elasticsearch8.x版本docker部署说明
前提,当前部署没有涉及证书和https访问
1、环境说明,我采用三个节点,每个节点启动两个es,用端口区分
| 主机 | 角色 | ip和端口 |
|---|---|---|
| 服务器A | master | 192.168.2.223:9200 |
| 服务器A | data | 192.168.2.223:9201 |
| 服务器B | data,master | 192.168.2.224:9200 |
| 服务器B | data | 192.168.2.224:9201 |
| 服务器C | data,master | 192.168.2.225:9200 |
| 服务器C | data | 192.168.2.225:9201 |
2、三个节点都需要执行创建部署文件目录
#es1需要的文件目录
mkdir -p /mydata/es/node1/data
chmod 777 /mydata/es/node1/data
mkdir -p /mydata/es/node1/conf
chmod 777 /mydata/es/node1/conf
mkdir -p /mydata/es/node1/plugins
chmod 777 /mydata/es/node1/plugins
mkdir -p /mydata/es/node1/logs
chmod 777 /mydata/es/node1/logs
#es2需要的文件目录
mkdir -p /mydata/es/node2/data
chmod 777 /mydata/es/node2/data
mkdir -p /mydata/es/node2/conf
chmod 777 /mydata/es/node2/conf
mkdir -p /mydata/es/node2/plugins
chmod 777 /mydata/es/node2/plugins
mkdir -p /mydata/es/node2/logs
chmod 777 /mydata/es/node2/logs
2、服务器A编写es1的yml文件
cd /mydata/es/node1/conf
vi elasticsearch.yml
#输入以下内容cluster.name: elasticsearch-cluster
#节点名称
node.name: es-node1
#节点通信ip
network.bind_host: 0.0.0.0
#节点ip
network.publish_host: 192.168.2.223
#节点通信端口
http.port: 9200
transport.port: 9300
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#节点角色
node.roles: [ master]
#和其他节点通信的ip端口
discovery.seed_hosts: ["192.168.2.223:9300","192.168.2.223:9301", "192.168.2.224:9300", "192.168.2.224:9301","192.168.2.225:9300","192.168.2.225:9301"]
#初始化master节点的配置,用于选举的mater节点ip,后续的节点不需要该配置
cluster.initial_master_nodes: [192.168.2.223,192.168.2.224,192.168.2.225]
#http配置
# Enable security features
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:enabled: false#keystore.path: certs/http.p12# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:enabled: false#verification_mode: certificate#keystore.path: certs/transport.p12#truststore.path: certs/transport.p12
保存退出
2、服务器A编写es2的yml文件
cd /mydata/es/node2/conf
vi elasticsearch.yml
#输入以下内容cluster.name: elasticsearch-cluster
node.name: es-node2
network.bind_host: 0.0.0.0
network.publish_host: 192.168.2.223
http.port: 9201
transport.port: 9301
http.cors.enabled: true
http.cors.allow-origin: "*"
node.roles: [ data]
discovery.seed_hosts: ["192.168.2.223:9300","192.168.2.223:9301", "192.168.2.224:9300", "192.168.2.224:9301","192.168.2.225:9300","192.168.2.225:9301"]# Enable security features
xpack.security.enabled: false
xpack.security.enrollment.enabled: false# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:enabled: false#keystore.path: certs/http.p12# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:enabled: false#verification_mode: certificate#keystore.path: certs/transport.p12#truststore.path: certs/transport.p12
4、启动es1和es2
#设置yml文件权限,不然会报错
chmod 777 /mydata/es/node1/conf/*
chmod 777 /mydata/es/node2/conf/*
#启动
docker run --restart=always -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 -v /mydata/es/node1/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/es/node1/data:/usr/share/elasticsearch/data -v /mydata/es/node1/plugins:/usr/share/elasticsearch/plugins --name es01 elasticsearch:8.6.2docker run --restart=always -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9201:9201 -p 9301:9301 -v /mydata/es/node2/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/es/node2/data:/usr/share/elasticsearch/data -v /mydata/es/node2/plugins:/usr/share/elasticsearch/plugins --name es02 elasticsearch:8.6.2
5、服务器B和服务器C配置参考服务器A进行部署,需要调整的就是ip和端口就行
6、安装kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://192.168.2.223:9200 \
-p 5601:5601 \
kibana:8.6.2
7、谷歌插件安装es-head,下载解压,拖到谷歌浏览器的插件上就好
百度云链接:https://pan.baidu.com/s/1V1tMlgPUQpcaKtqrFjGf2A
提取码:yzwf
8、验证,输入http://192.168.2.223:9200/_cat/nodes,生产环境需要自己去定义角色,自己去了解8.x的相关角色和架构,我这里就不解释了。
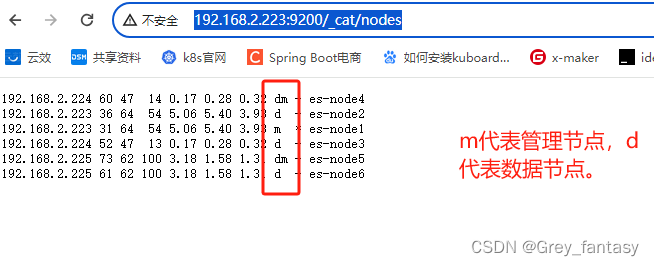
9、角色相关说明推荐博主博文链接
http://www.manongjc.com/detail/62-gdexfeqaydpetga.html
相关文章:
elasticsearch8.x版本docker部署说明
前提,当前部署没有涉及证书和https访问 1、环境说明,我采用三个节点,每个节点启动两个es,用端口区分 主机角色ip和端口服务器Amaster192.168.2.223:9200服务器Adata192.168.2.223:9201服务器Bdata,master192.168.2.224:9200服务器Bdata192.1…...

