基于BERT对中文邮件内容分类
用BERT做中文邮件内容分类
- 项目背景与意义
- 项目思路
- 数据集介绍
- 环境配置
- 数据加载与预处理
- 自定义数据集
- 模型训练
- 加载BERT预训练模型
- 开始训练
- 预测效果
项目背景与意义
本文是《用BERT做中文邮件内容分类》系列的第二篇,该系列项目持续更新中。系列的起源是《使用PaddleNLP识别垃圾邮件》项目,旨在解决企业面临的垃圾邮件问题,通过深度学习方法探索多语言垃圾邮件的内容、标题提取与分类识别。
在本篇文章中,我们使用PaddleNLP的BERT预训练模型,根据提取的中文邮件内容判断邮件是否为垃圾邮件。该项目的思路在于基于前一篇项目的中文邮件内容提取,在98.5%的垃圾邮件分类器基线上,通过BERT的finetune进一步提升性能。

项目思路
在《使用PaddleNLP识别垃圾邮件(一)》项目的基础上,我们使用BERT进行finetune,力求在LSTM的98.5%的基线上进一步提升准确率。同时,文章中详细介绍了BERT模型的原理和PaddleNLP对BERT模型的应用,读者可以参考项目PaddleNLP2.0:BERT模型的应用进行更深入的了解。
本项目参考了陆平老师的项目应用BERT模型做短文本情绪分类(PaddleNLP 2.0),但由于PaddleNLP版本迭代的原因,进行了相应的调整和说明。
数据集介绍
我们使用了TREC 2006 Spam Track Public Corpora,这是一个公开的垃圾邮件语料库,包括英文数据集(trec06p)和中文数据集(trec06c)。在本项目中,我们仅使用了TREC 2006提供的中文数据集进行演示。数据集来源于真实邮件,保留了邮件的原有格式和内容。
除了TREC 2006外,还有TREC 2005和TREC 2007的英文垃圾邮件数据集,但本项目仅使用了TREC 2006提供的中文数据集。数据集文件目录形式如下:
trec06c
│
├── data
│ │ 000
│ │ 001
│ │ ...
│ └───215
├── delay
│ │ index
└── full│ index
邮件内容样本示例:
负责人您好我是深圳金海实业有限公司...
GG非常好的朋友H在计划马上的西藏自助游...
环境配置
本项目基于Paddle 2.0编写,如果你的环境不是本版本,请先参考官网安装Paddle 2.0。以下是环境配置代码:
# 导入相关的模块
import re
import jieba
import os
import random
import paddle
import paddlenlp as ppnlp
from paddlenlp.data import Stack, Pad, Tuple
import paddle.nn.functional as F
import paddle.nn as nn
from visualdl import LogWriter
import numpy as np
from functools import partial
数据加载与预处理
项目中使用了PaddleNLP的BertTokenizer进行数据处理,该tokenizer可以将原始输入文本转化成模型可接受的输入数据格式。以下是数据加载与预处理的代码:
# 解压数据集
!tar xvf data/data89631/trec06c.tgz# 去掉非中文字符
def clean_str(string):string = re.sub(r"[^\u4e00-\u9fff]", " ", string)string = re.sub(r"\s{2,}", " ", string)return string.strip()# 从指定路径读取邮件文件内容信息
def get_data_in_a_file(original_path, save_path='all_email.txt'):email = ''f = open(original_path, 'r', encoding='gb2312', errors='ignore')for line in f:line = line.strip().strip('\n')line = clean_str(line)email += linef.close()return email[-200:]# 读取标签文件信息
f = open('trec06c/full/index', 'r')
for line in f:str_list = line.split(" ")if str_list[0] == 'spam':label = '0'elif str_list[0] == 'ham':label = '1'text = get_data_in_a_file('trec06c/full/' + str(str_list[1].split("\n")[0]))with open("all_email.txt", "a+") as f:f.write(text + '\t' + label + '\n')
自定义数据集
在项目中,我们需要自定义数据集,并使其数据格式与使用ppnlp.datasets.ChnSentiCorp.get_datasets加载后完全一致。以下是自定义数据集的代码:
class SelfDefinedDataset(paddle.io.Dataset):def __init__(self, data):super(SelfDefinedDataset, self).__init__()self.data = datadef __getitem__(self, idx):return self.data[idx]def __len__(self):return len(self.data)def get_labels(self):return ["0", "1"]def txt_to_list(file_name):res_list = []for line in open(file_name):res_list.append(line.strip().split('\t'))return res_listtrainlst = txt_to_list('train_list.txt')
devlst = txt_to_list('eval_list.txt')
