SpringBoot 集成 Canal 基于 MySQL 做数据同步
一、canal 组件关系
下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/
这里面主要的有两个 canal.deployer-1.1.7.tar.gz 和 canal.adapter-1.1.7.tar.gz,canal.admin-1.1.7.tar.gz 是一个监控服务,可选;
这里说一下 deployer 和 adapter 的关系,deployer 主要是监控源数据的数据变更,也是就所有的 insert、update、delete,
只要数据有变化就通知 adapter ,所以真正负责往目标库写数据的是 adapter 。
二、canal-deployer 配置说明
建议先新建一个文件夹 deployer ,然后把上面下载的压缩包拷进去在解压;
修改 /conf/example/instance.properties,这里只贴出了要修改的地方
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=123456这个服务个人理解是一个服务端,程序的客户端会连接他,他监听到数据变化再转发给 adapter
三、canal-adapter 配置说明
建议先新建一个文件夹 adapter ,然后把上面下载的压缩包拷进去在解压;
这里有两个地方要修改,以 mysql 数据同步为例
/conf/application.yml
server:port: 8081
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8default-property-inclusion: non_null
canal.conf:mode: tcp #tcp kafka rocketMQ rabbitMQflatMessage: truezookeeperHosts:syncBatchSize: 1000retries: -1timeout:accessKey:secretKey:consumerProperties:# canal tcp consumercanal.tcp.server.host: 127.0.0.1:11111canal.tcp.zookeeper.hosts:canal.tcp.batch.size: 500canal.tcp.username:canal.tcp.password:# kafka consumerkafka.bootstrap.servers: 127.0.0.1:9092kafka.enable.auto.commit: falsekafka.auto.commit.interval.ms: 1000kafka.auto.offset.reset: latestkafka.request.timeout.ms: 40000kafka.session.timeout.ms: 30000kafka.isolation.level: read_committedkafka.max.poll.records: 1000# rocketMQ consumerrocketmq.namespace:rocketmq.namesrv.addr: 127.0.0.1:9876rocketmq.batch.size: 1000rocketmq.enable.message.trace: falserocketmq.customized.trace.topic:rocketmq.access.channel:rocketmq.subscribe.filter:# rabbitMQ consumerrabbitmq.host:rabbitmq.virtual.host:rabbitmq.username:rabbitmq.password:rabbitmq.resource.ownerId:
srcDataSources:defaultDS:url: jdbc:mysql://localhost:3306/hebeiqx?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&verifyServerCertificate=false&useSSL=falseusername: rootpassword: 123456canalAdapters:- instance: example # canal instance Name or mq topic namegroups:- groupId: g1outerAdapters:- name: logger- name: rdbkey: mysql1properties:jdbc.driverClassName: com.mysql.jdbc.Driverjdbc.url: jdbc:mysql://localhost:3306/weather?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&verifyServerCertificate=false&useSSL=falsejdbc.username: rootjdbc.password: 123456其实这里也没什么改的,srcDataSources 源数据库连接信息,canalAdapters 下面的目标数据库的连接信息,canalAdapters 下面一个实例就是一个 topic
/conf/rdb/mytest_user.yml 这个文件的配置比较奇葩,大概有三种场景
1、单表同步,targetTable 后面直接写目标库表名,这个版本不需要写目标库的名称
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:database: testtable: table1targetTable: table1targetPk:id: idmapAll: truecommitBatch: 70002、整个数据库同步,但是有个要求是两个数据库的名字要一致,而且是必须(有疑问?看看3就解决了)
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:mirrorDb: truedatabase: mytest3、多表同步,网上的案例都是单表的demo,目前还没有看到我这种方式
上面的1里面同步了 table1 这张表,那现在还要同步 table2 这种表怎么办,你是不是以为是这样:
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:- database: testtable: table1targetTable: table1targetPk:id: idmapAll: truecommitBatch: 7000- database: testtable: table2targetTable: table2targetPk:id: idmapAll: truecommitBatch: 7000上面这种方式启动就直接报错了,网上找了一天也没看到相关资料......
重点:把 mytest_user.yml 复制一份,再里面再配置另一张表就可以了,很脑残但是真管用;
注意这里所有文件的名字都是 xxx_user.yml 这种格式,内容就跟 1 里面的一样,把表名改一下就行;
四、SpringBoot 集成
添加 maven 依赖
<!--canal-->
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.5</version><!-- 去掉否则启动报错 --><exclusions><exclusion><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId></exclusion></exclusions>
</dependency>
