MQ面试题之Kafka
前言
前文介绍了消息队列相关知识,并未针对某个具体的产品,所以略显抽象。本人毕业到现在使用的都是公司内部产品,对于通用产品无实际经验,但是各种消息中间件大差不差,故而本次选择一个相对较熟悉的Kafka进行详细介绍。
MQ面试题之Kafka
1. kafka架构

只需深入理解上图即可清楚Kafka的工作流程。
- 描述一下Kafka是什么,以及它的主要特点是什么?
Kafka是由Apache软件基金会开发的一个开源流处理平台,主要用于构建实时数据管道和流应用程序。它是一个高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。Kafka的主要特点包括:
高吞吐量:Kafka可以处理数百万的消息,每秒处理数以亿计的事件。
可持久化:Kafka将消息持久化到磁盘,这样即使消费者离线,也可以继续消费消息。
分布式系统:Kafka是分布式的,可以在多个服务器上运行,这样可以提高系统的可用性和扩展性。
实时性:Kafka可以在毫秒级别处理消息,满足实时数据处理的需求。
容错性:Kafka集群可以容忍节点的故障,如果一个节点出现故障,其他节点可以继续工作。
Kafka广泛应用于各种场景,如日志收集、消息传递、流数据处理等。它可以作为数据流平台,将数据从一个系统传输到另一个系统,并在传输过程中进行实时处理。此外,Kafka还可以与Hadoop等离线数据处理系统集成,提供实时的数据管道。
3. Kafka如何实现数据的高效读取?
Kafka通过以下几种方式实现数据的高效读取:
顺序写磁盘:Kafka的生产者将数据写入到log文件中时,采用顺序写的方式,即一直追加到文件末端,这充分利用了磁盘的顺序读写性能。由于磁盘的机械机构特性,顺序写的速度远高于随机写,因此在读写磁盘时能显著提高性能。
零拷贝技术:Kafka实现了零拷贝技术,直接在操作系统层面完成文件的操作,避免了在应用层进行数据的复制和拷贝,减少了CPU和内存的使用,提高了数据读取的效率。
分段日志+索引文件:Kafka将topic中的大文件分成多个小文件段,每个文件段对应一个小的索引文件。通过索引信息,可以快速定位message和确定response的最大大小。这样可以提高读取操作的效率和响应速度。
Pagecache(页面缓存):Kafka将数据持久化到Pagecache中,这样在读取数据时可以直接在内存中进行,避免了磁盘I/O操作,提高了读取效率。同时,Kafka会尽量利用所有空闲内存(非JVM内存),避免GC负担。
综上所述,Kafka通过多种方式实现了数据的高效读取,包括顺序写磁盘、零拷贝技术、分段日志+索引文件和Pagecache等。这些技术能够提高数据的读写速度和效率,满足了大规模数据处理和高并发访问的需求。
- Kafka中的ack机制有哪些级别,它们分别代表什么?
Kafka中的ack机制是用于确认消息已经被成功接收和处理的机制。以下是Kafka中的三种ack级别:
ack=0:这是最低级别的确认,代表生产者在发送消息后不需要等待来自服务器的任何确认。这意味着生产者无法知道消息是否成功存储在Kafka集群中,因此可靠性最低,但在处理大量数据时能提供最高的吞吐量。
ack=1:生产者会等待直到消息的领导者副本(Leader Replica)确认接收到消息。一旦领导者副本存储了消息,生产者会收到一个确认。这个级别在性能和数据可靠性之间提供了一个平衡,但如果领导者副本在确认后发生故障,而消息还未复制到追随者副本(Follower Replicas),则消息可能会丢失。
