Python编程 从入门到实践(项目二:数据可视化)
本篇为实践项目二:数据可视化。
配合文章python编程入门学习,代码附文末。
项目二:数据可视化
- 1.生成数据
- 1.1 安装Matplotlib
- 1.2 绘制简单的折线图
- 1.2.1 修改标签文字和线条粗细
- 1.2.2 校正图形
- 1.2.3 使用内置样式
- 1.2.4 使用scatter()绘制散点图并设置样式
- 1.2.5 使用scatter()绘制一系列点
- 1.2.6 自动计算数据
- 3.2.7 自定义颜色
- 1.2.8 使用颜色映射
- 1.2.9 自动保存图表
- 1.3 随机漫步
- 1.3.1 创建RandomWalk类
- 1.3.2 选择方向
- 1.3.3 绘制随机漫步图
- 1.3.4 模拟多次随机漫步
- 1.3.5 设置随机漫步图的样式
- 01. 给点着色
- 02. 重新绘制起点和终点
- 03. 隐藏坐标轴
- 04. 增加点数
- 05. 调整尺寸以适合屏幕
- 1.4 使用Plotly模拟掷骰子
- 1.4.1 安装Plotly
- 1.4.2 创建Die类
- 1.4.3 掷骰子
- 1.4.4 分析结果
- 1.4.5 绘制直方图
- 1.4.6 同时掷两个骰子
- 1.4.7 同时掷两个面数不同的骰子
- 2. 下载数据
- 2.1 CSV文件格式
- 2.1.1 分析CSV文件头
- 2.1.2 打印文件头及其位置
- 2.1.3 提取并读取数据
- 2.1.4 绘制温度图表
- 2.1.5 模块datetime
- 2.1.6 在图表中添加日期
- 2.1.7 涵盖更长的时间
- 2.1.8 再绘制一个数据系列
- 2.1.9 给图表区域着色
- 2.1.10 错误检查
- 2.1.11 自己动手下载数据
- 2.2 制作全球地震散点图:JSON格式
- 2.2.1 地震数据
- 2.2.2 查看JSON数据
- 2.2.3 创建地震列表
- 2.2.4 提取震级
- 2.2.5 提取位置数据
- 2.2.6 绘制震级散点图
- 2.2.7 另一种指定图表数据的方式
- 2.2.8 定制标记的尺寸
- 2.2.9 定制标记的颜色
- 2.2.10 其他渐变
- 2.2.11 添加鼠标指向时显示的文本
- 3. 使用API
- 3.1 使用Web API
- 3.1.1 Git和GitHub
- 3.1.2 使用API调用请求数据
- 3.1.3 安装Requests
- 3.1.4 处理API响应
- 3.1.5 处理响应字典
- 3.1.6 概述最受欢迎的仓库
- 3.1.7 监视API的速率限制
- 3.2 使用Plotly可视化仓库
- 3.2.1 设计图形样式
- 3.2.2 添加自定义工具提示
- 2.2.3 在图表中添加可单击的链接
- 3.2.4 定制标记颜色
- 3.2.5 深入了解Plotly和GitHub API
- 3.3 Hacker News API
- 4. 小结
1.生成数据
数据可视化指的是通过可视化表示来探索数据。它与数据分析紧密相关,而数据分析指的是使用代码来探索数据集的规律和关联。数据集可以是用一行代码就能表示的小型数字列表,也可以是数千兆字节的数据。
漂亮地呈现数据并非仅仅关乎漂亮的图片。通过以引人注目的简单方式呈现数据,能让观看者明白其含义:发现数据集中原本未知的规律和意义。
数据点并非必须是数,也可对非数值数据进行分析。在基因研究、天气研究、政治经济分析等众多领域,人们常常使用Python来完成数据密集型工作。最流行的工具之一是Matplotlib,它是一个数学绘图库,我们将使用它来制作简单的图表,如折线图和散点图。然后,我们将基于随机漫步概念生成一个更有趣的数据集——根据一系列随机决策生成的图表。
Plotly生成的图表可根据显示设备的尺寸自动调整大小,还具备众多交互特性,如在用户将鼠标指向图表的不同部分时突出数据集的特定方面。本章将使用Plotly来分析掷骰子的结果。
1.1 安装Matplotlib
这里将首先使用Matplotlib来生成几个图表,为此需要使用pip来安装它。pip是一个可用于下载并安装Python包的模块。请在终端提示符下执行如下命令:
python -m pip install --user matplotlib
这个命令让Python运行模块pip,并将matplotlib包添加到当前用户的Python安装中。在你的系统中,如果运行程序或启动终端会话时使用的命令不是python,而是python3,应使用类似于下面的命令:
python3 -m pip install --user matplotlib
注意 在macOS系统中,如果这样不管用,请尝试在不指定标志–user的情况下再次执行该命令。
要查看使用Matplotlib可制作的各种图表,请访问其官方网站,浏览示例画廊。通过单击画廊中的图表,可查看生成它们的代码。
1.2 绘制简单的折线图
下面使用Matplotlib绘制一个简单的折线图,再对其进行定制,以实现信息更丰富的数据可视化效果。我们将使用平方数序列1、4、9、16和25来绘制这个图表。
只需提供如下的数,Matplotlib将完成其他工作:
import matplotlib.pyplot as pltsquares = [1, 2, 9, 16, 25]
fig, ax = plt.subplots()
ax.plot(squares)plt.show()
首先导入模块pyplot,并为其指定别名plt,以免反复输入pyplot。(在线示例大多这样做,这里也不例外。)模块pyplot包含很多用于生成图表的函数。
我们创建了一个名为squares的列表,在其中存储要用来制作图表的数据。然后,采取了另一种常见的Matplotlib做法——调用函数subplots()。这个函数可在一张图片中绘制一个或多个图表。变量fig表示整张图片。变量ax表示图片中的各个图表,大多数情况下要使用它。
接下来调用方法plot(),它尝试根据给定的数据以有意义的方式绘制图表。函数plt.show()打开Matplotlib查看器并显示绘制的图表,在查看器中,你可缩放和导航图形,还可单击磁盘图标将图表保存起来。
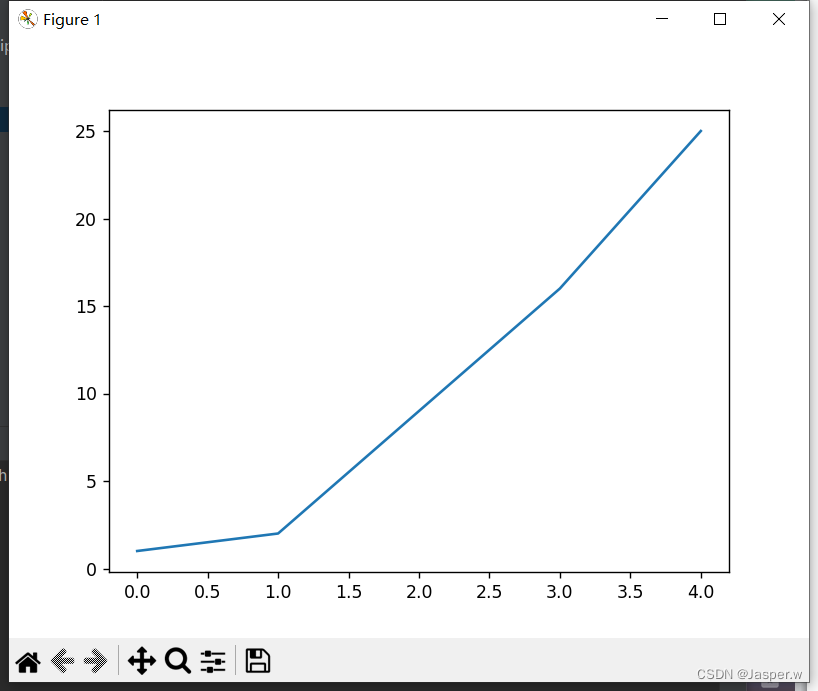
1.2.1 修改标签文字和线条粗细
如图所示的图形表明数是越来越大的,但标签文字太小、线条太细,难以看清楚。所幸Matplotlib让你能够调整可视化的各个方面。
下面通过一些定制来改善这个图表的可读性,如下所示:
import matplotlib.pyplot as pltfrom pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体squares = [1, 2, 9, 16, 25]fig, ax = plt.subplots()
ax.plot(squares, linewidth=3) # 决定plot()绘制的线条粗细# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24) # 指定标题
ax.set_xlabel("值", fontsize=14) # 方法set_xlabel()和set_ylabel()让你能够为每条轴设置标题
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', labelsize=14)plt.show()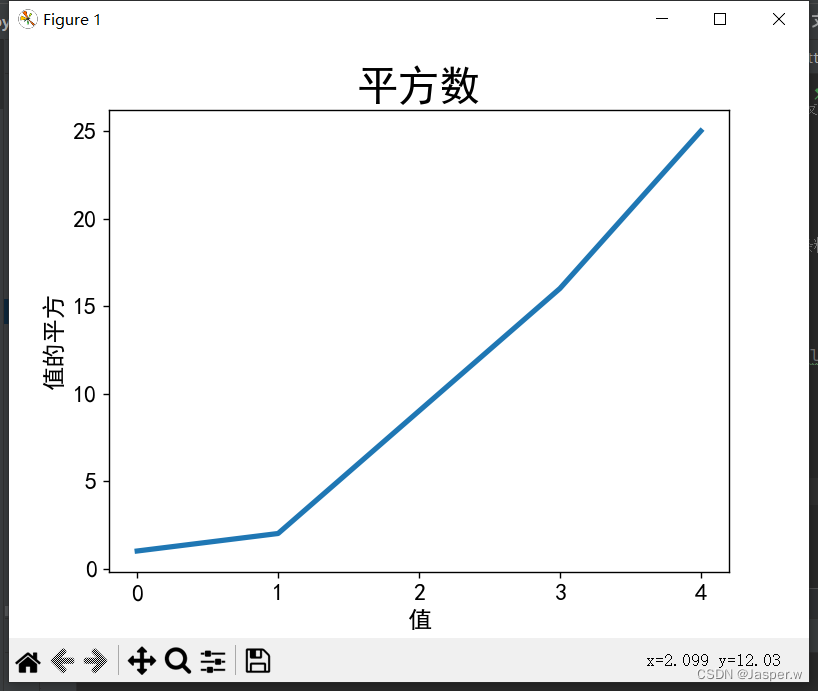
1.2.2 校正图形
图形更容易看清后,我们发现没有正确地绘制数据:折线图的终点指出4.0的平方为25!下面来修复这个问题。
向plot()提供一系列数时,它假设第一个数据点对应的 坐标值为0,但这里第一个点对应的 值为1。为改变这种默认行为,可向plot()同时提供输入值和输出值:
import matplotlib.pyplot as pltfrom pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体input_values = [1, 2, 3, 4, 5]
squares = [1, 2, 9, 16, 25]fig, ax = plt.subplots()
ax.plot(input_values, squares, linewidth=3) # 决定plot()绘制的线条粗细# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24) # 指定标题
ax.set_xlabel("值", fontsize=14) # 方法set_xlabel()和set_ylabel()让你能够为每条轴设置标题
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', labelsize=14)plt.show()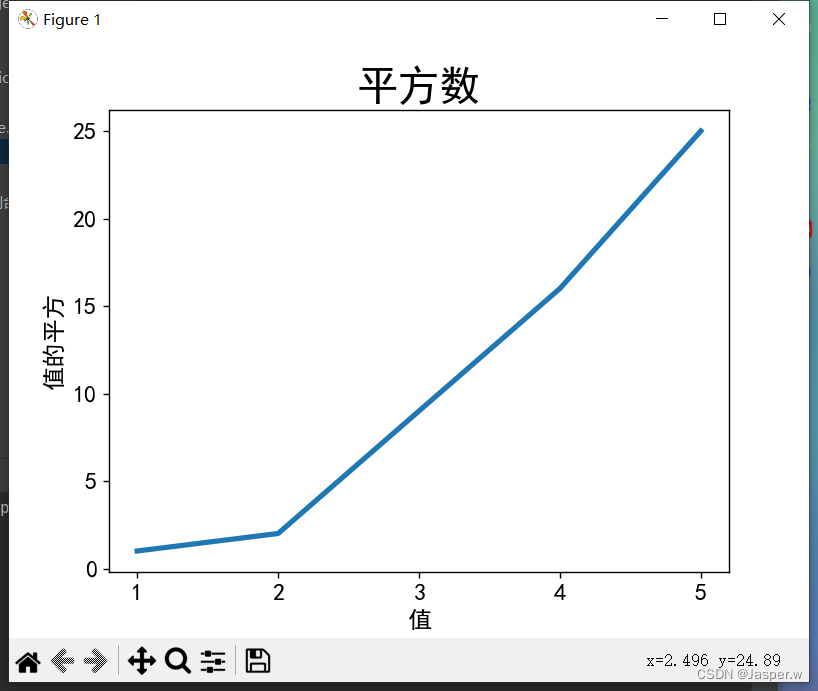
使用plot()时可指定各种实参,还可使用众多函数对图形进行定制。本章后面处理更有趣的数据集时,将继续探索这些定制函数。
1.2.3 使用内置样式
Matplotlib提供了很多已经定义好的样式,它们使用的背景色、网格线、线条粗细、字体、字号等设置很不错,让你无须做太多定制就可生成引人瞩目的可视化效果。要获悉在系统中可使用哪些样式,可在终端会话中执行如下命令:
import matplotlib.pyplot as plt
print(plt.style.available)
结果如下:
['Solarize_Light2', '_classic_test_patch', '_mpl-gallery', '_mpl-gallery-nogrid', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn-v0_8', 'seaborn-v0_8-bright', 'seaborn-v0_8-colorblind', 'seaborn-v0_8-dark', 'seaborn-v0_8-dark-palette', 'seaborn-v0_8-darkgrid', 'seaborn-v0_8-deep', 'seaborn-v0_8-muted', 'seaborn-v0_8-notebook', 'seaborn-v0_8-paper', 'seaborn-v0_8-pastel', 'seaborn-v0_8-poster', 'seaborn-v0_8-talk', 'seaborn-v0_8-ticks', 'seaborn-v0_8-white', 'seaborn-v0_8-whitegrid', 'tableau-colorblind10']
要使用这些样式,可在生成图表的代码前添加如下代码行:
import matplotlib.pyplot as pltinput_values = [1, 2, 3, 4, 5]
squares = [1, 2, 9, 16, 25]plt.style.use('seaborn') # 样式
fig, ax = plt.subplots()
ax.plot(input_values, squares, linewidth=3) # 决定plot()绘制的线条粗细# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24) # 指定标题
ax.set_xlabel("值", fontsize=14) # 方法set_xlabel()和set_ylabel()让你能够为每条轴设置标题
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', labelsize=14)plt.rcParams['font.sans-serif']=['SimHei'] # 设置默认字体
plt.show()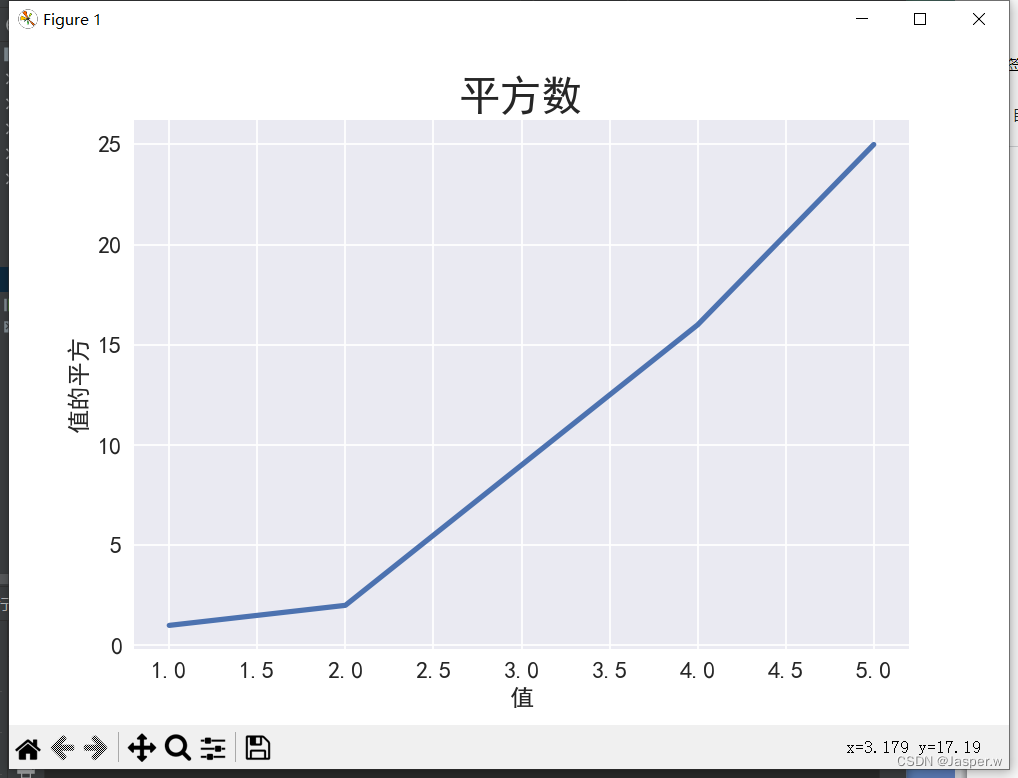
1.2.4 使用scatter()绘制散点图并设置样式
有时候,绘制散点图并设置各个数据点的样式很有用。例如,你可能想以一种颜色显示较小的值,用另一种颜色显示较大的值。绘制大型数据集时,还可对每个点都设置同样的样式,再使用不同的样式选项重新绘制某些点以示突出。
要绘制单个点,可使用方法scatter()。向它传递一对x坐标和y坐标,它将在指定位置绘制一个点:
import matplotlib.pyplot as pltplt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(2, 4)plt.show()
下面来设置图表的样式,使其更有趣。我们将添加标题,给坐标轴加上标签,并且确保所有文本都大到能够看清:
import matplotlib.pyplot as pltplt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(2, 4, s=200)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)plt.rcParams['font.sans-serif']=['SimHei'] # 设置默认字体
plt.show()
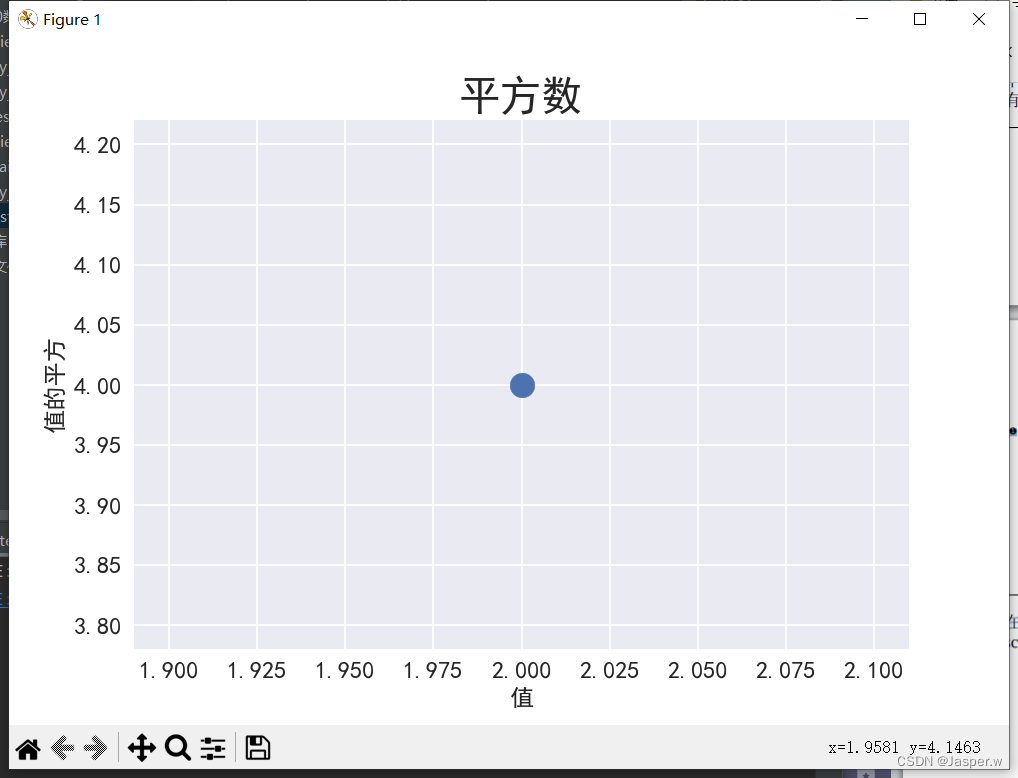
1.2.5 使用scatter()绘制一系列点
要绘制一系列的点,可向scatter()传递两个分别包含x值和y值的列表。
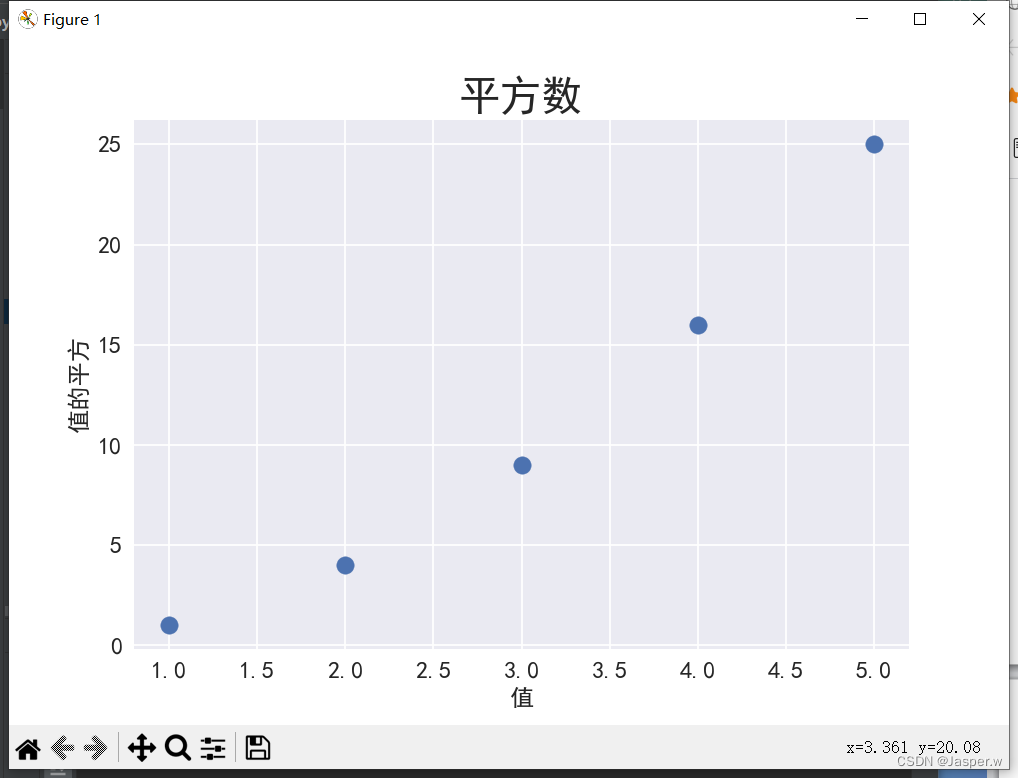
import matplotlib.pyplot as pltx_values = [1, 2, 3, 4, 5]
y_values = [1, 4, 9, 16, 25]plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, s=100)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)plt.rcParams['font.sans-serif']=['SimHei'] # 设置默认字体
plt.show()
列表x_values包含要计算平方值的数,列表y_values包含前述数的平方值。将这些列表传递给scatter()时,Matplotlib依次从每个列表中读取一个值来绘制一个点。要绘制的点的坐标分别为 (1, 1)、(2, 4)、(3, 9)、(4, 16)和(5, 25),最终的结果如图。
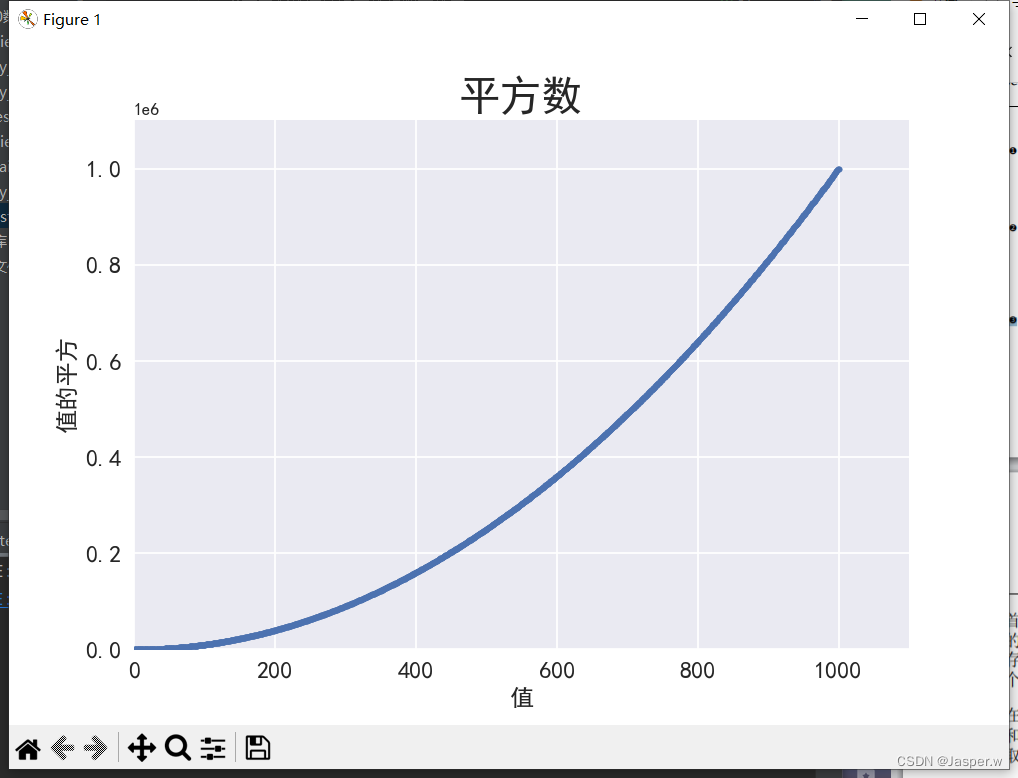
1.2.6 自动计算数据
手工计算列表要包含的值可能效率低下,需要绘制的点很多时尤其如此。我们不必手工计算包含点坐标的列表,可以用Python循环来完成。下面是绘制1000个点的代码。
import matplotlib.pyplot as pltx_values = range(1, 1001)
y_values = [x**2 for x in x_values]plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, s=10)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)# 设置每个坐标轴的取值范围
ax.axis([0, 1100, 0, 1100000])plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体
plt.show()首先创建了一个包含 值的列表,其中包含数1~1000。接下来,是一个生成 值的列表解析,它遍历x值(for x in x_values),计算其平方值(x**2),并将结果存储到列表y_values中。然后,将输入列表和输出列表传递给scatter()。这个数据集较大,因此将点设置得较小。
使用方法axis()指定了每个坐标轴的取值范围。方法axis()要求提供4个值:x和y坐标轴的最小值和最大值。这里将 坐标轴的取值范围设置为0~1100,并将 坐标轴的取值范围设置为0~1 100 000。
3.2.7 自定义颜色
要修改数据点的颜色,可向scatter()传递参数c,并将其设置为要使用的颜色的名称(放在引号内)
import matplotlib.pyplot as pltx_values = range(1, 1001)
y_values = [x**2 for x in x_values]plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, c='red', s=10)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)# 设置每个坐标轴的取值范围
ax.axis([0, 1100, 0, 1100000])plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体
plt.show()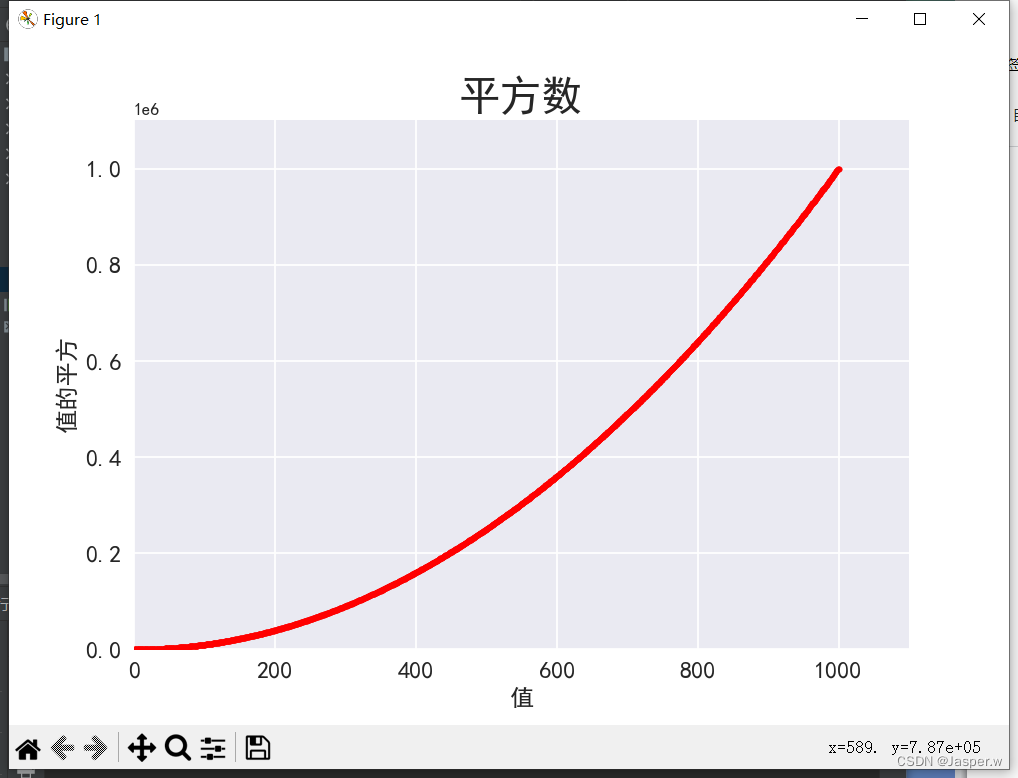
还可使用RGB颜色模式自定义颜色。要指定自定义颜色,可传递参数c,并将其设置为一个元组,其中包含三个0~1的小数值,分别表示红色、绿色和蓝色的分量。
ax.scatter(x_values, y_values, c=(0, 0.8, 0), s=10)
值越接近0,指定的颜色越深;值越接近1,指定的颜色越浅。
1.2.8 使用颜色映射
颜色映射(colormap)是一系列颜色,从起始颜色渐变到结束颜色。在可视化中,颜色映射用于突出数据的规律。例如,你可能用较浅的颜色来显示较小的值,并使用较深的颜色来显示较大的值。
模块pyplot内置了一组颜色映射。要使用这些颜色映射,需要告诉pyplot该如何设置数据集中每个点的颜色。下面演示了如何根据每个点的 值来设置其颜色:
import matplotlib.pyplot as pltx_values = range(1, 1001)
y_values = [x**2 for x in x_values]plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, c=y_values, cmap=plt.cm.Blues, s=10)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)# 设置每个坐标轴的取值范围
ax.axis([0, 1100, 0, 1100000])plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体
plt.show()我们将参数c设置成了一个 值列表,并使用参数cmap告诉pyplot使用哪个颜色映射。这些代码将y值较小的点显示为浅蓝色,并将y值较大的点显示为深蓝色。
注意 要了解pyplot中所有的颜色映射,请访问Matplotlib网站主页,单击Examples,向下滚动到Color,再单击Colormaps reference。
1.2.9 自动保存图表
要让程序自动将图表保存到文件中,可将调用plt.show()替换为调用plt.savefig():
