Day907.分区表 -MySQL实战
分区表
Hi,我是阿昌,今天学习记录的是关于分区表的内容。
经常被问到这样一个问题:
分区表有什么问题,为什么公司规范不让使用分区表呢?
一、分区表是什么?
为了说明分区表的组织形式,先创建一个表 t:
CREATE TABLE `t` (`ftime` datetime NOT NULL,`c` int(11) DEFAULT NULL,KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);

在表 t 中初始化插入了两行记录,按照定义的分区规则,这两行记录分别落在 p_2018 和 p_2019 这两个分区上。
可以看到,这个表包含了一个.frm 文件和 4 个.ibd 文件,每个分区对应一个.ibd 文件。
也就是说:
- 对于引擎层来说,这是 4 个表;
- 对于 Server 层来说,这是 1 个表。
可能会觉得这两句都是废话。
其实不然,这两句话非常重要,可以理解分区表的执行逻辑。
二、分区表的引擎层行为
先给举个在分区表加间隙锁的例子,目的是说明对于 InnoDB 来说,这是 4 个表。
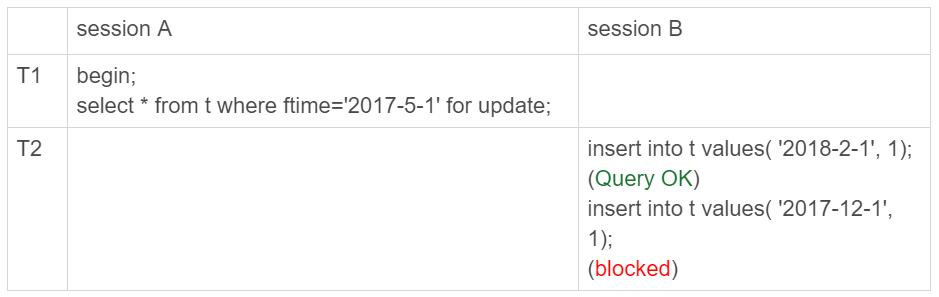
这里顺便回忆一下,在加锁规则的一些问题介绍的间隙锁加锁规则。
初始化表 t 的时候,只插入了两行数据, ftime 的值分别是,‘2017-4-1’ 和’2018-4-1’ 。
session A 的 select 语句对索引 ftime 上这两个记录之间的间隙加了锁。
如果是一个普通表的话,那么 T1 时刻,在表 t 的 ftime 索引上,间隙和加锁状态应该是图 3 这样的。
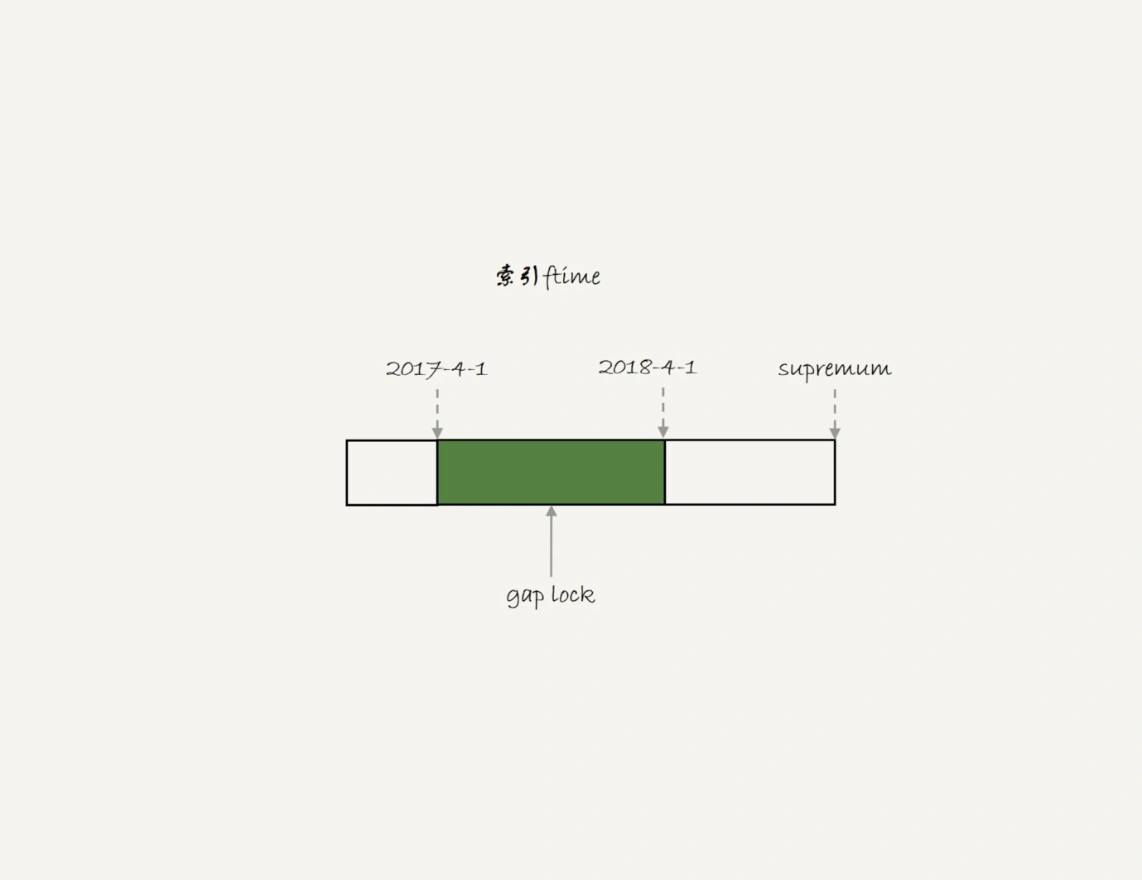
也就是说,‘2017-4-1’ 和’2018-4-1’ 这两个记录之间的间隙是会被锁住的。那么,sesion B 的两条插入语句应该都要进入锁等待状态。但是,从上面的实验效果可以看出,session B 的第一个 insert 语句是可以执行成功的。
这是因为,对于引擎来说,p_2018 和 p_2019 是两个不同的表,也就是说 2017-4-1 的下一个记录并不是 2018-4-1,而是 p_2018 分区的 supremum。
所以 T1 时刻,在表 t 的 ftime 索引上,间隙和加锁的状态其实是图 4 这样的:
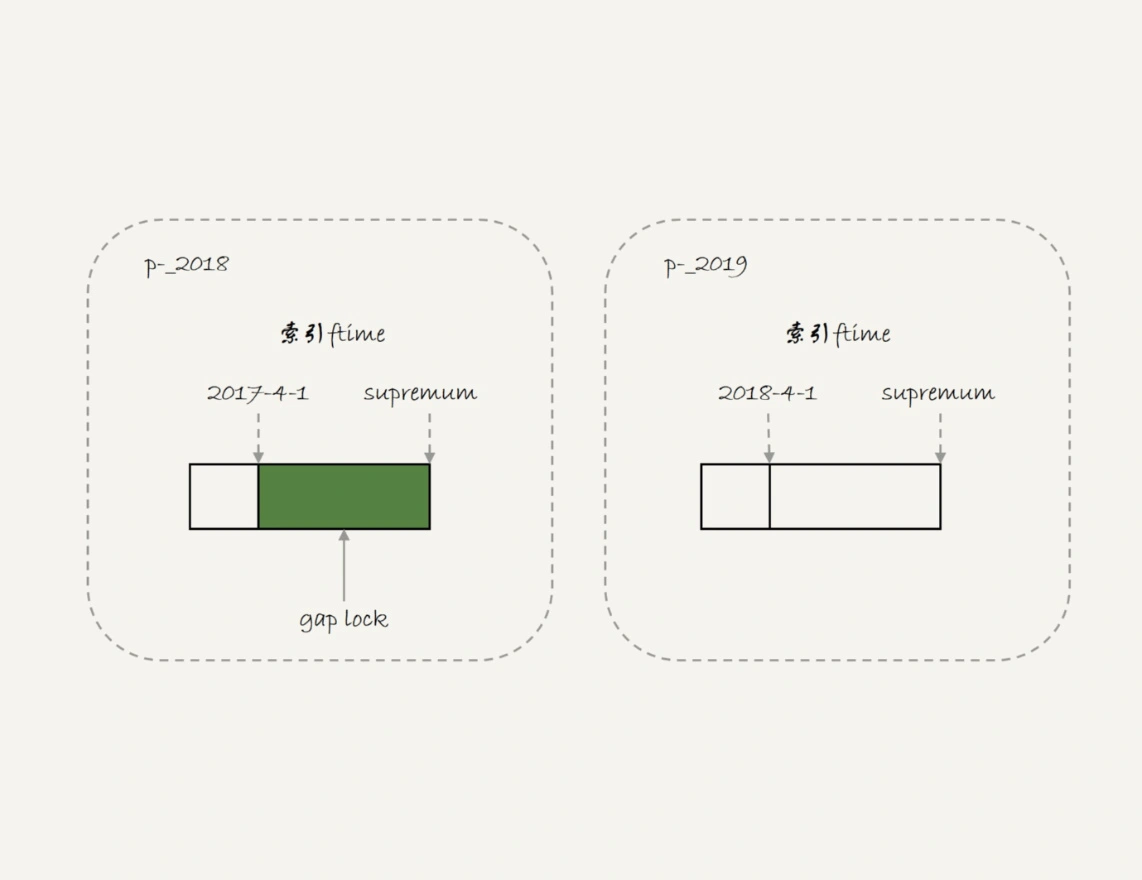
由于分区表的规则,session A 的 select 语句其实只操作了分区 p_2018,因此加锁范围就是图 4 中深绿色的部分。
所以,session B 要写入一行 ftime 是 2018-2-1 的时候是可以成功的,而要写入 2017-12-1 这个记录,就要等 session A 的间隙锁。
图 5 就是这时候的 show engine innodb status 的部分结果。

