PyTorch深度学习实战(33)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(33)——条件生成对抗网络
- 0. 前言
- 1. 条件生成对抗网络
- 1.1 模型介绍
- 1.2 模型与数据集分析
- 2. 实现条件生成对抗网络
- 小结
- 系列链接
0. 前言
条件生成对抗网络 (Conditional Generative Adversarial Network, CGAN) 是一种生成对抗网络 (Generative Adversarial Network, GAN),旨在通过给定特定条件信息的情况下生成符合条件的合成数据。这种网络结构通常用于生成图片、音频、文本等多种类型的数据。条件生成网络的核心思想是将条件信息与潜在空间中的噪声向量进行联合建模,以生成与条件一致的输出。常见的条件信息可以是类别标签、文本描述、图像特征等,这些信息可以指导网络生成具有特定属性、风格或类别的数据样本。在本节中,将构建 CGAN 根据条件向量生成指定性别的人脸图像。
1. 条件生成对抗网络
1.1 模型介绍
条件生成对抗网络 (Conditional Generative Adversarial Network, CGAN) 是生成对抗网络的一种扩展,它同时接受噪声数据和条件数据作为输入,以控制生成的数据样本。与标准的生成对抗网络 (Generative Adversarial Network, CGAN)不同,输入到 CGAN 的随机噪声向量和条件向量一起传递到生成网络中,以生成具有所需特征的样本,条件向量可以是数字或对象的标签,这样生成网络可以控制生成出来的图像具有特定的属性,例如,猫或狗的图像,或戴眼镜的人的图像。
条件生成网络由两部分组成:生成网络和判别网络。生成网络负责接收条件信息和噪声向量,通过一系列的神经网络层逐步生成合成数据。判别网络则用于评估生成的数据与真实数据之间的差异,以辨别生成数据的真实性。生成网络和判别网络通过对抗训练的方式相互竞争和改进,从而提高生成网络的性能。
条件生成网络的应用非常广泛。例如,在图像生成领域,条件生成网络可以根据特定的类别标签生成具有特定特征或风格的图像;在文本生成领域,条件生成网络可以根据给定的文本描述生成相应的文本段落或文章。
1.2 模型与数据集分析
为了训练对抗生成网络,我们需要了解本节所用的数据集,本节同样使用在 DCGAN 一节中介绍的人脸图像数据集,下载地址:https://pan.baidu.com/s/1dvDCBLSGwblg57p9RDBEJQ,提取码:y9fi。数据集包含男性和女性的面部图像及其相应的标签,在本节中,我们将学习如何根据随机噪声与条件向量生成指定性别的人脸图像,模型训练策略如下:
- 将图像标签转换为独热编码格式
- 将标签通过嵌入层以生成每个类别的多维表示
- 生成随机噪声并与嵌入层输出相连接
- 训练模型
2. 实现条件生成对抗网络
接下来,使用 PyTorch 根据以上分析实现条件生成对抗网络,构建条件生成对抗网络根据噪声和条件向量生成指定类别图像。
(1) 导入相关库:
from torchvision import transforms
import torchvision.utils as vutils
import cv2, numpy as np
import torch
import os
from glob import glob
from PIL import Image
from torch import nn, optim
from torch.utils.data import DataLoader, Dataset
from matplotlib import pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
(2) 创建数据集和数据加载器。
存储男性和女性图像路径:
female_images = glob('male_female_face_images/females/*.jpg')
male_images = glob('male_female_face_images/males/*.jpg')
裁剪图像,只保留面部区域并丢弃图像中的其他部分。首先,使用级联滤波器识别图像中的人脸:
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
OpenCV 提供了 4 个级联分类器用于人脸检测,可以从 OpenCV 官方下载这些级联分类器文件:
haarcascade_frontalface_alt.xml(FA1)haarcascade_frontalface_alt2.xml(FA2)haarcascade_frontalface_alt_tree.xml(FAT)haarcascade_frontalface_default.xml(FD)
创建两个新文件夹(一个对应男性,另一个对应女性图像)并将所有裁剪的人脸图像转储到相应的文件夹中:
if not os.path.exists('cropped_faces_female'):os.mkdir('cropped_faces_female')
if not os.path.exists('cropped_faces_male'):os.mkdir('cropped_faces_male')for i in range(len(female_images)):img = cv2.imread(female_images[i],1)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)faces = face_cascade.detectMultiScale(gray, 1.3, 5)for (x,y,w,h) in faces:img2 = img[y:(y+h),x:(x+w),:]cv2.imwrite('cropped_faces_female/'+str(i)+'.jpg', img2)
for i in range(len(male_images)):img = cv2.imread(male_images[i],1)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)faces = face_cascade.detectMultiScale(gray, 1.3, 5)for (x,y,w,h) in faces:img2 = img[y:(y+h),x:(x+w),:]cv2.imwrite('cropped_faces_male/'+str(i)+'.jpg', img2)
定义要对每个图像执行的转换:
transform=transforms.Compose([transforms.Resize(64),transforms.CenterCrop(64),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])
创建 Faces 数据集类,返回图像和其中人物的相应性别:
class Faces(Dataset):def __init__(self, folders):super().__init__()self.folderfemale = folders[0]self.foldermale = folders[1]self.images=sorted(glob(self.folderfemale))+sorted(glob(self.foldermale))def __len__(self):return len(self.images)def __getitem__(self, ix):image_path = self.images[ix]image = Image.open(image_path)image = transform(image)gender = np.where('female' in str(image_path),1,0)return image, torch.tensor(gender).long()
