optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录
- 0. 背景:why optuna
- 0.1 插播一个简单的grid search
- 0.2 参考
- 1. Optuna
- 1.1 a basic demo与部分参数释义
- 1.2 random的问题
- 1.3 Objective方法类
- 2. Optuna与grid search
- 4. optuna的剪枝prune
- 5. optuna与可视化
- 6. 未完待续
0. 背景:why optuna
-
小模型+参数量少+单卡跑不需要服务器,尝试了一下ray tune不是很适合。。而且很难用。。
-
再三尝试后,决定使用
optuna,选择的原因:- 我这个是小模型,希望调参工具不要太复杂,最好能具有良好的可视化功能
- 和ray tune一样,使用起来都只需要“几行代码”的包装,但是一定要比ray tune操心更少的参数就可以完成任务,或许大模型/分布式更适合ray tune?
- 官方文档新手友好,demo很多(optuna任何一个demo都非常言简意赅)
- 我这里调参以grid search 为主,但是也想尝试一下非grid search的东西
-
我本来是调参的。。结果却调了很多调参的工具老半天,所以分享一些零碎的经验和踩过的坑,查看本文之前最好已经对optuna(或者其他调参工具)的使用方式有一个基本的了解喔,
不要太指望这个写的很碎的教程能帮你从0起步…
0.1 插播一个简单的grid search
- 有一个知乎上的非常简单的grid search的代码,也贴一下,但是这个太简单了,也满足不了我的需求,找不到网址了。代码和荣誉属于这位朋友
# trainable params
parameters = dict(lr=[.01,.001],batch_size = [100,1000],shuffle = [True,False])
#创建可传递给product函数的可迭代列表
param_values = [v for v in parameters.values()]
#把各个列表进行组合,得到一系列组合的参数
#*号是告诉乘积函数把列表中每个值作为参数,而不是把列表本身当做参数来对待
for lr,batch_size,shuffle in product(*param_values):comment = f'batch_size={batch_size}lr={lr}shuffle={shuffle}'#这里写你调陈的主程序即可print(comment)
0.2 参考
- 一些文档很值得参考,首先是官方文档
- 所有函数的demo都非常简单而且说人话。。对于新手非常友好
- 结合李宏毅老师的demo设计了一个使用方法,对我帮助很大,也建议新手参考一下
- optuna可视化的参考:
- 文档有点长,不过还可以
- 官方文档
1. Optuna
1.1 a basic demo与部分参数释义
optimize函数与suggest_float的一个demo
import optuna
def objective(trial):x = trial.suggest_float("x", 0, 10)return x**2
study = optuna.create_study()
study.optimize(objective, n_trials=3,show_progress_bar=True)
-
optimize参数:objective: objecticve函数,就是包装一下training的过程,具体参考其他文档n_trials: objecticve函数执行的次数,每次执行都会抽取一个x,抽取规则是suggest_floatshow_progress_bar:多输出一点tuning的进展信息,默认是False,其实设置为True也不会有什么有价值的信息,就像tqdm一样会告诉你现在进行到第几个,还剩几个。
-
suggest_float函数 -
官方文档,值得参考:
-
含义:从0和10中抽取一个float数返回给x,当然如果想返回一个int,使用
suggest_int
1.2 random的问题
- 因为我有一个小小的诉求是,不要每次都重新抽取新的training data组成data loader,我希望 “固定住”training data"的split方式 ,然后观察一些参数的影响。重点在于:
- 已知
optimize会执行objective函数n_trials次,按照官方的写法,是不是每次执行都会重新抽取执行各种random程序:- 经过实验,是的
- 如何设计使得固定住training data?
- 我的方法是:重写
objectivefunction,写成Objectiveclass,因此objective = Objective(params) - 重写之后,一个是可以传递任意的参数给
objective函数(不然只能传一个trial),二是self.attr的值是不会变的
- 我的方法是:重写
- 已知
1.3 Objective方法类
- 参考官方文档
- 当重写之后,可以给objective函数传入自己需要的参数,并且
self.attr的值是不会变的,刚好解决了我需要的一切问题 - 根据官方重写的demo:
import optuna
import numpy as np
class Objective:def __init__(self, min_x, max_x):# Hold this implementation specific arguments as the fields of the class.self.min_x = min_xself.max_x = max_x# 注意这里的值不会变喔self.test_randn = np.random.randn(7)# 这个trial是必须的(也是唯一的?)def __call__(self, trial):# Calculate an objective value by using the extra arguments.x = trial.suggest_float("x", self.min_x, self.max_x)print(self.test_randn)return (x - 2) ** 2# Execute an optimization by using an `Objective` instance.