看完 InnoDB 引擎的例子,再来一个 MyISAM 分区表的例子。
首先用 alter table t engine=myisam,把表 t 改成 MyISAM 表;然后,再用下面这个例子说明,对于 MyISAM 引擎来说,这是 4 个表。
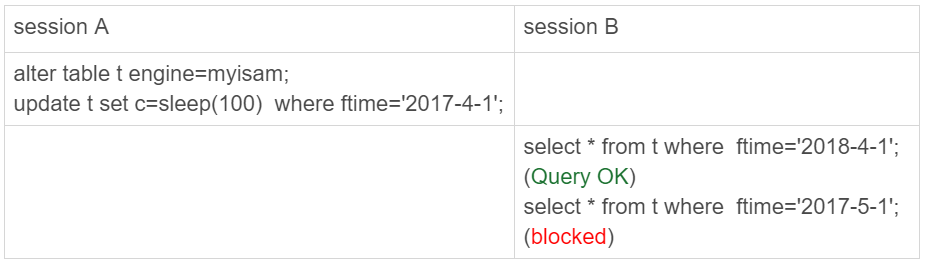
在 session A 里面,我用 sleep(100) 将这条语句的执行时间设置为 100 秒。由于 MyISAM 引擎只支持表锁,所以这条 update 语句会锁住整个表 t 上的读。但看到的结果是,session B 的第一条查询语句是可以正常执行的,第二条语句才进入锁等待状态。
这正是因为 MyISAM 的表锁是在引擎层实现的,session A 加的表锁,其实是锁在分区 p_2018 上。
因此,只会堵住在这个分区上执行的查询,落到其他分区的查询是不受影响的。
可能会说,分区表看来还不错嘛,为什么不让用呢?
使用分区表的一个重要原因就是单表过大。那么,如果不使用分区表的话,就是要使用手动分表的方式。
接下来,一起看看手动分表和分区表有什么区别。
比如,按照年份来划分,就分别创建普通表 t_2017、t_2018、t_2019 等等。
手工分表的逻辑,也是找到需要更新的所有分表,然后依次执行更新。在性能上,这和分区表并没有实质的差别。
分区表和手工分表,一个是由 server 层来决定使用哪个分区,一个是由应用层代码来决定使用哪个分表。
因此,从引擎层看,这两种方式也是没有差别的。其实这两个方案的区别,主要是在 server 层上。
从 server 层看,我们就不得不提到分区表一个被广为诟病的问题:打开表的行为。
三、分区策略
每当第一次访问一个分区表的时候,MySQL 需要把所有的分区都访问一遍。
一个典型的报错情况是这样的:如果一个分区表的分区很多,比如超过了 1000 个,而 MySQL 启动的时候,open_files_limit 参数使用的是默认值 1024,那么就会在访问这个表的时候,由于需要打开所有的文件,导致打开表文件的个数超过了上限而报错。
下图就是创建的一个包含了很多分区的表 t_myisam,执行一条插入语句后报错的情况。

