python版协同过滤算法图书管理系统
基于协同过滤算法的图书管理系统

一、简介(v信:1257309054)
本系统基于推荐算法给用户实现精准推荐图书。
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐,种被称为基于协同过滤的推荐。
本系统使用了三种推荐算法:基于用户的协同过滤算法、基于物品的协同过滤算法、基于机器学习k-means聚类的过滤算法,以及三种算法的混合推荐算法。
主要功能如下图:

二、使用到的技术
开发语言是python3.7,框架是Django3.0,采用的是djanog前后端相结合的技术,后台管理系统是xadmin,数据库是Mysql5.7。
1、Django的MTV架构
所谓MTV就是:数据模型(M)-前端界面(T)-调度控制器(V).
用户在浏览器发起一个请求:通过V对M和T进行连接,用户通过T(界面)对服务器进行访问(发送请求),T把请求传给V(调度),V调用M(数据模型)获取数据,把数据给模板T进行渲染,然后再把渲染后的模板返回给用户。
MTV框架是一种 把业务逻辑、数据、界面显示分离而设计创建的Web应用程序的开发模式。在web开发中应该尽量使代码高内聚低耦合,这样利于代码复用、维护、管理,MTV框架就是这样分层的。
M对应于Model,即数据模型(数据层),用于管理数据库,对数据进行增删改查;
T对应于视图,template(即T),模板,用于管理html文件,呈现给用户的界面;
V对应于控制层,views(即V),视图调度器,用于访问数据层,获取数据,把数据调度给模板进行渲染,把渲染的结果返回给客户端。
MTV框架的大体流程是:
1、客户端发起请求,路由对客户发起的请求进行统一处理和分发给控制层;
2、控制层获取请求,访问数据层;
3、数据层对数据进行增删改查,把数据返回给控制层;
4、控制层获取数据,把数据调度给视图(模板);
5、视图(模板)对数据进行渲染,形成html文件返回给控制层;
6、控制层把渲染后的视图(模板)返回给客户端。
三、开发流程
1、环境搭建:创建虚拟环境、创建数据库
2、创建数据库模型:用户表、图书标签表、用户选择类型表(用户解决推荐算法冷启动问题)、借书清单表、购书清单表、评分表、收藏表、点赞表、评论表、推荐反馈表。然后数据迁移,把表映射到数据库中。
3、爬取数据,然后把数据经过预处理存放到数据库中。
4、编写用户界面框架,完成各种功能点击响应事件
5、编写后台管理文件,管理数据。
6、系统测试,检验完成的功能。
具体开发过程可以查看【开发文档.pdf】
四、主要功能
1、前台用户
启动项目后,浏览器输入127.0.0.1:8000即可打开前端界面。
登录注册、修改密码、搜索、全部书籍、点赞收藏、评论评分、新书速递、热门书籍、图书分类、猜你喜欢、借阅书籍、购买书籍、购物车、个人中心。
1.1、注册界面

支付密码用于用户在购买书籍时模拟支付场景。
1.2、登录界面

1.3、全部书籍界面

书籍按照浏览量进行排序。
点击图片可以进去查看具体的书籍内容。
用户可以通过标题、作者进行搜索相关图书。
1.4、具体书籍

具体书籍界面有书籍的封面、标题、作者、简介、评分信息、点赞、收藏信息、评论信息。低下还有推荐的三本图书。
1.5、新书速递
按照图书上架时间返回书籍。
1.6、热门书籍
按照收藏图书人数返回书籍。
1.7、图书分类

根据不同的标签过滤显示该类型书籍。
1.8、猜你喜欢
猜你喜欢是根据用户推荐不同的书籍。
用户A刚注册登录时,由于用户A没有对书籍进行过评分,无法与其他用户、图书产生联系,所以只推荐用户A注册时选择的喜欢类型的图书。
当用户A对图书进行评分后,后台会根据余弦相似度计算出跟该用户最相似的用户B,然后把推荐的用户B喜欢的图书推荐给用户A。
1.9、借阅书籍

用户可以在平台上进行图书借阅,可以立即取走,也可以填写收货地址、电话号码进行邮寄。用户需要在规定的时间内归还,如果预期则扣除信誉值,当信誉值为0时将无法进行图书借阅。
1.20、购买书籍、购物车

