关于k8s中ETCD集群备份灾难恢复的一些笔记
写在前面
- 集群电源不稳定,或者节点动不动就 宕机,一定要做好备份,
ETCD的快照文件很容易受影响损坏。 - 重置了很多次集群,才认识到备份的重要
- 博文内容涉及
- etcd 运维基础知识了解
- 静态 Pod 方式 etcd 集群灾备与恢复 Demo
- 定时备份的任务编写
- 二进制 etcd 集群灾备恢复 Demo
- 理解不足小伙伴帮忙指正
我所渴求的,無非是將心中脫穎語出的本性付諸生活,為何竟如此艱難呢 ------赫尔曼·黑塞《德米安》
etcd 概述
etcd 是 CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。
etcd 内部采用 raft 协议作为一致性算法,etcd基于Go语言实现。
完全复制:集群中的每个节点都可以使用完整的存档高可用性:Etcd可用于避免硬件的单点故障或网络问题一致性:每次读取都会返回跨多主机的最新写入简单:包括一个定义良好、面向用户的API(gRPC)安全:实现了带有可选的客户端证书身份验证的自动化TLS快速:每秒10000次写入的基准速度可靠:使用Raft算法实现了强一致、高可用的服务存储目录
ETCD 集群运维相关的基本知识:
- 读写端口为:
2379, 数据同步端口:2380 ETCD集群是一个分布式系统,使用Raft协议来维护集群内各个节点状态的一致性。- 主机状态
Leader,Follower,Candidate - 当集群初始化时候,每个节点都是
Follower角色,通过心跳与其他节点同步数据 - 通过
Follower读取数据,通过Leader写入数据 - 当
Follower在一定时间内没有收到来自主节点的心跳,会将自己角色改变为Candidate,并发起一次选主投票 - 配置etcd集群,建议尽可能是
奇数个节点,而不要偶数个节点,推荐的数量为 3、5 或者 7 个节点构成一个集群。 - 使用 etcd 的内置备份/恢复工具从源部署备份数据并在新部署中恢复数据。恢复前需要清理数据目录
- 数据目录下
snap: 存放快照数据,etcd防止WAL文件过多而设置的快照,存储etcd数据状态。 - 数据目录下
wal: 存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中。 - 一个 etcd 集群可能不应超过七个节点,写入性能会受影响,建议运行五个节点。一个 5 成员的 etcd 集群可以容忍两个成员故障,三个成员可以容忍1个故障。
常用配置参数:
ETCD_NAME节点名称,默认为defaulETCD_DATA_DIR服务运行数据保存的路ETCD_LISTEN_PEER_URLS监听的同伴通信的地址,比如http://ip:2380,如果有多个,使用逗号分隔。需要所有节点都能够访问,所以不要使用 localhostETCD_LISTEN_CLIENT_URLS监听的客户端服务地址ETCD_ADVERTISE_CLIENT_URLS对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点ETCD_INITIAL_ADVERTISE_PEER_URLS对外公告的该节点同伴监听地址,这个值会告诉集群中其他节ETCD_INITIAL_CLUSTER集群中所有节点的信息ETCD_INITIAL_CLUSTER_STATE新建集群的时候,这个值为new;假如加入已经存在的集群,这个值为existingETCD_INITIAL_CLUSTER_TOKEN集群的ID,多个集群的时候,每个集群的ID必须保持唯一
静态 Pod方式 集群备份恢复
单节点ETCD备份恢复
如果 etcd 为单节点部署,可以直接 物理备份,直接备份对应的数据文件目录即可,恢复 的话可以直接把备份的 etcd 数据目录复制到 etcd 指定的目录。恢复完成需要恢复 /etc/kubernetes/manifests 内 etcd.yaml 文件原来的状态。
也可以基于快照进行备份
备份命令
┌──[root@vms81.liruilongs.github.io]-[/backup_20230127]
└─$ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" \--cert="/etc/kubernetes/pki/etcd/server.crt" \--key="/etc/kubernetes/pki/etcd/server.key" \--cacert="/etc/kubernetes/pki/etcd/ca.crt"
snapshot save snap-$(date +%Y%m%d%H%M).db
Snapshot saved at snap-202301272133.db
恢复命令
┌──[root@vms81.liruilongs.github.io]-[/backup_20230127]
└─$ETCDCTL_API=3 etcdctl snapshot restore ./snap-202301272133.db \--name vms81.liruilongs.github.io \--cert="/etc/kubernetes/pki/etcd/server.crt" \--key="/etc/kubernetes/pki/etcd/server.key" \--cacert="/etc/kubernetes/pki/etcd/ca.crt" \--initial-advertise-peer-urls=https://192.168.26.81:2380 \--initial-cluster="vms81.liruilongs.github.io=https://192.168.26.81:2380" \--data-dir=/var/lib/etcd
2023-01-27 21:40:01.193420 I | mvcc: restore compact to 484325
2023-01-27 21:40:01.199682 I | etcdserver/membership: added member cbf506fa2d16c7 [https://192.168.26.81:2380] to cluster 46c9df5da345274b
┌──[root@vms81.liruilongs.github.io]-[/backup_20230127]
└─$
具体对应的参数值,可以通过 etcd 静态 pod 的 yaml 文件获取
┌──[root@vms81.liruilongs.github.io]-[/var/lib/etcd/member]
└─$kubectl describe pods etcd-vms81.liruilongs.github.io | grep -e "--"--advertise-client-urls=https://192.168.26.81:2379--cert-file=/etc/kubernetes/pki/etcd/server.crt--client-cert-auth=true--data-dir=/var/lib/etcd--initial-advertise-peer-urls=https://192.168.26.81:2380--initial-cluster=vms81.liruilongs.github.io=https://192.168.26.81:2380--key-file=/etc/kubernetes/pki/etcd/server.key--listen-client-urls=https://127.0.0.1:2379,https://192.168.26.81:2379--listen-metrics-urls=http://127.0.0.1:2381--listen-peer-urls=https://192.168.26.81:2380--name=vms81.liruilongs.github.io--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt--peer-client-cert-auth=true--peer-key-file=/etc/kubernetes/pki/etcd/peer.key--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt--snapshot-count=10000--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
┌──[root@vms81.liruilongs.github.io]-[/var/lib/etcd/member]
└─$
集群ETCD备份恢复
集群节点状态
┌──[root@vms100.liruilongs.github.io]-[~/ansible/helm]
└─$ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" member list -w table
+------------------+---------+-----------------------------+-----------------------------+-----------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+-----------------------------+-----------------------------+-----------------------------+
| ee392e5273e89e2 | started | vms100.liruilongs.github.io | https://192.168.26.100:2380 | https://192.168.26.100:2379 |
| 11486647d7f3a17b | started | vms102.liruilongs.github.io | https://192.168.26.102:2380 | https://192.168.26.102:2379 |
| e00e3877df8f76f4 | started | vms101.liruilongs.github.io | https://192.168.26.101:2380 | https://192.168.26.101:2379 |
+------------------+---------+-----------------------------+-----------------------------+-----------------------------+
┌──[root@vms100.liruilongs.github.io]-[~/ansible/helm]
version 及 leader 信息。
┌──[root@vms100.liruilongs.github.io]-[~/ansible/kubescape]
└─$ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" endpoint status --cluster -w table
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.26.100:2379 | ee392e5273e89e2 | 3.5.4 | 37 MB | false | 100 | 3152364 |
| https://192.168.26.102:2379 | 11486647d7f3a17b | 3.5.4 | 36 MB | false | 100 | 3152364 |
| https://192.168.26.101:2379 | e00e3877df8f76f4 | 3.5.4 | 36 MB | true | 100 | 3152364 |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
┌──[root@vms100.liruilongs.github.io]-[~/ansible/kubescape]
└─$
集群情况下,备份可以单节点备份,前面我们也讲过,etcd 集群为完全复制,单节点备份
┌──[root@vms100.liruilongs.github.io]-[~]
└─$yum -y install etcd
没有 etcdctl 工具,需要安装一下 etcd 或者从其他的地方单独拷贝一下。这里我们安装下,然后把 etcetl 拷贝到其他集群节点。
备份
┌──[root@vms100.liruilongs.github.io]-[~]
└─$ENDPOINT=https://127.0.0.1:2379
┌──[root@vms100.liruilongs.github.io]-[~]
└─$ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot save snapshot.db
Snapshot saved at snapshot.db
校验快照 hash 值
┌──[root@vms100.liruilongs.github.io]-[~]
└─$ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 46aa26ed | 217504 | 2711 | 27 MB |
+----------+----------+------------+------------+
┌──[root@vms100.liruilongs.github.io]-[~]
└─$
恢复
这里的 etcd 集群部署,采用堆叠的方式,通过静态 pod 运行,位于每个控制节点的上。
一定要备份,恢复前需要把原来的数据文件备份清理,在恢复前需要确保 etcd 和 api-Service 已经停掉。获取必要的参数
┌──[root@vms100.liruilongs.github.io]-[~]
└─$kubectl describe pod etcd-vms100.liruilongs.github.io -n kube-system | grep -e '--'--advertise-client-urls=https://192.168.26.100:2379--cert-file=/etc/kubernetes/pki/etcd/server.crt--client-cert-auth=true--data-dir=/var/lib/etcd--experimental-initial-corrupt-check=true--experimental-watch-progress-notify-interval=5s--initial-advertise-peer-urls=https://192.168.26.100:2380--initial-cluster=vms100.liruilongs.github.io=https://192.168.26.100:2380--key-file=/etc/kubernetes/pki/etcd/server.key--listen-client-urls=https://127.0.0.1:2379,https://192.168.26.100:2379--listen-metrics-urls=http://127.0.0.1:2381--listen-peer-urls=https://192.168.26.100:2380--name=vms100.liruilongs.github.io--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt--peer-client-cert-auth=true--peer-key-file=/etc/kubernetes/pki/etcd/peer.key--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt--snapshot-count=10000--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
