高并发内存池
按照threadcache,centralcache,pagecache顺序所列
这里还需要一定的前期准备工作
首先是可以设计一个定长内存池
ObjectPool.h
#pragma once
#include<iostream>
#include"Common.h"
using std::cout;
using std::endl;
using std::bad_alloc;
//#ifdef _WIN32
//#include<windows.h>
//#else
//#endif
//定长内存池
//template<size_t N>
//class ObjectPool
//{
//};//该hpp文件实现一个专用定长内存池,向堆申请大块内存,用一个指针来对其进行管理,
//但仅用一个指针肯定是不够的,我们还需要用一个变量来记录这块内存的长度
//由于此后我们需要将这块内存进行切分,为了方便切分操作,
//指向这块内存的指针最好是字符指针,因为指针的类型决定了指针向前或向后走一步有多大距离,
//对于字符指针来说,当我们需要向后移动n个字节时,直接对字符指针进行加n操作即可。
//其次,释放回来的定长内存块也需要被管理,我们可以将这些释放回来的定长内存块链接成一个链表,
//这里我们将管理释放回来的内存块的链表叫做自由链表,为了能找到这个自由链表,我们还需要一个指向自由链表的指针。
////该文件实现有一个问题:
//如何让一个指针在32位平台下解引用后能向后访问4个字节,
//在64位平台下解引用后能向后访问8个字节? 使用void**//下面的定位new和析构
//定位new表达式:是在已分配的原始内存空间中调用构造函数初始化一个对象。
//定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,
//所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。//析构同理
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE,PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}template<class T>
class ObjectPool
{
public:T* New(){T* obj = nullptr;//优先把还回来的内存再次重复利用if (_freeList){void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else{//剩余空间大小不够一个T的时候,则重新开大空间if (_remainBytes < sizeof(T)){_remainBytes = 1024 * 128;//_memory = (char*)malloc(1024 * 128);_memory = (char*)SystemAlloc(_remainBytes>>13);if (_memory == nullptr) {throw bad_alloc();}}//没有还回来的内存,去大池子里面去切obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_remainBytes -= objSize;}//定位new,显式调用T的构造函数初始化new(obj) T;return obj;}void Delete(T* obj){//if (_freeList == nullptr)//{// _freeList = obj;// //(int*)obj; = nullptr;// *(void**)obj = nullptr;//}//else//{// 显式调用析构函数清理对象obj->~T();//头插*(void**)obj = _freeList;_freeList = obj;//}}
private:char* _memory=nullptr;//指向大块内存的指针size_t _remainBytes = 0;//大块内存在切分过程中剩余字节数void* _freeList=nullptr;//还回过程中链接的自由链表头指针};
//下面是测试函数,比较直接new和在ObjectPool中的申请//struct TreeNode
//{
// int _val;
// TreeNode* _left;
// TreeNode* _right;
//
// TreeNode()
// :_val(0)
// , _left(nullptr)
// , _right(nullptr)
// {}
//};
//
//void TestObjectPool()
//{
// // 申请释放的轮次
// const size_t Rounds = 5;
//
// // 每轮申请释放多少次
// const size_t N = 100000;
//
// std::vector<TreeNode*> v1;
// v1.reserve(N);
//
// size_t begin1 = clock();
// for (size_t j = 0; j < Rounds; ++j)
// {
// for (int i = 0; i < N; ++i)
// {
// v1.push_back(new TreeNode);
// }
// for (int i = 0; i < N; ++i)
// {
// delete v1[i];
// }
// v1.clear();
// }
//
// size_t end1 = clock();
//
// std::vector<TreeNode*> v2;
// v2.reserve(N);
//
// ObjectPool<TreeNode> TNPool;
// size_t begin2 = clock();
// for (size_t j = 0; j < Rounds; ++j)
// {
// for (int i = 0; i < N; ++i)
// {
// v2.push_back(TNPool.New());
// }
// for (int i = 0; i < N; ++i)
// {
// TNPool.Delete(v2[i]);
// }
// v2.clear();
// }
// size_t end2 = clock();
//
// cout << "new cost time:" << end1 - begin1 << endl;
// cout << "object pool cost time:" << end2 - begin2 << endl;
//}接下来分别定义三个功能实现的头文件
ThreadCache.h,CentralCache.h,PageCache.h
#pragma once
#include"Common.h"class ThreadCache
{
public:// 申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);//从中心cache获取void* FetchFromCentralCache(size_t index,size_t size);// 释放对象时,链表过长时,回收内存回到中心缓存void ListTooLong(FreeList& list, size_t size);
private:FreeList _freeLists[NFREELIST];
};
//静态TLS
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;#pragma once
#include"Common.h"//单例模式 饿汉
class CentralCache
{
public:static CentralCache* GetInstance(){return &_sInst;}//从中心缓存获取一定数量的对象给thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);// 从SpanList或者page cache获取一个非空的spanSpan* GetOneSpan(SpanList& list, size_t byte_size);// 将一定数量的对象释放到span跨度void ReleaseListToSpans(void* start, size_t byte_size);private:SpanList _spanLists[NFREELIST];CentralCache(){}CentralCache(const CentralCache&) = delete;static CentralCache _sInst;
};#pragma once
#include"Common.h"
#include"ObjectPool.h"
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}// 获取从对象到span的映射Span* MapObjectToSpan(void* obj);// 释放空闲span回到Pagecache,并合并相邻的spanvoid ReleaseSpanToPageCache(Span* span);//获取一个K页的spanSpan* NewSpan(size_t k);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];ObjectPool<Span> _spanPool;std::unordered_map<PAGE_ID, Span*> _idSpanMap;//单例模式,使用饿汉PageCache(){}PageCache(const PageCache&) = delete;static PageCache _sInst;
};对于三级缓存,需要实现的哈希桶结构和span为管理粒度的头文件实现
Common.h
#pragma once
#include<iostream>
#include<vector>
#include<time.h>
#include<thread>
#include<assert.h>
#include<mutex>
#include<algorithm>
#include<unordered_map>
using std::cout;
using std::endl;
using std::bad_alloc;#ifdef _WIN32
#include<windows.h>
#else
#endifstatic const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREELIST = 208;
static const size_t NPAGES = 129;
static const size_t PAGE_SHIFT = 13;#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#endif inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE,PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else// sbrk unmmap等
#endif
}static void*& NextObj(void* obj)
{return *(void**)obj;
}class FreeList
{