testlst = txt_to_list('test_list.txt')train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
模型训练
加载BERT预训练模型
项目中使用了PaddleNLP提供的BertForSequenceClassification模型进行文本分类的Fine-tune。由于垃圾邮件识别是二分类问题,所以设置num_classes为2。
以下是加载BERT预训练模型的代码:
# 加载预训练模型
model = ppnlp.transformers.BertForSequenceClassification.from_pretrained("bert-base-chinese", num_classes=2)
开始训练
为了监控训练过程,引入了VisualDL记录训练log信息。以下是开始训练的代码:
# 设置训练超参数
learning_rate = 1e-5
epochs = 10
warmup_proption = 0.1
weight_decay = 0.01num_training_steps = len(train_loader) * epochs
num_warmup_steps = int(warmup_proption * num_training_steps)def get_lr_factor(current_step):if current_step < num_warmup_steps:return float(current_step) / float(max(1, num_warmup_steps))else:return max(0.0,float(num_training_steps - current_step) /float(max(1, num_training_steps - num_warmup_steps)))# 学习率调度器
lr_scheduler = paddle.optimizer.lr.LambdaDecay(learning_rate, lr_lambda=lambda current_step: get_lr_factor(current_step))# 优化器
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=weight_decay,apply_decay_param_fun=lambda x: x in [p.name for n, p in model.named_parameters()if not any(nd in n for nd in ["bias", "norm"])])# 损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()# 评估函数
metric = paddle.metric.Accuracy()# 训练过程
global_step = 0
with LogWriter(logdir="./log") as writer:for epoch in range(1, epochs + 1): for step, batch in enumerate(train_loader, start=1):input_ids, segment_ids, labels = batchlogits = model(input_ids, segment_ids)loss = criterion(logits, labels)probs = F.softmax(logits, axis=1)correct = metric.compute(probs, labels)metric.update(correct)acc = metric.accumulate()global_step += 1if global_step % 50 == 0:print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))writer.add_scalar(tag="train/loss", step=global_step, value=loss)writer.add_scalar(tag="train/acc", step=global_step, value=acc)loss.backward()optimizer.step()lr_scheduler.step()optimizer.clear_gradients()eval_loss, eval_acc = evaluate(model, criterion, metric, dev_loader)writer.add_scalar(tag="eval/loss", step=epoch, value=eval_loss)writer.add_scalar(tag="eval/acc", step=epoch, value=eval_acc)
可以看到,在第2个epoch后验证集准确率已经达到99.4%以上,在第3个epoch就能达到99.6%以上。
预测效果
完成模型训练后,我们可以使用训练好的模型对测试集进行预测。以下是预测效果的代码:
data = ['您好我公司有多余的发票可以向外代开,国税,地税,运输,广告,海关缴款书如果贵公司,厂,有需要请来电洽谈,咨询联系电话,罗先生谢谢顺祝商祺']
label_map = {0: '垃圾邮件', 1: '正常邮件'}predictions = predict(model, data, tokenizer, label_map, batch_size=32)
for idx, text in enumerate(data):print('预测内容: {} \n邮件标签: {}'.format(text, predictions[idx]))
预测效果良好,一个验证集准确率高达99.6%以上、基于BERT的中文邮件内容分类顺利完成!
以上是本文的全部内容,希望对读者理解如何使用BERT进行中文邮件内容分类有所帮助。欢迎交流指导!
相关文章:
基于BERT对中文邮件内容分类
用BERT做中文邮件内容分类 项目背景与意义项目思路数据集介绍环境配置数据加载与预处理自定义数据集模型训练加载BERT预训练模型开始训练 预测效果 项目背景与意义 本文是《用BERT做中文邮件内容分类》系列的第二篇,该系列项目持续更新中。系列的起源是《使用Paddl…...

