Kafka常见指令及监控程序介绍
kafka在流数据、IO削峰上非常有用,以下对于这款程序,做一些常见指令介绍。

下文使用–bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
需自行填写各自对应的集群IP和kafka的端口。
该写法 等同
–bootstrap-server localhost:9092
kafka启动
kafka-server-start.sh
## 以上启动方式会启用$KAFKA_HOME/config下的配置文件## 如果指定是kraft集群模式启动,需要指定kraft的配置文件路径
kafka-server-start.sh $KAFKA_HOME/config/kraft/server.propertieskafka停止
kafka-server-stop.sh查看Kafka运行状态
kafka-server-status.shkafka主题创建
kafka-topics.sh --create \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 \
--partitions 3 \
--replication-factor 2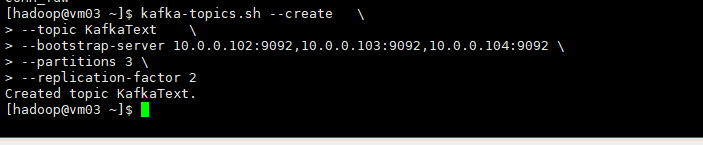
–create 指定创建主题的关键字
–topic 指定创建主题的主题名称
–bootstrap-server 指定创建主题的kafka集群列表
–partitions 指定分区数量
–replication-factor 指定副本数量
注:在主题名称中使用句点(‘.’)或下划线(‘_’)可能会导致与指标相关的问题。
查看kafka主题列表
kafka-topics.sh --list \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092查看kafka指定主题详情
kafka-topics.sh --describe \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
Topic: 主题的名称。
Partition Count: 分区的数量,指定了该主题被分割成的子集数目。
Replication Factor: 复制因子,表示每个分区的副本数量。
In-Sync Replicas (ISR): 在同步的副本数,指的是当前与主副本同步的副本数量。
Leader: 领导者副本,表示当前负责处理读写请求的副本。
Under-replicated Partitions: 未复制完成的分区数,指的是当前尚未达到指定复制因子的分区数量。
Isr Count: 在同步的副本数目,即处于同步状态的副本数。
Configurations: 主题的配置信息,包括一些自定义设置。
删除kafka指定主题
kafka-topics.sh --delete \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
修改主题分区数量
kafka-configs.sh --alter \
--entity-type topics \
--entity-name KafkaText \
--add-config max.message.bytes=2000000 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
## 这里add-config 可以指定相关参数进行重新赋值
这里新加入的参数可以在--describe 执行查看主题详情的时候,在Configurations项中找到。重复执行,会将参数值进行覆盖,相当于修改配置参数

