经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程
经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程
和之前实现的YOLOv1一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv2的大部分核心理念的前提下,重构一款较新的YOLOv2检测器,来对YOLOV2有更加深刻的认识。
书中源码连接: RT-ODLab: YOLO Tutorial
对比原始YOLOV2网络,主要改进点如下:
-
添加了后续YOLO中使用的neck,即SPPF模块
-
使用普遍用在RetinaNet、FCOS、YOLOX等通用目标检测网络中的解耦检测头(Decoupled head)
-
修改损失函数,分类分支替换为BCE loss,回归分支替换为GIou loss。
-
由基于边界框的正样本匹配策略,改为基于先验框的正样本匹配策略。
对比之前实现的YOLOV1网络,主要改进点:
-
主干网络由ResNet18改为DarkNet19
-
添加先验框机制
-
正样本匹配策略改为:基于先验框的正样本匹配策略
-
YOLOv2代码和之前实现的YOLOv1相比,修改之处不多,建议先看之前实现的YOLOv1的相关文章。
1、YOLOv2网络架构
1.1 DarkNet19主干网络
- 使用原版YOLOv2中提出的DarkNet19作为主干网络(backbone)。
- 不同于分类网络,我们去掉网络中的平均池化层以及分类层。DarkNet19网络的下采样倍数为32,一张图片(416×416×3)经过主干网络,得到13×13×1024的特征图。
- 根据官方的做法,DarkNet19需要现在ImageNet数据集上进行预训练。不过,作者提供了DarkNet19在ImageNet数据集上的预训练权重,因此,我们只需要直接加载即可。
- 这里我们不去实现原版YOLOv2中的passthrough层,仅仅输出一个尺度,即c5层。

# RT-ODLab/models/detectors/yolov2/yolov2_backbone.pyimport torch
import torch.nn as nnmodel_urls = {"darknet19": "https://github.com/yjh0410/image_classification_pytorch/releases/download/weight/darknet19.pth",
}__all__ = ['DarkNet19']# --------------------- Basic Module -----------------------
class Conv_BN_LeakyReLU(nn.Module):def __init__(self, in_channels, out_channels, ksize, padding=0, stride=1, dilation=1):super(Conv_BN_LeakyReLU, self).__init__()self.convs = nn.Sequential(nn.Conv2d(in_channels, out_channels, ksize, padding=padding, stride=stride, dilation=dilation),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.1, inplace=True))def forward(self, x):return self.convs(x)# --------------------- DarkNet-19 -----------------------
class DarkNet19(nn.Module):def __init__(self):super(DarkNet19, self).__init__()# backbone network : DarkNet-19# output : stride = 2, c = 32self.conv_1 = nn.Sequential(Conv_BN_LeakyReLU(3, 32, 3, 1),nn.MaxPool2d((2,2), 2),)# output : stride = 4, c = 64self.conv_2 = nn.Sequential(Conv_BN_LeakyReLU(32, 64, 3, 1),nn.MaxPool2d((2,2), 2))# output : stride = 8, c = 128self.conv_3 = nn.Sequential(Conv_BN_LeakyReLU(64, 128, 3, 1),Conv_BN_LeakyReLU(128, 64, 1),Conv_BN_LeakyReLU(64, 128, 3, 1),nn.MaxPool2d((2,2), 2))# output : stride = 8, c = 256self.conv_4 = nn.Sequential(Conv_BN_LeakyReLU(128, 256, 3, 1),Conv_BN_LeakyReLU(256, 128, 1),Conv_BN_LeakyReLU(128, 256, 3, 1),)# output : stride = 16, c = 512self.maxpool_4 = nn.MaxPool2d((2, 2), 2)self.conv_5 = nn.Sequential(Conv_BN_LeakyReLU(256, 512, 3, 1),Conv_BN_LeakyReLU(512, 256, 1),Conv_BN_LeakyReLU(256, 512, 3, 1),Conv_BN_LeakyReLU(512, 256, 1),Conv_BN_LeakyReLU(256, 512, 3, 1),)# output : stride = 32, c = 1024self.maxpool_5 = nn.MaxPool2d((2, 2), 2)self.conv_6 = nn.Sequential(Conv_BN_LeakyReLU(512, 1024, 3, 1),Conv_BN_LeakyReLU(1024, 512, 1),Conv_BN_LeakyReLU(512, 1024, 3, 1),Conv_BN_LeakyReLU(1024, 512, 1),Conv_BN_LeakyReLU(512, 1024, 3, 1))def forward(self, x):c1 = self.conv_1(x) # c1c2 = self.conv_2(c1) # c2c3 = self.conv_3(c2) # c3c3 = self.conv_4(c3) # c3c4 = self.conv_5(self.maxpool_4(c3)) # c4c5 = self.conv_6(self.maxpool_5(c4)) # c5return c5# --------------------- Fsnctions -----------------------
def build_backbone(model_name='darknet19', pretrained=False):if model_name == 'darknet19':# modelmodel = DarkNet19()feat_dim = 1024# load weightif pretrained:print('Loading pretrained weight ...')url = model_urls['darknet19']# checkpoint state dictcheckpoint_state_dict = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)# model state dictmodel_state_dict = model.state_dict()# checkfor k in list(checkpoint_state_dict.keys()):if k in model_state_dict:shape_model = tuple(model_state_dict[k].shape)shape_checkpoint = tuple(checkpoint_state_dict[k].shape)if shape_model != shape_checkpoint:checkpoint_state_dict.pop(k)else:checkpoint_state_dict.pop(k)print(k)model.load_state_dict(checkpoint_state_dict)return model, feat_dimif __name__ == '__main__':import timemodel, feat_dim = build_backbone(pretrained=True)x = torch.randn(1, 3, 416, 416)t0 = time.time()for layer in model.children():x = layer(x)print(layer.__class__.__name__, 'output shape:', x.shape)# y = model(x)t1 = time.time()print('Time: ', t1 - t0)
1.2 添加neck
- 和之前实现的YOLOv1一致,选择YOLOV5版本中所用的SPPF模块。
- 代码在RT-ODLab/models/detectors/yolov2/yolov2_neck.py文件中,不在赘述。