可以看到,这条 insert 语句,明显只需要访问一个分区,但语句却无法执行。
这时,你一定从表名猜到了,这个表用的是 MyISAM 引擎。是的,因为使用 InnoDB 引擎的话,并不会出现这个问题。MyISAM 分区表使用的分区策略,我们称为通用分区策略(generic partitioning),每次访问分区都由 server 层控制。
通用分区策略,是 MySQL 一开始支持分区表的时候就存在的代码,在文件管理、表管理的实现上很粗糙,因此有比较严重的性能问题。
从 MySQL 5.7.9 开始,InnoDB 引擎引入了本地分区策略(native partitioning)。这个策略是在 InnoDB 内部自己管理打开分区的行为。MySQL 从 5.7.17 开始,将 MyISAM 分区表标记为即将弃用 (deprecated),意思是“从这个版本开始不建议这么使用,请使用替代方案。
在将来的版本中会废弃这个功能”。从 MySQL 8.0 版本开始,就不允许创建 MyISAM 分区表了,只允许创建已经实现了本地分区策略的引擎。
目前来看,只有 InnoDB 和 NDB 这两个引擎支持了本地分区策略。
四、分区表的 server 层行为
接下来,再看一下分区表在 server 层的行为。
如果从 server 层看的话,一个分区表就只是一个表。
这句话是什么意思呢?接下来,就用下面这个例子来和你说明。
如图 8 和图 9 所示,分别是这个例子的操作序列和执行结果图。
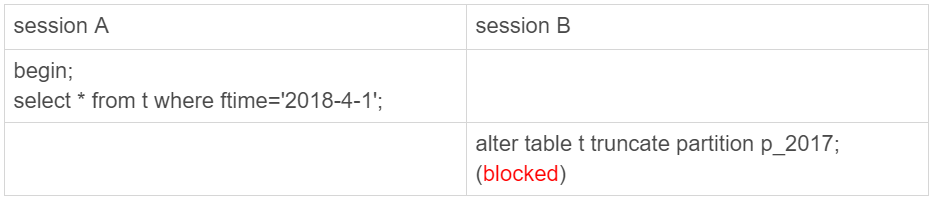