# 调用100次Objective function,self.test_randn是不会变的
study = optuna.create_study()
study.optimize(Objective(-100, 100), n_trials=100)
- 我的
Objectiveclass 大概这样:
class Objective:# 传递dataset以及opt,后者是一个dict,存放了各种不需要tune的参数def __init__(self, dataset, opt):# Hold this implementation specific arguments as the fields of the class.self.dataset = datasetself.opt = opt# Hold the data split!!self.shuffled_indices = save_data_idx(dataset,opt)def __call__(self, trial):# Calculate an objective value by using the extra arguments.# 需要tune的参数config = {'learning_rate': trial.suggest_categorical('learning_rate', [5e-2, 1e-2, 5e-3]),'lr_for_pi': trial.suggest_categorical('lr_for_pi', [1e-2, 5e-2, 1e-3])}print("idx check: ",self.shuffled_indices[0:5])# 每次split出来的data都是一致的train_loader, val_loader, test_loader = get_data_loader(self.dataset, self.shuffled_indices, self.opt)model = MLP(self.opt.N_gaussians).to(device) performance = trainer(train_loader, val_loader, model, config, self.opt, device)return performance2. Optuna与grid search
- 为了做到网格搜索
grid search,做了一些必要的修改,其实感觉还是有点笨重 - 修改1: 假设我们这里需要调2个参数,请把他们都设置成
trial.suggest_categorical,而不是什么int或者float,后面的list存放你想尝试的几个数据,比如[5e-2, 1e-2, 5e-3]就是我想尝试的3个数据
config = {'learning_rate': trial.suggest_categorical('learning_rate', [5e-2, 1e-2, 5e-3]),'lr_for_pi': trial.suggest_categorical('lr_for_pi', [1e-2, 5e-2, 1e-3])}
- 修改2: 在实例化一个
study时,加上参数sampler,并且选取GridSampler
# 里面所有的组合被cover之后会自动stop
sampler = optuna.samplers.GridSampler(search_space={'learning_rate': [5e-2, 1e-2, 5e-3], # 注意这里和config里保持一致'lr_for_pi': [1e-2, 5e-2, 1e-3] # 注意这里和config里保持一致})
study = optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
study.optimize(Objective(dataset), n_trials=100,show_progress_bar=True)- 注意
sampler里面的搜索空间search_space和上面的config保持一致 GridSampler的官方文档非常值得一读:
- 上述修改的作用:
- 即便
n_trials==100,只要搜索完了搜索空间search_space里的全部组合,就会自动停止,比如这里只需要搜索9个参数组合,那么执行9次之后就会自动停止 - 当
config不是suggest_categorical,也可以进行网格搜索,那么依然会等cover全部组合之后自动停止,因此这个时候的试探次可能不止9次
- 即便
4. optuna的剪枝prune
- optuna有一个默认的剪枝算法,这个剪枝比ray tune默认的早停算法要好多了。。ray tune默认的方法很难调。
- optuna默认的剪枝是
optuna.pruners.MedianPruner,这个的剪枝策略不一定最好但是足够通用,具体可以参考官方文档, - 但是并不是每一次都需要剪枝,不需要剪枝就使用
optuna.pruners.NopPruner():
pruner = optuna.pruners.NopPruner()
study = optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
5. optuna与可视化
- 这个是为什么我选择optuna的主要原因之一,可视化流程请见相关的官方文档(见0.2 参考),非常轻松加愉快的就执行完毕了。
- 执行的时候注意:
- 生成的数据库文件(应该可以这么叫?)的根目录在哪里,就在哪里执行命令打开dashboard
- 实例化study时,参数
study_name指定了数据库文件的名字,如果不指定会默认生成一个,但是注意这个名字的命名规则不允许有空格喔
optuna.create_study(study_name=study_name,direction='minimize',storage=storage_name,load_if_exists=True,sampler=sampler,pruner=pruner)
6. 未完待续
日后希望项目结束可以放上全部代码。希望大家也能留下自己的optuna使用经验。
相关文章:

optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录0. 背景:why optuna0.1 插播一个简单的grid search0.2 参考1. Optuna1.1 a basic demo与部分参数释义1.2 random的问题1.3 Objective方法类2. Optuna与grid search4. optuna的剪枝prune5. optuna与可视化6. 未完待续0. 背景:why optuna 小模型参…...

语法篇--汇编语言先导浅尝
一、相关概念 1.机器语言 机器语言(Machine Language)是一种计算机程序语言,由二进制代码(0和1)组成,可被计算机直接执行。机器语言是计算机硬件能够理解和执行的唯一语言。 机器语言通常由一系列的指令组…...

【ID:17】【20分】A. DS顺序表--类实现
时间限制1秒内存限制128兆字节题目描述用C语言和类实现顺序表属性包括:数组、实际长度、最大长度(设定为1000)操作包括:创建、插入、删除、查找类定义参考输入第1行先输入n表示有n个数据,即n是实际长度;接着输入n个数据…...
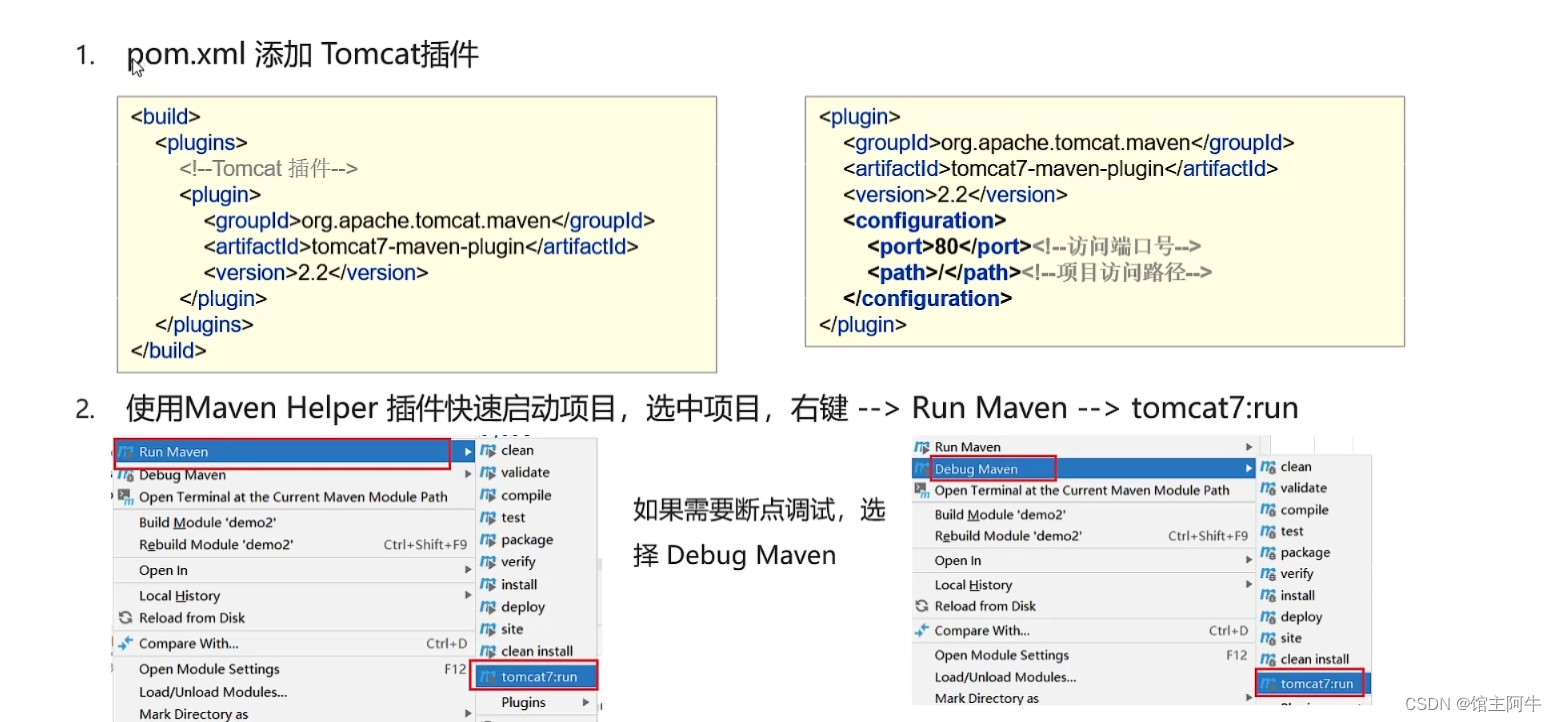
【java web篇】Tomcat的基本使用
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

