Elasticsearch 查询语句概述
目录
1. Match Query
2. Term Query
3. Terms Query
4. Range Query
5. Bool Query
6. Wildcard Query
7. Fuzzy Query
8. Prefix Query
9. Aggregation Query
Elasticsearch 是一个基于 Lucene 的搜索引擎,提供了丰富的查询DSL(Domain Specific Language)用于执行搜索操作。以下是Elasticsearch中常用的查询语句类型、作用、使用场景、注意事项以及每种查询的实际例子。
1. Match Query
- 作用:对文本进行全文搜索,包括模糊匹配。
- 使用场景:适用于搜索文本字段。
- 注意事项:默认情况下,对于多词搜索会采用OR操作符,可以通过operator参数修改。
- 例子:
{"query": {"match": {"message": "this is a test"}} }
2. Term Query
- 作用:用于精确值匹配,不会对搜索词进行分词。
- 使用场景:适用于关键字、数字、日期等精确值字段的精确查询。
- 注意事项:不适用于文本字段,因为文本字段会在索引时分词。
-
例子:
{"query": {"term": {"status": {"value": "active"}}} }
3. Terms Query
- 作用:与term query类似,但允许指定多个精确值。
- 使用场景:当需要匹配多个精确值时使用。
- 注意事项:与term query相同,不适用于文本字段。
- 例子:
{"query": {"terms": {"status": ["active", "pending"]}} }
4. Range Query
- 作用:用于查找在某个范围内的值。
- 使用场景:适用于数字、日期等类型的范围查询。
- 注意事项:可以使用gt、lt、gte、lte等操作符指定范围。
- 例子:
{"query": {"range": {"age": {"gte": 10,"lte": 20}}} }
5. Bool Query
- 作用:允许组合多个查询,如must、should、must_not。
- 使用场景:当需要执行复杂的查询逻辑时使用。
- 注意事项:should子句在没有must或filter时至少需要匹配一个条件。
- 例子:
{"query": {"bool": {"must": [{ "match": { "title": "search" } },{ "match": { "content": "Elasticsearch" } }],"must_not": [{ "range": { "age": { "gte": 30 } } }],"should": [{ "term": { "tag": "wow" } },{ "term": { "tag": "elasticsearch" } }],"minimum_should_match": 1,"boost": 1.0}} }
6. Wildcard Query
- 作用:支持使用通配符的模糊查询。
- 使用场景:在不确定完整词项时使用。
- 注意事项:通配符查询可能会影响性能,应谨慎使用。
- 例子:
{"query": {"wildcard": {"user": {"value": "ki*y"}}} }
7. Fuzzy Query
- 作用:基于Levenshtein编辑距离的模糊查询。
- 使用场景:在处理用户输入错误的情况下很有用。
- 注意事项:模糊查询会消耗更多的资源,应适度使用。
- 例子:
{"query": {"fuzzy": {"name": {"value": "kiim","fuzziness": 2}}} }
8. Prefix Query
- 作用:搜索具有指定前缀的词项。
- 使用场景:适用于自动补全功能。
- 注意事项:与通配符查询一样,可能会影响性能。
- 例子:
{"query": {"prefix": {"user": {"value": "ki"}}} }
9. Aggregation Query
- 作用:用于执行复杂的数据分析和汇总。
- 使用场景:统计分析,如计数、平均值、最大/最小值等。
- 注意事项:聚合查询可以消耗大量资源,应合理设计。
- 例子:
{"size": 0,"aggs": {"group_by_state": {"terms": {"field": "state.keyword"}}} }
相关文章:

Elasticsearch 查询语句概述
目录 1. Match Query 2. Term Query 3. Terms Query 4. Range Query 5. Bool Query 6. Wildcard Query 7. Fuzzy Query 8. Prefix Query 9. Aggregation Query Elasticsearch 是一个基于 Lucene 的搜索引擎,提供了丰富的查询DSL(Domain Specifi…...

kafka简单介绍和代码示例
“这是一篇理论文章,给大家讲一讲kafka” 简介 在大数据领域开发者常常会听到MQ这个术语,该术语便是消息队列的意思, Kafka是分布式的发布—订阅消息系统。它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年…...