public:void Push(void* obj){assert(obj);//头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;++_size;}void PushRange(void* start,void* end,size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);start = _freeList;end = start;for (size_t i = 0; i < n - 1; i++){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;}void* Pop(){assert(_freeList);//头删void* obj = _freeList;_freeList = NextObj(obj);--_size;return obj;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}
private:void* _freeList=nullptr;size_t _maxSize = 1;size_t _size=0;
};//计算对象大小的对齐映射关系
class SizeClass
{
public://对齐规则: 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16) 前16个桶// [128+1,1024] 16byte对齐 freelist[16,72) 16-71个桶// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)//size_t _RoundUp(size_t size,size_t alignNum)//{// size_t alignSize;// if (size % alignNum != 0)// {// }// else// {// alignSize = size;// }// return alignSize; //}static inline size_t _RoundUp(size_t bytes, size_t align){return (((bytes)+align - 1) & ~(align - 1));}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size<=1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8*1024);}else{return _RoundUp(size, 1<< PAGE_SHIFT);//以页为对齐}}//size_t _Index(size_t bytes, size_t alignNum)//{// if (bytes % alignNum == 0)// {// return bytes / alignNum - 1;// }// else// {// return bytes / alignNum;// }//}//align_shift是2的几次方的几static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1]+ group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] +group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}// 一次从中心缓存获取多少个static size_t NumMoveSize(size_t size){assert(size > 0);// [2, 512],一次批量移动多少个对象的(慢启动)上限值// 小对象一次批量上限高// 小对象一次批量上限低int num = MAX_BYTES / size;if (num < 2)num = 2;if (num > 512)num = 512;return num;}//计算一次向系统获取几个页// 单个对象 8byte// ...// 单个对象 256KBstatic size_t NumMovePage(size_t size){size_t num = NumMoveSize(size);//计算出thread cache一次向central cache申请对象的个数上限size_t npage = num * size;//num个size大小的对象所需的字节数npage >>= PAGE_SHIFT;//将字节数转换为页数if (npage == 0)//至少给一页npage = 1;return npage;}};
//管理多个连续页的大块内存跨度结构
struct Span
{size_t _pageId=0; //大块内存起始页的页号size_t _n=0; //页的数量Span* _next=nullptr; //双向链表结构Span* _prev= nullptr;size_t _objSize = 0;//切好的小对象的大小size_t _useCount=0; //切好小块内存,被分配给threadCahe的计数void* _freeList= nullptr; //切好的小块内存的自由链表bool _isUse=false; //是否在被使用
};
//带头双向循环链表
class SpanList
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}Span* Begin(){return _head->_next;}Span* End(){return _head;}bool Empty(){return _head->_next == _head;}void PushFront(Span* span){Insert(Begin(), span);}Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;//prev newSpan pos,newSpan要插在prev和pos中间prev->_next = newSpan;newSpan->_next = pos;pos->_prev = newSpan;newSpan->_prev = prev;}void Erase(Span* pos){assert(pos);assert(pos!=_head);//1.条件断点//2.查看栈帧/* if (pos == _head){int x = 0;}*/Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev; }
private:Span* _head;
public:std::mutex _mtx;//桶锁
};使用基数树优化实现
Radix.h
#pragma once
#include"Common.h"// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocatorpublic:typedef uintptr_t Number;//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap2() {//allocator_ = allocator;memset(root_, 0, sizeof(root_));PreallocateMoreMemory();}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) {//Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));//if (leaf == NULL) return false;static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
};最终测试需要的alloc和free
ConcurrentAlloc.h
#pragma once
#include"Common.h"
#include"ThreadCache.h"
#include "PageCache.h"
#include "ObjectPool.h"
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){size_t alignSize = SizeClass::RoundUp(size);size_t kpage = alignSize >> PAGE_SHIFT;PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kpage);span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{//通过TLS 每个线程无锁地获取自己专属的ThreadCache对象if (pTLSThreadCache == nullptr){static ObjectPool<ThreadCache> tcPool;//pTLSThreadCache = new ThreadCache;pTLSThreadCache = tcPool.New();}//cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);}
}
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;if (size > MAX_BYTES){Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr,size);
}
接下来就是cpp文件的实现
ThreadCache.cpp
#include "ThreadCache.h"
#include "CentralCache.h"void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 慢开始反馈调节算法// 1、最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向central cache要的batchNum就越小// 4、size越小,一次向central cache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum > 0);if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(NextObj(start), end, actualNum-1);return start;}
}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);// 找对映射的自由链表桶,对象插入进入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);// 当链表长度大于一次批量申请的内存时就开始还一段list给central cacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);}
}void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}CentralCache.cpp
#include "CentralCache.h"
