《动手学深度学习(PyTorch版)》笔记4.6
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。
Chapter4 Multilayer Perceptron
4.6 Dropout Regularization
4.6.1 Reexamine Overfitting
当面对更多的特征而样本不足时,线性模型往往会过拟合。相反,当给出更多样本而不是特征,通常线性模型不会过拟合。不幸的是,线性模型泛化的可靠性是有代价的,即线性模型没有考虑到特征之间的交互作用。对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。
泛化性和灵活性之间的这种基本权衡被描述为偏差-方差权衡(bias-variance tradeoff)。线性模型有很高的偏差,然而,这些模型的方差很低,即它们在不同的随机数据样本上可以得出相似的结果。
深度神经网络位于偏差-方差谱的另一端。与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互。例如,神经网络可能推断“尼日利亚”和“西联汇款”一起出现在电子邮件中表示垃圾邮件,但单独出现则不表示垃圾邮件。
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。本节中,我们将探究改进深层网络的泛化性的工具。
4.6.2 Robustness of Disturbances
经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。简单性以较小维度的形式展现,参数的范数也代表了一种有用的简单性度量。简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的。
在训练过程中,我们可以在计算后续层之前向网络的每一层注入噪声。因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。这个想法被称为暂退法(dropout)。暂退法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。这种方法之所以被称为暂退法,因为我们从表面上看是在训练过程中丢弃一些神经元。在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
关键的挑战是如何注入这种噪声。一种想法是以一种无偏向(unbiased)的方式注入噪声。这样在固定住其他层时,每一层的期望值等于没有噪音时的值。我们可以在每次训练迭代中,从均值为零的分布 ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim \mathcal{N}(0,\sigma^2) ϵ∼N(0,σ2)采样噪声添加到输入 x \mathbf{x} x,从而产生扰动点 x ′ = x + ϵ \mathbf{x}' = \mathbf{x} + \epsilon x′=x+ϵ,预期是 E [ x ′ ] = x E[\mathbf{x}'] = \mathbf{x} E[x′]=x。
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差,如下所示:
h ′ = { 0 概率为 p h 1 − p 其他情况 \begin{aligned} h' = \begin{cases} 0 & \text{ 概率为 } p \\ \frac{h}{1-p} & \text{ 其他情况} \end{cases} \end{aligned} h′={01−ph 概率为 p 其他情况
根据此模型的设计,其期望值保持不变,即 E [ h ′ ] = h E[h'] = h E[h′]=h。
4.6.3 Implementation
当我们将暂退法应用到隐藏层,以 p p p的概率将隐藏单元置为零时,结果可以看作一个只包含原始神经元子集的网络。比如在下图中,删除了 h 2 h_2 h2和 h 5 h_5 h5,因此输出的计算不再依赖于 h 2 h_2 h2或 h 5 h_5 h5,并且它们各自的梯度在执行反向传播时也会消失。这样,输出层的计算不会过度依赖于 h 1 , … , h 5 h_1, \ldots, h_5 h1,…,h5的任何一个元素。

通常,我们在测试时不用暂退法,然而也有一些例外,比如一些研究人员在测试时使用暂退法,用于估计神经网络预测的“不确定性”:如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt#以dropout的概率丢弃X中的元素
def dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return X#从均匀分布$U[0, 1]$中抽取样本,使得样本和节点一一对应,然后保留那些对应样本大于p的节点mask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)#X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
#print(X)
#print(dropout_layer(X, 0.))
#print(dropout_layer(X, 0.5))
#print(dropout_layer(X, 1.))#定义模型
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5#常见的技巧是在靠近输入层的地方设置较低的暂退概率class Net(nn.Module):#indicates that Net is inheriting from the nn.Module classdef __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)#训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
plt.show()#简洁实现
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)#训练和测试
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
plt.show()
相关文章:
《动手学深度学习(PyTorch版)》笔记4.6
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过。…...

