kafka简单介绍和代码示例
“这是一篇理论文章,给大家讲一讲kafka”

简介
在大数据领域开发者常常会听到MQ这个术语,该术语便是消息队列的意思,
Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份开源,成为Apache的顶级项目。Kafka是一个高吞吐量的、持久性的、分布式发布订阅消息系统。它主要用于处理活跃的数据(登录、浏览、点击、分享、喜欢等用户行为产生的数据)。
1.消息 Message
网络中的两台计算机或者两个通讯设备之间传递的数据。例如说:文本、音乐、视频等内容。
2.队列 Queue(栈的特点FILO 队列FIFO)
一种特殊的线性表(数据元素首尾相接),特殊之处在于只允许在首部删除元素和在尾部追加元素。入队、出队
3.消息队列 MQ
消息+队列,保存消息的队列。消息的传输过程中的容器;主要提供生产、消费接口供外部调用做数据的存储和获取。
消息队列分类
MQ主要分为两类:点对点(p2p)、发布订阅(Pub/Sub)
1.共同点
消息生产者生产消息发送到queue中,然后消息消费者从queue中读取并且消费消息。
2.不同点
p2p模型包括:消息队列(Queue)、发送者(Sender)、接收者(Receiver) ,一个生产者生产的消息只有一个消费者(Consumer)(即一旦被消费,消息就不在消息队列中)。比如说打电话。
Pub/Sub包含:消息队列(Queue)、主题(Topic)、发布者(Publisher)、订阅者(Subscriber)每个消息可以有多个消费者,彼此互不影响。比如我发布一个微博:关注我的人都能够看到。
Kafka的特点
Kafka如此受欢迎,而且有越来越多的系统支持与Kafka的集成,主要由于Kafka具有如下特性。
● 高吞吐量、低延迟:Kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。
● 可扩展性:Kafka集群同Hadoop集群一样,支持横向扩展。
● 持久性、可靠性:Kafka消息可以被持久化到本地磁盘,并且支持Partition数据备份,防止数据丢失。
● 容错性:允许Kafka集群中的节点失败,如果Partition(分区)副本数量为n,则最多允许n-1个节点失败。
● 高并发:单节点支持上千个客户端同时读写,每秒钟有上百MB的吞吐量,基本上达到了网卡的极限
Kafka组成
- Topic:主题,Kafka处理的消息的不同分类。
- Broker:消息代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中每个topic都是有分区的。
- Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候指定。
- Replica:数据副本,可以为保存在Kafka中的数据指定副本数,以提高数据冗余性,防止数据丢失;
- Message:消息,是通信的基本单位,每个消息都属于一个partition
Kafka服务相关
- Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
- Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
- Zookeeper:协调kafka的正常运行。
- KRaft:Kafka的KRaft模式在2.8.0版本中被引入。从2.8.0版本开始,Kafka提供了对KRaft的支持,其中最大的变化之一就是不再依赖外部的ZooKeeper来管理Kafka的元数据。因此,如果你使用2.8.0版本或更高版本的Kafka,你将能够使用KRaft模式,无需安装和配置ZooKeeper。
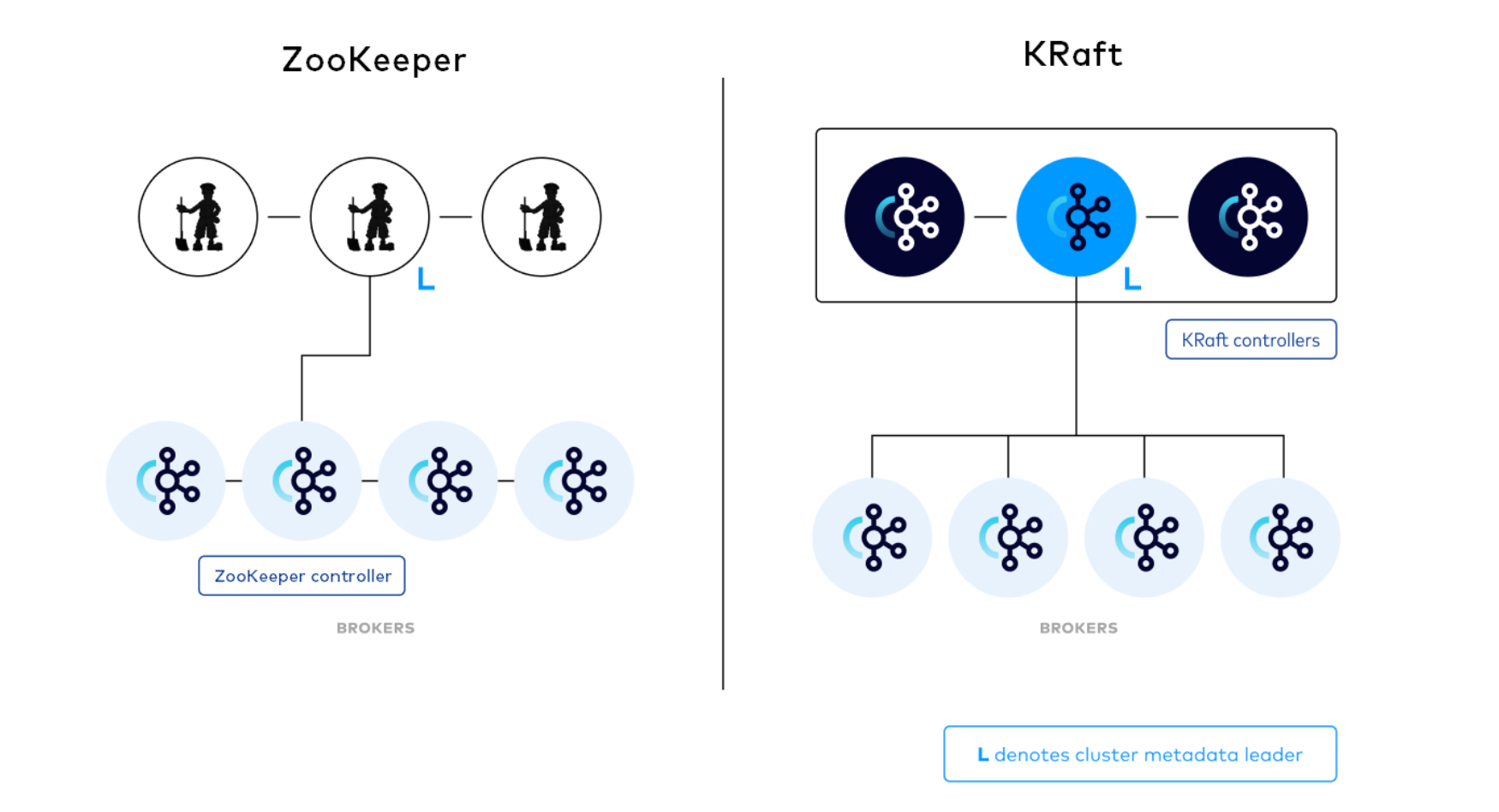
Kafka架构设计
一个典型的Kafka集群包含若干个生产者(Producer)、若干Kafka集群节点(Broker)、若干消费者(Consumer)以及一个Zookeeper集群或者KRaft模式。Kafka通过Zookeeper管理集群配置,选举Leader以及在消费者发生变化时进行负载均衡。生产者使用推(Push)模式将消息发布到集群节点,而消费者使用拉(Pull)模式从集群节点中订阅并消费消息。
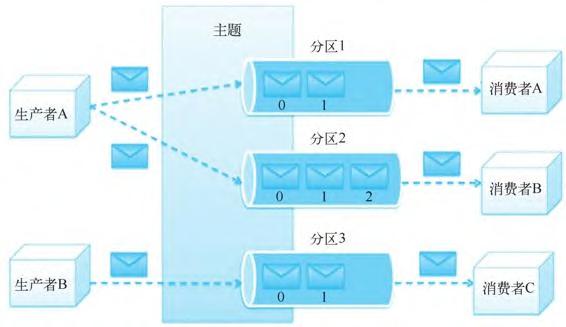
主题和分区的具体定义如下。
● 主题是生产者发布到Kafka集群的每条信息所属的类别,即Kafka是面向主题的,一个主题可以分布在多个节点上。
● 分区是Kafka集群横向扩展和一切并行化的基础,每个Topic可以被切分为一个或多个分区。一个分区只对应一个集群节点,每个分区内部的消息是强有序的。
● Offset(即偏移量)是消息在分区中的编号,每个分区中的编号是独立的。
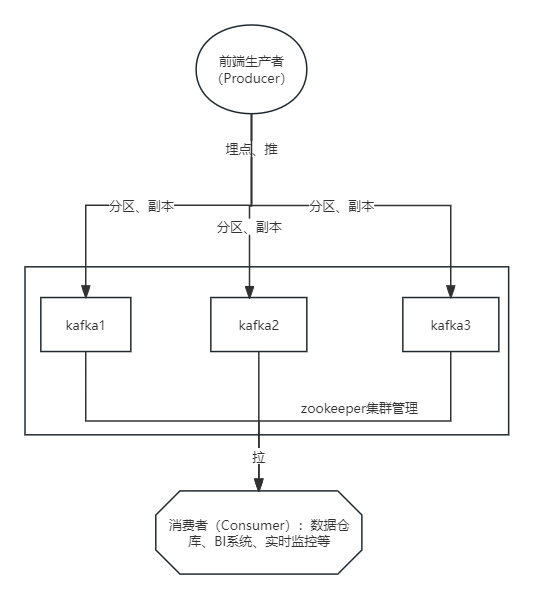
Kafka分布式集群的构建
在kafka2.0版本以前是依赖于zookeeper集群中安装
·|| Kafka使用Zookeeper作为其分布式协调框架,能很好地将消息生产、消息存储、消息消费的过程结合在一起。同时借助Zookeeper,Kafka能够将生产者、消费者和集群节点在内的所有组件,在无状态的情况下建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
可以看出Kafka集群依赖于Zookeeper,所以在安装Kafka之前需要提前安装Zookeeper。Zookeeper集群在前面Hadoop集群的构建过程中已经在使用,Kafka可以共用之前安装的Zookeeper集群,接下来只需要安装Kafka集群即可。
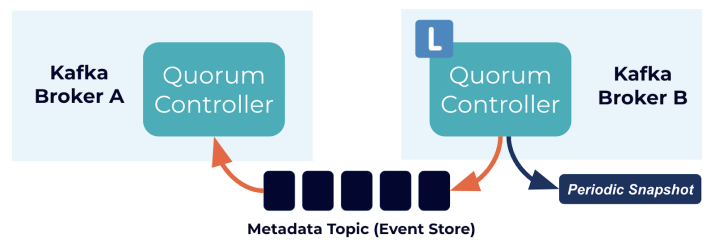
·|| 较新版本的 Apache Kafka(从2.8.0版本开始)引入了KRaft,这是一个内置的分布式存储 系统,用于管理Kafka的元数据信息,不再需要依赖外部的 ZooKeeper。因此,你在使用较新版本的Kafka时,不再需要单独安装和配置 ZooKeeper。
在KRaft模式下,Kafka内部有自己的元数据存储,这消除了对外部 ZooKeeper 的依赖。这样做的目的是简化 Kafka 集群的维护和部署,以及提高可用性。
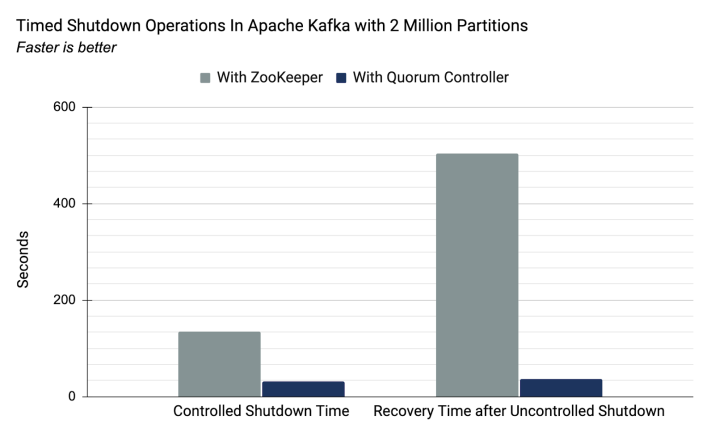
