使用Scrapy 爬取“http://tuijian.hao123.com/”网页中左上角“娱乐”、“体育”、“财经”、“科技”、历史等名称和URL
一、网页信息
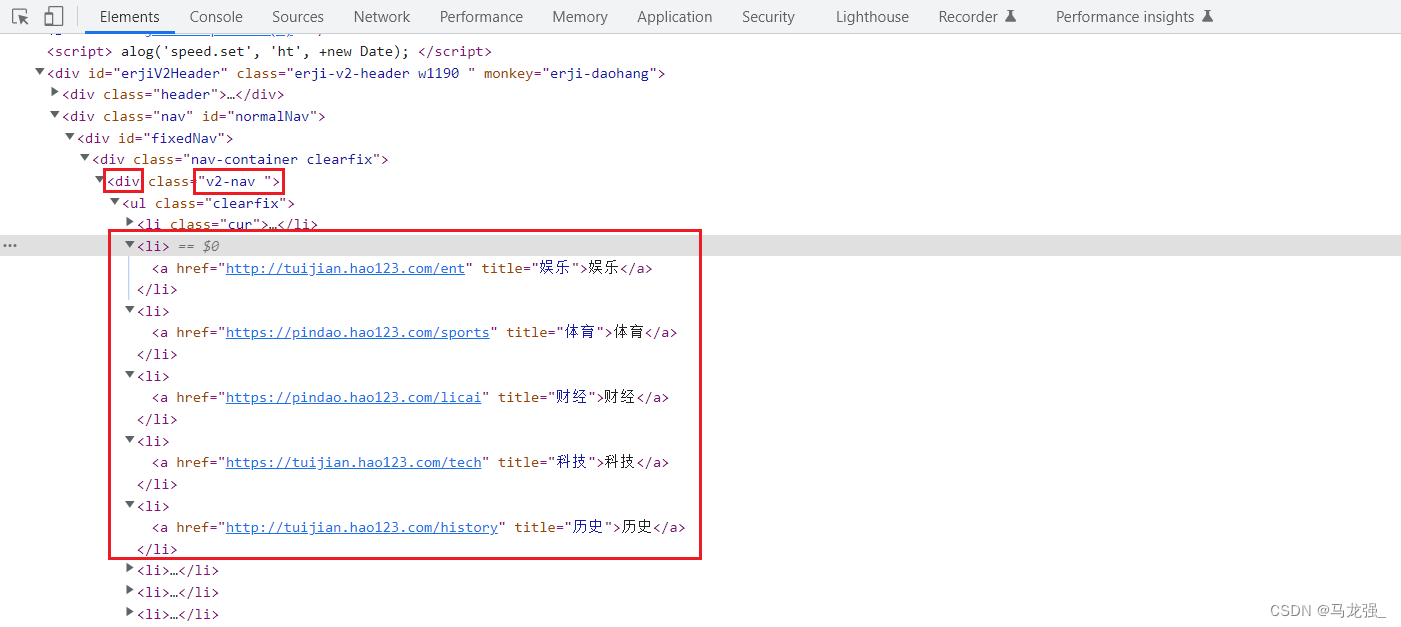
 二、检查网页,找出目标内容
二、检查网页,找出目标内容
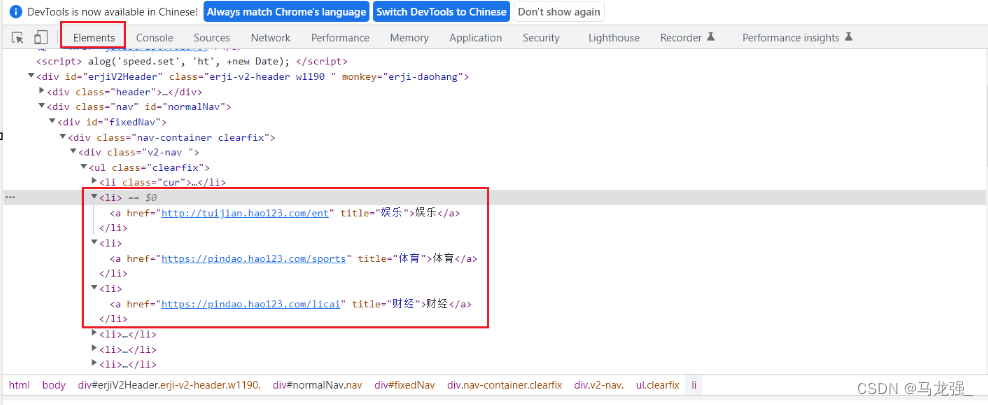
三、根据网页格式写正常爬虫代码
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
}
url = 'http://tuijian.hao123.com/'
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'soup = BeautifulSoup(response.text, 'html.parser')
list_div = soup.find('div', class_='v2-nav')
ul_tags = list_div.find_all('ul')[0]
li_tags = ul_tags.find_all('li')for li in li_tags:a_tag = li.find('a')if a_tag:title = a_tag.texthref = a_tag['href']if title in ["娱乐", "体育", "财经", "科技", "历史"]:print(f"{title}: {href}")四、创建Scrapy项目haohao
1.进入相关目录中,执行:scrapy startproject haohao
2.创建结果