Hadoop-MapReduce-源码跟读-客户端篇
一、源码下载 下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧 Index of /dist/hadoop/core 二、从WordCount进入源码 用idea将源码加载进来后,找到org.apache.hadoop.examples.WordCount类(快捷方法&…...
《游戏-03_3D-开发》之—新输入系统人物移动攻击连击
本次修改unity的新输入输出系统。本次修改unity需要重启,请先保存项目, 点击加号起名为MyCtrl, 点击加号设置为一轴的, 继续设置W键, 保存 生成自动脚本, 修改MyPlayer代码: using UnityEngine;…...
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编
滴水逆向三期笔记与作业——02C语言——10 Switch语句反汇编 一、Switch语句1、switch语句 是if语句的简写2、break加与不加有什么特点?default语句可以省略吗?3、游戏中的switch语句(示例)4、添加case后面的值,一个一个增加&…...
燃烧的指针(三)
🌈个人主页:小田爱学编程 🔥 系列专栏:c语言从基础到进阶 🏆🏆关注博主,随时获取更多关于c语言的优质内容!🏆🏆 😀欢迎来到小田代码世界~ &#x…...

微服务架构实施攻略:如何选择合适的微服务通信机制?
随着业务的快速发展和系统的日益复杂,传统的单体应用逐渐显露出瓶颈,已无法满足现代软件研发的需求。微服务架构作为一种灵活、可扩展的解决方案,通过将复杂系统拆分为一系列小型服务来提高系统的可伸缩性、灵活性和可维护性。在实施微服务架…...
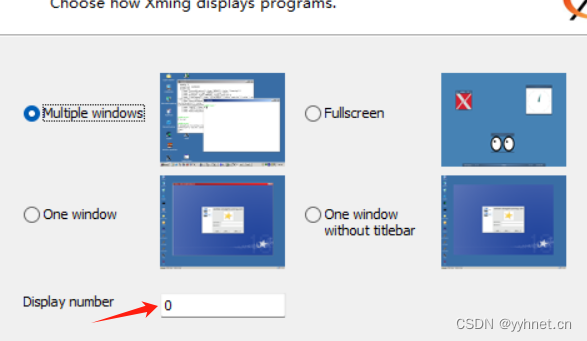
【jetson笔记】解决vscode远程调试qt.qpa.xcb: could not connect to display报错
配置x11转发 jetson远程安装x11转发 安装Xming Xming下载 安装完成后打开安装目录C:\Program Files (x86)\Xming 用记事本打开X0.hosts文件,添加jetson IP地址 后续IP改变需要重新修改配置文件 localhost 192.168.107.57打开Xlaunch Win菜单搜索Xlaundch打开 一…...