用户可以购买书籍并立即取走,也可添加到购物车,也可进行邮寄,填写地址、电话、支付密码模拟支付后即可。
1.21、个人中心

可以修改密码、修改喜欢的图书类型、查看我的借阅、点赞、收藏、评论、评分。
2、后台管理
启动项目后,浏览器输入127.0.0.1:8000\xadmin可打开后台界面。

可以通过后台管理数据:上架借阅书籍、购买书籍、物流发货等。
五、算法说明
1、基于用户协同过滤推荐算法
基于用户的协同过滤算法:就是把和你相似的用户喜欢的东西推荐给你。
协同过滤:利用用户的群体行为来计算用户的相关性。计算用户相关性的时候我们就是通过对比他们对相同物品打分的相关度来计算的
举例:
--------+--------+--------+--------+--------+| X | Y | Z | R |
--------+--------+--------+--------+--------+a | 5 | 4 | 1 | 5 |
--------+--------+--------+--------+--------+b | 4 | 3 | 1 | ? |
--------+--------+--------+--------+--------+c | 2 | 2 | 5 | 1 |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了4分,给Z打了1分
b用户给X物品打了4分,给Y打了3分,给Z打了1分
c用户给X物品打了2分,给Y打了2分,给Z打了5分
那么很容易看到a用户和b用户非常相似,但是b用户没有看过R物品,那么我们就可以把和b用户很相似的a用户打分很高的R物品推荐给b用户,这就是基于用户的协同过滤。
相关性
基于用户的协同过滤需要比较用户间的相关性,那么如何计算这个相关性呢?
我们可以利用两个用户对于相同物品的评分来计算相关性。
对于a,b用户而言,他们都对XYZ物品进行了评价,那么,a我们可以表示为(5,4,1),b可以表示为(4,3,1),经典的算法是把他们看作是两个向量,并计算两个向量间的夹角,或者说计算向量夹角的cosine值来比较,于是a和b的相关性为:

这个值介于-1到1之间,越大,说明相关性越大。
皮尔逊相关系数
到这里似乎cosine还是不错的,但是考虑这么个问题,用于用户间的差异,d用户可能喜欢打高分,e用户喜欢打低分,f用户喜欢乱打分。
--------+--------+--------+--------+| X | Y | Z |
--------+--------+--------+--------+d | 4 | 4 | 5 |
--------+--------+--------+--------+e | 1 | 1 | 2 |
--------+--------+--------+--------+f | 4 | 1 | 5 |
--------+--------+--------+--------+
很显然用户d和e对于作品评价的趋势是一样的,所以应该认为d和e更相似,但是用cosine计算出来的只能是d和f更相似。于是就有皮尔逊相关系数(pearson correlation coefficient)。

pearson其实做的事情就是先把两个向量都减去他们的平均值,然后再计算cosine值。
等价公式:

其中E是数学期望,N表示变量取值的个数。
示例代码传送门
2、基于物品协同过滤推荐算法
2.1、基于⽤户的协同过滤算法(UserCF)
该算法利⽤⽤户之间的相似性来推荐⽤户感兴趣的信息,个⼈通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的⽬的进⽽帮助别⼈筛选信息,回应不⼀定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
但两个问题,⼀个是稀疏性,即在系统使⽤初期由于系统资源还未获得⾜够多的评价,很难利⽤这些评价来发现相似的⽤户。
另⼀个是可扩展性,随着系统⽤户和资源的增多,系统的性能会越来越差。
算法讲解传送门
2.2、基于物品的协同过滤算法(ItemCF)
内容过滤根据信息资源与⽤户兴趣的相似性来推荐商品,通过计算⽤户兴趣模型和商品特征向量之间的向量相似性,主动将相似度⾼的商品发送给该模型的客户。
由于每个客户都独⽴操作,拥有独⽴的特征向量,不需要考虑别的⽤户的兴趣,不存在评价级别多少的问题,能推荐新的项⽬或者是冷门的项⽬。
这些优点使得基于内容过滤的推荐系统不受冷启动和稀疏问题的影响。
2.3、算法核心
通过分析用户行为记录(评分、购买、点击、浏览等行为)来计算两个物品的相似度,同时喜欢物品A和物品B的用户数越多,就认为物品A和物品B越相似。
2.4、流程
1.构建⽤户–>物品的对应表
2.构建物品与物品的关系矩阵(同现矩阵)
3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵
4.根据⽤户的历史记录,给⽤户推荐物品
2.5、构建用户与物品的对应关系表
如下表,⾏表⽰⽤户,列表⽰物品(电影),数字表⽰⽤户喜欢该物品的程度(评分)
| 用户\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| A | 5 | 1 | 2 | |||
| B | 4 | 2 | 3.5 | |||
| C | 2 | 4 | ||||
| D | 4 | 3 | ||||
| E | 4 | 3 |
2.6、构建物品与物品的关系矩阵(共现矩阵)
共现矩阵C表⽰同时喜欢两个物品的⽤户数,是根据⽤户物品对应关系表计算出来的。
如根据上⾯的⽤户物品关系表可以计算出如下的共现矩阵C:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| 唐伯虎点秋香 | 1 | 1 | 1 | 1 | ||
| 逃学威龙1 | 1 | 1 | 2 | |||
| 追龙 | 1 | 1 | ||||
| 他人笑我太疯癫 | 2 | |||||
| 喜欢你 | 1 | 2 | ||||
| 暗战 | 1 | 2 |
2.7、计算相似矩阵
两个物品之间的相似度如何计算?
设|N(i)|表⽰喜欢物品i的⽤户数,|N(i)⋂N(j)|表⽰同时喜欢物品i,j的⽤户数,则物品i与物品j的相似度为:

利用公式计算物品之间的余弦相似矩阵如下:
| 电影\电影 | 唐伯虎点秋香 | 逃学威龙1 | 追龙 | 他人笑我太疯癫 | 喜欢你 | 暗战 |
|---|---|---|---|---|---|---|
| 唐伯虎点秋香 | 0.41 | 0.7 | 0.5 | 0.5 | ||
| 逃学威龙1 | 0.41 | 0.58 | 0.82 | |||
| 追龙 | 0.71 | 0.58 | ||||
| 他人笑我太疯癫 | 0.82 | |||||
| 喜欢你 | 0.5 | 1.0 | ||||
| 暗战 | 0.5 | 1.0 |
2.8、给用户推荐物品
根据⽤户的历史记录,给⽤户推荐物品。
最终推荐的是什么物品,是由预测兴趣度决定的。
物品j预测兴趣度=⽤户喜欢的物品i的兴趣度×物品i和物品j的相似度
例如:A⽤户喜欢唐伯虎点秋香,逃学威龙1,追龙 ,兴趣度分别为5,1,2
在用户A的评分电影列表中只有唐伯虎点秋香与喜欢你有相似度,推荐喜欢你的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有唐伯虎点秋香与暗战有相似度,推荐暗战的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有逃学威龙1与他人笑我太疯癫有相似度,推荐他人笑我太疯癫的预测兴趣度=1 x 0.82 =0.82
3、基于机器学习K-means聚类推荐算法
原理:
从数据库中
1、首先获取书籍类别
2、获取用户注册时勾选喜欢的类别,勾选的为1,否则为0,得到一个样本数据
例:[1,0,1,0,0,...],[1,1,1,0,1,...],[0,0,1,0,0,...],
3、使用k-mean算法把用户分成6类【用户模型】
4、获取6类的【用户模型】的质心,比如[1,0,1,0,0,...]
把为1的类别找出来,然后获取该类别排行前3的书籍,组成一个推荐列表推荐给用户
5、类别书籍排行按收藏量来排序
6、用户购买书籍行为会动态更新样本数据
示例代码
六、程序文件说明

book是子应用名称,migrations是数据迁移文件,把数据模型映射到数据库中,templatetags是定义界面模板语法,__init__.py是导包文件,adminx.py存放的是后台管理代码,apps.py是子应用说明,forms.py是登录注册表单定义,models.py是数据模型,test.py是测试文件,urls.py是路由表,views.py是控制层调度器。
book_manager是项目应用管理起始文件夹,settings.py是项目数据库,静态文件等配置,urls.py是总路由表。
media保存的是媒体文件。
static保存的是界面的静态文件:css,html,js,图片等。
template保存的是前端界面模板代码。
book-k-mean.dat是k-means聚类后的模型。
manage.py是项目启动管理器。
recommend_books.py是推荐算法代码。
requirements.txt保存的是第三方库文件。
spider_get_data.py是爬虫代码。
七、数据库表说明
数据库表如下:

auth_group、auth_group_permissions、auth_permissions是后台管理的组、权限表。
auth_user、auth_user_group、auth_user_groups、auth_user_user_permissions是后台管理用户数据表。
book是图书表。
book_tags是图书标签表。
borrow_list是图书借阅表。
collect_book是图书收藏表。
comment_book是图书评论表。
django_admin_log是原始后台管理日志表。
django_content_type是django应用内容表。
django_migrations是数据迁移文件表。
django_session是django缓存表。
like_book是图书点赞表。
like_recommend_book是图书推荐反馈表。
purchase_list是购物车表
rate_book是评分表。
tags是图书标签表。
user是用户表。
user_select_types是用户注册时选择喜欢的图书类型表。
user_select_types_category是一个多对多表,存放的是图书标签id与user_select_types表id的对应关系。
xadmin_bookmark是是后台管理的标签表。
xadmin_log是后台管理操作日志表。
xadmin_usersettings是后台管理用户设置表。
xadmin_userwidget是后台管理小组件表。
用内容表。
django_migrations是数据迁移文件表。
django_session是django缓存表。
like_book是图书点赞表。
like_recommend_book是图书推荐反馈表。
purchase_list是购物车表
rate_book是评分表。
tags是图书标签表。
user是用户表。
user_select_types是用户注册时选择喜欢的图书类型表。
user_select_types_category是一个多对多表,存放的是图书标签id与user_select_types表id的对应关系。
xadmin_bookmark是是后台管理的标签表。
xadmin_log是后台管理操作日志表。
xadmin_usersettings是后台管理用户设置表。
xadmin_userwidget是后台管理小组件表。
相关文章:
python版协同过滤算法图书管理系统
基于协同过滤算法的图书管理系统 一、简介(v信:1257309054) 本系统基于推荐算法给用户实现精准推荐图书。 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然…...
Redis基础入门
文章目录前言一、redis是什么?二、安装步骤1.下载安装包2.安装三、Redis的数据类型redis是一种高级的key-value的存储系统,其中的key是字符串类型,尽可能满足如下几点:字符串(String)列表(List)集合(Set,不允许出现重复…...

【微服务】Feign实现远程调用和负载均衡
目录 1.什么是Feign 2 订单微服务集成Feign 2.1.引入依赖 2.2添加注解 2.3编写Feign的客户端 2.4修改OrderServiceImpl.java的远程调用方法 2.5重启订单服务,并验证 总结 1.什么是Feign Feign是Spring Cloud提供的⼀个声明式的伪Http客户端, 它…...

Windows使用QEMU搭建arm64 ubuntu 环境
1. 下载 QEMU: https://qemu.weilnetz.de/w64/ QEMU UEFI固件文件: https://releases.linaro.org/components/kernel/uefi-linaro/latest/release/qemu64/QEMU_EFI.fd arm64 Ubuntu镜像: http://cdimage.ubuntu.com/releases/20.04.3/rel…...

NodeJS安装
一、简介Node.js是一个让JavaScript运行在服务端的开发平台,Node.js不是一种独立的语言,简单的说 Node.js 就是运行在服务端的 JavaScript。npm其实是Node.js的包管理工具(package manager),类似与 maven。二、安装步骤…...

Gin 优雅打印请求与回包内容
文章目录1.Gin 的 Middleware2.使用 Middleware 打印请求与回包内容3.多次读取请求 Body 的问题4.多次读取响应 Body 的问题5.小结参考文献在开发 Web 应用程序时,难免不会遇到功能或性能等问题。为了快速定位问题,需要打印请求和响应的内容。本文将介绍…...

关于k8s中ETCD集群备份灾难恢复的一些笔记
写在前面 集群电源不稳定,或者节点动不动就 宕机,一定要做好备份,ETCD 的快照文件很容易受影响损坏。重置了很多次集群,才认识到备份的重要博文内容涉及 etcd 运维基础知识了解静态 Pod 方式 etcd 集群灾备与恢复 Demo定时备份的任务编写二进…...

【设计模式之美 设计原则与思想:设计原则】19 | 理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
关于 SOLID 原则,我们已经学过单一职责、开闭、里式替换、接口隔离这四个原则。今天,我们再来学习最后一个原则:依赖反转原则。在前面几节课中,我们讲到,单一职责原则和开闭原则的原理比较简单,但是&#x…...

2023年全国最新高校辅导员精选真题及答案13
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题 131.下列不属于我国国土空间具有的特点的是() A.水资…...

