Python多线程爬虫——数据分析项目实现详解
前言

前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z
「个人网站」:雪碧的个人网站

ChatGPT体验地址

文章目录
- 前言
- 爬虫
- 获取cookie
- 网站爬取与启动
- CSDN爬虫
- 爬虫启动
- 将爬取内容存到文件中
- 多线程爬虫
- 选择要爬取的用户
- 线程池
爬虫
爬虫是指一种自动化程序,能够模拟人类用户在互联网上浏览网页、抓取网页内容、提取数据等操作。爬虫通常用于搜索引擎、数据挖掘、网络分析、竞争情报、用户行为分析等领域。

我们以爬取某个用户的博文列表并存储到文件中实现多线程爬虫为例,带大家体验爬虫的魅力
获取cookie
首先我们在爬取网站的时候首先获取cookie
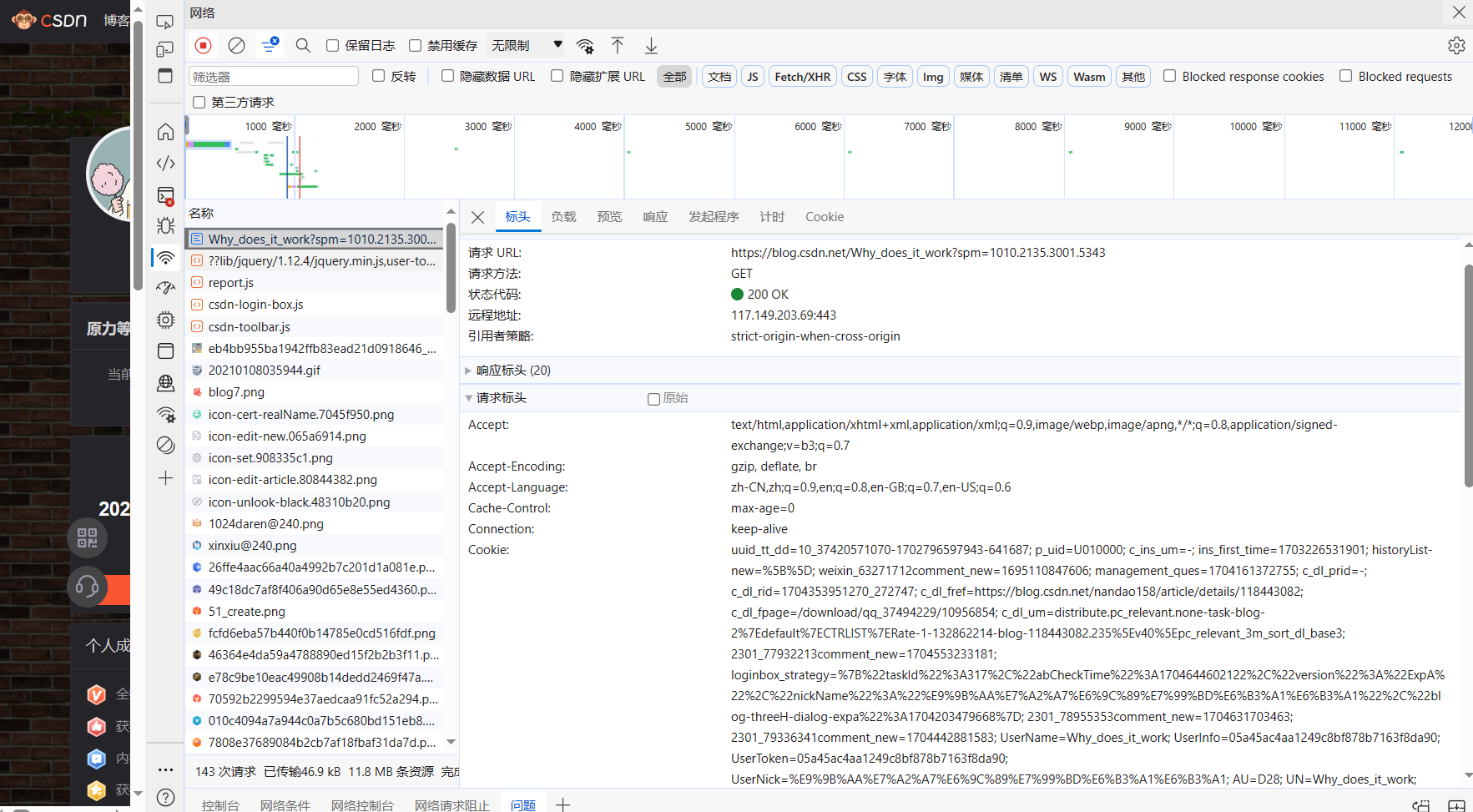
拿我的博客主页为例,用F12打开控制台,点击网络,找到cookie
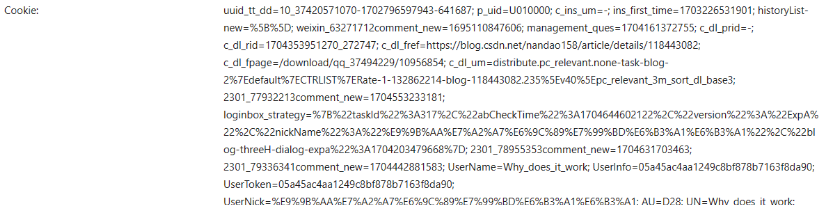
创建一个cookie文件,复制进去
然后从给定的cookie_path文件中读取cookie信息,并将其存储在一个字典中。函数返回这个字典。
具体如下
def get_headers(cookie_path:str):
cookies = {}
with open(cookie_path, "r", encoding="utf-8") as f:
cookie_list = f.readlines()
for line in cookie_list:
cookie = line.split(":")
cookies[cookie[0]] = str(cookie[1]).strip()
return cookies
网站爬取与启动
CSDN爬虫
class CSDN(object):
def init(self, username, folder_name, cookie_path):
# self.headers = {
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
# }
self.headers = get_headers(cookie_path)
self.s = requests.Session()
self.username = username
self.TaskQueue = TaskQueue()
self.folder_name = folder_name
self.url_num = 1
headers: 这是一个字典,用于存储请求头信息。s: 这是一个会话对象,用于保持与CSDN网站的连接。username: 这是一个字符串,表示CSDN用户的用户名。TaskQueue: 这是一个任务队列对象,用于管理待访问的URL。folder_name: 这是一个字符串,表示保存爬取结果的文件夹名称。_name: 这是一个整数,表示当前保存的文件夹编号。_num: 这是一个整数,表示当前爬取的页面编号。
爬虫启动
def start(self):num = 0articles = [None]while len(articles) > 0:num += 1url = u'https://blog.csdn.net/' + self.username + '/article/list/' + str(num)response = self.s.get(url=url, headers=self.headers)html = response.textsoup = BeautifulSoup(html, "html.parser")articles = soup.find_all('div', attrs={"class":"article-item-box csdn-tracking-statistics"})for article in articles:article_title = article.a.text.strip().replace(' ',':')article_href = article.a['href']with ensure_memory(sys.getsizeof(self.TaskQueue.UnVisitedList)):self.TaskQueue.InsertUnVisitedList([article_title, article_href])
