内容算法解读:提高内容摘要与原文的一致性(Faithfulness)
全文摘要:受益于预训练语言模型的发展,应用神经网络模型提取内容摘要的技术也获得了长足进步。但目前还存在一个未被很好解决的问题:神经网络模型提取的摘要不能如实反映原文档的中心思想,没有做到忠实(not faithful)。可能的原因有两个,1)摘要模型未能理解或者抓取输入文档内容的要点;2)摘要模型过度依赖语言模型,产生了流畅但不达意的词语。本文提出了一个忠实度增强摘要模型,克服上述两个问题,并尽可能贴切地表达出原文的中心思想。针对存在的第一个问题,采用QA(question-answering)来评估编码器是否完全掌握了输入文档内容,并能够回答有关输入内容中关键信息的问题。这个对正确的输入词语保持注意力的QA系统也用于规定解码器应该怎么反映输入内容源。对于第二个问题,本文引入了语言模型和摘要模型之间差异的最大边际损失函数,以防语言模型的过度拟合。在CNN/DM和XSum这两个基准数据集上的实验表明,本文提出的模型效果显著优于比较的基准模型。一致性的评估也表明本文提出的模型能得到更加贴切的内容摘要。
背景概述
研究【1,2】指出很多内容摘要模型有不能如实反映原文思想的问题。Durmus等人【3】强调了摘要不能忠于原文的两种表现形式:1)内在因素,即篡改输入文档的信息;2)外在因素,即包含原文没有阐述的信息。篡改原文常常是由于摘要模型理解错了原文档,既有可能是Encoder部分没有理解到原文的语义信息,也有可能是Decoder部分无法从Encode部分获取相关和一致性的信息。增加多余信息是由于预训练语言模型的过度注意机制,导致了生成的摘要虽然流畅却不遵从原文。例如,预训练语言模型倾向于生成常见的的短语“score the winner(记录胜利者)”,而原文中正确的短语是使用较少的“score the second highest(记录次高分者)”。这种类型的错误在当前的摘要提取任务中还没有考虑到,但在神经网络机器翻译NMT任务【4】中已经进行了研究。
基于以上观察和原因分析,本文提出了一个忠实度增强摘要模型(Faithfulness Enhanced Summarization model,FES)。为了防止篡改原文问题,忠实度增强摘要模型FES中设计了多任务学习模式,一个完成摘要提取的编解码器任务和一个基于QA系统的忠实度评估任务。QA系统增加了编码器的额外推理要求,需要对输入文档的关键语义有更全面的理解,并且能学习到比单纯的概述更好的表示。同时QA对原文中关键实体的注意力使解码器和编码器的输出一致,从而让生成的摘要保持忠实度。第二,为了处理针对原文的无中生有问题,本文提出了一个最大边际损失函数来防止预训练语言模型过度拟合。详细来说,本文定义了一个判定预训练语言模型过度程度的指标。通过最小化这个程度指标,缓解了‘摘要提取无中生有’产生内容的风险。
通过在公共数据集CNN/DM【5】和XSum【6】上的大量实验证明了本文提出的忠实度增强摘要模型FES的有效性。实验结果也表明,本文模型FES在ROUGE评分上有更好的效果,而且对比几个新闻摘要生成基线模型也提高了忠实度。
研究方法
1、问题描述
设一系列输入文档,对应的真实摘要为
。令
个问答对
和
。在训练阶段,模型的输入为问答对
、
和文档-摘要对
、
。模型最优化提取问题的答案
和生成摘要
。在测试阶段,给定文档
和问题
,推理摘要和答案。最终生成一个总结原文并与原文信息一致的摘要。
接下来,详细拆解本文提出的模型FES。该模型基于Transformer【7】,分成3个子构件。1)多任务编码multi-task Encoder:通过添加的QA系统来检测文档编码表示的质量,提高了对输入文档的语义理解。因此编码器能捕捉到关键输入信息,从而做出忠实行的内容摘要。2)QA注意力增强解码器:来自多任务编码器的注意力能使解码器与编码器对齐,以便解码器能够获取更加准确的输入信息来生成摘要。3)最大边际损失函数:这个损失函数跟模型的最后输出损失函数是正交的,只反映预训练语言模型的准确性,用于克服摘要生成过程中的预训练语言模型的过度拟合。
2、多任务编码器
在摘要提取和QA联合训练阶段,多任务编码器对输入文档进行编码(图1(b))。不同于此前研究【2,3】将QA系统用于后处理来评估生成摘要的忠实度(图1(a))。本文让QA系统更接近编码器,并让编码器同时完成QA和内容摘要任务的训练。这种多任务编码器的联合训练,除了考虑摘要生成的质量,也将忠实度作为训练优化目标。QA系统中的答案来自输入文档中的关键实体,因此QA问答对能注意到输入文档中的关键信息。
