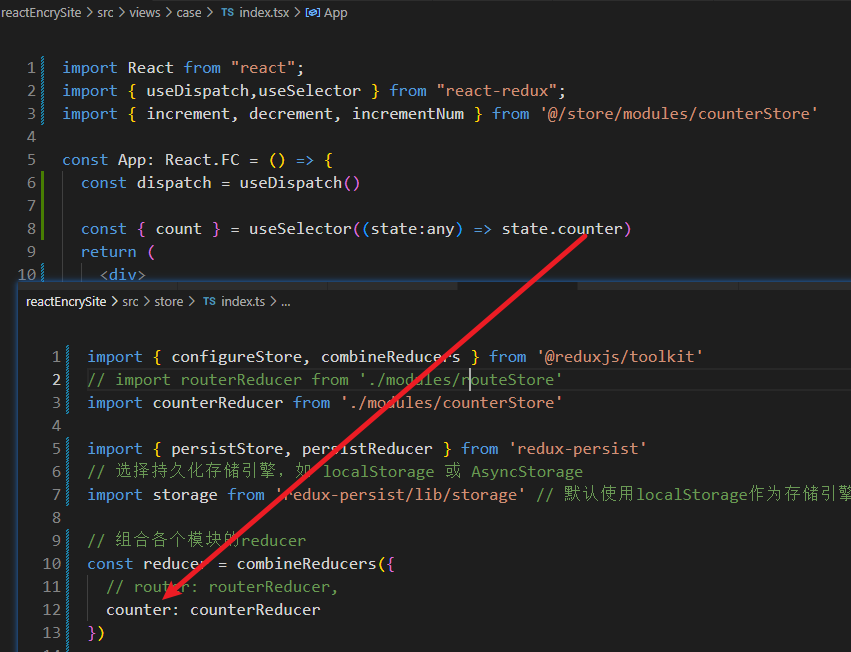
React Store及store持久化的使用
1.安装 npm insatll react-redux npm install reduxjs/toolkit npm install redux-persist2. 使用React Toolkit创建counterStore并配置持久化 store/modules/counterStore.ts: import { createSlice } from reduxjs/toolkit// 定义状态类型 interface Action {…...

Hive添加第三方Jar包方式总结
一、在 Hive Shell中加入—add jar hdfs dfs -put HelloUDF-1.0.jar /tmp beeline -u "jdbc:hive2://test.bigdata.com:10000" -n "song" -p "" add jar hdfs:///tmp/HelloUDF-1.0.jar; create function HelloUDF as org.example.HelloUDF USIN…...

Linux用户与文件的关系和文件掩码(umask)的作用
文章目录 1 前言2 Linux用户与文件的关系3 文件掩码(umask)4 总结 1 前言 阅读本篇文章,你将了解Linux的目录结构,用户与文件的关系,以及文件掩码的作用。为了方便大家理解,本文将通过实例进行演示…...

JS -- 正则表达式教程
1 概念 ECMAScript 通过 RegExp 类型支持正则表达式。 2 写法 2.1 类似 Perl 的简写语法: let pattern /a/g let pattern2 /a/i2.2 构造函数创建: let pattern new RegExp(a, g) let pattern new RegExp(a, i)上面两种是等价的正则表达式 3 修…...

详细介绍IP 地址、网络号和主机号、ABC三类、ip地址可分配问题、子网掩码、子网划分
1、 IP 地址: 网络之间互连的协议,是由4个字节(32位二进制)组成的逻辑上的地址。 将32位二进制进行分组,分成4组,每组8位(1个字节)。【ip地址通常使用十进制表示】ip地址分成四组之后,在逻辑上,分成网络号和主机号 2…...

滚动菜单+图片ListView
目录 Fruit.java FruitAdapter MainActivity activity_main.xml fruit.xml 整体结构 Fruit.java public class Fruit {private String name;private int imageId;public Fruit(String name, int imageId) {this.name name;this.imageId imageId;}public String getNam…...

武汉大学等高校联手揭露AI助手的“记忆盲区“:它们真的记得你吗?
这项由武汉大学、香港中文大学和香港科技大学联合开展的研究以预印本形式于2026年5月发表,论文编号为arXiv:2605.06527,有兴趣深入了解的读者可以通过该编号查询完整论文。你有没有试过这样一件事:你和手机里的AI助手聊了很久,告诉…...

CSDN热门文章评论区运营心法——从技术答疑到社区共建的进阶之路
评论区,是技术内容的第二战场。你发出去的文章只是第一招,真正的对话从这里开始。 引言:为什么评论区是"第二战场" 技术写作圈有个不成文的共识:文章发出去,战斗才刚开始。 很多人把写完文章当成终点&…...

Python小白也能学会!3个月蜕变AI应用开发者的收藏秘籍
本文针对程序员,特别是只会CRUD的开发者,提供了学习大模型的实用路径。文章强调大模型应用开发是“低门槛、高上限”的方向,并给出了一个12步学习路线,涵盖Python基础、Transformer理解、提示词工程、RAG等,以及LangCh…...

职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗
职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗相信很多职场人都有过这样的崩溃瞬间:明明是团队协作的任务,同事要么全程摸鱼划水,不干活、不配合,要么出了问题就第一时间甩锅&#x…...

终极QRazyBox指南:免费在线修复损坏二维码的完整教程
终极QRazyBox指南:免费在线修复损坏二维码的完整教程 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过重要二维码因为打印模糊、水渍污损或物理磨损而无法扫描的困扰&a…...

Delft3D建模、水动力模拟方法及在地表水环境影响评价中的实践技术应用
一:Delft3D软件介绍及建模原理和步骤对常见的地表水数值模型进行介绍,学习Delft3D软件的构成、界面内容,了解地表水数值模型的建模步骤:1.1地表水数值模拟常用软件介绍EFDC_Explorer(商业) Delft3D…...

5秒极速转换!m4s转换工具:B站缓存视频合并为MP4的完整指南
5秒极速转换!m4s转换工具:B站缓存视频合并为MP4的完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否在B站缓…...

当“数字孪生”有了坐标、时序和一棵“会落叶的树”:NNU‑Campus‑Geo3DGS 数据集深度解读
地理编码的3D高斯,联结了数字重建与“真实地面”之间的两条坐标轴线假设你是一名城市规划师,面对一座城市的数字孪生模型——楼宇轮廓完整、道路走向清晰、绿化植被葱郁——但无论怎样旋转视角,这座模型都“悬浮”在地理基准面之上࿰…...

土方车远程监控智慧运维系统方案
某企业聚焦于土方运输领域,拥有大量土方车分布于全国各大工地与矿山之间,承担土石方挖掘、装载、运输等任务。由于车辆分散作业、工作环境恶劣,总部难以实时掌握每台土方车的当前位置、载重状态及电机情况,且车辆故障频发、运维工…...

为什么92%的Lovable新手在第5小时放弃?——资深架构师拆解3个致命认知盲区
更多请点击: https://codechina.net 第一章:Lovable应用开发入门与环境搭建 Lovable 是一个面向现代 Web 应用的轻量级全栈框架,专为快速构建可维护、可扩展且富有表现力的交互式应用而设计。它融合了声明式 UI、响应式状态管理与内置服务抽…...