- 初始化一个变量
num,用于表示当前访问的文章页码。- 初始化一个列表
articles,用于存储待处理的文章信息。- 使用一个
while循环,当articles列表中的文章数量大于0时,执行循环体。- 更新
num变量,表示当前访问的文章页码。- 构造一个URL,该URL包含当前用户名、文章列表和页码。
- 使用
requests库发送请求,并获取响应。- 使用
BeautifulSoup库解析HTML内容,并提取相关的文章信息。- 遍历提取到的文章列表,提取文章标题和链接。
- 将文章标题和链接插入到任务队列
TaskQueue的未访问列表中。
将爬取内容存到文件中
- 打印爬取开始的信息。
- 计算并获取存储博文列表的文件路径。
- 使用
open函数以写入模式打开文件,并设置文件编码为utf-8。 - 写入文件头,包括用户名和博文列表。
- 遍历任务队列
TaskQueue中的未访问列表,将每篇文章的标题和链接写入文件。 - 在每篇文章标题和链接之间添加一个空行,以提高可读性。
- 更新一个变量
_num,用于表示当前已写入的文章序号。
代码如下
def write_readme(self):print("+"*100)print("[++] 开始爬取 {} 的博文 ......".format(self.username))print("+"*100)reademe_path = result_file(self.username,file_name="README.md",folder_name=self.folder_name)with open(reademe_path,'w', encoding='utf-8') as reademe_file:readme_head = "# " + self.username + " 的博文\n"reademe_file.write(readme_head)for [article_title,article_href] in self.TaskQueue.UnVisitedList[::-1]:text = str(self.url_num) + '. [' + article_title + ']('+ article_href +')\n'reademe_file.write(text)self.url_num += 1self.url_num = 1
列表文件生成之后,我们要对每一个链接进行处理
def get_all_articles(self):try:while True:[article_title,article_href] = self.TaskQueue.PopUnVisitedList()try:file_name = re.sub(r'[\/::*?"<>|]','-', article_title) + ".md"artical_path = result_file(folder_username=self.username, file_name=file_name, folder_name=self.folder_name)md_head = "# " + article_title + "\n"md = md_head + self.get_md(article_href)print("[++++] 正在处理URL:{}".format(article_href))with open(artical_path, "w", encoding="utf-8") as artical_file:artical_file.write(md)except Exception:print("[----] 处理URL异常:{}".format(article_href))self.url_num += 1except Exception:pass