plt.savefig('squares_plot.png', bbox_inches='tight')
import matplotlib.pyplot as pltx_values = range(1, 1001)
y_values = [x**2 for x in x_values]plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.scatter(x_values, y_values, c=y_values, cmap=plt.cm.Blues, s=10)# 设置图表标题并给坐标轴加上标签
ax.set_title("平方数", fontsize=24)
ax.set_xlabel("值", fontsize=14)
ax.set_ylabel("值的平方", fontsize=14)# 设置刻度标记的大小
ax.tick_params(axis='both', which='major', labelsize=14)# 设置每个坐标轴的取值范围
ax.axis([0, 1100, 0, 1100000])plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体
plt.savefig('squares_plot.png', bbox_inches='tight') # 保存图片文件
# plt.show()
第一个实参指定要以什么文件名保存图表,这个文件将存储到scatter_squares.py所在的目录。第二个实参指定将图表多余的空白区域裁剪掉。如果要保留图表周围多余的空白区域,只需省略这个实参即可。
1.3 随机漫步
这里使用Python来生成随机漫步数据,再使用Matplotlib以引人瞩目的方式将这些数据呈现出来。随机漫步是这样行走得到的路径:每次行走都是完全随机的、没有明确的方向,结果是由一系列随机决策决定的。你可以将随机漫步看作蚂蚁在晕头转向的情况下,每次都沿随机的方向前行所经过的路径。
在自然界、物理学、生物学、化学和经济领域,随机漫步都有其实际用途。例如,漂浮在水滴上的花粉因不断受到水分子的挤压而在水面上移动。水滴中的分子运动是随机的,因此花粉在水面上的运动路径犹如随机漫步。我们稍后编写的代码将模拟现实世界的很多情形。
1.3.1 创建RandomWalk类
为模拟随机漫步,将创建一个名为RandomWalk的类,它随机地选择前进方向。这个类需要三个属性:一个是存储随机漫步次数的变量,其他两个是列表,分别存储随机漫步经过的每个点的x坐标和y坐标。
RandomWalk类只包含两个方法:方法__init___()和fill_walk(),后者计算随机漫步经过的所有点。先来看看__init__(),如下所示:
from random import choiceclass RandomWalk:"""一个生成随机漫步数据的类"""def __init__(self, num_points=5000):"""初始化随机漫步的属性"""self.num_points = num_points# 所有随机漫步都始于(0, 0)self.x_values = [0]self.y_values = [0]
为做出随机决策,将所有可能的选择都存储在一个列表中,并在每次决策时都使用模块random中的choice()来决定使用哪种选择。接下来,将随机漫步包含的默认点数设置为5000。这个数大到足以生成有趣的模式,又小到可确保能够快速地模拟随机漫步。然后创建两个用于存储 值和 值的列表,并让每次漫步都从点(0,0)出发。
1.3.2 选择方向
我们将使用方法fill_walk()来生成漫步包含的点并决定每次漫步的方向,如下所示。
from random import choiceclass RandomWalk:"""一个生成随机漫步数据的类"""def __init__(self, num_points=5000):"""初始化随机漫步的属性"""self.num_points = num_points# 所有随机漫步都始于(0, 0)self.x_values = [0]self.y_values = [0]def fill_walk(self):"""计算随机漫步包含的所有点"""# 不断漫步,直到列表达到指定的长度while len(self.x_values) < self.num_points:# 决定前进方向以及沿这个方向前进的距离x_direction = choice([1, -1])x_distance = choice([0, 1, 2, 3, 4])x_step = x_direction * x_distancey_direction = choice([1, -1])y_distance = choice([0, 1, 2, 3, 4])y_step = y_direction * y_distance# 拒绝原地踏步if x_step == 0 and y_step == 0:continue# 计算下一个点的x值和y值x = self.x_values[-1] + x_stepy = self.y_values[-1] + y_stepself.x_values.append(x)self.y_values.append(y)建立一个循环,它不断运行,直到漫步包含所需的点数。方法fill_walk()的主要部分告诉Python如何模拟四种漫步决定:向右走还是向左走?沿指定的方向走多远?向上走还是向下走?沿选定的方向走多远?
使用choice([1, -1])给x_direction选择一个值,结果要么是表示向右走的1,要么是表示向左走的-1。接下来,choice([0, 1, 2, 3, 4])随机地选择一个0~4的整数,告诉Python 沿指定的方向走多远(x_distance)。通过包含0,不仅能够同时沿两个轴移动,还能够只沿一个轴移动。
将移动方向乘以移动距离,确定沿x轴和y轴移动的距离。如果x_step为正将向右移动,为负将向左移动,为零将垂直移动;如果y_step为正将向上移动,为负将向下移动,为零将水平移动。如果x_step和y_step都为零,则意味着原地踏步。我们拒绝这样的情况,接着执行下一次循环。
为获取漫步中下一个点的 值,将x_step与x_values中的最后一个值相加,对值也做相同的处理。获得下一个点的x值和y值后,将它们分别附加到列表x_values和y_values的末尾。
1.3.3 绘制随机漫步图
下面的代码将随机漫步的所有点都绘制出来:
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 创建一个RandomWalk实例
rw = RandomWalk()
rw.fill_walk()# 将所有点绘制出来
plt.style.use('classic')
fig, ax = plt.subplots()
ax.scatter(rw.x_values, rw.y_values, s=15)plt.show()
首先导入模块pyplot和RandomWalk类,再创建一个RandomWalk实例并将其存储到rw中
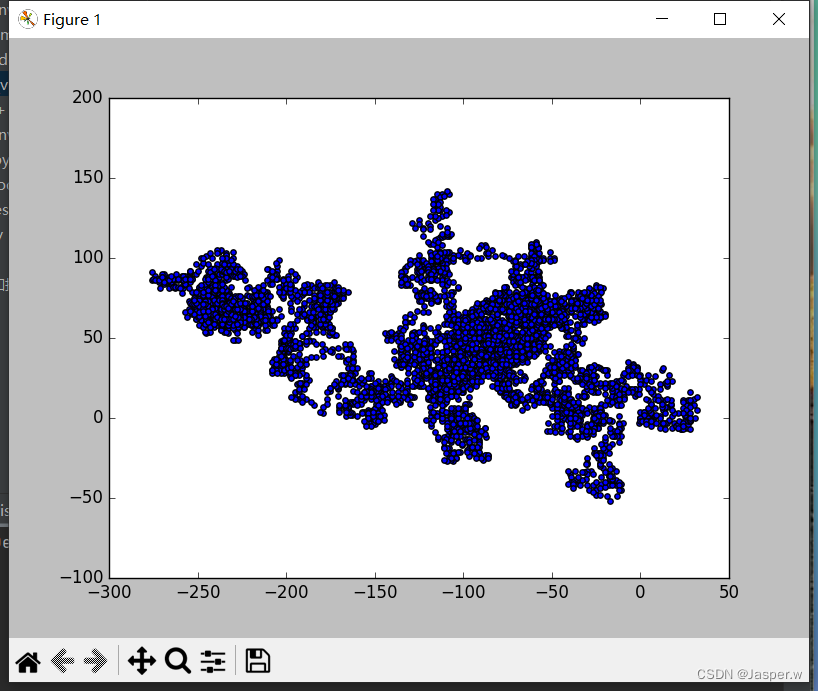
,并且调用fill_walk()。将随机漫步包含的 值和 值传递给scatter(),并选择合适的点尺寸。如下图显示了包含5000个点的随机漫步图。
1.3.4 模拟多次随机漫步
每次随机漫步都不同,因此探索可能生成的各种模式很有趣。要在不多次运行程序的情况下使用前面的代码模拟多次随机漫步,一种办法是将这些代码放在一个while循环中,如下所示:
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步。
while True:# 创建一个RandomWalk实例。rw = RandomWalk()rw.fill_walk()# 将所有的点都绘制出来。plt.style.use('classic')fig, ax = plt.subplots()ax.scatter(rw.x_values, rw.y_values, s=15)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break这些代码模拟一次随机漫步,在Matplotlib查看器中显示结果,再在不关闭查看器的情况下暂停。如果关闭查看器,程序将询问是否要再模拟一次随机漫步。如果输入y,可模拟在起点附近进行的随机漫步、大多沿特定方向偏离起点的随机漫步、漫步点分布不均匀的随机漫步,等等。要结束程序,请输入n。
1.3.5 设置随机漫步图的样式
定制图表,以突出每次漫步的重要特征,并让分散注意力的元素不那么显眼。为此,我们确定要突出的元素,如漫步的起点、终点和经过的路径。接下来确定要使其不那么显眼的元素,如刻度标记和标签。最终的结果是简单的可视化表示,清楚地指出了每次漫步经过的路径。
01. 给点着色
我们将使用颜色映射来指出漫步中各点的先后顺序,并删除每个点的黑色轮廓,让其颜色更为明显。为根据漫步中各点的先后顺序来着色,传递参数c,并将其设置为一个列表,其中包含各点的先后顺序。这些点是按顺序绘制的,因此给参数c指定的列表只需包含数0~4999,如下所示:
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk()rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots()point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=15)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break使用range()生成了一个数字列表,其中包含的数与漫步包含的点数量相同。接下来,将这个列表存储在point_numbers中,以便后面使用它来设置每个漫步点的颜色。将参数c设置为point_numbers,指定使用颜色映射Blues,并传递实参edgecolors='none’以删除每个点周围的轮廓。最终的随机漫步图从浅蓝色渐变为深蓝色。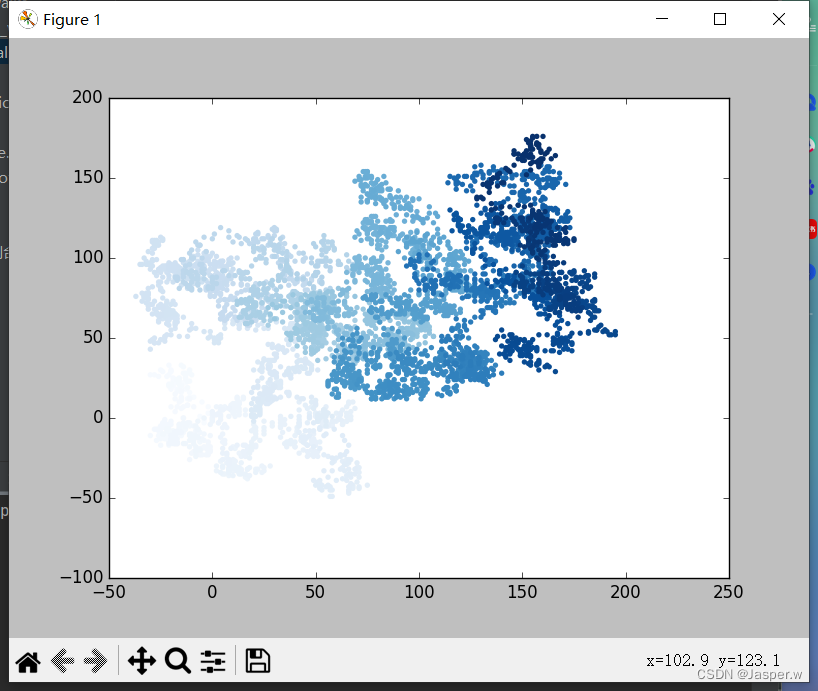
02. 重新绘制起点和终点
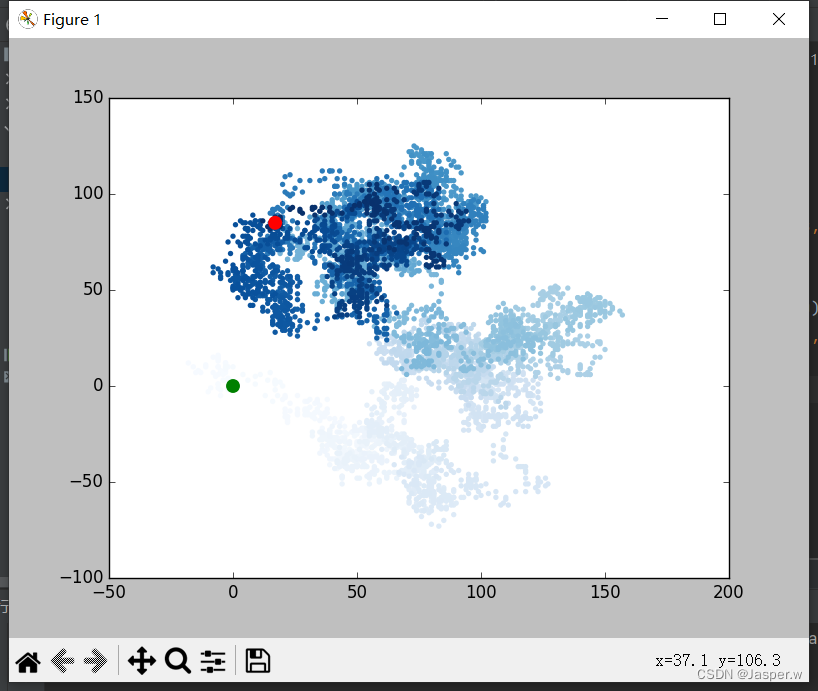
除了给随机漫步的各个点着色,以指出其先后顺序外,如果还能呈现随机漫步的起点和终点就好了。为此,可在绘制随机漫步图后重新绘制起点和终点。这里让起点和终点更大并显示为不同的颜色。
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk()rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots()point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=15)# 突出起点和终点ax.scatter(0, 0, c='green', edgecolors='none', s=100)ax.scatter(rw.x_values[-1], rw.y_values[-1], c='red', edgecolors='none', s=100)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break为突出起点,使用绿色绘制点(0, 0),并使其比其他点大(s=100)。为突出终点,在漫步包含的最后一个 值和 值处绘制一个点,将其颜色设置为红色,并将尺寸设置为100。务必将这些代码放在调用plt.show()的代码前面,确保在其他点之上绘制起点和终点。
03. 隐藏坐标轴
下面来隐藏这个图表的坐标轴,以免分散观察者对随机漫步路径的注意力。要隐藏坐标轴,可使用如下代码:
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk()rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots()point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=15)# 突出起点和终点ax.scatter(0, 0, c='green', edgecolors='none', s=100)ax.scatter(rw.x_values[-1], rw.y_values[-1], c='red', edgecolors='none', s=100)# 隐藏坐标轴ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break为修改坐标轴,使用方法ax.get_xaxis()和ax.get_yaxis()将每条坐标轴的可见性都设置为False。随着对数据可视化的不断学习和实践,你会经常看到这种串接方法的方式。
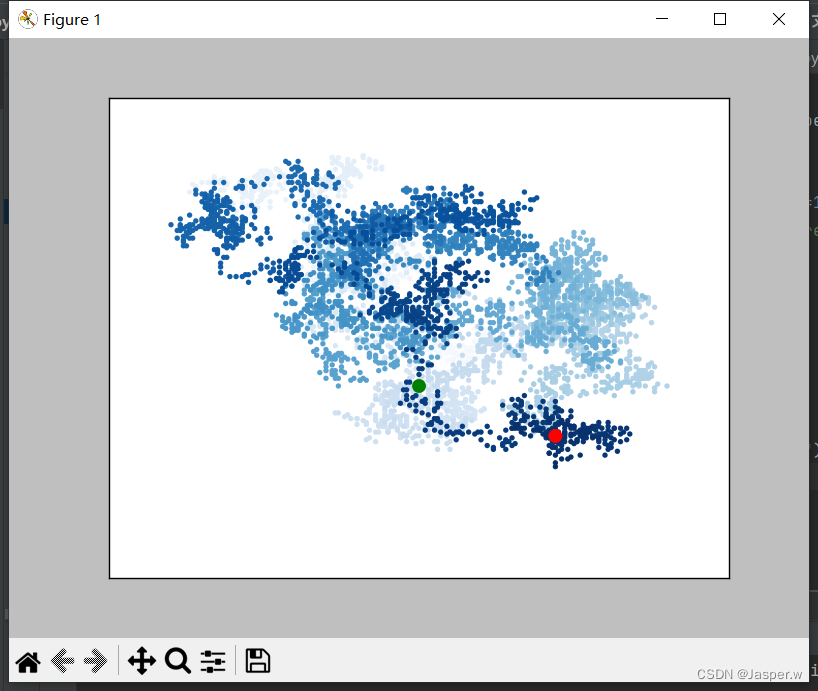
04. 增加点数
下面来增加点数,以提供更多数据。为此,在创建RandomWalk实例时增大num_points的值,并在绘图时调整每个点的大小。
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk(50_000)rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots()point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=1)# 突出起点和终点ax.scatter(0, 0, c='green', edgecolors='none', s=100)ax.scatter(rw.x_values[-1], rw.y_values[-1], c='red', edgecolors='none', s=100)# 隐藏坐标轴ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break这个示例模拟了一次包含50 000个点的随机漫步(以模拟现实情况),并将每个点的大小都设置为1。最终的随机漫步图更稀疏,犹如云朵。
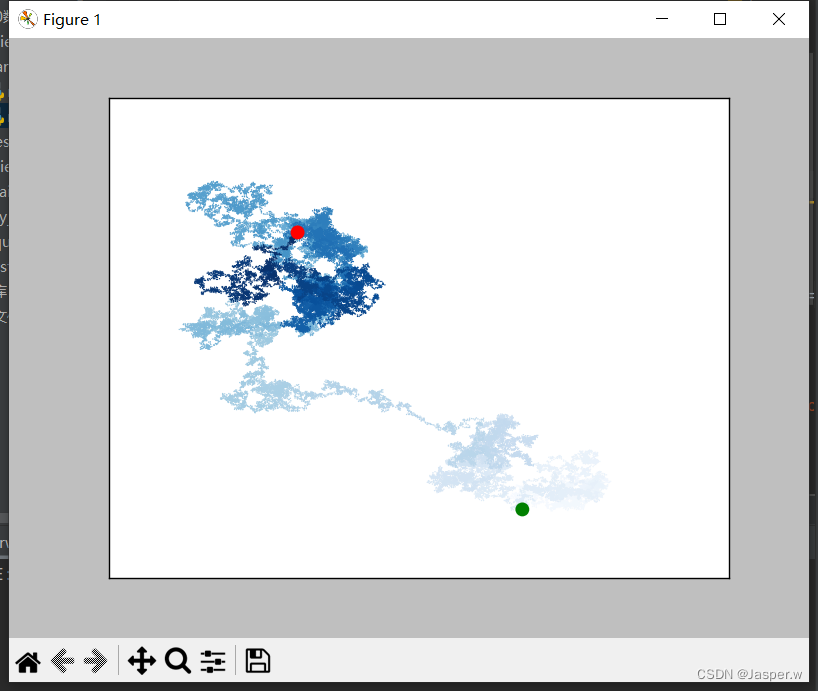
05. 调整尺寸以适合屏幕
图表适合屏幕大小时,更能有效地将数据中的规律呈现出来。为让绘图窗口更适合屏幕大小,可以像下面这样调整Matplotlib输出的尺寸:
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk(50_000)rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots(figsize=(15, 9)) # 屏幕尺寸point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=1)# 突出起点和终点ax.scatter(0, 0, c='green', edgecolors='none', s=100)ax.scatter(rw.x_values[-1], rw.y_values[-1], c='red', edgecolors='none', s=100)# 隐藏坐标轴ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break创建图表时,可传递参数figsize以指定生成的图形的尺寸。需要给参数figsize指定一个元组,向Matplotlib指出绘图窗口的尺寸,单位为英寸 。
Matplotlib假定屏幕分辨率为100像素/英寸。如果上述代码指定的图表尺寸不合适,可根据需要调整数字。如果知道当前系统的分辨率,可通过参数dpi向plt.subplots()传递该分辨率,以有效利用可用的屏幕空间。
import matplotlib.pyplot as pltfrom random_walk import RandomWalk# 只要程序处于活动状态,就不断地模拟随机漫步
while True:# 创建一个RandomWalk实例rw = RandomWalk(50_000)rw.fill_walk()# 将所有的点都绘制出来plt.style.use('classic')fig, ax = plt.subplots(figsize=(10, 6), dpi=128) # 屏幕尺寸point_numbers = range(rw.num_points)ax.scatter(rw.x_values, rw.y_values, c=point_numbers, cmap=plt.cm.Blues, edgecolors='none', s=1)# 突出起点和终点ax.scatter(0, 0, c='green', edgecolors='none', s=100)ax.scatter(rw.x_values[-1], rw.y_values[-1], c='red', edgecolors='none', s=100)# 隐藏坐标轴ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)plt.show()keep_running = input("Make another walk? (y/n): ")if keep_running == 'n':break
1.4 使用Plotly模拟掷骰子
这里将使用Python包Plotly来生成交互式图表。需要创建在浏览器中显示的图表时,Plotly很有用,因为它生成的图表将自动缩放以适合观看者的屏幕。Plotly生成的图表还是交互式的:用户将鼠标指向特定元素时,将突出显示有关该元素的信息。
在这个项目中,我们将对掷骰子的结果进行分析。抛掷一个6面的常规骰子时,可能出现的结果为1~6点,且出现每种结果的可能性相同。然而,如果同时掷两个骰子,某些点数出现的可能性将比其他点数大。为确定哪些点数出现的可能性最大,将生成一个表示掷骰子结果的数据集,并根据结果绘制一个图形。
在数学领域,掷骰子常被用来解释各种数据分析类型,而它在赌场和其他博弈场景中也有实际应用,在游戏《大富翁》以及众多角色扮演游戏中亦如此。
1.4.1 安装Plotly
要安装Plotly,可像本章前面安装Matplotlib那样使用pip:
python -m pip install --user plotly
在前面安装Matplotlib时,如果使用了python3之类的命令,这里也要使用同样的命令。要了解使用Plotly可创建什么样的图表,请在其官方网站查看图表类型画廊。每个示例包含源代码,让你知道这些图表是如何生成的。
1.4.2 创建Die类
为模拟掷一个骰子的情况,我们创建下面的类:
from random import randintclass Die:"""表示一个骰子的类"""def __init__(self, num_sides=6):"""骰子默认为6面"""self.num_sides = num_sidesdef roll(self):""""返回一个位于1和骰子面数之间的随机值"""return randint(1, self.num_sides)方法__init__()接受一个可选参数。创建这个类的实例时,如果没有指定任何实参,面数默认为6;如果指定了实参,这个值将用于设置骰子的面数。骰子是根据面数命名的,6面的骰子名为D6,8面的骰子名为D8,依此类推。