在基于zookeeper和kraft两种集群管理机制下,200万分区数据量下的耗时比较。基于自带的KRaft,性能表现会更优。
基于KRaft下的kafka安装
解压压缩包
tar -zxvf kafka_2.12-3.6.0.tgz -C kafka
编辑环境变量
export KAFKA_HOME=/home/hadoop/kafka/kafka_2.12-3.6.0
export PATH=$KAFKA_HOME/bin:PATH编辑配置文件server.properties
文件所在路径${KAFKA_HOME}/config/kraft/server.properties
该文件中几个重点参数
process.roles=broker,controller ##broker相当于从节点,controller相当于主节点
node.id=2 ##节点ID 每个节点必须唯一
controller.quorum.voters=1@vm02:9093,2@vm03:9093,3@vm04:9093
##参与主节点选举,格式(node.id)@(hostname):(port)
advertised.listeners=PLAINTEXT://hostname:9092 ##对外服务地址,消费者、生产者对该节点的访问
生成集群ID
kafka-storage.sh random-uuid
6foHn9NLQpiMAirIK7EG4A
##生成6foHn9NLQpiMAirIK7EG4A 的uuid
所有节点执行,kafka初始化
kafka-storage.sh format -t 6foHn9NLQpiMAirIK7EG4A -c ./$KAFKA_HOME/config/kraft/server.properties所有节点执行,启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/kraft/server.properties查看kafka进程
jps 
使用示例
创建topic
kafka-topics.sh --create --topic your_topic --bootstrap-server vm02:9092,vm03:9092,vm04:9092 --partitions 3 --replication-factor 2
注: --bootstrap-server vm02:9092,vm03:9092,vm04:9092 此处参数可以指定集群所有节点,也可以指定localhost:9092,创建的主题并不意味着后期的消费者和生产者只能指定在 localhost 节点上。这里的 --bootstrap-server 参数在创建主题时主要是为了指定初始的 Kafka 节点,它告诉 Kafka 工具在哪里查找集群的元数据。
后期的消费者和生产者在连接到 Kafka 集群时,会从指定的初始节点获取集群的元数据,然后与整个集群建立连接。一旦获取了元数据,消费者和生产者就可以与整个 Kafka 集群进行通信,而不仅仅限制在初始指定的节点上。因此,使用 --bootstrap-server localhost:9092 创建的主题对于后期的消费者和生产者,仍然可以在整个 Kafka 集群的任何节点上进行使用,只要它们能够连接到集群并获取到正确的元数据信息。
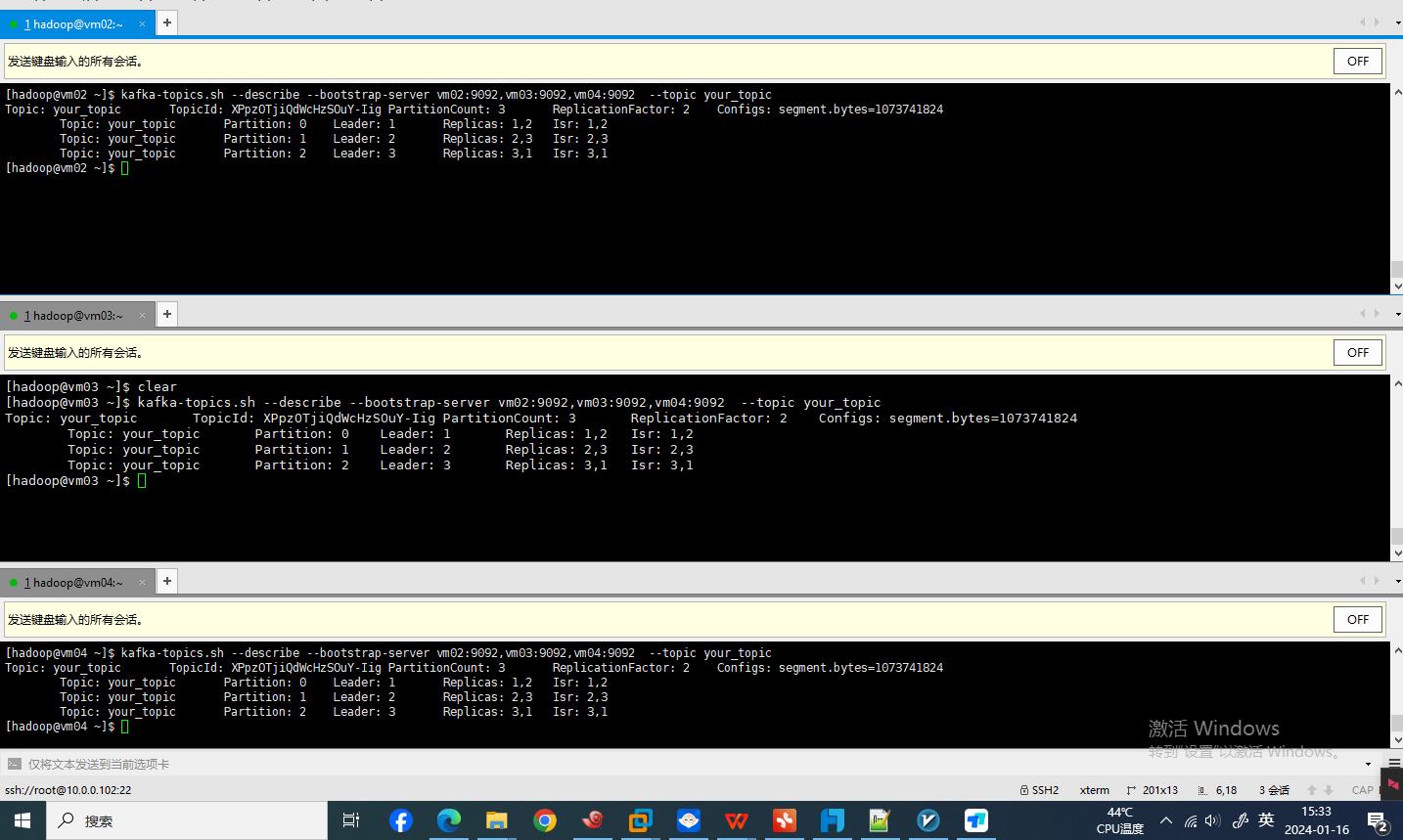
查看已创建的topic的详细信息
kafka-topics.sh --describe --bootstrap-server vm02:9092,vm03:9092,vm04:9092 --topic your_topic
修改已创建topic
在官方对于alter参数的解释中,
--alter Alter the number of partitions and replica assignment. Update the configuration of an existing topic via --alter is no longer supported here (the kafka-configs CLI supports altering topic configs with a -- bootstrap-server option). kafka-topics.sh --alter选项在最新版本中已不再支持更新现有主题的配置,这意味着一旦主题被创建,就不能使用–alter选项来更改其分区数和副本分配。可以通过使用kafka-configs.sh
修改主题的配置参数。
kafka-configs.sh --bootstrap-server vm02:9092,vm03:9092,vm04:9092 \
--entity-type topics --entity-name your_topic \
--alter --add-config retention.ms=86400000查看topic 定义相关参数信息。
kafka-configs.sh --bootstrap-server \
vm02:9092,vm03:9092,vm04:9092 \
--entity-type topics --entity-name your_topic --describe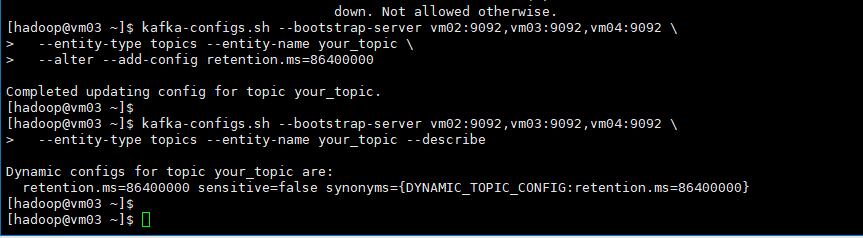
删除已创建topic
kafka-topics.sh --delete --topic your_topic --bootstrap-server vm02:9092,vm03:9092,vm04:9092
创建生产者producer
kafka-console-producer.sh --broker-list 192.168.56.101:9092 --topic mrt场景应用示例
以postgresql数据库中的public.conn_fdw表作为生产者producer身份把数据推向kafka,然后在使用kafka把数据推推向消费者数据库Oracle
在postgresql数据库中创建测试数据表,
CREATE TABLE public.conn_fdw (id int4 NULL,"name" varchar(50) NULL,age int4 NULL,city varchar(50) NULL,salary int4 NULL
);在Oracle中创建同样的表结构
create table SYSTEM.CONN_FDW