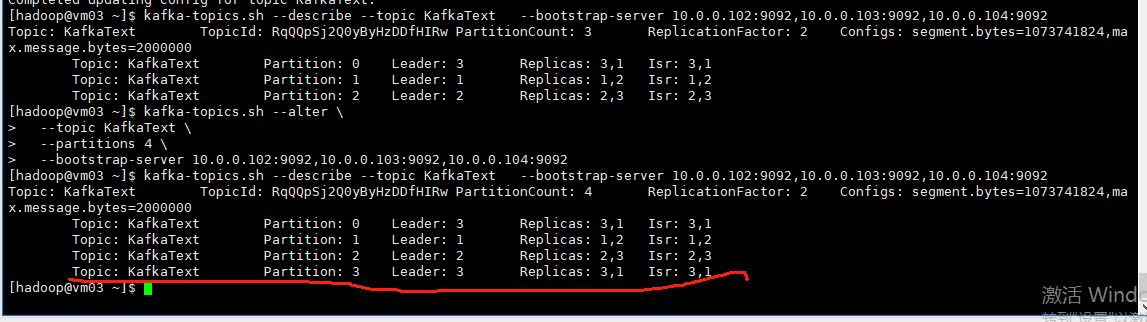
修主题分区数量
kafka-topics.sh --alter \--topic KafkaText \--partitions 4 \--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 这里新的分区数量只能增加、不能减少。
生产者发送消息
kafka-console-producer.sh --topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092会打开交互窗口,可以在交互窗口输入信息,以模拟信息推送
消费者消费信息(相当于查看主题KafkaText的元数据)
kafka-console-consumer.sh --topic KafkaText \
--from-beginning \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092会打开交互窗口,可以在交互窗口输入信息,以模拟信息接收
–from-beginning,它将会接收主题中所有分区的所有消息,包括在你启动消费者之前已发布到主题的消息
在消费组未命名消费组的情况下,每一次都会生成
console-consumer-<random_number>
##后缀增加一个五位数的随机数,以确保唯一。
该消费者的保留时间受到配置参数offsets.retention.minutes 的约束。
查看消费组列表
kafka-consumer-groups.sh --bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 --list查看消费者组消费情况
kafka-consumer-groups.sh --describe \
--group console-consumer-72017 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092这里–group 需要指定自己的消费组名称
查看特定主题元数据
kafka-console-consumer.sh --topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092参看配置参数信息
kafka-configs.sh --describe \
--entity-type brokers \
--entity-name 1 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 \
grep offsets.topic.retention.minutes–entity-name 指定kafka集群中节点的broker_id
|grep 后跟着参数名称的关键字
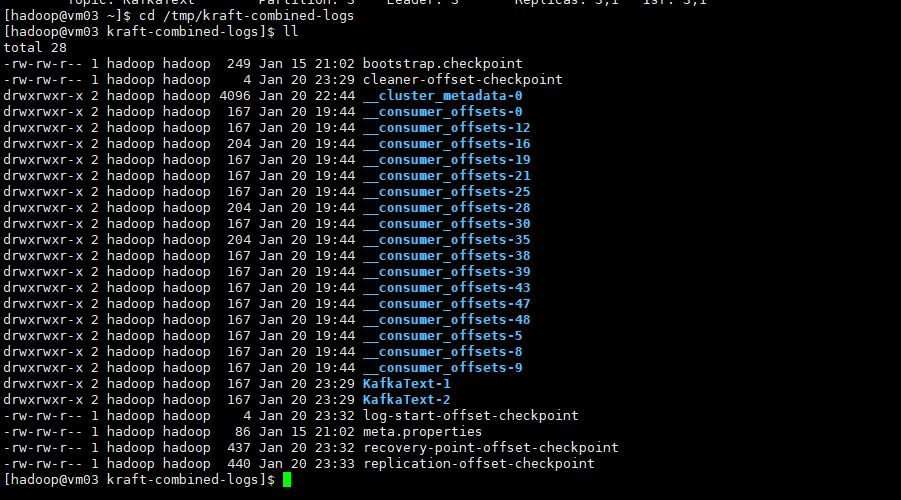
kafka 日志目录含义
在配置参数中log_dir 下默认得日志路径是/tmp/kraft-combined-logs
该路径下会生成很多文件
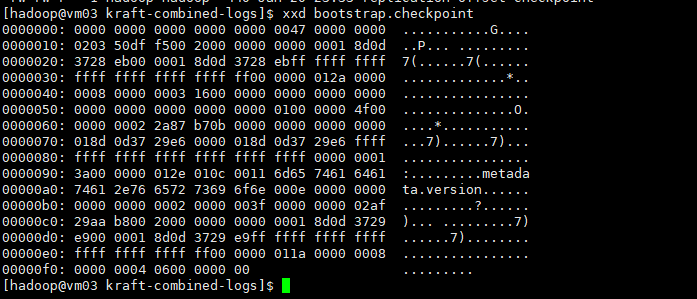
bootstrap.checkpoint:该文件与 Kafka 启动过程相关,可能包含有关启动过程状态或进度的信息。该文件为十六进制,使用xxd 进行查看
cleaner-offset-checkpoint:该文件存储由日志清理器使用的偏移量,表示它已清理的日志段的位置。日志清理器负责从日志段中删除过时的消息。默认情况下每隔10分钟会触发一次checkpoint
__cluster_metadata-0:此目录与集群元数据相关,主要是元数据得flush相关信息
__consumer_offsets-0, __consumer_offsets-12, …:
这些目录用于存储消费者组的偏移量。每个目录代表一个用于存储消费者组偏移量的分区。
KafkaText-0, KafkaText-2, …:
这些目录与 Kafka 主题相关。每个目录代表指定主题(例如,KafkaText)的一个分区,其中包含实际数据/消息的日志段。
log-start-offset-checkpoint:
该文件包含分区中第一条消息的偏移量。它表示从分区中读取消息的起始点。
meta.properties:
该文件包含 Kafka 本broker的属性。
recovery-point-offset-checkpoint:
该文件存储由所有同步副本完全复制并确认的最后一条消息的偏移量。在恢复期间,用于确定复制的起始点。
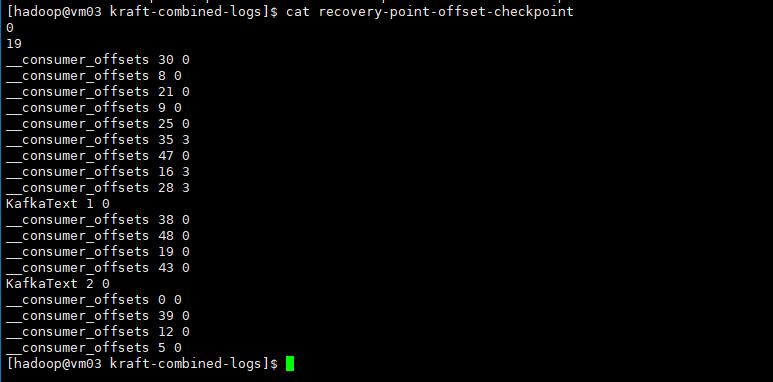
第一行的 0:
表示 __consumer_offsets 分区 0 的复制状态的起始点。
第二行的 19:
表示 __consumer_offsets 分区 19 的复制状态的恢复点偏移量。即,表示 __consumer_offsets 分区 19 已成功复制并确认的最后一个消息的偏移量。
从第三行开始的内容:
每一行表示一个分区的信息,包括分区名、复制状态的起始点和恢复点偏移量。
例如,__consumer_offsets 30 0 表示 __consumer_offsets 分区 30 的复制状态,起始点偏移量为 0,恢复点偏移量也为 0。
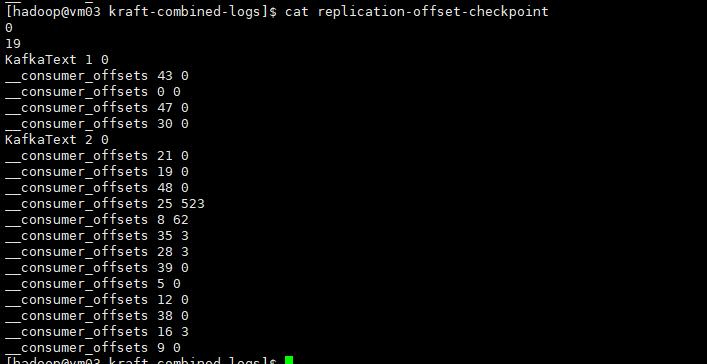
replication-offset-checkpoint:
该文件存储分区的高水位偏移量。它表示最后一条成功复制的消息的偏移量。这些文件和目录对于 Kafka 的正常运行非常重要,它们存储有关主题、消费者组偏移量、日志清理和复制等方面的各种元数据和信息。
第一行的 0:表示 __consumer_offsets 分区 0 的复制状态的起始点。
第二行的 19:表示 __consumer_offsets 分区 19 的复制状态的高水位偏移量。即,表示 __consumer_offsets 分区 19 已成功复制并确认的最后一个消息的偏移量。
从第三行开始的内容:每一行表示一个分区的复制状态,包括分区名和高水位偏移量。
例如,__consumer_offsets 43 0 表示 __consumer_offsets 分区 43 的复制状态,高水位偏移量为 0。
KafkaText 0 9 表示 KafkaText 分区 0 的复制状态,高水位偏移量为 9。
写了这么多,全是指令代码。大家肯定觉得很麻烦,如果有一款可可视化工具就好了。以下推荐给大家两款软件。
kafka可视化工具
kafka tool
http://www.kafkatool.com/download.html
目前对于仅支持到kafka3.6版本,必须是zookeeper集群管理下才可以支持,如果使用得kraft集群管理,将无法使用。
kafka-ui-lite
称为史上最轻便好用的kafka ui界面客户端工具,可以在生产消息、消费消息、管理topic、管理group;可以支持管理多个kafka集群
部署简便,可以一键启动,不需要配置数据库、不需要搭建web容器
支持zookeeper ui界面化操作;支持多环境管理
支持redis ui界面化操作;支持多环境管理
支持权限控制,可以自定义不同环境的新增、修改、删除权限;默认分配只读权限,避免用户的误操作
kafka ui
https://github.com/provectus/kafka-ui/releases
是github上的高星开源工具,使用jar打包,可应用在docker环境和非docker环境。
安装kafka-ui ,需要以下依赖
java 17 package or newer
git installed
docker installed
java 17是必备项目
将kafka-ui部署在非kafka集群节点
without docker环境下安装演示
安装JDK17
wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.tar.gz解压
tar -zxf jdk-17_linux-x64_bin.tar.gz 替换到当前jdk8文件
[root@vm08 jdk]# ll
total 0
drwxr-xr-x. 9 root root 136 Jan 20 22:31 jdk-17.0.10
drwxr-xr-x. 8 10 143 255 Jul 22 2017 jdk1.8.0_144
drwxr-xr-x. 8 root root 255 Jan 20 22:23 jdk1.8.0_144_bak
[root@vm08 jdk]# rm -rf jdk1.8.0_144