方法roll()使用函数randint()来返回一个1和面数之间的随机数。这个函数可能返回起始值1、终止值num_sides或这两个值之间的任何整数。
1.4.3 掷骰子
使用这个类来创建图表前,先来掷D6,将结果打印出来,并确认结果是合理的:
from die import Die# 创建一个D6
die = Die()# 掷几次骰子并将结果存储在一个列表之中
results = []
for roll_num in range(100):result = die.roll()results.append(result)print(results)
创建一个Die实例,其面数为默认值6。掷骰子100次,并将每次的结果都存储在列表results中。
1.4.4 分析结果
为分析掷一个D6的结果,计算每个点数出现的次数:
from die import Die# 创建一个D6
die = Die()# 掷几次骰子并将结果存储在一个列表之中
results = []
for roll_num in range(100):result = die.roll()results.append(result)# 分析结果
frequencies = []
for value in range(1, die.num_sides+1):frequency = results.count(value)frequencies.append(frequency)print(frequencies)由于将使用Plotly来分析,而不是将结果打印出来,因此可将模拟掷骰子的次数增加到1000。为分析结果,我们创建空列表frequencies,用于存储每种点数出现的次数。遍历可能的点数(这里为1~6),计算每种点数在results中出现了多少次,并将这个值附加到列表frequencies的末尾。接下来,在可视化之前将这个列表打印出来:
结果看起来是合理的:有6个值,对应掷D6时可能出现的每个点数;另外,没有任何点数
出现的频率比其他点数高很多。下面来可视化这些结果。
1.4.5 绘制直方图
有了频率列表,就可以绘制一个表示结果的直方图了。直方图是一种条形图,指出了各种结果出现的频率。创建这种直方图的代码如下:
from die import Diefrom plotly import offline
from plotly.graph_objs import Bar, Layout# 创建一个D6
die = Die()# 掷几次骰子并将结果存储在一个列表之中
results = []
for roll_num in range(1000):result = die.roll()results.append(result)# 分析结果
frequencies = []
for value in range(1, die.num_sides+1):frequency = results.count(value)frequencies.append(frequency)# 对结果进行可视化
x_values = list(range(1, die.num_sides+1))
data = [Bar(x=x_values, y=frequencies)]
x_axis_config = {'title': '结果'}
y_axis_config = {'title': '结果的频率'}
my_layout = Layout(title='掷一个D6 1000次的结果', xaxis=x_axis_config, yaxis=y_axis_config)
offline.plot({'data': data, 'layout': my_layout}, filename='d6.html')print(frequencies)为创建直方图,需要为每个可能出现的点数生成一个条形。我们将可能出现的点数(1到骰子的面数)存储在一个名为x_values的列表中。Plotly不能直接接受函数range()的结果,因此需要使用函数list()将其转换为列表。Plotly类Bar()表示用于绘制条形图的数据集,需要一个存储x值的列表和一个存储y值的列表。这个类必须放在方括号内,因为数据集可能包含多个元素。
每个坐标轴都能以不同的方式进行配置,而每个配置选项都是一个字典元素。这里只设置了坐标轴标签。类Layout()返回一个指定图表布局和配置的对象。这里设置了图表名称,并传入了 轴和 轴的配置字典。
为生成图表,我们调用了函数offline.plot()。这个函数需要一个包含数据和布局对象的字典,还接受一个文件名,指定要将图表保存到哪里。这里将输出存储到文件d6.html。
运行程序die_visual.py时,可能打开浏览器并显示文件d6.html。如果没有自动显示d6.html,可在任意Web浏览器中新建一个标签页,再在其中打开文件d6.html(它位于die_visual.py所在的文件夹中)。
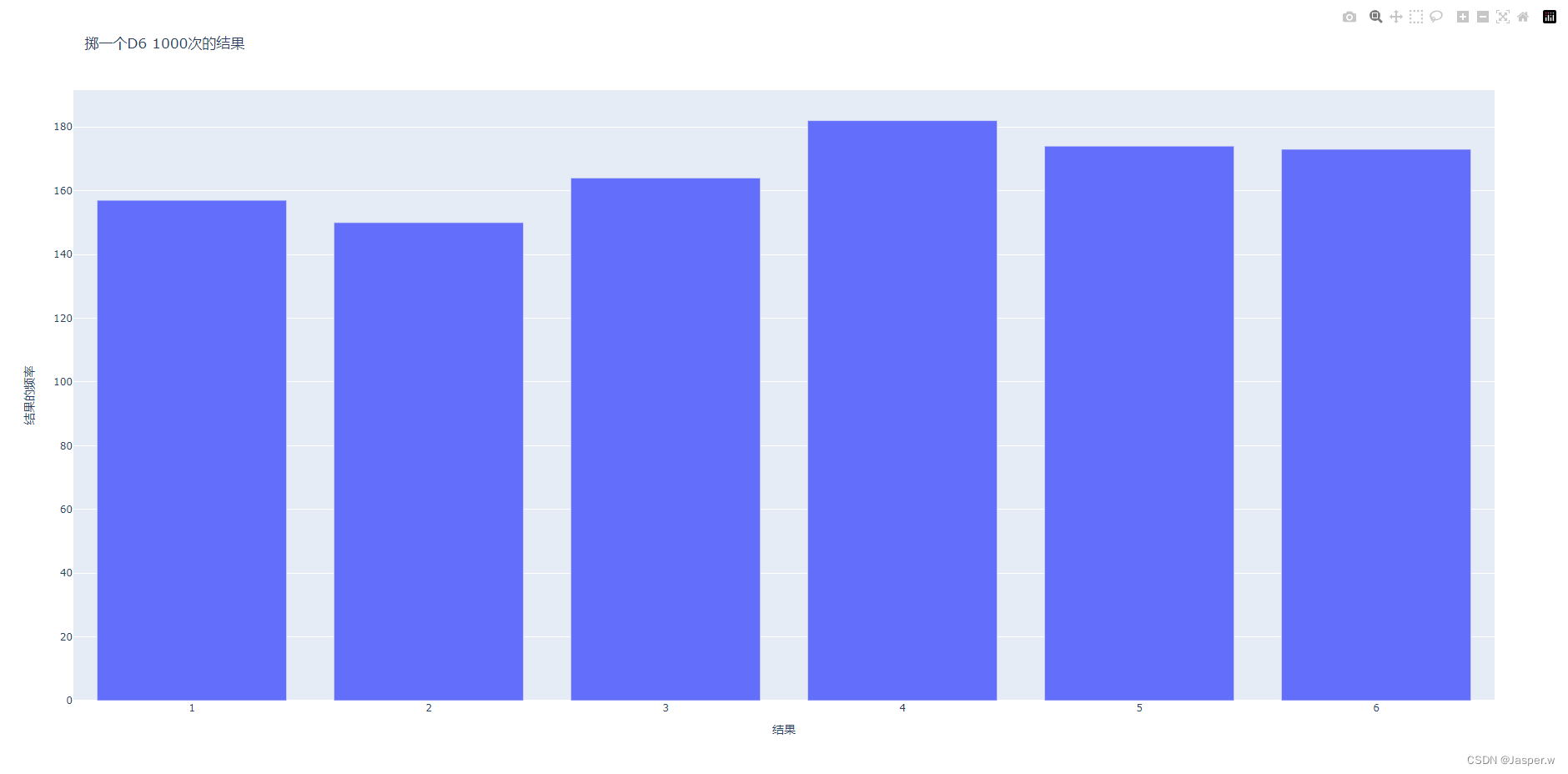
注意,Plotly让这个图表具有交互性:如果将鼠标指向其中的任意条形,就能看到与之相关联的数据。在同一个图表中绘制多个数据集时,这项功能特别有用。另外,注意到右上角有一些图标,让你能够平移和缩放图表以及将其保存为图像。
1.4.6 同时掷两个骰子
同时掷两个骰子时,得到的点数更多,结果分布情况也不同。下面来修改前面的代码,创建两个D6以模拟同时掷两个骰子的情况。每次掷两个骰子时,都将两个骰子的点数相加,并将结果存储在results中。请复制die_visual.py并将其保存为dice_visual.py,再做如下修改:
from die import Diefrom plotly import offline
from plotly.graph_objs import Bar, Layout# 创建两个D6
die_1 = Die()
die_2 = Die()# 掷几次骰子并将结果存储在一个列表之中
results = []
for roll_num in range(1000):result = die_1.roll() + die_2.roll()results.append(result)# 分析结果
frequencies = []
max_result = die_1.num_sides + die_2.num_sides
for value in range(1, max_result+1):frequency = results.count(value)frequencies.append(frequency)# 对结果进行可视化
x_values = list(range(1, max_result+1))
data = [Bar(x=x_values, y=frequencies)]x_axis_config = {'title': '结果', 'dtick': 1}
y_axis_config = {'title': '结果的频率'}
my_layout = Layout(title='掷两个D6 1000次的结果', xaxis=x_axis_config, yaxis=y_axis_config)
offline.plot({'data': data, 'layout': my_layout}, filename='d6_d6.html')print(frequencies)创建两个Die实例后,掷骰子多次,并计算每次的总点数。可能出现的最大点数
为两个骰子的最大可能点数之和(12),这个值存储在max_result中。可能出
现的最小总点数为两个骰子的最小可能点数之和(2)。
分析结果时,计算2到max_result的各种点数出现的次数。(我们原本可以使用range(2, 13),但这只适用于两个D6。模拟现实世界的情形时,最好编写可轻松模拟各种情形的代码。前面的代码让我们能够模拟掷任意两个骰子的情形,不管这些骰子有多少面。)
创建图表时,在字典x_axis_config中使用了dtick键。这项设置指定了 轴显示的刻度间距。这里绘制的直方图包含的条形更多,Plotly默认只显示某些刻度值,而设置’dtick’: 1让Plotly显示每个刻度值。另外,我们还修改了图表名称及输出文件名。
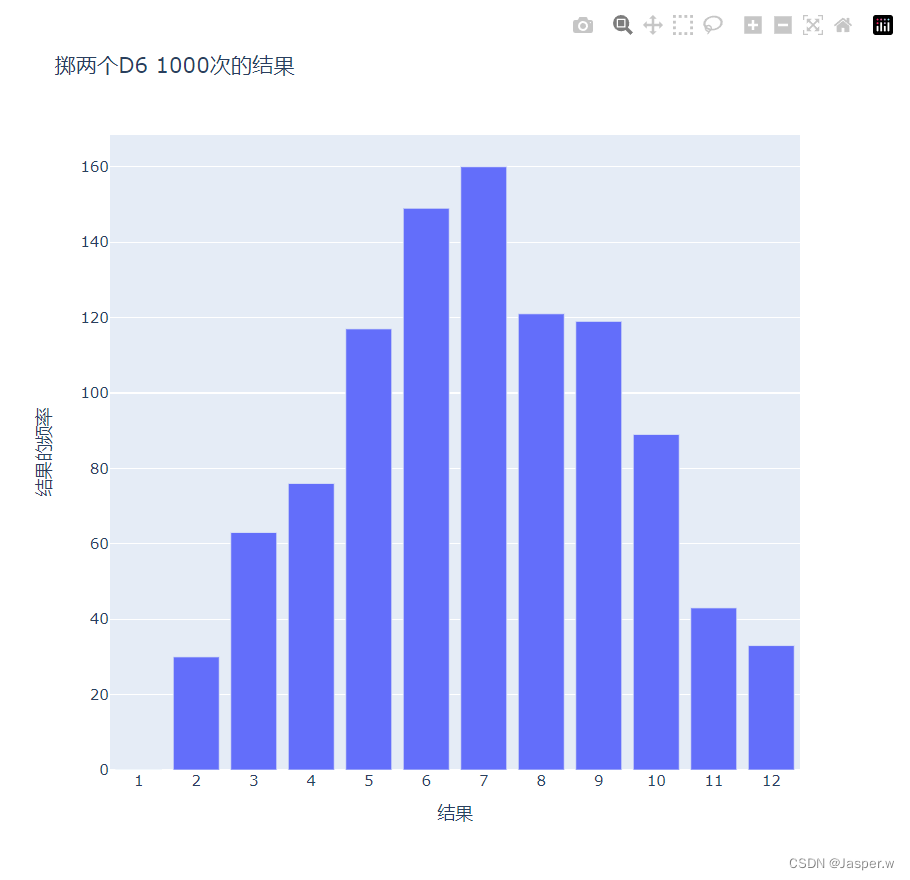
这个图表显示了掷两个D6时得到的大致结果。如你所见,总点数为2或12的可能性最小,而总点数为7的可能性最大。这是因为在下面6种情况下得到的总点数都为7:1和6、2和5、3和4、4和3、5和2以及6和1。
1.4.7 同时掷两个面数不同的骰子
下面来创建一个6面骰子和一个10面骰子,看看同时掷这两个骰子50 000次的结果如何:
from die import Diefrom plotly import offline
from plotly.graph_objs import Bar, Layout# 创建两个D6
die_1 = Die()
die_2 = Die()# 掷几次骰子并将结果存储在一个列表之中
results = []
for roll_num in range(50_000):result = die_1.roll() + die_2.roll()results.append(result)# 分析结果
frequencies = []
max_result = die_1.num_sides + die_2.num_sides
for value in range(1, max_result+1):frequency = results.count(value)frequencies.append(frequency)# 对结果进行可视化
x_values = list(range(2, max_result+1))
data = [Bar(x=x_values, y=frequencies)]x_axis_config = {'title': '结果', 'dtick': 1}
y_axis_config = {'title': '结果的频率'}
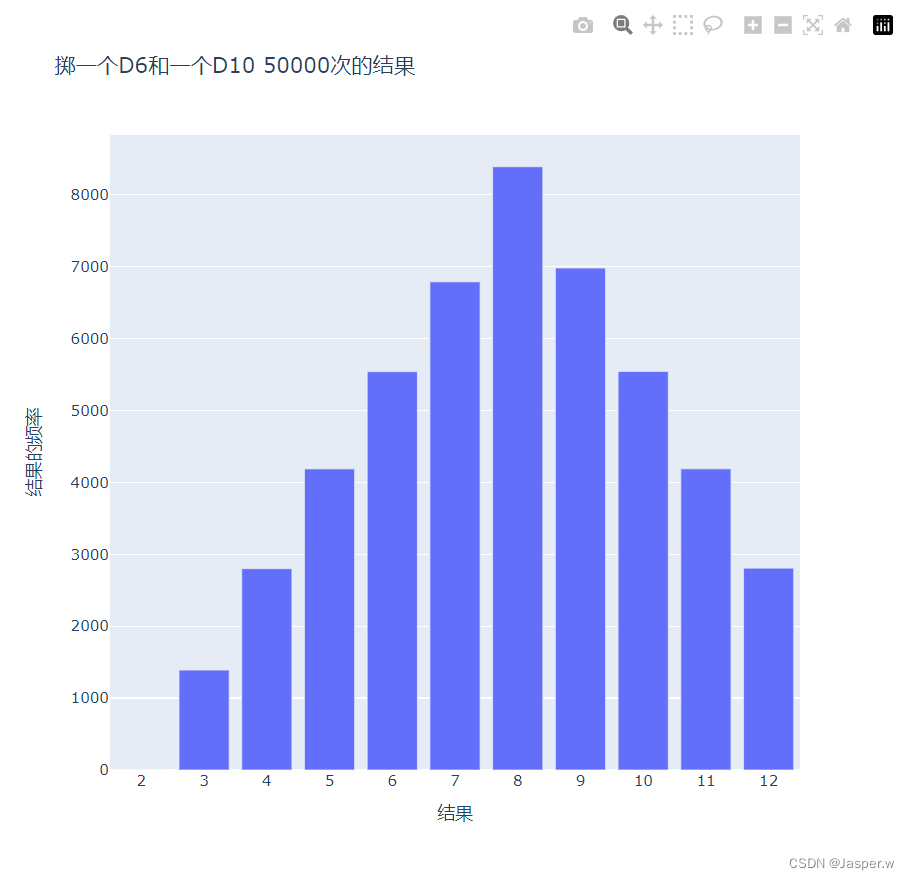
my_layout = Layout(title='掷一个D6和一个D10 50000次的结果', xaxis=x_axis_config, yaxis=y_axis_config)
offline.plot({'data': data, 'layout': my_layout}, filename='d6_d10.html')print(frequencies)为创建D10,我们在创建第二个Die实例时传递了实参10;修改了第一个循环,以模拟掷骰子50 000而不是1000次;还修改了图表名称和输出文件名。
图显示了最终的图表。可能性最大的点数不止一个,而是有5个。这是因为导致出现最小点数和最大点数的组合都只有一种(1和1以及6和10),但面数较小的骰子限制了得到中间点数的组合数:得到总点数7、8、9、10和11的组合数都是6种。因此,这些总点数是最常见的结果,它们出现的可能性相同。
2. 下载数据
这里将从网上下载数据,并对其进行可视化。网上的数据多得令人难以置信,大多未经仔细检查。如果能够对这些数据进行分析,就能发现别人没有发现的规律和关联。
将访问并可视化的数据以两种常见格式存储:CSV和JSON。我们将使用Python模块csv来处理以CSV格式存储的天气数据,找出两个地区在一段时间内的最高温度和最低温度。然后,使用Matplotlib根据下载的数据创建一个图表,展示两个不同地区的温度变化:阿拉斯加州锡特卡和加利福尼亚州死亡谷。然后,使用模块json访问以JSON格式存储的地震数据,并使用Plotly绘制一幅散点图,展示这些地震的位置和震级。
处理各种类型和格式的数据集,对如何创建复杂的图表有深入的认识。要处理各种真实的数据集,必须能够访问并可视化各种类型和格式的在线数据。
2.1 CSV文件格式
要在文本文件中存储数据,一个简单方式是将数据作为一系列以逗号分隔的值(commaseparated values)写入文件。这样的文件称为CSV文件。例如,下面是一行CSV格式的天气数据:
"USW00025333","SITKA AIRPORT, AK US","2018-01-01","0.45",,"48","38"
这是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度,还有众多其他的数据。CSV文件对人来说阅读起来比较麻烦,但程序可轻松提取并处理其中的值,有助于加快数据分析过程。
我们将首先处理少量CSV格式的锡特卡天气数据。请将文件sitka_weather_07_2021_simple.csv复制到存储程序的文件夹中。
注意 该项目使用的天气数据来自美国国家海洋与大气管理局(National Oceanic and Atmospheric Administration,NOAA)。
2.1.1 分析CSV文件头
csv模块包含在Python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴趣的值。先来查看这个文件的第一行,其中的一系列文件头指出了后续各行包含的是什么样的信息:
import csvfilename = 'data/sitka_weather_07-2018_simple.csv'with open(filename) as f:reader = csv.reader(f)header_row = next(reader)print(header_row)
首先导入csv模块和path类后,创建path对象,指向天气数据文件。读取文件后通过splitlines()方法来获取包含文件中各行的列表,再将列表赋给变量lines。调用csv.reader()并将前面存储的文件对象作为实参传递给它,从而创建一个与该文件相关联的阅读器对象。这个阅读器对象被赋给了reader。
模块csv包含函数next(),调用它并传入阅读器对象时,它将返回文件中的下一行。在上述代码中,只调用了next()一次,因此得到的是文件的第一行,其中包含文件头。将返回的数据存储到header_row中。header_row包含与天气相关的文件头,指出了每行都包含哪些数据。
reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一个元素存储在列表中。文件头STATION表示记录数据的气象站的编码。这个文件头的位置表明,每行的第一个值都是气象站编码。文件头NAME指出每行的第二个值都是记录数据的气象站的名称。
其他文件头则指出记录了哪些信息。当前,我们最关心的是日期(DATE)、最高温度(TMAX)和最低温度(TMIN)。这是一个简单的数据集,只包含降水量以及与温度相关的数据。你自己下载天气数据时,可选择涵盖众多测量值,如风速、风向以及详细的降水量数据。
2.1.2 打印文件头及其位置
为了让文件头数据更容易理解,将列表中的每个文件头及其位置打印出来:
from pathlib import Pathimport csvpath = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)
print(header_row)for index, colum_header in enumerate(header_row):print(index, colum_header)在循环中,对列表调用了enumerate()来获取每个元素的索引及其值。
从中可知,日期和最高温度分别存储在第三列和第六列。为研究这些数据,我们将处理sitka_weather_07-2021_simple.csv中的每行数据,并提取其中索引为2和4的值。
2.1.3 提取并读取数据
知道需要哪些列中的数据后,我们来读取一些数据。首先,读取每天的最高温度
from pathlib import Pathimport csvpath = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取最高温度
highs = []
for row in reader:high = int(row[4])highs.append(high)
print(highs)创建一个名为highs的空列表,再遍历文件中余下的各行。阅读器对象从其停留的地方继续往下读取CSV文件,每次都自动返回当前所处位置的下一行。由于已经读取了文件头行,这个循环将从第二行开始——从这行开始包含的是实际数据。每次执行循环时,都将索引4处(TMAX列)的数据附加到highs末尾。
2.1.4 绘制温度图表
为可视化这些温度数据,首先使用Matplotlib创建一个显示每日最高温度的简单图形。
from pathlib import Path
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取最高温度
highs = []
for row in reader:high = int(row[4])highs.append(high)
print(highs)# 根具最高温度绘图
plt.style.use('seaborn')
fig, ax = plt.subplots()
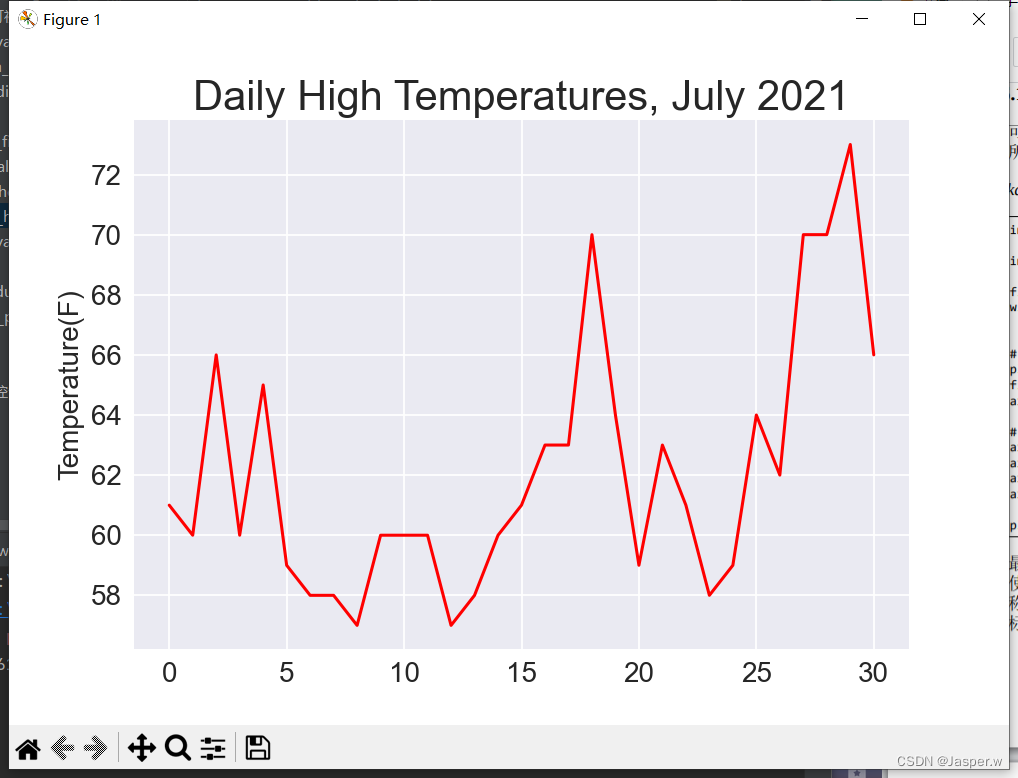
ax.plot(highs, color='red')# 设置绘图的格式
ax.set_title("Daily High Temperatures, July 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
ax.set_ylabel("Temperature(F)", fontsize=16)
ax.tick_params(labelsize=16)plt.show()将最高温度列表传给plot(),并传递c='red’以便将数据点绘制为红色。(这里使用红色显示最高温度,用蓝色显示最低温度。)接下来,设置了一些其他的格式,如名称和字号。鉴于还没有添加日期,因此没有给x轴添加标签,但ax.set_xlabel()确实修改了字号,让默认标签更容易看清。
2.1.5 模块datetime
下面在图表中添加日期,使其更有用。在天气数据文件中,第一个日期在第二行:
读取该数据时,获得的是一个字符串,因此需要想办法将字符串"2021-7-1"转换为一个表示相应日期的对象。为创建一个表示2018年7月1日的对象,可使用模块datetime中的方法strptime()。
from datetime import datetime
first_date = datetime.strptime('2021-07-01', '%Y-%m-%d')
print(first_date)
首先导入模块datetime中的datetime类,再调用方法strptime(),并将包含所需日期的字符串作为第一个实参。第二个实参告诉Python如何设置日期的格式。在这里,'%Y-‘让Python将字符串中第一个连字符前面的部分视为四位的年份,’%m-‘让Python将第二个连字符前面的部分视为表示月份的数,’%d’让Python将字符串的最后一部分视为月份中的一天(1~31)。
方法strptime()可接受各种实参,并根据它们来决定如何解读日期。