可以看到,虽然 session B 只需要操作 p_2017 这个分区,但是由于 session A 持有整个表 t 的 MDL 锁,就导致了 session B 的 alter 语句被堵住。
DBA 同学经常说的,分区表,在做 DDL 的时候,影响会更大。
如果使用的是普通分表,那么当在 truncate 一个分表的时候,肯定不会跟另外一个分表上的查询语句,出现 MDL 锁冲突。
到这里小结一下:
- MySQL 在第一次打开分区表的时候,需要访问所有的分区;
- 在 server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁;
- 在引擎层,认为这是不同的表,因此 MDL 锁之后的执行过程,会根据分区表规则,只访问必要的分区。
而关于“必要的分区”的判断,就是根据 SQL 语句中的 where 条件,结合分区规则来实现的。
比如上面的例子中,where ftime=‘2018-4-1’,根据分区规则 year 函数算出来的值是 2018,那么就会落在 p_2019 这个分区。但是,如果这个 where 条件改成 where ftime>=‘2018-4-1’,虽然查询结果相同,但是这时候根据 where 条件,就要访问 p_2019 和 p_others 这两个分区。如果查询语句的 where 条件中没有分区 key,那就只能访问所有分区了。
当然,这并不是分区表的问题。即使是使用业务分表的方式,where 条件中没有使用分表的 key,也必须访问所有的分表。
那么什么场景下适合使用分区表呢?
五、分区表的应用场景
分区表的一个显而易见的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。
还有,分区表可以很方便的清理历史数据。如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求。
这时候,按照时间分区的分区表,就可以直接通过 alter table t drop partition … 这个语法删掉分区,从而删掉过期的历史数据。
这个 alter table t drop partition … 操作是直接删除分区文件,效果跟 drop 普通表类似。
与使用 delete 语句删除数据相比,优势是速度快、对系统影响小。
六、总结
需要注意的是,我是以范围分区(range)为例和你介绍的。实际上,MySQL 还支持 hash 分区、list 分区等分区方法。可以在需要用到的时候,再翻翻手册。实际使用时,分区表跟用户分表比起来,有两个绕不开的问题:一个是第一次访问的时候需要访问所有分区,另一个是共用 MDL 锁。因此,如果要使用分区表,就不要创建太多的分区。见过一个用户做了按天分区策略,然后预先创建了 10 年的分区。
这种情况下,访问分区表的性能自然是不好的。这里有两个问题需要注意:
- 分区并不是越细越好。实际上,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已经是小表了。
- 分区也不要提前预留太多,在使用之前预先创建即可。比如,如果是按月分区,每年年底时再把下一年度的 12 个新分区创建上即可。对于没有数据的历史分区,要及时的 drop 掉。
至于分区表的其他问题,比如查询需要跨多个分区取数据,查询性能就会比较慢,基本上就不是分区表本身的问题,而是数据量的问题或者说是使用方式的问题了。
当然,如果你的团队已经维护了成熟的分库分表中间件,用业务分表,对业务开发同学没有额外的复杂性,对 DBA 也更直观,自然是更好的。
举例的表中没有用到自增主键,假设现在要创建一个自增字段 id。
MySQL 要求分区表中的主键必须包含分区字段。
如果要在表 t 的基础上做修改,会怎么定义这个表的主键呢?为什么这么定义呢?
如果不包含分区字段,那么对于主键和唯一键都可能冲突。
相关文章:
Day907.分区表 -MySQL实战
分区表 Hi,我是阿昌,今天学习记录的是关于分区表的内容。 经常被问到这样一个问题: 分区表有什么问题,为什么公司规范不让使用分区表呢? 一、分区表是什么? 为了说明分区表的组织形式,先创建…...
C++概览:工具链、基础知识、进阶及总结
本篇写给C初学者,作为概览,文中仅包含各方面基础知识,无深入分析。 C基础概念简介 C编译过程示意图 关键词:源文件、预编译、编译、汇编、链接 C工具链总结 cmake项目工程文件是一种中介工程文件,可以转化成其他…...
目标检测中回归损失函数(L1Loss,L2Loss,Smooth L1Loss,IOU,GIOU,DIOU,CIOU,EIOU,αIOU ,SIOU)
文章目录L-norm Loss 系列L1 LossL2 LossSmooth L1 LossIOU系列IOU (2016)GIOU (2019)DIOU (2020)CIOU (2020)EIOU (2022)αIOU (2021)SIOU (2022…...
JOSN数据转换和解析
文章目录JOSN数据转换和解析内容回顾Map 集合转成 JSON 字符串List 集合转换成 JSON 字符串Ajax 异步和同步异步概念同步概念异步和同步区别异步请求案例同步请求时间格式化旧时间 api 格式化格式化和解析的工具类JSTL 时间格式化JSTL 使用JOSN数据转换和解析 内容回顾 ajax …...

浅析Linux内核中进程完全公平CFS调度
一、前序 目前Linux支持三种进程调度策略,分别是SCHED_FIFO 、 SCHED_RR和SCHED_NORMAL;而Linux支持两种类型的进程,实时进程和普通进程。实时进程可以采用SCHED_FIFO 和SCHED_RR调度策略;普通进程则采用SCHED_NORMAL调度策略。从…...
)
安装 RustDesk 服务器 (适用 Rocky Linux, CentOS, RHEL 系列发行版)
环境:Rocky Linux 9.1 1. 安装 Docker Engine 可以参考 [[linux-docker-rocky-install]] https://cc01cc.com/2023/03/02/linux-docker-rocky-install/英文可以参考官方文档 Install Docker Engine on RHEL https://docs.docker.com/engine/install/rhel/ 2. 安装…...

23种设计模式-策略模式
策略模式是一种设计模式,它允许在运行时选择算法的行为。它定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户端。在本文中,我们将深入探讨策略模式的概念和实际应用&#…...