【EFCore仓储模式】介绍一个EFCore的Repository实现
阅读本文你的收获 了解仓储模式及泛型仓储的优点学会封装泛型仓储的一般设计思路学习在ASP.NET Core WebAPI项目中使用EntityFrameworkCore.Data.Repository 本文中的案例是微软EntityFrameworkCore的一个仓储模式实现,这个仓储库不是我自己写的,而是使…...

oracle篇—19c新特性自动索引介绍
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...

稳定性——JE流程
1. RuntimeInit.commonInit() 上层应用都是由Zygote fork孵化出来的,分为system_server进程和普通应用进程进程创建之初会设置未捕获异常的处理器,当系统抛出未捕获的异常时候都会交给异常处理器RuntimeInit.java的commonInit方法设置UncaughtHandler …...

【控制篇 / 分流】(7.4) ❀ 03. 对国内和国际IP网段访问进行分流 ❀ FortiGate 防火墙
【简介】公司有两条宽带用来上网,一条电信,一条IPLS国际专线,由于IPLS仅有2M,且价格昂贵,领导要求,访问国内IP走电信,国际IP走IPLS,那么应该怎么做? 国内IP地址组 我们已…...
01-开始Rust之旅
上一篇:00-Rust前言 1. 下载Rust 官方推荐使用 rustup 下载 Rust,这是一个管理 Rust 版本和相关工具的命令行工具。下载时需要连接互联网。 这边提供了离线安装版本。本人学习的机器环境为: ubuntu x86_64,因此选用第②个工具链&a…...
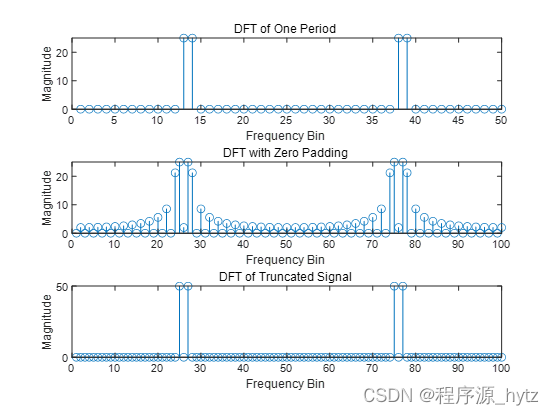
华南理工大学数字信号处理实验实验一(薛y老师版本)matlab源码
一、实验目的 1、加深对离散信号频谱分析的理解; 2、分析不同加窗长度对信号频谱的影响; 3、理解频率分辨率的概念,并分析其对频谱的 影响; 4、窗长和补零对DFT的影响 实验源码: 第一题: % 定义离散信…...
一篇文章看懂云渲染,云渲染是什么?云渲染如何计费?云渲染怎么选择
云渲染是近年兴起的新行业,很多初学者对它不是很了解,云渲染是什么?为什么要选择云渲染?它是如何计费的又怎么选择?这篇文章我们就带大家了解下吧。 云渲染是什么 云渲染简单来说就是把本地的渲染工作迁移到云端进行的…...

