时间序列预测 — CNN-LSTM-Attention实现多变量负荷预测(Tensorflow):多变量滚动
专栏链接:https://blog.csdn.net/qq_41921826/category_12495091.html
专栏内容
所有文章提供源代码、数据集、效果可视化
时间序列预测存在的问题
目录
1 数据处理
1.1 导入库文件
1.2 导入数据集
1.3 缺失值分析
2 构造训练数据
3 CNN_LSTM-Attention模型训练
3.1 CNN_LSTM模型
3.2 搭建Attention模型
3.3 搭建CNN_LSTM-Attention模型
4 CNN_LSTM-Attention模型预测
4.1 分量预测
4.2 可视化
1 数据处理
1.1 导入库文件
import scipy
import pandas as pd
import numpy as np
import math
import datetime
from matplotlib import pyplot as plt# 导入深度学习框架tensorflow
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential, layers, callbacks
from tensorflow.keras.layers import Input, Reshape,Conv2D, MaxPooling2D, LSTM, Dense, Dropout, Flatten, Reshape, TimeDistributed
from keras import backend as Kfrom sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, mean_absolute_percentage_error plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
plt.rcParams.update({'font.size':18}) #统一字体字号1.2 导入数据集
实验数据集采用数据集6:澳大利亚电力负荷与价格预测数据(下载链接),包括数据集包括日期、小时、干球温度、露点温度、湿球温度、湿度、电价、电力负荷特征,时间间隔30min。
# 导入数据
data_raw = pd.read_excel("澳大利亚电力负荷与价格预测数据.xlsx")
data_raw = data_raw[-365*24*6-49:-1].reset_index(drop=True)
data_raw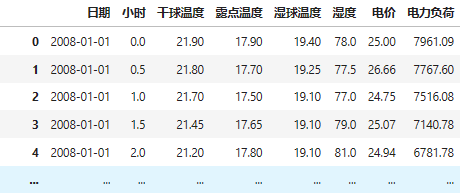
对数据进行可视化
from itertools import cycle
# 可视化数据
def visualize_data(data, row, col):cycol = cycle('bgrcmk')cols = list(data.columns)fig, axes = plt.subplots(row, col, figsize=(16, 4))fig.tight_layout()if row == 1 and col == 1: # 处理只有1行1列的情况axes = [axes] # 转换为列表,方便统一处理for i, ax in enumerate(axes.flat):if i < len(cols):ax.plot(data.iloc[:,i], c=next(cycol))ax.set_title(cols[i])else:ax.axis('off') # 如果数据列数小于子图数量,关闭多余的子图plt.subplots_adjust(hspace=0.6)plt.show()visualize_data(data_raw.iloc[:,2:], 2, 3)
单独查看部分负荷数据。
# 预测结果可视化
plt.figure(dpi=100, figsize=(14, 4))
plt.plot(data_raw['电力负荷'], markevery=5)
plt.xlabel('时间')
plt.ylabel('负荷')
plt.show()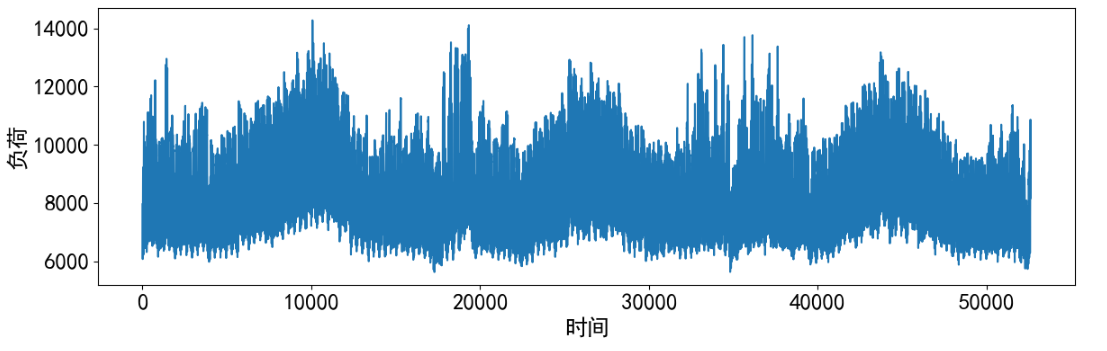
1.3 缺失值分析
首先查看数据的信息,发现并没有缺失值
data_raw.info()
进一步统计缺失值
data_raw.isnull().sum()
2 构造训练数据
构造数据前先将数据变为数值类型
data = data_raw.iloc[:,2:].values构造训练数据,也是真正预测未来的关键。首先设置预测的timesteps时间步、predict_steps预测的步长(预测的步长应该比总的预测步长小),length总的预测步长,参数可以根据需要更改。
timesteps = 48*7 #构造x,为48*7个数据,表示每次用前48*7个数据作为一段
predict_steps = 4 #构造y,为4个数据,表示用后4个数据作为一段
