特斯拉FSD的神经网络(Tesla 2022 AI Day)
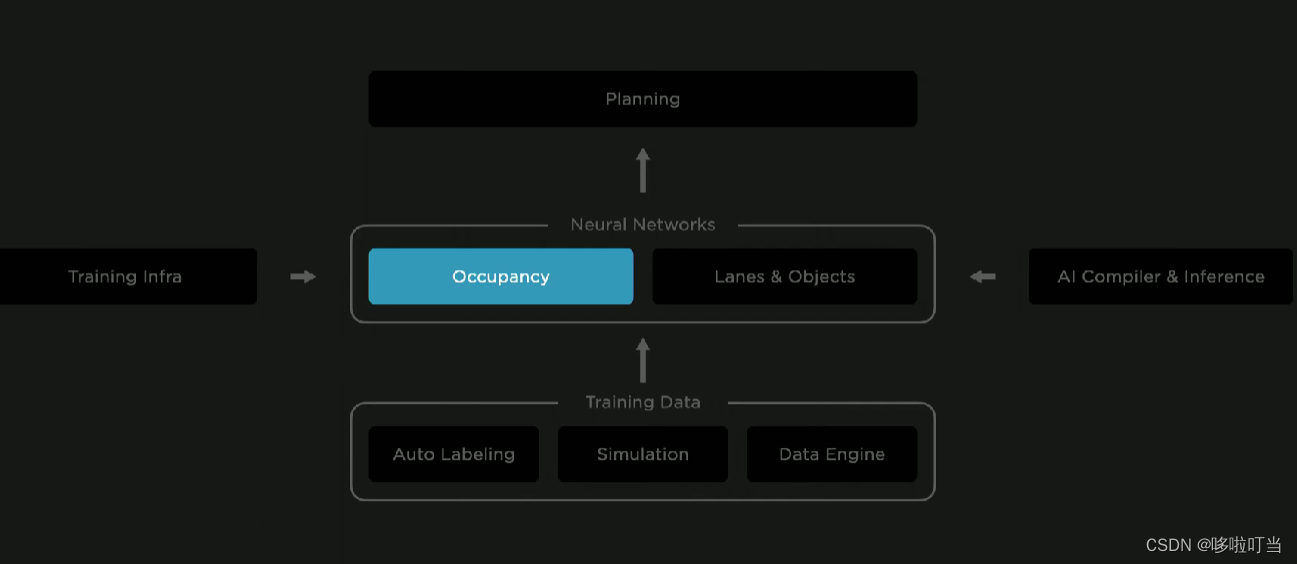
这是特斯拉的全自动驾驶(Full Self Driver)技术结构图,图中把自动驾驶模型拆分出分成了几个依赖的模块:
技术底座:自动标注技术处理大量数据,仿真技术创造图片数据,大数据引擎进不断地更新(大模型的数据基础)
核心部分:神经网络对场景的识别和理解(不仅仅是视觉技术的运用,结合了自然语言处理领域技术)
-
提出占有网络,这个网络能够实时地识别周围环境中各种物体的占有率,然后进行立体建模,体素化,还能够实现预测物体未来的运动趋势
-
然后进一步识别各种车道线,解决各种车道线交错的难题
增强神经网络的资源:AI训练集群,AI优化编译、接口
最终的目的是实现车端大模型直接处理原始的视频,做自动驾驶决策
基于Attention机制的占用网络
占有网络是特斯拉FSD中的核心部分,目的是识别周围物体占用空间中的部分,对空间做一个建模,并且区分物体,赋予不同的语义,然后还能够预测物体未来的变化趋势,即预测物体运动。
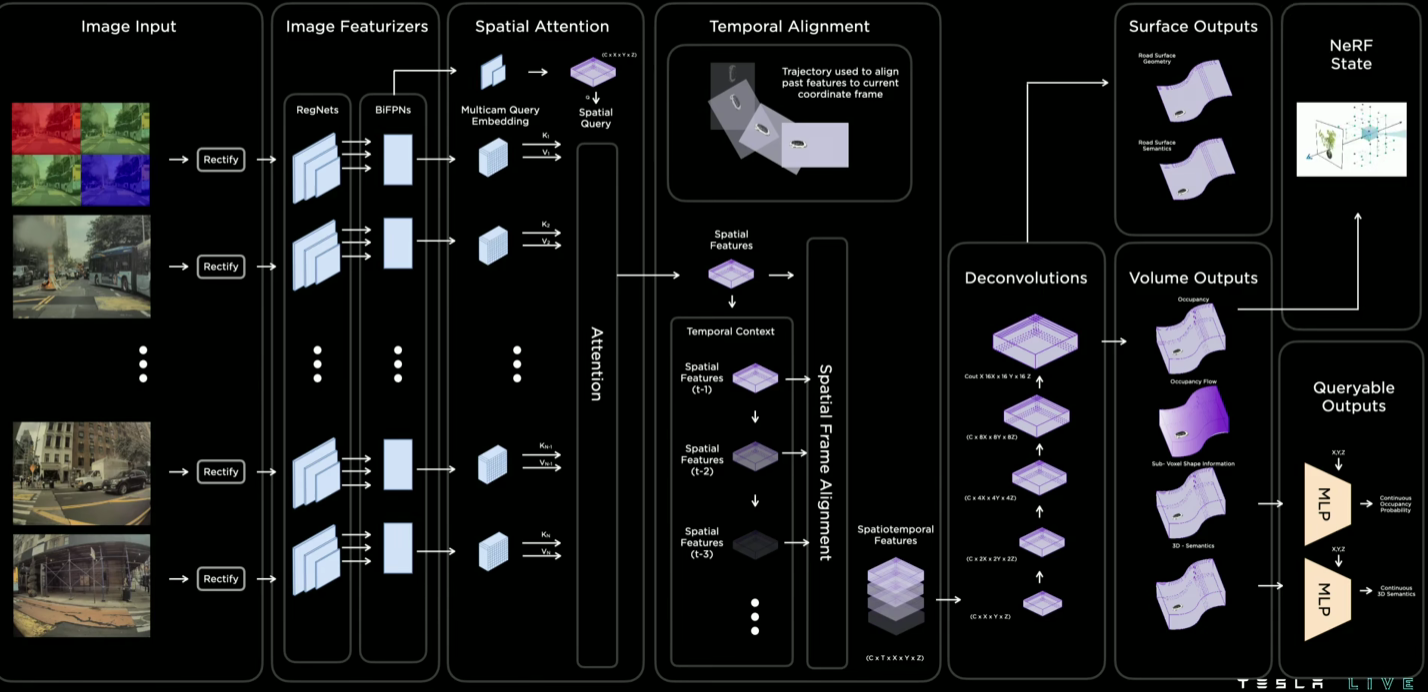
这个是Occupancy整体工作原理示意图,具体的流程如下:
-
输入图像校准,使用12位的原始图像,而非8位,这么做是因为可以获得更多的4位图像信息和16倍动态范围。
-
图片特征提取,用RegNet+BiFPN来实现图片的卷积特增提取和多尺度特征的提取结合
-
Spatial Attention空间注意力机制,这里先把图片加上相机特征做embedding,这样子Spatial Query就蕴含了空间位置信息,即含有三维空间特征的Query和二维的图片特征的Value做注意力机制。Attention实现了对多个相机的3D空间位置信息和2D图像的信息融合,模型从中学习对应的特征关系,最终输出高维的空间特征。
-
Temporal Alignment时空对齐,获得时空特征数据,利用行车的轨迹结合Attention得到的空间特征,做Channel维度的拼接,输出会进入反卷积的部分