五、创建爬虫项目haotuijian.py
1.进入相关目录中,执行:scrapy genspider haotuijian http://tuijian.hao123.com/

2.执行结果,目录中出现haotuijian.py文件
六、写爬虫代码和配置相关文件
1.haotuijian.py文件代码
import scrapy
from bs4 import BeautifulSoup
from ..items import HaohaoItemclass HaotuijianSpider(scrapy.Spider):name = 'haotuijian'allowed_domains = ['tuijian.hao123.com']start_urls = ['http://tuijian.hao123.com/']def parse(self, response):soup = BeautifulSoup(response.text, 'html.parser')list_div = soup.find('div', class_='v2-nav')ul_tags = list_div.find_all('ul')[0]li_tags = ul_tags.find_all('li')for li in li_tags:a_tag = li.find('a')if a_tag:title = a_tag.texthref = a_tag['href']if title in ["娱乐", "体育", "财经", "科技", "历史"]:item = HaohaoItem() # 创建一个HaohaoItem实例来传输保存数据item['title'] = titleitem['href'] = hrefyield item2.items.py文件代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass HaohaoItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()href = scrapy.Field()3.pipelines.py文件代码(保存数据到Mongodb、Mysql、Excel中)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymongo import MongoClient
import openpyxl
import pymysql#保存到mongodb中
class HaohaoPipeline:def __init__(self):self.client = MongoClient('mongodb://localhost:27017/')self.db = self.client['qiangzi']self.collection = self.db['hao123']self.data = []def close_spider(self, spider):if len(self.data) > 0:self._write_to_db()self.client.close()def process_item(self, item, spider):self.data.append({'title': item['title'],'href': item['href'],})if len(self.data) == 100:self._write_to_db()self.data.clear()return itemdef _write_to_db(self):self.collection.insert_many(self.data)self.data.clear()#保存到mysql中
class MysqlPipeline:def __init__(self):self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='789456MLq',db='pachong',charset='utf8mb4')self.cursor = self.conn.cursor()self.data = []def close_spider(self,spider):if len(self.data) > 0:self._writer_to_db()self.conn.close()def process_item(self, item, spider):self.data.append((item['title'],item['href']))if len(self.data) == 100:self._writer_to_db()self.data.clear()return itemdef _writer_to_db(self):self.cursor.executemany('insert into haohao (title,href)''values (%s,%s)',self.data)self.conn.commit()#保存到excel中
class ExcelPipeline:def __init__(self):self.wb = openpyxl.Workbook()self.ws = self.wb.activeself.ws.title = 'haohao'self.ws.append(('title','href'))def open_spider(self,spider):passdef close_spider(self,spider):self.wb.save('haohao.xlsx')def process_item(self,item,spider):self.ws.append((item['title'], item['href']))return item4.settings.py文件配置