(id NUMBER,name VARCHAR2(50),age NUMBER,city VARCHAR2(50),salary NUMBER,load_time timestamp default current_timestamp
);创建主题conn_fdw
kafka-topics.sh --create --topic conn_fdw \
--bootstrap-server vm02:9092,vm03:9092,vm04:9092 \
--partitions 3 \
--replication-factor 2查看已经创建的主题conn_fdw
kafka-topics.sh --describe \
--bootstrap-server vm02:9092,vm03:9092,vm04:9092 \
--topic conn_fdw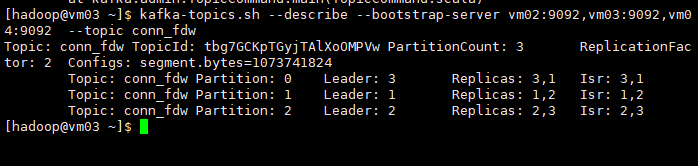
在此图中有
添加maven依赖
添加相应的依赖包,以作为java代码class的支持
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId><version>2.3.0</version></dependency><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.23</version> <!-- 使用你的 PostgreSQL 版本 --></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version> <!-- 请使用最新版本 --></dependency><dependency><groupId>com.oracle.database.jdbc</groupId><artifactId>ojdbc10</artifactId> <!-- 使用你的 Oracle JDBC 版本 --><version>19.8.0.0</version></dependency>Kafka生产者代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;public class PgKafkaProducer {public static void main(String[] args) {// Kafka 配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// PostgreSQL 连接配置String jdbcUrl = "jdbc:postgresql://10.0.0.108:5432/postgres";String username = "postgres";String password = "postgres";try (Connection connection = DriverManager.getConnection(jdbcUrl, username, password);Statement statement = connection.createStatement()) {// 查询 PostgreSQL 数据String query = "SELECT id,name,age,city,salary FROM public.conn_fdw";ResultSet resultSet = statement.executeQuery(query);// Kafka 生产者try (Producer<String, String> producer = new KafkaProducer<>(props)) {while (resultSet.next()) {// 将每一行数据作为消息发送到 Kafka 主题String key = String.valueOf(resultSet.getInt("id"));String value = resultSet.getString("name") + "," +resultSet.getInt("age") + "," +resultSet.getString("city") + "," +resultSet.getInt("salary");ProducerRecord<String, String> record = new ProducerRecord<>("conn_fdw", key, value);producer.send(record);}}} catch (Exception e) {e.printStackTrace();}}
}消费者代码
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.Collections;
import java.util.Properties;public class KafkaToOracleConsumer {public static void main(String[] args) {// Kafka 配置Properties kafkaProps = new Properties();kafkaProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092");kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "conn_fdw_groupid");kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// Oracle 连接配置String jdbcUrl = "jdbc:oracle:thin:@192.168.48.1:1521:orcl";String username = "system";String password = "system";try (Connection connection = DriverManager.getConnection(jdbcUrl, username, password);PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO SYSTEM.CONN_FDW (id, name, age, city, salary) VALUES (?, ?, ?, ?, ?)")) {// Kafka 消费者try (Consumer<String, String> consumer = new KafkaConsumer<>(kafkaProps)) {consumer.subscribe(Collections.singletonList("conn_fdw"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);records.forEach(record -> {// 解析 Kafka 消息String[] values = record.value().split(",");int id = Integer.parseInt(values[0]);String name = values[1];int age = Integer.parseInt(values[2]);String city = values[3];int salary = Integer.parseInt(values[4]);// 插入到 Oracle 数据库try {preparedStatement.setInt(1, id);preparedStatement.setString(2, name);preparedStatement.setInt(3, age);preparedStatement.setString(4, city);preparedStatement.setInt(5, salary);preparedStatement.executeUpdate();} catch (Exception e) {e.printStackTrace();}});}}} catch (Exception e) {e.printStackTrace();}}
}此时可以通过同时执行两段代码,在跑起来的过程中向生产者PG数据库插入以下数据库,然后到Oracle 数据库中观察数据流的流入情况。
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(1, 'John', 30, 'New York', 50000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(2, 'Alice', 25, 'Los Angeles', 60000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(3, 'Bob', 35, 'Chicago', 70000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(4, 'Eva', 28, 'San Francisco', 55000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(5, 'Mike', 32, 'Seattle', 65000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(6, 'Sophia', 29, 'Boston', 75000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(7, 'David', 27, 'Denver', 52000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(8, 'Emily', 31, 'Austin', 68000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(9, 'Daniel', 26, 'Phoenix', 58000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(10, 'Olivia', 33, 'Houston', 72000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(11, 'Liam', 24, 'Portland', 49000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(12, 'Ava', 34, 'Atlanta', 71000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(13, 'Logan', 30, 'Miami', 62000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(14, 'Mia', 28, 'Dallas', 54000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(15, 'Jackson', 29, 'Minneapolis', 67000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(16, 'Sophie', 31, 'Detroit', 59000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(17, 'William', 27, 'Philadelphia', 70000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(18, 'Emma', 32, 'San Diego', 66000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(19, 'James', 26, 'Raleigh', 63000);
INSERT INTO public.conn_fdw
(id, "name", age, city, salary)
VALUES(20, 'Avery', 35, 'Tampa', 71000);此时可以通过以下语句查看推送到conn_fdw主题的数据。
kafka-console-consumer.sh --bootstrap-server 10.0.0.102:9092,10.0.0.102:9092,10.0.0.102:9092 --topic conn_fdw --from-beginning
······希望文章能帮助到给位读者,对相关知识点如果有疑问,欢迎私信进行技术交流。如果文章对你有帮助,希望你能点赞关注