-
反卷积和体积空间输出,把时空特征数据做反卷积,得到空间占用流的输出
-
上一步得到的体素化是不够精确的,于是进一步设计了一个Queryable MLP部分来提高分辨率。这部分其实是多层感知机的解码器,用于对于生成任务。主要流程就是生成每个体素特征图,并将其输入到 MLP 中,以此进一步生产获得连续的体素语义,占用流信息,这也实现了对未来行为的预测
-
在反卷积后还输出表面的信息,目的是为了在坡道,弯曲路面灯地方实现精确的控制。表面和体素化的输出预测不是独立的,内在他们其实是一致的
-
最后基于生成的体素化信息结合NERF模型可以尝试还原真实的场景,这还需要未来的研究和探索
在特斯拉介绍的占有网络中,中间特征的学习部分用到了Attention的思想,即Spatial Attention部分。当我们用卷积网络去识别图像时,卷积核识的都是图像的局部信息,但是其实图像识别的时候每个部分对于识别的正确性的影响是不同的。注意力机制的引入就是为了解决这个问题,其实就是模拟人看图片时能够注意到的重点,抛弃不重要的局部信息。
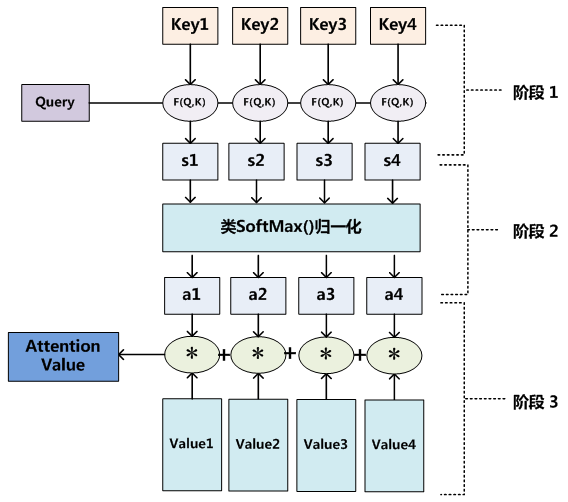
这个图片画出Attention计算的三个阶段,结合前面特斯拉的介绍可以进一步理解Attention被结合在占有网络这个视觉任务中的意义。找图片的特点其实就是找图片的图片的特征,构造Query矩阵来查找特征。占有网络这里用的是Spatial Query,就是结合了空间信息的一个询问。这里面比较特殊的地方是被询问的Value是来自图片,图片一开始是二维的,使用图片的特征信息都是源于二维的。通过Q*K做计算,然后更新Attention Value。这么做注意力机制的目的其实就是学习到他们之间的相关性,即三维特征和二维特征的联系,让模型学习图片中对应的物体占有的空间。学习到了这些就代表有了根据二维图片和相机空间位置对应三维空间中物体实际位置和体积的能力,依照这个思路特斯拉的占有网络才能有后面进一步训练和计算然以及体素化重建空间。