七、运行代码
1.进入相关目录,执行:scrapy crawl haotuijian
2.执行过程
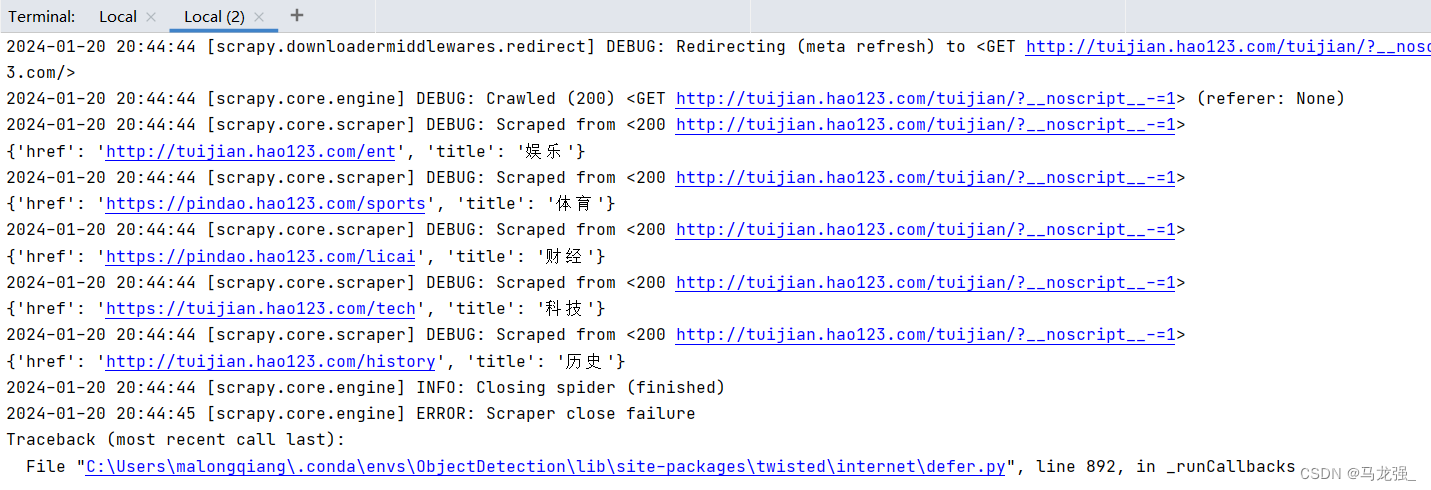
3.执行结果
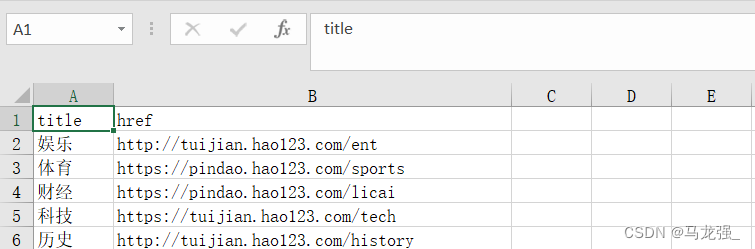
(1) haohao.excel
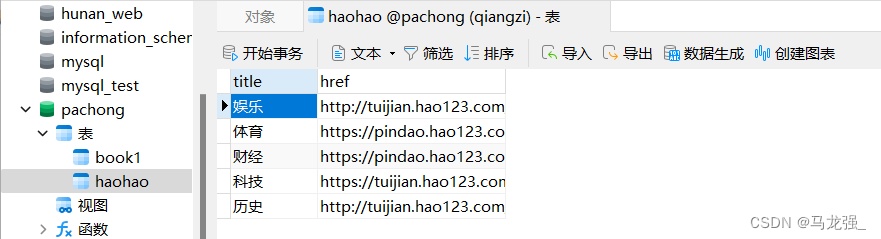
(2) Mysql:haohao (需提前创建表)
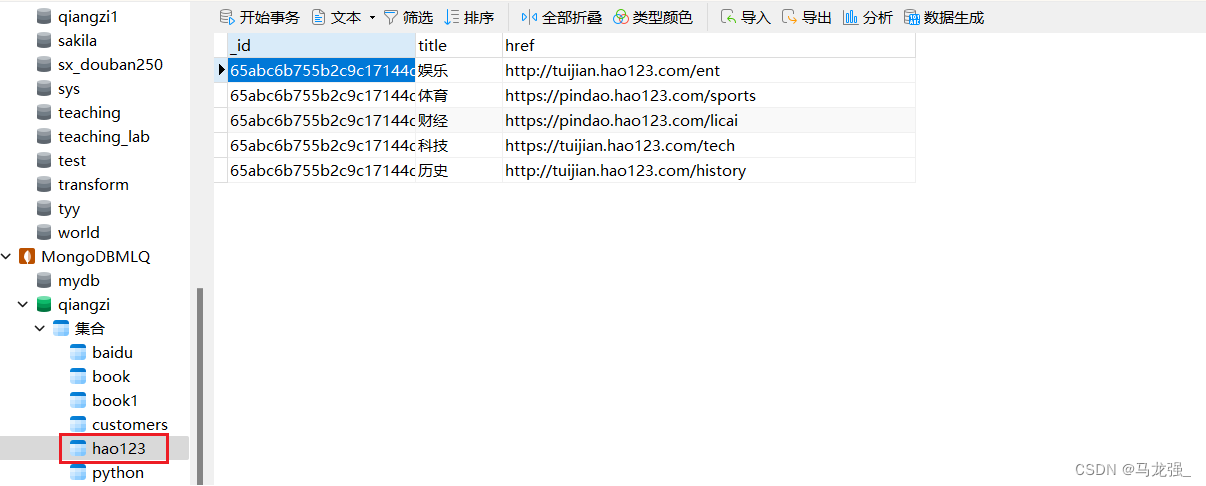