相关文章:
kafka简单介绍和代码示例
“这是一篇理论文章,给大家讲一讲kafka” 简介 在大数据领域开发者常常会听到MQ这个术语,该术语便是消息队列的意思, Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年…...

一次解决ForkJoinPool日志追踪的辛酸经历
本文主要分享了一次解决ForkJoinPool日志追踪的辛酸经历。历时3个月终于找到通用的解决方案,以此文分享给有需要的你。 一、需求背景 1.某日,某同事根据日志ID排查生产环境问题过程中,发现日志不全 2.经排查发现中间有很多线程为ForkJoinP…...
VM使用教程--SDK取图 视频笔记
本笔记均由海康机器人官网的V学院视频中记录所得,属于省流大师了[doge] 图像采集 图像采集包括1图像源,2多图采集,3输出图像,4缓存图像,5光源 1图像源 图像源包括本地图像,相机采图,SDK 本…...
)
11.spring boot 启动源码(一)
目录 概述SpringApplication静态方法构造方法run 实例方法配置文件Actuator 工作原理*EndpointAutoConfigurationBeansEndpointAutoConfigurationShutdownEndpointAutoConfiguration结束概述 spring boot 版本 2.6.13 spring boot 启动源码(一) 涉及 SpringApplication 中静态…...
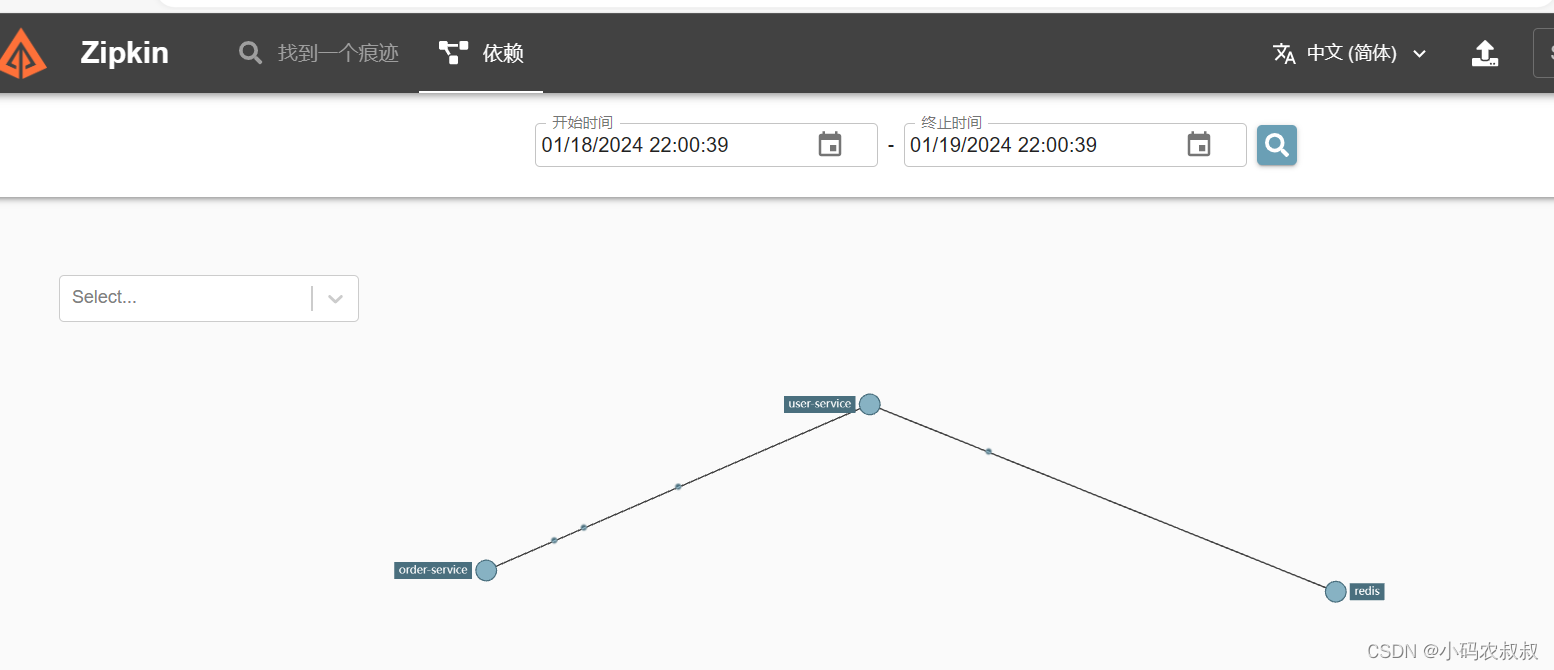
【微服务】springcloud集成sleuth与zipkin实现链路追踪
目录 一、前言 二、分布式链路调用问题 三、链路追踪中的几个概念 3.1 什么是链路追踪 3.2 常用的链路追踪技术 3.3 链路追踪的几个术语 3.3.1 span 编辑 3.3.2 trace 3.3.3 Annotation 四、sluth与zipkin概述 4.1 sluth介绍 4.1.1 sluth是什么 4.1.2 sluth核心…...