length = 48 #预测多步,预测48个数据
feature_num = 6 #特征的数量通过前timesteps行历史数据预测后面predict_steps个数据,需要对数据集进行滚动划分(也就是前timesteps行的数据和后predict_steps行的数据训练,后面预测时就可通过timesteps行数据预测未来的predict_steps行数据)。这里需要注意的是,因为是多变量滚动预测多变量,特征就是标签(例如,前5行[干球温度、露点温度、湿球温度、电价、电力负荷]预测第6行[干球温度、露点温度、湿球温度、电价、电力负荷],划分数据集时,就用前5行当做train_x,第6行作为train_y,此时的train_y有多列,而不是只有1列)。
# 构造数据集,用于真正预测未来数据
# 整体的思路也就是,前面通过前timesteps个数据训练后面的predict_steps个未来数据
# 预测时取出前timesteps个数据预测未来的predict_steps个未来数据。
def create_dataset(datasetx, datasety=None, timesteps=96*7, predict_size=12):datax = [] # 构造xdatay = [] # 构造yfor each in range(len(datasetx) - timesteps - predict_size):x = datasetx[each:each + timesteps]# 判断是否是单变量分解还是多变量分解if datasety is not None:y = datasety[each + timesteps:each + timesteps + predict_size]else:y = datasetx[each + timesteps:each + timesteps + predict_size]datax.append(x)datay.append(y)return datax, datay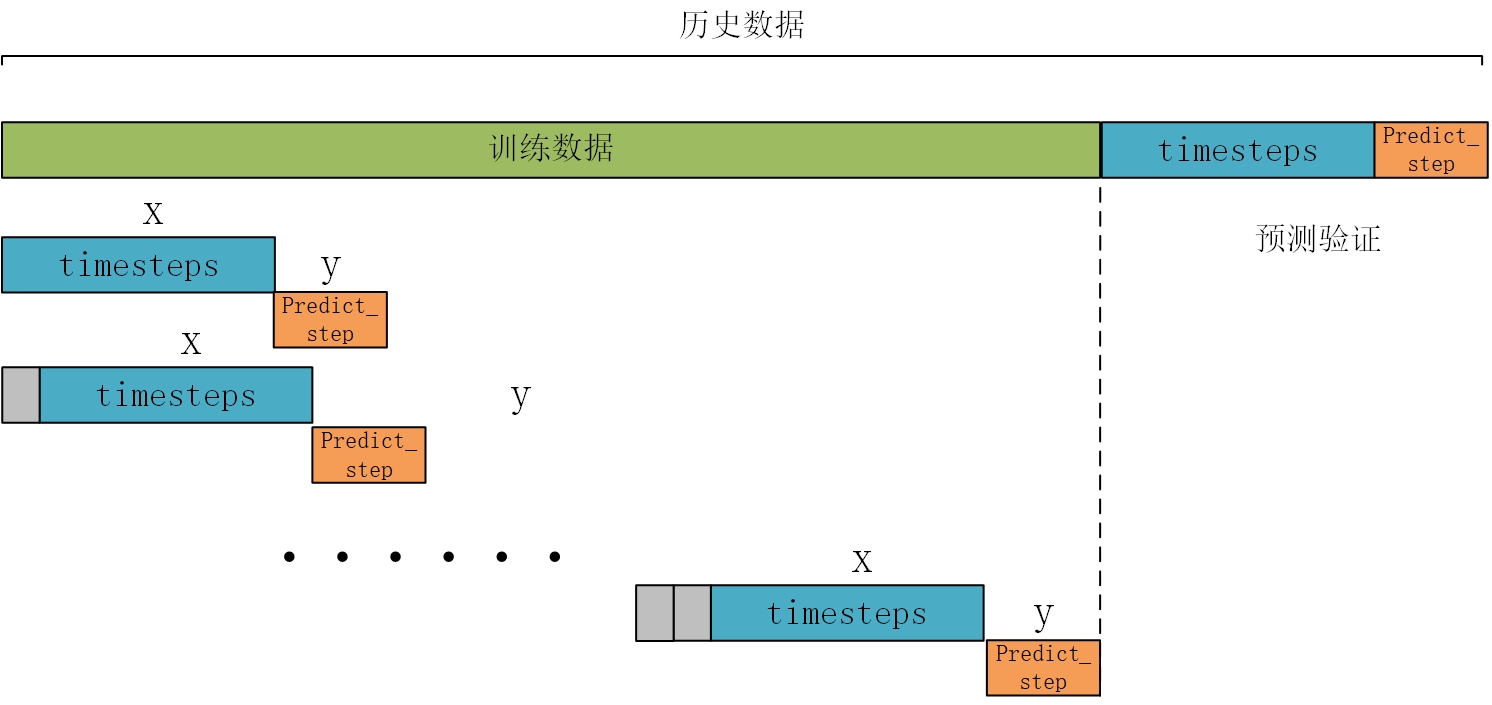
数据处理前,需要对数据进行归一化,按照上面的方法划分数据,这里返回划分的数据和归一化模型(单变量和多变量的归一化不同,多变量归一化需要将X和Y分开归一化,不然会出现信息泄露的问题),此时的归一化是相当于是单变量归一化,函数的定义如下:
# 数据归一化操作
def data_scaler(datax, datay=None, timesteps=36, predict_steps=6):# 数据归一化操作scaler1 = MinMaxScaler(feature_range=(0, 1)) datax = scaler1.fit_transform(datax)# 用前面的数据进行训练,留最后的数据进行预测# 判断是否是单变量分解还是多变量分解if datay is not None:scaler2 = MinMaxScaler(feature_range=(0, 1))datay = scaler2.fit_transform(datay)trainx, trainy = create_dataset(datax, datay, timesteps, predict_steps)trainx = np.array(trainx)trainy = np.array(trainy)return trainx, trainy, scaler1, scaler2else:trainx, trainy = create_dataset(datax, timesteps=timesteps, predict_size=predict_steps)trainx = np.array(trainx)trainy = np.array(trainy)return trainx, trainy, scaler1, None然后分解的数据进行划分和归一化。
trainx, trainy, scalerx, scalery = data_scaler(data[-48*8:-48], timesteps=timesteps, predict_steps=predict_steps)
3 CNN_LSTM-Attention模型训练
3.1 CNN_LSTM模型
CNN-LSTM 是一种结合了 CNN 特征提取能力与 LSTM 对时间序列长期记忆能力的混合神经网络。
CNN 主要由四个层级组成, 分别为输入层、 卷积层、 激活层(Relu 函数)和池化层。 每一层都会将数据处理之后送到下一层, 其中最重要的是卷积层, 这个层级起到的作用是将特征数据进行卷积计算, 将计算好的结果传到激活层, 激活函数对数据进行筛选。最后一层是 LSTM 层, 这一层是根据 CNN 处理后的特征数据,对其模型进行进一步的维度修偏, 权重修正等工作, 为下一步输出精度较高的预测值做好准备, 在 LSTM 训练的过程中, 由于其神经网络内部包括了输入、 遗忘和输出门, 通常的做法是通过增减遗忘门和输入门的个数, 来控制算法的精度。