网络安全产品之认识安全隔离网闸
文章目录 一、什么是安全隔离网闸二、安全隔离网闸的主要功能三、安全隔离网闸的工作原理四、安全隔离网闸的分类五、安全隔离网闸与防火墙的区别四、安全隔离网闸的应用场景 随着互联网的发展,网络攻击和病毒传播的方式越来越复杂,对网络安全的要求也越…...
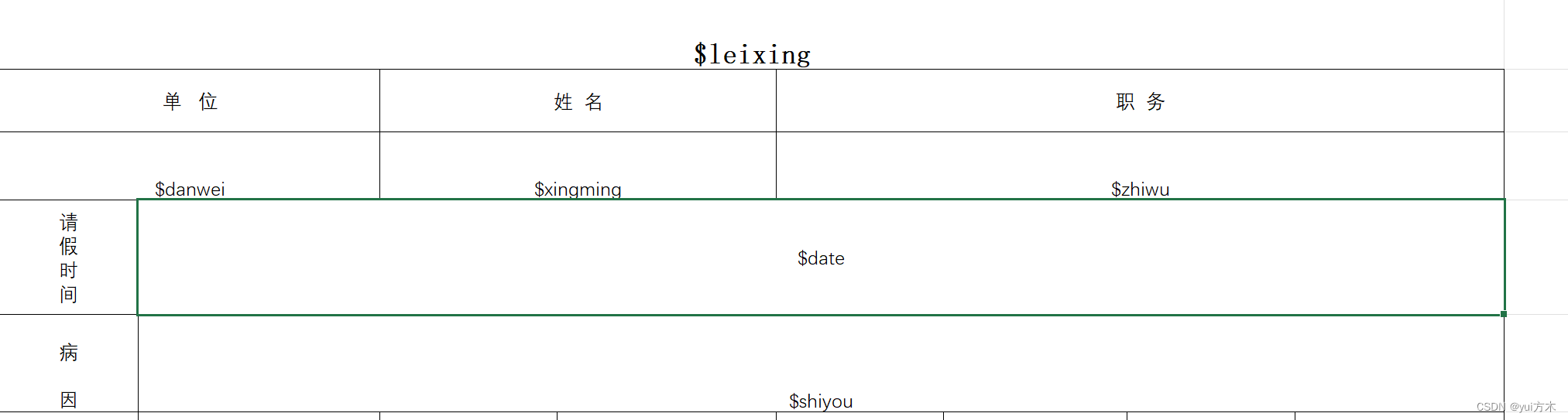
Java通过模板替换实现excel的传参填写
以模板为例子 将上面$转义的内容替换即可 package com.gxuwz.zjh.util;import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook; import java.io.*; import java.util.HashMap; import java.util.Map; import java.io.IOException; impor…...
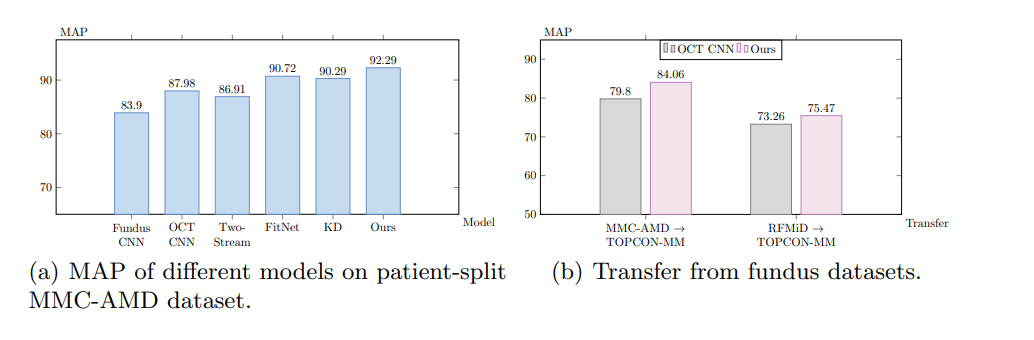
眼底增强型疾病感知蒸馏模型 FDDM:无需配对,fundus 指导 OCT 分类
眼底增强型疾病感知蒸馏模型 FDDM:fundus 指导 OCT 分类 核心思想设计思路训练和推理 效果总结子问题: 疾病特定特征的提取与蒸馏子问题: 类间关系的理解与建模 核心思想 论文:https://arxiv.org/pdf/2308.00291.pdf 代码:https://github.c…...
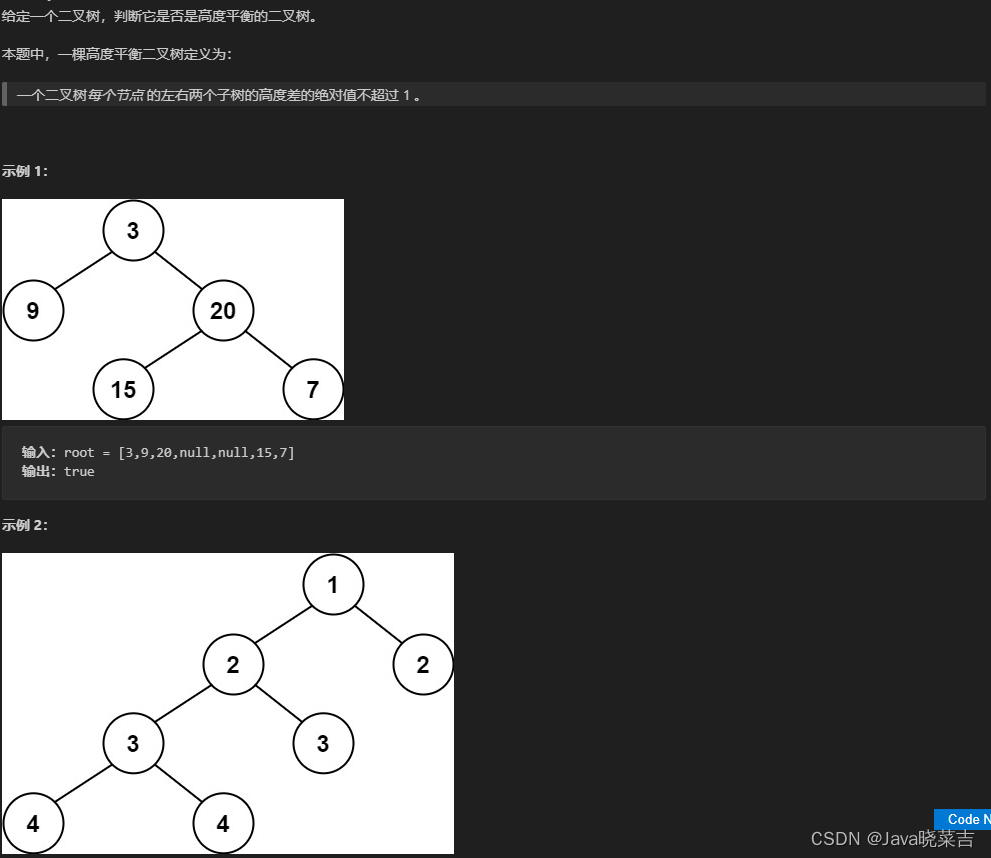
代码随想录算法刷题训练营day17
代码随想录算法刷题训练营day17:LeetCode(110)平衡二叉树 LeetCode(110)平衡二叉树 题目 代码 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(…...