一次解决ForkJoinPool日志追踪的辛酸经历
本文主要分享了一次解决ForkJoinPool日志追踪的辛酸经历。历时3个月终于找到通用的解决方案,以此文分享给有需要的你。 一、需求背景 1.某日,某同事根据日志ID排查生产环境问题过程中,发现日志不全 2.经排查发现中间有很多线程为ForkJoinP…...
VM使用教程--SDK取图 视频笔记
本笔记均由海康机器人官网的V学院视频中记录所得,属于省流大师了[doge] 图像采集 图像采集包括1图像源,2多图采集,3输出图像,4缓存图像,5光源 1图像源 图像源包括本地图像,相机采图,SDK 本…...
)
11.spring boot 启动源码(一)
目录 概述SpringApplication静态方法构造方法run 实例方法配置文件Actuator 工作原理*EndpointAutoConfigurationBeansEndpointAutoConfigurationShutdownEndpointAutoConfiguration结束概述 spring boot 版本 2.6.13 spring boot 启动源码(一) 涉及 SpringApplication 中静态…...
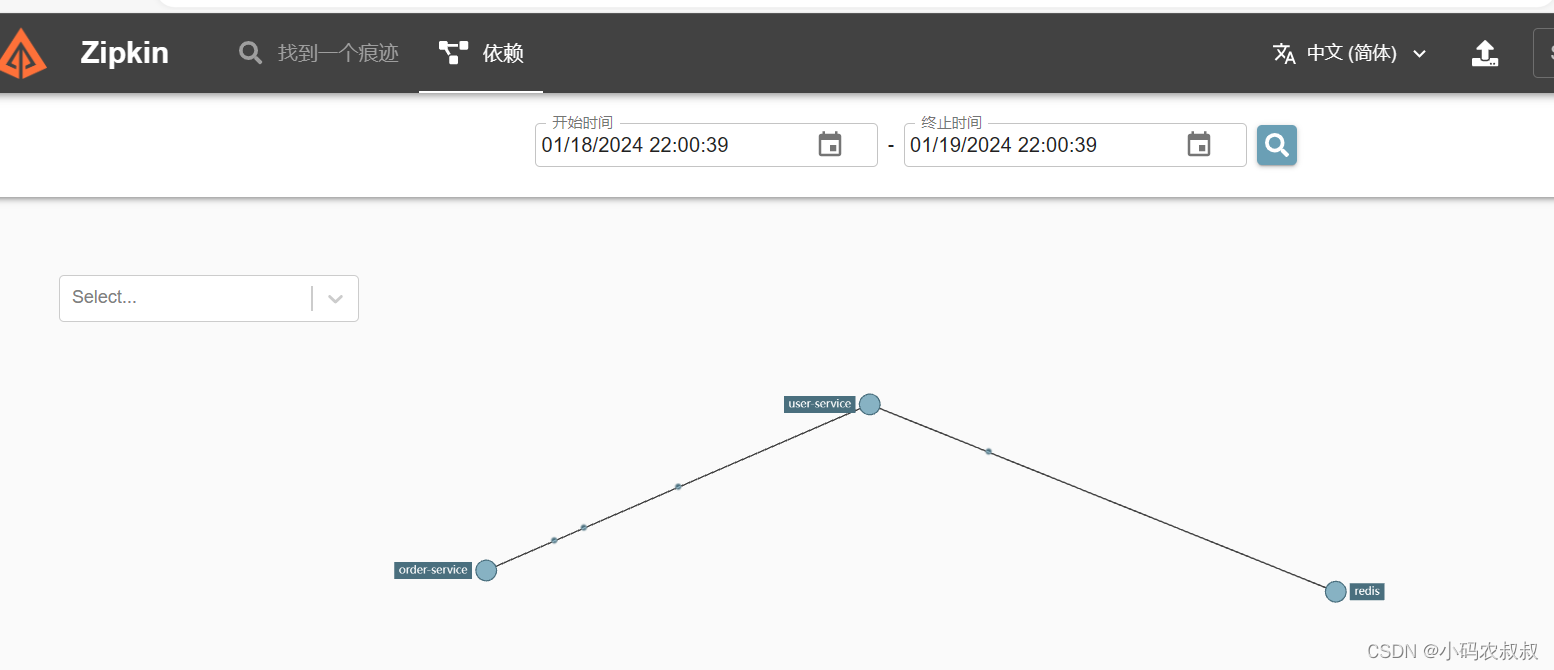
【微服务】springcloud集成sleuth与zipkin实现链路追踪
目录 一、前言 二、分布式链路调用问题 三、链路追踪中的几个概念 3.1 什么是链路追踪 3.2 常用的链路追踪技术 3.3 链路追踪的几个术语 3.3.1 span 编辑 3.3.2 trace 3.3.3 Annotation 四、sluth与zipkin概述 4.1 sluth介绍 4.1.1 sluth是什么 4.1.2 sluth核心…...