[root@vm08 jdk]# mv jdk-17.0.10/ jdk1.8.0_144
[root@vm08 jdk]# java -version
java version "17.0.10" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 17.0.10+11-LTS-240)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.10+11-LTS-240, mixed mode, sharing)安装kafka-ui
wget https://github.com/provectus/kafka-ui/releases/download/v0.7.1/kafka-ui-api-v0.7.1.jar创建启动配置文件
vim application.yml根据个人情况,修改相应的节点信息
kafka:clusters:- name: kafka_clusterbootstrapServers: 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092metrics:port: 9094type: JMX
##配置该集群的 JMX 相关配置,如果没有可省略。(在启动 kafka 时,启动命令行前面添加 JMX_PORT=9094 )
##使用kraft集群管理,不需要再配置zookeeper信息
##如何管理多套集群,只需在本目录继续增加name不同的kafka相关信息
spring:jmx:enabled: truesecurity:user:name: vmpassword: vm
##web的登录用户和密码
auth:type: LOGIN_FORM #LOGIN_FORM # DISABLEDserver:port: 10000
##web端口启用端口信息logging:level:root: INFOcom.provectus: INFOreactor.netty.http.server.AccessLog: INFOmanagement:endpoint:info:enabled: truehealth:enabled: trueendpoints:web:exposure:include: "info,health"配置ip映射
vim /etc/hosts
##加入节点信息
10.0.0.102 vm02
10.0.0.103 vm03
10.0.0.104 vm04启动kafka-ui
java -Dspring.config.additional-location=/home/hadoop/application.yml \
--add-opens java.rmi/javax.rmi.ssl=ALL-UNNAMED -jar kafka-ui-api-v0.7.1.jar
出现以上页面说明kafka-ui启动成功
出现以上页面说明kafka集群链接成功
使用配置文件中的name/password 进行登录
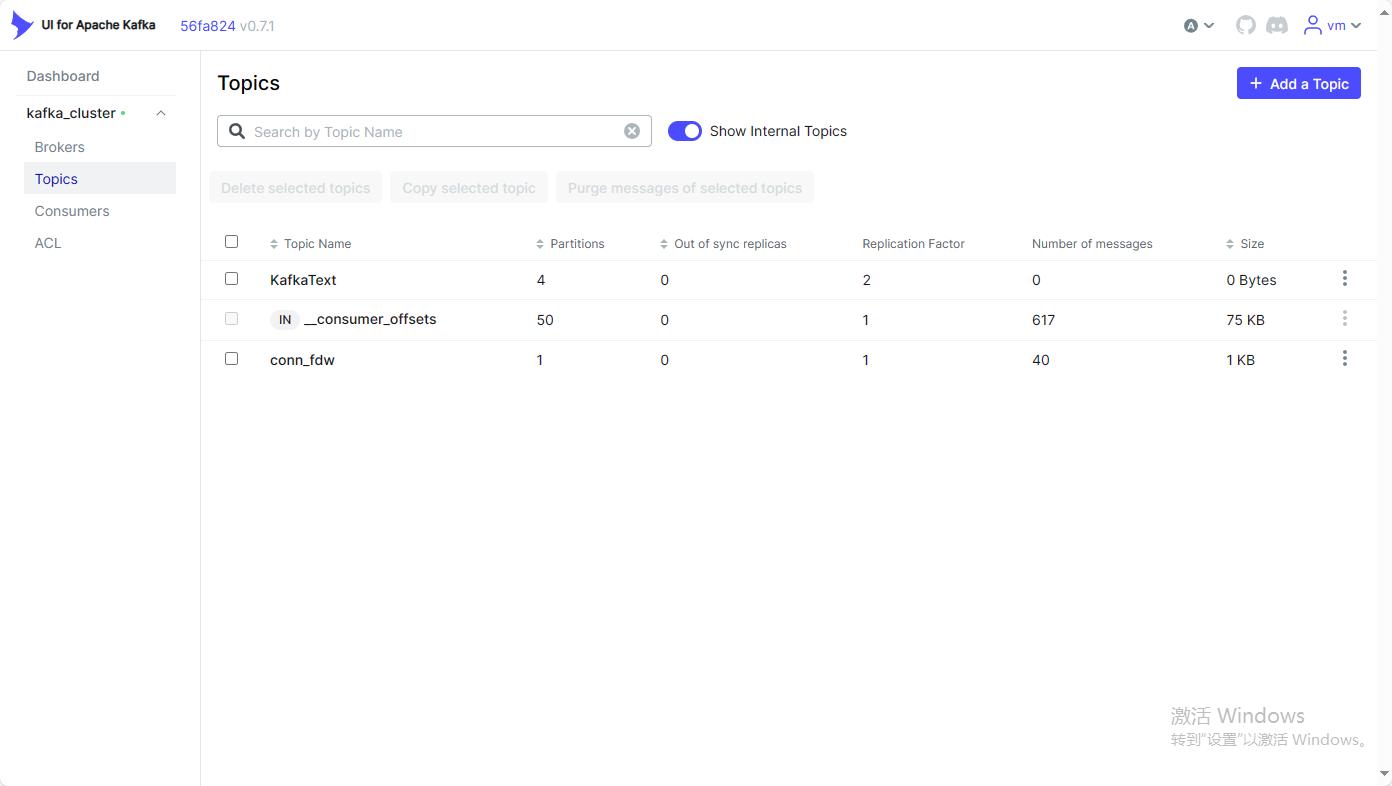
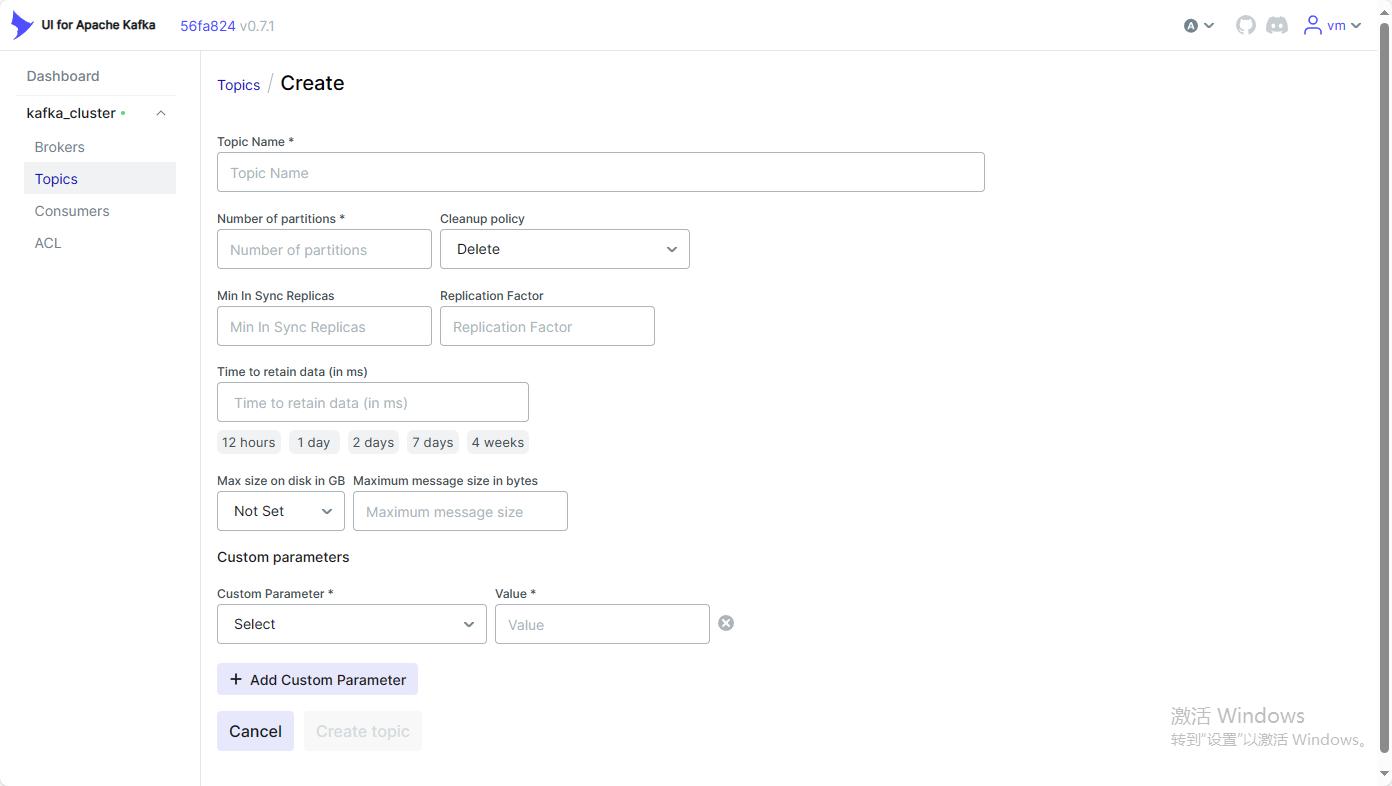
spring:jmx:enabled: truesecurity:user:name: vmpassword: vm登录到对应的页面可以查看相应的broker/topic/consumers/tcl等相关信息。
该页面可以执行创建topic等相关操作
合理使用工具 对于中间组件的学习会事半功倍。
相关文章:
Kafka常见指令及监控程序介绍
kafka在流数据、IO削峰上非常有用,以下对于这款程序,做一些常见指令介绍。 下文使用–bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 需自行填写各自对应的集群IP和kafka的端口。 该写法 等同 –bootstrap-server localhost:9092 …...
Docker 仓库管理
Docker 仓库管理 仓库(Repository)是集中存放镜像的地方。以下介绍一下 Docker Hub。当然不止 docker hub,只是远程的服务商不一样,操作都是一样的。 Docker Hub 目前 Docker 官方维护了一个公共仓库 Docker Hub。 大部分需求…...