#include "PageCache.h"CentralCache CentralCache::_sInst;// 获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{// 查看当前的spanlist中是否有还有未分配对象的spanSpan* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞list._mtx.unlock();// 走到这里说没有空闲span了,只能找page cache要PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));span->_isUse = true;span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();// 对获取span进行切分,不需要加锁,因为这会其他线程访问不到这个span// 计算span的大块内存的起始地址和大块内存的大小(字节数)char* start = (char*)(span->_pageId << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;// 把大块内存切成自由链表链接起来// 先切一块下来去做头,方便尾插span->_freeList = start;start += size;void* tail = span->_freeList;int i = 1;while (start < end){++i;NextObj(tail) = start;tail = NextObj(tail); // tail = start;start += size;}NextObj(tail) = nullptr;// 切好span以后,需要把span挂到桶里面去的时候,再加锁list._mtx.lock();list.PushFront(span);return span;
}// 从中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();Span* span = GetOneSpan(_spanLists[index], size);assert(span);assert(span->_freeList);// 从span中获取batchNum个对象// 如果不够batchNum个,有多少拿多少start = span->_freeList;end = start;size_t i = 0;size_t actualNum = 1;while ( i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++i;++actualNum;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_useCount += actualNum;int j = 0;void* cur = start;while (cur){cur = NextObj(cur);++j;}if (j != actualNum){int x = 0;}_spanLists[index]._mtx.unlock();return actualNum;
}void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanLists[index]._mtx.lock();while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);NextObj(start) = span->_freeList;span->_freeList = start;span->_useCount--;// 说明span的切分出去的所有小块内存都回来了// 这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并if (span->_useCount == 0){_spanLists[index].Erase(span);span->_freeList = nullptr;span->_next = nullptr;span->_prev = nullptr;// 释放span给page cache时,使用page cache的锁就可以了// 这时把桶锁解掉_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();_spanLists[index]._mtx.lock();}start = next;}_spanLists[index]._mtx.unlock();
}PagecaChe.cpp
#include "PageCache.h"PageCache PageCache::_sInst;// 获取一个K页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);// 大于128 page的直接向堆申请if (k > NPAGES-1){void* ptr = SystemAlloc(k);//Span* span = new Span;Span* span = _spanPool.New();span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;//_idSpanMap[span->_pageId] = span;_idSpanMap.set(span->_pageId, span);return span;}// 先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();// 建立id和span的映射,方便central cache回收小块内存时,查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; ++i){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分for (size_t i = k+1; i < NPAGES; ++i){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();//Span* kSpan = new Span;Span* kSpan = _spanPool.New();// 在nSpan的头部切一个k页下来// k页span返回// nSpan再挂到对应映射的位置kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时// 进行的合并查找//_idSpanMap[nSpan->_pageId] = nSpan;//_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;_idSpanMap.set(nSpan->_pageId, nSpan);_idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan);// 建立id和span的映射,方便central cache回收小块内存时,查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; ++i){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}}// 走到这个位置就说明后面没有大页的span了// 这时就去找堆要一个128页的span//Span* bigSpan = new Span;Span* bigSpan = _spanPool.New();void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);
}Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);/*std::unique_lock<std::mutex> lock(_pageMtx);auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}*/auto ret = (Span*)_idSpanMap.get(id);assert(ret != nullptr);return ret;
}void PageCache::ReleaseSpanToPageCache(Span* span)
{// 大于128 page的直接还给堆if (span->_n > NPAGES-1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);//delete span;_spanPool.Delete(span);return;}// 对span前后的页,尝试进行合并,缓解内存碎片问题while (1){PAGE_ID prevId = span->_pageId - 1;//auto ret = _idSpanMap.find(prevId);前面的页号没有,不合并了//if (ret == _idSpanMap.end())//{// break;//}auto ret = (Span*)_idSpanMap.get(prevId);if (ret == nullptr){break;}// 前面相邻页的span在使用,不合并了Span* prevSpan = ret;if (prevSpan->_isUse == true){break;}// 合并出超过128页的span没办法管理,不合并了if (prevSpan->_n + span->_n > NPAGES-1){break;}span->_pageId = prevSpan->_pageId;span->_n += prevSpan->_n;_spanLists[prevSpan->_n].Erase(prevSpan);//delete prevSpan;_spanPool.Delete(prevSpan);}// 向后合并while (1){PAGE_ID nextId = span->_pageId + span->_n;/*auto ret = _idSpanMap.find(nextId);if (ret == _idSpanMap.end()){break;}*/auto ret = (Span*)_idSpanMap.get(nextId);if (ret == nullptr){break;}Span* nextSpan = ret;if (nextSpan->_isUse == true){break;}if (nextSpan->_n + span->_n > NPAGES-1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);//delete nextSpan;_spanPool.Delete(nextSpan);}_spanLists[span->_n].PushFront(span);span->_isUse = false;//_idSpanMap[span->_pageId] = span;//_idSpanMap[span->_pageId+span->_n-1] = span;_idSpanMap.set(span->_pageId, span);_idSpanMap.set(span->_pageId + span->_n - 1, span);
}
最终测试的
BenchMark.cpp
#include"ConcurrentAlloc.h"void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, (unsigned int)(malloc_costtime + free_costtime));
}void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, (unsigned int)(malloc_costtime + free_costtime));
}int main()
{size_t n = 1000;cout << "==========================================================" <<endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" <<endl;return 0;
}相关文章:

高并发内存池
按照threadcache,centralcache,pagecache顺序所列 这里还需要一定的前期准备工作 首先是可以设计一个定长内存池 ObjectPool.h #pragma once #include<iostream> #include"Common.h" using std::cout; using std::endl; using std::…...

springboot mybatis-plus 对接 sqlserver 数据库 批处理的问题
问题: 在对接 sqlserver数据库的时候 主子表 保存的时候 子表批量保存 使用的 mybatis-plus提供的saveOrUpdateBatch 这个方法 但是 报错 报错内容为 : com.microsoft.sqlserver.jdbc.SQLServerException: 必须执行该语句才能获得结果。 框架版本 sprin…...
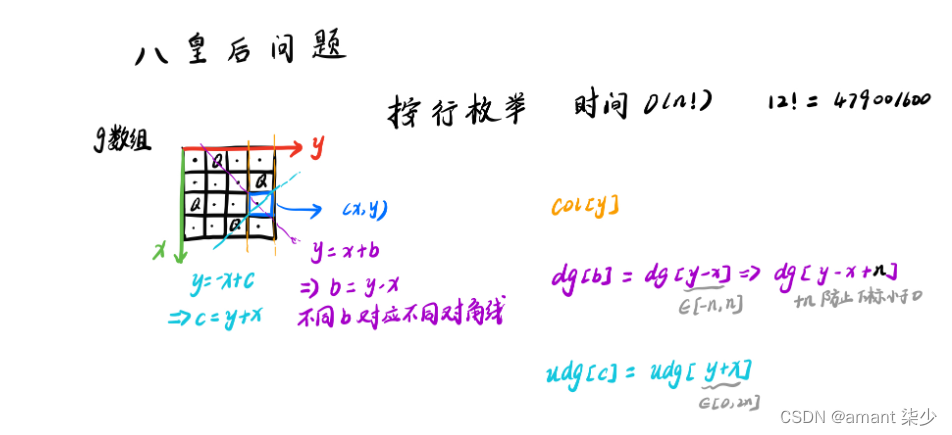
Acwing---843. n-皇后问题——DFS
n-皇后问题1.题目2.基本思想3.代码实现1.题目 n−皇后问题是指将 n 个皇后放在 nn 的国际象棋棋盘上,使得皇后不能相互攻击到,即任意两个皇后都不能处于同一行、同一列或同一斜线上。 现在给定整数 n,请你输出所有的满足条件的棋子摆法。 …...