1.3 Detection Head网络
- 和之前实现的YOLOv1一致,即使用解耦检测头(Decoupled head)。
- 代码在RT-ODLab/models/detectors/yolov2/yolov1_head.py文件中,不在赘述。

1.4 预测层
- 如下图,由于预测层多了先验框,因此预测层的输出通道的数量略有变化。

## 预测层# 与YoloV1相比,YoloV2每个网格会预测5个框(VOC数据集),因此需×5self.obj_pred = nn.Conv2d(head_dim, 1 * self.num_anchors, kernel_size=1)self.cls_pred = nn.Conv2d(head_dim, num_classes * self.num_anchors, kernel_size=1)self.reg_pred = nn.Conv2d(head_dim, 4 * self.num_anchors, kernel_size=1)
1.5 改进YOLOv2的详细网络图
- 与之前实现的YOLOv1相比,主干网络由ResNet18变为DarkNet19,每个网格预测5个anchor box,其他方面一致。
- 与原版的YOLOv2相比,做了更加符合当下的设计理念的修改,包括添加Neck模块、修改检测头等,但是没有引入passthrough层。
- 尽管和原版的YOLOv2有所差别,但内核思想是一致的,均是在YOLOv1的单级检测架构上引入了先验框。

# RT-ODLab/models/detectors/yolov2/yolov2.pyimport torch
import torch.nn as nn
import numpy as npfrom utils.misc import multiclass_nmsfrom .yolov2_backbone import build_backbone
from .yolov2_neck import build_neck
from .yolov2_head import build_head# YOLOv2
class YOLOv2(nn.Module):def __init__(self,cfg,device,num_classes=20,conf_thresh=0.01,nms_thresh=0.5,topk=100,trainable=False,deploy=False,nms_class_agnostic=False):super(YOLOv2, self).__init__()# ------------------- Basic parameters -------------------self.cfg = cfg # 模型配置文件self.device = device # cuda或者是cpuself.num_classes = num_classes # 类别的数量self.trainable = trainable # 训练的标记self.conf_thresh = conf_thresh # 得分阈值self.nms_thresh = nms_thresh # NMS阈值self.topk = topk # topkself.stride = 32 # 网络的最大步长self.deploy = deployself.nms_class_agnostic = nms_class_agnostic# ------------------- Anchor box -------------------self.anchor_size = torch.as_tensor(cfg['anchor_size']).float().view(-1, 2) # [A, 2]self.num_anchors = self.anchor_size.shape[0]# ------------------- Network Structure -------------------## 主干网络self.backbone, feat_dim = build_backbone(cfg['backbone'], trainable&cfg['pretrained'])## 颈部网络self.neck = build_neck(cfg, feat_dim, out_dim=512)head_dim = self.neck.out_dim## 检测头self.head = build_head(cfg, head_dim, head_dim, num_classes)## 预测层# 与YoloV1相比,YoloV2每个网格会预测5个框(VOC数据集),因此需×5self.obj_pred = nn.Conv2d(head_dim, 1 * self.num_anchors, kernel_size=1)self.cls_pred = nn.Conv2d(head_dim, num_classes * self.num_anchors, kernel_size=1)self.reg_pred = nn.Conv2d(head_dim, 4 * self.num_anchors, kernel_size=1)if self.trainable:self.init_bias()def init_bias(self):# init biasinit_prob = 0.01bias_value = -torch.log(torch.tensor((1. - init_prob) / init_prob))nn.init.constant_(self.obj_pred.bias, bias_value)nn.init.constant_(self.cls_pred.bias, bias_value)def generate_anchors(self, fmp_size):passdef decode_boxes(self, anchors, reg_pred):passdef postprocess(self, obj_pred, cls_pred, reg_pred, anchors):"""后处理代码,包括topk操作、阈值筛选和非极大值抑制"""pass@torch.no_grad()def inference(self, x):bs = x.shape[0]# 主干网络feat = self.backbone(x)# 颈部网络feat = self.neck(feat)# 检测头cls_feat, reg_feat = self.head(feat)# 预测层obj_pred = self.obj_pred(reg_feat)cls_pred = self.cls_pred(cls_feat)reg_pred = self.reg_pred(reg_feat)fmp_size = obj_pred.shape[-2:]# anchors: [M, 2]anchors = self.generate_anchors(fmp_size)# 对 pred 的size做一些view调整,便于后续的处理# [B, A*C, H, W] -> [B, H, W, A*C] -> [B, H*W*A, C]obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, 1) # [1, 845=13×13×5, 1]cls_pred = cls_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, self.num_classes)reg_pred = reg_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, 4)# 测试时,默认batch是1,# 因此,我们不需要用batch这个维度,用[0]将其取走。