LeetCode-410.分割数组的最大值
原题链接:https://leetcode.cn/problems/split-array-largest-sum/description 题面 给定一个非负整数数组 nums 和一个整数 k ,你需要将这个数组分成 k 个非空的连续子数组。设计一个算法使得这 k 个子数组各自和的最大值最小。 思路 数组定义ÿ…...

Redis和RediSearch的安装及使用
1. 安装要求 ReadiSearch要求Redis的版本在6.0以上RediSearch 要求使用 GNU Make 4.0 或更高版本 2. Redis的安装 查看redis的版本: redis-server --version或者,如果你已经启动了Redis服务器,你也可以使用redis-cli工具来获取版本信息&a…...

面向对象进阶--接口2
JDK8开始接口中新增的方法 接口中可以定义有方法体的方法(默认、静态)。 使用默认方法的作用:解决接口升级的问题。 接口中默认方法的定义格式: public default返回值类型 方法名(参数列表){} 接口中默…...

提升认知,推荐15个面向开发者的中文播客
前言 对于科技从业者而言,无论是自学成才的程序员,还是行业资深人士,终身学习是很有必要的,尤其是在这样一个技术快速迭代更新的时代。 作为一个摆脱了时间和空间限制的资讯分享平台,播客(Podcast&#x…...

数据分析-Pandas如何整合多张数据表
数据分析-Pandas如何整合多张数据表 数据表,时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中表格重整,重新调整,重塑数据表是很重要的技巧,…...

配置redis挂载
1. 暂停和删除redis 2.创建文件夹 /usr/local/software/redis/6379/conf/ /usr/local/software/redis/6379/data/ 把redis-conf文件上传到conf文件夹中 3.配置网络 docker network create --driver bridge --subnet172.18.12.0/16 --gateway172.18.1.1 wn_docker_net 4.运…...