┌──[root@vms100.liruilongs.github.io]-[~]
└─$
恢复的时候:停掉所有 Master 节点的 kube-apiserver和 etcd 这两个静态pod 。 kubelet 每隔 20s 会扫描一次这个目录确定是否发生静态 pod 变动。 移动Yaml文件 即可停掉。
这是使用 Ansible ,集群所有节点执行。
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "mv /etc/kubernetes/manifests/etcd.yaml /tmp/ " -i host.yaml
192.168.26.102 | CHANGED | rc=0 >>192.168.26.101 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "mv /etc/kubernetes/manifests/kube-apiserver.yaml /tmp/ " -i host.yaml
192.168.26.101 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>确实 静态 Yaml 文件发生移动
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "ls /etc/kubernetes/manifests/" -i host.yaml
192.168.26.102 | CHANGED | rc=0 >>
haproxy.yaml
keepalived.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
192.168.26.100 | CHANGED | rc=0 >>
haproxy.yaml
keepalived.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
192.168.26.101 | CHANGED | rc=0 >>
haproxy.yaml
keepalived.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$
清空所有集群节点的 etcd 数据目录
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "rm -rf /var/lib/etcd/" -i host.yaml
[WARNING]: Consider using the file module with state=absent rather than running 'rm'. If you need to use command because file is insufficient you can add 'warn:
false' to this command task or set 'command_warnings=False' in ansible.cfg to get rid of this message.
192.168.26.101 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>
复制快照备份文件到集群所有节点
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m copy -a "src=snap-202302070000.db dest=/root/" -i host.yaml
在 vms100.liruilongs.github.io 上面恢复
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ETCDCTL_API=3 etcdctl snapshot restore snap-202302070000.db \--name vms100.liruilongs.github.io \--cert="/etc/kubernetes/pki/etcd/server.crt" \--key="/etc/kubernetes/pki/etcd/server.key" \--cacert="/etc/kubernetes/pki/etcd/ca.crt" \--endpoints="https://127.0.0.1:2379" \--initial-advertise-peer-urls="https://192.168.26.100:2380" \--initial-cluster="vms100.liruilongs.github.io=https://192.168.26.100:2380,vms101.liruilongs.github.io=https://192.168.26.101:2380,vms102.liruilongs.github.io=https://192.168.26.102:2380" \--data-dir=/var/lib/etcd
2023-02-08 12:50:27.598250 I | mvcc: restore compact to 2837993
2023-02-08 12:50:27.609440 I | etcdserver/membership: added member ee392e5273e89e2 [https://192.168.26.100:2380] to cluster 4816f346663d82a7
2023-02-08 12:50:27.609480 I | etcdserver/membership: added member 70059e836d19883d [https://192.168.26.101:2380] to cluster 4816f346663d82a7
2023-02-08 12:50:27.609487 I | etcdserver/membership: added member b8cb9f66c2e63b91 [https://192.168.26.102:2380] to cluster 4816f346663d82a7
在 vms101.liruilongs.github.io 上恢复
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ssh 192.168.26.101
Last login: Wed Feb 8 12:48:31 2023 from 192.168.26.100
┌──[root@vms101.liruilongs.github.io]-[~]
└─$ETCDCTL_API=3 etcdctl snapshot restore snap-202302070000.db --name vms101.liruilongs.github.io --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" --endpoints="https://127.0.0.1:2379" --initial-advertise-peer-urls="https://192.168.26.101:2380" --initial-cluster="vms100.liruilongs.github.io=https://192.168.26.100:2380,vms101.liruilongs.github.io=https://192.168.26.101:2380,vms102.liruilongs.github.io=https://192.168.26.102:2380" --data-dir=/var/lib/etcd
2023-02-08 12:52:21.976748 I | mvcc: restore compact to 2837993
2023-02-08 12:52:21.991588 I | etcdserver/membership: added member ee392e5273e89e2 [https://192.168.26.100:2380] to cluster 4816f346663d82a7
2023-02-08 12:52:21.991622 I | etcdserver/membership: added member 70059e836d19883d [https://192.168.26.101:2380] to cluster 4816f346663d82a7
2023-02-08 12:52:21.991629 I | etcdserver/membership: added member b8cb9f66c2e63b91 [https://192.168.26.102:2380] to cluster 4816f346663d82a7
在 vms102.liruilongs.github.io 上恢复
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ssh 192.168.26.102
Last login: Wed Feb 8 12:48:31 2023 from 192.168.26.100
┌──[root@vms102.liruilongs.github.io]-[~]
└─$ETCDCTL_API=3 etcdctl snapshot restore snap-202302070000.db --name vms102.liruilongs.github.io --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes
/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" --endpoints="https://127.0.0.1:2379" --initial-advertise-peer-urls="https://192.168.26.102:2380"
--initial-cluster="vms100.liruilongs.github.io=https://192.168.26.100:2380,vms101.liruilongs.github.io=https://192.168.26.101:2380,vms102.liruilongs.github.io=https:/
/192.168.26.102:2380" --data-dir=/var/lib/etcd
2023-02-08 12:53:32.338663 I | mvcc: restore compact to 2837993
2023-02-08 12:53:32.354619 I | etcdserver/membership: added member ee392e5273e89e2 [https://192.168.26.100:2380] to cluster 4816f346663d82a7
2023-02-08 12:53:32.354782 I | etcdserver/membership: added member 70059e836d19883d [https://192.168.26.101:2380] to cluster 4816f346663d82a7
2023-02-08 12:53:32.354790 I | etcdserver/membership: added member b8cb9f66c2e63b91 [https://192.168.26.102:2380] to cluster 4816f346663d82a7
┌──[root@vms102.liruilongs.github.io]-[~]
└─$
恢复完成后移动 etcd,api-service 静态pod 配置文件
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "mv /tmp/kube-apiserver.yaml /etc/kubernetes/manifests/ " -i host.yaml
192.168.26.101 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "mv /tmp/etcd.yaml /etc/kubernetes/manifests/etcd.yaml " -i host.yaml
192.168.26.101 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$
确认移动成功。
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ansible k8s_master -m command -a "ls /etc/kubernetes/manifests/" -i host.yaml
192.168.26.100 | CHANGED | rc=0 >>
etcd.yaml
haproxy.yaml
keepalived.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
192.168.26.101 | CHANGED | rc=0 >>
etcd.yaml
haproxy.yaml
keepalived.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
192.168.26.102 | CHANGED | rc=0 >>
etcd.yaml
haproxy.yaml
keepalived.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
任意节点查看 etcd 集群信息。恢复成功
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$kubectl get pods
The connection to the server 192.168.26.99:30033 was refused - did you specify the right host or port?
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" endpoint status --cluster -w table
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.26.100:2379 | ee392e5273e89e2 | 3.5.4 | 37 MB | false | 2 | 146 |
| https://192.168.26.101:2379 | 70059e836d19883d | 3.5.4 | 37 MB | true | 2 | 146 |
| https://192.168.26.102:2379 | b8cb9f66c2e63b91 | 3.5.4 | 37 MB | false | 2 | 146 |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
┌──[root@vms100.liruilongs.github.io]-[~/ansible]
└─$
遇到的问题:
如果某一节点有下面的报错,或者集群节点添加不成功,添加了两个,需要按照上面的步骤重复进行。
panic: tocommit(258) is out of range [lastIndex(0)]. Was the raft log corrupted, truncated, or lost? 问题处理
┌──[root@vms100.liruilongs.github.io]-[~/back]
└─$ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" endpoint status --cluster -w table