使用scyllaDb 或者cassandra存储聊天记录
一、使用scyllaDb的原因 目前开源的聊天软件主要还是使用mysql存储数据,数据量大的时候比较麻烦; 我打算使用scyllaDB存储用户的聊天记录,主要考虑的优点是: 1)方便后期线性扩展服务器; 2)p…...
Visual Studio如何修改成英文版
1、打开 Visual Studio Installer 2、点击修改 3、找到语言包,选择需要的语言包,而后点击修改 4、等待下载 5、 安装完成后启动Visual Studio 6、在工具-->选项-->环境-->区域设置-->English并确定 7、重启 Visual Studio,配置…...
gin中使用swagger生成接口文档
想要使用gin-swagger为你的代码自动生成接口文档,一般需要下面三个步骤: 按照swagger要求给接口代码添加声明式注释,具体参照声明式注释格式。使用swag工具扫描代码自动生成API接口文档数据使用gin-swagger渲染在线接口文档页面 第一步&…...
最新AI创作系统ChatGPT网站系统源码,Midjourney绘画V6 ALPHA绘画模型,ChatFile文档对话总结+DALL-E3文生图
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…...

解析dapp:从底层区块链看DApp的脆弱性和挑战
每天五分钟讲解一个互联网只是,大家好我是啊浩说模式Zeropan_HH 在Web3时代,去中心化应用程序(DApps)已成为数字经济的重要组成部分。它们的同生性,即与底层区块链网络紧密相连、共存亡的特性,为DApps带来…...