C++ 实现游戏(例如MC)键位显示
效果: 是不是有那味儿了? 显示AWSD,空格,Shift和左右键的按键情况以及左右键的CPS。 彩虹色轮廓,黑白填充。具有任务栏图标,可以随时关闭字体是Minecraft AE Pixel,如果你没有装(大…...
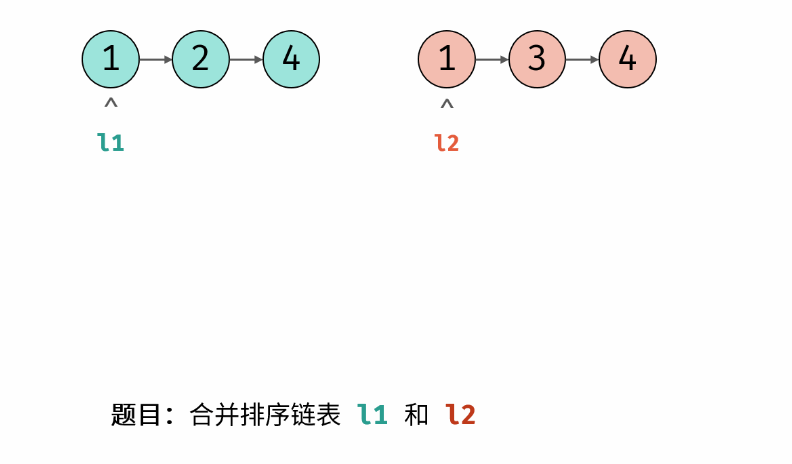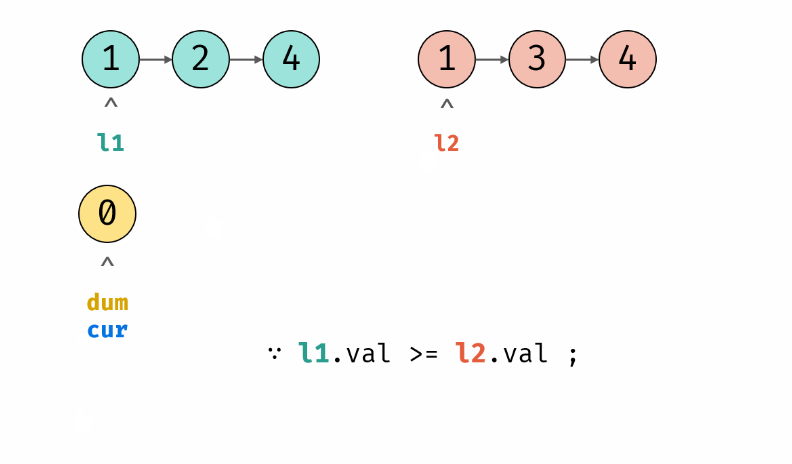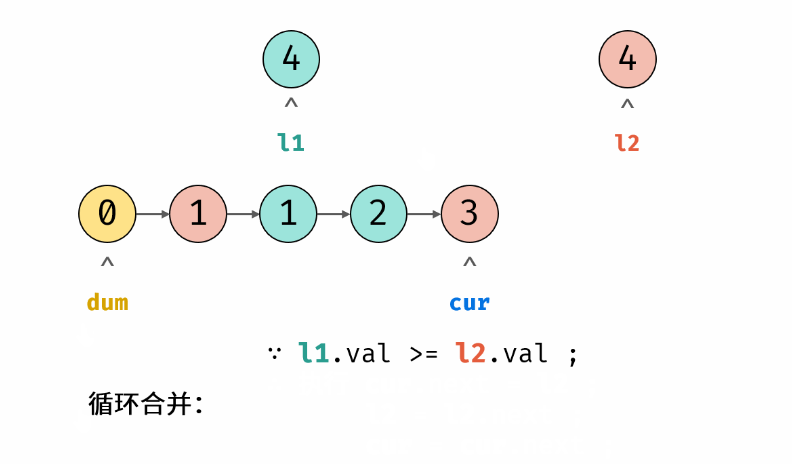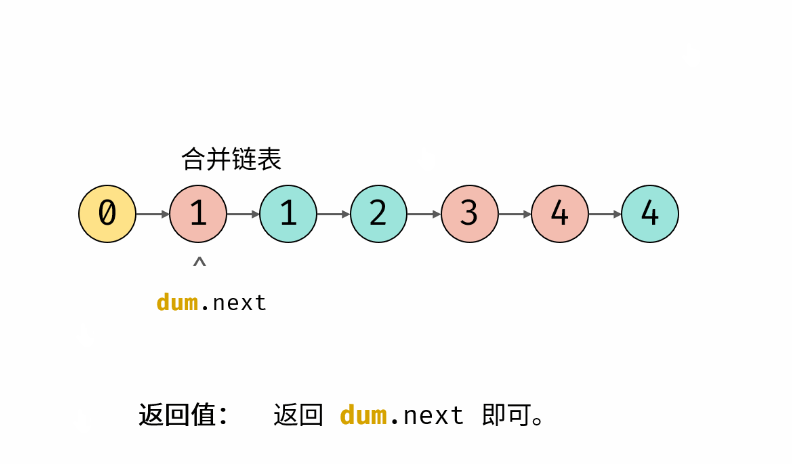
力扣hot100 合并两个有序链表 递归 双指针
Problem: 21. 合并两个有序链表 文章目录 💖 递归思路 💖 双指针 💖 递归 思路 👨🏫 参考地址 n , m n,m n,m 分别为 list1 和 list2 的元素个数 ⏰ 时间复杂度: O ( n m ) O(nm) O(nm) 🌎 空间复杂…...