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.26.100:2379 | ee392e5273e89e2 | 3.5.4 | 37 MB | true | 2 | 85951 |
| https://192.168.26.101:2379 | 70059e836d19883d | 3.5.4 | 37 MB | false | 2 | 85951 |
+-----------------------------+------------------+---------+---------+-----------+-----------+------------+
备份定时任务编写
这里的定时备份通过,systemd.service 和 systemd.timer 实现,定时运行 etcd_back.sh 备份脚本,并设置开机自启
很简单没啥说的
┌──[root@vms81.liruilongs.github.io]-[~/back]
└─$systemctl cat etcd-backup
# /usr/lib/systemd/system/etcd-backup.service
[Unit]
Description= "ETCD 备份"
After=network-online.target[Service]
Type=oneshot
Environment=ETCDCTL_API=3
ExecStart=/usr/bin/bash /usr/lib/systemd/system/etcd_back.sh[Install]
WantedBy=multi-user.target
每天午夜执行一次
┌──[root@vms81.liruilongs.github.io]-[~/back]
└─$systemctl cat etcd-backup.timer
# /usr/lib/systemd/system/etcd-backup.timer
[Unit]
Description="每天备份一次 ETCD"[Timer]
OnBootSec=3s
OnCalendar=*-*-* 00:00:00
Unit=etcd-backup.service[Install]
WantedBy=multi-user.target
备份脚本
┌──[root@vms100.liruilongs.github.io]-[~/ansible/backup]
└─$cat etcd_back.sh
#!/bin/bash#@File : erct_break.sh
#@Time : 2023/01/27 23:00:27
#@Author : Li Ruilong
#@Version : 1.0
#@Desc : ETCD 备份
#@Contact : 1224965096@qq.comif [ ! -d /root/back/ ];thenmkdir -p /root/back/
fi
STR_DATE=$(date +%Y%m%d%H%M)ETCDCTL_API=3 etcdctl \
--endpoints="https://127.0.0.1:2379" \
--cert="/etc/kubernetes/pki/etcd/server.crt" \
--key="/etc/kubernetes/pki/etcd/server.key" \
--cacert="/etc/kubernetes/pki/etcd/ca.crt" \
snapshot save /root/back/snap-${STR_DATE}.dbETCDCTL_API=3 etcdctl --write-out=table snapshot status /root/back/snap-${STR_DATE}.dbsudo chmod o-w,u-w,g-w /root/back/snap-${STR_DATE}.db
服务和定时任务的备份部署
┌──[root@vms100.liruilongs.github.io]-[~/ansible/backup]
└─$cat deply.sh
#!/bin/bash#@File : erct_break.sh
#@Time : 2023/01/27 23:00:27
#@Author : Li Ruilong
#@Version : 1.0
#@Desc : ETCD 备份部署
#@Contact : 1224965096@qq.comcp ./* /usr/lib/systemd/system/
systemctl enable etcd-backup.timer --now
systemctl enable etcd-backup.service --now
ls /root/back/日志查看
┌──[root@vms100.liruilongs.github.io]-[~/ansible/backup]
└─$journalctl -u etcd-backup.service -o cat
...................
Starting "ETCD 备份"...
Snapshot saved at /root/back/snap-202301290120.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 74323316 | 640319 | 2250 | 27 MB |
+----------+----------+------------+------------+
Started "ETCD 备份".
Starting "ETCD 备份"...
Snapshot saved at /root/back/snap-202301290120.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| e75a16bf | 640325 | 2255 | 27 MB |
+----------+----------+------------+------------+
Started "ETCD 备份".
Starting "ETCD 备份"...
Snapshot saved at /root/back/snap-202301290121.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| eb5e9e86 | 640388 | 2318 | 27 MB |
+----------+----------+------------+------------+
Started "ETCD 备份".
Starting "ETCD 备份"...
Snapshot saved at /root/back/snap-202301290121.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 30a91bb6 | 640402 | 2333 | 27 MB |
+----------+----------+------------+------------+
Started "ETCD 备份".
二进制 集群备份恢复
二进制集群的备份恢复和 静态 pod 的方式基本相同。
这里不同的是,下面的恢复方式使用,先恢复前两个节点,构成集群,第三个节点加入集群的方式。当前集群信息
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -m shell -a "etcdctl member list"
192.168.26.101 | CHANGED | rc=0 >>
2fd4f9ba70a04579: name=etcd-102 peerURLs=http://192.168.26.102:2380 clientURLs=http://192.168.26.102:2379,http://localhost:2379 isLeader=false
6f2038a018db1103: name=etcd-100 peerURLs=http://192.168.26.100:2380 clientURLs=http://192.168.26.100:2379,http://localhost:2379 isLeader=false
bd330576bb637f25: name=etcd-101 peerURLs=http://192.168.26.101:2380 clientURLs=http://192.168.26.101:2379,http://localhost:2379 isLeader=true
192.168.26.102 | CHANGED | rc=0 >>
2fd4f9ba70a04579: name=etcd-102 peerURLs=http://192.168.26.102:2380 clientURLs=http://192.168.26.102:2379,http://localhost:2379 isLeader=false
6f2038a018db1103: name=etcd-100 peerURLs=http://192.168.26.100:2380 clientURLs=http://192.168.26.100:2379,http://localhost:2379 isLeader=false
bd330576bb637f25: name=etcd-101 peerURLs=http://192.168.26.101:2380 clientURLs=http://192.168.26.101:2379,http://localhost:2379 isLeader=true
192.168.26.100 | CHANGED | rc=0 >>
2fd4f9ba70a04579: name=etcd-102 peerURLs=http://192.168.26.102:2380 clientURLs=http://192.168.26.102:2379,http://localhost:2379 isLeader=false
6f2038a018db1103: name=etcd-100 peerURLs=http://192.168.26.100:2380 clientURLs=http://192.168.26.100:2379,http://localhost:2379 isLeader=false
bd330576bb637f25: name=etcd-101 peerURLs=http://192.168.26.101:2380 clientURLs=http://192.168.26.101:2379,http://localhost:2379 isLeader=true
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
准备数据
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.100 -a "etcdctl put name liruilong"
192.168.26.100 | CHANGED | rc=0 >>
OK
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "etcdctl get name"
192.168.26.102 | CHANGED | rc=0 >>
name
liruilong
192.168.26.100 | CHANGED | rc=0 >>
name
liruilong
192.168.26.101 | CHANGED | rc=0 >>
name
liruilong
在任意一台主机上对 etcd 做快照
#在任何一台主机上对 etcd 做快照
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.101 -a "etcdctl snapshot save snap20211010.db"
192.168.26.101 | CHANGED | rc=0 >>
Snapshot saved at snap20211010.db
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
此快照里包含了刚刚写的数据 name=liruilong,然后把快照文件复制到所有节点
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.101 -a "scp /root/snap20211010.db root@192.168.26.100:/root/"
192.168.26.101 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.101 -a "scp /root/snap20211010.db root@192.168.26.102:/root/"
192.168.26.101 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
清空数据所有节点数据
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "etcdctl del name"
192.168.26.101 | CHANGED | rc=0 >>
1
192.168.26.102 | CHANGED | rc=0 >>
0
192.168.26.100 | CHANGED | rc=0 >>
0
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
在所有节点上关闭 etcd,并删除/var/lib/etcd/里所有数据:
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$# 在所有节点上关闭 etcd,并删除/var/lib/etcd/里所有数据:
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "systemctl stop etcd"
192.168.26.100 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.101 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -m shell -a "rm -rf /var/lib/etcd/*"
[WARNING]: Consider using the file module with state=absent rather than running 'rm'. If you need to
use command because file is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
192.168.26.102 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>192.168.26.101 | CHANGED | rc=0 >>
在所有节点上把快照文件的所有者和所属组设置为 etcd:
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "chown etcd.etcd /root/snap20211010.db"
[WARNING]: Consider using the file module with owner rather than running 'chown'. If you need to use
command because file is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
192.168.26.100 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>192.168.26.101 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$# 在每台节点上开始恢复数据:
在 100,101 节点上开始恢复数据
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.100 -m script -a "./snapshot_restore.sh"
192.168.26.100 | CHANGED => {"changed": true,"rc": 0,"stderr": "Shared connection to 192.168.26.100 closed.\r\n","stderr_lines": ["Shared connection to 192.168.26.100 closed."],"stdout": "2021-10-10 12:14:30.726021 I | etcdserver/membership: added member 6f2038a018db1103 [http://192.168.26.100:2380] to cluster af623437f584d792\r\n2021-10-10 12:14:30.726234 I | etcdserver/membership: added member bd330576bb637f25 [http://192.168.26.101:2380] to cluster af623437f584d792\r\n","stdout_lines": ["2021-10-10 12:14:30.726021 I | etcdserver/membership: added member 6f2038a018db1103 [http://192.168.26.100:2380] to cluster af623437f584d792","2021-10-10 12:14:30.726234 I | etcdserver/membership: added member bd330576bb637f25 [http://192.168.26.101:2380] to cluster af623437f584d792"]
}
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$cat -n ./snapshot_restore.sh1 #!/bin/bash23 # 每台节点恢复镜像45 etcdctl snapshot restore /root/snap20211010.db \6 --name etcd-100 \7 --initial-advertise-peer-urls="http://192.168.26.100:2380" \8 --initial-cluster="etcd-100=http://192.168.26.100:2380,etcd-101=http://192.168.26.101:2380" \9 --data-dir="/var/lib/etcd/cluster.etcd"10
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$sed '6,7s/100/101/g' ./snapshot_restore.sh
#!/bin/bash# 每台节点恢复镜像etcdctl snapshot restore /root/snap20211010.db \
--name etcd-101 \
--initial-advertise-peer-urls="http://192.168.26.101:2380" \
--initial-cluster="etcd-100=http://192.168.26.100:2380,etcd-101=http://192.168.26.101:2380" \
--data-dir="/var/lib/etcd/cluster.etcd"┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$sed -i '6,7s/100/101/g' ./snapshot_restore.sh
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$cat ./snapshot_restore.sh
#!/bin/bash# 每台节点恢复镜像etcdctl snapshot restore /root/snap20211010.db \
--name etcd-101 \
--initial-advertise-peer-urls="http://192.168.26.101:2380" \
--initial-cluster="etcd-100=http://192.168.26.100:2380,etcd-101=http://192.168.26.101:2380" \
--data-dir="/var/lib/etcd/cluster.etcd"┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.101 -m script -a "./snapshot_restore.sh"
192.168.26.101 | CHANGED => {"changed": true,"rc": 0,"stderr": "Shared connection to 192.168.26.101 closed.\r\n","stderr_lines": ["Shared connection to 192.168.26.101 closed."],"stdout": "2021-10-10 12:20:26.032754 I | etcdserver/membership: added member 6f2038a018db1103 [http://192.168.26.100:2380] to cluster af623437f584d792\r\n2021-10-10 12:20:26.032930 I | etcdserver/membership: added member bd330576bb637f25 [http://192.168.26.101:2380] to cluster af623437f584d792\r\n","stdout_lines": ["2021-10-10 12:20:26.032754 I | etcdserver/membership: added member 6f2038a018db1103 [http://192.168.26.100:2380] to cluster af623437f584d792","2021-10-10 12:20:26.032930 I | etcdserver/membership: added member bd330576bb637f25 [http://192.168.26.101:2380] to cluster af623437f584d792"]
}
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
所有节点把/var/lib/etcd 及里面内容的所有者和所属组改为 etcd:etcd 然后分别启动 etcd
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "chown -R etcd.etcd /var/lib/etcd/"
[WARNING]: Consider using the file module with owner rather than running 'chown'. If you need to use
command because file is insufficient you can add 'warn: false' to this command task or set
'command_warnings=False' in ansible.cfg to get rid of this message.
192.168.26.100 | CHANGED | rc=0 >>192.168.26.101 | CHANGED | rc=0 >>192.168.26.102 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "systemctl start etcd"
192.168.26.102 | FAILED | rc=1 >>
Job for etcd.service failed because the control process exited with error code. See "systemctl status etcd.service" and "journalctl -xe" for details.non-zero return code
192.168.26.101 | CHANGED | rc=0 >>192.168.26.100 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
把剩下的 102 节点添加进集群
# etcdctl member add etcd_name –peer-urls=”https://peerURLs”
[root@vms100 cluster.etcd]# etcdctl member add etcd-102 --peer-urls="http://192.168.26.102:2380"
Member fbd8a96cbf1c004d added to cluster af623437f584d792ETCD_NAME="etcd-102"
ETCD_INITIAL_CLUSTER="etcd-100=http://192.168.26.100:2380,etcd-101=http://192.168.26.101:2380,etcd-102=http://192.168.26.102:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.26.102:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
[root@vms100 cluster.etcd]#
测试恢复结果
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.102 -m copy -a "src=./etcd.conf dest=/etc/etcd/etcd.conf force=yes"
192.168.26.102 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python"},"changed": false,"checksum": "2d8fa163150e32da563f5e591134b38cc356d237","dest": "/etc/etcd/etcd.conf","gid": 0,"group": "root","mode": "0644","owner": "root","path": "/etc/etcd/etcd.conf","size": 574,"state": "file","uid": 0
}
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible 192.168.26.102 -m shell -a "systemctl enable etcd --now"
192.168.26.102 | CHANGED | rc=0 >>┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -m shell -a "etcdctl member list"
192.168.26.101 | CHANGED | rc=0 >>
6f2038a018db1103, started, etcd-100, http://192.168.26.100:2380, http://192.168.26.100:2379,http://localhost:2379
bd330576bb637f25, started, etcd-101, http://192.168.26.101:2380, http://192.168.26.101:2379,http://localhost:2379
fbd8a96cbf1c004d, started, etcd-102, http://192.168.26.102:2380, http://192.168.26.102:2379,http://localhost:2379
192.168.26.100 | CHANGED | rc=0 >>
6f2038a018db1103, started, etcd-100, http://192.168.26.100:2380, http://192.168.26.100:2379,http://localhost:2379
bd330576bb637f25, started, etcd-101, http://192.168.26.101:2380, http://192.168.26.101:2379,http://localhost:2379
fbd8a96cbf1c004d, started, etcd-102, http://192.168.26.102:2380, http://192.168.26.102:2379,http://localhost:2379
192.168.26.102 | CHANGED | rc=0 >>
6f2038a018db1103, started, etcd-100, http://192.168.26.100:2380, http://192.168.26.100:2379,http://localhost:2379
bd330576bb637f25, started, etcd-101, http://192.168.26.101:2380, http://192.168.26.101:2379,http://localhost:2379
fbd8a96cbf1c004d, started, etcd-102, http://192.168.26.102:2380, http://192.168.26.102:2379,http://localhost:2379
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible etcd -a "etcdctl get name"
192.168.26.102 | CHANGED | rc=0 >>
name
liruilong
192.168.26.101 | CHANGED | rc=0 >>
name
liruilong
192.168.26.100 | CHANGED | rc=0 >>
name
liruilong
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
博文部分内容参考
文中涉及参考链接内容版权归原作者所有,如有侵权请告知
https://etcd.io/docs/v3.5/faq/
https://etcd.io/docs/v3.6/op-guide/recovery/#restoring-a-cluster
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/configure-upgrade-etcd/
https://docs.vmware.com/en/VMware-Application-Catalog/services/tutorials/GUID-backup-restore-data-etcd-kubernetes-index.html
https://github.com/etcd-io/etcd/issues/13509
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
相关文章:

关于k8s中ETCD集群备份灾难恢复的一些笔记
写在前面 集群电源不稳定,或者节点动不动就 宕机,一定要做好备份,ETCD 的快照文件很容易受影响损坏。重置了很多次集群,才认识到备份的重要博文内容涉及 etcd 运维基础知识了解静态 Pod 方式 etcd 集群灾备与恢复 Demo定时备份的任务编写二进…...

【设计模式之美 设计原则与思想:设计原则】19 | 理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
关于 SOLID 原则,我们已经学过单一职责、开闭、里式替换、接口隔离这四个原则。今天,我们再来学习最后一个原则:依赖反转原则。在前面几节课中,我们讲到,单一职责原则和开闭原则的原理比较简单,但是&#x…...

2023年全国最新高校辅导员精选真题及答案13
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 一、单选题 131.下列不属于我国国土空间具有的特点的是() A.水资…...

【XXL-JOB】XXL-JOB定时处理视频转码
【XXL-JOB】XXL-JOB定时处理视频转码 文章目录【XXL-JOB】XXL-JOB定时处理视频转码1. 准备工作1.1 高级配置1.2 分片广播2. 需求分析2.1 作业分片方案2.2 保证任务不重复执行2.2.1 保证幂等性3. 视频处理业务流程3.1 添加待处理任务3.2 查询待处理任务3.3 更新任务状态3.4 工具…...