(3)Mongodb: hao123
八、知识补充
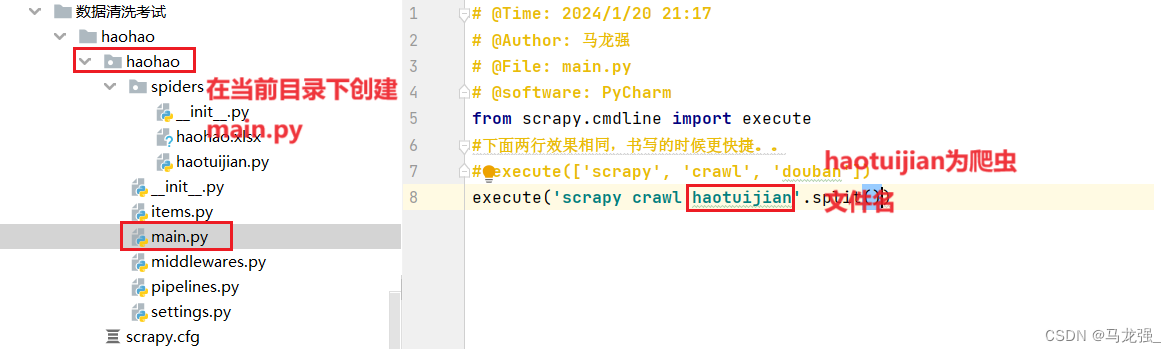
1.创建main.py文件,并编写代码
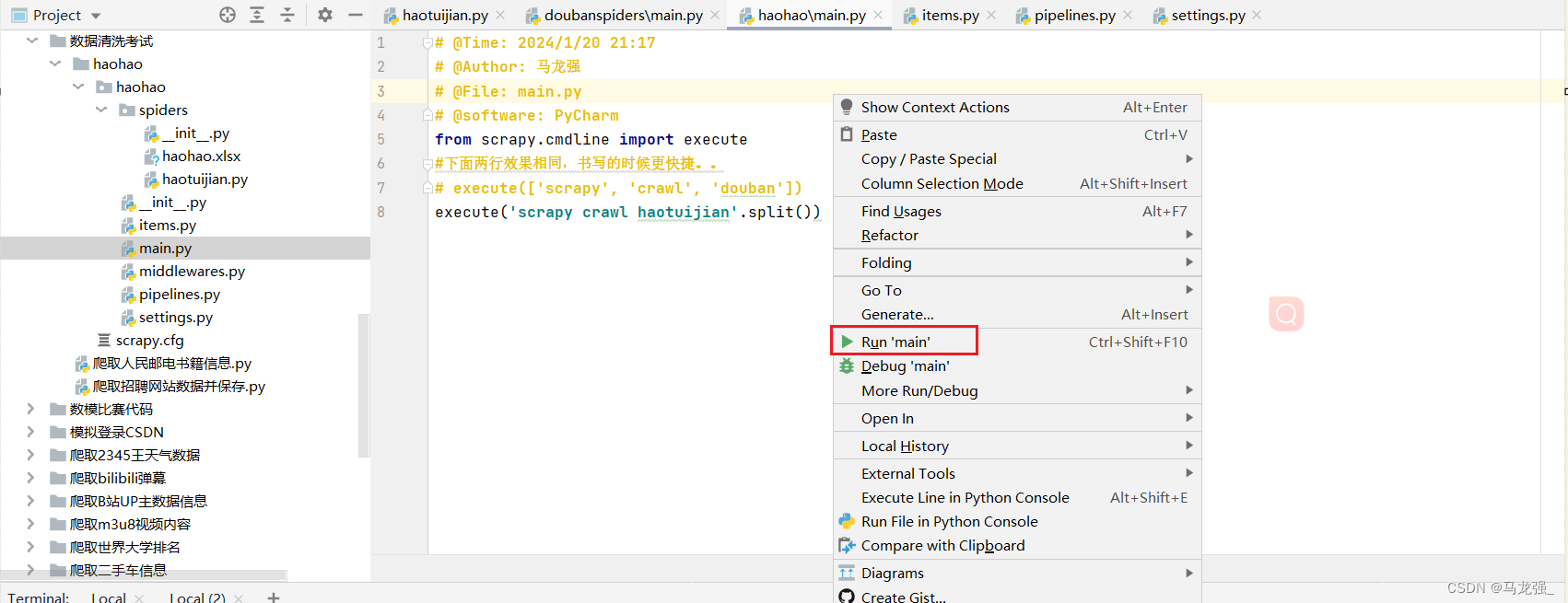
2.直接运行main.py文件
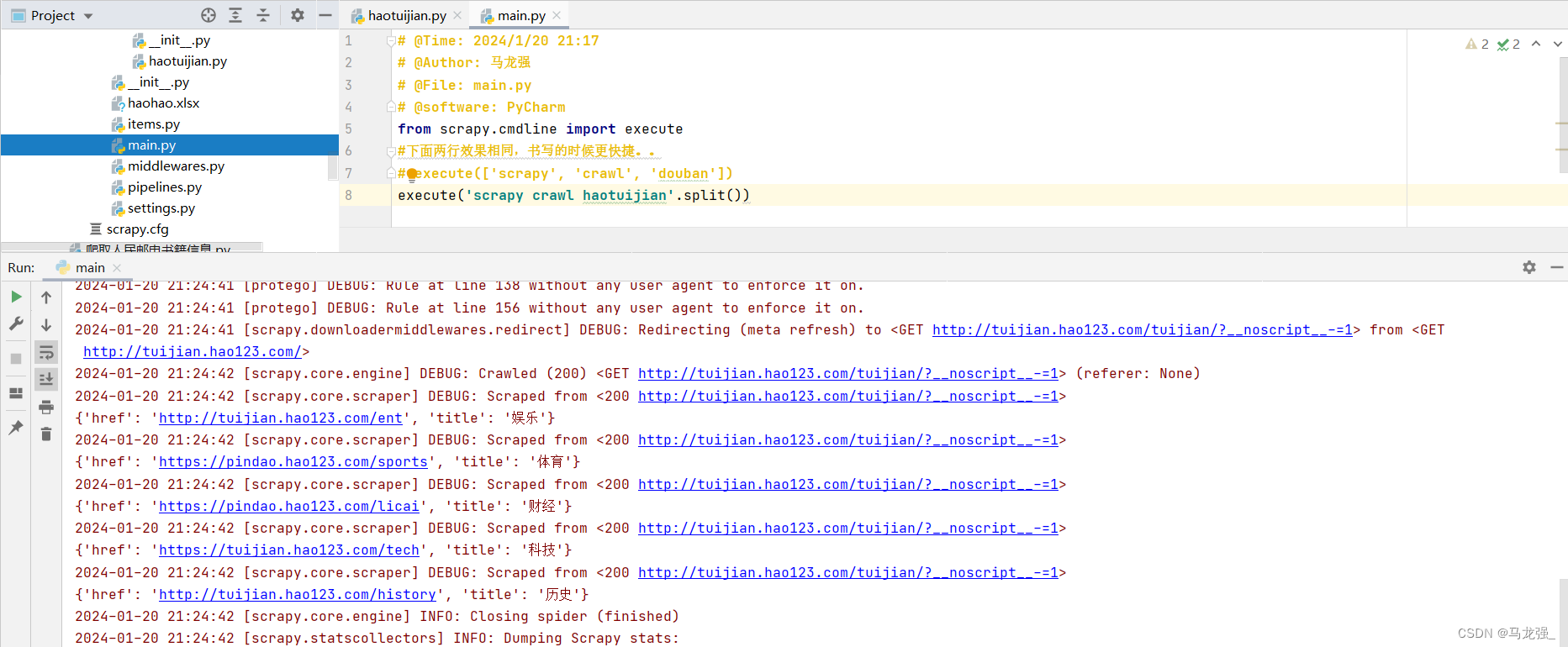
3.运行结果与使用指令运行结果相同(只不过运行过程变成了红色,但可以像普通python代码一样可以随时暂停)
相关文章:
使用Scrapy 爬取“http://tuijian.hao123.com/”网页中左上角“娱乐”、“体育”、“财经”、“科技”、历史等名称和URL
一、网页信息 二、检查网页,找出目标内容 三、根据网页格式写正常爬虫代码 from bs4 import BeautifulSoup import requestsheaders {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/53…...