10个常用python自动化脚本
大家好,Python凭借其简单和通用性,能够为解决每天重复同样的工作提供最佳方案。本文将探索10个Python脚本,这些脚本可以帮助自动化完成任务,提高工作效率。无论是开发者、数据分析师还是仅仅想简化工作流程的普通用户,…...
)
C++中函数的默认参数(缺省参数)
一、函数默认参数的概念 在函数声明时,预先对函数参数进行赋值,该参数即为函数的默认参数,也叫缺省参数。 如下函数func1包含默认参数,若调用函数func1时没有给函数传入实参,则默认实参为10086 void func1(int a 1…...
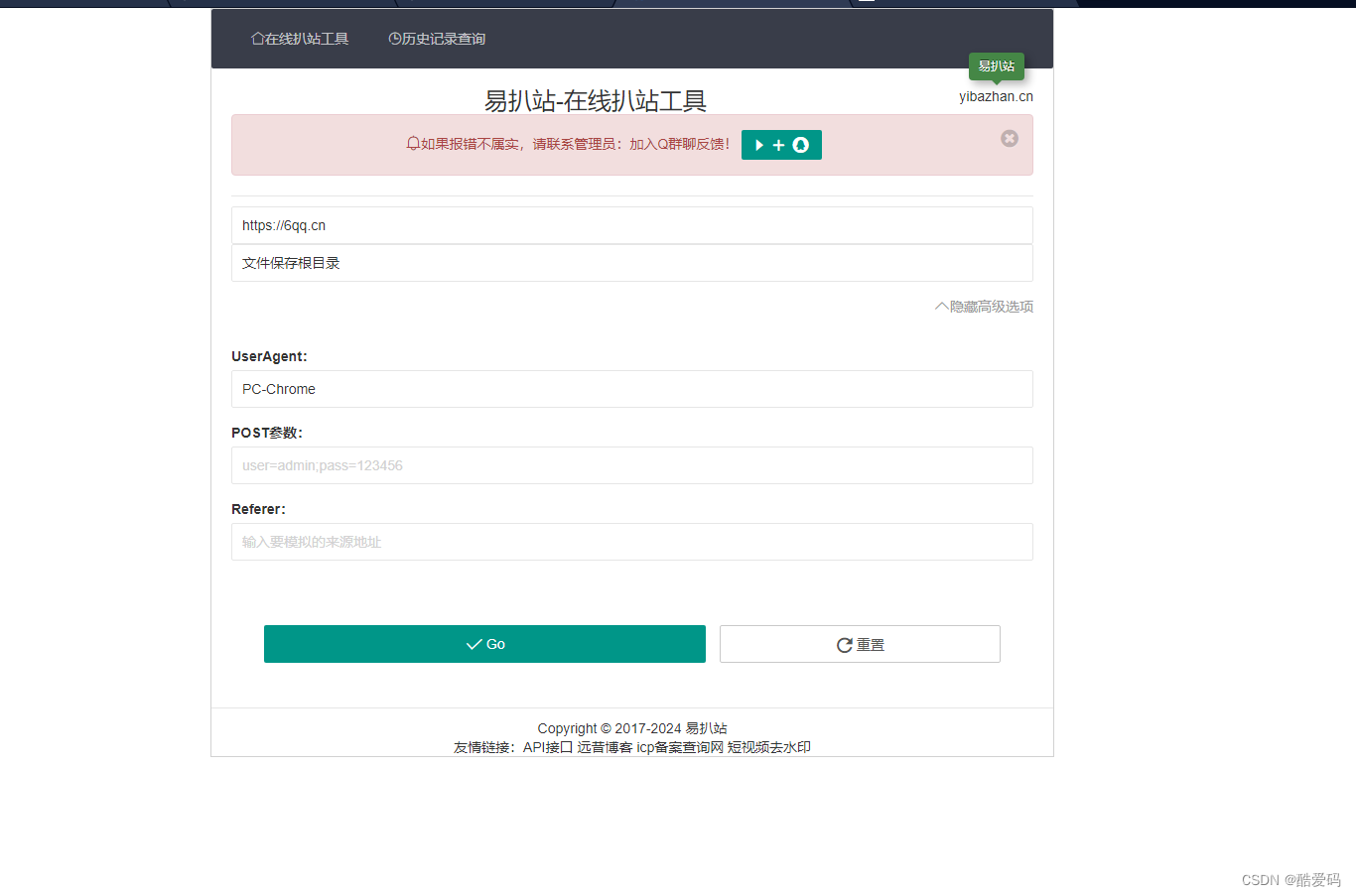
在线扒站网PHP源码-在线扒站工具网站源码
源码介绍 这是一款在线的网站模板下载程序,也就是我们常说的扒站工具,利用它我们可以很轻松的将别人的网站模板样式下载下来,这样就可以大大提高我们编写前端的速度了!注:扒取的任何站点不得用于商业、违法用途&#…...

vue+elementUI el-select 中 没有加clearable出现一个或者多个×清除图标问题
1、现象:下方截图多清除图标了 2、在全局common.scss文件中加一个下方的全局样式noClear 3、在多清除图标的组件上层div加noClear样式 4、清除图标去除成功...
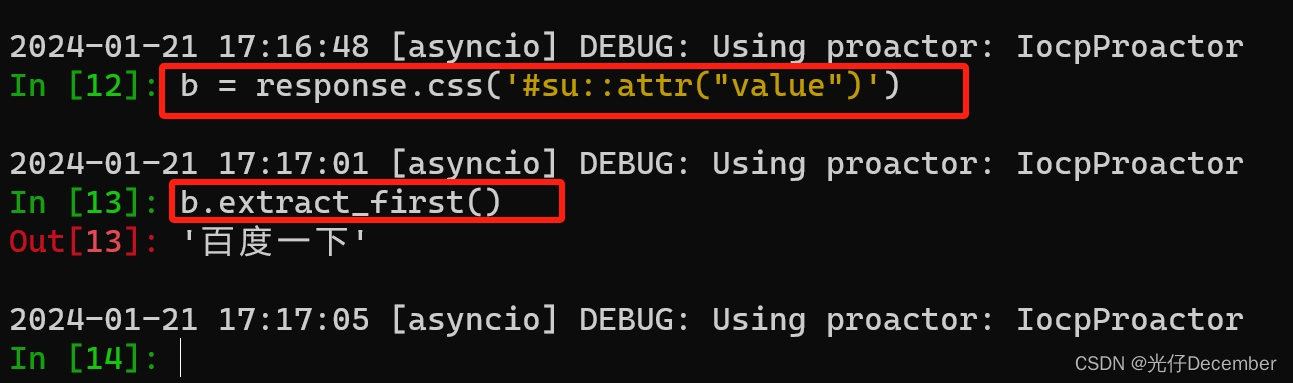
【Python从入门到进阶】47、Scrapy Shell的了解与应用
接上篇《46、58同城Scrapy项目案例介绍》 上一篇我们学习了58同城的Scrapy项目案例,并结合实际再次了项目结构以及代码逻辑的用法。本篇我们来学习Scrapy的一个终端命令行工具Scrapy Shell,并了解它是如何帮助我们更好的调试爬虫程序的。 一、Scrapy Sh…...