- 从任务队列
TaskQueue中弹出未访问的文章链接和标题。- 尝试获取一个文件名,该文件名由文章标题生成,以避免文件名中的特殊字符。
- 计算并获取存储文章的文件路径。
- 创建一个Markdown文件头,包括文章标题。
- 获取文章内容,并将其添加到Markdown文件头。
- 将处理后的Markdown内容写入文件。
- 打印正在处理的URL。
- 更新一个变量
_num,用于表示已处理的文章数量。
多线程爬虫
实现多线程爬虫,以提高爬取速度。在循环中,会不断地创建新的线程来处理任务队列中的任务,直到任务队列为空。这样可以充分利用计算机的多核性能,提高爬取效率。
def muti_spider(self, thread_num):while self.TaskQueue.getUnVisitedListLength() > 0:thread_list = []for i in range(thread_num):th = threading.Thread(target=self.get_all_articles)thread_list.append(th)for th in thread_list:th.start()
我们在多线程爬虫的时候,要保证系统有足够的内存空间。通过使用contextlib库的contextmanager装饰器,可以轻松地实现上下文管理,确保内存分配和释放的正确性。
lock = threading.Lock()
total_mem= 1024 * 1024 * 500 #500MB spare memory
@contextlib.contextmanager
def ensure_memory(size):global total_memwhile 1:with lock:if total_mem > size:total_mem-= sizebreaktime.sleep(5)yield with lock:total_mem += size
在__enter__方法中,使用with lock语句模拟加锁,确保在执行内存分配操作时,不会发生竞争条件。然后判断当前系统的总内存是否大于所需分配的内存空间,如果大于,则减少总内存,并跳出循环。
选择要爬取的用户
def spider_user(username: str, cookie_path:str, thread_num: int = 10, folder_name: str = "articles"):if not os.path.exists(folder_name):os.makedirs(folder_name)csdn = CSDN(username, folder_name, cookie_path)csdn.start()th1 = threading.Thread(target=csdn.write_readme)th1.start()th2 = threading.Thread(target=csdn.muti_spider, args=(thread_num,))th2.start()
- 检查文件夹
folder_name是否存在,如果不存在,则创建该文件夹。 - 创建一个CSDN对象
csdn,用于模拟用户登录和爬取文章。 - 创建一个线程
th1,目标为_readme。 - 创建一个线程
th2,目标为_spider,并传入参数(thread_num,),用于指定线程数量。
这个函数的目的是爬取指定用户的CSDN博客文章,并将文章保存到文件夹folder_name中。通过创建线程,可以实现多线程爬虫,提高爬取速度。
线程池
线程池存储爬虫代理 IP 的数据库或集合。在网络爬虫中,由于目标网站可能会针对同一 IP 地址的访问频率进行限制,因此需要使用池来存储多个代理 IP 地址,以实现 IP 地址的轮换和代理。池可以提高爬虫的稳定性和效率,避免因为 IP 地址被封禁而导致的爬虫失效。
爬虫和池是爬虫领域中不可或缺的概念,池能够提高爬虫的稳定性和效率,同时帮助爬虫更好地适应目标的反爬虫策略。