2.1.6 在图表中添加日期
现在,可以通过提取日期和最高温度并将其传递给plot(),对温度图形进行改进,如下所示:
from pathlib import Path
from datetime import datetime
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/sitka_weather_07-2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取日期和最高温度
dates, highs = [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')high = int(row[4])dates.append(current_date)highs.append(high)# 根具最高温度绘图
plt.style.use('seaborn')
fig, ax = plt.subplots()
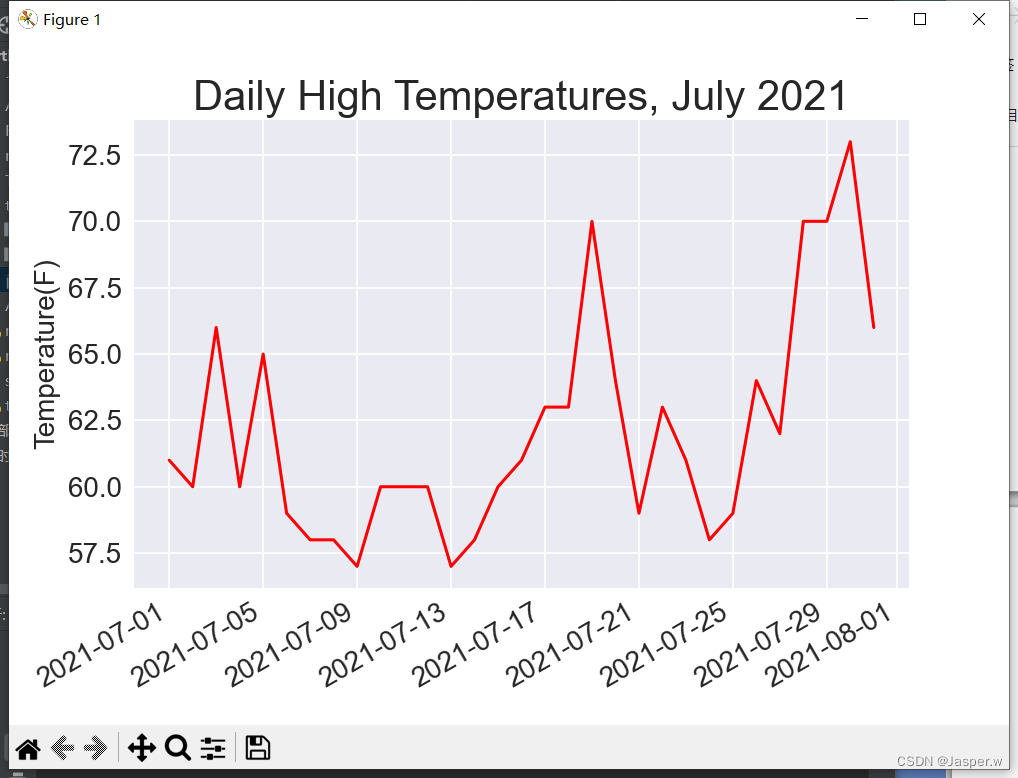
ax.plot(dates, highs, color='red')# 设置绘图的格式
ax.set_title("Daily High Temperatures, July 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
fig.autofmt_xdate()
ax.set_ylabel("Temperature(F)", fontsize=16)
ax.tick_params(labelsize=16)plt.show()我们创建了两个空列表,用于存储从文件中提取的日期和最高温度。然后,将包含日期信息的数据(row[0])转换为datetime对象,并将其附加到列表dates末尾。将日期和最高温度值传递给plot()。调用fig.autofmt_xdate()来绘制倾斜的日期标签,以免其彼此重叠。
2.1.7 涵盖更长的时间
设置好图表后,我们来添加更多的数据,生成一幅更复杂的锡特卡天气图。请将文件sitka_weather_2021_simple.csv复制到本章程序所在的文件夹,该文件包含整年的锡特卡天
气数据。
from pathlib import Path
from datetime import datetime
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/sitka_weather_2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取日期和最高温度
dates, highs = [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')high = int(row[4])dates.append(current_date)highs.append(high)# 根具最高温度绘图
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red')# 设置绘图的格式
ax.set_title("Daily High Temperatures, 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
fig.autofmt_xdate()
ax.set_ylabel("Temperature(F)", fontsize=16)
ax.tick_params(labelsize=16)plt.show()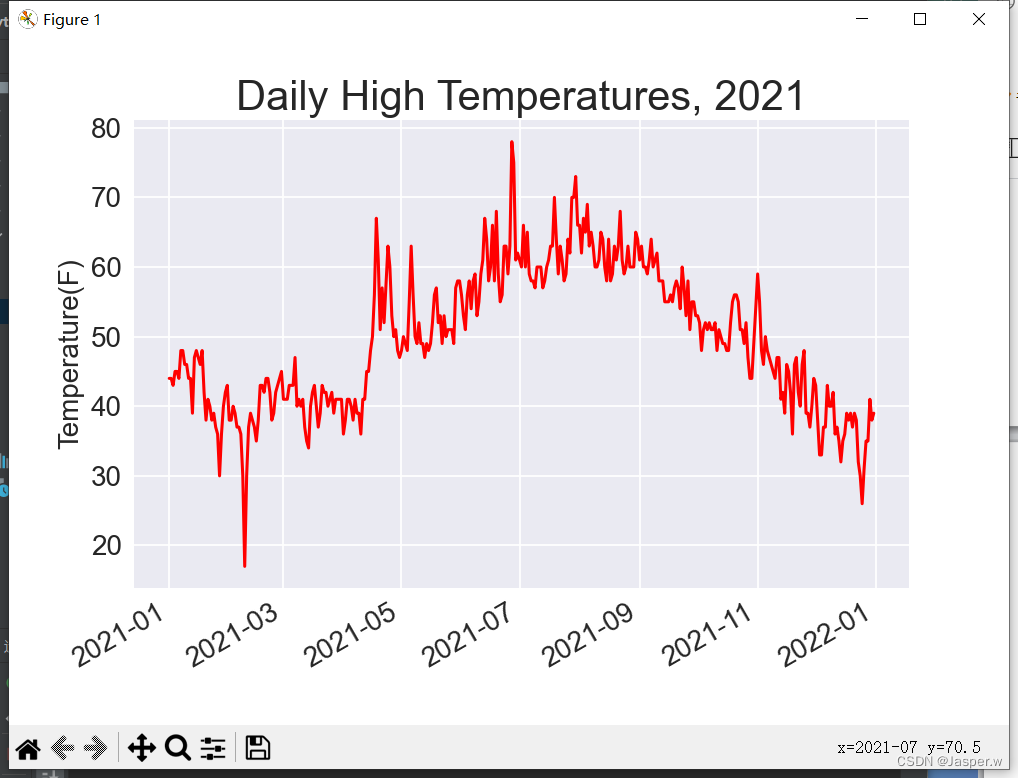
2.1.8 再绘制一个数据系列
虽然改进后的图表已经显示了丰富的数据,但是还能再添加最低温度数据,使其更有用。为此,需要从数据文件中提取最低温度,并将它们添加到图表中。
from pathlib import Path
from datetime import datetime
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/sitka_weather_2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取日期,最低温度和最高温度
dates, highs, lows = [], [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')high = int(row[4])low = int(row[5])dates.append(current_date)highs.append(high)lows.append(low)# 根具最高温度绘图
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red')
ax.plot(dates, lows, color='blue')# 设置绘图的格式
ax.set_title("Daily High And Low Temperatures, 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
fig.autofmt_xdate()
ax.set_ylabel("Temperature(F)", fontsize=16)
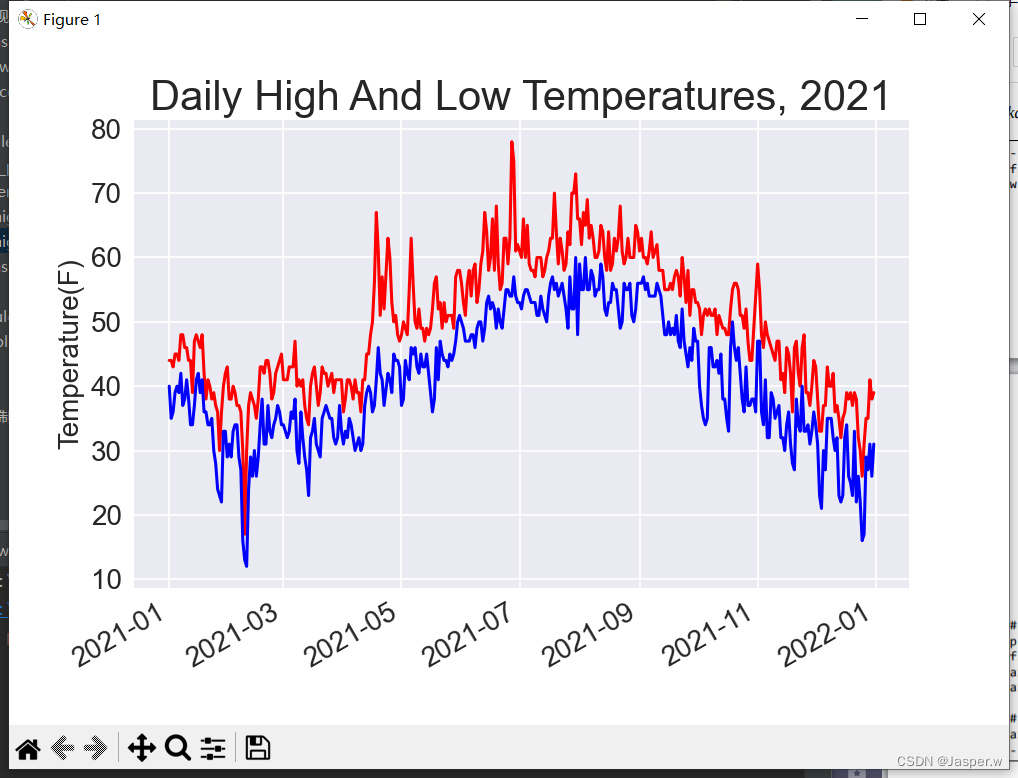
ax.tick_params(labelsize=16)plt.show()添加空列表lows,用于存储最低温度。接下来,从每行的第七列(row[5])提取最低温度并存储。添加调用plot()的代码,以使用蓝色绘制最低温度。最后,修改标题。这样绘制出来的图表如下。
2.1.9 给图表区域着色
添加两个数据系列后,就可以知道每天的温度范围了。下面来给这个图表做最后的修饰,通过着色来呈现每天的温度范围。为此,将使用方法fill_between()。它接受一个x值系列和两个y值系列,并填充两个y值系列之间的空间。
from pathlib import Path
from datetime import datetime
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/sitka_weather_2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)# 提取日期,最低温度和最高温度
dates, highs, lows = [], [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')high = int(row[4])low = int(row[5])dates.append(current_date)highs.append(high)lows.append(low)# 根具最高和最低温度绘图
plt.style.use('seaborn')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='red', alpha=0.5) # alpha设置透明度
ax.plot(dates, lows, color='blue', alpha=0.5)
ax.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)# 设置绘图的格式
ax.set_title("Daily High And Low Temperatures, 2021", fontsize=24)
ax.set_xlabel('', fontsize=16)
fig.autofmt_xdate()
ax.set_ylabel("Temperature(F)", fontsize=16)
ax.tick_params(labelsize=16)plt.show()实参alpha指定颜色的透明度。alpha值为0表示完全透明,为1(默认设置)表示完全不透明。通过将alpha设置为0.5,可让红色和蓝色折线的颜色看起来更浅。
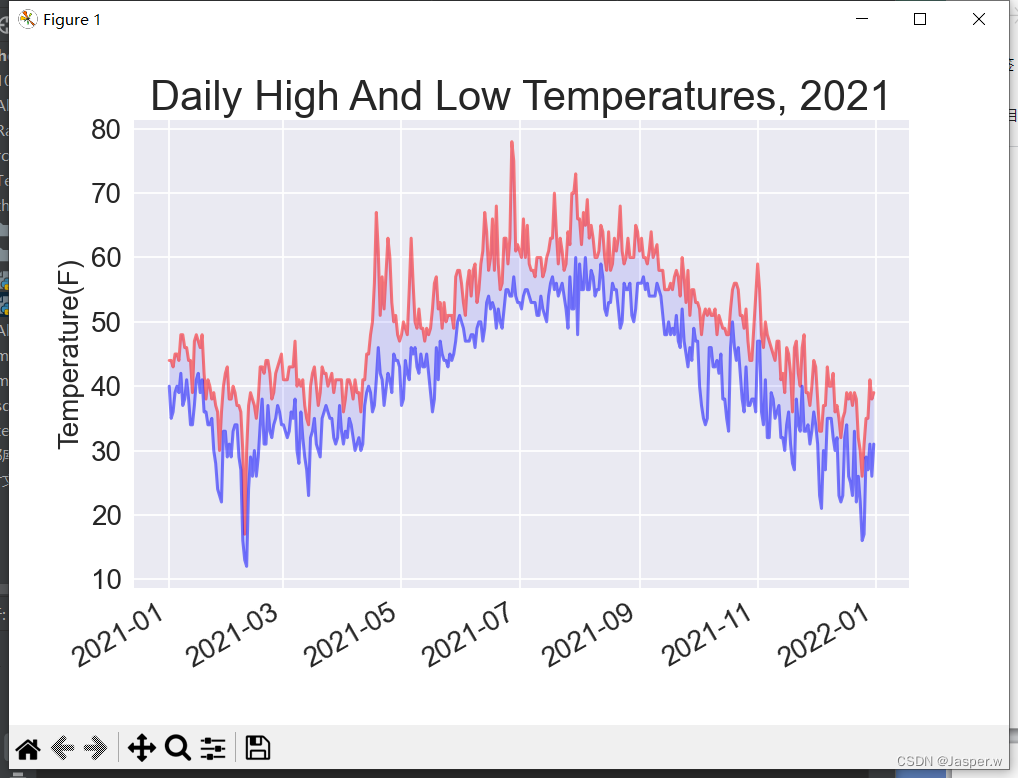
向fill_between()传递一个 值系列(列表dates),以及两个y值系列(highs和lows)。实facecolor指定填充区域的颜色,还将alpha设置成了较小的值0.1,让填充区域将两个数据系列连接起来的同时不分散观察者的注意力。
2.1.10 错误检查
我们应该能够使用任何地方的天气数据来运行sitka_highs_lows.py中的代码,但有些气象站收集的数据种类不同,有些气象站会偶尔出现故障,未能收集部分或全部应收集的数据。缺失数据可能引发异常,如果不妥善处理,可能导致程序崩溃。
from pathlib import Path
from datetime import datetime
import csvimport matplotlib.pyplot as pltpath = Path('weather_data/death_valley_2021_simple.csv')
lines = path.read_text().splitlines()reader = csv.reader(lines)
header_row = next(reader)for index, column_header in enumerate(header_row):print(index, column_header)
与前面一样,日期也在索引2处,但最高温度和最低温度分别在索引4和索引5处,因此需要修改代码中的索引,以反映这一点。另外,这个气象站没有记录平均温度,而记录了TOBS,即特定时点的温度。
为演示缺失数据时将出现的状况,我故意从这个文件中删除了一项温度数据。下面来修改sitka_highs_lows.py,使用前面所说的索引来生成死亡谷的天气图,看看将出现什么状况。
# 从文件中获取日期、最高温度和最低温度。
dates, highs, lows = [], [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')
high = int(row[4])
low = int(row[5])
dates.append(current_date)
修改索引,使其对应于这个文件中TMAX和TMIN的位置。
运行这个程序时出现了错误,如下述输出的最后一行所示:
Traceback (most recent call last):
File "death_valley_highs_lows.py", line 15, in <module>
high = int(row[4])
ValueError: invalid literal for int() with base 10: ''
该traceback指出,Python无法处理其中一天的最高温度,因为无法将空字符串(‘’)转换为整数。我们只要看一下文件death_valley_2018_simple.csv,就知道缺失了哪项数据,但这里不这样做,而是直接对缺失数据的情形进行处理。
为此,在从CSV文件中读取值时执行错误检查代码,对可能出现的异常进行处理,如下所
示:
# Extract dates, and high and low temperatures.
dates, highs, lows = [], [], []
for row in reader:current_date = datetime.strptime(row[2], '%Y-%m-%d')try:high = int(row[3])low = int(row[4])except ValueError:print(f"Missing data for {current_date}")else:dates.append(current_date)highs.append(high)lows.append(low)
对于每一行,都尝试从中提取日期、最高温度和最低温度。只要缺失其中一项数据,Python就会引发ValueError异常。我们这样进行处理:打印一条错误消息,指出缺失数据的日期。打印错误消息后,循环将接着处理下一行。如果获取特定日期的所有数据时没有发生错误,就运行else代码块,将数据附加到相应列表的末尾。这里绘图时使用的是有关另一个地方的信息,因此修改标题以指出这个地方。
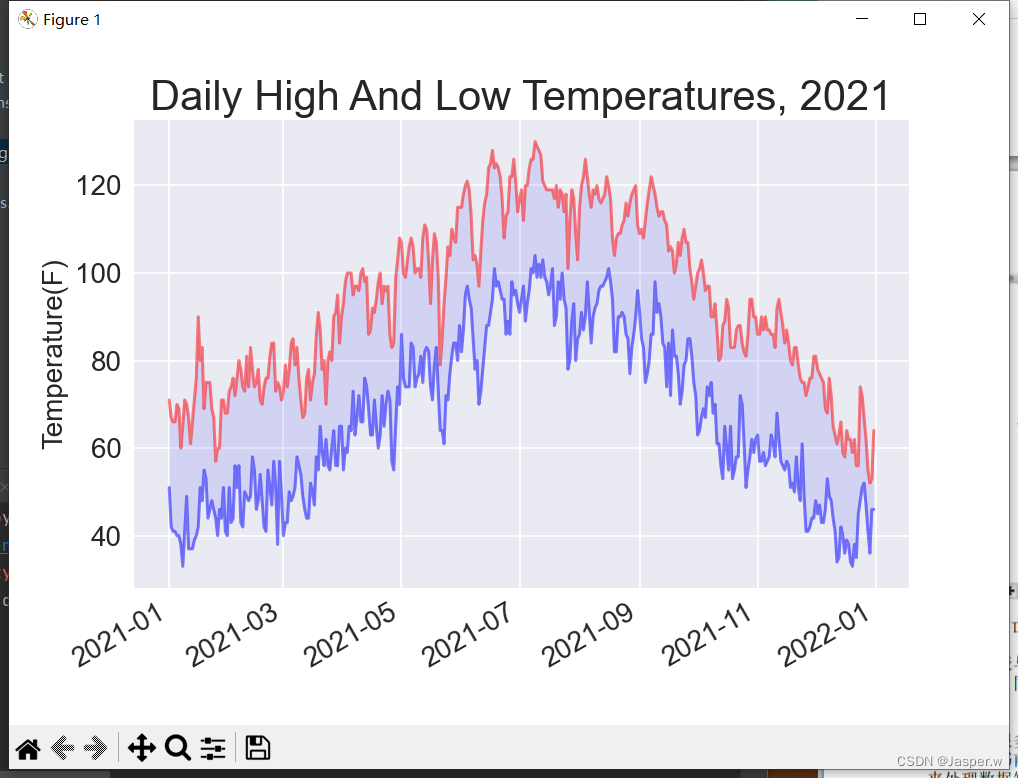
将这个图表与锡特卡的图表进行比较可知,总体而言,死亡谷比阿拉斯加东南部暖和,这符合预期。同时,死亡谷沙漠中每天的温差也更大——从着色区域的高度可以看出这一点。
你使用的很多数据集都可能缺失数据、格式不正确或数据本身不正确。对于这样的情形,可使用之前的工具来处理。在这里,使用了一个try-except-else代码块来处理数据缺失的问题。在有些情况下,需要使用continue来跳过一些数据,或者使用remove()或del将已提取的数据删除。只要能进行精确而有意义的可视化,采用任何管用的方法都是可以的。
2.1.11 自己动手下载数据
如果你想自己下载天气数据,可采取如下步骤。
(1) 访问网站NOAA Climate Data Online。在Discover Data By部分,单击Search Tool。在下拉列表Select a Dataset中,选择Daily Summaries。
(2) 选择一个日期范围,在Search For下拉列表中ZIP Codes,输入你感兴趣地区的邮政编码,再单击Search按钮。
(3) 在下一个页面中,你将看到指定地区的地图和相关信息。单击地区名下方的View Full Details或单击地图再单击Full Details。
(4) 向下滚动并单击Station List,以显示该地区的气象站,再选择一个气象站并单击Add to Cart。虽然这个网站使用了购物车图标,但提供的数据是免费的。单击右上角的购物车。
(5) 在Select the Output中选择Custom GHCN-Daily CSV。确认日期范围无误后单击Continue。
(6) 在下一个页面中,可选择要下载的数据类型。可以只下载一种数据(如气温),也可以下载该气象站提供的所有数据。做出选择后单击Continue。
(7) 在最后一个页面,你将看到订单小结。请输入你的电子邮箱地址,再单击Submit Order。你将收到一封确认邮件,指出收到了你的订单。几分钟后,你将收到另一封邮件,其中包含用于下载数据的链接。
2.2 制作全球地震散点图:JSON格式
下载一个数据集,其中记录了一个月内全球发生的所有地震,再制作一幅散点图来展示这些地震的位置和震级。这些数据是以JSON格式存储的,因此要使用模块json来处理。Plotly提供了根据位置数据绘制地图的工具,适合初学者使用。你将使用它来进行可视化并指出全球的地震分布情况。
2.2.1 地震数据
请将文件eq_data_1_day_m1.json复制到存储本章程序的文件夹中。地震是以里氏震级度量的,而该文件记录了(截至写作本节时)最近24小时内全球发生的所有不低于1级的地震。
2.2.2 查看JSON数据
如果打开文件eq_data_1_day_m1.json,你将发现其内容密密麻麻,难以阅读:
{"type":"FeatureCollection","metadata":{"generated":1550361461000,...
{"type":"Feature","properties":{"mag":1.2,"place":"11km NNE of Nor...
{"type":"Feature","properties":{"mag":4.3,"place":"69km NNW of Ayn...
{"type":"Feature","properties":{"mag":3.6,"place":"126km SSE of Co...
{"type":"Feature","properties":{"mag":2.1,"place":"21km NNW of Teh...
{"type":"Feature","properties":{"mag":4,"place":"57km SSW of Kakto...
这些数据适合机器而不是人来读取。不过可以看到,这个文件包含一些字典,还有一些我们感兴趣的信息,如震级和位置。
模块json提供了各种探索和处理JSON数据的工具,其中一些有助于重新设置这个文件的格式,让我们能够更清楚地查看原始数据,继而决定如何以编程的方式来处理。
我们先加载这些数据并将其以易于阅读的方式显示出来。这个数据文件很长,因此不打印出来,而是将数据写入另一个文件,再打开该文件并轻松地在数据中导航:
from pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.dumps(contents)# 将数据文件转换为更易于阅读的版本
path = Path("eq_data/readable_eq_data.geojson")
readable_contents = json.dumps(all_eq_data, indent=4)
path.write_text(readable_contents)首先将这个数据文件作为字符串进行读取,并使用json.loads()将这个文件的字符串表示转换为对象python对象。我们将整个数据集转换为一个字典,并将其赋给变量all_eq_data。indent指定数据结构中嵌套元素的缩进量。
如果你现在查看目录data并打开其中的文件readable_eq_data.json,将发现其开头部分像下面这样:
{
"type": "FeatureCollection",
"metadata": {
"generated": 1550361461000,
"url": "https://earthquake.usgs.gov/earthquakes/.../1.0_day.geojson",
"title": "USGS Magnitude 1.0+ Earthquakes, Past Day",
"status": 200,
"api": "1.7.0",
"count": 158
},
"features": [
这个文件的开头是一个键为"metadata"的片段,指出了这个数据文件是什么时候生成的,以及能够在网上的什么地方找到。它还包含适合人类阅读的标题以及文件中记录了多少次地震:在过去的24小时内,发生了158次地震。
这个geoJSON文件的结构适合存储基于位置的数据。数据存储在一个与键"features"相关联的列表中。这个文件包含的是地震数据,因此列表的每个元素都对应一次地震。这种结构可能有点令人迷惑,但很有用,让地质学家能够将有关每次地震的任意数量信息存储在一个字典中,再将这些字典放在一个大型列表中。
我们来看看表示特定地震的字典:
nip--
{
"type": "Feature",
"properties": {
"mag": 0.96,
"title": "M 1.0 - 8km NE of Aguanga, CA"
},
"geometry": {
"type": "Point",
"coordinates": [-116.7941667,33.4863333,
3.22
]
},
键"properties"关联到了与特定地震相关的大量信息。我们关心的主要是与键"mag"相关联的地震震级以及地震的标题,因为后者很好地概述了地震的震级和位置。
键"geometry"指出了地震发生在什么地方,我们需要根据这项信息将地震在散点图上标出来。在与键"coordinates"相关联的列表中,可找到地震发生位置的经度和纬度。
这个文件的嵌套层级比我们编写的代码多。如果这让你感到迷惑,也不用担心,Python将替你处理大部分复杂的工作。我们每次只会处理一两个嵌套层级。我们将首先提取过去24小时内发生的每次地震对应的字典。
注意 说到位置时,我们通常先说纬度、再说经度,这种习惯形成的原因可能是人类先发现了纬度,很久后才有经度的概念(横纬竖经)。然而,很多地质学框架都先列出经度、后列出纬度,因为这与数学约定(x,y)一致。geoJSON格式遵循(经度, 纬度)的约定,但在使用其他框架时,获悉其遵循的约定很重要。
2.2.3 创建地震列表
首先,创建一个列表,其中包含所有地震的各种信息
from pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))我们提取与键’features’相关联的数据,并将其存储到all_eq_dicts中。我们知道,这个文件记录了160次地震。
注意,我们编写的代码很短。格式良好的文件readable_eq_data.json包含超过6000行内容,但只需几行代码,就可读取所有的数据并将其存储到一个Python列表中。下面将提取所有地震的震级。
2.2.4 提取震级
有了包含所有地震数据的列表后,就可遍历这个列表,从中提取所需的数据。下面来提取每次地震的震级:
from pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))mags = []
for eq_dict in all_eq_dicts:mag = eq_dict['properties']['mag']mags.append(mag)print(mags[:10])接下来,我们将提取每次地震的位置信息,然后就可以绘制地震散点图了。
2.2.5 提取位置数据
位置数据存储在"geometry"键下。在"geometry"键关联的字典中,有一个"coordinates"键,它关联到一个列表,而列表中的前两个值为经度和纬度。下面演示了如何提取位置数据:
from pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:mag = eq_dict['properties']['mag']title = eq_dict['properties']['title']lon = eq_dict['geometry']['coordinates'][0]lat = eq_dict['geometry']['coordinates'][1]mags.append(mag)titles.append(title)lons.append(lon)lats.append(lat)print(mags[:10])
print(titles[:2])
print(lons[:5])
print(lats[:5])我们创建了用于存储位置标题的列表titles,来提取字典’properties’里’title’键对应的值,以及用于存储经度和纬度的列表。代码eq_dict[‘geometry’]访问与"geometry"键相关联的字典。第二个键(‘coordinates’)提取与"coordinates"相关联的列表,而索引0提取该列表中的第一个值,即地震发生位置的经度。
2.2.6 绘制震级散点图
有了前面提取的数据,就可以绘制可视化图了。首先要实现一个简单的震级散点图,在确保显示的信息正确无误之后,我们再将注意力转向样式和外观方面。绘制初始散点图的代码如下。