【ARM 嵌入式 编译系列 2.2 -- GCC 编译参数学习 assembler-with-cpp 使用介绍】
请阅读【嵌入式开发学习必备专栏 之 ARM GCC 编译专栏】 文章目录 GCC 编译选项 assembler-with-cpp GCC 编译选项 assembler-with-cpp 在 rt-thread 的编译脚本中经常会看到下面编译参数: AFLAGS -c DEVICE -x assembler-with-cpp -Wa,-mimplicit-itthumb a…...

深入理解java对象的内存布局
概述: 在HotSpot虚拟机里,对象在堆内存中的存储布局可以划分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。 在HotSpot虚拟机里,…...

MetaGPT中提到的SOP
MetaGPT框架中的提及的SOP概念指的是什么,有什么优点和缺点,为什么要使用SOP? 在MetaGPT框架中,SOP(Set of Procedures)指的是一套标准化的流程和步骤,用于指导模型完成特定任务。SOP可以帮助模型更好地理…...
第15届蓝桥杯嵌入式省赛准备第三天总结笔记(使用STM32cubeMX创建hal库工程+串口接收发送)
因为我是自己搞得板子,原本的下程序和串口1有问题,所以我用的是串口2,用的PA2和PA3 一,使用CubeMX配置串口 选择A开头的这个是异步通信。 配置串口参数,往届的题基本用的9600波特率,所以我这里设置为9600…...

centos安装redis,但是启动redis-server /home/redis/conf/redis7000.conf卡住,怎么解决
如果你在启动 Redis 服务器时发现过程卡住,这可能是由于几种不同的原因。下面是一些可能导致这种情况的原因以及相应的解决方法: 1. 后台启动 Redis 默认在前台运行。如果你在命令行启动 Redis 并且没有指定它在后台运行,它将在前台运行&am…...

JPEG2000在Matlab中的实现源码
JPEG2000在Matlab中的实现源码 【下载地址】JPEG2000在Matlab中的实现源码 JPEG2000在Matlab中的实现源码欢迎来到JPEG2000的Matlab实现资源页面 项目地址: https://gitcode.com/open-source-toolkit/0665cd 欢迎来到JPEG2000的Matlab实现资源页面。本资源旨在提供一套完…...

【免费下载】 Airplayer:苹果设备投屏的终极解决方案
Airplayer:苹果设备投屏的终极解决方案 【下载地址】Airplayer苹果投屏软件 Airplayer是一款专为苹果设备设计的高效投屏软件,它允许用户轻松地将iPhone或iPad屏幕的内容无线传输到电脑上显示。无论是播放视频、展示照片、进行会议演示还是游戏分享&…...
双频互补提精度 + 轻量分解保空间[特殊字符])
YOLOv8改进策略【卷积层】| TGRS2024 小波变换特征分解器(WTFD)双频互补提精度 + 轻量分解保空间[特殊字符]
一、本文介绍 本文记录的是利用WTFD小波变换特征分解器优化YOLOv8的目标检测网络模型。 WTFD(小波变换特征分解器)通过Haar小波变换双迭代分解与分通道轻量化特征映射结合,为纯空间域分割网络引入互补的频域特征分支。本文利用WTFD模块,先通过点卷积增强输入空间特征的非…...

第二章:Compose入门—声明式UI编程
第二章:Compose 入门 — 声明式 UI 编程 Compose 的核心理念:用 Kotlin 代码声明 UI,而不是用 XML 布局文件。 2.1 传统 View 系统 vs Compose 对比项传统 View 系统Jetpack ComposeUI 描述XML 布局文件Kotlin 代码状态更新findViewById 手…...

巅峰共鸣,实力同频|盖茨中国热烈祝贺张雪机车WSBK捷克站双冠耀世,改写37年垄断史!
引擎轰鸣震彻赛道,中国红闪耀世界舞台!2026 年 5 月 17 日,WSBK 捷克莫斯特站 WorldSSP 组别圆满落幕,中国品牌张雪机车再创历史,车手 Valentin Debise 驾驶自研 ZX820RR 赛车,包揽两回合冠军,斩…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍
告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 还在为直播观…...

从开题到终稿,9 款 AI 毕业论文工具横评:okbiye 领衔,帮你告别熬夜改稿循环
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 论文季的深夜,你是不是也对着空白文档反复刷新浏览器?开题报告被导师打回三次、文献综述东拼西凑逻辑不通、终稿排版…...

从医院PACS到你的Python脚本:手把手教你用pydicom库读写和修改DICOM文件
从医院PACS到Python脚本:pydicom实战医学影像处理指南 医学影像数据正以每年30%的速度增长,而DICOM作为医疗影像存储与传输的国际标准,承载着CT、MRI等设备产生的海量数据。在临床研究、AI模型训练和医疗信息化建设中,开发者经常需…...

手势识别技术全解析:从光学、雷达到IoT集成的实战指南
1. 项目概述:从“看见”到“看懂”,手势交互的破局点最近在跟进一个智能家居的集成项目,客户提了个挺有意思的需求:能不能让家里的灯、空调、窗帘,不用说话,也不用找手机,就靠“挥挥手”来控制&…...