创建数据集对象 ds 和数据加载器:
ds = Faces(folders=['cropped_faces_female/*.jpg','cropped_faces_male/*.jpg'])
dataloader = DataLoader(ds, batch_size=64, shuffle=True, num_workers=8)
(3) 定义权重初始化函数,使权重的分布较小:
def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:nn.init.normal_(m.weight.data, 1.0, 0.02)nn.init.constant_(m.bias.data, 0)
(4) 定义判别网络模型类。
定义模型架构:
class Discriminator(nn.Module):def __init__(self, emb_size=32):super(Discriminator, self).__init__()self.emb_size = 32self.label_embeddings = nn.Embedding(2, self.emb_size)self.model = nn.Sequential(nn.Conv2d(3,64,4,2,1,bias=False),nn.LeakyReLU(0.2,inplace=True),nn.Conv2d(64,64*2,4,2,1,bias=False),nn.BatchNorm2d(64*2),nn.LeakyReLU(0.2,inplace=True),nn.Conv2d(64*2,64*4,4,2,1,bias=False),nn.BatchNorm2d(64*4),nn.LeakyReLU(0.2,inplace=True),nn.Conv2d(64*4,64*8,4,2,1,bias=False),nn.BatchNorm2d(64*8),nn.LeakyReLU(0.2,inplace=True),nn.Conv2d(64*8,64,4,2,1,bias=False),nn.BatchNorm2d(64),nn.LeakyReLU(0.2,inplace=True),nn.Flatten())self.model2 = nn.Sequential(nn.Linear(288,100),nn.LeakyReLU(0.2,inplace=True),nn.Linear(100,1),nn.Sigmoid())self.apply(weights_init)
在模型类中,CGAN 使用附加参数 emb_size,emb_size 表示将输入类别标签转换成的嵌入尺寸,并将转换后的嵌入存储为 label_embeddings。将输入类别标签从独热编码形式转换为高维嵌入,以便模型具有更高的调整自由度以处理不同的类别。虽然模型类与 DCGAN 类似,不同之处在于,CGAN 还需要初始化另一个用于执行分类任务的模型 model2。
定义前向计算方法 forward,将图像和图像的标签作为输入:
def forward(self, input, labels):x = self.model(input)y = self.label_embeddings(labels)input = torch.cat([x, y], 1)final_output = self.model2(input)return final_output
在 forward 方法中,获取第一个模型的输出 self.model(input) 和通过 label_embeddings 传递标签的输出,然后将这些输出连接起来。接下来,将连接后的输出传递给第二个模型 self.model2,从而获取判别网络的输出。
self.model2 的输入维度为 288,因为 self.model 的每个数据样本输出结果有 256 个值,然后将其与输入类别标签的 32 个嵌入值连接起来,因此总共有 256 + 32 = 288 个输入值传递给 self.model2。
(5) 定义生成网络类 Generator。
定义 __init__ 方法:
class Generator(nn.Module):def __init__(self, emb_size=32):super(Generator,self).__init__()self.emb_size = emb_sizeself.label_embeddings = nn.Embedding(2, self.emb_size)
在以上代码中,使用 nn.Embedding 将 2D 输入(类别标签)转换为 32 维向量 (self.emb_size):
self.model = nn.Sequential(nn.ConvTranspose2d(100+self.emb_size,64*8,4,1,0,bias=False),nn.BatchNorm2d(64*8),nn.ReLU(True),nn.ConvTranspose2d(64*8,64*4,4,2,1,bias=False),nn.BatchNorm2d(64*4),nn.ReLU(True),nn.ConvTranspose2d(64*4,64*2,4,2,1,bias=False),nn.BatchNorm2d(64*2),nn.ReLU(True),nn.ConvTranspose2d(64*2,64,4,2,1,bias=False),nn.BatchNorm2d(64),nn.ReLU(True),nn.ConvTranspose2d(64,3,4,2,1,bias=False),nn.Tanh())
在以上代码中,利用 nn.ConvTranspose2d 执行上采样得到图像作为输出。
应用权重初始化:
self.apply(weights_init)
定义前向计算方法 forward,将随机噪声 (input_noise) 和输入标签 (labels) 作为输入生成图像输出:
def forward(self,input_noise,labels):label_embeddings = self.label_embeddings(labels).view(len(labels), self.emb_size, 1, 1)input = torch.cat([input_noise, label_embeddings], 1)return self.model(input)
实例化生成网络与判别网络对象:
generator = Generator().to(device)
discriminator = Discriminator().to(device)
(6) 定义函数 noise() 生成随机噪声并将其注册到设备中:
def noise(size):n = torch.randn(size, 100, 1, 1, device=device)return n.to(device)
(7) 定义判别网络训练函数 discriminator_train_step()。
判别网络包含 4 个输入,真实图像 (real_data)、真实图像标签 (real_labels)、生成图像 (fake_data)、生成图像标签 (fake_labels)、损失函数 (loss) 和优化器 (d_optimizer):