ack=-1(或all):生产者等待领导者副本和所有追随者副本都存储了消息后才进行确认。这种模式下,数据可靠性最高,但效率最低。如果存在追随者副本故障的情况,可能会造成数据重复。
- 解释Kafka中的偏移量概念,以及它的重要性是什么?
Kafka中的偏移量是用于标识每条消息在分区中的位置的数字。每个消息都有一个唯一的偏移量,由Kafka分配,并在分区中递增。偏移量可以用于回溯分区中的消息,也可以用于跟踪已经消费的消息。
偏移量的重要性主要体现在以下几个方面:
保证消息可靠性:Kafka通过保证消息的有序性来确保消息的可靠性,而偏移量是衡量消息有序性的重要指标。通过偏移量,Kafka能够追踪每条消息的位置,确保消息的可靠传输和正确处理。
避免消息重复消费:在消费消息时,如果偏移量设置不当,可能导致消费者重复消费同一消息。通过合理设置偏移量,可以有效避免这种情况的发生,确保每条消息只被消费一次。
实现消息的Exactly-Once语义:在某些场景下,需要确保消息只被处理一次,即Exactly-Once语义。通过偏移量,Kafka能够提供这种语义保证,确保每条消息在处理过程中只被处理一次。
追踪和监控:偏移量可以用于追踪和监控消费者进度,以及检查是否有缺失的消息。通过获取当前消费的偏移量,可以了解消费者所在的位置和进度,便于监控和管理。
容错机制:Kafka中的偏移量还可以作为实现消费者的容错机制的重要依据。当消费者发生故障时,可以从偏移量中恢复消费者的位置,继续从上次消费的位置开始消费,避免了数据的丢失或重复。
综上所述,Kafka中的偏移量是实现消息可靠传输和处理的关键因素,对于保证消息的有序性、避免消息重复、实现Exactly-Once语义、监控和追踪以及容错机制等方面都具有重要的作用。
- Kafka如何保证消息的顺序性?
Kafka通过以下两种方式来保证消息的顺序性:
单分区有序:Kafka只保证单partition有序,即生产者发送到同一个partition的所有消息都按照发送的顺序进行存储和消费。这样可以确保在单partition内部,消息是有序的。
全局顺序:如果需要全局顺序,即所有消息按照发送的顺序被消费,可以设置topic只有一个partition。这样,无论哪个生产者发送消息,都只能发送到这一个partition中,从而保证了全局顺序。
在Kafka中,消费者按照其拉取消息的顺序来消费消息。消费者从broker拉取数据时,会按照broker中的存储顺序拉取数据。如果消费者按照相同的消费速度进行消费,那么拉取的顺序就是消费的顺序。这就保证了Kafka可以按照发送的顺序消费消息。
然而,如果Kafka需要保证多分区消息的全局顺序,就可能会出现问题。因为如果一个生产者同时向多个partition发送消息,由于网络延迟或者硬件性能的问题,可能会导致不同partition的消息接收时间不同,从而影响全局顺序。在这种情况下,可以使用一些编程技巧或者调整Kafka的配置参数来尽量保证全局顺序,但是不能完全保证。
- Kafka的数据持久性如何?
Kafka的数据持久性非常高,主要体现在以下几个方面:
数据持久化到磁盘:Kafka将数据持久化到磁盘上,而不是仅仅保存在内存中。这样即使在服务器突然断电或宕机的情况下,数据也不会丢失。Kafka使用了一种叫做“日志文件”的方式来进行数据存储,这种方式能够保证数据的可靠性和持久性。
消息持久化:Kafka的消息在发送之后会被持久化到磁盘上,保证了消息的可靠传输和持久化存储。Kafka通过将数据追加到日志文件中,实现了高效的顺序写磁盘,从而提高了数据持久化的速度和效率。