obj_pred = obj_pred[0] # [H*W*A, 1]cls_pred = cls_pred[0] # [H*W*A, NC]reg_pred = reg_pred[0] # [H*W*A, 4]if self.deploy:scores = torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())bboxes = self.decode_boxes(anchors, reg_pred)# [n_anchors_all, 4 + C]outputs = torch.cat([bboxes, scores], dim=-1)return outputselse:# post processbboxes, scores, labels = self.postprocess(obj_pred, cls_pred, reg_pred, anchors)return bboxes, scores, labelsdef forward(self, x):if not self.trainable:return self.inference(x)else:bs = x.shape[0]# 主干网络feat = self.backbone(x)# 颈部网络feat = self.neck(feat)# 检测头cls_feat, reg_feat = self.head(feat)# 预测层obj_pred = self.obj_pred(reg_feat)cls_pred = self.cls_pred(cls_feat)reg_pred = self.reg_pred(reg_feat)fmp_size = obj_pred.shape[-2:]# A就是Anchor的数量,VOC数据集上设置为5# anchors: [M, 2], M = H*W*Aanchors = self.generate_anchors(fmp_size)# 对 pred 的size做一些view调整,便于后续的处理# [B, A*C, H, W] -> [B, H, W, A*C] -> [B, H*W*A, C]obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, 1)cls_pred = cls_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, self.num_classes)reg_pred = reg_pred.permute(0, 2, 3, 1).contiguous().view(bs, -1, 4)# decode bboxbox_pred = self.decode_boxes(anchors, reg_pred)# 网络输出outputs = {"pred_obj": obj_pred, # (Tensor) [B, M, 1]"pred_cls": cls_pred, # (Tensor) [B, M, C]"pred_box": box_pred, # (Tensor) [B, M, 4]"stride": self.stride, # (Int)"fmp_size": fmp_size # (List) [fmp_h, fmp_w]} return outputs
2、YOLOV2的前向推理
在1.5代码中,还遗留几个问题:
- 如何从边界框偏移量reg_pred解耦出边界框坐标box_pred?
- 如何实现后处理操作?
- 如何计算训练阶段的损失?
2.1 解耦边界框坐标
2.1.1 先验框矩阵的生成
YOLOv2网络配置参数如下,我们从中能看到anchor_size变量。这是基于kmeans聚类,在COCO数据集上聚类出的先验框,由于COCO数据集更大、图片更加丰富,因此我们将这几个先验框用在VOC数据集上。
# RT-ODLab/config/model_config/yolov2_config.py
# YOLOv2 Configyolov2_cfg = {# input'trans_type': 'ssd','multi_scale': [0.5, 1.5],# model'backbone': 'darknet19','pretrained': True,'stride': 32, # P5'max_stride': 32,# neck'neck': 'sppf','expand_ratio': 0.5,'pooling_size': 5,'neck_act': 'lrelu','neck_norm': 'BN','neck_depthwise': False,# head'head': 'decoupled_head','head_act': 'lrelu','head_norm': 'BN','num_cls_head': 2,'num_reg_head': 2,'head_depthwise': False,'anchor_size': [[17, 25],[55, 75],[92, 206],[202, 21],[289, 311]], # 416# matcher'iou_thresh': 0.5,# loss weight'loss_obj_weight': 1.0,'loss_cls_weight': 1.0,'loss_box_weight': 5.0,# training configuration'trainer_type': 'yolov8',
}
-
回想一下,在之前实现的YOLOv1中,我们通过构造矩阵G,得到了每一个网格(grid_x,grid_y)的坐标。
-
由于我们在YOLOv2中引入了先验框,因此,我们不仅需要每一个网格(grid_x,grid_y)的坐标,还要包含先验框(5个)的尺寸信息。
-
先验框矩阵生成代码如下
# RT-ODLab/models/detectors/yolov2/yolov2.pydef generate_anchors(self, fmp_size):"""fmp_size: (List) [H, W]默认缩放后的图像为416×416,那么经过32倍下采样后,fmp_size为13×13"""# 1、特征图的宽和高fmp_w, fmp_h = fmp_size# 2、生成网格的x坐标和y坐标anchor_y, anchor_x = torch.meshgrid([torch.arange(fmp_h), torch.arange(fmp_w)])# 3、将xy两部分的坐标拼接起来,shape为[H, W, 2]# 再转换下, shape变为[HW, 2]anchor_xy = torch.stack([anchor_x, anchor_y], dim=-1).float().view(-1, 2)# 4、引入了anchor box机制,每个网格包含A个anchor,因此每个(grid_x, grid_y)的坐标需要复制A(Anchor nums)份# 相当于 每个网格左上角的坐标点复制5份 作为5个不同宽高anchor box的中心点# [HW, 2] -> [HW, A, 2] -> [M, 2]anchor_xy = anchor_xy.unsqueeze(1).repeat(1, self.num_anchors, 1)anchor_xy = anchor_xy.view(-1, 2).to(self.device)# 5、将kmeans聚类得出的5组anchor box的宽高复制13×13份# [A, 2] -> [1, A, 2] -> [HW, A, 2] -> [M, 2]anchor_wh = self.anchor_size.unsqueeze(0).repeat(fmp_h*fmp_w, 1, 1)anchor_wh = anchor_wh.view(-1, 2).to(self.device)# 6、将中心点和宽高cat起来,得到的shape为[M, 4]# 其中M=13×13×5 表示feature map为13×13,每个网格有5组anchor box# 4代表anchor box的位置(x_center, y_center, w, h)# 需要注意:# x_center, y_center是feature map上的坐标位置,需要×stride 才能得到缩放后原始图像上的中心点# w, h是针对缩放后原始图像anchors = torch.cat([anchor_xy, anchor_wh], dim=-1)return anchors
2.1.2 解耦边界框