import plotly.express as pxfrom pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:mag = eq_dict['properties']['mag']title = eq_dict['properties']['title']lon = eq_dict['geometry']['coordinates'][0]lat = eq_dict['geometry']['coordinates'][1]mags.append(mag)titles.append(title)lons.append(lon)lats.append(lat)fig = px.scatter(x=lons,y=lats,labels={"x": "经度", "y": "纬度"},range_x=[-200, 200],range_y=[-90, 90],width=800,height=800,title="全球地震散点图",
)fig.write_html("global_earthquakes.html")
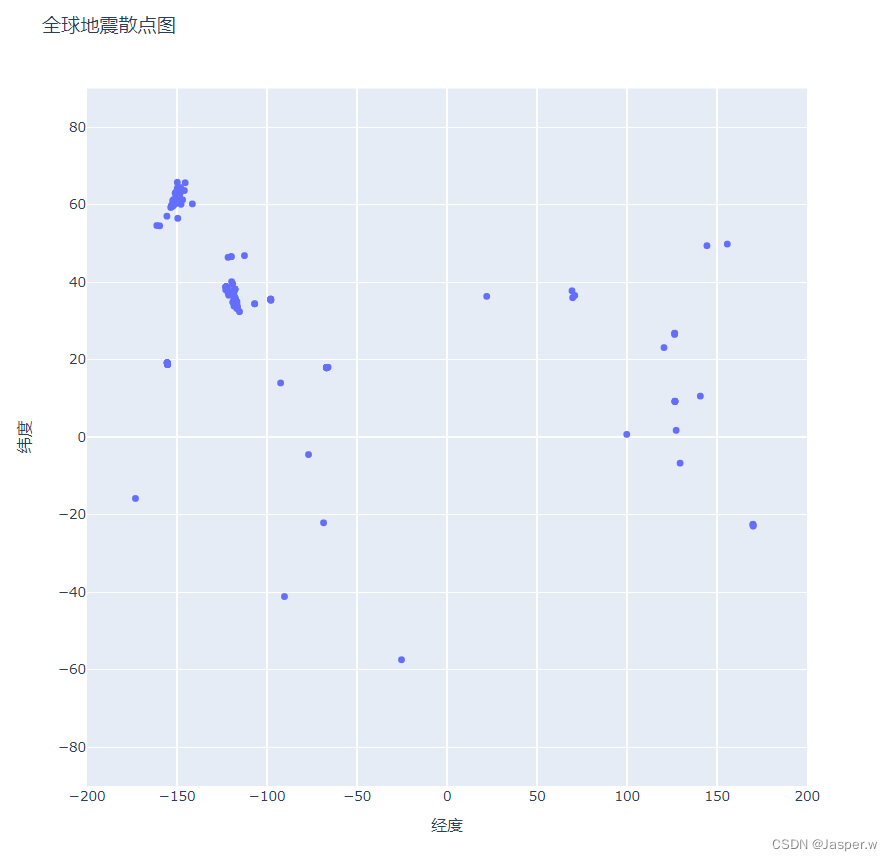
fig.show()首先,导入plotly.express,用别名px表示。Plotly Express是Plotly的高级接口,简单易用,语法与Matplotlib类似。然后,调用px.scatter函数配置参数创建一个fig实例,分别设置 轴为经度[范围是[-200, 200](扩大空间,以便完整显示东西经180° 附近的地震散点)]、 轴为纬度[范围是[-90, 90]],设置散点图显示的宽度和高度均为800像素,并设置标题为“全球地震散点图”。
只用14行代码,简单的散点图就配置完成了,这返回了一个fig对象。fig.write_html方法可以将可视化图保存为html文件。在文件夹中找到global_earthquakes.html文件,用浏览器打开即可。另外,如果使用Jupyter Notebook,可以直接使用fig.show方法直接在notebook单元格显示散点图。
2.2.7 另一种指定图表数据的方式
配置这个图表前,先来看看另一种稍微不同的指定Plotly 图表数据的方式。当前,经纬度数据是手动配置的:
fig = px.scatter(x=lons,y=lats,labels={"x": "经度", "y": "纬度"},
这是在Plotly Express中给图表定义数据的最简单方式之一,但在数据处理中并不是最佳的。下面是另一种给图表定义数据的等效方式,需要使用pandas数据分析工具。首先创建一DataFrame,将需要的数据封装起来:
import plotly.express as px
import pandas as pdfrom pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:mag = eq_dict['properties']['mag']title = eq_dict['properties']['title']lon = eq_dict['geometry']['coordinates'][0]lat = eq_dict['geometry']['coordinates'][1]mags.append(mag)titles.append(title)lons.append(lon)lats.append(lat)data = pd.DataFrame(data=zip(lons, lats, titles, mags), columns=['经度', '纬度', '位置', '震级']
)fig = px.scatter(data,x=lons,y=lats,labels={"x": "经度", "y": "纬度"},range_x=[-200, 200],range_y=[-90, 90],width=800,height=800,title="全球地震散点图",
)fig.write_html("global_earthquakes.html")
fig.show()在这种方式中,所有有关数据的信息都以键值对的形式放在一个字典中。如果在eq_plot.py中使用这些代码,生成的图表是一样的。相比于前一种格式,这种格式让我们能够无缝衔接数据分析,并且更轻松地进行定制。
2.2.8 定制标记的尺寸
确定如何改进散点图的样式时,应着重于让要传达的信息更清晰。当前的散点图显示了每次地震的位置,但没有指出震级。我们要让观察者迅速获悉最严重的地震发生在什么地方。
为此,根据地震的震级设置其标记的尺寸
fig = px.scatter(data,x=lons,y=lats,labels={"x": "经度", "y": "纬度"},range_x=[-200, 200],range_y=[-90, 90],width=800,height=800,title="全球地震散点图",size="震级",size_max=10,
)
Plotly Express支持对数据系列进行定制,这些定制都以参数表示。这里使用了size参数来指定散点图中每个标记的尺寸,我们只需要将前面data中的"震级"字段提供给size参数即可。另外,标记尺寸默认为20像素,还可以通过size_max=10将最大显示尺寸缩放到10。
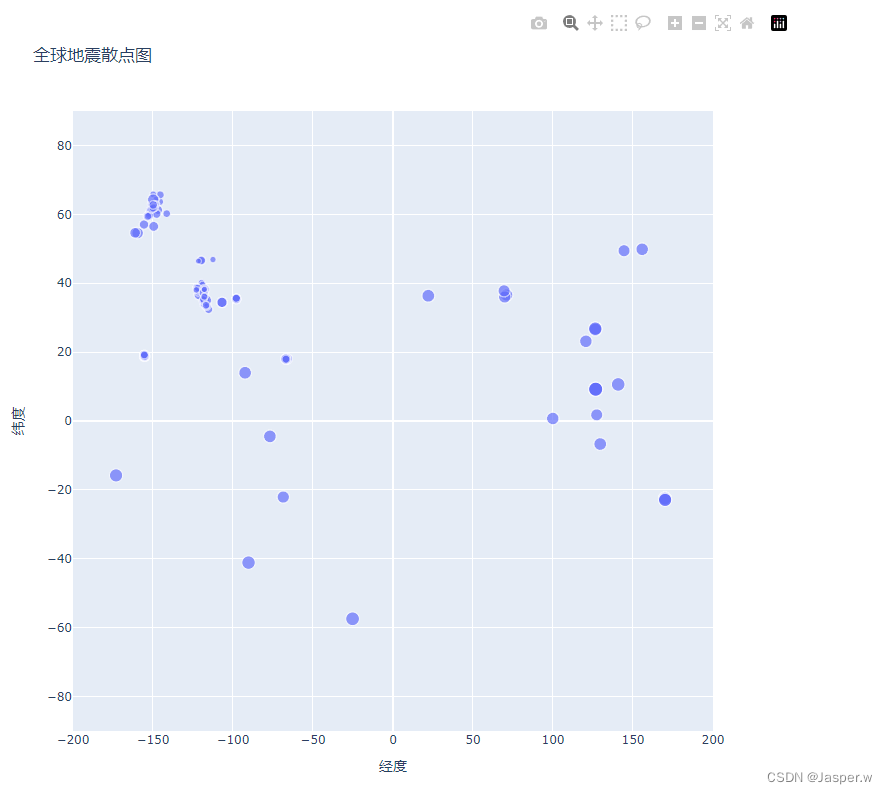
2.2.9 定制标记的颜色
我们还可以定制标记的颜色,以呈现地震的严重程度。执行这些修改前,将文件eq_data_30_day_m1.json复制到你的数据目录中,它包含30天内的地震数据。通过使用这个更大的数据集,绘制出来的地震散点图将有趣得多。
fig = px.scatter(data,x=lons,y=lats,labels={"x": "经度", "y": "纬度"},range_x=[-200, 200],range_y=[-90, 90],width=800,height=800,title="全球地震散点图",size="震级",size_max=10,color="震级",
)
首先修改文件名,以使用30天的数据集。为了让标记的震级按照不同的颜色显示,只需要配置color="震级"即可。默认的视觉映射图例渐变色范围是从蓝到红再到黄,数值越小则标记越蓝,而数值越大则标记越黄。
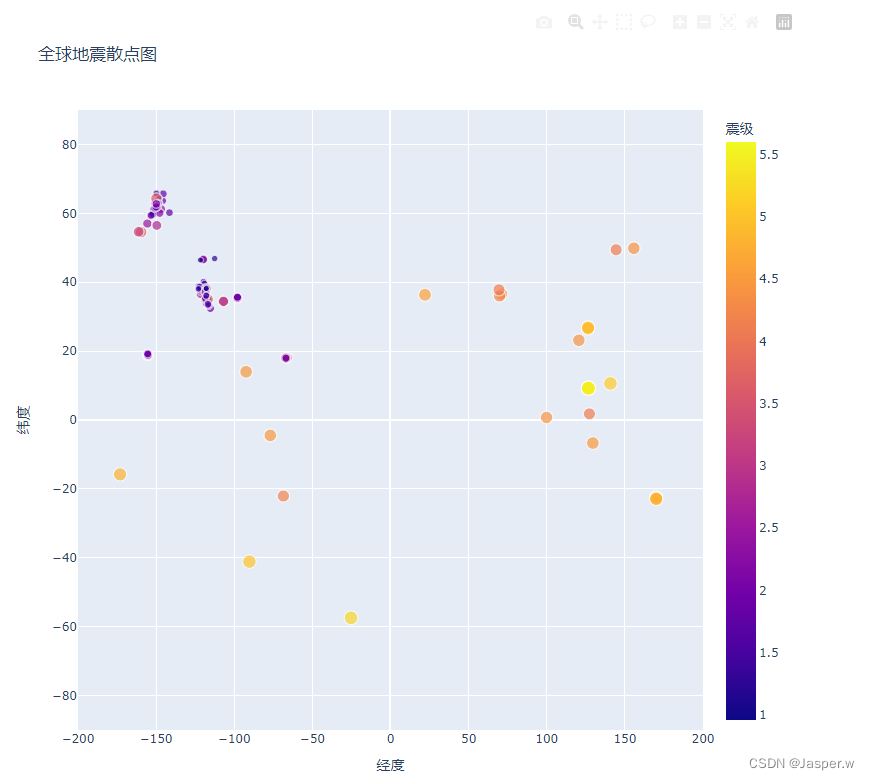
2.2.10 其他渐变
Plotly Express有大量的渐变可供选择。要获悉有哪些渐变可供使用,运行下面这个简短的程序
import plotly.express as px
for key in px.colors.named_colorscales():print(key)
Plotly Express将渐变存储在模块colors中。这些渐变是在列表px.colors.named_colorscales()中定义的。
请尝试使用这些渐变其实映射到一个颜色列表。使用px.colors.diverging.RdYlGn[::-1]可以将对应颜色的配色列表反转。
注意 Plotly除了有px.colors.diverging表示连续变量的配色方案,还有px.colors.sequential和px.colors.qualitative表示离散变量。随便挑一种配色,例如px.colors.qualitative.Alphabet,你将看到渐变是如何定义的。每个渐变都有起始色和终止色,有些渐变还定义了一个或多个中间色。Plotly会在这些定义好的颜色之间插入颜色。
2.2.11 添加鼠标指向时显示的文本
为完成这幅散点图的绘制,我们将添加一些说明性文本,在你将鼠标指向表示地震的标记时显示出来。除了默认显示的经度和纬度外,还将显示震级以及地震的大致位置:
import plotly.express as px
import pandas as pdfrom pathlib import Path
import json# 将数据作为字符串读取并转换为python对象
path = Path("eq_data/eq_data_1_day_m1.geojson")
contents = path.read_text()
all_eq_data = json.loads(contents)# 查看数据集中所有的地震
all_eq_dicts = all_eq_data['features']mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:mag = eq_dict['properties']['mag']title = eq_dict['properties']['title']lon = eq_dict['geometry']['coordinates'][0]lat = eq_dict['geometry']['coordinates'][1]mags.append(mag)titles.append(title)lons.append(lon)lats.append(lat)data = pd.DataFrame(data=zip(lons, lats, titles, mags), columns=['经度', '纬度', '位置', '震级']
)fig = px.scatter(data,x=lons,y=lats,labels={"x": "经度", "y": "纬度"},range_x=[-200, 200],range_y=[-90, 90],width=800,height=800,title="全球地震散点图",size="震级",size_max=10,color="震级",hover_name='位置',
)fig.write_html("global_earthquakes.html")
fig.show()Plotly Express的操作非常简单,只需要将hover_name参数配置为data的"位置"字段即可。
太令人震惊了!通过编写大约40行代码,我们就绘制了一幅漂亮的全球地震活动散点图,并通过30天地震数据大致展示了地球的板块结构。Plotly Express提供了众多定制可视化外观和行为的方式。使用它提供的众多选项,可让图表和散点图准确地显示你所需的信息。
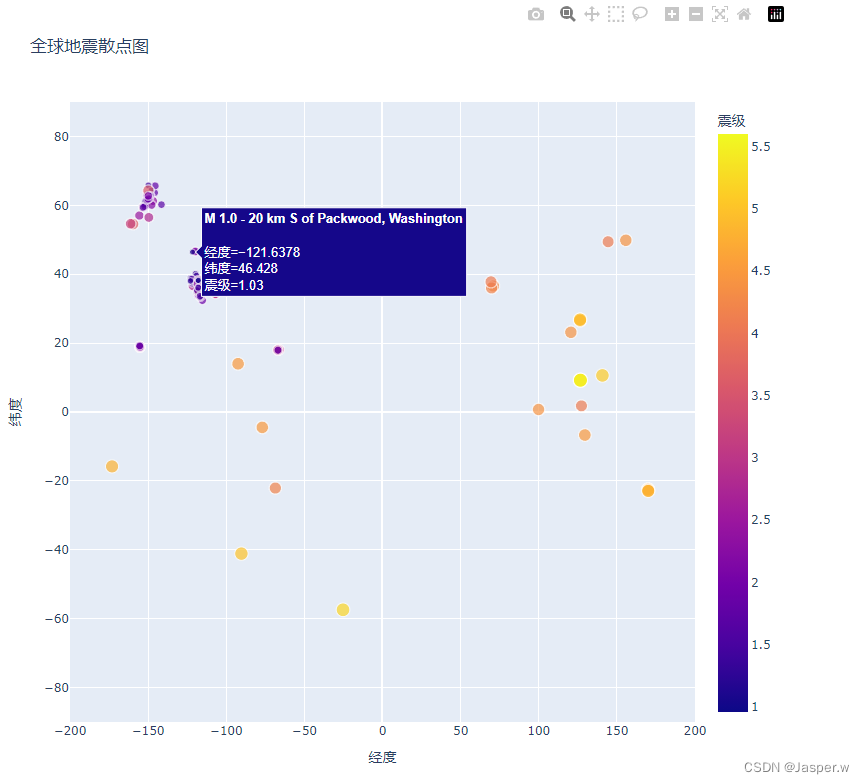
3. 使用API
如何编写独立的程序,对获取的数据进行可视化。这个程序将使用Web应用程序编程接口(API)自动请求网站的特定信息而不是整个网页,再对这些信息进行可视化。由于这样编写的程序始终使用最新的数据进行可视化,即便数据瞬息万变,它呈现的信息也是最新的。
3.1 使用Web API
Web API是网站的一部分,用于与使用具体URL请求特定信息的程序交互。这种请求称为
API调用。请求的数据将以易于处理的格式(如JSON或CSV)返回。依赖于外部数据源
的大多数应用程序依赖于API调用,如集成社交媒体网站的应用程序。
3.1.1 Git和GitHub
本章的可视化基于来自GitHub的信息,这是一个让程序员能够协作开发项目的网站。我们
将使用GitHub的API来请求有关该网站中Python项目的信息,再使用Plotly生成交互式可视
化图表,呈现这些项目的受欢迎程度。
GitHub的名字源自Git,后者是一个分布式版本控制系统,帮助人们管理为项目所做的工
作,避免一个人所做的修改影响其他人所做的修改。在项目中实现新功能时,Git跟踪你
对每个文件所做的修改。确定代码可行后,你提交所做的修改,而Git将记录项目最新的
状态。如果犯了错,想撤销所做的修改,你可以轻松地返回到以前的任何可行状态。(要
更深入地了解如何使用Git进行版本控制,请参阅附录D。)GitHub上的项目都存储在仓库
中,后者包含与项目相关联的一切:代码、项目参与者的信息、问题或bug报告,等等。
GitHub用户可以给喜欢的项目加星(star)以表示支持,还可以跟踪自己可能想使用的项
目。在本章中,我们将编写一个程序,自动下载GitHub上星级最高的Python项目的信息,
并对这些信息进行可视化。
3.1.2 使用API调用请求数据
GitHub的API让你能够通过API调用来请求各种信息。要知道API调用是什么样的,请在浏览器的地址栏中输入如下地址并按回车键:
https://api.github.com/search/repositories?q=language:python&sort=stars
这个调用返回GitHub当前托管了多少个Python项目,以及有关最受欢迎的Python仓库的信息。下面来仔细研究这个调用。开头的https://api.github.com/将请求发送到GitHub网站中响应API调用的部分,接下来的search/repositories让API搜索GitHub上的所有仓库。
repositories后面的问号指出需要传递一个实参。q表示查询,而等号(=)让我们能够开始指定查询。我们使用language:python指出只想获取主要语言为Python的仓库的信息。最后的&sort=stars指定将项目按星级排序。
从响应可知,该URL并不适合人工输入,因为它采用了适合程序处理的格式。GitHub目前总共有九百万个Python项目。“incomplete_results"的值为false,由此知道请求是成功的(并非不完的)。倘若GitHub无法处理该API,此处返回的值将为true。接下来的列表中显示了返的"items”,其中包含GitHub上最受欢迎的Python项目的详细信息。
3.1.3 安装Requests
Requests包让Python程序能够轻松地向网站请求信息并检查返回的响应。要安装Requests,可使用pip:
python -m pip install --user requests
这个命令让Python运行模块pip,并在当前用户的Python安装中添加Requests包。如果你运行程序或安装包时使用的是命令python3或其他命令,请务必在这里使用同样的命令。
注意 如果该命令在macOS系统上不管用,可以尝试删除标志–user再次运行。
3.1.4 处理API响应
下面来编写一个程序,它自动执行API调用并处理结果,以找出GitHub上星级最高的Python项目:
导入模块requests。存储API调用的URL。最新的GitHub API版本为第3版,因此通过指定headers显式地要求使用这个版本的API,再使用requests调用API。
我们调用get()并将URL传递给它,再将响应对象赋给变量r。响应对象包含一个名为status_code的属性,指出了请求是否成功(状态码200表示请求成功)。打印status_code,核实调用是否成功。
这个API返回JSON格式的信息,因此使用方法json()将这些信息转换为一个Python字典,并将结果存储在response_dict中。
注意 像这样简单的调用应该会返回完整的结果集,因此完全可以忽略与’incomplete_results’关联的值。但在执行更复杂的API调用时,应检查这个值。
3.1.5 处理响应字典
将API调用返回的信息存储到字典后,就可处理其中的数据了。我们来生成一些概述这些信息的输出。这是一种不错的方式,可确认收到了期望的信息,进而开始研究感兴趣的信息。
import requests# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories'
url += "?q=language:python+sort:stars+stars:>10000"headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")# 将API响应转换为字典
response_dict = r.json()
print(f"Total repositories: {response_dict['total_count']}")
print(f"Compete results: {not response_dict['incomplete_results']}")# 探索有关仓库的信息
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")# 研究第一个仓库
repo_dict = repo_dicts[0]
print(f"\nKeys: {len(repo_dict)}")
for key in sorted(repo_dict.keys()):print(key)打印与’total_count’相关联的值,它指出了GitHub总共包含多少个Python仓库。
与’items’关联的值是个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。将这个字典列表存储在repo_dicts中。接下来,打印repo_dicts的长度,以获悉获得了多少个仓库的信息。
为更深入地了解每个仓库的信息,提取repo_dicts中的第一个字典,并将其存储在repo_dict中。接下来,打印这个字典包含的键数,看看其中有多少信息。打印这个字典的所有键,看看其中包含哪些信息。
Status code: 200
Total repositories: 436
Compete results: True
Repositories returned: 30Keys: 80
allow_forking
archive_url
archived
assignees_url
blobs_url
branches_url
clone_url
collaborators_url
comments_url
commits_url
compare_url
contents_url
contributors_url
created_at
default_branch
deployments_url
description
disabled
downloads_url
events_url
fork
forks
forks_count
forks_url
full_name
git_commits_url
git_refs_url
git_tags_url
git_url
has_discussions
has_downloads
has_issues
has_pages
has_projects
has_wiki
homepage
hooks_url
html_url
id
is_template
issue_comment_url
issue_events_url
issues_url
keys_url
labels_url
language
languages_url
license
merges_url
milestones_url
mirror_url
name
node_id
notifications_url
open_issues
open_issues_count
owner
private
pulls_url
pushed_at
releases_url
score
size
ssh_url
stargazers_count
stargazers_url
statuses_url
subscribers_url
subscription_url
svn_url
tags_url
teams_url
topics
trees_url
updated_at
url
visibility
watchers
watchers_count
web_commit_signoff_requiredGitHub的API返回有关仓库的大量信息:repo_dict包含78个键。通过仔细查看这些键,可大致知道可提取有关项目的哪些信息。(要准确地获悉API将返回哪些信息,要么阅读文档,要么像这里一样使用代码来查看。)
import requests# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories'
url += "?q=language:python+sort:stars+stars:>10000"headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")# 将API响应转换为字典
response_dict = r.json()
print(f"Total repositories: {response_dict['total_count']}")
print(f"Compete results: {not response_dict['incomplete_results']}")# 探索有关仓库的信息
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")# 研究第一个仓库
repo_dict = repo_dicts[0]
print(f"\nKeys: {len(repo_dict)}")
for key in sorted(repo_dict.keys()):print(key)# 研究有关仓库的信息
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")# 研究第一个仓库
repo_dict = repo_dicts[0]print("\nSelected information about first repository:")
print(f"Name: {repo_dict['name']}")
print(f"Owner: {repo_dict['owner']['login']}")
print(f"Stars: {repo_dict['stargazers_count']}")
print(f"Repository: {repo_dict['html_url']}")
print(f"Created: {repo_dict['created_at']}")
print(f"Updated: {repo_dict['updated_at']}")
print(f"Description: {repo_dict['description']}")这里打印的值对应于表示第一个仓库的字典中的很多键。打印了项目的名称。项目所有者是由一个字典表示的,因此使用键owner来访问表示所有者的字典,再使用键key来获取所有者的登录名。打印项目获得了多少个星的评级,以及该项目GitHub仓库的URL。接下来,显示项目的创建时间和最后一次更新的时间。最后,打印仓库的描述。
Selected information about first repository:
Name: public-apis
Owner: public-apis
Stars: 275926
Repository: https://github.com/public-apis/public-apis
Created: 2016-03-20T23:49:42Z
Updated: 2024-01-23T08:48:13Z
Description: A collective list of free APIsGitHub上星级最高的Python项目为awesome-python,其所有者为用户vinta,有60 000多位GitHub用户给这项目加星了。我们可以看到这个项目仓库的URL,其创建时间为2014年6月,且最近更新了。最后,描述指出项目awesomepython包含一系列深受欢迎的Python资源。
3.1.6 概述最受欢迎的仓库
对这些数据进行可视化时,我们想涵盖多个仓库。下面就来编写一个循环,打印API调用返回的每个仓库的特定信息,以便能够在可视化中包含所有这些信息:
import requests# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories'