在上面这个图片中蓝色代表的是占有网络预测的部分。在这里占有网络很容易就预测到了大巴要转弯的动作且很好地拟合了体积,这在传统的视觉技术上是很复杂的问题,可以看作是多个层长方体的拟合,但是这个地方简化成了空间被占有的部分,模型就更容易理解和拟合了。对于坡面也是如此,占有网络可以更快更准确实现地面的预测。
来语言模型的灵感

之前的神经网络已经实现了分割当前行驶的车道线和其他的车道线,这个是在汽车驾驶环境比较单一的时候才比较好用,比如高速公路保持行驶。但是现实中会有很多的线条交错的场景,比如在一个多分叉的路口,这种地方分割、识别车道线就不好用了,只有进一步研究车道线之间的拓扑连接关系,才能实现更好的规划。
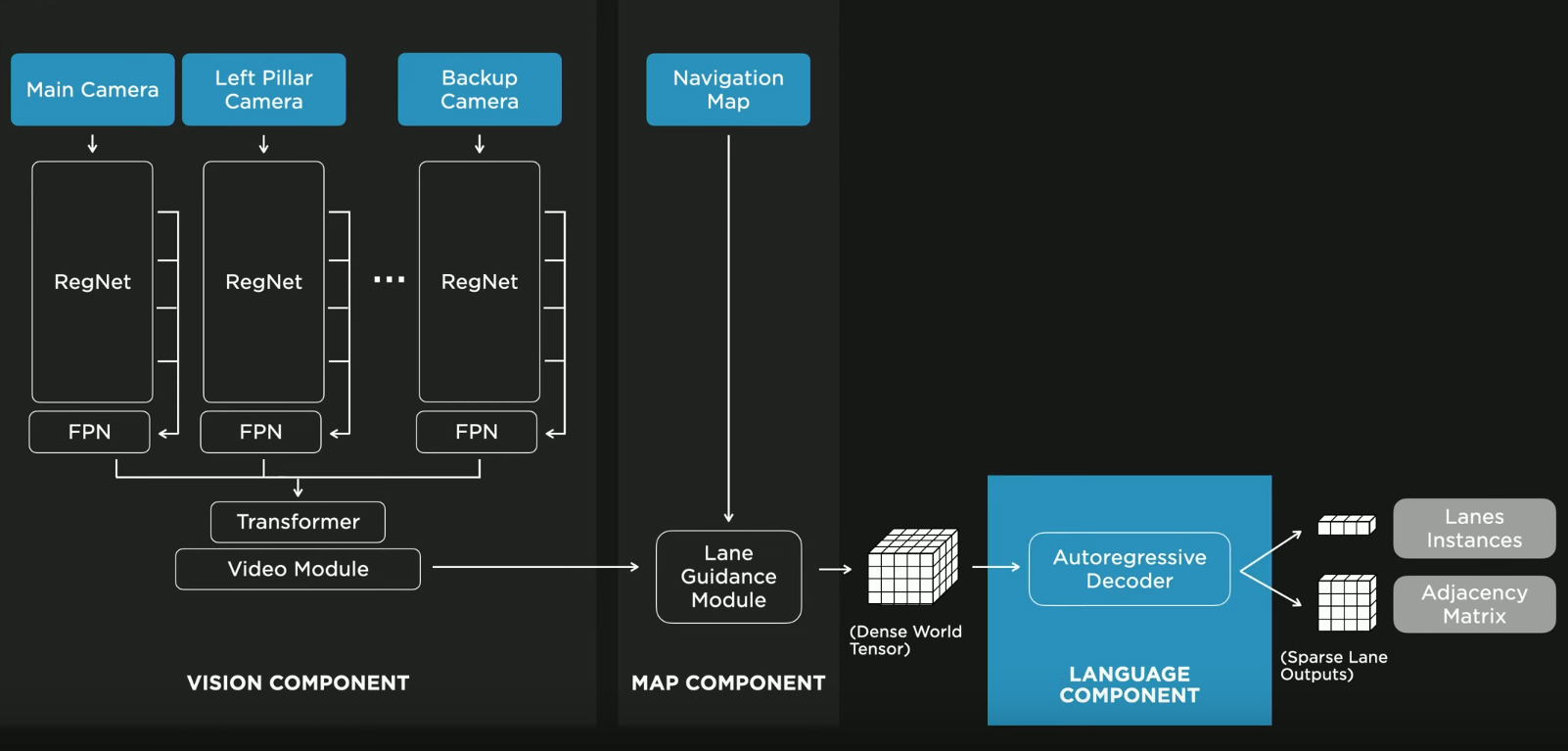
特斯拉车道神经网络Lanes Neural Network示意图,网络主要是由三个部分组成:Vision,Map,Language。
Vision部分是采集车身上的摄像头的视频流做一个编码,并且希望他产生丰富的视觉内容,所以这里用到了卷积层,注意力层等提取特征,任何用到Transformer做编码。
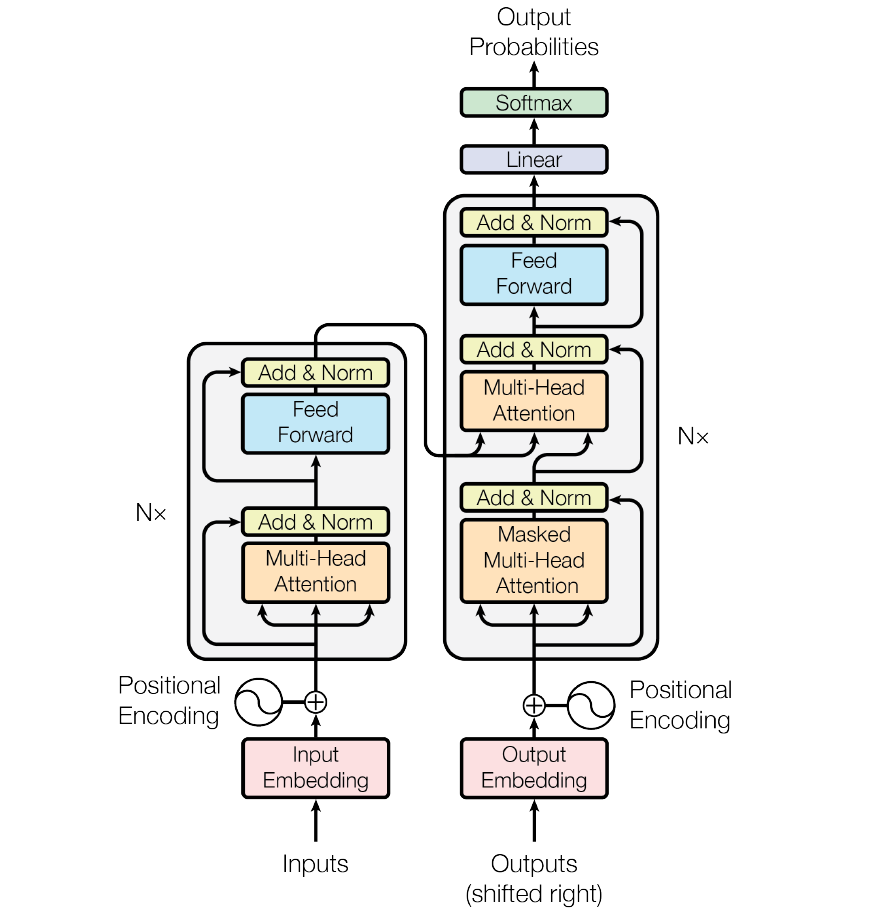
这是Transformer的结构示意图,可以发现它是由编解码两块组成的,Encoder和Decoder。特斯拉在这里使用Transformer来进行编码是认为Encoder能够实现图片的基于位置的编码,然后里面的自注意力和多头注意力可以学习到很多有用的特征,输出的是蕴含内容十分丰富的向量,有助于下一步的训练。