def discriminator_train_step(real_data, real_labels, fake_data, fake_labels, loss, d_optimizer):d_optimizer.zero_grad()
在以上代码中,重置判别网络对应的梯度。
计算对应于真实数据预测 (prediction_real) 的损失值,将 real_data 和 real_labels 通传递到判别网络中,输出的预测结果与期望值 (torch.ones(len(real_data),1).to(device)) 进行比较,得到损失 error_real 后执行反向传播:
prediction_real = discriminator(real_data, real_labels)error_real = loss(prediction_real, torch.ones(len(real_data), 1).to(device))error_real.backward()
计算对应于生成数据预测 (prediction_fake) 的损失值,将 fake_data 和 fake_labels 传递到判别网络中,输出的预测结果与期望 (torch.zeros(len(fake_data),1).to(device)) 进行比较,得到损失 error_fake 后执行反向传播:
prediction_fake = discriminator(fake_data, fake_labels)error_fake = loss(prediction_fake, torch.zeros(len(fake_data), 1).to(device))error_fake.backward()
更新权重并返回损失值:
d_optimizer.step()return error_real + error_fake
(8) 定义生成网络训练函数,将生成图像 (fake_data) 和生成图像标签 (fake_labels) 作为输入传递:
def generator_train_step(fake_data, fake_labels, loss, g_optimizer):g_optimizer.zero_grad()prediction = discriminator(fake_data, fake_labels)error = loss(prediction, torch.ones(len(fake_data), 1).to(device))error.backward()g_optimizer.step()return error
generator_train_step 函数类似于 discriminator_train_step,不同之处在于 generator_train_step 函数的期望输出是 torch.ones(len(fake_data),1).to(device))。
(9) 定义生成网络和判别网络模型对象、损失优化器和损失函数:
discriminator = Discriminator().to(device)
generator = Generator().to(device)
loss = nn.BCELoss()
d_optimizer = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
g_optimizer = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
fixed_noise = torch.randn(64, 100, 1, 1, device=device)
fixed_fake_labels = torch.LongTensor([0]*(len(fixed_noise)//2) + [1]*(len(fixed_noise)//2)).to(device)
loss = nn.BCELoss()n_epochs = 80
img_list = []
d_loss_epoch = []
g_loss_epoch = []
在以上代码中,定义 fixed_fake_labels 时,指定一半图像对应类别 0,另一半对应于类别 1,并定义 fixed_noise 用于根据随机噪声生成图像。
(10) 训练模型。
遍历批图像及其标签:
for epoch in range(n_epochs):N = len(dataloader)d_loss_items = []g_loss_items = []for bx, (images, labels) in enumerate(dataloader):
初始化 real_data 和 real_labels:
real_data, real_labels = images.to(device), labels.to(device)
初始化 fake_data 和 fake_labels:
fake_labels = torch.LongTensor(np.random.randint(0, 2, len(real_data))).to(device)
fake_data = generator(noise(len(real_data)), fake_labels)
fake_data = fake_data.detach()
使用 discriminator_train_step 函数训练判别网络以计算判别网络损失 (d_loss):
d_loss = discriminator_train_step(real_data, real_labels, fake_data, fake_labels, loss, d_optimizer)
重新利用生成网络生成图像 (fake_data) 和图像标签 (fake_labels) 并使用 generator_train_step 函数训练生成网络,计算生成网络损失 (g_loss):
fake_labels = torch.LongTensor(np.random.randint(0, 2, len(real_data))).to(device)fake_data = generator(noise(len(real_data)), fake_labels).to(device)g_loss = generator_train_step(fake_data, fake_labels, loss, g_optimizer)
记录模型训练过程中的关键指标:
d_loss_items.append(d_loss.item())g_loss_items.append(g_loss.item())d_loss_epoch.append(np.average(d_loss_items))g_loss_epoch.append(np.average(g_loss_items))
训练完成后,测试模型生成图像:
if (epoch+1) % 20 == 0:with torch.no_grad():fake = generator(fixed_noise, fixed_fake_labels).detach().cpu()imgs = vutils.make_grid(fake, padding=2, normalize=True).permute(1,2,0)img_list.append(imgs)plt.imshow(imgs)plt.show()
在以上代码中,将噪声 (fixed_noise) 和标签 (fixed_fake_labels) 传递给生成网络以生成图像,训练结束后,模型的输出结果如下所示:

从上图中,我们可以看到前 32 幅图像对应男性图像,而后 32 幅图像对应女性图像。
小结
条件生成对抗网络通过整合条件信息和潜在空间噪声,能够根据特定的条件生成具有一定属性或风格的合成数据,为许多创造性和应用型任务提供了强大的工具和手段。本节中,介绍了条件生成对抗网络的基本原理,并利用 PyTorch 实现条件生成对抗网络生成指定性别的人脸图像。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)
PyTorch深度学习实战(26)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(27)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(28)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(29)——神经风格迁移
PyTorch深度学习实战(30)——Deepfakes
PyTorch深度学习实战(31)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(32)——DCGAN详解与实现
相关文章:
PyTorch深度学习实战(33)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(33)——条件生成对抗网络 0. 前言1. 条件生成对抗网络1.1 模型介绍1.2 模型与数据集分析 2. 实现条件生成对抗网络小结系列链接 0. 前言 条件生成对抗网络 (Conditional Generative Adversarial Network, CGAN) 是一种生成对抗网络…...

编写Bash脚本程序从记录文件中提取history命令的优化,再介绍linux bash语法和结构
目 录 一、引言 二、脚本代码实现 三、bash语法和结构 (一)基本语法 1、脚本开始与结束 2、注释 3、变量 4、数据类型 5、控制结构 6、循环控制 7、函数 8、算术运算 9、算术操作符和逻辑操作符 (二)命令相关…...