机器学习整理
绪论 什么是机器学习? 机器学习研究能够从经验中自动提升自身性能的计算机算法。 机器学习经历了哪几个阶段? 推理期:赋予机器逻辑推理能力 知识期:使机器拥有知识 学习期:让机器自己学习 什么是有监督学习和无监…...
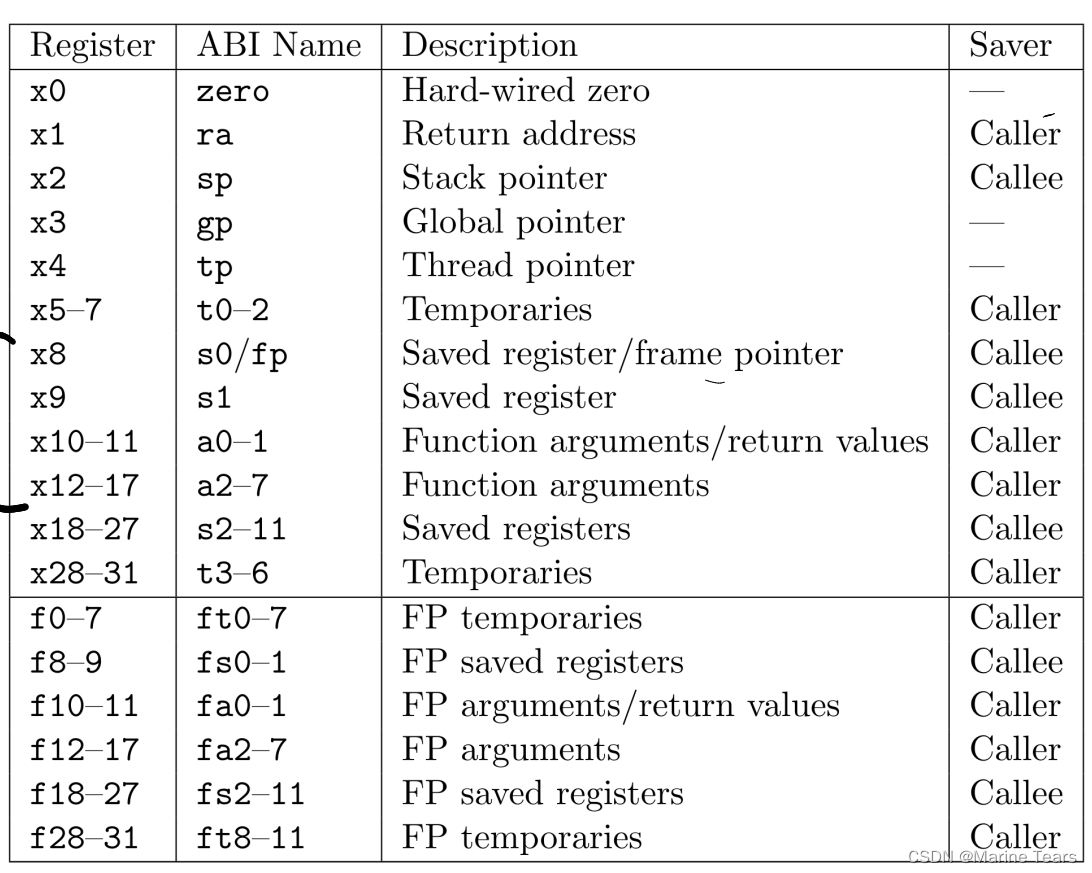
RISC-V常用汇编指令
RISC-V寄存器表: RISC-V和常用的x86汇编语言存在许多的不同之处,下面将列出其中部分指令作用: 指令语法描述addiaddi rd,rs1,imm将寄存器rs1的值与立即数imm相加并存入寄存器rdldld t0, 0(t1)将t1的值加上0,将这个值作为地址,取…...
第二篇:数据结构与算法-链表
概念 链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不必须相邻, 可以给每个元素附加一个指针域,指向下一个元素的存储位 置。 每个结点包含两个域:数据域和指针域,指针域存储下一个结点的地址&…...

低代码配置-小程序配置
数据结构 {"data": {"layout": {"api":{"pageApi":{//api详情}},"config":{"title":"页面标题",},"listLayout": {"fields": [{"componentCode": "grid…...

第十八讲_HarmonyOS应用开发实战(实现电商首页)
HarmonyOS应用开发实战(实现电商首页) 1. 项目涉及知识点罗列2. 项目目录结构介绍3. 最终的效果图4. 部分源码展示 1. 项目涉及知识点罗列 掌握HUAWEI DevEco Studio开发工具掌握创建HarmonyOS应用工程掌握ArkUI自定义组件掌握Entry、Component、Builde…...

OJAC近屿智能张立赛博士揭秘GPT Store:技术创新、商业模式与未来趋势
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 亲爱的伙伴们: 1月31日晚上8:30,由哈尔滨工业大学的…...

Java接收curl发出的中文请求无法解析
最近做项目遇到了这种情况,Java接收curl发出的中文请求无法解析,英文请求一切正常,中文请求则对方服务器无法解析,可以猜测是中文导致的编码问题,但是奇怪的是,本地输出json也没有乱码,编解码正…...