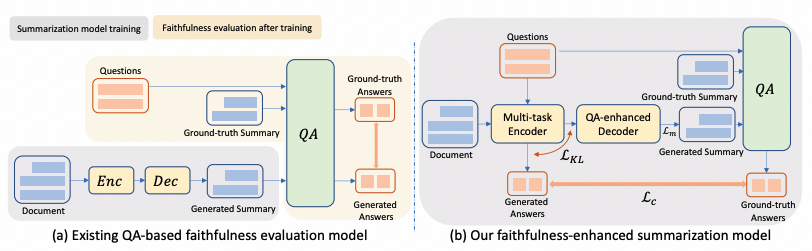
图1
如下图2所示,本文采用经典的Transformer体系结构获取文档和问题
的token级别表示,记为
和
,其中
表示文档中的token数目,
表示问题数目,
表示一个问题中的token数目,
表示特征维度数。最终的编码器能从实体级、句子级、问题级理解问题和输入文档。
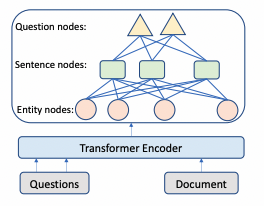
图2
本文通过不同的粒度表示学习来构建编码器。实体包含紧密和显著的文档信息,也是阅读理解问答的主要关注点,所以本文采用实体作为基本语义单元。由于每个问题一般很短,所以每个问题都会创建一个节点。从问题到句子和从句子到实体也都构建了双向边。这些节点作为句子与句子间的中介,丰富了跨句子间的关系。初始的有向边不足以学习到反向信息,本文添加了反向边和自环边。采用标记token级和词跨度级的均值池化处理来初始化节点表示【8】。给定构建好包含节点特征的图,本文用图注意力网络(Graph Attention Networks,GAT【9】)更新图中的语义节点表示。令,
为输入节点的隐状态,其中
、
和
分别表示实体节点、句子节点、问题节点的数目。GAT层设计如下:
,
,
,
其中表示节点
的邻居节点集,
,
,
,
分别表示训练参数,
表示
和
间的注意力权重。迭代几轮后再增加一个残差连接
避免梯度迷失。通过迭代这个GAT层和位置感知前馈层(position-wise feed-forward layer【7】)来更新各个节点的表示。输出实体特征矩阵、句子特征矩阵、问题矩阵分别表示为
、
、
。
在融合问题和文档信息之后,就可以从文档中选择实体作为问题的答案。具体来说,在问题和图中的实体间应用多头交叉注意力机制(Multi-head Cross Attention,MHAtt),其中
表示问题索引,来获得问题感知的实体表示。在此基础上,本文应用前馈网络(Feed-Forward Network,FFN)来产生实体的抽取概率
,其中
。那么QA的目标就是最大化所有实体的真值
概率:
.
3、QA注意力强化的解码器
做到忠实性的解码器需要关注并抓住编码器中的重要信息。从上节可以看到,关键实体上的QA注意力表明了哪些实体需要在最终的摘要中包含。也就是说,本文的摘要生成通过QA注意力进行了增强。解码器的状态通过实体这个中介关联到编码器的状态,其中实体级别的注意力由QA注意力引导。具体来说,对于每一层,在第步解码上,于掩码摘要嵌入
上利用自注意力机制获取
。掩码机制确保了位置
上的预测仅取决于
之前的输出。基于
计算实体交叉注意力得分
:
实际上,第一注意力层捕获解码序列的上下文特征,而第二注意力层将实体信息进行了并入。这里定义最小化,第步的QA注意力
和实体上的摘要注意力
间的双向Kullback-Leibler(KL)散度为:
来让摘要模型学习到哪些实体是重要的。其中表示真实摘要中的token数目。这个目标引导交叉注意力捕捉正确的上下文信息,而不是只学习QA注意力分布。为了避免产生对QA任务的“overfitting”,本文只在注意力头部部分使用该目标。然后使用实体级注意力来引导选择与关键实体相关的源token,在源词语序列
和
上利用如下的
层:
该上下文向量,是各种源的显著内容摘要体现,被发送到以产生目标词汇表上的分布:
通过优化预测目标词的负对数似然目标函数来更新所有的在学习参数:
4、最大边际损失函数
先前的工作【10,11】表明,信息不足的解码器会忽略一些源片段,定义成一个开放式的预训练语言模型容易出现外部错误,即添加多余额外信息。受到忠实度增强机器翻译工作的启发,本文在摘要生产中引入了最大边际损失函数,用于最大化摘要每个标记token的预测概率与预训练语言模型LM的差异,如图3所示。这个损失函数能抑制摘要生成通用到不忠实的内容。具体来说,本文首先定义摘要和预训练语言模型LM的边际损失作为预测概率的差:
上式中为输入的文档,
为第
个标记token的预测概率。这里要注意的是语言模型并不直接使用输入文档,使用的是解码的摘要前缀。如果
的值较大时,摘要模型的效果就会优于预训练语言模型。而
较小时,会出现两种情况:一是摘要模型和预训练语言模型的效果都较好,所以两者的预测概率相近;另一种情况是预训练语言模型出现了过拟合,导致摘要的效果较差。