Map部分是结合粗糙地图数据做进一步的增强,即使这里是低精度的地图,但是已经包含了在交叉口车道的拓扑信息。车道和车道数信息都在其中,把这些信息和前面Transformer产生出的蕴含丰富信息的向量编码进行融合,经过重新编码后再拿来训练可以学习到很多有用的信息。最终Vision模块和Map模块结合后输出了Dense World Tensor这个多维度且内容十分丰富的向量,这个向量就是对于周围世界信息的编码。接下来再输入第三个Language部分。
第三个部分之所以取名Language是结合了自然语言处理的思路。特斯拉在这个部分把车道相关信息和各种的车道节点位置、点位属性:起点、终点、分叉、合并等以及车道曲线几何参数进行编码。这个编码是基于创造新语言单词的思路去做的。目的就是实现了一种视觉问题到语言问题的转换,用这些创造出来的词组成句,帮助描述他们各种图像场景,这样就能够进一步去使用当前先进的自然语言处理技术来尝试解决问题。
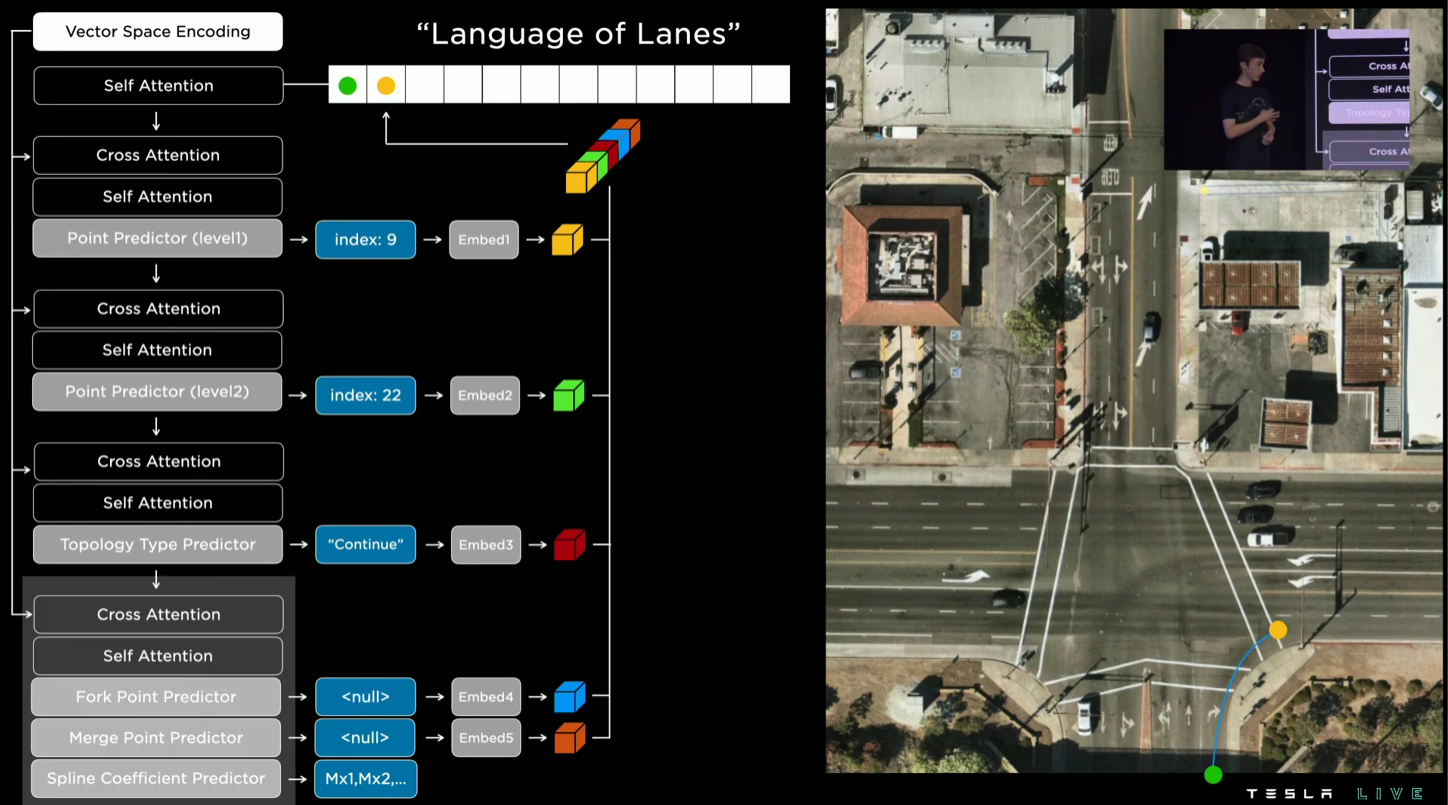
这是Language of Lanes的流程演示。这是一个Self Attention的过程。直接把整个图片分成很多的点,然后直接预测车道线是不可行的,计算成本很高。他们的思路是先选取一个粗略的点,即第一集的点预测,目的是划分出一个可行的预测区域,然后再进一步改进,得到准确的点,就是二级预测的结果。一级和二级的操作是重复的。然后对于这个点就能够预测他的类型,这个是利用到了前面提到的编码。最后一步是结合判断是否为分叉点,合并点并且用回归的方式做线条的拟合。最终得到的结果会加入句子,即更新Attention的结果。
可以注意到在获得车道线的语言的过程中除了自注意力机制Self Attention之外还用到了交叉注意力机制Cross Attention。这两者之间是有区别的,后者可以看作是对前者思想的一个扩展,自注意力机制是在当前的序列中获取上下文信息,而交叉注意力是让模型在两个序列之间建立交互。在特斯拉的任务中,交替使用这两种Attention可以让模型结合整体和局部的各种信息,学习到其中的关联性和依赖性。