相关文章:
Python多线程爬虫——数据分析项目实现详解
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z 「个人网站」:雪碧的个人网站 ChatGPT体验地址 文章目录 前言爬虫获取cookie网站爬取与启动CS…...
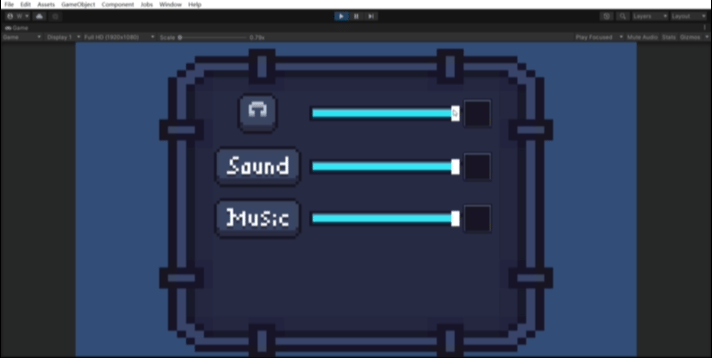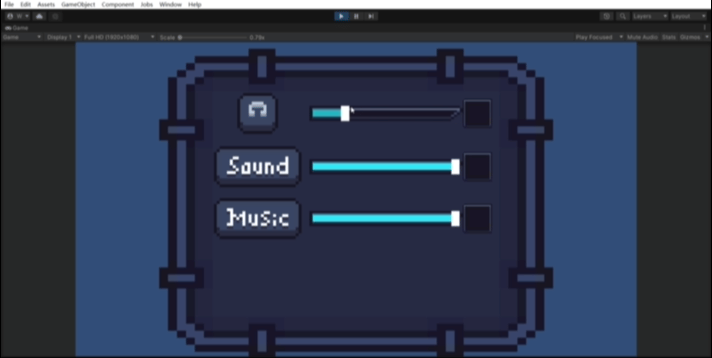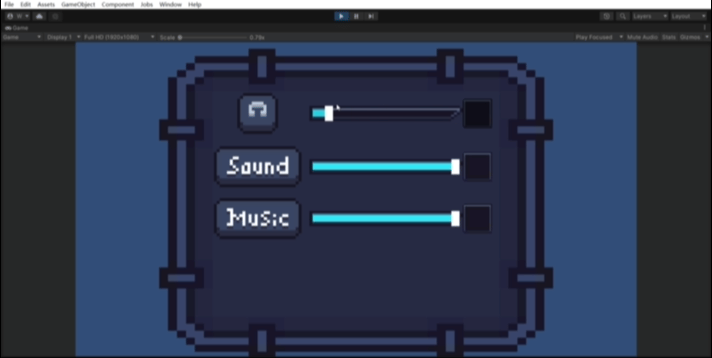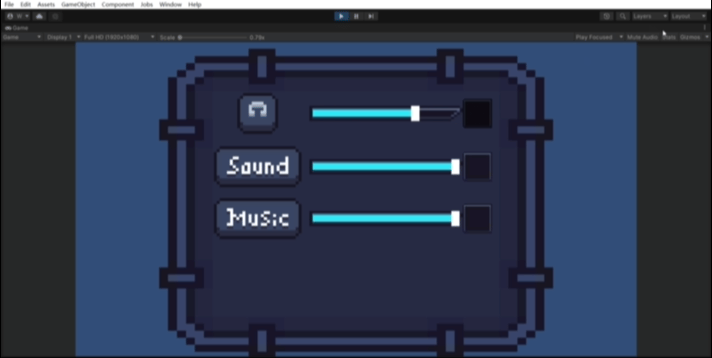
unity全局音量管理/全局音量设置与音量设置界面(含静音功能)
前言 本文将会介绍如何使用audiomixer实现全局音量控制,并且会介绍如何实现游戏内的含静音功能的音量设置界面。 本人也是个初学者,在看过一些关于音量管理的教程后,发现使用audiomixer实现全局音量控制可能是最方便、功能最完备、强大的&a…...