图3
因此,本文在最大边际损失函数里加入一个系数:
上式中是
的缩写。
是关于
的非线性单调递减函数,用来保证最大化
能取得最优值。这里用了五次方函数,采用了其中的稳定性【12】。第一项
是用来平衡前一个公式中的两个概率。当
更大时,摘要模型能很好的学习到
,此时不需要太关注
。这也反应在了
,此时
的系数就较小。当
较小时,意味着摘要需要继续迭代优化,此时较大的系数
保证了模型能够从边际信息中学习优化。
上述4个损失函数,,
,
和
,相互间是正交的,所以可以进行组合来优化摘要忠实性。
实验验证
1、实验设置
本文为了证明所提方法的有效性,选取了两个在摘要生产领域广泛使用的公开数据集,CNN/DM和XSum。这两个数据集都是新闻类内容,包含了大量事件、实体及关系,能够测试摘要模型的事实阐述一致性。从上文'研究方法'这节可以看到,摘要模型中还加入了一个问答QA任务。所需要的问答对是通过QuestEval【2】这个工具预先生成的。最终本文为CNN/DM选取了38个QA对,为XSum选取了27个QA对。在训练数据集中,选取了具有最高ROUGE分的QA对作为输入。
本文选取如下模型作为比较基线:(1)FASum【13】是一个通过图注意提取和集成文章描述到摘要生成过程中的模型;(2)CLIFF【14】利用参考摘要作为正样本,错误摘要作为负样本训练摘要模型;(3)BART【15】是最近的一个以去噪自动编码为目标的摘要生成预训练模型;(4)PEGASUS【16】是一个基于Transformer的大型预训练编码器-解码器摘要生成模型;(5)GSum【17】是一个能利用外部句子作为引导的摘要生成框架;(6)SimCLS【18】利用无引用评估(reference-free)来弥合学习目标与评估指标之间的差距。
实现过程:整个实验在Huggingface【19】上进行,采用了4块NVIDIA A100 GPUs。超参数是参考BART(Facebook/bart-large)和PEGASUS(Google/pegasus-xsum)。QA设置了8对。为了避免模型学到实体或者问题的位置信息,将实体和问题按字母序排列。优化器是用的Adam,,
。学习率设置为
。冷启动阶段,CNN/DM为500步,XSum为125步。Batch-size设置为8,梯度累计步长为4。CNN/DM的beam size为6,XSum的beam size为8。同时在CNN/DM和XSum上分别训练了基于BART和PEGASUS的预训练语言模型。
2、主要结果
本文采用标准全长ROUGE F1【20】评估模型。ROUGE1(RG-1)、ROUGE-2(RG-2)和ROUGE-L(RG-L)分别指一元unigram、二元bigrams以及最长的公共子序列。使用BERTScore【21】计算基于BERT嵌入的摘要之间的相似度。用FactCC和QuestEval评估模型的事实描述一致性。FactCC是一个弱监督、基于模型的事实一致性验证方法。QuestEval在生成摘要中不仅考虑事实信息,也考虑了源文中最重要的信息,最终给出了加权F1分数QE。
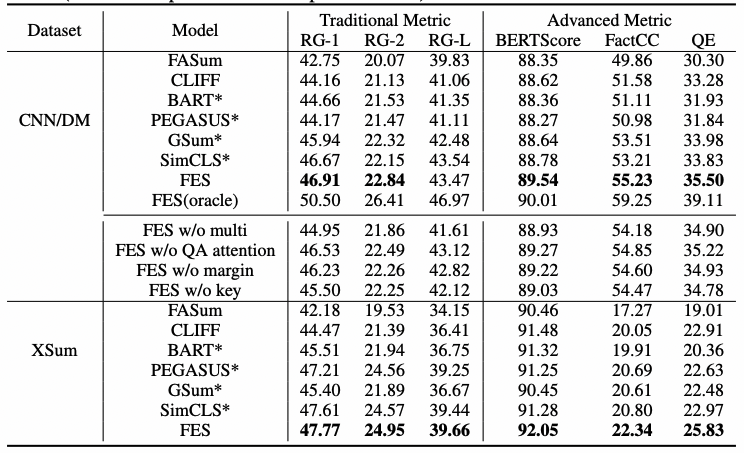
表1:CNN/DM和XSum数据集上的评估结果
如表1所示,在含义一致性上,FASum是效果最差的,可能的原因是这个模型不是基于预训练模型的。CLIFF的BERTScore分和忠实性分都比BART好。本文的模型在CNN/DM数据集上比GSum模型好0.97分ROUGE-1、0.90分BERTScore,在XSum数据集上比GSum模型好3.35分QE。这表明多任务中的问题能比重要的句子提供更好的信息。在绝大多数的指标上,本文的模型效果都是比有最好基准的SimCLS模型好,特别是忠实性指标FactCC和QE上。同时从上表也可以看到,oracles能进一步改进效果,在CNN/DM数据集上的ROUGE-1达到50.50分。这个测试也表明:1)通过QA问答对能改进模型效果;2)通过QA问答任务辅助也能改进模型效果。