【XXL-JOB】XXL-JOB定时处理视频转码
【XXL-JOB】XXL-JOB定时处理视频转码 文章目录【XXL-JOB】XXL-JOB定时处理视频转码1. 准备工作1.1 高级配置1.2 分片广播2. 需求分析2.1 作业分片方案2.2 保证任务不重复执行2.2.1 保证幂等性3. 视频处理业务流程3.1 添加待处理任务3.2 查询待处理任务3.3 更新任务状态3.4 工具…...

optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录0. 背景:why optuna0.1 插播一个简单的grid search0.2 参考1. Optuna1.1 a basic demo与部分参数释义1.2 random的问题1.3 Objective方法类2. Optuna与grid search4. optuna的剪枝prune5. optuna与可视化6. 未完待续0. 背景:why optuna 小模型参…...

语法篇--汇编语言先导浅尝
一、相关概念 1.机器语言 机器语言(Machine Language)是一种计算机程序语言,由二进制代码(0和1)组成,可被计算机直接执行。机器语言是计算机硬件能够理解和执行的唯一语言。 机器语言通常由一系列的指令组…...

【ID:17】【20分】A. DS顺序表--类实现
时间限制1秒内存限制128兆字节题目描述用C语言和类实现顺序表属性包括:数组、实际长度、最大长度(设定为1000)操作包括:创建、插入、删除、查找类定义参考输入第1行先输入n表示有n个数据,即n是实际长度;接着输入n个数据…...
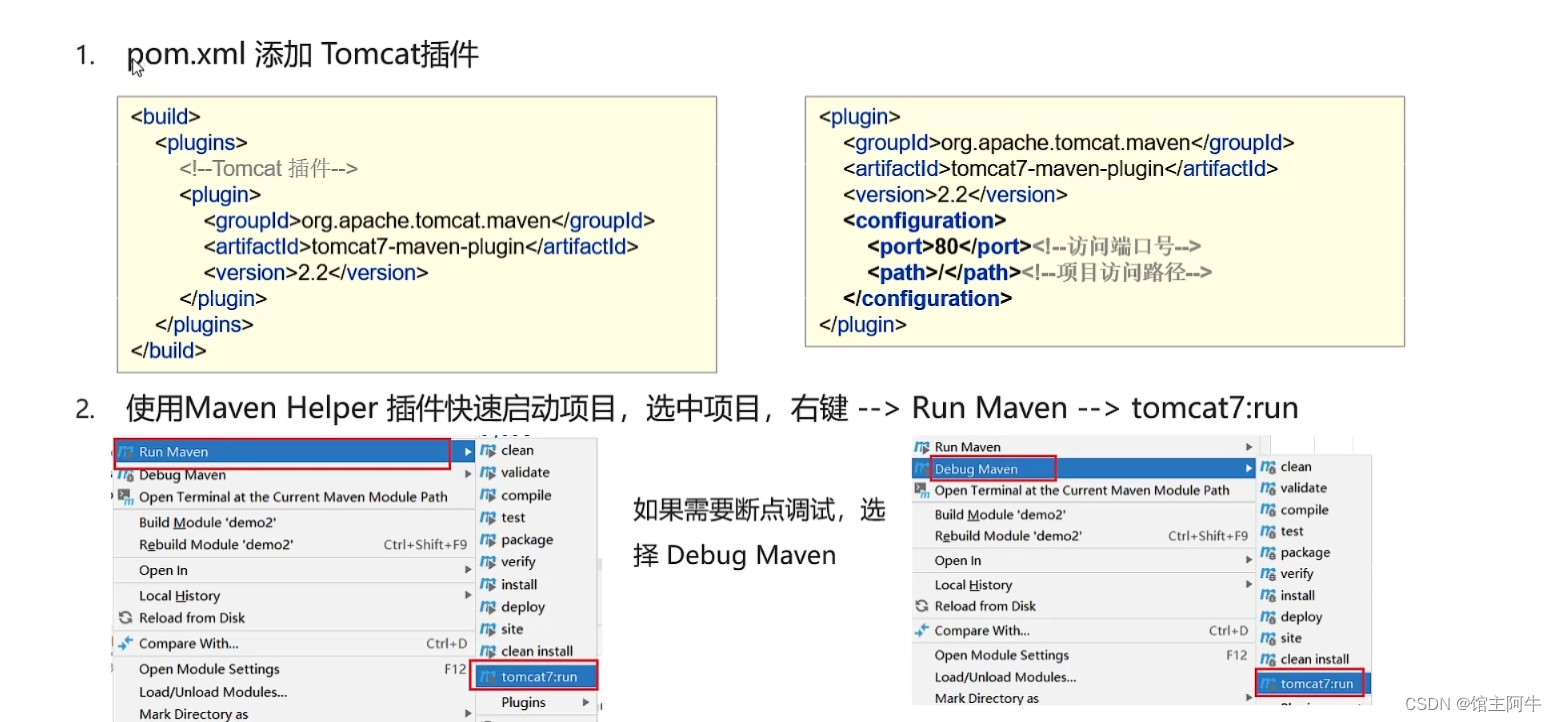
【java web篇】Tomcat的基本使用
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