- 生成先验框矩阵后,我们就能通过边界框偏移量reg_pred解耦出边界框坐标box_pred》。
- 计算预测边界框的中心点坐标与之前计算YOLOv1是一致的,但是计算宽高发生了变化。这是因为YOLOv2中,我们引入了先验框,而且我们先验框的尺寸设定是相对于resize后图像大小,因此不需要乘stride。
def decode_boxes(self, anchors, reg_pred):"""1、依据预测值reg_pred(t_x,t_y,t_w,t_h)结算出边界框中心点坐标c_x, c_y和宽高b_w, b_hc_x = ( grid_x + sigmoid(t_x) ) × stridec_y = ( grid_y + sigmoid(t_y) ) × strideb_w = p_w × exp(t_w)b_h = p_h × exp(t_h)其中 grid_x,grid_y,p_w,p_h为先验框的结果,即anchors结果2、转换为常用的x1y1x2y2形式。注意:预测的宽高不是相对于feature map的,而是相对于resize后图像大小,因此不需要×stride"""# 1、计算预测边界框的中心点坐标和宽高pred_ctr = (anchors[..., :2] + torch.sigmoid(reg_pred[..., :2])) * self.stridepred_wh = anchors[..., 2:] * torch.exp(reg_pred[..., 2:]) # 不需要×stride# 2、将所有bbox的中心点坐标和宽高换算成x1y1x2y2形式pred_x1y1 = pred_ctr - pred_wh * 0.5pred_x2y2 = pred_ctr + pred_wh * 0.5pred_box = torch.cat([pred_x1y1, pred_x2y2], dim=-1)return pred_box
2.2 后处理操作
- 之前YOLOv1的后处理操作,仅仅包含了阈值筛选和非极大值抑制NMS,这里由于引入了先验框,因此我们后处理的框的数量由之前的13×13变成了13×13×5(845)个。
- 这845个框不都是高质量的,因此我们先做一个topk,依据得分从高到低取前k个。对于COCO数据集来说,一张图片的目标数量不超过100,因此一般只需要设定topk=100。这里,作者为了提高测试的mAP,默认设置topk=1000。
- topk操作后,继续进行阈值筛选和非极大值抑制。
# RT-ODLab/models/detectors/yolov2/yolov2.pydef postprocess(self, obj_pred, cls_pred, reg_pred, anchors):"""后处理代码,包括topk操作、阈值筛选和非极大值抑制1、topk操作:在coco数据集中,检测对象的数量一半不会超过100,因此先选择得分最高的k个边界框,这里为了取得更高的mAP,取k=1000在实际的场景中,不需要把k值取这么大2、滤掉低得分(边界框的score低于给定的阈值)的预测边界框;3、滤掉那些针对同一目标的冗余检测。Input:obj_pred: (Tensor) [H*W*A, 1]cls_pred: (Tensor) [H*W*A, C]reg_pred: (Tensor) [H*W*A, 4]anchors: (Tensor) [H*W*A, 4]其中,H*W*A = 13×13×5 = 845"""# (H x W x A x C,)# 13×13×5×20 = 16900scores = torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid()).flatten()# 1、topk操作# Keep top k top scoring indices only.num_topk = min(self.topk, reg_pred.size(0))# torch.sort is actually faster than .topk (at least on GPUs)predicted_prob, topk_idxs = scores.sort(descending=True)topk_scores = predicted_prob[:num_topk]topk_idxs = topk_idxs[:num_topk]# 2、滤掉低得分(边界框的score低于给定的阈值)的预测边界框# filter out the proposals with low confidence scorekeep_idxs = topk_scores > self.conf_threshscores = topk_scores[keep_idxs]topk_idxs = topk_idxs[keep_idxs]# 获取flatten之前topk_scores所在的idx以及相应的labelanchor_idxs = torch.div(topk_idxs, self.num_classes, rounding_mode='floor') # 获取labels = topk_idxs % self.num_classesreg_pred = reg_pred[anchor_idxs]anchors = anchors[anchor_idxs]# 解算边界框, 并归一化边界框: [H*W*A, 4]bboxes = self.decode_boxes(anchors, reg_pred)# to cpu & numpyscores = scores.cpu().numpy()labels = labels.cpu().numpy()bboxes = bboxes.cpu().numpy()# 3、滤掉那些针对同一目标的冗余检测。# nmsscores, labels, bboxes = multiclass_nms(scores, labels, bboxes, self.nms_thresh, self.num_classes, self.nms_class_agnostic)return bboxes, scores, labels
接下来,就到了正样本的匹配和损失函数计算了。
- 原版YOLOv2会先解耦出边界框,
计算边界框和目标框的IoU,只有IoU最大的才被标记为正样本,用来计算置信度损失、类别损失以及边界框位置损失,其他预测的边界框均为负样本,仅仅计算置信度损失。 - 这样,先验框没有为正样本匹配带来直接影响,仅仅被用于解算边界框的坐标。
- 既然先验框有边界框的先验尺寸信息,那么它可以直接参与正样本的匹配,因此我们接下来采用当下更加常用的策略来发挥先验框在标签匹配中的作用,
即基于先验框的正样本匹配策略。
相关文章:
经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程
经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程 和之前实现的YOLOv1一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv2的大部分核心理念的前提下,重构一款较新的YOLOv2检测器,来对YOLOV2有…...