optuna用于pytorch的轻量级调参场景和grid search的自定义设计
文章目录0. 背景:why optuna0.1 插播一个简单的grid search0.2 参考1. Optuna1.1 a basic demo与部分参数释义1.2 random的问题1.3 Objective方法类2. Optuna与grid search4. optuna的剪枝prune5. optuna与可视化6. 未完待续0. 背景:why optuna 小模型参…...

语法篇--汇编语言先导浅尝
一、相关概念 1.机器语言 机器语言(Machine Language)是一种计算机程序语言,由二进制代码(0和1)组成,可被计算机直接执行。机器语言是计算机硬件能够理解和执行的唯一语言。 机器语言通常由一系列的指令组…...

【ID:17】【20分】A. DS顺序表--类实现
时间限制1秒内存限制128兆字节题目描述用C语言和类实现顺序表属性包括:数组、实际长度、最大长度(设定为1000)操作包括:创建、插入、删除、查找类定义参考输入第1行先输入n表示有n个数据,即n是实际长度;接着输入n个数据…...
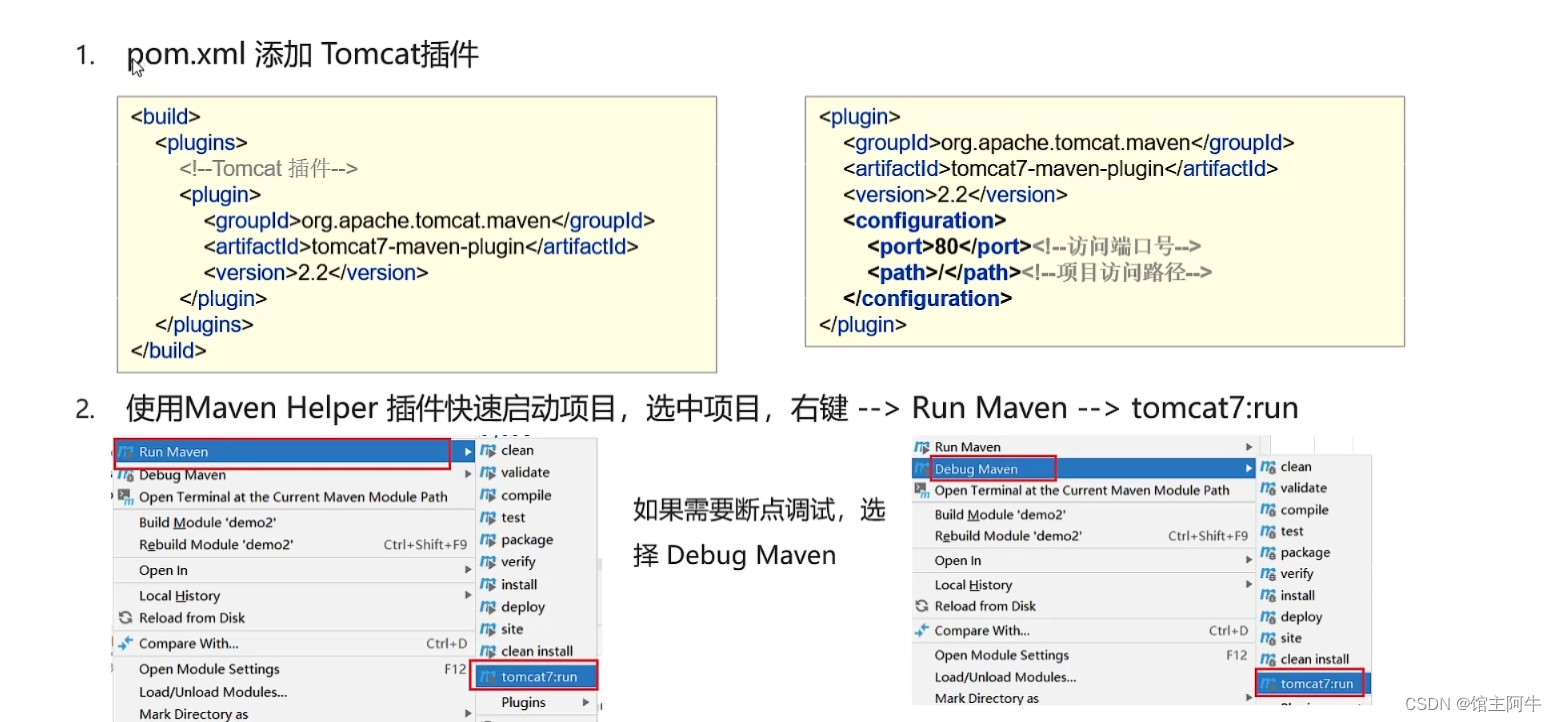
【java web篇】Tomcat的基本使用
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