MySQL实战解析底层---行锁功过:怎么减少行锁对性能的影响
目录 前言 从两阶段锁说起 死锁和死锁检测 前言 MySQL 的行锁是在引擎层由各个引擎自己实现的但并不是所有的引擎都支持行锁,比如MyISAM 引擎就不支持行锁不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有…...
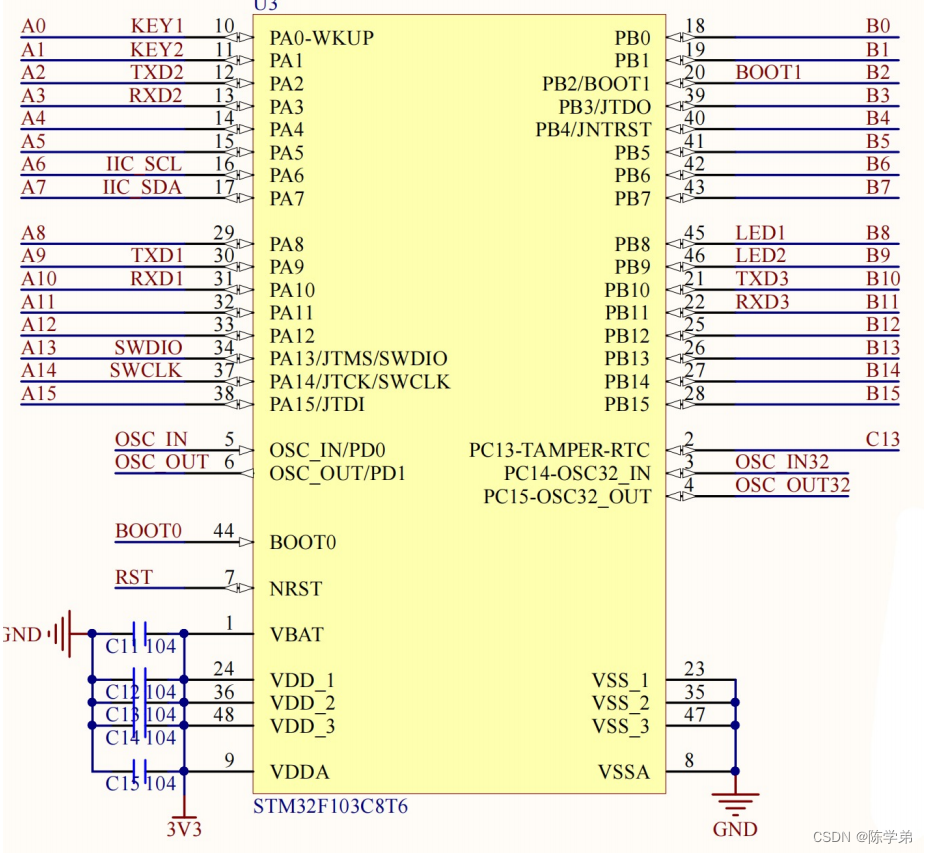
初识STM32单片机
目录 初识STM32单片机 什么是单片机? STM系列单片机命名规则 STM32F103C8T6单片机简介 标准库与HAL库区别 通用输入输出端口GPIO 什么是GPIO? 定义 命名规则 内部框架图 推挽输出与开漏输出 如何点亮一颗LED灯 编程实现点灯 按键点亮LED灯…...

数据结构与算法系列之单链表
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 这里写目录标题test.hSList.h注意事项一级指针与二级指针的使用assert的使用空…...

MySQL基础
本单元目标 一、为什么要学习数据库 二、数据库的相关概念 DBMS、DB、SQL 三、数据库存储数据的特点 四、初始MySQL MySQL产品的介绍 MySQL产品的安装 ★ MySQL服务的启动和停止 ★ MySQL服务的登录和退出 ★ MySQL的常见命令和语法规范 五、…...