高可靠性:Kafka通过副本机制和分布式架构的设计,保证了数据的高可靠性。每个分区都有多个副本,主副本负责写操作,而其他副本作为备份。这样即使主副本出现问题,也可以从其他副本中恢复数据。
监控和日志记录:Kafka提供了完善的监控和日志记录功能,能够实时监控系统的运行状态和数据的流动情况。通过查看日志和监控数据,可以及时发现和解决潜在的问题,进一步保证了数据的持久性和可靠性。
综上所述,Kafka的数据持久性非常高,通过持久化到磁盘、消息持久化、高可靠性和监控日志记录等方式,保证了数据的可靠传输和持久化存储。这些特性使得Kafka在实时数据处理、日志收集、消息队列等领域得到了广泛应用。
- 如何在Kafka中配置和调整消费者的行为?
使用auto.offset.reset配置来重置消费者的偏移量。主要有三种策略:latest,从最大位点开始消费;earliest,从最小位点开始消费;none,不做任何操作,也即不重置。
调整消费者的session.timeout.ms和heartbeat.interval.ms配置。session.timeout.ms是消费者超时时间,默认是10秒。超过这个时间,Kafka会认为消费者挂掉了,并重新进行均衡。heartbeat.interval.ms是心跳监测时间,默认值是3秒。消费者每3秒发送一次心跳给协调者。
调整消费者的批量消费配置。可以通过设置ConcurrentKafkaListenerContainerFactory.setBatchListener(true)开启批量消费,并配置批量消费数ConsumerFactory.MAX_POLL_RECORDS_CONFIG = 100,默认为500。
调整消费者的线程池配置。消费者使用线程池进行批量消费数据,可以调整线程池大小来优化性能。
调整消费者的拉取大消息的配置。在拉取大消息时,需要注意控制拉取速度,修改配置:max.poll.records,默认值:500。如果单条消息超过1 MB,建议设置为1。
- Kafka的适用场景是什么?
日志收集:Kafka可以作为一个高效的日志收集器,收集分布在不同服务器上的大量日志数据,供后续分析和处理。
实时流处理:Kafka可以将实时流数据存储在队列中,供实时流处理框架(如Storm、Spark Streaming、Flink等)进行处理,支持数据实时处理和分析。
消息系统:Kafka可以作为消息系统使用,提供可靠的消息传输和处理,用于实现异步通信和解耦应用程序的组件。它比其他传统的消息系统有更好的吞吐量,内置分区、副本和故障转移等功能,可以处理大规模的消息。
网站活动跟踪:Kafka可以用于跟踪网站上的活动,如用户浏览、点击、搜索等,进行实时的统计和分析。
数据管道:Kafka可以用于搭建数据管道,将数据从不同的数据源(如数据库、文件系统等)传输到不同的数据目的地(如Hadoop、Elasticsearch等)。
分布式应用程序:Kafka可以用于分布式应用程序之间的数据通信,实现不同节点之间的数据共享和协作。
此外,Kafka还适用于需要异步处理、流量削峰等场景。例如,在处理订单状态时,如果后一个流程需要等待前一个流程执行完成后才能执行,可以使用Kafka将业务流程变成异步的,提高效率。在流量削峰方面,Kafka可以控制客户端的流量,避免后端服务崩溃,保证服务的稳定性。
综上所述,Kafka适用于多种场景,特别是需要处理大规模数据、实时处理和分析、可靠消息传输和分布式处理等场景。
- 如何理解Kafka的分区和副本机制?
Kafka的分区和副本机制是其高可靠性和高吞吐量的重要保障。