Language of Lanes最终就是表示了一组车道线的连接关系。因为是语言描述的场景,所以还能实现行为的预测。比如上图这个场景,有一辆车是因为事故停在了红绿灯前面,而有一个车是走到红绿灯前减速停车等红灯,模型有了语言的描述,就能够从语义中理解和识别场景里面的物体并预测行为,从而实现避让这个场景中的事故车辆的智能驾驶动作。
相关文章:
特斯拉FSD的神经网络(Tesla 2022 AI Day)
这是特斯拉的全自动驾驶(Full Self Driver)技术结构图,图中把自动驾驶模型拆分出分成了几个依赖的模块: 技术底座:自动标注技术处理大量数据,仿真技术创造图片数据,大数据引擎进不断地更新&…...

LLM自回归解码
在自然语言处理(NLP)中,大型语言模型(LLM)如Transformer进行推理时,自回归解码是一种生成文本的方式。在自回归解码中,模型在生成下一个单词时会依赖于它之前生成的单词。 使用自回归解码的公式…...
)
#Uniapp:uni.request(OBJECT)
uni.request(OBJECT) 发起网络请求。 示例 uni.request({url: https://www.example.com/request, //仅为示例,并非真实接口地址。data: {text: uni.request},header: {custom-header: hello //自定义请求头信息},success: (res) > {console.log(res.data);thi…...