怎样使用崭新的硬盘
新买的一块硬盘,接到电脑上,打开机器,却找不到新的硬盘,怎么回事?新的硬盘是坏的么?怎样才能把新硬盘用起来? 可能有几种原因导致您的电脑无法识别新的硬盘。以下是一些建议的解决方法ÿ…...

Kafka-多线程消费及分区设置
目录 一、Kafka是什么?消息系统:Publish/subscribe(发布/订阅者)模式相关术语 二、初步使用1.yml文件配置2.生产者类3.消费者类4.发送消息 三、减少分区数量1.停止业务服务进程2.停止kafka服务进程3.重新启动kafka服务4.重新启动业…...
计算机导论06-人机交互
文章目录 人机交互基础人机交互概述人机交互及其发展人机交互方式人机界面 新型人机交互技术显示屏技术跟踪与识别(技术)脑-机接口 多媒体技术多媒体技术基础多媒体的概念多媒体技术及其特性多媒体技术的应用多媒体技术发展趋势 多媒体应用技术文字&…...
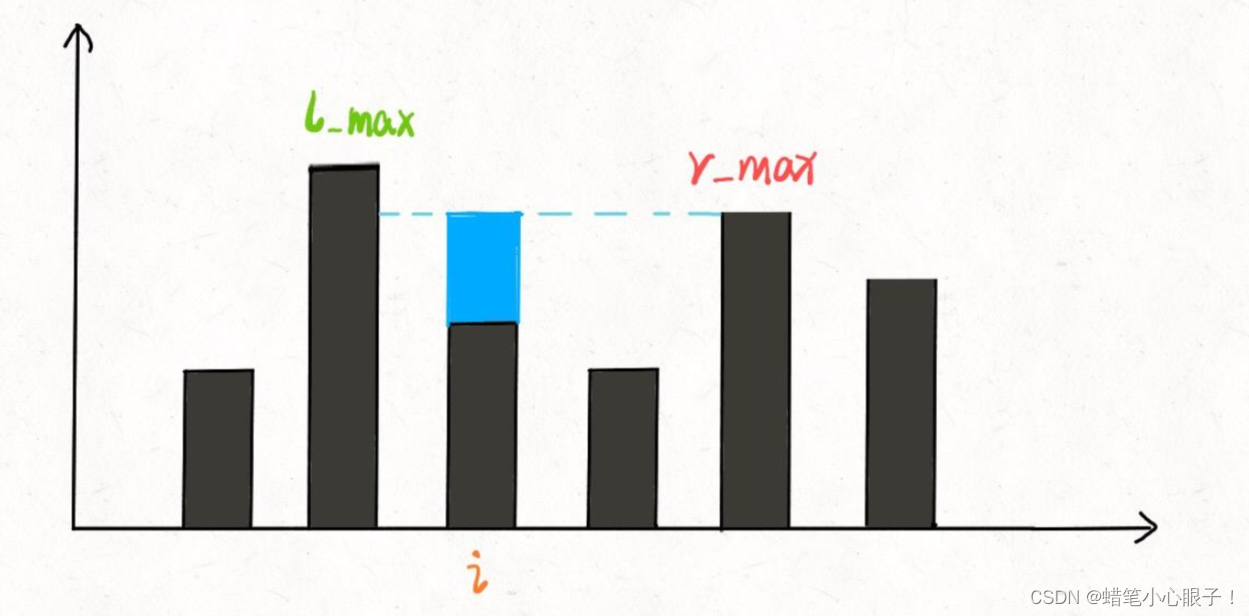
hot100:07接雨水
题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 算法思想: 这里采取的是暴力解法和双指针的解法,但是这个题目还有其他的两种解法(单调栈和动态规划,同学可以自行了解ÿ…...
)
Docker安装MySQL教程分享(附MySQL基础入门教程)
docker安装MySQL Docker可以通过以下命令来安装MySQL容器: 首先确保已经在计算机上安装了Docker。如果没有安装,请根据操作系统的不同进行相应的安装。 打开终端或命令提示符,并运行以下命令拉取最新版本的MySQL镜像: docker pu…...
麒麟V10挂载iso,配置yum源
本文介绍yum 如何挂载本地镜像源 1) 拷贝镜像到本地 2) 执行以下命令: # mount -o loop 镜像路径及镜像名字 /mnt(或 media) 挂载前 挂载后 3) 进入/etc/yum.repos.d(yum.repos.d 是一个目录,该目录是分析 RPM 软件…...
《Linux C编程实战》笔记:信号的捕捉和处理
Linux系统中对信号的处理主要由signal和sigaction函数来完成,另外还会介绍一个函数pause,它可以用来响应任何信号,不过不做任何处理 signal函数 #include <signal.h> void (*signal(int signum, void (*handler)(int)))(int);可以分解…...
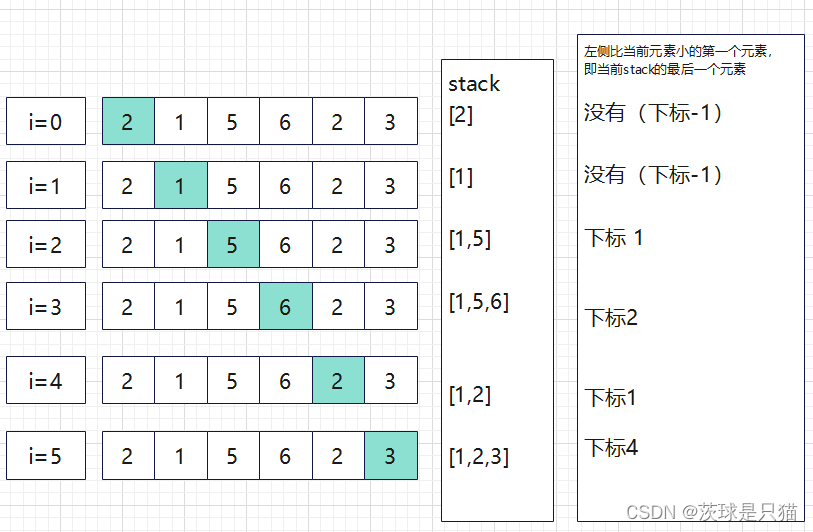
python算法与数据结构---单调栈与实践
单调栈 单调栈是一个栈,里面的元素的大小按照它们所在栈的位置,满足一定的单调性; 性质: 单调递减栈能找到左边第一个比当前元素大的元素;单调递增栈能找到左边第一个比当前元素小的元素; 应用场景 一般用…...