C#开发的OpenRA的游戏主界面怎么样创建
通过前面加载界面布局数据,可以把整个界面逻辑的数据加载到内存, 但是这些数据怎么显示出来,又是没有定义的。比如前面定义了多个界面的布局, 又是怎么样知道需要显示哪一个界面? 现在就来解决这个问题,其实整个游戏都是可以通过yaml文件进行配置的, 所以我们需要从yaml…...

考研还是工作?两战失败老道有话说
老道入职第一周自我介绍谈谈考研谈谈工作新的启程自我介绍 大家好!在下是一枚考研失败两次的自认为聪明能干的有点小帅的实则超级垃圾的三非名校毕业的自动化渣男。大一下就加入实验室,在实验室焊板子、画板子、培训、打比赛外加摸鱼;参加过…...

引用是否有地址的讨论的
说在前头,纯属个人理解,关于引用是否有地址,实际上并没有一个很统一的说法, C标准没有规定一个引用是否需要占用一块内存。 这里引用知乎“C 中引用是一块内存的标记,那引用本身有地址吗_百度知道 (baidu.com)”里面的…...
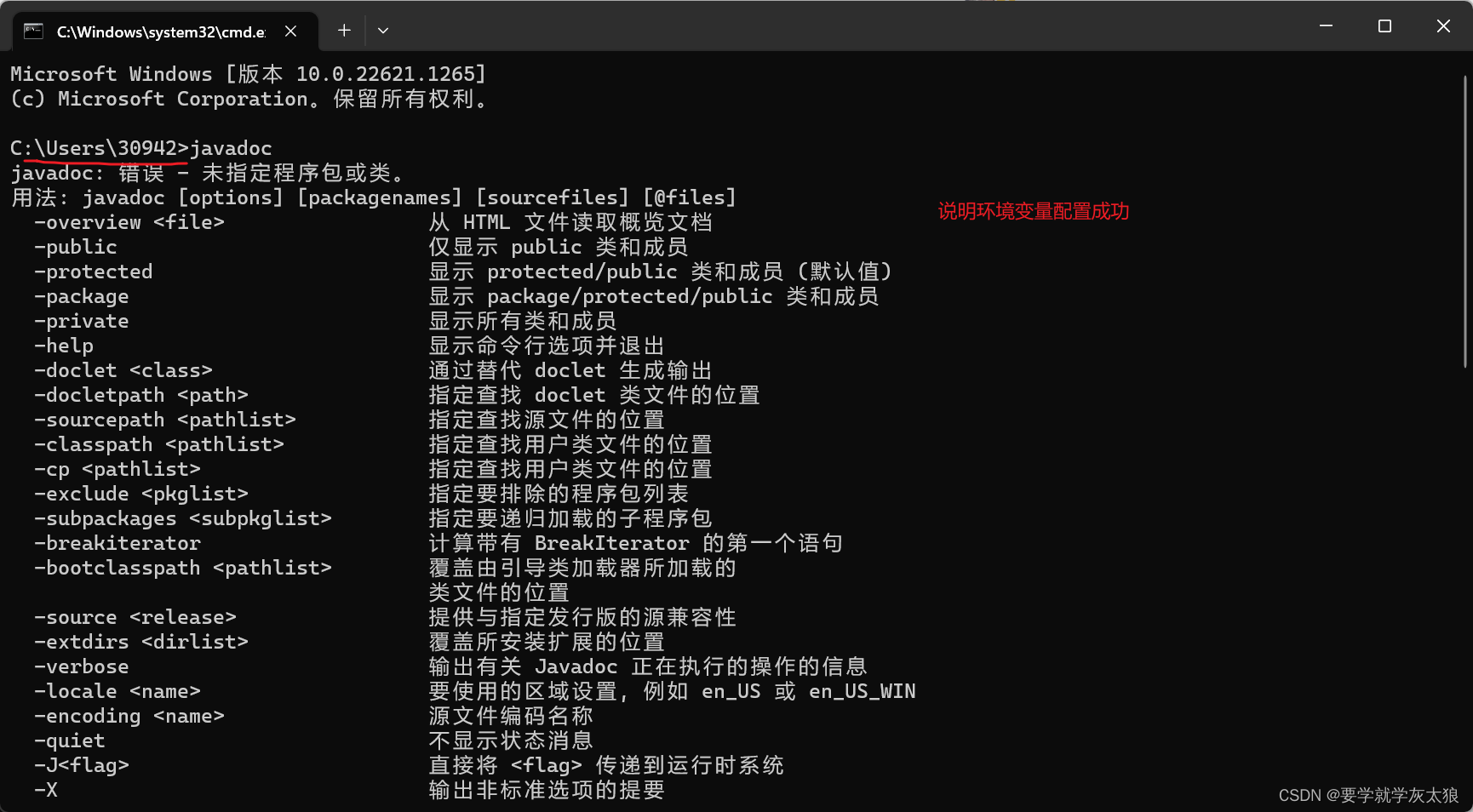
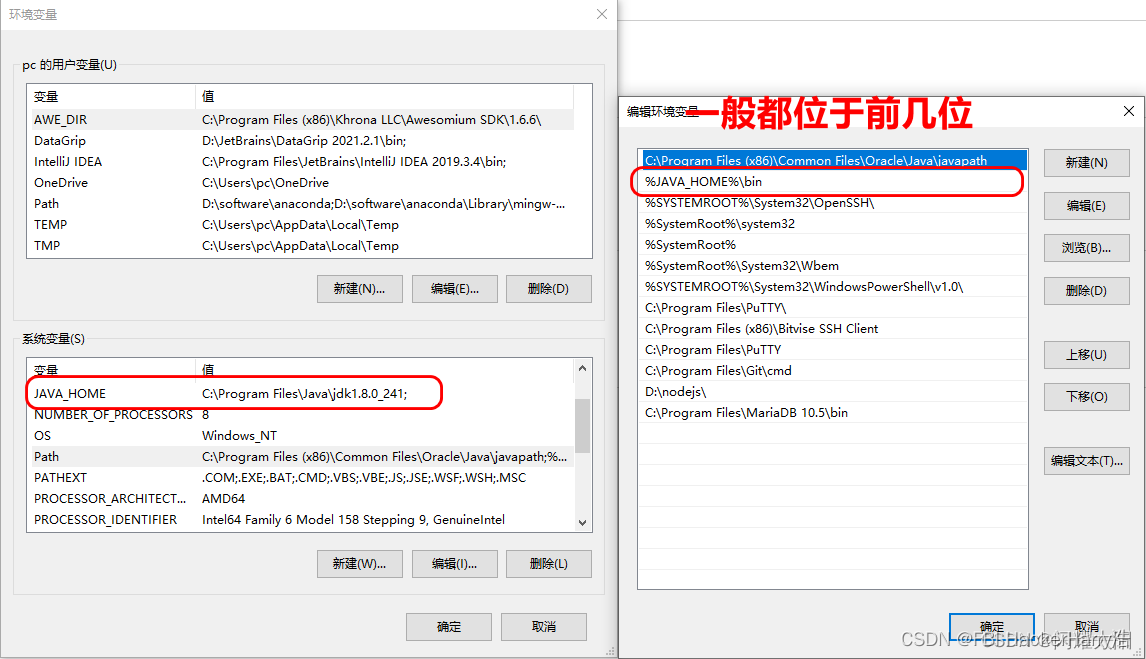
1、JAVA 开发环境搭建 - JDK 的安装配置
文章目录一、下载 JDK81、官网地址:[**https://www.oracle.com**](https://www.oracle.com)二、安装 JDK1、鼠标右键安装包,以管理员身份运行(无脑下一步即可)2、细节说明三、配置环境变量1、为啥要配置环境变量呢?2、原因分析3、配置环境变量…...