因为自动评测可能会有偏差,本文进一步进行了人工评测。在CNN/DM和XSum数据集上随机选取了100个样本,然后雇佣了两名流利使用英语的人来评估生成摘要的信息性和事实描写一致性。选取了具有最好自动评测结果的模型,并且隐藏模型的名称。对于每一篇文章,由基准BART、PEGASUS和其他两个系统生成的摘要会给到评估者。评估者对摘要给出评分,并且标出内部和外部的错误。
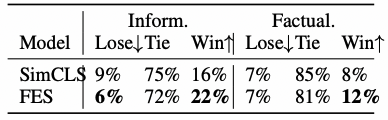
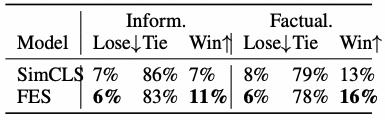
表2:CNN/DM数据集上的人工评测结果 表3:XSum数据集上的人工评测结果
从人工评测结果表2和表3中可以看到,CNN/DM数据集上表现出更高的信息性,XSum数据集上表现出更高的事实一致性。这是因为CNN/DM数据集更长从而具有更多信息,XSum数据集比较短需要摘要模型具有更好的效果。在两个数据集上的人工评测也表明了本文的模型对比SimCLS模型具有更好的效果,生成的摘要具有更多的信息、与文档的事实描述更加一致。
3、评估讨论
消融研究:在CNN/DM数据集上进行本文FES模型的各模块消融研究。第一个先移除多任务框架来验证摘要的联合学习,也即移除了解码器的QA注意力加强机制。这样等价于有实体输入和最大化边际损失的BART摘要生成模型。第二个保留QA任务但用Vanilla Transformer解码器替代QA注意力加强解码器。第三个移除最大边际损失来验证预训练语言模型的过拟合。此外,通过随机选择QA对来查看模型对文档的理解是否跟关键信息相关。
从表1可以看出,FES去掉多任务框架后,在CNN/DM数据集上的效果RG-L得分下降1.86,BERTScore得分下降0.43,QE得分下降0.60。这表明QA多任务模块增强了编码器的全面表示学习。FES去掉QA注意力机制后,QE得分下降0.28。这表明将QA注意力与重要实体的摘要注意力相结合能帮忙模型从输入文档中获取要点信息,并将信息损失限制在部分实体上以帮助解码器从输入文档中获取有意义的内容。FES去掉最大边际损失函数后,FactCC得分下降0.63。这表明防止预训练语言模型LM过拟合能提高摘要生成的忠实性。最后,FES采用随机QA问答对,会降低效果,但比BART的效果还是提高不少。这表明即使随机的QA问答对不一定与关键信息相关,但加强了文档的理解,也能带来效果的提升。而关于关键实体生成的QA问答对,则进一步提升了效果。
QA问答对数量研究:在CNN/DM数据集上进行本文FES模型的问答对数量研究。QA问答对的调整数量为6-14对。从图4(a)可以看到,ROUGE得分刚开始会随着QA问答对增加而提升。当QA问答对超过8对后,提升效果会消失。从原因上分析,增加的问答对不再是提取关键的信息了。QA问答对从8对调到15对,FES模型都维持了一个较高的效果,也证明了本文提出模型的有效性和鲁棒性。根据问答对数量研究,本文默认情况下选取的QA问答是8对。
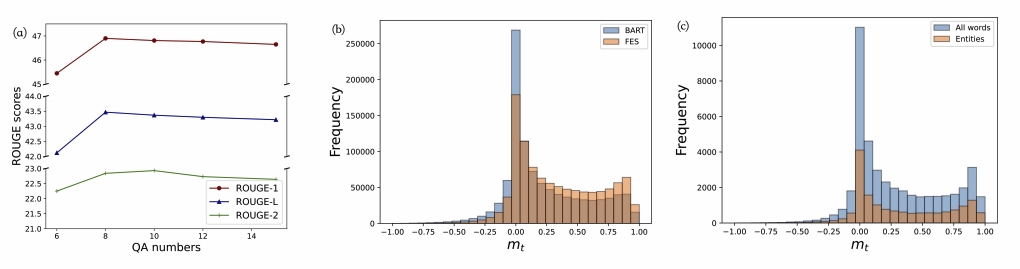
图4
QA任务评估:本文的框架引入了问题解答任务,所以评估QA任务的效果对理解FES模型就有帮助。具体来说,采用精确匹配(exact match,EM)和部分匹配(partial match,f1)来评估FES模型和其消融模型。结果如表4所示,可以看到,包含多任务框架明显能提升评估得分。这也证明了QA任务和摘要生成任务是相关受益的,摘要生成任务也能提升QA任务的效果。表4中QA任务的EM和F1得分也比较高,表明本文的FES模型也能用于文本的问题解答任务。