分区是Kafka主题的一部分,它将主题中的数据分割为多个有序的、独立的片段,每个分区都有一个唯一的偏移量,通过这个偏移量,消费者可以按顺序读取和访问消息。分区可以提高数据的并行处理能力,因为可以同时在多个分区上处理数据。
Kafka的副本机制是为了实现数据的高可用性。每个分区都有多个副本,其中一个副本是主副本,其他副本是从副本。主副本负责接收所有的写入请求,并将数据同步复制到所有的从副本中。当主副本发生故障时,Kafka会自动从副本中选择一个新的主副本,以保证数据的可靠性和可用性。这种机制能够提高系统的容错能力,当某个Broker上的分区数据丢失时,仍然可以从其他Broker上的副本中获取数据。
总的来说,Kafka的分区和副本机制是其作为分布式流处理平台的重要特性,能够保证数据的可靠性和可用性,同时提高系统的吞吐量和处理能力。
- Kafka如何处理重复消费和数据丢失的问题?
消费者偏移量管理:Kafka维护了每个消费者在每个分区中消费的偏移量信息。消费者可以在消费消息后提交偏移量,表示已经成功处理了该消息。当消费者重新启动或发生故障时,可以使用已提交的偏移量来从上次消费的位置继续消费,避免重复消费。
幂等性处理:应用程序的消费逻辑可以设计为幂等的,即使消息被重复消费,也不会导致副作用。通过在应用程序逻辑中实现幂等性,即使消息重复消费,也不会产生错误结果。
消息去重技术:可以通过在应用程序中维护一个已处理消息的记录或使用外部存储(如数据库)来实现消息的去重。
唯一标识符:在每条消息中添加一个唯一标识符,并在应用程序中记录已经处理的标识符。
幂等性生产者:在消息的生产端实现幂等性,确保相同的消息重复发送时不会引起重复消费。
设置副本因子:副本因子是用于设置每个分区存储的副本数量。副本因子的值至少应该大于1,以保证数据的安全性。
配置参数设置:通过合理设置一些参数,如log.flush.interval.messages和log.flush.interval.ms,可以控制数据写入磁盘的时间间隔,从而避免数据丢失。
断电或机器故障时的处理:当Kafka的数据一开始就存储在PageCache上时,定期flush到磁盘上。如果出现断电或机器故障等,PageCache上的数据会丢失。可以通过配置参数log.flush.interval.messages和log.flush.interval.ms来控制flush间隔,但并不能完全避免数据丢失。
- 你如何理解Kafka的消费者组?在实际项目中是如何使用它的?
Kafka的消费者组是其提供的一种消费者机制,用于实现消息的并行处理和负载均衡。在消费者组中,可以有多个消费者实例,它们共享一个公共的ID即Group ID,并协调消费订阅主题的所有分区。每个分区只能由同一个消费者组中的一个Consumer实例来消费,保证了消息的单播。
在实际项目中,使用Kafka的消费者组可以实现以下功能:
并行处理:消费者组可以将消息分散到多个实例上进行并行处理,提高了处理速度和吞吐量。
负载均衡:通过将消息分配给多个实例进行消费,消费者组可以实现负载均衡,避免某个实例成为瓶颈。
容错处理:当某个实例发生故障时,消费者组会自动将其从消费组中剔除,并将该实例消费的分区分配给其他实例,保证了系统的可用性和可靠性。
消息一致性:通过使用Kafka的幂等性和事务机制,可以实现消息的一致性消费和处理。
在具体使用时,需要考虑以下几个方面:
确定合适的消费者数量:根据业务需求和资源情况,合理配置消费者数量,避免过多的消费者导致资源浪费或过少的消费者导致处理速度受限。
选择合适的负载均衡策略:根据业务需求和数据分布情况,选择合适的负载均衡策略,如轮询、随机等。
处理消费者的异常情况:在实际应用中,需要考虑到消费者的异常情况,如进程崩溃、网络故障等,并采取相应的措施进行容错处理。