MySQL实战解析底层---行锁功过:怎么减少行锁对性能的影响
目录 前言 从两阶段锁说起 死锁和死锁检测 前言 MySQL 的行锁是在引擎层由各个引擎自己实现的但并不是所有的引擎都支持行锁,比如MyISAM 引擎就不支持行锁不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有…...
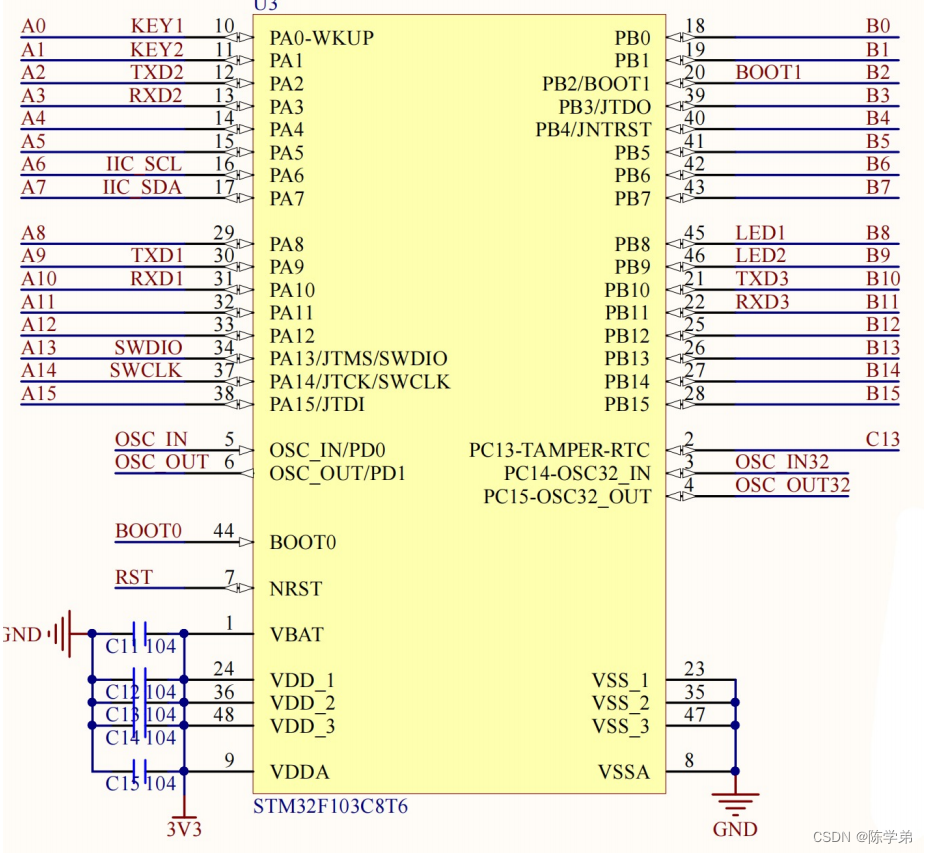
初识STM32单片机
目录 初识STM32单片机 什么是单片机? STM系列单片机命名规则 STM32F103C8T6单片机简介 标准库与HAL库区别 通用输入输出端口GPIO 什么是GPIO? 定义 命名规则 内部框架图 推挽输出与开漏输出 如何点亮一颗LED灯 编程实现点灯 按键点亮LED灯…...