Java设计模式-外观模式(11)
大家好,我是馆长!今天开始我们讲的是结构型模式中的外观模式。老规矩,讲解之前再次熟悉下结构型模式包含:代理模式、适配器模式、桥接模式、装饰器模式、外观模式、享元模式、组合模式,共7种设计模式。。 外观模式(Decorator Pattern) 定义 外观(Facade)模式一种通…...
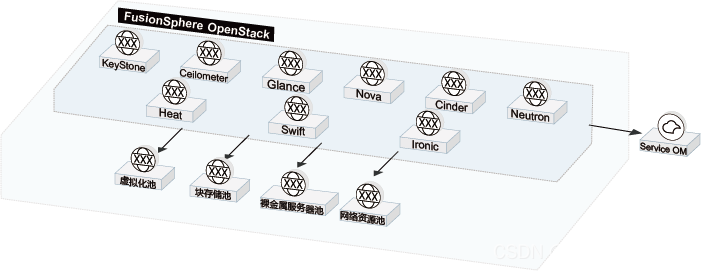
HCS-华为云Stack-FusionSphere
HCS-华为云Stack-FusionSphere FusionSphere是华为面向多行业客户推出的云操作系统解决方案。 FusionSphere基于开放的OpenStack架构,并针对企业云计算数据中心场景进行设计和优化,提供了强大的虚拟化功能和资源池管理能力、丰富的云基础服务组件和工具…...

C++类模板实现顺序表SeqList
main函数 #include<iostream> #include<stdlib.h> #include"SeqList.cpp"using namespace std;typedef int ElementType; int main(void) {SeqList< ElementType, 10> SeqList(1);cout << SeqList.ListLength() << endl;bool result;…...
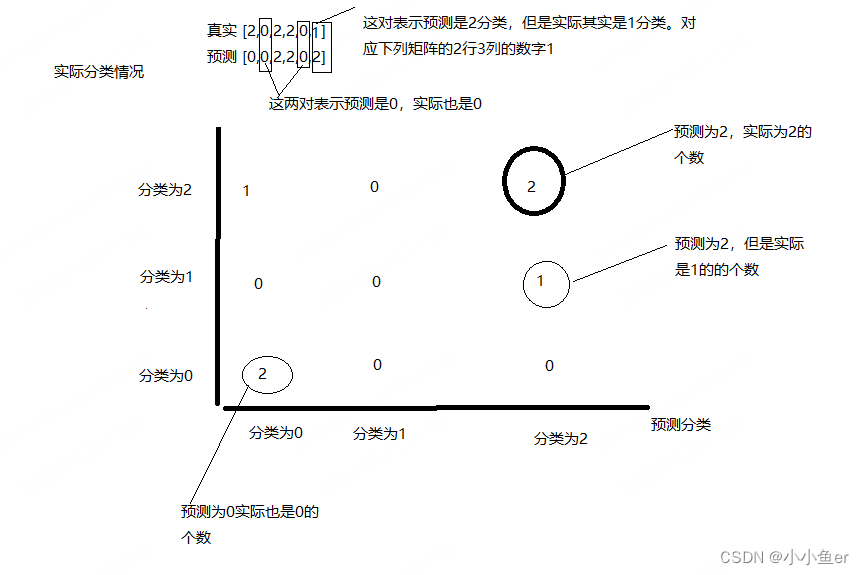
sklearn 学习-混淆矩阵 Confusion matrix
混淆矩阵Confusion matrix:也称为误差矩阵,通过计算得出矩阵的结果用来表示分类器的精度。其每一列代表预测值,每一行代表的是实际的类别。 from sklearn.metrics import confusion_matrixy_true [2, 0, 2, 2, 0, 1] y_pred [0, 0, 2, 2, 0…...
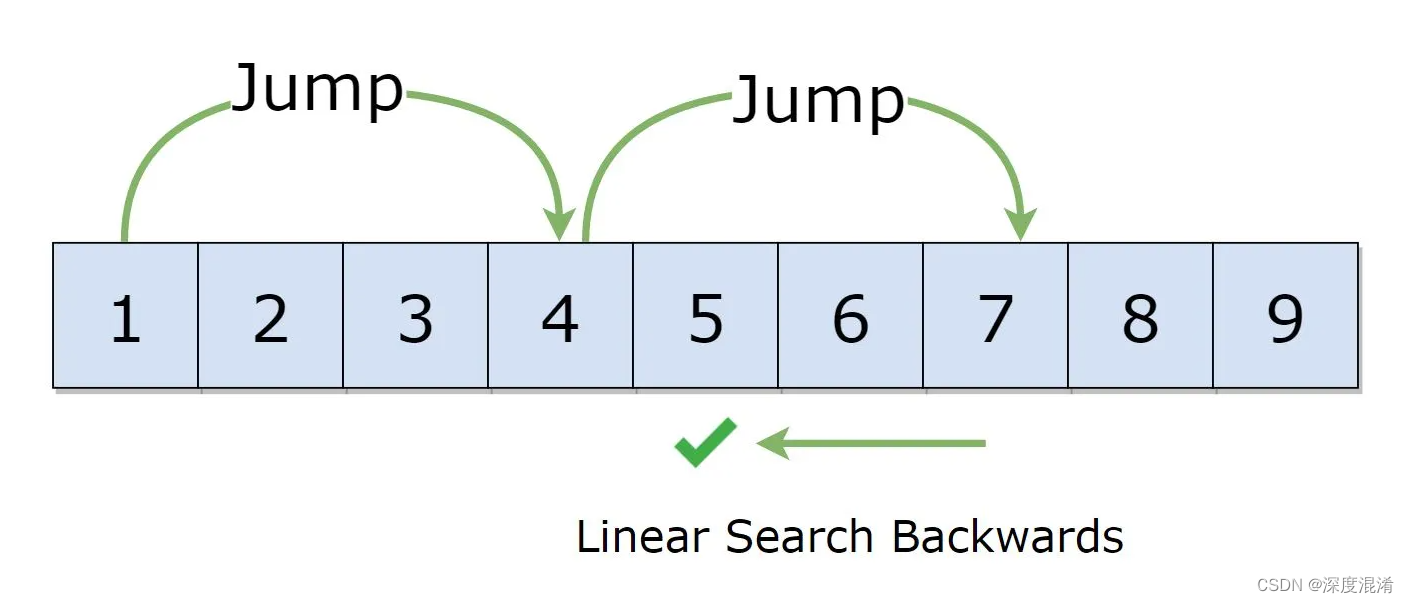
C#,数据检索算法之跳跃搜索(Jump Search)的源代码
数据检索算法是指从数据集合(数组、表、哈希表等)中检索指定的数据项。 数据检索算法是所有算法的基础算法之一。 本文提供跳跃搜索的源代码。 1 文本格式 using System; namespace Legalsoft.Truffer.Algorithm { public static class ArraySe…...
——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH)
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH-CSDN博客 1.SearchType ES的搜索类型 有一个类SearchType(如下图示),关于该类的描述: Search type repre…...
那些年与指针的爱恨情仇(一)---- 指针本质及其相关性质用法
关注小庄 顿顿解馋 (≧∇≦) 引言: 小伙伴们在学习c语言过程中是否因为指针而困扰,指针简直就像是小说女主,它逃咱追,我们插翅难飞…本篇文章让博主为你打理打理指针这个傲娇鬼吧~ 本节我们将认识到指针本质,何为指针和…...