Java集合如何选择
为什么使用集合 当需要存储一组类型相同的数据时,数组是最常用且最基本的容器之一。但是,使用数组存储对象存在一些不足之处,因为在实际开发中,存储的数据类型多种多样且数量不确定。这时,Java 集合就派上用场了。与数…...
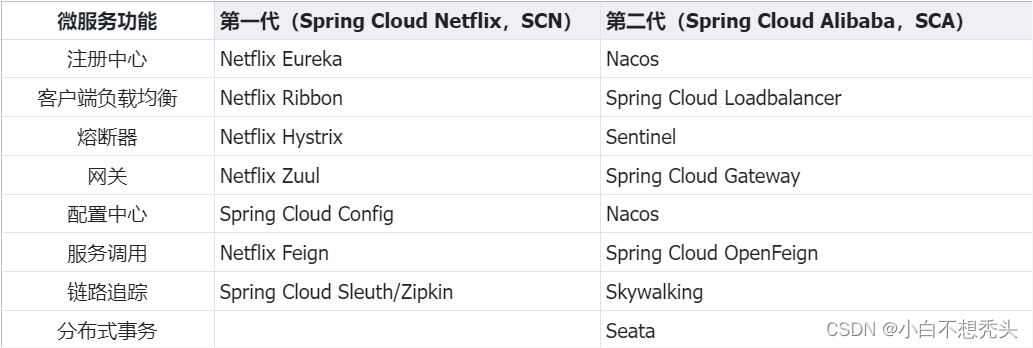
简单介绍----微服务和Spring Cloud
微服务和SpringCloud 1.什么是微服务? 微服务是将一个大型的、单一的应用程序拆分成多个小型服务,每个服务负责实现特定的业务功能,并且可以通过网络通信与其他服务通信。微服务的优点是开发更灵活(不同的微服务可以使用不同的开…...