文心一言使用分享
ChatGPT 和文心一言哪个更好用? 一个直接可以用,一个还需要借助一些工具,还有可能账号会消失…… 没有可比性。 通用大模型用于特定功能的时候需要一些引导技巧。 import math import time def calculate_coordinate(c, d, e, f, g, h,…...
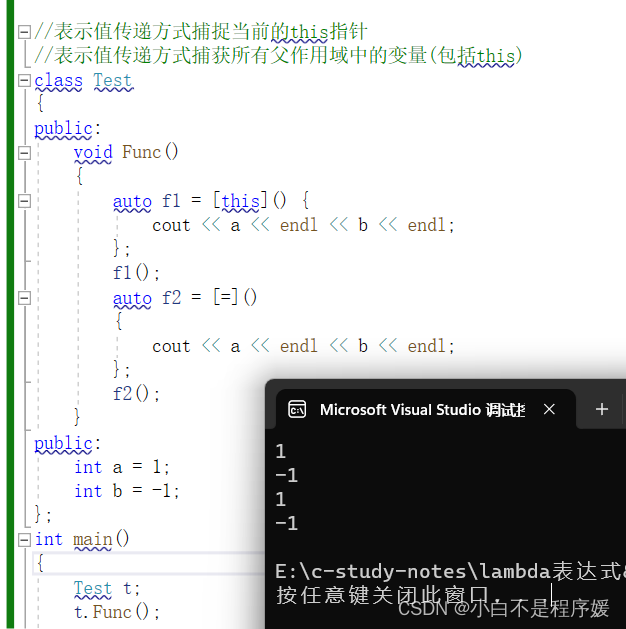
【C++干货铺】C++11新特性——lambda表达式 | 包装器
个人主页点击直达:小白不是程序媛 C系列专栏:C干货铺 代码仓库:Gitee 目录 C98中的排序 lambda表达式 lambda表达式语法 表达式中的各部分说明 lambda表达式的使用 基本的使用 [var]值传递捕捉变量var 编辑 [&var]引用传递捕…...

在 EggJS 中实现 Redis 上锁
配置环境 下载 Redis Windows 访问 https://github.com/microsoftarchive/redis/releases 选择版本进行下载 - 勾选 [配置到环境变量] - 无脑下一步并安装 命令行执行:redis-cli -v 查看已安装的 Redis 版本,能成功查看就表示安装成功啦~ Mac brew i…...