来源:基于改进的 CNN-LSTM 短期风功率预测方法研究
对于输入到 CNN-LSTM 的数据,首先,经过 CNN 的卷积层对局部特征进行提取,将提取后的特征向量传递到池化层进行特征向量的下采样和数据体量的压缩。然后,将经过卷积层和池化层处理后的特征向量经过一个扁平层转化成一维向量输入到 LSTM 中, 每一层 LSTM 后加一个随机失活层以防止模型过拟合。
3.2 搭建Attention模型
参考文章:https://www.cnblogs.com/jiangxinyang/p/9367497.html
(1) Attention思想
深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。
(2) Encoder-Decoder框架
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。seq2seq问题简单的说,就是根据一个输入序列x,来生成另一个输出序列y。Encoder-Decoder模型中的编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
Encoder-Decoder(编码-解码)是深度学习中非常常见的一个模型框架,准确的说,Encoder-Decoder并不是一个具体的模型,而是一类框架。Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN,RNN,BiRNN、LSTM、GRU等等。所以基于Encoder-Decoder,我们可以设计出各种各样的应用算法。
Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,应用场景异常广泛,下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:
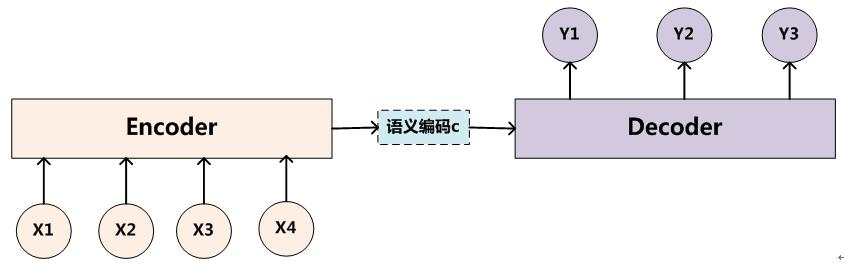
(3) Attention模型
在Encoder-Decoder框架中,在预测每一个yi时对应的语义编码c都是一样的,也就意味着序列X中点对输出Y中的每一个点的影响都是相同的。这样就会产生两个弊端:一是语义向量无法完全表示整个序列的信息,再者就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了。
为了解决上面的弊端,就需要用到我们的Attention Model(注意力模型)来解决该问题。在机器翻译的时候,让生成词不是只能关注全局的语义编码向量c,而是增加了一个“注意力范围”,表示接下来输出词时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出。模型结构如下:
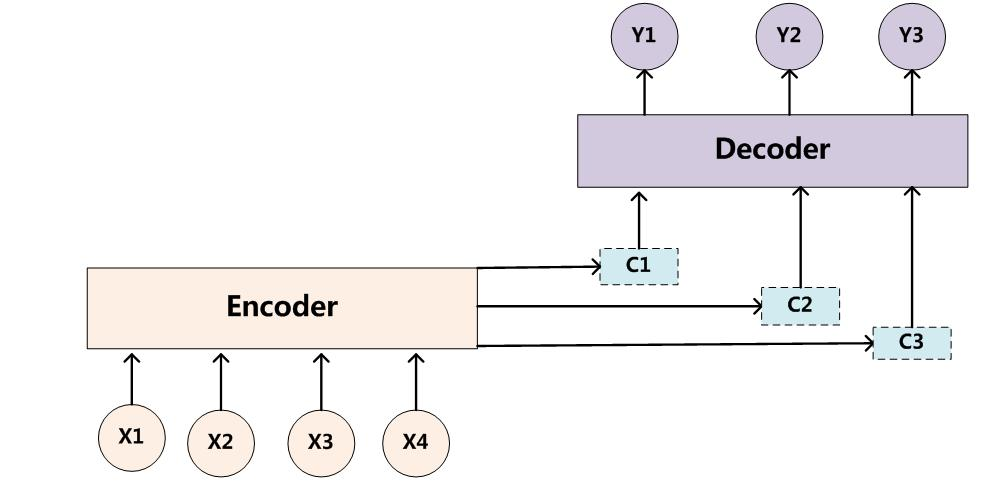
关于模型的更多介绍可以查阅相关文献,下面给出Attention的代码
# CNN_LSTM_Attention模型
from keras.layers import multiply, Permute, RepeatVector, Multiply, Lambda
from keras.models import Modeldef attention_function(inputs, single_attention_vector=False): # 获取 inputs 的时间步数和特征维度 TimeSteps = K.int_shape(inputs)[1]input_dim = K.int_shape(inputs)[2]a = Permute((2, 1))(inputs) #将 inputs 的维度进行转置,维度顺序变为 (特征维度, 时间步维度) a = Dense(TimeSteps, activation='softmax')(a) #经过全连接层# 如果为 True,单一注意力操作if single_attention_vector:a = Lambda(lambda x: K.mean(x, axis=1))(a) #对第二个维度进行求平均,得到单一注意力向量a = RepeatVector(input_dim)(a) # 将单一注意力向量进行复制,使其与 inputs 的维度一致 a_probs = Permute((2, 1))(a) # 再次将注意力权重进行转置,维度顺序变为 (时间步维度, 特征维度) output_attention_mul = Multiply()([inputs, a_probs]) # 使用 Multiply 层将 inputs 和注意力权重进行元素级乘法操作return output_attention_mul3.3 搭建CNN_LSTM-Attention模型
首先搭建模型的常规操作,然后使用训练数据trainx和trainy进行训练,进行50个epochs的训练,每个batch包含64个样本(建议使用GPU进行训练,增加epochs)。