数学建模-预测人口数据
目录 中国09~18年人口数据 创建时间 绘制时间序列图 使用专家建模器 得到结果 预测结果 残差的白噪声检验 中国09~18年人口数据 创建时间 路径:数据-> 定义日期和时间 绘制时间序列图 使用专家建模器 看看spss最终判断是那个模型最佳的契合 得到结果 预…...

SpringBoot 集成 Canal 基于 MySQL 做数据同步
一、canal 组件关系 下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/ 这里面主要的有两个 canal.deployer-1.1.7.tar.gz 和 canal.adapter-1.1.7.tar.gz,canal.admin-1.1.7.tar.gz 是一个监控服务,可选…...

【CVE-2022-22733漏洞复现】
Apache ShardingSphere ElasticJob-UI漏洞 漏洞编号:CVE-2022-22733 文档说明 本文作者:SwBack 创作时间:2024/1/21 19:19:19 知乎:https://www.zhihu.com/people/back-88-87 CSDN:https://blog.csdn.net/qq_30817059 百度搜索: SwBack漏洞描述 Apache ShardingSphere Elast…...
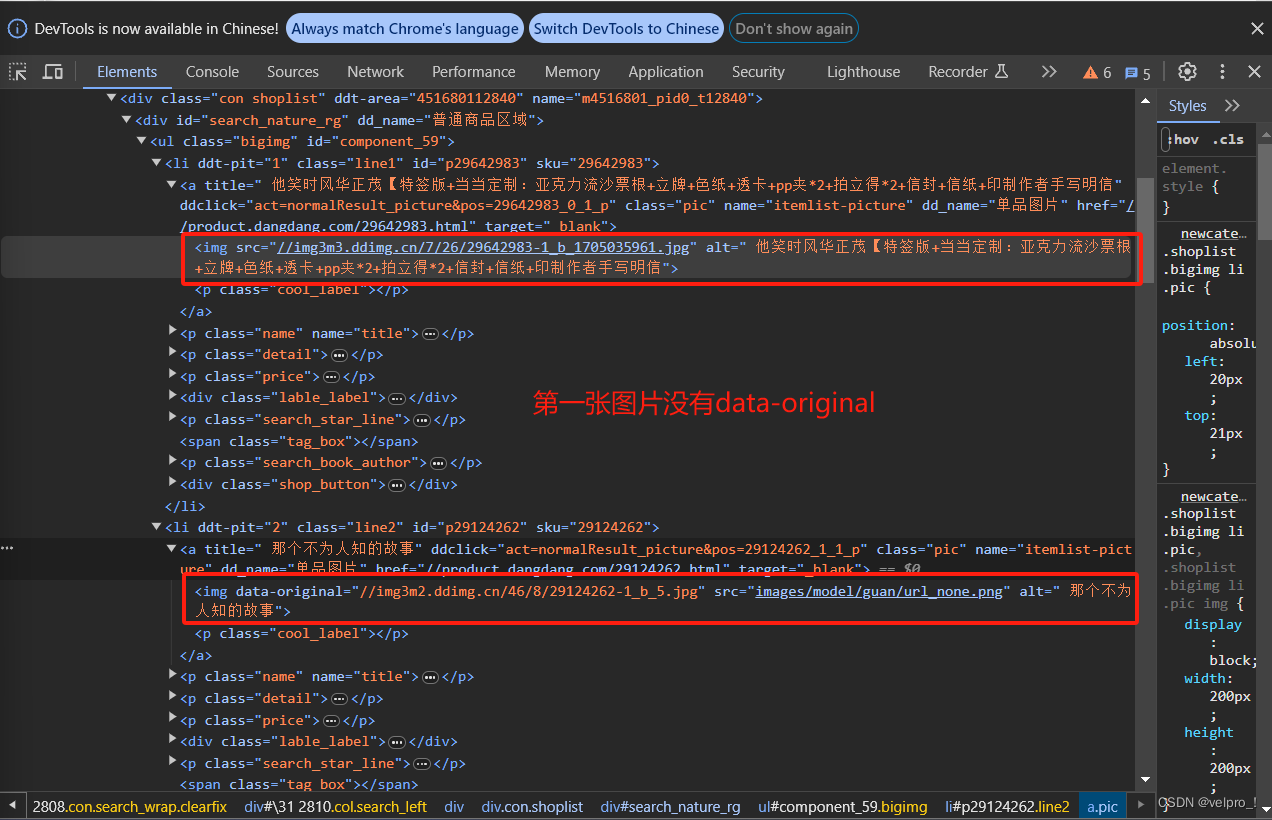
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapy from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name "dang" # 名字# 如果是多页下载的话, …...