数据结构与算法系列之单链表
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 这里写目录标题test.hSList.h注意事项一级指针与二级指针的使用assert的使用空…...

MySQL基础
本单元目标 一、为什么要学习数据库 二、数据库的相关概念 DBMS、DB、SQL 三、数据库存储数据的特点 四、初始MySQL MySQL产品的介绍 MySQL产品的安装 ★ MySQL服务的启动和停止 ★ MySQL服务的登录和退出 ★ MySQL的常见命令和语法规范 五、…...

面试热点题:环形链表及环形链表寻找环入口结点问题
环形链表 问题: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接…...

【算法】DFS与BFS
作者:指针不指南吗 专栏:算法篇 🐾题目的模拟很重要!!🐾 文章目录1.区别2.DFS2.1 排列数字2.2 n-皇后问题3.BFS3.1走迷宫1.区别 搜索类型数据结构空间用途过程DFSstackO( n )不能用于最短路搜索到最深处&a…...

湖州银行冲刺A股上市:计划募资约24亿元,资产质量水平较高
3月4日,湖州银行股份有限公司(下称“湖州银行”)递交招股书,准备在上海证券交易所主板上市。本次冲刺上市,湖州银行计划募资23.98亿元,将在扣除发行费用后全部用于补充该行资本金。 湖州银行在招股书中表示…...
高性能网络I/O框架-netmap源码分析
前几天听一个朋友提到这个netmap,看了它的介绍和设计,确实是个好东西。其设计思想与业界不谋而合——因为为了提高性能,几个性能瓶颈放在那里,解决方法自然也是类似的。 netmap的出现,它既实现了一个高性能的网络I/O框…...
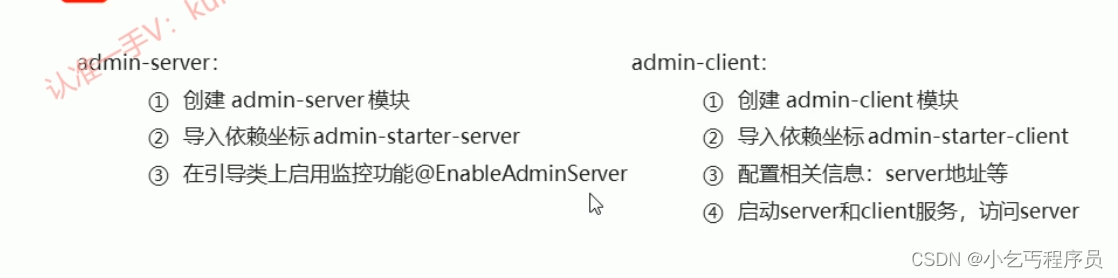
SpringBoot监听机制-以及使用
11-SpringBoot事件监听 Java中的事件监听机制定义了以下几个角色: ①事件:Event,继承 java.util.EventObject 类的对象 ②事件源:Source ,任意对象Object ③监听器:Listener,实现 java.util…...
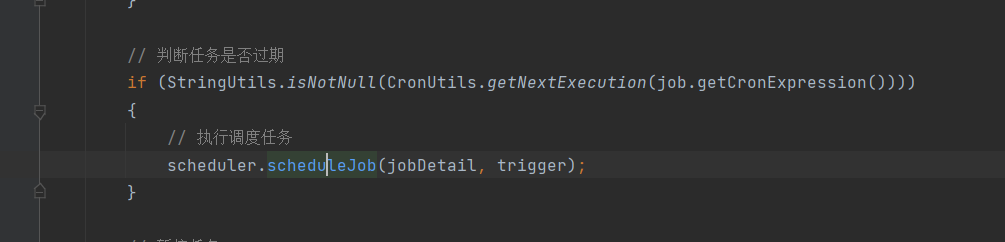
若依学习——定时任务代码逻辑 详细梳理(springboot整合Quartz)
springboot整合Quartz关于若依定时任务的使用可以去看视频默认定时任务的使用关于springboot整合quartz的整合参考(150条消息) 定时任务框架Quartz-(一)Quartz入门与Demo搭建_quarzt_是Guava不是瓜娃的博客-CSDN博客(150条消息) SpringBoot整合Quartz_springboot quartz_桐花思…...
)
C++---最长上升子序列模型---拦截导弹(每日一道算法2023.3.4)
注意事项: 本题为"线性dp—最长上升子序列的长度"的扩展题,这里只讲贪心思路,dp去这个看。 题目: 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。 但是这种导弹拦截系统有一个缺陷:虽然它…...