Python中Numba库装饰器
一、运行速度是Python天生的短板 1.1 编译型语言:C 对于编译型语言,开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件,可执行程序里面包含的就是机器码。只要我们拥有可执行程序,就可以随…...
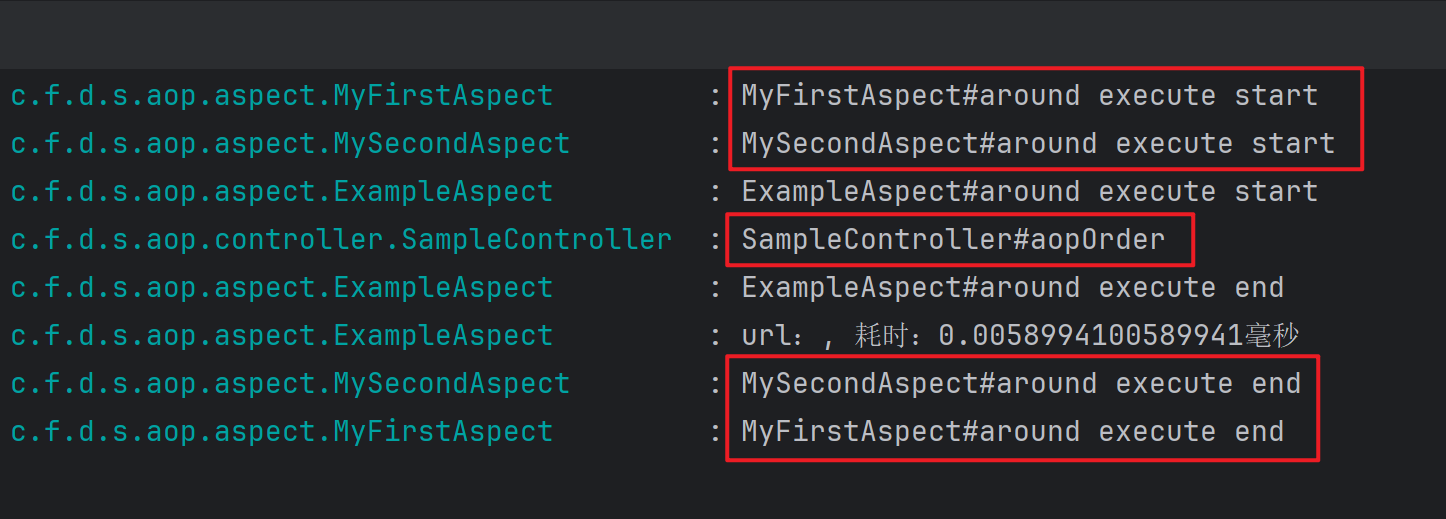
Spring Boot Aop 执行顺序
Spring Boot Aop 执行顺序 1. 概述 在 spring boot 项目中,使用 aop 增强,不仅可以很优雅地扩展功能,还可以让一写多用,避免写重复代码,例如:记录接口耗时,记录接口日志,接口权限&…...