【机器学习】机器学习四大类第01课
一、机器学习四大类 有监督学习 (Supervised Learning) 有监督学习是通过已知的输入-输出对(即标记过的训练数据)来学习函数关系的过程。在训练阶段,模型会根据这些示例调整参数以尽可能准确地预测新的、未见过的数据点的输出。 实例&#x…...

下述默认构造函数有什么问题?
12.4 // points to string allocated by new // holds length of string 独立的、相同的数据,而不会重叠。由于同样的原因,必须定义赋值操作符。对于每一种情况,最终目的 都是执行深度复制,也就是说,复制实际的数据,而不仅仅是复制指向数据的指针。 对象的存储持续性为自动或…...

vite和mockjs配合使用
vite mockjs 当后端还没准备完成之前,前端可以使用 mock 模拟后端响应,提高开发效率 1、安装插件 使用 vite-plugin-mock 插件,配合mockjs完成项目的 mock 配置 npm install mockjs vite-plugin-mock2、vite配置插件 在 vite.config.js…...
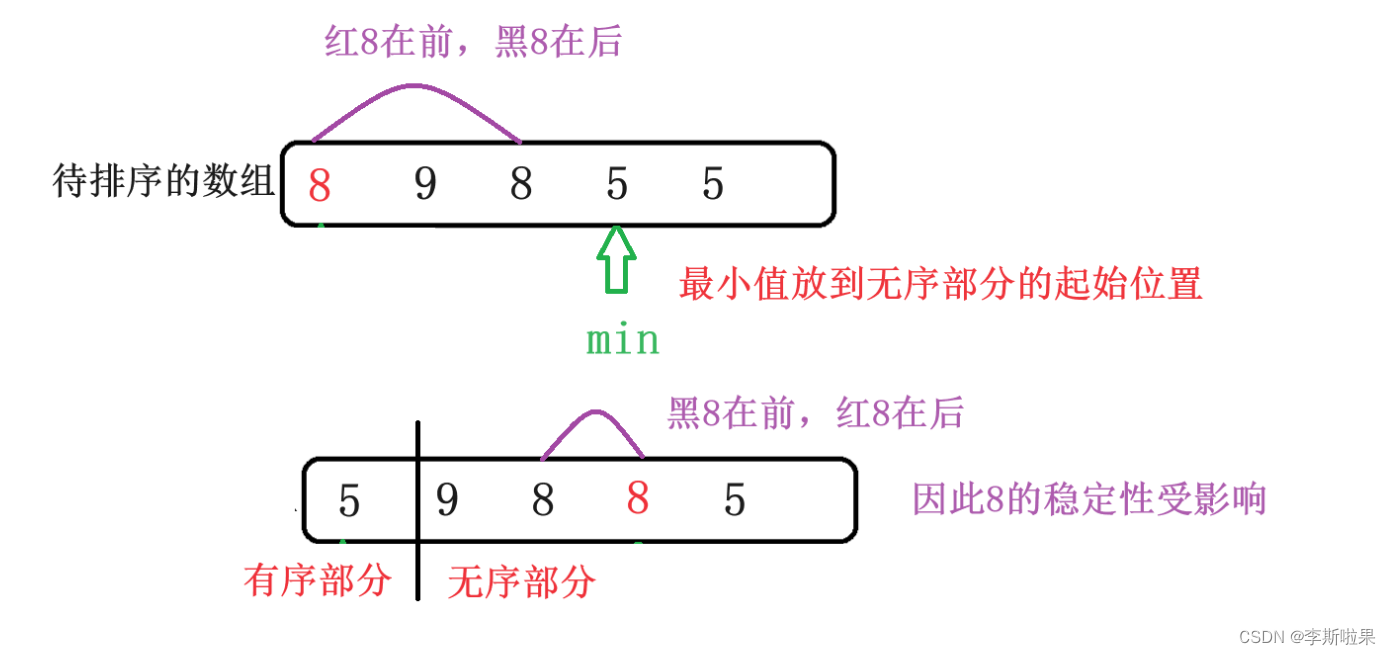
【数据结构】常见八大排序算法总结
目录 前言 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 6.1Hoare版本 6.2挖坑法 6.3前后指针法 6.4快速排序的递归实现 6.5快速排序的非递归实现 7.归并排序 8.计数排序(非比较排序) 9.补充:基数排序 10.总结…...