【机器学习面试】百面机器学习笔记和问题总结+扩展面试题
第1章 特征工程 1、为什么需要对数值类型的特征做归一化? (1)消除量纲,将所有特征统一到一个大致相同的区间范围,使不同指标之间具由可比性; (2)可以加快梯度下降收敛的速度&#…...
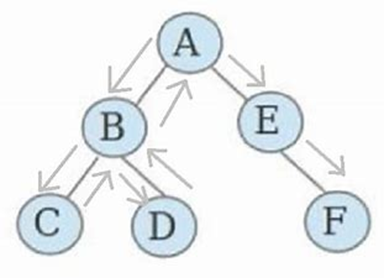
【2021.12.28】ctf逆向中的迷宫问题(含exe及wp)
【2021.12.28】ctf逆向中的迷宫问题(含exe及wp) 文章目录【2021.12.28】ctf逆向中的迷宫问题(含exe及wp)1、迷宫简介(1)简单例子(2)一般的迷宫代码2、二维迷宫(1…...
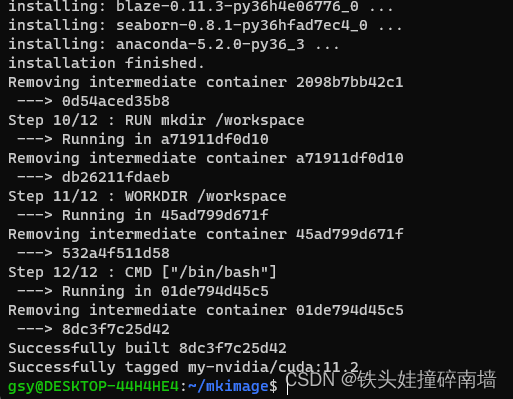
WSL2使用Nvidia-Docker实现深度学习环境自由部署
1. Win11 显卡驱动的安装 注意:WSL2中是不需要且不能安装任何显卡驱动的,它的显卡驱动完全依赖于 Win11 中的显卡驱动,因此我们只需要安装你显卡对应的 Win11 版本显卡驱动版本(必须是 Win11 版本的驱动),…...
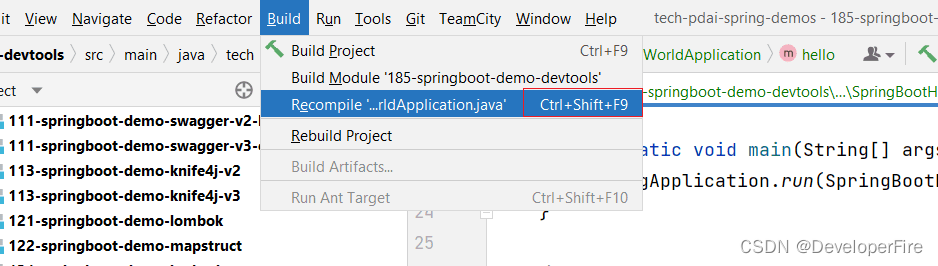
SpringBoot入门 - 配置热部署devtools工具
在SpringBoot开发调试中,如果我每行代码的修改都需要重启启动再调试,可能比较费时间;SpringBoot团队针对此问题提供了spring-boot-devtools(简称devtools)插件,它试图提升开发调试的效率。准备知识点什么是…...