url += "?q=language:python+sort:stars+stars:>10000"headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")# 将API响应转换为字典
response_dict = r.json()
print(f"Total repositories: {response_dict['total_count']}")
print(f"Compete results: {not response_dict['incomplete_results']}")# 探索有关仓库的信息
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")# 研究第一个仓库
repo_dict = repo_dicts[0]
print(f"\nKeys: {len(repo_dict)}")
for key in sorted(repo_dict.keys()):print(key)# 研究有关仓库的信息
repo_dicts = response_dict['items']
print(f"Repositories returned: {len(repo_dicts)}")print("\nSelected information about each repository:")for repo_dict in repo_dicts:print(f"\nName: {repo_dict['name']}")print(f"Owner: {repo_dict['owner']['login']}")print(f"Stars: {repo_dict['stargazers_count']}")print(f"Repository: {repo_dict['html_url']}")print(f"Description: {repo_dict['description']}")遍历repo_dicts中的所有字典。在这个循环中,打印每个项目的名称、所有者、星级、在GitHub上的URL以及描述:
Status code: 200
Total repositories: 436
Compete results: True
Repositories returned: 30Keys: 80
allow_forking
archive_url
archived
assignees_url
blobs_url
branches_urlName: gpt4free
Owner: xtekky
Stars: 51898
Repository: https://github.com/xtekky/gpt4free
Description: The official gpt4free repository | various collection of powerful language modelsName: gpt_academic
Owner: binary-husky
Stars: 51000
Repository: https://github.com/binary-husky/gpt_academic
Description: 为GPT/GLM等LLM大语言模型提供实用化交互接口,特别优化论文阅读/润色/写作体验,模块化设计,支持自定义快捷按钮&函数插件,支持Python和C++等项目剖析&自译解功能,PDF/LaTex论文翻译&总结功能,支持并行问询多种LLM模型,支持chatglm3等本地模型。接入通义千问, deepseekcoder, 讯飞星火, 文心一言, llama2, rwkv, claude2, moss等。在上述输出中,有些有趣的项目可能值得一看。但不要在这上面花费太多时间,因为即将创建的可视化图表能让你更容易地看清结果。
3.1.7 监视API的速率限制
大多数API存在速率限制,也就是说,在特定时间内可执行的请求数存在限制。要获悉是否接近了GitHub的限制,请在浏览器中输入https://api.github.com/rate_limit,你将看到类似于下面的响应:
{
"resources": {
"core": {
"limit": 60,
"remaining": 58,
"reset": 1550385312
},
"search": {
"limit": 10,
"remaining": 8,"reset": 1550381772
},
我们关心的信息是搜索API的速率限制。极限为每分钟10个请求,而在当前分钟内,还可执行8个请求。reset值指的是配额将重置的Unix时间或新纪元时间(1970年1月1日午夜后多少秒。用完配额后,你将收到一条简单的响应,由此知道已到达API极限。到达极限后,必须等待配额重置。
注意 很多API要求注册获得API密钥后才能执行API调用。本书编写期间,GitHub没有这样的要求,但获得API密钥后,配额将高得多。
3.2 使用Plotly可视化仓库
有了一些有趣的数据后,我们来进行可视化,呈现GitHub上Python项目的受欢迎程度。我们将创建一个交互式条形图:条形的高度表示项目获得了多少颗星。单击条形将带你进入项目在GitHub上的主页。请复制前面编写的python_repos_visual.py,并将副本修改成下面这样:
import requests
import plotly.express as px# 执行API调用并存储响应
url = "https://api.github.com/search/repositories"
url += "?q=language:python+sort:stars+stars:>10000"headers = {"Accept": "application/vnd.github.v3+json"}
r = requests.get(url, headers=headers)
print(f"Status code: {r.status_code}")# 处理结果
response_dict = r.json()
print(f"Complete results: {not response_dict['incomplete_results']}")# 处理有关仓库的信息
repo_dicts = response_dict['items']
repo_links, stars, hover_texts = [], [], []
for repo_dict in repo_dicts:# Turn repo names into active links.repo_name = repo_dict['name']repo_url = repo_dict['html_url']repo_link = f"<a href='{repo_url}'>{repo_name}</a>"repo_links.append(repo_link)stars.append(repo_dict['stargazers_count'])# Build hover texts.owner = repo_dict['owner']['login']description = repo_dict['description']hover_text = f"{owner}<br />{description}"hover_texts.append(hover_text)# 可视化
title = "Most-Starred Python Projects on GitHub"
labels = {'x': 'Repository', 'y': 'Stars'}
fig = px.bar(x=repo_links, y=stars, title=title, labels=labels,hover_name=hover_texts)fig.update_layout(title_font_size=28, xaxis_title_font_size=20,yaxis_title_font_size=20)fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)导入Plotly中的Bar类和模块offline。这里也打印API响应的状态,以便知道是否出现了问题。现在不是探索阶段,早已确定了所需的数据是存在的,因此删除部分处理API响应的代码。
接下来,创建两个空列表,用于存储要在图表中呈现的数据。我们需要每个项目的名称,用于给条形添加标签,还需要知道项目获得了多少个星,用于指定条形的高度。在循环中,将每个项目的名称和星级分别附加到这两个列表末尾。
然后,定义列表data。它像之前的列表data一样包含一个字典,指定了图表的类型,并提供了 值和 值: 值为项目名称, 值为项目获得了多少个星。使用字典定义图表的布局。这里没有创建Layout实例,而是创建了一个包含布局规范的字典,并在其中指定了图表的名称以及每个坐标轴的标签。
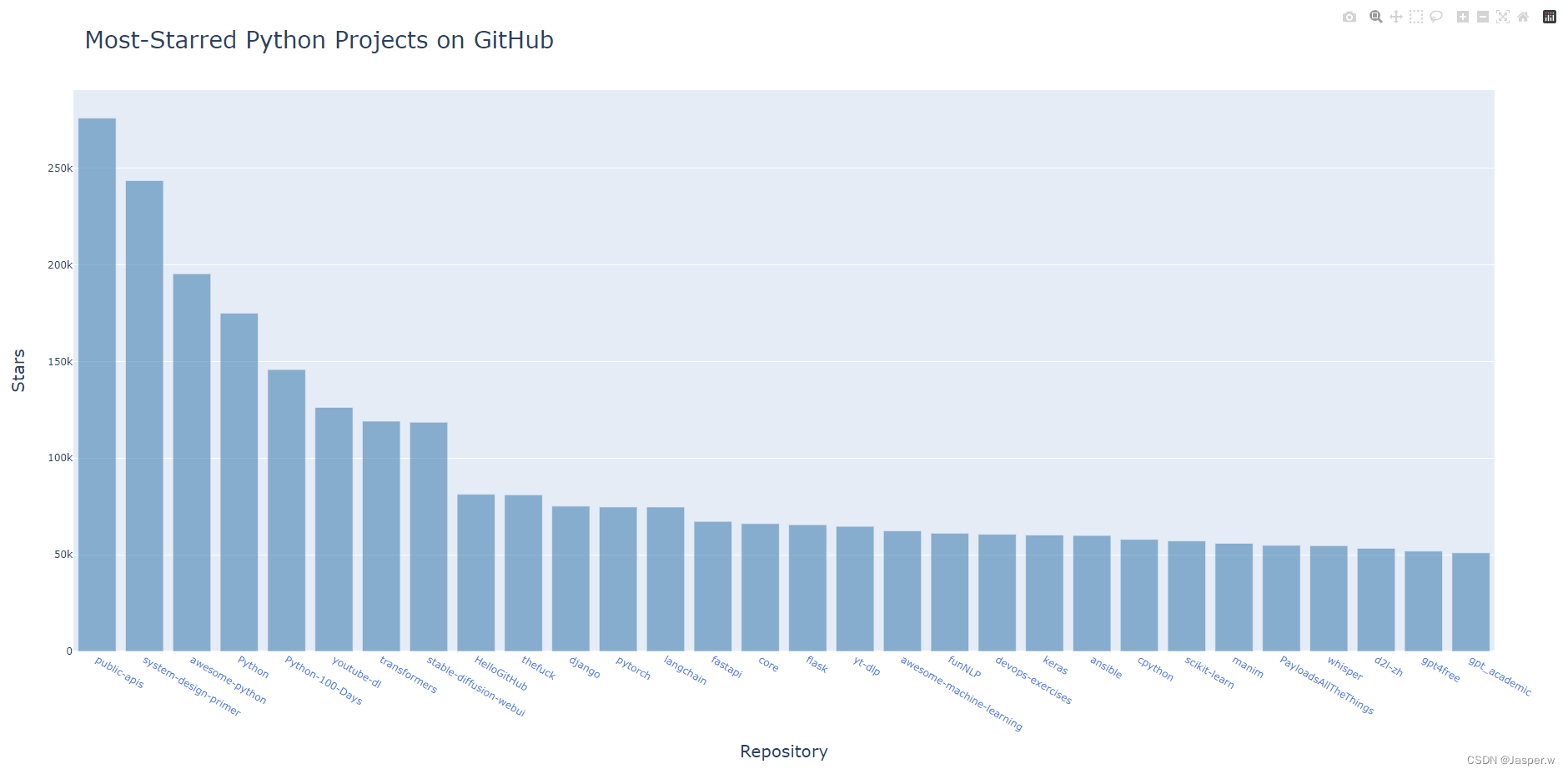
3.2.1 设计图形样式
Plotly提供了众多定制图形以及设置其样式的方式,可在确定信息被正确的可视化后使用。
对px.bar()做出修改,调用创建的fig对象做进一步调整。
# 可视化
title = "Most-Starred Python Projects on GitHub"
labels = {'x': 'Repository', 'y': 'Stars'}
fig = px.bar(x=repo_links, y=stars, title=title, labels=labels,hover_name=hover_texts)fig.update_layout(title_font_size=28, xaxis_title_font_size=20,yaxis_title_font_size=20)fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)fig.show()
添加图形标题,并且给坐标轴添加标题。使用fig.update_layout()方法修改一些图形元素。不同的元素命名和修改方式是一致的。
3.2.2 添加自定义工具提示
在Plotly中,将鼠标指向条形将显示其表示的信息。这通常称为工具提示。在本例中,当前显示的是项目获得了多少个星。下面来创建自定义工具提示,以显示项目的描述和所有者。
为生成这样的工具提示,需要再提取一些信息:
# 处理有关仓库的信息
repo_dicts = response_dict['items']
repo_links, stars, hover_texts = [], [], []
for repo_dict in repo_dicts:# Turn repo names into active links.repo_name = repo_dict['name']repo_url = repo_dict['html_url']repo_link = f"<a href='{repo_url}'>{repo_name}</a>"repo_links.append(repo_link)stars.append(repo_dict['stargazers_count'])# 创建悬停文本owner = repo_dict['owner']['login']description = repo_dict['description']hover_text = f"{owner}<br />{description}"hover_texts.append(hover_text)# 可视化
title = "Most-Starred Python Projects on GitHub"
labels = {'x': 'Repository', 'y': 'Stars'}
fig = px.bar(x=repo_links, y=stars, title=title, labels=labels,hover_name=hover_texts)fig.update_layout(title_font_size=28, xaxis_title_font_size=20,yaxis_title_font_size=20)fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)fig.show()
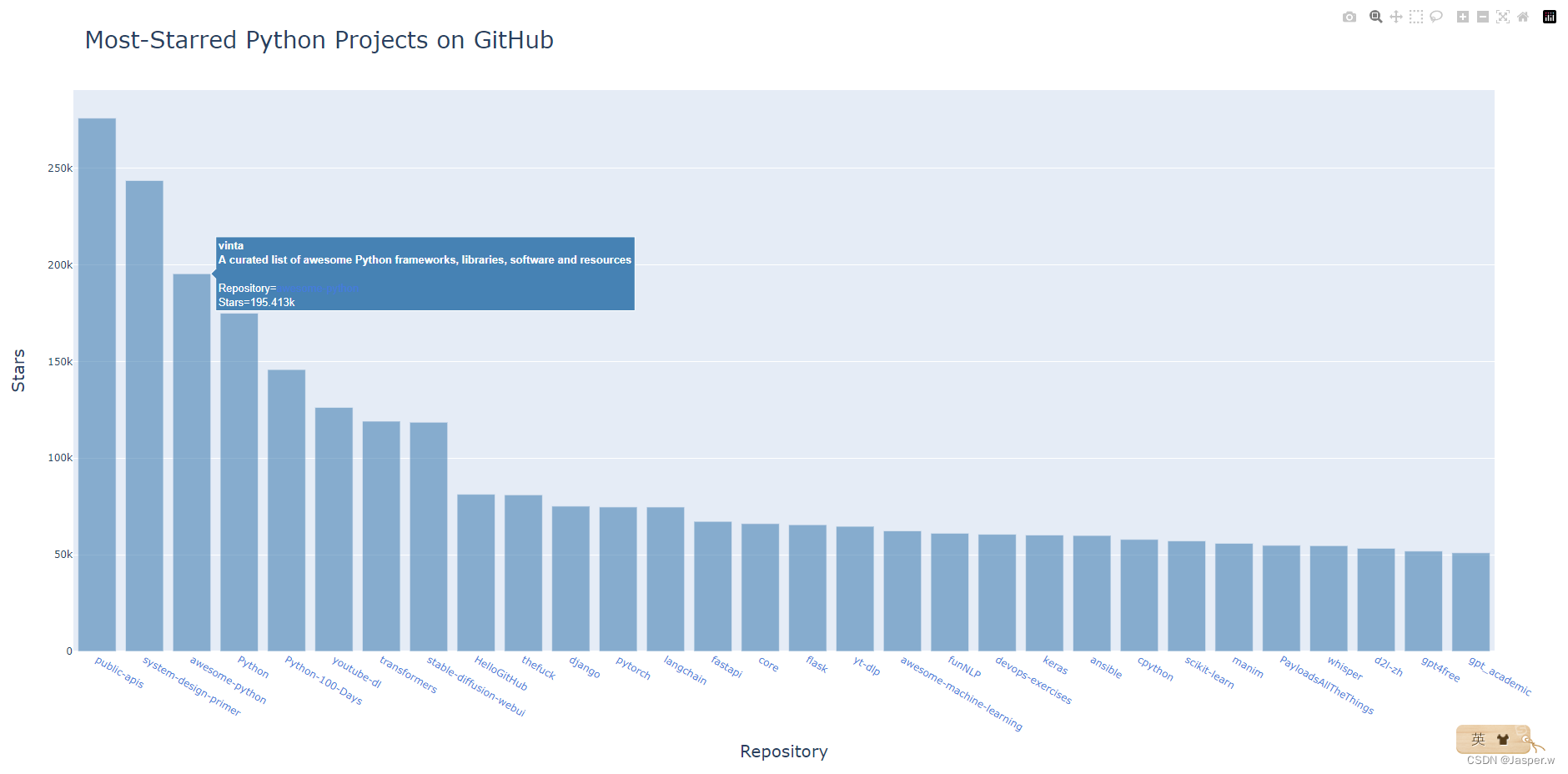
2.2.3 在图表中添加可单击的链接
Plotly允许在文本元素中使用HTML,让你能够轻松地在图表中添加链接。下面将x轴标签作为链接,让观察者能够访问项目在GitHub上的主页。为此,需要提取URL并用其生成x轴标签:
# 处理有关仓库的信息
repo_dicts = response_dict['items']
repo_links, stars, hover_texts = [], [], []
for repo_dict in repo_dicts:# Turn repo names into active links.repo_name = repo_dict['name']repo_url = repo_dict['html_url']repo_link = f"<a href='{repo_url}'>{repo_name}</a>"repo_links.append(repo_link)stars.append(repo_dict['stargazers_count'])# 创建悬停文本owner = repo_dict['owner']['login']description = repo_dict['description']hover_text = f"{owner}<br />{description}"hover_texts.append(hover_text)# 可视化
title = "Most-Starred Python Projects on GitHub"
labels = {'x': 'Repository', 'y': 'Stars'}
fig = px.bar(x=repo_links, y=stars, title=title, labels=labels,hover_name=hover_texts)fig.update_layout(title_font_size=28, xaxis_title_font_size=20,yaxis_title_font_size=20)fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)fig.show()将这个列表用作图表的x值。生成的图表与前面相同,但观察者可单击图表底端的项目名,以访问项目在GitHub上的主页。至此,我们对API获取的数据生成了可视化图表——它是交互性的,包含丰富的信息!
3.2.4 定制标记颜色
创建图形后,可使用以update_打头的方法来定制其各个方面。使用update_traces()定制图形呈现的数据。
fig.update_traces(marker_color='SteelBlue', marker_opacity=0.6)
3.2.5 深入了解Plotly和GitHub API
要深入地了解如何生成Plotly图表,有两个不错的地方可以查看。第一个是Plotly User Guide in Python。通过研究该资源,可更深入地了解Plotly是如何使用数据来生成可视化图表的,以及它采取这种做法的原因。
第二个不错的资源是Plotly网站中的Python Figure Reference,其中列出了可用来配置Plotly可视化的所有设置。这里还列出了所有的图表类型,以及在各个配置选项中可设置的属性。
要更深入地了解GitHub API,可参阅其文档。通过阅读文档,你可以知道如何从GitHub提取各种信息。如果有GitHub账户,除了向公众提供的有关仓库的信息外,你还可以提取有关自己的信息。
3.3 Hacker News API
为探索如何使用其他网站的API调用,我们来看看Hacker News。在Hacker News网站,用户分享编程和技术方面的文章,并就这些文章展开积极的讨论。Hacker News的API让你能够访问有关该网站所有文章和评论的信息,且不要求通过注册获得密钥。
下面的调用返回本书编写期间最热门的文章的信息:
https://hacker-news.firebaseio.com/v0/item/19155826.json
如果在浏览器中输入这个URL,将发现响应位于一对花括号内,表明这是一个字典。如果不改进格式,这样的响应难以阅读。通过方法json.dump()来运行这个URL,以便对返回的信息进行探索:
import requests
import json# 执行API调用并存储响应
url = 'https://hacker-news.firebaseio.com/v0/item/31353677.json'
r = requests.get(url)
print(f"Status code: {r.status_code}")# 探索数据的结构
response_dict = r.json()
response_string = json.dumps(response_dict, indent=4)
print(response_string)输出是一个字典,其中包含有关ID为31353677的文章的信息。
这个字典包含很多键。与键’descendants’相关联的值是文章被评论的次数。与键’kids’相关联的值包含文章所有评论的ID。每个评论本身也可能有评论,因此文章的后代(descendant)数量可能比其’kids’的数量多。这个字典中还包含当前文章的标题和URL。
下面的URL返回一个列表,其中包含Hacker News上当前排名靠前的文章的ID。
https://hacker-news.firebaseio.com/v0/topstories.json
通过使用这个调用,可获悉当前有哪些文章位于主页,再生成一系列类似于前面的API调用。通过使用这种方法,可概述当前位于Hacker News主页的每篇文章
from operator import itemgetter
import requests# 执行API调用并存储响应
url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print(f"Status code: {r.status_code}")# 处理有关每篇文章的信息
submission_ids = r.json()
submission_dicts = []
for submission_id in submission_ids[:30]:# 对于每篇文章,都执行一个API调用url = f"https://hacker-news.firebaseio.com/v0/item/{submission_id}.json"r = requests.get(url)print(f"id: {submission_id}\tstatus: {r.status_code}")response_dict = r.json()# 对于每篇文章,都创建一个字典submission_dict = {'title': response_dict['title'],'hn_link': f"http://news.ycombinator.com/item?id={submission_id}",'comments': response_dict['descendants'],}submission_dicts.append(submission_dict)submission_dicts = sorted(submission_dicts, key=itemgetter('comments'),reverse=True)for submission_dict in submission_dicts:print(f"\nTitle: {submission_dict['title']}")print(f"Discussion link: {submission_dict['hn_link']}")print(f"Comments: {submission_dict['comments']}")首先,执行一个API调用,并打印响应的状态。这个API调用返回一个列表,其中包含Hacker News上当前最热门的500篇文章的ID。接下来,将响应对象转换为一个Python列表,并将其存储在submission_ids中。后面将使用这些ID来创建一系列字典,其中每个字典都存储了一篇文章的信息。
创建一个名为submission_dicts的空列表,用于存储前面所说的字典。接下来,遍历前30篇文章的ID。对于每篇文章,都执行一个API调用,其中的URL包含submission_id的当前值。我们打印请求的状态和文章ID,以便知道请求是否成功。
为当前处理的文章创建一个字典,并在其中存储文章的标题、讨论页面的链接和评论数。然后,将submission_dict附加到submission_dicts末尾。
Hacker News上的文章是根据总体得分排名的,而总体得分取决于很多因素,包含被推荐的次数、评论数和发表时间。我们要根据评论数对字典列表submission_dicts进行排序,为此使用了模块operator中的函数itemgetter()。我们向这个函数传递了键’comments’,因此它从该列表的每个字典中提取与键’comments’关联的值。这样,函数sorted()将根据这个值对列表进行排序。我们将列表按降序排列,即评论最多的文章位于最前面。
对列表排序后遍历它,并打印每篇热门文章的三项信息:标题、讨论页面的链接和评论数:
Status code: 200
id: 39098603 status: 200
id: 39081876 status: 200
无论使用哪个API来访问和分析信息,流程都与此类似。有了这些数据后,就可进行可视化,指出最近哪些文章引发了最激烈的讨论。基于这种方式,应用程序可以为用户提供网站(如Hacker News)的定制化阅读体验。要深入了解通过Hacker News API可访问哪些信息,请参阅其文档页面。
4. 小结
至此,我们的数据可视化学习就算成了,其中有很多细节需要注意和学习,稍有疏漏便会溃不成塔。这只是Python编程从入门到实践的第二个项目,之后还有多个项目可供学习,基础知识可参考python编程入门,项目源代码下载请在资源下载处自行选择下载。
相关文章:
Python编程 从入门到实践(项目二:数据可视化)
本篇为实践项目二:数据可视化。 配合文章python编程入门学习,代码附文末。 项目二:数据可视化 1.生成数据1.1 安装Matplotlib1.2 绘制简单的折线图1.2.1 修改标签文字和线条粗细1.2.2 校正图形1.2.3 使用内置样式1.2.4 使用scatter()绘制散点…...
Linux版本下载Centos操作
目录 一、Centos7 二、下载Centos7镜像 三、下载Centos7 买了个硬件安装裸机(一堆硬件) 把安装盘放到虚拟机里面,给机器加电 配置设置 编辑 网络配置 开启网络功能 四、安装linux客户端 Xshell是什么 Xshell使用(连接…...
Offer必备算法_二分查找_八道力扣OJ题详解(由易到难)
目录 二分查找算法原理 ①力扣704. 二分查找 解析代码 ②力扣34. 在排序数组中查找元素的第一个和最后一个位置 解析代码 ③力扣69. x 的平方根 解析代码 ④力扣35. 搜索插入位置 解析代码 ⑤力扣852. 山脉数组的峰顶索引 解析代码 ⑥力扣162. 寻找峰值 解析代码…...