def CNN_LSTM_Attention_train(trainx, trainy, timesteps, feature_num, predict_steps):# 调用GPU加速gpus = tf.config.experimental.list_physical_devices(device_type='GPU')for gpu in gpus:tf.config.experimental.set_memory_growth(gpu, True)#搭建cnn模型inputs = Input(shape=(timesteps, feature_num))reshaped = Reshape((timesteps, feature_num, 1))(inputs)conv2d = Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu")(reshaped)maxpool = MaxPooling2D(pool_size=2, strides=1, padding="same")(conv2d)dropout = Dropout(0.3)(maxpool)reshape2 = Reshape((timesteps, -1))(dropout)#搭建atttention模型attention_out = attention_function(reshape2)#搭建lstm模型lstm1 = LSTM(128, return_sequences=True, dropout=0.2)(attention_out)lstm2 = LSTM(128, return_sequences=False, dropout=0.2)(lstm1) repeat_vector = RepeatVector(predict_steps)(lstm2) outputs = TimeDistributed(Dense(feature_num))(repeat_vector)model = Model(inputs=inputs, outputs=outputs)model.compile(loss="mean_squared_error", optimizer="adam", metrics=['accuracy'])print(model.summary())model.fit(trainx, trainy, epochs=50, batch_size=128)return model
然后进行训练,将训练的模型、损失和训练时间保存。
# 模型训练
model = CNN_LSTM_Attention_train(trainx, trainy, timesteps, feature_num, predict_steps)
# 模型保存
model.save('cnn_lstm_attention.h5')4 CNN_LSTM-Attention模型预测
4.1 分量预测
下面介绍文章中最重要,也是真正没有未来特征的情况下预测未来标签的方法。整体的思路也就是取出预测前48*7行数据预测未来的4行个数据,然后将4行数据添加进历史数据,再预测4行数据,滚动预测。因为每次只预测4行数据,但是我要预测48个数据,所以采用的就是循环预测12次的思路。
# #滚动predict
# #因为每次只能预测4行数据,但是我要预测48行数据,所以采用的就是循环预测的思路。
# #每次预测的4行数据,添加到数据集中充当预测x,然后在预测新的4行y,再添加到预测x列表中,如此往复,最终预测出48行。