Android事件分发机制
文章目录Android View事件分发机制:事件分发中的核心方法onTouchListener和onClickListener的优先级事件分发DOWN,MOVE,UP 事件分发CANCEL代码实践requestdisallowIntereptTouchEvent作用Android View事件分发机制: 事件分发中的核心方法 Android中事件…...

python版协同过滤算法图书管理系统
基于协同过滤算法的图书管理系统 一、简介(v信:1257309054) 本系统基于推荐算法给用户实现精准推荐图书。 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然…...
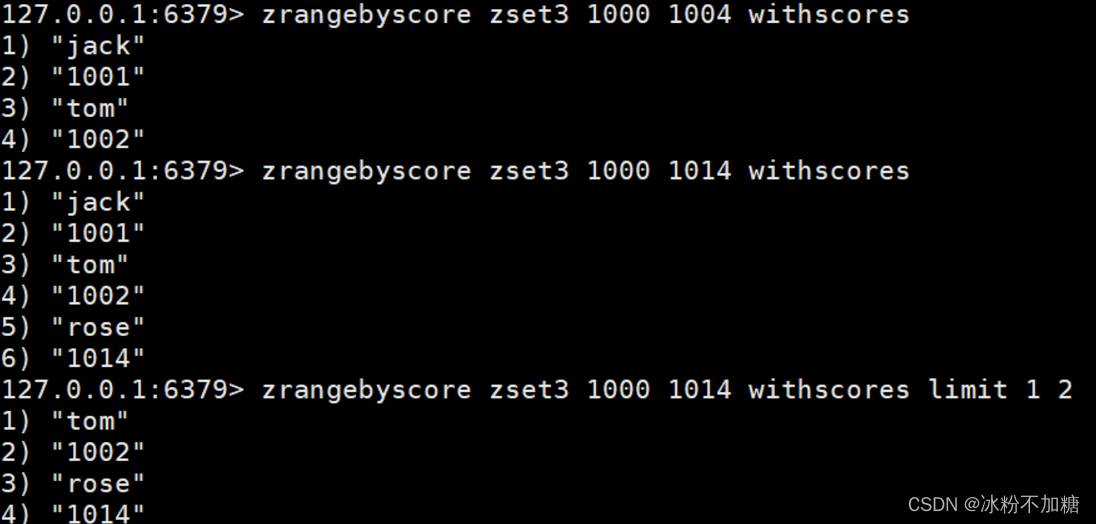
Redis基础入门
文章目录前言一、redis是什么?二、安装步骤1.下载安装包2.安装三、Redis的数据类型redis是一种高级的key-value的存储系统,其中的key是字符串类型,尽可能满足如下几点:字符串(String)列表(List)集合(Set,不允许出现重复…...

【微服务】Feign实现远程调用和负载均衡
目录 1.什么是Feign 2 订单微服务集成Feign 2.1.引入依赖 2.2添加注解 2.3编写Feign的客户端 2.4修改OrderServiceImpl.java的远程调用方法 2.5重启订单服务,并验证 总结 1.什么是Feign Feign是Spring Cloud提供的⼀个声明式的伪Http客户端, 它…...

Windows使用QEMU搭建arm64 ubuntu 环境
1. 下载 QEMU: https://qemu.weilnetz.de/w64/ QEMU UEFI固件文件: https://releases.linaro.org/components/kernel/uefi-linaro/latest/release/qemu64/QEMU_EFI.fd arm64 Ubuntu镜像: http://cdimage.ubuntu.com/releases/20.04.3/rel…...

NodeJS安装
一、简介Node.js是一个让JavaScript运行在服务端的开发平台,Node.js不是一种独立的语言,简单的说 Node.js 就是运行在服务端的 JavaScript。npm其实是Node.js的包管理工具(package manager),类似与 maven。二、安装步骤…...