微软DebugMCP:可视化调试MCP协议,解决AI与工具通信黑盒问题
1. 项目概述:当你的AI助手开始“自言自语”,你需要一个调试器 最近在折腾AI应用开发的朋友,估计没少跟各种“智能体”打交道。无论是基于OpenAI的GPTs,还是那些能联网、能调用工具的自定义助手,它们背后的核心通信协议…...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

Otter多模态大模型实战:从架构解析到部署应用的完整指南
1. 项目概述:当多模态大模型学会“看”与“说”最近在开源社区里,一个名为Otter的多模态大模型项目引起了我的注意。它来自EvolvingLMMs-Lab,这个实验室的名字就很有意思,“Evolving LMMs”—— 进化中的大型多模态模型。Otter 这…...

数据模型代码生成器:从OpenAPI/Schema自动生成Python类型安全模型
1. 项目概述:当数据模型遇上代码生成如果你经常和数据模型打交道,无论是OpenAPI规范、JSON Schema,还是数据库的DDL,那你一定体会过手动编写对应数据类(Data Class)或Pydantic模型的繁琐。一个字段类型写错…...

渠道输水控制系统模型在环测试【附仿真】
✨ 长期致力于渠道输水、水动力数值模拟、控制系统、模型在环测试、胶东调水工程研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)Preissmann四点隐式格…...

5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表
5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 还在为绘制复杂的UML图表而烦恼吗?你…...
)
紧急更新!Midjourney刚推送的--stylize 1000级调优补丁,已实测提升立体主义结构清晰度达4.8倍(附对比数据集下载)
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格的本质解构 立体主义并非简单地将物体“打碎再拼合”,而是一种对多维时空感知的视觉转译——Midjourney 通过其隐式扩散先验,以概率化方式重构了布拉克与…...