100天精通鸿蒙从入门到跳槽——第16天:ArkTS条件渲染使用教程
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通Golang》 — Go语言学习之旅!《100天精通鸿蒙》 — 从Web/安卓到鸿蒙大师!100天…...

【Linux C | 进程】Linux 进程间通信的10种方式(1)
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
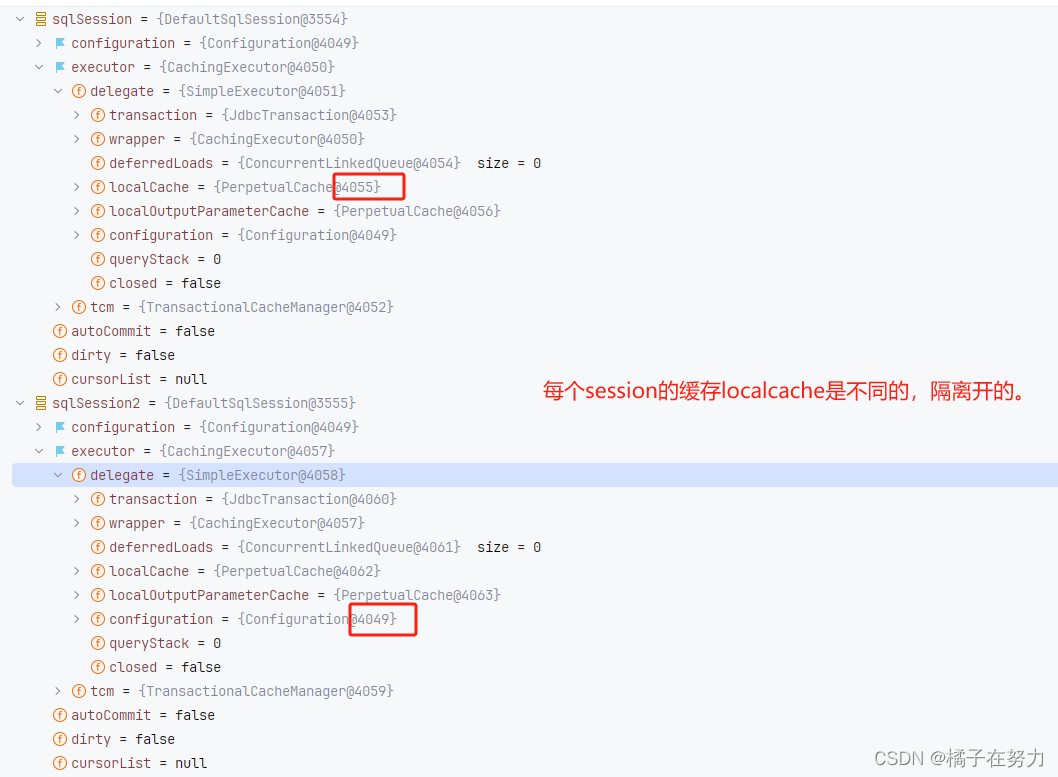
橘子学Mybatis08之Mybatis关于一级缓存的使用和适配器设计模式
前面我们说了mybatis的缓存设计体系,这里我们来正式看一下这玩意到底是咋个用法。 首先我们是知道的,Mybatis中存在两级缓存。分别是一级缓存(会话级),和二级缓存(全局级)。 下面我们就来看看这两级缓存。 一、准备工作 1、准备数据库 在此之…...
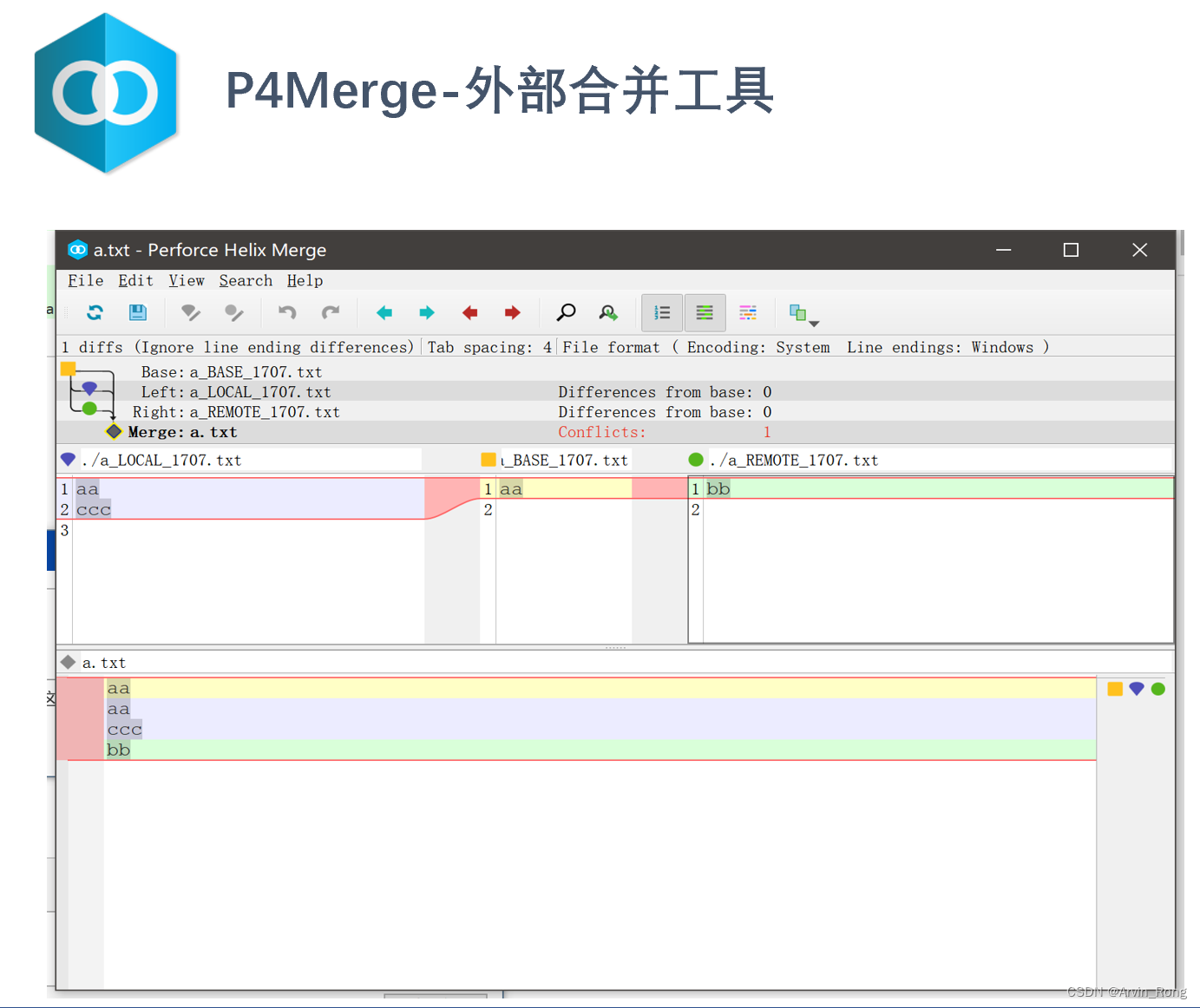
看图说话:Git图谱解读
很多新加入公司的同学在使用Git各类客户端管理代码的过程中对于Git图谱解读不太理解,我们常用的Git客户端是SourceTree,配合P4Merge进行冲突解决基本可以满足日常工作大部分需要。不同的Git客户端工具对图谱展示会有些许差异,以下是SourceTre…...