系统学英语 — 句法 — 常规句型
目录 文章目录 目录5 大基本句型复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句补语从句 谓语句型 5 大基本句型 主谓:主语发出一个动作,例如:He cried.主谓宾:we study English.主系表:主语具有某些特…...
Github操作网络异常笔记
Github操作网络异常笔记 1. 源由2. 解决2.1 方案一2.2 方案二 3. 总结 1. 源由 开源技术在国内永远是“蛋疼”,这些"政治"问题对于追求技术的我们,形成无法回避的障碍。 $ git pull ssh: connect to host github.com port 22: Connection ti…...
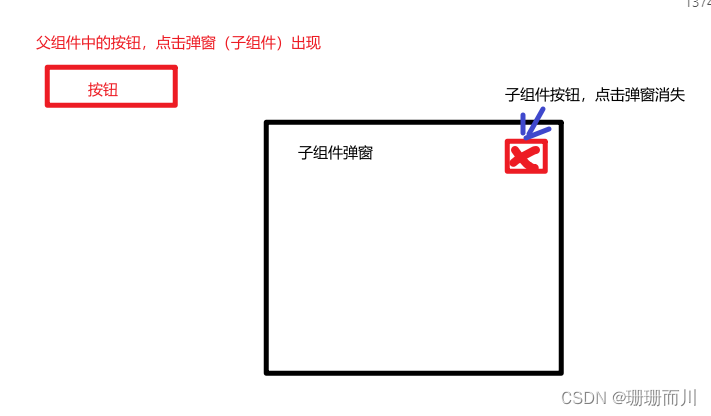
Vue3新特性defineModel()便捷的双向绑定数据
官网介绍 传送门 配置 要求: 版本: vue > 3.4(必须!!!)配置:vite.config.js 使用场景和案例 使用场景:父子组件的数据双向绑定,不用emit和props的繁重代码 具体案例 代码实…...

vue列表飞入效果
效果 实现代码 <template><div><button click"add">添加</button><TransitionGroup name"list" tag"ul"><div class"list-item" v-for"item in items" :key"item.id">{{ i…...