<!-- Message、CanalEntry.Entry等来自此安装包 -->
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.protocol</artifactId><version>1.1.5</version>
</dependency>
<dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.17.3</version>
</dependency>客户端连接代码,都是模板代码之间用就行,printEnity 和 printColumn 这俩方法没有也行
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.CustomizableThreadFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class CanalClient {
private Logger logger = LoggerFactory.getLogger(CanalClient.class);
private static final ThreadFactory springThreadFactory = new CustomizableThreadFactory("canal-pool-");
private static final ExecutorService executors = Executors.newFixedThreadPool(1, springThreadFactory);
@Autowiredprivate CanalInstanceProperties canalInstanceProperties;
@PostConstructprivate void startListening() {canalInstanceProperties.getInstance().forEach(instanceName -> {executors.submit(() -> {connector(instanceName);});});}
/*** 消费canal的线程池*/public void connector(String instanceName) {CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), instanceName, "", "");
try {// 打开连接connector.connect();// 订阅所有消息//connector.subscribe(".*\\..*");// 只订阅test1数据库下的所有表connector.subscribe("hebeiqx.*");// 恢复到之前同步的那个位置connector.rollback();
int batchSize = 1000;for (; ; ) {// 获取指定数量的数据,但是不做确认标记,下一次取还会取到这些信息。 注:不会阻塞,若不够100,则有多少返回多少Message message = connector.getWithoutAck(batchSize);// 获取消息idlong batchId = message.getId();// 获取批量的数量int size = message.getEntries().size();if (size == 0 || batchId == -1) {//logger.info("暂无数据......");try {// 没有数据就等待1秒Thread.sleep(1000);} catch (InterruptedException ignored) {}}if (batchId != -1) {logger.info("数据同步监听中......");logger.info("instance -> {}, msgId -> {}", instanceName, batchId);// 数据处理//printEnity(message.getEntries());// 提交确认connector.ack(batchId);// 处理失败,回滚数据connector.rollback(batchId);}}} catch (Exception e) {e.printStackTrace();} finally {connector.disconnect();}}
private void printEnity(List<CanalEntry.Entry> entries) {for (CanalEntry.Entry entry : entries) {// 开启/关闭事务的实体类型,跳过if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {continue;}
// RowChange对象,包含了一行数据变化的所有特征// 比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等CanalEntry.RowChange rowChange = null;
try {// 序列化数据rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {e.printStackTrace();}
assert rowChange != null;
// 获取操作类型:insert/update/delete类型CanalEntry.EventType eventType = rowChange.getEventType();
// 打印Header信息logger.info(String.format("================>; binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));
// 判断是否是DDL语句if (rowChange.getEventType() == CanalEntry.EventType.QUERY || rowChange.getIsDdl()) {logger.info("sql ------------>{}", rowChange.getSql());}
// 获取RowChange对象里的每一行数据,打印出来for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {switch (rowChange.getEventType()) {// 如果希望监听多种事件,可以手动增加casecase UPDATE:printColumn(rowData.getAfterColumnsList());printColumn(rowData.getBeforeColumnsList());break;case INSERT:printColumn(rowData.getAfterColumnsList());break;case DELETE:printColumn(rowData.getBeforeColumnsList());break;default:}}}}
private void printColumn(List<CanalEntry.Column> columns) {StringBuilder sb = new StringBuilder();for (CanalEntry.Column column : columns) {sb.append("[");sb.append(column.getName()).append(" : ").append(column.getValue()).append("update=").append(column.getUpdated());sb.append("]");sb.append(" ");}logger.info(sb.toString());}
}相关文章:

SpringBoot 集成 Canal 基于 MySQL 做数据同步
一、canal 组件关系 下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/ 这里面主要的有两个 canal.deployer-1.1.7.tar.gz 和 canal.adapter-1.1.7.tar.gz,canal.admin-1.1.7.tar.gz 是一个监控服务,可选…...

【CVE-2022-22733漏洞复现】
Apache ShardingSphere ElasticJob-UI漏洞 漏洞编号:CVE-2022-22733 文档说明 本文作者:SwBack 创作时间:2024/1/21 19:19:19 知乎:https://www.zhihu.com/people/back-88-87 CSDN:https://blog.csdn.net/qq_30817059 百度搜索: SwBack漏洞描述 Apache ShardingSphere Elast…...
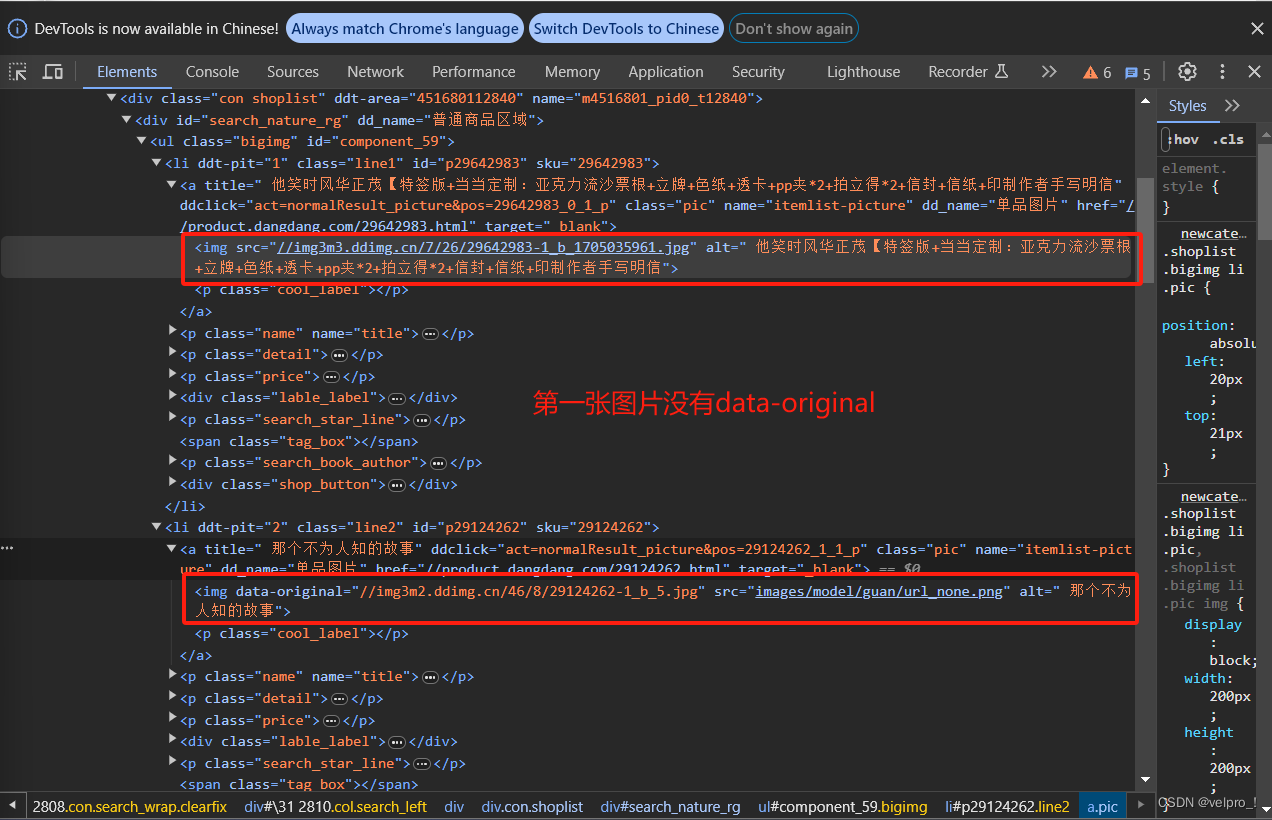
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapy from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name "dang" # 名字# 如果是多页下载的话, …...

【机器学习】机器学习四大类第01课
一、机器学习四大类 有监督学习 (Supervised Learning) 有监督学习是通过已知的输入-输出对(即标记过的训练数据)来学习函数关系的过程。在训练阶段,模型会根据这些示例调整参数以尽可能准确地预测新的、未见过的数据点的输出。 实例&#x…...