2018年认证杯SPSSPRO杯数学建模D题(第二阶段)投篮的最佳出手点全过程文档及程序
2018年认证杯SPSSPRO杯数学建模 D题 投篮的最佳出手点 原题再现: 影响投篮命中率的因素不仅仅有出手角度、球感、出手速度,还有出手点的选择。规范的投篮动作包含两膝微屈、重心落在两脚掌上、下肢蹬地发力、身体随之向前上方伸展、同时抬肘向投篮方向…...
软件资源管理下载系统全新带勋章功能 + Uniapp前端
测试环境:php7.1。ng1.2,MySQL 5.6 常见问题: 配置好登录后转圈圈,检查环境及伪静态以及后台创建好应用 上传图片不了,检查php拓展fileinfo 以及public文件权限 App个人主页随机背景图,在前端uitl文件…...

高性能前端UI库 SolidJS | 超棒 NPM 库
SolidJS是一个声明式的、高效的、编译时优化的JavaScript库,用于构建用户界面。它的核心特点是让你能够编写的代码既接近原生JavaScript,又能够享受到现代响应式框架提供的便利。 SolidJS的设计哲学强调了性能与简洁性。它不使用虚拟DOM(Vir…...

聊聊PowerJob的AliOssService
序 本文主要研究一下PowerJob的AliOssService DFsService tech/powerjob/server/extension/dfs/DFsService.java public interface DFsService {/*** 存储文件* param storeRequest 存储请求* throws IOException 异常*/void store(StoreRequest storeRequest) throws IOEx…...

【VRTK】【Unity】【PICO】PICO项目打包后闪退的根本原因
【背景】 一开始打包运行好好的PICO项目,中途用Preview模式开发了一阵后,再次打包就闪退了。 【分析】 项目设置没有动过,那么可能是Preview开发过程中引入的包导致的问题。 【答案】 千万不要在PICO项目中导入Oculus包。我原本想用一些…...

《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(21)
接前一篇文章:《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(20) 2.4 PCI总线的配置 PCI总线定义了两类配置请求,一个是Type 00h配置请求,另一个是Type 01h配置请求。PCI总线使用这些配置请求…...
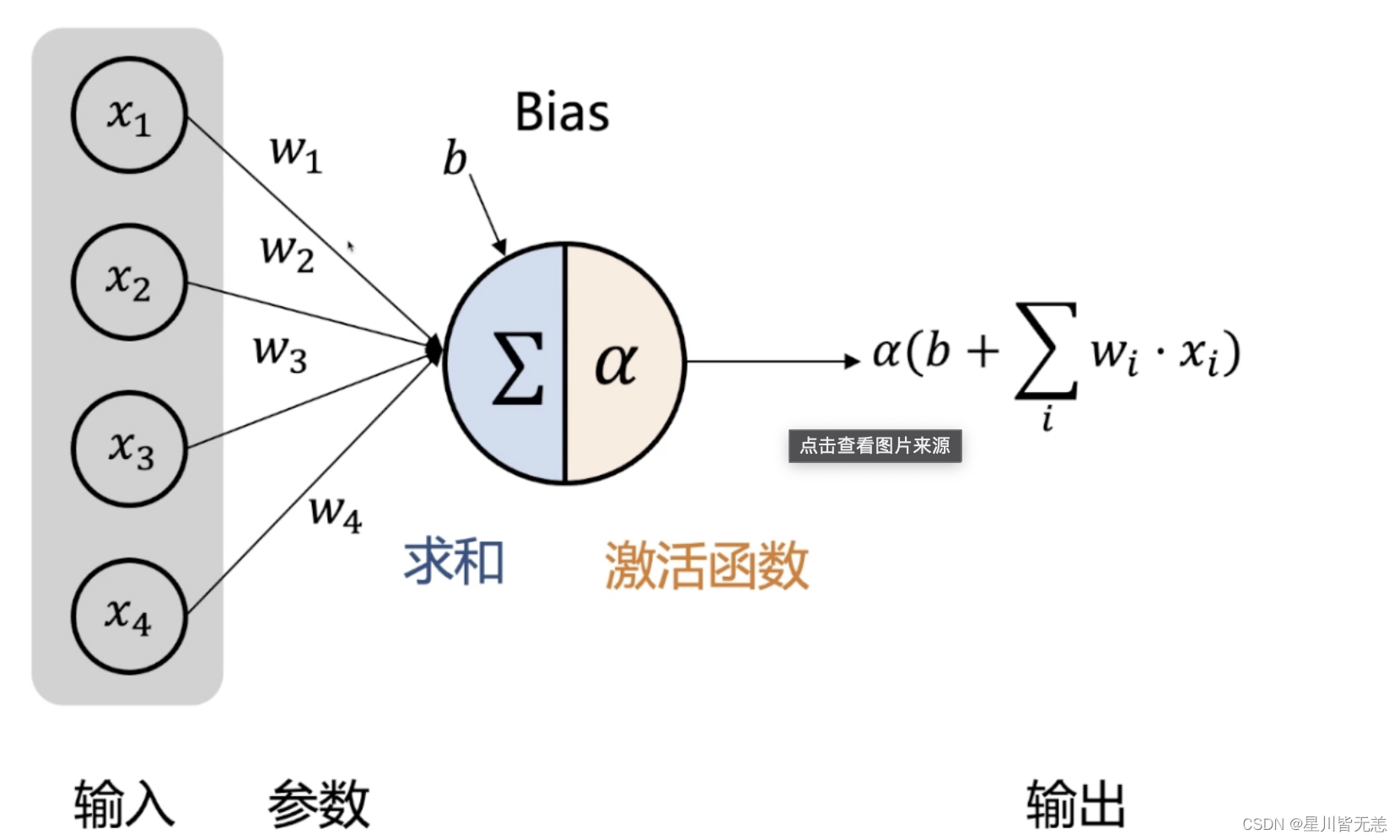
大数据前馈神经网络解密:深入理解人工智能的基石
文章目录 大数据前馈神经网络解密:深入理解人工智能的基石一、前馈神经网络概述什么是前馈神经网络前馈神经网络的工作原理应用场景及优缺点 二、前馈神经网络的基本结构输入层、隐藏层和输出层激活函数的选择与作用网络权重和偏置 三、前馈神经网络的训练方法损失函…...