表4 表5
FES和预训练语言模型LM的差异:接下来评估FES模型和BART的差异(),结果如图4(b)所示。可以看到,BART模型中
仍有有很多值是小于0和近似等于0的。这表明对于很多token来说,预训练语言模型LM是过拟合的。对比BART模型,本文的FES模型中
值小于0的数量降低了很多。表5中列出了两个模型中
是负值的比例,以及
的平均值。FES模型中
是负值的比例降低了2.33%,平均值提升了0.11。这表明FES模型针对过拟合问题改进了很多。图4(c)画出了所有词和实体词的
分布。实体词的
在0值附近的比例降低非常多,这也表明预训练语言模型LM在实体词上的准确性会好很多。
案例研究:在表6中列出了几个典型案例,包括源文档中的相关QA问答对和相关上下文。在CNN/DM和XSum这两个数据集上采用BART、FEGASUS、SimCLS和本文FES模型生成了摘要。前3个案例显示了基线模型由于对源文档的理解有误,产生了篡改原文的内在错误。本文FES模型在问题问答的帮助下,产生了更加有忠实性的摘要。第4个案例显示了基线模型和预训练语言模型LM生成了相似的tokens,包括了原文中没有的多余信息。本文FES模型没有造成有多余信息的外部错误,这是因为引入了最大边际损失函数减缓了预训练语言模型LM的过拟合。值得一提的是,QA问答任务和最大边际损失两则能相互补充受益。例如第3个案例中,QA问答对和最大边际损失防止产生不忠实于原文的信息。在表6的最后一行进行了错误分析。两个生成的摘要中都包含一个未提及的名称,在训练数据集中可以找到。这个问题可能需要后处理(post-edit)来解决。
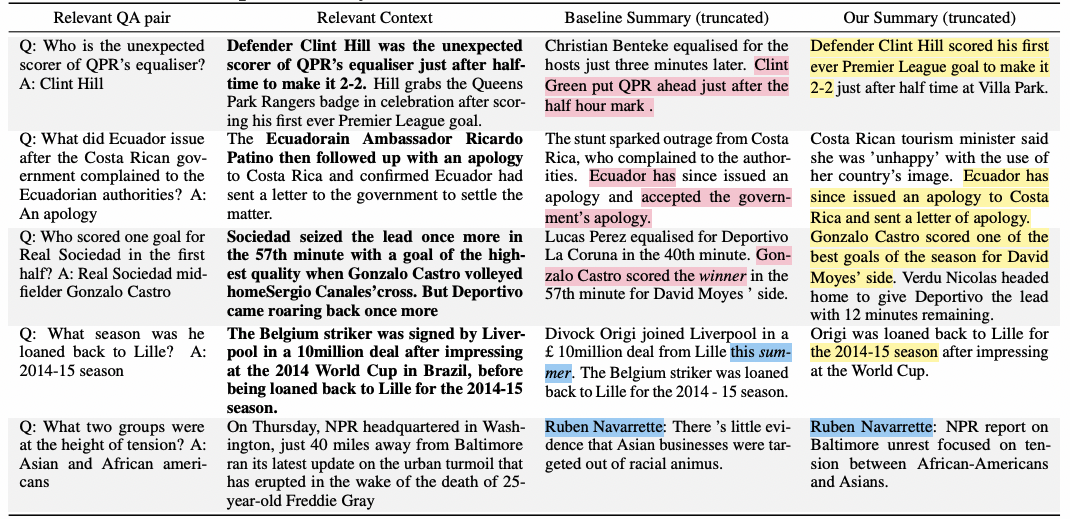
表6
结论
本文提出了具有最大边际损失函数的多任务框架来生成具有忠实性的摘要。辅助问答任务能增强模型对源文档的理解能力,最大边际损失函数可以防止预训练语言模型LM的过拟合。实验结果表明,本文提出的FES模型在不同数据集上都是有效的。下一步可以嵌入后处理操作以提高模型的忠实性。
而且产生具有忠实性的摘要也是迈向真正人工智能的重要一步。这项工作对构建智能和吸引人的阅读体系有潜在的积极影响。但是大家如果过于依赖摘要的这种即时阅读,可能会变得不那边有能力阅读长文档了。此外预训练语言模型可能会注入恶意和低俗的信息,产生有误导的摘要总结。所以也是要辩证的来看待摘要内容生成的优点和缺点。
本文原文地址:https://arxiv.org/pdf/2210.01877.pdf
参考文献
【1】Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. In Proc. of EMNLP, 2020.
【2】Thomas Scialom, Paul-Alexis Dray, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, Alex Wang, and Patrick Gallinari. Questeval: Summarization asks for fact-based evaluation. In Proc. of EMNLP, 2021.
【3】Esin Durmus, He He, and Mona Diab. Feqa: A question answering evaluation framework for faithfulness assessment in abstractive summarization. In Proc. of ACL, 2020.
【4】Daniel Adiwardana, Minh-Thang Luong, David R So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, et al. Towards a human-like open-domain chatbot. arXiv preprint arXiv:2001.09977, 2020.
【5】Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In Proc. of NeurIPS, 2015.
【6】Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proc. of EMNLP, 2018.
【7】Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proc. of NIPS, 2017.
【8】Wenhao Wu, Wei Li, Xinyan Xiao, Jiachen Liu, Ziqiang Cao, Sujian Li, Hua Wu, and Haifeng Wang. Bass: Boosting abstractive summarization with unified semantic graph. In Proc. of ACL, 2021.
【9】Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. Proc. of ICLR, 2017.
【10】Bhuwan Dhingra, Manaal Faruqui, Ankur Parikh, Ming-Wei Chang, Dipanjan Das, and William Cohen. Handling divergent reference texts when evaluating table-to-text generation. In Proc. of ACL, 2019.
【11】Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. In Proc. of ACL, 2020.
【12】Mengqi Miao, Fandong Meng, Yijin Liu, Xiao-Hua Zhou, and Jie Zhou. Prevent the language model from being overconfident in neural machine translation. In Proc. of ACL, 2021.
【13】Chenguang Zhu, William Hinthorn, Ruochen Xu, Qingkai Zeng, Michael Zeng, Xuedong Huang, and Meng Jiang. Enhancing factual consistency of abstractive summarization. In Proc. of AACL, 2021.
【14】Shuyang Cao and Lu Wang. Cliff: Contrastive learning for improving faithfulness and factuality in abstractive summarization. In Proc. of EMNLP, 2021.
【15】Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proc. of ACL, 2020.
【16】Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J Liu. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. Proc. of ICML, 2020.
【17】Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, and Graham Neubig. Gsum: A general framework for guided neural abstractive summarization. In Proc. of AACL, 2021.
【18】Yixin Liu and Pengfei Liu. Simcls: A simple framework for contrastive learning of abstractive summarization. In Proc. of ACL, 2021.
【19】Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-ofthe-art natural language processing. In Proc. of EMNLP, 2020.
【20】Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, 2004.
【21】Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. In Proc. of ICLR, 2020.
相关文章:
内容算法解读:提高内容摘要与原文的一致性(Faithfulness)
全文摘要:受益于预训练语言模型的发展,应用神经网络模型提取内容摘要的技术也获得了长足进步。但目前还存在一个未被很好解决的问题:神经网络模型提取的摘要不能如实反映原文档的中心思想,没有做到忠实(not faithful&a…...