Gin 优雅打印请求与回包内容
文章目录1.Gin 的 Middleware2.使用 Middleware 打印请求与回包内容3.多次读取请求 Body 的问题4.多次读取响应 Body 的问题5.小结参考文献在开发 Web 应用程序时,难免不会遇到功能或性能等问题。为了快速定位问题,需要打印请求和响应的内容。本文将介绍…...

关于k8s中ETCD集群备份灾难恢复的一些笔记
写在前面 集群电源不稳定,或者节点动不动就 宕机,一定要做好备份,ETCD 的快照文件很容易受影响损坏。重置了很多次集群,才认识到备份的重要博文内容涉及 etcd 运维基础知识了解静态 Pod 方式 etcd 集群灾备与恢复 Demo定时备份的任务编写二进…...

【设计模式之美 设计原则与思想:设计原则】19 | 理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
关于 SOLID 原则,我们已经学过单一职责、开闭、里式替换、接口隔离这四个原则。今天,我们再来学习最后一个原则:依赖反转原则。在前面几节课中,我们讲到,单一职责原则和开闭原则的原理比较简单,但是&#x…...

2023年全国最新高校辅导员精选真题及答案13
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题 131.下列不属于我国国土空间具有的特点的是() A.水资…...

【XXL-JOB】XXL-JOB定时处理视频转码
【XXL-JOB】XXL-JOB定时处理视频转码 文章目录【XXL-JOB】XXL-JOB定时处理视频转码1. 准备工作1.1 高级配置1.2 分片广播2. 需求分析2.1 作业分片方案2.2 保证任务不重复执行2.2.1 保证幂等性3. 视频处理业务流程3.1 添加待处理任务3.2 查询待处理任务3.3 更新任务状态3.4 工具…...

optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录0. 背景:why optuna0.1 插播一个简单的grid search0.2 参考1. Optuna1.1 a basic demo与部分参数释义1.2 random的问题1.3 Objective方法类2. Optuna与grid search4. optuna的剪枝prune5. optuna与可视化6. 未完待续0. 背景:why optuna 小模型参…...

语法篇--汇编语言先导浅尝
一、相关概念 1.机器语言 机器语言(Machine Language)是一种计算机程序语言,由二进制代码(0和1)组成,可被计算机直接执行。机器语言是计算机硬件能够理解和执行的唯一语言。 机器语言通常由一系列的指令组…...

【ID:17】【20分】A. DS顺序表--类实现
时间限制1秒内存限制128兆字节题目描述用C语言和类实现顺序表属性包括:数组、实际长度、最大长度(设定为1000)操作包括:创建、插入、删除、查找类定义参考输入第1行先输入n表示有n个数据,即n是实际长度;接着输入n个数据…...
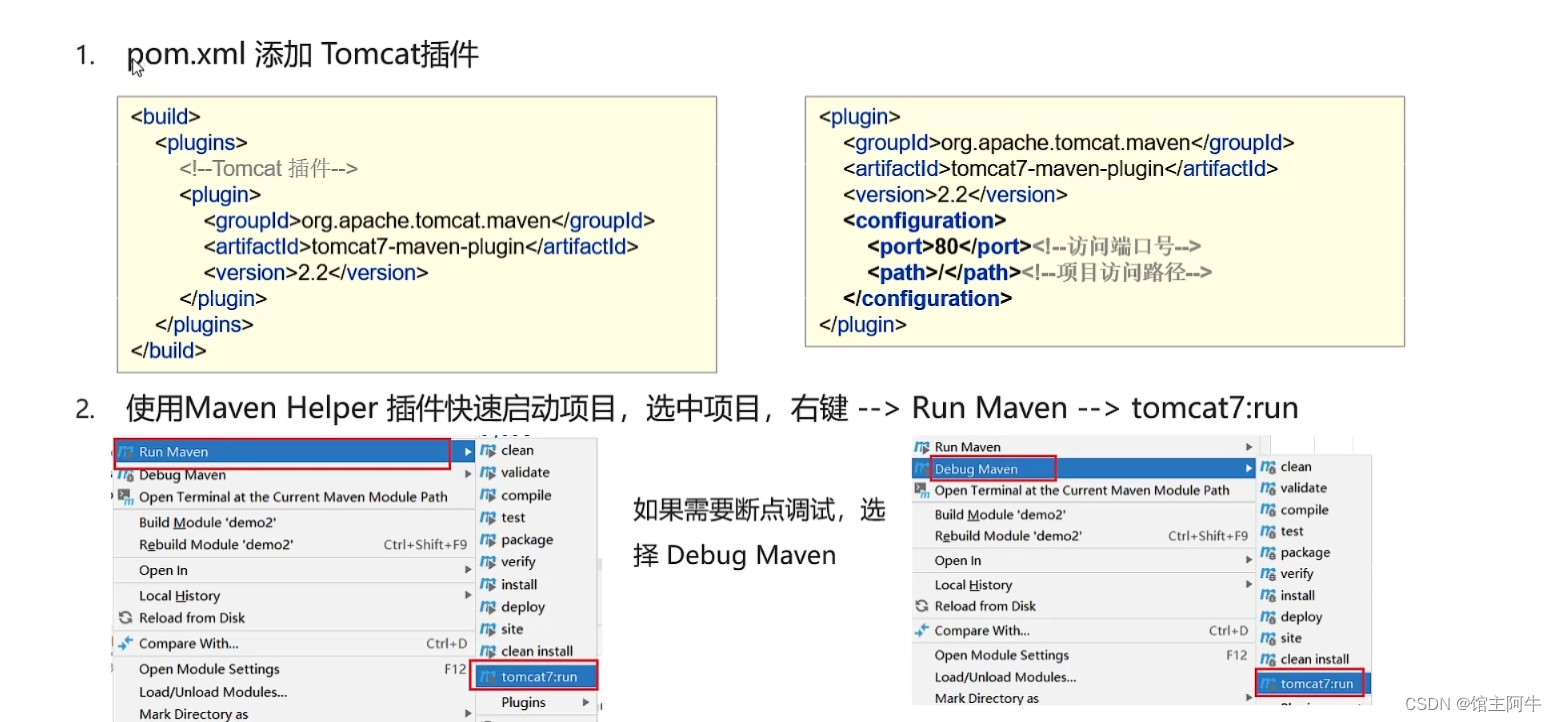
【java web篇】Tomcat的基本使用
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