数学建模-预测人口数据
目录 中国09~18年人口数据 创建时间 绘制时间序列图 使用专家建模器 得到结果 预测结果 残差的白噪声检验 中国09~18年人口数据 创建时间 路径:数据-> 定义日期和时间 绘制时间序列图 使用专家建模器 看看spss最终判断是那个模型最佳的契合 得到结果 预…...

SpringBoot 集成 Canal 基于 MySQL 做数据同步
一、canal 组件关系 下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/ 这里面主要的有两个 canal.deployer-1.1.7.tar.gz 和 canal.adapter-1.1.7.tar.gz,canal.admin-1.1.7.tar.gz 是一个监控服务,可选…...

【CVE-2022-22733漏洞复现】
Apache ShardingSphere ElasticJob-UI漏洞 漏洞编号:CVE-2022-22733 文档说明 本文作者:SwBack 创作时间:2024/1/21 19:19:19 知乎:https://www.zhihu.com/people/back-88-87 CSDN:https://blog.csdn.net/qq_30817059 百度搜索: SwBack漏洞描述 Apache ShardingSphere Elast…...
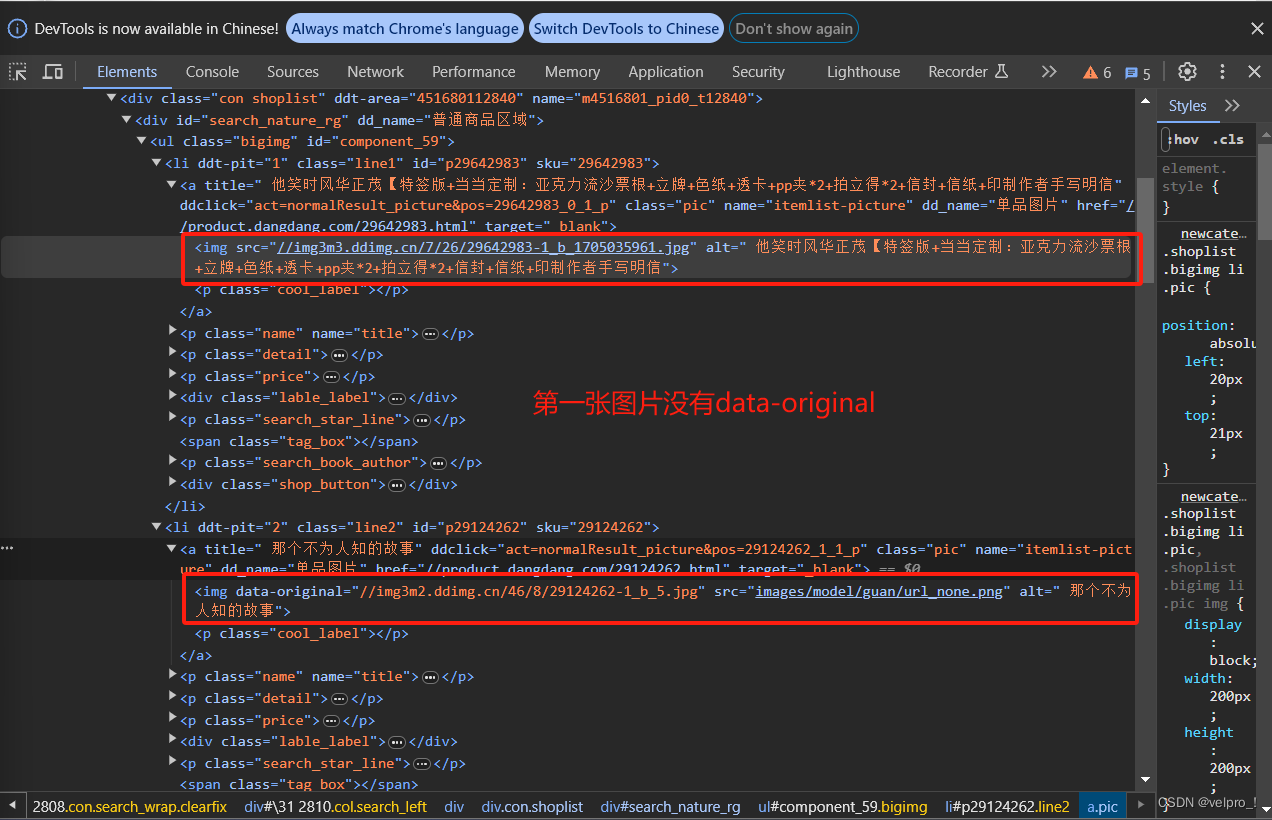
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapy from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name "dang" # 名字# 如果是多页下载的话, …...

【机器学习】机器学习四大类第01课
一、机器学习四大类 有监督学习 (Supervised Learning) 有监督学习是通过已知的输入-输出对(即标记过的训练数据)来学习函数关系的过程。在训练阶段,模型会根据这些示例调整参数以尽可能准确地预测新的、未见过的数据点的输出。 实例&#x…...