监控和日志记录:对消费者组进行实时监控和日志记录,以便及时发现和处理问题。
综上所述,Kafka的消费者组是一种强大的机制,可以实现消息的并行处理、负载均衡、容错处理和消息一致性等功能。在实际项目中,需要根据业务需求和资源情况合理使用消费者组,以实现最佳的性能和可靠性。
- 在设计Kafka集群时需要考虑哪些因素?
硬件配置:包括服务器的CPU、内存、磁盘和网络等硬件配置。需要根据业务需求和数据规模来合理配置硬件资源,保证Kafka集群的性能和稳定性。
操作系统:Kafka可以在不同的操作系统上运行,如Linux、Windows等。选择合适的操作系统可以提高Kafka的性能和稳定性,同时需要考虑到操作系统的维护和管理的便利性。
网络架构:Kafka集群的网络架构包括网络拓扑结构、网络带宽、网络延迟等。需要考虑如何合理地设计网络架构,以保证Kafka集群的性能和稳定性。
数据存储:Kafka将数据存储在磁盘上,需要考虑如何合理地设计数据存储方案,以保证数据的可靠性和性能。
副本机制:Kafka提供了副本机制来保证数据的可靠性和可用性。需要考虑如何合理地设计副本方案,以保证数据的可靠性和性能。
监控和日志记录:需要考虑如何对Kafka集群进行实时监控和日志记录,以便及时发现和处理问题。
安全性:需要考虑如何保证Kafka集群的安全性,如数据加密、身份认证等。
扩展性:需要考虑如何保证Kafka集群的扩展性,以便在业务规模增长时能够快速地扩展集群规模。
- Kafka的性能优化有哪些方法?
调整Kafka Broker配置:根据实际业务需求和硬件配置,合理调整Kafka Broker的配置参数,如num.partitions、num.consumer-fetchers、replica.fetch.max.bytes等,可以提高Kafka的性能和吞吐量。
优化生产者和消费者代码:通过优化生产者和消费者的代码,可以减少不必要的处理和网络传输,提高Kafka的性能和吞吐量。例如,使用批量发送、减少序列化开销、使用压缩等。
选择合适的压缩算法:Kafka支持多种压缩算法,如Snappy、LZ4、GZIP等。根据实际业务需求和数据规模,选择合适的压缩算法可以提高Kafka的性能和压缩效率。
使用快速存储器:Kafka的数据存储在磁盘上,使用快速存储器可以提高数据读写的速度,从而提高Kafka的性能和吞吐量。
优化网络配置:网络延迟和带宽是影响Kafka性能的重要因素。通过优化网络配置,如调整Kafka Broker的网络缓冲区大小、减少网络延迟等,可以提高Kafka的性能和吞吐量。
分区策略优化:在设计Kafka主题时,需要考虑分区策略。合理的分区策略可以提高Kafka的性能和吞吐量。例如,根据业务需求将数据分散到多个分区中,避免某个分区过大或过小等情况。
使用合适的消费者模型:Kafka提供了多种消费者模型,如Simple Consumer、Consumer Groups等。根据实际业务需求和数据规模,选择合适的消费者模型可以提高Kafka的性能和可靠性。
监控和日志记录:通过实时监控Kafka集群的状态和日志信息,可以及时发现和解决性能瓶颈和问题。同时,定期进行性能测试和负载压力测试,可以帮助发现潜在的性能问题。
综上所述,Kafka的性能优化可以从多个方面入手,包括调整配置参数、优化生产者和消费者代码、选择合适的压缩算法、使用快速存储器、优化网络配置、分区策略优化、使用合适的消费者模型以及监控和日志记录等。需要根据实际业务需求和数据规模进行合理的优化,以提高Kafka的性能和可靠性。
15. kafka数据存储