linux新增用户,指定home目录和bash脚本且加入到sudoer列表
前言 近3年一直用自动化脚本,搞得连useradd命令都不会用了。哈哈。 今天还碰到一个问题,有个系统没有‘useradd’和‘passwd’命令,直接蒙了。当然直接用apt install就能安装,不然还得自己编译折腾一会。新建用户 useradd -d /h…...

经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程
经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程 和之前实现的YOLOv2一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv3的大部分核心理念的前提下,重构一款较新的YOLOv3检测器,来对YOLOv3有…...
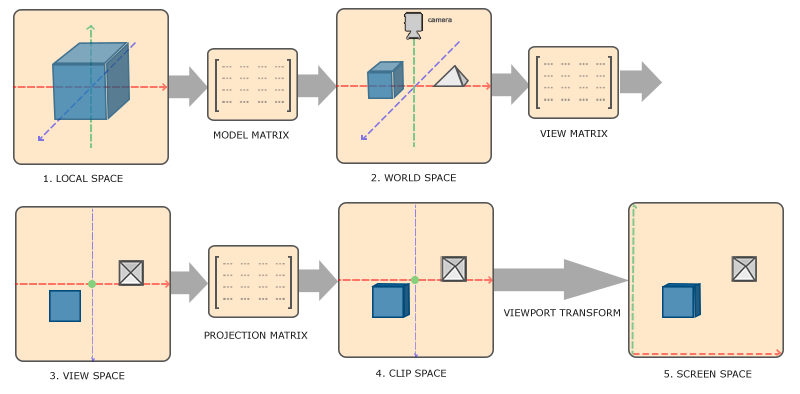
OpenGL/C++_学习笔记(四)空间概念与摄像头
汇总页 上一篇: OpenGL/C_学习笔记(三) 绘制第一个图形 OpenGL/C_学习笔记(四)空间概念与摄像头 空间概念与摄像头前置科技树: 线性代数空间概念流程简述各空间相关概念详述 空间概念与摄像头 前置科技树: 线性代数 矩阵/向量定…...

C语言2024-1-27练习记录
#define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>//int main() //{ // char c[15] { I, ,a,n,d, ,you,. }; // int i; // for(i 0; i < 15; i) //这个地方有几个地方需要注意一下,首先变量指定之后必须要加上英文状态下的分号 // printf("%c&q…...

深入解析HTTPS:安全机制全方位剖析
随着互联网的深入发展,网络传输中的数据安全性受到了前所未有的关注。HTTPS,作为HTTP的安全版本,为数据在客户端和服务器之间的传输提供了加密和身份验证,从而确保了数据的机密性、完整性和身份真实性。本文将详细探讨HTTPS背后的…...