C++ vector 数组转换、查找、最大最小值、排序、排行的几种用法
C vector中常用到排序、取最值,一些场景可能还会要计算某个元素的排行,以下就是一些实际例子,精简、有效。 【1】会涉及到数组转vector: vector<int> v(arr, arr N); // N为数组size,可用sizeof(arr)/sizeof(i…...
vmware 安装Rocky-9.3系统
安装系统截图 安装完成,启动 查看版本和内核 开启远程登陆授权 1、编辑配置文件 #提升权限,输入su,并输入密码 su #编辑ssh文件开启root远程登陆 vi /etc/ssh/sshd_config找到以下内容:#PermitRootLogin prohibit-password 添加:…...

C++提高编程——模板
本专栏记录C学习过程包括C基础以及数据结构和算法,其中第一部分计划时间一个月,主要跟着黑马视频教程,学习路线如下,不定时更新,欢迎关注。 当前章节处于: ---------第1阶段-C基础入门 ---------第2阶段实战…...

单线程、同步、异步、预解析、作用域、隐式全局变量、对象创建、new
单线程 进程 cpu 资源分配的最小单位一个进程可以有多个线程 线程 cpu调度的最小单位线程建立在进程的建立基础上的一次程序的运行单位 线程分为:单线程 多线程 单线程:js是单线程 (同一个时间只能完成一个任务)多线程&…...

《设计模式的艺术》笔记 - 外观模式
介绍 外观模式中外部与一个子系统的通信通过一个统一的外观角色进行,为子系统中的一组接口提供一个一致的入口。外观模式定义了一个高层接口,这个接口使得子系统更加容易使用。外观模式又称为门面模式,它是一种对象结构型模式。 实现 myclas…...

sql 查询时间范围内的数据
要查询特定时间范围内的数据,您可以使用 SQL 中的 BETWEEN 运算符。以下是一个示例查询,它从名为 your_table 的表中检索在 start_date 和 end_date 之间创建的所有记录: SELECT * FROM your_table WHERE created_date BETWEEN start_date AN…...

TestNG中的@BeforeSuite注释
目录 什么是BeforeSuite注解? BeforeSuite带注释的方法何时执行? BeforeSuite annotation有什么用? 所以,是时候集思广益了 我们可以在一个类中使用多个BeforeSuite注释方法吗? BeforeSuite放在超类上时如何工作…...

[学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs
RNN存在信息瓶颈的问题。 注意力机制的核心就是在decoder的每一步,都把encoder的所有向量提供给decoder模型。 具体的例子 先获得encoder隐向量的一个注意力分数。 注意力机制的各种变体 一:直接点积 二:中间乘以一个矩阵 三:…...

图像处理工具包Pillow的使用分享
Pillow 是 Python 中一个流行的图像处理库,它是 PIL(Python Imaging Library)的一个友好的分支版本。Pillow 提供了许多功能,使得图像处理变得容易和方便。下面是一些基本用法和示例: 安装 Pillow 首先,你…...

python进程间通信——命名管道(Named Pipe、FIFO)
文章目录 Python中的命名管道:深入理解进程间通信1. 命名管道简介2. 创建和删除命名管道3. 写入命名管道4. 读取命名管道5. 示例:进程间通信write_to_pipe.pyread_from_pipe.py测试运行 6. 注意事项和限制命名管道的半双工机制命名管道读写任意一方未打开…...

03 OSPF 学习大纲
参考文章 1 初步认识OSPF的大致内容(第三课)-CSDN博客 2...

HJ7 取近似值【C语言】
【华为机试题 HJ7】取近似值 描述输入描述:输出描述:示例1示例2参考代码1参考代码2参考代码3描述 写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于 0.5 ,向上取整;小于 0.5 ,则向下取整。 数据范围:保证输入的数字在 32 位浮点数范…...
php基础学习之常量
php常量的基本概念 常量是在程序运行中的一种不可改变的量(数据),常量一旦定义,通常不可改变(用户级别)。 php常量的定义形式 使用define函数:define("常量名字", 常量值);使用cons…...