C语言·预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 __FILE__ 进行编译的源文件 __LINE__ 文件当前的行号 __DATE__ 文件被编译的日期 __TIME__ 文件被编译的时间 __STDC__ 如果编译器遵循ANSI C,…...

服务器与普通电脑的区别,普通电脑可以当作服务器用吗?
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

VK视频下载终极指南:3种方法轻松保存珍贵回忆
VK视频下载终极指南:3种方法轻松保存珍贵回忆 【免费下载链接】VK-Video-Downloader Скачивайте видео с сайта ВКонтакте в желаемом качестве 项目地址: https://gitcode.com/gh_mirrors/vk/VK-Video-Downloade…...
)
告别手动重启!用Python+PyAutoGUI写个游戏防崩溃守护脚本(附完整源码)
告别手动重启!用PythonPyAutoGUI打造游戏防崩溃守护脚本 深夜挂机刷副本时突然游戏崩溃,第二天醒来发现角色还在主城发呆?竞技场自动匹配因为断线重连失败而错过赛季奖励?这些问题对于MMO玩家和挂机游戏爱好者来说简直如同噩梦。本…...

别再死记硬背了!用‘IP地址与运算’这个技巧,5分钟搞懂子网掩码和网络地址
子网掩码实战:5分钟掌握IP与运算的核心技巧 网络工程师面试时总会被问到"如何快速计算网络地址",而很多初学者面对子网掩码和IP地址的二进制转换就头疼不已。其实有个被大多数教材忽略的技巧——IP地址主机位置零法,能让你不用完整…...

SQL server 2017镜像库主从同步架构部署
SQL server 2017镜像库主从同步架构部署 目录: 1.主库配置 2.镜像库配置 3.检查状态 4.手工故障转移测试-主备切换 5.添加见证服务器实现自动主备切换 6.自动故障切换测试-主备切换角色 IP 状态 主机名 主库 192.168.56.120 可读写 sqldb2 镜像库(从库&a…...

洞悉.NET 11:Blazor 与 Microsoft.Extensions.AI 的融合创新实践
洞悉.NET 11:Blazor 与 Microsoft.Extensions.AI 的融合创新实践 前言 在现代 Web 应用开发领域,提升用户体验和智能化交互至关重要。Blazor 凭借其在构建交互式 Web 界面的优势,与专注于 AI 集成的 Microsoft.Extensions.AI 相结合ÿ…...
)
告别Python依赖!用SpringBoot+LangChain4j从零搭建企业级RAG知识库(附避坑指南)
告别Python依赖!用SpringBootLangChain4j从零搭建企业级RAG知识库(附避坑指南) 在AI技术快速落地的今天,检索增强生成(RAG)已成为企业知识管理的热门解决方案。然而,当大多数团队都在Python生态…...

5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南
5步快速上手OmenSuperHub:彻底掌控暗影精灵性能的终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否对官方Omen Gaming Hub的臃肿…...
)
MyBatis-Plus详解(速成版)
一、介绍MyBatis-Plus: 1.概念 MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 MyBatis-Plus的官网简介:https://baomidou.com/introduce/ 2.特点: 无侵入ÿ…...

杨立昆转推“Meta AI 已死”:一场大厂AI战略的自杀式摇摆
好家伙,杨立昆(Yann LeCun)亲自转发“讣告”了。 就昨天,这位 Meta 的首席 AI 科学家,在 X 上转了一条推,内容直指自家公司——Meta AI 部门“已死”。原文副标题更狠:“自研人才流失࿰…...
)
告别充电焦虑!用FS4066系列芯片DIY一个支持USB PD快充的2-4串锂电池充电器(附完整电路图)
用FS4066系列芯片打造高效多串锂电池快充方案 在创客圈子里,给多节串联锂电池设计充电电路一直是个既令人兴奋又充满挑战的课题。想象一下,当你精心组装的无人机因为充电效率低下而频繁停飞,或者户外电源设备因为充电管理不当导致电池寿命骤减…...