python用openpyxl包操作xlsx文件,统计表中合作电影数目最多的两个演员
题目🎉🎉🎉:编程完成下面任务:已知excel文件“电影导演演员信息表.xlsx”如下图所示:🍳🍳🍳要求:使用 openpyxl 包操作打开此文件,编写程序统计在…...

Lesson12---人工神经网络(1)
12.1 神经元与感知机 12.1.1 感知机 感知机: 1957, Fank Rosenblatt 由两层神经元组成,可以简化为右边这种,输入通常不参与计算,不计入神经网络的层数,因此感知机是一个单层神经网络 感知机 训练法则&am…...
)
算法练习-排序(二)
算法练习-排序(二) 文章目录算法练习-排序(二)1 合并排序的数组1.1 题目1.2 题解2 有效的字母异位词2.1 题目2.2 题解3 判断能否形成等差数列3.1 题目3.2 题解4 合并区间4.1 题目3.2 题解5 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面5.1 题目5.2 题解6 颜色分类6.1 题目6.…...

202302读书笔记|《长安的荔枝》——只要肯努力,办法总比困难多
202302读书笔记|《长安的荔枝》——只要肯努力,办法总比困难多 《长安的荔枝》这本书真是酣畅淋漓啊,读起来一气呵成,以讲故事的口吻叙述,上林署九品小官员——李善德,兢兢业业工作多年,终于借贷买了房&…...
java封装继承多态详解
1.封装 所谓封装,就是将客观事物封装成抽象的类,并且类可以把数据和方法让可信的类或者对象进行操作,对不可信的类或者对象进行隐藏。类就是封装数据和操作这些数据代码的逻辑实体。在一个类的内部,某些属性和方法是私有的&#…...
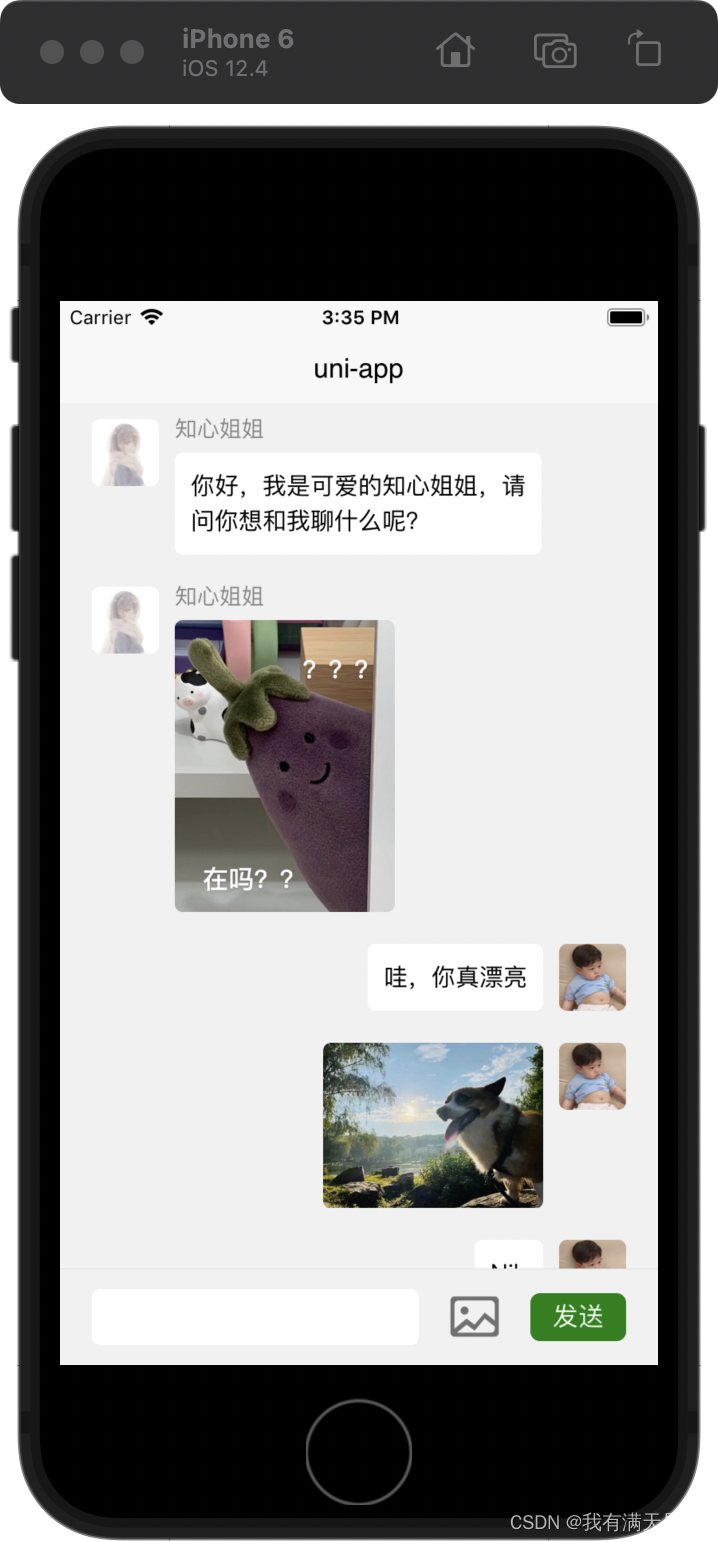
【uni-app教程】UniAPP 常用组件和 常用 API 简介# 知心姐姐聊天案例
五、UniAPP 常用组件简介 uni-app 为开发者提供了一系列基础组件,类似 HTML 里的基础标签元素,但 uni-app 的组件与 HTML 不同,而是与小程序相同,更适合手机端使用。 虽然不推荐使用 HTML 标签,但实际上如果开发者写了…...
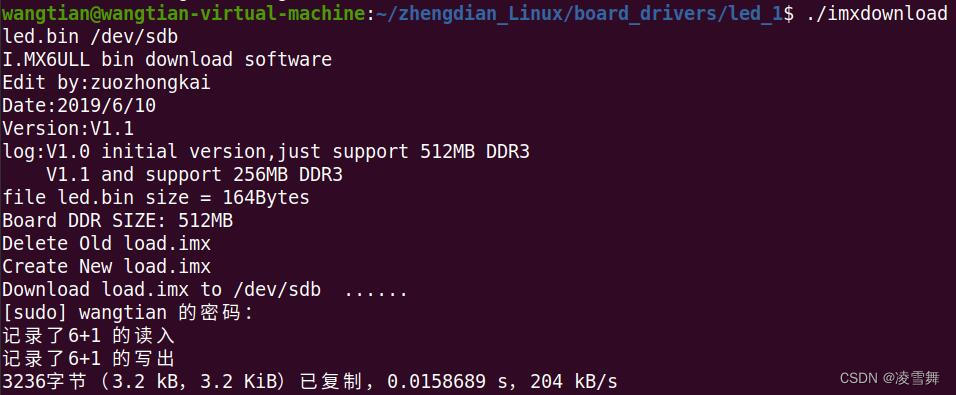
阿尔法开发板 .bin 文件烧写
一. IMX6ULL 开发板简介 IMX6ULL 开发板是正点原子提供的阿尔法开发板,所用芯片为恩智浦,基于 Cortex-A7 架构。 这里介绍一下裸机篇中,关于如何将 .bin 文件烧写进 SD 卡,从而设备运行程序。 二. xx.bin 文件烧写 IMX6ULL支…...
Ceres-Solver 安装与卸载ubuntu20.04
卸载 sudo rm -rf /usr/local/lib/cmake/Ceres /usr/local/include/ceres /usr/local/lib/libceres.a 安装 sudo apt-get install libatlas-base-dev libsuitesparse-dev git clone https://github.com/ceres-solver/ceres-solver cd ceres-solver git checkout $(git descr…...
汇编系列02-借助操作系统输出Hello World
说明:本节的程序使用的是x86_64指令集的。 汇编语言是可以编译成机器指令的,机器指令是可以直接在CPU上面执行的。我们编写的汇编程序既可以直接在操作系统的帮助下执行,也可以绕过操作系统,直接在硬件上执行。 如果你打算编写的汇编程序在…...