【新书推荐】Web3.0应用开发实战(从Web 2.0到Web 3.0)
第一部分 Flask简介 第1章 安装 1.1 创建应用目录 1.2 虚拟环境 1.2.1 创建虚拟环境 1.2.2 使用虚拟环境 1.3 使用pip安装Python包 1.4 使用pipregs输出包 1.5 使用requirements.txt 1.6 使用pipenv管理包 第2章 应用的基本结构 2.1 网页显示过程 2.2 初始化 2.3 路由和视图函数…...

vue3中状态管理库pinia的安装和使用方法介绍及和vuex的区别
文章目录 Pinia 的主要特点:如何使用:1.安装2.定义3.使用 pinia和vuex的对比 Pinia 与 Vuex 一样,是作为 Vue 的“状态存储库”,用来实现 跨页面/组件 形式的数据状态共享。它允许你跨组件或页面共享状态。如果你熟悉组合式 API 的…...
领略指针之妙
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary-walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...
迭代器模式介绍
目录 一、迭代器模式介绍 1.1 迭代器模式定义 1.2 迭代器模式原理 1.2.1 迭代器模式类图 1.2.2 模式角色说明 1.2.3 示例代码 二、迭代模式的应用 2.1 需求说明 2.2 需求实现 2.2.1 抽象迭代类 2.2.2 抽象集合类 2.2.3 主题类 2.2.4 具体迭代类 2.2.5 具体集合类 …...

算法每日一题: 最大字符串匹配数目 | 哈希 | 哈希表 | 题意分析
hello 大家好,我是星恒 今天给大家带来的是hash,思路有好几种,需要注意的是这中简单的题目需要仔细看条件,往往他们有对应题目的特殊的解法 题目:leetcode 2744给你一个下标从 0 开始的数组 words ,数组中包…...

自然语言处理(Natural Language Processing,NLP)解密
专栏集锦,大佬们可以收藏以备不时之需: Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9 Python 专栏:http://t.csdnimg.cn/hMwPR Redis 专栏:http://t.csdnimg.cn/Qq0Xc TensorFlow 专栏:http://t.csdni…...

【DevOps-08-5】目标服务器准备脚本,并基于Harbor的最终部署
一、简要描述 告知目标服务器拉取哪个镜像判断当前服务器是否正在运行容器,停止并删除如果目标服务器已经存在当前镜像,删除当前版本的镜像目标服务器拉取Harbor上的镜像将拉取下来的镜像运行成容器二、准备目标服务器脚本文件 1、在部署的目标服务器准备deploy.sh部署脚本 …...

用Java实现01背包问题 用贪心算法
贪心算法不是解决01背包问题的有效方法,因为贪心算法只能保证得到一个近似最优解,而无法保证得到最优解。因此,我们需要使用动态规划来解决01背包问题。以下是使用Java实现的动态规划解法: public class KnapsackProblem {public…...

JUC并发编程-8锁现象
5. 8锁现象 如何判断锁的是谁!锁到底锁的是谁? 锁会锁住:对象、Class 深刻理解我们的锁 问题1 两个同步方法,先执行发短信还是打电话 public class dome01 {public static void main(String[] args) {Phone phone new Phon…...
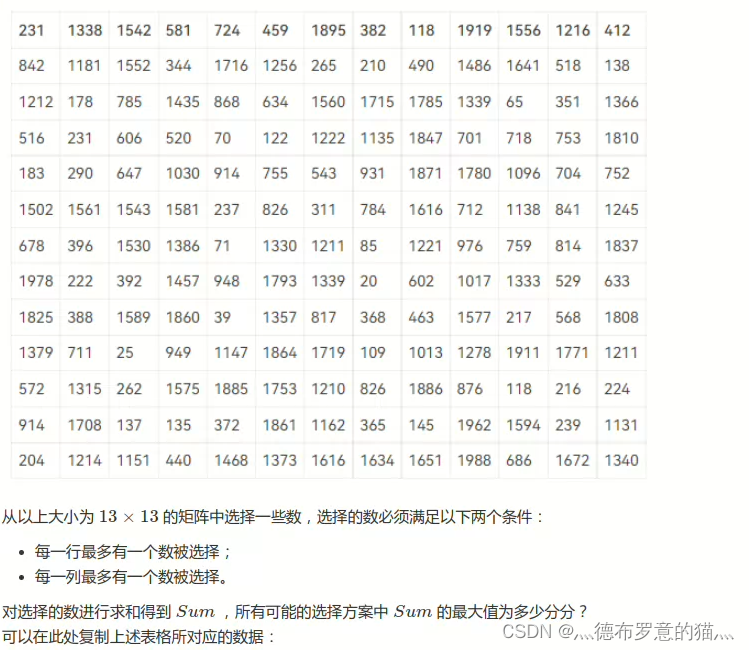
集美大学“第15届蓝桥杯大赛(软件类)“校内选拔赛 D矩阵选数
经典的状态压缩DP int dp[15][(1<<14)10]; int a[15][15]; void solve() {//dp[i][st]考虑到了第i行 并且当前考虑完第i行以后的选择状态是st的所有方案中的最大值for(int i1;i<13;i)for(int j1;j<13;j)cin>>a[i][j];for(int i1;i<13;i){for(int j0;j<…...