旅游项目day14
其他模块数据初始化 搜索实现 请求一样,但是参数不一样,根据type划分。 后台需要提供一个搜索接口。 请求分发器: 全部搜索 目的地搜索 精确搜索、无高亮展示 攻略搜索 全文搜索、高亮显示、分页 游记搜搜 用户搜索 丝袜哥...

关于缓存 db redis local 取舍之道
文章目录 前言一、影响因素二、db or redis or local1.db2.redis3. local 三、redisson 和 CaffeineCache 封装3.1 redisson3.1.1 maven3.1.2 封装3.1.3 使用 3.2 CaffeineCache3.1.1 maven3.1.2 封装3.1.3 使用 总结 前言 让我们来聊一下数据缓存,它是如何为我们带…...

imgaug库图像增强指南(33):塑造【云层】效果的视觉魔法
引言 在深度学习和计算机视觉的世界里,数据是模型训练的基石,其质量与数量直接影响着模型的性能。然而,获取大量高质量的标注数据往往需要耗费大量的时间和资源。正因如此,数据增强技术应运而生,成为了解决这一问题的…...

树莓派ubuntu:CSI接口摄像头安装驱动程序及测试
树莓派中使用OV系列摄像头,网上能搜到的文章资源太老了,文章中提到的摄像头配置选项在raspi-config中并不存在。本文重新测试整理树莓派摄像头的驱动安装、配置、测试流程说明。 libcamera 新版本中使用libcamera作为摄像头驱动程序。 libcamera是一个…...

Webpack5入门到原理6:处理图片资源
处理图片资源 过去在 Webpack4 时,我们处理图片资源通过 file-loader 和 url-loader 进行处理 现在 Webpack5 已经将两个 Loader 功能内置到 Webpack 里了,我们只需要简单配置即可处理图片资源 1. 配置 const path require("path");modul…...
有哪些?)
大语言模型(LLM)有哪些?
国际大语言模型 目前国际上有以下几个知名的大语言模型: GPT-4 GPT-4由OpenAI团队开发,是闭源的。GPT(Generative Pre-trained Transformer)系列是目前最著名的大语言模型之一。最早的版本是GPT-1,之后发展到了GPT-2和GPT-3&…...