面试热点题:环形链表及环形链表寻找环入口结点问题
环形链表 问题: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接…...

【算法】DFS与BFS
作者:指针不指南吗 专栏:算法篇 🐾题目的模拟很重要!!🐾 文章目录1.区别2.DFS2.1 排列数字2.2 n-皇后问题3.BFS3.1走迷宫1.区别 搜索类型数据结构空间用途过程DFSstackO( n )不能用于最短路搜索到最深处&a…...

六种强鲁棒性永磁同步电机Simulink仿真模型:开启深度探索之旅
六种强鲁棒性永磁同步电机simulink仿真模型(在线参数辩识和扰动观测器) 共包含六个PMSM强鲁棒性(抗模型失配)仿真模型,有助于对比学习: 1.经典的无差预测控制参数失配模型 2.在线参数辩识: 最小…...

KinhDown:突破百度网盘限速的效率革命
KinhDown:突破百度网盘限速的效率革命 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 在数字化时代,云存储已成为我们工作与生活中不可或缺的一部分。然而,百度网盘对免费用户实施的严格限…...

如何绕过App Store限制:iOS第三方应用安装的终极指南
如何绕过App Store限制:iOS第三方应用安装的终极指南 【免费下载链接】AltStore AltStore is an alternative app store for non-jailbroken iOS devices. 项目地址: https://gitcode.com/gh_mirrors/al/AltStore 还在为苹果App Store的严格限制而烦恼吗&…...

如何快速实现单图像3D重建:TripoSR完整实战指南
如何快速实现单图像3D重建:TripoSR完整实战指南 【免费下载链接】TripoSR 项目地址: https://gitcode.com/GitHub_Trending/tr/TripoSR 想要从一张普通图片快速生成逼真的3D模型吗?TripoSR正是你需要的终极解决方案!这个革命性的开源…...

Nacos 2.2.0连接达梦数据库踩坑实录:从驱动版本到SQL脚本的完整避坑指南
Nacos 2.2.0与达梦数据库深度适配实战:从驱动选型到容器化部署的全链路解析 当微服务架构遇上国产数据库,技术适配的每个环节都可能成为关键战场。最近在将Nacos 2.2.0与达梦数据库进行生产级适配时,我经历了从驱动版本冲突到SQL脚本优化的完…...

Celery 入门与原理剖析:从使用到理解
在现代 Web 应用和后台系统中,异步任务处理是提升系统响应速度、解耦业务逻辑的关键技术。Celery 作为 Python 生态中最流行的分布式任务队列框架,因其简洁的 API 和强大的功能被广泛采用。本文将分为两部分:首先演示如何基于 Redis 快速上手…...

为什么你的USB摄像头总掉帧?深入UVC协议Alternate Setting配置避坑指南
为什么你的USB摄像头总掉帧?深入UVC协议Alternate Setting配置避坑指南 工业视觉检测线上,一台标称30fps的USB摄像头突然掉到15帧,导致传送带上的缺陷品漏检;手术内窥镜画面在关键时刻出现卡顿,医生不得不暂停操作——…...
)
别再死记公式了!用Python的SymPy库5分钟搞定雅可比矩阵计算(附机器人学实例)
用SymPy解放双手:5分钟完成雅可比矩阵的符号计算与机器人学应用 记得研究生时期推导机械臂动力学方程,我曾在草稿纸上密密麻麻写满三页偏导数,最后发现一个正负号错误导致全部重算。直到遇见SymPy——这个Python符号计算库彻底改变了我的工作…...

西电B测:基于SystemView的2PSK调制解调全流程仿真解析
1. 2PSK通信系统仿真入门指南 第一次接触SystemView做2PSK仿真时,我也被满屏的波形和参数搞得头晕。后来发现只要抓住几个关键点,这个实验其实比想象中简单得多。2PSK(二进制相移键控)是数字通信中最基础的调制方式之一ÿ…...

Pandas API on Spark 配置选项系统、默认索引与性能调优
1. 什么是 Pandas API on Spark 的选项系统 Pandas API on Spark 提供了一个选项系统,用来定制运行时行为。最常见的是显示类选项,比如控制最大展示行数,但它也支持影响计算行为、索引生成方式、绘图后端等。选项名采用“点式命名”ÿ…...