认真理解上图即可。
相关文章:
MQ面试题之Kafka
前言 前文介绍了消息队列相关知识,并未针对某个具体的产品,所以略显抽象。本人毕业到现在使用的都是公司内部产品,对于通用产品无实际经验,但是各种消息中间件大差不差,故而本次选择一个相对较熟悉的Kafka进行详细介绍…...
2023年CSDN年底总结-独立开源创作者第一年
2023年最大的变化,就是出来创业,当独立开源创作者,这一年发起SolidUI开源项目,把知乎重新开始运营起来。CSDN粉丝破万,CSDN博客专家和AI领域创作者。 2023年年度关键词:创业 https://github.com/CloudOrc…...

hardware simulation——编译框架优化
目录 介绍 修改前的最新代码和框架 学习和修改 最终版本 介绍 -------------------------------------------------------------------------------------------------------------------------- https://www.cnblogs.com/wittxie/p/9836097.html 上次那个虽然能完成基本…...
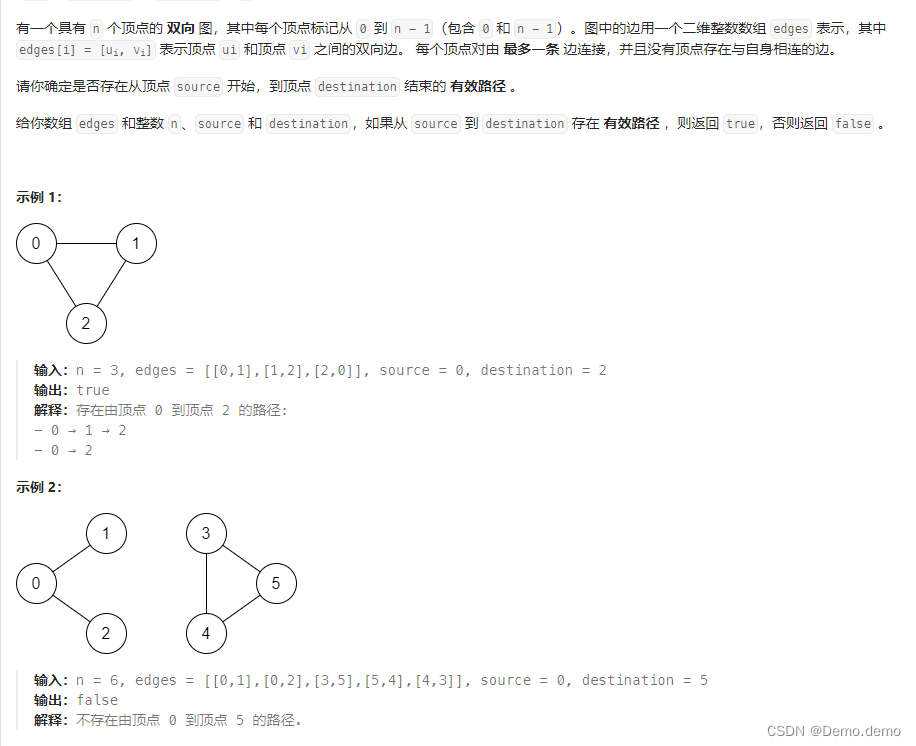
Leetcode刷题笔记题解(C++):1971. 寻找图中是否存在路径
思路: 1.建立图集,二维数组,path[0]里面存放的就是与0相连的节点集合 2.用布尔数组来记录当前节点是否被访问过,深度优先会使用到 3.遍历从起点开始能直接到达的点(即与起点相邻的点),判断那…...