下述默认构造函数有什么问题?
12.4 // points to string allocated by new // holds length of string 独立的、相同的数据,而不会重叠。由于同样的原因,必须定义赋值操作符。对于每一种情况,最终目的 都是执行深度复制,也就是说,复制实际的数据,而不仅仅是复制指向数据的指针。 对象的存储持续性为自动或…...

vite和mockjs配合使用
vite mockjs 当后端还没准备完成之前,前端可以使用 mock 模拟后端响应,提高开发效率 1、安装插件 使用 vite-plugin-mock 插件,配合mockjs完成项目的 mock 配置 npm install mockjs vite-plugin-mock2、vite配置插件 在 vite.config.js…...
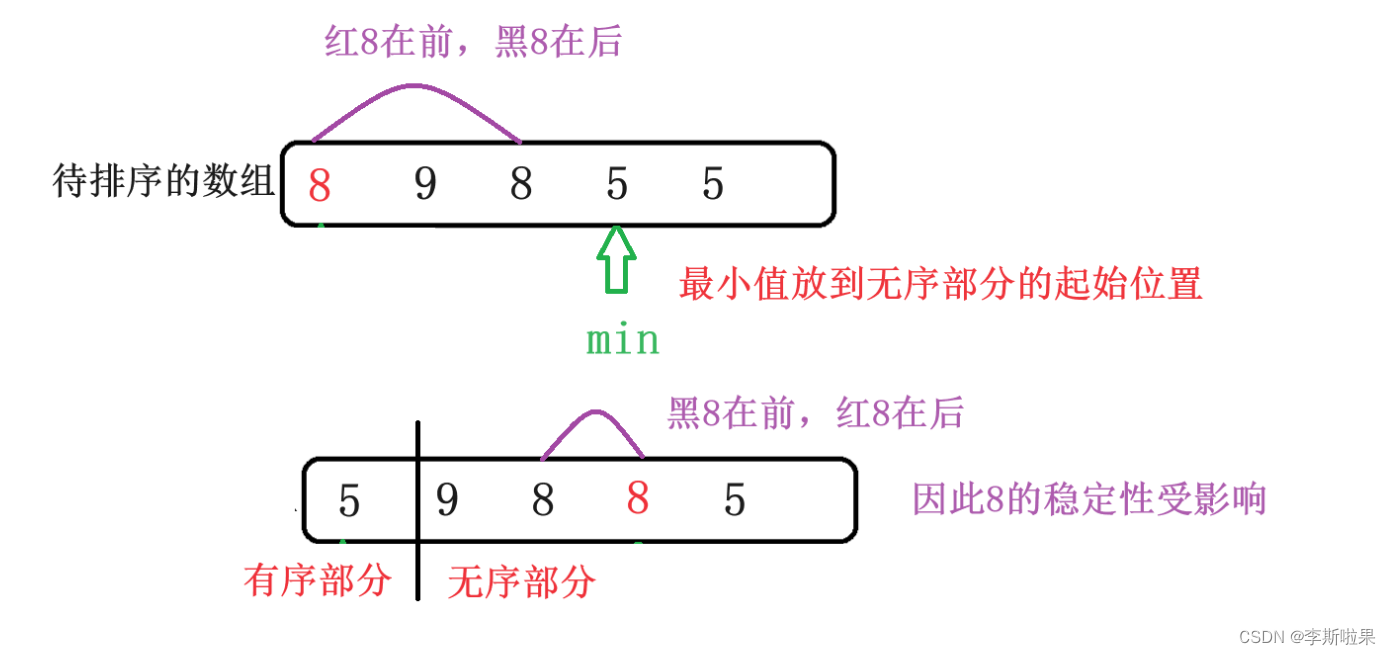
【数据结构】常见八大排序算法总结
目录 前言 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 6.1Hoare版本 6.2挖坑法 6.3前后指针法 6.4快速排序的递归实现 6.5快速排序的非递归实现 7.归并排序 8.计数排序(非比较排序) 9.补充:基数排序 10.总结…...

系统学英语 — 句法 — 常规句型
目录 文章目录 目录5 大基本句型复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句补语从句 谓语句型 5 大基本句型 主谓:主语发出一个动作,例如:He cried.主谓宾:we study English.主系表:主语具有某些特…...
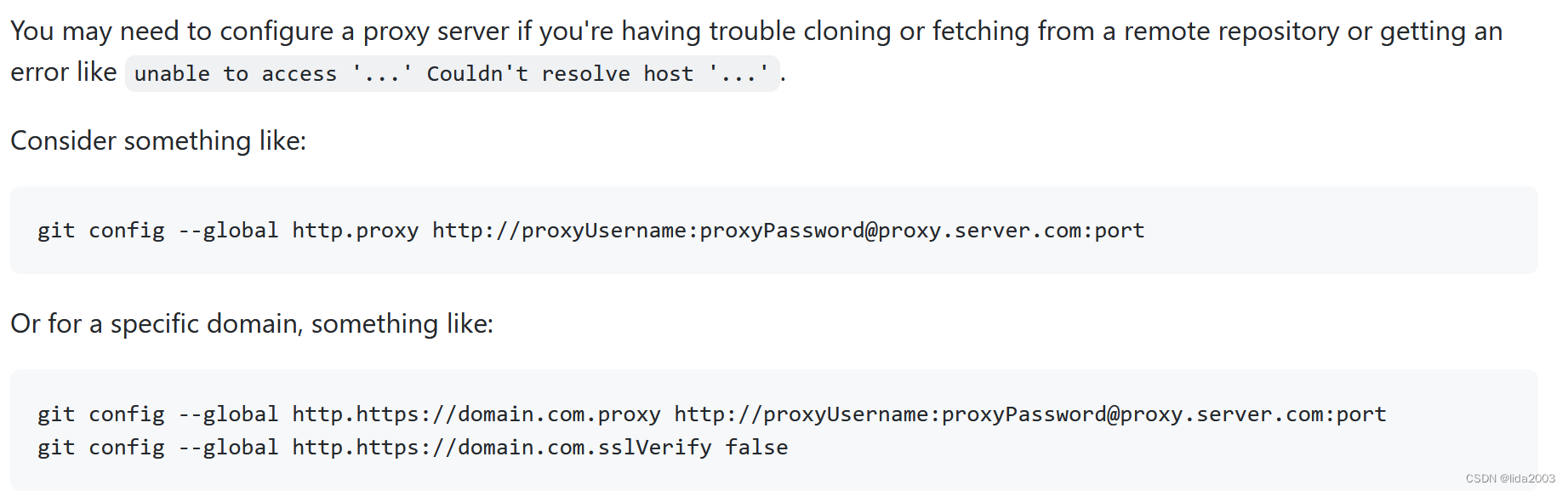
Github操作网络异常笔记
Github操作网络异常笔记 1. 源由2. 解决2.1 方案一2.2 方案二 3. 总结 1. 源由 开源技术在国内永远是“蛋疼”,这些"政治"问题对于追求技术的我们,形成无法回避的障碍。 $ git pull ssh: connect to host github.com port 22: Connection ti…...
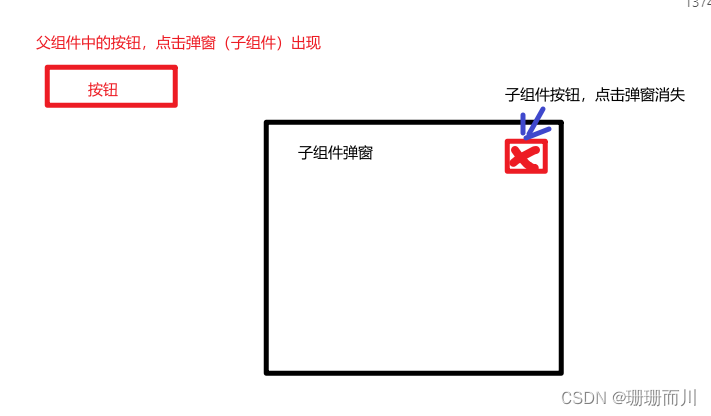
Vue3新特性defineModel()便捷的双向绑定数据
官网介绍 传送门 配置 要求: 版本: vue > 3.4(必须!!!)配置:vite.config.js 使用场景和案例 使用场景:父子组件的数据双向绑定,不用emit和props的繁重代码 具体案例 代码实…...