Android System Service系统服务--1
因为工作中经常需要解决一些framework层的问题,而framework层功能一般都是system service 的代理stub,然后封装相关接口,并提供给APP层使用,system service则在不同的进程中运行,这样实现了分层,隔离&#…...

【RT-DETR有效改进】华为 | Ghostnetv1一种专为移动端设计的特征提取网络
前言 大家好,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PP…...
)
别再到处找汉化包了!PowerDesigner 15.1 保姆级安装与汉化教程(附资源)
PowerDesigner 15.1 完整安装与汉化实战指南 对于数据库设计领域的初学者和专业开发者来说,PowerDesigner无疑是一款功能强大的建模工具。然而,英文界面常常成为非英语母语用户的第一道门槛。本文将提供一份从零开始的完整解决方案,涵盖软件安…...

如何用AI智能分层技术将单张插画转化为可编辑的PSD文件
如何用AI智能分层技术将单张插画转化为可编辑的PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对一张精美的插画,想要对…...

游戏逆向实战:从CALL定位到功能复现,构建自动化辅助框架
1. 游戏逆向基础:理解CALL与基址 游戏逆向工程的核心目标之一就是找到并理解游戏中的关键功能调用(CALL)。这些CALL就像是游戏的"遥控器按钮",按下它们就能触发特定功能。比如释放技能、打开背包、自动寻路等操作&…...

企业级应用如何借助Taotoken实现大模型API的容灾与负载均衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何借助Taotoken实现大模型API的容灾与负载均衡 在构建依赖大模型能力的企业级应用时,服务的连续性与稳定性…...

2026年最新推荐 很多一线老师都在用的英语作文批改工具
行业共性痛点拆解我们团队做英语教育技术落地5年,接触过全国上千位初高中英语老师,发现作文批改是大家公认的效率洼地。人工批改模式下,一个45人班的作文,每篇要改语法、逻辑、表达、扣题四个维度,最少花3分钟…...

RimWorld模组管理终极指南:3步掌握RimSort智能排序,告别游戏崩溃烦恼
RimWorld模组管理终极指南:3步掌握RimSort智能排序,告别游戏崩溃烦恼 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a…...

告别命令行!用这个免费软件5分钟搞定Abaqus三维Voronoi泡沫模型
五分钟可视化构建Abaqus三维Voronoi泡沫模型:零代码解决方案全指南 在材料科学与工程仿真领域,三维Voronoi泡沫结构的建模一直是学术研究和工业应用的热点。这种仿生多孔结构因其优异的力学性能和轻量化特性,被广泛应用于缓冲材料、骨科植入物…...

3.1 FiRa UCI规范解析——命令、响应与通知的交互逻辑
1. FiRa UCI规范的核心交互机制 第一次接触FiRa UCI规范时,我被它严谨的消息交互设计所震撼。这个看似简单的命令-响应机制,实际上蕴含着UWB通信的精妙控制逻辑。就像交通信号灯指挥车辆通行一样,UCI规范通过明确的指令流向和状态反馈&#…...
)
告别模型水土不服:用TENT的熵最小化,5分钟搞定测试时域自适应(附PyTorch代码)
实战TENT:5行代码解决模型部署中的“水土不服”问题 想象一下这样的场景:你花费数月训练的自动驾驶视觉模型在实验室测试中准确率高达98%,但当它遇到真实世界的暴雨天气时,识别率瞬间暴跌至60%。这种"实验室王者,…...

【Perplexity专利搜索黄金法则】:20年资深IP专家首度公开3大反直觉检索技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity专利搜索黄金法则的底层逻辑 Perplexity 作为基于语言模型的智能搜索工具,其在专利检索场景中的卓越表现并非源于简单关键词匹配,而是植根于对专利文本结构化语义、法…...