def predict_using_LSTM(model, data, timesteps, predict_steps, length, feature_num, scaler):# 初始化预测输入和输出predict_xlist = np.array(data).reshape(1, timesteps, feature_num) predict_y = np.array([]).reshape(0, feature_num)while len(predict_y) < length:# 从最新的predict_xlist取出timesteps个数据,预测新的predict_steps个数据predictx = predict_xlist[:,-timesteps:,:]# 预测新值lstm_predict = model.predict(predictx)# 将新预测出来的predict_steps个数据,加入predict_xlist列表,用于下次预测predict_xlist = np.concatenate((predict_xlist, lstm_predict), axis=1)# 预测的结果y,每次预测的predict_steps个数据,添加进去,直到预测length个为止lstm_predict = scaler.inverse_transform(lstm_predict.reshape(-1, feature_num))predict_y = np.concatenate((predict_y, lstm_predict), axis=0)return predict_y然后对数据进行预测,得到预测结果。
from tensorflow.keras.models import load_model# 加载模型
model = load_model('CNN_LSTM_Attention.h5')
pre_x = scalerx.transform(data[-48*8:-48])
y_true = data[-48:, -1]
# 预测
y_predict = predict_using_LSTM(model, pre_x, timesteps, predict_steps, length, feature_num, scalerx)4.2 可视化
对预测的结果进行可视化并计算误差。
# 预测并计算误差和可视化
def error_and_plot(y_true,y_predict):# 计算误差r2 = r2_score(y_true, y_predict)rmse = mean_squared_error(y_true, y_predict, squared=False)mae = mean_absolute_error(y_true, y_predict)mape = mean_absolute_percentage_error(y_true, y_predict)print("r2: %.2f\nrmse: %.2f\nmae: %.2f\nmape: %.2f" % (r2, rmse, mae, mape))# 预测结果可视化cycol = cycle('bgrcmk')plt.figure(dpi=100, figsize=(14, 5))plt.plot(y_true, c=next(cycol), markevery=5)plt.plot(y_predict, c=next(cycol), markevery=5)plt.legend(['y_true', 'y_predict'])plt.xlabel('时间')plt.ylabel('功率(kW)')plt.show() return 0error_and_plot(y_true,y_predict[:,-1])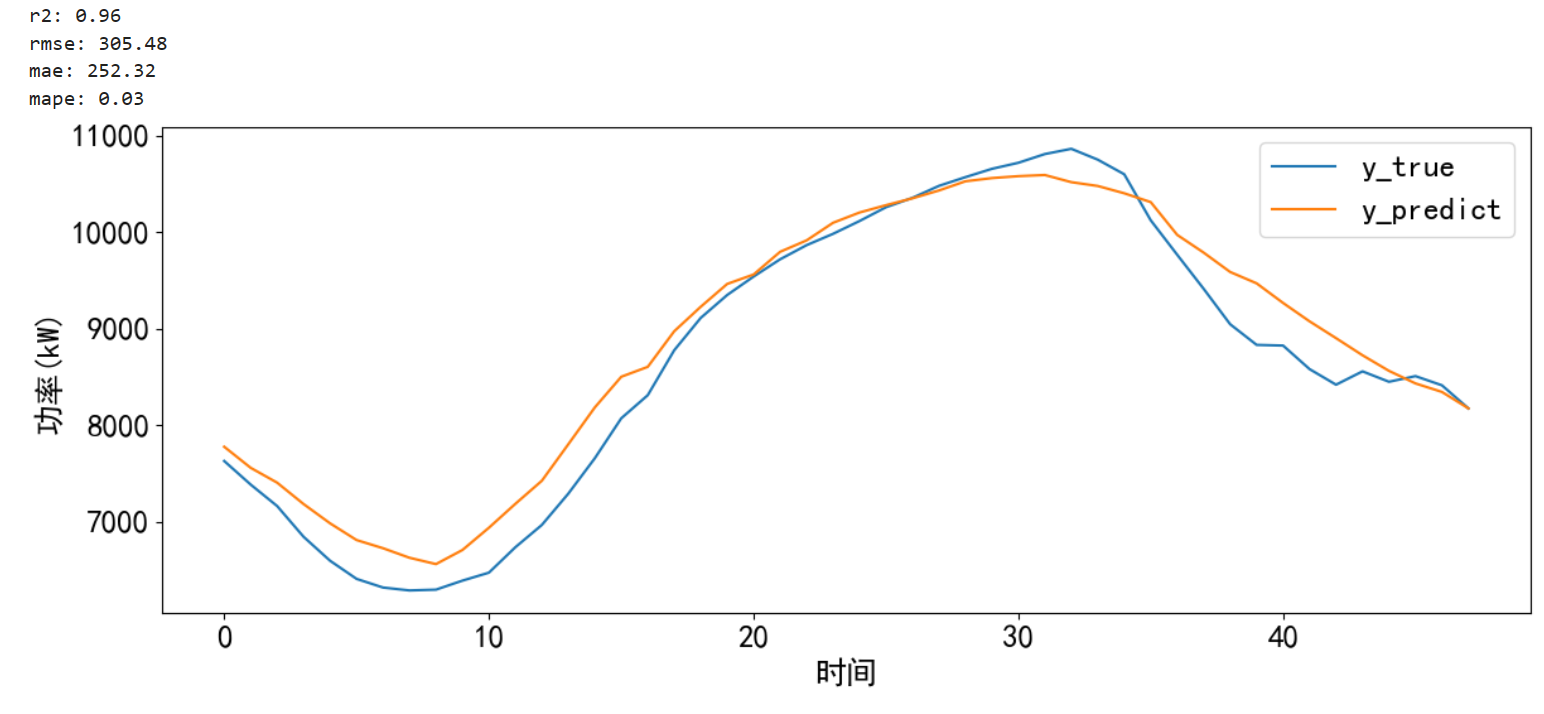
相关文章:
时间序列预测 — CNN-LSTM-Attention实现多变量负荷预测(Tensorflow):多变量滚动
专栏链接:https://blog.csdn.net/qq_41921826/category_12495091.html 专栏内容 所有文章提供源代码、数据集、效果可视化 文章多次上领域内容榜、每日必看榜单、全站综合热榜 时间序列预测存在的问题 现有的大量方法没有真正的预测未…...