MySQL实战解析底层---行锁功过:怎么减少行锁对性能的影响
目录 前言 从两阶段锁说起 死锁和死锁检测 前言 MySQL 的行锁是在引擎层由各个引擎自己实现的但并不是所有的引擎都支持行锁,比如MyISAM 引擎就不支持行锁不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有…...
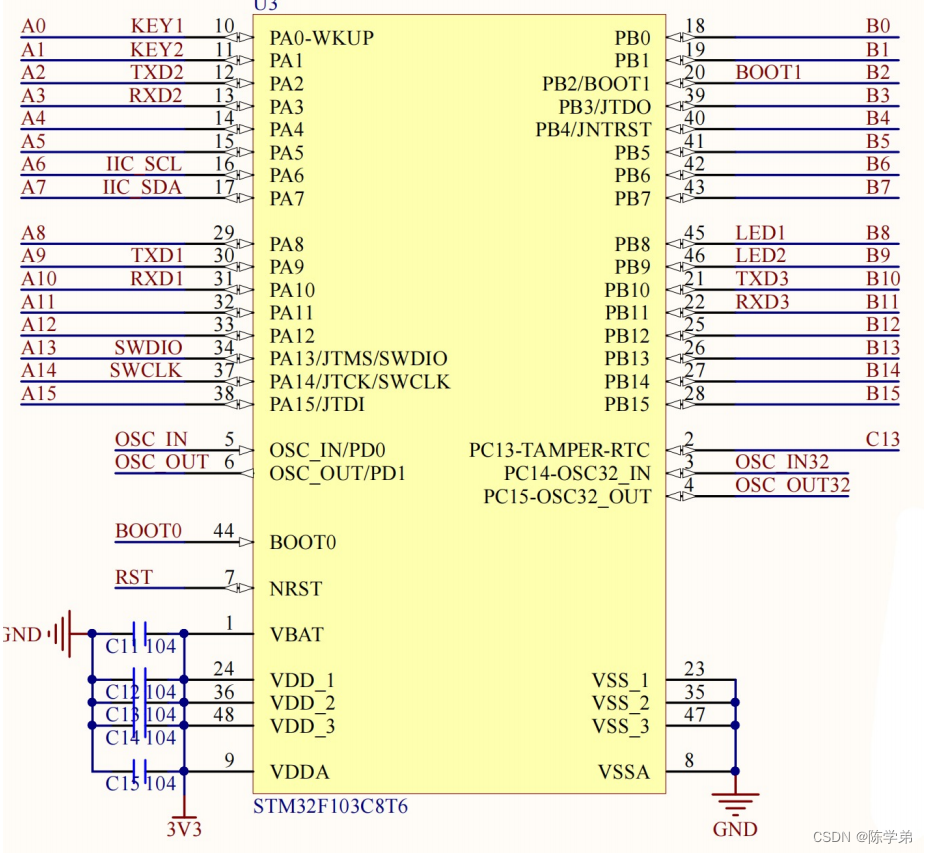
初识STM32单片机
目录 初识STM32单片机 什么是单片机? STM系列单片机命名规则 STM32F103C8T6单片机简介 标准库与HAL库区别 通用输入输出端口GPIO 什么是GPIO? 定义 命名规则 内部框架图 推挽输出与开漏输出 如何点亮一颗LED灯 编程实现点灯 按键点亮LED灯…...