CANFDNET-200U-UDP配置与数据收发控制
一、启动ZCANPRP,打开设备管理页面,选择类型CANFDNET-200U-UDP,如图1 图1 二、打开设备,启动,在相应页面如图2,配置协议,CANFD 加速,本地端口,IP地址,工作端口。 图2 三、发送相应数…...

JETSON平台SDKManager一站式部署指南:从刷机到外置存储系统迁移
1. 开箱即用:JETSON开发板基础准备 刚拿到JETSON开发板时,很多开发者会对着这块巴掌大的硬件发懵。以我经手过的几十块JETSON TX2 NX为例,正确的开箱姿势应该是先检查配件完整性。除了开发板本体,你还需要准备: 5V/4…...
)
【Python并发革命】:GIL解除后首个生产级无锁插件生态正式开放下载(限时72小时)
第一章:Python并发革命的里程碑意义 Python 并发模型的演进并非渐进式改良,而是一场深刻重塑编程范式的革命。从早期依赖线程与锁的阻塞式模型,到 asyncio 的异步 I/O 抽象、async/await 语法糖的引入,再到结构化并发(…...

半导体制造中的ProcessJob与Control Job:从定义到实战避坑指南
半导体制造中的ProcessJob与Control Job:从定义到实战避坑指南 在半导体制造的高精度世界里,每一片晶圆的流转都像一场精密编排的交响乐。而ProcessJob(PJ)和Control Job(CJ)就是这场演奏中不可或缺的指挥…...
)
复现顶刊《金融研究》- 金融周期如何影响房地产价格?(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案
Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 学术研究中ÿ…...

OBS多平台直播同步解决方案:从配置到优化的完整指南
OBS多平台直播同步解决方案:从配置到优化的完整指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 在当今内容创作领域,多平台同步直播已成为扩大受众覆盖的关键…...

MogFace人脸检测模型-large应用指南:从图片上传到结果分析,手把手教学
MogFace人脸检测模型-large应用指南:从图片上传到结果分析,手把手教学 1. 认识MogFace-large:为什么选择这个人脸检测模型 在开始实际操作之前,我们先简单了解下MogFace-large的核心优势。这个模型已经在Wider Face六项榜单上霸榜…...

PyTorch 2.8镜像实际项目:电商短视频自动生成平台从0到1部署纪实
PyTorch 2.8镜像实际项目:电商短视频自动生成平台从0到1部署纪实 1. 项目背景与需求分析 电商行业正面临内容生产的巨大挑战。每天需要制作大量商品展示视频,传统方式需要专业团队拍摄剪辑,成本高、周期长、效率低。我们团队决定基于PyTorc…...
)
Notepad++插件安装失败?手把手教你搞定NppFTP(含离线安装包和兼容性解决方案)
Notepad插件安装失败?手把手教你搞定NppFTP(含离线安装包和兼容性解决方案) 作为开发者日常必备的文本编辑器,Notepad凭借轻量高效的特点广受欢迎。而NppFTP插件更是让这款编辑器如虎添翼,实现了直接通过FTP/SFTP协议远…...

Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择
Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择 【免费下载链接】Mask2Former Code release for "Masked-attention Mask Transformer for Universal Image Segmentation" 项目地址: https://gitcode.com/gh_mirrors/ma/Mask2Former Ma…...