【Storm】【六】Storm 集成 Redis 详解
Storm 集成 Redis 详解 一、简介二、集成案例三、storm-redis 实现原理四、自定义RedisBolt实现词频统计一、简介 Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用: <dependency><groupId>org.apache.storm…...

算法代码题——模板
文章目录1. 双指针: 只有一个输入, 从两端开始遍历2. 双指针: 有两个输入, 两个都需要遍历完3. 滑动窗口4. 构建前缀和5. 高效的字符串构建6. 链表: 快慢指针7. 反转链表8. 找到符合确切条件的子数组数9. 单调递增栈10. 二叉树: DFS (递归)]11. 二叉树: DFS (迭代)12. 二叉树: …...
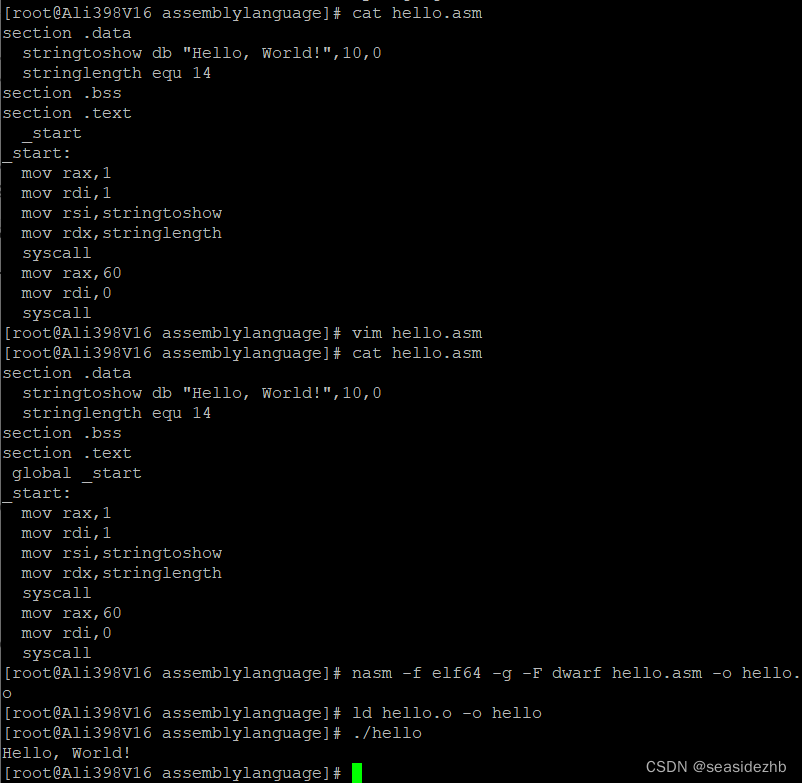
CentOS 7.9汇编语言版Hello World
先下载、编译nasm汇编器。NASM汇编器官网如下图所示: 可以点图中的List进入历史版本下载网址: 我这里下载的是nasm-2.15.05.tar.bz2 在CentOS 7中,使用 wget http://www.nasm.us/pub/nasm/releasebuilds/2.15.05/nasm-2.15.05.tar.bz2下载…...