下述默认构造函数有什么问题?
12.4 // points to string allocated by new // holds length of string 独立的、相同的数据,而不会重叠。由于同样的原因,必须定义赋值操作符。对于每一种情况,最终目的 都是执行深度复制,也就是说,复制实际的数据,而不仅仅是复制指向数据的指针。 对象的存储持续性为自动或…...

vite和mockjs配合使用
vite mockjs 当后端还没准备完成之前,前端可以使用 mock 模拟后端响应,提高开发效率 1、安装插件 使用 vite-plugin-mock 插件,配合mockjs完成项目的 mock 配置 npm install mockjs vite-plugin-mock2、vite配置插件 在 vite.config.js…...
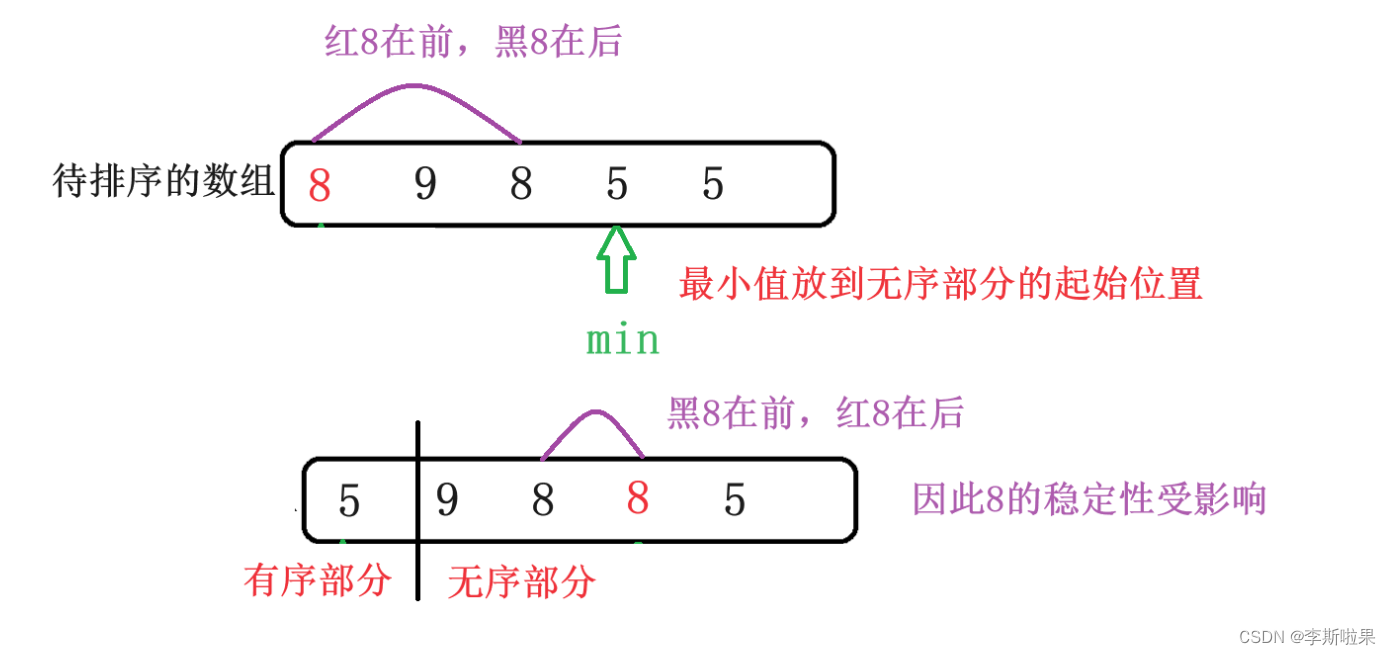
【数据结构】常见八大排序算法总结
目录 前言 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 6.1Hoare版本 6.2挖坑法 6.3前后指针法 6.4快速排序的递归实现 6.5快速排序的非递归实现 7.归并排序 8.计数排序(非比较排序) 9.补充:基数排序 10.总结…...