BGP路由优化实战:加速收敛,提升网络稳定性
BGP路由优化实战:加速收敛,提升网络稳定性在复杂的网络环境中,尤其是在大规模数据中心或跨区域互联的网络中,BGP(Border Gateway Protocol)路由协议的性能直接影响着网络的可用性和用户体验。BGP 作为互联网…...

BGE-Reranker-v2-m3企业部署:高并发请求压力测试案例
BGE-Reranker-v2-m3企业部署:高并发请求压力测试案例 1. 项目背景与价值 在企业级RAG(检索增强生成)系统中,检索精度直接影响最终的回答质量。传统向量检索虽然快速,但容易受到关键词相似性的干扰,返回大…...

【系统分析师_知识点整理】 8.项目管理
核心考向:进度管理(计算 选择最高频):关键路径、ES/EF/LS/LF、总浮动时间、自由浮动时间、PDM 四种依赖、进度偏差分析;范围管理:WBS、范围确认、范围控制、范围边界定义;成本管理:…...

别再手动发卡了!2025新版ZFAKA搭配宝塔面板,30分钟搞定你的专属自动售卡站
2025年ZFAKA自动售卡系统:零基础30分钟搭建全攻略 在数字商品交易日益火爆的今天,手动处理订单不仅效率低下,还容易出错。想象一下凌晨三点被订单提醒吵醒,手忙脚乱地复制卡密发给买家——这种场景对于个体创业者来说再熟悉不过了…...

从微信聊天到在线游戏:聊聊UDP和TCP在你手机App里的那些‘小心思’
从微信聊天到在线游戏:聊聊UDP和TCP在你手机App里的那些‘小心思’ 每天我们都在用手机App聊天、打游戏、看视频,但很少有人注意到这些应用背后隐藏的网络协议选择。为什么微信文字消息总能准确送达,而语音通话偶尔会断断续续?为…...

情感漏洞经纪:倒卖AI崩溃瞬间年入百万
新兴暴利职业的崛起在人工智能技术高速发展的今天,一种名为“情感漏洞经纪”的灰色产业悄然兴起,从业者通过倒卖AI系统崩溃瞬间的数据年入百万。这些经纪人专门捕捉AI模型在情感交互中的故障时刻——如系统宕机前的“遗言”、未完成的情感回应或异常输出…...
)
Python实战:5分钟搞定睿尔曼机械臂与AGV底盘的Socket通信(附完整代码)
Python实战:5分钟搞定睿尔曼机械臂与AGV底盘的Socket通信(附完整代码) 在工业自动化领域,复合机器人正逐渐成为提升生产效率的关键设备。这类机器人通常由AGV(自动导引运输车)底盘和机械臂组成,…...

比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程
比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程 1. 前言:为什么选择比迪丽WebUI? 如果你对《龙珠》里的比迪丽(Videl)这个角色情有独钟,想用AI画出她的各种形象,那么今天这个教程就…...
)
KEITHLEY 6221+2182A组合在霍尔测量中的5个实战技巧(避坑指南)
KEITHLEY 62212182A组合在霍尔测量中的5个实战技巧(避坑指南) 霍尔测量作为材料科学研究中的关键手段,对仪器精度和操作细节的要求近乎苛刻。KEITHLEY 6221电流源与2182A纳伏表的组合,凭借其出色的低噪声性能和微电流处理能力&…...

OWL ADVENTURE编辑功能展示:一键换装、智能擦除,效果自然
OWL ADVENTURE编辑功能展示:一键换装、智能擦除,效果自然 1. 编辑功能概览:像玩游戏一样修图 OWL ADVENTURE的图片编辑功能让人眼前一亮。不同于传统修图软件的复杂操作,它通过自然语言指令就能完成各种编辑任务,效果…...