SpringBoot对Bean的管理
Bean扫描 Spring中使用标签扫描或者注解 Springboot中没有使用标签或者注解它是怎么扫描的我的controlelr,service等等 核心在于springboot启动类中的SpringBootApplication注解 此注解其实是一个组合注解 它组合了一个ComponentScan注解,相当于在启…...
体验 AutoGen Studio - 微软推出的友好多智能体协作框架
体验 AutoGen Studio - 微软推出的友好多智能体协作框架 - 知乎 最近分别体验了CrewAI、MetaGPT v0.6、Autogen Studio,了解了AI Agent 相关的知识。 它们的区别 可能有人要问:AutoGen我知道,那Autogen Studio是什么? https://g…...

超简单的正则表达式从入门到精通
正则表达式,又称规则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。 概念 正则表达式是对字…...

webpack常用配置
1.webpack概念 本质上,webpack 是一个用于现代 JavaScript 应用程序的 静态模块打包工具。当 webpack 处理应用程序时,它会在内部从一个或多个入口点构建一个 依赖图(dependency graph),然后将你项目中所需的每一个模块组合成一个或多个 …...

nodejs学习计划--(六)包管理工具
包管理工具 1. 介绍 包是什么 『包』英文单词是 package ,代表了一组特定功能的源码集合包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作 借助包管理工具,可以快…...