CoreData数据库探索
CoreData是什么 Core Data 是苹果公司提供的一个对象-关系映射框架(Object-Relational Mapping,ORM),用于管理应用程序的数据模型。Core Data 提供了一个抽象层,使开发人员能够使用面向对象的方式访问和操作数据&…...
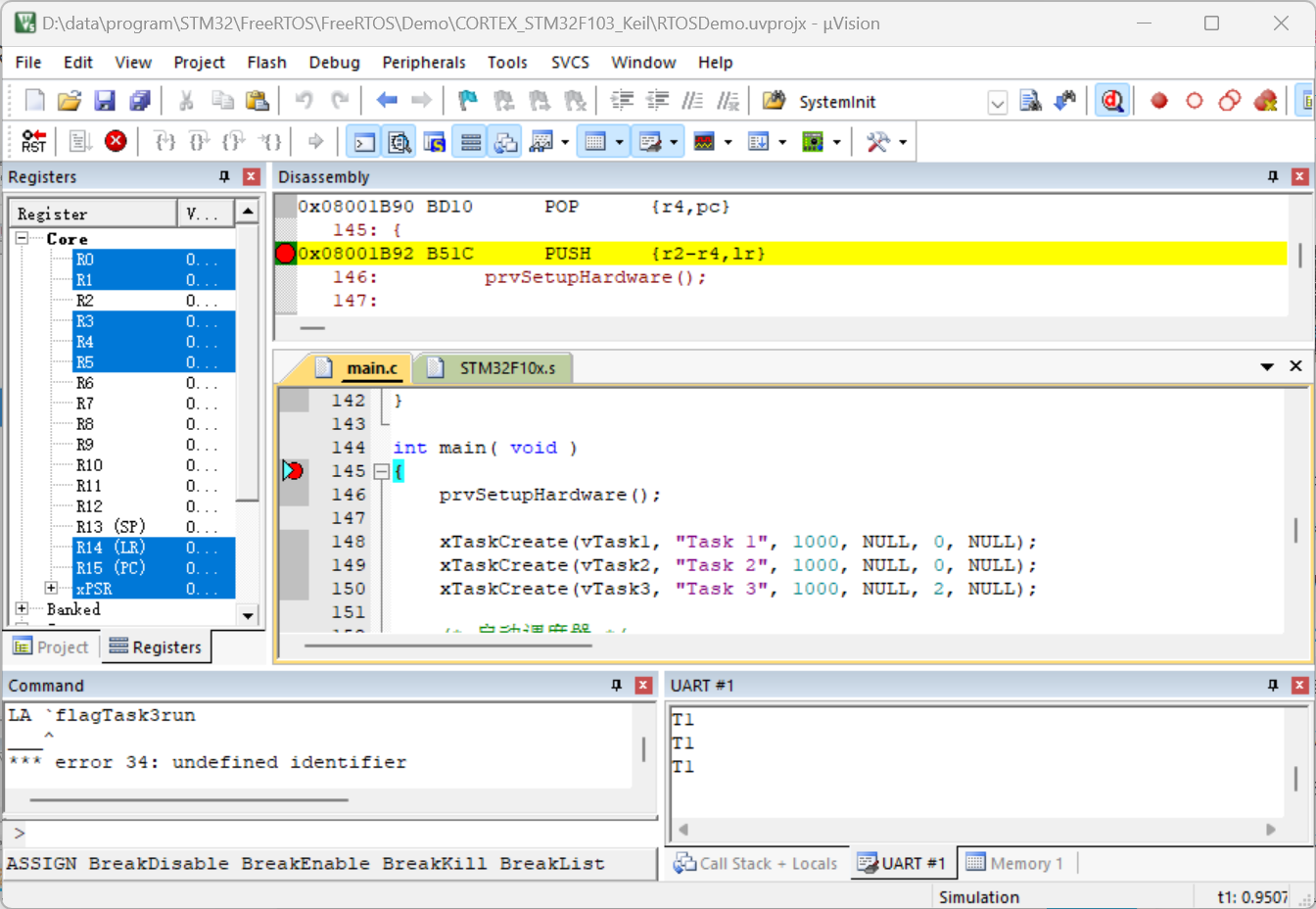
FreeRTOS入门
目录 一、简介 二、堆的概念 三、栈的概念 四、从官方源码中精简出第一个FreeRTOS程序 五、修改官方源码增加串口打印 一、简介 FreeRTOS是一个迷你的实时操作系统内核。作为一个轻量级的操作系统,功能包括:任务管理、时间管理、信号量、消息队列、…...
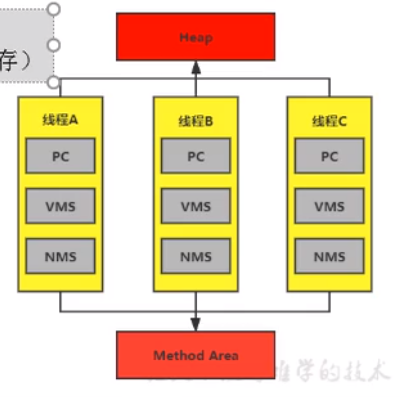
JVM运行时数据区划分
Java内存空间 内存是非常重要的系统资源,是硬盘和cpu的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了JAVA在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的jvm对于内存的划分方式和管理机…...
重装系统一半电脑蓝屏如何解决
小编相信大家在使用电脑或者给电脑重装系统的时候都遇到过电脑蓝屏等等故障问题。最近有用户就遇到了这样一个问题,问小编重装系统一半电脑蓝屏怎么办,那么今天小编就告诉大家重装系统一半电脑蓝屏的解决方法。 工具/原料: 系统版本&#x…...
SpringBoot(tedu)——day01——环境搭建
SpringBoot(tedu)——day01——环境搭建 目录SpringBoot(tedu)——day01——环境搭建零、今日目标一、IDEA2021项目环境搭建1.1 通过 ctrl鼠标滚轮 实现字体大小缩放1.2 自动提示设置 去除大小写匹配1.3 设置参数方法自动提示1.4 设定字符集 要求都使用UTF-8编码1.5 设置自动编…...