【197】JAVA8调用阿里云对象存储API,保存图片并获取图片URL地址。
实际工作中,需要用阿里云对象存储保存图片,并且在上传图片到阿里云对象存储服务器后,获取图片在阿里云对象存储服务器的URL地址,以便给 WEB 前端显示。 阿里云对象存储上传图片的工具类 package zhangchao;import com.aliyun.os…...

2024.1.24 C++QT 作业
思维导图 练习题 1.提示并输入一个字符串,统计该字符中大写、小写字母个数、数字个数、空格个数以及其他字符个数 #include <iostream> #include <string.h> #include <array> using namespace std;int main() {string str;cout << "…...

jenkins部署过程记录
一、jenkins部署git链接找不到 原因分析: 机器的git环境不是个人git的权限,所以clone不了。Jenkins的master节点部署机器已经部署较多其他的job在跑,如果直接修改机器的git配置,很可能影响到其他的job clone 不了代码,…...

JS-策略设计模式
设计模式:针对特定问题提出的简洁优化的解决方案 一个问题有多种处理方案,而且处理方案随时可能增加或减少比如:商场满减活动 满50元减5元满100元减15元满200元减35元满500元减100元 // 满减金额计算函数 function count(money, type) {if …...

漏洞复现-EduSoho任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

「QT」QString类的详细说明
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C++」C/C++程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「...
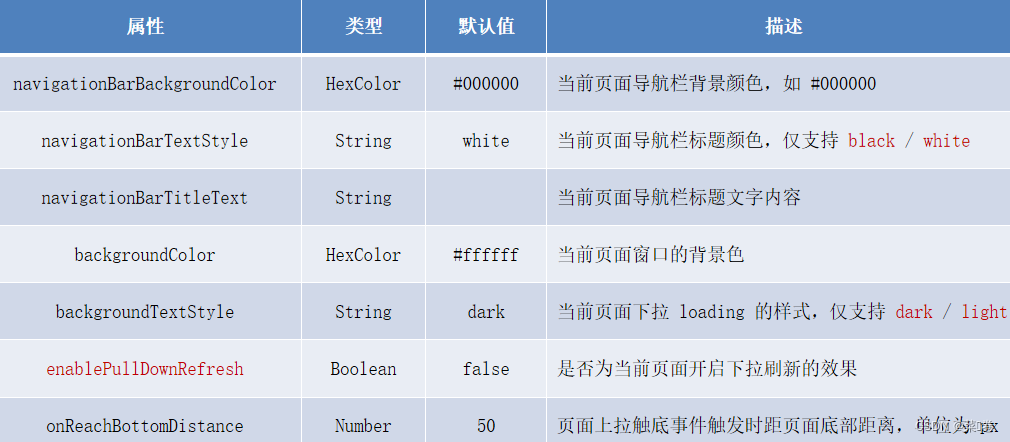
微信小程序-04
rpx(responsive pixel)是微信小程序独有的,用来解决屏适配的尺寸单位。 import 后跟需要导入的外联样式表的相对路径,用 ; 表示语句结束。 定义在 app.wxss 中的样式为全局样式,作用于每一个页面。 在页面的 .wxss 文…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...

红外信号逆向工程:破解电磁炉协议实现抽油烟机智能联动
1. 项目概述:当电磁炉与抽油烟机“对话”厨房里的自动化,听起来像是未来智能家居的专属,但其实很多乐趣和便利就藏在身边已有的设备里。我最近给家里的厨房换上了一台新的电磁炉,在翻阅说明书时,偶然发现了一个名为“h…...

Charles弱网测试六维参数实战:从丢包率到DNS延迟的精准复现
1. 为什么弱网测试不能只靠“模拟3G”按钮点一下就完事做移动端或Web前端的同学,大概率都听过这句话:“上线前跑一遍Charles,切个2G网络测下加载。”——听起来很专业,实际一查日志,发现90%的团队连Charles的Throttlin…...

Pearcleaner:macOS深度清理终极指南,让磁盘空间翻倍
Pearcleaner:macOS深度清理终极指南,让磁盘空间翻倍 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经卸载了macOS应用&…...