MySQL实战解析底层---行锁功过:怎么减少行锁对性能的影响
目录 前言 从两阶段锁说起 死锁和死锁检测 前言 MySQL 的行锁是在引擎层由各个引擎自己实现的但并不是所有的引擎都支持行锁,比如MyISAM 引擎就不支持行锁不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有…...
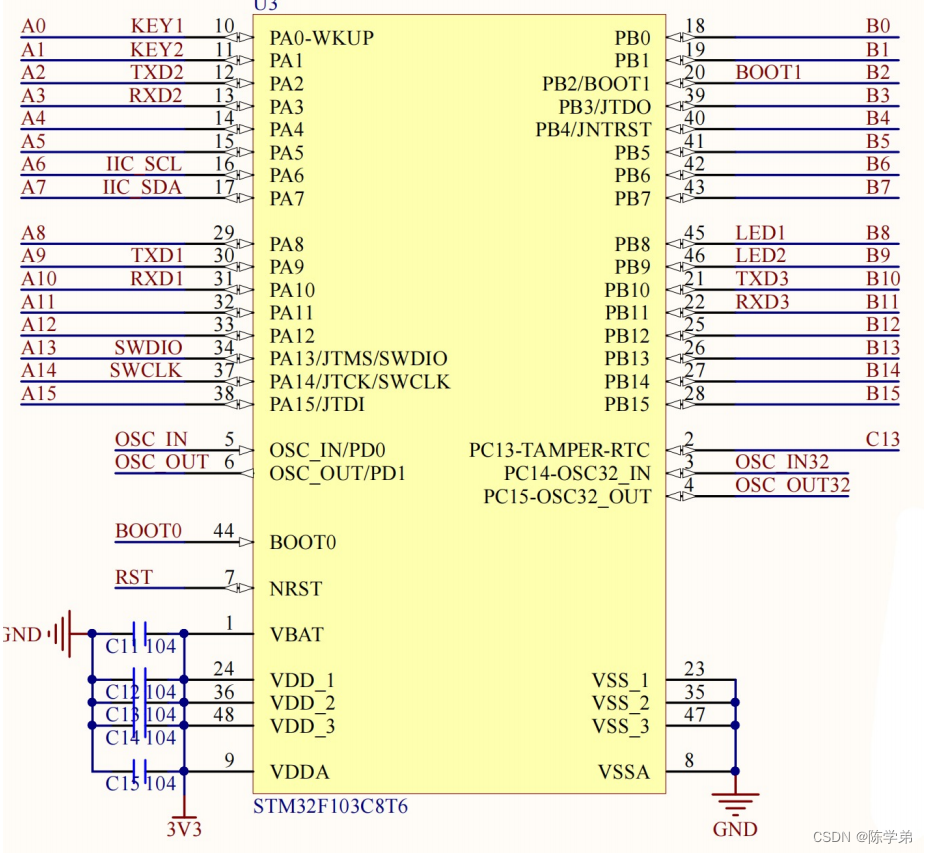
初识STM32单片机
目录 初识STM32单片机 什么是单片机? STM系列单片机命名规则 STM32F103C8T6单片机简介 标准库与HAL库区别 通用输入输出端口GPIO 什么是GPIO? 定义 命名规则 内部框架图 推挽输出与开漏输出 如何点亮一颗LED灯 编程实现点灯 按键点亮LED灯…...

数据结构与算法系列之单链表
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 这里写目录标题test.hSList.h注意事项一级指针与二级指针的使用assert的使用空…...

MySQL基础
本单元目标 一、为什么要学习数据库 二、数据库的相关概念 DBMS、DB、SQL 三、数据库存储数据的特点 四、初始MySQL MySQL产品的介绍 MySQL产品的安装 ★ MySQL服务的启动和停止 ★ MySQL服务的登录和退出 ★ MySQL的常见命令和语法规范 五、…...

面试热点题:环形链表及环形链表寻找环入口结点问题
环形链表 问题: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接…...

【算法】DFS与BFS
作者:指针不指南吗 专栏:算法篇 🐾题目的模拟很重要!!🐾 文章目录1.区别2.DFS2.1 排列数字2.2 n-皇后问题3.BFS3.1走迷宫1.区别 搜索类型数据结构空间用途过程DFSstackO( n )不能用于最短路搜索到最深处&a…...