vue列表飞入效果
效果 实现代码 <template><div><button click"add">添加</button><TransitionGroup name"list" tag"ul"><div class"list-item" v-for"item in items" :key"item.id">{{ i…...

C语言·预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 __FILE__ 进行编译的源文件 __LINE__ 文件当前的行号 __DATE__ 文件被编译的日期 __TIME__ 文件被编译的时间 __STDC__ 如果编译器遵循ANSI C,…...

服务器与普通电脑的区别,普通电脑可以当作服务器用吗?
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

数字身份所有权:Web3时代用户数据的掌控权
随着Web3时代的来临,数字身份的概念正焕发出崭新的光芒。在这个数字化的时代,用户的个人数据变得愈加珍贵,而Web3则为用户带来了数字身份所有权的概念,重新定义了用户与个人数据之间的关系。本文将深入探讨Web3时代用户数据的掌控…...

别再焊错线了!51单片机+L298N驱动小车底盘,保姆级接线避坑指南
51单片机L298N驱动小车底盘:从零避坑到一次点亮 当你第一次把51单片机、L298N电机驱动模块、红外传感器和电源组装在一起时,是否曾被那些密密麻麻的杜邦线弄得晕头转向?每个初学者都可能经历过接错线导致芯片冒烟的惨痛教训。本文将用实战经验…...

工具推荐:HTML5+AI开发必备的前端调试工具
工具推荐:HTML5AI开发必备的前端调试工具 工具推荐:HTML5AI开发必备的前端调试工具📝 本章学习目标:本章聚焦职业发展,帮助读者规划HTML5AI的学习与职业路径。通过本章学习,你将全面掌握"工具推荐&…...

通过简单的Python示例代码快速上手Taotoken API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过简单的Python示例代码快速上手Taotoken API 对于希望快速接入多个大语言模型的开发者而言,Taotoken 提供了一个标准…...

Windows桌面终极整理方案:NoFences免费开源桌面分区工具完全指南
Windows桌面终极整理方案:NoFences免费开源桌面分区工具完全指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都在混乱的Windows桌面上寻找需要的文…...

瑞萨RH850芯片HSM软件实现:从硬件隔离到安全通信
1. RH850芯片HSM模块的硬件基础 第一次接触瑞萨RH850芯片的HSM(Hardware Security Module)功能时,我被它精妙的硬件设计所震撼。这颗芯片内部其实藏着两个"大脑":主处理器(Host)和专为安全设计的…...

ncmdumpGUI:Windows平台终极NCM解密工具,3分钟解锁网易云音乐格式限制
ncmdumpGUI:Windows平台终极NCM解密工具,3分钟解锁网易云音乐格式限制 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐…...

全志D1s开发板RT-Smart环境搭建:从工具链到烧录的完整实践指南
1. 项目概述与核心价值最近在折腾一块搭载了全志D1s芯片的开发板,目标是在上面跑RT-Smart实时操作系统。这听起来像是一个标准的嵌入式开发流程,但实际操作下来,从环境搭建到第一个程序跑起来,中间踩的坑一个接一个,远…...

APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南
APK Installer:Windows平台上无缝安装Android应用的技术实现与实战指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在Windows电脑上想要运行某…...

RK3568扩展模块实战:4G/Wi-Fi 6/多串口集成与Linux驱动适配
1. 项目概述:当“小”模块遇上“大”平台最近在折腾一块瑞芯微的RK3568开发板,这板子性能不错,四核A55加上独立的NPU,做边缘计算、多媒体网关或者轻量级服务器都挺合适。但在实际项目落地时,我遇到了一个几乎所有硬件开…...

IfcOpenShell技术架构深度解析:开源IFC引擎的模块化设计与高性能实现
IfcOpenShell技术架构深度解析:开源IFC引擎的模块化设计与高性能实现 【免费下载链接】IfcOpenShell Open source IFC library and geometry engine 项目地址: https://gitcode.com/gh_mirrors/if/IfcOpenShell IfcOpenShell作为开源建筑信息模型(…...