系统学英语 — 句法 — 常规句型
目录 文章目录 目录5 大基本句型复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句补语从句 谓语句型 5 大基本句型 主谓:主语发出一个动作,例如:He cried.主谓宾:we study English.主系表:主语具有某些特…...
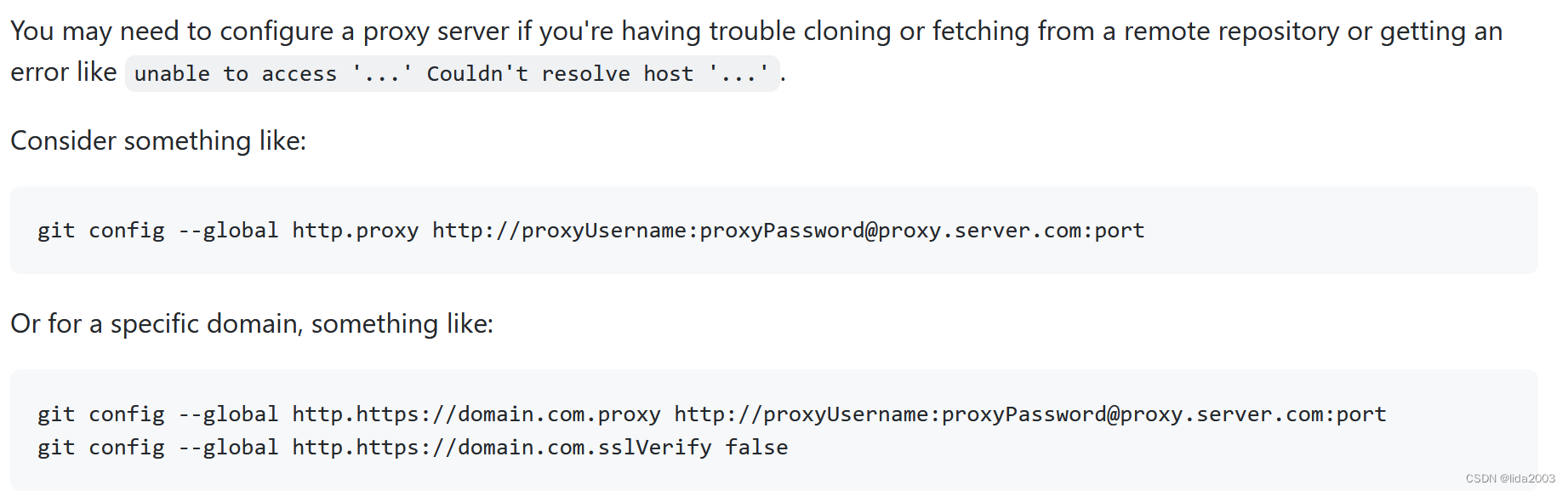
Github操作网络异常笔记
Github操作网络异常笔记 1. 源由2. 解决2.1 方案一2.2 方案二 3. 总结 1. 源由 开源技术在国内永远是“蛋疼”,这些"政治"问题对于追求技术的我们,形成无法回避的障碍。 $ git pull ssh: connect to host github.com port 22: Connection ti…...
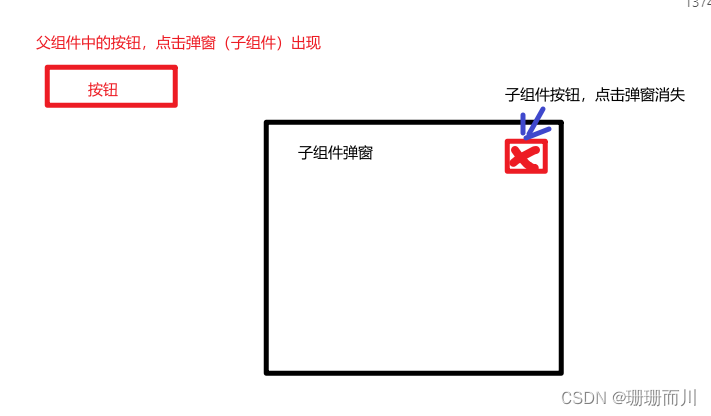
Vue3新特性defineModel()便捷的双向绑定数据
官网介绍 传送门 配置 要求: 版本: vue > 3.4(必须!!!)配置:vite.config.js 使用场景和案例 使用场景:父子组件的数据双向绑定,不用emit和props的繁重代码 具体案例 代码实…...

vue列表飞入效果
效果 实现代码 <template><div><button click"add">添加</button><TransitionGroup name"list" tag"ul"><div class"list-item" v-for"item in items" :key"item.id">{{ i…...

C语言·预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 __FILE__ 进行编译的源文件 __LINE__ 文件当前的行号 __DATE__ 文件被编译的日期 __TIME__ 文件被编译的时间 __STDC__ 如果编译器遵循ANSI C,…...