angular-tree-component组件中实现特定节点自动展开
核心API 都在 expandToNode这个函数中 HTML treeData的数据结构大概如下 [{"key": "3293040275","id": "law_category/3293040275","name": "嘿嘿嘿嘿","rank": 0,"parentKey": "0&q…...

Linux系统下安装Vcpkg,并使用Vcpkg安装、编译OpenSceneGraph
环境:CentOS7 内存:8g(内存过少编译osg时会出现内存不足导致编译失败的情况,内存设置为4G时失败了,我直接加到了8g,所以就以8g为准了) 安装和配置vcpkg cd ~/ git clone https://www.github.com/microsoft/vcpkg cd …...
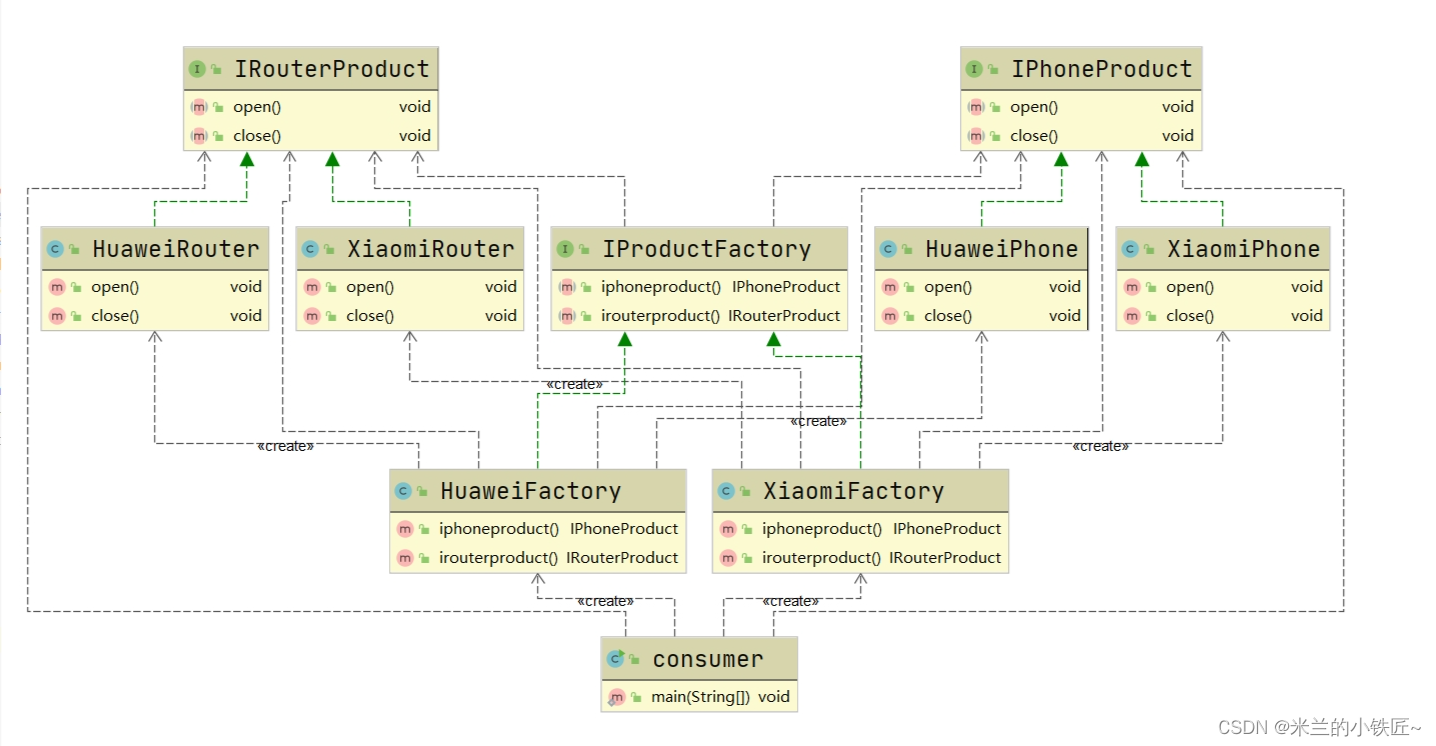
设计模式二(工厂模式)
本质:实例化对象不用new,用工厂代替,实现了创建者和调用者分离 满足: 开闭原则:对拓展开放,对修改关闭 依赖倒置原则:要针对接口编程 迪米特原则:最少了解原则,只与自己直…...