数字地球开放平台农作物长势监测解决方案
数字地球开放平台农作物长势监测解决方案 利用遥感技术进行产量预测是一种高效而准确的方法,通过监测植被的生长状况、土地利用、气象等因素,可以为农业决策提供有力支持。数字地球开放平台拥有200颗卫星,为您提供一站式卫星遥感服务。 农情监…...

react hooks 的useState:
React 的 useState Hook 是一种用于在函数组件中管理状态的机制。它可以让函数组件具有类似于类组件的状态管理能力。 useState Hook 接收一个初始值作为参数,并返回一个包含状态值和更新状态值的数组。 import { useState } from react;const [state, setState] …...
编程那么难,为什么不弄一个大众一学就会的计算机语言呢?
大家好!今天要和大家聊聊一个有趣的想法: 想象一下,如果编程变得像拼乐高积木一样简单,那将是多么美妙的事情啊!不需要费尽心思去学习繁杂的语法规则和复杂的逻辑,只需要将代码块像积木一样拼接起来&#x…...

论文阅读2---多线激光lidar内参标定原理
前言:该论文介绍多线激光lidar的标定内参的原理,有兴趣的,可研读原论文。 1、标定参数 rotCorrection:旋转修正角,每束激光的方位角偏移(与当前旋转角度的偏移,正值表示激光束逆时针旋转&…...

Ubuntu 22.04 apt 安装 ros1 ros Noetic Ninjemys
众所周知 ros2还有很多功能没有移植,而ros1官方不再支持 ubuntu 20.04 之后的版本。另一方面Ubuntu 22.04 更新了很多对新硬件的驱动,有更好的兼容性和体验,这就变的很纠结。 如果想在 22.04 使用最新版本的 ros noetic 只有自己编译一个办法…...

单片机学习笔记---矩阵键盘
目录 矩阵键盘的介绍 独立按键和矩阵按键的相同之处: 矩阵按键的扫描 代码演示 代码模块化移植 Keil自定义模板步骤: 代码编写 矩阵键盘就是开发板上右下角的这个模块 这一节的代码是基于上一节讲的LCD1602液晶显示屏驱动代码进行的 矩阵键盘的介…...

第八篇 交叉编译华为云Iot SDK到Orangepi3B
本篇主要内容: 一、交叉编译华为云Iot SDK依赖1.宿主机安装交叉编译工具链(1)选择下载交叉编译工具链(2)解压、添加环境变量、重启2.交叉编译依赖库(0) 准备工作(1) 交叉…...

软件工程测试2
1.【单选】“数据流的分解一般达到2层数据流就截止”的说法是否正确 A. 正确 B. 错误 答案:B 2.【单选】 在类图中,哪种关系表达总体与局部的关系 A. 泛化 B. 实现 C. 聚合 D. 依赖 答案:C 3.【多选】从UML时序图中我们能够得到(…...
)
31.【TypeScript 教程】混入(Mixins)
TypeScript 混入(Mixins) 混入(Mixins)是面向对象编程中的一个比较重要的概念。本节将会通过一个实例逐步介绍混入是如何在 TypeScript 中使用的。 1. 解释 在 TypeScript 中,可以根据不同的功能定义多个可复用的类,它们将作为 …...

C语言常见面试题:什么是联合体,联合体的作用是什么?
联合体(union)是一种特殊的数据类型,它可以在同一块内存单元中存储不同的数据类型。联合体的作用在于能够节省内存空间,并且可以用来实现数据的共享和交换。 联合体的定义方式是在C语言中通过关键字union来定义,例如&…...
Nginx进阶篇【五】
Nginx进阶篇【五】 八、Nginx实现服务器端集群搭建8.1.Nginx与Tomcat部署8.1.1.环境准备(Tomcat)8.1.1.1.浏览器访问:8.1.1.2.获取动态资源的链接地址:8.1.1.3.在Centos上准备一个Tomcat作为后台web服务器8.1.1.4.准备一个web项目,将其打包为war8.1.1.5.启动tomcat进…...

IndexedDB
Web SQL Database | Can I use... Support tables for HTML5, CSS3, etc IndexedDB | Can I use... Support tables for HTML5, CSS3, etc 为什么websql被废弃?_笔记大全_设计学院 WebSQL有兼容、性能、安全问题,要考虑使用IndexedDB替代。 一文看懂 In…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

BiscuitLang:专为Web业务逻辑设计的轻量级脚本语言
1. 项目概述:一个为现代Web开发而生的轻量级语言如果你和我一样,长期在Web前端和全栈开发的泥潭里摸爬滚打,那你一定对JavaScript生态的“臃肿”与“复杂”深有体会。一个简单的项目动辄node_modules文件夹体积惊人,工具链配置繁琐…...

Windows Terminal 预览版:从安装到深度配置,打造现代化命令行工作流
1. 项目概述:为什么我们需要一个现代化的Windows终端?如果你和我一样,在Windows上敲了十几年命令行,从古老的cmd.exe到后来的PowerShell,一个绕不开的痛点就是:这终端工具,用起来总感觉差点意思…...

基于LangGraph构建智能邮件自动化系统:从工作流引擎到AI集成实践
1. 项目概述:用LangGraph构建一个智能邮件自动化系统最近在折腾一个挺有意思的东西,一个基于LangGraph框架的邮件自动化系统。这玩意儿本质上是一个智能化的邮件处理流水线,它能自动读取、理解、分类你的邮件,然后根据预设的规则或…...