Unity-场景
创建场景 创建新的场景后: 文件 -> 生成设置 -> Build中的场景 -> 将项目中需要使用的场景拖进去 SceneTest public class SceneTest : MonoBehaviour {// Start is called before the first frame updatevoid Start(){// 两个类: 场景类、场…...
MATLAB R2023b for Mac 中文
MATLAB R2023b 是 MathWorks 发布的最新版本的 MATLAB,适用于进行算法开发、数据可视化、数据分析以及数值计算等任务的工程师和科学家。它包含了一系列新增功能和改进,如改进了数据导入工具,增加了对数据帧和表格对象的支持,增强…...
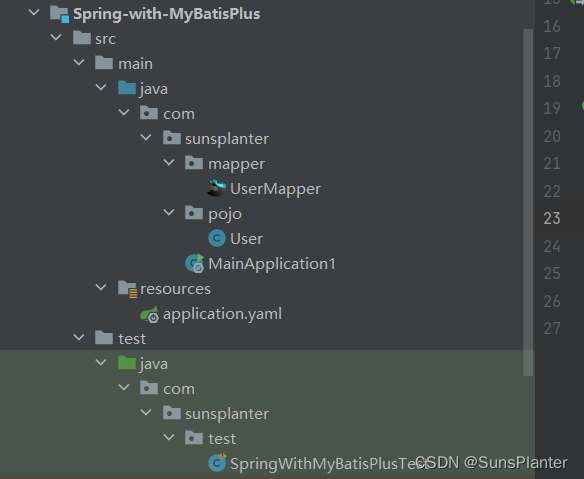
01 MyBatisPlus快速入门
1. MyBatis-Plus快速入门 版本 3.5.31并非另起炉灶 , 而是MyBatis的增强 , 使用之前依然要导入MyBatis的依赖 , 且之前MyBatis的所有功能依然可以使用.局限性是仅限于单表操作, 对于多表仍需要手写 项目结构: 先导入依赖,比之前多了一个mybatis-plus…...
HarmonyOS 应用开发入门
HarmonyOS 应用开发入门 前言 DevEco Studio Release版本为:DevEco Studio 3.1.1。 Compile SDK Release版本为:3.1.0(API 9)。 构建方式为 HVigor,而非 Gradle。 最新版本已不再支持 (”Java、JavaScrip…...
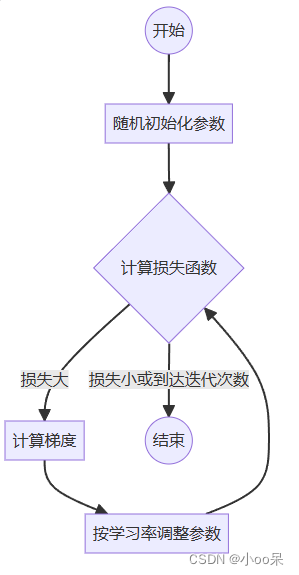
【机器学习300问】9、梯度下降是用来干嘛的?
当你和我一样对自己问出这个问题后,分析一下!其实我首先得知道梯度下降是什么,也就它的定义。其次我得了解它具体用在什么地方,也就是使用场景。最后才是这个问题,梯度下降有什么用?怎么用? 所以…...

第13章 1 进程和线程
文章目录 程序和进程的概念 p173函数式创建子进程Process类常用的属性和方法1 p175Process类中常用的属性和方法2 p176继承式创建子进程 p177进程池的使用 p178并发和并行 p179进程之间数据是否共享 p180队列的基本使用 p180使用队列实现进程之间的通信 p182函数式创建线程 p18…...
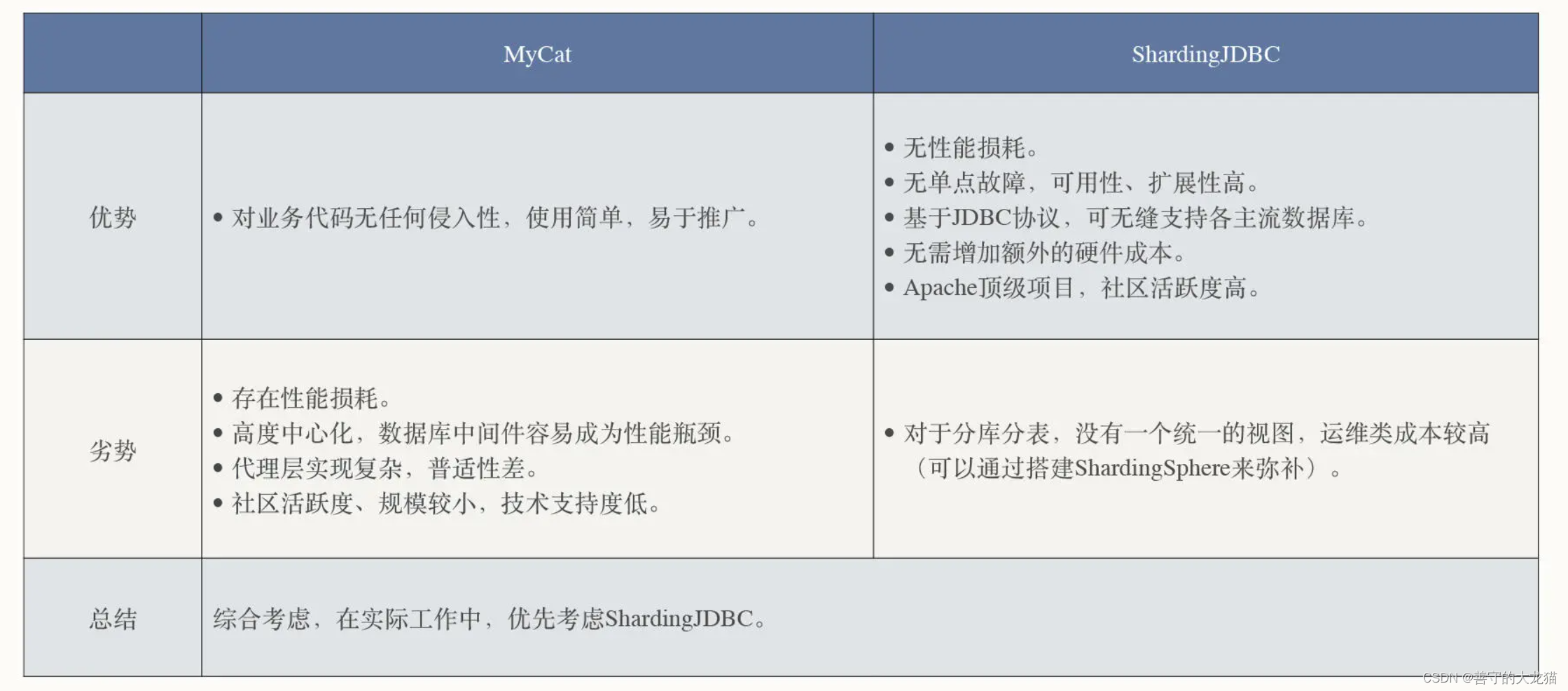
什么是中间件?
文章目录 为什么需要中间件?中间件生态漫谈数据库中间件读写分离分库分表引进数据库中间件MyCat 服务端代理模式ShardingJDBC 客户端代理模式 总结 IT 系统从单体应用逐渐向分布式架构演变,高并发、高可用、高性能、分布式等话题变得异常火热,…...