Maven应用手册
没加载出来就reimport,这个时候clean和install没用,那是编译安装项目的。 reimport干了什么? 结合idea的maven教程 父子模块 子模块不需要groupId ruoyi中父模块还添加了子模块的依赖,,, 先安装父再是子…...

笨蛋学设计模式行为型模式-状态模式【20】
行为型模式-状态模式 8.7状态模式8.7.1概念8.7.2场景8.7.3优势 / 劣势8.7.4状态模式可分为8.7.5状态模式8.7.6实战8.7.6.1题目描述8.7.6.2输入描述8.7.6.3输出描述8.7.6.4代码 8.7.7总结 8.7状态模式 8.7.1概念 状态模式是指对象在运行时可以根据内部状态的不同而改变它们…...
)
C++从零开始的打怪升级之路(day18)
这是关于一个普通双非本科大一学生的C的学习记录贴 在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料 那么开启正题 今天分享的是关于vector的题目 1.只出现一次的数字1 136. 只出…...

浅谈安科瑞直流电表在新加坡光伏系统中的应用
摘要:本文介绍了安科瑞直流电表在新加坡光伏系统中的应用。主要用于光伏系统中的电流电压电能的计量,配合分流器对发电量进行计量。 Abstract: This article introduces the application of Acrel DC meters in PV system in Indonesia.The device is …...
C++参悟:数值运算相关
数值运算相关 一、概述二、常用数学函数1. 基础运算1. 浮点值的绝对值( |x| )2. 浮点除法运算的余数3. 除法运算的有符号余数4. 除法运算的有符号余数和最后三个二进制位5. 混合的乘加运算6. 两个浮点值的较大者7. 两个浮点值的较小者8. 两个浮点值的正数…...

【Web前端开发基础】CSS的定位和装饰
CSS的定位和装饰 目录 CSS的定位和装饰一、学习目标二、文章内容2.1 定位2.1.1 定位的基本介绍2.1.2 定位的基本使用2.1.3 静态定位2.1.4 相对定位2.1.5 绝对定位2.1.6 子绝父相2.1.7 固定定位2.1.8元素的层级关系 2.2 装饰2.2.1 垂直对齐方式2.2.2 光标类型2.2.3 边框圆角2.2.…...
[pytorch入门] 3. torchvision中的transforms
torchvision中的transforms 是transforms.py工具箱,含有totensor、resize等工具 用于将特定格式的图片转换为想要的图片的结果,即用于图片变换 用法 在transforms中选择一个类创建对象,使用这个对象选择相应方法进行处理 能够选择的类 列…...
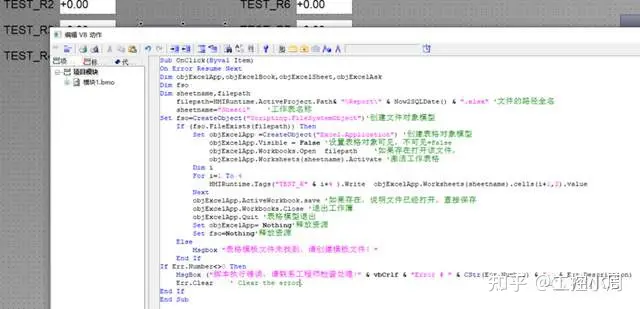
WINCC读写EXCEL-VBS
原创 RENHQ WINCC 关于VBS操作EXCEL的文档不管在论坛上还是在网上,相关的脚本已经很多,但是依然有很多人在问这个问题,于是把我以前在论坛上发的一个集合帖子的脚本拿来,重新开个帖子,如果再有人问的话,可…...

Python os模块
简介 Python的os模块是一个标准库模块,用于提供与操作系统相关的功能(相当于接口)。os模块允许Python程序与文件系统、目录结构、进程管理等操作系统级别的功能进行交互。 主要功能 文件和目录操作 创建、删除、重命名文件和目录…...

Elasticsearch:2023 年 Lucene 领域发生了什么?
作者:来自 Elastic Adrien Grand 2023 年刚刚结束,又是 Apache Lucene 开发活跃的一年。 让我们花点时间回顾一下去年的亮点。 社区 2023 年,有: 5 个次要版本(9.5、9.6、9.7、9.8 和 9.9),1 …...