ARM常用汇编指令
文章目录 前言一、处理器内部数据传输指令MOV: 将数据从一个寄存器复制到另一个寄存器。MRS: 将特殊寄存器(CPSR,SPSR)中的数据传给通用寄存器。MSR: 将通用寄存器中的数据传给特殊寄存器(CPSR,SPSR)。 二、存储器访问指令LDR:用于从内存中加…...

kali系统入侵电脑windows(win11系统)渗透测试,骇入电脑教学
本次渗透测试将使用kali虚拟机(攻击机)对本机(靶机)进行入侵并监控屏幕 声明:本篇仅仅是将本机作为靶机的一次简易渗透测试,实际情况中基本不可能出现如此简单的木马骇入(往往在上传木马时就被防…...

力扣hot100 矩阵置零 标识位
Problem: 73. 矩阵置零 文章目录 思路复杂度Code 思路 👨🏫 参考 复杂度 时间复杂度: O ( n m ) O(nm) O(nm) 空间复杂度: O ( 1 ) O(1) O(1) Code class Solution {public static void setZeroes(int[][] matrix) {int n matrix.length;i…...

Android App开发-简单控件(3)——常用布局
3.3 常用布局 本节介绍常见的几种布局用法,包括在某个方向上顺序排列的线性布局,参照其他视图的位置相对排列的相对布局,像表格那样分行分列显示的网格布局,CommonLayouts以及支持通过滑动操作拉出更多内容的滚动视图。 3.3.1 线…...
Linux使用二进制包安装MySQL
目录 一、软件包下载 二、上传软件包到Linux根目录 1、使用xftp将软件包上传到根目录 2、解压缩 三、准备工作 四、初始化软件 五、设置MySQL的配置文件 六、配置启动脚本 一、软件包下载 官网下载:MySQL :: Download MySQL Community Server 二、上传软件…...

【vue3-pbstar-admin】一款基于vue3和nodejs的简洁后台管理系统
Vue3-pbstar-admin 是一个简洁的后台解决方案,提供了基础的用户体系和页面接口权限配置,方便用户进行自定义开发,避免不必要的代码冗余。该方案结合了 Vue3、Element-Plus、Pinia 和 Vite 等先进技术,实现高效的页面布局、状态管理…...

顺序表和链表【数据结构】【基于C语言实现】【一站式速通】
目录 顺序表 顺序表的优点 顺序表的实现 1.结构体的定义 2.初始化数组 3.插入数据 4.其余接口函数的实现 5.释放内存 顺序表的缺陷 单向链表 单向链表的优点 单向链表的实现 1.链表的定义 2.链表的初始化 3.其余接口函数的实现 5.释放内存 单向链表的缺陷 双…...

SpringBoot 有什么优点?
Spring Boot 是一个用于简化和加速 Spring 框架应用程序开发的项目。它构建在 Spring 框架之上,提供了一种快速开发、简化配置和集成的方式。以下是 Spring Boot 的一些优点: 1、简化配置: Spring Boot 使用约定大于配置的理念,通…...

扫地机器人(二分算法+贪心算法)
1. if(robot[i]-len<sweep)这个代码的意思是——如果机器人向左移动len个长度后,比现在sweep的位置(现在已经覆盖的范围)还要靠左,就是覆盖连续不起来,呢么这个len就是有问题的,退出函数,再…...
Unity中创建Ultraleap 3Di交互项目
首先,创建新的场景 1、创建一个空物体,重命名为【XP Leap Provider Manager】,并在这个空物体上添加【XR Leap Provider Manager】 在物体XP Leap Provider Manager下,创建两个子物体Service Provider(XR)和Service Provider(…...

【Matlab】音频信号分析及FIR滤波处理——凯泽(Kaiser)窗
一、前言 1.1 课题内容: 利用麦克风采集语音信号(人的声音、或乐器声乐),人为加上环境噪声(窄带)分析上述声音信号的频谱,比较两种情况下的差异根据信号的频谱分布,选取合适的滤波器指标(频率指标、衰减指标),设计对应的 FIR 滤波器实现数字滤波,将滤波前、后的声音…...

C数据类型
目录 1. 数据类型分类 2. 整数类型 3. 浮点类型 4. void 类型 5. 类型转换 1. 数据类型分类 在 C 语言中,数据类型指的是用于声明不同类型的变量或函数的一个广泛的系统。变量的类型决定了变量存储占用的空间,以及如何解释存储的位模式。 C 中…...