springboot整合redis
1.redis的数据类型,一共有5种.后面结合Jedis和redistemplate,以及单元测试junit一起验证 1)字符串 2)hash 3)列表 4)set(无序集合) 5)zset(有序集合) 2.Jedis的使用 a)引入依赖 <!--加入springboot的starter的起步依赖--><dependency><groupId>…...

哈佛医学院做了5679次组学分析:大模型能力没差别,关键在验证
哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。在理解 MEDEA 的设计逻辑之前,先看一组来自消融实验的数据。在细胞类型特异性靶点发现任务中,研究团队将M…...

OpenClaw+Qwen3-4B创意助手:自动生成营销文案与设计建议
OpenClawQwen3-4B创意助手:自动生成营销文案与设计建议 1. 为什么需要个人创意助手? 去年夏天,我接手了一个小型咖啡品牌的社交媒体运营工作。每天需要产出5-6条不同风格的文案,还要设计配套的视觉方案。连续两周后,…...

1-1 从零实现邻接矩阵:构建无向图的核心步骤与实战解析
1. 邻接矩阵与无向图:从概念到代码的桥梁 第一次接触图论时,我完全被那些抽象的概念搞晕了。直到有一天,导师在黑板上画了个简单的社交网络图:"你看,每个人是一个点,好友关系是连线,这不就…...

Zemax中的色差分析与优化策略
1. 色差基础:为什么你的镜头拍不出清晰照片? 每次用手机拍夕阳时,总发现边缘有紫色光晕?这就是色差在作怪。作为光学设计中最常见的像差之一,色差会让不同颜色的光无法汇聚在同一点,导致成像模糊和颜色失真…...

在Jetson Orin NX上为PyTorch 2.0编译TorchVision 0.15:一份完整的避坑与问题解决记录
在Jetson Orin NX上为PyTorch 2.0编译TorchVision 0.15:一份完整的避坑与问题解决记录 Jetson Orin NX作为英伟达新一代边缘计算设备,凭借其强大的AI算力和紧凑的尺寸,成为众多开发者的首选。然而,当我们需要在ARM架构上为特定版本…...

AI辅助开发:让快马智能生成带安全验证的路由器手机登录界面
最近在做一个路由器管理后台的移动端登录页面,需要实现192.168.1.1这个常见路由器地址的手机端登录功能。作为一个前端开发者,我发现用AI辅助开发可以大大提升效率,特别是处理安全验证这类复杂逻辑时。下面分享下我的实践过程。 需求分析 首先…...

训练自定义游戏,构建Gymnasium训练环境
认识Gymnasium使用stable_baseline3只需要定义好Gymnasium环境,关注训练的奖励机制,将重点放在业务的开发上而不是复杂的算法。Gymnasium提供了几个核心的api:方法功能返回值reset()将环境重置为初始状态,开始新回合。obs, infost…...

Vibe coding对程序员的影响
一、深化核心能力数学与算法基础掌握离散数学、概率论等基础理论熟练应用动态规划、图论等算法范式示例:优化算法时间复杂度 O(n\log n)--O(n)系统设计能力理解计算机组成原理与操作系统机制构建高可用分布式系统(如CAP定理)二、适应技术演进…...

Phi-4-mini-reasoning效果验证:在MMLU-Pro数学子集上的实际推理准确率展示
Phi-4-mini-reasoning效果验证:在MMLU-Pro数学子集上的实际推理准确率展示 1. 模型概述 Phi-4-mini-reasoning是一款3.8B参数的轻量级开源模型,由微软Azure AI Foundry团队开发。这款模型专为数学推理、逻辑推导和多步解题等强逻辑任务设计,…...

不止于上传预览:在若依框架中构建一个轻量级企业文档管理模块
若依框架下的企业级文档中心设计与实战 在数字化转型浪潮中,企业文档管理正从简单的文件存储向智能化协作平台演进。基于若依微服务框架构建文档中心模块,不仅能满足基础的PDF上传预览需求,更能为企业提供版本控制、权限管理、全文检索等进阶…...