C++进阶--哈希表模拟实现unordered_set和unordered_map
哈希表模拟实现unordered_set和unordered_map 一、定义哈希表的结点结构二、定义哈希表的迭代器三、定义哈希表的结构3.1 begin()和end()的实现3.2 默认成员函数的实现3.2.1 构造函数的实现3.2.2 拷贝构造函数的实现(深拷贝)3.2.3 赋值运算符重载函数的实…...
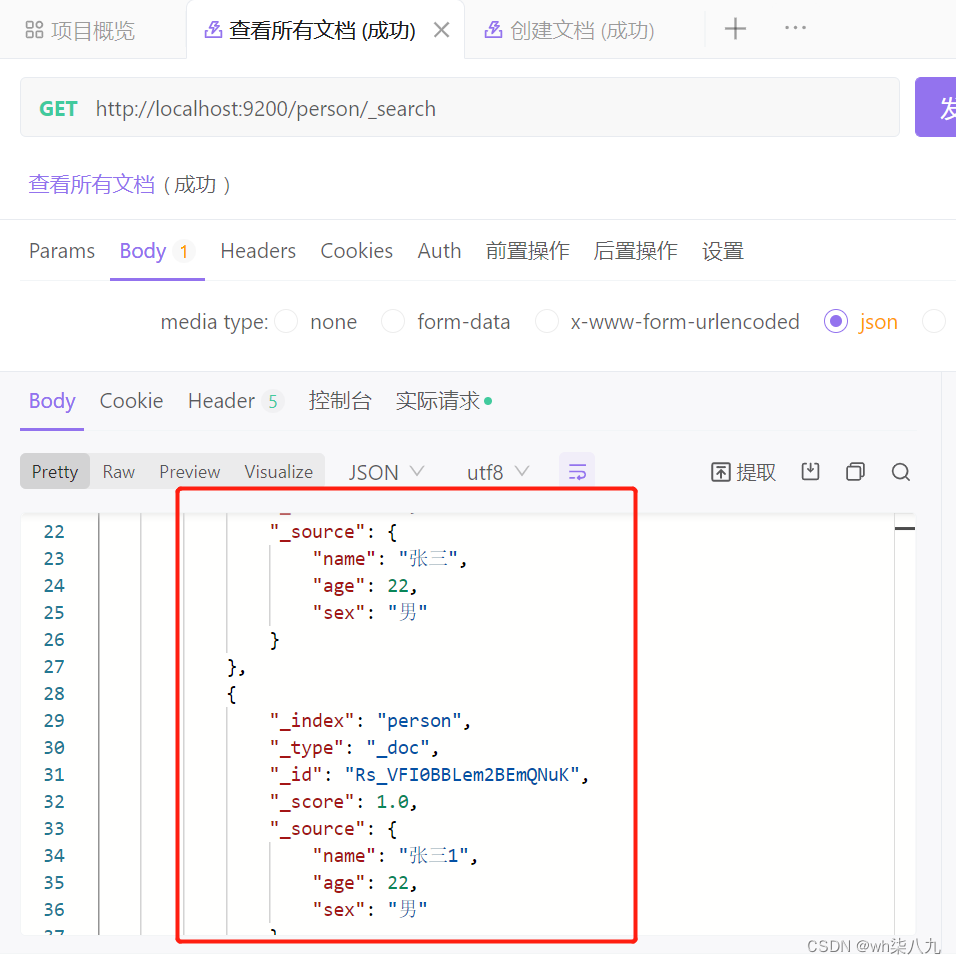
Elasticsearch各种高级文档操作
本文来记录下Elasticsearch各种文档操作 文章目录 初始化文档数据查询所有文档匹配查询文档关键字精确查询文档多关键字精确查询文档字段匹配查询文档指定查询字段查询文档过滤字段查询文档概述指定想要显示的字段示例指定不想要显示的字段示例 组合查询文档范围查询文档概述使…...

激光无人机打击系统——光束控制和指向系统
激光无人机(UAV)打击系统中的光束控制和指向系统通常包括以下几个关键组件和技术: 激光发射器:这是系统的核心,负责生成高能量的激光束。常用的激光类型包括固体激光器、化学激光器、光纤激光器等,选择取决…...

pycharm import torch
目录 1 安装 2 conda环境配置 3 测试 开始学习Pytorch! 1 安装 我的电脑 Windows 11 Python 3.11 Anaconda3-2023.09-0-Windows-x86_64.exe cuda_11.8.0_522.06_windows.exe pytorch (管理员命令行安装) pycharm-community-2023.3.2.exe 2 c…...

flask 与小程序 购物车删除和编辑库存功能
编辑 : 数量加减 价格汇总 数据清空 mina/pages/cart/index.wxml <!--index.wxml--> <view class"container"><view class"title-box" wx:if"{{ !list.length }}">购物车空空如也~</view>…...