JAVA和Go的不解之缘
JAVA和Go的不解之缘 Java和Go是两种不同的编程语言,它们在语法、特性和设计理念上存在一些明显的异同之处。 1. 语法和特性: Java是一种面向对象的语言,而Go则是一种面向过程的语言。Java拥有类、继承、接口等传统的面向对象特性ÿ…...
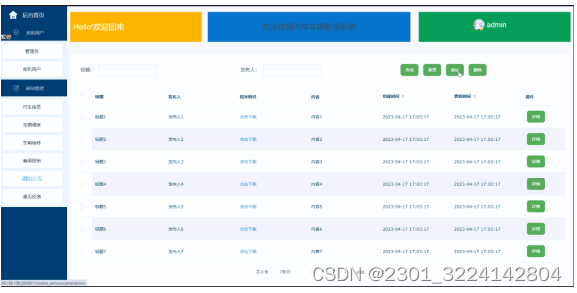
(免费领源码)java#SSM#MySQL汽车车辆管理系统68424-计算机毕业设计项目选题推荐
摘 要 科技进步的飞速发展引起人们日常生活的巨大变化,电子信息技术的飞速发展使得电子信息技术的各个领域的应用水平得到普及和应用。信息时代的到来已成为不可阻挡的时尚潮流,人类发展的历史正进入一个新时代。在现实运用中,应用软件的工作…...
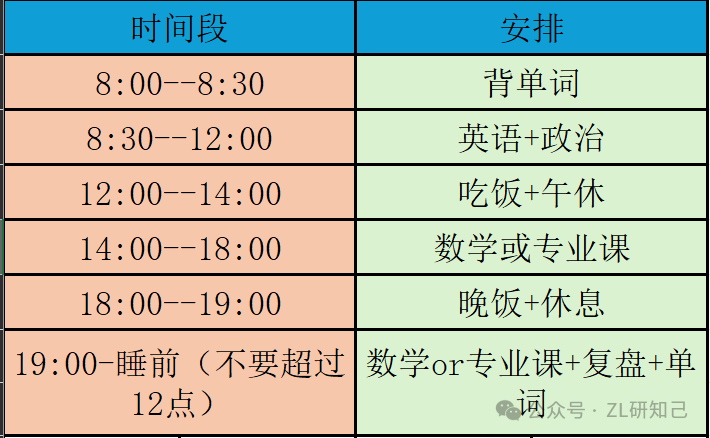
25考研每日的时间安排
今天要给大家分享一下25考研每日的时间安排。 没有完美的计划,只有合适的计划。 仅供参考 很多人说复习不要只看时长而是要看效率,所以学多长时间不重要,重要的高效率完成任务。 完美的计划 这个计划看起来很完美,从早到晚有学习…...
小程序直播项目搭建
项目功能: 登录实时聊天点赞功能刷礼物取消关注用户卡片直播带货优惠券直播功能 项目启动: 1 小程序项目创建与配置: 第一步 需要登录小程序公众平台的设置页面进行配置: 首先需要是企业注册的才可以个人不能开通直播功能。服务类…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...
)
内存申请和使用的场景分析(以AP->kernal->ISP为例)
在 ISP(Image Signal Processor)系统中,AP 与 ISP 之间的内存交互本质上是一个**“AP 申请可 DMA 访问的共享内存 → 内核建立映射 → 硬件寻址读写 → 同步与回收”**的过程。下面按数据流分层详细拆解。一、ISP 内存需求的特殊性 与普通应用…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...

从配置到运行时:Forge Admin 的动态 API 配置管理是怎么做的
问题:同一个接口,今天要加认证、明天要加加密、后天要限流,这些行为散落在拦截器、过滤器、注解里,改一次牵一发动全身,怎么集中管理和动态刷新? 1. 这个问题在企业后台里为什么常见 在企业后台开发中&am…...

TII投稿避坑指南:LaTeX模板编译报错‘xxx-eps-converted-to.pdf not found’的终极解决方案
TII投稿LaTeX避坑实战:从编译报错到完美PDF生成的终极指南 凌晨三点的实验室,屏幕上闪烁的xxx-eps-converted-to.pdf not found错误提示仿佛在嘲笑你连续八小时的徒劳尝试。这不是科幻场景,而是每位用LaTeX撰写TII论文的研究者都可能遭遇的真…...

Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化
Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南
告别烧录烦恼:用Etcher三步打造完美启动盘的终极指南 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾因烧录系统镜像而误删硬盘数据…...