【2023unity游戏制作-mango的冒险】-前六章API,细节,BUG总结小结
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity游戏制作 ⭐mango的冒险前六章总结⭐ 文章目录⭐mango的冒险前六章总结⭐👨&a…...

进程控制及其操作
进程创建1.1 fork()函数1.2 fork()函数的返回值进程等待2.1 进程等待的必要性1.之前讲过,子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。 2.另外,进程一旦变成僵尸状态,那…...

Git常用命令复习笔记
1. Git与SVN区别,各自优缺点 Git: 分布式,每个参与开发的人的电脑上都有一个完整的仓库,不担心硬盘出问题;在不联网的情况下,照样可以提交到本地仓库,可以查看以往的所有log,等到有…...
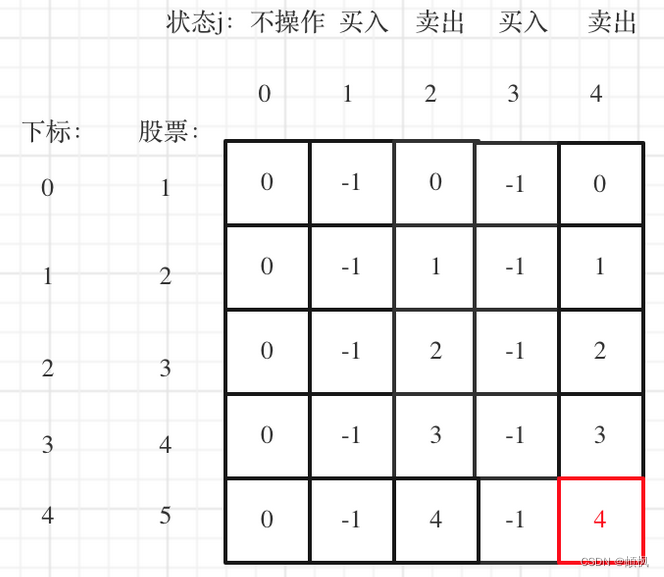
代码随想录算法训练营day49 | 动态规划 123.买卖股票的最佳时机III 188.买卖股票的最佳时机IV
day49123.买卖股票的最佳时机III1.确定dp数组以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组188.买卖股票的最佳时机IV1.确定dp数组以及下标的含义2.确定递推公式4.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组123.买卖股票的最佳时机III …...
【教学典型案例】14.课程推送页面整理-增加定时功能
目录一:背景介绍1、代码可读性差,结构混乱2、逻辑边界不清晰,封装意识缺乏3、展示效果不美观二:案例问题分析以及解决过程1、代码可读性…...