2024最新面试经验分享
目录 重点掌握的知识点JavaMySQLRedis 微服务分布式系统项目亮点场景题/设计题短链抢红包多租户 开放性问题自我介绍为什么跳槽团队规模如何带团队如何看待加班职业规划 主要针对Java程序员,当然也包含一些通用的内容。 重点掌握的知识点 需要重点掌握的知识点必须…...
《WebKit 技术内幕》之八(1):硬件加速机制
《WebKit 技术内幕》之八(1):硬件加速机制 1 硬件加速基础 1.1 概念 这里说的硬件加速技术是指使用GPU的硬件能力来帮助渲染网页,因为GPU的作用主要是用来绘制3D图形并且性能特别好,这是它的专长所在,它…...
子表单扫码录入,显著节省填写时间
01/17 主要更新模块概览 扫 码 识 别 新 增 字 号 登 录 配 置 匹 配 搜 素 扫码识别 路径:表单设计 >> 字段属性 功能简介 之前对子表单扫码录入,是单独在组件内设置扫码,操作需重新点击扫码功能,手工新增子表数据&a…...

【Redis】Ubuntu安装配置
目录 一、安装Redis 1.1 从APT仓库安装Redis 二、启动&关闭&重启 三、Redis核心配置 3.1 CONFIG命令 3.2 redis.conf文件说明 一、安装Redis 1.1 从APT仓库安装Redis 从APT仓库可以安装最新的Redis稳定版,步骤如下: 【1】安装需要用到的…...

idea远程服务调试
1. 配置idea远程服务调试 这里以 idea 新 ui 为例,首先点击上面的 debug 旁边的三个小圆点,然后在弹出的框框中选择 “Edit”,如下图所示。 然后进入到打开的界面后,点击左上角的 “” 进行添加,找到 “Remote JVM De…...

使用Taotoken后我们如何清晰观测各模型的用量与延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后我们如何清晰观测各模型的用量与延迟表现 当团队在项目中同时接入多个大语言模型时,一个常见的困扰随之…...

抖音视频收藏革命:从水印困扰到纯净收藏的完美蜕变
抖音视频收藏革命:从水印困扰到纯净收藏的完美蜕变 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾经在抖…...

Legacy iOS Kit:让旧款iOS设备重获新生的终极免费工具
Legacy iOS Kit:让旧款iOS设备重获新生的终极免费工具 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

JetBrains IDE 试用期重置指南:3种简单方法恢复30天免费使用
JetBrains IDE 试用期重置指南:3种简单方法恢复30天免费使用 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在紧张的项目开发中,突然发现你的 JetBrains IDE(如 Int…...
实战:从自然行为到工程优化)
【智能算法】长鼻浣熊优化算法(COA)实战:从自然行为到工程优化
1. 长鼻浣熊优化算法(COA)初探 第一次听说长鼻浣熊优化算法(COA)时,我正为一个工业参数优化问题头疼不已。传统遗传算法在这个问题上陷入了局部最优,粒子群优化又收敛得太快。直到看到2023年M Dehghani团队…...

Hitboxer:3分钟解决游戏按键冲突的SOCD重映射利器
Hitboxer:3分钟解决游戏按键冲突的SOCD重映射利器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对战中因按键冲突而错失良机?Hitboxer是一款专业的SOCD按键重映射工…...

Linux密钥权限检查排查方法
Linux密钥权限检查排查方法本文面向具备一定 Linux 基础的技术人员,围绕密钥权限检查展开,重点讨论授权文件、私钥权限和登录失败。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

GPU缓存架构优化与AI加速器内存技术解析
1. GPU缓存架构与AI加速器的内存挑战在AI计算领域,内存子系统已成为制约性能提升的关键瓶颈。传统GPU采用的多级缓存架构(L1/L2/L3)虽然能有效缓解"内存墙"问题,但随着Transformer等大模型参数量呈指数级增长࿰…...

Arm SMIN指令解析:多向量最小值计算与优化实践
1. Arm SMIN指令深度解析:多向量最小值计算实战指南在Armv9架构的SVE2指令集中,SMIN(Signed Minimum)指令作为向量处理的重要成员,专门用于计算多组向量元素间的有符号最小值。我第一次在嵌入式AI项目中用到这个指令时…...

3分钟掌握无人机日志分析:免费在线工具UAV Log Viewer完全指南
3分钟掌握无人机日志分析:免费在线工具UAV Log Viewer完全指南 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 面对复杂的无人机飞行数据,你是否曾为分析日志文件…...