湖州银行冲刺A股上市:计划募资约24亿元,资产质量水平较高
3月4日,湖州银行股份有限公司(下称“湖州银行”)递交招股书,准备在上海证券交易所主板上市。本次冲刺上市,湖州银行计划募资23.98亿元,将在扣除发行费用后全部用于补充该行资本金。 湖州银行在招股书中表示…...
高性能网络I/O框架-netmap源码分析
前几天听一个朋友提到这个netmap,看了它的介绍和设计,确实是个好东西。其设计思想与业界不谋而合——因为为了提高性能,几个性能瓶颈放在那里,解决方法自然也是类似的。 netmap的出现,它既实现了一个高性能的网络I/O框…...
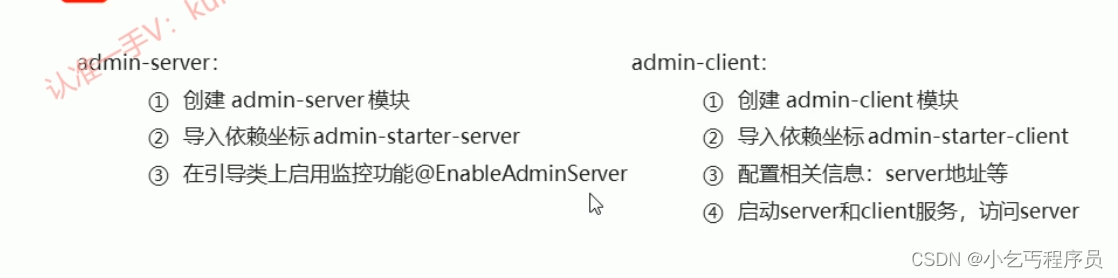
SpringBoot监听机制-以及使用
11-SpringBoot事件监听 Java中的事件监听机制定义了以下几个角色: ①事件:Event,继承 java.util.EventObject 类的对象 ②事件源:Source ,任意对象Object ③监听器:Listener,实现 java.util…...
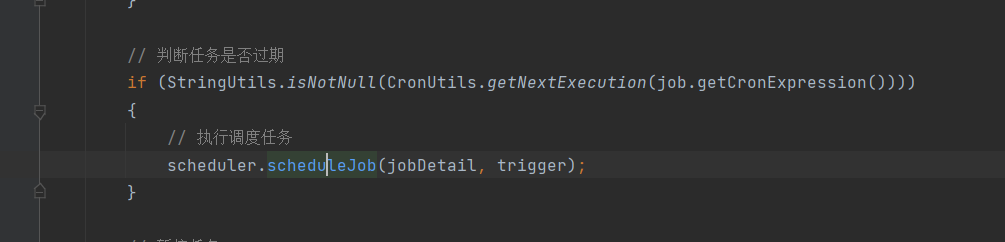
若依学习——定时任务代码逻辑 详细梳理(springboot整合Quartz)
springboot整合Quartz关于若依定时任务的使用可以去看视频默认定时任务的使用关于springboot整合quartz的整合参考(150条消息) 定时任务框架Quartz-(一)Quartz入门与Demo搭建_quarzt_是Guava不是瓜娃的博客-CSDN博客(150条消息) SpringBoot整合Quartz_springboot quartz_桐花思…...
)
C++---最长上升子序列模型---拦截导弹(每日一道算法2023.3.4)
注意事项: 本题为"线性dp—最长上升子序列的长度"的扩展题,这里只讲贪心思路,dp去这个看。 题目: 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。 但是这种导弹拦截系统有一个缺陷:虽然它…...

【机器学习面试】百面机器学习笔记和问题总结+扩展面试题
第1章 特征工程 1、为什么需要对数值类型的特征做归一化? (1)消除量纲,将所有特征统一到一个大致相同的区间范围,使不同指标之间具由可比性; (2)可以加快梯度下降收敛的速度&#…...

直流电流采样电路实战指南:从检流电阻到霍尔传感器的四种方案解析
1. 为什么电流采样是硬件设计的“基本功”? 大家好,我是老张,一个在硬件和嵌入式领域摸爬滚打了十多年的工程师。今天想和大家聊聊一个看似基础,但实际项目中“坑”特别多的技术点——直流电流采样。不管你是在做电池管理系统&…...

Grokking 现象解析:小数据集下神经网络的泛化之谜
1. 什么是Grokking?一个让AI研究者困惑的“顿悟”现象 想象一下,你在教一个学生做数学题。你给了他10道例题,他一开始完全不会,只能靠死记硬背把答案背下来。你考他这10道原题,他都能答对,但稍微变一下数字…...

深入解析FLAC与APE:无损音频格式的技术差异与应用场景
1. 从“听个响”到“听细节”:为什么我们需要无损音频? 不知道你有没有这样的经历:几年前用手机随便听听歌,觉得128kbps的MP3已经很满足了。后来偶然间,在朋友家或者某个展会上,用一套不错的耳机或音响&…...

数电核心:从74HC194到序列信号,揭秘移位寄存器的三大实战应用
1. 从“记忆”到“流动”:重新认识移位寄存器 很多刚接触数字电路的朋友,一听到“寄存器”这个词,头就大了,总觉得它和锁存器、触发器搅在一起,分不清楚。其实,你可以把它们想象成仓库管理员。锁存器就像一…...
)
Android16进阶之MediaPlayer.getAudioSessionId调用流程与实战(二百三十七)
简介: CSDN博客专家、《Android系统多媒体进阶实战》作者 博主新书推荐:《Android系统多媒体进阶实战》🚀 Android Audio工程师专栏地址: Audio工程师进阶系列【原创干货持续更新中……】🚀 Android多媒体专栏地址&a…...

小米米家8键蓝牙开关硬件设计与低功耗实现解析
1. 项目概述小米米家8键蓝牙无线开关-V2是一款面向智能家居场景的低功耗无线控制终端,其核心设计目标是提供一种高可靠性、易部署、免布线的物理交互入口。该设备不依赖Wi-Fi或Zigbee等传统智能家居协议栈,而是基于蓝牙5.0 Low Energy(BLE&am…...

利用快马平台与mcp协议快速搭建你的第一个ai智能体原型
最近在尝试快速搭建AI智能体原型时,我接触到了一个挺有意思的概念——MCP(模型上下文协议)。简单来说,它就像给不同的AI模型和外部工具之间制定了一套“普通话”,让它们能顺畅沟通。为了验证这个想法,我决定…...

SecGPT-14B部署基础教程:Ubuntu 22.04 + vLLM + Chainlit全流程
SecGPT-14B部署基础教程:Ubuntu 22.04 vLLM Chainlit全流程 想快速体验一个专为网络安全打造的智能助手吗?SecGPT-14B就是这样一个模型,它能帮你分析漏洞、解读日志、识别威胁,就像一个随时待命的安全专家。今天,我…...

效率提升秘籍:用快马AI一键生成专业级谷歌账号注册教程页面
最近在做一个教学类的小项目,需要制作一个谷歌账号注册的教程页面。这种页面结构其实挺典型的:有概述、有材料清单、有分步指导、还有FAQ。如果从头开始写HTML、CSS和JavaScript,光是调整样式和实现交互就得花上大半天。这次我尝试了一个新方…...

毕业设计在线健身与健康管理平台:从零构建高可用后端架构的技术实践
做毕业设计,尤其是像“在线健身与健康管理平台”这类综合性项目,对很多同学来说,第一次从零搭建一个完整的后端系统,挑战不小。我当初也踩了不少坑,比如把所有功能都塞在一个大项目里,改一处代码心惊胆战&a…...