Java算法 leetcode简单刷题记录4
Java算法 leetcode简单刷题记录4 买卖股票的最佳时机: https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/ 笨办法: 记录当天的值及之后的最大值,相减得到利润; 所有的天都计算下,比较得到利润最大值&…...
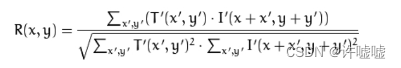
opencv#27模板匹配
图像模板匹配原理 例如给定一张图片,如上图大矩阵所示,然后给定一张模板图像,如上图小矩阵。 我们在大图像中去搜索与小图像中相同的部分或者是最为相似的内容。比如我们在图像中以灰色区域给出一个与模板图像尺寸大小一致的区域,…...
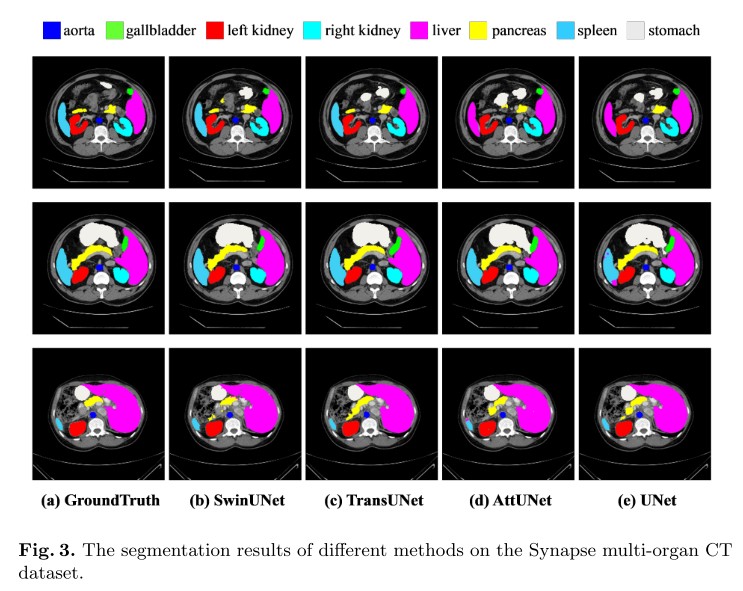
【论文阅读笔记】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
1.介绍 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation Swin-Unet:用于医学图像分割的类Unet纯Transformer 2022年发表在 Computer Vision – ECCV 2022 Workshops Paper Code 2.摘要 在过去的几年里,卷积神经网络ÿ…...
IS-IS:01 ISIS基本配置
这是实验拓扑,下面是基本配置: R1: sys sysname R1 user-interface console 0 idle-timeout 0 0 int loop 0 ip add 1.1.1.1 24 int g0/0/0 ip add 192.168.12.1 24 qR2: sys sysname R2 user-interface console 0 idle-timeout 0 0 int loop 0 ip add …...

基于极限学习机的曲线分类,基于极限学习机的光谱分类,基于极限学习机的分类预测
目录 背影 极限学习机 基于极限学习机的曲线分类,基于极限学习机的光谱分类,基于极限学习机的分类预测 主要参数 MATLAB代码 效果图 结果分析 展望 完整代码下载链接:基于极限学习机的曲线分类,基于极限学习机的光谱分类,基于极限学习机的分类预测的MATLAB代码资源-CSDN…...

miniconda安装
Miniconda是一个小型版的Anaconda,它包含了一个包管理工具conda和Python。Miniconda适用于那些只需要管理Python包和环境,而不需要Anaconda中包含的大部分科学计算工具的用户。 Miniconda的安装过程相对简单。你可以从清华大学开源软件镜像站下载Minico…...
)
【计算机网络硬核指南】子网划分终极篇:定长+VLSM+超网三合一实战(3道大厂真题逐字节演算)
【计算机网络硬核指南】子网划分终极篇:定长VLSM超网三合一实战(3道大厂真题逐字节演算) 前言 在上一篇文章中,我们系统学习了IP地址基础和子网划分的核心方法,逐题演算了9道经典真题。很多读者反馈说,看…...

KAN神经网络在GPT架构中的可解释性实验与实现
1. 项目概述:当KAN神经网络遇上GPT,一场关于可解释性的实验最近在开源社区里,一个名为“kan-gpt”的项目引起了我的注意。这个项目将两个看似不相关的领域——KAN(Kolmogorov–Arnold Networks)神经网络和GPTÿ…...

FastbootEnhance:让安卓设备调试变得简单高效的Windows工具箱
FastbootEnhance:让安卓设备调试变得简单高效的Windows工具箱 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾经在刷机、调试…...

ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程
ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾被ThinkPad风扇的突然加速打扰了工作专注&#…...

Arm Corstone SSE-300内存架构与安全设计解析
1. Arm Corstone SSE-300内存架构深度解析在嵌入式系统设计中,内存映射是连接软件与硬件的关键纽带。作为Arm最新推出的子系统解决方案,Corstone SSE-300通过精心设计的内存架构,为开发者提供了高性能、高安全性的开发平台。我在实际项目中使…...
)
小白程序员必看!收藏这份AI学习指南,从0到1逆袭高薪职业(内含经验分享)
作者原UI设计师,因职业瓶颈被辞退后转行AI领域。文章分享了学习AI的动机、遇到的困难、心得体会以及成功转行后的薪资提升经历。强调主动拥抱变化的重要性,建议多练习、多总结,并感谢老师们的耐心指导。最后,作者表示将继续深耕AI…...

实战指南:vCenter Server Appliance 核心账户密码恢复与安全策略配置
1. 紧急救援前的准备工作 遇到vCenter Server Appliance密码丢失的情况,千万别急着操作。我见过太多同行因为心急直接动手,结果把问题搞得更复杂。咱们先做好这三件事,能避免90%的意外状况。 首先必须创建虚拟机快照,这个步骤的重…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...