蓝桥杯真题(Python)每日练Day3
题目 题目分析 为了找到满足条件的放置方法,可以带入总盘数为2和3的情景,用递归做法实现。 2. A中存在1 2两个盘,为了实现最少次数放入C且上小下大,先将1放入B,再将2放入C,最后将1放入C即可。同理当A中存在…...

结构体大揭秘:代码中的时尚之选(上)
目录 结构结构的声明结构成员的类型结构体变量的定义和初始化结构体成员的访问结构体传参 结构 结构是一些值的集合,这些值被称为成员变量。之前说过数组是相同类型元素的集合。结构的每个成员可以是不同类型的变量,当然也可以是相同类型的。 我们在生活…...
【unity学习笔记】语音驱动blendershape
1.导入插件 https://assetstore.unity.com/packages/tools/animation/salsa-lipsync-suite-148442 1.选择小人,点击添加组件 分别加入组件: SALSA EmoteR Eyes Queue Processor(必须加此脚本):控制前三个组件的脚本。…...
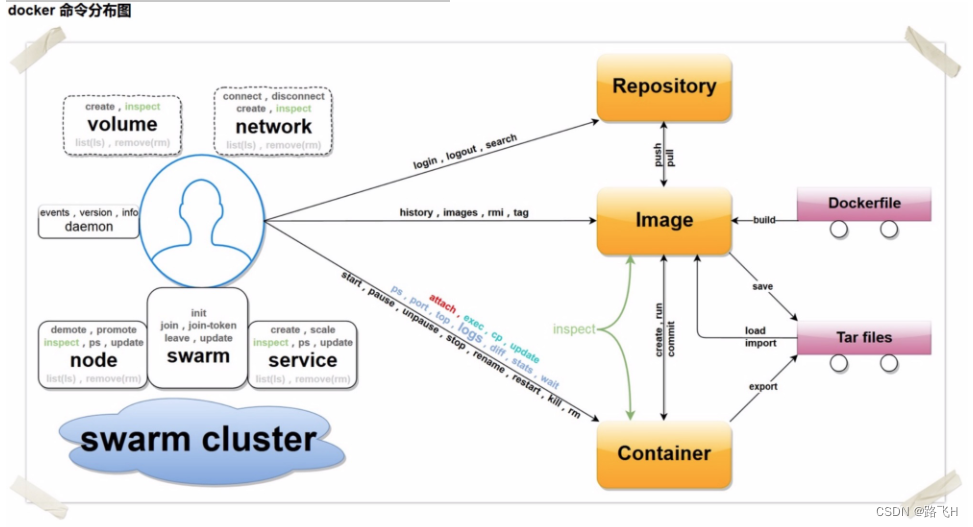
docker常用基础命令
文章目录 1、Docker 环境信息命令1.1、docker info1.2、docker version 2、系统日志信息常用命令2.1、docker events2.2、docker logs2.3、docker history 3、容器的生命周期管理命令3.1、docker create3.2、docker run 总结 1、Docker 环境信息命令 1.1、docker info 显示 D…...

自动驾驶中的坐标系
自动驾驶中的坐标系 自动驾驶中的坐标系 0.引言1.相机传感器坐标系2.激光雷达坐标系3.车体坐标系4.世界坐标系4.1.地理坐标系4.2.投影坐标系4.2.1.投影方式4.2.2.墨卡托(Mercator)投影4.2.3.高斯-克吕格(Gauss-Kruger)投影4.2.4.通用横轴墨卡托UTM(UniversalTransve…...

js数组的截取和合并
在JavaScript中,你可以使用slice()方法来截取数组,使用concat()方法来合并数组。 截取数组 slice()方法返回一个新的数组对象,这个对象是一个由原数组的一部分浅复制而来。它接受两个参数,第一个参数是开始截取的位置(…...