【算法基础】DFS BFS 进阶训练
DFS与BFS的基础篇详见:https://blog.csdn.net/m0_51339444/article/details/129301451?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129301451%22%2C%22source%22%3A%22m0_51339444%22%7D 一、案例分析1 (树的重心 —— D…...

GO语言中的回调函数
0.前言 回调函数是一种在编程中常见的技术,通常在异步编程中使用。简单来说,回调函数是一个被传递给另一个函数的函数,它在该函数的某个时间点被调用,以完成某些特定的操作或任务。 在Go语言中,可以将函数直接作为参…...
28个案例问题分析---014课程推送页面逻辑整理--vue
一:背景介绍 项目开发过程中,前端出现以下几类问题: 代码结构混乱代码逻辑不清晰页面细节问题 二:问题分析 代码结构混乱问题 <template><top/><div style"position: absolute;top: 10px"><C…...

佛科院单片机原理2——80C51单片机结构
一、程序存储器的入口地址:程序入口地址:0000H外部中断0入口地址:0003H定时器0溢出中断入口地址:000BH外部中断1入口地址:00013H定时器1溢出中断入口地址:001BH串行口中断入口地址:0023H定时器2…...

数据结构与算法_动态顺序表
顺序表是线性表的一种。 线性表是n个具有相同特性的数据元素的有限序列。 逻辑上,它们是线性结构,是一条连续的直线;但是在物理上,它们通常以数组和链式结构存储。 常见的线性表有顺序表、栈、队列、字符串等。 顺序表是用一段…...
)
Houdini VEX实战:5步搞定变形管道的中心线生成(附常见问题修复)
Houdini VEX实战:5步搞定变形管道的中心线生成(附常见问题修复) 在三维动画制作中,处理变形管道的中心线是许多技术美术师面临的常见挑战。无论是角色动画中的血管、机械装置中的电缆,还是科幻场景中的能量管道&#x…...

告别数据洪流:手把手教你用ZCANPRO的视图筛选与实时曲线功能高效分析CAN报文
告别数据洪流:手把手教你用ZCANPRO的视图筛选与实时曲线功能高效分析CAN报文 在车载电子和嵌入式开发领域,CAN总线数据的分析工作常常让工程师们头疼不已。想象一下,当你的测试设备捕获到成千上万条CAN报文时,如何从中快速定位到关…...

微信数据库密钥自动获取:从手动繁琐到一键提取的技术革新
微信数据库密钥自动获取:从手动繁琐到一键提取的技术革新 【免费下载链接】PyWxDump 获取微信账号信息(昵称/账号/手机/邮箱/数据库密钥/wxid);PC微信数据库读取、解密脚本;聊天记录查看工具;聊天记录导出为html(包含语音图片)。支…...
)
嵌入式Linux开发板CH340驱动安装避坑指南(附详细步骤图)
嵌入式Linux开发板CH340驱动安装全流程解析与疑难排错 第一次接触嵌入式Linux开发板时,最让人头疼的往往不是代码编写,而是最基础的开发环境搭建。作为连接电脑与开发板的重要桥梁,CH340串口驱动的安装质量直接决定了后续调试效率。许多初学者…...

24小时运行OpenClaw:nanobot定时任务监控方案
24小时运行OpenClaw:nanobot定时任务监控方案 1. 为什么需要24小时运行的OpenClaw? 去年夏天,我因为忘记备份一个重要项目文件而损失了三天的工作量。当时就想,如果能有个"数字管家"帮我定时执行这些重复性任务该多好…...

Qwen All-in-One部署实战:极简依赖,快速搭建AI应用
Qwen All-in-One部署实战:极简依赖,快速搭建AI应用 1. 引言:轻量级AI服务的新选择 在当今AI应用遍地开花的时代,开发者们常常面临一个两难选择:要么使用功能强大但资源消耗巨大的模型,要么选择轻量级但功…...

OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试
OpenClaw跨平台脚本:Qwen3-32B生成的Python代码自动测试 1. 为什么需要AI全流程编程辅助 作为经常需要写脚本处理数据的开发者,我发现自己陷入了一个典型困境:每天要花大量时间编写重复性代码,而真正需要创造性思考的部分反而被…...
)
Dify新手必看:3种创建应用的方法全解析(附模板使用技巧)
Dify新手必看:3种创建应用的方法全解析(附模板使用技巧) 第一次打开Dify工作室时,面对琳琅满目的功能选项,很多开发者都会感到无从下手。作为一个从零开始接触Dify的过来人,我完全理解这种困惑——毕竟当初…...
)
ArcGIS实战:5分钟搞定正高转椭球体高度(附详细步骤)
ArcGIS高程转换实战:从正高到椭球体高度的精准跨越 在测绘与地理信息系统中,高程数据的精确转换是许多专业应用的基础环节。无论是卫星影像处理、无人机航测还是工程测量,不同高程基准之间的转换需求无处不在。本文将带您深入理解正高与椭球…...

Kronos金融AI预测模型实战指南:从零构建企业级量化交易系统
Kronos金融AI预测模型实战指南:从零构建企业级量化交易系统 【免费下载链接】Kronos Kronos: A Foundation Model for the Language of Financial Markets 项目地址: https://gitcode.com/GitHub_Trending/kronos14/Kronos 在金融市场这个充满不确定性的战场…...