服务器与普通电脑的区别,普通电脑可以当作服务器用吗?
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

数字身份所有权:Web3时代用户数据的掌控权
随着Web3时代的来临,数字身份的概念正焕发出崭新的光芒。在这个数字化的时代,用户的个人数据变得愈加珍贵,而Web3则为用户带来了数字身份所有权的概念,重新定义了用户与个人数据之间的关系。本文将深入探讨Web3时代用户数据的掌控…...

python爬虫如何写,有哪些成功爬取的案例
编写Python爬虫时,常用的库包括Requests、Beautiful Soup和Scrapy。以下是三个简单的Python爬虫案例,分别使用Requests和Beautiful Soup,以及Scrapy。 1. 使用Requests和Beautiful Soup爬取网页内容: import requests from bs4 …...

PLC物联网网关BL104实现PLC协议转MQTT、OPC UA、Modbus TCP
随着物联网技术的迅猛发展,人们深刻认识到在智能化生产和生活中,实时、可靠、安全的数据传输至关重要。在此背景下,高性能的物联网数据传输解决方案——协议转换网关应运而生,广泛应用于工业自动化和数字化工厂应用环境中。 无缝衔…...

explain工具优化mysql需要达到什么级别?
explain工具优化mysql需要达到什么级别? 一、explain工具是什么?二、explain查询后各字段的含义三、explain查询后type字段有哪些类型?四、type类型需要优化到哪个阶段? 一、explain工具是什么? explain是什么&#x…...

RHCE作业
架设一台NFS服务器,并按照以下要求配置 1、开放/nfs/shared目录,供所有用户查询资料 2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录,并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210 3、将/home/to…...
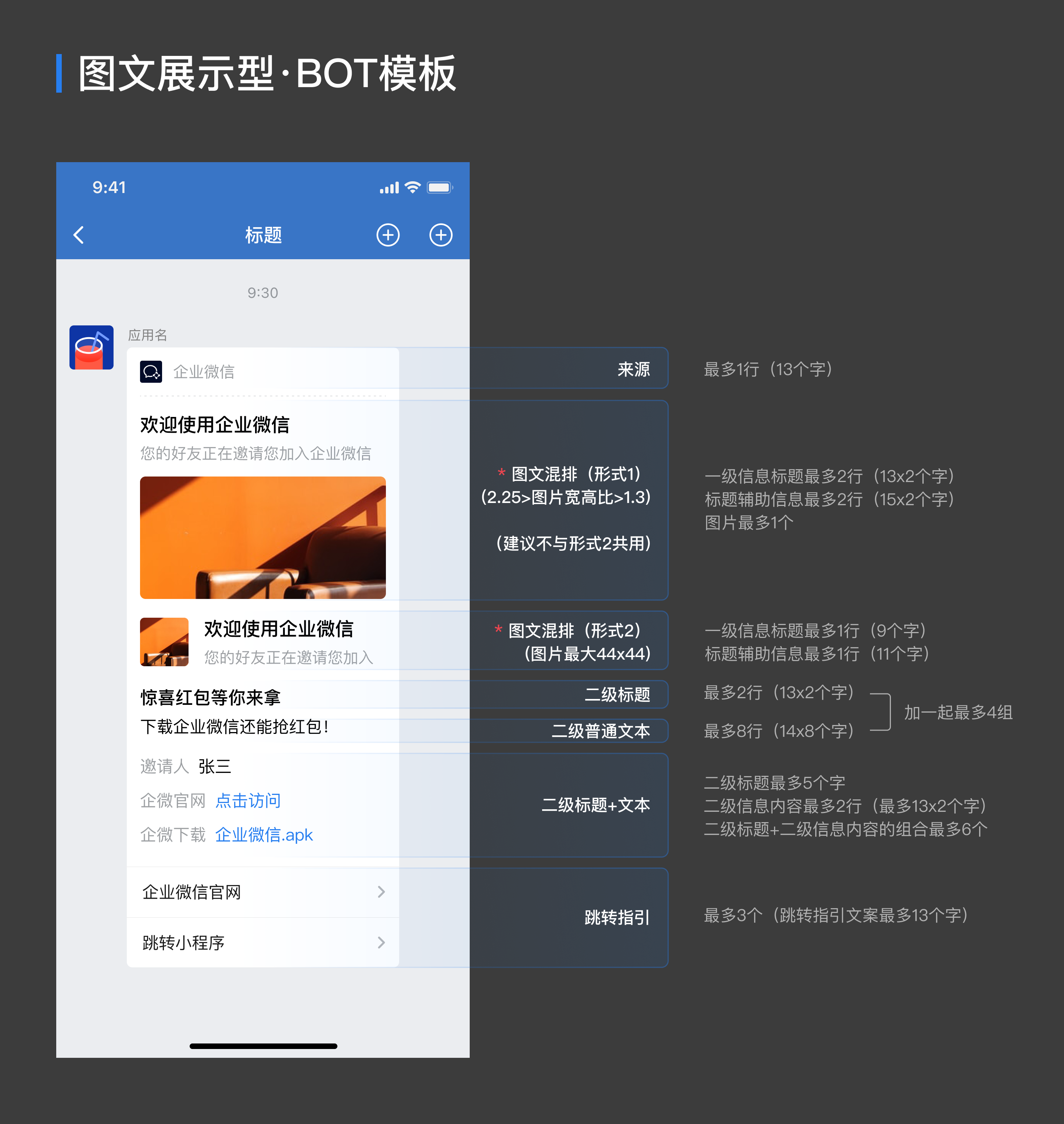
在Java中调企微机器人发送消息到群里
目录 如何使用群机器人 消息类型及数据格式 文本类型 markdown类型 图片类型 图文类型 文件类型 模版卡片类型 文本通知模版卡片 图文展示模版卡片 消息发送频率限制 文件上传接口 Java 执行语句 String url "webhook的Url"; String result HttpReque…...
鸿蒙开发(四)UIAbility和Page交互
通过上一篇的学习,相信大家对UIAbility已经有了初步的认知。在上篇中,我们最后实现了一个小demo,从一个UIAbility调起了另外一个UIAbility。当时我提到过,暂不实现比如点击EntryAbility中的控件去触发跳转,而是在Entry…...