汽车售后服务客户满意度调查报告
本文由群狼调研(长沙旅行社满意度调查)出品,欢迎转载,请注明出处。汽车售后服务客户满意度调查报告通常包括以下内容: 1.调研概况:介绍调研的目的、背景和范围,包括调研的时间、地点和样本规模等…...

FF14副本动画跳过插件终极指南:3分钟告别冗长等待
FF14副本动画跳过插件终极指南:3分钟告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 你是否曾在《最终幻想14》国服副本中,看着那些无法跳过的动画感到无比焦虑&…...

终极指南:如何一键解决所有Visual C++运行库缺失问题
终极指南:如何一键解决所有Visual C运行库缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为"缺少MSVCP140.dll"、"找不…...

利用Taotoken的Token Plan套餐,为创业项目实现精准成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的Token Plan套餐,为创业项目实现精准成本控制 对于创业团队和独立开发者而言,在项目初期&…...

基础设施监控:全面监控基础设施状态
基础设施监控:全面监控基础设施状态 一、基础设施监控概述 1.1 基础设施监控的定义 基础设施监控是指对IT基础设施的状态、性能和可用性进行持续监控和管理的过程。它包括服务器、网络、存储和应用等方面的监控,确保基础设施的稳定运行和高效利用。 1.2 …...

边缘网络:构建边缘计算的网络基础设施
边缘网络:构建边缘计算的网络基础设施 一、边缘网络概述 1.1 边缘网络的定义 边缘网络是指部署在网络边缘的网络基础设施,它将计算、存储和网络资源扩展到离用户更近的位置。边缘网络支持低延迟数据处理、实时响应和分布式计算,是边缘计算的关…...
)
告别充电焦虑!用FS4066系列芯片DIY一个支持USB PD快充的2-4串锂电池充电器(附完整电路图)
用FS4066系列芯片打造高效多串锂电池快充方案 在创客圈子里,给多节串联锂电池设计充电电路一直是个既令人兴奋又充满挑战的课题。想象一下,当你精心组装的无人机因为充电效率低下而频繁停飞,或者户外电源设备因为充电管理不当导致电池寿命骤减…...
理解AMBA AXI总线上的数据流(以Cortex-A53为例))
手把手教你用Wireshark(或类似工具)理解AMBA AXI总线上的数据流(以Cortex-A53为例)
实战解析:用Wireshark透视Cortex-A53的AXI总线数据流 在嵌入式系统开发中,AXI总线如同SoC的神经系统,承载着处理器核心与各功能模块间的关键通信。对于底层驱动工程师和FPGA开发者而言,能够直观观察总线上的数据流动,就…...
)
保姆级教程:在Windows上用CMake搞定Qt 6.5与WebRTC M114的集成(附完整代码)
Windows平台Qt 6.5与WebRTC M114深度集成实战指南 环境准备与工具链配置 在Windows平台上进行Qt与WebRTC的集成开发,首先需要搭建完整的工具链环境。不同于简单的库引用,这种深度集成对工具版本和系统配置有着严格要求。 必备组件清单: Visua…...

3分钟掌握MPC Video Renderer:免费开启Windows高清视频播放新体验
3分钟掌握MPC Video Renderer:免费开启Windows高清视频播放新体验 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 你是否厌倦了Windows系统上平淡无奇的视频播放效…...

基于RL78 MCU的低功耗声音采集系统设计与实现详解
1. 项目概述:一个基于RL78的低功耗声音采集系统最近在整理一个老项目的技术文档,正好翻出来一个挺有意思的案例:一个基于瑞萨RL78系列MCU的低功耗声音采集与显示系统。这个项目的核心目标很明确,就是实现一个能够长时间、稳定地采…...