2 - 部署Redis集群架构
部署Redis集群架构 部署Redis集群部署管理主机第一步 准备ruby脚本的运行环境第二步 创建脚本第三步 查看脚本帮助信息 配置6台Redis服务器第一步 修改配置文件启用集群功能第二步 重启redis服务第三步 查看Redis-server进程状态(看到服务使用2个端口号为成功&#…...
NOIP2003提高组T1:神经网络
题目链接 [NOIP2003 提高组] 神经网络 题目背景 人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。对神经网络的研究一直是当今的热门方向&am…...

Doris数据库误删除恢复
如果不小心误删除了表,doris提供了恢复机制,但时间间隔不能超过一天,记得要迅速 首先查看当前能恢复的记录有那些 可以通过 SHOW CATALOG RECYCLE BIN 来查询当前可恢复的元信息,也可以在语句后面加 WHERE NAME XXX 来缩小查询…...

C# byte转int:大小端读取
参考:byte[]数组和int之间的转换 文章目录 Byte转为INT小端存储方式转int大端存储方式转int 大端模式和小端模式是计算机存储多字节数据时的两种方式。内存地址从小往大增长。 大端模式:最高有效(最高位)的字节存放在最小地址上&…...

安全通信网络
1.网络架构 1)应保证网络设备的业务处理能力满足业务高峰期需要。 设备CPU和内存使用率的峰值不大于设备处理能力的70%。 在有监控环境的条件下,应通过监控平台查看主要设备在业务高峰期的资源(CPU、内存等)使用 情况ÿ…...
深度学习笔记(九)——tf模型导出保存、模型加载、常用模型导出tflite、权重量化、模型部署
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 本篇博客主要是工具性介绍,可能由于软件版本问题导致的部分内容无法使用。 首先介绍tflite: TensorFlow Lite 是一组工具,可帮助开…...

七Docker可视化管理工具
Docker可视化管理工具 本节介绍几款Docker可视化管理工具。 DockerUI(ui for Docker) 官方GitHub:https://github.com/kevana/ui-for-docker 项目已废弃,现在转投Portainer项目,不建议使用。 Portainer 简介:Portainer是一个…...

vue和react的差异梳理
特性VueReact响应式系统使用Object.defineProperty()或Proxy使用不可变数据流和状态提升模板系统HTML模板语法JSX(JavaScript扩展语法)组件作用域样式支持scoped样式需要CSS-in-JS库(如styled-components)状态管理Vuex(…...
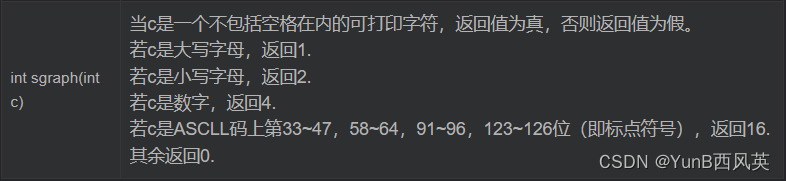
(笔记总结)C/C++语言的常用库函数(持续记录,积累量变)
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...
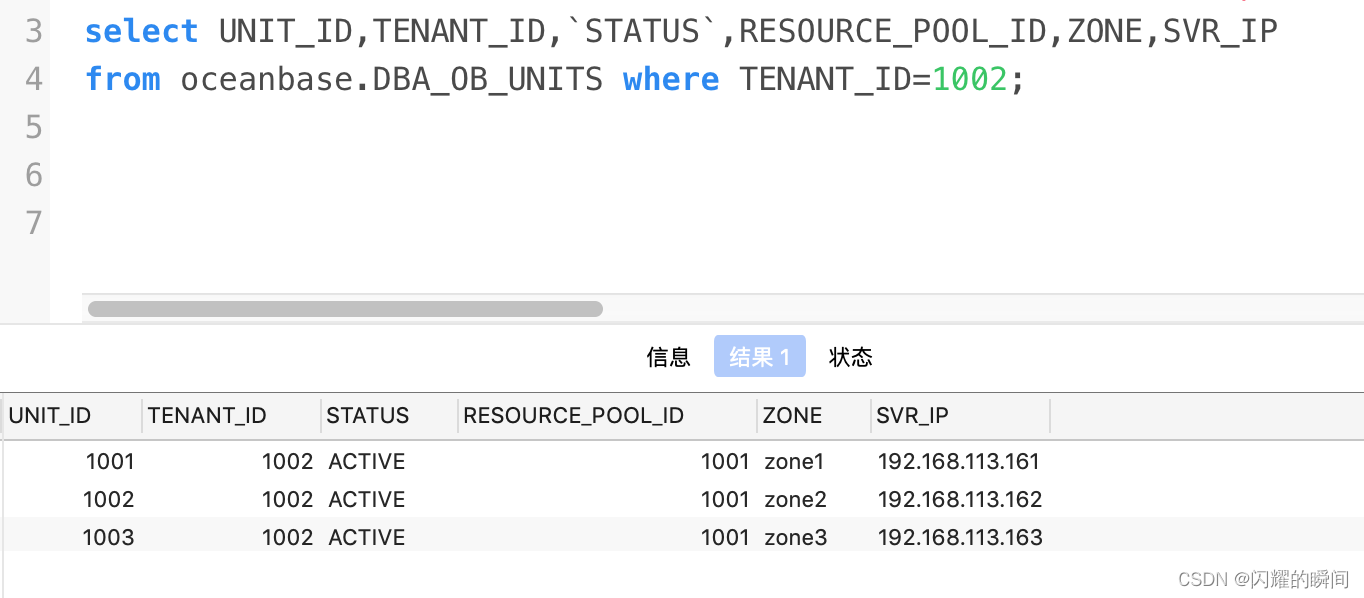
OceanBase集群扩缩容
OceanBase 数据库采用 Shared-Nothing 架构,各个节点之间完全对等,每个节点都有自己的 SQL 引擎、存储引擎、事务引擎,天然支持多租户,租户间资源、数据隔离,集群运行的最小资源单元是Unit,每个租户在每…...