2024美赛数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

新手必看:Qwen2.5-VL-7B图文对话模型部署与使用全攻略
新手必看:Qwen2.5-VL-7B图文对话模型部署与使用全攻略 1. 环境准备与快速部署 1.1 镜像简介 Qwen2.5-VL-7B-Instruct-GPTQ是基于Qwen2.5-VL-7B-Instruct模型的GPTQ量化版本,专门用于图文对话任务。这个镜像已经预装了vllm推理框架和chainlit前端界面&…...

YOLOv8模型训练避坑指南:GTX16系列显卡兼容性问题解决方案
GTX16系列显卡用户必读:YOLOv8模型训练全流程避坑手册 当你在GTX16系列显卡上运行YOLOv8训练脚本时,是否遇到过这样的场景:训练过程看似正常,但最终输出的P(精确率)、R(召回率)、mAP…...

Z-Image-Turbo-rinaiqiao-huiyewunv 模型微调实战:使用自定义数据集训练专属风格
Z-Image-Turbo-rinaiqiao-huiyewunv 模型微调实战:使用自定义数据集训练专属风格 想不想让AI画出专属于你的独特风格?比如,你是一位插画师,希望AI能学会你笔下那种温暖治愈的线条;或者你经营一个品牌,需要…...

如何在Linux系统上快速配置BepInEx:Unity游戏插件框架的完整指南
如何在Linux系统上快速配置BepInEx:Unity游戏插件框架的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专业的Unity/XNA游戏补丁和插件框架&…...

YOLO12快速上手:基于星图GPU的零代码WebUI体验教程
YOLO12快速上手:基于星图GPU的零代码WebUI体验教程 想体验最新的YOLO12目标检测模型,但又不想写一行代码?觉得命令行操作太麻烦,只想有个直观的界面点点鼠标就能看到效果? 今天我来带你体验一种完全不同的方式——通…...

OV7670 UART摄像头驱动开发:基于Camera_LS_Y201的嵌入式图像采集实现
1. Camera_LS_Y201 模块底层驱动技术解析Camera_LS_Y201 是一款基于 OV7670 图像传感器的低成本串口摄像头模组,其核心特征在于通过 UART 接口实现图像数据的一次性整帧传输(Bulk Transfer),而非传统逐行或分包发送方式。该方案由…...

Element UI表格进阶:手把手教你自定义el-table展开按钮样式与排序功能
Element UI表格深度定制:从展开按钮到排序逻辑的全方位改造指南 在企业级前端开发中,数据表格的交互体验直接影响用户操作效率。Element UI的el-table组件虽然提供了开箱即用的功能,但面对复杂业务场景时,默认配置往往难以满足个性…...
)
操作系统面试必考:银行家算法10问10答(含真题解析)
操作系统面试必考:银行家算法10问10答(含真题解析) 银行家算法作为操作系统中经典的死锁避免算法,几乎成为所有技术面试的必考题。无论是校招还是社招,面试官总喜欢用它来考察候选人对资源分配与系统安全的理解深度。本…...
原理剖析:co_await的实现机制)
C++协程(C++20)原理剖析:co_await的实现机制
C20引入的协程机制为异步编程带来了革命性变化,其中co_await作为核心操作符,其实现机制值得深入探讨。本文将剖析co_await背后的魔法,揭示协程如何通过挂起与恢复实现高效异步。 协程三要素解析 协程由promise对象、协程句柄和协程状态三部…...

OpenClaw+QwQ-32B客服模拟:电商问答自动化测试
OpenClawQwQ-32B客服模拟:电商问答自动化测试 1. 为什么需要自动化客服测试 去年双十一前,我们团队遇到了一个棘手问题:每次大促前,客服团队都要手动测试上百个产品页面的问答话术。人工测试不仅耗时耗力,还经常遗漏…...