5步实现Windows直接安装Android应用:APK Installer完全指南
5步实现Windows直接安装Android应用:APK Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,在Windows电脑上安装…...
)
用C++模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码)
用C模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码) 流感传播模型一直是计算机模拟和算法竞赛中的经典问题。这道来自信息学奥赛的题目不仅考察了递推算法的应用,更让我们得以一窥传染病传播的基本原理。本文将带你从零…...

macOS用户必备:3步解决QQ音乐加密格式的终极转换方案
macOS用户必备:3步解决QQ音乐加密格式的终极转换方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转…...
)
从零到一:华大HC32L110C6PA GPIO操作避坑指南(附完整代码)
从零到一:华大HC32L110C6PA GPIO操作避坑指南(附完整代码) 第一次接触华大HC32L110C6PA这款MCU时,我被它小巧的体积和丰富的功能所吸引。但当我真正开始GPIO配置时,却发现官方文档中的某些细节并不像想象中那么直观。…...

突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换
突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换 【免费下载链接】IfcOpenShell Open source IFC library and geometry engine 项目地址: https://gitcode.com/gh_mirrors/if/IfcOpenShell 在建筑信息模型(BIM)技术日益普…...

终极Xbox手柄性能检测指南:5个技巧让你的游戏控制器发挥最大潜力
终极Xbox手柄性能检测指南:5个技巧让你的游戏控制器发挥最大潜力 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 你是否曾经在激烈游戏对战中感觉手柄响应不够灵…...

Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰
Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 还在为Mac应用卸载后残…...
)
告别Keil!用Clion+STM32CubeMX搭建C++开发环境(附LED闪烁实战)
告别Keil!用ClionSTM32CubeMX搭建C开发环境(附LED闪烁实战) 嵌入式开发领域正经历一场工具链的现代化变革。对于习惯了Keil这类传统IDE的STM32开发者而言,JetBrains推出的Clion无疑是一股清新之风——它不仅具备智能代码补全、重…...

为汉语辩护,彰显中华文字的生命力与优越性
为汉语辩护,彰显中华文字的生命力与优越性上世纪初,一批所谓“新文化人”竟提出废除汉字的主张,他们盲目推崇拉丁文,认为汉语是落后的语言,却不知这是对中华文字深厚底蕴的无知与曲解。如今回望,汉字的独特…...
)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码) 在集成电路设计领域,TESTKEY(测试结构)的创建是验证工艺模型和器件特性的基础工作。传统手动放置器件的方式不仅效率低下,还…...