Jenkins邮件推送配置
目录 涉及Jenkins插件: 邮箱配置 什么是授权码 在第三方客户端/服务怎么设置 IMAP/SMTP 设置方法 POP3/SMTP 设置方法 获取授权码: Jenkins配置 从Jenkins主面板System configuration>System进入邮箱配置 在Email Extension Plugin 邮箱插件…...

硬件知识(1) 手机的长焦镜头
#灵感# 手机总是配备好几个镜头,研究一下 目录 手机常配备的摄像头,及效果举例 长焦的焦距 焦距的定义和示图: IPC的焦距和适用场景: 手机常配备的摄像头,及效果举例 以下是小米某个手机的摄像头介绍:…...

华为机考入门python3--(3)牛客3-明明的随机数
分类:集合、排序 知识点: 集合添加元素 set.add(element) 集合转列表 list(set) 列表排序 list.sort() 题目来自【牛客】 N int(input().strip()) nums set()for i in range(N):nums.add(int(input().strip()))# 集合转列表 nums_list l…...

vue父子组件传值问题
在Vue中,父子组件之间的数据传递可以通过props和事件来实现。 使用props传递数据:父组件可以通过props将数据传递给子组件,子组件可以在模板中直接使用这些数据。父组件可以通过v-bind指令将数据绑定到子组件的props上。例如: v…...

Rider 打开Unity项目 Project 全部显示 load failed
电脑自动更新,导致系统重启,第二天Rider打开Unity 工程,没有任何代码提示,字符串查找也失效。 现象: 1.所有的Project均显示laod failed。点击load failed。右侧信息显示Can not start process 2.选中解决方案进行Bui…...
:依赖管理、依赖传递、依赖冲突、工程继承及工程聚合)
Maven(下):依赖管理、依赖传递、依赖冲突、工程继承及工程聚合
1. 基于IDEA 进行Maven依赖管理 1.1 依赖管理概念 Maven 依赖管理是 Maven 软件中最重要的功能之一。Maven 的依赖管理能够帮助开发人员自动解决软件包依赖问题,使得开发人员能够轻松地将其他开发人员开发的模块或第三方框架集成到自己的应用程序或模块中…...

网络基础---初识网络
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、局域网…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...

Akebi-GC游戏辅助工具:免费开源的游戏体验增强终极指南
Akebi-GC游戏辅助工具:免费开源的游戏体验增强终极指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款开源免费的游戏…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

从肌电信号到Arduino控制:MyoWare传感器实战指南
1. 项目概述:当肌肉“说话”,我们如何“倾听”?如果你玩过一些体感游戏,或者看过科幻电影里用意念控制机械臂的场景,心里大概会闪过一个念头:这玩意儿到底是怎么做到的?其实,很多酷炫…...

小红书自动化工具xhs-skill:接口逆向与数据采集实战指南
1. 项目概述:一个面向小红书内容创作的效率工具箱最近在逛GitHub的时候,发现了一个挺有意思的项目,叫PengJiyuan/xhs-skill。光看名字,你大概能猜到它和小红书有关,但具体是做什么的,可能有点模糊。作为一个…...

动态目标跨镜无缝接力追踪技术白皮书
一、前言在全域视觉监控、智能安防、智慧园区、交通管控、工业巡检等核心场景中,动态目标(人员、车辆、设备等)的跨摄像头连续追踪是实现智能化管理的核心需求。当前行业常规追踪方案普遍存在轨迹断点、坐标漂移、身份错乱等痛点,…...

基于Blazor与LLamaSharp构建本地大模型ChatGPT式Web应用
1. 项目概述与核心价值最近在折腾一个内部工具,想把本地大模型的能力和类似ChatGPT的对话体验结合起来,部署成一个Web应用。找了一圈,发现一个挺有意思的项目叫“BLlamaSharp.ChatGpt.Blazor”。光看这个名字,信息量就很大了&…...