html 3D 倒计时爆炸特效
下面是代码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>HTML5 Canvas 3D 倒计时爆炸特效DEMO演示</title><link rel"stylesheet" href"css/style.css" media"screen&q…...

从 API Key 管理与审计日志功能看 Taotoken 的企业级安全支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从 API Key 管理与审计日志功能看 Taotoken 的企业级安全支持 对于将大模型能力集成到业务流程中的企业而言,API 访问的…...

Ubuntu 20.04远程桌面翻车记:手把手教你从LightDM救回默认GNOME桌面
Ubuntu 20.04桌面环境救援指南:从LightDM回归GNOME的完整方案 那天下午,实验室的Ubuntu服务器突然变得陌生——熟悉的GNOME桌面消失了,取而代之的是一个简陋的登录界面。前一天还能流畅运行的深度学习模型,现在连Jupyter Noteboo…...

告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案
告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为《赛博朋克2077》的模组冲突而烦恼吗&#x…...

【信息科学与工程学】计算机科学与自动化——第二百篇 综合类算法篇01
Net-B1-001 Transformer 推理引擎 列 内容 (对应“大规模预训练Transformer模型的推理与优化”) 编号 Net-B1-001 类型 AI推理与优化系统 领域 人工智能 / 深度学习 模块 Transformer 推理引擎 内存模式【主内存/GPU内的内存/Soc中的内存/其他芯片中的内存】…...

FastGithub终极加速指南:3步解决GitHub访问卡顿难题
FastGithub终极加速指南:3步解决GitHub访问卡顿难题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub加速是每个国内开发者都关心的话题。你是否经常因…...

redis:AOF
Redis AOF(Append Only File)核心知识点总结一、核心定义与作用AOF 是 Redis 的一种持久化方式,以文本 / 二进制形式记录所有写命令(如 set、lpush 等),核心作用是保存数据、实现宕机后的数据恢复ÿ…...
)
Python开发被内网卡脖子?5分钟用Docker搭个Pypiserver救急(含避坑指南)
Python内网开发救星:Docker化Pypiserver极速搭建指南 当你在客户现场调试代码时,突然发现内网环境无法连接PyPI官方源;当你在保密项目部署时,发现所有外网访问都被严格限制——这种"被卡脖子"的困境,相信不少…...
)
学一下PLC2--软件PLC(TODO)
既然你手头有 Raspberry Pi Pico,你甚至不需要买任何新的 PLC 硬件,可以直接把它变成一个标准的工业 PLC! 实现原理: OpenPLC 是一个开源的符合 IEC 61131-3 国际标准的 PLC 软件系统。 它完美支持 Raspberry Pi Pico (RP2040)。…...

对比在ubuntu上直接使用原厂api与通过taotoken调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比在 Ubuntu 上直接使用原厂 API 与通过 Taotoken 调用的账单清晰度差异 在 Ubuntu 开发环境中集成大模型能力,无论是…...

Snipe-IT终极指南:如何构建企业级IT资产管理系统
Snipe-IT终极指南:如何构建企业级IT资产管理系统 【免费下载链接】snipe-it A free open source IT asset/license management system 项目地址: https://gitcode.com/GitHub_Trending/sn/snipe-it 在当今数字化时代,企业IT资产管理已成为组织运营…...